What's also pretty interesting that they actually didn't sell more chips this quarter - they ... just pretty much doubled the prices (hence the huge margin).
This is what having a monopoly looks like !
This is also why companies that manufacture their cards didn't report any uptick in profits. I'm wondering how this play out in some months ? Do they have any pricing power with respect to NVidia ? Or NVidia could just switch to another manufacturer ?
As someone who has been in the AI/ML space for over a decade, and even had an AMD/Radeon card for more than half of that, I can't help but feel that this is partially AMD's own fault.
For many, many years it seemed to me that AMD just didn't take AI/ML seriously whereas, for all it's faults, NVIDIA seemed to catch on very early that ML presented a tremendous potential market.
To this day getting things like Stable Diffusion to run on an AMD card requires extra work. At least from my perspective it seems like dedicating a few engineers to getting ROCm working on all major OSes with all major scientific computing/deep learning libraries would have been a pretty good investment.
Is there some context I'm missing for why AMD never caught up in this space?
Until very recently, AMD was struggling for survival. Rather than making the big bet on AI, they went for the sure thing by banking on revolutionary CPU tech. I'm sure if they were in a better financial position 5 years ago, they would have gone bigger on AI.
And arguable their bet on CPU tech worked! AMD is in a much better position today than they were 5+ years ago. They have some catching up to do but that doesn't mean their completely out of the game.
It's ... difficult to compare a low-power SoC released in 2015 (so, design dating back to 2014 if not earlier) with high-power consoles developed in 2019 onwards.
That doesn't mean they're meaningfully comparable (in the context we are talking about). A $100 budget android phone that was released at the same time as the latest iphone also belongs to the same generation, but that doesn't mean the chip manufacturers profit equally from the two (of course apple makes their own chips so in a literal sense this comparison doesn't make sense, but I'm sure you understand what I mean)
And I don't mean to disparage the switch, just point out that the way it's designed is very different which makes the comparison questionable
However, a lot of this has to do with the fact that AMD was on the brink of bankruptcy before the launch of Zen in 2016 (when their share price was ~$10). They simply did not have the capital to the kind of things Nvidia was doing (since '08 ?).
The bet on OpenCL and the 'open-source' community failed. However, ROCM/HIP etc. really seems to be catching up (I even see them packaged on Arch linux).
What really strikes me is Nvidia's been working hard on doing practical work on their GPUs even just 10~15 years ago with PhysX, while both Intel and AMD just existed.
Nvidia's dominance today is the product of at least over a decade of work and investments to make better products. Today they are finally reaping their rewards.
I remember meeting NVIDIA in the late aughts (2007?) first launching their CUDA efforts. Really the product was a re-branded 780GTX or whatever their high end gaming card was at the time more or less, but they already laid out a clear pathway to today (more or less).
I remember meeting with them in the mid aughts when they were first talking to HPC folks about using their cards for science. I'll never forget what the chief scientist from nVidia said. "What is the color of a NaN? That is, when you render a texture with a nan value, what does it look like? I'll tell: it's nvidia green."
That is a funny way to signal their commitment to HPC! But compared to other tooling (non GPU) CUDA is still really clunky. Way ahead of everything else in the GPGPU space but still surprisingly clunky. Also I don't get what they are fearing with all their "Account required for download" (e.g. for CuDNN) what are they fearing? And is it really worth the trade-off for the pain it causes for dev environments and CI pipelines? It really seems like Intel and AMD have to step in to break this monopoly to force them to improve the situation for everyone.
No, you're not missing anything, NVIDIA's software is super clunky by the standards of most of the software world. However, for the last decade, the competition has been much worse: OpenCL development on AMD would be riddled with VRAM leaks, hard lockups, invisible limits on things like function length and registers that would cause the hard lockups when you tripped over them without any indication as to what you did wrong or how to fix it, that sort of thing. Cryptic error messages would lead to threads scattered around the internet, years old, with pleas for help and no happy endings.
The thing that caused me to ragequit the AMD ecosystem was when I took an OpenCL program I had been fighting for two days straight and ran it on my buddy's Nvidia system in hopes of getting an error message that might point me in the right direction. Instead, the program just ran, and it ran much faster, even though the nvidia card was theoretically slower.
In terms of quality, I expect the competition to catch up in a generation or two, but then there is still the decade+ of legacy code to consider. Hopefully with how fast AI/ML churns that isn't actually an insurmountable obstacle.
Years ago I gave up on OpenCL (1.2 on an AMD card) because of those hard lockups, with no way to debug it. nVidia didn't even support OpenCL 1.2 (and IIRC didn't support the synchronisation primitives I wanted in CUDA either -- AMD was more capable on paper). Thanks, I feel better to hear just how bad it was -- so it wasn't just my fault for quitting.
It's a quality meme but I'm having trouble figuring out the settings that make it work. It looks like RGBA8 would be blue:
>>> struct.pack('f',math.nan)
b'\x00\x00\xc0\x7f'
maybe that becomes green if you composite over white or something? Or maybe there is a common type of NaN that fills some of the unspecified bits? ("Just use the particular NaN that makes it green" is cheating unless you have an excuse)
32-bit NaN is encoded:
s111 1111 1xxx xxxx xxxx xxxx xxxx xxxx
Where both the sign (s) and the x bits can be anything and it will still be treated as a NaN.
There are lots of ways to encode colour, but there would be too much red with RGBA, and ARGB could be almost any opaque colour, but the red channel has to be at least 0x80, which is still too much red.
"For Nvidia, decreasing the baseline CPU performance by using x87 instructions and a single thread makes GPUs look better."
Nvidia magically released PhysX compiled with multithreading enabled and without flags disabling SSE a week after this publication. But couple of days before release they made those funny statements:
"It's fair to say we've got more room to improve on the CPU. But it's not fair to say, in the words of that article, that we're intentionally hobbling the CPU," Skolones told Ars.
"nobody ever asked for it, and it wouldn't help real games anyway because the bottlenecks are elsewhere"
>Nvidia's dominance today is the product of at least over a decade of work
"Number one: Nvidia Gameworks typically damages the performance on Nvidia hardware as well, which is a bit tragic really. It certainly feels like it’s about reducing the performance, even on high-end graphics cards, so that people have to buy something new.
"That’s the consequence of it, whether it’s intended or not - and I guess I can’t read anyone’s minds so I can’t tell you what their intention is. But the consequence of it is it brings PCs to their knees when it’s unnecessary. And if you look at Crysis 2 in particular, you see that they’re tessellating water that’s not visible to millions of triangles every frame, and they’re tessellating blocks of concrete – essentially large rectangular objects – and generating millions of triangles per frame which are useless."
"Unnecessary geometric detail slows down all GPUs, of course, but it just so happens to have a much larger effect on DX11-capable AMD Radeons than it does on DX11-capable Nvidia GeForces. The Fermi architecture underlying all DX11-class GeForce GPUs dedicates more attention (and transistors) to achieving high geometry processing throughput than the competing Radeon GPU architectures."
> But GameWorks' capabilities are necessarily Nvidia-optimized; such code may perform poorly on AMD GPUs.
From the arstechnica article about Witcher 3.
How dare Nvidia optimize their game enhancing effects for Nvidia hardware and forget to do it for their competitors hardware as well! And as for a lot of these complaints, could it be that a lot of companies only optimize for hardware that has the largest market share?
According to the steam hardware survey in July of 2023, Nvidia accounts for 75% of the GPUs[0]. Nvidia and Amd have a lot of incompatibilities, and it can be hard to make the same code performant on both. It makes sense, as a game company, to prioritize optimizations for the largest market. No collusion and evil corporate mega lord scheming needed for this.
Edit: Also, Nvidia does put out a lot of research efforts for free. Path rendering on the GPU for example (PhysX being another). You can find research papers and videos published by Nvidia for these things. I would consider that practical work. You can hate on Nvidia for lots of things, but this is one thing I find weird to be combative over.
Second Edit: Also, why do you find the statements Nvidia said about the PhysX improvements funny? They’re right. Most games 13 years ago left a lot of idle time on the GPU while the CPU worked overtime to do logic, physics, sound, culling, etc. Lots of that stuff has also been moved to the GPU to minimize the amount of idle time on either the CPU or GPU. Nothing funny about what they said there.
And their antics shutting out Nvidia (eg: FSR only, no DLSS) aren't being received well, not the least because their offerings are objectively inferior to Nvidia's.
While Nvidia isn’t doing these silly antics today, they’ve absolutely done them in the past. None of the large consumer silicon companies have clean hands with respect to anticompetitive/anti-consumer behaviours. They’ve all got too much power frankly.
This is factually jot the case as confirmed by Crytek developers at the time. Wireframe mode turns off clipping and cranks up LOD to max, and normally neither the water table would be visible (under the ground) nor would that block be rendered at that LOD.
100% this. I, and many others, bought multiple AMD cards due to disliking NVidia and tried to get ROCm set up to no avail. It just never worked except under hard to maintain configurations. I switched to an nvidia card and within the hour import tensorflow just worked
Do you want solid dependability and settings that are right first time, because you've only got one PC and if the graphics get broken you've got no browser to google for a fix?
Do you want the absolute most up-to-date drivers, to support the very newest GPUs, while running an LTS version of your OS?
Do you want to always run the latest driver version and upgrade without testing or worrying, like we do for web browsers?
Do you want to run CUDA and ML stuff, but also want to run Steam which for some reason wants 32-bit support available?
Do you want to run on a laptop with hybrid graphics, and have suspend/resume work reliably every time?
Do you have a small /boot/ partition, because you expected initrd.img to be 50MB or less?
Do you want to support Secure Boot?
If you want to achieve all these things at once, it'll take you a few tries to get it right :)
Catching up in this space requires a significant, sustained investment over multiple years and competent software engineers. It's not a simple thing for a hardware company to suddenly become competitive with Nvidia in AI/ML.
Instead, they've been going after the CPU market (and winning), HPC/scientific computing (high FP64 performance, in contrast to Nvidia's focus on low-precision ML compute), and integrating Xilinx.
However, I agree that it's an unfortunate situation, and I hope AMD becomes competitive in this space soon.
I think their hardware is comparable with nvidia. The problem is the software is awful by comparison. It’s hard to run any of the AI workloads with AMD, and even when you can the performance is poor. The software investment just hasn’t been made. Until then they are not even in the game.
AMD should do a high-memory-density MCD variant of 7900XT/XTX with a MCD that has 4 PHYs instead of 2. You could get 7900XTX to 48GB with no clamshell and 96GB with clamshell, which is getting into H100 territory.
Nvidia and really all chip designers are limited by the fab companies who are trying to scale as fast as they can. But all the cutting edge fabs are limited by one single supplier - ASML. ASML make the lithography machines and have a total monopoly. Even they cannot make lithography machines fast enough to satisfy demand - their lithography machines are sold out 2 years in advance
```
CoWoS stands for Chip on Wafer on Substrate. It is a high-density packaging technology for high-performance chips. TSMC developed CoWoS in 2012.
In CoWoS, multiple silicon dies are placed on a silicon interposer, which is an intermediate layer on the package board.
The interposer acts as a communication layer for the active die on top. CoWoS is a 2.5D packaging technology. It is widely used in high performance computing.
```
There probably isn't another manufacturer they can switch high end stuff to. They recently tried moving at least some of their cards to Samsung but switched back last generation due to yield issues.
If they treat their AIBs for their enterprise stuff anything like they do in the consumer space, they don't really have anything to worry about there (aside from the rest of them giving up on dealing with Nvidia's BS, I guess).
Isn't this more a case of supply and demand? Huge ramp on chip demand by every FAAMG, every dev and their grandmothers for AI with a mostly inelastic supply (foundry constrained and very specialized atoms tech involved).
It's not like Intel and AMD don't exist, but if everyone is pushing each other at the door for Nvidia chips..
You know, Meta and Alphabet which every one outside of their respective CEOs still call Facebook and Google.
And by saying FAAMG instead of FAANG I make the statement that Cramer was high as a kite when he put Netflix in there instead of Microsoft. Today you might make a case for an N, but not at Microsoft's expense.
It's cornier and yet still technically incorrect by not using Alphabet. And MAMAA is even cornier without putting in another vowel; arguably Nvidia's N but I feel like it doesn't quite belong. So I stand by my FAAMG, it sounds right, and everyone uses Facebook and Google rather than Meta and Alphabet anyway.
Not sure if you're intentionally choosing to ignore their point, but what they meant is Nvidia can unilaterally choose to raise the prices and customers can't do anything since they're a monopoly. You can't just say well, i'll go to the next shop and buy something for cheaper.
AMD is the closest to a competitor NVIDIA has, but they are also very far away from even being close to their market-share.
I'm sure in AI/ML spaces, NVIDIA holds a even higher market-share due to CUDA and the rest of the ecosystem, at least in gaming things are pretty much "plug and play" when it comes to switching between AMD/NVIDIA hardware, but no such luck in most cases with AI/ML.
AMD seem to be catching up quickly lately. I'm running Stable Diffusion, Llama-2, and Pytorch on a 7900XTX right now. Getting it up and running even on an unsupported Linux distro is relatively straightforward. Details for Arch are here: https://gitlab.com/-/snippets/2584462
The HIP interface even has almost exact interoperability with CUDA, so you don't have to rewrite your code.
I interned at NVIDIA in 2009 on the kernel mode driver team. Was super fun there in terms of the project work and the people. If the code still exists, I created the main class that schedules work out to the GPU on Windows.
That level of programming gave such rewarding moments in between difficult debugging sessions. When I wanted to test a new kernel driver build I needed to walk into some massive room with all of these interconnected machines that emulated the non-yet-fabricated GPU hardware. One of the full time people on my team was going insane trying to track down a memory corruption issue between GPU memory and main memory when things paged out the entire time I was there.
Back then the stock was around $7/share and the CEO announced a 10% paycut across the board (even including my intern salary) and had an all hands with everyone in the cafeteria. It's pretty cool they went from that vulnerable state, with Intel threatening to build in GPU capabilities, to the powerhouse they are today.
I joined as a new college grad (full time) the same year. I remember the 10% pay cut announcement. I didn't get any stock granted to me in the 4 years I was there as a SWE working on CUDA. They had an ESPP you could put 10% of your paycheck into or something like that though.
I vaguely remember that I could participate in the employee purchase program. This was during the financial crisis though and I was an undergrad intern with a paltry ability to invest.
Even if I had hit received some great stock award in all likelihood I would have sold it for index funds at my first opportunity. I imagine some of my old coworkers made out quite well though.
I do wonder though, why has moore's law stopped in its tracks? Using CS:GO benchmark, a 1070 got 218 FPS, while a 4090 is at 477 FPS. Only a ~2.2x increase in FPS in 6 years? :(
Between those 2 GPUs, the fp32 perf went up 12.7x according to TechPowerUp’s specs. The SM count went up 8.5x (which represents Moore’s law and note is almost exactly in line with Moore’s prediction), and the clock rate went up 1.5x. The FPS of CSGO (or any game) is not a good measure of Moore’s law. Games have all kinds of complexities and caveats that will prevent them from scaling linearly. I used to write some of those bottlenecks :P What are the 2080 and 3080 datapoints for CSGO? Did it approach 400-500 fps on the 2080 and never get any faster after that?
Wow, didn't expect to get so many comments. It's just interesting to me that we have 500hz monitors, yet games are still coming out that only run at ~70 fps on a 3080, etc. I used CS:GO as a comparison just because it was an example capable of coming near 500 FPS. Avg FPS are not going up fast enough in my opinion. I understand some games purposefully limit FPS for physics calculations, but there are many that do not.
> Avg FPS are not going up fast enough in my opinion.
I've never had hardware to run above 1080p at 60fps (monitors, GPUs), so my desires are a bit orthogonal - I wish more games let you customize the graphics settings so that you could maintain a consistent framerate (be it 30 on a low spec laptop, 60 on a regular PC or more fps) at a resolution of your choice.
Things like switching between baked or dynamic shadows, their type/filtering, things like ambient occlusion and tessellation, various post processing effects and filters, model LOD limits and texture resoltion, resolution scaling and so on.
More so, it would actually be nice if games let you download a version with lower fidelity assets (like War Thunder sort of does, for example), so you don't need 100 GB of models and textures if you're realistically only ever going to see 20 GB of those on your hardware.
Thankfully, most modern game engines scale both up and down decently, for example, Unity's URP (though historically a bit half baked and fragmented the community/assets). It's just up to the developers to get over the hubris of wanting "low" settings to still be pretty, that choice should be up to the user.
>There’s a good reason to never go above 70fps: human perception experts tend to agree that our visual system gives us quickly diminishing returns above 60fps, we can’t really see things any faster than that
No. Please don't spread this nonsense rumor. It hasn't ever been true and still isn't.
There are always diminishing returns, but human vision is perfectly capable of noticing the difference between 60 and say, 120. You can literally try this yourself just moving your mouse around on a 120Hz monitor and then capping the refresh rate. In general human vision is really complicated and not tied to any specific "speed".
Also, displays are more complicated. There isn't just a refresh rate, there's differing pixel responses at differing brightness and a variety of different processing delays all the way from the moment you put in some hardware input (like the mouse), to the final result. It's a huge chain.
The end result is that two 120hz displays can behave completely differently in terms of motion clarity.
We are pretty quickly approaching the point where a "frame scanout" is going to lose meaning. Areas of the image will be rendered and scanned out optimally ala "foveated rendering" and also sent over the pipe in this fashion too.
TAA fundamentally decouples the sample generation from the output generation. TAA samples (even native res) have no direct correspondence to the output grid, they are subpixel sampled and jittered. The output grid takes the samples nearby and uses them to generate an output for each pixel.
TAAU/DLSS2 take this further and decouple the input grid from the output grid resolutions entirely. So now you have a 720p grid feeding a 1080p grid or whatever. Thinking of it as "input/output frames" is clunky especially when (again) the input frame doesn't even correspond directly to the input samples - they're still jittered etc. Think of it as a 720p grid overlaid over a 1080p grid, and DLSS is the transform function between these two (real/continuous) spaces. Samples are randomly (or purposefully) thrown onto that grid.
OLEDs are functionally capable of individual pixel addressing if we wanted to. Current ones probably can scan out lines in non-linear order already, so you could scan out the center more than the top/bottom, for example. And OLEDs are already capable of effectively >1000hz real-world response time from their pixels. They just are absolutely critically bottlenecked by the ability to shove pixels through the link and monitor controller quickly enough (give me 540p 2000hz mode, you cowards)
This all leads to a question of why you are still sampling and transmitting the image uniformly. If there's parts of the image that are moving faster, render those areas faster, and with more samples! Maybe you render the sword moving at 200fps but the clouds only render at 8fps. And Optical Flow Accelerator can also allow you to identify movement within the raster output and correlate this with input - if you think about oculus framewarp, what happens if we framewarped just one object? Translate it around against the background, stretch it to simulate some motion aspect, etc. And if you further refine that to a 1x1 region, then you have individual pixel framewarp.
You can also have a neural net which suggests which regions are best to render next, for "optimal" total-image quality after the upscaling/framewarp stages, based on object motion across the frame and knowledge of the temporal buffer history depth in a particular pixel/region (and this is the sort of abstract, difficult optimization problem ML is great at). And those pixels actually might be rendered at multiple resolutions in the same frame - there might be "canary pixels" rendered at low resolution that check whether an area has changed at all, before you bother slapping a bunch of samples into it, or you might render superfine samples around a high-motion/high-temporal-frequency area (fences!). So now you have "profile guided rendering" based on DLSS metrics/OFA analysis of the actual scene being rendered right now.
Another random benefit is that "missed frames" lose all meaning. The input side just continues generating input for as long as possible, as many samples at whatever places will be most efficient. If it's not fully done generating input samples when it comes time to start generating output... oh well, some cloud has less temporal history/fewer samples. But DLSS does fine with that! As long as you still have some history for that region you will get some output, and I'm sure if it was important then it'll be first thing scheduled in the next frame.
You can use this idiom with traditional scanout/raster-line monitors, but ideally to take advantage of OLED's ability to draw specific pixels, you probably end up with something that looks a lot like a realtime video codec - you're sending macroblocks/coding tree units that target a specific region of the image with updates. Or you use something like Delta Compression encoding, like with lossless texture compression.
This already is sort of what Display Stream Compression is doing, but that's just runlength encoding, and if the monitor can draw arbitrary pixels at will (rather than being limited to lines) then you can do better.
And again, you can't transmit the whole image at 1000fps, but you can target the "minimum error approximation" so that on the whole the image is as correct as possible, considering both high-motion and low-motion areas. This is sort of an example of the concept - notice the scanline errors in high-motion areas. Great demo but linked to the direct example:
This also raises the extremely cursed idea of "compiled sprites" inside the monitor controller - instead of just running a codec, you could put a processor on the other side (like the G-Sync FPGA module) and what you send is actually the program that draws the video you want. Executable Stream Compression, if you will. ;)
(but there's no reason you couldn't put THUMB or RISC-V style compressed instructions in this - and you certainly could change up the processor architecture however you want, as long as you don't mind doing a Gsync-like compatibility story. It makes upgrading capabilities a lot easier if you control both ends of the pipe, that's why NVIDIA did g-sync in the first place! And there is probably nothing more flexible or powerful than allowing arbitrary instruction streams to operate on the framebuffer (or a history buffer, whether frame history or macroblock/instruction history) or to draw directly to the frame itself. With the bottlenecks that DP2.0 and HDMI2.1 present, this is probably the way forward if you want lots more bandwidth out of a given link speed.)
I said a long time ago that this is basically a "JIT/runtime" sort of approach and people kinda laughed or said they didn't get it. But it's funny that trixter actually used the same analogy there for his demo. But basically DLSS is an engine unto itself already, DLSS is what does the rasterizing, and the engine just feeds samples (that are entirely disconnected from the output, they go into the black box and that's the end of it). And with fractional rendering you can basically view that as a big JIT/runtime. DLSS provides quality-of-service to pixels by choosing which ones to schedule for "execution" and with what time quanta, to produce optimal image quality ("total QOS") over the whole image. And then the resulting macroblocks are individually sent over when ready.
Effectively this works like the biological eye - there is no "frame", changes happen dynamically across the whole frame constantly. Or another analogy would be "what if we could 'chase the beam' but across arbitrary pixels in the frame"? If the motion is predictable then you can schedule the rendering so that the output and blit happens at the exact proper time, down to 0.1ms accuracy. It's Reflex for Pixels.
DLSS knows when a person is running and about to peek out from behind a wall. DLSS knows when someone was sitting there and can render the lowest-latency-possible update when they suddenly pop out of cover and AWP you (can't read minds/make network latency disappear, but it can update it as quick as it can). That already shakes out of the motion vector data and just needs to be generalized to a world where you can render out specific regions/lines at 1000hz.
(I guess technically "frame" still exists as a notional concept inside the game loop, you are generating game state in 60fps intervals or whatever, but rendering is totally decoupled from that and you run the GPU on whatever parts of the image would benefit the most from touchups at a particular moment.)
But again you can see how this whole idea fundamentally inverts control of the game engine - Reflex already tells the game when to sleep and when to start processing the next game-loop, now DLSS will tell the engine what pixels it wants sampled, and handles rasterizing the samples and compressing/blitting them to the monitor. The engine is just providing some "ground truth" visual input samples and calling hooks in DLSS.
(sorry, long post, but I've been musing about this elsewhere and I looooove to chitchat lol)
This is a very good point. It would be ideal to spend the budget rendering only fractional updates to the image, and allow those updates to happen much faster than what would be 60fps. This way we could get 1000hz updates without it costing 10x more than 100hz. While I’m skeptical about the supposed perceptual benefits of full frame rates above 120hz or 240hz outside of the latency argument, foveated fractional rendering could end up being the fastest and best and cheapest.
> you are generating game state in 60fps intervals or whatever
This is also an excellent point that might question my suggestion that high frame rate is being used to reduce latency. Games state updates are already decoupled from rendering in lots of games. Having an extremely high render refresh might not mean that the latency between controls and visuals is reduced proportionally. Or maybe it helps but has a limit to how much.
DLSS is an interesting topic here. Do you see it eventually working for fractional updates? We’d possibly need a new style of NN or of inference? DLSS currently operates on a full frame, and the new version even hallucinates interpolated frames to boost fps artificially. This doesn’t help with control latency at all, in fact it makes it worse.
> DLSS is an interesting topic here. Do you see it eventually working for fractional updates? We’d possibly need a new style of NN or of inference? DLSS currently operates on a full frame, and the new version even hallucinates interpolated frames to boost fps artificially. This doesn’t help with control latency at all, in fact it makes it worse.
Yeah I've been playing fast and loose with terminology here, there's several overlapping but synergistic ideas that aren't the same things. To try and clean this up:
DLSS1 required the full image, it actually was an image-to-image transformer that "hallucinated" a full-res image from an input image. This sucked and NVIDIA gave it up (except for the 500mb of DLSS models that live eternally in the driver for the 2 games that opted for driver-level model distribution). Nobody cares about this anymore at all.
DLSS2 does not need a full image, because it is a TAAU algorithm that weights samples using a ML model. If there aren't enough samples in an area oh well, you just get crappy output (like immediately after a scene change). It manifests as either obvious resolution pop/detail pop, or visual artifacts on moving/high-res things. IIRC this can be assisted by drawing invisible (1% alpha) objects in motion/fences/etc to "warm up" DLSS sample history on the (invisible) edges before just popping them into existence iirc lol.
You need at least some samples near that area, it can't render from nothing, but DLSS2 is not dependent on rendering out the full image to work - if some unrelated part of the image doesn't have samples, oh well. (and this may allow mGPU scaling with reasonable correctness for partitioning an image!). Personally I consider this "loosy goosy correctness" attribute of ML models to be extremely desirable for GPGPU programming - if some edge case messes up 0.1% of samples, the ability of ML models to just ride over it and spit out a reasonable output is super desirable. This includes things like camera noise, dead pixels, etc. Extremely tolerant of data ingest etc. Like if 10 threads aren't quite finished with their sample output because you don't want to wait for kernelfence sync when it's time to start rendering the output buffer... just start going. It'll be fine.
Fractional rendering is a separate and unrelated idea, but I think the time is right with OLEDs here, and with everyone searching for a way to extend perf/tr with costs spiraling it makes sense to see if you can render "better" imo.
Variable rate sampling is another concept that builds on fractional rendering. Render some areas at a higher rate than others. And again this is something that DLSS2 plays nicely with.
--
DLSS3 is actually the successor to DLSS2 and is supported by all RTX cards (yup). Framegen is one of the features in this, and that is only supported on Ada. Supporting framegen requires the inclusion of Reflex, which does benefit everyone hugely.
Reflex basically flips the "render+wait" model to be a "wait+render", by adding a wait at the start of the game loop that delays until the last possible second to start processing the frame, so it's as fresh (input latency) as possible. And this does legitimately cut latency significantly (by ~half) in highly gpu-bound scenarios. And that gives NVIDIA some headroom to play with in framegen tbh. Igor's Lab and Battlenonsense both found NVIDIA to have much lower click-to-photon latency than AMD Antilag, by like 20-30ms in overwatch f.ex.
Framegen as currently implemented is interpolation and yeah that does increase latency. But NVIDIA do have some headroom to play with there, in CPU-bound situations (which is different!). And tbh most people who actually have used it generally seem to find it not too bad, it's the "eew I tried it at the store and it was awful!"/"i've never tried it" who are most vocal about the latency. It's at least an option in the toolbox (see again: starfield).
I think it is possible to move to extrapolation and I hope the current framegen is only an intermediate step. And I think Optical Flow Accelerator is a really cool building block for that. The performance and precision has improved a bunch over the gens, and now it can support 1x1 object tracking (which I mentioned above as seeming like a significant threshold/milestone) so it's flowing pixels really. I see that as being a Tensor Core-like moment that people scoff at but has big implications in hindsight. Being able to incorporate realtime image data back into the upscaling/TAA pipeline seems big even beyond just framegen itself, I don't doubt DLSS3.5 will make further progress too.
You don't need extrapolation (or interpolation) at all. but if you can extrapolate per-pixel, the ability to do a low-cost "spacewarp" that accomplishes most of the squeeze of a full re-render (in terms of moving edges/texture blocks) at much lower cost could would be very interesting. And the OFA could end up being a key building block in that sort of thing.
--
Again kind of a topic shift but there's also this issue of display connection (there is never enough bandwidth) and whether it's lines or macroblocks etc. That's a capability that's offered by OLEDs in theory, and could be explored with a similar FPGA approach/etc. If you can do that, it pairs with variable rate sampling concepts (and ML input tolerance for bad data) very nicely - render out the regions you're updating whenever they're ready, or whenever is optimal for that element to be drawn (to get minimum error).
And in fact quite a few of these ideas synergize nicely together. If you put it all together.
--
These are all kinda separate in general but quite a few of them synergize if you put them together. And I think the zeitgeist is ripe on some, brian heemskirk was talking about some similar ideas on MLID's show a few months ago (not the most recent appearance).
This is great stuff. I don’t have anything useful to add, just wanted to say thank you, TIL. You don’t have links to any write ups about the latency testing by Igor’s Lab & Battlenonsense do you? I’d be interested to learn more about what typical click-to-photon latencies are today for given refresh rates, and how the latency changes wrt refresh rate. The latencies must be absolutely horrendous if we’re talking about differences of 20-30ms? That would tend to justify super high frame rates (assuming they actually reduce latency!), but it’s funny to me that rendering frames faster and faster is seen as the solution, rather than attacking the issue of a render+display pipeline with insane and growing latency.
Yes I agree that driver overhead+latency reduction in the pipeline matters a lot and that's the tool Intel just dropped (and has probably optimized their own driver for of course). Classic Tom Peterson, lol, just like FCAT.
I don’t disagree with your points, vision is indeed complex and not discrete, displays and games can all be different, but there is plenty of scientific perception research to back up my statement that 500 fps is not 5x better than 100 fps to a human. We don’t need 500fps movies, ever. Games want high fps because there’s a feedback loop.
Do you have sources that show otherwise and back up your claim that this idea is “nonsense”? I will dig up some scientific sources. Are you perhaps reading into my comment and not responding to what I said literally?
You aren’t really addressing what was main point: that fps throughput isn’t the reason for high frame rates in games. The primary reason for this happening is to decrease latency.
We wouldn’t need 500fps for games if we lowered the latency. Or at the very least, the benefits would be much lower. Reducing latency is a great reason to want high fps, but there are other ways to reduce latency.
You replied to the wrong comment, btw. I almost didn’t catch your reply.
Edit: links that discuss the measured speed of human perception:
“there are diminishing returns when it comes to the refresh rate. Most people can perceive improvements to smoothness and responsiveness up to around 240Hz; however, the difference between a 240Hz and 360Hz panel is so small that even competitive gamers might have a hard time telling them apart. If you have a choice between a 1440p 240Hz and a 1080p 360Hz monitor, you're probably better off getting the 1440p option, as the increase in resolution has a much larger impact on the overall user experience.”
(Mentions seeing a single frame of color at 500fps. This is true! Humans can see a flash of light that’s much shorter than 2ms. For perceiving imagery and tracking motion, the available evidence shows little benefit to going higher than 120fps.)
You're twisting my words and changing what you claimed.
>my statement that 500 fps is not 5x better than 100 fps to a human
I never said that. I also stated that I know about diminishing returns. You claimed "There’s a good reason to never go above 70fp". There absolutely is a large difference in motion clarity between 70 and something like 120/240/etc. Is the difference from 70->120 as large as 30->60? No, absolutely not. But it is significant and can be seen easily with a cheap monitor.
>You aren’t really addressing what was main point: that fps throughput isn’t the reason for high frame rates in games. The primary reason for this happening is to decrease latency.
>We wouldn’t need 500fps for games if we lowered the latency. Or at the very least, the benefits would be much lower. Reducing latency is a great reason to want high fps, but there are other ways to reduce latency.
While there is a latency improvement and some people care about that, the motion clarity is also significantly improved. (again, just drag some windows around on a 120hz monitor) That's true of movies just as well as games. Movies have pulled a lot of tricks to mask this issue over the years, but 60 is quickly becoming the standard over 30. (And once bandwidth and processing improves, it's likely some day decades from now it will jump even higher)
>You replied to the wrong comment, btw. I almost didn’t catch your reply.
Alright we’re in a cycle of misunderstanding each other, and rabbit holing on something that is rather tangential to my original point. I acknowledge I should not have used the word “never”. I meant rarely, and I meant for “most” games, not literally never, and not all games.
When you said “No. Please don't spread this nonsense rumor. It hasn't ever been true and still isn't.”, combined with the downvote, I assumed you were referring and objecting to everything I said including diminishing returns (even though I see you acknowledging it next paragraph.)
We are mostly agreeing violently, I acknowledge that there’s no known hard fps threshold above which nobody can see something. I acknowledge that there are benefits above 60fps, even if they grow smaller.
But it’s still true that the primary reason games are going to 500fps is for the latency benefits, not for the smoothness or high flicker rate. A frame rate that high isn’t generally perceptible, while the latency of today’s games - a latency of multiple frames - is actually well inside the known measurable threshold of response times. The problem isn’t generally the need for more frames per second, the big problem is the time between input and the visible change on screen.
The other topic that would be nicer to discuss is the quality trade offs. High frame rate takes away from other options.
> games are still coming out that only run at ~70 fps on a 3080, etc.
Graphical fidelity in games improves until it maxes out current hardware. This is natural. You can always turn the settings down to get higher FPS, but you can't turn down the high FPS you get in older games into more modern graphics.
> Avg FPS are not going up fast enough in my opinion.
FPS isn't the one and only metric. Audiences generally care more about graphical fidelity. FPS just has to be good enough and stable. Typically that sweet spot is 60fps, though we're slowly moving to 144fps being the standard.
> It’s just interesting to me that we have 500hz monitors, yet games are still coming out that only run at ~70fps on a 3080, etc.
Of course new games are running at 70 fps. Most games are absolutely not designed for 500hz, and have zero reason to do that. Cs:go wan’t designed for 500fps, I bet the designers of cs:go never intended people to play at 500fps, or even imagined that would ever happen; it wasn’t possible when the game came out.
There’s a good reason to never go above 70fps: human perception experts tend to agree that our visual system gives us quickly diminishing returns above 60fps, we can’t really see things any faster than that, so I’m quite skeptical that 500fps is necessary.
The whole reason 500fps is useful for competitive esports gaming is to reduce latency, not really to keep increasing frame rates forever. Because games are triple-buffering and sometimes monitors are too, and there’s another frame of latency for controller inputs to be recognized, you might still have 10ms or more of latency between controller input and changes on-screen, even if your game is rendering at 500hz. This means you could get away with 100fps if you had zero latency. When your fps is 60hz and there’s 5 frames of latency, you don’t see responses to your controller until almost 100ms later(!).
It’s been about a decade since I was a game dev, but it’s wild to me that anyone would want 500 fps, or that any games would aim for that. This gives you a grand total of 2 milliseconds do to everything, gameplay + animation + physics + audio + rendering. It’s not a lot of time, and you have to compromise your visuals and rendering (by 10x!) in order to achieve that frame rate. Looks like a lot of new gaming monitors are 144hz, and these new 240/360/480hz monitors are pretty extreme and still a bit rare.
> I understand that some games purposefully limit FPS for physics calculations, but there are many that do not.
FWIW, this isn’t the way I’d frame it, it’s kinda misleading. Very few games are purposefully limiting FPS for the sake of slowing it down. All games, however, have a budget. There are always limited compute & render resources, and both game devs and players want the highest quality available for their budget. Until very recently most games aimed for 30fps, and only really fast twitchy games went for a relatively very smooth 60fps. The games that went for 60 had to cut their polygon counts and physics and gameplay in half in order to achieve high frame rate, so you are totally trading away a richer experience in favor of high frame rates. Only certain kinds of games should even try to do that.
Looks like you were specifically a console game dev? PC games have not aimed for 30fps either ever or at least for the last 2 decades. Consoles are hilariously far behind PC in this aspect.
The whole "science says the human eye cannot see beyond 30fps :)" is actually a very old meme at this point. You are correct that high FPS/Hz is about decreasing latency, but you underestimate the importance of it. 144hz is a very clear improvement over 60hz and the PC ecosystem is going to move over to it as a new standard relatively soon. You don't need to be playing a hyper-competitive FPS to notice it either, any game with significant movement will do.
> Because games are triple-buffering and sometimes monitors are too, and there’s another frame of latency for controller inputs to be recognized, you might still have 10ms or more of latency between controller input and changes on-screen, even if your game is rendering at 500hz. This means you could get away with 100fps if you had zero latency. When your fps is 60hz and there’s 5 frames of latency, you don’t see responses to your controller until almost 100ms later(!).
You're assuming VSync or something. There's no guarantee that the input will line up with the next frame, so an input latency of 10ms while running at 100 fps equals a worst-case latency of roughly 20ms, not 10ms. That's why the higher fps & hz numbers really matter.
Guilty as charged, yes you’re right I was a console game dev. Fair enough, yes PCs are way ahead of consoles and I overstated the perceptual limits of frame rates. I didn’t really mean to suggest that competitive twitchy PC games have no reason to go above 60fps, I meant that there’s a whole swath of other kinds of games that don’t need it (consoles, mobile, puzzle games, etc. etc.). I was reacting more to the idea of 500fps which is really far above 144hz, and the implied suggestion by top comment that maybe even 500 isn’t enough and that everything should be trying go there.
> an input latency of 10ms while running at 100fps equals a worst-case latency of roughly 20ms, not 10ms. That’s why the higher fps & hz numbers really matter.
Yes exactly, I agree and this was the point I was trying and I guess failing to make. Latency is typically multiple frames, so at 100hz, latency can easily be longer than known science-meme perception times. Even with vsync there’s up to one frame to recognize inputs, then another frame to produce new game state & submit the render, then 1 or 2 more for double or triple buffering, then maybe supersampling and/or denoising, then whatever the monitor does, and I might be missing some steps that add latency. So I suspect 500hz has nothing to do with seeing smoother motion compared to 144hz, and everything to do with getting overall control latency down to below, say, 10ms.
Does that really work though? Does CS:GO and do other modern games poll the controller at the display refresh rate? I know it’s pretty common for a lot of games to decouple rendering from game state. That can mean a lot of different things, but one of the implications might be that controller latency is limited to one or two frames of, say, 60hz game state updates, followed by 3-5 frames of 500hz display refresh. Is latency in today’s PC games limited by the game state update, regardless of what the display refresh rate is?
I’m curious where the perceptual limits really are, and what the max framerate we actually need is. Suppose an imaginary world where worst case input-to-screen latency is 2 frames. Then in that case, how high should the FPS be? What if there was zero latency - like if the next rendered frame magically reflected mid-frame controller inputs and magically displayed with no latency - then what should the ideal FPS be? Would there be any benefit to going higher than 144, or would we be wasting electrons?
> Even with vsync there’s up to one frame to recognize inputs, then another frame to produce new game state & submit the render, then 1 or 2 more for double or triple buffering, then maybe supersampling and/or denoising, then whatever the monitor does, and I might be missing some steps that add latency.
VSync introduces latency, so it always gets disabled, same with double/triple buffering. I don't think gaming monitors do anything to process the image, they're usually advertised with ~1ms response times.
> Does CS:GO and do other modern games poll the controller at the display refresh rate?
Modern gaming mice and possibly keyboards use 1000hz polling.
> I know it’s pretty common for a lot of games to decouple rendering from game state.
I think all modern games do. Some old games have issues running at fps other than 60 due to this coupling.
> I’m curious where the perceptual limits really are, and what the max framerate we actually need is.
I don't know exactly; there are definitely diminishing returns, like you've mentioned:
- 30fps: 33ms / frame
- 60fps: 17ms / frame (2x cost for -16 ms)
- 144fps: 7ms / frame (2.4x cost for -10 ms)
- 240fps: 4ms / frame (1.6x cost for -3 ms)
- 500fps: 2ms / frame (2x cost for -2 ms)
- 1000fps: 1ms / frame (2x cost for -1 ms)
Just from looking at those numbers, 144fps is still a clear win and 240fps probably makes sense too, if you've optimized your setup for latency. Everything beyond is probably pointless, unless it's your job to play competitive FPS games ;)
For anyone that doesn't understand why this matters, the CPU still needs to prepare the full scene before sending it over to the GPU for polygons to get rasterized and shaders to get calculated. Most of the time the CPU does all of the physics as well. So even if GPU render time goes to 0ms, 2ms spent by the CPU per frame means 500fps is the best you'll get without a better CPU or better code. And I suspect game devs aren't looking to shrink their budgeted CPU time just so someone benchmarking can see 1000fps.
CS:GO also doesn't use any of the new approaches that reduce CPU time in those operations and more effectively saturate the GPU. Compare CS:GO against Doom:Eternal, which runs at high fps while providing massive improvements to visuals.
This is essentially folk wisdom - but I think you can trust the other people in this thread that it's accurate. I doubt anyone has done a scientific study on this, but you could see this for yourself by setting your computer's clock rate lower and re-running the benchmark.
I expect that if you have a 4090, you have an Intel or AMD CPU that exposes a core clock multiplier. You could run this benchmark with whatever value it's at, then reduce the modifier by say, half. That should halve your CPU's clock rate, and I'm guessing you'll see the frame rate decline similarly. You can conclude that the game is "CPU bound", then.
Even if your GPU was infinitely fast, you have to remember that game developers are not optimizing for the game event loop to run in sub-millisecond times. If the core loop in the game takes under 16ms to run on a common CPU, such as one in a console: that's better than 60hz and the overwhelming majority of video game players will never see a benefit.
Some game developers, I see someone in another thread mentioned Doom Eternal, pride themselves on that optimization. With a fast enough CPU and GPU, you could probably reach 1000 FPS on Doom Eternal. A quick search suggests this might have been accomplished with a liquid cooled, this was done with a liquid nitrogen cooled PC with a 6.6GHz CPU: https://www.pcgamer.com/heres-doom-eternal-running-at-1000-f...
Actually kinda yes, look at AMD’s 3d v cache. There’s a very recent review by the verge on an Asia laptop with the AMD chip, and it does hit like 600-700 fps. CPUs can absolutely make such a difference.
Study, lol. Run the game with uncapped FPS and see your CPU vs GPU usage. Your modern GPU is probably going to be chilling at 30% while your CPU will be pegged in some way (most likely at least one core at 100%).
Moore's law is about transistors, not CS:GO. CS:GO benchmarks stopped advancing as quickly because Moore's law is - objectively, despite the protestations of semiconductor companies - dead.
You can't just use an arbitrary game to test your hypothesis like that. You need to test with something that caps out the 4090 at 100% usage and then see how a 1070 performs in comparison. It's not quite that simple of course, so just look up some benchmarks ;)
Admittedly knowing nothing, I’m going to assume that a great deal of the advantages of the latest generation aren’t going to improve performance in a decade old game since the engine won’t touch them.
How does a 1070 fare versus a 4090 in Hogwarts Legacy or another modern game at 1440 or 4K?
My guess is that we've reached a peak in the amount of new investment that can be made annually, based on tech nearing total proliferation throughout society. The tech can sort of only advance as fast as tech companies can grow, and they can't grow exponentially after they account for some percentage of the global workforce.
My guess is that we'll see improvements at closer to the current rate rather than at an increasing rate.
The good new is that Nvidia's high GPU prices motivate everyone (Intel, AMD, ARM, Google, etc.) to try and tackle the problem by making new chips, making more efficient use of current chips, etc. For all the distributed computing efforts that have existed (prime factorization, SETI@Home, Bitcoin, etc.), I'm surprised there isn't some way for gamers to rent out use of their GPU's when idle. It wouldn't be efficient, but at these prices it could still make sense.
They’re all pretty motivated, they’ve been motivated for years, and almost nothing is happening. This situation isn’t exactly a poster child for the Efficient Markets Hypothesis.
Every year just sounds like “Nvidia’s new consumer GPUs are adding new features, breaking previous performance ceilings, running games at huge resolutions and framerates. Their datacenter cards are completely sold out because they can spin straw into gold, and Nvidia continues to develop new AI and graphics techniques built on their proprietary CUDA framework (that no one else can implement). Meanwhile AMD has finally sorted out raytracing, and their consumer GPUs are… well not as good as Nvidia’s but they’re a better value if you’re looking for a competitor to one of Nvidia’s 60 or 70 line GPUs!”
> The efficient market hypothesis (EMH), alternatively known as the efficient market theory, is a hypothesis that states that share prices reflect all information and consistent alpha generation is impossible.
I honestly dont. I'm trying to think of what principle they could have meant with "This situation isn’t exactly a poster child for X" where X is any economic principle and coming up empty.
Best I've got is "central planning". One firm being able to handily out perform others despite them also being both motivated and well capitalised lends itself pretty heavily towards markets being good, but I hardly think they were referring to "central planning" when they wrote "efficient market hypothesis".
If it's so obvious to you that you're dropping ellipsis, care to clue us in?
My impression was that they used "Efficient Market Hypothesis" to mean "the theory that free-market competition rapidly drives down prices and breaks up monopolies on its own".
Well, patents are certainly a good way to create monopolies, which wouldn't exist in an actually free market with no patents. In addition, there's interventions in place which don't allow certain tech exports to China, for example. Not sure how much better the situation would be without these.
I think the principle is called perfect market or perfect competition, but it's only a theoretical concept. However, it's certainly possible that the market is less perfect than it could be due to interventions and regulations.
Not endorsing that theory, just offering my best guess at what the person probably meant when they used "Efficient Market Theory" in their comment, based on the context.
That theory is still valid, the issue is that the competition can't or won't even try to make a better product or a cheaper one. The rule only applies if there exist competing products in the first place.
If there was any, the prices would go down as we have seen a billion times.
It’s not happening because 10,000 people who have more intimate knowledge of the business than you or I ever will have made decisions to best suit their current conditions. This isn’t an exception to the rule, you’re just looking at a small timeframe and a remarkably performant company. Why is it so bad for a company to be successful when they have provided so much back to society in the form of R&D? Besides, if I’m doing ML my boss has paid for the card anyway so the price doesn’t concern me.
This is a textbook situation that would be perfect for a competitor to come in and undercut. However not only is that not happening, nobody is even trying.
Making the “theory” pretty worthless if it’s not even applicable in cases that would naturally produce this market entrant.
The reality is that private equity does not actually want to compete with large global brands.
> This is a textbook situation that would be perfect for a competitor to come in and undercut.
Is it? A competitor can enter the market and undercut by producing a cheaper and otherwise undifferentiated commodity-type product. Nvidia's focus is adding moats that prevent competing on pure specs such as CUDA, design, and so on.
I didn't know CUDA was in development for that long, thanks! I'm curious if there were serious attempts to create something similar over the years and how far they managed to progress. I've never used OpenCL but from looking at it from afar its adoption always seemed limited.
Irrespectively though I don't see how a competitor can replicate the context and tacit knowledge associated building something like CUDA for close to 20 years without putting in a similar amount of time.
The first version of CUDA was released in 2007 so I would not be surprised if they started working on it in the 90s. These things take time.
Nvidia also made sure that CUDA runs on gaming GPUs and supports Windows. This is why its tools are so good. You don't need to buy a datacenter GPU, no need to mess with Linux. Just buy any gaming GPU, install CUDA SDK and you're good to go.
AMD wasn't like that. Their alternative - ROCM didn't even work on gaming GPUs. Their datacenter GPUs didn't even support Windows. Basically the opposite approach of NVIDIA. Now AMD is rushing to add Windows and consumer GPU support to ROCM, but it's a bit too little too late.
> This is a textbook situation that would be perfect for a competitor to come in and undercut.
Do you have any idea how much R&D it takes to make a GPU, let alone something that could possibly compete with NVIDIA?
This is not something a dozen people in a large garage are going to do.
> However not only is that not happening, nobody is even trying.
AMD has been trying to compete for years. If you're a gamer that doesn't care about getting the top performance and just wants to optimize price/performance, their offerings aren't bad.
> The reality is that private equity does not actually want to compete with large global brands.
Because the barrier of entry into the GPU market is probably at least a couple billion dollars.
> This is a textbook situation that would be perfect for a competitor to come in and undercut.
They already are undercutting.
Some business that are really into hyper-scaling are already pouring man-hours into making those "undercut" alternative products work. Specifically because sometimes you can't affort Nvidia at that scale. Or they have a large enough scale that they can make it work with suboptimal tech.
It's just that for most business the man-hours required to make "undercut" products work still aren't cheap enough to win in cost-benefit.
No, spell it out because it’s complete nonsense as it is. The efficient market hypothesis has zero relationship to barriers of entry, network effects, or any of the other dozen concepts that maybe are actually at play here.
> This situation isn’t exactly a poster child for the Efficient Markets Hypothesis.
I'm unsure why you're criticizing the Efficient Markets Hypothesis or even using it here, but you need to also analyze this with some time horizon because the market and marketplaces are not static.
Tech design and development seems, to me at least, pretty much naturally opposed to the "being kept in check with competition" state - as design isn't really a cost that scales per-unit, the company that sells slightly more can afford to put more into development at the same per-unit margin, which snowballs. At some point, they own the entire market - or enough that they functionally control it, and start leveraging this position. I'd argue we're seeing this from Nvidia right now.
People talk about AMD being competition - but from most stats I've seen, they're ~10% of dGPU sales, with Nvidia being the other 90% (with new Intel offerings being pretty much noise now). That means that if they invest the same proportion into development, NVidia nearly have 10x the resources.
It may be that tech companies like this would "naturally" form a monopoly without outside (IE government) interference, as the only reason that multiplier of development resources doesn't completely crush new entrants is rather extreme mismanagement, or a new segment is created where the design resource don't really cross over that much.
I don't see anything like that happening in the short term, if anything there seems to be more opportunity for cross pollination of development within these corporations, as there's a fair bit of design similarities between various silicon (GPUs, CPUs, accelerators for the current ML techniques etc.) that may encourage more consolidation in the whole semi market to take advantage of that, not less. But again the only thing stepping in the way of that seems to be governments trying to keep national interests, like the blocking of NVidia buying ARM to pull in one of the big CPU players. Plus all their other IP that they may benefit from, like low power GPU designs or other accelerators ARM have designed.
At the end of the day, what nvidia does is just producing IP. All manufacture is by other companies.
This means that nvidia capital is spend on testing/development infrastructure and creative labor.
So, you don’t need monopoly breaking to handle nvidia if it keeps growing, but instead rethink IP laws.
Testing infrastructure is less capital investment than production manufacture. (See ASML and TSMC beeing booked), and humans can be persuaded to work elsewhere.
This means Nvidia cannot fall a sleep, even if they keep snowballing. In a few years a rival can always arrive, or current ones snag key people or have dev/test infra breakthrough, or IP law could change as its critics rise every year.
Sure, if Nvidia keeps its good game it will keep on growing and get even bigger share, but if it doesn’t, it will happen what happened with intel, intel got greedy on its position, and the company got fat.
As long as nvidia keeps its game, it’ll be good for customers even if they swallow more market share, as prices are always limited by the value business customers get from AI, and the investment needed for a competitor is not even close to infrastructure or resource extraction stuff like high end chip fabs, oil extraction, energy grids, telecom grids.
Again, Nvidia does not produce any physical goods, only designs.
I think Intel having in-house manufacturing was one of the big causes of them getting "Too fat and slow to respond" - from the outside much of their fall from grace was due to massively delayed production improvements rather than designs and IP. As far as I can see, the architectures were pretty much done and ready to go, just the expected targeted process missed it's mark.
With Nvidia and other GPU competitors being IP-focused, effectively outsourcing all this "manufacturing stuff" (to the same 3rd party much of the time), that's one less thing for them to keep up with, and one less think that'll hurt if they do start "falling asleep". I can't see this happening to Nvidia in quite the same way right now. My point was that not having manufacturing makes advantages of consolidation larger, not smaller.
I wonder what would have happened if Intel realized it's manufacturing wasn't hitting targets and "quickly" added TSMC as an option, would AMD even have had a chance with ryzen? There was clearly a time when AMD had superior manufacturing processes through them, if Intel's designs of the time were on the same process would they have managed to grab the headlines?
And no, I Strongly disagree that NVidia running unchecked over the entire market being "Good for consumers", and not sure if the capital expenditure of getting over this moat is really much smaller than things like resource acquisition or infrastructure, they have $billions in current software ecosystems and hardware designs. Those $billions probably could buy you a fair bit of infrastructure investment on the scale you mentioned. Look how much Intel is burning right now just to get a toe into the market and not laughed out the door - and they're still clearly behind their competitors right now. Their chips aren't anywhere near competitive from a performance-per-area point of view, and their software is rather poor for the vast majority of use cases.
It's not like designing this kind of product is easy; or that Nvidia's designers are sitting idle; or that everybody else's design team is not busy building something else. There are in fact many competent design teams, chipping at their own business.
There are in fact startups, also doing what they can (and probably not trying to go head on against the most productive competitor they can find.) And it has been reported countless times that some of the biggest customers of Nvidia are actually trying to design their own.
If you want to point out a market with broken competition, this isn't it.
The situation is created by artificial restrictions on free market (namely state enforced monopolies on "IPR", or as some call it, imaginary property).
Are they motivated? Seems like a massive coincidence how the big two of the GPU world are cousins, and one has been having massive success on the CPU, the other on GPU/AI, and every attempt from both side to enter the other's niche has been pretty weak.
AMD compute is nowhere compared to NVIDIA. NVIDIA wanted to buy ARM, has got its finger in RISC-V, but apart from that, they don't really care. To be fair AMD has done decent with GPUs, but never enough to dethrone NVIDIA, whose playbook for the past few gens is "just make everything bigger than last gen and increase the frequency." Surely AMD could have chosen the same lazy approach to surpass the 4090 only just, but instead they didn't, so it's still NV undefeated in its space because AMD forgot to squeeze the last 1% out of their card.
The market is powerless if the competitors aren't really competing. Intel is the only chance, unless they manage to get their own Taiwanese CEO somehow related to Huang and Su.
Leaving aside the weird conspiracy stuff, I don't know how you can see stuff like the nvlink C2C that makes Grace Hopper possible and think they went "just make everything bigger".
> motivate everyone (Intel, AMD, ARM, Google, etc.) to try and tackle the problem by making new chips
Yes, there has been repeated efforts to chip at Nvidia's market share, but there's also a graveyard full of AI accelerator companies that fail to find product market fit due to lack of software toolchain support - and that applies even for older Nvidia GPUs and their compatible toolchains, let alone other players like AMD. This isn't a hit on Nvidia, I'm just saying things move so quickly in the space that even the only-game-in-town is trying to catch up.
Nvidia is also leading by being one or two hardware cycles ahead of their competition. I'm pretty confident AI workloads in enterprise is their next major focus [1]. I think this more than anything else will accelerate AI adoption in enterprise if well executed.
To your point, I think the industry needs to focus more on the toolchains that sit right between the deep learning frameworks (PyTorch, Tensorflow etc.) and hardware vendors (Nvidia, AMD, Intel, ARM, Google TPU etc.) Deep learning compilers will dictate if we allow all AI workloads run on just Nvidia or several other chips.
"The Render Network® Provides Near Unlimited Decentralized GPU Computing Power For Next Generation 3D Content Creation."
"Render Network's system can be broken down into 2 main roles: Creators and Node Operators. Here's a handy guide to figure out where you might fit in on the Render Network:
Maybe you're a hardware enthusiast with GPUs to spare, or maybe you're a cryptocurrency guru with a passing interest in VFX. If you've got GPUs that are sitting idle at any time, you're a potential Node Operator who can use that GPU downtime to earn RNDR."
I am certain that several years ago, I was given an ad for exactly such a service and even tried it out, but I cannot for the life of me remember its name. It had some cute salad motif, and its users are named "chefs".
You can do that for inference, but most gamers have a single GPU with <24GB VRAM which kinda sucks for training. 3090 or 4090 is the minimum to use reasonable batch sizes
The good new is that Nvidia's high GPU prices motivate everyone (Intel, AMD, ARM, Google, etc.) to try and tackle the problem by making new chips...
Or their dominance leads to competition throwing in the towel and investing resources in a market with less stiff competition.
I wouldn't be surprised to see AMD start to pair back ivnestment on high-end GPUs if things continue down this path. I would say Intel likely keeps pushing, but I'm less convinced they can actually make much headway in the near future.
As was mentioned in another thread on a slightly different topic, it wouldn't be surprising to see all non-Nvidia parties unit around some non-CUDA open standard.
I must admit my previous comment was mildly sarcastic.
What I was after is: OpenCL is that language/framework that is consortium driven and open.
It’s been there since the start of time.
Still it cannot dethrone CUDA…
Nvidia struck gold with CUDA and its lock-in
> I would say Intel likely keeps pushing, but I'm less convinced they can actually make much headway in the near future.
It seems that Intel is making great headway on their fabs and may somehow pull off 5 nodes in 4 years. Intel 3 is entering high volume production soon and according to Gelsinger 20A is 6 months ahead of schedule and planned for H2 2024.
If they do pull this off and regain leadership that would change outlook.
I'm not familiar with all the varied uses of GPUs but it seems like image generation could feasibly be distributed: large upfront download of models, then small inputs of text and settings, and small output of resulting images.
If you're in a data center and running large training jobs then RDMA over Nvidia Mellanox Infiniband cards over high speed ethernet (like 100GB) are used to ship coefficients around without having that transfer bottleneck in the CPU.
> I'm surprised there isn't some way for gamers to rent out use of their GPU's when idle.
The main reason why you need massive ammounts of fast VRAM in the first place is that the main limitation of AI is memory bandwidth. Can't simply distribute an algorithm that is already throughput limited by memory bandwidth and distribute it with awful latency and bandwidth and hope for any improvement.
In bitcoin mining, GPU phase lasted only two years, before been outcompeted first by specialized FPGAs and then by ASICs. Nobody used GPUs for bitcoin mining since 2013. Maybe ML will follow similar path. But the computation is much different from ML, doesnt need memory at all.
if they have transistors for gaming, this is extra unneeded cost from the matrix multiplication point of view. If they have not, those are not GPUs anymore.
The larger language models now employ a trillion parameters. This is faster when memory and computing is tighter, not distributed. Cerebus's million core super-wafer addresses this.
There have been various attempts but you need a workload that's basically public and also runs on a single GPU (because you don't have NVLink or similar).
Incredible company. It’s absolutely insane how far ahead they are with the investments they made over a decade ago.
So nice to see a “hard” engineering (from silicon to software) SV-founded company getting all this recognition. Especially after what has felt like a decade of SV hype software companies dominating the mainstream financial markets pre-pandemic with a spate of overpriced IPOs or large ad-revenue generating mega corporations.
The moniker of "hard" engineering is neither precise nor useful. What makes engineering hard? Is solving problems with distributed systems, even if these systems are for ads, hard? Or do you mean hardware? In that case even Nvidia is not hard enough since they don't fabricate their own chips. Or do you mean designing hardware? Then what makes writing system verilog at a desk hard but writing Python not hard?
I’m really speaking about Nvidia’s ability to perform well in both hardware and software, at chip-scale and datacenter-scale. Also speaking of their product/business direction that revolutionizes multiple industries (leaders in graphics with ray tracing and AI frame/resolution sacking; leaders in AI infra and datacenter systems, etc.) all resulting in big impacts to their respective industries.
You’re right that many of those software-only companies do very real engineering with distributed systems and such. I should’ve been more precise and was really complaining about the SV hype of the 2010s focusing on regulating-breaking companies like Airbnb, Uber, wework, etc. and on companies like Meta and Google who focus on pushing ads for their revenue.
I suppose the difference is engineering something deterministic (i.e., physics, electronics, logic) versus something soft and indistinct (SEO, ad impressions, customer conversion rate).
It's hard to get complex systems correct. There's far less margin for error when you get a hardware design wrong. Correcting a Python software mistake is orders of magnitude easier and cheaper to resolve, it doesn't cost multiple billions and take 6 months to iterate. You might consider the hardware design harder in that respect.
> Software and hardware from competitors will catch up, crunching 4/8/16 bit width numbers is no rocket science.
I used to think like that, until I got a job there and... Oh, boy! I left five years later still amazed at all the ever more mind bending ways you can multiply two damn matrices. It was the most tedious yet also most intellectually challenging work I've ever done. My coworkers there were also the brightest group of engineers I've ever met.
Its similar story with iPhone/ iOS vs Android. Endless talk about how Android is about to get so much better in performance compared to iPhone didn't yield much. I guess lately people have accepted perf will never match up. At least Android massive market share in rest of the world so with perf/pricing/compatibily/ localization it will remain competitive in some sense.
I hope but do really foresee that AI/ML systems will have similar competitive stack like Nvidia.
I haven’t crossed over to the other side in a while, what do you find lacking in Android performance? I was under the impression that these days it’s solidly in “good enough not to notice” territory.
Nvidia has a small lead on the industry in a few places, adding up to super attractive backend hardware options. They aren't invincible, but they profit off the hostility between their competitors. Until those companies gang up to fund an open alternative, it's open season for Nvidia and HPC customers.
The recent Stable Diffusion results are great news, but also don't include comparisons to an Nvidia card using the same optimizations. Nvidia claims that Microsoft Olive doubles performance on their cards too, so it might be a bit of a wash: https://blogs.nvidia.com/blog/2023/05/23/microsoft-build-nvi...
Plus, none of those optimizations were any more open than CUDA (since it used DirectML).
> crunching 4/8/16 bit width numbers is no rocket science.
The problem with that "15 competing standards" XKCD is that normally one big proprietary standard wins. Nvidia has the history, the stability, the multi-OS and multi-arch support. The industry can definitely overturn it, but they have to work together to obsolete it.
Perhaps RDNA3 GPUs get comparable results, but RDNA2 GPUs are behind.
I bought a RX 6800XT to do some AI work because of the 16GB VRAM, and while the VRAM allows me to do stuff that my 6GB RTX 2060 wasn't able to, on performance side it's actually a downgrade in many aspects.
But the main issue is software support. To get acceptable performance you need to use ROCm, which is Linux only. There was some Windows release of ROCm few weeks ago, but I am not sure how usable it is and none of the libraries have picked up on it yet.
Even with a Linux installed, most frameworks still assume CUDA and it's an effort to get them to use ROCm. For some tools all it takes is uninstalling PyTorch or Tensorflow and installing a special ROCm enabled version of those libraries. Sometimes it will be enough, sometimes it wasn't. Sometimes the project uses some auxiliary library like bitsandbytes which doesn't have an official ROCm fork, so you have to use unofficial ones (that you have to compile manually and Makefiles quickly get out of date). Which once again, may work or may not.
I have things set up for stable diffusion and text generation (oobabooga), and things mostly work, but sometimes they still don't. For example I can train stable diffusion embeddings and dreambooth checkpoints, but for some reason it crashes when I attempt to train a LORA. And I don't have enough expertise to debug it myself.
For things like video encoding most tools also assume CUDA will be present so you're stuck with CPU encoding which takes forever. If you're lucky, some tools may have a DirectML backend, which kinda works under Windows for AMD, but it's performance is usually far behind a ROCm implementation.
However AMD is still as terrible at H264 as ever, and their AV1 encoder also has a hardware defect they’ve patched by forcing it to round up to 16 line multiples, so it is incapable of encoding a 1080p video and instead outputs 1082p that won’t be ingested properly when streaming.
Also the AV1 quality is not as good as intel+nvidia even with resolutions that aren’t glitched. AMD seemingly went big on HEVC (supposedly because of stadia?) but everything else is a mess.
And most places won’t touch HEVC because of the licensing costs. Microsoft makes it a windows store plugin you have to buy separately etc. somewhat odd that google picked HEVC for stadia but I guess those customers are actually directly paying you vs YouTube being a minus on their balance sheet (at least until recently possibly)
Whelp, I guess those September NVDA call options I sold are going to get exercised. Who woulda guessed after the crypto fallout that "AI" would come along and bump the price back up.
Record revenues, and a dividend of $0.04 on a $450 stock? That's not even worth the paperwork. For example, if you bought 100 shares, that's $45K. From that, around September $4 will show up in your account, which you have to pay taxes on. So $3 or so net on a $45,000 investment. Sure, there were stock buybacks, but why keep the token dividend around?
It's probably good for the long term share price if they can say in 20 years they've had a dividend for 20 years, even if that dividend was actually measly.
A stock buyback trades certainty of wealth transfer (you're not sure the price will go up, or by how much!) for flexibility in when the investor takes the gains for purposes of fiscal planning.
For large shareholders, the dividend would still be worthwhile. From what I could find, Jensen has 1.3 million shares, so he'd receive over $200k in dividends this year. You might think that's chump change, but another source lists his salary at just under $1m; another 20% bump in liquid income is nothing to sneeze at.
> From what I could find, Jensen has 1.3 million shares, so he'd receive over $200k in dividends this year. You might think that's chump change, but another source lists his salary at just under $1m; another 20% bump in liquid income is nothing to sneeze at.
Jensen Huang is worth $42 billion and has been a billionaire for probably a decade or so now? Any CEO with that net worth would use stock-secured loans/LOCs for liquidity. 200k is very much chump change.
I'll get right on that...after I go look up what that means. :-) I'm but a simple options trader who sells calls to unload stock I didn't want anymore anyway, and the premium is the icing on that cake. Left some money on the table this time, but I otherwise would have just sold the shares outright, and I did make some bank regardless.
Gonna be missing that sweet, sweet $0.04 dividend, though.
A call credit spread simply means buying an even more out-of-the-money call along with the one you sold. It would have reduced the premium collected, but the long call would appreciate on sudden moves like today's.
Theta gang ftw. But I would advise you to stay away from NVDA, as soon as the first quarter with flat or decreasing revenues comes (and it WILL come), the fall would be one to tell your grandchildren about.
This benefit is basically only to large shareholders who can't sell stock. Which might be insiders like Jensen and... anyone else? Everyone else can just sell, like, 0.0001% of their stock or whatever.
To remind us all, they're selling capitalized assets, not contracts or services.
Is the marginal demand for GPU chips over the next 3 years enough to sustain (or grow?) current revenues and keep this valuation afloat? To me, it feels like a comparatively fragile situation to find themselves in, to convince the world of 2025 that they need even more chips, unless "everybody needs to train their own LLM" is a secular trend.
I'm not sure if investors fully appreciate the nuances of this boom, or if I'm not fully appreciating how many GPUs "need" to be held by different companies (and sovereign entities, if you've read the headlines in the last couple weeks) to train LLMs in the coming decade.
it will be sticky as long as there's a cambrian explosion of AI innovations happening. NVIDIA built the best swiss-army-knife for handling GPGPU problems in general, spent 15 years building the ecosystem and adoption around it, and then tailored it to AI specifically.
Once the tech settles down a bit, Google and Amazon and others can absolutely snipe the revenue at a lower cost, just like they did with the previous TPUs/gravitons. But then some new innovation comes out that the ASICs (or, ARM+accelerator) don't do, and everyone's back to using NVIDIA because it just works.
AMD potentially has a swiss-army knife too, but, they also have a crap software stack that segfaults just running demos in the supported OS/ROCm configurations, and a runtime with a lot of paper features and feature gaps. And NVIDIA's just works and has a massive ecosystem of libraries and tools available. And moreover they just have a mindshare advantage. Innovation happens on NVIDIA's platform (because NVIDIA spent billions of dollars building the ecosystem to make sure it happens on their platform). And it actually does just work and has a massive codebase etc. Sure it's a cage but it's got golden bars and room service.
So I guess I'd say it's sticky until the technology settles. Steady-state, I think competitors will capture a lot of that revenue. But during the periods of innovation everyone flocks back to NVIDIA. AMD could maybe break that trend but they'll have to actually do the work first, they have tried the "do nothing and let the community write it" strategy for the last 15 years and it hasn't worked. You gotta get the community to the starting line, at least. Writing a software ecosystem is one thing, writing runtime/drivers is another.
Which is - excuse my French - fucking insane. The current PE ratio of 244 is pants on head ridiculous. That's 244 years worth of exceptionally high profit just to break even. Your great great great great great great great great grandchildren could take over your shares at the same value as today and the company would still be overpriced. That's centuries worth of technological change and high volatility baked into the price. There is no way on Earth the company is worth anywhere near that. No one can impute that kind of extraordinary risk effectively. This is now officially a meme stock. Nvidia is proof positive we currently have an equities bubble. Not even Tesla was this overpriced, and they're still down 40% since their all time high.
No I agree. Tesla still has a realistic path to fairly significant increase in revenue. I still think it's too high, but compared to Nvidia, it's downright reasonable.
I meant the sudden increase seems to be similar to what happened to Teslas valuation in the past. Both have products/profits/valuation that have a lot of hype and huge margin partially driven by shortages.
Up more than 10% after hours compared to close yesterday. I really thought NVDA had hit its ceiling at $1+ trillion, apparently not. Really does feel like a huge opportunity for Intel to me. They have the fab capacity to pump out at least reasonably competitive GPUs if they can figure out the software side of things.
P/E still above 50 even after the AI craze 9x'd eps this quarter. Still hard for me to see that valuation ever makes sense but what do i know.
Intel doesn't seem to be able to execute. It's not just pumping out GPUs - for AI you need drivers, and the equivilent of CUDA and all the various libraries built on CUDA like cuDNN. They do have OneAPI but it hasn't caught on like CUDA in that space. It's kind of too bad since OneAPI is open and CUDA is not.
Right but the market is saying that a dominant GPU business is worth more than a trillion dollars. Just hard for me to believe that they can't get the business off the ground with that kind money on the table. Can't they just hire all of nvidia's developers and pay them 5x as much?
>Can't they just hire all of nvidia's developers and pay them 5x as much?
As time goes on I don’t see how you break the CUDA moat even if you had all of nvidia Al’s engineers.
CUDA means you need everyone in AI to target your new (hopefully open) platform and that platform is faster than CUDA is. Given how most frameworks of the last 10 years have been optimized for CUDA you would need to turn around a global sized cruise ship.
If Intel’s GPUs are only 3% faster, will that be enough to rewrite my entire software stack for something not CUDA? If intel opts for a translation layer, could they ever match nvidia’s performance?
Well I'm not super experienced with GPU development but aren't most people using packages built on top of CUDA like pytroch etc? Would it be impossible to throw tons of resources at those packages so they handle whatever intel comes up with as well as they handle CUDA?
If Intel is 10% slower but 50% cheaper and the open source stack you use has been heavily updated to work well with Intel drivers would that not be an enticing product?
> aren't most people using packages built on top of CUDA like pytorch etc?
Yes, and in fact both AMD and Intel have libraries. You can run Stable Diffusion and suchlike on AMD GPUs today, apparently. And you can export models from most ML frameworks to run in the browser, on phones and suchlike.
> If Intel is 10% slower but 50% cheaper [...] would that not be an enticing product?
Sometimes, yes. Some of the largest models apparently cost $600,000 in compute time to train [1], so halving that would be pretty appealing.
However, part of the reason for nvidia's dominance is that if you're hiring an ML engineer for $160,000/year spending $1,600 to give them an RTX 4090 is chump change.
Intel's been trying this for several years now (OneAPI and OpenVINO), but so far they haven't gotten the traction. CUDA is just really entrenched at this point.
for a trillion dollars though... eventually you have to believe Pat gets fired and replaced by someone who is 100% all in on GPUs if he can't figure this out
I'd argue that Intel being stingy with salaries is a big part of why they're so behind here. They just don't seem to be very serious about this. Intel has made several runs at the GPU market over the years and they just keep ending up where they are. And now NVDA has such a huge advantage (software and hardware) that it just gets harder and harder (and more expensive) to overcome.
Probably Intel's best bet now would be to try to be the fab for NVDA.
Maybe everything changes at $1 trillion, but I definitely see smaller (but public) companies leaving money on the table because it would require cultural change.
The market is also saying that Tesla is worth more than BMW, VW, Audi, Mercedes, Toyota, Hyundai, Fiat, Ford, and dozens of others combined. Mehh, I don't know.
Exactly, the market isn't always rational. There's a lot of work on quantization in neural nets, for example, that can allow them to work sufficiently well on less capable hardware. It could be that some breakthrough there would obviate the need for NVDA hardware (or at least reduce how many are needed).
It is rational if you interpret market capitalization and share price movements as “the market is saying Tesla WILL be worth more than x,y z combined between time now and time whenever you want to sell it.”
For different people, the timespan between now and when they may want or need to sell it is different, and thus different people will arrive at different conclusions.
And note that “worth more” above simply means growth in market capitalization, so as long as someone is willing to buy the shares at a price supporting that increased market cap, then it does not matter if Tesla is still selling fewer cars than the others combined.
And as somebody with a significant short position, I would add - "The market can stay irrational longer than you can stay solvent" !
Their numbers for this and next Q are absolutely amazing. It's also quite "refreshing" - a company with great product, almost without competition (so far - it will come real quick). And fun part being their main advantage is probably CUDA and not even the chips itself (which by the way they don't manufacture - they "only" do the design).
But still - even with those numbers, and even with this pace of growth (both being absolutely not sustainable, and will probably reverse hard next year) - the valuation doesn't make any sense, especially given the current interest rates.
Yeah, there is no world where Nvidia grows into this valuation. It would have to be bigger than the entire semiconductor business today by itself. If you think AI can bring that much growth, well then it could happen, but it seems extremely unlikely to me.
I can really see Intel figuring this out. A lot of people on HN talking about Intel as an also-ran just like they spoke about AMD before Zen.
Raptor Lake is at 7nm and incredibly competitive there (~2700 single core on geekbench, taken with a pinch of salt). They’re still planning on being on 1.8nm/18A within 2 years, while at the same time ramping up their GPU efforts (albeit using TSMC for 4nm). Nvidia is very much in the lead, but this is just the beginning.
They lost most of their talent in the early/mid 2010s but you're right to an extent for non-software. For software they're not a terrible place to accumulate domain specific knowledge but don't really retain people long enough or promote quick enough to make a difference.
In reality it literally is as simple as “intel says it’s 7nm so it’s 7nm”, but density is what determines the node number, insofar as anything determines it beyond marketing.
So, if intel 7 is a 10nm class node then so is tsmc N7. But the whole industry cooked their node names a decade ago and intel is allowed to do the same terminology. To do anything otherwise would be a needless marketing disadvantage. If someone’s cheating on marketing, everyone has to - and the reality was everyone but intel was already cheating.
This, but also if we took it at face value (we shouldn't for the reasons in the reply above), then this means Intel is even further ahead when adjusting for the difference in node sizes.
i.e. This would mean Intel will be getting a four-node-scale jump in performance (10nm->7nm->5nm->3nm->1.8nm) from where they are with Raptor Lake by 2025 if they can stay on track.
I don't have any insight into this but I would hope Pat Geslinger is righting the salary, perks and incentive structure as a matter of priority to stop the shedding of talent.
> I don't have any insight into this but I would hope Pat Geslinger is righting the salary, perks and incentive structure as a matter of priority to stop the shedding of talent.
Absolutely not and this is one of the strongest headwinds intel faces. They just did a big round of layoffs and then everyone who didn’t get cut got a surprise 20% pay cut after, and retention bonuses for seniors was typically low-3-digits to high-2-digits. Principle engineers were solidly 3 digits though. And then they did stock buybacks that exceeded the size of the layoffs and pay cuts.
Intel is fucking broke and they’re gonna have to cut every cost they can to focus on their key markets, and do it with personnel that were already underpaid and have better opportunities elsewhere. Not that labor is the straw that’s breaking intel’s back here but the situation is really AMD-in-2012 level dire, they have an incredibly long and expensive road to return to profitability and they will have to do it with whatever they can scrape up out of a staff that was already abused even in the “good times”.
Oh and they want you to move from desirable west-coast locations (well, except Arizona) to Ohio. And they’re massively behind on their tech stack (fighting uphill is not what everyone wants) in a failing org with a ton of middle-management rot and neglect. And they’re still failing to execute a huge amount of the time, causing massive delays, etc.
It’s really really dire and just because intel has staunched the worst of the financial bleeding doesn’t mean there’s much light at the end of the tunnel. Like Boeing I don’t think they will be allowed to go under, they’re strategically too important, but they’re gonna have a bad time for a while and probably legitimately do need a bunch of subsidy and “pity contracts” for national labs HPC computers to stay on their feet - just like AMD did.
Hot, literal desert in the climate change era with few local water supplies and powerful stakeholders with river water rights, mediocre politics in an unstable era, not really a tech hotspot outside TSMC/Intel. It's not awful but it's not folsom or hillsboro or seattle, it's kind of ohio-lite (with slightly less culture wars, but much worse water problems).
(oh and to be clear by "2 to 3 digits" I don't mean 10-999% bonus... I mean they gave senior engineers a $75-125 retention bonus and principals might get 2 or 3 hundred. Those are the people who will build Intel's next foundational architectures and the nodes and the packaging technologies that lead themselves and their foundry customers to success. Have fun with that.)
Over the past decade Intel seems to have become more interested in social causes than in technology, maybe with a side of government backrubbing to keep some income flowing.
Nah, the biggest problem is that Intel became very risk averse. Yeah, they'll talk a good game on taking risks, but when it comes down to it people who took risks that failed tend to not be at Intel and other employees see that and think that maybe they need to play it safe.
> Yeah, they'll talk a good game on taking risks, but when it comes down to it people who took risks that failed tend to not be at Intel and other employees see that and think that maybe they need to play it safe.
I worked at Sears corporate when Amazon was getting big, about 25 years ago.
Always made me chuckle when armchair quarterbacks on TV would wonder why Sears couldn't do what Amazon did.
Bezos took tremendous risks in the late 90s and early 00s, while Sears was trying to figure out how to wring a few more pennies out of their stores. Sears Corporate was 110% focused on taking the existing business and maximizing profits, not on innovation of any kind whatsoever.
I wonder if this is what Nancy Pelosi's husband actually bought all his NVDA in preparation for, way back then. Their prices have been shit for consumers since then, but it's still been good for them.
The fundamental model of company valuation is that the company's equity is worth the accumulation of the company's future cash flows, typically discounted by some rate so that predicted cash flows 5 years from now are worth some % less than 100%, with the intent of pricing in uncertainty.
Nvidia has had a watershed moment of revenue growth, because they're the only significant player in the space of top-of-the-line GPUs for training LLMs.
Their current valuation bakes in the assumption that not only is this unprecedented level of pricing power durable, but that top line revenue will also grow significantly over the next few years.
Reminder that Nvidia is selling chips, mostly to datacenters, whose purchasing habits are primarily driven by "customer" demand (where customers are, in this case, tech companies wanting to train neural nets).
So a bet that they go up from here is a bet that datacenters will want at least as many chips in the next N continuous quarters, and will be willing to pay the current premium that Nvidia is charging, today. The corollary is you're betting that "customer demand" for ever-improving GPUs is climbing an incredibly upwards, secular (read: permanent, non-cyclical) trajectory, such that it outpaces the assumptions of these already-lofty expectations.
I think betray my own opinion, but the price is what it is. :)
So you think demand for AI driven software and tools is going to stop growing over the next few years? It’s a big call. I think it’s just the beginning personally but time will tell.
Note it isn’t the demand for AI driven software and tools that has to be sustained or increased, it’s the demand for massive GPUs that are used to train AI tools.
To make a flawed analogy, but if people want oil (AI), NVDA sells drills (means of AI production). Demand for each is obviously correlated, but the profile of demand for the two products is really different.
Nvidia is the pickaxe seller in a gold rush. Their valuation is very much tied to how big AI grows in the next several years, and how quickly competitors can arise. I could easily see them continuing to go up from here, especially if AI keeps on expanding utility instead of leveling off as some fear.
Very much so. Nvidia was lucky with the perfect sequence of video and compute farms, then cryptocurrency and model training, and now the model training direction is flowering into application (hopes) left and right. But they did great with their luck. And now they are yet again in the position of selling tools to soak up everyone else's capital investment power. They are still now (and yet again) at the perfect spot for a giant new market.
But that's still a high valuation - that is even if that new market grows to the sky, it's not clear that it can justify that new valuation.
Is Nvidia failing anytime soon? No. Is it the best investment you can find? That's harder to tell which is why the complaint of "very high valuation already". It's not in doubt that it's a great business. It's less easy to decide whether it's a great investment to get in right now.
But everything is relative a PE around 40-60 is NOT historically crazy high for the verge of a giant new market. And yet it is very high for a trillion dollar market cap. This is exciting: a trillion dollar market cap at the verge of a giant new market!
It's pretty overpriced already if you're looking at the fundamentals, and has been for a while. But fundamentals haven't really mattered in tech stocks for a long time.
If you want the responsible advice, it's overpriced. If you want my personal advice, well I bought more yesterday afternoon.
I don't see it. It would have been overpriced if not for this insane report. 854% YoY earnings growth. A PE that's now below 50 (even taking into account the $500 share price).
Its not overpriced anymore. In fact if there's anything left in the tank or this is at all sustained it's cheap.
Can you add a little more color on what fundamentals is it overpriced? Have you looked at their QoQ growth (not even YoY) for last few quarters? I would say the stock price is just trying to keep up with the numbers they are putting out.
Their quarterly dividend is only $0.04 per share, total assets at 50B (vs 350B+ for other 1T companies), they cannot easily sell more chips and increasing price can only go so far.
In my opinion it's likely mostly pull forward demand. Companies are racing to buy as many chips as possible and hoard them.
I already saw a few posts here on HN from companies that threw down insane amounts of $$ on H100s and are now looking to rent out their excess capacity. I'm guessing we'll be seeing a lot more posts like that soon.
Valuation fundamentals don't justify current prices. That said it could easily go higher (much higher). Passive investing has created a constant bid that has significantly distorted price discovery compared to pre passive era.
I would not predict a peak if I didn't predict this rise (which most people didn't?). A new crypto that requires GPU mining, continued AI boom, GPUs being used for something else?, etc.. Their price could go infinitely up.
It’s basically a meme stock now. I don’t think anyone should be surprised by wide swings and irrational pricing going forward into the next few months.
I don't think the market leader for graphics cards -- a technically complex product compared to a bunch of brick stores selling video games -- is what you can consider a meme stock
Yeah, every company of any note is planning how to use AI, and a lot of the use cases are already proved out. This isn’t speculative nonsense. The question is how big does it get, not will it be big.
Crypto and blockchain never had an actual proved out use case. There was an interesting idea but no one ever could figure out a way it was useful. The costs associated were much higher than the risks of not using it.
People who think this is a meme aren’t paying attention, and they’re certainly not in the rooms of power where AI planning is happening at megacorps. I’ve been in them, and it’s serious and material and we are just now beginning to scratch the surface.
I’m saying all of that growth has been priced in for multiple years now. It’s likely to have very solid fundamentals and new relationships in enterprises everywhere for years to come. As such it’s ripe for overvaluation by both retail and institutional traders. If I had a horse in this race I would ride the wave for a while as others piled on, then take a nice honest profit before one of their many competitors turns in a healthy AI driven quarter like this. It will still be a strong stock, but expect some significant flux in a correction.
(Not sure if it's true), but a meme stock is one whose price is propped up by retail traders, and spreads through social media / word-of-mouth, as memes do.
Retail investors make up a low single digit percent of individual stock ownership. /r/wallstreetbets is not putting even a dent in a $1T company's stock price.
> The aftermarket trading is up over 8% as of right now, roughly $41 USD to approximately $513 a share. Insane.
8% is close to nothing in stocks. Biotech stocks go up and down more than that without earnings announcements.
> Anyone who is a lot more versed in company valuation methodology see this as being near peak value, or does Nvidia have a lot more room to run?
As long as fine-tuning, training or even using these models are inefficient and no other efficient alternatives to that without these GPUs, then Nvidia will remain unchallenged unless that changes.
EDIT: It is true like it or not AI bros. There are too many to list. For example, just yesterday:
> Not if you understand what stocks are and how betting on biotech stocks is not a wise investment.
So you're giving investment advice for putting money in NVDA stock at the top or all time highs, right now on earnings as a 'wise investment' to make 8% (after hours) when others are clearly taking their money out of the market.
Unless you already invested in NVDA stock last year, that move is gone and you're just telling retail late comers to throw money at NVDA at the top for others to take their profits.
If you think Nvidia isn’t a volatile stock then you have no business discussing stocks at all. By any standard industry measure, Nvidia stock is highly volatile and it can be seen mathematically by just looking at the IV over time.
> If you think Nvidia isn’t a volatile stock then you have no business discussing stocks at all.
After warning not to buy stocks like NVIDIA at the top when other investors with larger capital are taking their money off the table?
An 8% move in reaction to earnings is close to nothing to what I've seen as 'volatile' compared to the stocks shown in my original comment, which were up / down > 20% in ONE day without earnings. 8% is close to nothing for retail investors like almost everyone here and likely yourself.
Also I'm not the one giving advice over looking at the IV or telling retail investors to jump into Nvidia stock at the top as a 'wise investment' or to use 0DTE option gambling strategies, a popular favourite with lots of retail traders.
Now it is 10% down after the smart money started taking their profits off the top as I warned days ago whilst many retail investors who bought in at the top are now left stuck in the market.
Volatility in stocks is measured in terms of “IV” (implied volatility) and Nvidia (and Tesla) have some of the highest IV in the stock market which is why they are so interesting for people trading in options making money from theta decay.
Also I would add, volatility measures continued volatility over periods of time, not single days. Most pharma stocks are essentially static for months or years until they announce one good result and the stock jumps 30% in a day. This doesnt mean they are volatile stocks, compare Gileads IV to Tesla for example.
> which is why they are so interesting for people trading in options making money from theta decay.
Exactly, using the IV for supporting their highly risky 0DTE option trading strategies and gambling on earnings rather than investing long term?
> Most pharma stocks are essentially static for months or years until they announce one good result and the stock jumps 30% in a day.
That is the point on long term 'investing'.
A much lower risk and patient strategy to invest and buy such low priced stocks at the bottom for the long term and take profit after the price jump rather than gambling on ridiculous short term option trades or the retail favourite of 0DTE trading strategies which that is just plain gambling.
Stocks are lottery tickets and Biotech stocks are stocks.
> You're just gambling on binary results.
The risks are no better than most of the AI bros buying Nvidia and overpriced stocks at the very top or all time highs or extremely risky 0DTE strategy trades on earnings announcements.
Do AI bros who jumped in late really have to be married to their stocks that are already overpriced to make 8% on earnings when the very early folks start selling to take their profits?
It s come to the point that people are begging competitors to do something in the space. Who knows, maybe some cheap Chinese asic that can do matrix multiplication ends up eating their lunch.
You d think that, at the level of capitalization of tech companies, competition would be cutthroat
You're kinda underselling what exactly Nvidia is doing right now. If any Chinese company could compete with something like the DGX GH200, they would be building GPUs for the PRC, not exporting them.
There's also the problem of industry hostility, anyways. Even if Nvidia was dethroned in the hardware-space, it's unlikely their successor would improve the lock-in situation. It will take an intersectional effort to change things.
Capitalization in itself is meaningless. If you have 50% of NVidia outstanding shares, and you try to sell 10% of that, the capitalization would crater.
What really counts is the profit. It is pretty huge now, but not 'that' huge (at least yet).
Nvidia is dragging the entire gaming industry forward with ray/path tracing and AI-based resolution and frame scaling. Everyone else (I.e., AMD) is following Nvidia’s lead.
In what way has Nvidia “forgotten” gamers with the rise of their datacenter business?
The card prices have gone up pretty significantly and availability has been bad for the last few years, they also have been segmenting their product line in ways where some of the lower tier cards are not very compelling vs previous release cycles. I don't know if that's attributable to them "forgetting about gamers" but it's what people are upset about.
So even without crypto, the prices of GPUs are still expensive regardless.
The hoarding isn't going to stop unless there are either efficient alternatives that are competitive on performance and price.
Perhaps that is why I keep seeing gamers crying over GPU prices and unable to find cheap Nvidia cards due to the AI bros hoarding them for their 'deep learning' pet projects.
Raytracing isn't a thing no matter how much nvidia wants to push it. The performance penalty is too big for what amounts to something that takes a trained eye to notice. AI-resolution scaling is nice to have on lower end devices but the max resolution people actually use is 4k and I can only think of VR where having more than 4k would be nice to have.
My main gripe is that at 4k resolution, top of the line GPUs shouldn't be using AI frame scaling to get decent fps unless you are taking the raytracing penalty for funsies.
Feels like this comment is stuck in 2019 or something. Have you seen DLSS3.5 announced yesterday with ray reconstruction? Have you seen path tracing in CP2077?
Seems like you’re really dismissing the massive speed ups these past few years. Agreed that ray tracing in games is only at the beginning. A lot of that is gated by the consoles/AMD but that’s generally how it goes. Would love to see Nvidia in one of the powerful consoles to accelerate adoption of these technologies.
Agree on raytracing, disagree on upscaling. DLSS/FSR are gamechangers. They do annoyingly muddy the waters for all the claims of "we run X game at Y FPS on Z resolution" though.
It's a combination of algorithms and hardware, but raytracing has gone from path traced quake 1 to path traced Cyberpunk 2077 in just a few years. The raytracing side of things hardware wise has doubled in perf for the same tier card each generation.
In a world where transistor-per-$ growth is running at most 10-20% per generation, you have to get more out of the transistors you have, or else prices go up. Or both.
So raw performance has stagnated and gains have been concentrated in things like DLSS 2.5 that let you get native quality at a 30% speedup or better than native DLAA at 0% speedup, or FSR2 Quality level quality at 50-70% speedup. Cause that gets you more performance out of a small increase of transistors/cost.
Why do GPUs get so much more expensive compared to the rest of the system? CPUs, hard drives, prebuilt systems, laptops etc. haven't gotten ridiculously more expensive.
It used to be that $200 would get you a low-range GPU, $400 a midrange, and $600 a pretty darned good one. The 1070 launched at $379 (or $480 in 2023 dollars), the 2070 at $499, the 3070 at $499, then all of a sudden the 4070 now is $599. That's a big difference, even accounting for inflation.
The 1080 Ti was $699, an already-unfathomable price back then that cost more than a whole console setup. Today? The 4080 is $1200. That's often more than the rest of the system put together.
It’s because CPUs tend to be fundamentally limited in the ways they can efficiently utilize transistors to scale performance, by things like cache latency, reorder depth, branch prediction, etc. While gpus have always been god’s strongest soldier for putting transistors on silicon scalably. They were the perfect machine for a world where transistors per dollar doubled every 18 months.
On the other hand now that it’s stopped, so has raw performance scaling. There was a few generations of cleanup, but you can’t squeeze blood from a stone forever. Maxwell arguably cut too far and pascal had to start adding functionality back. Gpus are like e-cores, large powerful cores mean you get fewer of them and that often works out to a lower PPA. There aren’t many opportunities for cool tricks and the model doesn’t favor using lots of area. The coding is written for extreme parallelism already, so, that’s not a problem, it’s inherent to the platform.
Transistor per $ growth hasn’t completely stopped but it’s certainly nowhere near what it was 10 years ago, even if you factor in things like packaging/stacking the total wafer area still runs up a big bill that offset most of the density gains. And that’s what we’ve been seeing over the last 10 years in gpus too. 4070 is about the same area and cutdown as GTX 1070 but wafers cost like 8x as much.
What you have to do in this operating regime is find ways to get more performance per transistor - and that’s exactly what Jensen made a big bet on 5 years ago with dlss. 7% more transistors that with DLSS 2.5 give 30% speedup at native quality and 50-70% speedup at iso-quality with FSR2 Quality mode.
That’s what the future looks like - rewriting your applications to take advantage of new accelerators that provide large speedups. And the rewriting is very minimal for any application that uses TAAU already. It sucks but if cost/transistor is not going to come down you have to get more out of the transistors you have. Work smarter not harder.
So if they're running into hardware fab limits, how does running deep learning on that limited hardware equate to a doubling of price? I don't quite follow the logic there?
Yeah the upscaling is nice, but I dunno about $1200 nice...
It was cool when they instead focused on things like creating mobile smaller versions of the cards with laptop level power draws, or better cooling systems that weren't as noisy etc. While staying within reason price points. Just the mundane stuff, not necessarily real time raytracing (gimmicky and not very noticeable IMO, even as someone who uses 4080s on Geforce Now). Something like the Steam Deck package with its integrated console-like APU is much more consumer friendly, but also much much weaker than a 4090 I guess. Different priorities that Nvidia might've reconsidered if not for the AI supersampling stuff also bleeding into crypto and ML, justifying their bet.
Edit: Yeah their AI profits are skyrocketing, while gaming is a has-been. Good bet for the company, bad omens for gamers :/
> So if they're running into hardware fab limits, how does running deep learning on that limited hardware equate to a doubling of price? I don't quite follow the logic there? Yeah the upscaling is nice, but I dunno about $1200 nice...
Because moore's law wasn't just about transistor count but about the economic impact of exponential growth in transistors-per-$. In a world without moore's law, using more transistors will result in a higher-cost product. If you want to hold product cost fixed, or even contain the cost spiral, you need to do more with the same amount of transistors - performance-per-transistor is the metric that matters now.
AMD and NVIDIA have already stripped down their pure-raster implementation as far as they can go, with RDNA1 and Maxwell respectively. Maxwell actually cut too far (software scheduling, "minimal" DX12 support, etc) honestly. So where do you keep making perf/tr gains after that?
The gaming world has already pretty well settled on TAA (although some people will never accept it) and upscaling is already common in the console world. So, do TAA upscaling better such that you get the performance gains but not the reduction in visual quality that usually comes with it.
Tensor makes up a relatively small amount of die area (5.9% of total Turing die area, based on comparisons between Turing Major/RTX and Turing Minor/GTX SM engine die shots). And that gets you to about 30% faster than FSR2 for a given level of visual output quality. So the perf-per-transistor metric increases. Also, unlike a fixed-function accelerator, it can be used for all kinds of other stuff too. It's basically a whole programmable sub-processor, an accelerator for your accelerator.
Now, why ML as opposed to just running it on shaders? Same logic as adding an AVX unit, math density is a lot higher and it can do a lot of work for applications that are specifically tailored to it. DLSS2 uses a relatively standard TAAU (similar to FSR2) but determines the weighting of the samples using a neural net. This produces a lot higher quality than a procedural algorithm currently can - especially under "bad conditions" like higher degrees of upscaling, low framerate/limited sample count, or temporally unstable/high-temporal-frequency areas of the image.
FSR2 does ok at 4K quality mode, but at 1440p and (especially) 1080p output resolutions and in performance modes it does much worse. FSR2 quality 1080p is more like DLSS2 performance mode or maybe balanced mode, so NVIDIA gets more speedup at a given level of visual quality. And DLAA can produce a better-than-native image when running with a native input quality.
The neural weighting just is a lot more efficient at using its samples, it understands what is going on in the scene (moving edges/occlusion etc) and can extract a higher signal-to-noise ratio from the samples and the textures. It's like an op-amp, the ratio of input:output pixels is the "gain factor", and FSR2 and other traditional TAAU algorithms are simply noisier at any given level of gain, whether that's unity or extreme gain, and have other edge-cases like turn-on threshold (bad performance with low samples). ML is the "schottky diode" of graphics amplification (dangerously mixed metaphor, lol), it's simply a lot more agile at shaping the signal than what came before.
(and while on paper plenty of people have argued that procedural programs should be able to do anything ML can, it's not like AMD and others haven't tried to improve TAAU with FSR2, and many others before them. DLSS2 is better, just like LLMs and Stable Diffusion are a lot better than procedural algorithms in their own niches.)
--
All of this exists completely orthogonally to actual wafer costs or packaging or other things. Packaging may boost that transistors/$ metric a little bit but that just gives you a little more to play with. It does allow you to make chips with twice the transistors at twice the cost and have them yield at high rates, but fundamentally 2x400mm2 is still 800mm2 of silicon even if you yield at 100% - you're using more wafer, which drives up costs. Wafer costs have been increasing nearly as fast as density (and predicted to match/pass at 3nm) but there has been a small gain in tr/$, certainly nowhere near the rate of moore's law days. But if wafers cost 8x what they did for 28nm, and are continuing to increase at ~50% per generation, and you keep using more wafer area to compensate for slowing shrinks, then costs will go up (even more than they have).
There is no direct link between "running deep learning" and costs going up. That is just happening independently and affects AMD too, even when they didn't go in on deep learning. TSMC prices keep going up (as do their margins, even now) and even if they went to zero, the design+validation costs are still going up too. A lot of these costs are driven by hard physics problems and not just TSMC profit margin (although it doesn't help).
--
> It was cool when they instead focused on things like creating mobile smaller versions of the cards with laptop level power draws, or better cooling systems that weren't as noisy etc.
I think a 30% performance boost at native visual quality, without power increase is pretty cool. Don't laptops benefit from having 30% higher perf/w just from turning on a setting? And Ada itself is a ~60% perf/w increase over previous generations too.
Like Ada is one of the most efficiency-focused generations ever, much moreso than Ampere or Turing with their trailing nodes. DLSS just stacks on top of this - and unlike FSR2, NVIDIA doesn't fall apart at 1080p resolutions that laptops tend to be using.
Cost is higher than people want, but on the other hand (a) that's going to be the reality unless there is a breakthrough in transistors-per-$, you can't make a fixed number of transistors infinitely fast, there is some asymptotic limit. And (b) people are cherrypicking favored examples or comparing against trailing-node products that had larger dies on slower, less energy efficient nodes to keep costs down.
GTX 970 at $329 was an outlier and the lowest x70 product of all time, on a trailing node (28nm again after 20nm fell through). GTX 670 launched at $399 for a similarly sized die over 10 years ago. GTX 1070 launched at $449 7 years ago with another similarly-sized (~300mm2) die. Turing, Ampere, and Maxwell were all abnormally cheap due and large due to the trailing-node but you paid for this with worse efficiency. There has never been a x70 product launched at $299 and you are welcome to check this!
And yes I think the consensus is that nodes like 8nm probably are "good enough" especially if they are much cheaper, especially at the low end where PHY size is becoming a problem. PHYs don't shrink, so you can't scale a product arbitrarily small - the logic may shrink by 70% but those PHYs are just as big as ever. So there is a de-facto "minimum die size" that is ever worth producing, because there is a fixed PHY area that you simply cannot eliminate. And in a world where wafer costs are going up, that area costs more and more every generation.
A 3060 Ti 16GB wouldn't even need clamshell (it has 8 PHYs, 8x2GB per module=16GB) and could probably have hit $299 or $329 launch cost, if NVIDIA had gone down that road. And it's Good Enough for 1080p, and avoids some weird compromises that shake out of the need to trim PHY area.
AMD already did exactly this with the 7600 - which is held back on 6nm (N7 family) rather than using N5P (N5 family) like the rest of the RDNA2 lineup. Why? Cost.
That's fine, and gamers can no longer be expected to upgrade every generation or two, like they used to, if the improvements are going to be marginal between generations. The enthusiast market will just shrink and of course that no longer matters to Nvidia as they are playing in bigger leagues now.
GPUs will be bought like TVs. It took 4060, about 6 years to double the Passmark score over 1060.
I think both this comment and GP comment are true in their own ways. Nvidia is still pushing the gaming / 3D industry faster than its competitors and I would still recommend an Nvidia card for reliability and performance over others.
BUT that comes at a price - Nvidia consumer chips are also notoriously expensive, but if you want best-of-breed for gaming, it does come at a price.
I am hoping that AMD and Intel will be able to compete with Nvidia someday but I'm not holding my breath.
I actually have current gen GPUs from all 3 manufacturers through my job and I'm glad there are choices now but I'd still recommend Nvidia over AMD or Intel to anyone. Of course it depends on the budget, the games you play etc. but DLSS alone is such a difference that AMD still couldn't catch up with. I really hope Starfield will deliver because that will be the first game with FSR3.0 and introducing the technology, yet DLSS3.5 was just revealed yesterday. It's a huge gamble for sure going all in on Starfield but tbh that's one of the hypest game of the year so worth it. And Intel is nowhere near that (apart from the price and getting 16GB for cheap)
Well, they still make gamer cards. As a company with more than one employee they are able to multitask, and the knock on benefits of all the investment will improving their gaming products as well. I think there are a fair amount of dual use cards being sold - I know I’ve got a 4090 that I use for local AI stuff, and it renders RTX Witcher 3 like a beast.
Ok? But the other RTX models are fine - I know I had a 3070 until recently. Yes, there is a continuum of models with progressively more power. That’s good - the high end blazes a trail for the low end. The architecture that supports AI also support gaming. It’s the same overall architecture just different scales and price points. That’s good, it ensures enormous investment at the high end which is scaled down for different price points. If it were not for gaming and crypto and others driving money at nvidia they would have a lot less capital to dedicate towards improving the architecture. The fact they continue to drive forward real time ray tracing and other features is indicative of their continued focus on gaming.
Yes, it's fine to have a large product line with different price points for different consumers, but I don't think it's quite fair to add the last generation's cards in there too (because they won't be around forever). Typically they only keep 2-3 generations alive in the marketplace at any given time, and if the prices keep going up, once the 30xxs disappear, so too will the affordability. Even an entry-level 4060 is $299 these days and doesn't have much RAM.
My fear is that Nvidia, seeing record-high profits for their datacenter cards, will gradually phase out budget/midrange gaming cards in favor of the higher end stuff. Maybe AMD and Intel will step up their game to tackle that segment, who knows. Or maybe Apple Silicon gaming will gradually take off. But if neither of those happen, there might just be a huge void left in the "affordable PC gaming" segment (which used to be most of it, not so long ago).
On the other hand... I do have to give them credit and say that GeForce Now is AMAZING -- limited library aside. If they can keep growing that segment, hell, maybe the future of PC gaming is just in the cloud, like everything else, and nobody would want to buy expensive GPUs for home use that just become obsolete in a couple years anyway.
Perhaps - but as long as they’re are profitable skus I don’t see that happening. The lower and mid range build scale for them. If they need more scale for the high end they can simply produce fewer, but by making as many as they can at any cost point they improve economics. Also often there is a probability distribution of quality of components, and by having a low end to saturate the excess that is below high end grade they can improve margins and efficiency.
But aren't most hardware producers these days fab-limited, with Apple, Samsung, Nvidia, etc. all competing for the same few foundries, especially at the smaller processes?
If they only have X amount of production available a year, it seems like they'd want to focus those on the super-high-margin high-end datacenter cards rather than the leftover low-end stuff. Or maybe the high/low stuff are manufactured on different pipelines altogether, that don't suffer from the same production limits? I'm not sure how that works...
When was that? Surely it must have been at least a decade before the GTX 970 "4GB" but maybe after all the driver cheating in the late 90s and early 2000s.
I no longer buy nvidia hardware but I do enjoy stock price getting higher. I just wish I had the sense to buy more, a lot more, stock when it was much cheaper. How does a chicken shit like me make big money :(
The tantrum over 970 has gotten even sillier since Microsoft used exactly this same bus structure (with fast/slow segments) on the Xbox series X and S.
That’s a product designed and manufactured by AMD, eight?
It would be consistent to complain about both, although games have to be specifically ported to Xbox so they can work around hardware quirks. And I would give the blame to MS since they control the high-level design.
I literally just replaced my GTX 970 a week ago. Fantastic GPU, lasted me a good ten years. Baldur's Gate 3 finally got me to update it, which it could run it but I dunno a new game got me excited. It ran Elden Ring just fine last year though.
On the flip side, I often wonder if the current AI revolution would have stalled if not for the mature and abundant supply of high powered graphics cards that just happen to also be great for ML.
I've seen a regular stream of reports on HN about people "sort of" getting AI done on laptops and non and lowly GPU machines. Is it unreasonable or far-fetched to imagine that someone figures out how to efficiently get it all done without GPUs and pull the rug out from under Nvidia?
Just like existence of MariaDB does not prevent Snowflake from being worth $50B, just being good enough on laptop is not enough to replace the need for the cutting edge.
If this happens we will just get more things done with the same amount of compute (see: Blinn's law). The demand for GPUs does not really come from algorithmic compute requirements but from social expectation of progress in the field of AI. People will use all the compute they can get doing research using the budget they are given. What matters is how this budget is set.
Let's assume for a moment you could sort of trade parallel computation for vast space, fast search and retrieval. So in this hypotheticals computational theory, you could build a lookup machine from CPUs and ssds.. squeezing the parallel cores into one CPU, by squeezing the shaders running into a million hashes.. And before you know it your simulating a micro verse trying desperately to find out how to avoid climate change. What if God hates recursion?
The current giants have shown that "it" can be done. From now on we can reasonnably hope for massive progress in efficency at the low end - as well as massive capability improvements at the high end. That goes both ways, probably.
I have an options strategy that is riding on this possibility right now.
All you have to do is take 5 seconds in a typical code base to determine that the way we write software today isn't exactly... ideal. Given another 6-12 months, I cannot comprehend another ~OOM not being extracted somewhere simply by making the software better.
Their GPUs have been very performant for my research (DNN training). However, their VRAM could be much larger. In my mind CPU ram is very cheap (for 32GB, it is currently around $65). But their GPUs for DNN that I use oh HPC are always less than 32GB but the GPUs are very pricey. Does anyone know why they don't increase their VRAM capacity so I can test models that require higher VRAM? Is VRAM considerably more expensive to attach to GPU versus CPU ram?
Folks on Reddit's /r/pcmasterrace have been discussing this for years - the consensus seems to be that Nvidia could add more VRAM to its GPUs without too much additional cost - but they don't want to, in order to push higher spending businesses and consumers to buy their more expensive chips to get more VRAM at exponential higher costs.
That's their price differentiator. It's the reason for their profits. nVidia is now <20% gaming in terms of revenue and that gaming revenue has much tighter margins than the 80% datacenter/professional market revenue which is almost all profit sine 80gb ram doesn't cost $40k more.
So yes it'd be nice if nVidia made it so there was no reason for their $40k AI cards to exist. But they aren't going to do that.
I hope Intel, as the underdog, can do mid-tier cards, but with lot more VRAM. I can see myself using multiple LLM models at once, not necessarily running at once, but interleaved.
Agreed. I think people would accept the <50% perf as long as there's plenty of RAM to play in. I think that's the biggest risk to Nvidia right now.
No one's catching up to the topline perf or even power efficiency (Intel actually suck at perf/power right now) but they might be able to compete with raw GPU costs at least. Give us a $2k card with 256gb ram and we'll probably take it over the $40k 80gb cards despite the power efficiency and topline perf that the $40k card has.
You’re looking at it as if there’s some sort of technical bottleneck. Is not, it’s business. VRAM capacity is how they segregate data center/AI workloads versus gaming.
Yes it is quite expensive. The issue is memory bandwidth is a lot more constrained when youre routing to hundreds or thousands of cores instead of the handful you need to support on a CPU.
So the higher cost from higher VRAM comes from the implementation of higher bandwidth to accommodate more data flow because there are more cores versus CPU?
A tangent to this I've been thinking about quite a bit is how big a moat drivers are to the software/hardware ecosystem.
They're a major moat/hurdle (depending on your perspective) for operating systems, new hardware platforms, graphics cards, custom chips, and more.
It's interesting to think that we're not _that_ far from being able to generate decent drivers for things on the fly with the latest code gen advancements. Relevant to this, that could reduce the monopolies here, but perhaps as interesting is we can have more new complete OSes with more resources allocated to the user experience vs hardware compatibility.
I’ve been a longtime Nvidia investor (since ~2014 or so) and have no plans on selling anytime soon. Their market dominance will be tough to unseat, and the only other company making strides in silicon is Apple.
I thought Nvidia just make graphics cards for games, how did they end up making general purpose CPUs like Intel that actually is more powerful than Intel
Their revenues are seriously supply restricted. ~2x revenue if chip manufacturing could keep up with demand. Packaging seems to be the bottleneck just now.
It's such a shame that these big companies are allowed to make so much profit, 'the shareholder is the customer' only furthers disproportionate wealth distribution.
That and possibly way more than that is already priced in. Nvidia's stock is extremely expensive not because of they are making now (which is not a lot relative to valuation, they just barely surpassed Intel this quarter in revenue) but because investors expect pretty much exponential growth over the next few years..
It remains debatable whether mass enterprise adoption of AI would happen first, or Nvidia's competitors coming up with equivalent chips would happen first.
It's hard to imagine Nvidia will maintain what is right now effectively 100% market share for training forever, especially given the $ being thrown around.
On the surface, it's not debatable. Enterprises are going full steam ahead on AI. Building out an ecosystem to challenge Nvidia seems like a decade long battle, if it's even possible.
What is full steam ahead for enterprises? It's not like they're throwing autoregressive LLMs into production any time soon.
In any case Nvidia is expecting to ship ~550k H100s in 2023, hardly enough to satisfy every user.
Tesla decided to in-house. TPUv4 and Gaudi2 exceeded A100 performance, they just never hit scale or the market and then Hopper added optimization for transformers rendering these chips relatively obsolete.
Nvidia's lead is not unassailable and it seems incredibly unlikely that they would not face serious competition within the next 2-3 years given the $ being thrown around.
Large enterprises are already putting them into production. I have direct experience with it.
It's not unassailable. But it's going to take a lot to make any difference to Nvidia's volume or pricing, let alone a meaningful difference. They already face serious competitors in google and aws with TPU and inferentia, but those competitors are at a pretty big disadvantage for now (and others too). The cuda ecosystem is a big advantage. Nvidia has a lot of leverage with semi manufacturers because of volume. They spend way more on chip R&D than their competitors in the space. They have brand recognition. You can buy and own Nvidia chips v tpu and inferentia. It's... a tough road ahead for competitors.
> Large enterprises are already putting them into production. I have direct experience with it.
For what function have you experienced LLMs being used at significant scale in production right now? It seems unlikely most enterprises have built up sufficient technical know-how to run these workloads in-house already.
> They already face serious competitors in google and aws with TPU and inferentia
TPUv4s aren't widely available and are not competitive with Hopper. Inferentia isn't for training and is also not competitive on throughput.
> The cuda ecosystem is a big advantage.
Is it really though? A year ago it wasn't the case (see TPUs). Nvidia hasn't maintained a stranglehold on the software stack.
> Nvidia has a lot of leverage with semi manufacturers because of volume.
With TSMC*. If we believe Pat Gelsinger, Intel is starting to catch-up and their roadmap would place them ahead of TSMC in H2 2024.
> They have brand recognition. You can buy and own Nvidia chips v tpu and inferentia.
Intel, AMD and Google don't have brand recognition? There isn't a competitive alternative today for sale or rent, that doesn't mean this can't/won't change. It also doesn't mean they won't become available for enterprise purchase when we're talking about 60B/year in revenue.
> It's... a tough road ahead for competitors.
While hard I disagree that their moat is as wide as being touted. At the end of the day, whoever gets the most FLOPS, can deliver product faster and/or is cheaper will win as long as it's trivial to migrate workloads.
I really don't believe anyone actually cares who the manufacturer is.
Customer support. I've never seen so many people get up to speed so fast on something. It's unlike anything ever.
Yep.
I believe so.
I don't believe Pat.
With the relevant audience, Nvidia is the brand which is the strongest. Google could just drop support for TPU, AMD isn't viewed as currently credible for people doing the work, nor Intel.
You may be right, only time will tell. I've been involved with GPU use for general purpose workloads since Cuda was launched. At every step of the way there was apparently credible competition at different layers of the stack just around the corner. That's over 15 years. OpenCL, ASICs, FPGA, Intel this that and the other, AMD this that and the other. TPU. Others I've forgotten.
> Customer support. I've never seen so many people get up to speed so fast on something. It's unlike anything ever.
Are you saying that you've seen enterprises developing, training and running their own in-house LLMs from scratch directly on large (i.e. 100s to 1000s) GPU clusters, whether on-prem or cloud, for this to be relevant to Nvidia?
Pardon my skepticism but it seems odd that a generic Fortune 500 co has the in-house talent and will-power to manage large distributed training runs when much easier and cheaper alternatives like OpenAI/open-source models or one of the Google/MS/AWS MLaaS options are available.
> With the relevant audience, Nvidia is the brand which is the strongest. Google could just drop support for TPU, AMD isn't viewed as currently credible for people doing the work, nor Intel.
I think we're confusing some things here. Right now, there is no good alternative for anyone requiring H100s for loyalty to even matter, this could very easily change with the next generation of accelerator chips.
Intel had the strongest CPU "brand" for a while and enterprises/datacenters readily switched to AMD when it became the better option.
> You may be right, only time will tell. I've been involved with GPU use for general purpose workloads since Cuda was launched. At every step of the way there was apparently credible competition at different layers of the stack just around the corner. That's over 15 years. OpenCL, ASICs, FPGA, Intel this that and the other, AMD this that and the other. TPU. Others I've forgotten.
The TAM, and profit margin, for enterprise-grade GPUs (or accelerators) is several orders of magnitude larger than it has ever been including the crypto craze.
You seem to be moving the goalposts. First it was using in production, now it's building foundation models.. But, to answer: Not foundation models (although, Bloomberg did that for another use case). Fine tuned versions of falcon, now llama 2, open assistant and others. They are running both the fine tuning (not that it's much) and inference on A100s, inferentia and TPU. The skillset required to fine tune a model for a customer support use case is night and day from building a (good) foundation model.
Right now it doesn't matter, but you are suggesting there will be real competition soon. I'm saying, it will matter.
Intel did have a great brand. And they proceeded to screw up and it caught up with them, but it took a long time. A company with a moat can destroy it with time and effort.
It is huge market. And it's a huge lift to build a product that can compete with Nvidia at this point. I'd handicap it at 2-1 against someone being a real competitor within a decade.
> You seem to be moving the goalposts. First it was using in production, now it's building foundation models..
I'm not moving the goal posts but maybe I wasn't clear. When we talk about corporations adopting fine-tuning and inference that's not especially relevant to H100 sales which is the main cash-cow (~10B of revenue at 80-90% margins) and Nvidia's massive market cap growth. What is relevant is corporations like Inflection AI building 22k H100 clusters.
I work in academia so PyTorch is more common but are people in industry fine-tuning LLMs actually working directly with CUDA that much for this to be a big moat?
Companies are using both A100 and H100 for inference. The datacenter numbers include both, and I don't believe they break it down further. And no, by and large, large enterprises are not building out large clusters - but they are much of the demand for all those cloud provider build outs.
No, no one is using CUDA directly. But if you are a vendor with a new equivalent, it's no small feat integrating it with a framework like PyTorch. There is a lot of work required by various parties.
It would be interesting to see what the breakdown is on H100/A100 users. I would expect most inference users are similar to my lab and max out at a DGX node rather than being the bulk of users.
PyTorch has gotten a lot better on TPUs this year, I don’t believe there’s much of a performance hit now. Jax and TF (I don’t use the latter anymore) of course work. I never used Gaudi2 but it apparently works.
All of this to say, is it possible that Intel gets their fabs working and strategically partners with their long-time partner MS and OpenAI to extend Triton to Gaudi3 or 4 and be a threat to Nvidia within 2-3 years? Absolutely.
Is it similarly possible that Google increases development on Jax and TPUv5? Sure.
Neither of these possibilities, regardless if you think they’re probable or improbable, would need a decade to catch up to Nvidia.
this is a totally insane statement to make. 10 years? it will take at _most_ 2-3 years for the software and hardware ecosystem to rearrange around a competitive landscape. The only reason nvidia has a large time window of opportunity is because of the lead time required to create such a complex ecosystem and the "suddenness" of how meaningful particular category of workloads are (which nvidia happened to be good at, because... pixels)
> Once enterprise adoption of AI picks up, demand for chips will increase 2-3 times further.
Possibly their greatest asset, as an investment, is their crazy high margins. Nvidia in 2023 is where Intel was in 2007, where they could basically charge almost any price because they were so dominant in the market. I remember when E5s were selling for $2000 a pop and data centers were using thousands of them.
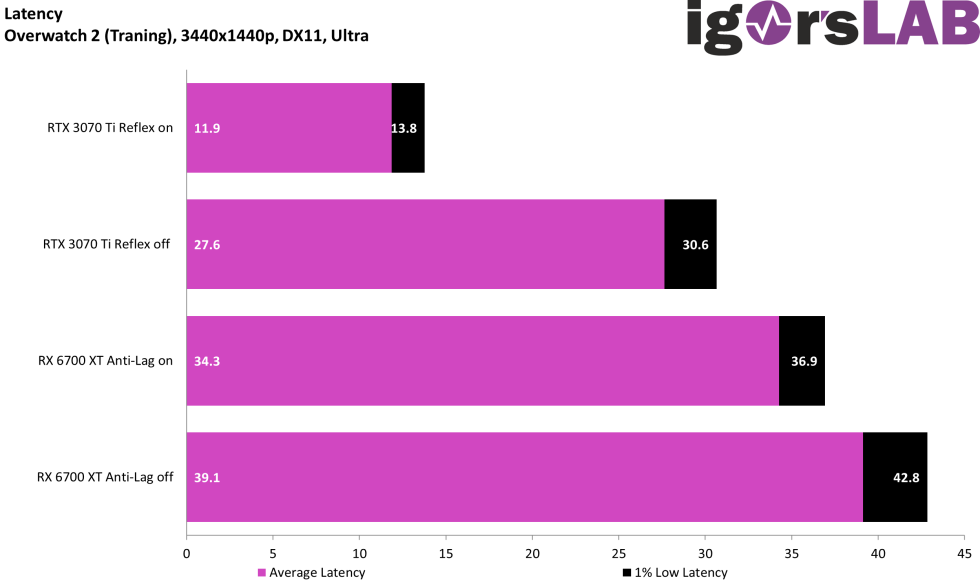{kind=link}
This is what having a monopoly looks like !
This is also why companies that manufacture their cards didn't report any uptick in profits. I'm wondering how this play out in some months ? Do they have any pricing power with respect to NVidia ? Or NVidia could just switch to another manufacturer ?