As far as I know, these processors are not yet released. What's the confidence level that this user benchmark will be indicative of real life expected performance?
It seems implausible that this user benchmark is a good indicator. The Zen 1 architecture exhibited nothing of the sort[0] -- it would be an order of magnitude performance regression.
I expect we'll start to see more accurate tests once the processors are actually released into the wild.
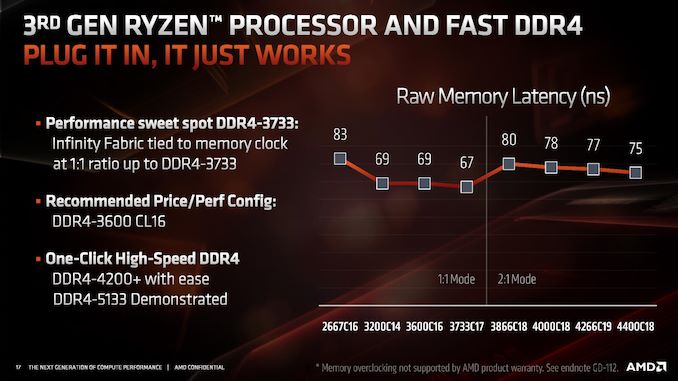
I was curious as to what Intel’s number’s look like. Found the 2nd gen Ryzen matched the random latency for the 7th gen i7, but while the 3rd gen at 3733CL17 gets 67ns, it’s 53-54 ns for the 8th and 9th gen i7/i9. So that’s narrowed to 13 ns slower, a 24% drop in performance (or a 20% improvement, depending on how you look at it...) While it does matter, we’re comparing 8 core parts to 12 core parts, so it’s possible that 50% more cores outweighs a 24% increase in memory latency, or alternatively that 33% fewer cores could hurt performance more than 20% faster memory latency. Ehh... it’s a mixed bag for me. I can see how increased memory latency hurts performance, and it’s unclear what the minimum random latency is at different CL settings and speeds on the Intel side. Also there’s a slight single digit ns penalty to sharing memory across units, a concept the comparable Intel parts don’t have, if I’m reading this right.
That said, the X570 chipset has PCIe 4.0 with improved power management to match, even at the ITX end. But PCIe 4 will likely go through implementation improvements and right now is only useful for storage in really fast Raid configurations, 15GB/sec performance from 4 drives has been demonstrated at a relatively cheap cost, comparable to high end commodity NVMe PCI 3 storage.
I wish it were obvious which part was “best” but different implementations lead to different optimizations/costs/benefits...
For memory latency to matter, you need the worst case scenario to play out, which is a miss on all caches.
For cache to be made entirely irrelevant in performance, you'd need a situation where every access is a cache miss.
Yet even a pattern of completely random memory accesses will hit cache once in a while. And even then, a completely random access pattern is absolutely in disconnect with real world applications.
Thus, performance is not determined by memory latency. It is only a factor. And latency has actually improved, like other metrics, when compared to previous generations.
In short, wait for benchmarks. Just some three hours left for NDA lift.
True, and the benchmarks told a very different story for Ryzen 3700 and 3900, that for most of these workloads, the gains from the extra cores far outweigh anything else including tiny RAM timing differences. The tests I saw ran with 3600 speed RAM though, for both.
A very interesting article is https://www.pcworld.com/article/3298859/how-memory-bandwidth... which brings up Linux vs Windows, and compares the slightly older ThreadRipper 2nd gen to the 7th gen i9 part. Which means it’s possible the i9 outperforms the Zen 2 parts still, if random access memory is required and you’re on Windows where the difference is more apparent...
Well, to be devil's advocate: just because AMD improved their memory latency does not mean it was state-of-the-art. Indeed, looking at some random user benchmarks of Zen 1, it looks like the memory latency is similar with Zen 1. (See my reply to parent for a couple links, but I think you could also just find random Ryzen 2700X benches and see the same.)
Of course, the effects of ~20ns more latency on system memory accesses may not be as easy to observe in practice, especially if throughput is excellent. But we'll see, I guess; 'gaming' benchmarks should be a good test. (Meanwhile, I'm just going to be happy with Zen 2 if it provides a large speedup in compile times.)
Actually, the L3 cache is also sharded across chiplets, so there's a small (~8MB) local portion of L3 that is fast, while remote slices will have to go over AMD's interdie connection fabric and incur a serious latency penalty. On first gen Epyc/Threadripper, nonlocal L3 hits were almost as slow as DRAM at ~100ns (!).
Only insofar as there are diminishing returns on increasing memory, in general. If you can map your entire application instructions in a low latency block of memory, you're going to see massive benefits over swapping in/out portions repeatedly (where RAM latencies come into play).
Memory access typically follows a pareto distribution with a long tail. So doubling the size of the cache increases access speed more towards the tail, so the speedup is always less than the speedup of the previous cache size increase. The actual effect will vary by application but if the data doesn't all fit in cache, and access patterns follow that long tail distribution, its true that increasing the cache size had diminishing returns. Which is the case for almost all applications.
Sure, but that applies to main memory as well. Ergo, having a larger cache will offer a benefit over memory correlatively; it's only diminishing relative to itself.
That makes sense. I was mostly looking at one of the Tom's Hardware benchmarks in particular; I don't know what the userbenchmark is actually _doing_. So it's probably more fair to compare userbenchmark to userbenchmark like you did.
However, I think it's still true that the actual release of the Zen 2 processors will make userbenchmark scores much more reliable as the scores regress to the mean.
{kind=link}
It seems implausible that this user benchmark is a good indicator. The Zen 1 architecture exhibited nothing of the sort[0] -- it would be an order of magnitude performance regression.
I expect we'll start to see more accurate tests once the processors are actually released into the wild.
[0]https://www.tomshardware.com/reviews/amd-ryzen-7-2700x-revie...