This is a great write-up and I love all the different ways they collected and analyzed data.
That said, it would have been much easier and more accurate to simply put each laptop side by side and run some timed compilations on the exact same scenarios: A full build, incremental build of a recent change set, incremental build impacting a module that must be rebuilt, and a couple more scenarios.
Or write a script that steps through the last 100 git commits, applies them incrementally, and does a timed incremental build to get a representation of incremental build times for actual code. It could be done in a day.
Collecting company-wide stats leaves the door open to significant biases. The first that comes to mind is that newer employees will have M3 laptops while the oldest employees will be on M1 laptops. While not a strict ordering, newer employees (with their new M3 laptops) are more likely to be working on smaller changes while the more tenured employees might be deeper in the code or working in more complicated areas, doing things that require longer build times.
This is just one example of how the sampling isn’t truly as random and representative as it may seem.
So cool analysis and fun to see the way they’ve used various tools to analyze the data, but due to inherent biases in the sample set (older employees have older laptops, notably) I think anyone looking to answer these questions should start with the simpler method of benchmarking recent commits on each laptop before they spend a lot of time architecting company-wide data collection
I totally agree with your suggestion, and we (I am the author of this post) did spot-check the performance for a few common tasks first.
We ended up collecting all this data partly to compare machine-to-machine, but also because we want historical data on developer build times and a continual measure of how the builds are performing so we can catch regressions. We quite frequently tweak the architecture of our codebase to make builds more performant when we see the build times go up.
I think there's something to be said for the fact that the engineering organization grew through this exercise - experimenting with using telemetry data in new ways that, when presented to other devs in the org, likely helped them to all level up and think differently about solving problems.
Sometimes these wandering paths to the solution have multiple knock-on effects in individual contributor growth that are hard to measure but are (subjectively, in my experience) valuable in moving the overall ability of the org forward.
I didn't see any analysis of network building as an alternative to M3s. For my project, ~40 million lines, past a certain minimum threshold, it doesn't matter how fast my machine is, it can't compete with the network build our infra-team makes.
So sure, an M3 might make my build 30% faster than my M1 build, but the network build is 15x faster. Is it possible instead of giving the developers M3s they should have invested in some kind of network build?
Network full builds might be faster, but would incremental builds be? Would developers still be able to use their favourite IDE and OS? Would developers be able to work without waiting in a queue? Would developers be able to work offline?
If you have a massive, monolithic, single-executable-producing codebase that can't be built on a developer machine, then you need network builds. But if you aren't Google, building on laptops gives developers better experience, even if it's slower.
i hate to say it but working offline is not really a thing at work anymore. it is no one thing, but a result of k8s by and large. i think a lot of places got compliant when you could just deploy a docker image, fuck how long that takes and how slow it is on mac
That depends entirely on the tech stack, and how much you care about enabling offline development. You can definitely run something like minikube on your laptop.
That is a very large company if you have a singular 40 million line codebase, maybe around 1000 engineers or greater? Network builds also takes significant investment in adopting stuff like bazel and a dedicated devex team to pull off most of the time. Setting up build metrics to determine a build decision and the other benefits that come from it is a one month project at most for one engineer.
It's like telling an indie hacker to adopt a complicated kubernetes setup for his app.
A company with ~1000 software engineers is probably in the top 100 in software company sizes in the world, especially if they are not a sweat shop consultancy, bank or defense contractor, which are all usually large companies themselves.
I mean, the vast majority of software engineers in the world are not in software engineering companies. If we are purposefully limiting ourselves to Bay Tech companies, then sure, I guess 1,000 software engineers is big. But the companies in the world that are around the top 100 employers in the world, like you suggested, these places have 150,000 to 250,000 employees. 1,000 programmers for internal CRUD and system integration is quite realistic; the IT staff alone for a company that size is like 5,000 people, that is not even accounting for their actual business (which these days almost always has a major software component).
This is also not including large government employers like the military, intelligence, or all of the large services like the mail.
> This is a great write-up and I love all the different ways they collected and analyzed data.
> [..] due to inherent biases in the sample set [..]
But that is an analysis methods issue. This serves as a reminder that one cannot depend on AI-assistants when they are not themselves enough knowledgeable on a topic. At least for the time being.
For once, as you point, they conducted a t-test on data that are not independently sampled, as multiple data points were sampled by different people, and there are very valid reasons to believe that different people would have different tasks that may be more or less compute-demanding, which confound the data. This violates one of the very fundamental assumptions of the t-test, which was not pointed out by the code interpreter. In contrast, they could have modeled their data with what is called "linear mixed effects model" where stuff like person (who the laptop belongs to) as well as possibly other stuff like seniority etc could be put into the model as "random effects".
Nevertheless it is all quite interesting data. What I found most interesting is the RAM-related part: caching data can be very powerful, and higher RAM brings more benefits than people usually realise. Any laptop (or at least macbook) with more RAM than it usually needs has most of the time its extra RAM filled by cache.
I agree, it seems like they were trying to come up with the most expensive way to answer the question possible for some reason. And why was the finding in the end to upgrade M1 users to more expensive M3s when M2s were deemed sufficient?
If employees are purposefully isolated from the company's expenses, they'll waste money left and right.
Also, they don't care since any incremental savings aren't shared with the employees. Misaligned incentives. In that mentally, it's best to take while you can.
I would think you would want to capture what/how was built, as like:
* Repo started at this commit
* With this diff applied
* Build was run with this command
Capture that for a week. Now you have a cross section of real workloads, but you can repeat the builds on each hardware tier (and even new hardware down the road)
The dev telemetry sounds well intentioned… but in 5-10 years will some new manager come in and use it as a productivity metric or work habit tracking technique, officially or unofficially?
As a scientist, I'm interested how computer programmers work with data.
* They drew beautiful graphs!
* They used chatgpt to automate their analysis super-fast!
* ChatGPT punched out a reasonably sensible t test!
But:
* They had variation across memory and chip type, but they never thought of using a linear regression.
* They drew histograms, which are hard to compare. They could have supplemented them with simple means and error bars. (Or used cumulative distribution functions, where you can see if they overlap or one is shifted.)
I'm glad you noted programmers; as a computer science researcher, my reaction was the same as yours. I don't think I ever used a CDF for data analysis until grad school (even with having had stats as a dual bio/cs undergrad).
It's because that's usually the data scientist's job, and most eng infra teams don't have a data scientist and don't really need one most of the time.
Most of the time they deal with data the way their tools generally present data, which correlate closely to most analytics, perf analysis and observability software suites.
Expecting the average software eng to know what a CDF is the same as expecting them to know 3d graphics basics like quaternions and writing shaders.
A standard CS program will cover statistics (incl. calculus-based stats e.g. MLEs), and graphics is a very common and popular elective (e.g. covering OpenGL). I learned all of this stuff (sans shaders) in undergrad, and I went to a shitty state college. So from my perspective an entry level programmer should at least have a passing familiarity with these topics.
Does your experience truly say that the average SWE is so ignorant? If so, why do you think that is?
I find these statements to be extremely doubtful. Why would a CS program cover statistics? Wouldn't that be the math department? If there any required courses, it's most likely Calc 1/2, Linear Algebra, and Discrete Math.
Also, out of the hundreds of programmers I've met, I don't know any that has done graphics programming. I consider that super niche.
Thankfully all programmers have a CS degree, as there are absolutely no career paths into the industry that could possibly bypass a four year degree. What a relief, imagine the horror of working with plebians that never took a course on statistics!
>Expecting the average software eng to know what a CDF is the same as expecting them to know 3d graphics basics like quaternions and writing shaders.
I did write shaders and used quaternions back in the day. I also worked on microcontrollers, did some system programming, developed mobile and desktop apps. Now I am working on a rather large microservice based app.
> ChatGPT punched out a reasonably sensible t test!
I think the distribution is decidedly non normal here and the difference in the medians may well have also been of substantial interest -- I'd go for a Wilcox test here to first order... Or even some type of quantile regression. Honestly the famous Jonckheere–Terpstra test for ordered medians would be _perfect_ for this bit of pseudoanalysis -- have the hypothesis that M3 > M2 > M1 and you're good to go, right?!
Note that in some places they used boxplots, which offer clearer comparisons. It would have been more effective to present all the data using boxplots.
> They drew histograms, which are hard to compare.
Like you, I'd suggest empirical CDF plots for comparisons like these. Each distribution results in a curve, and the curves can be plotted together on the same graph for easy comparison. As an example, see the final plot on this page:
I think you might want to add the caveat "young computer programmers." Some of us grew up in a time where we had to learn basic statistics and visualization to understand profiling at the "bare metal" level and carried that on throughout our careers.
> cumulative distribution functions, where you can see if they overlap or one is shifted
Why would this be preferred over a PDF? I've rarely seen CDF plots after high school so I would have to convert the CDF into a PDF inside my head to check if the two distributions overlap or are shifted. CDFs are not a native representation for most people
I can give a real example. At work we were testing pulse shaping amplifiers for Geiger Muller tubes. They take a pulse in, shape it to get a pulse with a height proportional to the charge collected, and output a histogram of the frequency of pulse heights, with each bin representing how many pulses have a given amount of charge.
Ideally, of all components are the same, there is no jitter, and if you feed in a test signal from a generator with exactly the same area per pulse, you should see a histogram where every count is in a single bin.
In real life, components have tolerances, and readouts have jitter, so the counts spread out and you might see, with the same input, one device with, say, 100 counts in bin 60, while a comparably performing device might have 33 each in bins 58, 59, and 60.
This can be hard to compare visually as a PDF, but if you compare CDF's, you see S-curves with rising edges that only differ slightly in slope and position, making the test more intuitive.
If one line is to the right of the other everywhere, then the distribution is bigger everywhere. (“First order stochastic dominance” if you want to sound fancy.) I agree that CDFs are hard to interpret, but that is partly due to unfamiliarity.
I am part of a medium-sized software company (2k employees). A few years ago, we wanted to improve dev productivity. Instead of going with new laptops, we decided to explore offloading the dev stack over to AWS boxes.
This turned out to be a multi-year project with a whole team of devs (~4) working on it full-time.
In hindsight, the tradeoff wasn't worth it. It's still way too difficult to remap a fully-local dev experience with one that's running in the cloud.
Kind of interesting to think that CI is significantly slower in practice and both systems need to be maintained. Is it just the overhead of pushing through git or are there other reasons as well?
The way we do things is that we build everything in the cloud and store in a central container registry. So if I trigger a build during dev, the CI runner can re-use that, e.g. if it’s needed before running a test or creating a preview env.
Similarly if another dev (or a CI runner) triggers a build of one of our services, I won’t have to next time I start my dev environment. And because it’s built in the cloud there’s no “works on my machine”.
Same applies to tests actually. They run in the cloud in an independent and trusted environment and the results are cached and stored centrally.
Garden knows all the files and config that belong to a given test suite. So the very first CI run may run tests for service A, service B, and service C. I then write code that only changes service B, open a PR and only the relevant tests get run in CI.
And because it’s all in prod-like environments, I can run integ and e2e tests from my laptop as I code, instead of only having that set up for CI.
You would need a very perfect and flexible CI system in place that wouldn't need to rebuild anything it doesn't need and only run the tests you want or only recently failed tests etc.
Many CI systems would spin up a new box instead of using persistent so likely have to rebuild if no cache, etc.
So basically I would say most of the overhead is in not having a persistent box with knowledge of last build or ability to choose what to run in there, which pretty much just equals to local capabilities.
Often you also have the CI system designed in a way to verify a “from scratch” build that avoids any issues with “works on my machine” scenarios due to things still being cached that shouldn’t be there anymore.
I tried Garden briefly but didn't like it for some reason. DevSpace was simpler to set up and works quite reliably. The sync feature where they automatically inject something into the pod works really well.
DevSpace is a great tool but it’s bummer you didn’t like Garden.
Admittedly, documentation and stability weren’t quite what we’d like and we’ve done a massive overhaul of the foundational pieces in the past 12 months.
If you want to share feedback I’m all ears, my email is in my profile.
This might have to do with scale. At my employer (~7k employees) we started down this path a few years ago as well, and while it has taken longer for remote to be better than local, it now definitively is and has unlocked all kinds of other stuff that wasn't possible with the local-only version. One example is working across multiple branches by switching machines instead of files on local has meant way lower latency when switching between tasks.
One thing I've never understood (and admittedly have not thoroughly researched) is how a remote workspace jives with front-end development. My local tooling is all terminal-based, but after ssh'ing into the remote box to conduct some "local" development, how do I see those changes in a browser? Is the local just exposed on an ip:port?
Facebook's web repo which includes all the PHP and JS for facebook.com and a bunch of other sites is one big massive repo. For development you claim out a server that has a recent checkout of the codebase. Right after claiming it it syncs in your personal commits/stacks you're working on, ready to rebase. You access that machine on a subdomain of any of the FB websites. As far as I remember it was something along the lines of 12345.od.facebook.com, but the format changed from time to time as infra changed. Client certificate authentication and VPN needed (that may no longer be the case, my info is 1y+ old).
There was an internal search provider (bunnylol) that had tools like putting @od in front of any FB URL to generate a redirect of that URL to your currently checked out On Demand server. Painless to work with! Nice side benefit of living on the same domain as the main sites is that the cookies are reused, so no need to log in again.
Have you tried vs code remote development plugin? It can do port forwarding (e.g. forwarding port 8080 on your local machine to port 8080 on the remote machine).
Are you using a public cloud to host the dev boxen? Is compilation actually faster than locally – assuming that your pc's having been replaced to lower-specced versions since they don't do any heavy lifting anymore?
I work for a not-really-tech company (and I'm not a full-time dev either), so I've been issued a crappy "ultra-portable" laptop with an ultra-low-voltage CPU. I've looked into offloading my dev work to an AWS instance, but was quite surprised that it wasn't any faster than doing things locally for things like Rust compiles.
In our case it is mostly faster when provisioning a machine with significantly more cores. In cloud machines you get “vcores” which are not the same as a core on a local cpu.
I’ve been integrating psrecord into our builds to track core utilisation during the built and see that a lot of time is spent in single threaded activities. Effort is required to compile modules in parallel but that is actually quite straightforward. Running all tests in parallel is harder.
We get the most out of the cloud machines by being able to provision a 16+ core machine to run more complicated (resilience) tests and benchmarks.
Also note that typically the cloud machines run on lower clocked CPUs than you would find in a workstation depending on which machine you provision.
Haha, as I read more words of your comment, I got more sure that we worked at the same place. Totally agree, remote devboxes are really great these days!
However, I also feel like our setup was well suited to remote-first dev anyway (eg. syncing of auto-generated files being a pain for local dev).
My company piles so much ill-considered Linux antivirus and other crap in cloud developer boxes that even on a huge instance type, the builds are ten or more times slower than a laptop, and hundreds of times slower than a real dev box with a Threadripper or similar. It's just a pure waste of money and everyone's time.
It turns out that hooking every system call with vendor crapware is bad for a unix-style toolchain that execs a million subprocesses.
My dev box died (that I used for remote work), and instead of buying something new immediately, I moved my setup to a Hetzner cloud vps. Took around 2 days. Stuff like setting up termux on my tablet and the cli environment on the vps was 90 percent of that. The plus side was that I then spent the remaining summer working outside in the terrace and in the park. Was awesome. I was able to do it because practically all of my tools are command line based (vim, etc).
How much does this cost you? I've been dealing with a huge workstation-server thing for years in order to get this flexibility and while the performance/cost is amazing, reliability and maintenance has been a pain. I've been thinking about buying some cloud compute but an equivalent workstation ends up being crazy expensive (>$100/mo).
This is honestly a bit overkill for a dev workstation (unless you compile Rust!), but since it’s a dedicated server it can also host any number of fully isolated services for homelab or saas. There’s nothing else like it in the wild, afaik.
6 eur/month. It's the most basic offering. I don't really need power for what I'm doing. Running tests locally took a bit longer than I had been used to, but just a bit. I'm pretty used to underpowered environments though. I find that underpowering is a good way to enforce a sort of hygiene in terms of what you do and how.
I’d be careful with Hetzner. I was doing nothing malicious and signed up. I had to submit a passport which was valid US. It got my account cancelled. I asked why and they said they couldn’t say for security reasons. They seem like an awesome service, I don’t want knock them I just simply asked if I could resubmit or something the mediate and they said no. I don’t blame them just be careful. I’m guessing my passport and face might have trigged some validation issues? I dunno.
It of course steongly depends on what your stack is, my current job provides a full remote dev server for our backend and it's the best experience I've seen in a long time. In particular having a common DB is suprinsingly uneventful (nobody's dropping tables here and there) while helping a lot.
We have interns coming in and fully ready within an hour or two of setup. Same way changing local machines is a breeze with very little downtime.
Isn't the point of a dev environment precisely that the intern can drop tables? Idk, I've never had a shared database not turn to mush over a long enough period, and think investing the effort to build data scripts to rebuild dev dbs from scratch has always been the right call.
Dropping tables to see what happens or resetting DBs every hour is fine with a small dataset, but it becomes impractical when you work on a monolith that talks to a set of DB with a hundred+ tables in total and takes 5 hours to restore.
As you point out rebuilding small test datasets instead of just filtering the prod DB is an option, but those also need maintenance, and take a hell of time to make sure all the relevant cases are covered.
Basically, trying to flee from the bulk and complexity tends to bring a different set of hurdles and missing parts that have to be paid in time, maintenance and bugs only discovered in prod.
PS: the test DB is still reset everyday. Eorse thing happening is we need to do something else for a few hours until it's restored.
> We have interns coming in and fully ready within an hour or two of setup. Same way changing local machines is a breeze with very little downtime.
This sounds like the result of a company investing in tooling, rather than something specific to a remote dev env. Our local dev env takes 3 commands and less than 3 hours to go from a new laptop to a fully working dev env.
If I understand correctly, they're not talking about remote desktops. Rather, the editor is local and responds normally, while the heavy lifting of compilation is done remotely. I've dabbled in this myself, and it's nice enough.
Thanks for the insight. It maybe depends on each team too.
While my team (platform & infra) much prefer remote devbox, the development teams are not.
It could be specific to my org because we have way too many restrictions on the local dev machine (eg: no linux on laptop but it's ok on server and my team much prefer linux over crippled Windows laptop).
I suspect things like GitHub's Codespaces offering will be more and more popular as time goes on for this kind of thing. Did you guys try out some of the AWS Cloud9 or other 'canned' dev env offerings?
My experience with GitHub Codespaces is mostly limited to when I forgot my laptop and had to work from my iPad. It was a horrible experience, mostly because Codespaces didn’t support touch or Safari very well and I also couldn’t use IntelliJ which I’m more familiar with.
Can’t really say anything for performance, but I don’t think it’ll beat my laptop unless maven can magically take decent advantage of 32 cores (which I unfortunately know it can’t).
Even where a task being automated is likely to be done, automation can mean it’s done more reliably or quickly. Automation is generally needed to advance to greater and greater levels of complexity, time-efficient or not.
Also not all minutes have equal value, spending a few hours to save 5 minutes in an emergency with automation can be well worth it.
One thing that jumps out at me is the assumption that compile time implies wasted time. The linked Martin Fowler article provides justification for this, saying that longer feedback loops provide an opportunity to get distracted or leave a flow state while ex. checking email or getting coffee. The thing is, you don't have to go work on a completely unrelated task. The code is still in front of you and you can still be thinking about it, realizing there's yet another corner case you need to write a test for. Maybe you're not getting instant gratification, but surely a 2-minute compile time doesn't imply 2 whole minutes of wasted time.
If you can figure out something useful to do during a two minute window, I envy you.
I really struggle with task switching, and two minutes is the danger zone. Just enough time to get distracted, by something else; too little time to start meaningful work on anything else...
Hour long compiles are okay, I plan them, and have something else to do while they are building.
30 second compiles are annoying, but don't affect my productivity much (except when doing minor tweaks to UI or copywriting).
Spot on. The mind often needs time and space to breathe, especially after it's been focused and bearing down on something. We're humans, not machines. Creativity (i.e., problem solving) needs to be nurtured. It can't be force fed.
More time working doesn't translate to being more effective and more productive. If that were the case then why are a disproportionate percentage of my "Oh shit! I know what to do to solve that..." in the shower, on my morning run, etc.?
I love those moments. Your brain has worked on it in the background like a ‘bombe’ machine cracking the day’s enigma code. And suddenly “ding… the days code is in!”
I agree to some extent. Though, I don't think it has to be a trade-off though. After a sub-5 second compile time, I go over to get a coffee to ponder the results of the compile rather than imagine what those results might be. Taking time to think is not mutually exclusive to a highly responsive dev process.
I get what you are saying but I still think fast compilation is essential to a pleasant dev experience. Regardless of how fast the compiler is, there will always be time when we are just sitting there thinking, not typing. But when I am implementing, I want to verify that my changes work as quickly as possible and there is really no upside to waiting around for two minutes.
Yes! Pauses allow you to reflect on your expectations of what you're actually compiling. As you sit in anticipation, you reflect on how your recent changes will manifest and how you might QA test it. You design new edge cases to add to the test suite. You sketch alternatives in your notebook. You realize oh compilation will surely fail on x because I forgot to add y to module z. You realize your logs, metrics, tests and error handling might need to be tweaked to unearth answers to the questions that you just now formulated. This reflection time is perhaps the most productive time a programmer will spend in their day. Calling it "wasted" reflects a poor understanding of the software development process.
- M3 Pro is nerfed (only 6 perf cores) to better distinguish and sell M3 Max, basically on par with M2 Pro
So, in the end, I got a slightly used 10 core M1 Pro and am very happy, having spent less than half of what the base M3 Pro would cost, and got 85% of its power (and also, considering that you generally need to have at least 33 to 50 % faster CPU to even notice the difference :)).
The M3 Pro being nerfed has been parroted on the Internet since the announcement. Practically it’s a great choice. It’s much more efficient than the M2 Pro at slightly better performance. That’s what I am looking for in a laptop. I don’t really have a usecase for the memory bandwidth…
The M3 Pro and Max get virtually identical results in battery tests, e.g. https://www.tomsguide.com/news/macbook-pro-m3-and-m3-max-bat.... The Pro may be a perfectly fine machine, but Apple didn't remove cores to increase battery life; they did it to lower costs and upsell the Max.
In all M generations, the max and pro are effectively different layouts so can’t be put down to binning. Each generation did offer binned versions of the Pro and Max with fewer cores though.
AI is the main use case for memory bandwidth that I know of. Local LLM’s are memory bandwidth limited when running inference, so once you fall into that trap you end up wanting the 400 gb/s max memory bandwidth of the m1/m2/m3 max, paired with lots and lots of RAM. Apple pairs memory size and bandwidth upgrades to core counts a lot more in m3 which makes the m3 line-up far more expensive than the m2 line-up to reach comparable LLM performance. Them touting AI as a use case for the m3 line-up in the keynote was decidedly odd, as this generation is a step back when it comes to price vs performance.
I picked up an M3Pro/11/14/36GB/1TB to 'test' over the long holiday return period to see if I need an M3 Max. For my workflow (similar to blog post) - I don't! I'm very happy with this machine.
Die shots show the CPU cores take up so little space compared to GPUs on both the Pro and Max... I wonder why.
My experience was similar: In real world compile times, the M1 Pro still hangs quite closely to the current laptop M2 and M3 models. Nothing as significant as the differences in this article.
I could depend on the language or project, but in head-to-head benchmarks of identical compile commands I didn’t see any differences this big.
That's interesting you saw less of an improvement in the M2 than we saw in this article.
I guess not that surprising given the different compilation toolchains though, especially as even with the Go toolchain you can see how specific specs lend themselves to different parts of the build process (such as the additional memory helping linker performance).
You're not the only one to comment that the M3 is weirdly capped for performance. Hopefully not something they'll continue into the M4+ models.
Yep, there appears to be no reason for getting M3 Pro instead of M2 Pro, but my guess is that after this (unfortunate) adjustment, they got the separation they wanted (a clear hierarchy of Max > Pro > base chip for both CPU and GPU power), and can then improve all three chips by a similar amount in the future generations.
I also made this calculation recently and ended up getting an M1 Pro with maxed out memory and disk. It was a solid deal and it is an amazing computer.
I love my M1 MacBook Air for iOS development. One thing, I'd like to have from Pro line is the screen, and just the PPI part. While 120Hz is a nice thing to have, it won't happen on Air laptops.
I am ex-core contributor Chromium and Node.js and current core contributor to gRPC Core/C++.
I am never bothered with build times. There is "interactive build" (incremental builds I use to rerun related unit tests as I work on code) and non-interactive build (one I launch and go get coffee/read email). I have never seen hardware refresh toggle non-interactive into interactive.
My personal hardware (that I use now and then to do some quick fix/code review) is 5+ year old Intel i7 with 16Gb of memory (had to add 16Gb when realized linking Node.js in WSL requires more memory).
My work laptop is Intel MacBook Pro with a touch bar. I do not think it has any impact on my productivity. What matters is the screen size and quality (e.g. resolution, contrast and sharpness) and storage speed. Build system (e.g. speed of incremental builds and support for distributed builds) has more impact than any CPU advances. I use Bazel for my personal projects.
Somehow programmers have come to accept that a minuscule change in a single function that only result in a few bytes changing in a binary takes forever to compile and link. Compilation and linking should be basically instantaneous. So fast that you don't even realize there is a compilation step at all.
Sure, release builds with whole program optimization and other fancy compiler techniques can take longer. That's fine. But the regular compile/debug/test loop can still be instant. For legacy reasons compilation in systems languages is unbelievably slow but it doesn't have to be this way.
This is the reason why I often use tcc compiler for my edit/compile/hotreload cycle, it is about 8x faster than gcc with -O0 and 20x faster than gcc with -O2.
With tcc the initial compilation of hostapd it takes about 0.7 seconds and incremental builds are roughly 50 milliseconds.
The only problem is that tcc's diagnostics aren't the best and sometimes there are mild compatibility issues (usually it is enough to tweak CFLAGS or add some macro definition)
I mean yeah I've come to accept it because I don't know any different. If you can share some examples of large-scale projects that you can compile to test locally near-instantly - or how we might change existing projects/languages to allow for this - then you will have my attention instead of skepticism.
I am firmly in test-driven development camp. My test cases build and run interactively. I rarely need to do a full build. CI will make sure I didn’t break anything unexpected.
I too come from Blaze and tried to use Bazel for my personal project which involves backend + frontend dockerized, the build rules got weird and niche real quick and I was spending lots of time working with the BUILD files making me question the value against plain old Makefiles, this was 3 years ago, maybe the public ecosystem is better now.
Aren’t M series screen and storage speed significantly superior to your Intel MBP? I transitioned from an Intel MBP to M1 for work and the screen was significantly superior (not sure about storage speed, our builds are all on a remote dev machine that is stacked).
When I worked at Chromium there were two major mitigations:
1. Debug compilation was split in shared libraries so only a couple of them has to be rebuilt in your regular dev workflow.
2. They had some magical distributed build that "just worked" for me. I never had to dive into the details.
I was working on DevTools so in many cases my changes would touch both browser and renderer. Unit testing was helpful.
Bazel is significantly faster on m1 compared to i7 even if it doesn’t try to recompile protobuf compiler code which it’s still attempting to do regularly
The Threadripper PRO branding was only introduced 3.5 years ago. The first two generations didn't have any split between workstation parts and enthusiast consumer parts. You must have a first-generation Threadripper, which means it's somewhere between 8 and 16 CPU cores.
If you would not significantly benefit from upgrading, it's only because you already have more CPU performance than you need. Today's CPUs are significantly better than first-generation Zen in performance per clock and raw clock speed, and mainstream consumer desktop platforms can now match the top first-generation Threadripper in CPU core count and total DRAM bandwidth (and soon, DRAM capacity). There's no performance or power metric by which a Threadripper 1950X (not quite 6.5 years old) beats a Ryzen 7950X. And the 7950X also comes in a mobile package that only sacrifices a bit of performance (to fit into fairly chunky "laptops").
I guess I should clarify: I am a rust and C++ developer blocked on compilation time, but even then, I am not able to justify the cost of upgrading from a 1950X/128GB DDR4 (good guess!) to the 7950X or 3D. It would be faster, but not in a way that would translate to $$$ directly. (Not to mention the inflation in TRx costs since AMD stopped playing catch-up.) performance-per-watt isn’t interesting to me (except for thermals but Noctua has me covered) because I pay real-time costs and it’s not a build farm.
If I had 100% CPU consumption around the clock, I would upgrade in a heart beat. But I’m working interactively in spurts between hitting CPU walls and the spurts don’t justify the upgrade.
If I were to upgrade it would be for the sake of non-work CPU video encoding or to get PCIe 5.0 for faster model loading to GPU VRAM.
sTR4 workstations are hard to put down! I'll replace mine one day, probably with whatever ASRock Rack Epyc succeeds the ROMED8-2T with PCIe 5.0.
In the meantime, I wanted something more portable, so I put a 13700K and RTX 3090 in a Lian Li A4-H2O case with an eDP side panel for a nice mITX build. It only needs one cable for power, and it's as great for VR as it is a headless host.
To people who are thinking about using AI for data analyses like the one described in the article:
- I think it is much easier to just load the data into R, Stata etc and interrogate the data that way. The commands to do that will be shorter and more precise and most importantly more reproducible.
- the most difficult task in data analysis is understanding the data and the mechanisms that have generated it. For that you will need a causal model of the problem domain. Not sure that AI is capable of building useful causal models unless they were somehow first trained using other data from the domain.
- it is impossible to reasonably interpret the data without reference to that model. I wonder if current AI models are capable of doing that, e.g., can they detect confounding or oversized influence of outliers or interesting effect modifiers.
Perhaps someone who knows more than I do on the state of current technology can provide a better assessment of where we are in this effort
so ChatGPT can build a causal model for a problem domain? How does it communicate that (using a DAG?)? It would be important for the data users to understand that model.
> All developers work with a fully fledged incident.io environment locally on their laptops: it allows for a <30s feedback loop between changing code and running it, which is a key factor in how productively you can work with our codebase.
This to me is the biggest accomplishment.
I've never worked at a company (besides brief time helping out with some startups) where I have been able to run a dev/local instance of the whole company on a single machine.
There's always this thing, or that, or the other that is not accessible. There's always a gotcha.
I never couldn't run the damn app locally until my latest job. Drives me bonkers. I don't understand how people aren't more upset and this atrocious devex. Damn college kids don't know what they're missing.
I can’t imagine not having this. We use k3s to run everything locally and it works great. But we (un)fortunately added snowflake in the last year — it solves some very real problems for us, but it’s also a pain to iterate on that stuff.
We used to have that, but it's hard to support as you scale. The level of effort is somewhat quadratic to company size: linear in the number of services you support and in the number of engineers you have to support. Also divergent use cases come up that don't quite fit, and suddenly the infra team is the bottleneck to feature delivery, and people just start doing their own thing. Once that Pandora's Box is opened, it's essentially impossible to claw your way back.
I've heard of largeish companies that still manage to do this well, but I'd love to learn how.
That said, yeah I agree this is the biggest accomplishment. Getting dev cycles down from hours or days to minutes is more important than getting them down from minutes to 25% fewer minutes.
Like if you have logic apps and azure Data pipelines, how do you create and more importantly keep current the local development equivalents for those?
I'm not saying if you are YouTube that all the videos on YouTube must fit on a developer's local machine but would be nice if you could run the whole instance locally or if not, at least be able to reproduce the whole set up on a different environment without six months worth of back and forth emails.
Yeah, the whole top down vs bottom up quandary. Top down is more boring but easier to support at scale. Bottom up is more dynamic but cross cutting changes end up taking inordinate effort.
I’m currently doing my best to make this possible with an app I’m building. I had to convince the CEO the M2 Max would come in handy for this (we run object detection models and stable diffusion). So far it’s working out!
Lots of stuff in this from profiling Go compilations, building a hot-reloader, using AI to analyse the build dataset, etc.
We concluded that it was worth upgrading the M1s to an M3 Pro (the max didn’t make much of a difference in our tests) but the M2s are pretty close to the M3s, so not (for us) worth upgrading.
Happy to answer any questions if people have them.
Thanks for the detailed analysis.
I’m wondering if you factored in the cost of engineering time invested in this analysis, and how that affects the payback time (if at all).
Author here: this probably took a 2.5 days to put together, all in.
The first day was spent hacking together a new hot reloaded but this also fixed a lot of issues we’d had with the previous loader such as restarting into stale code, which was really harming people’s productivity. That was well worth even several days of effort really!
The second day I was just messing around with OpenAI to figure out how I’d do this analysis. We’re right now building an AI assistant for our actual product so you can ask it “how many times did I get paged last year? How many were out-of-hours? Is my incident workload increasing?” Etc and I wanted an excuse to learn the tech so I could better understand that feature. So for me, well worth investing a day to learn.
Then the article itself took about 4hrs to write up. That’s worth it for us given exposure for our brand and the way it benefits us for hiring/etc.
We trust the team to make good use of their team and allowing people to do this type of work if they think it’s valuable is just an example of that. Assuming I have a £1k/day rate (I do not) we’re still only in for £2.5k, so less than a single MacBook to turn this around.
I'm curious how you came to the conclusion the Max SKUs aren't much faster, the distributions in the charts make them look faster but the text below just says they look the same.
Interesting idea, but the quality of data analysis is rather poor IMO and I'm not sure that they are actually learning what they think they are learning. Most importantly, I don't understand why they would see such a dramatic increase of sub 20s build times going from M1 Pro to M2 Pro. The real-world performance delta between the two on code compilation workloads is around 20-25%. It also makes little sense to me that M3 machines have fewer sub-20s builds than M2 machines. Or that M3 Pro with half the cores has more sub-20s builds than M3 Max.
I suspect there might be considerable difference in developer behavior which results in these differences. Such as people with different types of laptops typically working on different things.
And a few random observations after a very cursory reading (I might be missing something):
- Go compiler seems to take little advantage from additional cores
- They are pooling data in ways that makes me fundamentally uncomfortable
- They are not consistent in their comparisons, sometimes they use histograms, sometimes they use binned density plots (with different y axis ranges), it's real unclear what is going on here...
- Macs do not throttle CPU performance on battery. If the builds are really slower on battery (which I am not convinced about btw looking at graphs), it will be because of "low power" setting activated
Oh, yes, you are. The optimising steps, linking and the link-time optimisation (LTO) are very heavily memory bound, especially on large codebases.
The Rust compiler routinely hits the 45-50Gb/sec ballpark of the intra-memory transfer speed on compiling a medium sized project, more if the code base large. Haskell (granted, a fringe yet revealing case) case just as routinely hits the 60-70 Gb/sec memory transfer speed at the compile time, and large to very large C++ codebases add a lot of stress on the memory at the optimisation step. If I am not mistaken, Go is also very memory bound.
Then there comes the linking and particularly the LTO that want all the memory bandwidth they can get to get the job done quickly, and the memory speed becomes a major bottleneck. Loading the entire codebase into memory, in fact, the major optimisation technique used in mold[0] that can vastly benefit from a) faster memory, b) a wider memory bus.
Which hardware were these results obtained on? Are you talking about laptops or large multi-core workstations? I am not at all surprised that linking needs a lot of memory bandwidth (after all, it’s mostly copying), but we are talking about fairly small CPUs (6-8 cores) by modern standards. To fully saturate M3 Pro’s 150GB/s on a multicore workload you’d need to transfer ~8 bytes per cycle/core between L2 and the RAM on average, which is a lot for a compile workload. Maybe you can hit it during data transfer spikes but frankly, I’d be shocked if it turned out that 150GB/s is the compilation bottleneck.
Regarding mold… maybe it can indeed saturate 150GB/s on a 6-core laptop. But they were not using mold. Also, the timing differences we observe here are larger than what would be expected with a linker like mold with a 25% reduction in bandwidth. I mean mold can link clang in under 3 seconds. Reducing bandwidth would increase this by a second at most. We see much larger variation in M2 vs. M3 results here.
I was directly addressing the «saturate» part of the statement, not memory becoming the bottleneck. Since builds are inherently parallel nowadays, saturating the memory bandwidth is very easy since each CPU core runs a scheduled compiler process (in the 1:1 core to process mapping scenario), and all CPU cores suddenly start competing for memory access. This is true for all architectures and designs where memory is shared. The same reasoning does not apply to NUMA architectures but those are nearly entirely non-existant apart from certain fringe cases.
Linking, in fact, whilst benefitting from faster/wider memory is less likely to result in the saturation unless the linker is heavily and efficiently multithreaded. For insance, GNU ld is single threaded, gold is multi-threaded but Ian Taylor has reported very small performance gains from the use of multithreading in gold, and mold takes the full advantage of the concurrent processing. clang's lld is somewhere in between.
In M1/M2/M3 Max/Ultra, the math is a bit different. Each performance core is practically capped at the ~100Gb/sec memory transfer speed. Then the cores are organised into core clusters of n P and m E cores, and each core cluster is capped at the ~240Gb/sec speed. The accumulative memory transfer is ~400Gb/sec (800Gb/sec for the Ultra setup) for the entire SoC, but that is also shared with GPU, ANE and other compute acceleration cores/engines. Since each core cluster has multiple cores, a large parallel compilation process can saturate the memory bandwidth easily.
Code optimisation and type inference in strongly statically typed languages with polymorphic types (Haskell, Rust, ML and others) are very memory intensive, esp. at scale. There are multiple types of optimisation and most of them are of either the constraint solving or NP completeness type, but the code inlining coupled with the inter-procedural optimisations require very large amounts of memory on large codebases, and there are other memory bound optimisation techniques as well. Type inference for polymorphic types in the Hindley–Milner type system is also memory intensive due to having to maintain a large depth (== memory) in order to be able to successfully deduce the type. So it is not entirely unfathomable that «~8 bytes per cycle/core between L2 and the RAM on average» is rather modest for a highly optimising modern compiler.
In fact, I am of the opinion that the inadequate computing hardware coupled with the severe memory bandwidth and capacity constraints was a major technical contributing factor that led to the demise of the Itanium ISA (coupled with less advanced code optimisers of the day).
This is only tangentially related, but I'm curious how other companies typically balance their endpoint management and security software with developer productivity.
The company I work for is now running 5+ background services on their developer laptops, both Mac and Windows. Endpoint management, priviledge escalation interception, TLS interception and inspection, anti-malware, and VPN clients.
This combination heavily impacts performance. You can see these services chewing up CPU and I/O performance while doing anything on the machines, and developers have complained about random lockups and hitches.
I understand security is necessary, especially with the increase in things like ransomware and IP theft, but have other companies found better ways to provide this security without impacting developer productivity as much?
> have other companies found better ways to provide this security without impacting developer productivity as much?
only way i've seen is if things get bad, report it to it/support and tell them what folder/files to exclude from inspection so your build temp files and stuff don't clog and slow up everything
Same here, but IMO, if company believes that such software is useful (and they wouldn't be using it if company believed otherwise), then why do they often (always?) include node_modules in exclusion rules? After all, node_modules usually contains a lot of untrusted code/executables
> People with the M1 laptops are frequently waiting almost 2m for their builds to complete.
I don't see this at all... the peak for all 3 is at right under 20s. The long tail (i.e. infrequently) goes up to 2m, but for all 3. M2 looks slightly better than M1, but it's not clear to me there's an improvement from M2 to M3 at all from this data.
The upshot: M3 Pro is slightly better than M2 and significantly better than M1 Pro is what I've experienced with running local LLMs on my Macs; currently M3 memory bandwidth options are lower than for M2, and that may be hampering the total performance.
Performance per watt and rendering performance are both better in the M3, but I ultimately decided to wait for an M3 Ultra with more memory bandwidth before upgrading my daily driver M1 Max.
This is pretty much aligned with our findings (am the author of this post).
I came away feeling that:
- M1 is a solid baseline
- M2 improves performance by about 60%
- M3 Pro is marginal on the M2, more like 10%
- M3 Max (for our use case) didn’t seem that much different on the M3 Pro, though we had less data on this than other models
I suspect Apple saw the M3 Pro as “maintain performance and improve efficiency” which is consistent with the reduction in P-cores from the M2.
The bit I’m interested about is that you say the M3 Pro is only a bit better than the M2 at LLM work, as I’d assumed there were improvements in the AI processing hardware between the M2 and M3. Not that we tested that, but I would’ve guessed it.
Yeah, agreed. I'll say I do use the M3 Max for Baldur's gate :).
On LLMs, the issue is largely that memory bandwidth: M2 Ultra is 800GB/s, M3 Max is 400GB/s. Inference on larger models are simple math on what's in memory, so the performance is roughly double. Probably perf / watt suffers a little, but when you're trying to chew through 128GB of RAM and do math on all of it, you're generally maxing your thermal budget.
Also, note that it's absolutely incredible how cheap it is to run a model on an M2 Ultra vs an H100 -- Apple's integrated system memory makes a lot possible at much lower price points.
I've been considering buying a Mac specifically for LLMs, and I've come across a lot of info/misinfo on the topic of bandwidth. I see you are talking about M2 bandwidth issues that you read about on linkedin, so I wanted to expand upon that in case there is any confusion on your part or someone else who is following this comment chain.
M2 Ultra at 800 GB/s is for the mac studio only. So it's not quite apples to apples when comparing against the M3 which is currently only offered for macbooks.
M2 Max has bandwidth at 400 GB/s. This is a better comparison to the current M3 macbook line. I believe it tops out at 96GB of memory.
M3 Max has a bandwidth of either 300 GB/s or 400 GB/s depending on the cpu/gpu you choose. There is a lower line cpu/gpu w/ a max memory size of 96GB, this has a bandwidth of 300 GB/s. There is a top of the line cpu/gpu with a max memory size of 128GB, this has the same bandwidth as the previous M2 chip at 400 GB/s.
The different bandwidths depending on the M3 max configuration chosen has led to a lot of confusion on this topic, and some criticism for the complexity of trade offs for the most recent generation of macbook (number of efficiency/performance cores being another source of criticism).
Sorry if this was already clear to you, just thought it might be helpful to you or others reading the thread who have had similar questions :)
Worth noting that when AnandTech did their initial M1 Max review, they never were able to achieve full 400GB/s memory bandwidth saturation, the max they saw when engaging all CPU/GPU cores was 243GB/s - https://www.anandtech.com/show/17024/apple-m1-max-performanc....
I have not seen the equivalent comparisons with M[2-3] Max.
Interesting! There are anecdotal reports here and there on local llama about real world performance, but yeah I'm just reporting what Apple advertises for those devices on their spec sheet
If money is no object, and you don't need a laptop, and you want a suggestion, then I'd say the M2 Ultra / Studio is the way to go. If money is still no object and you need a laptop, M3 with maxed RAM.
I have a 300GB/s M3 and a 400 GB/s M1 with more RAM, and generally the LLM difference is minimal; the extra RAM is helpful though.
If you want to try some stuff out, and don't anticipate running an LLM more than 10 hours a week, lambda labs or together.ai will save you a lot of money. :)
The tech geek in me really wants to get a studio with an M2 ultra just for the cool factor, but yeah I think cost effectiveness wise it makes more sense to rent something in the cloud for now.
Things are moving so quickly with local llms too it's hard to say what the ideal hardware setup will be 6 months from now, so locking into a platform might not be the best idea.
This is the most shocking part of the article for me since the difference between M1 and M2 build times has been more marginal in my experience.
Are you sure the people with M1 and M2 machines were really doing similar work (and builds)? Is there a possibility that the non-random assignment of laptops (employees received M1, M2, or M3 based on when they were hired) is showing up in the results as different cohorts aren’t working on identical problems?
The build events track the files that were changed that triggered the build, along with a load of other stats such as free memory, whether docker was running, etc.
I took a selection of builds that were triggered by the same code module (one that frequently changes to provide enough data) and compared models on just that, finding the same results.
This feels as close as you could get for an apples-to-apples comparison, so I'm quite confident these figures are (within statistical bounds of the dataset) correct!
Side note, I like the casual technical writing style used here, with the main points summarized along the way. Easily digestible and I can go back and get the details in the main text at any point if I want.
If dev machine speed is important, why would you develop on a laptop?
I really like my laptop. Spend a lot of time typing into it. It's limited to a 30W or similar power budget on thermal and battery constraints. Some of that is spent on a network chip which grants access to machines with much higher power and thermal budgets.
Current employer has really scary hardware behind a VPN to run code on. Previous one ran a machine room with lots of servers. Both expected engineer laptops to be mostly thin clients. That seems obviously the right answer to me.
Thus marginally faster dev laptops don't seem very exciting.
> Current employer has really scary hardware behind a VPN to run code on. Previous one ran a machine room with lots of servers. Both expected engineer laptops to be mostly thin clients. That seems obviously the right answer to me.
It's quite expensive to set up, regardless of whether we're talking about on-prem or cloud hardware. Your employer is already going to buy you a laptop; why not try to eke out what's possible from the laptop first?
The typical progression, I would think, is (a) laptop only, (b) compilation times get longer -> invest in a couple build cache servers (e.g. Bazel) to support dozens/hundreds of developers, (c) expand the build cache server installation to provide developer environments as well
This is bad science. You compared the thing you had to the thing you wanted, and found a reason to pick the thing you wanted. Honesty should have compelled you to at least compare against a desktop–class machine, or even a workstation with a Threadripper CPU. Since you know that at least part of your workload is concurrent, and 14 CPUs are better than 10, why not check to see if 16, 32, or 64 is better still? And the linker is memory bound, so it is worth considering not just the quantity of memory but the actual memory bandwidth and latency as well.
Being Mac only can be an advantage - I’ve been on both sides of trying to maintain & use non-trivial dev environments and the more OSes you bring in for people to work on, the harder it gets.
Bringing in Windows or Linux has a set up cost and a maintenance cost that may exclude it from even being considered.
Edit: plus, Macs are ARM, other options are inevitably x86. So it’s also two CPU architectures to maintain support for, on top of OS specific quirks - and even if you use eg Docker, you still have a lot of OS specific quirks in play :/
My biggest issue with Mac-only shops is that almost nobody actually deploys to Mac. The majority of Mac-only firms I've worked at deploy to x86 Linux and develop in a VM on their Macbook (even pre-M1). Unless your business is writing Mac-native apps, MacOS is probably going to be a second-class deployment platform for you.
Even in an ideal scenario where your app already works on ARM, you will be dealing with OS-specific quirks unless your production machine runs MacOS.
These are fair points, and definitely a rough spot.
Eg at work we use M1/M2 macs and dev on those using docker - so that’s a Linux VM essentially with some nice tooling wrapped around it.
We certainly see differences - mostly around permissions (as docker for Mac doesn’t really enforce any access checks on files on the host), but we also mostly deploy to ARM Linux on AWS.
We went Mac only from a mix of Linux, Windows and Mac as we found the least overall friction there for our developers - Windows, even with WSL, had lots of problems, including performance issues. Linux we had issues finding nice laptops, and more support issues (developers are often not *nix experts!). Mac was a nice middle ground in the end.
This is the same issue as before. Laptops are shiny so people don’t even bother considering a regular desktop machine. And yet desktops can be so much more powerful simply because they don’t have the thermal and power delivery restrictions that desktops have.
Laptops have advantages though - for a remote team, they're often a lot more convenient. A lot of people don't have space for a full permanent desk setup for a work desktop on top of their personal use - UK houses aren't huge!
Desktops work if you have an office, but our dev team is entirely remote. But you can't take a desktop into a meeting, or take a desktop on the train to our office for in-person meetings/events.
Those are all bad excuses. And they all have fixes other than compromising on the quality of your computer. Laptops for managers who go to meetings, workstations for engineers who actually accomplish things.
They’re looking at their particular use case. That may limit the applicability of this to other people or companies, but that doesn’t make it politics.
When your CEO decides that your company will only buy Apple laptops, that is definitely a political football. Your CEO likes shiny things, and is willing to purchase the shiniest of them without regard to effectiveness or cost.
I wonder why they didn't include Linux since the project they're building is Go? Most CI tools, I believe, are going to be Linux. Sure, you can explicitly select macOS in Github CI but Linux seems like it would be the better generic option?
*EDIT* I guess if you needed a macOS specific build with Go you would us macOS but I would have thought you'd use Linux too. Can you build a Go project in Linux and have it run on macOS? I suppose architecture would be an issue building on Linux x86 would not run on macOS Apple Silicon but the reverse is true too a build on Apple Silicon would not work on Linux x86 maybe not even Linux Arm.
I know nothing about Go, but if it's like other platforms, builds intended for production or staging environments are indeed nearly always for x86_64, but those are done somewhere besides laptops, as part of the CI process. The builds done on the laptops are to run each developer's local instance of their server-side application and its front-end components, That instance is always being updated to whatever is in-progress at the time. Then they check that code in, and eventually it gets built for prod on an Intel, Linux system elsewhere.
Cross compilation is probably easiest in Go. If I recall you can just give it a different arch parameter and it will produce a working build for any supported platform.
Last month I upgraded from an M1 Pro to an M3 Pro - 16GB RAM, 512 GB. Here is an honest review of my experience. The chassis of both the machines are exactly the same. The bad thing about that is the newer MacBooks come with a matte finish for the keyboard and the finish wears off like in just 3 weeks even with proper care. As a matter of fact, in the newer machine, I used ISP 70% with water to wipe it off after each use thinking it was due to grease/oil from the fingers. However the finish still wore off, suggesting that it has more to do with the finish itself.
With that out of the way, I maintain a very large site with over 50,000 posts in a static site setup. It is built on a Phoenix/Elixir setup I wrote from scratch and has been serving my client well without hiccups for the last 5 years. From time to time, some of the writers may mess up something and they would want us to run a sweep occasionally - back track to the last X number of posts and re-publish them. Usually about 100-500 posts which covers a few weeks/months worth of posts depending on the run.
So, for a 100 post sweep, the M3 pro was slightly faster, by an order of magnitude of over 1.5x. But, for other everyday tasks, like say opening Affinity Designer/Photo and editing files, I didn't notice much improvements. And Apple's website is notoriously deceptive about the improvements. Their graphs always showcase comparisons with a top specc'ed M3 machine with a base M1 variant or M2 which makes no sense to me as a developer. Disk (SSD) speeds were slightly slower on the M3 than on my old M1 variant. But, I am unable to attribute it to the processor as it could be a bad driver or software version. For those interested, it is one of those internal Samsung SSDs connected via a SATA-USBC converter.
Long story short, if you are on M2 - Not worth upgrading. If you are on an M1 or M1 Pro, you can still hold on to it a bit longer, the only reason you would want to upgrade is if you got a good deal like me. I sold my 21' M1 Pro for almost $1800 US (it still had Apple care) and got a student discount (I'm in the middle of some certification programs) on the new M3 Pro, so I got it. If I didn't have these financial incentives, probably wouldn't have been worth upgrading. Hope this helps someone.
Honestly, I found the analysis a little difficult to read. Some of the histograms weren't normalized which made the comparison a bit difficult.
One thing that really stood out to me was:
> People with the M1 laptops are frequently waiting almost 2m for their builds to complete.
And yet looking at the graph, 120s is off the scale on the right side, so that suggests almost literally no one is waiting 2m for a build, and most builds are happening within 40s with a long tail out to 1m50s.
Fun read, I like how overkill it is. When I was still employed, I was building our django/postgres thing locally in Docker, with 32gb of ram, and it was a wild improvement in terms of feedback loop latency over my shitty 13" intel mbp, and I think it's seriously underappreciated how important it is to keep that pretty low, or as low as is cost effective. Now that I'm not employed and don't hope to be for a while, I do think the greatest bottleneck in my overall productivity is my own discipline since I'm not compiling anything huge or using Docker. The few times I do really notice how slow it is, it's in big I/O or ram operations like indexing, or maybe the occasional xcode build, but it's still low in absolute terms and the lack of some stressful deadline doesn't have me worrying so much about it. That makes me happy in some ways, because I used to feel like I could just throw new hardware at my overall productivity and solve any issues, but I think that's true only for things that are extremely computationally expensive. Normally, I'd just spend the cash, even as a contractor, because it's investment in my tools and that's good, but the up-charge for ram and ssd is so ludicrously high that I have no idea when that upgrade will come, and the refurb older models of M1 and M2 just aren't that much lower. My battery life also sucks, but it's not $5k sucky yet. Also worth joting I'm just a measly frontend developer, but there have been scenarios in which I've been doing frontend inside either a big Docker container or a massive Tomcat java app, and for those I'd probably just go for it.
I don't know where in the world you are, but B&H in US still sells new 16" M1 Max machines with 64GB memory, 2TB SSD for 2499-2599 depending on the current deal. This is around the price of base M3 Pro with 18/512 configuration, I figure you'll still get 5+ years of use with such machine and never worry about storage or memory.
Good point, although it would feel odd to spend what would amount to about $3500 after tax in CAD on a 3 y.o laptop, albeit a new 3 y.o laptop. For now I'll just stick it out with my Intel thing, since that $3500 is a more expensive $3500 than ever anyway, until my requirements get more demanding.
Does anyone have any anecdoctal evidence around the snappiness of VsCode with Apple Silicon? I very begrudgingly switched over from SublimeText this year (after using it as my daily driver for ~10yrs). I have a beefy 2018 MBP but VScode just drags. This is the only thing pushing me to upgrade my machine right now but I'd be bummed if there's still not a significant improvement with an m3 pro.
If you're using an Intel Mac at this point, you should 100% upgrade. The performance of the MX chips blows away the Intel chips and there's almost no friction with the arm architecture at this point.
I don't use VSCode but most of my team do and I frequently pair with them. Never noticed it to be anything other than very snappy. They all have M1s or up (I am the author of this post, so the detail about their hardware is in the link).
I work on a team that does BYO devices. Some have arm/mac, but most are on amd64/other. This forced us to make our development environment cross arch, even though our production environment is amd64/Linux only.
Some challenges included Docker images being arch specific, old Terraform modules lacking ARM support (forcing an upgrade we'd otherwise defer), and reduction in tooling we'd consider for production. We generally worry about arch specific bugs, although I don't believe we've seen any (other than complete failure to run certain tools).
Kind of a edge case, but we were attempting to migrate from Docker to Podman, and found running x86 container images in Podman Desktop on M-series Macs to be unacceptably slow. Docker Desktop supports Rosetta 2 virtualization which performs fine, but Podman Desktop does not.
I have 2x intel macbook pro's that are honestly paperweights. Apple Silicon is infinitely faster.
It's a bummer because one of them is also a 2018 fully loaded and I would have a hard time even selling it to someone because of how much better the M2/M3 is. It's wild when I see people building hackintoshes on like a Thinkpad T480 ... its like riding a pennyfarthing bicycle versus a ducati.
My M2 Air is my favorite laptop of all time. Keyboard is finally back to being epic (esp compared to 2018 era, which I had to replace myself and that was NOT fun). It has no fan so it never makes noise. I rarely plug it in for AC power. I can hack almost all day on it (using remote SSH vscode to my beefy workstation) without plugging in. The other night I worked for 4 hours straight refactoring a ton of vue components and it went from 100% battery to 91% battery.
I have a rack in my basement with a combined 96 cores and 192gb of ram (proxmox cluster), and a 13900k/64gb desktop workstation for most dev work. I usually will offload workloads to those before leveraging one of these old laptops that is usually dead battery. If I need something for "browser tasks" (I am interpreting this as cross-browser testing?) I have dedicated VMs for that. For just browsing the web, my M2 is still king as it has zero fan, makes no noise, and will last for days without charging if you are just browsing the web or writing documentation.
I would rather have a ton of beefy compute that is remotely accessible and one single lightweight super portable laptop, personally.
I should probably donate these mac laptops to someone who is less fortunate. I would love to do that, actually.
Indeed. I keep around a 2015 MBP with 16GB (asked my old job's IT if I could just keep it when I left since it had already been replaced and wouldn't ever be redeployed) to supplement my Mac Mini which is my personal main computer. I sometimes use screen sharing, but mostly when I use the 2015 it's just a web browsing task. With adblocking enabled, it's 100% up to the task even with a bunch of tabs.
Given probably 80% of people probably use webapps for nearly everything, there's a huge amount of life left in a late-stage Intel Mac for people who will never engage in the types of tasks I used to find sluggish on my 2015 (very large Excel sheet calculations and various kinds of frontend code transpilation). Heck, even that stuff ran amazingly better on my 16" 2019 Intel MBP, so I'd assume for web browsing your old Macs will be amazing for someone in need, assuming they don't have bad keyboards.
My 2018 has a brand new keyboard and battery that I replaced myself. It's certainly still a good computer all things considered... but for a software developer, someone with means to afford a more modern box, I would def go Apple Silicon.
My 2015 Retina is running Arch linux as an experiment. That was kinda fun. I used it as a main dev rig for a few weeks years ago when the 2018 battery finally kicked the bucket.
I went the complete opposite of you. I enjoy being able run everything on my laptop, be it at home, at a cafe, at work or on the train. So I’ve maxed out a MacBook Pro instead. It doesn’t have 96 cores, but it’ll go head to head with your dev workstation and even let me play around with LLMs locally. Fans as usually silent, except when using the GPU for LLMs.
One thing that I could do with your rig though would be to start benchmarks to check for performance regressions, and then just put my laptop in my backpack.
Tailscale helps here. I run all my stuff remotely and just reconnect my shell with tmux, and vscode reconnects automatically. The only area this hurts is on an airplane. I was in Germany recently and still developed remotely using my workstation as the compute. It was super quick with no discernible latency. My laptop is essentially a dumb terminal. It could get stolen or run over by a truck and I’d be back in business after installing tmux and Tailscale.
I’ve replayed this pattern with other targets, too. For instance a system I maintain relies on a whitelisted IP in our VPC to interact with certain API’s at a vendor. I could proxy to that node and use that IP, but I’ve found it much easier to hack on that project (running on a dedicated EC2 node) by just vscode attaching there, using it live, and committing the changes from the end server running the system.
Being able to kill my laptop and know everything is still running remotely is nice. I rely on tmux heavily.
I don’t do much development but I have a fast Apple Silicon laptop in my office for mostly multimedia editing and some local LLM—though that’s also where I do development when I do. An old iMac in my office for video calls and a lot of web app work and and old MacBook in my kitchen for looking up stuff and when I want a change of scenery for web app work.
> It's a bummer because one of them is also a 2018 fully loaded and I would have a hard time even selling it to someone
I'd happily fix that for you if you want. I'd even pay shipping to take it off your hands. Anything would be an upgrade for my mom's old toshiba laptop ;) email in profile
If you find your compiles are slow, I found a bug in vscode where builds would compile significantly faster when the status bar and panel are hidden. Compiles that took 20s would take 4s with those panels hidden.
The 2018 macbook pros weren't even using the best silicon of the time - they were in the middle of Intel's "14nm skylake again" period, and an AMD GPU from 2016.
I suspect one of the reasons why Apple silicon looks so good is the previous generations were at a dip of performance. Maybe they took the foot off the gas WRT updates as they knew the M series of chips was coming soon?
I do regularly try VSCode to see what I’m missing.
VS Code has great remote editing that I do use.
However, on my M1 Pro 16”, VS Code is noticeable laggier than sublime Text!
Just clicking on a file in the side bar and waiting for text to appear has lag. Many non-nerdy people might think it’s instant, but I can see the lag clearly! LOL
For my tastes the VS Code UI is cluttered and generally feels slow. The extensions are great but also a nightmare of updates and alerts of things broken.
If it’s your thing, you can use CoPilot in Sublime Text through a plugin that actually works really well!
I’m on the fence about CoPilots benefits though.
Sometimes I’ll flick over to VS Code to use the chat copilot if I need an answer for an API call etc….
If I had to stick with one, I’m sticking with Sublime Text.
On my 2019 MBP, I found VSCode performance poor enough to be annoying on a regular basis, enough so that I would frequently defer restarting it or my machine to avoid the lengthy interruption. Doing basically anything significant would have the fans running full blast pretty much constantly.
On my M2 Max, all of that is ~fully resolved. There is still some slight lag, and I have to figure it’s just the Electron tax, but never enough to really bother me, certainly not enough to defer restarting anything. And I can count the times I’ve even heard the fans on one hand… and even so, never for more than a few seconds (though each time has been a little alarming, just because it’s now so rare).
It depends on what specifically you find slow about VSCode. In my experience, some aspects of VSCode feel less responsive than Sublime simply due to intentional design choices. For example, VSCode's goto files and project symbol search is definitely not as snappy as Sublime's. But this difference is due to VSCode's choice to use debouncing (search is triggered after typing has stopped) as opposed to throttling (restricts function execution to a set time interval).
I've got a 12700k desktop with windows and an M1 macbook (not pro!) and my pandas notebooks run noticeably faster on the mac unless I'm able to max out all cores on the Intel chip (this is after, ahem, fixing the idiotic scheduler which would put the background python on E-cores.)
I couldn't believe it.
Absolutely get an apple silicon machine, no contest the best hardware on the market right now.
I get a bit of a toxic vibe from a couple comments in that article.
Chiefly, I think the problem is that the CTO solved the wrong problem: the right problem to solve includes a combination of assessing why company public opinion is generating mass movements of people wanting a new MacBook literally every year, if this is even worth responding to at all (it isn't), and keeping employees happy.
Most employees are reasonsble enough to not be bothered if they don't get a new MacBook every year.
Employers should already be addressing outdated equipment concerns.
Wasting developer time on a problem that is easily solvable in one minute isn't worthwhile. You upgrade the people 2-3 real generations behind. That should already have been in the pipeline, resources notwhistanding.
I just dislike this whole exercise because it feels like a perfect storm of technocratic performativity, short sighted "metric" based management, rash consumerism, etc.
If it’s useful: Pete wasn’t really being combative with me on this. I suggested we should check if the M3 really was faster so we could upgrade if it was, we agreed and then I did the analysis. The game aspect of this was more for a bit of fun in the article than how things actually work.
And in terms of why we didn’t have a process for this: the company itself is about two years old, so this was the first hardware refresh we’d ever needed to schedule. So we haven’t a formal process in place yet and probably won’t until the next one either!
Hah, yes. There's a balancing act, and investing in tools is important.
I also worked at a company whose CIO put out an email noting how "amazing" a coincidence it was just how many company iPhones got broken/water damaged/lost or stolen in the 2 months following a new iPhone announcement event.
> Most employees are reasonsble enough to not be bothered if they don't get a new MacBook every year.
If you compare a jump between Intel and M1 and then numbers for newer generation I think they validate the desire to have a newer machine. It's not about having a new shiny object, but a tool that improves work. You only have one life and those seconds and minutes wasted on waiting on things add up.
This is especially important for neurodivergent people, with conditions like ADD. Even waiting few seconds less for something to finish can have an impact - it may get the result just before one completely moved their train on thought on different tracks.
I wouldn't like to work for an employer with such a patronising and nonchalant view of equipment.
Your comment is actually toxic.
I feel like there is a correlation between fast-twitch programming muscles and technical debt. Some coding styles that are rewarded by fast compile times can be more akin to "throw it at the wall, see if it sticks" style development. Have you ever been summoned to help a junior colleague who is having a problem, and you immediately see some grievous errors, errors that give you pause. You point the first couple out, and the young buck is ready to send you away and confidently forge ahead, with no sense of "those errors hint that this thing is really broken".
but we were all young once, I remember thinking the only thing holding me back was 4.77MHz
There's a lot of value in a short iteration loop when debugging unexpected behavior. Often you end up needing to keep trying different variations until you understand what's going on.
Yeah there’s a large body of research that shows faster feedback cycles help developers be more productive.
There’s nothing that says you can’t have fast feedback loops _and_ think carefully about your code and next debugging loop, but you frequently need to run and observe code to understand the next step.
In those cases even the best programmer can’t overcome a much slower build.
> I feel like there is a correlation between fast-twitch programming muscles and technical debt.
Being fast doesn't mean you do everything at maximum speed. Usain Bolt doesn't sprint everywhere he goes, but he can sprint quite fast when he needs to do so.
I didn't say faster build times weren't faster. I said people whose entire focus is on speed will speed-read the cliff notes instead of fully reading the original Shakespeare. There's a difference.
Since RAM was a major metric, there should have been more focus on IO Wait to catch cases where OSX was being hindered by swapping to disk. (Yes, the drives are fast but you don’t know until you measure)
This. I’ve routinely got a 10-15GB page file on an M2 pro and need to justify bumping the memory up a notch or two. I’m consistently in the yellow memory and in the red while building.
How can I tell how much I would benefit from a memory bump?
My main metrics are 1) does the fan turn on, 2) does it respond faster than I think and move?
Can't be any happier with the M2 at top end specs. It's an amazing silent beast.
2,356 € is way over my budget. The machine is amazing but the specs are stingy. Returning it and getting a cheaper one would give me a lot of disposable money to spend in restaurants
Get a 10-core M1 Pro then - I got mine for about 1200 eur used (basically undistinguishable from new), and the difference (except GPU) is very small.
https://news.ycombinator.com/item?id=38810228
Not really in a laptop though—and certainly not with the same efficiency (battery life, fan noise, weight). If you want a laptop, the MacBooks are pretty indisputably king these days.
If a desktop is fine then yes you can build some great Windows rigs for much less money.
Actually it seems at this time you're more or less right. In the past there was quite a spread between a beefy thinkpad and a mac. Looks like rightnow you can get comparable thinkpad vs MBP14 (with various specs) within $200 of eachother, which means you're really choosing between nuanced and highly personal preference differences. (such as appearance, OS, keyboard feel etc).
Beyond those superficial differences you mention though, the MacBook Pro is probably lighter than the beefy ThinkPad you’re imagining. It’s undoubtedly quieter—you’ll rarely hear the MacBook’s fans even under heavy load. The screen of the MacBook is high refresh rate and likely higher quality than the ThinkPad. The MacBook speakers are astoundingly best in class. And the MacBook likely gets better battery life to boot.
And here’s another kicker—all those “comparable” Wintel laptops viciously throttle their performance the second you unplug them from the wall. Not the MacBooks. They keep being just as performant on battery as they do plugged in, while still delivering that excellent battery life. It’s remarkable.
I really can’t in good conscience recommend anything but a MacBook to a prospective laptop buyer right now, unless the user requires specific software that only runs on Windows. Save a couple hundred bucks only to end up with a vastly inferior machine? It just doesn’t make sense.
Maybe before buying M3 MacBook for everyone you should consider splitting your 1M line code base to avoid recompiling the whole thing for every change..
I don't know well the go ecosystem at all but it seems to me you should really consider optimizing your code base for compilation speed before creating fancy build time chart per cpu with AI and buying hundreds of super powerfull and expensive machines to compile it a bit faster...
We do frequently adjust the codebase to improve build times, but the developer productivity hit we’d take by splitting our app into several microservices would be much more substantial than much slower build times than we currently see.
We’re super happy with 30s as an average build time right now. Assume we spent about £50k for the entire teams laptops, how much time would an engineer need to break our monolith into microservices? How much extra investment would we need to make it work as well as our monolith, or debug production issues that are now much more complex?
I’d wager it’s much more than half an engineers time continually, at which point you’ve blown the money you saved on a solution that works far less well for dev productivity and debugging simplicity in production.
Maybe you could split the code base without going full micro service. Keep the monolith base, and split some parts in independent module/libraries that won't be rebuild every time, something like that.
I wish I needed a fast computer. It’s the CI/CD that’s killing me.
All this cloud stuff we use - can’t test anything locally anymore. Can’t use the debugger. I’m back to glorified fmt.Printf statements that hopefully have enough context that the 40 min build/deploy time was worth it. At least it’s differential ¯\_(ツ)_/¯ All I can say is “I compiles… I think?” The unit tests are mostly worthless and the setup for sending something to a lambda feels like JCL boiler plate masturbation from that z/OS course I took out of curiosity last year.
I only typing this out because I just restarted CI/CD to redeploy what I already pushed because even that’s janky. Huh, it’s an M3 they gave me.
Yeah everything you just said is exactly why we care so much about a great local environment. I've not seen remote tools approach the speed/ease/flexibility you can get from a fast local machine yet, and it makes a huge difference when developing.
there is a perpetual ESG argument that always wins, older computers which are slower use more energy than the new one thats fast. older computers that were top of the line use waaay more energy than the new one that’s fast.
My problem with this analysis is ignoring the fact of who is using which computer. So far new people in the company get the M3, while old people have M2, and the people who has been the longest time in the company have an M1. Who is going to work on more critical tasks with more changes in the code? who is going to work mostly in easy bugs until they get some experience with the code in the company? I bet you if you give both populations the same computer the compiling times are going to be faster for the new people. For me the analysis doesn't have enough dimensions, it should take into account the time since the person was hired in the company and the seniority. I would also have added more type of graphs (boxplots seems a better way to compare the information), and also I would have measure the total % of CPU usage. The battery/AC analysis gave me the impression that M3 might be underutilized and that it is going to be impossible to get lower compiling times without faster single core speeds (which might be a relevant information for the future).
I ditched my desktop once "plug in a single USB-C cable and get dual 4k monitors + peripherals all ready to go" became a thing. I love the flexibility of a laptop combined with a dedicated workstation setup.
It matters in the sense that my 2015 Macbook Pro required multiple cables to unplug/replug in at my desk which seems like a small thing but significantly reduced the convenience factor for me.
Plus I can now dock either my Lenovo or my MacBook with the same multi-monitor dock making it even more versatile. I don't game or do anything more intensive than web development so I recognize it wouldn't work as well for everyone.
How does the build time average time being around 400 (seconds?) for M1 and M2 and around 200 for M3 make the M2 a substantial upgrade over M1 but M3 "an incremental improvement on M2"?
Also would it hurt the author if they had kept the same max y-value on all plots?
To play devil’s advocate: did you see any improvement in ticket velocity, features shipped, bugs dispatched, prod events resolved - i.e. is this improvement in productivity measurable by what you judge the business by, or does it just feel better and make devs happy?
The machines haven’t arrived yet but I wouldn’t expect we’d have the data to prove this out. As you’ll know, number of tickets complete is a weak proxy for value delivered, and can be so wrong as to imply a team that you know is 2x as productive is half as much as another, or worse.
The best way (imo) to measure this is setting a threshold that we agree is bad (in our case, this is 1m+ builds) and continually measuring it so we catch when that starts to happen more frequently. And listening to devs when they say things have got slow/have become irritating.
It's interesting to me that being on A/C and Battery power showed a performance difference: when I benchmarked a M1 Pro MBPro against an Intel 2015 MBPro two years ago, I didn't notice any performance differences between being on battery or using mains power in either laptop, which surprised me at the time:
My M2 defaults to using a "low power mode" when on battery, which I noticed initially because some graphics code I was writing was getting significantly lower frame rates when on battery.
Network full builds might be faster, but would incremental builds be? Would developers still be able to use their favourite IDE and OS? Would developers be able to work without waiting in a queue? Would developers be able to work offline?
If you have a massive, monolithic, single-executable-producing codebase that can't be built on a developer machine, then you need network builds. But if you aren't Google, building on laptops gives developers better experience, even if it's slower.
I just upgraded to the top M3 Max CPU from the top M2 Max CPU.
I benchmarked several test suites to compare the machines. The test suites for two different Rails applications were around 10% faster on the M3 Max. A test suite for a Go web application that does significant integration testing in parallel (i.e. multiple complete stacks of database, application server, and browser) improved by around 20%. The extra P-cores help. Miscellaneous other tests and benchmarks were around 7-10% faster.
Didn't notice any difference in normal usage.
So not likely worth the upgrade unless your workload can really make use of the extra cores.
They’re normalised histograms so the y axis is deliberately adjusted so you can compare the shape of the distribution, as the absolute number of builds in each bucket means little when there are a different count of builds for each platform.
1. If, and only if, you are doing ML or multimedia, get a 128GB system and because of the cost of that RAM, it would be foolish not to go M3 Max SoC (notwithstanding the 192GB M2 Ultra SoC). Full Stop. (Note: This is also a good option for people with more money than brains.)
2. If you are doing traditional heavyweight software development, or are concerned with perception in an interview, promotional context or just impressing others at a coffee shop, get a 32GB 16” MBP system with as large a built-in SSD as you can afford (it gets cheaper per GB as you buy more) and go for an M2 Pro SoC, which is faster in many respects than an M3 Pro due to core count and memory bandwidth. Full Stop. (You could instead go 64GB on an M1 Max if you keep several VMs open, which isn’t really a thing anymore (use VPS), or if you are keeping a 7-15B parameter LLM open (locally) for some reason, but again, if you are doing much with local LLMs, as opposed to being always connectable to the 1.3T+ parameter hosted ChatGPT, then you should have stopped at #1.)
3. If you are nursing mature apps along, maybe even adding ML, adjusting UX, creating forks to test new features, etc.. then your concern is with INCREMENTAL COMPILATION and the much bigger systems like M3 Max will be slower (bc they need time to ramp up multiple cores and that’s not happening with bursty incremental builds), so might as well go for a 16GB M1 MBA (add stickers or whatever if you’re ashamed of looking like a school kid) and maybe invest the savings in a nice monitor like the 28” LG DualUp (bearing in mind you can only use a single native-speed external monitor on non-Pro/Max SoCs at a time). (In many cases, can even use an 8GB M1 MBA for incremental builds because, after loading the project, the MacOS memory compressor is really good and the SSD is really fast and you can use a real device instead of a Simulator. But do you want any M2 MBA? No, it has inferior thermals, is heavier, larger, fingerprints easy, lack’s respect and the price performance doesn’t make sense given the other options. Same goes for 13” M1/M2 Pro and all M3 Pro.)
Also, make sure you keep hourly (or better) backups on all Apple laptops WHILE CODING. There is a common failure scenario where the buck converter that drops voltage for the SSD fails, sending 13VDC into the SSD for long enough to permanently destroy the data on it.
https://youtu.be/F6d58HIe01A
> You can even get by with the 8GB M1 MBA because the MacOS memory compressor is really good and the SSD is really fast.
I thought that general consensus was that 8GB Macs were hammering the life of the SSDs? Yeah, they're fast, but people were talking about dozens of GB a day of swapping happening. And these aren't enterprise class SSDs, despite what Apple charges for them.
..seems to be enabled by Apple's new MLX framework (which could become even faster https://github.com/ml-explore/mlx/issues/18 --ANE support would be particularly important on a lowly M1, which is the main system that would have been configured with only 8GB)
Opening Xcode and a small to medium project targeting a physical device with its own RAM will be fine..no SSD killing. If you are not doing INCREMENTAL builds or start flipping between apps, web tabs, streaming video and messaging while also Xcoding, the amazing thing is that it will work, but as you say, it will likely be hammering the SSD. I wouldn’t really recommend a dev buy 8GB if they can afford 16GB, but I wouldn’t really let them use only having 8GB as an excuse not to be able to make small to medium apps either, they just have to be more intelligent about managing the machine. (Xcode is I/O bound anyway.)
Sure, it operates on an over allocation pattern. If you try to use most of the RAM, the system will begin compressing blocks of memory and will eventually begin swapping them to super fast NVMe storage. This may be fine for desktop productivity apps and web browsing, but will make the system feel sluggish when flipping between unrelated contexts.
> and the much bigger systems like M3 Max will be slower (bc they need time to ramp up multiple cores and that’s not happening with bursty incremental builds)
Is there some microbenchmark that illustrates the problem, or is this just wild extrapolation from some deep misunderstanding (maybe a bad car analogy about turbo lag?)
Hmm..at least you reasoned that it is a "problem" (and I would say it's more analogous to VLOM switchover than turbo lag ROFL).
For now, if you infrequently do full builds (and instead do incremental builds) and are mainly dragging things around, adding small features, etc. you're better off with less cores, even if those cores do run slower.
I don't really want Apple to "care deeply" us [slowing our phones], so I'mma not help illustrate further because a proper solution could involve a massive Engineering task (maybe Nuvia knows) and even with $3T market cap, they pretty much cheap bastards unless it comes to food courts and office chairs.
Ok, so I'm pretty much convinced now that you're full of shit. I asked for information to understand what the hell you're talking about, and you just went further off the rails. Please don't behave like that here.
A freelancer might be interviewed by a client in Entertainment, Hospitality, Construction, Real Estate or Academia and if they show up with a pimped MBA, all their prospect is going to see is that this person asking for a chunk of cash is using the same ‘puter as their kid, so they lose pricing power or maybe the whole gig. Likewise, a dev might go for an interview with a bunch of Pentium heads who think you need a Razor laptop with RGB keys to be legit and they’re going to want to see at least a 16” form-factor as table stakes. There is some variation between those extremes for devs trapped in a corporate setting, but none of it based in reality, the perception is the reality.
Bottom line: M1-MBA16 (or M1-MBA8) for incremental builds, 16” M2P-MBP32 (or M1M-MBP64) for full development or 16” M3M-MBP128 (or M2U-MS192) for AI/media dev ..the other models aren’t really for devs.
Hahah good question: 2.5 days all in, including building the new hot-reloader which fixed a number of outstanding bugs.
- 1 day for hot-reload (I don’t think this should count tbh)
- 1 day for messing with data
- 0.5 day for write-up
Assuming my day rate is £1k/day (it is not) we land at £1.5k, less than a laptop and less than I’d pay for the impressions I got from my post sharing this on LinkedIn, so feels worthwhile!
It's pretty cool how it works, too: the OpenAI Assistant uses the LLM to take your human instructions like "how many builds is in the dataset?" and translate that into Python code which is run in a sandbox on OpenAI compute with access to the dataset you've uploaded.
Under the hood everything is just numpy, pandas and gnuplot, you're just using a human interface to a Python interpreter.
We've been building an AI feature into our product recently that behaves like this and it's crazy how good it can get. I've done a lot of data analysis in my past and using these tools blew me away, it's so much easier to jump into complex analysis without tedious setup.
And a tip I figured out halfway through: if you want to, you can ask the chat for an iPython notebook of it's calculations. So you can 'disable autopilot' and jump into manual if you ever want finer control over the analysis it runs. Pretty wild.
I also got surprised about using it for this kind of work. I don't have access to copilot and gpt-4 at work but my first instinct is to ask, did you double check its numbers?
Knowing how it works now makes more sense that it would make less mistakes but I'm still skeptical :P
Lots of interesting data, but for me, clear examples of why histograms are not particularly useful for comparing performance. Box plots would have been much more informative, particularly for comparisons of M2/M3 and memory effects, where the histograms look a little different, but it is unclear how different.
To me, that is just another Data Set to prove how most of the MacBook are used in tech industry. And their upgrade cycle. 37 Million Registered Developers ( Many Overlap ). And many Devs using it for Web development. It seems Apple could have 40M of software developers using their platform. Out of ~125M active Mac users.
M1 is such a big difference. I bought mine two years ago and it still feels like and performs like new.
Never had even remotely similar experience to Intel laptops.
I am hoping that companies that are getting rid of their M1 stock, put them on a second hand market rather than through disposal service (where they get physically destroyed).
Companies spend billions of dollars building BI tools that can do analysis against a data warehouse and they just... exported a CSV and asked ChatGPT to analyze it. One of the biggest shifts you can imagine in terms of the value of pre-AI and post worlds.
Great write up. Would personally be interested to see something similar for TypeScript/Vite as that's what I personally use (less likely to actually improve with beefier machine).
Am OP: the Docker for Mac daemon can claim a lot of system resources and the FS can have a lot of latency.
This means devs have less system memory available for their host because it’s in the VM, battery is often harmed because the VM box is constantly churning, and as we run our Postgres database in docker the FS latency makes for a noticeably slower dev environment.
Docker is great for standardising the dev env but honestly, running Postgres locally isn’t hard, and we don’t have many other deps. If the quality of experience is better at the cost of the occasional “let me help you out with this pg_upgrade” then I’d consider that a win.
For new laptops this might hold, but for early upgrades you need to also calculate in the overhead of setting up the new laptops. This could be substantial depending on how it’s done.
I’m not sure this would work well for our use case.
The distributed build systems only really benefit from aggressively caching the modules that are built, right? But the majority of the builds we do are almost fully cached, having changed just one module that needs recompiling then the linker sticks everything back together, which the machines would then need to download from the distributed builder and at 300MB a binary that’s gonna take a while.
I may have this totally wrong though. Would distributed builds actually get us a new binary faster to the local machine?
I suspect we wouldn’t want this anyway (lots of our company work on the go, train WiFi wouldn’t cut it for this!) but interested nonetheless.
Sooooo... C? You didn't answer the question and I would be surprised to hear that freaking Java had support for distributed compilation, and that has been around since the 90s.
Take your pretentious non-answers elsewhere please.
If you want a GCP instance that is comparable to an M3 Pro 36GB, you're looking at an n2-standard-8 with a 1TB SSD, which comes out at $400/month.
Assuming you have it running just 8 hours a day (if your developers clock in at exact times) and you can 1/3 that to make it $133/month, or $1600/year.
We expect these MacBooks to have at least a 2 year life, which means you're comparing the cost of the MacBook to 2 years of running the VM for 8 hours a day, which means $2800 vs $3200, so the MacBook still comes in $400 cheaper over it's lifetime.
And the kicker is you still need to buy people laptops so they can connect to the build machine, and you can no longer work if you have bad internet connection. So for us the trade-off doesn't work whichever way you cut it.
1. With a savings plan or on-demand?
2. Keeping one instance on per developer indefinitely, or only when needed?
3. Shared nodes? Node pools?
4. Compared to what other instance types/sizes?
5. Spot pricing?
Shared nodes brought up on-demand with a savings plan and spot pricing is the same cost if not cheaper than dedicated high-end laptops. And on top of that, they can actually scale their resources much higher than a laptop can, and do distributed compute/test/etc, and match production. And with a remote dev environment, you can easily fix issues with onboarding where different people end up with different setups, miss steps, need their tooling re-installed or to match versions, etc.
1. That was assuming 8 hours of regular usage a day that has GCP's sustained use discounts applied, though not the committed usage discounts you can negotiate (but this is hard if you don't want 24/7 usage).
2. The issue with only-when-needed is the cold-start time starts hurting you in ways we're trying to pay to avoid (we want <30s feedback loops if possible) as would putting several developers on the same machine.
3. Shared as in cloud multi-tenant? Sure, we wouldn't be buying the exclusive rack for this.
4. n2-standard-8 felt comparable.
5. Not considered.
If it's interesting, we run a build machine for when developers push their code into a PR and we build a binary/container as a deployable artifact. We have one machine running a c3-highcpu-22 which is 22 CPUs and 44GB memory.
Even at the lower frequency of pushes to master the build latency spikes a lot on this machine when developers push separate builds simultaneously, so I'd expect we'd need a fair bit more capacity in a distributed build system to make the local builds (probably 5-10x as frequent) behave nicely.
At one of my former jobs, some members of our dev team (myself included) had manager-spec laptops. They were just good enough to develop and run the product on, but fairly anemic overall.
While I had no power over changing the laptops, I was co-administrator of the dev datacenter located 20 meters away and we had our own budget for it. Long story short, that dev datacenter soon had a new, very beefy server dedicated for CI jobs "and extras".
One of said extras was providing Docker containers to the team for running the product during development, which also happened to be perfectly suitable for remote development.
Apple Silicon devices can get the same performance as a desktop in a laptop size. The only reason to get a desktop is if you need the Ultra chip.
And, the laptop gives you extra freedom for very, very little sacrifice (at least for Apple Silicon devices). I don't see any way you can argue for a desktop.
I have the first generation of the M1 (M1 Max) and this is the first Apple laptop I own that doesn't seem to hit any thermal or power limit. I do use an app to spin the fans faster when doing something like encoding a blu-ray movie with HandBrake, but it keeps going for hours without any noticeable drop in performance.
If you look at stress tests from a M1 on a Macbook Pro and a M1 on a Mac desktop, performance is similar. There might be a difference on sustained performance on the M1 Air, but that's because it doesn't have any fans.
Nothing. GP is making an assumption that all people need the same kind of hardware for the same kind of work as they do. None of my work touches on ML or heavy data processing (in the numeric sense), so hardware like that is useless to me and my coworkers. A beefier workstation is still useful (more cores, more RAM), but recent-ish laptops (post 2020 definitely, tail-end of the 2010s is still fine) provide more than enough horsepower.
Perhaps many people building code do not need multiple 16x PCI-Express cards in their day to day workflow, but like being able to move around with their laptop?
For lots of workloads it is basically true, though. Not something exclusive to Apple laptops of course, others have also been capable programming workhorses for quite some years. It's just weird to say that no compiling should be done on a laptop - that might've been true 10 years ago.
Great if your company allows it, but the “working vacation” thing has been either discourage or disallowed at every remote job I’ve had due to past abuse.
Some jobs can handle truly asynchronous work and some people can be responsible about getting their work done away from home, but for every 1 employee who was pulling it off well we had 3-5 more who were just writing short responses in Slack and to emails to pretend they weren’t actually on vacation. Ruined it quickly for everyone.
Lately I try to look for jobs at smaller companies where everyone can be trusted and there isn’t room for people to get away with those games. Seems much more likely to find more WFH freedom in those environments.
Can't agree more. My M2 MacBook Air has been a major game changer. No battery anxiety, no throttling, no heat issues, etc. Allows me to work from anywhere. The productivity boost has been excellent.
If you genuinely don’t understand any of the perks of having a portable workstation, that’s one thing, but this comes across as a snide deliberate dismissal without even acknowledging them.
Our team frequently work when travelling or from home, where they'd prefer not to have a desktop station.
They also have an on-call rota where they need to respond to incidents remotely: I'd rather not chain my on-callers to their work desks throughout the night!
But as a lot of the other comments say, the latest MacBooks are comparable in build performance to pretty decent desktop machines. You can use them for really serious work, in fact you'll find lots of AI hackers are buying up the M2 Max right now because the AI processing it can achieve is well beyond similarly priced desktop hardware, and can happily run open-source models locally.
I'm unsure of your background but laptops as work computers has been the case in all my jobs for the last 10 years, including a stint in Amazon, consultancies, and several start-ups. It's the norm now, and it comes with few downsides.
Ferry* and maybe plane i understand, but especially the later is changing with many flights offering (complimentary) internet service afaik, but your aunt i don't.
The alternative, to me normal setup would be using a workstation at the office and then remoting into it via SSH (behind a VPN, VSCode supports this great). This allows for a thinner client (eg Macbooks Air) which need less replacement and where battery runtime/portability can be weighed more.
Sure now connectivity is a concern but to me that's mostly a non issue where i travel/the work spots i choose, but i guess it can become more of a problem in other (less developed) parts of the world...
* this will probably also change with naval Starlink becoming deployed more...
> A laptop compromises performance in order to be lightweight, portable, and stylish.
I'd agree with this ~2 years ago. Then I bought a MBP with a M1 Max and honestly I don't see many compromises with this machine. Coming from a 2019 Macbook Pro, it was a night and day difference. Ports, performance, efficiency, heat, battery life, etc.
Now, of course this laptop doesn't have the fastest CPU or GPU available, but it's so fast that it's no longer a compromise for me. It's actually faster than the desktop I upgraded a few months before buying this laptop, and since then Apple has released faster machines.
Fwiw I've spent my whole career doing data analysis but the ease at which I was able to use OpenAI to help me for this post (am author) blew me away.
The fact that I can do this type of analysis is why I appreciate it so much. It's one of the reasons I'm convinced AI engineering find its way into the average software engineer's remit (https://blog.lawrencejones.dev/2023/#ai) because it makes this analysis far more accessible than it was before.
I still don't think it'll make devs redundant, though. Things the model can't help you with (yet, I guess):
- Providing it with clean data => I had to figure out what data to collect, write software to collect it, ship it to a data warehouse, clean it, then upload it into the model.
- Knowing what you want to achieve => it can help suggest questions to ask, but people who don't know what they want will still struggle to get results even from a very helpful assistant.
These tools are great though, and one of the main reasons I wrote this article was to convince other developers to start experimenting with them like this.
I'm a data scientist and it's my first time seeing analysis of a dataset using prompts (as opposed to code: i.e. python/R/SQL). I'm slightly blown away! The plot titled 'Distribution of Builds by Platform and Outcome' looks professional and would take me 10-60 minutes using ggplot. The spacings between the text and other graphical elements are done well and would be time-consuming (not to mention bland) for humans.
I'm wondering if we'll soon see Jupyter notebooks with R, Python, Julia, and OpenAI-assistant kernels! (the latter being human readable plain text instructions like the ones used in your analysis E.g. rather than 20 lines of matplotlib or ggplot "Show me the distribution of builds by machine platform, where the platforms are ordered by M1 to M3, and within the platform class Pro comes before Max.".
This has blown my mind.
I'm still unclear on the exact tech stack you used. If I understand correctly, the steps were:
- generate data locally,
- use an ETL tool to push data to Google BigQuery,
- use BigQuery to generate CSVs
- give CSVs to an OpenAI assistant.
From there you asked OpenAI assistant questions and it generates the plots? Is this understanding correct?
Last question: how many times did you have to re-submit or rewrite the prompts? Were the outputs mostly from the first attempts, or was there a fair bit of back and forth re wording the prompts?
I think we’ll definitely see AI find its way to the notebook tools. Funny enough, you can ask the model to give you an iPython notebook of its workings if you want to move your analysis locally, so in a way it’s already there!
On the process: we’re using OpenAI’s assistants feature alongside the ‘code interpreter’. This means the LLM that you speak to is fine tuned to produce Python code that can do data analysis.
You upload your files to OpenAI and make them available in the assistant. Then you speak to the LLM and ask questions about your data, it generates Python code (using pandas/numpy/etc) and runs the code on OpenAI infra in a sandbox, pulling the results out and having them interpreted by the LLM.
So the plots you see are coming direct from Python code the LLM generated.
On how many times did I resubmit: quite a few. I’d ask for a graph and it would give me what I needed, but maybe the layout was bad so you’d say “repeat the above but show two histograms a row and colour each machine model differently”.
I was using a very recent model that’s in preview. It was a bit slow (30s to 2m to get a response sometimes) but that’s expected on a preview and this stuff will only get faster.
> it makes this analysis far more accessible than it was before
How does the average engineer verify if the result is correct? You claim (and I believe you) to be able to do this "by hand", if required. Great, but that likely means you are able to catch when LLM makes an mistake. Any ideas on how average engineer, without much experience in this area, should validate the results?
I mentioned this in a separate comment but it may be worth bearing in mind how the AI pipeline works, in that you’re not pushing all this data into an LLM and asking it to produce graphs, which would be prone to some terrible errors.
Instead, you’re using the LLM to generate Python code that runs using normal libraries like Pandas and gnuplot. When it makes errors it’s usually generating totally the wrong graphs rather than inaccurate data, and you can quickly ask it “how many X Y Z” and use that to spot check the graphs before you proceed.
My initial version of this began in a spreadsheet so it’s not like you need sophisticated analysis to check this stuff. Hope that explains it!
The medium is the message here, the macbook is just bait.
The pure LLM is not effective on tabular data (so many transcripts of ChatGPT apologizing it got a calculation wrong.). To be working as well as it seems to work they must be loading results into something like a pandas data frame and having the agent write and run programs on that data frame, tap into stats and charting libraries, etc.
I’d trust it more if they showed more of the steps.
We’re using the new OpenAI assistants with the code interpreter feature, which allows you to ask questions of the model and have OpenAI turn those into python code that they run on their infra and pipe the output back into the model chat.
It’s really impressive and removes need for you to ask it for code and then run that locally. This is what powers many of the data analysis product features that are appearing recently (we’re building one ourselves for our incident data and it works pretty great!)
You need to be a little bit more gentle and understanding. A lot of folks have no idea there are alternatives to apple’s products that are faster, of higher quality, and upgradeable. Many seem to be blown away by stuff that has been available with other brands for a while - fast RAM speeds being one of them. Few years back when i broke free from apple i was shocked how fast and reliable other products were. Not to mention the size of my ram is larger than an entry level storage option with apple’s laptops.
> Many seem to be blown away by stuff that has been available with other brands for a while - fast RAM speeds being one of them.
What specifically is this bit referring to? Server CPUs with far more memory channels than consumer products, or GPUs with fast and wide memory interfaces but low memory capacity?
MacBooks are a waste of money. You can be just as productive with a machine just as fast for 1/2 the price that doesn't include the Apple Tax.
Moreover, if your whole stack (plus your test suite) doesn't fit in memory, what's the point of buying an extremely expensive laptop? Not to mention constantly replacing them just because a newer, shinier model is released? If you're just going to test one small service, that shouldn't require the fastest MacBook.
To test an entire product suite - especially one that has high demands on CPU and RAM, and a large test suite - it's much more efficient and cost effective to have a small set of remote servers to run everything on. It's also great for keeping dev and prod in parity.
Businesses buy MacBooks not because they're necessary, but because developers just want shiny toys. They're status symbols.
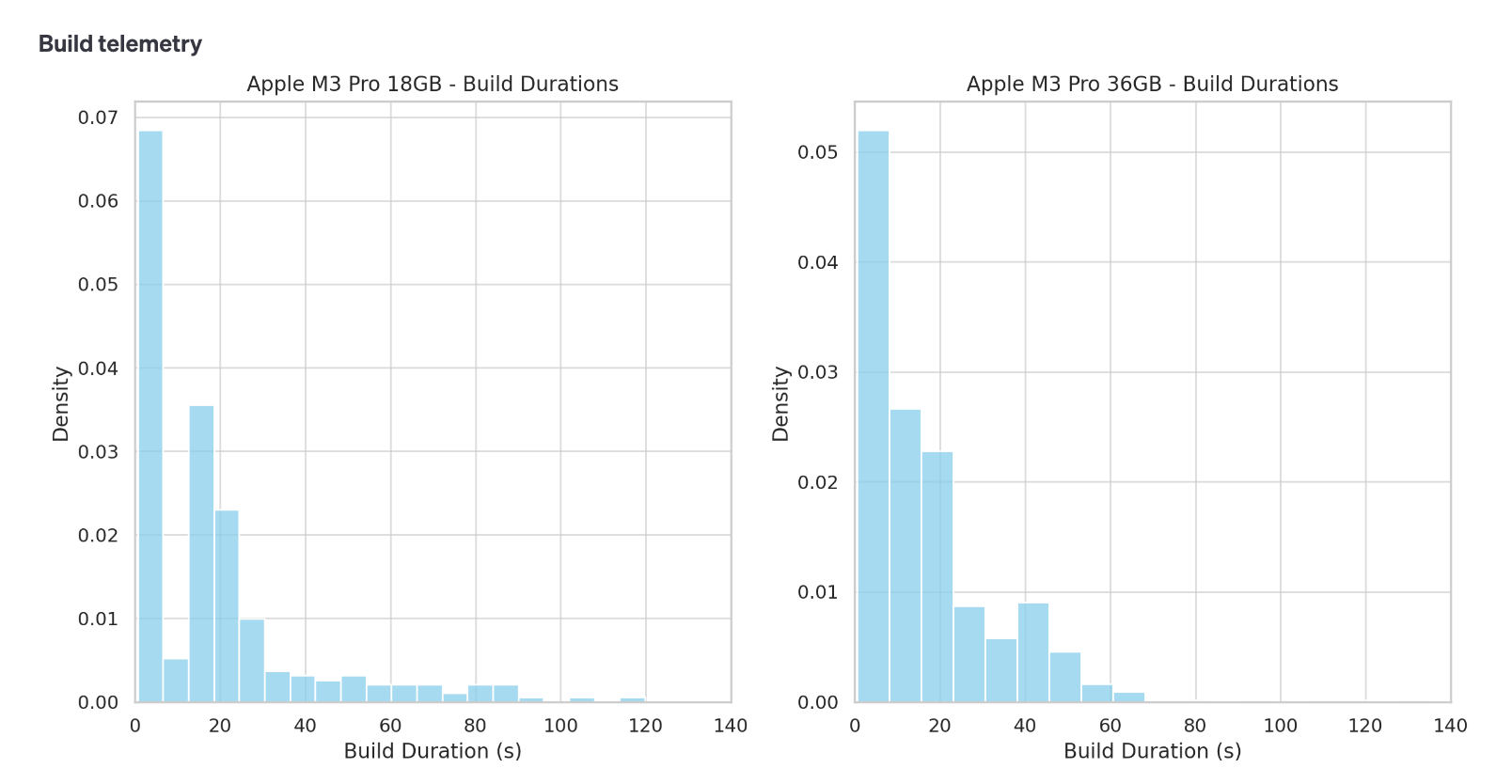{kind=link}
That said, it would have been much easier and more accurate to simply put each laptop side by side and run some timed compilations on the exact same scenarios: A full build, incremental build of a recent change set, incremental build impacting a module that must be rebuilt, and a couple more scenarios.
Or write a script that steps through the last 100 git commits, applies them incrementally, and does a timed incremental build to get a representation of incremental build times for actual code. It could be done in a day.
Collecting company-wide stats leaves the door open to significant biases. The first that comes to mind is that newer employees will have M3 laptops while the oldest employees will be on M1 laptops. While not a strict ordering, newer employees (with their new M3 laptops) are more likely to be working on smaller changes while the more tenured employees might be deeper in the code or working in more complicated areas, doing things that require longer build times.
This is just one example of how the sampling isn’t truly as random and representative as it may seem.
So cool analysis and fun to see the way they’ve used various tools to analyze the data, but due to inherent biases in the sample set (older employees have older laptops, notably) I think anyone looking to answer these questions should start with the simpler method of benchmarking recent commits on each laptop before they spend a lot of time architecting company-wide data collection