We are pretty quickly approaching the point where a "frame scanout" is going to lose meaning. Areas of the image will be rendered and scanned out optimally ala "foveated rendering" and also sent over the pipe in this fashion too.
TAA fundamentally decouples the sample generation from the output generation. TAA samples (even native res) have no direct correspondence to the output grid, they are subpixel sampled and jittered. The output grid takes the samples nearby and uses them to generate an output for each pixel.
TAAU/DLSS2 take this further and decouple the input grid from the output grid resolutions entirely. So now you have a 720p grid feeding a 1080p grid or whatever. Thinking of it as "input/output frames" is clunky especially when (again) the input frame doesn't even correspond directly to the input samples - they're still jittered etc. Think of it as a 720p grid overlaid over a 1080p grid, and DLSS is the transform function between these two (real/continuous) spaces. Samples are randomly (or purposefully) thrown onto that grid.
OLEDs are functionally capable of individual pixel addressing if we wanted to. Current ones probably can scan out lines in non-linear order already, so you could scan out the center more than the top/bottom, for example. And OLEDs are already capable of effectively >1000hz real-world response time from their pixels. They just are absolutely critically bottlenecked by the ability to shove pixels through the link and monitor controller quickly enough (give me 540p 2000hz mode, you cowards)
This all leads to a question of why you are still sampling and transmitting the image uniformly. If there's parts of the image that are moving faster, render those areas faster, and with more samples! Maybe you render the sword moving at 200fps but the clouds only render at 8fps. And Optical Flow Accelerator can also allow you to identify movement within the raster output and correlate this with input - if you think about oculus framewarp, what happens if we framewarped just one object? Translate it around against the background, stretch it to simulate some motion aspect, etc. And if you further refine that to a 1x1 region, then you have individual pixel framewarp.
You can also have a neural net which suggests which regions are best to render next, for "optimal" total-image quality after the upscaling/framewarp stages, based on object motion across the frame and knowledge of the temporal buffer history depth in a particular pixel/region (and this is the sort of abstract, difficult optimization problem ML is great at). And those pixels actually might be rendered at multiple resolutions in the same frame - there might be "canary pixels" rendered at low resolution that check whether an area has changed at all, before you bother slapping a bunch of samples into it, or you might render superfine samples around a high-motion/high-temporal-frequency area (fences!). So now you have "profile guided rendering" based on DLSS metrics/OFA analysis of the actual scene being rendered right now.
Another random benefit is that "missed frames" lose all meaning. The input side just continues generating input for as long as possible, as many samples at whatever places will be most efficient. If it's not fully done generating input samples when it comes time to start generating output... oh well, some cloud has less temporal history/fewer samples. But DLSS does fine with that! As long as you still have some history for that region you will get some output, and I'm sure if it was important then it'll be first thing scheduled in the next frame.
You can use this idiom with traditional scanout/raster-line monitors, but ideally to take advantage of OLED's ability to draw specific pixels, you probably end up with something that looks a lot like a realtime video codec - you're sending macroblocks/coding tree units that target a specific region of the image with updates. Or you use something like Delta Compression encoding, like with lossless texture compression.
This already is sort of what Display Stream Compression is doing, but that's just runlength encoding, and if the monitor can draw arbitrary pixels at will (rather than being limited to lines) then you can do better.
And again, you can't transmit the whole image at 1000fps, but you can target the "minimum error approximation" so that on the whole the image is as correct as possible, considering both high-motion and low-motion areas. This is sort of an example of the concept - notice the scanline errors in high-motion areas. Great demo but linked to the direct example:
This also raises the extremely cursed idea of "compiled sprites" inside the monitor controller - instead of just running a codec, you could put a processor on the other side (like the G-Sync FPGA module) and what you send is actually the program that draws the video you want. Executable Stream Compression, if you will. ;)
(but there's no reason you couldn't put THUMB or RISC-V style compressed instructions in this - and you certainly could change up the processor architecture however you want, as long as you don't mind doing a Gsync-like compatibility story. It makes upgrading capabilities a lot easier if you control both ends of the pipe, that's why NVIDIA did g-sync in the first place! And there is probably nothing more flexible or powerful than allowing arbitrary instruction streams to operate on the framebuffer (or a history buffer, whether frame history or macroblock/instruction history) or to draw directly to the frame itself. With the bottlenecks that DP2.0 and HDMI2.1 present, this is probably the way forward if you want lots more bandwidth out of a given link speed.)
I said a long time ago that this is basically a "JIT/runtime" sort of approach and people kinda laughed or said they didn't get it. But it's funny that trixter actually used the same analogy there for his demo. But basically DLSS is an engine unto itself already, DLSS is what does the rasterizing, and the engine just feeds samples (that are entirely disconnected from the output, they go into the black box and that's the end of it). And with fractional rendering you can basically view that as a big JIT/runtime. DLSS provides quality-of-service to pixels by choosing which ones to schedule for "execution" and with what time quanta, to produce optimal image quality ("total QOS") over the whole image. And then the resulting macroblocks are individually sent over when ready.
Effectively this works like the biological eye - there is no "frame", changes happen dynamically across the whole frame constantly. Or another analogy would be "what if we could 'chase the beam' but across arbitrary pixels in the frame"? If the motion is predictable then you can schedule the rendering so that the output and blit happens at the exact proper time, down to 0.1ms accuracy. It's Reflex for Pixels.
DLSS knows when a person is running and about to peek out from behind a wall. DLSS knows when someone was sitting there and can render the lowest-latency-possible update when they suddenly pop out of cover and AWP you (can't read minds/make network latency disappear, but it can update it as quick as it can). That already shakes out of the motion vector data and just needs to be generalized to a world where you can render out specific regions/lines at 1000hz.
(I guess technically "frame" still exists as a notional concept inside the game loop, you are generating game state in 60fps intervals or whatever, but rendering is totally decoupled from that and you run the GPU on whatever parts of the image would benefit the most from touchups at a particular moment.)
But again you can see how this whole idea fundamentally inverts control of the game engine - Reflex already tells the game when to sleep and when to start processing the next game-loop, now DLSS will tell the engine what pixels it wants sampled, and handles rasterizing the samples and compressing/blitting them to the monitor. The engine is just providing some "ground truth" visual input samples and calling hooks in DLSS.
(sorry, long post, but I've been musing about this elsewhere and I looooove to chitchat lol)
This is a very good point. It would be ideal to spend the budget rendering only fractional updates to the image, and allow those updates to happen much faster than what would be 60fps. This way we could get 1000hz updates without it costing 10x more than 100hz. While I’m skeptical about the supposed perceptual benefits of full frame rates above 120hz or 240hz outside of the latency argument, foveated fractional rendering could end up being the fastest and best and cheapest.
> you are generating game state in 60fps intervals or whatever
This is also an excellent point that might question my suggestion that high frame rate is being used to reduce latency. Games state updates are already decoupled from rendering in lots of games. Having an extremely high render refresh might not mean that the latency between controls and visuals is reduced proportionally. Or maybe it helps but has a limit to how much.
DLSS is an interesting topic here. Do you see it eventually working for fractional updates? We’d possibly need a new style of NN or of inference? DLSS currently operates on a full frame, and the new version even hallucinates interpolated frames to boost fps artificially. This doesn’t help with control latency at all, in fact it makes it worse.
> DLSS is an interesting topic here. Do you see it eventually working for fractional updates? We’d possibly need a new style of NN or of inference? DLSS currently operates on a full frame, and the new version even hallucinates interpolated frames to boost fps artificially. This doesn’t help with control latency at all, in fact it makes it worse.
Yeah I've been playing fast and loose with terminology here, there's several overlapping but synergistic ideas that aren't the same things. To try and clean this up:
DLSS1 required the full image, it actually was an image-to-image transformer that "hallucinated" a full-res image from an input image. This sucked and NVIDIA gave it up (except for the 500mb of DLSS models that live eternally in the driver for the 2 games that opted for driver-level model distribution). Nobody cares about this anymore at all.
DLSS2 does not need a full image, because it is a TAAU algorithm that weights samples using a ML model. If there aren't enough samples in an area oh well, you just get crappy output (like immediately after a scene change). It manifests as either obvious resolution pop/detail pop, or visual artifacts on moving/high-res things. IIRC this can be assisted by drawing invisible (1% alpha) objects in motion/fences/etc to "warm up" DLSS sample history on the (invisible) edges before just popping them into existence iirc lol.
You need at least some samples near that area, it can't render from nothing, but DLSS2 is not dependent on rendering out the full image to work - if some unrelated part of the image doesn't have samples, oh well. (and this may allow mGPU scaling with reasonable correctness for partitioning an image!). Personally I consider this "loosy goosy correctness" attribute of ML models to be extremely desirable for GPGPU programming - if some edge case messes up 0.1% of samples, the ability of ML models to just ride over it and spit out a reasonable output is super desirable. This includes things like camera noise, dead pixels, etc. Extremely tolerant of data ingest etc. Like if 10 threads aren't quite finished with their sample output because you don't want to wait for kernelfence sync when it's time to start rendering the output buffer... just start going. It'll be fine.
Fractional rendering is a separate and unrelated idea, but I think the time is right with OLEDs here, and with everyone searching for a way to extend perf/tr with costs spiraling it makes sense to see if you can render "better" imo.
Variable rate sampling is another concept that builds on fractional rendering. Render some areas at a higher rate than others. And again this is something that DLSS2 plays nicely with.
--
DLSS3 is actually the successor to DLSS2 and is supported by all RTX cards (yup). Framegen is one of the features in this, and that is only supported on Ada. Supporting framegen requires the inclusion of Reflex, which does benefit everyone hugely.
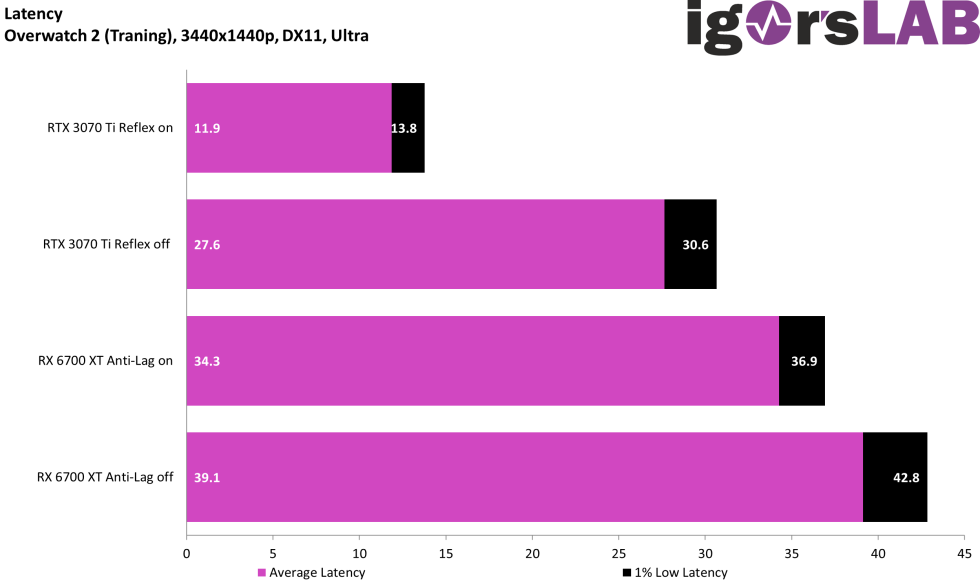
Reflex basically flips the "render+wait" model to be a "wait+render", by adding a wait at the start of the game loop that delays until the last possible second to start processing the frame, so it's as fresh (input latency) as possible. And this does legitimately cut latency significantly (by ~half) in highly gpu-bound scenarios. And that gives NVIDIA some headroom to play with in framegen tbh. Igor's Lab and Battlenonsense both found NVIDIA to have much lower click-to-photon latency than AMD Antilag, by like 20-30ms in overwatch f.ex.
Framegen as currently implemented is interpolation and yeah that does increase latency. But NVIDIA do have some headroom to play with there, in CPU-bound situations (which is different!). And tbh most people who actually have used it generally seem to find it not too bad, it's the "eew I tried it at the store and it was awful!"/"i've never tried it" who are most vocal about the latency. It's at least an option in the toolbox (see again: starfield).
I think it is possible to move to extrapolation and I hope the current framegen is only an intermediate step. And I think Optical Flow Accelerator is a really cool building block for that. The performance and precision has improved a bunch over the gens, and now it can support 1x1 object tracking (which I mentioned above as seeming like a significant threshold/milestone) so it's flowing pixels really. I see that as being a Tensor Core-like moment that people scoff at but has big implications in hindsight. Being able to incorporate realtime image data back into the upscaling/TAA pipeline seems big even beyond just framegen itself, I don't doubt DLSS3.5 will make further progress too.
You don't need extrapolation (or interpolation) at all. but if you can extrapolate per-pixel, the ability to do a low-cost "spacewarp" that accomplishes most of the squeeze of a full re-render (in terms of moving edges/texture blocks) at much lower cost could would be very interesting. And the OFA could end up being a key building block in that sort of thing.
--
Again kind of a topic shift but there's also this issue of display connection (there is never enough bandwidth) and whether it's lines or macroblocks etc. That's a capability that's offered by OLEDs in theory, and could be explored with a similar FPGA approach/etc. If you can do that, it pairs with variable rate sampling concepts (and ML input tolerance for bad data) very nicely - render out the regions you're updating whenever they're ready, or whenever is optimal for that element to be drawn (to get minimum error).
And in fact quite a few of these ideas synergize nicely together. If you put it all together.
--
These are all kinda separate in general but quite a few of them synergize if you put them together. And I think the zeitgeist is ripe on some, brian heemskirk was talking about some similar ideas on MLID's show a few months ago (not the most recent appearance).
This is great stuff. I don’t have anything useful to add, just wanted to say thank you, TIL. You don’t have links to any write ups about the latency testing by Igor’s Lab & Battlenonsense do you? I’d be interested to learn more about what typical click-to-photon latencies are today for given refresh rates, and how the latency changes wrt refresh rate. The latencies must be absolutely horrendous if we’re talking about differences of 20-30ms? That would tend to justify super high frame rates (assuming they actually reduce latency!), but it’s funny to me that rendering frames faster and faster is seen as the solution, rather than attacking the issue of a render+display pipeline with insane and growing latency.
Yes I agree that driver overhead+latency reduction in the pipeline matters a lot and that's the tool Intel just dropped (and has probably optimized their own driver for of course). Classic Tom Peterson, lol, just like FCAT.
{kind=link}
TAA fundamentally decouples the sample generation from the output generation. TAA samples (even native res) have no direct correspondence to the output grid, they are subpixel sampled and jittered. The output grid takes the samples nearby and uses them to generate an output for each pixel.
TAAU/DLSS2 take this further and decouple the input grid from the output grid resolutions entirely. So now you have a 720p grid feeding a 1080p grid or whatever. Thinking of it as "input/output frames" is clunky especially when (again) the input frame doesn't even correspond directly to the input samples - they're still jittered etc. Think of it as a 720p grid overlaid over a 1080p grid, and DLSS is the transform function between these two (real/continuous) spaces. Samples are randomly (or purposefully) thrown onto that grid.
OLEDs are functionally capable of individual pixel addressing if we wanted to. Current ones probably can scan out lines in non-linear order already, so you could scan out the center more than the top/bottom, for example. And OLEDs are already capable of effectively >1000hz real-world response time from their pixels. They just are absolutely critically bottlenecked by the ability to shove pixels through the link and monitor controller quickly enough (give me 540p 2000hz mode, you cowards)
This all leads to a question of why you are still sampling and transmitting the image uniformly. If there's parts of the image that are moving faster, render those areas faster, and with more samples! Maybe you render the sword moving at 200fps but the clouds only render at 8fps. And Optical Flow Accelerator can also allow you to identify movement within the raster output and correlate this with input - if you think about oculus framewarp, what happens if we framewarped just one object? Translate it around against the background, stretch it to simulate some motion aspect, etc. And if you further refine that to a 1x1 region, then you have individual pixel framewarp.
You can also have a neural net which suggests which regions are best to render next, for "optimal" total-image quality after the upscaling/framewarp stages, based on object motion across the frame and knowledge of the temporal buffer history depth in a particular pixel/region (and this is the sort of abstract, difficult optimization problem ML is great at). And those pixels actually might be rendered at multiple resolutions in the same frame - there might be "canary pixels" rendered at low resolution that check whether an area has changed at all, before you bother slapping a bunch of samples into it, or you might render superfine samples around a high-motion/high-temporal-frequency area (fences!). So now you have "profile guided rendering" based on DLSS metrics/OFA analysis of the actual scene being rendered right now.
Another random benefit is that "missed frames" lose all meaning. The input side just continues generating input for as long as possible, as many samples at whatever places will be most efficient. If it's not fully done generating input samples when it comes time to start generating output... oh well, some cloud has less temporal history/fewer samples. But DLSS does fine with that! As long as you still have some history for that region you will get some output, and I'm sure if it was important then it'll be first thing scheduled in the next frame.
You can use this idiom with traditional scanout/raster-line monitors, but ideally to take advantage of OLED's ability to draw specific pixels, you probably end up with something that looks a lot like a realtime video codec - you're sending macroblocks/coding tree units that target a specific region of the image with updates. Or you use something like Delta Compression encoding, like with lossless texture compression.
https://en.wikipedia.org/wiki/Coding_tree_unit
This already is sort of what Display Stream Compression is doing, but that's just runlength encoding, and if the monitor can draw arbitrary pixels at will (rather than being limited to lines) then you can do better.
And again, you can't transmit the whole image at 1000fps, but you can target the "minimum error approximation" so that on the whole the image is as correct as possible, considering both high-motion and low-motion areas. This is sort of an example of the concept - notice the scanline errors in high-motion areas. Great demo but linked to the direct example:
https://youtu.be/MWdG413nNkI?t=176
https://trixter.oldskool.org/2014/06/20/8088-domination-post...
This also raises the extremely cursed idea of "compiled sprites" inside the monitor controller - instead of just running a codec, you could put a processor on the other side (like the G-Sync FPGA module) and what you send is actually the program that draws the video you want. Executable Stream Compression, if you will. ;)
(but there's no reason you couldn't put THUMB or RISC-V style compressed instructions in this - and you certainly could change up the processor architecture however you want, as long as you don't mind doing a Gsync-like compatibility story. It makes upgrading capabilities a lot easier if you control both ends of the pipe, that's why NVIDIA did g-sync in the first place! And there is probably nothing more flexible or powerful than allowing arbitrary instruction streams to operate on the framebuffer (or a history buffer, whether frame history or macroblock/instruction history) or to draw directly to the frame itself. With the bottlenecks that DP2.0 and HDMI2.1 present, this is probably the way forward if you want lots more bandwidth out of a given link speed.)
I said a long time ago that this is basically a "JIT/runtime" sort of approach and people kinda laughed or said they didn't get it. But it's funny that trixter actually used the same analogy there for his demo. But basically DLSS is an engine unto itself already, DLSS is what does the rasterizing, and the engine just feeds samples (that are entirely disconnected from the output, they go into the black box and that's the end of it). And with fractional rendering you can basically view that as a big JIT/runtime. DLSS provides quality-of-service to pixels by choosing which ones to schedule for "execution" and with what time quanta, to produce optimal image quality ("total QOS") over the whole image. And then the resulting macroblocks are individually sent over when ready.
Effectively this works like the biological eye - there is no "frame", changes happen dynamically across the whole frame constantly. Or another analogy would be "what if we could 'chase the beam' but across arbitrary pixels in the frame"? If the motion is predictable then you can schedule the rendering so that the output and blit happens at the exact proper time, down to 0.1ms accuracy. It's Reflex for Pixels.
DLSS knows when a person is running and about to peek out from behind a wall. DLSS knows when someone was sitting there and can render the lowest-latency-possible update when they suddenly pop out of cover and AWP you (can't read minds/make network latency disappear, but it can update it as quick as it can). That already shakes out of the motion vector data and just needs to be generalized to a world where you can render out specific regions/lines at 1000hz.
(I guess technically "frame" still exists as a notional concept inside the game loop, you are generating game state in 60fps intervals or whatever, but rendering is totally decoupled from that and you run the GPU on whatever parts of the image would benefit the most from touchups at a particular moment.)
But again you can see how this whole idea fundamentally inverts control of the game engine - Reflex already tells the game when to sleep and when to start processing the next game-loop, now DLSS will tell the engine what pixels it wants sampled, and handles rasterizing the samples and compressing/blitting them to the monitor. The engine is just providing some "ground truth" visual input samples and calling hooks in DLSS.
(sorry, long post, but I've been musing about this elsewhere and I looooove to chitchat lol)