A $5 DO droplet will easily handle peak HN traffic with a bit of optimization. Set cache headers, cache static assets on the server side (or even better, with an external CDN), or even cache the entire page if there's no dynamic content.
Without optimization, Nginx defaults to allowing a maximum of one worker process with 512 connections and 60s timeout. 20 unique visitors per second will lead to 500 errors in less than a minute.
It does not matter how fast the backend is. A persistent HTTP connection will last 60 seconds following the latest client request, unless the browser goes out of its way to explicitly close the connection.
P.S. OP's website uses Apache but the same issue of overly conservative limits still apply.
There's no way the connection just sits idle and the worker can't serve other requests for the full timeout, right? That just sounds... Wrong. And is not consistent with load testing I've done before with a nginx setup
There are multiple strategies for caching in the server, without them IIRC the php code will be interpreted on each request, files parsed, and obviously hit the database for each request.
There's fastcgi caching in nginx, php opcode in php-fpm, and WP specific cave plugins like Super Cache. At least this was the case ~10 years ago.
Also for $5/mo you can use Cloudflare APO to cache WordPress pages at the edge. Yes it will cache even the "dynamic" pages (unless you're logged in of course)
That's fine, I was just listing another option. It should be noted you should still do server side caching. This just lets you serve from Cloudflare's caching layers too
Are you sure? My understanding was that nginx would fill up all free connections up to the max, but then would begin draining idle connections so it could create new ones for new visitors.
I run a few big sites on WordPress, and would totally recommend you use the simply static plugin, and configure nginx to serve those cached files directly so it never hits php. I also usually put cloudflare in front as well, but you can have a screaming fast wordpress site that scales really far by itself without it just with that trick.
If you need some dynamism, w3 total cache is also a great choice.
Check out this thread for recommendations on static site generator plugins on top of Wordpress. Best of both worlds for folks who want high-level publishing.
Looks like the free one has only 1GB outbound transfer which wouldn't be enough for a single hug, but the $5/month one has 40GB which might be enough for a hug with text only content.
They were grateful the thing got so much attention, and deferred to other hosts to supplement serving that attention. Not looking for uptime solutions.
(Now that I’ve tried to RTFA, it seems homie has a runtime dependence (db?) or something colocated on the host failing? OWASP, right? Having a resource limit reached maybe? Nextjs seems like a cool approach to manage partially ~runtime-dynamic systems like this/cms/etc)
I was thinking about this same problem for a couple of days. Another question I have is: do we have a higher number of top-level comments on a given number of months or not?
It's a static site, no reason for the server not to be able to handle thousands of connections at once with almost no configuration changes with some like Nginx or Apache. Or even a domain which points directly to a S3 bucket. Hope you're not looking at devop roles on who is hiring posts.
Here's a query for a rough reproduction of what's asked in the title:
WITH whoishiring_threads AS (
SELECT id FROM `bigquery-public-data.hacker_news.full`
WHERE `by` = "whoishiring"
AND REGEXP_CONTAINS(title, "Ask HN: Who is hiring?")
)
SELECT FORMAT_TIMESTAMP("%Y-%m", `timestamp`) as year_month,
COUNT(*) as num_toplevel_posts
FROM `bigquery-public-data.hacker_news.full`
WHERE parent IN (SELECT id FROM whoishiring_threads)
GROUP BY 1
ORDER BY 1
Google is infamous for breaking backward compatibility, and sunsetting things, so I will not advice anyone to use this to build any products. However it is fine for one-off tasks, like fetching data for this blog post.
It’s not less illegal because anyone could do it. I have copyright to my comments, and many of them can be considered personal data, especially if they are connected to my username. My rights are not waived because I publish something publicly.
Puzzling comment. Perhaps you should read the Terms of Service.
User Content Transmitted Through the Site: With respect to the content or other materials you upload through the Site or share with other users or recipients (collectively, “User Content”), you represent and warrant that you own all right, title and interest in and to such User Content, including, without limitation, all copyrights and rights of publicity contained therein. By uploading any User Content you hereby grant and will grant Y Combinator and its affiliated companies a nonexclusive, worldwide, royalty free, fully paid up, transferable, sublicensable, perpetual, irrevocable license to copy, display, upload, perform, distribute, store, modify and otherwise use your User Content for any Y Combinator-related purpose in any form, medium or technology now known or later developed. However, please review the Applications Privacy Policy located at https://www.ycombinator.com/apply/privacy, for more information on how we treat information included in applications submitted to us.
There are so many problems with that with regard to GDPR. It’s not even linked from the signup page, so I’ve never even been informed about it. I’ve never been given the option to consent or reject consent to anything. You also can’t just say it’s “irrevocable” and pretend like GDPR doesn’t apply.
I hope the downvotes are for the sarcasm, not the point expressed. But considering other threads about this have been flagged[1] I guess this topic is taboo.
I think many people have the opinion that GDPR 'should not' apply outside the European region (or other countries that have enacted GDPR legislation).
A common sense approach would be to say that if someone in Europe chooses to submit their details to an entity based outside of Europe then that's just their choice to waive their rights to their data.
Lawyers and legislators might make arguments and talk about analogous laws and situations but that simple doesn't convince a lot of people. Hence you will get downvotes for saying something so common is illegal.
(As a side-note it's interesting that you personally choose to submit your copyrighted comments to HN given your knowledge of how you're losing effective control of your information.)
It is illegal, whether people wish it wasn’t or think it’s sensible or downvote comments that point it out. Personally I think the gist of GDPR is more sensible than what you’re proposing as common sense - each person should have the right to decide what happens to data about them.
I started and abandoned a little side project a while ago where I wanted to see which employers tended to have the exact same (or fuzzy-the-same) "Who's Hiring" post month after month. Goal would be to find some signal about which posts were actually resulting in hiring (in other words, the company didn't come back with the same posting) and which ones were just trawling for the same job month after month without actually hiring anyone. Was going to call it "Who's Not Hiring?"
I know some of the recruiters at my employer, various teams have started testing and hiring multiple vacancies off of a single job ad which is kept open for longer.
To an external person it's odd because the assumption is one ad = one vacancy, but company policies and processing speed makes them try odd things to be able to hire what they need.
So while your idea is nice it wouldn't work because not every company lhas the same recruitment process, frontend or backend (visible to the candidate vs workable for the recruitment teams)
Companies posting every month could just as easily be continuously growing (or, I suppose, have consistent attrition problems). Most of the places I've worked at have had a perpetually-open listings for SWEs, despite regularly hiring them.
You know I've wondered that about companies that post hiring announcement here constantly, in particular Tesorio ( https://news.ycombinator.com/from?site=tesorio.com ) which as far as I can tell post every time the rate limit permits them to do so. After 7 years are they a healthy successful company or is it just endless spam?
In my experience, long-standing unexplained openings in small companies, including early stage startups, are signal that something is wrong.
I did see this in one example in the “who’s hiring” thread here, but also in following the newsletter for a startup I applied to.
Two reasons I saw in my last job hunt:
1. The company is lowballing wages.
2. The hiring manager for the position does not want to hire or is not aligned with the startup team‘s decision that they should hire for the role.
You can get good at qualifying for these scenarios early, but if you don’t have experience looking for and actively screening these out, a list of repeat posts might save some people time.
At least it might add weight to a possible dismissal.
We tend to hire multiple developers in bursts, and recycle our text between months. We only remove the role-specific blurb if we hit capacity for that role.
So, not sure this methodology identify quite what you're looking for.
The US Digital Service posts in pretty much every hiring thread, because many folks who work for USDS are on a temporary “tour” that only lasts a year or two.
I’m sure there are other reasons companies would post each month: churn, or always on the lookout for strong talent, etc.
Since I spent a lot of time looking at "Who is hiring post" for fun anyway, I was looking for a way to make it productive and came up with a different idea [0].
I was wondering if you could detect the slow rise of a new technology and profit from it. Either by retraining or more directly, in the case of crypto, by trading on that info.
I put together something, focused on a couple of crypto technologies and as luck would have it, it's still online !
I like this. I'd also love to see the venn diagram of "Who is Hiring?" top-level comments and a mix of the best and worst feedback about those companies and their hiring processes during that time. I want to see if companies are getting better or worse. I just wasted over a month with a company only to get feedback like, "The CTO wanted you to know the Bitcoin whitepaper more". Companies, as the market gets more competitive, are only doing shadier and shadier things with their time and communication.
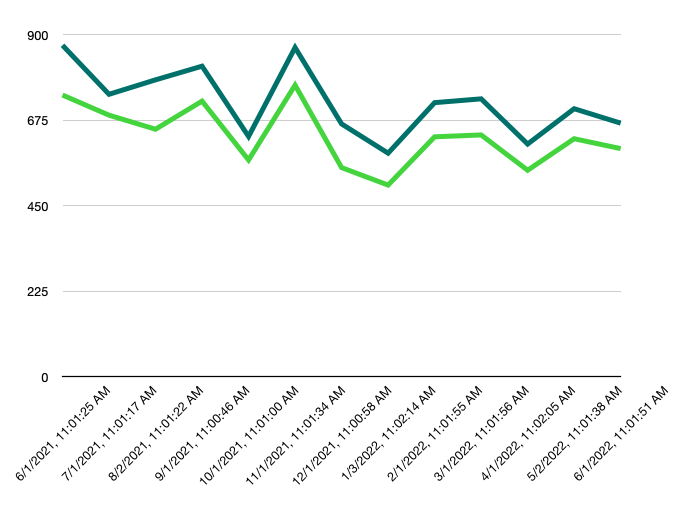
Looks like you have June 2021 as the all time high as well. Doesn't look like June 2022 is going to get even close, which makes sense based on current freezes/layoffs.
If you started that chart in 2020 it would be pretty eerie. If I worked at motley fool I’d regurgitate this as a blog post, Reddit dd thread, and so much more.
But really if I knew finance I’d be interested to see - since who’s hiring is posted the first day of the month, using month over month/etc post volume to inform trades.
Your blog post starts by discussing posts being down this month (June 2022) but the graph provided starts in 2011. For the sake of the discussion, a second graph that starts June 2021 to current, and in monthly increments would be more enlightening. Because ultimately I think that's what we all want to know. In your copious free time would you mind adding that?
Anecdotally, after two years of literally just looking at tumbleweed in the application inbox, as a still-hiring company I have rarely felt as swamped with really interesting candidates and annoying recruiters as in the past four weeks.
Senior dev with my own anecdote. There are more open positions with interesting companies than there is time in the day to apply for them. I’m able to filter them by turn around time on hiring and interview process because I’m spoiled for choice.
Very cool! Would be interesting to try to control for hacker news popularity - something like total upvotes or total comments as a denominator might make this look even worse.
Forgetting which bit of macroeconomics this comes from, but the labor market is one of the slowest to settle (i.e. find equilibrium). Capital (real estate/manufacturing investments, stuff used to make stuff) are the slowest. So the capital unemployment rate should generally be greater than the unemployment rate, for instance.
The anecdote of Tesla posting a bunch of jobs just before the 10% reduction was announced comes to mind. Lagging indicator stuff.
I find it matters a lot with what sort of tech work you're doing. If you are operations, a big company needs to keep their current stuff up and running. Exploratory new programs shrivel up when things get tight, though.
Meta-side question I've had since being part of this community for awhile, how come when a YC staked company posts they are hiring comments are disabled? As I post this "Generally Intelligent" (YC S17) is hiring for ML people (spot 15 per my last refresh.)
" If job ads were threads, each thread would be a generic referendum on the company. Worse, it would be the same referendum over and over.
Job ads are boring, so there wouldn't be anything to discuss other than how one feels about the company, and that's boring except to people who have strong feelings on the topic, and strong feelings on the internet tend to be negative, so the threads would fill up with negative generic comments.
I believe that the hivemind resents boring things, such as submissions where the only new information is "X is hiring", so it gets cranky and fills the vacuum with indignation, basically as the only way to amuse itself in the absence of anything interesting to discuss. It doesn't want to, it just doesn't know any better way to have fun in a vacuum. In practice, what this would look like in a job thread is "I applied in 2015 and never heard back", plus—if there has ever been a negative story X about the company—every variation of X, X, X, repeated increasingly snarkily.
Actually, it's worse. Building a business is a long hard slog. One needs to hire far more often than one has scintillating new information for the community to have fun discussing. Therefore, each successive job ad would be even more boring than the previous one, leading to monotonically increasing resentment. Repetition is the enemy of curiosity.
Launch posts don't suffer from this dynamic because by definition, the startup is new, so there's something new to discuss. "
From another point I would like to check who wants to be hired posts by comparing who is hiring. I can see that hundreds of ML engineers and Data Scientists looking for a job but on the other side there are not that many jobs for ML folks.
Another way to interpret these results is that HN has gotten more popular as a place to source talent. It would be interesting to see top-level comments by number of total users on the site (as a proxy for popularity).
Very cool to see this data analyzed! I wonder if the number of posts could be normalized against some other measure of HN popularity. Maybe total number of posts?
Good thought, though fiscal year v calendar year probably messes that up. Oracle did budgeting in FYQ1 and so tended to not hire much during that quarter, but then hired a lot in Q2, then slightly less Q3/4.
Hacking your spouse is not exactly fair nor is it legal. This is why you have to get yourself an experienced hacker like I did when I could not take my husband's infidelity no more. Now we are seperated due to all i found out, could not stomach it all. The hacker was so discreet, calm and collected,no leaks. Reach him via wisetechacker @gmail com Thanks
Before anyone in the West was aware of the virus, much less taking it seriously, information was leaking out around the East. Given how much connection there is between Silicon Valley and China, it's possible some tech companies were hearing non-specific dangers from their partners in the East. Or it could be entirely coincidental. Probably will never know for sure.
{kind=link}
{kind=link}