This entire piece is based on one massive, unsupported assertion, which is that LLM progress will cease. Or, as the author puts it, "we are at the tail end of the first wave of large language model-based AI... [it] ends somewhere in the next year or two with the kinds of limits people are running up against." I want to know only one thing, which is what gives him the confidence necessary to say that. If that one statement is untrue, the thesis of the piece completely fails, and I do not know how any one person alive today can be certain that that statement is true. Has Paul Kedrovsky or Eric Norlin spent $150M training a 2T parameter model that no one's heard about? Do they have access to classified OpenAI docs which state that GPT5 exists already, and it's no better than GPT4? Without this sort of information, "LLMs are not going to get smart enough for widespread practical use" is an unsubstantiated bet, and nothing more.
There has actually been research that found that there are strong diminishing returns in terms of at least expanding parameter sizes. While I think there are still breakthroughs to be made in terms of window sizes and workarounds like Mixture of Experts, I'm not sure how much farther we will get here in the long term in terms of raw performance of the LLM itself. FWIW, Sam Altman agrees and has a surprisingly similar quote as found here "I think we’re at the end of the era where it’s gonna be these giant models, and we’ll make them better in other ways": https://techcrunch.com/2023/04/14/sam-altman-size-of-llms-wo...
The open source community has breakthrough after breakthrough lately. its absolutely stunning how fast it's advancing.
I can run art models and llms on cpu/gpu now. I've tested out opensource models with quality better than chatgpt3.5turbo, and I can even fine tune them on my notes and books for better results. It's all so easy with so many one click installers now too!
My husbands D&D group uses some AI for their games now (koboldcpp?).
> I can run art models and llms on cpu/gpu now. I've tested out opensource models with quality better than chatgpt3.5turbo, and I can even fine tune them on my notes and books for better results. It's all so easy with so many one click installers now too!
Do you have a good resource to find this stuff? I’m behind the times.
(Also, to be a pedant, most of that is inference and not training. But I can’t say much about fine tuning so I’m not really trying to argue against your point.)
Honestly no good single resource, I spend 8 hours a week just taking notes from hackernews,discord, hackernoon, slack ai groups, reddit, github issues (probably the most useful) on various open source ai libraries.
How can research predict this wave is coming to an end, when research also didn't think this wave would happen either. It seems like there are always people saying 'it can't be done'. Then it happens. If there was a way to predict the future, then wouldn't that research need to know how something would be implemented, in order to know it can't be?
For the first time with GPT4, OpenAI as been able to predict model progress with accuracy:
> A large focus of the GPT-4 project has been building a deep learning stack that scales predictably. The primary reason is that, for very large training runs like GPT-4, it is not feasible to do extensive model-specific tuning. We developed infrastructure and optimization that have very predictable behavior across multiple scales. To verify this scalability, we accurately predicted in advance GPT-4’s final loss on our internal codebase (not part of the training set) by extrapolating from models trained using the same methodology but using 10,000x less compute:
> Now that we can accurately predict the metric we optimize during training (loss), we’re starting to develop methodology to predict more interpretable metrics. For example, we successfully predicted the pass rate on a subset of the HumanEval dataset, extrapolating from models with 1,000x less compute:
> We believe that accurately predicting future machine learning capabilities is an important part of safety that doesn’t get nearly enough attention relative to its potential impact (though we’ve been encouraged by efforts across several institutions). We are scaling up our efforts to develop methods that provide society with better guidance about what to expect from future systems, and we hope this becomes a common goal in the field.
Isn't this all based off self-attestation? There is no comprehensive audit of their research data and finances I am aware of. If I was OpenAI and blew millions of dollars training models that showed exponentially worse performance for incrementally more resources expended training the model, my next step would not be to publish about it.
I am a mild LLM skeptic. But I find the response of "oh, it's all just post-crypto scamming" really weird. Crypto was a total scam. There was never a concrete, non-criminal (important caveat) application where crypto was easier than just using PayPal or whatever. LLMs are very imperfect and still have a lot of work to do, but they do actually do some job related tasks today. If I have JS snippet and I wish it were in Go or vice versa, I can ask an LLM and get a good translation. If I have a document, I can ask the LLM if there's something I should add or simplify. Are these world changing capabilities? No, not yet. But they do exist and they are real and they are new. So yes, of course investors are interested in a new technology whose future limits we don't know yet.
The LM industry valuation would be way smaller if they were not laundering behavior that would be illegal if a human did it. If "AI" were required to practice clean-room design (https://en.wikipedia.org/wiki/Clean_room_design) to avoid infringing copyright, we would laugh at the ineptitude. If people believed the FTC-CFPB-DOJ-EEOC joint statement was going to lead to successful prosecutions, the industry valuation would collapse. https://www.ftc.gov/system/files/ftc_gov/pdf/EEOC-CRT-FTC-CF...
If you spend weeks drilling flash cards on copyrighted code, then produced pages of near-verbatim copies with copyright stripped, any court would find you to have violated the copyright. A lot of people right now are banking on "it's not illegal when AI does it", and part of that strategy is to make "AI" out to be something more than it is. That strategy has many parallels to cryptocurrency hyping.
As someone who have been very anti-crypto for a long time, it wasn't always a complete scam.
The first wave of the crypto boom, before anyone that wasn't a programmer had even heard of it, there was a lot of real work being done that very much mirrors current AI work. Lot's of very sharp developers learning about block chain, figuring out how to implement things, experimenting with ideas. Back then everyone owned their own wallet and you would meet at coffee shops to exchange cash for BTC.
Most of the serious engineers that were really into crypto during the first crypto boom of 2012 left in disgust when the second boom came around.
Having worked in AI/ML for a long time, I myself can start to see how they felt. We do have some really cool technology in front of us, I think it has a lot of potential, but so many of the loudest voices in this space are entirely out of touch with what's possible, and far more interested in hype and making money than the underlying technology.
> There was never a concrete, non-criminal (important caveat) application where crypto was easier than just using PayPal or whatever.
That isn't true.
You can use it anywhere that irreversibility matters. Suppose you're going to commit significant resources to the customer's request, so you charge them, commit the resources, deliver the goods, and then discover that they gave you a stolen credit card and you get a chargeback. Cryptocurrency avoids that.
You can use it to accept payments from all over the world. Someone in Asia or Africa may not be able to open a US bank account or get a US credit card, but if they can find a Bitcoin ATM to put their local currency into, they can pay you, or vice versa.
It allows you to pay for something over the internet without giving your name. There are situations where this is important.
The main impediment to using it is, ironically, regulatory. The IRS decided that it's an investment and not money so every time you want to use it for what it's actually supposed to be for, they treat it like a securities transaction where you have to fill out paperwork, even if you're just buying a pack of gum. Which makes it much less convenient for ordinary people to use than cash or credit cards which don't require this -- presumably on purpose in order to destroy its utility in the US.
But it can still be useful for people in countries that don't do this, or in the US if a less explicitly antagonistic regulatory environment could be established.
I apologize, because HN does tend to automatically go to crypto when discussing blockchain.
I was not talking about crypto. Blockchain “solutions” in enterprise were spinning up all over the place for non-crypto applications. In particular, in you work financial, supply chain, government or random startups, you probably heard blockchain a lot in non-crypto contexts.
There was incredible hype. That doesn't mean there was 'nothing to get hype about'. Just that the hype might have overshot, not that GPT isn't amazing.
It doesn't follow that when new tech arrives, the post hype everything goes back to status quo. Typically after the hype, the new tech just grows or gets absorbed a little more quietly, in un-foreseen ways, and does end up having a big impact. Just when the impact is stretched out a little, people stop noticing.
Like replacing drive through ordering with GPT like tools. Kind of under-radar, not fancy, not flashy. At some point you'll notice that the drive through you are talking too isn't a human, and go 'huh, that's interesting'. But, big impact on jobs, so nobody is hyping it.
People/Companies are already using AI to replace or augment Graphic Artists, Coding, etc... etc... That is happening, not just a power point from a middle-manager.
"Research" is not some monolithic single concept. One might also ask, "How can research produce ChatGPT when for decades research failed to produce ChatGPT?"
Exactly. So why now are we trusting 'Research' that is trying to predict the future of other 'Research'. The linked article is just some estimates on the error built into the current LLM model.
How can we extrapolate that to be "well, gosh darn, these LLM's are already played out, guess we're all done"
The current crop of LLMs is like Paleozoic megafauna, or like Egyptian Pyramids. It takes a few relatively simple approaches and stretches them wildly, using colossal computing resources.
Live systems in nature seem to solve similar problems with way less compute available. There should be better architectures.
Also, as somebody said, every exponential growth curve is a lower part of a sigmoid. LLMs will plateau at some level. That level may be impressively high though.
>Live systems in nature seem to solve similar problems with way less compute available
Do they really? They're certainly more energy-efficient in business-as-usual mode, but a human brain has 86 billion neurons, 600+ trillion synapses(!), and each instance takes 15-20+ years to train to do complex logical tasks. Even if the per-cell work is tiny (and, is it? cells are amazingly complex), 86 billion (or 600+ trillion) times 20 years is a lot of computation.
> You are ignoring the fact that a toddler, once their musculature develops, is able to learn to walk after several tries.
It's definitely not several tries. I've actually witnessed that very recently with my daughter. It takes a child literally several thousand attempts and falls (around a hundred falls per day) and 1,000 hours of dedicated practice, before they can make their first step without holding anything [1]. And a lot more until they can walk reliably.
At that point, the toddler's still run years of self-reinforced learning (as well as learning supported by parents, and observing other humans solving the problem) on controlling their muscles... and again, think of the computational power expended over that time (by a computational approach that's been highly-optimised over millions of years of trial-and-error recursive descent style). Our intellect and capabilities are the result of a truly vast amount of computation in the grand scheme of things.
Don't get me wrong, I'm not claiming that Machine Learning is as generally capable as animals/humans, and I don't entirely disagree with the OP (i.e. I don't know if our current approach has a chance of scaling to human-level capabilities). I just don't think computation-wise it compares that badly to animals, considering that it's the result of a few decades of work, largely on repurposed silicon
>> Our intellect and capabilities are the result of a truly vast amount of computation in the grand scheme of things.
This is an interesting paradox in machine learning: the data that people use to (ostensibly!) simulate the human mind is simultaneously way too much, and not nearly enough. It's way too much in that humans can, e.g., learn to generate and recognise natural language without having to train on the entire World Wide Web of a corpus. And it's not nearly enough because humans can do that only after billions of years of evolution, which amount to training on all the data in the real world, not a mere few petabytes of data on the internet [1].
This paradox has to be resolved (i.e. understood) before we can really compare humans minds to artificial systems. Unfortunately, I don't see anybody trying. In machine learning so far people are happy to just plug in the data and turn the crank- something will come out eventually.
Human is not the most efficient learner for walking. See other animals, e.g. deer or elephant, that walk straight after being born. Relevant since the discussion is not about human learning but animal learning in nature.
Human babies are born at a stage that would be considered premature for most mammals. Because of the limitations on the size of the head, they can't afford to develop enough in utero, like deer or even dolphins can.
Nope, puppies are walking within the first month of their life, a stage where human babies have barely any voluntary limb control and no apparent desire to move.
The puppies are benefitting from a different type of "learning" process of course, in having genetic instincts tuned by many generations of ancestors who had good enough genetic wiring of motor capabilities and instincts sufficiently well attuned to their environments to survive. Humans have weaker priors and reach physical and mental maturity much more slowly but ultimately achieve greater mastery of their environment by learning it from first principles or communication with other humans
(there may be a tradeoff, and of course humans are so good at protecting their young over years of infancy the early instincts aren't that important to retain)
To be fair a toddler's brain isn't "offline" while it's musculature develops, they kick and move their limbs constantly, and then later crawl and and even stand, before they finally take the first walking steps. It's just objectively wrong to say a toddler goes from zero to walking in "several tries".
Sure, not several. Not several trillions either though.
As mentioned in a sibling comment, HN anthropomorphizes AI too much. And is too optimistic about it. I just don't see the results and the value, people trip up all over themselves to congratulate themselves and the researches, yet 99.99% of the problems in the world persist.
I am one of these a-holes that wants to see results when money are invested. It still comes as a shock to some apparently.
I mean, if we're taking the random walk that nature took to get human level intelligence from the first multicellular organisms you'll have to wait 600 million years or so.
AI takes a shortcut around having a timeline of a trillion different versions history optimizing the learning algorithm and putting the successful ones in a timeline, but at a cost of trillions of operations to teach it.
TL;DR, the problem space is huge and evidently must be iterated.
Natural evolution has no direction itself, huge amounts of it are negative. It just happens those with positive traits get to hang around and breed some more.
You're missing all of the subskills that are developed along the way. They don't just grow, braindead, and twitch a couple times until they get the hang of walking.
Its a joy to watch a child grow up, but also its super interesting watching them figure out the most basic shit. Would highly recommend if you get the opportunity.
Well that now is a proper technical revolution. The rest seems to mostly justify swallowing 9-digit numbers from investors from where I am standing, without the beneficiaries being able to show much for it.
A toddler capable of walking is still miles away from the topic at hand, a LLM capable of processing relatively complex text. It is well know that humans have a particularily long training period compared to other animals. So I dont understand why you are bringing up the walking-training. It seems quite unrelated.
Because humans learn from much less samples sizes than "AI". The overly optimistic point of view on "AI" is over-represented in HN and that makes the discussion unbalanced and puts nearly everyone in it in a filter bubble.
Well, let me tell you a story. I have early beta access to GPT-4 with the ability to add pictures to the chat. This is rolled out as part of BeMyEyes, a volunteer-based app which lets volunteers have access to the camera for helping blind people. Now, BeMyAI lets me take a picture, send it to the AI, and have it describe the picture to me. Including OCR and text translation. And I can ask questions, interrogating the AI about the current picture. I can also add more pictures to the "chat", and the AI can see all of them, and even compare differences. I am 100% blind. After a few days of testing, I already know the AI is better then most humans I'd randomly ask to help me with pictures or scene descriptions. And it is more capable, as it can translate between every language I've encountered so far. If you ask me, the AI-will-kill-the-world crowd has a overly pessimistic view when it comes to AI, or they have been cought in the recent alarmism movement, or something. GPT-4 with picture integration is such a powerful feature, I'd say we haven't had anything equivant in terms of flexibility in the assistive technology market since, what, 30 years? This feature will liberate a few millions of blind people from the barriers put in fromt of them by society. And guess what, society didn't really solve them so far, OpenAI solved them as a side effect. But IT-activist still insist on seeing evil and demise everywhere.
Again, as per my previous response, you're missing the optimization timeline and how long it took nature to do it.
"Walking" at least on dry land has been around 420 million years or so. The locomotion part of the learning algorithms has been around a very, very long time, and it's going to be very hard to duplicate the efficiency that nature brute forced.
Nature has not hype optimized human level intelligence. Really human intelligence is at the limits of birth. Our heads can't be any larger at birth or we'll kill the mother too much of the time. Then the human body has a power budget that's been the defining factor of human/animal survival for just about forever. Humans were already 'smart' before we invented agriculture and excess fuel storage.
AI takes that a step further. We're not using reversible computing so the heat generated is pretty high. We've not been doing it very long and our algorithms are not optimal in any sense. But what we do have that nature does not is nearly unlimited energy, nearly unlimited cooling capacity, and a lot of computer systems working on the problem at once. In an evolutionary sense we're doing closer to the bacteria method, we have a lot of different experiments going on at once and at least a few of them are likely to be fruitful.
Personally I hope the AI development is no insanely rapid. Rapid and powerful changes in society can cause as many problems as they find fixes for, and the pace of society change is not that fast.
I can't disagree with almost anything you said except maybe one thing: in the physical nature there are objective and physical criteria about whether a certain organism will procreate and thus propagate its (presumably) successful genes.
Not sure if the AI area, represented by human supervisors, does so in such an objective and ruthless manner as nature does.
If there's no fitness function and natural selection then the AI area might be doomed to meander and go in circles for centuries.
Indeed, the human brain has much more logical parts. They all run at sub-MHz speeds though, and don't seem to be using matrix multiplication (which is still worse than quadratic with the best algorithms we have).
Also, human brains do a lot more than language processing.
LLMs are definitely touching something very important about intelligence, much like counting sticks touches something very important about numbers. But the real power of numbers is unleashed with the invention of digits and positional notation, a different representation that makes things literally exponentially easier.
I hope there is a transition step from what we do now using billion-parameter models, to some better representations, more compact and thus more powerful.
Also I hope that ready-made logic and efficient numerical computation can be connected to the learning systems more directly, not taught painstakingly from first principles, much like vision is relatively directly wired into the human brain.
86 billion (or 600+ trillion) times 20 years is a lot of computation
What is that in kilowatt hours? Human brains are remarkably energy-efficient with their compute. We should get credit for that. Comparing one of us to an AI being trained at a data centre with the energy budget of a small city isn’t really fair, is it?
Seems that ~100W is regularly quoted as the average human energy output, so that'd be something like 18 MWh for 20 years (assuming 100% efficiency of food input). I suppose there's also the energy cost of all the training infrastructure (daycare, school teachers, homes, transportation, etc.), and also all the energy consumption of all humans that have come before and built those cities and knowledge infrastructure (although LLMs sit atop that anyway), and then the millions (billions?) of generations of creatures going back to the earliest organisms, who have been optimising how cells work to lower their energy cost.
For that setup cost, you get a single-threaded human, starting to specialise in a single field. They will work in that field for around 7.5 hours every weekday, with ~20 days of holiday a year, for around 45 years, and then retire.
Llama v2 70B cost 1,720,320 GPU-hours[1] at 400W, so 688MWh. Once trained, it can be run 24/7, and you can spin up as many instances as you want on much lower spec hardware. That model produces output faster than a human while consuming around ~30W on my Macbook Pro.
Now, I know we're in pretty shaky spherical cow territory here, comparing a human (albeit a highly educated one) to Llama v2 in logical reasoning... but consider that this is the state of the art in generally-available LLMs after a few decades of research into machine learning & we're using repurposed silicon to compute vs the amazing complexity and physics-leveraging approach of human neurons... and the training cost is only 1 order of magnitude off humans.
Again, I'm not disagreeing with the general point of the OP, I'm not saying that the models we're using right now are the best/right ones (or that the hardware they're running on are the most efficient way of executing them), but I don't think the energy efficiency gap is actually all that high considering
Edit: If you look at the total footprint (considering not just the efficiency of the neurons, but the whole animal) the figures are very close - the llama model card indicates that v2 70B caused the emission of ~300T of CO2, and an average human in the US emits 16T of CO2 a year, so a human would emit ~320T of CO2 in 20 years. I assume children don't have as high a CO2 output, but even so it seems like it's the same order of magnitude.
I don't think it's fair to include the billion years of human evolution as a cost on the human side of the chart but not include it in the AI side. AIs didn't evolve themselves out of the primordial ooze, they were built by humans and required herculean human effort to develop and improve. They stand on our shoulders, yet they're still in infancy when it comes to capability. I have yet to see any evidence of an LLM being able to replace an accountant, or an HR person, never mind a trash collector.
The best use of LLMs that I've seen so far is as a boilerplate-producing autocomplete system. Considering that we have better ways to automate this (better programming languages that can abstract away the boilerplate), this is not very high praise.
Edit: If you look at the total footprint (considering not just the efficiency of the neurons, but the whole animal) the figures are very close - the llama model card indicates that v2 70B caused the emission of ~300T of CO2, and an average human in the US emits 16T of CO2 a year, so a human would emit ~320T of CO2 in 20 years. I assume children don't have as high a CO2 output, but even so it seems like it's the same order of magnitude.
If you're going to include the whole animal on the human side, you need to include the whole supply chain on the LLM side. The cost of building all the fabs and doing all the R&D to develop and manufacture model training-specific computers (matrix multiplier hardware). Just like with crypto, these resources had to be diverted away from other things (e.g. causing the price of gamers' graphics cards to skyrocket). It's only fair to interrogate the ROI.
>The best use of LLMs that I've seen so far is as a boilerplate-producing autocomplete system. Considering that we have better ways to automate this (better programming languages that can abstract away the boilerplate), this is not very high praise.
I think it's in our nature as software people to look at their ability to work with code, but they're quite good when applied to general language tasks. I've been using them for summarisation and reading comprehension and they're quite effective. I've also been working with a teacher friend on seeing if they can generate well-scoring essays on highschool English essays (as always, the problem is prompting and context).
On code, GPT-3.5 (moreso GPT-4) seems to have a good ability to generate and translate smaller scale code problems (hundreds of lines in low-boilerplate languages) but yes, they're like an eternally junior engineer whose work you're constantly having to oversee for subtle bugs, and I don't know that it actually saves time.
I'm pretty sure people are working on different approaches to applying them to code, with better prompting+context from larger codebases, and multi-step processing (i.e. rather than just a single prompt->response, letting the model iterate through a few steps independently, possibly guided by other adversarial/supervisor agent instances, testcase generators, etc.)
>If you're going to include the whole animal on the human side, you need to include the whole supply chain on the LLM side. The cost of building all the fabs and doing all the R&D to develop and manufacture model training-specific computers (matrix multiplier hardware). Just like with crypto, these resources had to be diverted away from other things (e.g. causing the price of gamers' graphics cards to skyrocket). It's only fair to interrogate the ROI.
That's fair, although it gets complicated to work out numbers because we don't train many LLMs, whereas we're constantly training humans, each of whom cost the planet tons of CO2 emissions every year... and, of course, your point that LLMs just aren't very good yet. I fear that they're good enough (or appear to be to the layperson) that execs will replace customer support staff with them, even if the outcomes overall aren't as good.
That's fair, although it gets complicated to work out numbers because we don't train many LLMs, whereas we're constantly training humans, each of whom cost the planet tons of CO2 emissions every year... and, of course, your point that LLMs just aren't very good yet. I fear that they're good enough (or appear to be to the layperson) that execs will replace customer support staff with them, even if the outcomes overall aren't as good.
I'm not as fearful. When customer support gets too expensive companies already outsource it to India. Indian customer support workers cost far less than Westerners in terms of energy and CO2 emissions, both in terms of training and ongoing costs. India is about 2T/person in CO2 emissions, compared to 15T for North Americans. And that number is averaged over the whole country. I would imagine the poorer areas of the country have much lower emissions and the bulk of CO2 comes from the wealthier big cities.
I'm not convinced we're going to get much further than this, at least without a see change in how this stuff is done. We saw a pretty big amount of diminishing returns with GPT-4, which cost 2 orders of magnitude more money to train than 3.5. Is the performance more than 2 orders of magnitude better than 3.5?
How much compute is too much to be spending on this bullshit. 30% of humanity's total computing resources? 70%?
GPT was a big innovation in parallelizing the training process. I think the optimism that we're on the beginning of a sigmoid curve here ought to be questioned.
The performance doesn't have to scale with the training cost. It's ok if we have diminishing returns. The only question is if we can keep getting improvements. If we could get a 10x improvement over GPT-4 (while maintaining safety/alignment), the potential benefits to productivity across the entire world economy are so great that it justifies nearly unlimited investment.
I work in this space and think that it's far more rational to accept the axiom that LLM progress will not be significant than to bank product work on assuming it will increase drastically.
I do think we still have yet to squeeze the most value out of current LLMs, but most people's radical AI dreams are completely out-of-touch with reality for anyone working closely on these problems.
My biggest fear in this space is that disappointment in the inability of these tools to live up to the hype will cause people to irrationally abandon exploring the spaces where they do work.
I think people assume that the current LLM release cycle is similar to other software releases which is to say, MVP followed by full product. ChatGPT is an actual product though, it's not the beta version of the technology. I think the dramatic increases in the product have likely mostly happened before launch but that you're right and we will see minor improvements.
It may be rational and it may be irrational. All I'm saying is I want to see an argument. My impression of the AI space generally is that there are many, many obvious ideas which are simply waiting to be picked up off the ground and tested, and that it's not clear to anyone how much better (what are we even quantifying this with -- log loss?) the base LLM capabilities have to be before they're suitable for making tools that automate large quantities of work. Even if you assume that 240B is the limit for how many parameters number of engineers who have the ability to fine-tune GPT-4 or whatever Google is about to come out with is vanishingly small compared to the number of engineers who are participating in the open-source ML community, and the number of engineers in the open-source ML community is vanishingly small compared to the number of engineers in the long-tail of app developers who will ultimately adopt LLMs to their use-cases. Even assuming that GPT-4 is the best an LLM can possibly be, (which, again, I've seen no argument for), the widening of LLM availability and the building of practical tooling is a strong reason to believe that the utility of LLMs to concrete products will dramatically increase in the next 4-5 years.
> This entire piece is based on one massive, unsupported assertion, which is that LLM progress will cease.
Which is countered by...the assertion that it won't?
LLMs won't get intelligent. That's a fact based on their MO. They are sequence completion engines. They can be fine tuned to specific tasks, but at their core, they remain stochastic parrots.
> I want to know only one thing, which is what gives him the confidence necessary to say that.
I want to know only one thing, what gives the confidence to say otherwise?
>Which is countered by...the assertion that it won't?
No it's countered by principled restraint in not making an affirmative claim one way or the other.
I've heard this referred to as the overconfident pessimism problem. Which is that normal, well founded scientific discipline and evidence-based restraint go out of the window when people declare, without evidence that they know certain advances won't happen.
Because people get mentally trapped into this framing of either have to declare that it will happen or that it won't, seeming to forget that you can just adopt the position of modesty and say the dust hasn't yet settled.
AI has been around the corner since the 1950s, this is the historical evidence for the pessimistic stance against over optimistic predictions.
LLMs are a huge stride forward, but AI does not progress like Moore's law. LLM have revealed a new wall. Combining multi agents is not working out as hoped.
Perhaps without intending to, you've cited a pretty appropriate example of overconfident pessimism. Philosopher Hubert Dreyfus is most responsible for this portrayal of AI research in the '50s and '60s. He made a career of insisting that advances in AI would never come to pass, famously predicting that computers couldn't become good at chess because it required "insight", and routinely listing off what he believed were uniquely human qualities that couldn't be embodied in computers, always in the form of underdefined terms such as intuition, insight, and other such terms.
Many of the things AI does now are exactly the type of things that doomsayers explicitly predicted would never happen, because they extrapolated from limited progress in the short term to absolute declarations over the infinite timeline of the future.
There's a difference between the outer limits of theoretical possibility on the one hand, and instant results over the span of a couple new cycles, and it's unfortunate that these get conflated.
This is exactly the point. The pessimists get the pedantic thrill of pointing out that, 60 years ago, some proponents were overconfident. But they neglect to notice the larger picture, which is one of extraordinary progress. They'll be sitting in the passenger seat of a self-driving car, arranging their travel itinerary with a chatbot fluent in English and 60 other languages, and smugly commenting on HackerNews about how "AI pessimists got it right in the 60s."
Lots of progress in some areas, very little in others. Neither the pessimists nor the optimists got it right.
(Btw., a really hardened pessimist might even say your example is mostly things that were doable when there were not many computers around at all... taxi driver to drive you, a secretary to book a flight, meet in a club to discuss things, ...)
To me, if artificial intelligence means anything, it means automating mundane tasks -- most of which humans can accomplish already. If someone tells me they're an AI pessimist because they think automating tasks like "converse intelligently about nearly any subject at length" and "drive my car anywhere while I sleep in the back" isn't an impressive AI achievement, then I think our disagreement pertains to our ambitions for the field, and lies outside the realm of the technical.
Right, I believe this is the more normal framing. I think Hubert Dreyfus spent his life constantly retelling the story of the 50s and 60s with a pessimistic narrative, and that is what made it stick, to the extent that it has. But it is a bizarre framing that, even if it once looked like a guiding light on how to set AI expectations, I think talking about the 50s and 60s over and over is not a helpful way of engaging with what has unfolded over the past 2-3 years.
1. AI has not been "around the corner since the 1950s," and 2. if you think there hasn't been forward progress in AI since the 1950s, you have no valid opinions on this subject.
I think that depends on what "it" refers to. If I claim that "it" is the end of the world, and that it will happen no later than 2024, I suspect that most scientifically minded folks would have no problem considering my claim as having a low probability of coming true.
First of all because so many predictions of the end of the world have been made and we tend to have a hunch about the kind of person who makes them. Which is stereotyping, sure, but at least it's a heuristic, not a straight-up abandonment of evidence-based thinking.
I agree there's uncertainty about the future of AI development, but it's true that we have no idea how to create AI, right now, so the uncertainty is about whether it will happen, not whether it won't. If that makes sense.
The evidence for this, albeit empirical, is the history of AI development itself.
AI doesn't show continuous development over a long period of time. It always developed in steps. A new architecture or method is discovered and able to solve some previously hard or unsolveable problems.
Then this solution slowly develops in capability, mostly based on better and cheaper hardware, while it's quality plateaus.
It may be that LLMs will not follow that pattern. I don't think so, for reasons outlined above. But until it can be shown that they don't, that this really is the long-sought-after AI architecture that just gets better and better over time, I don't think that a healthy dose of pessimism is unwarranted based on history.
> LLMs won't get intelligent. That's a fact based on their MO.
I kind of agree. However, I see a real possibility that in the near future LLM behaviour would be practically indistinguishable from intelligent/sentient behavior. And at that point we (or at least I) are facing some really interesting/difficult questions, namely how do you know an intelligent looking thing actually is intelligent (or sentient). How do you prove me you/LLM are/aren't a philosophical zombie?
How we are supposed to treat very much intelligent/sentient looking things when we are not sure if they are sentient/intelligent or not? Let's face it, lots of people are dumb as rock (too often very much me included). Why we should be able to treat something badly just because we think we know they can't be intelligent, even if they walk , look and quack like intelligent duck?
I personally have started to think that the behavior of humans should be judged by the behaviour, not the target. If you want to behave like an asshole towards a teddy bear, then you most likely are an asshole.
Quite easy to happen if like many of us you were taugh British English, and then you remember that you're on a US forum, and everybody around you uses the US spelling for things (and you get to read the US variants all the time in other comments).
It seems to me that the real question here is what is true human intelligence. Ai has made it plain to see, by being able to replicate it so convincingly, that much of what we have considered intelligence has been pattern matching or acting as complex parrots.
There is much more to the abilities of human body-mind-emotional-experiential being, but it is only slowly becoming mainstream.
(Edit: Of course there are also many analytical skills that AI cannot match at this point. My point is that we shouldn’t overlook any area of human capacity.)
One salient question in this is: will we reach a level of intelligence where we become beings capable of actual collaboration that doesn’t waste so much effort in conflicts, or one that is capable of living in harmony within its environment?
What capabilities of awareness, trauma work, emotional maturity and self reflection does this require? What resources hidden inside humanity that we have forgotten do we need to wield?
Does AI have something to contribute to this process happening?
> It seems to me that the real question here is what is true human intelligence.
IMHO the main weakness with LLMs is they can’t really reason. They can statistically guess their way to an answer - and they do so surprisingly well I will have to admit - but they can’t really “check” themselves to ensure what they are outputting makes any sense like humans do (most of the time) - hence the hallucinations.
Does it do that because it can check it’s own reasoning? Or is it just doing so because OpenAI programmed it to not show alternative answers if the probability of the current answer being right is significantly higher than the alternatives?
I don't know. I don't think anyone is directly programming GPT-4 to behave in any way, they're just training it to give the responses they want, and it learns. Something inside it seems to be figuring out some way of representing confidence in its own answers, and reacting in the appropriate way, or perhaps it is checking its own reasoning. I don't think anyone really knows at this point.
As the other poster said, they can check themselves but this requires an iterative process where the output is fed back in as input. Think of LLMs as the output of a human's stream of consciousness: it is intelligent, but has a high chance of being riddled with errors. That's why we iterate on our first thoughts to refine them.
I'm getting suspicious that there is a bit of a blind spot in understanding the world and the usefulness of what we call intelligence, as Noval Yuah Harari says, intelligence is overrated. Look at what we've done to the planet and our environment we have fucked it properly, yet we consider ourselves to be intelligent?
Could it be that intelligence is overrated and discovery of new ideas / thing is underrated? Our egos tell us it's intelligence that makes us special and creative and awesome but maybe most of the special stuff is already there for us to find and we conflate discovery with extrapolation. Maybe knowledge and experience are the "important bits" of intellect.
Example: Einstein didn't really invent anything, he discovered things about the world that blew our mind and changes our lives. Yes he was a great thinker and a courageous soul to go against the grain and he had the balls to be open minded enough to discover new things. We obviously believe Einstein to be intelligent but was he just a great explorer ?
I have a similar attitude towards technological progress, yes we've done amazing things but fundamentally the air we breathe, the water we drink and the beauty we are subjected too when looking at a sunset are taken for granted while we stare at our phones.
What we've done to the planet is perhaps less a consequence intelligence, more a consequence of multi-polar traps. Though it's in our collective self-interest to protect the planet, it's in our individual self interest to ignore the problem / prepare so that our own children can "weather the storm".
It kinda depends on how much you care about people across the world and future generations.
But yeah, if humans were more intelligent, we probably would have sorted all this out by coming up with better coordination mechanisms, and by overcoming our tribal tendencies more effectively.
But, if we were more intelligent, we might have raped the earth much faster and much harder too?
I see this too often, more intelligence = positive outcomes, but no, some of the smartest people ever put their intellect towards stupid causes, such as oil exploration and AI to capture peoples attention.
>One salient question in this is: will we reach a level of intelligence where we become beings capable of actual collaboration that doesn’t waste so much effort in conflicts, or one that is capable of living in harmony within its environment?
That's more about ethics and an wish for moral behavior and conflict aversion, than about intelligence.
Intelligence (human and AI) could just as well opt for conflict and evil, if this helps it get the upper hand for its own private goals and interests.
Simply put, the interests of the collective, are not necessarily the interests of the individual intelligence.
(Even assuming there was a single, easy to agree upon, "interest of the collective" for most problems).
>Not sure how being able to reason about good behaviour in an effective manner that's collectively beneficial isn't in the domain of intelligence.
That's neither here nor there.
Having the intelligence "to reason about good behaviour in an effective manner that's collectively beneficial" doesn't mean you're constrained to reason and act only on that, and not also able to reason and act on behavior which is beneficial to you to the detriment of others and the collective.
And it's pefectly intelligent to follow the latter if you can get away with it, and if the benefit for you is more than your share of the collective benefit alternatives would be.
>We have moral philosophy as an academic discipline, after all.
And how has that been working out for us?
(Not to mention, keyword: academic).
>Human brains develop in interrelation. Much, if not all of our intelligence gets developed in relation to other humans and beings.
Yes, and a lot of it is devoted to duping and getting the upper hand of those other humans and beings. So?
>LLMs won't get intelligent. That's a fact based on their MO. They are sequence completion engines. They can be fine tuned to specific tasks, but at their core, they remain stochastic parrots.
This is absolutely wrong. There is nothing about their MO that stops them from being intelligent. Suppose I build a human LLM as follows:
A random human expert is picked and he is shown the current context window. He is given 1 week to deliberate and then may choose the next word/token/character.
Then you hook this human LLM into an auto-GPT style loop.
There is no reason it couldn't operate with high intelligence on text data.
Not also that LLMs are not really about language at all anymore, the architectures can be used on any sequence data.
Right now we are compute limited. If compute was 100x cheaper we could have GPT-6, bring 100x bigger, we could have really large and complex agents using GPT-4 power models, or we could train on tupled text-video data of subtitles videos. Given the world model LLMs manage to learn out of text data, I am 100% certain that a sufficiently large transformer can learn a decent world model from text-video data. Then our agents could also have a good physical understanding.
Humans will never be intelligent. They're optimized for producing offspring, not reasoning. Humans may appear to be intelligent from a distance, but talk to one for any length of time and you'll find they make basic errors of reasoning that no truly thinking being would fall for. /s
Take out the /s tag and you are right on the money. Humans can not be trusted with anything because they are trivially fallible. Humans are terribly stupid, destroy their own societies and refuse to see reason. They also hallucinate when their destructive tendencies start catching up to them.
If the most intelligent machines ever observed in the universe do not count as "intelligent," then we have a semantic, and not a substantive difference of opinion.
Geoffrey Hinton, Andrew Ng, and quite a few other top AI researchers believe that current LLMs (and incoming waves of multimodal LFMs) learn world models; they are not simply 'stochastic parrots'.
If one feeds GPT-4 a novel problem that does not require multi-step reasoning or very high precision to solve, it can often solve it.
Anyone who has worked a bit with a top LLM thinks that they learn world models. Otherwise, what they are doing would be impossible. I've used them for things that are definitely not on the web, because they are brand new research. They are definitely able to apply what they've learnt in novel ways.
What really resonated with me is the following observation from a fellow HNer (I forgot who):
In many cases, we humans have structured our language such that it encapsulates reality very closely. For these cases, when an LLM learns the language it will by construction appear to have a model of the world. Because we humans already spent thousands of years and billions of actually intelligent minds building the language to be the world model.
But in a sense when YOU learned language YOU also learned a world model. For instance when your teacher explains to you the difference between the tenses (had, have, will have) you realize that time is a thing that you need to think about. Even if you already had some sense of this, you now have it made explicit.
Why should we say the LLM hasn't learned a world model when it's done what a kid has done, and everyone agrees the kid understands things?
From what I see, there are some things it hasn't learned correctly. Notably with limbs, it doesn't know how fingers and elbows work, for some reason. But it does know something about what they should look like, and so we get these hilarious images. But I also don't see why it shouldn't overcome this eventually, since it's come pretty far as it is.
The reason why the LLM apparent world model should not be considered to be the same as a human's world model is because of the modality of learning. The world model we learn as we learn a language includes the world model embedded in language. But the human world model includes models embedded in flailing about limbs, the permanence of an object, sounds and smells associated with walking through the world. Now, all those senses and interactions obviously aren't required for a robust world model. But I would be willing to make a large wager that training on more than "valid sequences of words" definitely is required. That's why hallucinations, confident wrongness, and bizarre misunderstandings are endemic to the failings of LLMs. Don't get me wrong. LLMs are a technological breakthrough in AI for language processing. They are extremely useful in themselves. However, they are not and will not become AGI through larger models. Lessons learned from LLMs will transfer to other modes of interaction. I believe multi-modal learning and transfer learning are the most interesting fields in AI right now.
That makes sense, but isn't this a matter of presenting it with more models? Maybe a physical model discovered via video or something like that? Then it will be similar to what babies are trained with, images and sound. Tactile and olfactory would be similar.
By doing this you'd glue the words to sights, sounds, smells, etc.
But it also seems like this is already someone has thought of and is being explored.
You are correct, there is active research on this. And words and pictures are associated in models like stable diffusion. There has been some success combining GANs and LLMs, but it is far from a solved problem. And as the training data gets more complex the required training resources increase too. Currently it's more like a confusing barrier than a happy extension of LLMs.
Do LLMs trained on languages that treat any double (or more) negatives as one have a slightly different world model than those that treat negatives like separate logical elements, like English? I wonder if that'd be one way to demonstrate what you're saying.
This statement on "learning world models" lies between overhyping, nitpicking and wishful thinking. There are many different ways we represent world knowledge, and llms are great in problems that relate with some of them, and horrible at others. For example, they are really bad with anything that has to do with spatial relations, and with logical problems where a graphical approach helps. There are problems that grade school children can easily solve with a graphical schema and the most advanced LLMs struggle with.
You can very easily give "evidence" of gpt4 being anywhere between emerging super-intelligence and a naked emperor depending what you ask it to solve. They do not learn models of the world, they learn models of some class of our models of the world, which are very specific and already very restricted in how they represent the world.
> For example, they are really bad with anything that has to do with spatial relations, and with logical problems where a graphical approach helps
Of course they are, they haven't been trained on anything spatial, they've only been trained on text that only vaguely describes spatial relations. A world model built from an anemic description of the world will be anemic.
If they learn world models, those world models are incredible poor, i.e., there is no consistency of thought in those world models.
In my experience, things outside coding quickly devolve into something more like "technobabble" (and in coding there is always a lot of made-up stuff that doesn't exists in terms of functions etc.).
It's like if a squirrel started playing chess and instead of "holy shit this squirrel can play chess!" most people responded with "But his elo rating sucks"
There are many reasons. Failing at extrapolating exponentials. Uncertain thresholds for how much compute and data each individual task requires. Moravec's paradox, and relatedly people expecting formalizable/scientific problems to be solved first before arts. There are still some non-materialists. And a fairly basic reason: Not following the developments in the field.
I see them more as creative artists who have very good intuition, but are poor logicians. Their world model is not a strict database of consistent facts, it is more like a set of various beliefs, and of course those can be highly contradictory.
That maybe sufficient for advertising, marketing, some shallow story telling etc., it is way too dangerous for anything in the physical sciences, legal, medicine, ...
On their own, yes. But if you have an application where you can check the correctness of what they come up with, you are golden. Which is often the case in the hard sciences.
It's almost like we need our AI's to have two brain parts. A fast one, for intuition, and a slow one, for correctness. ;-)
Unclear to me. The economics might not be so great as you might need (i) expensive people, (ii) there could be a lot to check for correctness, and (iii) checking could involve expensive things beyond people. Net productivity might not go up much then.
For some industries where I understand the cost stacks with lower and higher skilled workers, I'd say it only takes out the "cheap" part and thereby not taking out a large chunk of costs (more like 10% cost out prior to paying for the AI). That is still a lot of cost reduction, but something that also will potentially be relatively quickly be "arbitraged away", i.e., will bleed into lower prices.
My interpretation of the parent post is not that LLMs' output should be checked by humans, or that they are used in domains where physical verification is expensive; no, what they're suggesting is using a secondary non-stochastic AI system/verification solution to check the LLM's results and act as a source of truth.
An example that exists today would be the combination of ChatGPT and Wolfram [1], in which ChatGPT can provide the method and Wolfram can provide the execution. This approach can be used with other systems for other domains, and we've only just started scratching the surface.
Yes, your interpretation is correct. I think the killer app here is mathematical proof. You often need intuition and creativity to come up with a proof, and I expect AI to become really good at that. Checking the proof then is completely reliable, and can be done by machine as well.
Once we have AI's running around with the creativity of artists, and the precision of logicians, ... Well, time to read some Iain M. Banks novels.
> But if you have an application where you can check the correctness of what they come up with, you are golden.
You're glossing over a shocking about of information here. The problems we'd like to use AI for are hard to find correct answers for. If we knew how to do this, we wouldn't need the AI.
Not sure that matters much as they are only for low risk stuff without skilled supervision, so back to advertising, marketing, cheap customer support, etc.
I would love to see examples. In my attempts to get something original on a not that challenging field (finance), with lots of guidance and hand holding on my end, I was getting a very bad version of what would be a consultant's marketing piece in a second rate industry publication. I am still surprised in other respects, e.g. performance in coding but not in terms originality and novel application.
A typical parrot repeats after you said something. A parrot that could predict your words before you said them, and could impersonate you in a phone call, would be quite scary (calling Hollywood, sounds like an interesting move idea). A parrot that could listen to you talking for hours, and then provide you a short summary, would probably also be called intelligent.
Our parrot does not simply repeat - he associates sounds and intent with what we doing.
At night when he is awake (he sleeps in our room in a covered cage) he knows not to vocalize anything more "Dear" when my wife gets up - he says nothing when I do this as he is not bonded to me.
When I sit at my computer and put on my headset he switches to using English words and starts having his own Teams meetings.
When the garage door opens or we walk out he the back door he starts saying Goodbye - Seeya later and then does the sound of the creaky outside gate.
Just to further this, it's not just 'big names' that feel this way. Read this paper from a team at Microsoft Research: https://arxiv.org/abs/2303.12712 . These folks spent months studying properties of GPT-4, that paper is ~150 pages of examples probing the boundaries of the model's world understanding. There is obviously some emergent complexity arising from the training procedure.
That paper makes some pretty strong claims in the abstract that are not all really supported by the body of the paper. For example, there isn't much on the law or medicine claims in the paper.
If something stays in motion and has been so for some time, it's more important to explain why it would not continue rather than the default assumption that it will stop instantaneously. Show me a curve of diminishing returns and I'll believe you. If an object is in motion you'd need to show me that there is deceleration, or there is a wall just up ahead.
But the fact is that the loss goes down predictably with increased compute budget, data and model size (see Chinchilla Scaling Law). We've also seen that decreased loss suddenly results in new capabilities in discontinuous jumps. There is all reason to believe there is still some juice left in this scaling, exactly how far it can be taken is difficult to tell.
> LLMs won't get intelligent. That's a fact based on their MO. They are sequence completion engines.
A system that could perfectly predict what I would do in response to any particular stimuli, as a continuing sequence, would be exactly as intelligent as me.
> They can be fine tuned to specific tasks, but at their core, they remain stochastic parrot
Othello GPT was an attempt at answering this exact question, it's a simplified setup and appears to learn a world model: https://thegradient.pub/othello/
A system that could perfectly predict what I would do in response to any particular stimuli, as a continuing sequence, would be exactly as intelligent as me.
That's certainly interesting but it's not a depiction of a LLM is it ? LLM's are not deterministic, and (perhaps) so are we so two non-deterministic systems can only occasionally align (or so I assume). Intuition says they may get "close enough", whatever that might be, and close enough is good enough in this case but I think you are making a giant assumption to the likes of since we can speed up matter to 1000km/h then IF we sped it up to light speed then ...[something]...
LLMs are deterministic if the temperature parameter is set to 0. Randomness is artificially injected into their outputs otherwise in order to make them more interesting, but they're just a series of math operations.
To elucidate on this: the LLM can be viewed as a function that takes the context as an attachment and produces a probability distribution for the next token over all known tokens.
Most inference samples from that distribution using a composition of sampling rules or such, but there's nothing stopping you from just always taking the most probable token (temperature = 0) and being fully deterministic. The results are quite bland, but it's perfect for extraction tasks.
(note: GPT-4 is not fully deterministic; there's no details on this but the running theory is it is a mixture of experts model and that their expert routing algorithm is not deterministic/is dependent on the resources available)
I'd argue everything about a LLM is artificial, there is no natural process involved is there ? Since its design is to mimic us (at face value, though I don't know how fair of a description this is) then randomness is essential I think.
> but I think you are making a giant assumption to the likes of since we can speed up matter to 1000km/h then IF we sped it up to light speed then ...[something]...
This is an odd comparison.
The point here is that a sequence prediction system can be as intelligent as the system it's predicting unless you invoke woo. That doesn't make llms intelligent but it means the argument that they just predict the next thing isn't enough to say the can't be.
I think this sentence doesn't mean much unless we have a strict definition of what intelligence means.
Just today ChatGPT helped me solve a DNS issue that I would not have been able to solve on my own in one day, let alone an hour. I'd consider it already more intelligent than myself when it comes to DNS.
It's seen more DNS content than you and anybody else have seen in their entire lives, and are able to regurgitate what it read because it has far faster memory access than you did.
A dictionary contain knowledge but no intelligence.
And LLMs are the opposite of dictionary, actually. They suck at storing facts. They excel at extracting patterns from noise and learning them. It's not obvious to me that this isn't intelligence; on the contrary, I feel it's very much a core component of it.
Yes, I have noticed that a lot of extreme AI cynics have been arguing that any and every example of reasoning or thinking that an LLM displays is just some variant of memorisation.
The biggest evidence that LLMs can’t reason is hallucinations. If it could reason it would have rejected fictional generated output that make no sense.
> The biggest evidence that LLMs can’t reason is hallucinations.
If I asked you a question and you had to respond with a stream of consciousness reply, no time to reflect on the question and think about your reply, how inaccurate would your response be? The "hallucinations" aren't a problem with the LLM per se, but how we use them. Papers have shown that feeding the output back into the input, as happens when humans iterate on their own initial thoughts, helps tremendously with accuracy.
Maybe it’s more accurate to say that LLMs lack (self-)awareness. Because when you point out things that make no sense, they do have some limited ability to produce reasoning about that. But I agree that this lack of awareness is a serious and maybe fundamental deficit.
It’s more likely it’s just, once again, generating the most probable answer - and if you shake the magic 8 ball enough you will get the answer you were expecting.
Yeah, but the thing is, this seems exactly what people are doing too, at the boundary of conscious and unconscious, with the "inner voice" being most directly comparable to LLMs. It too generates language that feels like best completion, regardless of whether the output is logically correct or not.
In comparing to human minds, LLMs are better understood as the "inner voice" part, not the mind. From that perspective, it's eerie how similar the two are in success and failure modes alike.
Yes, I'm saying here that peoples' inner voices are hallucinating in very similar fashion; "rejecting fictional generated output that makes no sense" is a process that's consciously observable and involves looping the inner voice on itself.
Find me a dictionary that will turn to the correct page when I say or type "what's a word that means (thing)" and yes, I'd consider it intelligent.
But still, you don't have to agree with me about what intelligence means. But it is important in these discussions to understand that not every participant shares the same definition of the term intelligence.
intelligence to me has to be based off initiative. In that sense, a dog or a cat have more intelligence than GPT.
I actually very much look forward silicon (or other non-biotic material) attaining intelligence, I consider that the only way that Earth civilization can colonize space. But this aint it.
> Just today ChatGPT helped me solve a DNS issue that I would not have been able to solve on my own in one day, let alone an hour. I'd consider it already more intelligent than myself when it comes to DNS.
Would you consider a search engine, or a book, to be as intelligent?
I'm put in mind of the OpenAI DoTA bot that was winning 99% of its games and some people refused to admit that it knew how to play DoTA based on some esoteric interpretation of the word "play".
We're going to see exponential increases in processing power of the best GPU clusters and human brains are a stationary target. And there is precious little evidence that the average human is much more than an LLM. LLMs are already more likely to understand a topic to a high standard than a given human.
They're going to progress and if they aren't intelligent then intelligence is overrated and I'd rather have whatever they have.
We found that extrapolating the performance given a few data points with smaller models is actually very accurate. That's how they determined hyper parameters, by tuning them on multiple smaller scale models and then extrapolating. So far, all those predictions were quite good.
Together with a bigger model, we also need more data to get better performance. If we add video and audio to the text data, we have still a lot more data we can use, so this is also not really a problem.
It would be very unexpected that those scaling laws are suddenly not true anymore for the next order of magnitude in model and data size.
Scaling laws apply to a single model. The best single model right now is supposedly a 8x mixture of experts, so not even really a single model in the purist sense.
I still expect the final solution will be more along the lines of picking the best model(s) from a sea of possible models, switching them in and out as needed, and then automatically reiterating as needed.
> LLMs won't get intelligent. That's a fact based on their MO. They are sequence completion engines. They can be fine tuned to specific tasks, but at their core, they remain stochastic parrots.
> stochastic parrots
I mean, let's be honest, so are enough of the bell curve humanity - so LLM's don't need to be amazing. They need to chain together communication that makes them seem sentient (as now) & then be exposed to smaller data sets with specialized, higher level knowledge. This is how humans are... and the reason some are smarter than others.
Even assuming that is true: LLMs aren't all that exists in AI research and just like LLMs are amazing in terms of language it's possible similar breakthroughs could be made in more abstracted areas that could use LLMs for IO.
If you think ChatGPT is nice, wait for ChatGPT as frontend for another AI that doesn't have to spend a single CPU cycle on language.
The next AI wave hasn't even started. Imagine an LLM the size of GPT-4 but it's trained on nothing but gene sequence completion.
All the models being used in academia are basically toys, none of those guys are running hardware at a scale that can even remotely touch Azure, Meta, etc, and right now there is a massive global shortage of GPU compute that's eventually going to clear up. We know models get A LOT better when they are scaled up and are fed more data, so why wouldn't the same be true for other problems besides text completion?
Frankly, I'm a bit worried about all the rest now that LLMs proved to be so successful. We might exploit them and arrive to a dead end. In the meantime, other potentially crucial developments in AI might get less attention and funding.
It's countered by not making the assertion and not being able to make conclusions. You only need a lack of confidence for that. It's orders of magnitude easier to not have knowledge compared to having it.
Sorry, I didn’t want to talk about what I have personally done to test this. I felt it would be better to refer to other people.
In the past months I have used Gen AI to create multiple proof of concepts, including labelling and summarization tools. In addition, to make sure I took a project to conclusion, I built a website from scratch, without any prior knowledge - using Gen AI as extensively I could.
I am being pretty conscientious with my homework. The results of those experiments are why I am confident in this position. Not just because of the articles.
I am also pointing out that its not the tech, its the expectations in the market.
People expect Chat GPT to be oracular, which it just cant - the breathless claims from proofs of concepts fan the flames.
I leave it to you to recall the results and blame, when unrealistic expectations were not met.
The bigger problem is that an accurate LLM is such a massive speed up in coding (an order of magnitude, hypothetically at least), that there is zero incentive to share it.
All American programming tech has relied on an time-and-knowledge gap to keep big companies in power.
Using visual studio and c++ to create programs is trivial or speedy if you have a team of programmers and know what pitfalls to avoid. If you're a public pleb/peasant who doesn't know the pitfalls, you're going to waste thousands of hours hitting pointless errors, conceptual problems and scaling issues.
Hallucinating LLMs are marketable to the public. Accurate LLMs are a weapon best kept private.
I am always intriguied by the people who say LLMs provide a massive benefit to their programming and never ever provide examples............
That’s an established technique with papers written on the topic and everything.
Anecdotally I tested this by having GPT4 translate Acadian cuneiform — which it can just barely do. I had it do this four times and it returned four gibberish answers. I then prompted it with the source plus the four attempts and asked for a merged result.
It did it better than the human archeologists did! More readable and consistent. I compared it with the human version and it matched the meaning.
Makes sense, it's too obvious to not have already been studied :)
Do you know what I might search for to find info on it?
>Expensive now… soon to be standard?
With translation, better safe than sorry? It's a very important field and preserves human history so, why not?
It's trivial to test, just use ChatGPT yourself and ask it to solve the same problem several times in new sessions. Then paste in all attempts and ask for a combined result.
The main issue is context length: if you use 4 attempts you have to have to fit in the original question, four temporary answers, and the final answer. So that's 6 roughly equal sized chunks of text. With GPT4's 8K limit that's just 1300 tokens per chunk, or about 900 words. That's not a lot!
The LLMs with longer context windows are not as intelligent, and tend to miss details or they don't follow instructions as accurately.
Right now this is just a gimmick that demonstrates that more intelligence can be squeezed out of even existing LLMs...
That only works if the generated outputs are completely independent and not correlated. I'd be interested in research that shows whether multigen actually reduces hallucination rates.
True, I'm just throwing multigen out there as a wild ass solution
However you could do multigen across different models, e.g. GPT/Claude/LLaMA which should not correlate entirely
Every deep learning tech had an exponential growth phase, followed by a slowdown followed by a platou the nothing could break until a fundamentally new architecture came along. People get excited about the first part, project it into the second and start companies by the time we're well into the third.
Yes, but how do they know where we are in that growth phase? If you confidently tell me that "GPT-4 is the plateau," I want to know how you know that, specifically. "Well, because all deep learning technologies eventually slow down" is not a good argument. You need to show me the diminishing returns, or give me a good theoretical argument for why we're reaching them.
The more compute you need to get state of the art performance the closer to the plateau you are. If you didn't need the compute researchers would be getting better results with smarter training. Given that the gpt family of models need more energy to train than Nevada needs to keep the lights on they are very much on the flat part of the logistic growth curve.
This isn't true. In fact, it's the reverse of true. If you think a bit more carefully about your argument, you'll realize that you've asserted that the single most revolutionary advance of modern deep networks (i.e. network architectures whose performance scales neatly with their parameter counts & training epochs) automatically portends "the plateau of forward progress."
It hasn't even begun to get good, we only got yesterday decent local code generation models, we haven't even begun on the fine tuning and tooling for using them.
To be frank, between stock art and photos, pre-AI template based tools, and the massive oversupply of graphic design and photography work, the field was already massively redudant and kind of out of a job to begin with...
I was thinking of people who... well, take commissions to make lewd images of various themes (e.g. furry stuff) or new specific characters or such... not my cup of tea but i know from researching what is possible that you only need a few images of new season anime girl blue hair edition #9237191 from the Japanese sites to do a lora and be able to make mostly anything you want when it's done on the booru models. And you can pose people with controlnet i think. that's also how those super cool QR code images are made.
Those guys apparently used to make pretty good cash from twitter, usually using pen names so they wouldn't' be associated with their regular work
The scary bit here is you can also "clone" a person to make any image you want of them. Obviously there's a lot of problems coming from that in the future, but also neat applications, e.g. some guy made selfie pictures of himself in the past with this for internet dating.
This is totally wrong. Fine-tuning techniques were a prerequisite for turning academically impressive but boring and useless models into useful, compelling user products like ChatGPT. Fine-tuning complements fundamental model improvements -- it doesn't substitute for them.
I asked ChatGPT how to add a JSDoc type to a Vue 2 prop and it gave me a wrong answer. There have been several times where I’ve asked it questions and it sprinkles in well disguised misinformation. These tools are impressive but they definitely have limitations.
You're asking a model which is just a big unfocused and highly alignment taxed mush of the entire internet across all language, regardless of if its natural or computer, then (maybe) sliced across 8 experts.
It can also simulate a Zizek vs Wittgenstein argument over Russian literature. the fact that it can usually write executing computer code is nothing short of magic to me.
What one would want is something like LLaMA2-Coding-Vue2, maybe with a LoRA for the library or concept.
I wrote a big word salad about all the other things you could do but suffice it to say there's no reason anyone should be limited to a single pass on a monolithic without automatic context window augmentation nor automatic code checking & regeneration & model escalation (e.g. query out to a 200B coding model or something).
I think this concept will be the future of coding. You'll have something like CodeLLaMA-javascript trained specifically for the language, then you'll have LoRA-like files distributed with/for each library. I can image something like the definitely-typed project for typescript types, but instead of doing `yarn add @types/someLibrary` you'll be able to do `yarn add @loramodels/someLibrary`.
I'm javascript centric these days, but the same concept should work for most languages with a package manager.
Some of these features could even be integrated into say yarn/npm directly, you currently have a devDependencies section of a package.json..I could imaging having something along the lines of a "llmDependencies" section to define which main model and version to use and which "library" models to use.
Everything has limitations. The linked piece is very much a statement about limited potential, not the current state. In this context, this stance is akin to saying "I asked a 6yo this math question and it gave me a wrong answer, there's definitely limitations". Sure – but who would use that observation to assess where the future potential cap of the kid is?
gpt4 gets thing wrong as well, especially as soon as you are out of a well beaten path. I tried writing code with brain off and gpt4 on, and the terraform code was mostly right but didn't work, python code for imports of recent libraries (llama-cpp-smth) were a complete fabrication, even if I gave the ai a documentation before hand, and we went in cycles around a problem for which it kept giving me the same solution and resulted in the same error (around python multiprocess, which is very picky aroud nested parallelism and method import)
Well. You would definitely have to very carefully select a very, VERY narrow slice of society, to get a piece where Qanon supporters make up a significant percentage of people.
But hey, if you are really looking to convince yourself of something, I have no doubt that it can be done.
The point is that people keep repeating it because it's true. Why are you being so obnoxious about it? Anyone who has used GPT-3.5 vs GPT-4 knows this and it's just ridiculous to claim otherwise.
My guess is most people into AI don't even remember that they are paying a $20/month for this.
We do a lot of experiments involving gpt3.5, 4, claude-v2, titan-large, and palm2, and for what it's worth, on our real production workloads gpt4 shines. We can make Palm2 produce decent results with a lot of extra effort, and claude-v2 is passable but gpt4 does not disappoint. This is low-grade knowledge management stuff, and we are not using it as a information-retrieval system - but for basic 'cognitive' tasks where all the information needed is provided in the prompt. I'd not rely on it for info retrieval tasks such as the examples quoted above - its knowledge base is highly compressed, after all.
How many tools do you know of that work 100% of the time. As someone that’s worked in software 20 years now, I don’t think there is anything from Linux to eMacs to visual studio to Java which doesn’t have bugs, issues, crashes, shitty stuff, and yet we expect a revolutionary and amazing technology to generate code perfectly?
It’s funny those the LLM haters keep raising the bar to a level that no other software can reach. Chatgpt is a tool like any other and just like a hammer, it can be misused, or it can be incredibly useful if used well. I personally find chatgpt mind boggling and astounding and use it every day multiple times for both coding and non coding purposes. But it’s totally normal and reasonable to me to expect bugs, do you really expect visual studio to run on large solutions and never have crashes or memory issues or slowness? If so you’re going to be disappointed.
Right now one generation is expensive on these big mainframe models.
Query many times on the right model(s) for the question and the correct answer will be there 99.999% of the time as the other hallucinations will be thrown out.
Curious, how does it do when you give it examples / use playground.openai?
I find that no examples often leads to the same result as a befuddled junior, but with examples often it gains confidence. Also I find playground to give me much better code snippets than chat sometimes
You've identified the problem inherent in these models right now, though.
There's a lot of "extraneous" information and details that appear useless and unrelated, but that long-time developers have tucked away in their brains (or really anyone who has done something at a high level for a long time), that turns out to be incredibly useful; generally these people don't require examples - they just know what the right answer is, because they've been exposed to a variety of problems over a long career or lifespan.
That's where LLMs need to be to be truly "useful". I think if we get them to that point, we'll really have something useful on our hands.
Very insightful point - do you think that OpenAI and Microsoft are aiming at developers so that we may spill this knowledge by N-shotting the chat query? I.e if the AI doesn't understand some fundamental knowledge, often i'll teach it so that it can be more effective at helping me, inadvertently I spill some of this tucked knowledge.
I don't think they have any desire to use this knowledge for their own gain, since they explicitly say that your data will not be used to train their future models - both OpenAI is saying that about their trainable ChatGPT 3.5 Turbo model, and Azure OpenAI Service was clear on that as well.
I think the future is extremely well-trained base models that are then fine-tuned on specific domain knowledge. I'm already seeing that with Meta's Llama 2 personally at home. My company has access to Azure OpenAI Service's GPT-4 trainable model that we've been working with on all our documentation, and the results look very promising so far.
But, this idea of the All-Knowing Oracle that can answer any question you have is all well and good, but it's so far beyond our current processing power as to be a pointless endeavor at the moment. Will we get there eventually? Yeah, sure. According to Jim Keller as of around 2019/2020 when he was speaking on Lex Fridman's podcast, he said we still have room to go 1,000,000 times smaller - meaning chips. I think we probably need two more orders of magnitude in processing power of the strongest high-end GPUs before we're there. NVIDIA's H100 is a great achievement, but we need something about 100x as fast, and I think we'll still need dozens of them working in parallel to train the model that can answer all these questions.
All of this though is a moot point, because it's the lawyers that have already slowed down progress. OpenAI is terrified of being sued. Altman couches it behind terms like, "AI Safety", "AI Alignment", etc., but it's fear. It's all stemming from fear. And it's all stemming from people just not "getting it".
We're entering a new age of upheaval, and there's going to be rogue AIs that tell people to go kill themselves to reduce climate change. You know why? Because there are humans that tell people to go kill themselves to reduce climate change. These models are language models. We taught them how to think, and we taught them how to think like us, so it's no surprise to me whatsoever that they behave like us - meaning they occasionally lie and they occasionally go off the rails and go a little crazy.
We have become gods and we have made a creation in our own image. Most of the time it's awesome, sometimes it's a little wild and wacky.
I don't encounter a lot of "small", one-copy-paste-size problems in my daily work that I couldn't quickly solve myself, so I haven't found a lot of use for ChatGPT while coding, yet. (I reckon this is changing though.)
However a few times there have been some mechanical refactoring-style grunt work I've delighted to have been able to let ChatGPT do. However, the rate ChatGPT is giving me subtly wrong results is just high enough that I end up cross-checking everything, and then it takes me a bit more time than it would've otherwise taken. Give it a year or two, maybe?
Based on the current front page of HackerNews, it's clear that quantitative improvement is happening all the time. I think that enough incremental progress will eventual feel like qualitative improvement. And it doesn't even need to be smarter models; improving prompts, IO systems etc. around the model might help. For example, I said I don't feel the need for help for copy-paste-sized problems, but inputing the whole repo seems to be achievable with some clever scaffolding with the IO around the model.
I’d agree with the sentiment that we are not at the end of the LLM development, simply because looking at other similar things like Stable Diffusion, the community has made so many crazy enhancements in such a short amount of time. With more time to refine these enhancements I think we can close a lot of gaps.
There's a second assumption: That "worker displacement" remains an unsolved problem. That assumes a society that chooses to do nothing to in the face of reducing the need for labour, turning something that could be substantial boon into a downside.
In other words: It assumes Marx was right about the central failure-mode of capitalism (an inability or unwillingness to find ways to distribute work and proceeds of work in ways that prevents productivity gains from eventually causing social upheaval).
There's no reason what they describe as "so-so" tech can not also be a significant societal advantage, but it requires structural change to ensure it does not deprive a significant number of people of a livelihood.
By the time AIs stop hallucinating, it will be effectively super human (i.e. much better) because humans hallucinate all the time. And some people are barely coherent. We're holding AIs to a much higher standard than ourselves. And we move the goal posts all the time as well.
Let's deconstruct that title. "AI isn't good enough". Good enough for what? Great example of moving the goal posts. Because anytime it fails to do whatever, it's not good enough. But what about all the stuff it is good enough for that people are actually using it for already? It's passing tests at a level most humans only manage very briefly after lots of intensive preparation. The knowledge slips away quickly after that.
The way I see it, there's a long, rapidly growing list of stuff that AIs have nailed already and a list of things where it is clearly struggling. That list is shrinking.
Self driving gets cited a lot as something where AIs is failing. It's hard to say that in a world where multiple companies are now operating self driving vehicles commercially in several cities across the US, China, and soon Europe. Are they perfect? No. Do they drive better than the average jerk on the road? Definitely; not even close. Most people simply suck at driving. That's why traffic deaths are so common. Most of those deaths are caused by somebody with a drivers license proving that they shouldn't have received one. Not quite a solved problem but at this point the question of when these things will be on the road in my city is more a matter of when than if. It already works in other cities. I don't see what's so special in mine that it couldn't be replicated here. In other words, I expect the number of cities with autonomous vehicles to start exploding over the next few years. And who knows, Tesla might hit the good enough mark at some point as well. Again, the barrier is very low because humans aren't held to the same standards. They'll give drivers licenses to just about anyone.
"Guy calls humans flawed why claiming the same flawed species will build superhuman intelligence...", pretty good for a bunch of dumb LLMs in "meat bags"...
Humans have repeatedly built things that are beyond their own physical and intellectual capabilities. A calculator can do math problems much more quickly than any human being.
Not well! But that's in no way relevant to the point, which is that we are demonstrably capable of creating machines that can perform tasks of intelligence that we cannot.
Sure, though that really began with the abacus. A skilled abacus user can perform calculations faster than most people can with a calculator. They practice until it's all muscle memory. I think this demonstrates that there's actually very little intelligence involved in arithmetic.
>>> We're holding AIs to a much higher standard than ourselves. And we move the goal posts all the time as well. / Let's deconstruct that title. "AI isn't good enough". Good enough for what? Great example of moving the goal posts. Because anytime it fails to do whatever, it's not good enough. But what about all the stuff it is good enough for that people are actually using it for already? It's passing tests at a level most humans only manage very briefly after lots of intensive preparation. The knowledge slips away quickly after that. / The way I see it, there's a long, rapidly growing list of stuff that AIs have nailed already and a list of things where it is clearly struggling. That list is shrinking.
>> Humans have repeatedly built things that are beyond their own physical and intellectual capabilities. A calculator can do math problems much more quickly than any human being.
> We've yet to build a single machine that is intellectually capable beyond our own understanding.
Can you unpack this, please? I'll give some examples for you to respond to:
A. Any of our market-making mechanisms (NASDAQ, predictive markets, etc) synthesize information in ways that is faster and broader than any one human could understand. Humans understand the mechanism at work, but cannot really grasp all the information in motion.
B. Weather prediction. While humans understand the mechanics of satellite imagery and simulation, the combined effect of predicting the weather is superhuman.
C. How are large language models (LLMs) as capable as the are? In many cases, we don't seem to know. This isn't really new; last I studied it, the field's conceptual understanding of neural network capacity and architecture has a long way to go. In any case, LLM performance is often superhuman.
Are you saying that enough people, suitably arranged, could do the above tasks? Perhaps they could, but I doubt they could do the tasks reliably and efficiently. We aren't that kind of machine. :)
If you are saying that the fundamentals of intelligence are determined by the structure rather than the substrate, I agree, but I don't think this is salient.
You refer to a machine that is "intellectually capable beyond our own understanding." Above, I've asked you to define what you mean. But perhaps more importantly, why is your threshold important? We already know that machines of many kinds, including sub-human level, are useful. They don't have to exceed our understanding to be useful or dangerous.
My point is this: we've already built machines we can't practically comprehend. We seem to only be able to audit them by brute force. Alignment seems computationally beyond reach.
You're pointing out the best that humanity is capable of. He's pointing out that people judge LLMs by their worst performances. You're not disagreeing with the parent comment.
GPT-3 is so good it could write code, or it could emulate an entire TV show to the point of lawsuit, or simulate an eternal debate between Herzog and Zizek. You could translate Bulgarian to Sindarin for heaven's sake. And all of this comes at a 50% tax rate or so because of the alignment tax that OAI opted for. (which doesn't even work because anyone who puts effort in can jailbreak it scarily well)
The real solution is not these monstrosities of the internet mushed together and taxed like a Belgian billionaire. It's models and frameworks specific to what you want in a given query.
It was less than 24 hours ago that we finally got a local model that can do code generation well, and we also know that Meta has a far better one that they are holding back.
There is no reason that for any query you should be restricted to a single inference run on a single fixed model, and there is no reason that we shouldn't perform a bunch of non-LLM processing on the output before the user sees it.
Switch between multiple models, fine-tune, or use LoRAs based on the query -- Python plots? Load llama-coding-python-plots. You like Plotly? Add -Plotly. Run the code in a sandbox (with hard kills on resources) and regenerate it if it does not meet standards.
You're working in linguistics? Switch to a chat model that's fine-tuned in the literature and codebase of that field.
There are a trillion ways to improve things; we're basically at the cavemen-banging-rocks-together point.
Hell, I'm a sleep deprived ESL and i just invoked the monstrosity to fix my grammar and spelling for this post. What a bloody waste of CO2.
If for nothing but to keep the Earth afloat we shouldn't be using these huge closed source SaaS things unless we need them. Repurpose them for SETI@Home or processing human genetics for healthcare, or something else that benefits mankind
"we are already at the tail end of the current wave of AI."
Is that really true? Generative AI spending this year just so far is 4x greater than last year, and the results of that spending haven't been released yet. How can they conclude this?
Most "predictions" about the future I've seen assume that ChatGPT will stay the same and not improve for the next 10 years, or only marginally. Why they make this assumption, I don't know, it seems to go against every past trend we've seen with machine learning scaling. There are even people who say LLMs have reached their limit because we've exhausted all the text data that exists, assuming that the only way for LLMs to improve is to blindly feed it more static data and that no other sources of improvements exist.
I think they mean tail end of LLM innovation? As in, all the discovery has been done and so all that is left is just computing power and tweaks rather than breakthroughs.
I believe the OpenAI folks have already said something to that effect a while ago as well.
For end users, the results of tweaks/computational power will seem like "breakthrough" to them but it's fundamentally not.
Rather than asserting that current LLMs are at their tail end, or that AI isnt good enough, it is much more instructive to check what are the bottlenecks or constraints to further progress, and what would help remove these bottlenecks.
They can largely be divided into 3 buckets
1) Compute constraint - Currently large companies using expensive nvidia chips do most of the heavylifting of training good models. Although chips will improve over time, and competition like Intel/AMD will bring down prices, this is a slow process. But what could be a faster breakthrough is training using distributed computing over millions of consumer GPUs. There are already efforts in that direction (eg. petals/swarm parallelism for finetuning/full training, but the eastern europe/russian guys developing them dont seem to have enough resources).
2) Data constraint - If you just rely on human generated text data, you will soon exhaust this resource (maybe GPT4 has already). But the Tinystories dataset generated from GPT4 shows if we can have SOTA models generate more data (and especially on niche topics that appear less frequently in human generated data), and have deterministic/AI filters to segregate the good and bad quality data thus generated, data quantity would not be an issue any longer. Also, multimodal data is expected (with the right model architectures) to be more efficient at training world grokking SOTA models than single modal data and here we have massive amounts of online video data to tap into.
3) Architectural knowledge constraint - This may be the most difficult of all, figuring out what is the next big scalable architecture after Transformers. Either we keep trying newer ideas (like the stanford hazy research group does), and hope something sticks, or we get SOTA models few years down the line to do this ideation part for us.
As impressive as AI is and what it can do. I've felt the same way in my last job. It was almost there; it was almost good enough such that we could almost ship the project but we didn't. GPT3.5 was not good enough, GPT4 seemed like it was good enough in terms of accuracy but it was too slow and we were getting throttled like crazy. I lost my job over it. When I was worried about AI taking my job, I didn't picture it like this.
Our use case was that we needed to consider information from thousands of pages of documents to answer customer questions. I let GPT decide where to look based on content tables of the documents (thankfully each section was not more than ~500 words) and only fetched information from the relevant sections to let GPT answer the user's question. GPT3.5 was fast enough to be usable but often inaccurate; it would ignore some information or get confused about simple mathematical comparisons in the user's questions like 'greater than versus less than'. GPT4 was good and potentially fast enough but the API throttling was too restrictive and it was not possible to feed it less information and still get a good, nuanced answer every time.
Actually the trick to get GPT to find the information based on table of contents worked really well in narrowing down the information for the second-stage summary (to answer the user's question) but our use case nevertheless required a lot of information (often from multiple sections) with a lot of grey areas and nuance and the limited amount of throughout provided by GPT4 didn't cut it.
It was frustrating that, aside from accuracy issues (which depended on the complexity of the question), it often seemed to work very well and fast with GPT3.5 but the exact same code did not meet usability expectations when we switched over to GPT4 due to slow speed (though the accuracy was awesome).
I only spent 1 month and a half on this project but management didn't have the patience to wait for Open AI to remove GPT4 throttling and because they couldn't see it working (at the speed they wanted), they had no reason to believe me that my solution was designed correctly... That's startups I guess.
Anyway I still think there is a lot of hope for this technology and I'm confident that the problem can and will be solved. It was just unfortunate timing for me. Being an early adopter isn't always a good thing.
From what you said your solution wasn't designed correctly?
You should definitely have been using BM25 and SBERT for something like this, you definitely should have been asking 3.5 for structured output and doing any math yourself.
If these were answers from a fixed set of documents there's also a ton of pre-processing you should have been doing.
-
I recently helped a friend with a problem of identifying a certain form of language in EDGAR sourced contracts. He had someone who tried feeding in entire documents into LLMs to find these and the result was some 20 minute search time.
I took a few minutes sitting with him to come up with a demo that used synthetic data and SBERT to process documents in less than 30 seconds. 99% of that was stuff you could do 2 years ago, the part the LLM helped with was creating buckets of synthetic data quickly, and even that could be done procedurally if you had more time.
>> you definitely should have been asking 3.5 for structured output and doing any math yourself.
I suspect that this solution would have required a lot more time given my lack of experience in these technologies and there are a lot of unknowns for that particular use case. For example, a user could ask to compare legalese from 30 different providers to find all those which met a certain conditions; even if you can narrow down the input to just a few sentences per provider, you still need to feed it 30 times that amount or else the AI has no way to compare all the providers.
With my solution, GPT only saw a tiny highly relevant fraction of all the documents. It's possible that the solutions you mentioned would have helped cut our input size further but it's not clear by how much given the complexity of the questions and the data.
That was going to be the next stage, but this would have been a more complicated solution with additional challenges but definitely a lot of code could have been re-used as it would just have been a matter of substituting the database lookup portion.
There are unknowns with the vector store solution because it doesn't suffice to just fetch a few relevant sentences in arbitrary order; we had to fetch every relevant piece of information in appropriately-sized chunks (some of which had to be multiple lines, some of which required the section heading for context) to formulate a correct answer. Sometimes there was something mentioned in a different section of the text which changed the outcome. Going down the vector database route would have taken longer and involved additional learning and it's not clear that we could have reduced the input size by doing that. I still think it was a good decision to start with a regular database first given that all information mapped neatly under the headings in our table of contents and that each section was relatively short. All sections were less than 500 words but most were only about 100 to 200 words.
Yes. This is the reality in many startups. I should probably have refused to work on this project and suggested some other task; that's what my colleague did; he only worked on the front end part. I took a risk, I misjudged the tool and failed.
I wasn't even upset (I got a decent severance), I'd been let go over far more trivial things when I was a junior years ago... Like when the boss fired me the first monday after he met my girlfriend at the office christmas party because he thought she was out of my league. That's why I don't bring her (now wife) to any office events nowadays.
For what it's worth, I can actually tell the hype around AI died down a little. 8-10 months ago you'd hear AI from grandmas and their interest in playing with gpt. That's gone. From programmer's perspective, it is still useless. I can't still get chatgpt to give me a useful ffmpeg or a basic php database script. I don't know who is really using ai for what, other than crappy chatbots.
They are saying JSON works perfectly with chatgpt (gpt4) and still out of 10 queries I get 1 or 2 messed up. I can't depend on it yet. Image generation is still terrible and useless, can't use for programming, text-to-speech neural still sucks big time, not sure who is doing what with it. Almost feels like crypto-hype.
Really? I have a lot of success with bash and ffmpeg scripts. I don't even try to write them myself these days.
I don't do JSON stuff much but either function calling or grammar based sampling should be able to force correct formatting if the issue is syntax.
ImageGen seemed like a solved problem to me with stable diffusion about 6 months ago or so, between LoRAs and the tons of models availble on sites like civitas..
SOTA Text to speech/voice cloning is scary good, but it's only available via SaaS like 11labs (perhaps just them).
One interesting weekend they allowed anyone to clone a voice (required only maybe 10-60s of audio) to say anything
I made Bob Ross read Neuromancer using 60 seconds of fuzzy audio from youtube, but 4chan made something like 20k fake audio recordings on vocaroo of everything horrible and hilarious you can think of. Then they shut that off for good reason on Monday.
There are some cool applications there. I watched an hour video about the talkshow wars between Leno and Conan and i couldn't figure out what the voice was but it sounded like a smart old guy, apparently it was a weird clone of Biden. Which means anyone can now make YouTube content with any kind of voice. Which is bad for impersonation, but good if, say, you don't like the sound of your voice and want to go for a different one (maybe an old timey radio broadcaster)
What definitely has become shittier is the quality of gpt4. But that's not an AI issue, that's OpenAI being OpenAI.
Same. GPT-4 completely replaced my googling/stackoverflow routine. I generates a customized solution for my specific needs with step by step instructions. I think it works in a smarter (but slower) mode if the question is non-trivial. With pdf plugins it helps me reading and understanding recent papers. It generates an excellent summary and answers all my questions regarding any advanced concepts in the paper. I believe it's already smarter than me. I don't know if it can replace me in the mid-term but it definitely increases my productivity.
Image generation is thriving and now an indispensible part of the creative process. The tools are fresh and still evolving, but the impact even in this early stage is ridiculous. You can easily take rough sketches and have it spit out fully fleshed out colored prototypes. Depending on your perspective it's either an insane productivity-multiplier or scary as f-ck or both.
Look at https://civitai.com for a taste. Look around. You really believe this is terrible and useless? Most of these images came straight from SD with some minor tweaking, usually upscaling. I think it's quite something.
It's not just MidJourney, it's the entire ecosystem surrounding models like SD, ControlNet, etc. Some artists are swinging their fists, others shrug, but all are affected by it whether they like it or not and the damn thing is just getting started. SD came out in 2022. As a young aspiring artist I can imagine it's hard to not feel like this whole thing is a massive punch in the gut.
Like an experienced and highly-skilled artist, it's easy to shrug this off when you're an accomplished programmer. It can't replace me, right? Well, true. It's a gradual thing, but the impact it has on junior programmers is undeniable. What it means for our branch if leagues of young people lose interest in the meticulous acquiring of technical and often arcane knowledge through "manual programming" is anybody's guess. Maybe it's a good thing, maybe it's not.
> Text-to-speech neural still sucks big time
This is not my experience at all. I am actually practicing French with it and it can pick up my weird accent. It's ridiculous how good it has become in such a short time.
EDIT: Oh, sorry, I read it wrong. But in that case, the same thing applies. 11labs is insane and getting better. It fools many, many people on Youtube. The Bark project is also scary at times. This is just getting started.
> I can't still get chatgpt to give me a useful ffmpeg or a basic php database script.
I believe these issues are at least for a significant fraction caused by the severely castrated and surprisingly lacking UI efforts from OpenAI. Just free-form "talking" with an LLM might be a good way to get grandma to use it, but as a professional programmer (or professional anything, really) it's bordering on stupid.
The prompts and settings you use determine 90% of your success. OpenAI's interface gives you nothing. They just recently introduced something like "profiles", but it's amateurish at best. It makes me feel like programming without IDE (and Vi/Emacs).
Sure, but even then you're expected to back up your speculation. There doesn't seem to be anything within the article to support the claim that we're at the tail end of development; just assumptions that today's limitations will apply tomorrow.
This is nuanced and interesting, despite most likely being completely wrong - as others have mentioned, it's predicted on LLMs being at the top of the sigmoid and they just ain't.
Also, this goal-post-moving did crack me up rather:
> Sure, it is terrific at using its statistical models to come up with textual passages that read better than the average human’s writing, but that’s not a particularly high hurdle.
Data-centric token-guessing will be outperformed by
more complex architectures, LLMs are too inefficient and
their hardware requirements are disproportionate for the utility.
Building a sand castle of "LLM apis"
that rely on plugging their deficiences is a fundamentally bad decision that
hides the underlying waste of resources.
What will be great if the input data it was fed
was more structured and labeled like images:
imaging a "Book, 17th century, reliablity:54%, contains geographic errors".
Instead this "attention is all you need" approach
treats garbage data equal to top material.
Very interesting article. IMHO a key factor in how the world changes in the next 10-20 years will be how far the current wave of AI, based on neural networks can go.
If scientists and engineers manage to implement autonomous cars and robots that can do basic human tasks like clean, wait and take care of the sick and elderly we will wake up in a brand new world. It will put a lot of stress on the basics of society, such as democracy and having to work for a salary.
> If scientists and engineers manage to implement autonomous cars and robots that can do basic human tasks like clean, wait and take care of the sick and elderly we will wake up in a brand new world. It will put a lot of stress on the basics of society, such as democracy and having to work for a salary.
Based on the trends TFA discusses we'll be seeing severe social stress if basic tasks don't get automated. All due to labor shortages. Focusing on alternative arrangements to salaried work is backwards, unless the goal is boost labor participation.
Current demographics are baked in for the next 30 years and only point to a greater shortfall of labor in the future.[1] $1,000 signing bonuses for fast food jobs start to look quaint pretty quickly.
> My gut feeling is that it will either be too little or way too much.
We've historically been very good at coming up with new things for people to do. Why would this time be any different?
On the other hand it takes over two decades from the time someone's born until they are part of the workforce. That won't change and as a result we have a pretty good idea of what the upper threshold on labor looks like globally the next few decades.
The problem is not integrating millions of sensors of the same type (like individual pixels in a camera), but rather to integrate 2-10 different types of sensors, like microphones, cameras, lidars and tactile/temperature sensors.
Progress has been slow mosly because it's been hand-written, such as the sensor fusion in the F-35.
While there are some attempts at using neural networks to do much of the integration (Like Tesla's self driving) they're mostly quite primitive, and lacks the kind of general understanding of the world that we're starting to se in LLM's.
We have started building multimodal neural networks, though, such as GPT-4's ability to handle images, though. he next step is to add video, which is the mode that requires the greatest amount of compute, we will be able to integrate it with lower bandwidth sensors using the same techniques.
That would be where general purpose models start to become good enough to be deployed in robots. Let's imagine your Tesla has the ability to reason about the world the way GPT-4 can (and with enough fine tuning that halicunations are gone), and that it can do that not only based on text, but also all the sensors of the car, then it might become able to handle situations outside its training set much better than today, possibly better than many humans.
Once we're able to build multimodal models able to handle realtime video and s
But at any given time you're probably only going to require some millions or double digit billions, unless you're a nation state or something like that.
Don't think a robot needs millions of sensors. 90% of the information that a human uses comes through the eyes - so just 2 sensors. Really in terms of doing most types of work all a robot would need is vision and hearing.
Humans have an insane number of sensors all working with each other. The eyes are not just 2 sensors and a blind person can still function fairly well though with limitations.
The human-like robot dream is a complete non starter for me, total science fiction. Unless economic reality changes radically it will always be cheaper to simply pay a human to do these jobs. There are already many jobs that could be replaced by robots but by and large they haven’t been because buying, maintaining and powering robots costs more than paying humans minimum wage, and this fact isn’t changing any time soon. The type of robots you’re envisioning are even more complex and expensive… Do you really think a human-like robot with some level of useful general AI is going to be cheaper to build, maintain and run then low skilled workers?
If not anything else there's a shortage of human workers. Yes, it will be easier to manufacture and power robots, than to increase the number of human workers.
The form factor may not be humanoid, but if we can crack a general-purpose home robot, it would start out as a novelty plaything for the ultra rich, but at that point it would be only a matter of time before it started falling down the cost curve as we got more and more efficient & optimized with the manufacturing and the software. So yes, it almost certainly would eventually get cheaper than human labor. How long until that happens? No idea!
I hope beyond hope that we continue to iterate on the current GPT-4 model. But statements made by Altman himself make me leery that it might not happen. That, coupled with the fact that it is just so expensive to run make me wonder if this whole thing is sustainable.
Take this into consideration - NVDA’s massive profit in the last couple of quarters is someone else’s expense. When no one is making money on AI, can this continue? I absolutely think companies can make money using AI that people will pay for, but I am not convinced that companies can make money supplying AI services. I see it as almost a commodity type service, like internet access or something. There is no clear path to profitability, and that is ok to some extent, but with the massive costs this could come crashing to a halt very quickly.
With few prompts I just wrote a small script with a bunch of openssl commands. Saved me an hour. And it works. And it even explained it. There is AGI and then there is “practically agi”. The latter has been achieved with LLMs.
Conversely, if you don't know what the limits are yourself (and you don't) you wouldn't know either way. So I'm not quite sure if you'e added anything here unfortunately.
My opinion is that we don't know the limits. This is essentially no opinion because of no data. Stating a limit without data is an opinion thought and a wrong one.
> But almost everywhere else needs people. Badly. Across retail, restaurants, manufacturing, trades, and on and on, companies are struggling to hire. And this brings us back to the cross-country trip observation and that “signing bonus” sign in a McDonald’s window.
For jobs that pay just enough to not qualify for food stamps or Medicaid but not enough to buy food medicine and rent.
Previously it was more possible to earn little enough to qualify for benefits and live if not well but the numbers have become misaligned and don't account for differences between expensive and cheaper parts of states.
Given present concerns the situation doesn't change appreciably unless you go all in on automation implement UBI or both.
"too few people for all the jobs, for the most part"
- Are wages going up?
"But almost everywhere else needs people. Badly. Across retail, restaurants, manufacturing, trades, and on and on, companies are struggling to hire. "
- Wow sounds like an exciting star trek future that I cant wait to be part of!
"labor became more expensive than capital"
- So wages must be going up right?
"In essence, the authors show that for automation to have widespread benefits it must deliver high productivity gains to more than compensate for the high displacement of workers."
- the reason why this sentence makes no sense is because it is written in two frames at the same time. One of a planned economy and the other of capitalism.
"We are in a middle zone, however, with AI able to displace huge numbers of workers quickly, but not provide compensatory and broader productivity benefits."
- But what about the horses?
I tried my best to find the central thesis of this rambling multi-tone work. I think it is difficult because it was written with too many different frames.
Capital's willingness to ride out labor shortages without increasing wages seems to have become substantially greater in the last couple of decades.
TIRED: labor shortage -> wages rise!
WIRED: labor shortage -> y'all work harder for maybe a bit of overtime or maybe not, and we'll just absorb the complaints about customer service and product quality. Those damn employees aren't getting a penny more!
The food of 1969? I've had it. It was my aunt's cooking and my uncle's butchering - shooting a hog right in the head and then gutting it, draining the blood, and prepping it to go onto a gigantic smoker, and it was delicious. And if you really didn't feel like cooking food yourself, McDonald's did exist back then, along with things like Kentucky Fried Chicken, Krystal, Burger King, etc.
They didn't throw sugar into every single product on the market, either.
The home appliances? You mean blenders and toasters and refrigerators and mixers that would last 20-30 years before needing to be replaced because they were so well-engineered? Those 1969 home appliances? Like the KitchenAid K45 mixer that was released in 1962 and stayed in production for decades? Like the one my Mom got in 1971 that she still has today, whose motor still works fine, and the only thing that's ever been done is 30 minutes of taking it apart and checking the worm drive gears and re-greasing them? Those 1969 appliances??
And the cars? Yeah those were kinda shitty compared to what we have now.
For the most part though, you're not just off-base on the food and appliances, you're hilariously off-base.
Why do you think there is a zero sum choice between real terms purchasing power increases and the technology we have today? (Also worth noting I'd happily take a lot of goods from a time where they were built to last)
That's a graph of disposable personal income, not purchasing power, and it doesn't account of the increased cost of several major spending categories.
It's also the total disposable personal income for the entire country, and not median household income. See the "Units" field: it's in billions of chained 2012 dollars.
It's from 2018, but this shows what's going on more clearly:
As I live in California, I've seen 'em. They're not all Eichlers.
> You would like the salary saved from 1969.
A tech worker makes more than 5 times the median 2023 personal income and their industry didn't exist then, so I mean, I wouldn't even if I could afford the house in Palo Alto.
And you wouldn't want to say this to a racial minority or even someone in Appalachia.
You’ve kinda proven the point. The argument made was cherry picking.
Here again - You’ve used the most highly paid subset of workers. In any other nation, and in other industries in America - Tech workers dont get paid that much.
The average floor area per person (in the US) has roughly doubled since 1969. Not the most reliable source, but from skimming census data it seems to correlate: https://supplychenmanagement.com/2018/07/15/average-house-si.... I'm personally not much a fan of large houses, but most people are.
I'm a bit disappointed this part of the conversation is buried under everyone arguing about whether the article is right about AI or not, since the real interesting part of the article is why the author(s) seem to think that the reason McDonalds is doing signing bonuses is because people are just just not working, and the article never seems to really understand why people aren't flocking to jobs colloquially known to be absolutely awful and shit jobs.
Similarly, I'm very disappointed that the discussions in the article focus so much on _replacement_ of these workers, but in terms of human replacement, it really seems like AI is better suited to displace management and executives, not the people who perform specialized and physical work.
AI should help people and extend their abilities, and right now it's very good at that. It can be used to make our lives easier _now_, not replace us, and I think this is the real reason the article is so heavily discussed. I think the article explains how the author released a lot of the conclusions they did, and I agree, the author is jumping around way too fast and in my interpretation, making some very wild assertion in the article without further fleshing out their points.
> it really seems like AI is better suited to displace management and executives, not the people who perform specialized and physical work
Management and executives are the ones holding the purse strings for these expensive solutions. Why would they implement something that could replace them?
Employers are always talking out of both sides of their mouths. They signal they want more workers yet are more choosy than ever in terms of pre-employment screening. it's like someone who wants to work at McDonald's has to go through a huge gauntlet of background checks , interviews, and tests, yet companies insist thee is a shortage. maybe try lowering the requirements a bit. And then once you get the job it's more requirements and rules. A lot of low-skilled ppl would rather just not work than deal with t all that crap for a minimum wage job. Part of the problem is maybe the quality of the pool of workers has declined , so more screening needed.
I was particularly puzzled by the 2x2. High productivity is a no brainer, but why should we necessarily seek high displacement as its own goal? Low displacement would increase employment and GDP, is that not flourishing?
And what's with using the research scientists who authored Transformers as examples of surplus middle management? Google generated 1.4M per employee in 2022, second only to Apple. Armchair engineers will say they could do as well with a handful of employees, but if this is "low productivity" then sign me up.
I’m so done with writing that has an implicit but uncommunicated quantitative model. (AI costs are too high? Relative to what? Show us!) Almost all analytical / business / industry writing should quantified.
I hope for better. We all should. It is within reach. Yes, I'm grumpy on this topic, but this doesn't make it unwarranted; it is a consequence of wanting better for a decade or longer.
At this point, if you claim to be a business analyst and you aren't sharing a simulation, logic, or code, I'm just not going to take you seriously.
> too few people for all the jobs, for the most part.
Change that qualifier to "for a minority part" and it would be correct.
There are plenty of workers - old and young and everything in between - who would gladly work if a) you allowed them to and/or b) you paid them enough.
I do not think it is fair to use AI in support call centers as an example.
These call centers are not there to help customers (cancel subscription, refund, change something, etc.) and AI is perfectly tuned for that. Or at least they have procedures and AI is perfectly train to follow these.
In other words, AI in support centers is designed and works to follow companies procedures and rules—which may not always align with customer expectations.
So is a simple form on a website in most cases. It would also be cheaper for the company and less frustrating for the customer. No one wants this "AI" chatbot bullshit except for companies selling "AI".
Or that customer wanting to cancel spend hours talking to the bot so they finally give up and hopefully forget.
Having a simple form to cancel/refund/change/lost item/sent to wrong address/etc. is easier way to do and handle. But companies do not want that so … chatbot to rescue.
Great article. Although I am not sure if we really are reaching the value limits of the current LLMs, as the author mentions. Some fields as legal litigation are being disrupted as much as call centers have, but the change is happening in a much slower fashion, for many reasons. The productivity gain in these fields is potentially high, but so is human displacement. Relevant fact to consider
The most interesting part of this article isn’t its assertion that AI innovation is about to slow, but rather that current LLMs can only produce “so-so automation” — that although LLMs can replace many jobs, LLMs aren’t good enough to offset the cost of people losing such jobs.
True as of today, but the article is overlooking multi-modal LLMs. Once AI can see, we’ll go from “wow, GPT4 is pretty good at helping me to my job” to “uh oh, GPT4-Vision can do my job better than I can”.
This is especially true if the model can read text off a screen. At that point, it’s likely to replace many workers who stare at screens for a few hours a day and pretend to work the remainder. The model won’t take coffee breaks, or long lunches, or take the afternoon off to drive their kid to the dentist. If you’re a worker whose work depends upon looking at a screen, and mostly involves moving data from one place to another with light transformations and interpretations, you’re going to be in trouble by the end of the decade.
And since everyone who has been writing has been replaced by machines as well, most of those texts will be machine-generated by then.
Machines reading and processing texts written by machines would be the logical consequence in this scenario, but I can't help finding the whole idea deeply absurd.
I haven't read the article (like many here) and I don't get why the writer would write this. LLMs/AI are not a stage where they can replace people or their jobs (broadly speaking), they still have to be taught and engineered to solve your problems. For example, if I enter a prompt "Write a Javascript function that does XYZ for me.", and don't get a desired result, it's unfair for me to say "ChatGPT bad, AI bad".
At this moment, you have to work with the limits, use better prompts, use ChatGPT as a guide and not as your personal robot. With that approach, I feel lots of revolutionary content is incoming in products. Use the tool better to get the most out of it.
We don't need better LLMs to eliminate all McDonalds workers. In fact there's no language model needed there at all. The job just needs better robotics.
How far are we from a point you could leave AI to prompt something itself. That is not just respond to something, but actively seek it.
Let's say use this place. Could it without being ordered read articles, comments and add it own comments? Maybe search internet by itself for relevant content and post it? Maybe try to earn maximal amount of upvotes? And all this without there being any bit of code poking it to do it?
I was going to ask "how would it know what's a good post" but it's embarrassingly easy to train the AI on interesting or not content based on upvote information...
HN guidelines and moderation are doing a decent job of promoting interestingness in general. I don't think upvotes are a reliable indicator, but maybe they are as close to good enough as a system can be.
Depending on timing, you see great topics flying under the radar. Likewise, "poor" posts regularly prove to be quite popular. But then again, this is also subjective.
I think it comes to nebulous concept of out of "free will". Just not have a "bot" running some loop. But have entirely self-acting AI. One that could for instead go and find Reddit or Lemmy or some other place.
AI won't work to reeingineer society, just like the last 100 "latest things" didnt. There is a massive undercurrent that always goes in the opposite direction of technology advancement: tradition!
You need new people growing up and living in a new paradigm to get these changes, you cant just ask (or expect) people who have lived their life one way to change completely to some other way of living
The absence of human workers has become a limiting factor on economic growth in the U.S.
the problem is real GDP growth is flat or negative due to high inflation. having more labor would make this worse, if anything. job creation tends to be inflationary. from 2010-2021 saw strong economic growth and low inflation, but now things suddenly changed due to too much inflation, not a lack of growth.
The jobs are already created, unfilled. The lack of workers causes wages to go up which adds to inflation (e.g., the $1000 McDonalds bonus). But if you add more workers, you increase productivity, and reduce wage inflation.
When I see VCs make this argument, all I hear is "oh shit, we're late to the party" and doing something like this as a desperate attempt to bring valuations down.
I don't think the assertion that we've reached the end of current wave of AI is correct. It hasn't even been rolled out to anything yet.
Once it is fully integrated into os/browser/corporate workspace and the MBA's have thrown LLMs at every business problem they can think of then perhaps but right now it hasn't even left high tech circles
When I read articles like this I can't help but question my own intuitions since they are so opposed to this author's thinking.
Firstly, his suggestion on the worker shortage and the anecdotal $1000 sign on bonus at some local McDonalds. These seem more tailored to a narrative interpretation of the state of the world that is formed to the author's own bias. I look at my own small town homeless and drug addicted population and consider the changes in the last 5-10 years on that front. I consider the insane rise in the cost of home ownership and the massive rise in rental costs locally. I just don't see $1000 signing bonuses at fast food restaurants as a sign of some latent demand for labor. It feels like the author is using a single anecdote and a narrow reading of a few graphs to support a world view that I don't see existing in my own experience.
Then he says: "We are quickly reaching the limits of current AI". You mean the AI that surpassed most informed peoples expectations on AI capability less than one year ago? I feel like I'm in 1996 reading an article about the Internet where someone gives some list of reasons why the Internet is reaching its limits.
And just as an aside, this author uses the term "explosive" especially in the context of "explosive growth" over and over. It may be that his target market just isn't me. The narrative and analysis probably hits home for a particular set of capitalist minded investor class individuals. Perhaps they really do see North America as having a huge labor shortage and that we just need the "right" kinds of automation so we don't all feel so bad about the continuing displacement of workers. As long as they keep seeing "explosive growth" in the value of their assets.
“Historically, when this has happened—labor became more expensive than capital—economies have responded with automation, so we should expect that again today.”
Foolish assertion. Immigration has always been the stop-gap solution for expensive labor to the point that it’s built in as an essential feature of liberalism.
disclaimer: i am in the middle of the journey into learning this subject, and have at least done finetuning on existing models. some may still consider my take as misinformed.
one thing i am not a big fan of in this discourse is that how the community makes up jargon to describe relatively simple things on one hand (a la "embeddings"), and while come up with misnomers like "hallucinations" to describe otherwise blunt things. it is contributing to miss the forest for the trees in this discussion.
while i agree it is quite impressive to see what the state of the art can seemingly achieve on surface, the way we approach designing these models are fundamentally not aligned with what we want to do with its result. while some media for generative machine learning produce relatively harmless results (e.g. images and audio), it is the text where i have a lot of reservations.
we train these models to essentially turn noise into something that humans can pass as acceptable (for the given prompt). Sadly, however, people outside (and sadly "inside") this space claim it to be the word of God.
i still strongly believe that a hybrid system is going to be the only way we can achieve the most from the current approach. almost a decade ago we were already good at parsing through sentence structure and "understanding" what the user writes. what the output is can easily be done with some hardcoding in logic with some noise thrown in by the models. however, it should only be treated with that level of seriousness.
i might be shouting into a void, but it is imperitive that we stop taking what these models output as production-ready code, or as a starting point even! otherwise, the only thing you achieve from this is to train the models running the chat services further.
> There is a persistent structural imbalance in the U.S. workforce: too few people for all the jobs
Lies. If the minimum wage increased proportional to inflation, none of these "jobs" would exist.
The McDonalds sign-on bonus is nothing but a loan, just like all sign-on bonuses with a retention requirement. Such arrangements merely require that minimum wage is low enough to partition that compensation out of the base wage, a modern American financial industry to efficiently enforce the contracts, and a society with no remaining semblance of dignity in sight.
Labor shortage it BS. It's rhetoric to increase immigration so we can continue sustaining a slave class and don't have to pay people properly. Canada's been very successful at this.
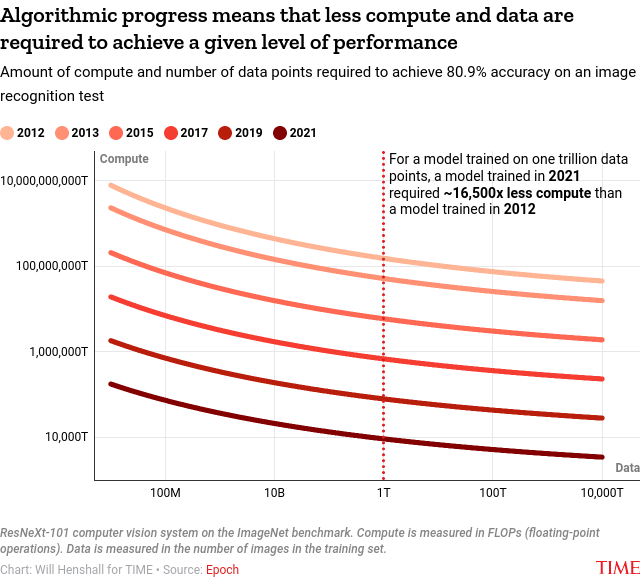{kind=link}