I work on juju (https://github.com/juju/juju), which all told is about 1M LOC. In my almost 3 years on the project, I have not been bothered by lack of generics, basically at all (and I worked for 10 years in C# on projects that used a lot of generics, so it's not like I don't know what I'm missing).
Do we have 67 implementations of sort.Interface? Sure. Is that, by any stretch of the imagination, a significantly difficult part of my job? No.
Juju is a distributed application that supports running across thousands of machines on all the major clouds, on OSes including CentOS, Ubuntu, Windows, and OSX, on architectures including amd64, x86, PPC64EL, s390x... and stores data in a replicated mongoDB and uses RPC over websockets to talk between machines.
The difficult problems are all either intrinsic to the solution space (e.g. supporting different storage back ends for each cloud), or problems we brought on ourselves (what do you mean the unit tests have to spin up a full mongodb instance?).
Generics would not make our codebase significantly better, more maintainable, or easier to understand.
A lot of people are focusing on your sorting comment, but I want to point out that your 1M LOC is already benefiting from generics. Slices, map and chan are polymorphic types, and functions like make(), len(), append(), copy(), etc. are generic.
The only distinction is that they're built in. But they are demonstrably useful, and your codebase would be worse without them.
It's hard to argue the hypothetical effect, good or worse, of generics on a codebase. You can't claim to know it for certain, seeing as the definition of generics isn't even completely defined. Maybe it wouldn't be hugely better. I don't think anyone is claiming that generics would be magical.
But well-designed generics (Haskell, Ocaml) can improve in other ways, some more or less subtle than others: You get less boilerplate, more code reuse, expressiveness. Go is pretty easy to read, but I find that the lack of expressiveness tends to obscure the meaning more than it reveals it. For example, you tend to end up with clunky C-style loops where a map would be much more concise, expressive and readable.
Another example: map types. I frequently find myself writing awkward code to copy maps, merge them, apply a common access pattern (such as [1], which coincidentally horrific and probably not performant) and so on. The ergonomics are terrible.
I disagree that it's not a "bother". It probably depend on what the project is; I also work on distributed apps, though.
I've had a very similar experience from about 3 years of writing Go. The lack of generics hardly affected me. When it did, it was dead simple to write the type-specific code and move on.
I've been working on a Java project recently, and by contrast, this code base abuses generics to an almost pathological level. I've also been burned by Java's runtime type erasure, and wow that leads to some nasty bugs. (That's not the fault of generics in principle, but Java's poor implementation of them.)
While I appreciate generics in theory, in practice I think Go is better as-is. Too often I've seen generics lead to complexity and abuse which greatly outweigh their utility.
Too often I've seen [X] lead to complexity and abuse which greatly outweigh their utility.
Programmer hubris is a problem. There was a widely acknowledged problem in Smalltalk with the overuse of #doesNotUnderstand: and other esoterica to do "clever" stuff which then makes it difficult for new programmers to debug and understand the system.
There is a reason why certain methodologies emphasize "the simplest thing that could possibly work." As a group, we programmers sometimes waste our own and other's time being too clever by half...an order of magnitude. (Is it any wonder why our estimates are often off by that much?)
Yep. I remember spending a day trying to genericize a Rules Engine type system in C# and finally realized it was idiotic and made the code more complicated, and we'd probably only ever use the code exactly how it was now (i.e. not generic), and so I left it as-is (and to my knowledge, yes, it stayed exactly the same for forever).
I see the same tendencies in many programmers - "hey, I want to write this once and cover every single case that could ever come up"... even when they really only need to solve one specific problem, and making the solution more generic makes the code a lot more complicated than it needs to be for the specific problem you're solving.
One place where I worked had a rule that you couldn't invoke DRY until something had been repeated at least 3 times. Empiricism wins in the end when the goal is to seek truth.
Yes, thank you. When you use generics for a sortable collection class, that makes sense--it's a perfectly reasonable application of the technology. Problem is that "clever" programmers go hog-wild with generics and create APIs that resemble Greek tragedies where everybody dies in the end.
I think that the Go core team acknowledges this tendency, and that's why they resist adding features which tend towards complexity/abuse when those "clever" programmers get ahold of them. Sure, it means some minor pain when implementing the Sort API for your class. The unseen benefit is that you don't get the horrific abuse of generics that I'm seeing in my current Java job.
>Generics would not make our codebase significantly better, more maintainable, or easier to understand.
Generics are literally a form of abstraction. You might as well be arguing that abstraction doesn't help. Why do you even have subtype polymorphism then? Why not just reimplement everything? That's not a significantly difficult part of your job as you said.
One of the best things about Go is it seems to be a strong signaler of the type of engineering team I avoided.
Is your unstated assumption then that all forms of abstraction must be used? If you've done substantive projects, you'll come to realize that abstractions have a cost, and that everything should be considered on a cost/benefit basis.
You might as well be arguing that abstraction doesn't help.
This is a black and white binary fallacy invoked to then create a straw man, which also seems to suggest that you haven't learned the importance of considering cost/benefit.
One of the best things about Go is it seems to be a strong signaler of the type of engineering team I avoided.
I would agree, this would seem to be a good signaler.
can you articulate the exact cost of adding generics? The benefits are profound, and the PL community has been doing research on it for the last forty some odd years.
Some of the benefits are opportunities for
* specialization
* reduction in boilerplate
* parametricity
* free theorems
* type classes
Objectively, a collections library written with generics and no subtyping will be much better and cleaner than a subtype based one.
The problem is, I've never heard generics argued against by someone who really understands generics. It's usually folks who got confused by them in java or really didn't dig into the theory behind them. An argument from ignorance isn't much of an argument.
Your comment is illustrative of a lack of awareness of context. You don't specify the context, but it seems like you're stuck in this academic/language theory mindset. From that standpoint, I rather like generics. It's clear to see how they can enable DRY if used judiciously. (Clear from even a freshman CS undergrad perspective.)
However, as a professional who gets paid to wrangle C++, I find the "Tragedy of the Commons" that results from every bright-eyed recent grad wanting to leave their mark on a system...tiresome. I recently fixed a bug caused by a small find-replace mistake, where a static_cast<int> was left out, resulting in an int() operator being generated by a confluence of preprocessor macros, inlined functions, and composed templates, where the call breaking in the stack trace was expressed nowhere in the code-base. It's one thing to DRY, but taking it one step too far to "Don't State Yourself In The First Place" is way too implicit. Abstractions have a cost, and sometimes the cost is epiphenomenal and gets paid years afterwards.
An argument from ignorance isn't much of an argument.
The decision of the Go team to not include generics is conservative and pragmatic. The context they consider is across an entire language community, and their decision is informed by observations made on code-bases at Google and elsewhere. How many 500k+ line code bases that have been around more than a decade have you worked on? I'm on something like my 4th. My conclusion from that is that we programmers as a group are mostly too anxious to be "clever" and biased towards doing too much when they evaluate the cost-benefit of "clever."
Do you have good data/experience on the epiphenomenal harm done by many, many "clever" programmers over years?
Ah, so you can't argue with me, so you're going to try the ol' appeal to authority ("i've worked on such big code bases that you'll never see").
You seem to assume I'm some naive recent grad. I've worked on more than a few 500k LOC applications. I'm a lead at a very large tech company (Fortune 50). The idea that '"clever"' programmers is a thing is incorrect.
There are good programmers and bad programmers. It doesn't matter if the lack of abstraction used by one type creates a monolithic mess of spaghetti code or if they use overly obscure attempts at abstraction. Bad code causes technical debt either way, and I've seen both done quite often.
Ah, so you can't argue with me, so you're going to try the ol' appeal to authority ("i've worked on such big code bases that you'll never see").
Uh, no. I asked if you understand such a context and if you have such data. Going by what you state, you do. A simple "yes" would have sufficed, and you could have left out the projection. Thank you for including the projection, as it is another valuable "signal."
The idea that '"clever"' programmers is a thing is incorrect.
There are good programmers and bad programmers.
Bad code causes technical debt either way, and I've seen both done quite often.
You do understand the use of quotes, then? "Clever" programming is thought to be clever by the perpetrator, but is actually bad programming and comprises technical debt. So either you are contradicting yourself above, or you are implying that "bad programmers" know they are bad, but do bad things anyways? This doesn't fit my experience.
Generics introduce more complexity in the type system which in turn makes the compiler slower.
Generics introduce more complexity for the reader of the code because it's another abstraction to understand.
It's debatable but when your brain is thinking about generics or context-switching because it has to wait on the compiler to finish, it's less time making progress on the actual thing that needs to be done.
I suppose it depends on the level of understanding that you want from your code. Generics introduce another dimension which you have to think about when you want a good level of control on allocations for example. Different data types also have different optimizations available which could be missed when blindly relying on the generic algorithm (think sorting on a fixed set for example)
(granted, 10 are under the .git directory, so I guess 57)
But in any other language, we'd still have the same 57 definitions of how to sort a type.... we'd just have 3 fewer lines of boilerplate for each of those (which live off in the bottom of a file somewhere and will never ever need to change).
Aside from trivial types, like strings or integers, how does the language know how to sort a list of values, if you don't tell it how to?
Translate this into whatever language you like:
Machine {
Name string
OS string
RAM int
}
You have 3 places that want to sort a list of machines, one by name, one by OS, and one by RAM. You're telling me there's a language that can do that without having to write some kind of code like this for each?
sort(machines, key: Name)
I don't understand how that's possible, but I welcome your explanation.
Sorting on all three fields in priority order is what I had in mind, and that's trivial in Haskell by adding "deriving(Ord)" to the data type definition and then just using the standard "sort :: Ord a => [a] -> [a]".
If you're always going to sort them based on some (other)
relation between the fields, make your type a custom instance of Ord, e.g. "instance Ord Machine where compare = compare `on` name".
To sort the same type with distinct comparators, you'll obviously need to distinguish them, as in e.g. "osSort = sortBy (compare `on` os)".
So... you will still need 57 spots in the code where you define how to sort a type.
Maybe my reference to sort.Interface is confusing people. When I say we have 57 implementations of sort.Interface, that's 57 different types and/or different ways of sorting one of those types. So, like, sorting Machine by Name would be one implementation, sorting Machine by Name then OS then RAM would be another implementation. You write an implementation of sort.Interface for every type, and for each way you would like to be able to sort it.
An implementation of sort.Interface just requires three methods:
Len() int // return the length of the list
Swap(i, j int) // swap items at indices i and j
Less(i, j int) bool // return true if list[i] is less than list[j]
It's the implementation in Less that determines the order.
That's not really so different than what you're describing in Haskell, it's just not part of the type, it's a new type that you convert the original type into, to pass into the sort.Sort() function (and because the underlying type is a slice, which is a glorified struct with a pointer to an array, that also sorts the original value).
It's possible to make one implementation for a type that supports multiple orderings, at the cost of another indirection [0]. This turns O(N*M) implementations for N types and M sorting orders into just O(N). (I'm not counting an inline anonymous function as a new implementation.)
In practice, it's rare to need to sort a slice more than one way.
This is an extensively solved problem in modern programming languages.
As a bonus, the opportunity for making an error each time you want to sort a new type of array in a new way is reduced if you only have to write one line of code each time.
The canonical solution to this problem is to provide a function to perform the comparison, or to require the types implement a "Sortable" or "Comparable" interface.
yes, which for 57 different types and/or comparison methods requires 57 different functions... which is basically the exact same thing you do in Go. It's just in go, you define a new type based on the original value, rather than just a function.
Just to nitpick, that is 4 lines because you add a type too.
Also, I noticed this in controller.go:
// Unreachable based on the rules of there not being duplicate
// environments of the same name for the same owner, but return false
// instead of panicing.
return false
Guess what, I worked with a sort function with the same kind of assumptions, but the implicit rules was broken: the "should never happen" path happened (names were not unique, after all). I found about that only after I wrote my own sort which was careful enough to check that the order was indeed total and when results diverged for some tests.
I really disliked that because sorting was an important part in that tool (maybe it is not in yours).
> >Generics would not make our codebase significantly better, more maintainable, or easier to understand.
> Generics are literally a form of abstraction. You might as well be arguing that abstraction doesn't help.
You missed one word: "significantly". Sure, abstractions help. That wasn't the claim. The claim was that, in a million lines, the lack of that particular way of doing abstractions did not significantly hurt.
Would it have helped? Sure. Would it have helped enough to matter "very much"? No (by NateDad's standards, which may differ from yours).
67 implementations of sort.Interface? Sure, I don't like it, but in a million lines, you've got much bigger things to worry about.
I can feel the pain on the Sort issue. I've personally found sorting annoying in Go - I had a bunch of structs representing data entities from a database that all had the same field and I wanted to be able to sort them by this field.
Seemed like a LOT of work (basically implementing the same sort that was 99% identical for every struct) or use weird reflection-workarounds to get this to happen. In Java I would not even given this a second thought and be back to coding up the important part of the code ages ago.
I am a new go-lang user so would love to know what the best approach to resolve this is without a) repeating the same thing for every struct, or b) relying on "unsafe" reflect techniques (since AppEngine rejects code that does that) - surely sorting structs is a super-common, basic thing for a systems language? I've seen someone just nonchalantly say "Use interfaces" but I'm not sure still.
I like the language generally but this is a real "WTF?" moment for me.
I had the same feeling first. But practically in my code, I found that ok, you need to copy/paste a bit first but then if it works it stays there, you are not "sorting" new kind of "types" every day. The time spent on coding is way more "around" the algorithms than "within" them.
I suppose that we will see more and more code generators which will practically remove the need of generics. We already use them without complaining for serialization in JSON/Protocolbuffer/etc...
If code generation is used to make up for something missing in a language (be it generics, metaprogramming etc.) then that's a pretty clear sign something is wrong.
It's definitely acceptable to use a workaround for a missing feature once or twice in a language, because no language is perfect, and no language benefits from being burdened with all features imaginable.
But if a workaround becomes part of the day-to-day workflow, then you are likely using the wrong language.
Examples could be: using (textual) code generation for generics, or using type annotations throughout a dynamic language project.
Everyone agrees something is wrong, even the Go team. The debate is whether it's meaningfully wrong, or just "someone's wrong on the Internet" wrong --- because the cost of righting this wrong will be high.
Well put. Though I would add that though generics are convenient, they are not as needed nearly often enough to be a crucial missing feature in a language. Yes, it's uncanny to copy here and there, and certainly, the Go team should try and resolve this. But from where I'm standing this (i.e. generics) is one of the very few fair criticisms of Go which can be leveled from the Java, C++ or C# communities.
Code generation is not about a deficiency in the language, C++ has templating but I will often use code generation since you only need to run that once and templating bloats the compile time for ever.
Yes of course, but compiling the code is faster than generating the code and then compiling it. Templates are much slower than just compiling code straight.
With the exception of pathological metaprogramming examples -- and even those have largely been fixed -- there's no way you could even measure this, let alone justify such a strong, broad opinion. You're using incomplete information to justify sloppy engineering and promoting it to others.
Templatizing/de-templatizing enough code to see a difference would be a significant effort on any non-trivial code base. But I'll spare you the trouble: instantiating a template is less work than parsing a duplicated file. Some of the early C++ compilers had problems but it hasn't been an issue in 20+ years. If you look at both the G++ and Clang test suites you'll see they verify performance, memory usage and correctness with complicated templates by doing basically this exercise for you.
I am writing a chemoinformatics database, so for my practical use, these are a lot of lines of codes with pretty involved algorithms and I am practically not annoyed by the lack of generics.
For the ones down-voting me, have you coded something in Go, big enough to be a real in production project, where at the end the lack of generics is a real issue (performance because using interfaces or maintenance because copy/paste to have the performance)?
I'm part of a project team that uses quite a lot of Go in production (for analytics work), and lack of generics was particularly painful.
>(performance because using interfaces or maintenance because copy/paste to have the performance)?
I don't like interfaces (namely, interface{}) for their lack of safety for generic work -- performance comes second to that.
And I don't like copy/paste like ever.
>For the ones down-voting me, have you coded something in Go, big enough to be a real in production project, where at the end the lack of generics is a real issue (performance because using interfaces or maintenance because copy/paste to have the performance)?
Isn't that a sure fire way to selection bias? The ones that ended up coding something significant in Go will usually be those that put up with the Generics issue (or don't even know what they are missing).
It's like asking C programmers if they mind missing GC, closures, etc.
It's not like the utility of Generics is some open question in PL either. It's a settled matter. Even Go uses them, but doesn't offer them to the programmer, or suggests generic but not type-safe solutions like interface{}.
I wrote some big things in Go and didn't find the lack of generics particularly problematic. Different languages are good for different things-- Go is good for building things that are relatively concrete. For something like a symbolic math package or a scripting language you might want a different language that makes different tradeoffs.
> For the ones down-voting me, have you coded something in Go, big enough to be a real in production project, where at the end the lack of generics is a real issue (performance because using interfaces or maintenance because copy/paste to have the performance)?
The Go community doesn't hate protocolbuffers, but it does tend to think that generics are evil and shouldn't exist.
I'm certain that generic generators will be shunned by the community at large, due to solving a problem they don't believe needs solving. Without the network effect to build up a user and developer-based, they'll languish in obscurity.
You might be right, this is the best solution in Go at this moment, but that's a local optimum. You don't have to solve this kind of problems in many other languages.
The generator given as an example in the official blog [0] is called "stringer". It is made of 639 lines [1] mixing ast parsing/traversing and printf statements. If this is what I am supposed to write then of course copy-pasting becomes a pragmatic alternative.
And that's exactly why I am not convinced that Go is as maintainable as often claimed. 30 seconds for you, but how many hours for the poor souls who will come after you and ask: should I change this copy too or is it a separate case?
This thread is about sort interface implementations. Their general form will never change, and the only specifics unique to any given copy are those specific to their type. It is obvious to any Go programmer what can and cannot be changed in this situation.
The thread was more about mattlondon's problem with sorting according to the same key in different structs. I used of modified version of this example[0] to illustrate what I think is his problem[1]: you can sort circles and planet by radius, and probably many other things in the original case, but you are required to copy-paste the definitions.
I can understand that instantiating templates by hand is not so bad. But once it is written, maintaining the code is not so obvious for someone not acquainted with it.
Did I introduce a bug or not in the code? Not easy to tell without context.
The problem with code duplication is not about being lazy, or having to type. I love typing.
When you dive into a codebase full of vaguely similar yet different blocks, it starts being more than mildly annoying to understand the intent of the code and make the correct change.
type userList []*User
func (u userList) Len() int { return len(u) }
func (u userList) Swap(i, j int) { u[i], u[j] = u[j], u[i] }
func (u userList) Less(i, j int) bool { return u[i].Name() < u[j].Name() }
What change would you ever need to make to this code that would be at all difficult? The first two methods on userList are never ever ever going to change. The only thing you could possibly want to change is how to sort inside the Less method... and that code would be the exact same code you'd have to change no matter what language you're in. You still have to define the sort one way or another for non-trivial types.
So, yes, it's some extra typing... but saying that it makes maintenance harder is just plain wrong.
Yes, I agree completely. Take leftpad, for example....
And more seriously, there are times when factoring out "common" code makes the code significantly more complicated, and often turns your common code into a morass of special cases as your application progresses, and these cases that looked "the same" end up being "not quite the same".
Why not write an interface for getting the radius and a radius sorter for sorting on that interface? I made a modified version of your code to illustrate.
Thanks a lot for your example. I would certainly take this approach and I am happy that you took the time to write it.
I feel a little sorry for you because I put a trap for the parent poster in the original code.
I wrote "a[j] < a[i]".
You "fixed" it while refactoring, which would be the good thing to do if I made a typo. If however I really wanted to sort circles differently from planets, then you made an error while refactoring what looked like copy-pasta but wasn't.
My original point was that when you "have" to copy-paste, you cannot clearly see what is or isn't part of the copy and what is new.
You found a way to rewrite the code without much copy- pasting, and I am happy to see that. Still, in other places where code duplication arise, there could be similar problems from a maintenance point of view.
What if I'd done that 20 times around my code-base and then later I discover there's an off-by-one error in the original code that's maybe been inherited into all 20 copies?
If I could actually reuse code properly I'd only have to fix it once.
Without effective code reuse, I have to hunt down the copies, each of which may have slight modifications to make them better fit their use case (and might be hard to grep for as a result), figure out whether or not the bug exists in that copy (and whether it can actually be triggered), and fix it there.
Then one day you find a bug in your code and now will have to find all copies of it and to make things worse someone else modified some of the copies so now not all of them are identical.
No, it's the opposite. It would appeal to people who built large Go codebases and eventually realised that they were tied to a toolchain that was years behind the state of the art.
A Go for the JVM would immediately give Go developers much better optimising compilers, high quality cross platform IDE-integrated debugging and profiling, much stronger garbage collectors, ability to access the large quantity of Java libraries that are out there, ability to mix in other non-Java languages too (javascript, ruby, R ...), code hotswap, better monitoring tools, a vastly larger standard library, better code synthesis tools and so on.
The JVM is hardly a liability. It adds features and carries a cost, but Go is substantially similar to Java in many ways and getting closer with time. I do not see any credible plan from the Go developers to beat the JVM developers in terms of GC or compiler quality, for instance.
Go GC since 1.6 openly claims <=10ms STW pauses. Does any open source Java GC offers that? Also Go uses an order of magnitude less memory for running process compare to something similar in Java so I do not see how optimizing compilers in Java are doing any better job.
In my experience Java brings a mindset that there must be some complex way to solving a problem so lets find out that.
Go 1.6 GC is exactly what I mean. It's a design that gives tiny pauses by not being generational, or incremental, or compacting. Those other features weren't developed by GC researchers because it was more fun than Minesweeper. They were developed to solve actual problems real apps had.
By optimising for a single metric whilst ignoring all other criteria, Go's GC is setting its users up for problems. Just searching Google for [go 1.6 gc] shows the second result is about a company that can't upgrade past Go 1.4 because newer versions have way worse GC throughput: https://github.com/golang/go/issues/14161
Their recommended solution is, "give the Go app a lot more memory". Well, now they're back in the realm of GC tuning and trading off memory to increase throughput. Which is exactly what the JVM does (you can make the JVM use much less memory for any given app if you're willing to trade it off against CPU time, but if you have free RAM then by default the JVM will use it to go faster).
BTW the point of an optimising compiler is to make code run faster, not reduce memory usage. Go seems to impose something like a 3x overhead vs C, at least, that was the perf hit from converting the Go compiler itself from C to Go (which I read was done using some sort of transpiler?). The usual observed overheads of Java vs C are 0 to 0.5x overhead. The difference is presumably what the compilers can do. Go's compiler wasn't even using SSA form until recently, so it's likely missing a lot of advanced optimisations.
tl;dr - I have seen no evidence that the Go developers have any unique insight or solutions to the question of building managed language runtimes. They don't seem to be fundamentally smarter or better than the JVM or .NET teams. That's why I think eventually Go users will want to migrate, because those other teams have been doing it a lot longer than the Go guys have.
>
Go GC since 1.6 openly claims <=10ms STW pauses. Does any open source Java GC offers that?
Yes. HotSpot has had configurable max pause times for years and years [1]. If you want less than 10ms, set MaxGCPauseMillis to 10ms. It also has a state-of-the-art generational GC, which is very important for throughput, as bump allocation in the nursery is essentially impossible to beat with a traditional malloc implementation.
> The following example JVM settings are recommended for most production engine tier servers:
-server -Xms24G -Xmx24G -XX:PermSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=20 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70
So Oracle mentions 200ms for most prod use. I am not sure how you are able to deduct ~10ms pause from that link.
And just because one can configure ~10ms does not mean at JVM will start respecting it. There is nothing in any official document by Oracle about max GC pause time. The results Google threw are mostly around ~150ms as min pause.
You can ask for 10ms latency and you will get it. This is basic functionality of any incremental/concurrent GC. The throughput will suffer if you do that. But HotSpot's GC is far beyond that of Go in regards to throughput, for the simple fact that it's generational.
Nongenerational GC pretty much always without exception loses to generational in heavily GC'd languages like Java and Go. There is no silver bullet for GC; it requires lots of hard engineering work, and HotSpot is way ahead.
sievebrain - Did you read the full issue? This is an edge case - a program running on a 40 core machine that the developers were trying to keep to a 5MB heap. And yes, the answer was "use more RAM", but by "more" they mean "40MB". Not like gigabytes or anything.
There's always going to be edge cases in any GC/compiler/etc ... you just can't account for every case. I suppose with java's infinite knobs, you might be able to... but then you have to tune the GC. In Go, there's just one knob (a slider, really, more CPU vs. more RAM), and 98% of the time you'll never need to touch it. I had honestly forgotten it exists, and I work on a large Go project daily at work.
Go's unique proposition, IMHO, is compile times. If you have a codebase that's 10 million lines, with 10 or 100 developers working on it for 10 or 20 years, compile times really matter.
Can you build a language that runs on the JVM that compiles as fast as Go? Perhaps. Java sure ain't it, though.
Have you done a comparison? JavaC is extremely fast and compiles incrementally. Turnaround time from editing a file to seeing the change on screen is measured in a couple of seconds on my laptop. I don't think Go has any speed benefit in this regard.
I doubt it. I did Java for over a decade, but jumped at the opportunity to use Go with its statically compiled binaries. The JVM is great, but being tied to it is kind of a hassle. Being able to hand a small binary to someone and say "here, run this" with no worry about dependencies- it's a beautiful thing.
You can use the 'javapackager' tool in Java 8 to make a tarball that contains a JRE. It's not small, but that's a result of the age of the platform; it just has a lot of features (in Java 9 there is a tool that can make a bundled but stripped and optimised package).
Go binaries are getting larger and the compiler is getting slower over time, as they add features. They don't have any magical solution for bloat: eventually, they'll add the ability to break the runtime out into a dynamic library as it gets fatter and fatter.
Or of course they can just refuse to add features and doom their users to a mediocre, frustrating experience forever.
No, the sort package requires you to define methods on the slice of what you want to sort. For instance, if you defined a struct S, you need to implement Less, Swap and Len on an alias type of []S (since you cannot implement methods on slice types).
And whilst this Sort could work, how do you call it? []int isn't []Comparable, and can't be converted to one: you have to make a new array. Then, when you want an array of ints on the other end, you have to convert it back, which now involves run-time type assertions.
Even an array of something that implements Comparable isn't compatible - it can't be, because Go doesn't know Sort won't take Bar[] and put a Foo in it, if Foo and Bar both implement Comparable.
And, whilst you can define Compare for int, the other argument will be a Comparable, not a int, so you'll have to have a run-time type assertion for each comparison.
You still can't sort []int, and your comparison function can't know it's receiving int, so it will have to type-assert both arguments at each comparison.
The whole problem is that there is a common interface, but it's a PITA to reimplement it every time (which means copy-pasting a little less than 10 lines) when every other language gives you sorting with a single, simple, 1-line function (or even a single argument of an already existing function).
Completely oblivious about Go, but can you not provide a key function to the sorter that reaches into the struct and pulls out the field you want to sort on? (And presumably explodes in some spectactular fashion if it doesn't exist.)
Or is that the "unsafe" reflection you're talking about?
For struct's at least, the answer would be to use an interface method which exposes the key field you want to use. This would be type-safe - you wouldn't be able to pass a non-conforming struct to the sorter.
EDIT: I'd argue what we need in Go is something like a type-class for interfaces, so we can match on fieldsets the struct contains, and not just methods.
I think matching on fieldsets would be the ticket here.
I guess right now I could add a pointless no-op "marker method" to make each struct match a "CanBeSorted" interface, then have my sort function work in terms of things implementing CanBeSorted, but that does not guarantee the fields I want to use are there.
Sigh.
I am hoping that the "no backwards incompatible changes" thing Go has wont prevent fixing things like this sorting nonsense. Right now, whichever way I approach this sort of thing just feels icky.
I agree with the Sort issue, I faced the same problem. However, I cannot see how generics would fit well into code that is supposed to be easier to understand and maintain.
After watching Rob Pike's Go Proverbs talk I am pretty convinced generics, as much as some would want it, will never happen. He proselytizes "just copy a little code here and there" quite clearly, which is at odds with the complexity that generics would add.
Rob Pike's repository 'filter'[0] contains implementations of map ("Apply"), filter ("Choose", I believe), and fold/reduce ("Reduce"). The code is an ugly mess, and the implementation shows that he probably hasn't used any of these standard functions in other languages (see the weird permutations of 'filter' in apply.go, or my patch for his fold/reduce implementation[1]). The README is also quite arrogant, IMO.
> I wanted to see how hard it was to implement this sort of thing in Go, with as nice an API as I could manage. It wasn't hard.
> Having written it a couple of years ago, I haven't had occasion to use it once. Instead, I just use "for" loops.
+ People keep telling me we should be able to implement a map function in go.
+ I implemented a map function in go.
+ The map function was ugly, slow, unsafe and generally an abomination.
Conclusion? You don't need a map function in go.
You may not agree but you have to admire his dedication to the One True Way whatever is put in his way. Even if it's him that's erecting pretty impressive roadblock himself.
I'll grant that Go is lacking in generics, but IMHO, the opposite is true. Go is thriving because although not perfect, it is one of the few languages which seems to have learned lessons from the failings of C++, Java; and from the successes of the more dynamic/scripting languages (team Python, Ruby etc.). Go isn't a step down, it's a step backwards from the edge of the cliff.
That's just rhetoric. What does it mean? What lessons have been learned? What is it about generics that makes them the 'edge of the cliff'? Personally I couldn't live without generics, and would never choose a language that doesn't have them; otherwise you end up doing cartwheels with untyped references and reflection to try and write reusable code (as you see above). The idea that generics adds complexity is nonsense. It might add complexity to the compiler, but that's about it. For the end user and the compiled code it's easier and faster respectively.
I clearly stated that Go is lacking on the generics front. The cliff is forced, rigid OOP and complicated tool-chains.
> Personally I couldn't live without generics, and would never choose a language that doesn't have them
I'm kind of confused here. Yes, Go needs generics, but are generics even that key a feature? I mean how often do you have to define a generic type, and how much copying does it really take? Is it a hassle? Of course. But at the end of the matter, Go much, much better when it comes to combining expressibility, efficiency, and simplicity then many of the other options available today.
> The cliff is forced, rigid OOP and complicated tool-chains.
How are generics related to OOP or tool chains? Generics have a strong grounding in type theory and are used equally successfully in both OO and functional languages.
> Yes, Go needs generics, but are generics even that key a feature?
I believe so.
> I mean how often do you have to define a generic type
Many times a day. But not just generic types, generic functions, which I believe are just as strong an argument for generics.
> I mean how often do you have to define a generic type, and how much copying does it really take? Is it a hassle? Of course.
It's not just the hassle of copying and pasting. It's the ongoing maintenance of code. If you have a list class for example, then you're going to need a ListOfInt, ListOfChar, ListOf... If you have a single bug in your list implementation in a language with generics, that is now N bugs in Go. If you write an untyped List class then you are constantly coercing the type and potentially working with unsound values that you only discover at the point of use, not the point of compilation. In a large application that's as painful as the null dereference issue has been for all of time.
Even in the code example by Rob Pike he mentions that he can get by using a for loop. for loops are less declarative and less expressive than map, filter, fold, etc. They mix loop iteration scaffolding with code intent.
> But at the end of the matter, Go much, much better when it comes to combining expressibility, efficiency, and simplicity then many of the other options available today.
More rhetoric. Please tell me how? Is there something that makes this better? I remember C# before generics, and it was a pain to work with (collection types especially, that's why I mention it above). The only issue I see with generics now in C# is the visual clutter. If that's what you're referring to, then fine, but that's still not a good reason for the language to not implement them. If you look at F#, OCaml, Haskell etc, they all have generics in one form or another that you barely see. The expressiveness is there, but also type safety.
I find it hard to believe that a language with static typing can get away with not having generics today. It makes the language semi-dynamic, which is the worst of both worlds because you end up manually doing type coercion (which would be automatic in a dynamic language), but still have the lack of safety of a dynamically typed language to boot.
> How are generics related to OOP or tool chains? Generics have a strong grounding in type theory and are used equally successfully in both OO and functional languages.
Once again, I never said there was anything wrong with generics! And I agree that Go should have them, I just don't think they are nearly necessary enough a feature to justify overlooking the numerous qualities the language has to offer. Please look at my initial comment: I never said anything negative about generics.
> More rhetoric. Please tell me how? Is there something that makes this better?
The "options" I'm referring to are Java/C++/C# and Python/Perl/Ruby/PHP. The former languages are too verbose, and cluttered, and Java requires the overhead of the JVM, C# is essentially Windows-only. The scripting languages lack typing and efficiency. Go is able to combine the performance and control advantages of low-level languages (to a high degree) with the simplicity of higher-level languages like Python. I'm not saying it's perfect, and I'm definitely not crazy enough to put it up against the functional languages (Haskell etc.). But when it comes to web applications, it looks like Go will soon be the one of the most practical choices available.
The lesson Go seems to have learned is that, since C++ and Java burned their fingers, clearly fire is too dangerous for humans.
The thing that makes it painfully obvious to me that Rob Pike hasn't bothered to learn anything from the PL community is that Go has nil. That just shouldn't happen in a modern language.
> The lesson Go seems to have learned is that, since C++ and Java burned their fingers, clearly fire is too dangerous for humans.
I think that's a little bit unfair, since Go introduces many powerful ideas not (traditionally) available in Java or C++: namely first class concurrency and functional primitives. Its handling of typing, the ability to define types not necessarily based on structs, the excellent design of interfaces are other examples. Go is an extremely powerful and expressive language that opens up the doors for programming in new paradigms, while making it easy to maintain readability and simplicity.
Fair point with the nil issue, I think that's one of Go's other weaknesses. But it does make up for that with its excellent error handling paradigm.
https://golang.org/doc/faq#nil_error is not an excellent design. It's a serious bug that converting nil to an interface sets the type field to a meaningless value (nil doesn't have a type!) and ridiculous that the interface doesn't compare equal to nil (if it's not nil, what does it point to?)
It means that every single type in the language has one extra value it may contain, 'nil', and your code will crash or behave erratically if it contains this value and you haven't written code to handle it. This has caused billions of dollars in software errors (null dereferences in C/C++, NullPointerExceptions in Java, etc.). See "Null References: The Billion Dollar Mistake" by Tony Hoare, the guy who invented it:
A better solution is an explicit optional type, like Maybe in Haskell, Option in Rust, or Optional in Swift. Modern Java code also tends to use the NullObject pattern a lot, combined with @NonNull attributes.
Beside the fact you're wrong (structs, arrays, bools, numeric values, strings and functions can't be nil, for instance), I'm always a little puzzled when I read the argument that "nil costs billions of $".
First, most of the expensive bugs in C/C++ programs are caused by undefined behaviors, making your program run innocently (or not, it's just a question of luck) when you dereference NULL or try to access a freed object or the nth+1 element of an array. "Crashing" and "running erratically" are far from being the same. If those bugs were caught up-front (just like Java or Go do), the cost would be much less. The Morris worm wouldn't have existed with bound-checking, for instance.
Second point, since we're about bound checking. Why is nil such an abomination but trying to access the first element of an empty list is not? Why does Haskell let me write `head []` (and fail at runtime) ? How is that different from a nil dereference exception ? People never complain about this, although in practice I'm pretty sure off-by-one errors are much more frequent than nil derefs (well, at least, in my code, they are).
> $1bn over the history of computing is about $2k per hour. I would not be astonished if a class of bugs cost that much across the industry.
It's not about knowing whether it's $1bn, or 10bn, or just a few millions. The question is to know whether fighting so hard to make these bugs (the "caught at runtime" version, not the "undefined consequences" version) impossible is worth the cost or not.
Can you guarantee that hiring a team of experienced Haskell developers (or pick any strongly-typed language of your choice) will cost me less than hiring a team of experienced Go developers (all costs included, i.e from development and maintenance cost to loss of business after a catastrophic bug)? Can you even give me an exemple of a business that lost tons of money because of some kind of NullPointerException ?
>fighting so hard to make these bugs ... impossible is worth the cost or not.
In this case the solution is trivial, just don't include null when you design the language. It's so easy in fact, that the only reason I can imagine Go has null, is because its designers weren't aware of the problem.
Not including null has consequences, you can't just keep your language as it is, remove null and say you're done.
What's the default value for a pointer in the absence of null? You can force the developer to assign a value to each and every pointer at the moment they are declared, rather than rely on a default value (and the same thing for every composite type containing a pointer), but then you must include some sort of ternary operator when initialization depends on some condition, but then you cannot be sure your ternary operator won't be abused, etc.
You can also go the Haskell way, and have a `None` value but force the user to be in a branch where you know for sure your pointer is not null/None before dereferencing it (via pattern matching or not). But then again you end up with a very different language, which will not necessarily be a better fit to the problem you are trying to solve (fast compile times, easy to make new programmers productive, etc.).
I think it has consequences on the design of the language, making it more complex and more prone to "clever" code, i.e code harder to understand when you haven't written it yourself (or you wrote it a rather long time ago). I've experienced it myself, I spent much more time in my life trying to understand complex code (complex in the way it is written) than to correct trivial NPEs.
That being aside, it is less easy to find developers proficient in a more complex language, and it is more expensive to hire a good developer and let him time to teach himself that language.
I'm not sure it costs "very much", though. I might be wrong. But that's the point: nobody knows for sure. I just think we all lack evidence about those points, although PL theory says avoiding NULL is better, there have been no studies to actually prove it in the "real-world" context. Start-ups using Haskell/OCaml/F#/Rust and the like don't seem to have an undisputable competitive advantage over the ones using "nullable" languages, for instance, or else the latter would simply not exist.
But a bunch types you do expect to work can: Slices, maps and channels.
var m map[string]bool
m["foo"] = 1 // Nil, panic
var a []string
a[0] = "x" // Nil, panic
var c chan int
<-c // Blocks forever
This violates the principle of least surprise. Go has a nicely defined concept of "zero value" (for example, ints are 0 and strings are empty) until you get to these.
The most surprising nil wart, however, is this ugly monster:
package main
import "log"
type Foo interface {
Bar()
}
type Baz struct{}
func (b Baz) Bar() {}
func main() {
var a *Baz = nil
var b Foo = a
fmt.Print(b == nil) // Prints false!
}
This happens is because interfaces are indirections. They are implemented as a pointer to a struct containing a type and a pointer to the real value. The interface value can be nil, but so can the internal pointer. They are different things.
I think supporting nils today is unforgivable, but the last one is just mind-boggling. There's no excuse.
I don't think you're right that interfaces are implemented as a pointer to a struct. The struct is inline like any other struct, and it contains a pointer to a type and a pointer to the value, like `([*Baz], nil)` in your example. The problem is that a nil interface in Go is compiled to `(nil, nil)` which is different.
I don't think using nil to represent uninitialized data is a major issue-- if it were possible to catch uninitialized but queried variables at compile-time, that could be an improvement, but we want to give the programmer control to declare and initialize variables separately.
Interesting, because (reading up on this) value types can not be nil.
How often does typical Go code use values vs. interfaces or pointers? It seems like the situation is pretty similar to modern C++, which also does not allow null for value or reference types (only pointers) and encourages value-based programming. Nil is still a problem there, but less of one than in, say, Java, where everything is a reference.
In my own experience, nil basically only shows up when I've failed to initialize something (like forgetting to loop over and make each channel in an array of channels), or when returning a nil error to indicate a function succeeded. I've never run into other interfaces being nil, but I also haven't worked with reflection and have relatively little Go experience (~6 months).
The code that I've written regularly uses interfaces and pointers, but I'd guess 80% works directly with values.
> I call it my billion-dollar mistake. It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language (ALGOL W). My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn't resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
I believe it is thriving because it was well-designed, by extremely influential individuals, and the early library work was stellar. Also, several other experienced and influential programmers tried it, and expressed something along the lines of "programming is fun again!"
Inside Google, the two main programming languages are C++ and Java, not Go (at least when I left, in September). The Go tooling is generally less capable, but the interfaces smaller, and often nicer: they have the dual benefits of hindsight, and a small but very smart team that really cares about conciseness and clean APIs.
Of course, it's undeniable that the Google name helps a bit. And paying a team of very experienced (and presumably very expensive) developers to work on it makes a huge difference. But I think it would be as successful if those same developers were sponsored by Redhat, or Apple, or just about anyone.
Dart is also Google sponsored and no one uses it despite the fact that it's actually a pretty great general purpose language. People use go because it's productive and had a PHENOMENAL standard library for networking.
It clarifies the fact that Go is successful for more reasons than just being pushed by Google. So it focuses the question to "what is it that people like about it". And then we can have a better conversation.
Your theory fails to account for the lack of success with respect to Dart; so, it seems more like something you have an urge to believe (despite a lack of evidence).
Dart has been abandoned by Google the day that Angular team has chosen Typescript instead of believing in Dart, thus sending to the world the message that the company doesn't believe in it.
Whereas there are a few production examples of Go at Google.
My understanding is that Dart is used by Google Fiber for their routers, so I wouldn't call that abandoned yet. But, the point is that Google supporting a language does not seem to imply its eventual success.
He who takes his examples of generics from C++ and Java has a huge blind spot. The FP crowd came up with simple and useable generics (Hindley-Milner type inference) in 1982.
It's like Go's creators haven't even read Pierce's Types and Programming languages. This is inexcusable. Even more so from Rob Pike and Ken Thomson —you'd expect better from such big shots.
It's like you assume that, since they didn't do it your way, they're either stupid, ignorant, or malicious - which I also find to be pretty inexcusable.
Well… I have seen generics that (i) don't blow up the compile times like C++ templates do, (ii) are very simple to use, and (iii) are relatively simple to implement. (I'm thinking of Hindley-Milner type inference and system F.) So when some famous guys state they avoided generics for simplicity's sake, yeah, I tend to assume they missed it.
And it's not hard to miss either. When you google "generics", you tend to stumble upon Java, C#, and maybe C++. The FP crowd talks about "parametric polymorphism". Plus, if you already know Java, C# and C++, 3 mainstream examples of generics, fetching a fourth example looks like a waste of time. I bet they expected "parametric polymorphism" (ML, Haskell…) to be just as complex as "generics" (C++, Java, C#).
On the other hand, when you study PL theory, you learn very quickly about Hindley-Milner type inference and System-F. Apparently they haven't. Seriously, one does not simply make a language for the masses without some PL theory.
> On the other hand, when you study PL theory, you learn very quickly about Hindley-Milner type inference and System-F. Apparently they haven't.
Again you assume that, since they didn't include it, they must not have known about it. You keep claiming that. Given the breadth of these guys' knowledge (it's not just Java, C#, and C++, not by a long shot), I really struggle to see any justification for you assuming that.
I know you think that system F is all that and a bag of chips, but it is not the only reasonable way to design a language! Assuming that they did it wrong because they didn't do it the way you think is right... that's a bit much.
But I'll ask you the same question I asked aninhumer: How fast does Go compile compared to Haskell? And, is that a fair comparison? If not, why not?
> Again you assume that, since they didn't include it, they must not have known about it.
That's not why I assumed ignorance. I assumed ignorance because their stated reasons for doing so are false. Generics can be simple. They skipped them "for simplicity's sake". Therefore they didn't know generics could be simple.
Besides, generics could have probably helped them simplify other parts of the language. (But I'm getting ahead of myself.)
> How fast does Go compile compared to Haskell?
I don't know. I have reasons to guess Haskell is much slower however.
> And, is that a fair comparison?
Probably not: both languages are bootstrapped, so their respective implementation use very different languages (Go and Haskell, respectively). Haskell is non-strict, so it needs many optimizations to get acceptable performance. Haskell's type system is much more complex than your regular HM type inference: it has type classes, higher-order types, and many extensions I know nothing about —it's a research language after all.
Qualitative analysis would be better at assessing how generics affect compile time. My current answer is "not much": the effects of a simple type system (let's say system-F with local type inference) are all local. You don't have to instantiate your generics several times like you would do with templates, you can output generic assembly code instead. To avoid excessive boxing, you can use pointer tagging, so generic code can treat pointers and integers the same way —that's how Ocaml does it.
> Therefore they didn't know generics could be simple.
I wouldn't call Hindley-Milner type inference simple, though. I think you underestimate what has to be available in the language for a ML-like parametric polymorphism to be implemented in the language. For instance, can an interface be generic? Can a non-generic type implement a generic interface? How do you say your type is generic, but "only numeric types allowed" ? Does it mean the language must implement a type hierarchy of some kind ? How well does it play with pointers? Is `*int` a numeric type?
Once you introduce generics, you have no choice but to make a more complex language overall. You say generics would have simplified the language, I find it hard to believe. Care to mention a language that is easier to grasp than go (i.e I can be productive in less than a week) and that also offers efficient generics?
I'd like to give them the benefit of the doubt, but even within their stated goal of "simplicity", some of their design choices still seem ignorant of PL theory. The obvious one being including a null value, which is widely recognised to be a terrible idea with pretty much no redeeming qualities.
Another subtler example is the use of multiple return values for error handling, rather than some kind of sum type. It just suggests the designer doesn't have any experience working with ADTs. (Not that I'm suggesting Go should have used full blown ADTs, just that they change the way you think about data.)
Simplicity is, I think, a secondary goal. A big part of the motivation for creating Go was 45 minute C++ compile times. A major reason for the emphasis on simplicity is to keep the compiler fast, even on huge codebases.
So: How much would adding sum types slow down the compiler? I don't know. How fast does Go compile compared to Haskell? (Is that a fair comparison?)
I'm a little dubious of the speed advantage to be honest. Sure compile time is important, and C++ is pretty bad on this front, but you don't need to try that hard to do better.
And no, I don't think sum types would slow the compiler down much, especially if they were limited to a special case for error handling (which seems more in line with the rest of Go).
Well I don't think zero values are a very good idea to start with (if you want a default value, make it explicit), but if one insists on having them, they can just use the first case. So for your example it would be int 0.
// goodFunc verifies that the function satisfies the signature, represented as a slice of types.
// The last type is the single result type; the others are the input types.
// A final type of nil means any result type is accepted.
func goodFunc(fn reflect.Value, types ...reflect.Type) bool
This. For better and for worse, Go was designed for "simplicity", and generics are anything but simple. I'd be very, very surprised if Go thinks about generics in earnest anytime soon.
I don't say this in anyway to eulogize Go: In some ways, Go is pathetically unexpressive. That said, it currently fills that gap for writing middleware between C sacrificing too much developer productivity and Perl/Python/Ruby/PHP sacrificing too much performance. Generics would be nice to have for this core use case for Go, but it's probably not critical.
Go doesn't do inheritance either. It has type embedding, but it's not the same.
In the most recent of Ian Lance Taylor's proposals (Type parameters, 2013 [1]) he summarizes:
> The implementation description is interesting but very complicated. Is any compiler really going to implement all that? It seems likely that any initial implementation would just use macro expansion, and unclear whether it would ever move beyond that. The result would be increased compile times and code bloat.
So I'm pretty sure that the logic is acceptable, but it conflicts with Go's core goals of simplicity and compilation speed.
This is generally brought up as the reason that Go doesn't need generics.
I tend to agree with this. I've yet to come across a use-case where the current system is too difficult to deal with, but there are other people who have hit this limitation.
Maybe this can be solved by simply modifying the parsing of the keyword "type" (Or adding a reserved type "T") and telling developers that the functionality of "go generate" will automatically (in the compiler) expand and create type methods at compile time, and build the type generation into the compile phase, rather than a manual pre-compilation phase. I haven't considered the problems with this approach, but I assume Ian et al have.
It seems to me that the generated code approach could be spliced into the compiler with a few key-word parsing changes, but I'm not going to assume that the Go team haven't already thought of this, and there are probably problems with the idea that I haven't considered, above and beyond spec / compatibility promises etc.
> This is generally brought up as the reason that Go doesn't need generics.
Which I find nonsensical, but my point was that Go's interfaces are a form of subtyping, which as eru and tel note tend to have challenging interactions with generics.
I don't see why you'd choose Go instead of a JVM language like Java, you get the language simplicity (plus features like Generics) and the performance upside too.
But setup a java toolchain, building, deploying, and a lot of other configuration if some heavy framework is involved, is non-trivial. Gradle is like a must for modern Java application, and mastering itself takes some efforts. Go, when coming to toolchain, it is pretty much battery-included, best-practice-builtin, sometimes even a little forced.
Language wise, Java recently has seem a more aggressive adoption of new and modern features, which is quite welcome for me personally, but it is still more LOC comparing to Go.
I think Go is the new Python for light to middle complexity web service, with fewer people. Java is more for mature stuff, for larger scale collaboration.
A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted. You only need to start consulting the Gradle manual once you start doing things like defining custom build tasks or wanting to use custom plugins.
Go's toolchain doesn't even bother with versioning. That's like the opposite of batteries-included, forced-best-practices. But of course it will seem simpler than a tool that does handle these basic things.
If you want the benefits of Java with a lighter syntax then look at Kotlin.
> A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted
...and that code is written in Apache Groovy. Strange why they'd bundle a Turing-complete scripting language for their build file DSL when it's only 7 or 8 lines long.
My experience is the exact opposite: Go takes more lines to do something than Java.
I would say that in large part, this is because the error handling restricts expressions to a rather small size, and then because without streams, collection manipulation has to be written out longhand.
I agree with you on the error handling part, although it is not a big pain for me yet.
But in terms of parallel programming, when doing in Java, I constantly find myself basically building a lot of stuff where Go has as a part of its own semantic. Queues -> Channel, Executors -> M in Go, and Runnables -> Go functions. Java8's Lambada and ForkJoinPool is an advance in the right direction but still not quite there.
Language simplicity? I disagree, Java is only agreable if you're comfortable with (1) being forced to work in an OOP-only environment and (2) using the JVM. And while you can argue for the upsides of both of these (which I believe are few and far between) they certainly add a great deal of clunky complexity, which many programmers are fleeing to Golang to avoid.
If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
Toolchains normally mean build systems, debuggers, profilers, editors and other things.
Java itself doesn't require any build tool at all, you could do it all with a custom shell script. The next step up after that is an IDE like IntelliJ where you press "new project" and just start writing code. The IDE's build system will do it all for you. There is no complexity.
But most people want features like dependency management, IDE independence, command line builds, ability to customise the build with extra steps and so on. That's when you upgrade to something like Gradle (or maybe Maven if you like declarative XML). That'll give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features. Many IDEs can create a Gradle project for you.
When I first encountered Java it seemed the most popular build tool was Maven, which looked very over complex at first due to its poor docs and love of inventing new words, but pretty quickly found that it wasn't so bad in reality. Gradle avoids the custom dictionary and uses a much lighter weight syntax. It's pretty good.
>If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
The point was about Java, so I was responding to that, but yes, I steer clear of C++ (when possible) for the same reason.
> Gradle [...] give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features.
I don't see your point. If you have a collection of source files, then something must search the directory tree to find them and feed them to the compiler ... ideally, only the files that have changed, to give fast incremental compilation.
If you use a typical Java IDE like IntelliJ then the program that does that will be the IDE. There is no "one more layer" because that's the first and only layer.
If the IDE build system does not provide enough features or you'd like your codebase to be IDE independent, you can also use a separate build tool, or a combination of both (in which case the IDE will sync itself to the other build tool).
In that case there are two layers. But Go does not have any magical solution to that. There will be Go apps that need more than the little command line tool can do as well.
Right, so then it is more complex than `go build`. QED.
To be clear, I'm not claiming that Go is "better"; I'm just pointing out that this is why one would chose Go over Java. Sometimes this particular benefit doesn't outweigh the costs relative to developing in Java, but language/toolchain simplicity remains -- nonetheless -- the reason why people prefer one over the other.
Yes, "gradle build" wants to see a "build.gradle" file in the current directory, but you can run "gradle init" to get one. And after that everything except specifying dependencies is by convention.
There's really little to no difference in complexity here. What Go saves by not having a build file it loses by not encoding enough information about dependencies in the source, which leads to horrible hacks like vendoring.
Nobody forces you to use a complex toolchain for Java. You can use javac and ed if you like. But Java is sufficiently simple and sufficiently popular for pretty awesome tooling to be available. Refactoring Java code is a breeze because your IDE understands the code perfectly.
A text editor, javac and java that's what I used for a few years when I started using it. I wrote a lot of code like that. I don't see why you couldn't?
> I remember the Go language specification to be about as long as the table of contents for the Java language specification.
I'm not sure where you got that from. On my browser and screen, the JLS8 TOC[0] is 16 pages high which brings me about 20% into the Go language spec[1].
But then again that's a completely inane appeal to emotions: because it's a specification for cross-platform and cross-implementation compatibility (not a user-targeted documentation):
* the JLS is exactingly precise, the JLS's "lexical structure" section is about 3 times longer than GoSpec's "Lexical Elements", the JLS's "Execution" section is about 6 times longer than GoSpec's "Program initialization and execution"
* the JLS contains entire sections which don't get a mention in GoSpec, like binary compatibility concern, or the language's entire execution model (calling a function gets a page in gospec, it gets 20+ in the JLS) and its multithreaded memory model
The JLS is longer because its goal is that you be able to reimplement a Java compiler and runtime just from it, it's Java's entire rulebook.
Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
> Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
That's not correct. The Go spec is designed to be a precise specification of the language, targeted at language implementers. Ian Lance Taylor (incidentally, the author of these generics proposals) wrote gccgo based on that spec. There have been a couple of other implementations based on that spec since.
The main Go compiler itself was implemented from that spec, too. The spec comes first.
You are absolutely right, it's a silly comparison. The Go language spec is indeed vague.
I did this comparison a while ago. It wasn't very accurate. The Go spec has probably changed. Unfortunately, it seems they don't keep older specs around(!) If I adjust the font size in the ToC of the JLS I get 23 pages and the Go Spec is 84 pages (27%). Not quite "about the same length", still.
I took a compiler course in university where we implemented a compiler for a subset of java 1.3 (I believe), and the next year I was a TA in the compiler course. I got to read the (older) JLS quite a lot. I do find Java to be a more complicated language than Go. This does not mean I find it simpler to write programs in Go (c.f. Brainfuck).
RoboVM is one that compiles AOT ARM binaries, it's intended for the iPhone but it runs on MacOS too.
Avian is a JIT compiling JVM but one which is much smaller than HotSpot. It has a mode where it statically links your JAR into the binary itself, so you get a single self contained executable. With ProGuard and other optimisations like LZMA compression built in, such binaries can be remarkably small. Try their example:
You can make an executable "fat jar" with Capsule. It has a little shell script prepended to the JAR which means you can run it like "chmod +x foo.jar; ./foo.jar"
You can do dead code elimination and other forms of LTO using ProGuard. Just watch out for code that uses reflection. Java 9 will include a less aggressive version of the same thing which performs various link time optimisations like deleting modules (rather than individual methods/fields), statically pre-computing various tables, and converting from JAR into a more optimised (but platform specific) format.
That tool can also bundle a JRE in with your app, giving you an "tar xzvf and run" deployment model. It's not a single file, but it makes little difference in practice. The same tool can build DEBs, RPMs, Mac DMGs and Windows EXE/MSI installers with a bundled and stripped JRE too.
I'm a big fan of Capsule, actually. My point was not that Java and the JVM ecosystem are terrible (I quite like them), but rather that there is a spectrum of size and complexity and that Go's static binaries seem to be on the simpler to build side of JARs and on the smaller side of JARs.
Also, I don't think there's much of a case to be made that bundling a JRE with your JAR is small, even though the tooling might be simple and it might resolve many deployment issues.
Putting a jar on your classpath works just like depending on a shared library but with much stronger compatibility guarantees and better chances for optimization.
Memory usage and as a consequence of that excessive GC pauses. I'm not looking at any JVM language again before they introduce value types in a couple of years (maybe).
I build soft real time simulation systems in Java. GC pauses haven't been a problem since 1.2 was released around 2000. Memory usage isn't a concern either for big applications, as there's not a lot of overhead in the runtime. There is the fact that one can't embed value types directly in objects, but I don't find that a problem in practice.
Then your experience is very different from mine and that of many other people who resort to all sorts of off-heap solutions and distributing stuff across multiple VMs. I guess it depends a lot on the specific use case.
You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
If you want no GC pauses at all, ever, well, Go can't do that either. But if you are willing to pay money to Azul, you can buy a JVM that can. It also concurrently compacts the heap, which Go's GC does not.
The issue is not Java. The issue is the quality of freely available garbage collectors, which are very good, but not pauseless.
>You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
For what percentile of collections? I'm not wasting my time with incessant GC tuning only to delay that 5 minute stop the world pause for a bit longer. It's still going to hit eventually. For projects that might grow into that sort of heap size I use C++ (with an eye on Rust for the future).
You are right that Go is not a panacea for very large memory situations, but you can do a lot more before Go even needs that amount of memory.
The point is that languages without value types, such as Java and JavaScript, waste a huge amount of memory and generate a lot more garbage, thereby exacerbating all other related issues, including GC.
I have done quite a lot of testing for our workloads. Java memory usage is consistently two to three times higher than that of Go or C++. I'm unwilling to waste our money on that.
In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
To get 10msec pause times with such huge heaps requires burning a LOT of CPU time with the standard JDK collectors because they can trade off pause latency vs CPU time.
This presentation shows tuning with 100msec as the target:
2. Older collectors like CMS (still the default) sometimes take long pauses, like 5 seconds (not 5 minutes).
3. The new GC (G1) must be explicitly requested in Java 8. The plan is for it to be the default in Java 9, but switching to a new GC by default is not something to be taken lightly. G1 is, theoretically, configurably by simply setting a target pause time (lower == better latency but more CPU usage). Doing so eliminated all the long pauses, but a few collections were still 400msec (10x improvement over CMS).
4. With tuning, less than 1% of collections were over 300 msec and 60% of pauses were below the target of 100 msec.
Given that the Go collector, even the new one, isn't incremental or compacting I would be curious how effective it is with such large heaps. It seems to be that a GC that has to scan the whole 100GB every time, even if it does so in parallel, would experience staggeringly poor throughput.
Value types will certainly be a big, useful upgrade.
>In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
So you use a language without value types that makes you pay for two or three times more memory than comparable languages, and then you spend your time re-tuning the GC every time your allocation or usage patterns change. Then you hope to never trigger a full GC that could stall the VM for many seconds (or in extreme cases that I have seen even minutes). That makes very little sense to me.
I cannot speak to the performance of the current Go GC for 100G heap sizes. I never tried it and I haven't read anything about it. It's not my language of choice for that sort of task either.
They aren't comparable at all. Go doesn't collect incrementally and doesn't compact. So good luck collecting garbage fast enough to keep up with a heap-heavy app (which if you have a 100GB heap, your app probably is).
In other words, the issue is not pause time, it's also throughput.
But Go programs use way less memory than Java applications... so the java application that uses 100GB might only use 40GB (or less) in Go. And there are tweaks you can make to hot code in Go to not generate garbage at all (pooling etc).
Java's higher memory usage is not only related to value types, for example, in Java 8 strings always use 16 bit characters. That is fixed in Java 9. It resulted in both memory savings and speed improvements.
There are other sources of overhead too, but again - you seem to think Go has some magic solution to these problems. Since the new GC, Go is often using a heap much larger (such as twice the size) of actual live data. That's a big hit right there. And yes, you have to tune the Go GC:
Value types are the main culprit behind Java's insane memory consumption. I found out through weeks of testing and benchmarking.
I mostly benchmarked a small subset of our own applications and data structures. We use a lot of strings, so I never even started to use Java's String class, only byte[].
I tried all sorts of things like representing a sorted map as two large arrays to avoid the extra Entry objects. I implemented a special purpose b-tree like data structure. I must have tried every Map implementation out there (there are many!). I stored multiple small strings in one large byte[].
The point is, in order to reduce Java's memory consumption, you must reduce the number of objects and object references. Nothing else matters much. It leads to horribly complex code and it is extremely unproductive. The most ironic thing about it is that you can't use Java's generics for any of it, because they don't work with primitives.
I also spent way too much time testing all sorts of off-heap solutions. At the end of the day, it's just not worth it. Using Go or C# (or maybe Swift if it gets a little faster) for small to medium sized heaps and C++ or Rust for the humungous sizes is a lot less work than making the JVM do something it clearly wasn't built to do.
But I think your conclusion is not quite right. I said above that pointer overhead is only one source of Java memory consumption, and pointed to (hah) strings as another source. You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
If your application is so memory sensitive that you can't use basic data structures like maps or strings then yes, you really need to be using C++ at that point.
In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code and the JVM can do optimisations like deduplicate strings from the heap (already). Of course how much that helps depends a lot on the application in question. But the sources of gain and loss are quite complex.
>You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
I see what you mean, but when I said that Java uses two or three times as much memory as Go or C++, I didn't include tons of UTF-16 strings either, assuming most people don't use as many strings as I do. If your baseline does include a large number of heap based Java String objects, the difference would be much greater than two or three times because strings alone would basically double Java's memory usage (or triple it if you store mostly short strings like words using the short string optimization in C++ for comparison)
>In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code
I'd love to see that theory :-) But let's say it was magic and the bytecode as well as the VM itself would require zero memory, any difference would still only be tens of MB. So it would be negligible if we're talking about heap sizes on the order of tens or hundereds of GB.
Yes, if your heap is huge then code size savings don't matter much. I used to work with C++ apps that were routinely hundreds of megabytes in size though (giant servers that were fully statically linked). So code size isn't totally ignorable either.
WRT the theory, that depends what the heap consists of.
Imagine an app where memory usage is composed primarily of std::wstring, for example, because you want fast access to individual characters (in the BMP) and know you'll be handling multiple languages. And so your heap is made up of e.g. some sort of graph structure with many different text labels that all point to each other.
The JVM based app can benefit from three memory optimisations that are hard to do in C++ ... compressed OOPs, string deduplication and on-the-fly string encoding switches. OK, the last one is implemented in Java 9 which isn't released yet, but as we're theorising bear with me :)
Compressed OOPs let you use 32 bit pointers in a 64 bit app. Actually in this mode the pointer values are encoded in a way that let the app point to 4 billion objects not bytes, so you can use this if your heap is less than around 32 gigabytes. So if your graph structure is naturally pointer heavy in any language and, say, 20 gigabytes, you can benefit from this optimisation quite a lot.
String deduplication involves the garbage collector hashing strings and detecting duplicates as it scans the heap. As a String object points to the character array internally, that pointer can be rewritten and the duplicates collected, all in the background. If the labels on your graph structure are frequently duplicated for some reason, this gives you the benefits of a string interning scheme but without the need to code it up.
Finally the on-the-fly character set switching means strings that can be represented as Latin1 in memory are, with 16 bit characters only used if it's actually necessary. If your graph labels are mostly English but with some non-Latin1 text mixed in as well, this optimisation could benefit significantly.
Obviously, as they are both Turing complete, the C++ version of the app could implement all these optimisations itself. It could use 32 bit pointers on a 64 bit build, it could do its own string deduplication, etc. But then you have the same problem as you had with off-heap structures in Java etc: sure, you can write code that way, but it's a lot more pleasant when the compiler and runtime do it for you.
CLR (the C# runtime) generics are fully reified and about the most complicated and robust implementation available. It dynamically emits and loads types whenever a new generic parameter is seen for a function or type. This is very, very hard to get right and is not very performant. It also puts a lot of burden on the runtime vs. the compiler. Go expressly tries to keep the runtime as small as possible.
CLR-style just-in-time monomorphization is plenty performant: in fact, it's just about ideal. It's also not that difficult when you have a JIT when compared to the complexity you need for speculative optimizations of hot spots anyway.
In any case, the .NET approach isn't an option for AOT compilers like those of Go. For Go, the only reasonable option is ahead of time monomorphization, which really isn't that bad.
Monomorphization is not a reasonable option, in my opinion.
It forces the compiler to accept some truly awful running times for pathological cases. Atleast quadratic, probably exponential.
For languages that have reflection or pointer maps for GC or debug information for types, it can force large blowups in space as well. Go has all three of these.
The implementation would likely require runtime code-generation (or accept warts like Rust's "object safety").
Indeed, all of Ian's proposed implementations are polymorphic and seem to avoid each of these issues at first glance. The only advantage of a monomorphic implementation is performance, and considering the downsides, this'd be premature optimization forced by a language spec.
If its actually performance critical, I imagine it'd be easy to write a program that monomorphized a particular instantiation of the generic types. Indeed, the compiler would be free to do that itself, if it felt it would be worth it. Small, guaranteed non-pathological scenarios for instance.
Where if you guarantee monomorphization in a language spec, the compiler and all users are forced to accept the downsides in all instances, in exchange for often meaningless performance gains (example: any program that does computation then IO).
It's really not bad in practice. I've measured the amount of compilation time that generic instantiations take up and it's always been pretty low. Something like 20% (it's been a while, so take with a grain of salt), and that's with a naive implementation that doesn't try to optimize polymorphic code or perform ahead of time mergefunc. 20% is well within the project's demonstrated tolerance for compiler performance regressions from version to version. And you can do better with relatively simple optimizations. Generic compilation has been well-studied for decades; there are no unsolved problems here.
I would heavily advise against trying to do better than monomorphization with intensional type analysis (i.e. doing size/alignment calculations at runtime). We tried that and it was a nightmare. It didn't even save on compilation time in practice because of high constant factor overhead, IIRC.
Monomorphization is one of those things, like typechecking in ML, where the worst-case asymptotic time bounds look terrible on paper, but in practice it works out fine.
People point to C++ compilation times as a negative counterexample, but most of the compilation time here is in the parsing and typechecking, which a strongly typed generics implementation will dodge.
If generics were not a studied and well implemented concept I would agree. But we live in a world where this is just not the case. I would take a slightly slower compiler with generics support any day over the mess that go devolves into because of the lack of it.
Bear in mind that .NET will use a shared instantiation when the generic arguments are normal reference types; a hidden parameter is required for static methods under this scheme, to pass the concrete type info. Monomorphization is only required when the vector of generic arguments has a distinct permutation of reference types vs value types.
This gives you the best of both worlds: memory efficient generics for the majority of instantiations, and compute efficient generics for the types most likely to benefit (like primitives).
I think Go people have a very strange definition for simplicity, much like the population at large actually, but that's a shame really.
Simple means composed of a single element, not compound, unentangled, being the opposite of "complex", which of course means consisting of many different and connected parts. Instead Go people prefer the term to mean the now more popular meaning, which is "easy to understand, familiar".
I think a parallel can be drawn with another word from the English language: "free". You see, English doesn't have a word for the latin "liber" (libre, at liberty), like other romance languages have and I can name at least Italian, Spanish, French and Romanian (my own tongue). In these romance languages there's a firm distinction between libre and gratis, whereas in English there's no adjective signifying liberty without also meaning "at no monetary cost". I find that to be interesting and I bet it happened most probably because at some point in time these 2 issues were correlated.
Back to simplicity, while you can often correlate simplicity with easiness, mixing the terms is unjust because sometimes simple things aren't easy at all and sometimes easy things aren't simple at all (much like how sometimes gratis things are restricted and liberties aren't gratis). Speaking of which in my own native tongue the word for "easy" is also used to signify weightlessness (light, soft). Makes sense in a way, but you can see how language works.
And it would be a shame to lose the true meaning of "simple", just because its usage is at hand when trying to describe things that are or are not desirable. As in the end, this is how the meaning of words gets diluted and lost: because of our constant desire to make other people believe our ideas and buy our shit. So we exaggerate. Just a little, after all, we are only going to end up with a language that's ambiguous. What does it matter if "open source" has had a clear definition since OSI and that it wasn't in use before that, it's marketable dammit, so lets use it for all shit that has source-code available. Etc, etc.
And I get it, saying that generics aren't easy isn't so appealing, because that would be an acknowledgement of one's own capabilities and knowledge, being a metric relative to the one who's speaking. Whereas simple is an objective metric, with things being simple or complex irregardless of the person that's passing judgement. Still, generics are only as complex as static type systems. When you have a statically typed language, generics are a natural consequence. And if you don't add generics, then you need to add an "Object", "Any", "dynamic" or whatever you want to call it, which would be a whole in that static type system, not to mention introducing special cases (like the builtin arrays and maps) and that's complex by definition. Java did as well, introducing generics at version 5, when it was too late to do it cleanly and the result isn't nice at all ;-)
True, GPL is significantly more complex, as it makes a difference between usage and distribution, not to mention it tries to prevent loopholes, like Tivoization and patent threats. Complex is not necessarily worse, of course it depends on context. I prefer APL 2 if you ask me.
But what matters in this case are that both correspond to the open source and free software definitions. For such licenses it means that there are things you can rely on. Like you know usage is OK for any purpose, including commercial ones. You know that you can share it with anybody, you know that derivate works are OK, again for any purpose, even though you can have restrictions on distribution. Etc.
For me clear definitions are important because then you immediately know what you can rely on and ambiguous language is bad because then we can't have a meaningful conversation. Are generics complicated? No. Are Java's generics complicated? Yes, but that's only because it was added later ;-)
It's also at odds with hard-learned lessons of the rest of the software industry, like don't repeat yourself. Golang is doomed to relearn these lessons.
First of all, generics is hardly DRY to its extreme. I think that everyone agrees that copying e.g. a balancing red-black tree implementation just to specialize it for another value type is a pretty bad idea. So then you either end up with some kind of runtime polymorphism or parametric polymorphism. Some Go users argue that runtime polymorphism is enough, but you often run into cases where you have a
func frobber(s []SomeInterface) ...
However, you end up having a
[]ConcreteType
where ConcreteType implements SomeInterface. However, you cannot simply pass a []ConcreteType to frobber because the memory representation is different and you have to construct a new slice with the interface type, etc.
Also, I don't think left-pad is an example of extreme DRY (though it should be part of a standard library). It's not an example of extreme DRY, because I think a substantial amount of programmers wil implement it incorrectly. As long as many Java-wielding friends still believe that a single char can represent any unicode code point, I have no reason to believe that the average monolingual English-speaking Go programmer will realize that you can't simply do something like:
The way I work is, I make an interface{} red-black-tree, and then when I need to store things in it I create functions around it.
Suppose I'm storing Tiles in a Level: the Level struct will contain a (private) RedBlackTree and I'll define GetTile(Pos) Tile and PutTile(Pos, Tile) on Level which do the casting to and from interface{}.
I still have type safety since I cannot put/get anything but Tiles in the RedBlackTree. But I didn't need generics.
From your description, it is not completely clear what you are ordering on, but typically in an RB tree you (at the very least) want to require some interface/function that specifies ordering and equality.
Of course, in some cases you can do casting on your interface boundaries. But in many other cases this is not possible, e.g. if you want the API to return an ordered set or map.
Exactly what lesson do you think was learned? Do you think that languages that have had left-padding functionality in their standard library since forever (and there are lots of them) are going to remove it now?
There was definitely a lesson to be learned there, but it wasn't the one you're implying.
The left-pad debacle was due to tools encouraging a badly non-hermetic build process and devs not being wise enough to resist, not DRY. Only depending on one third-party library won't save you if you "upgrade" to a broken version without testing.
> DRY is a great suggestion but shouldn't be looked at as any type of hard rule
Agree that nothing should be a hard and fast rule. But the significance of DRY is that it increases quality. Not even having the option to "stay DRY" for many problems implemented in Golang will increase bugs. That's just how it is.
Given the tradeoff between the supposed complexity of generics and the very real cost of bugs that will happen from maintaining duplicated code, I'm not sure there's much of a debate to be had.
> It's also at odds with hard-learned lessons of the rest of the software industry, like don't repeat yourself.
There is nothing wrong with repeating things. It's important to NOT repeat many things but everything? No way. DRY is a great suggestion but shouldn't be looked at as any type of hard rule.
For instance I've been on projects where DRY was taken to such an extreme that even the function decorators (plus their COMMENTS) were abstracted away because a few words or, at least, a single line could be duplicated. This would require looking through multiple files and figuring out the abstraction code just so I would know where the REST endpoints where.
So I'm not the biggest fan of GO but I see zero reason why it's going to be relearning this specific lesson.
I'm not seeing where the parent poster suggested taking DRY to such extremes.
The fact that a feature can be abused doesn't mean that it's a worthless feature. If that were the case there'd be no progress in programming languages because basically every feature can be abused. What matters is the balance between how easy it is to abuse (accidentally or not) vs. how useful it is when not abused (such as added expressivity/safety/DRYness/etc.).
To it's credit, most of the times I feel like I'm repeating myself in Go I usually later find I'm needing to specialize anyway. Go tends to help you avoid premature optimizations which you'll "totally fix later" - i.e. handle your errors now, not then.
Linus is clearly throwing his weight around here. If anyone else were to act this way and use such language we would all call him or her an asshole. Besides his main point is that C++ is not great for low level code. I don't see how this applies here.
He is being called asshole and worse innumerable times. The only difference is that Twitter commenters and Corporate HRs do not control his livelihood in ways it does to most professionals so he is free to say things the way he feels.
we see things differently. In my view Linus is speaking free here. Many others refrain from speaking free and truthfully for fear of being called an asshole.
I see different main point. In my view Linus narrows the domain of his speech to system-level (not low-level!) code just out of basic intellectual honesty which implies to speak with authority only where your experience and knowledge are.
When he says, "YOU are full of bullshit," is that the intellectual honesty part? Some people are merely assholes constrained by social pressure other people are actually being honest when they are nice. It's hard to believe this when you are one of the former.
I agree with your system-level vs. low-level point except that he also talks about git which is neither.
>When he says, "YOU are full of bullshit," is that the intellectual honesty part?
if the guy is full of it then not saying it would be intellectual dis-honesty :). You and me belong to the different mindsets separated by a Grand Canyon. Man, i understand the reasons behind PC-culture, yet i just don't agree with the required trade-off. It is pretty much the same as security vs. privacy & other freedoms - there is really no meaningful debate possible beside clearly stating your own position as these mindsets are separated by the same size canyon. It is not separation of reasoning, it is separation of the choice of the top priority - in most cases that choice is deeply unconscious, and i have my personal theory connecting it to evolution and natural selection :) It is not that people on different sides don't understand the reasons of the other side, it is just people on each side are separated by their choice of the reasoning they assign higher priority to, like me and you in this case.
Generics as a language retrofit tend to be ugly. See C++.
I was at one time plugging for parameterized types. Go already has parameterized types; "map" and "chan" are parameterized types. You write "make(chan int)" and "make(map[string] int)". You just can't define new parameterized types; "map" and "chan" are all you get. With parameterized types, you could create more generic data structures; if you needed a generic b-tree or a quadtree library, you could have one. Maps in Go are more special than they should be.
Parameterized types are less powerful than generics, but not too far from what Go now has. The goals in the document mentioned here require generics with all the bells and whistles. Remember, Go still has reflection; if you don't need high performance, you can simulate generics at runtime.
Reflection comes without the compile time guarantees (parametric polymorphism offers), and that is a far greater loss than the missed performance opportunities.
"The intent is not to add generics to Go at this time, but rather to show people what a complete proposal would look like. We hope this will be of help to anyone proposing similar language changes in the future."
This started in 2010. Hopefully an illustration that go's developers are not against generics in general, this ought to quell some of the negativity... Pick one of the four proposals you like :)
The proposal document itself may have existed for that long, but it's only been public for 14 days. To me, the important portion is the link to the discussion issue [1] created 2 hours ago, which to me seems like a more significant step towards doing the actual work.
Before, the default response was "we're thinking about it." Now, it's "let's all talk about it."
It isn't a new stance either. For years people have been posting their ideas for Go generics to golang-nuts, and the questions inevitably lead to asking how they'd implement it, how it would interact with interfaces, and so on. Most of the time the proposer hadn't thought it all the way through in those regards. The point of publishing these proposals is to help speed up that process: now the first response can be to point at these and ask for a similar level of thoroughness.
but the existence of the proposals assumes there were internal discussions, which is counter to the argument that go devs don't care about generics. had anything good come out of that it would've been published in the open. as it stands, the negatives outweigh the positives. hopefully the new discussion will change that, or an entirely new proposal will make everyone see the light.
This was actually mentioned during the Golang team's AMA on reddit. They have wanted to make the proposals for generics public for a while, it probably just took some effort to organize it all and make sure it was OK to publish.
> Some people on the Go team have sunk considerable time in producing generics proposals, but they've all had serious drawbacks. I'm hoping those proposals will be published at some point so people can see the depth of complexity that generics bring; it's almost always underestimated.
>This started in 2010. Hopefully an illustration that go's developers are not against generics in general, this ought to quell some of the negativity...
Wouldn't the fact that this started 6 years ago and gone nowhere re-enforce the negativity?
I haven't really looked at Swift properly but from what I see on the iOS dev blogs I follow, it's a lot more complex than Go and I can't see how productivity / etc. would be improved sufficiently to make the learning and general brain investment worthwhile for me.
As long as programmers that are comfortable with (and prefer) 30+/40+ year old PL paradigms are at the helm of Go's design, it's not very likely the language will grow Generics.
To paraphrase Max Plank:
"A new language-level feature does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it."
That said, he talked about questions of physics, not "truth".
Now, those new theories might or might not be truth.
But the fact that (in his phrasing) they only prevail not because of extra proof, convincing etc., but just because a generation that didn't like them died, doesn't make them seem particularly "truth" based.
Mostly "generational-fashion" based.
It could of course be that the new generation of physicists is also more capable to accept the truth (and Plank might believed that), but this doesn't derive directly from the statement.
The statement only goes as far to say that new generations of physicists are more capable to accept newer theories (the ones that grew with them, and they are more familiar with them than the oldsters are).
I suppose you paraphrased him to draw an analogy. And you did it by replacing "scientific truth" by "language level feature".
>That said, he talked about questions of physics, not "truth"
Here's what he said:
A scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die and a new generation grows up that is familiar with it.
Similarily, proponents of generics like to portray the creators of Go as the old guard that is in denial of an indisputable scientific truth.
But whether or not the added expressivity of generics is worth the added complexity they introduce into a language is a matter for debate dependent on context, not a settled scientifc question.
>Similarily, proponents of generics like to portray the creators of Go as the old guard that is in denial of an indisputable scientific truth.
Well, they are the old guard (both in age and in adopting 30+ years of PL research).
And it is an indisputable truth that Generics are both safer and/or faster than the workarounds (copypasta, interface{}).
>But whether or not the added expressivity of generics is worth the added complexity they introduce into a language is a matter for debate dependent on context, not a settled scientifc question.
I don't think we do/should consider generics complex anymore. Even Java programmers, the most tame of the bunch, got along with them just fine for a decade now.
Besides, Go has closures and channels, two things that seemed alien just 1-2 decades ago to enterprise programmers. Surely generics, an even older and more widespread concept is not that foreign...
Besides, Go already has generics -- it just doesn't allow the programmer to use them too.
My code is full of map, filter, reduce/fold and similar generic reusable functions.
How do people deal with such things in Go? Do they really make copies of such functions for every type they're working with? (And by type I don't mean just int/string, but all model entities/classes.)
map and filter are often just syntactic sugar for a loop, so I just write a loop.
I work on a ~1M LOC codebase in Go and it's really not a problem. map and filter would not make my life significantly easier. They're solving easy problems.
Sure, I have some of this style code:
var names []string
for _, m := range machines {
names = append(names, m.Name)
}
But, really, is that so much worse than this?
names = [m.Name for m in machines]
Sure, it's spread across a few more lines, but line returns don't cost extra money... and if you decide you want to later do something more inside the loop for each machine (default the name, cache the ID, etc), you can do that trivially by adding lines inside the loop.
This code is not hard code to write. If you're used to just being able to slap out map/filter etc in a single line, I could see how it could be annoying... but it's easy, just write it. There are far more difficult things to figure out in our jobs, why worry about the easy stuff?
It's a death by a thousand cuts. That's 3 dense lines that you need every time you map across a collection.
Which obscures whatever else is happening in the rest of the method/function, so now you've got that much more cognitive load to figure out what it's actual core purpose is.
Which may be subtly modified by the writer purposefully, but you miss it because you assume it's the same "it's just map idiom".
Which may be modified by the writer accidentally, but you miss it because you've trained yourself to parse it as a lump and take its correctness for granted.
For those not familiar with Go, the sort.Sort line is converting the list of machines into a type that matches the interface that sort.Sort expects. The list of machines is sorted in-place
The only part that can be subtly changed is the Less function, which determines the sort order. And as I've said elsewhere... that definition of sort order is something you have to define in any language (for non-trivial types).
byName is a type. It's a named type based (likely) on a slice of machines. The byName type implements the functions necessary to support the interface that the sort.Sort function requires:
sort.Sort takes an interface type that has the methods Len, Swap, and Less, as defined in the signatures above, and uses them in a sorting algorithm which sorts the values in-place.
Mostly, yes (you can finagle your way out of rewriting Len and Swap if all you need to do is change the Less function, but it's probably not worth it from a code clarity point of view).
In a million lines of code, this costs us approximately 114 extra lines of code beyond the minimum necessary for any language where you need to specify a sort order (assuming you need at least one line of code per type/sort algo to tell the computer how to sort your random list of objects).
>> But, really, is that so much worse than this?
names = [m.Name for m in machines]
You can take that code and interpret that as database query, like C# LINQ.
you frist example is 'how' vs 'what' of second example. Once you stop telling the computer how to do things and just tell it what you want all kinds of things become possible.
But then you have no idea what the computer is actually doing. There's a big performance difference between an in-memory loop and querying a database. This is one of the things I like about Go... what the computer actually does in response to any random line of code is pretty obvious (except for function calls, which of course can do anything). When you hide away the loop inside a map statement, you get people doing dumb things like this:
names = [m.Name for m in machines]
ids = [m.ID for m in machines]
addrs = [m.Address for m in machines]
So now we're iterating of over the list of machines 3 times... or making 3 database queries or whatever.
That's the nice thing about Go code... I almost always know exactly what it'll make the computer do. I know how much memory will get allocated, what the likely CPU usage is going to be, etc. The abstraction between the code and the computer is low, which helps lets a lot in understanding why your code is slow, or why it's producing a lot of garbage. "oh hey, here's a loop in a loop... oops, N^2 time".
What the computer actually does is dramatically different between reading a register and reading a block of a mapped file, but I value concisely expressing the intent rather than elaborately repeating mechanics that might change (e.g., I could optimize machines.__iter__ without rewriting all the statements).
It's worth noting you'd probably want to write this out in Go as follows:
names := make([]string, len(machines))
for i, m := range machines {
names[i] = m.Name
}
append() is pretty costly, and should be avoided when possible for performance. This is actually relevant to your how vs what concern-- on the one hand, we could trust the compiler and the builtins to always take the most efficient approach, and only program 'what' we want. That could avoid something like using append in a loop where you know the length of your intended output slice. On the other hand, if there are edge cases which the built-ins take into account that we don't care about and want to ignore, being able to and having the intention of programming 'how' can have performance benefits.
I like writing 'how' because I get to benchmark and test different approaches to solve the same problem, whereas 'what' might take a usually-fast approach that isn't a good solution in our specific case.
It's not about how hard or easy the code is to write, at all.
Any line of code you don't write, is a bug you didn't write either. I worked on a significantly size go codebase and the number of stupid bugs that popped up, like bad loops instead of a simple `filter` function, were just silly.
Having all this memory safety and other stupid bugs ruled out but not map, filter, or reduce just felt lazy on the Go authors part.
Of course, now that a member of the go team has said it, we'll see a huge shift in what the go team thinks about generics. I'm glad I don't deal with the go community anymore.
Lack of generics was one of the reasons I abandoned Go halfway through a hobby project (the other reason was lack of normal exceptions).
But. Go's principle is simplicity and understanding the concepts you're working with. And generics as a concept is a little bit more complex than simple List<int> explanation leads you believe. As C# developer (language with very good generics support), most of other C# developers I've met, unfortunately, can not easily and confidently explain covariance and contravariance concepts in an interview setting — which means that they don't understand generics concept completely. Mix it up with "null" virtual type, and you've got yourself a type system that you think you understand, but really don't, and will discover this misunderstanding in the worst possible moment.
So, while Go sucks for projects that I personally usually work on, its qualities make it a great language for other kinds of projects, and for these projects, generics may not be wort it with a trade off with simplicity.
Maybe instead of adding generics to Go it's time to look into alternative programming languages which already implement generics, like for example Nim.
You forgot that most of golangers are ex-php programmers and students with no experience. Just look at what they're talking about: they think generics are the opposite of simplicity and can make performance and compilation time worse. Meanwhile, Nim has generics with other useful features and has faster compilation time along with better optimization. If google would put 'goto' into go golangers would still use it anyway.
I've tried go a few times and it was full with repetition and boilerplate - felt like java 1.0. It seems like new coders like to repeat themselves more often than learn how to use proven concepts.
Consider using the D language instead if generics is a problem. Go is what it is and shouldn't change. It has it's advantages that make it optimal for particular contexts. Otherwise you'll turn it into another c++. There is a strong benefit in keeping Go simple as it is.
Let me give a concrete example of how I've been personally impacted by the lack of generics. My project makes liberal use of pointers to represent "optional" fields, since they need to be distinguished from the zero-type. Alternatives would be to have a boolean associated with every field, but that clutters the API and still faces a lot of the problems with using pointrs, such as:
- Easy to forget to check that pointer != nil
- Overloaded semantics: it's unclear whether a pointer represents an optional type, or is being used to pass-by-refrence (i.e. unclear whether a value should be treated read-only)
- Need to deep copy every struct, which is easy to forget and inefficient (at least the reflect version)
There are solutions to each of these points, but they all add complexity (e.g. generating code), and most take a lot of extra effort. With generics I could have Optional<T>, With a Get() function returning 2 values: the value type, and present (i.e. the way maps work). The caller is forced to handle both returns, making it much harder to forget to check it.
A lot of arguments for generics focus on higher-level functional programming abstractions, but this is a simple and extremely common use-case, and the lack of a solution is responsible for many real-world bugs.
There was a time when the only language with decent platform support had to have turing-complete meta-programming support, inheritance, polymorphism, lambdas, preprocessor, custom allocators, placement new, std::erase_if, etc, etc. because we were basically stuck with it.
Those times are now way behind us. Today, there is a plethora of languages to choose from, each with their strengths and weaknesses, each most powerful in the niche it's designed for.
Go is not a language with generics. If you need generics, don't use Go.
Go should not have generics unless it's trying to dominate the world. And we all know that no language can achieve world domination nowadays, not anymore. So it should rather trying to be the best language possible in the niche it was designed for. That niche doesn't need generics. On the contrary, a vocal part of the community says generics would taint Go.
Go doesn't have generics. It's however got a proper FFI. Use it. Or don't.
Isn't a huge issue with generics the compilation time?
Much as I love Haskell, I'm not going to sit here and tell you that a big program compiles quickly.
That might be an individual issue with Haskell, but regardless, isn't type-inference kind of expensive in compilation-land? And wouldn't that kind of kill one of the big features of Go?
Type inference isn't synonymous with generics, and it isn't necessarily expensive. It depends exactly how much you leave up to the compiler.
Some very strong kind of type inference are undecidable in general and can be very expensive to compute when there is an answer.
But you might bear in mind that almost all static compilers, including Go, already determine the types of arguments to functions so they can complain if you're passing the wrong type. Comparing that against a set of functions isn't much of a stretch, especially if the type matching rules were pretty strict, as they normally are in Go.
Not all generics are generic functions, anyway. A more limited, but still potentially useful, form of generics is generic packages. Generic packages have type parameters, whilst inside the package refer to the specific concrete type the package is being instantiated for.
A hypothetical sort package might have a single parameter denoting the element type it sorts. Conceivably it could be defined as
Admittedly I've never implemented a compiler, or a type system, so I was just speaking out of my behind to an extent, but your explanation makes sense.
At this point, I have to just conclude that Go isn't "for me". I respect the great things the community has produced. But I'm just not interested in a static language without generics.
As an outsider, I've been following Go for a while, and given the lack of common high productive language features such as Generics and optional function arguments with default values, to me, it seems like right now Go is much better than C, and in some dimensions better than Java and in others worse.
If it just adds a few things, and then when you account for portability and speed, it could be better than the dynamic languages that people often compare it to.
I have some biased doubts (come from the JVM world) about needing really fast compiling and is often cited as the reason Go does things the way it does (or is).
Is binary dependency management just not an option ever?
I have a friend that works for Google and supposedly they have a proprietary build infrastructure that will offload the building of C++ code into a cluster. I sort of wish Google open sourced that as I believe it basically does some form of binary dependency management.
Yes I know Go like C++ can target lots of platform (and thus needs many binaries built) but an organization only needs the major ones. And yes I know the language statically compiles to a single binary but that doesn't mean things can't be precompiled.
Go these days seems to be mainly used for microservices or small utilities and thus you don't need and should not have a gigantic code base for such things. I can understand monolithic UI apps having large code bases but this is clearly not what Go is being used for these days.
There are many other languages that compile to native that seem to compile fairly fast (OCaml and Rust from my experience but I don't have huge code bases).
Is compilation speed really an issue given the use cases for Go?
>Is compilation speed really an issue given the use cases for Go?
Yes, I find compilation speed to be one of the most important things. But it is not a selling point for go. The go compiler is not very fast, and speed is not an acceptable excuse for a lack of parametric polymorphism. Ocaml has not just parametric polymorphism, but many other basic type system features. And yet ocamlopt is both 5-10 times faster than the go compiler, and still produces faster binaries.
That is what I'm saying (I think we agree). It seems like a focus of Go's simplicity is to improve compilation speed and yet there are languages like Ocaml that do have generics (and a whole lot more) that seem to compile faster.
> Does Bazel require a build cluster?
Google's in-house flavor of Bazel does use build clusters, so Bazel does have hooks in the code base to plug in a remote build cache or a remote execution system.
The open source Bazel code runs build operations locally. We believe that this is fast enough for most of our users.
Unless you have a very advanced infrastructure sitting around, their version of the distributed pieces is going to be worthless. Same reason tensorflow was initially released without it.
This makes me wonder if this has happened before in another language. I can totally imagine 10 years ago someone saying "oh we'll never need that in PHP" and voila 10 years later you've now got feature X in PHP. Any of you wise old timers want to share such examples? Does history keep repeating itself with these sorts of things?
> As Russ pointed out, generics are a trade off between programmer time, compilation time, and execution time
This misses the most important metric: quality. Lack of generics forces copying and pasting of code which inevitably lowers quality and increases defects. It's amazing to me that with the all the expense that crappy software causes, we're more focused on compilation and execution time. Last time I checked Golang's performance numbers, the supposed benefits of this focus were not present while the downsides of being a language that forces programmers to do the wrong thing were present as well.
I often get crap when I mention most of the time execution speed is just not important.
However it is important vastly more important for google than me or you. Simply because google and a lot of other web companies are running on such tight margins.
Consider my company is paying maybe $200/mo for AWS. When we are doing half a million a month in business. Each cpu cycle for us represents a lot more revenue for us than google is making. The flip side is programmer time matters a lot more to you and me than to google.
The one thing that makes Go special is that it's pure "Engineering-Zen".
While that doesn't make programming in Go the most fun exercise it makes it a profound one (after some getting used to).
Less distractions, less eGo (forgive the pun).
Disclaimer:
I'm still having a hard time embracing all of that myself - I don't even like Go.
I really miss all the functional cleverness I've come to get used to over the years - especially talking Erlang/OTP as the main (losing) "competitor" for most of my backend projects here (microservices, kubernetes yaddayadda).
The way I've coped with this so far is to embrace it and just work through the given task - less warm-fuzzy-feeling and more "manual work" and time needed for sure but it wasn't that big a deal once I just let "go"...
Not having list comprehensions definitely is one of those things which makes me feel more like a "stupid coding monkey" but again you can be productive with less elegant tooling as well...
Could anyone here tell me why, in practice, it isn't possible to write generic algorithms such as sorting or Red/Black T using interfaces only in GO ? It seems like having interfaces such as "comparable, equatable,etc" should work in theory.
I've read somewhere that it was memory usage related, but i've got trouble picturing why (maybe an example would help)
Came for a Proposal. This article only provides motivation for generics.
Are there any concrete proposals on the table? I don't recall seeing any, and it would be great to work from that and pick it apart. Otherwise, we're just arguing the opinion that they're useful, against the opinion that they'd soil the language.
If it was up to me I would break with ASCII for the syntax. It would make parsing easier for the compiler while simultaneously making it slightly annoying to use for the programmer.
Having to reach for a complex key combination would be enough to remind everyone that Generics should be used sparingly.
The four proposals linked at the bottom of the page are very interesting, and prove that a lot of work have already been invested in bringing generics to Go. It makes me confident that it will happen one day, when the pieces fit together in a nice way.
can I tell u the BEST thing about golang? Strings cannot be nil! It's amazing. They are always "" or you know, "something" so you never have to test for if s == nil || s == "" or in ruby s.blank? to cover both cases. that is all.
In sane languages (see: Haskell, Swift, Rust), this is the case for all types. Having non-nullability only be the case for one type might be worse than having everything nullable, actually.
The point of generics is so that you can use the same code with many different types. With dynamic typing, you can use the same code with anything, it just complains at runtime if you call an operation that isn't supported on a particular type. It's like every operation is implicitly generic.
You could look at generics as a way to bring some of the flexibility of dynamic languages to a static type system, so you get the expressivity benefits without sacrificing type-safety.
Generics are not "all the things". Last i checked there was still no object inheritance (in a subtype sense for interface implementations), no operator overloading, no bytecode/vm/jit, no inline asm, no macros, no pluggable gc, no call/cc, no (idiomatic) exceptions, no currying, no weak typing or implicit conversions, no way of enforcing referential transparency, no STM, no laziness, no assertions, no contracts, no untagged unions, no algebraic data types, no covariant return types, no pattern matching, no method overloading, no simd, no decorations/annotations.... I am sure i missed a lot.
EDIT: of course this is good; such a language would be beyond nightmarish. By which i mean c++ or scala.
but having all those things go would become another C++ with a different syntax.
I like the direction Go is going of "there are no options to choose", like unconfigurable fmt, or the fact that there is no way to create "exotic" implementations.
However, generics would be my number #1 on the list of "maybe let's add that". Would be nice to have less "interface {}" in reusable libraries.
Exceptions would be probably second, but that would come with some sort of runtime cost. With them Go would start to drift towards "generic programming language".
Exceptions don't have any runtime costs beyond those which Go is already paying by mandating unwinding.
In fact, C++-style exceptions are strictly less expensive in the non-exceptional case than defer, because of defer's dynamic semantics. Go's semantics require a slower exceptional control flow scheme than almost any other language I'm aware of, including dynamic ones like JavaScript.
IIRC the idea is that the conceptual overhead of exceptions is much larger than the runtime cost, hence the minimal syntax/runtime support beyond defer (which is easy to follow, if hard to implement efficiently).
I am not so sure I would agree with this, but I don't use go enough to have a firm opinion myself.
As you probably already know, panic/recover/defer are not supposed to be used in the same way as try/catch/finally. They're different features for different purposes.
If you want error handling in Go, use error values.
I think what's happening here is pcwalton is a language implementer, so when you talk about 'conceptual complexity' he thinks about how the feature is specified, whereas you or I think about how the users of the feature think about and use it. We're all talking past each other a bit, I think.
Well he answered me as if he understood me, so I am going to go ahead with that assumption. This thread is not at all difficult to follow. Anyone who uses rescue should be shot on sight--it takes a masochist to introduce panic as a stack unwind mechanism intended to be caught. The process should stop. I have never seen rescue used in the wild, so it seems as if the only thing this has in common with exceptions is stack unwinding. It is apples and oranges and the performance difference is meaningless unless you try to use them as the same.
To be fair, pcwalton was not advocating this. He was pointing out that defer is already more costly runtime wise than exceptions, correcting another person.
A big problem with both Rust and Go is that the marketing says there are no exceptions, and because we all know exceptions are bad/slow/hard to understand that the languages are superior. I strongly object to this idea because from an implementation POV both Go and Rust are 90% there for all the complexities that exceptions cause but now nobody is aware of it.
(This is also why I'm a huge proponent of Results in Rust and disabling unwinding altogether)
Well, as I said earlier, stack unwinding does not imply that the stack unwinding is NORMAL; I'm fine with it in exceptional cases.
Defer has its own quirks that irritate me but I wouldn't call them exceptional so much as dynamic RAII.... or something.
Either way, if the languages allow me to avoid tracking down every possible http connection exception I need to trap to avoid bringing down my process I'd say it's a net win.
I disagree completely. We're talking about a feature that can affect the execution path of your code even if you're not using it yourself. For such a feature, you have to work under the assumption that someone will be using it somewhere and you have to deal with it.
The whole reasoning behind not supporting a ton of features in Go is that excuses like "don't need it? Don't use it!" are invalid when it comes to programming language features. And nowhere is this more relevant than for a feature that can unwind the stack without warning.
>but having all those things go would become another C++ with a different syntax.
Haskell and CL have "all those things" and they are not "C++ with a different syntax".
I don't know why people repeat these cliches... It's not like a language can't have many features and be designed well at the same time. It just takes preparation and effort instead of ad-hoc additions (like with C++).
That reminds me of the "If those books say something worthwhile, it will be in the Kuran, too, so it's ok to burn them. If they don't, they it's ok to burn them anyway" argument -- something a sultan is alleged to have said as the justification for burning the library of Alexandria.
The thing is, it's not just the feature set, different languages have lots of different things going (or not going) for them too.
One might like Go's syntax over Haskell's.
Another might not like Haskell's purity.
A third might not like Haskell's heavyweight platform installation and tooling.
Another might be forced to use Go because of his work but still hate the lack of Generics.
Yet another might prefer Go over Haskell just for the fact that you can find Go jobs, where Haskell jobs are too few and far between.
> EDIT: of course this is good; such a language would be beyond nightmarish. By which i mean c++ or scala.
Then go and compare the same code in go and Scala and see which is more "nightmarish". You see Scala as a complex language because you need to learn something before you use it while go is almost the opposite - you may get it in an afternoon and create repetitive, boilerplatish and unmaintanable mess.
> You see Scala as a complex language because you need to learn something before you use it
No, I see Scala as a complex language because—much like C++—each library uses its own curious dialect. There is no community consensus on the balance between the object-oriented and functional. It's a mess, albeit a mess I'd prefer over most other languages. But dealing with implicits, language changes between versions, and "default" trait implementations (e.g. `val foo = Set()` is a simple example) makes me consider the language nightmarish.
If they accept generics, then there is an implication that the language design isn't infallible as a result of being written by Rob Pike, and then the whole house of cards falls down as people start clamouring for things like real exceptions.
Not to mention Ian Lance Taylor, who's been on the Go team since before it was public, authored the GCC Go frontend, was de-facto leading the team when I left Google in 2014, and also happens to be the author of the proposal.
Yeah they haven't done it yet, and might still never do it, to save face. What could have been a simple 1.0 missing feature has been politicized into Go's defining feature/mistake.
There is nothing political about it, and speaking as someone on the inside it is simply ridiculous to think of it that way. What these real proposals show is that a lot of sincere effort has been spent by members of the core team writing, reviewing, and debating generics proposals over a span of multiple years. Ian only recently felt comfortable releasing them publicly, and so here they are.
I don't want to start a flame war, but parametric polymorphism has been exhaustively studied for decades. Any technical difficulties of bolting it on Go at this stage probably stem from uncertainty about Go's existing semantics rather than the new feature itself. So I hope there are non-technical reasons that have led to the features delay.
That's precisely it. We don't want to "bolt on" any feature to Go. The features should interact nicely. Language design is all about tradeoffs like this.
There's a lot of information out there about Go's design process and goals. If you read up on it (and the proposals that are the subject of this thread) you can see why parametric polymorphism isn't something that you can just shove into the language.
My point is that if Go was properly formalized as it should have been all along, this would be a lot easier.
These past proposals are needlessly informal---running the risk of missing any important details. For future proposals, I highly recommend the use of judgements / a sequent calculus to formally specify the type system.
Unfortunately they aren't. But those are all worked on by people with academic (or equivalent) PL backgrounds whose hand-waving I trust much more. Also don't forget the existence of GHC's core, and Rust's Mir (OCaml I'd hope have a good well-defined core language). Basically, for human purposes, there is a spectrum of "quasi-formality" and Go is not winning.
So, basically, you're criticizing Go for something that even languages like Haskell, OCaml and Rust, worked on by people with academic PL backgrounds, don't do.
Having a well-defined core language like GHC's Core or Rust's MIR doesn't give your a proper formalisation. It just makes the formalisation easier by reducing the scope of the language. Even ECMAScript 6 "desugars" to a core language. It doesn't make the language more formalised.
The fact is that none of Go, Rust, OCaml and Haskell are "properly formalised", as of 2016. Nobody wins here.
I agree with the author's request, I'm just not convinced he proposes a design. I mean I recognize see the need for some sort of generic programming, but the big question is how not why, right?
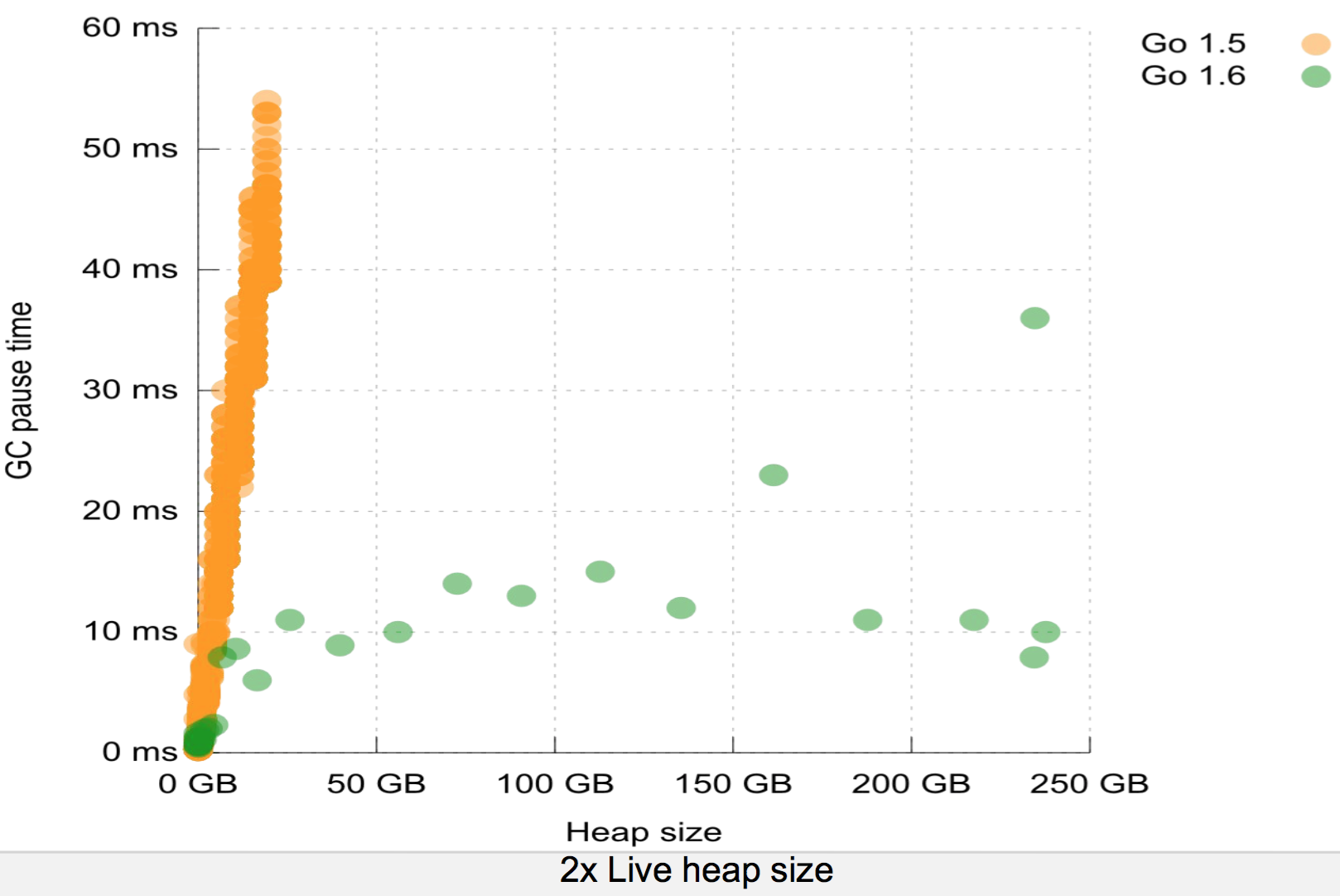{kind=link}
Do we have 67 implementations of sort.Interface? Sure. Is that, by any stretch of the imagination, a significantly difficult part of my job? No.
Juju is a distributed application that supports running across thousands of machines on all the major clouds, on OSes including CentOS, Ubuntu, Windows, and OSX, on architectures including amd64, x86, PPC64EL, s390x... and stores data in a replicated mongoDB and uses RPC over websockets to talk between machines.
The difficult problems are all either intrinsic to the solution space (e.g. supporting different storage back ends for each cloud), or problems we brought on ourselves (what do you mean the unit tests have to spin up a full mongodb instance?).
Generics would not make our codebase significantly better, more maintainable, or easier to understand.