This isn't directly related to Zen 2 (sorry), but it's something I've been wondering about:
How do processors that split ops into uops implement precise interrupts? I sort of understand how the ROB is used to implement precise interrupts even with pipelining and OOO, but I don't quite see how processors map uops back to the original instruction sequence.
First, most uops can't throw exceptions, so fusing a shift and an add instruction together doesn't require any complex tracking here.
If a uop throws an exception (let's say a fused add+ld), each uop can have a tag that helps you backtrace to its PC (instruction address) of let's say the start of the sequence, so you know what to inform the Privileged Architecture as to what "instruction" excepted. For many reasons, you need to store a list of PCs of the inflight instructions somewhere (although it is heavily compressed), so having a small ID tag to help reconstruct a given uop's PC isn't too onerous.
Ideally, multiple instructions may map to a single uop, but either none (or up to one) can throw an exception. The hard one here is something like load-pair uops; since each load can throw an exception. Some machines, if a fault is encountered, will refetch the pair and re-execute as independent/unfused loads. Other designs will just pay the pain of tracking which of the pair excepted and do some simple arithmetic off of that.
Instructions such as shift and add that have memory operands can throw exceptions on x86/amd64. (This was some of the motivations of RISC, separating loads/stores from ALU ops made exception handling cleaner).
Heh, random note, I just looked up shift instructions on x86, there are 6 different ones, not RISC. But today there's a lot over 1000 instructions so a few shift variants are peanuts.
Correcting myself, the issue was uops and not instructions. But this turns out to be still similar: at least intel nowadays keeps the memory addressing part in uops (most cases) and doesn't split instructions into load/store uops + alu ops.
I thought there was two different uop ISAs on big x86 cores with two different purposes these days. One is pretty close to the original instructions, just decoded and fixed width (on AMD at least, this is what's in the uCode ROM). Then those are cracked to another ISA that the ROB knows about because instructions will cross functional unit boundaries.
So in say 'rol mem_addr, shift', your inner ISA would be cracked to something like.
ld reg_temp0, mem_addr
rol reg_temp0, shift
st reg_temp0, mem_addr
This is all hearsay though; I could have certainly misheard/misremembered.
My understanding on ISAs that require it is that the uops are marked with the PC of the instruction, and are in the ROB in program order so you can reverse the ROB. Intermediate results aren't fully committed until all of the uops have completed, so there's always the possibility of rollback.
I'm not an expert but I believe what accomplishes this task is the reorder buffer. This allows the instruction execution and its side effects to be separated.
The parent's ROB is the reorder buffer. AIUI it causes the instructions to be retired in order (with exceptions stored until retirement, then exposed). The original question, though is how a particular u-op is mapped back to the original macro-instruction, so we know what macro-instruction excepted.
And I don't know. I guess is if each u-op is tagged with the instruction address within the process, that would do, but that's carrying around at least 32 bits, which is quite a large tag.
Alternatively tag indirectly, which is more likely (you can have maybe 256 instructions 'hot' at any time so an 8-bit tag on each u-op pointing to a 32 or 64-bit table entry (edit: holding the actual address of the macro-op). And the window for the ROB and the other thing that does instruction issue, is ~200 instructions, so that sounds more plausible).
Your alternative is sort of close. What happens is that every x86 instruction is assigned a ROB entry. Every uop that has results (stores are handled separately) is assigned a clean register out of the physical register file, and the address of this register (or multiple registers in case of multi-uop instructions) is stored in the corresponding ROB entry. The ROB acts like an in-order circular list -- the retire phase drains it in order from the oldest first, retiring the oldest instruction if and only if all the corresponding PRF registers have been written to. This is the point where any and all side-effects are made visible.
I realise you're describing a dataflow engine. Suddenly it's starting to fall into place. Tomasulo's algorithm (which this is about?) is starting to fall into place.
Which is a) amazing and b) OMG the frigging complexity of something that has to run at sub-ns speeds. It's like sausages, the closer you look the less there is to enjoy.
Thanks. The bit im not sure about is how to prevent ending up Ina state in the middle of a single instruction if one instruction gets split into multiple uops. Like if one instruction gets split into two uops and the first one completes but the second one raises an exception.
OK, let me try (Tuna-Fish, put me right at any point).
> Like if one instruction gets split into two uops and the first one completes but the second one raises an exception.
That's not a problem. It's just one of n exception types that instruction can raise. Suppose a macro (say x64 instruction, if something like this exists) division instruction where one operand could be fetched from memory, you could have
r2 <- r3 / ^r4
where ^r4 fetches the contents of memory at address held in r4.
suppose it's split up into u-ops
tr6 <- ^r4 ;; tr6 is temporary register 6, invisible to programmer
r2 <- r3 / tr6
you could have a division by zero at u-op 2, or an invalid address exception for u-op 1. Either of those are valid exceptions for the original single macro-op.
Extrapolating from what Tuna-Fish said, the ROB is list of macro instructions, each instruction I assume will be tagged with its actual macro-op address, and each u-op must link back to the originating macro-op so macro-op retirement can take place, so we have a small (8 bit? Because ROB queue is small) pointer from each u-op back into the macro-op in the ROB.
Follow the 8-bit u-op ptr to the ROB, get the originating macro-op address, raise exception at that address.
Assuming I'm right, and assuming I understood you question correctly. I'll have to read his answer more carefully again.
edit: swapped ^ for asterisk as deref operation, as stars interpreted as formatting. Edit 2: slightly clearer.
Perhaps there are two copies of the program pointer, one at the "top of the pipe" updated by instruction decode and branch prediction, and one at the "bottom of the pipe" updated by the ROB. Then uops only need to carry the amount by which the program counter is advanced, and certain events can cause a pipeline flush and copy the bottom of pipe version of the counter to the top of the pipe.
I see what they mean then. I read the question a bit too fast.
I was mostly assuming that the issue of the operation reserved a spot in the outstanding buffer which would ensure sequencing of the write or commit after execution which would walk through the buffer in sequence.
But you're right that there are still more questions to how some of that data is tracked through the pipeline.
I'd assume the simplest thing to do would be to flush the pipeline as if you had a branch mispredict, the interrupt can be delivered instead of an alternate branch target.
Few games will suffer greatly from it, but there are several titles with RAM bottlenecks, like PUBG and FarCry.
Anyway, AMD has a much better price/performance offer than Intel. For general puprose Intel is totaly anihilated, but for the games they are still more than competitive.
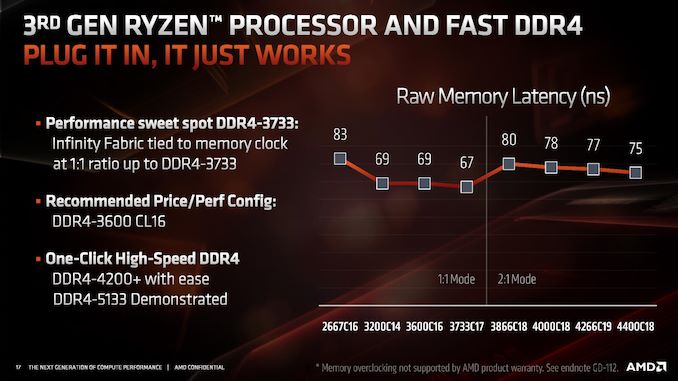
I was kind of curious what the latencies might be for other contemporary processors/builds, and I'm not sure 70ns is actually really outside the normal margins.
Here's an i7-8700k build that is already pretty close to 70ns: https://www.userbenchmark.com/UserRun/18173216 - Also acknowledging that, this is not the 'best case' performance. But seems to be not so unusual either.
(edit: Removed section about latency ladder as I just realized it was caching and not system memory latency that we were most likely seeing initially, and therefore not terribly relevant.)
As far as I can tell, Zen 1 has similar latency characteristics[0][1]... so I guess I won't notice any degradation when upgrading to Zen 2.
I will distill your post to: most user builds are bad balanced to begin with and they wont see a difference and would had a better price / more cores. Valid point, i agree with it. Still could be argued about a need for a better memory for Ryzen. This equalizes total build cost and you need to be informed about this platform trait beforehand, which will results in even worse average build balance. Imagine prebuilt PCs from wallmart with 2400 leftovers.
But my point is more about advanced user builds and press benchmarks.
[0] - 2400 cl16. It's much worse than 3600 cl16, used in referenced Ryzen 3000 test. It would be interesting to see how Ryzen would perform with it. May be zen2 comparison with 2400 vs 3400 (3600 is very rarely achievable there as IMC trait of the platform) would be a good illustration.
[1] - 3200 C16. But it performs way bellow expectations. Modern Intel chip should have ~55ns with it. With 3600 cl16 intel will have ~40ns.
You seem pretty certain this will manifest as a noticeable performance hit. Can this kind of thing be easily measured in practice? I don't know if my workloads would be memory latency sensitive and worse, I don't even have a clue how I would find out.
I'm not too concerned though, since I already use Zen 1 and it looks to be around the same. If I had to take a shot in the dark, I'm guessing it's just a consequence of the chiplet designs of Zen and Zen 2 that enabled them to scale so well. If it is such a tradeoff and there is not future gains to be made on latency for Zen platforms, I can accept that.
Though it does make me curious if Intel will ever stumble upon the same problems.
You can manually increase the DRAM access latency in BIOS, leaving clock alone, and measure. It impacts throughput somewhat, but may be a little closer to an apples-to-apples comparison. I don't know that anyone has attempted to do this for video games on Zen 2 specifically (especially considering Zen 2 is only commercially available for the first time, like, today).
Here is a fresh Zen1 timings comparison from Reddit[1].
Most increase is between 3200cl14 vs 3200cl12. 12%. Difference between this two is almost purely a Latency.
Then compare 3200cl12 and 3600cl14 - 3%, marginally no increase. Almost no difference in latency, only throughput and IF.
Past 3200 RAM throughput and inter-core-communication (IF) has very little influence for Zen1 gaming. For Zen2 this scenario would differ in some ways but not too much.
I think that linked list with randomly distributed nodes is a good benchmark. Each jump will be hit miss and cause load from RAM and you can't prefetch anything because next address depends on content of fetch. Performance of simple iteration of that linked list should correspond to random memory access performance.
> I don't know if my workloads would be memory latency sensitive and worse, I don't even have a clue how I would find out.
If you develop on something unix-ish valgrind's cachegrind will tell you about your L1 performance. On recent Linux you can get this straight from the kernel with `perf stat` https://perf.wiki.kernel.org/index.php/ (cache-misses are total misses in all levels)
The most basic question is: are you randomly accessing more then your processor's cache worth of memory?
You keep claiming this is going to ruin gaming performance based on napkin math. Why wouldn't you just reference ACTUAL benchmarks, which show your theory to be incorrect?
As far as I know, these processors are not yet released. What's the confidence level that this user benchmark will be indicative of real life expected performance?
It seems implausible that this user benchmark is a good indicator. The Zen 1 architecture exhibited nothing of the sort[0] -- it would be an order of magnitude performance regression.
I expect we'll start to see more accurate tests once the processors are actually released into the wild.
I was curious as to what Intel’s number’s look like. Found the 2nd gen Ryzen matched the random latency for the 7th gen i7, but while the 3rd gen at 3733CL17 gets 67ns, it’s 53-54 ns for the 8th and 9th gen i7/i9. So that’s narrowed to 13 ns slower, a 24% drop in performance (or a 20% improvement, depending on how you look at it...) While it does matter, we’re comparing 8 core parts to 12 core parts, so it’s possible that 50% more cores outweighs a 24% increase in memory latency, or alternatively that 33% fewer cores could hurt performance more than 20% faster memory latency. Ehh... it’s a mixed bag for me. I can see how increased memory latency hurts performance, and it’s unclear what the minimum random latency is at different CL settings and speeds on the Intel side. Also there’s a slight single digit ns penalty to sharing memory across units, a concept the comparable Intel parts don’t have, if I’m reading this right.
That said, the X570 chipset has PCIe 4.0 with improved power management to match, even at the ITX end. But PCIe 4 will likely go through implementation improvements and right now is only useful for storage in really fast Raid configurations, 15GB/sec performance from 4 drives has been demonstrated at a relatively cheap cost, comparable to high end commodity NVMe PCI 3 storage.
I wish it were obvious which part was “best” but different implementations lead to different optimizations/costs/benefits...
For memory latency to matter, you need the worst case scenario to play out, which is a miss on all caches.
For cache to be made entirely irrelevant in performance, you'd need a situation where every access is a cache miss.
Yet even a pattern of completely random memory accesses will hit cache once in a while. And even then, a completely random access pattern is absolutely in disconnect with real world applications.
Thus, performance is not determined by memory latency. It is only a factor. And latency has actually improved, like other metrics, when compared to previous generations.
In short, wait for benchmarks. Just some three hours left for NDA lift.
True, and the benchmarks told a very different story for Ryzen 3700 and 3900, that for most of these workloads, the gains from the extra cores far outweigh anything else including tiny RAM timing differences. The tests I saw ran with 3600 speed RAM though, for both.
A very interesting article is https://www.pcworld.com/article/3298859/how-memory-bandwidth... which brings up Linux vs Windows, and compares the slightly older ThreadRipper 2nd gen to the 7th gen i9 part. Which means it’s possible the i9 outperforms the Zen 2 parts still, if random access memory is required and you’re on Windows where the difference is more apparent...
Well, to be devil's advocate: just because AMD improved their memory latency does not mean it was state-of-the-art. Indeed, looking at some random user benchmarks of Zen 1, it looks like the memory latency is similar with Zen 1. (See my reply to parent for a couple links, but I think you could also just find random Ryzen 2700X benches and see the same.)
Of course, the effects of ~20ns more latency on system memory accesses may not be as easy to observe in practice, especially if throughput is excellent. But we'll see, I guess; 'gaming' benchmarks should be a good test. (Meanwhile, I'm just going to be happy with Zen 2 if it provides a large speedup in compile times.)
Actually, the L3 cache is also sharded across chiplets, so there's a small (~8MB) local portion of L3 that is fast, while remote slices will have to go over AMD's interdie connection fabric and incur a serious latency penalty. On first gen Epyc/Threadripper, nonlocal L3 hits were almost as slow as DRAM at ~100ns (!).
Only insofar as there are diminishing returns on increasing memory, in general. If you can map your entire application instructions in a low latency block of memory, you're going to see massive benefits over swapping in/out portions repeatedly (where RAM latencies come into play).
Memory access typically follows a pareto distribution with a long tail. So doubling the size of the cache increases access speed more towards the tail, so the speedup is always less than the speedup of the previous cache size increase. The actual effect will vary by application but if the data doesn't all fit in cache, and access patterns follow that long tail distribution, its true that increasing the cache size had diminishing returns. Which is the case for almost all applications.
Sure, but that applies to main memory as well. Ergo, having a larger cache will offer a benefit over memory correlatively; it's only diminishing relative to itself.
That makes sense. I was mostly looking at one of the Tom's Hardware benchmarks in particular; I don't know what the userbenchmark is actually _doing_. So it's probably more fair to compare userbenchmark to userbenchmark like you did.
However, I think it's still true that the actual release of the Zen 2 processors will make userbenchmark scores much more reliable as the scores regress to the mean.
A latency hit is not a prime concern for retail builds of AAA games. Cache coherency can be done to a very fine-grained degree in a AAA asset pipeline when a few developers are pointed entirely at that optimization problem, since most game scenes are mostly static or have "canned" dynamic elements that can be kept in static pools(e.g. up to 12 NPCs at a time). As such, a substantial part of inner loop processing will take place in cache: what's really at stake when discussing memory performance for games is how the architecture hides latency in its caching implementation, and how that interacts with existing software, since the software in most cases is making an effort to present favorable scenarios with a limited worse-case. Games tend to bottleneck not on the memory, but on single-core performance, since there's a ton of synchronization logic in the game loop that gets in the way of distributing the processing load across all cores, and this has historically been where the Core chips have had big wins over Zen.
For heavily dynamic applications like editing tools where the user is free to shape the data as they please and the worst case is much worse, latency becomes a much bigger issue.
I think people get a little over zealous with CPU requirements on games. If my eight year old Xeon 5676 can handle every past and present game I throw at it, I think you'll be beyond spec for years to come with a Zen 2(or any modern processor).
it depends a lot on the type of game and what you care about for that type of game.
if you're playing a AAA singleplayer game, the GPU will almost certainly be the bottleneck. any i5/i7 tier CPU from the last eight years will be powerful enough not to starve the GPU most of the time. when I play this sort of game, I mostly just care about the average framerate. I don't care too much if every 10-15 minutes a complex scene causes a brief stutter. if this is the only kind of game I played, I would just get a cheap midrange processor (unless I had requirements due to unrelated workloads).
on the other hand, when I play a fast-paced multiplayer game (especially fps), I care a lot more about worst case framerates than average. in a game like counterstrike, framerate drops tend to happen when there are smokes, flashes, and/or multiple players onscreen simultaneously. in other words, they happen in the most important moments of the game! while I'm happy to average around 45-60 fps in the witcher, I want the minimum in csgo to be no less than 120. if you have a goal like this, even an old source engine game becomes pretty demanding.
there are also games like factorio where the simulation itself is difficult or impossible to split into multiple threads. singlethreaded performance and memory bandwidth set an upper bound to how big your base can be while still having a playable game.
I suppose if your goal is 100+ fps that's probably valid for high fidelity multiplayer games like battlefield, but there is no way even an ancient CPU can't handle games like CSGO at many multiples of that. I value real estate and image quality, so my panels are 30" and IPS. Which means I'm limited to 60fps. However if I unsync, the framerate is in the 150 range in Overwatch. This is on a gtx 1070 with ALL settings maxed at 2560x1600.
keep in mind I'm talking about 99th percentile frames. I'm running a 4670k right now which easily gets over 250 fps most of the time in csgo. with multiple players, flashes, smokes, and weapon animations on screen, it can drop down to around 70. it's hard for me to notice this visually, but it does make the input feel weird.
That benchmark only has a few samples on an unreleased cpu. Typical ballpark numbers for memory latency are usually 100ns. There are also a lot of factors that can influence random memory access such as whether the lookup is going through virtual memory that isn't a page in the TLB cache. I'm skeptical this benchmark tells us much.
Also games that are sensitive to memory latency are very poorly written games. This is not a new or contraversial opinion of PubG, which is know for being terribly written (and that is supposedly a reason for fortnite taking its audience so easily). It is also written using Unity and C#, which don't require hopping around in memory, but do make that the most obvious path, which is a trap for people who don't know better.
Farcry is not a game I would expect to have these problems. Ubisoft seems generally technically sound, despite releasing wildly unstable games, but it will take real numbers to get a clearer picture.
As other users have pointed out with concrete sources, this comment seems to come to the conclusion that Zen 2 will not be competitive enough based on cache information. But looks to me that the timings are much lower on 16 MiB, and that's on a dedicated benchmark.
It also seems to ignore the comment on userbenchmark itself that indicates that latency is less of a bottleneck than bandwidth.
I'll say coming to the conclusion that Zen 2 is less than competitive in comparison to Intel offering a day ahead of launch is more than brave.
I had no issues with an FX-8320e and gaming. I was concerned at first about the memory latency of Zen when I upgrade to a Ryzen R7 1700 but it's been a non issue.
This has been a problem with AMD for as long as I can remember. I remember about 10 years ago when AMD made a strong push against Intel and they traded memory latency for larger LL cache sizes and a directory based cache architecture where the better utilization was supposed to make up for the smaller L1/2 sizes.
Didn't work. Intel smoked them, especially on server workloads that were cache optimized. I wonder if the same things is going to repeat itself?
I haven't build a desktop in almost a decade, so I was thinking of it when the top shelf ryzen chips hit the market. I don't play any games, but would use it for server dev and basic ML work.
Cache optimized means that either the processor is able to prefetch the data before it is needed or it is already in cache. It's exactly this situation in which memory doesn't matter at all. Workloads like web servers or databases that run on servers are generally not cache optimized at all. Your Java, python or php program is going to use a lot of pointers which will incur memory accesses. So yes Intel cpus would be better at this but calling these workloads cache optimized is completely wrong.
I'm taking specifically about the workloads I was interested in at the time where cache optimised means it took pains take advantage of larger L1s and took pains to get L1 hits. But this was a general problem too and noted at the time by many people.
AMDs smaller L1 was as definite negative at the time. This was back when hyperthreading could be a net negative because of the reduced L1 cache per thread so we would turn that off to.
Hashed probably means that some features are mapped to a desired perceptron weight via a hash function. This serves as an implicit regularization and can be much more efficient (no need for a predetermined feature vector, sparse representation etc.). It's called hash trick in ML. Perceptron is a single layer NN. Dynamic predictor, a branch predictor that adapts to program input, not just some predetermined state (like a formula that was shown to be good enough for a collection of programs).
In this case, I'm pretty sure it means that multiple instruction addreses are hashed to the same perceptron (or is what you said effectively the same thing in ML-speak).
Since you don't have branch predictors for each address, you share the same prediction data for multiple addresses (this is one often underlooked cost to heavily branchy code).
A perceptron is a simple type of neural network that is very fast to use when already trained. So it is a real network, I don't know what hashed perceptron is but I'd guess it would have to do something with hashing the inputs to the perceptron?
"Hashed" in this case simply means they did some extra work to deal with the perceptron's XOR problem, since a straight mapping of PC and branch history would led to an inability to distinguish XOR patterns.
I wish AMD enabled Secure Encrypted Memory by default for all devices, and also bring Secure Encrypted Virtualization (or something similar) to consumer Ryzen chips, too.
Even Microsoft has made VM-sandboxing a consumer feature. It's time for AMD to join the bandwagon and help along the way, not keep the virtualization/other security features exclusive to server customers.
At least AMD made DRTM (SKINIT) available on consumer CPUs, where Intel still keeps DRTM (TXT) limited to business vPro chipsets. ECC is available on some CPU/motherboard/bios combinations for Ryzen, although ECC and low-power for Ryzen APUs is segmented to "Pro" models only available to OEMs.
It's still near impossible to buy devices with Ryzen Embedded, despite several system announcements from ASRock, but SEV is available today on Supermicro Epyc 3000 mITX motherboards.
This is a really good article. I am finally at the point in my college education where I can understand what they are talking about!
Are there any articles like this about Apple or Intel chips? I like hearing about actual implementations, not just educational processors. (I am looking through the other articles on this site.)
The site has a search function, did ya find anything?
I remember Stokes had a recommended book and quite a few articles on Ars Technica back in the day. Covering older hardware, but typically a prereq in understanding newer compatible designs.
>"Perceptrons are the simplest form of machine learning and lend themselves to somewhat easier hardware implementations compared to some of the other machine learning algorithms."
Can someone explain what is it about perceptrons that make them easier to implement in hardware?
All you need for a perceptron is to add up all of the inputs after they’ve been multiplied by their weight. This would probably be done in parallel with a fused multiply add circuit which is fairly simple and some place to store the weights. When they change the perceptron all they need to do is record the current weights and load in the new values.
Wait, how is K-NN harder to implement than a perception... Even in hardware? What about linear regression? What about decision trees? What about naive Bayes?
A single layer perceptron IS linear regression + some non-linearity of the output. I think in reality they could have used the word "logistic regression" but chose perceptron because it sounds better.
Performing nearest neighbors search is much more expensive than a simple multiply-add. I don’t know about the other, my idea is that a perceptron is much easier to implement in hardware/low-level operations.
You don't have long to wait. Zen 2 goes retail tomorrow, so the embargo on benchmarks ends and a bunch of reporting from the usual suspects will appear.
The verdict is in. Aside from games Ryzen 3000 is a big win; "practical" application run substantially faster on these CPUs. Intel still has a small absolute lead for a bunch of traditional gaming benchmarks, but work loads like compression, rendering, compiling, transcoding are nearly all faster than anything Intel offers.
{kind=link}
How do processors that split ops into uops implement precise interrupts? I sort of understand how the ROB is used to implement precise interrupts even with pipelining and OOO, but I don't quite see how processors map uops back to the original instruction sequence.