Memory usage and as a consequence of that excessive GC pauses. I'm not looking at any JVM language again before they introduce value types in a couple of years (maybe).
I build soft real time simulation systems in Java. GC pauses haven't been a problem since 1.2 was released around 2000. Memory usage isn't a concern either for big applications, as there's not a lot of overhead in the runtime. There is the fact that one can't embed value types directly in objects, but I don't find that a problem in practice.
Then your experience is very different from mine and that of many other people who resort to all sorts of off-heap solutions and distributing stuff across multiple VMs. I guess it depends a lot on the specific use case.
You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
If you want no GC pauses at all, ever, well, Go can't do that either. But if you are willing to pay money to Azul, you can buy a JVM that can. It also concurrently compacts the heap, which Go's GC does not.
The issue is not Java. The issue is the quality of freely available garbage collectors, which are very good, but not pauseless.
>You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
For what percentile of collections? I'm not wasting my time with incessant GC tuning only to delay that 5 minute stop the world pause for a bit longer. It's still going to hit eventually. For projects that might grow into that sort of heap size I use C++ (with an eye on Rust for the future).
You are right that Go is not a panacea for very large memory situations, but you can do a lot more before Go even needs that amount of memory.
The point is that languages without value types, such as Java and JavaScript, waste a huge amount of memory and generate a lot more garbage, thereby exacerbating all other related issues, including GC.
I have done quite a lot of testing for our workloads. Java memory usage is consistently two to three times higher than that of Go or C++. I'm unwilling to waste our money on that.
In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
To get 10msec pause times with such huge heaps requires burning a LOT of CPU time with the standard JDK collectors because they can trade off pause latency vs CPU time.
This presentation shows tuning with 100msec as the target:
2. Older collectors like CMS (still the default) sometimes take long pauses, like 5 seconds (not 5 minutes).
3. The new GC (G1) must be explicitly requested in Java 8. The plan is for it to be the default in Java 9, but switching to a new GC by default is not something to be taken lightly. G1 is, theoretically, configurably by simply setting a target pause time (lower == better latency but more CPU usage). Doing so eliminated all the long pauses, but a few collections were still 400msec (10x improvement over CMS).
4. With tuning, less than 1% of collections were over 300 msec and 60% of pauses were below the target of 100 msec.
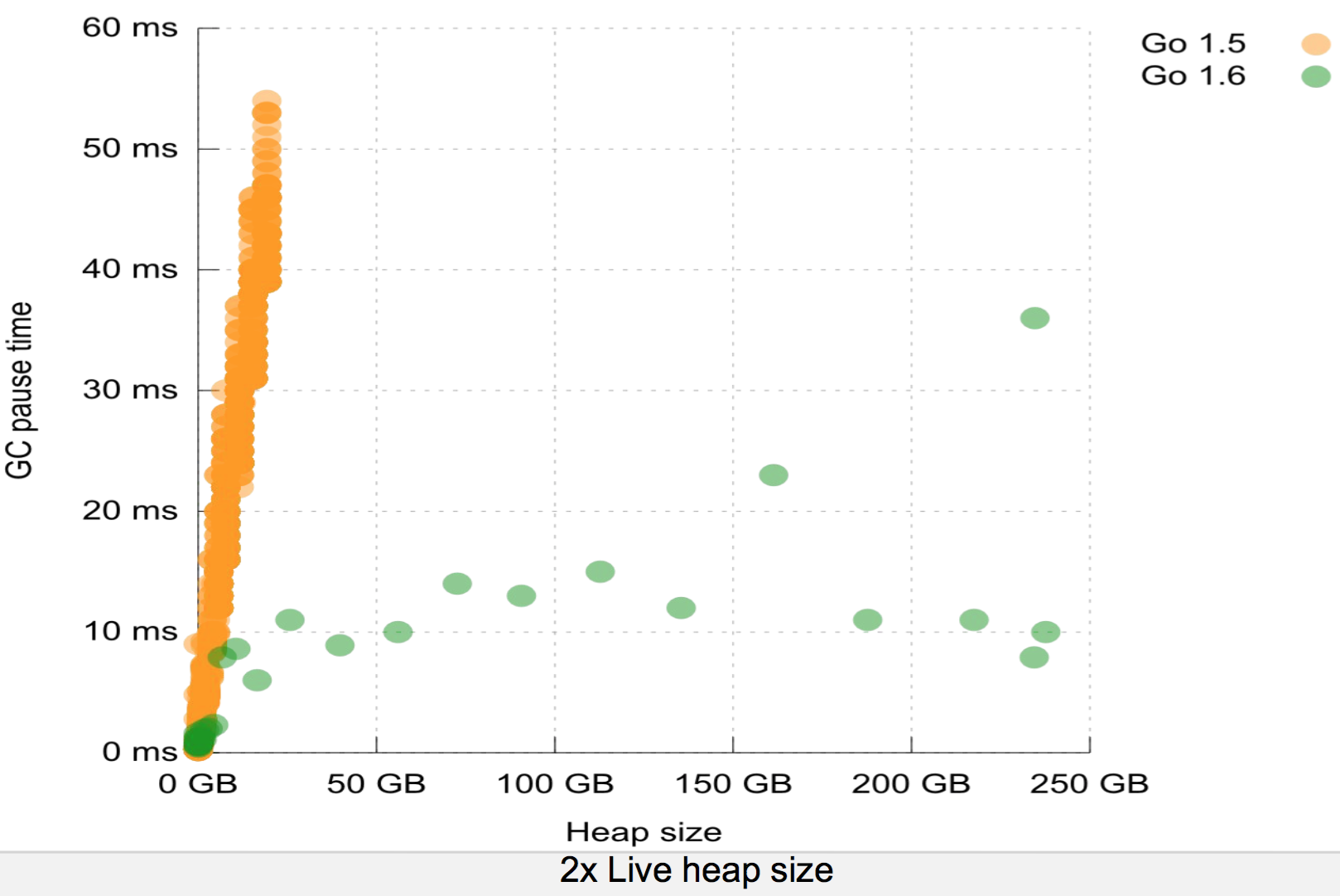
Given that the Go collector, even the new one, isn't incremental or compacting I would be curious how effective it is with such large heaps. It seems to be that a GC that has to scan the whole 100GB every time, even if it does so in parallel, would experience staggeringly poor throughput.
Value types will certainly be a big, useful upgrade.
>In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
So you use a language without value types that makes you pay for two or three times more memory than comparable languages, and then you spend your time re-tuning the GC every time your allocation or usage patterns change. Then you hope to never trigger a full GC that could stall the VM for many seconds (or in extreme cases that I have seen even minutes). That makes very little sense to me.
I cannot speak to the performance of the current Go GC for 100G heap sizes. I never tried it and I haven't read anything about it. It's not my language of choice for that sort of task either.
They aren't comparable at all. Go doesn't collect incrementally and doesn't compact. So good luck collecting garbage fast enough to keep up with a heap-heavy app (which if you have a 100GB heap, your app probably is).
In other words, the issue is not pause time, it's also throughput.
But Go programs use way less memory than Java applications... so the java application that uses 100GB might only use 40GB (or less) in Go. And there are tweaks you can make to hot code in Go to not generate garbage at all (pooling etc).
Java's higher memory usage is not only related to value types, for example, in Java 8 strings always use 16 bit characters. That is fixed in Java 9. It resulted in both memory savings and speed improvements.
There are other sources of overhead too, but again - you seem to think Go has some magic solution to these problems. Since the new GC, Go is often using a heap much larger (such as twice the size) of actual live data. That's a big hit right there. And yes, you have to tune the Go GC:
Value types are the main culprit behind Java's insane memory consumption. I found out through weeks of testing and benchmarking.
I mostly benchmarked a small subset of our own applications and data structures. We use a lot of strings, so I never even started to use Java's String class, only byte[].
I tried all sorts of things like representing a sorted map as two large arrays to avoid the extra Entry objects. I implemented a special purpose b-tree like data structure. I must have tried every Map implementation out there (there are many!). I stored multiple small strings in one large byte[].
The point is, in order to reduce Java's memory consumption, you must reduce the number of objects and object references. Nothing else matters much. It leads to horribly complex code and it is extremely unproductive. The most ironic thing about it is that you can't use Java's generics for any of it, because they don't work with primitives.
I also spent way too much time testing all sorts of off-heap solutions. At the end of the day, it's just not worth it. Using Go or C# (or maybe Swift if it gets a little faster) for small to medium sized heaps and C++ or Rust for the humungous sizes is a lot less work than making the JVM do something it clearly wasn't built to do.
But I think your conclusion is not quite right. I said above that pointer overhead is only one source of Java memory consumption, and pointed to (hah) strings as another source. You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
If your application is so memory sensitive that you can't use basic data structures like maps or strings then yes, you really need to be using C++ at that point.
In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code and the JVM can do optimisations like deduplicate strings from the heap (already). Of course how much that helps depends a lot on the application in question. But the sources of gain and loss are quite complex.
>You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
I see what you mean, but when I said that Java uses two or three times as much memory as Go or C++, I didn't include tons of UTF-16 strings either, assuming most people don't use as many strings as I do. If your baseline does include a large number of heap based Java String objects, the difference would be much greater than two or three times because strings alone would basically double Java's memory usage (or triple it if you store mostly short strings like words using the short string optimization in C++ for comparison)
>In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code
I'd love to see that theory :-) But let's say it was magic and the bytecode as well as the VM itself would require zero memory, any difference would still only be tens of MB. So it would be negligible if we're talking about heap sizes on the order of tens or hundereds of GB.
Yes, if your heap is huge then code size savings don't matter much. I used to work with C++ apps that were routinely hundreds of megabytes in size though (giant servers that were fully statically linked). So code size isn't totally ignorable either.
WRT the theory, that depends what the heap consists of.
Imagine an app where memory usage is composed primarily of std::wstring, for example, because you want fast access to individual characters (in the BMP) and know you'll be handling multiple languages. And so your heap is made up of e.g. some sort of graph structure with many different text labels that all point to each other.
The JVM based app can benefit from three memory optimisations that are hard to do in C++ ... compressed OOPs, string deduplication and on-the-fly string encoding switches. OK, the last one is implemented in Java 9 which isn't released yet, but as we're theorising bear with me :)
Compressed OOPs let you use 32 bit pointers in a 64 bit app. Actually in this mode the pointer values are encoded in a way that let the app point to 4 billion objects not bytes, so you can use this if your heap is less than around 32 gigabytes. So if your graph structure is naturally pointer heavy in any language and, say, 20 gigabytes, you can benefit from this optimisation quite a lot.
String deduplication involves the garbage collector hashing strings and detecting duplicates as it scans the heap. As a String object points to the character array internally, that pointer can be rewritten and the duplicates collected, all in the background. If the labels on your graph structure are frequently duplicated for some reason, this gives you the benefits of a string interning scheme but without the need to code it up.
Finally the on-the-fly character set switching means strings that can be represented as Latin1 in memory are, with 16 bit characters only used if it's actually necessary. If your graph labels are mostly English but with some non-Latin1 text mixed in as well, this optimisation could benefit significantly.
Obviously, as they are both Turing complete, the C++ version of the app could implement all these optimisations itself. It could use 32 bit pointers on a 64 bit build, it could do its own string deduplication, etc. But then you have the same problem as you had with off-heap structures in Java etc: sure, you can write code that way, but it's a lot more pleasant when the compiler and runtime do it for you.
{kind=link}