After watching Rob Pike's Go Proverbs talk I am pretty convinced generics, as much as some would want it, will never happen. He proselytizes "just copy a little code here and there" quite clearly, which is at odds with the complexity that generics would add.
Rob Pike's repository 'filter'[0] contains implementations of map ("Apply"), filter ("Choose", I believe), and fold/reduce ("Reduce"). The code is an ugly mess, and the implementation shows that he probably hasn't used any of these standard functions in other languages (see the weird permutations of 'filter' in apply.go, or my patch for his fold/reduce implementation[1]). The README is also quite arrogant, IMO.
> I wanted to see how hard it was to implement this sort of thing in Go, with as nice an API as I could manage. It wasn't hard.
> Having written it a couple of years ago, I haven't had occasion to use it once. Instead, I just use "for" loops.
+ People keep telling me we should be able to implement a map function in go.
+ I implemented a map function in go.
+ The map function was ugly, slow, unsafe and generally an abomination.
Conclusion? You don't need a map function in go.
You may not agree but you have to admire his dedication to the One True Way whatever is put in his way. Even if it's him that's erecting pretty impressive roadblock himself.
I'll grant that Go is lacking in generics, but IMHO, the opposite is true. Go is thriving because although not perfect, it is one of the few languages which seems to have learned lessons from the failings of C++, Java; and from the successes of the more dynamic/scripting languages (team Python, Ruby etc.). Go isn't a step down, it's a step backwards from the edge of the cliff.
That's just rhetoric. What does it mean? What lessons have been learned? What is it about generics that makes them the 'edge of the cliff'? Personally I couldn't live without generics, and would never choose a language that doesn't have them; otherwise you end up doing cartwheels with untyped references and reflection to try and write reusable code (as you see above). The idea that generics adds complexity is nonsense. It might add complexity to the compiler, but that's about it. For the end user and the compiled code it's easier and faster respectively.
I clearly stated that Go is lacking on the generics front. The cliff is forced, rigid OOP and complicated tool-chains.
> Personally I couldn't live without generics, and would never choose a language that doesn't have them
I'm kind of confused here. Yes, Go needs generics, but are generics even that key a feature? I mean how often do you have to define a generic type, and how much copying does it really take? Is it a hassle? Of course. But at the end of the matter, Go much, much better when it comes to combining expressibility, efficiency, and simplicity then many of the other options available today.
> The cliff is forced, rigid OOP and complicated tool-chains.
How are generics related to OOP or tool chains? Generics have a strong grounding in type theory and are used equally successfully in both OO and functional languages.
> Yes, Go needs generics, but are generics even that key a feature?
I believe so.
> I mean how often do you have to define a generic type
Many times a day. But not just generic types, generic functions, which I believe are just as strong an argument for generics.
> I mean how often do you have to define a generic type, and how much copying does it really take? Is it a hassle? Of course.
It's not just the hassle of copying and pasting. It's the ongoing maintenance of code. If you have a list class for example, then you're going to need a ListOfInt, ListOfChar, ListOf... If you have a single bug in your list implementation in a language with generics, that is now N bugs in Go. If you write an untyped List class then you are constantly coercing the type and potentially working with unsound values that you only discover at the point of use, not the point of compilation. In a large application that's as painful as the null dereference issue has been for all of time.
Even in the code example by Rob Pike he mentions that he can get by using a for loop. for loops are less declarative and less expressive than map, filter, fold, etc. They mix loop iteration scaffolding with code intent.
> But at the end of the matter, Go much, much better when it comes to combining expressibility, efficiency, and simplicity then many of the other options available today.
More rhetoric. Please tell me how? Is there something that makes this better? I remember C# before generics, and it was a pain to work with (collection types especially, that's why I mention it above). The only issue I see with generics now in C# is the visual clutter. If that's what you're referring to, then fine, but that's still not a good reason for the language to not implement them. If you look at F#, OCaml, Haskell etc, they all have generics in one form or another that you barely see. The expressiveness is there, but also type safety.
I find it hard to believe that a language with static typing can get away with not having generics today. It makes the language semi-dynamic, which is the worst of both worlds because you end up manually doing type coercion (which would be automatic in a dynamic language), but still have the lack of safety of a dynamically typed language to boot.
> How are generics related to OOP or tool chains? Generics have a strong grounding in type theory and are used equally successfully in both OO and functional languages.
Once again, I never said there was anything wrong with generics! And I agree that Go should have them, I just don't think they are nearly necessary enough a feature to justify overlooking the numerous qualities the language has to offer. Please look at my initial comment: I never said anything negative about generics.
> More rhetoric. Please tell me how? Is there something that makes this better?
The "options" I'm referring to are Java/C++/C# and Python/Perl/Ruby/PHP. The former languages are too verbose, and cluttered, and Java requires the overhead of the JVM, C# is essentially Windows-only. The scripting languages lack typing and efficiency. Go is able to combine the performance and control advantages of low-level languages (to a high degree) with the simplicity of higher-level languages like Python. I'm not saying it's perfect, and I'm definitely not crazy enough to put it up against the functional languages (Haskell etc.). But when it comes to web applications, it looks like Go will soon be the one of the most practical choices available.
The lesson Go seems to have learned is that, since C++ and Java burned their fingers, clearly fire is too dangerous for humans.
The thing that makes it painfully obvious to me that Rob Pike hasn't bothered to learn anything from the PL community is that Go has nil. That just shouldn't happen in a modern language.
> The lesson Go seems to have learned is that, since C++ and Java burned their fingers, clearly fire is too dangerous for humans.
I think that's a little bit unfair, since Go introduces many powerful ideas not (traditionally) available in Java or C++: namely first class concurrency and functional primitives. Its handling of typing, the ability to define types not necessarily based on structs, the excellent design of interfaces are other examples. Go is an extremely powerful and expressive language that opens up the doors for programming in new paradigms, while making it easy to maintain readability and simplicity.
Fair point with the nil issue, I think that's one of Go's other weaknesses. But it does make up for that with its excellent error handling paradigm.
https://golang.org/doc/faq#nil_error is not an excellent design. It's a serious bug that converting nil to an interface sets the type field to a meaningless value (nil doesn't have a type!) and ridiculous that the interface doesn't compare equal to nil (if it's not nil, what does it point to?)
It means that every single type in the language has one extra value it may contain, 'nil', and your code will crash or behave erratically if it contains this value and you haven't written code to handle it. This has caused billions of dollars in software errors (null dereferences in C/C++, NullPointerExceptions in Java, etc.). See "Null References: The Billion Dollar Mistake" by Tony Hoare, the guy who invented it:
A better solution is an explicit optional type, like Maybe in Haskell, Option in Rust, or Optional in Swift. Modern Java code also tends to use the NullObject pattern a lot, combined with @NonNull attributes.
Beside the fact you're wrong (structs, arrays, bools, numeric values, strings and functions can't be nil, for instance), I'm always a little puzzled when I read the argument that "nil costs billions of $".
First, most of the expensive bugs in C/C++ programs are caused by undefined behaviors, making your program run innocently (or not, it's just a question of luck) when you dereference NULL or try to access a freed object or the nth+1 element of an array. "Crashing" and "running erratically" are far from being the same. If those bugs were caught up-front (just like Java or Go do), the cost would be much less. The Morris worm wouldn't have existed with bound-checking, for instance.
Second point, since we're about bound checking. Why is nil such an abomination but trying to access the first element of an empty list is not? Why does Haskell let me write `head []` (and fail at runtime) ? How is that different from a nil dereference exception ? People never complain about this, although in practice I'm pretty sure off-by-one errors are much more frequent than nil derefs (well, at least, in my code, they are).
> $1bn over the history of computing is about $2k per hour. I would not be astonished if a class of bugs cost that much across the industry.
It's not about knowing whether it's $1bn, or 10bn, or just a few millions. The question is to know whether fighting so hard to make these bugs (the "caught at runtime" version, not the "undefined consequences" version) impossible is worth the cost or not.
Can you guarantee that hiring a team of experienced Haskell developers (or pick any strongly-typed language of your choice) will cost me less than hiring a team of experienced Go developers (all costs included, i.e from development and maintenance cost to loss of business after a catastrophic bug)? Can you even give me an exemple of a business that lost tons of money because of some kind of NullPointerException ?
>fighting so hard to make these bugs ... impossible is worth the cost or not.
In this case the solution is trivial, just don't include null when you design the language. It's so easy in fact, that the only reason I can imagine Go has null, is because its designers weren't aware of the problem.
Not including null has consequences, you can't just keep your language as it is, remove null and say you're done.
What's the default value for a pointer in the absence of null? You can force the developer to assign a value to each and every pointer at the moment they are declared, rather than rely on a default value (and the same thing for every composite type containing a pointer), but then you must include some sort of ternary operator when initialization depends on some condition, but then you cannot be sure your ternary operator won't be abused, etc.
You can also go the Haskell way, and have a `None` value but force the user to be in a branch where you know for sure your pointer is not null/None before dereferencing it (via pattern matching or not). But then again you end up with a very different language, which will not necessarily be a better fit to the problem you are trying to solve (fast compile times, easy to make new programmers productive, etc.).
I think it has consequences on the design of the language, making it more complex and more prone to "clever" code, i.e code harder to understand when you haven't written it yourself (or you wrote it a rather long time ago). I've experienced it myself, I spent much more time in my life trying to understand complex code (complex in the way it is written) than to correct trivial NPEs.
That being aside, it is less easy to find developers proficient in a more complex language, and it is more expensive to hire a good developer and let him time to teach himself that language.
I'm not sure it costs "very much", though. I might be wrong. But that's the point: nobody knows for sure. I just think we all lack evidence about those points, although PL theory says avoiding NULL is better, there have been no studies to actually prove it in the "real-world" context. Start-ups using Haskell/OCaml/F#/Rust and the like don't seem to have an undisputable competitive advantage over the ones using "nullable" languages, for instance, or else the latter would simply not exist.
But a bunch types you do expect to work can: Slices, maps and channels.
var m map[string]bool
m["foo"] = 1 // Nil, panic
var a []string
a[0] = "x" // Nil, panic
var c chan int
<-c // Blocks forever
This violates the principle of least surprise. Go has a nicely defined concept of "zero value" (for example, ints are 0 and strings are empty) until you get to these.
The most surprising nil wart, however, is this ugly monster:
package main
import "log"
type Foo interface {
Bar()
}
type Baz struct{}
func (b Baz) Bar() {}
func main() {
var a *Baz = nil
var b Foo = a
fmt.Print(b == nil) // Prints false!
}
This happens is because interfaces are indirections. They are implemented as a pointer to a struct containing a type and a pointer to the real value. The interface value can be nil, but so can the internal pointer. They are different things.
I think supporting nils today is unforgivable, but the last one is just mind-boggling. There's no excuse.
I don't think you're right that interfaces are implemented as a pointer to a struct. The struct is inline like any other struct, and it contains a pointer to a type and a pointer to the value, like `([*Baz], nil)` in your example. The problem is that a nil interface in Go is compiled to `(nil, nil)` which is different.
I don't think using nil to represent uninitialized data is a major issue-- if it were possible to catch uninitialized but queried variables at compile-time, that could be an improvement, but we want to give the programmer control to declare and initialize variables separately.
Interesting, because (reading up on this) value types can not be nil.
How often does typical Go code use values vs. interfaces or pointers? It seems like the situation is pretty similar to modern C++, which also does not allow null for value or reference types (only pointers) and encourages value-based programming. Nil is still a problem there, but less of one than in, say, Java, where everything is a reference.
In my own experience, nil basically only shows up when I've failed to initialize something (like forgetting to loop over and make each channel in an array of channels), or when returning a nil error to indicate a function succeeded. I've never run into other interfaces being nil, but I also haven't worked with reflection and have relatively little Go experience (~6 months).
The code that I've written regularly uses interfaces and pointers, but I'd guess 80% works directly with values.
> I call it my billion-dollar mistake. It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language (ALGOL W). My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn't resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
I believe it is thriving because it was well-designed, by extremely influential individuals, and the early library work was stellar. Also, several other experienced and influential programmers tried it, and expressed something along the lines of "programming is fun again!"
Inside Google, the two main programming languages are C++ and Java, not Go (at least when I left, in September). The Go tooling is generally less capable, but the interfaces smaller, and often nicer: they have the dual benefits of hindsight, and a small but very smart team that really cares about conciseness and clean APIs.
Of course, it's undeniable that the Google name helps a bit. And paying a team of very experienced (and presumably very expensive) developers to work on it makes a huge difference. But I think it would be as successful if those same developers were sponsored by Redhat, or Apple, or just about anyone.
Dart is also Google sponsored and no one uses it despite the fact that it's actually a pretty great general purpose language. People use go because it's productive and had a PHENOMENAL standard library for networking.
It clarifies the fact that Go is successful for more reasons than just being pushed by Google. So it focuses the question to "what is it that people like about it". And then we can have a better conversation.
Your theory fails to account for the lack of success with respect to Dart; so, it seems more like something you have an urge to believe (despite a lack of evidence).
Dart has been abandoned by Google the day that Angular team has chosen Typescript instead of believing in Dart, thus sending to the world the message that the company doesn't believe in it.
Whereas there are a few production examples of Go at Google.
My understanding is that Dart is used by Google Fiber for their routers, so I wouldn't call that abandoned yet. But, the point is that Google supporting a language does not seem to imply its eventual success.
He who takes his examples of generics from C++ and Java has a huge blind spot. The FP crowd came up with simple and useable generics (Hindley-Milner type inference) in 1982.
It's like Go's creators haven't even read Pierce's Types and Programming languages. This is inexcusable. Even more so from Rob Pike and Ken Thomson —you'd expect better from such big shots.
It's like you assume that, since they didn't do it your way, they're either stupid, ignorant, or malicious - which I also find to be pretty inexcusable.
Well… I have seen generics that (i) don't blow up the compile times like C++ templates do, (ii) are very simple to use, and (iii) are relatively simple to implement. (I'm thinking of Hindley-Milner type inference and system F.) So when some famous guys state they avoided generics for simplicity's sake, yeah, I tend to assume they missed it.
And it's not hard to miss either. When you google "generics", you tend to stumble upon Java, C#, and maybe C++. The FP crowd talks about "parametric polymorphism". Plus, if you already know Java, C# and C++, 3 mainstream examples of generics, fetching a fourth example looks like a waste of time. I bet they expected "parametric polymorphism" (ML, Haskell…) to be just as complex as "generics" (C++, Java, C#).
On the other hand, when you study PL theory, you learn very quickly about Hindley-Milner type inference and System-F. Apparently they haven't. Seriously, one does not simply make a language for the masses without some PL theory.
> On the other hand, when you study PL theory, you learn very quickly about Hindley-Milner type inference and System-F. Apparently they haven't.
Again you assume that, since they didn't include it, they must not have known about it. You keep claiming that. Given the breadth of these guys' knowledge (it's not just Java, C#, and C++, not by a long shot), I really struggle to see any justification for you assuming that.
I know you think that system F is all that and a bag of chips, but it is not the only reasonable way to design a language! Assuming that they did it wrong because they didn't do it the way you think is right... that's a bit much.
But I'll ask you the same question I asked aninhumer: How fast does Go compile compared to Haskell? And, is that a fair comparison? If not, why not?
> Again you assume that, since they didn't include it, they must not have known about it.
That's not why I assumed ignorance. I assumed ignorance because their stated reasons for doing so are false. Generics can be simple. They skipped them "for simplicity's sake". Therefore they didn't know generics could be simple.
Besides, generics could have probably helped them simplify other parts of the language. (But I'm getting ahead of myself.)
> How fast does Go compile compared to Haskell?
I don't know. I have reasons to guess Haskell is much slower however.
> And, is that a fair comparison?
Probably not: both languages are bootstrapped, so their respective implementation use very different languages (Go and Haskell, respectively). Haskell is non-strict, so it needs many optimizations to get acceptable performance. Haskell's type system is much more complex than your regular HM type inference: it has type classes, higher-order types, and many extensions I know nothing about —it's a research language after all.
Qualitative analysis would be better at assessing how generics affect compile time. My current answer is "not much": the effects of a simple type system (let's say system-F with local type inference) are all local. You don't have to instantiate your generics several times like you would do with templates, you can output generic assembly code instead. To avoid excessive boxing, you can use pointer tagging, so generic code can treat pointers and integers the same way —that's how Ocaml does it.
> Therefore they didn't know generics could be simple.
I wouldn't call Hindley-Milner type inference simple, though. I think you underestimate what has to be available in the language for a ML-like parametric polymorphism to be implemented in the language. For instance, can an interface be generic? Can a non-generic type implement a generic interface? How do you say your type is generic, but "only numeric types allowed" ? Does it mean the language must implement a type hierarchy of some kind ? How well does it play with pointers? Is `*int` a numeric type?
Once you introduce generics, you have no choice but to make a more complex language overall. You say generics would have simplified the language, I find it hard to believe. Care to mention a language that is easier to grasp than go (i.e I can be productive in less than a week) and that also offers efficient generics?
I'd like to give them the benefit of the doubt, but even within their stated goal of "simplicity", some of their design choices still seem ignorant of PL theory. The obvious one being including a null value, which is widely recognised to be a terrible idea with pretty much no redeeming qualities.
Another subtler example is the use of multiple return values for error handling, rather than some kind of sum type. It just suggests the designer doesn't have any experience working with ADTs. (Not that I'm suggesting Go should have used full blown ADTs, just that they change the way you think about data.)
Simplicity is, I think, a secondary goal. A big part of the motivation for creating Go was 45 minute C++ compile times. A major reason for the emphasis on simplicity is to keep the compiler fast, even on huge codebases.
So: How much would adding sum types slow down the compiler? I don't know. How fast does Go compile compared to Haskell? (Is that a fair comparison?)
I'm a little dubious of the speed advantage to be honest. Sure compile time is important, and C++ is pretty bad on this front, but you don't need to try that hard to do better.
And no, I don't think sum types would slow the compiler down much, especially if they were limited to a special case for error handling (which seems more in line with the rest of Go).
Well I don't think zero values are a very good idea to start with (if you want a default value, make it explicit), but if one insists on having them, they can just use the first case. So for your example it would be int 0.
// goodFunc verifies that the function satisfies the signature, represented as a slice of types.
// The last type is the single result type; the others are the input types.
// A final type of nil means any result type is accepted.
func goodFunc(fn reflect.Value, types ...reflect.Type) bool
This. For better and for worse, Go was designed for "simplicity", and generics are anything but simple. I'd be very, very surprised if Go thinks about generics in earnest anytime soon.
I don't say this in anyway to eulogize Go: In some ways, Go is pathetically unexpressive. That said, it currently fills that gap for writing middleware between C sacrificing too much developer productivity and Perl/Python/Ruby/PHP sacrificing too much performance. Generics would be nice to have for this core use case for Go, but it's probably not critical.
Go doesn't do inheritance either. It has type embedding, but it's not the same.
In the most recent of Ian Lance Taylor's proposals (Type parameters, 2013 [1]) he summarizes:
> The implementation description is interesting but very complicated. Is any compiler really going to implement all that? It seems likely that any initial implementation would just use macro expansion, and unclear whether it would ever move beyond that. The result would be increased compile times and code bloat.
So I'm pretty sure that the logic is acceptable, but it conflicts with Go's core goals of simplicity and compilation speed.
This is generally brought up as the reason that Go doesn't need generics.
I tend to agree with this. I've yet to come across a use-case where the current system is too difficult to deal with, but there are other people who have hit this limitation.
Maybe this can be solved by simply modifying the parsing of the keyword "type" (Or adding a reserved type "T") and telling developers that the functionality of "go generate" will automatically (in the compiler) expand and create type methods at compile time, and build the type generation into the compile phase, rather than a manual pre-compilation phase. I haven't considered the problems with this approach, but I assume Ian et al have.
It seems to me that the generated code approach could be spliced into the compiler with a few key-word parsing changes, but I'm not going to assume that the Go team haven't already thought of this, and there are probably problems with the idea that I haven't considered, above and beyond spec / compatibility promises etc.
> This is generally brought up as the reason that Go doesn't need generics.
Which I find nonsensical, but my point was that Go's interfaces are a form of subtyping, which as eru and tel note tend to have challenging interactions with generics.
I don't see why you'd choose Go instead of a JVM language like Java, you get the language simplicity (plus features like Generics) and the performance upside too.
But setup a java toolchain, building, deploying, and a lot of other configuration if some heavy framework is involved, is non-trivial. Gradle is like a must for modern Java application, and mastering itself takes some efforts. Go, when coming to toolchain, it is pretty much battery-included, best-practice-builtin, sometimes even a little forced.
Language wise, Java recently has seem a more aggressive adoption of new and modern features, which is quite welcome for me personally, but it is still more LOC comparing to Go.
I think Go is the new Python for light to middle complexity web service, with fewer people. Java is more for mature stuff, for larger scale collaboration.
A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted. You only need to start consulting the Gradle manual once you start doing things like defining custom build tasks or wanting to use custom plugins.
Go's toolchain doesn't even bother with versioning. That's like the opposite of batteries-included, forced-best-practices. But of course it will seem simpler than a tool that does handle these basic things.
If you want the benefits of Java with a lighter syntax then look at Kotlin.
> A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted
...and that code is written in Apache Groovy. Strange why they'd bundle a Turing-complete scripting language for their build file DSL when it's only 7 or 8 lines long.
My experience is the exact opposite: Go takes more lines to do something than Java.
I would say that in large part, this is because the error handling restricts expressions to a rather small size, and then because without streams, collection manipulation has to be written out longhand.
I agree with you on the error handling part, although it is not a big pain for me yet.
But in terms of parallel programming, when doing in Java, I constantly find myself basically building a lot of stuff where Go has as a part of its own semantic. Queues -> Channel, Executors -> M in Go, and Runnables -> Go functions. Java8's Lambada and ForkJoinPool is an advance in the right direction but still not quite there.
Language simplicity? I disagree, Java is only agreable if you're comfortable with (1) being forced to work in an OOP-only environment and (2) using the JVM. And while you can argue for the upsides of both of these (which I believe are few and far between) they certainly add a great deal of clunky complexity, which many programmers are fleeing to Golang to avoid.
If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
Toolchains normally mean build systems, debuggers, profilers, editors and other things.
Java itself doesn't require any build tool at all, you could do it all with a custom shell script. The next step up after that is an IDE like IntelliJ where you press "new project" and just start writing code. The IDE's build system will do it all for you. There is no complexity.
But most people want features like dependency management, IDE independence, command line builds, ability to customise the build with extra steps and so on. That's when you upgrade to something like Gradle (or maybe Maven if you like declarative XML). That'll give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features. Many IDEs can create a Gradle project for you.
When I first encountered Java it seemed the most popular build tool was Maven, which looked very over complex at first due to its poor docs and love of inventing new words, but pretty quickly found that it wasn't so bad in reality. Gradle avoids the custom dictionary and uses a much lighter weight syntax. It's pretty good.
>If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
The point was about Java, so I was responding to that, but yes, I steer clear of C++ (when possible) for the same reason.
> Gradle [...] give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features.
I don't see your point. If you have a collection of source files, then something must search the directory tree to find them and feed them to the compiler ... ideally, only the files that have changed, to give fast incremental compilation.
If you use a typical Java IDE like IntelliJ then the program that does that will be the IDE. There is no "one more layer" because that's the first and only layer.
If the IDE build system does not provide enough features or you'd like your codebase to be IDE independent, you can also use a separate build tool, or a combination of both (in which case the IDE will sync itself to the other build tool).
In that case there are two layers. But Go does not have any magical solution to that. There will be Go apps that need more than the little command line tool can do as well.
Right, so then it is more complex than `go build`. QED.
To be clear, I'm not claiming that Go is "better"; I'm just pointing out that this is why one would chose Go over Java. Sometimes this particular benefit doesn't outweigh the costs relative to developing in Java, but language/toolchain simplicity remains -- nonetheless -- the reason why people prefer one over the other.
Yes, "gradle build" wants to see a "build.gradle" file in the current directory, but you can run "gradle init" to get one. And after that everything except specifying dependencies is by convention.
There's really little to no difference in complexity here. What Go saves by not having a build file it loses by not encoding enough information about dependencies in the source, which leads to horrible hacks like vendoring.
Nobody forces you to use a complex toolchain for Java. You can use javac and ed if you like. But Java is sufficiently simple and sufficiently popular for pretty awesome tooling to be available. Refactoring Java code is a breeze because your IDE understands the code perfectly.
A text editor, javac and java that's what I used for a few years when I started using it. I wrote a lot of code like that. I don't see why you couldn't?
> I remember the Go language specification to be about as long as the table of contents for the Java language specification.
I'm not sure where you got that from. On my browser and screen, the JLS8 TOC[0] is 16 pages high which brings me about 20% into the Go language spec[1].
But then again that's a completely inane appeal to emotions: because it's a specification for cross-platform and cross-implementation compatibility (not a user-targeted documentation):
* the JLS is exactingly precise, the JLS's "lexical structure" section is about 3 times longer than GoSpec's "Lexical Elements", the JLS's "Execution" section is about 6 times longer than GoSpec's "Program initialization and execution"
* the JLS contains entire sections which don't get a mention in GoSpec, like binary compatibility concern, or the language's entire execution model (calling a function gets a page in gospec, it gets 20+ in the JLS) and its multithreaded memory model
The JLS is longer because its goal is that you be able to reimplement a Java compiler and runtime just from it, it's Java's entire rulebook.
Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
> Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
That's not correct. The Go spec is designed to be a precise specification of the language, targeted at language implementers. Ian Lance Taylor (incidentally, the author of these generics proposals) wrote gccgo based on that spec. There have been a couple of other implementations based on that spec since.
The main Go compiler itself was implemented from that spec, too. The spec comes first.
You are absolutely right, it's a silly comparison. The Go language spec is indeed vague.
I did this comparison a while ago. It wasn't very accurate. The Go spec has probably changed. Unfortunately, it seems they don't keep older specs around(!) If I adjust the font size in the ToC of the JLS I get 23 pages and the Go Spec is 84 pages (27%). Not quite "about the same length", still.
I took a compiler course in university where we implemented a compiler for a subset of java 1.3 (I believe), and the next year I was a TA in the compiler course. I got to read the (older) JLS quite a lot. I do find Java to be a more complicated language than Go. This does not mean I find it simpler to write programs in Go (c.f. Brainfuck).
RoboVM is one that compiles AOT ARM binaries, it's intended for the iPhone but it runs on MacOS too.
Avian is a JIT compiling JVM but one which is much smaller than HotSpot. It has a mode where it statically links your JAR into the binary itself, so you get a single self contained executable. With ProGuard and other optimisations like LZMA compression built in, such binaries can be remarkably small. Try their example:
You can make an executable "fat jar" with Capsule. It has a little shell script prepended to the JAR which means you can run it like "chmod +x foo.jar; ./foo.jar"
You can do dead code elimination and other forms of LTO using ProGuard. Just watch out for code that uses reflection. Java 9 will include a less aggressive version of the same thing which performs various link time optimisations like deleting modules (rather than individual methods/fields), statically pre-computing various tables, and converting from JAR into a more optimised (but platform specific) format.
That tool can also bundle a JRE in with your app, giving you an "tar xzvf and run" deployment model. It's not a single file, but it makes little difference in practice. The same tool can build DEBs, RPMs, Mac DMGs and Windows EXE/MSI installers with a bundled and stripped JRE too.
I'm a big fan of Capsule, actually. My point was not that Java and the JVM ecosystem are terrible (I quite like them), but rather that there is a spectrum of size and complexity and that Go's static binaries seem to be on the simpler to build side of JARs and on the smaller side of JARs.
Also, I don't think there's much of a case to be made that bundling a JRE with your JAR is small, even though the tooling might be simple and it might resolve many deployment issues.
Putting a jar on your classpath works just like depending on a shared library but with much stronger compatibility guarantees and better chances for optimization.
Memory usage and as a consequence of that excessive GC pauses. I'm not looking at any JVM language again before they introduce value types in a couple of years (maybe).
I build soft real time simulation systems in Java. GC pauses haven't been a problem since 1.2 was released around 2000. Memory usage isn't a concern either for big applications, as there's not a lot of overhead in the runtime. There is the fact that one can't embed value types directly in objects, but I don't find that a problem in practice.
Then your experience is very different from mine and that of many other people who resort to all sorts of off-heap solutions and distributing stuff across multiple VMs. I guess it depends a lot on the specific use case.
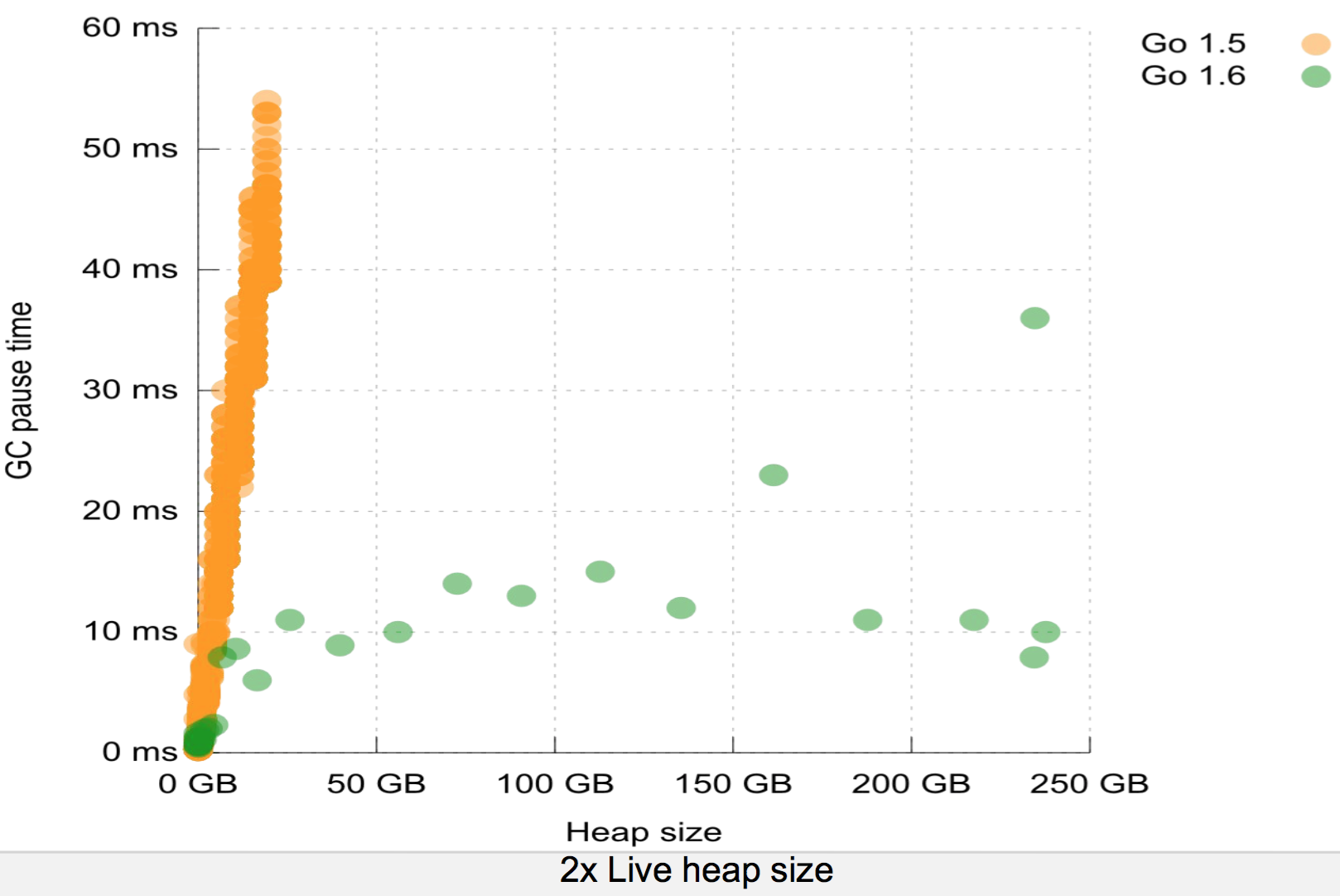
You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
If you want no GC pauses at all, ever, well, Go can't do that either. But if you are willing to pay money to Azul, you can buy a JVM that can. It also concurrently compacts the heap, which Go's GC does not.
The issue is not Java. The issue is the quality of freely available garbage collectors, which are very good, but not pauseless.
>You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
For what percentile of collections? I'm not wasting my time with incessant GC tuning only to delay that 5 minute stop the world pause for a bit longer. It's still going to hit eventually. For projects that might grow into that sort of heap size I use C++ (with an eye on Rust for the future).
You are right that Go is not a panacea for very large memory situations, but you can do a lot more before Go even needs that amount of memory.
The point is that languages without value types, such as Java and JavaScript, waste a huge amount of memory and generate a lot more garbage, thereby exacerbating all other related issues, including GC.
I have done quite a lot of testing for our workloads. Java memory usage is consistently two to three times higher than that of Go or C++. I'm unwilling to waste our money on that.
In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
To get 10msec pause times with such huge heaps requires burning a LOT of CPU time with the standard JDK collectors because they can trade off pause latency vs CPU time.
This presentation shows tuning with 100msec as the target:
2. Older collectors like CMS (still the default) sometimes take long pauses, like 5 seconds (not 5 minutes).
3. The new GC (G1) must be explicitly requested in Java 8. The plan is for it to be the default in Java 9, but switching to a new GC by default is not something to be taken lightly. G1 is, theoretically, configurably by simply setting a target pause time (lower == better latency but more CPU usage). Doing so eliminated all the long pauses, but a few collections were still 400msec (10x improvement over CMS).
4. With tuning, less than 1% of collections were over 300 msec and 60% of pauses were below the target of 100 msec.
Given that the Go collector, even the new one, isn't incremental or compacting I would be curious how effective it is with such large heaps. It seems to be that a GC that has to scan the whole 100GB every time, even if it does so in parallel, would experience staggeringly poor throughput.
Value types will certainly be a big, useful upgrade.
>In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
So you use a language without value types that makes you pay for two or three times more memory than comparable languages, and then you spend your time re-tuning the GC every time your allocation or usage patterns change. Then you hope to never trigger a full GC that could stall the VM for many seconds (or in extreme cases that I have seen even minutes). That makes very little sense to me.
I cannot speak to the performance of the current Go GC for 100G heap sizes. I never tried it and I haven't read anything about it. It's not my language of choice for that sort of task either.
They aren't comparable at all. Go doesn't collect incrementally and doesn't compact. So good luck collecting garbage fast enough to keep up with a heap-heavy app (which if you have a 100GB heap, your app probably is).
In other words, the issue is not pause time, it's also throughput.
But Go programs use way less memory than Java applications... so the java application that uses 100GB might only use 40GB (or less) in Go. And there are tweaks you can make to hot code in Go to not generate garbage at all (pooling etc).
Java's higher memory usage is not only related to value types, for example, in Java 8 strings always use 16 bit characters. That is fixed in Java 9. It resulted in both memory savings and speed improvements.
There are other sources of overhead too, but again - you seem to think Go has some magic solution to these problems. Since the new GC, Go is often using a heap much larger (such as twice the size) of actual live data. That's a big hit right there. And yes, you have to tune the Go GC:
Value types are the main culprit behind Java's insane memory consumption. I found out through weeks of testing and benchmarking.
I mostly benchmarked a small subset of our own applications and data structures. We use a lot of strings, so I never even started to use Java's String class, only byte[].
I tried all sorts of things like representing a sorted map as two large arrays to avoid the extra Entry objects. I implemented a special purpose b-tree like data structure. I must have tried every Map implementation out there (there are many!). I stored multiple small strings in one large byte[].
The point is, in order to reduce Java's memory consumption, you must reduce the number of objects and object references. Nothing else matters much. It leads to horribly complex code and it is extremely unproductive. The most ironic thing about it is that you can't use Java's generics for any of it, because they don't work with primitives.
I also spent way too much time testing all sorts of off-heap solutions. At the end of the day, it's just not worth it. Using Go or C# (or maybe Swift if it gets a little faster) for small to medium sized heaps and C++ or Rust for the humungous sizes is a lot less work than making the JVM do something it clearly wasn't built to do.
But I think your conclusion is not quite right. I said above that pointer overhead is only one source of Java memory consumption, and pointed to (hah) strings as another source. You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
If your application is so memory sensitive that you can't use basic data structures like maps or strings then yes, you really need to be using C++ at that point.
In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code and the JVM can do optimisations like deduplicate strings from the heap (already). Of course how much that helps depends a lot on the application in question. But the sources of gain and loss are quite complex.
>You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
I see what you mean, but when I said that Java uses two or three times as much memory as Go or C++, I didn't include tons of UTF-16 strings either, assuming most people don't use as many strings as I do. If your baseline does include a large number of heap based Java String objects, the difference would be much greater than two or three times because strings alone would basically double Java's memory usage (or triple it if you store mostly short strings like words using the short string optimization in C++ for comparison)
>In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code
I'd love to see that theory :-) But let's say it was magic and the bytecode as well as the VM itself would require zero memory, any difference would still only be tens of MB. So it would be negligible if we're talking about heap sizes on the order of tens or hundereds of GB.
Yes, if your heap is huge then code size savings don't matter much. I used to work with C++ apps that were routinely hundreds of megabytes in size though (giant servers that were fully statically linked). So code size isn't totally ignorable either.
WRT the theory, that depends what the heap consists of.
Imagine an app where memory usage is composed primarily of std::wstring, for example, because you want fast access to individual characters (in the BMP) and know you'll be handling multiple languages. And so your heap is made up of e.g. some sort of graph structure with many different text labels that all point to each other.
The JVM based app can benefit from three memory optimisations that are hard to do in C++ ... compressed OOPs, string deduplication and on-the-fly string encoding switches. OK, the last one is implemented in Java 9 which isn't released yet, but as we're theorising bear with me :)
Compressed OOPs let you use 32 bit pointers in a 64 bit app. Actually in this mode the pointer values are encoded in a way that let the app point to 4 billion objects not bytes, so you can use this if your heap is less than around 32 gigabytes. So if your graph structure is naturally pointer heavy in any language and, say, 20 gigabytes, you can benefit from this optimisation quite a lot.
String deduplication involves the garbage collector hashing strings and detecting duplicates as it scans the heap. As a String object points to the character array internally, that pointer can be rewritten and the duplicates collected, all in the background. If the labels on your graph structure are frequently duplicated for some reason, this gives you the benefits of a string interning scheme but without the need to code it up.
Finally the on-the-fly character set switching means strings that can be represented as Latin1 in memory are, with 16 bit characters only used if it's actually necessary. If your graph labels are mostly English but with some non-Latin1 text mixed in as well, this optimisation could benefit significantly.
Obviously, as they are both Turing complete, the C++ version of the app could implement all these optimisations itself. It could use 32 bit pointers on a 64 bit build, it could do its own string deduplication, etc. But then you have the same problem as you had with off-heap structures in Java etc: sure, you can write code that way, but it's a lot more pleasant when the compiler and runtime do it for you.
CLR (the C# runtime) generics are fully reified and about the most complicated and robust implementation available. It dynamically emits and loads types whenever a new generic parameter is seen for a function or type. This is very, very hard to get right and is not very performant. It also puts a lot of burden on the runtime vs. the compiler. Go expressly tries to keep the runtime as small as possible.
CLR-style just-in-time monomorphization is plenty performant: in fact, it's just about ideal. It's also not that difficult when you have a JIT when compared to the complexity you need for speculative optimizations of hot spots anyway.
In any case, the .NET approach isn't an option for AOT compilers like those of Go. For Go, the only reasonable option is ahead of time monomorphization, which really isn't that bad.
Monomorphization is not a reasonable option, in my opinion.
It forces the compiler to accept some truly awful running times for pathological cases. Atleast quadratic, probably exponential.
For languages that have reflection or pointer maps for GC or debug information for types, it can force large blowups in space as well. Go has all three of these.
The implementation would likely require runtime code-generation (or accept warts like Rust's "object safety").
Indeed, all of Ian's proposed implementations are polymorphic and seem to avoid each of these issues at first glance. The only advantage of a monomorphic implementation is performance, and considering the downsides, this'd be premature optimization forced by a language spec.
If its actually performance critical, I imagine it'd be easy to write a program that monomorphized a particular instantiation of the generic types. Indeed, the compiler would be free to do that itself, if it felt it would be worth it. Small, guaranteed non-pathological scenarios for instance.
Where if you guarantee monomorphization in a language spec, the compiler and all users are forced to accept the downsides in all instances, in exchange for often meaningless performance gains (example: any program that does computation then IO).
It's really not bad in practice. I've measured the amount of compilation time that generic instantiations take up and it's always been pretty low. Something like 20% (it's been a while, so take with a grain of salt), and that's with a naive implementation that doesn't try to optimize polymorphic code or perform ahead of time mergefunc. 20% is well within the project's demonstrated tolerance for compiler performance regressions from version to version. And you can do better with relatively simple optimizations. Generic compilation has been well-studied for decades; there are no unsolved problems here.
I would heavily advise against trying to do better than monomorphization with intensional type analysis (i.e. doing size/alignment calculations at runtime). We tried that and it was a nightmare. It didn't even save on compilation time in practice because of high constant factor overhead, IIRC.
Monomorphization is one of those things, like typechecking in ML, where the worst-case asymptotic time bounds look terrible on paper, but in practice it works out fine.
People point to C++ compilation times as a negative counterexample, but most of the compilation time here is in the parsing and typechecking, which a strongly typed generics implementation will dodge.
If generics were not a studied and well implemented concept I would agree. But we live in a world where this is just not the case. I would take a slightly slower compiler with generics support any day over the mess that go devolves into because of the lack of it.
Bear in mind that .NET will use a shared instantiation when the generic arguments are normal reference types; a hidden parameter is required for static methods under this scheme, to pass the concrete type info. Monomorphization is only required when the vector of generic arguments has a distinct permutation of reference types vs value types.
This gives you the best of both worlds: memory efficient generics for the majority of instantiations, and compute efficient generics for the types most likely to benefit (like primitives).
I think Go people have a very strange definition for simplicity, much like the population at large actually, but that's a shame really.
Simple means composed of a single element, not compound, unentangled, being the opposite of "complex", which of course means consisting of many different and connected parts. Instead Go people prefer the term to mean the now more popular meaning, which is "easy to understand, familiar".
I think a parallel can be drawn with another word from the English language: "free". You see, English doesn't have a word for the latin "liber" (libre, at liberty), like other romance languages have and I can name at least Italian, Spanish, French and Romanian (my own tongue). In these romance languages there's a firm distinction between libre and gratis, whereas in English there's no adjective signifying liberty without also meaning "at no monetary cost". I find that to be interesting and I bet it happened most probably because at some point in time these 2 issues were correlated.
Back to simplicity, while you can often correlate simplicity with easiness, mixing the terms is unjust because sometimes simple things aren't easy at all and sometimes easy things aren't simple at all (much like how sometimes gratis things are restricted and liberties aren't gratis). Speaking of which in my own native tongue the word for "easy" is also used to signify weightlessness (light, soft). Makes sense in a way, but you can see how language works.
And it would be a shame to lose the true meaning of "simple", just because its usage is at hand when trying to describe things that are or are not desirable. As in the end, this is how the meaning of words gets diluted and lost: because of our constant desire to make other people believe our ideas and buy our shit. So we exaggerate. Just a little, after all, we are only going to end up with a language that's ambiguous. What does it matter if "open source" has had a clear definition since OSI and that it wasn't in use before that, it's marketable dammit, so lets use it for all shit that has source-code available. Etc, etc.
And I get it, saying that generics aren't easy isn't so appealing, because that would be an acknowledgement of one's own capabilities and knowledge, being a metric relative to the one who's speaking. Whereas simple is an objective metric, with things being simple or complex irregardless of the person that's passing judgement. Still, generics are only as complex as static type systems. When you have a statically typed language, generics are a natural consequence. And if you don't add generics, then you need to add an "Object", "Any", "dynamic" or whatever you want to call it, which would be a whole in that static type system, not to mention introducing special cases (like the builtin arrays and maps) and that's complex by definition. Java did as well, introducing generics at version 5, when it was too late to do it cleanly and the result isn't nice at all ;-)
True, GPL is significantly more complex, as it makes a difference between usage and distribution, not to mention it tries to prevent loopholes, like Tivoization and patent threats. Complex is not necessarily worse, of course it depends on context. I prefer APL 2 if you ask me.
But what matters in this case are that both correspond to the open source and free software definitions. For such licenses it means that there are things you can rely on. Like you know usage is OK for any purpose, including commercial ones. You know that you can share it with anybody, you know that derivate works are OK, again for any purpose, even though you can have restrictions on distribution. Etc.
For me clear definitions are important because then you immediately know what you can rely on and ambiguous language is bad because then we can't have a meaningful conversation. Are generics complicated? No. Are Java's generics complicated? Yes, but that's only because it was added later ;-)
It's also at odds with hard-learned lessons of the rest of the software industry, like don't repeat yourself. Golang is doomed to relearn these lessons.
First of all, generics is hardly DRY to its extreme. I think that everyone agrees that copying e.g. a balancing red-black tree implementation just to specialize it for another value type is a pretty bad idea. So then you either end up with some kind of runtime polymorphism or parametric polymorphism. Some Go users argue that runtime polymorphism is enough, but you often run into cases where you have a
func frobber(s []SomeInterface) ...
However, you end up having a
[]ConcreteType
where ConcreteType implements SomeInterface. However, you cannot simply pass a []ConcreteType to frobber because the memory representation is different and you have to construct a new slice with the interface type, etc.
Also, I don't think left-pad is an example of extreme DRY (though it should be part of a standard library). It's not an example of extreme DRY, because I think a substantial amount of programmers wil implement it incorrectly. As long as many Java-wielding friends still believe that a single char can represent any unicode code point, I have no reason to believe that the average monolingual English-speaking Go programmer will realize that you can't simply do something like:
The way I work is, I make an interface{} red-black-tree, and then when I need to store things in it I create functions around it.
Suppose I'm storing Tiles in a Level: the Level struct will contain a (private) RedBlackTree and I'll define GetTile(Pos) Tile and PutTile(Pos, Tile) on Level which do the casting to and from interface{}.
I still have type safety since I cannot put/get anything but Tiles in the RedBlackTree. But I didn't need generics.
From your description, it is not completely clear what you are ordering on, but typically in an RB tree you (at the very least) want to require some interface/function that specifies ordering and equality.
Of course, in some cases you can do casting on your interface boundaries. But in many other cases this is not possible, e.g. if you want the API to return an ordered set or map.
Exactly what lesson do you think was learned? Do you think that languages that have had left-padding functionality in their standard library since forever (and there are lots of them) are going to remove it now?
There was definitely a lesson to be learned there, but it wasn't the one you're implying.
The left-pad debacle was due to tools encouraging a badly non-hermetic build process and devs not being wise enough to resist, not DRY. Only depending on one third-party library won't save you if you "upgrade" to a broken version without testing.
> DRY is a great suggestion but shouldn't be looked at as any type of hard rule
Agree that nothing should be a hard and fast rule. But the significance of DRY is that it increases quality. Not even having the option to "stay DRY" for many problems implemented in Golang will increase bugs. That's just how it is.
Given the tradeoff between the supposed complexity of generics and the very real cost of bugs that will happen from maintaining duplicated code, I'm not sure there's much of a debate to be had.
> It's also at odds with hard-learned lessons of the rest of the software industry, like don't repeat yourself.
There is nothing wrong with repeating things. It's important to NOT repeat many things but everything? No way. DRY is a great suggestion but shouldn't be looked at as any type of hard rule.
For instance I've been on projects where DRY was taken to such an extreme that even the function decorators (plus their COMMENTS) were abstracted away because a few words or, at least, a single line could be duplicated. This would require looking through multiple files and figuring out the abstraction code just so I would know where the REST endpoints where.
So I'm not the biggest fan of GO but I see zero reason why it's going to be relearning this specific lesson.
I'm not seeing where the parent poster suggested taking DRY to such extremes.
The fact that a feature can be abused doesn't mean that it's a worthless feature. If that were the case there'd be no progress in programming languages because basically every feature can be abused. What matters is the balance between how easy it is to abuse (accidentally or not) vs. how useful it is when not abused (such as added expressivity/safety/DRYness/etc.).
To it's credit, most of the times I feel like I'm repeating myself in Go I usually later find I'm needing to specialize anyway. Go tends to help you avoid premature optimizations which you'll "totally fix later" - i.e. handle your errors now, not then.
Linus is clearly throwing his weight around here. If anyone else were to act this way and use such language we would all call him or her an asshole. Besides his main point is that C++ is not great for low level code. I don't see how this applies here.
He is being called asshole and worse innumerable times. The only difference is that Twitter commenters and Corporate HRs do not control his livelihood in ways it does to most professionals so he is free to say things the way he feels.
we see things differently. In my view Linus is speaking free here. Many others refrain from speaking free and truthfully for fear of being called an asshole.
I see different main point. In my view Linus narrows the domain of his speech to system-level (not low-level!) code just out of basic intellectual honesty which implies to speak with authority only where your experience and knowledge are.
When he says, "YOU are full of bullshit," is that the intellectual honesty part? Some people are merely assholes constrained by social pressure other people are actually being honest when they are nice. It's hard to believe this when you are one of the former.
I agree with your system-level vs. low-level point except that he also talks about git which is neither.
>When he says, "YOU are full of bullshit," is that the intellectual honesty part?
if the guy is full of it then not saying it would be intellectual dis-honesty :). You and me belong to the different mindsets separated by a Grand Canyon. Man, i understand the reasons behind PC-culture, yet i just don't agree with the required trade-off. It is pretty much the same as security vs. privacy & other freedoms - there is really no meaningful debate possible beside clearly stating your own position as these mindsets are separated by the same size canyon. It is not separation of reasoning, it is separation of the choice of the top priority - in most cases that choice is deeply unconscious, and i have my personal theory connecting it to evolution and natural selection :) It is not that people on different sides don't understand the reasons of the other side, it is just people on each side are separated by their choice of the reasoning they assign higher priority to, like me and you in this case.
{kind=link}