Intel unveiled their infamous "Tick-Tock Model" around 2007 [1]. It went according to plan for all of four years, and then it COMPLETELY fell apart. If anything, I'm willing to bet they KNEW they could hit the first few iterations. I'm guessing for hardware, you've probably got a really good idea if you're going to be able to even manufacture something in two years, let alone mass-distribute, produce, and sell it at the price point you want. I'm also pretty certain they KNEW they wouldn't hit the rest of the roadmap.
Honestly, I think it was purposefully misleading investors. I heard from dozens of engineers at the company around 2008 that there was NO WAY they would have 10nm chips around 2012 -- what the roadmap was more or less promising. And surprise, we didn't get them until 2018. Now they're promising 1.5nm in a similar time frame. I'm skeptical.
> I heard from dozens of engineers at the company around 2008 that there was NO WAY they would have 10nm chips around 2012 -- what the roadmap was more or less promising.
(Cannon Lake-U 10nm technically shipped in 2018, but I don't think anyone really considers it volume-enough to count?)
They pretty much nailed tick/tock flawlessly up until 10nm, 10 years out from when tick/tock was first announced. Expecting perfect 10 year predictions is some insane expectations for any company/person. There's no way in hell tick/tock's 2007 unveil could possibly be considered "misleading investors."
>Where did they promise 10nm in 2012? This presentation from 2011 shows 10nm in 2017:
Your link shows 7nm in 2017, 10nm was for 2015.
>Tick/tock was a process shrink every 2-3 years. Using the more aggressive 2 year cadence:
You are confusing "Tick Tock" with "Process, Architecture, Optimization". Tick Tock is strictly 2 years cadence.
So yes 10nm missed by a large margin.
> 10 nm – 2018/2019
Intel has been making 10nm chip irrespective of yield, the current batch were months of stock piling chip before the rush to roll out in Xmas. In reality they barely got it out of the gate in 2019. And if you count Cannon-Lake as 2018, you might as well count TSMC 5nm in 2019.
>There's no way in hell tick/tock's 2007 unveil could possibly be considered "misleading investors."
There were not misleading in 2007, the executed their plan flawlessly, Intel had decent people back then. Pat Gelsinger left in 2009. It was still doing great up to 2012, Otellini retired, BK became CEO in 2013, still promising Tick Tock. That is the point where misleading investor began.
And I forgot to mention during All investor meetings Intel continue to reiterate 10nm is on track all the way until BK was gone. If that is not "misleading investors" I am not sure what is.
That's a little harsh on the history of the Tick-Tock roadmap. It didn't have its first real hiccup until 2014 with Haswell Refresh v Broadwell, and then Skylake was delivered on time a year later. It was Intel's complete failure to follow-up Skylake with a process shrink "Tick" that was—and still is—Intel's big problem. So it really worked out alright for Intel for about 8 years before hitting a wall.
Big lies seem self-reinforcing, particularly in public companies.
Or to put it another way, nobody is going to charge you with a crime for staying with the herd. That's a passive choice.
But when there's a dissenting voice, suddenly you have to make an active decision to ignore them. And that's when the lawsuits start producing emails about who knew what when.
End result: People intentionally (if they know better) or unintentionally (if people smarter than them are all saying the same thing) agree with the party line, even in the face of demonstrable facts otherwise.
It’s easy to rag on Intel, but the market changed for them pretty fundamentally. Customers ultimately rule.
On the server side, big hyperscale datacenter customers have large, narrow purchase patterns. They are upending the market — ask around and figure out how many HPE or Dell CEs are still around servicing servers these days.
On the client side, similar patterns exist at a smaller scale. At the higher end Apple probably does 90% of their Intel business with like 10 SKUs. At the lower end, there’s a huge demand for cheap, and many companies skipped refresh cycles.
This was impactful imo as the old ways of dealing with manufacturing issues (sell underclocked parts, etc) are harder when Amazon has prepaid for 30 million units of SKU x.
But even if Intel isn't the one to do it, someone will. And given that AMD is just using contract fabs, it means we will have x86-64 chips with these technologies at roughly these times.
I wonder if a x86-64 CPU will exceed 1024 cores before the end 2029? It feels like that is where we are headed.
If there's something useful about having 32 32-core chiplets connected to an I/O hub talking to a bunch of PCIe5 lanes and a huge pile of DDR6 RAM, that could happen.
But getting all that compute logic coordinated in one place might not be that economically desirable compared to offloading to GPU-style specialized parallel processors, or building better coordination software to run distributed systems, or...
> connected to an I/O hub talking to a bunch of PCIe5 lanes and a huge pile of DDR6 RAM
So, basically a mainframe on a chip?
Honestly, how would that work? Is all that memory coherent? There are a couple of reasons why mainframes cost so much, and some of them are technical.
I keep expecting servers to evolve into a multi-CPU non-coherent RAM, but the industry keeps doubling down on coherent RAM¹. At some point servers will turn into a single-board blade hack (that you can mount on a blade hack, piled on a hack), I wonder for how long CPU designers can sustain our current architecture.
1 - Turns out people working full time on the problem have more insight on it than me, go figure.
Bigger servers just get divided up into more VMs. As long as it's cost effective to scale vertically, it will continue to happen at the cloud platform level.
It'll be interesting to see what these high core count servers do to The Cloud though.
Fifteen years ago a lot of medium-sized organizations had a full rack of single and dual-core servers in their offices that cost half a million dollars and consumed >10KW of electricity day and night.
That made it attractive to put everything in the cloud -- spend $250K on cloud services instead of $500K on local hardware and you're ahead.
But their loads haven't necessarily changed a lot since then, and we're now at the point where you can replace that whole rack with a single one of these high core count beasts with capacity to spare. Then you're back to having the latency and bandwidth of servers on the same LAN as your users instead of having to go out to the internet, not having to pay for bandwidth (on both ends), not having to maintain a separate network infrastructure for The Cloud that uses different systems and interfaces than the ones you use for your offices, etc.
People might soon figure out that it's now less expensive to buy one local server once every five years.
I think it's always been vastly cheaper for the hardware. But it gets more complex when you look at the TCO. With the in house server you need at least two, in case one fails. Although now probably everyone is running their own mini cloud with kubernetes, even in the cloud - and that should make it relatively cheap.
Then you need someone to plan, provision, troubleshoot, and maintain the physical servers. So at best a full time fully loaded position which costs the company roughly 2x the salary. And that's only if you know your workload so well that you can guarantee the shape of your hardware usage 3-5 years out. Rarely possible in practice.
I'd say always start with the cloud, and you'll know if or when you could do (part) of it cheaper yourself.
> With the in house server you need at least two, in case one fails.
That doesn't really change much when the difference is a four figure sum spread over five years.
> Then you need someone to plan, provision, troubleshoot, and maintain the physical servers. So at best a full time fully loaded position which costs the company roughly 2x the salary.
Would it really take a full time position to maintain two physical servers? That's a day or two for initial installation and configuration which gets amortized over the full lifetime, OS updates managed by the same system you need in any case for the guests, maybe an hour a year if you get a power supply or drive failure.
If the maintenance on two physical machines add up to a full week out of the year for the person already maintaining the guests, something has gone terribly wrong. Which itself gets balanced against the time it would take the same person to configure and interact with the cloud vendor's provisioning system -- probably not a huge difference in the time commitment.
> And that's only if you know your workload so well that you can guarantee the shape of your hardware usage 3-5 years out. Rarely possible in practice.
Most companies will do about the same business this year as they did last year plus or minus a few percent, so it's really the common case. And if you unexpectedly grow 200% one year then you use some of that unexpected revenue to buy a third server.
Where the scalability could really help is if you could grow 200,000% overnight, but that's not really a relevant scenario to your average company operating a shopping mall or a steel mill.
Certainly if you have someone already on the payroll who can take responsibility for the hardware part time, that makes it a lot cheaper. That's a different skill set though, so it's not true for every company.
With respect to changing workloads, I wasn't thinking so much about scale, which I think isn't that hard to plan for, but more about changing requirements. If you add, remove, or change a piece of your stack the cloud gives a lot of flexibility. Add memcached, no problem, spin up some high mem instances. Need more IO on the database server, switch to an instance with fast SSDs, or a bigger instance. I think those kinds of changes are common and hard to plan for. Until it happens you probably don't know if you are disk, network, memory, or CPU bound.
Once your stack is sufficiently mature and not changing much the workload gets a lot more predictable. The cloud is really good for starting out. The danger is it's also really good at locking you in, then you are stuck with it.
> Certainly if you have someone already on the payroll who can take responsibility for the hardware part time, that makes it a lot cheaper. That's a different skill set though, so it's not true for every company.
True, though all the physical hardware stuff is pretty straight forward, to the point that anybody competent could figure it out in real time just by looking at the pictures in the manual. Configuring a hypervisor is the main thing you actually have to learn, and that's a fundamentally similar skillset to systems administration for the guests. Or for that matter the cloud vendor's provisioning interface. It's just different tooling.
> If you add, remove, or change a piece of your stack the cloud gives a lot of flexibility. Add memcached, no problem, spin up some high mem instances. Need more IO on the database server, switch to an instance with fast SSDs, or a bigger instance. I think those kinds of changes are common and hard to plan for. Until it happens you probably don't know if you are disk, network, memory, or CPU bound.
I see what you're saying.
My point would be that the hardware cost is now so low that it doesn't really matter. You may not be able to predict whether 8 cores will be enough, but the Epyc 7452 at $2025 has 32. 256GB more server memory is below $1000. Enterprise SSDs are below $200/TB. 10Gbps network ports are below $100/port.
If you don't know what you need you could spec the thing to be able to handle anything you might reasonably want to throw at it and still not be spending all that much money, even ignoring the possibility of upgrading the hardware as needed.
> Once your stack is sufficiently mature and not changing much the workload gets a lot more predictable. The cloud is really good for starting out. The danger is it's also really good at locking you in, then you are stuck with it.
Right. And the cloud advantage when you're starting out is directly proportional to the cost of the hardware you might need to buy in the alternative at a time when you're not sure you'll actually need it. But as the cost per unit performance of the hardware comes down, that advantage is evaporating.
I don't think the hardware is that trivial. I used to think that, but I've learned a lot more respect for the people who understand how to troubleshoot it, how to purchase compatible components, and spot troublesome products and brands. It's a whole career, it has its nuances.
But you make some good points. In general I agree it's cheaper to vastly over provision than to use the cloud. And you can do things like build an insane IO system for your database, which you can only sort of do in the cloud.
Of course this is an advantage for hosting internal company stuff, for web facing things you may need to place hardware in remote datacenters, and then you do need people on location on call who can service it. You have to generally have much larger scale for that to make sense. Even Netflix, because of the variability of their load still use a combination of cloud and their own hardware.
> I don't think the hardware is that trivial. I used to think that, but I've learned a lot more respect for the people who understand how to troubleshoot it, how to purchase compatible components, and spot troublesome products and brands. It's a whole career, it has its nuances.
I didn't mean to suggest there isn't a skillset there. And that's really important when you're doing it at scale. The person who knows what they're doing can do it in a fifth of the time -- they don't have to consult the manual because they already know the answer, they don't have to spend time exchanging an incompatible part for the right one.
But when you're talking about an amount of work that would take the expert three hours a year, having it take the novice fifteen hours a year is not such a big deal.
> Of course this is an advantage for hosting internal company stuff, for web facing things you may need to place hardware in remote datacenters, and then you do need people on location on call who can service it. You have to generally have much larger scale for that to make sense.
On the other hand you have to have rather larger scale to even need a remote datacenter. A local business that measures its web traffic in seconds per hit rather than hits per second hardly needs to be colocated at a peering exchange.
It's really when you get to larger scales that shared hosting starts to get interesting again. Because on the one hand you can use your scale to negotiate better rates, and on the other hand your expenses start to get large enough that a few percent efficiency gain from being able to sell the idle capacity to someone else starts to look like real money again.
The Xeon Phi[1] CPUs were already up to 72c/288t in 2016, if the market demanded it I'm sure Intel could built it, but more than likely the high core counts are a GPU/Compute card's territory until ARM scales it's way up that high.
I actually heard and memorized the opposite : people tend to overestimate what they can do in 10 years (for example, in 1980, some people thought flying cars would be a thing in year 2000) and they underestimate what happens in 1-3 (for example, our smartphones or computers get twice as fast, but the change is so incremental that people don't notice it)
Soviet tractor quality wasn't that bad, especially considering they shared a lot with tanks. And for the price they were likely even better :) . Not to mention that they came with capabilities to be repaired - something Intel in its chips will likely, and sadly, not include...
The kind of tank design that appeared in World War I. They were designed to cross the cratered wastelands and trenches created by the fighting. The crews fought from gun ports and mounted cannons/machineguns, rather than a rotating turret.
Socialist design is generally pretty good, in my experience. I preferentially buy DDR-made tools when it makes sense, because they tend to be very solid, and very easy to maintain and repair. The furniture can also be nice.
And were typically indestructible once they did run. Soviet pre-fall engineering was ugly and the factories sucked but the designs were solid and could run for ever with very little maintenance.
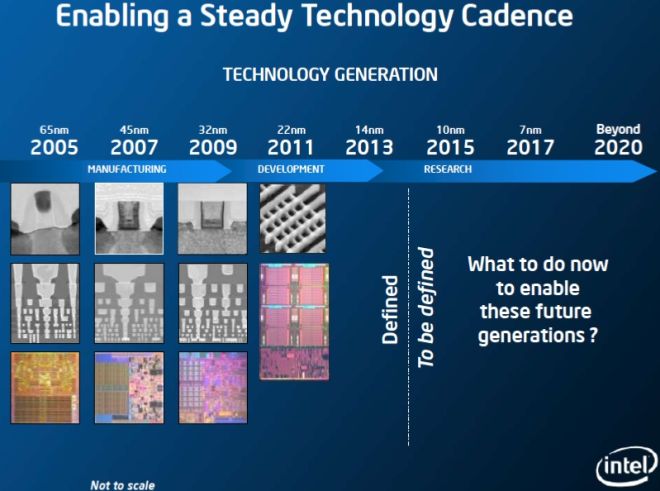
OOC, do you view Intel's projections as being too slow or just plain wrong (i.e., impossible)? I am not knowledgeable about this industry or the engineering behind it, just follow it casually, and I'm shocked to see 1.4nm on a slide.
I don't know that they actually are. Like most of the S&P500, Intel is actively participating in billion-dollar stock buyback programs. These allow for these companies with scrooge-mcduck-scale money bins to maintain vanity stock prices while their fundamentals are on fire.
It's a pretty rich multiple if one believes their fundamentals have been deteriorating. Intel has spent the last decade abandoning market after market while simultaneously not being able to execute in the markets they were still in. If something doesn't change soon, even that 12.9 p/e won't be sustainable.
are they? maybe if you push people really hard (completely unrealistic) they will still deliver much more than otherwise ("just" unrealistic). You might not land a rocket on Mars, but you can still land it on water...
Even if you don't need the power (and you sometimes do, and even if you don't right now there'll be some electron app that will make you wish you had a 1.4nm CPU eventually) improving the process usually means better efficiency too which is important to make batteries last longer and datacenter less wasteful. It'll probably make for some good looking videogames too.
You're thinking is flawed. Consumers don't give a damn for the most part, but Intel isn't building this tech for them. They're doing this for enterprise data centers which demand smaller, more powerful, and energy efficient chips constantly.
Consumers also care about getting better energy efficiency out of their battery powered devices. It's really just the desktop PC market where being stuck with 14nm CPUs is a non-issue, because wall power is cheap and cooling is easy.
I agree, they care about battery performance, but they don't understand the correlation of CPU to battery so they don't purchase based on that criteria.
The vendor that makes the device definitely cares though I wonder how much Intel cares about consumer oroducts as percentage of mkt share compared to servers.
I like to write emulators as a hobby so I definitely feel your pain, but I'm not holding my breath for a significant frequency boost in the near future. A 4GHz CPU means that every cycle light itself only moves about 7.5cm in a vacuum. If you have a fiber optic cable running at 10GHz at any given time you effectively have one bit "stored" in the fiber every 3cm or so.It's frankly insane that we manage to have such technology massed produced and in everybody's pocket nowadays. My "cheap" android phone's CPU runs at 2.2GHz, 2.2 billion cycles per second.
We can probably still increase the frequencies a bit but we definitely seem pretty close to some fundamental limit in our current understanding of physics. The frequency doublings every other year we experienced until the early 2000's are long gone I'm afraid, and they might never come back until we manage to make a breakthrough discovery in fundamental physics.
I think it’s more of a power dissipation issue. The amount of charge, thus current, you are moving in and out of the gate capacitance is proportional to clock frequency. Sine power is I^2*R, then it is proportional to f^2.
Smaller transistors reduce the I, but R goes up with smaller interconnects. The RC time constant also adds delay, probably more so than length.
That being said, 3D stacking won’t help with heat, and dielets won’t help with delay. I rather have 4 cores at 10 GHz than 64 cores at 3 GHz.
It’s electromagnetic simulation, specifically finite element. You can parallelize some of the math, but mostly not. You can break the structure into smaller sub-domains, but that has issues too. Not much gain beyond 2-4 cores.
Not my area of expertise, but I was under the impression that finite element analysis, like other sparse algebra problems, are reasonably well suited for GPUs, which are much more parallel than 2 or 3 cores. Have you looked into that?
The time domain codes work well with GPUs and multiple cores, but the frequency domain ones don’t. I don’t know enough of what’s going on under the hood, but it’s like that for all of them.
I've worked with applied math PDE people and they use supercomputers to full effect. Granted it's a real pain and your cross connect bandwidth matters (hence supercomputer), but you can scale up pretty well.
Everyone wants faster CPU cores. Can you imagine how much simpler it would be to just program a 40GHz processor instead of writing a program that supports 10 4Ghz processor cores?
I might not need more improvement than today's state of the art Consumer CPU. But even the best in class GPU are not over powered for gaming. With Ray Tracing and 4K I could easily use another 4 - 8x transistor density.
I know that past performance does not indicate future results but looking at their 2013-2016 roadmap [1] which promises 10nm at Q1 2016 (which never happened!), I strongly doubt their future roadmap will hold.
And for the previous 40 years Intel was always about 1 year ahead of their competitors. I would never bet against Intel, that's been a losing game for far too long.
Irrelevant. AMD doesn’t own its own fabs anymore, and I think they rely on the expertise for whoever happens to be fanning their chips, allowing them to simply choose the fab with the best process while they focus on architecture.
No. It’s just the reality of the situation. Perhaps intel would do better to separate their fab and architecture divisions, or maybe they are already sufficiently separated internally anyways.
Yes, and in those years* Intel also had the largest leading edge wafer output. I.e They managed to sustain that lead because they had the volume. So what has changed? Even if Intel continue to ship 200M leading edge node to PC market they still would not compare to the GPU + AI + Mobile SoC Market in volume. Those days are gone. TSMC now has that advantage.
I don't think it's fair to say a leaked roadmap counts as Intel promising something, nor should 1 miss prediction immediately result in the dismissal of everything else. There's no pattern of Intel missing their roadmap to justify much suspicion. It's odd to put out something like this while 10nm's failures are hot in everyone's minds, but still.
At what point does this become securities fraud? How many retail investors are going to get annihilated when intel runs through their buy back authorization? This all feels like a ponzi scheme but with intel turning the crank using their own cash.
Woah there pal, you're forgetting that they spun up their 22nm process again in 2018 [1]. Intel has a lot of fab headaches right now. A reminder that 22nm debuted in 2011, and 14nm was 2014.
Meanwhile TSMC is out there shipping 10nm equivalent for a year now, including in Threadripper and Apple's AX chips. Wonder if AMD will ship a next gen TSMC fabbed product prior to 10nm Shipping en Masse.
TSMC's 5 nm node is on track for high volume in Q2 2020[1]. They also have the announced 6 nm which they expect most clients to transition to[2]. If Intel's 10 nm is equivalent to TSMC's 7 nm then their 6 nm should be noticeably better even before 5 nm starts shipping.
So if Intel actually stayed on track for this roadmap, they're saying "we only have 10 years left to advance our fabs". Unless 1.4nm is actually meaningless, they'd be edging up to electron tunneling issues with a contacted gate pitch of ~10 atoms across.
I'm being optimistic with this guesswork. Intel's historical naming is that cpp = 3-5x node name [1]. Silicon lattice spacing is ~0.54nm.
> "we only have 10 years left to advance our fabs"
Well, only 10 years left to advance with silicon wafers; once improvement truly becomes impossible there presumably we'll see even more resources go into trying to find practical replacements.
> It’s worth also pointing out, based on the title of this slide, that Intel still believes in Moore’s Law.
> Just don’t ask how much it’ll cost.
I once got an opportunity to ask something similar to an Apple executive during a presentation on their hardware capabilities (it was a university event).
He laughed and answered another part of my question.
This is pretty well known in the semi-conductor industry.
Everyone believes 5-7nm is the cost wall for just about everyone but Apple or Intel. Some companies are actually going the opposite direction or re-spinning new chips on older processes because of cost.
That's not quite correct. It's about the number of transistors per integrated circuit that minimises per-transistor cost. From the actual 1965 paper:
> "The complexity for minimum component costs has increased at a rate of roughly a factor of two per year (see graph on next page). Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000."
There's also the 1975 speech where he revised it down from a yearly doubling to once every two years.
A poorly held secret in the semi industry is that transistors have stopped scaling at around 30nm - the practical limit of 193nm litho.
What has been scaling was the amount of free space in between them, metal layers, design rules, cell designs and such.
Before transistor scaling stalled, any process node shrink was an automatic performance gain without any side effects, but not so much after. Some designs may well be seeing net losses with process shrinks these days.
From 10nm on, higher density is actually hurting your performance, not adding it. For a process technologist, you have now to work on both performance, and density in parallel, and not solely on the last one thinking that gains in it will automatically translate into gains in performance.
So its a tricky business now to both squeeze more transistors into a design, and have a net gain from it.
Just as an interesting aside does anyone have a list of weird engineering hacks used in these processes to get smaller and smaller transistor densities? There must be some very clever stuff to jam them in there and still be able to etch the lines.
The first part covers EUV, which is key to advanced nodes. Then it moves on to more futuristic and tentative techniques. But the EUV part is a nice introduction for non specialist, with pointers to dig if one is interested.
EUV is an amazing nightmare, but the etching part of the process is pretty straightforward. The difficulty is in finding materials that don't absorb it all and/or break constantly. In my mind, the really interesting tricks and hacks are all the ways they've managed to take 193nm light and etch things that are so much smaller than the wavelength.
It quickly introduces the various hacks we do in order to get ~30nm features on silicon. But the talk is quite dated (early 2010's), but never ceases to amaze me. Semiconductors are indistinguishable from magic indeed.
There is this interesting talk by Jim Keller.
Talks about new approaches (different transistor tech, architecture, etc) to keep moores law going for another decade or so. You should defintely check it out if have time.
https://www.youtube.com/watch?v=oIG9ztQw2Gc
You can always count on Intel's marketing team for top notch slide presentations.
However, Intel is closer to 22nm than 7nm let alone anything smaller than that. ( I'm talking about consistent product lines that anyone can buy at a store ), not some Houdini show.
On the commercial side they have a huge footing and large tentacles so they don't need to worry too much about time-frames, let's hope they also don't worry too little..
Names with nm are just so called commercial names. They don't match from company to company.
Transistor density in millions of transistors per square millimeter is more relevant. For example: Intel 10nm is 101 MTr/mm², TSMC 7nm Mobile is 97 MTr/mm² so they are very similar.
When comparing across generations, you'll get the most accurate picture if you stick with the same kind of chip (eg. desktop-class GPUs) and same vendor so that they're more likely to count transistors the same way from one year to the next.
Because "nm" doesn't mean nanometer anymore. Not in the context of CPUs anyway. Some time back, around the 34nm era, CPU components stopped getting materialy smaller.
Transistor count plateaued. Moore's law died.
To avoid upseting and confusing consumers with this new reality, chip makers agreed to stop delineating their chips by the size of their components, and to instead group them in to generations by the time that they where made.
Helpfully, in another move to avoid confusion, the chip makers devised a new naming convention, where each new generation uses "nm" naming as if Moore's law continued.
Say for example in 2004 you had chips with a 34nm NAND, and your next gen chips in 2006 are 32nm, then all you do is calculate what the smallest nm would have been if chip density doubled, and you use that size for marketing this generation. So you advertise 17nm instead of 32nm.
Using this new naming scheme also makes it super easy to get to 1.4nm and beyond. In fact, because it's decoupled from anything physical, you can even get to sub-plank scale, which would be impossible on the old scheme.
Edit: Some comments mention that transistor count and performance are still increasing. While that is technically true, I did the sums, the Intel P4 3.4Ghz came out 2004, if Moore's law continued, we would have 3482Ghz or 3.48 TERAHERTZ by now.
> Some time back, around the 34nm era, CPU components stopped getting materialy smaller.
> Transistor count plateaued.
No. Transistor count has continued to increase. The "nm" numbers still correlate with overall transistor density. The change is that transistor density is no longer a function purely of the narrowest line width that the lithography can produce. Transistors have been changing shape and aren't just optical shrinks of the previous node.
The fact that frequencies stopped going up was the breakdown of Dennard Scaling[1], not a breakdown of Moore's Law[2]. We're still finding ways to pack transistors closer together and make them use less power even if frequency scaling has stalled.
You appear to be confounding a few different issues here.
1) Transistor density has continued to increase. The original naming convention was created when we just used planar transistors. That is not the case anymore. More modern processes create tertiary structures of "nodes" which condense the footprint of packs of transistors. Moore's law didn't die. It just slowed.
2) Clock speed is not correlated to transistor size. The fundamentals of physics block increases in clock speed. Light can only travel ~11cm in 1 billionth of a second (1GHz). Electricity can only ever move at 50%-99% the speed of light dependent on the conductor. What's the point of having a 1THz clock when you will just be wasting most of those clock cycles propagating signals across the chip or waiting on data moving to/from memory. Increasing clock speed increases cost of use because it requires more power so at some point a trade-off decision must be made.
You're incorrect, transistor count has not plateaued. [1] Furthermore Moor's law is about transistor count, NOT clock speeds. The fact that we are not at X.XX THz has nothing in relation do with Moor's law.
In recent years the node names don't correspond to any physical dimensions of the transistors anymore. But since density improvements are still being made, they just continued the naming scheme.
Because the naming is based on the characteristics as measured against a “hypothetical” single layer plain CMOS process at that feature size, this isn’t new the nm scale stopped corresponding to physical feature size a long time ago.
"Recent technology nodes such as 22 nm, 16 nm, 14 nm, and 10 nm refer purely to a specific generation of chips made in a particular technology. It does not correspond to any gate length or half pitch. Nevertheless, the name convention has stuck and it's what the leading foundries call their nodes"
..."At the 45 nm process, Intel reached a gate length of 25 nm on a traditional planar transistor. At that node the gate length scaling effectively stalled; any further scaling to the gate length would produce less desirable results. Following the 32 nm process node, while other aspects of the transistor shrunk, the gate length was actually increased"
That's some pretty bullshit quote-mining there. You stopped right before the important part:
"With the introduction of FinFET by Intel in their 22 nm process, the transistor density continued to increase all while the gate length remained more or less a constant."
I'll repeat it for you see you seem to keep missing it: transistor density continued to increase
This isn't marketing fraud because you aren't being sold transisters like you buy lumber at Home Depot.
Instead, you buy working chips with certain properties whose process has a name "10 nm" or "7 nm". Intel et. al. have rationalizations for why certain process nodes are named in certain ways; that's enough.
>However, even the dimensions for finished lumber of a given nominal size have changed over time. In 1910, a typical finished 1-inch (25 mm) board was 13⁄16 in (21 mm). In 1928, that was reduced by 4%, and yet again by 4% in 1956. In 1961, at a meeting in Scottsdale, Arizona, the Committee on Grade Simplification and Standardization agreed to what is now the current U.S. standard: in part, the dressed size of a 1-inch (nominal) board was fixed at 3⁄4 inch; while the dressed size of 2 inch (nominal) lumber was reduced from 1 5⁄8 inch to the current 1 1⁄2 inch.[11]
Despite the change from unfinished rough cut to more dimensionally stable, dried and finished lumber, the sizes are at least standardized by NIST. Still a funny observation!
So the theory is that Intel and others do this for marketing purposes. In other words, they predict that they will sell more parts if they name them this way instead of quoting the physical dimensions. There is no other reason to do this than for marketing purposes.
That must mean, that this marketing works to some degree. Therefore, it cannot be common knowledge amongst everyone who buys PC parts. Or it might be somewhat known but still affecting their shopping choices. If it was truly common knowledge, there would be no incentive to keep naming them this way?
>I did the sums, the Intel P4 3.4Ghz came out 2004, if Moore's law continued, we would have 3482Ghz or 3.48 TERAHERTZ by now.
Comparing raw CPU speed seems like a bad metric. A new i5 clocked at 3.1Ghz will absolutely wipe the floor with a 3.4Ghz Pentium, even for single threaded workloads
Another name for this in a properly regulated industry would be fraud. It's like if your 4 cylinder car engine was still called and labeled a V8 because "it has the power of a V8."
the "nm" doesn't mean what you think it means, since some time ago it's become unrelated to actual physical dimensions, and now it just means "a better process".
This comment is the first time I've seen the why of this number explained, thanks. Like, makes sense, it must be tied to some relative scale that's vaguely comparable across companies otherwise it's just kind of silly. I obviously can understand the 'marketing speak' argument but past a certain point it becomes literally nonsense if people are just using arbitrary numbers.
One extra complicating factor is that each process node will have several different transistor libraries that make different tradeoffs between density and power/frequency. So a smartphone SoC will tend to have a higher MT/mm^2 number than a server CPU or GPU.
Yeah, the difference is more or less a factor of 3. The node gives you a smallest transistor size but making some transistors bigger than others lets you reach higher frequencies.
yeah it's probably just the precision of the process but you might need 2-3 nm actual layers and features to operate. That said, people were dubious of 7nm and said it will never happen. Now we're talking about >2nm .. so who knows
People were dubious of 7nm back in 2005 because back then we had '90nm' devices where the 90nm referred to the gate width.
Due to the fact that making a 7nm gate width is not only impractical (even the most advanced EUV lithography can't do it) but also would make the transistors work terribly--the fact that everyone form 2005 was referring to--the industry was forced to innovate. Their clever solution was to change their naming convention, and instead of naming each technology node after the actual gate width they just assign them a arbitrary number which follows moores law. [1]
The actual gate width for a '7nm' process is somewhat ill defined (they look nothing like a textbook transistor), but depending on how you measure it the number comes in somewhere between 30-60nm. [2] Note that there is a number in the 7nm dimensional chart that comes in at 6nm, but that is the gate oxide thickness, and is actually getting _thicker_ over time. For example back in 90nm it was 1-2nm thick.
That said, those skeptical of us ever producing a '7nm' transistor back in 2005 were right--by the naming convention used in 2005 we are still at ~40nm. I am sure that you will be able to buy a '2nm' processor according to the roadmap, but the actual transistors are still going to have a gate width closer to 30nm and their electrical performance is going to be within a factor of 2 of our current '7nm', and honestly probably going to be clocked slower.
Measuring gate width also stopped being relevant. Densities continue to increase, and significantly so, despite gate-width staying relatively constant.
A 45nm process:
i7-880, 45nm
774 million transistors
296 mm2
A "14nm" process:
i7-6700k, 14nm
1.75 billion transistors
122 mm²
That's still a huge increase in density. It no longer means what it used to, but the spirit of the definition is still very much alive.
It is a significant increase in density, but falls well short of the expectation. Density is somewhat hard to compare because it depends on the way the chip is laid out and the amount of cache vs logic, but if we go by the size of a single sram cell (containing 4 transistors) we can make a relatively fair comparison. In 90nm a sram cell was 1um^2 and in 7nm a ram cell is .027um^2, an increase in density of 37x.
The expected scaling is that transistor density should have scaled with gate length squared (since the structures are laid out in a 2-D grid, for example the 0.8um process used in the 8088 had a sram density of 120um^2, compared to 1um^2 squared for 90nm, a factor of 120x for a roughly 10 times smaller process), so one would have expected a 165x improvement moving from 90nm to 7nm.
Unsurprisingly, the missing factor of 5 is the same factor between the process node name ('7nm') and actual gate length (~35nm).
What kind material science improvement would make non-marketing, real ~10nm scales a reality? I literally have no idea how RnD works in this field. Is it trial and error? How do these scientists come up with ideas that increases the transistor density? Do our current gen CPUs have 2d or 3d curcuit layout? How one can learn about these stuff without working in the field?
A less than 10nm transistor with the same design transistors had 20 years ago does basically not work (you can do some analog hackery, but it's does not behave like a transistor).
Every semiconductor has a lower limit, for silicon it's ~10nm.
The biggest bottleneck is the laser (physics) used for etching of the layers ( and at some point, the number of electrons passing throught the gate, which intel solved using a "3D" gate.)
Adding to my previous post, a lot of people don't understand where 10nm EUV litho stands in the grand plan of thins.
"If EUV doesn't make a more performant chip, what it does?" EUV is there to alleviate extreme process costs associated with multiple patterning, and process cycle time.
Even if EUV tool does 1 exposure a little bit slower than quadruple patterning, it can do 4 patterning steps in one — a very huge thing in process technology.
You have then lessen the amount of thermal processes performed on the device. You may have more defects, but on overall higher quality, higher performance devices in the end.
> Even if EUV tool does 1 exposure a little bit slower than quadruple patterning, it can do 4 patterning steps in one — a very huge thing in process technology.
Would that also remove some patterning constraints? Give the pattern "more freedom".
> Intel expects to be on 2 year cadence with its manufacturing process node technology, starting with 10nm in 2019 and moving to 7nm EUV in 2021
Not to say it could never happen, but given how many years Intel has spent on 10nm with it always been 'next year' tech year after year, 7nm in 2021 seems overly optimistic for me.
I guess time will tell if they got it right this time.
It seems reasonably likely that they will succeed. Intel's 10nm and its 7nm are very different beasts with 7nm arguably being a lot simpler thanks to EUV and a 2x density transistor improvement goal (vs 2.7x for 10nm). The lack of EUV and very high density goals for 10nm meant they had to do a lot of multi-patterning which ended up screwing their yields. That plus the uncharted waters of using cobalt interconnects rather than copper meant it was basically Intel getting overconfident and being too ambitious for their own good.
There were also a whole laundry list of other technologies Intel was trying to put into 10nm. Contact over active gate, COAG, was heavily used in the GPU portion of the die and its failure is why none of the very few 10nm parts released in 2018 had any GPU at all.
As far as I know there is no reason to think that Intel's problems with 10nm process have effect to new processes they are developing for 7nm. Core technologies change and missing a step is something that might happen to others in the future.
In fact GlobalFoundries also failed their 7LP (7nm). As a result they stopped pathfinding and research for 5 nm and 3 nm and quit the race. They are moving to more specialized chips.
Fab cost for new process has grown each year for decades. Now it's something like $20 billion. Stakes grow at same time as things get more hairy and complicated 'down there'.
The "backporting" doctrine clearly implies total lack of faith in process roadmaps, to the point of compromising processor designs and increasing cost and time to market to avoid committing to a millstone around the neck.
Smaller transistors bring everything. They have lower resistance and capacitance resisting a switch, you can build more of them at the same time (so, approximately by the same cost), a signal takes less time to pass through them (and to get from one to another), and they have a larger surface/volume ratio for cooling down.
That said, transistors actually stopped shrinking a while ago. They are getting packaged nearer to each other, they have changed from horizontal to vertical, and they are changing the width/length ratio, but they are not really shrinking.
Less power consumption and/or the ability to cram more transistors into the same area.
Less power consumption also means less heat generated. I think heat dissipation is the main roadblock to faster CPUs (faster in terms of clock speed).
IANAEE but I think the speed of light becomes a big issue at higher clock speeds. Putting transistors physically closer to each other helps reduce problems with propagation delay.
All change requires energy, and we're going to have less energy, so the speed of change inevitably has to go down.
Because the only energy added to the planet comes from the sun and the only viable option to collect that energy are trees and plants.
(I'm going to post this comment on every naive technology optimist post, you can downvote me all you want, I have to do this to be able to sleep at night, fake karma is not more valuable than real karma)
What perplexes me is that neither Intel, AMD, IBM, or any other company, as far as I can tell, is pursuing the bootstrapping path of self-assembling nanotech. Once someone does it, every other company is going to be left several orders of magnitude in the dust, so it surprises me that no one is going for it.
Well, you can laugh, but it's legitimate stuff. Right now, all we have is self-assembling dna structures, but there's a bootstrappable path towards "tiny robots".
We have self-assembling dna structures, which we don't even fully understand and which are the result of millions of years of evolution. The steps are being made towards such tiny robots, but it's preposterous to mention them as a viable alternative to the current chip fab strategy.
Oh no, it is extremely complex. However, every step along the path towards it provides benefits and, slowly but surely, researchers are moving forward. I think the field just needs more funding and more scientists dedicated towards it.
I believe that the nanobots required to perform such a feat are at least several decades away, if not further.
You're essentially trying to replicate what cells do in a growing embryo, and even with several billion years of evolution that is still a very very error-prone process.
You're right about the self-replicating part, that's probably very far away (and not necessary for this). But I think self-assembling nano-mechanisms are closer. We can already sort of do it with self-assembling dna mechanisms and, theoretically, those can bootstrap into more complex tech made out of better materials
{kind=link}
{kind=link}
{kind=link}
They might ship 1.4nm, but it has a good chance of having Soviet tractor quality.