Remember, if you have a DevOps Team, then you are absolutely not doing DevOps. Developers should be involved in managing everything about their applications, including infrastructure.
Any sufficiently complicated infrastructure that has uptime requirements and significant revenue associated with it is going to have a DevOps Team (or the equivalent) ultimately responsible for ensuring that things are working. I guess it's possible to turn your entire dev team into part-time DevOps engineers, while still calling them Software Engineers, but I've usually found that doesn't work long-term and causes employee retention issues. It's like saying your company does 'No-Support' because you don't hire Support Engineers, while in fact you've enlisted your Software Engineering team to handle all support requests.
Also, if you're working in a regulated field like Healthcare or Finance, or anything that touches PII, your developers often can't have access to deploy code directly to production. Again, you could maybe work around this in the short-term by turning all developers into developers+devops, but they're different skillsets.
Developers should be involved in managing everything about their applications, including infrastructure.
As a software engineer, there is just no way I can stay up to date with my craft as well as everything there is to know about infrastructure AND the all important security. I don't know about all the latest kernel patches and firewall rules. I don't know about monitoring failed hard drives. Etc.
I mean, I do know a lot about deploying and maintaining my running software, but Ops has a ton of other concerns that themselves are a full time job and I already have my time fully consumed by development tasks. I'm also ok with being pushed enough of the work so that I don't accidentally make software that's a PITA to deploy or manage and that I don't needlessly wake somebody else. That doesn't mean that I can take on the entire job (well, I can, but I wouldn't be doing as good a job, especially when security and such is concerned, and I wouldn't be doing as good a development job either). What next - DevOpsSalesMarkettingAccounting?
Much better, IMO, is to have small tightly-knit cross-functional teams which include an ops engineer.
I couldn't agree more. Not only that, but trying to context switch between ops and development is a nightmare. The two positions are nothing alike. Most of my time as a sysdamin, I spent waiting and reading HN while super slow shit happens. It's basically a glorified secretarial position that deals with machines rather than humans. Every few minutes, I have to run another command, check output, respond to some AWS rep, etc. Basically, the absolute opposite mindset and skillset of what's needed to do proper development. After a few hours of that, switching back to development is almost impossible.
Sure, but any advantage from that is lost in the fact that I've lost a ton of development time on doing ops tasks, which I don't have time to do properly and don't have time to learn how to do properly. Even bad communication to a competent ops person who does have time to, you know, do their job, and does have time to stay up to date, will result in much better results than if I tried to fit the work into my schedule.
For example, in my current work, I could try to figure all the ops stuff out, but I've already got a backlog of months of development tasks for a project that needs to be done asap.
In my personal experience, writing complex software with complex infrastructure requirements, I have never had an advantage in not allowing other, more specialised people, to handle concerns outside my core competency (which is software developnent). Other people may be smarter or more efficient than I, or have more time available, or have simpler requirements.
The statement touches on a real issue. I would revise the statement to:
If your DevOps people reside in a separate group outside of the development team, then you are not doing DevOps.
Architecture and Infrastructure go hand in hand, and DevOps is the glue that merges them together. I've worked with both DevOps and Architecutre groups in larger companies where Development, DevOps, and Infrastructure have been separated and siloed. This invariably leads to waste that undercuts any advantage provided by modern development practices.
The core of the issue is the designs will only consider trade offs within their skill set. Problems that are easily solved with a combination of dev/devOps/inf are instead solved using complex designs within a single skill set. The other end of the spectrum is that decisions get made in one group that will undercut the efforts of another group.
Real life examples:
The dev group wants to deploy backend service version 2 with fail back option in production. The API's are identical, the database is unchanged. Instead of using a load balancer and monitoring to automate role back the dev group builds another system with the job of routing traffic between the two systems, identifying failures, and then stop sending traffic to the new system.
The dev group designs a system with "micro-services" in mind. The developers have all containerized the services and run them on their laptop. The infrastructure and/or devops group doesn't want to deal with containers and instead deploys one service per VM. (In these scenarios the dev group will get a bill for the extra services).
The problem is that it's easier to grab the people sitting next to design something than scheduling a meeting with groups you rarely see. This is a key driver of Conway's law.
> If your DevOps people reside in a separate group outside of the development team, then you are not doing DevOps
Devops and swdevs sitting and working together, understanding each other's problems and needs, and keeping them in mind when designing solutions, is indeed a beautiful thing to watch.
I think this is basically just an argument about terms.
If you write code, you're a developer. If you run servers, your in ops. If you are doing both, it's devops. So when discussing the idea of having a total separate team for running the servers, OP says it's not devops and he's right, because the definition of devops is not having the teams be separate. And you say that it's often totally needed to have that separation and you're also right.
> I guess it's possible to turn your entire dev team into part-time DevOps engineers,
I think you mean, it's possible to turn your entire dev team into part-time ops engineers. Which is 1) the entire concept of "devops", and 2) often a horrible idea. :)
(Sorry, but people who use "devops" to mean "ops" is a pet peeve of mine. If you're not a developer, it's just ops.)
Most devops teams that I see don't manage the servers. They provide tooling that makes it easier for dev teams to manage their own servers.
If a devops teams is actually managing all the servers, I agree that they aren't doing devops, but at a large enough company it makes sense to have a team working just on things that make it easier for the company to do devops.
Yeah, I was doing "DevOps" back when it was still called "wow, good sysadmins are really expensive! I know..."
The rebranding is cute and all, and the tooling's a fair bit better, but nothing I've seen suggests that
combining these two full-time roles in the same people is any more a good idea today than it was fifteen years ago.
Thanks for the flashbacks of supporting failing services at 3:00 AM. :D Even today, I am amazed at how absolutely terrible this type of decision making was and still is. The idea that you can "save some money" by having your engineers supporting your infrastructure "part time" is always going to cost your more in the long run. Because of the long-term effect of having an unskilled (in the area of question) individual attempting to do the job of a system admin (bad security practices, etc) and the turn-over you end up with due to burn-out.
Whenever I've been in this position, or run teams this way, its been less about saving money and more about making sure developers have to live with their own bad calls on tech. I've worked in places where dev teams would just throw code over a wall with the equivalent of a sticker saying "Works on my machine!" and weren't the ones getting woken up in the middle of the night when that overeager query taps out the memory limits, and its a recipe for headbanging.
All things being equal (i.e. I've got the money to have someone who's role is more ops than dev but still does both) having that person to "own" the production configuration is valuable, but developers still need to be in touch with what their code does in production. Otherwise you eventually end up with the equivalent of a cool interaction design that's damn near impossible to implement on the web (another pet peeve of mine...)
There's a fundamental difference between holding engineers accountable for the downstream impact of their technical decisions and making engineers take on the added responsibilities of an additional position without compensating them accordingly for the added responsibility. In an organization that prioritizes stability there is an appropriate balance between engineering and system administration as well as potential overlap given the right boundaries and understanding of job responsibilities. The engineering team will be held accountable by the system administration team and changes will happen because of it.
The inherent failing in this structure is when one of two things happens; one, the system administration team does not have the appropriate channels (and clout) to provide push back against the engineering team; two, the technical teams (both engineering and system administration) don't have the ability to get technical debt payed off properly due to an improperly structured project management process.
Anecdotally, I've been witness to the second issue a number of times. If there isn't an immediate understanding of ROI for a proposed change then it isn't prioritized to be worked on. The thought process is generally along the lines of, "Engineers are an expensive resource, having them working on something that won't make the company money is obviously not the priority."
While some of this is on the engineering leadership as their job is to provide insight into ROI for technical matters there also needs to be a balance where the non-technical leadership trusts the technical leadership to know when to prioritize projects with non-obvious ROI.
Definitely agree with much of that, though I don't think it detracts too much from my main point. Most of the companies I work with don't have the luxury of dedicated ops people, and those that do I still think insulate developers too much from the production environment.
It feels like QA is an antiquated notion these days. Why is a prod-like test environment too much to ask for? As a developer, if you call me in the middle of the night and tell me we are in crisis mode, my first thought might be "Did anyone test this thing with any kind of rigor at all?"
I've been a sysadmin, I've been a software engineer, and now they call what I do devops. My experience is that the title is useless in terms of identifying what people actually do or how companies actually use them.
Some places just rebrand administration as devops. Shiny new title for you, stakeholders can be told we're not missing the trendy new hotness, carry on.
Some places will pull in a "devops person" and drop them on the IT team. This seems to usually result in something between "Jenkins? The devops guy sites over there" and incremental improvements.
Better than that is the model where the "devops person" is something of a liaison as well as an individual contributor - they sit in engineering standups, collaborate on how things are going to be built with an eye towards deployment and manageability, and generally play both sides of the fence. This, however, requires a "devops person" who is also a bit of a politician, and that's not usually contemplated when hiring. It also requires engineering to let the person meaningfully take part, which can become even more political some places.
Best, in theory, is more of less of a merger, but that does ignore that IT is a very different beast than engineering, and that the workplace has been dealing with the distinction for a very long time. Changing that is not a technical issue, it is a (big) management and perception issue. If you get it wrong, the power balance gets wonky and causes the usual problems when you have managers who are IT-clueless managing IT people[1].
All that said, and putting aside org-chart and political issues, I like to think two things are true:
- That someone who has done both engineering and administration is more likely to spot friction, second-order effects, and various traps and dead ends than someone who hasn't.
- That treating the various "devopsy" things - deployment, integration, monitoring, etc. as first-class requirements alongside product features leads to better results along multiple dimensions.
So it reduces to people-problems. There just aren't many folks who have lived on both sides of the fence who also want to do this sort of role[2]. And if you adopt "devops" as a cost-savings measure, you're doomed up-front.
[1] You never see IT managers promoted over engineering, for obvious reasons. The reasons why the reverse happens are obvious to me in descriptive terms, but not in normative terms.
[2] Of course, keep in mind that I'm in this category. I don't write this as ego fluffing - I believe these things to be true - but here's my disclaimer.
I've used those scripts - I've written those scripts! - and I have no idea what you're talking about. Puppet is a marvel, and when it's too heavyweight for the task at hand, there's Ansible. Both are far, far preferable to
me@homebox $ for host in foo bar baz; do cat random_stuff_who_knows_if_it_works.sh | ssh $host 'bash -'; done
Immutable configuration (puppet) is a godsend. No more digging into backups of etc and wondering who wrote something there, when (was it before or after the emergency?) and why. Now you place everything into a repository with commit logs like any piece of code.
That said, immutable configuration is static, so the need for grumpy admin style scripts did not go away. It just reduced.
Oh, I still perpetrate cryptic Bash one-liners myself, on a more or less daily basis. What's nice today, by comparison with the before time, is having a realistic option to do otherwise, and having that option not be Perl.
I had used very readable and documented scripts that would build images, boot VMs, deploy on physicals, configure network devices with hundreds of SLOC by simply calling the right CLI tools instead of (re)writing many thousands of lines in $language.
I was in a company around 2002 doing immutable deployments by updating images from git-tracked config files for whole datacenters.
E.g. calling to debootstrap takes few lines. Generating an ISO. Configuring PXE to serve it...
That must've been amazing, back in the day! The organization was clearly far, far ahead of the curve, not least in that they adopted Git three years or more prior to its initial public release. Fantastic as it no doubt was, though, I'm glad that such awe-inspiring wizardry is no longer required to achieve a similar quality of result.
I think originally 'DevOps' was intended to mean that dev/eng teams deserve to have a stable environment on par with c-suite email. Then it morphed into yet another way to pay people less by over-specializing them into tool operators.
The skillsets and tools have converged. Fifteen years ago sysadmins used shell, perl, and maybe little bits of C, while application developers used C++ or Java; these days both use Python or Rust or what have you.
+1. Nothing promotes the ability to produce quality code like being woken at 3am to troubleshot a problem 3 microservices away from your own.
In my anecdotical experience, the ability to recover from such incidents degrades with age, so nowadays I regard "everybody [but management] does DevOps" as codeword for ageism.
> Any sufficiently complicated infrastructure that has uptime requirements and significant revenue associated with it is going to have a DevOps Team (or the equivalent) ultimately responsible for ensuring that things are working.
I don't think these are mutually exclusive; I think you can both have a dedicated applicative operations (rebranded DevOps or SRE) team and still allow developers to rapidly provision and deploy. The point is a change in responsibilities and workflow on the part of operations: whereas their task was originally to deploy, verify success, rollback if necessary, monitoring, etc., their new task is to embed those tasks in code, so that developers can safely and reliably perform those tasks by themselves. You can have an organization where developers can automatically provision infrastructure which is behind your enterprise firewalls, hooked up to up-to-date enterprise artifact repositories, has enterprise PKI management already set up, etc., because expecting developers to know the ins and outs of setting that up manually is moronic and much of that should be scripted for ease of management anyway.
> Remember, if you have a DevOps Team, then you are absolutely not doing DevOps. Developers should be involved in managing everything about their applications, including infrastructure.
I think the intent here is a good one. You as a developer should be involved with how your software is deployed and managed. It's just that there is a pretty grey boundary between where developer involvement ends and ops involvement begins.
Another issue is that devops is extremely poorly defined. Some people insist this means only writing chef scripts. Some people it's diagnosing and fixing production issues. Some people it's just sysadmin work. Or other responsibilities and combinations.
Where's that quote about how software architecture evolves to reflect the organisational structure of the business?
Amazon does it this way because it's made of teams that are not just loosely coupled but somewhat firewalled from each other, along with a brutal internally competitive process.
The parent is arguing that the concept of a "DevOps Team" that does Ops makes sense and is not an oxymoron. Yet "DevOps" literally means doing Dev and Ops together.
Otherwise have a "Developer Team" and an "Operations|Engineering|SRE|SysAdmin Team".
Microservices are just one option of refactoring that can be considered at later stage of life of the system.
Even big guys who are using microservices started with monolith. Many people can't seem to catch this important detail - they started as monolith that was later refactored/modularised/split/microserviced. It doesn't mean, the moment they did it, that humanity found a better way of writing software called "microservices". It just means that, at that stage of life of the project, it made sense. Starting with monolith is still, in most cases, the best way to write projects, even if later they evolve into microservices.
Starting projects with maximum split into microservices is, in most cases, just a plain, stupid idea.
The most important part when starting project is avoiding friction at all levels - from dev setup, contribution, deployments, database evolution (migrations), interaction between different parts of the system (it's easier to just call a function from a module than to do rpc - which involves implementing rpc on the other side, managing it's deployment, keeping interfaces in sync etc)...
Microservices are for mature services with crystallized interfaces. They emerge naturally and the split is obvious at later stage - this information is not available at the beginning.
I've mostly focused on front-end stuff, but it's amazing to me how much advice similar to "start off doing <simple-even-if-perhaps-not-proper> and then later when the problem space becomes clearer or you begin to suffer <then-do-proper-refactor-or-concern-separation>" hits a chord with just about everything I've ever worked on.
Even when doing incredibly small front-end projects, I have a hard time thinking about times where I didn't regret optimizing or modularizing things before it was obviously necessary. Would usually later uncover that it was either useless or that I had built the wrong abstractions, needing to start over again. Conversely, every time where I've spun something quickly using the most straightforward patterns and optimized or refactored only when it became abundantly clear that it was necessary, the right way to abstract the code always felt like a no-brainer and I would always end up with very useful abstractions which allowed me to build meaningfully on top of them.
As a full-stack dev this is my exact experience as well. As Martin Fowler says in his book Refactoring -- don't go ahead of yourself, code your way out of the business problems, stay on top of your code, refactor periodically (even if it's only to remind yourself what does a module do!) and the best patterns for your project will emerge by themselves.
We had a guy who was an OK developer, but he read all these articles about this and that. He decided to make a 2 page application "micro serviced." It contained 56 projects and counting. For a 2 page application. It was the most convoluted piece of garbage I have ever seen.
> Microservices are just one option of refactoring
Breaking down a monolithic platform into different microservices is not something I would call refactoring.
> Microservices are for mature services with crystallized interfaces.
You are not making any sense here. What exactly is a 'mature service'? Just throwing technical jargon around?
> The most important part when starting project is avoiding friction at all levels - from dev setup, contribution, deployments, database evolution (migrations), interaction between different parts of the system (it's easier to just call a function from a module than to do rpc - which involves implementing rpc on the other side, managing it's deployment, keeping interfaces in sync etc)...
Those things are pretty important for any kind of project.
> They emerge naturally and the split is obvious at later stage - this information is not available at the beginning.
Most microservices are plain boring and extremely predictable. Have an eCommerce site? Then you have a user service, a cart service, payment service, etc.
1. Refactoring is pretty much anything that you do to improve the system that doesn't change anything to the outside observer - in other words, your boss can ask you the stupid question "so you've been working all this time, committing changes like crazy and nothing has changed at all?": and your answer is "yes, but...". Extracting scattered logic and encapsulating it into modules (classes, whatever) with clear responsibilities is refactoring for example. Extracting your module into separate dependency package is refactoring as well. Similarly extracting module to some kind of RPC is also a task that falls into refactoring bag - because it doesn't change anything for the outsider.
2. Mature service is your app after several cycles of release. At the beginning the project is just a dance with the client, going in circles, changing things all the time, until she's happy (with at least parts of the system). The thing is that at the beginning you don't know how the system will look like and more importantly - she doesn't know as well. The only tool that we have, that we know works well, is rapid prototyping with quick feedback loop. You want to minimize the friction of changes. She asks you to do something, you do it, then she changes her mind, rearranges things etc - often those changes require schema changes, shuffling hierarchy or adding some indirection layers etc. You can't do it fast if you have to coordinate several microservices to use new schema. You need to promote all of them to the new version and you need to orchestrate it on live, production system. With monolith you don't have this problem, everything is in one place, you run migrations on deployment to bring the system to the new state and presto, you're done. This kind of friction echoes through all environments - from your local dev, through staging to production. If you're working with more colleagues, your changes can easily block others' work.
3. So we agree that avoiding friction is important for any kind of project. I'm saying this implying that microservices are adding extra friction to the development. Instead of just calling function in your system you now have to maintain separate, coordinated, interface compatible service. All changes now need to go to two places. They need to be coordinated on migration/deployment, have their own devops setup etc.
4. ...and then you introduce discount codes, different countries, tax information, translations, connecting users with paypal and what not - all spanning across multiple microservices, you need to duplicate new communication schema across all of them, versioning apis, sometimes managing breaking changes which are pain in the ass in microservice world... all that for what? What exactly are you gaining? Are you really maxing out on thousands of requests per second on any one of those components? Is microservice going to save you because you can scale horizontally? Aren't they writing to the same store that's a bottleneck and scaling out the middleware won't improve anything at all? If they are separate then how are your joins doing when you need to match multiple, cross database collections? For example to update some kind of aggregate information for every user? Or any kind of reporting?
E-commerce site with user, cart, payment and all the rest is trivial in monolith webapp as described in full in beginners book Agile Web Development with Rails for example. There's no need to clutter basic app like that with microservices IMHO.
There are good points in there, but I disliked some of the scare quotes.
Microservices were not just concocted by a team at Netflix, and everyone then followed. Instead, microservices emerged across many different companies and teams concurrently. The architectural style was a natural reaction to many simultaneous forces that were being applied across the broader development ecosystem.
Of course, I'm biased because I built two similar architectures at the same time that micro service was becoming a buzz word, and I only knew that the type of architecture had a name much later. But, me and my team just did it that way because we were trying to find the architecture that worked best for us, our tools, and our environment. That is, the form followed the function. And, this was the type of design that naturally turned out.
Microservices were not just concocted by a team at Netflix
In the distant past, "microservices" were called "loosely coupled architectures" and these have been around since the early 80's I believe, but probably earlier. There isn't anything new about microservices, and they are a great idea in theory. In practice, there are all kinds of challenges, and these will have to weigh in on the architectural decision to deploy this particular pattern.
I am genuinely curious as to why we in information technology have such an astounding capacity for re-inventing (and re-labeling) the wheel. I rarely see as much "Not Invented Here" and "Not In My Backyard" as I do in our field.
The field is really badly taught. Formal CS does exist, but the corresponding architectural and craftsmanship issues often aren't really.
Conversely, the field is full of autodidacts. It's much easier to teach yourself by doing. Companies like it this way and fill themselves with smart kids who reinvent the wheel. Let's not forget that often it's easier to reinvent the wheel than look for existing solutions, especially with the risk of running across a software patent (never read these!).
I don't think there is a single starting place. It really depends on the context.
As an example, we're talking about microservices, so one could start looking into things that people brought up, like the Unix Philosophy.
The thing developers really need to constantly be aware of is this - if you think of it today, another developer has already thought of it 30 years ago. Go find out what he knows.
I remember my dad telling me that a "science history" class would be mostly useless from a practical standpoint as the study of science would include all of the really important bits of the history of science as a matter of course. This may be accurate when approaching physics, but CS is a very young field.
Just reading Knuth can give you a fantastic window into what has been done before. Looking into the history of Bell labs and Xerox PARC can make you understand the reality of what you suggest.
I'm not in any way suggesting that there's nothing new to invent in CS, but the current mindframe in many devs is that the state of the art is akin to quantum mechanics following Newtonian physics by a couple of decades.
The current revolutions in CS are mostly capability based rather than concept based. The ideas are relatively old, but the technology has allowed them to come to fruition.
I think it would be beneficial for all new CS practitioners to have access to a history of CS, as they would not just realise that the current trends aren't particularly new, but that there are a huge number of equally old ideas that are probably ready for prime time, but weren't feasible when first suggested.
History and Philosophy of science is definitely a field of study: http://www.hps.cam.ac.uk/ - it definitely doesn't come through from learning the subject in the normal manner, because that tends to present a "finalised" view of science that doesn't include any of the dead ends or lengthy mysteries.
HPS for CS wouldn't be a whole graduate course, but would be a worthwhile module in a larger course.
I'm pretty certain that I'm not the only Cambridge HPS graduate here.
It would be interesting to see some of the thinking behind current approaches to HPS being applied to development teams, both as teams and as part of the larger community of developers
The wiki linked above was established in the mid 90s by a group of practitioners who were attempting to document much of the history of software development - best practices, gotchas, etc. It was a great reference then, capturing a lot of what was otherwise being discussed on newsgroups and mailing lists. It still probably has a lot of gems.
I am genuinely curious as to why we in information technology have such an astounding capacity for re-inventing (and re-labeling) the wheel.
I like to call it "ego-driven/fashion development" and I pretty much see some form of it nowadays every time I work with a team of devs with members under the age of 30.
You could say that as developers "age out" (by becoming managers, moving to other industries) of the development world that this cycle will repeat itself over and over.
I've noticed this phenomenon too and I have some theories:
First, the subject is very wide and diverse, such that one individual might take decades to come across a reasonable percentage of it all, and by that time 75% of the field would have churned to new stuff.
Second, relatively little is written about real life software, certainly until quite recently. Most books and papers are about academic subjects and issues, not closely related to rubber hitting road and war in the trenches.
The result is that techniques get reinvented without the new inventors ever having realize the thing they invented already existed. So now it has a new name and even the people who did know about the old thing don't realize the new thing is the same with a different name.
It's a combination of (at least) two things, in my opinion.
1. Incorrect or incomplete understanding of the differences between CS and software engineering
2. Ego and arrogance. There are plenty of very arrogant high achieving physics and engineering PhDs I know from my former life as an academic who would be ashamed at the arrogance of a lot of the folks in this field. In my view there is a very deep strain of "I know better than those who came before (and, incidentally, better than many now)." I've never seen anything quite like it in any other context.
I suspect it is this way because that's how people learn to program: by building things that already exist in an effort to learn how to build such things.
Actually, I remember service oriented architectures were in use long before this became popular in today's blogosphere and picked up by the constant stream of startup hype/BS, albeit with some minor differences. [1]
I think the biggest thing most organizations miss is that microservices are just another potential tool in the toolbox. You can have both monolithic and microservices architectures that co-exist across different applications. I'd say that there is even a potential mixture of both.
I too feel there were good points, but I'm not ready to throw the baby out with the bathwater because there have been failures in organizations because they chose to adopt the pattern without a great reason for why.
I keep forgetting the old axiom: don't use technology to solve a social problem.
The biggest problem I have with microservice is that they lock you into a particular data flow up front. And the only times I've worked on a project where the data flow didn't change substantially from first implementation to having a rich set of features and many customers? Those were the projects that never got anywhere.
No battle plan survives contact with the enemy, and microservices are making decisions early on that are difficult to change later. Because you've picked one decomposition and then erected fences around the parts.
> The biggest problem I have with microservice is that they lock you into a particular data flow up front.
You say that as if that's an unalterable fact.
> No battle plan survives contact with the enemy, and microservices are making decisions early on that are difficult to change later. Because you've picked one decomposition and then erected fences around the parts.
If you know about that problem, then don't do that! :P
In my experience, if you slice your microservice boundaries with the philosophy that each of them should be able to be sold as a white label product (or more realistically be reused for a completely different product internally), microservices can survive pretty large pivots of the startup/project with little changes.
> In my experience, if you slice your microservice boundaries with the philosophy that each of them should be able to be sold as a white label product (or more realistically be reused for a completely different product internally), microservices can survive pretty large pivots of the startup/project with little changes.
Once you're at the point of having multiple products you've already made it past the valley of death. In my experience you only understand the system well enough to be able to decompose it correctly if it's already working end-to-end.
I agree. Microservices enable startups to pivot very easily, or to implement or diverge into new sales channels quicker than with monolithic solutions.
The same applies to larger business. With microservices, ie. large banks can easily offer API services, enabling new revenue streams that were nearly impossible to offer before.
Microservices are an excellent way to deal with future changes. The unknown unknowns like some would put it.
If you have people that are experienced with microservices I think it can even benefit a 2 person team.
The anecdote that comes with that:
I joined a startup as the second developer. The first developer built everything in a microservices architecture with the background that we were supposed to grow as a devteam significantly in the next 6 months. One of my first tasks was setting up CI/CD for the microservices so we can launch the product, which is a pretty routine setup for me since I've done the same thing ~5 times before. Then startup things happened and we stayed a 2 person team for a long long time.
In the beginning, I was skeptical if the microservice architecture was really the right choice there, but overall I think we came out ahead. There were a lot of instances where we needed to upgrade libraries to fix some bugs or get some newer features and only had to upgrade very little of the whole codebase, allowing us to iterate faster. This would not have been possible in a monolith. We also experienced some of the microservices downsides, like slower refactoring and network connections being less reliable than in-process function calls, but with the right approach and tools, they were not much of a problem.
Microservices are not a free lunch, but they can be a cheap and tasty one.
Where does this axiom stem from? A quick google search shows many instances of proclaiming the opposite.
Body cameras on police address a social problem.. If you're talking in absolute terms, such as something being the perfect solution that vanquishes an issue (i.e. a silver bullet) then I think it's a disingenuous stance to take. Social problems aren't solved overnight, and the greatest ones have always required incremental approaches.
This feels akin to saying, "I need code that's 100% bug-free", but in reality, writing bugless code isn't the goal.
You misunderstood: the phrase would be more accurately stated as "don't use code to solve internal process problems that are driven by corporate politics".
For example: when a bank's retail locations are using different lending criteria than the corporate call center, there's no amount of code that will solve the turf war between corporate and retail.
Like many aphorisms, it's 95% true or so. Almost always when facing a social problem within a company you should be solving it socially. If you don't understand why that's true 95% of the time (i.e., trying to argue that it's completely untrue), you're not going to be able to identify the 5% of the time that it's false, and following the aphorism will likely serve you well. Understand the aphorisms before breaking them
However, there is that 5% that matters. In my opinion, one of the things that separates a good "architect" from "a really senior engineer with lots of responsibilities" is the ability to engage with the social and political implications of code design, and convert social concerns into lines of code. (This further reinforces the idea that architects must code, on the grounds that in general, this degree of understanding of a situation is not transferable. Especially to people who don't even believe these issues exist or are relevant to a design, which is quite a lot of even quite senior engineers.) The 5% is not equally distributed and a lot of it will concentrate on to the architects, so for instance I find myself thinking about this stuff a lot because of my position. But it's still the exception, it just happens that I get a lot of that exception.
Of that 5%, the vast majority of it relates to Conway's Law: "Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations." I first encountered this in a list of funny jokes and such that had been knocking about since the old UNIX days, and at first I figured it was a joke too. Then as I grew more experienced, I thought it was a lament, in the style of "The first 90% takes 90% of the time. The remaining 10% takes 90% of the time." Now I understand it simply to be a law of software design. Like gravity, if you intend to defy it you'd better have a really solid story as to how you intend to avoid it. It is often much better to reorganize teams rather than fix this with code, but even optimal organizations of teams will still have a certain amount of Conway's Law issues, because the real world is messier than team structures should be. Plus engineers suggesting team reorganizations doesn't always go well; if nothing else you will confuse the heck out of your management even proposing it, like, "what are you doing thinking about that?". You may be forced as an architect to deal with suboptimal organizations anyhow.
And thus we wrap back around to microservices... once an organization hits a certain size, you are almost inevitably constrained to use microservices, because organizationally it is simply impossible to have 500 people working on "the same thing". You'll either use microservices, or a monolith that contains an ad-hoc, informally-specified, bug-ridden, slow implementation of microservices, even strictly de facto in the form of "this code belongs to this team, that code belongs to that team".
(The generic form of Greenspun's 10th rule is "Any sufficiently complicated program in a certain domain will inevitably be pushed towards certain solutions based on the domain, and if the designers attempt to resist that solution, that will simply result in an ad-hoc, informally-specified, bug-ridden, and slow implementation of those solutions." Or, in short, "use the right tool for the right job, even if you thing you don't like that tool.")
> You'll either use microservices, or a monolith that contains an ad-hoc, informally-specified, bug-ridden, slow implementation of microservices, even strictly de facto in the form of "this code belongs to this team, that code belongs to that team".
That metaphor isn't good here. You gain nothing by including network communication between those different pieces of code. The ad-hoc solution is often more formally specified, less bug-ridden, and faster than the microservices solution.
Microservices solve some technical problems, not social ones.
"You gain nothing by including network communication between those different pieces of code."
I consider the network aspect of the communication a bit of a side show here. What's important is the information flow. Even if you've got a monolith, you've got some components, and if you are taking such good "advantage" of your monolith that the communication flow between modules is not something that is clearly specifiable and understandable because of the global variables and shared state and shared everything else, what you've got there is a mess, not a beautiful shining example of architecture that obviates the need for microservices.
Or possibly, you've just got something too small for the microservices to be relevant. Which is totally a thing, and I totally agree with the various things that say "Don't write your startup as microservices".
But eventually as your size grows large enough, you will either end up with components so nicely separated that putting a network between them doesn't affect them all that much, or you will have a big ball of mud that nobody can move around anymore. If you don't have one of those, you just aren't large enough yet. Humans can not code the way biology tends to work; we need bite-sized chunks of a larger system to get our heads around.
Services interfaces are among the least maintainable kind of interface we have on IT, and REST services are at the less maintainable end of that.
When you add that network communication, you remove coherent type enforcement, timing restrictions, availability guarantees, causality guarantees, unicity guarantees, and likely more stuff that are just not on my mind right now. Those are all characteristics of the information flow.
Conway's law has been popping up a lot lately for me. Can you share some typical examples of "communication structures of these organizations" and the systems they inevitably result in?
It's hard because in a small example you can always say "well why not just restructure the team some other way?", because there's no collection of real forces to balance against. But a simple example would be, let's say you're offering several services to the public. You want all of them to have a single sign on. Then you'd better create an "authentication" team, because if you leave authentication up to each of your 5 services, you'll end up with 5 authentication schemes. (Usually to make the "authentication" task large enough that team will also be responsible for the central record about billing info, contact info, etc.)
It's tempting if you don't believe in Conway's Law to say "What's so hard about having everyone share authentication services? We'll just mandate that they have to use one service without having to create a separate structural team to do it." But it will not generally work.
One element that contributes to this is that the teams are not just technical, they are embedded in a company in a larger context. If you create product teams A, B, and C, the larger company will be grading the management of A, B, and C on the revenue they generate, or other appropriate metric. Thus, the management for those projects will tend to be very focused on that metric. If you tell each of them that they are responsible for authentication, they will each want to spend as little as possible on it because it is not a revenue generator. (Who has ever signed up for a service because its authentication was just so awesome?) They will each correctly come to the conclusion that the cheapest thing is just to bash something that vaguely resembles authentication into their own system, because the costs of coordinating between the three teams will be too large. So you really have to carve out this interest into a team that will be measured on the goals relevant to authentication, such as scalability and security rather than revenue.
Engineers are also constitutionally inclined to say "Well, the solution is just to stop measuring teams A, B, and C by revenue and instead measure them by..." but then it's somewhat hard to figure out what the next words are. "Code quality" is something engineers would love to say, but even engineers on some level tend to recognize that does not actually put food on the table, so to speak. (It is an important element of considerations of how to spend resources, and I would agree that it is often underestimated. But it makes no sense for it to be the prime measurement of a team's output, even before we get into the issues involved in objective measurement of code quality.) It's really hard to avoid having at least some of your development teams being measured directly in dollars in one form or another, and from there the rest of these forces tend to flow.
> No battle plan survives contact with the enemy, and microservices are making decisions early on that are difficult to change later. Because you've picked one decomposition and then erected fences around the parts
Why would merging two or more microservices be any more difficult than turning a monolith into several microservices?
I'm not implying one would be harder than the other. I'm really curious to understand the downsides of going each route.
Typically you solve that through a rewrite, followed by migration and depreciation. Since the microservice is small, you can ideally accomplish the rewrite in under a week.
But if you are changing the factoring of the microservices you are necessarily rewriting more than one. Sure it can be done, but you know what's easier than refactoring microservice boundaries? Refactoring service object boundaries in a single app with one coherent test suite.
It's time to stop hand-waving away the overhead of microservices. The two big reasons to introduce microservices are because you have different workload profiles that need to scale independently, or because you have separate teams with bounded areas of responsibility and you want them to operate independently and minimize communication overhead. I'll also give a pass for microservices where the interface is very obvious and stable, and there are low cross-cutting concerns.
But in a lot of cases devs are just complexifying things for their own resume and ego.
> But in a lot of cases devs are just complexifying things for their own resume and ego.
I wouldn't even go that far. The complexities of communications between network services simply escapes most devs who think in terms of features.
They see most of the issues as an ops problem that they can chuck over the wall. Many of them don't stay in one place too long, so they've not really hard to live with the consequences of their decisions.
The problem is, working with more buzzwords and moving about is the best way to further your career as a dev. Being a stable hand will likely result in you being underpaid and under valued, and at the end of the day most of us live in expensive cities and are quickly in our 30s where we want a family. Of course, we're going to chase the shiney that pays well.
"Minimise communication overhead" - in the environments i've worked in it's usually to decouple release schedules rather than scaling, so i guess that falls under minimise comms overhead.
Evolving enterprise systems is hard, being able to eliminate wait barriers between new dependencies being made available is a massive benefit to the wider release schedule.
You can release new functionality on your teams schedule and turn it on later when collaborating teams are ready. For various reasons enabling a feature is usually much easier than releasing a version bump.
1) never change data exchange formats between trivially connected parts of the application (e.g. splitting billing and delivery address in the payment system, no way you can do that easily with microservices)
2) effectively have 3 versions of every service running essentially constantly, and at the same time. This is more work than just running 3 versions : they must also be developed so they CAN run at the same time (e.g. they must tolerate the non-existence of a delivery address in the same example)
This is partly a limitation of the mediocre inter-process communication system in the Linux/Unix world. Calling another service is a Big Deal.
I've done a complex robotic system which had about ten processes running on QNX.
Most of them were running some microservice - GPS, INS, LIDAR, mapping, logging,
short-term vehicle control, etc. This worked fine. That's because QNX does interprocess communication well. MsgSend/MsgReceive is like making a subroutine call on the send side. The receive side is more like an event loop.
This sort of thing is common in robotics. ROS does something similar, although the interprocess communication is slower. Usually you have dummy services for simulation purposes, so you can run the operational code in a simulated environment. We could run the system for real, or run it entirely with simulated inputs and outputs, or could put the robot vehicle up on blocks and run the system with fake inputs while operating the real vehicle, engine running and wheels spinning but going nowhere.
Everything could be run on one desktop, or on the vehicle's own computers, or partially split. There were shell files to launch the various configurations. We could plug in shims between services and watch the data go by.
I don't see the fear of multiple intercommunicating processes. Even on Linux, there are decent ways to distribute. They're not as good at hard real time as QNX, but they work.
Very little of this blog post is concerned about performance. We're talking about microservices running on different hosts, and IPC takes the form of a network socket, and typically HTTP.
We're also talking about very, very large scale systems, like hundreds of API endpoints, not ten, with multiple on-call rotations, each assigned their own section of the microservices surface, running in front of customers at all times, without the engineering effort to make sure things are close to perfect before exposing to customers.
What happens here is a combinatorial explosion. 1 faulty service can end up affecting it and its transitive dependencies, but operationally, it's hard to distinguish symptom from cause. Worse, a problem on one team may be cause by an unmonitored problem two teams across the network, increasing time to resolution, as each on-call is woken up to discover the root cause is another layer up the network.
It would be interesting to see a IPC system that abstracted away where the other process was running or treated processes running on an entirely different machine or VM as another local process.
Since scalability is probably a bigger concern in web architectures than robotics, expecting to be able to use IPC to communicate between two services is unlikely. I would imagine in many web architectures being able to scale systems independently and dynamically makes up for the overhead in communication protocols.
ROS is pub/sub, but that works because most of the data traffic is one way, sensor->compute->actuator. ROS isn't usually used for function call type operations. If nobody's listening to a sensor, that doesn't hurt the sensor any.
> It would be interesting to see a IPC system that abstracted away where the other process was running or treated processes running on an entirely different machine or VM as another local process.
Erlang does do this. In fact, it dawned on me that OTP is basically a system for writing "micro services" inside the app itself, complete w/ monitoring, queues (mailboxes) & supervision.
Developers are forced to export public module functions to provide a smooth api for other services (processes, in the same runtime, or distributed).
Thankfully, Erlang provides the protocols and so on, instead of requiring some nasty hand-crafted json weirdness over http.
> It would be interesting to see a IPC system that abstracted away where the other process was running or treated processes running on an entirely different machine or VM as another local process.
Forcing everything into the same abstraction can have issues. For instance, calling a different machine has orders of magnitude more overhead and different error scenarios than making a call to a local process. If you make them look identical, you obscure that.
Lots of problems can benefit from well defined interfaces: security, complexity, maintenance, HR/project matching, need for parallelized or decoupled development (eg. multi-team/timezone), use of existing codebases, etc. As always the devil is in the details.
It is an old maxim in programming that correctly modeling the data is a huge percentage of the design. For example:
Pike's 5th Rule: Data dominates. If you've chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming. - Rob Pike, Notes on C Programming (1989)
In that sense, in nontrivial problem spaces, if forced to generalize, then I am generally more for spending time carefully developing interfaces (ie. a paradigm potentially more closely aligned (in a network services context) with the microservices model = older coders with maintenance chops) than immediately writing actual code (ie. approach of the keyboard-happy iterative tweaker = young coder with fire-and-forget habit).
Any real world project lies somewhere between these extremes.
What is central to a program is not the data structure or the algorithm but the thing it intends to accomplish for human beings. If you start with a data structure and say "what can we let people do with this?" you're going to write bad software.
I don't feel they are saying start with the data, before you even have an idea. More, "What data do we need, and how do we structure it for this problem?".
I agree with your first point, but I find microservices (which almost always means JSON in practice) tend to lead to less well designed interfaces than monoliths in a well-typed (i.e. ML-family) language.
I use Thrift when my systems have to be distributed, but it and GRPC's type systems are still a long way behind what you can do in Haskell/Scala/Idris. So I still say build your system to be deployed monolithically at first (of course split it up into modules and libraries), and move to distributed only when it becomes too large to deploy monolithically (or rather, when you have so many developers that you can't deploy a monolith frequently enough).
how do you guarantee atomicity across module boundaries?
The more fundamental answer is: It depends upon questions such as whether the system seeks to exhibit parallel processing properties or not, and the application-specific data generation/processing/storage/retrieval/consistency goals.
The short answer is: Ideally you don't, because architecturally you are likely creating a monster.
The longer answer is that in the case that it is justified (and such cases do exist) you would generally either use a reference to a transaction (potentially knowing that it may be out of date and having a planned strategy for eventual consistency carefully limiting the effect of such to a non-critical scope), or eat the latency overheads and use an established algorithm - see https://en.wikipedia.org/wiki/Atomic_operationhttps://en.wikipedia.org/wiki/Consensus_(computer_science) and https://en.wikipedia.org/wiki/Consistency_model - which for most of us simply means 'choose your database/network replication layer carefully'.
Found three rather boring very technical concerns to harp upon for what Microservices are supposed to deliver and why they're not the bee's knees.
What microservices actually work towards is a viable strategy towards the Two Pizza rule, where teams can be kings and queens of their kingdoms & drive their own agenda forward without needing to consult with everyone else working on the monolith. Containerizing your software allows containerizing your culture, keeps there from being ancient legacy top-down hierarchical culture and praxis set forth long ago and which will dwell ever on in the monolith your whole company must collectively lurchingly keep trying to push forward. Free yourself from the more brutal pieces of Conway's Law. Create an organization that can continue to try new ideas, that allows team's freedom to work without always bumping elbows with others.
At the end of a somewhat different thread amid these comments, gloverkcn happened upon a wonderful synopsis:
The problem is that it's easier to grab the people sitting next to design something than scheduling a meeting with groups you rarely see. This is a key driver of Conway's law.
Microservices & their platform infrastructure are the answer to make this not a problem, to free you from tight organizational grips of Conway's Law.
For small and new companies, technical and organizational structuring has not accrued. These are not major problems in early stages, because everything is small enough to be changed easily anyways. But as time goes on, as software or head count grows, maintaining the liberty to ongoingly innovate and pick up new ideas and new technologies is a liberty that has to be fought for. Making your way from a 1->many service organization comes with a lot of complexity and cost, but it is a key step to allowing diversity and innovation and technical growth, particularly for multi-department organizations.
Did you read the section titled "Dependencies"? That was about social as much as technical concerns.
I don't think the author disagrees with the goal of reducing dependencies or coupling between dev teams. What they disagree with is whether moving to microservices is necessary to achieve this. They think a "a monolith, composed of well-defined modules, with well-defined interfaces" can get you the upside without the downsides.
Good call out, great. To speak more directly to that particular section, I focus on saying you can't decouple people or systems socially without decoupling them technically.
Trying to upgrade from Netty 3 -> Netty 4 (like Twitter Finagle had to do) in less than a big bang? Say hello to remarkable levels of pain and suffering one has to do, probably shading one's own Netty and pointing other dependent libraries at that shaded version. No matter how much decoupling you try to build into APIs within your monolith, trying to get the thing to build and ship together forces a co-interactivity of teams, coheres everyone to common technical underpinnings and which exposes all folk involved to any of the technical risk attempted by any one team. Decoupling may allow some modularity, some ability to replace X with Y, but it's will always have to be done within a common framing, a common framing that as the project grows will become immensely harder to un-stick and push forward, will be much more resistant to experimentation & great leaps forward.
Any software project has so much diversity and risk budget associated with it: a willingness to innovate technically that depletes with use. Even if you "decouple" you monolith, if everyone has to build and ship together you are going to forever be bound into deep interdependencies. Trying to update a logging framework or trying out a Reactive Functional Programming is going to encounter vastly more resistance when you're working on the same sandcastle as perhaps hundreds of other devs, dozens of other teams. And if it is low resistance? Well then you're in more trouble- your monolith grows boundlessly, with everyone being exposed to the rapidly growing risk and diversity that other teams experiment with.
Isolation, containerization, is a good defense. I think Conway would approve. Apologies, paragraphs above are a bit thought soupy- havent the time to edit.
No apologies needed. You highlighted precisely the issue that is causing us to move to proper "microservices" at Eventbrite. Without splitting our monolith into separate processes, migrating to newer versions of Django or to Python 3 simply isn't tractable for us. Luckily we've already decoupled much of the monolith by moving functionality into a homegrown service framework that lets you run services either remotely or colocated in the same process without code changes.
Microservices have their place, but - as often happens - they were overhyped to be a solution to everything and for everybody... Now the cooldown period begins...
In computing, someone names something then other people start writing blogs about it. These blogs get passed around. Joe average developer who always wants to keep his resume up to date reads these blogs and starts trying to find a way to use the 'new' hotness. The world suffers through poorly designed code for a while as things break and / or fail. Then, as you say, there's a cool down period while Joe Average developer waits for the next thing to add to his resume.
It depends how you do micro services. There are middle grounds. One big gain of micro-services is that it guarantees things are separate and can be handled by separate teams if the need arises. That doesn't mean you need to start out that way. For instance in Python I use hug to create my microservices https://github.com/timothycrosley/hug, then I can just install them to create a "monolithic" services that consumes all the microservices, the great thing is that hug allows you to expose both as a webservices, and as a Python library so I can consume as a Python library with no overhead, until the need to split is evident, and then can split up the services with very little work. Of course the need may never arrive, but the modularity that is forced when using micro-services pays dividends quickly regardless
No, I, don't because they are my own at home projects that haven't taken off, but I'm able to use the same library and code structure at work for things that absolutely do need microservice because of the power of the framework. And if any of my at home projects take off and I have huge teams and load then I may need microservices. It becomes a deployment question instead of a code question with the right framework.
It always bothers me that developers who are working with a team they can't trust to build a disciplined, modular application advocate moving to a more technically challenging architecture as a solution.
I would love if each micro service article would start by defining what they mean with "micro service". Wikipedia says "In a microservices architecture, services should be fine-grained and the protocols should be lightweight."[1], but that leaves lot of things open, especially what does the micro mean size wise.
When these kind of things are not defined, people may take good advice and apply it wrong way. You read articles how large companies are embracing micro services. However a "micro" for them might mean very much different thing than what is means for smaller company. Just like with "big data".
It seems to me that the answer really depends on application.
There are two kinds of scalability requirements. Some applications scale almost linearly with number of users, for example, Google Maps. That happens if users need interact with each other in limited ways. For such, horizontal scalability of a monolith is almost always a better answer than microservices, and splitting the data before processing is almost always better solution than Spark or Hadoop.
The second kind of scalability requirement is where the users interact, and so the processing required scales more than linearly (quadratically) with number of users. The examples are social networks, the more users you have, then you need to deliver quadratically more messages to all of them. In this case, microservices (and Spark and Hadoop) are probably better, since you can't solve the problem just by scaling the monolith horizontally.
> For such, horizontal scalability of a monolith is almost always a better answer
This would be scaling vertically since your only option is to increase the resources dedicated to that single application instance (more CPU, RAM, Disk, etc). The definition of a monolith is a single application running on a single platform so scaling a true monolithic application horizontally (adding more instances of the application) is not usually possible.
Maybe I just understand the word "monolith" differently. I understand it as an application that cannot be easily broken to pieces that run on different machines. So the only option is to scale horizontally, if at all.
What I mean is that you can e.g. run two monoliths on two machines, and process half of your users at the 1st machine, and the 2nd half of your users at the 2nd machine. If the users don't need to interact (or in a limited way, for instance, you need to recalculate something each day or so), it's a good enough solution just using horizontal scaling.
This whole thing is about polyglot development and deployment.
"Micro" is a meaningless prefix. This is all SOA - service oriented architecture. A "service" can be anything, it's a vague definition of whatever is a natural encapsulation of a bit of logic in your application (or company). This encapsulation can be easily done with separate classes, namespaces, or even packages, while still running together in the same process.
In the end, you're putting some binaries on a server. The machine doesn't care how often you do that or how many different binaries you choose to use, so the only real reasons are multiple languages that aren't compatible in the same process or massive apps/organizations that need to have completely separate projects to make forward progress.
For everything else, microservices are a silly solution to no actual problem.
This. For languages with a good module system, it's almost trivial to use modules either in-process (e.g., monolithically), or out-of-process exposed via HTTP or some other network interface (as microservices). Then the discussion becomes about writing modular code rather than microservices.
The separation of concerns inherent to microservices is such a great advantage, that in my opinion it's critical even for small teams. You can bring an extra hand into the team without them having to have to understand other parts of the code to do their job. A monolith with clearly delimited packages will give you this too, but it won't allow you for example to place each service under its own repo which would also provide you with the ability to limit code access. That requires a lot more up-front investment, but it's worth over the long run, unless your project has a very limited life-span, which is rare and sometimes really unknown.
> The separation of concerns inherent to microservices is such a great advantage
It is not. Not even close.
You have to manage separate onboarding processes, ensure the standards are completely up to date, ensure that training is extremely relevant and covers every single critical component of the system.
You have to maintain up to date documentation of integration state, data flow, testing capabilities, etc.
> You can bring an extra hand into the team without them having to have to understand other parts of the code to do their job.
That sounds awful.
> won't allow you for example to place each service under its own repo which would also provide you with the ability to limit code access
Let me guess, you are not paying for engineering talent? The notion of having distributed teams for most of the companies is so ridiculous it's not even funny.
What happens if a lead person on team X and Y quits? Are you going to retain a full-time person to manage your deployment process now?
What happens if your budget is cut in half and you need to fire half of the team? Do you expect other engineers to pick up something they have not touched for the duration of their stay without slowing down business?
> That requires a lot more up-front investment, but it's worth it over the long run
I've seen monoliths running on 10 year old technology using runtimes and development kits that have been deprecated or are no longer supported by their maintainers. These applications are being used in production today by billion dollar companies. With microservices this never has to be the case. I think it's madness for a company to be running old software with security vulnerabilities and performance liabilities because no one wants to touch what's basically a digital Jenga tower. Then you have people writing articles like this one. I think we're beyond fads and buzzwords here. There are real world advantages for building software this way. If you're afraid to embrace the future, please step aside. You're making my job far more difficult than it should be. These are my observations as a 40 year old developer.
The free Microservices vs SOA book gives an excellent run down of the difference between microservices and SOA. It's really useful to have this in mind when having any conversation about microservices.
"One of the fundamental concepts to remember is that microservices architecture is a share-as-little-as-possible architecture pattern that places a heavy emphasis on the concept of a bounded context, whereas SOA is a share-as-much-as-possible architecture pattern that places heavy emphasis on abstraction and business functionality reuse."
Two things jump out at me initially. First, the assertion that cargo-culting is bad is hardly revelatory, regardless of the paradigm. Secondly, the five point list at the end of the diatribe is exactly what any transition from legacy monolithic system would follow in order to pursue a microservice infrastructure.
I can't decide if the author actually has a problem with an appropriately deployed microservice architecture (and no, you do not need 100 engineers to support such a thing... I replaced a legacy back-end system for a $100M/yr revenue company with such an architecture using 4 devs) or if this is just a misapplied generic rant about cargo culting that has been applied to $THINGIREADABOUTTODAY.
Hi, author here. Thank you for your feedback, and I'll be sure to take it into account in future writing.
I don't have any preference for or against microservices, as long as the benefits they bring outweigh the drawbacks which come along with such an approach.
The goal wasn't so much to rant against cargo culting, but to provide some counter points along with a more measured progression for moving towards microservices.
I agree that the points at the end should be what such a transition looks like, but it's amazing how often companies skip the first two steps and try to immediately break up their monolith as a form of technical bankruptcy, which is rarely warranted.
I agree overuse of almost everything is bad. Currently, I am working with one another seasoned architect, who is very proponent of Microservices and AWS lambda on same lines as mentioned in the article. My discussion with whom has always articulated that let's do traditional portion(user management, permissions, payments, etc) in a traditional way (we are using Django so in that) and whatever tasks we have, lets do them in a microservices way.
In a traditional sense, we are implementing a system in Django that will be deployed to AWS lambda via Zappa or SAM. All, the traditional task-queue tasks will be separate microservices (lambda). So, We are implementing fusion and I personally see future in that.
One of our customers are developing a service, which in turn consist of four minor services. They are completely separate services, one provide the core functionality and the rest a supporting tools, but the core can run without them. To me that's a completely reasonable seperation, and it allows multiple teams to work in parallel.
One of the "services" above however consist of 10 to 15 smaller services, all of which are communicating via http. The idea as I understand it is that these are small components that can be reused in other projects, if needed. What I don't understand is why these aren't just made into library that can be reused, rather than having them as micro-services.
This project is an example of where microservices is done both right and wrong.
That's why what I am trying is seems more right. Those task-queue tasks, we anyway put to queue and then access it through workers. They usually, do computation/IO intensive work or sending out email or notifications, etc. So, its logical to deploy those as separate to aws lambda kind of service to decrease total service turn around time.
Our architecture is more resilient than what you think. With using Django on lambda, we could also deploy that code to machines. So, we are safe there.
Other components will be just functions that could be deployed to Docker with any queue as necessary. So, its calculated risk to leverage the Lambda's benefits of no DevOps, scalability and lower pricing (initially).
As always, it depends. Personally I have been working for a corporation where we use a microservice approach and it has been great for productivity, turn around times on projects, and the systems/services are quite easy to understand. We are full CI. Our microservices maybe aren't as micro as others, we have a pattern of having monolith 'data services' and micro business/functional/api services. The monolith 'data service', effectively a layer that exposes CRUD over data, in some cases has 10 microservices that interface. I could go on and on, but it works very well for us.
Could anyone explain what microservices are? I'm still learning as a junior dev and haven't quite understood what this word means. How would you break down an existing monolith into smaller 'micro-services'?
It's basically breaking down your app in several smaller web apps. Mostly to ease development and define responsibility. It doesn't make sense if you have only one tech team.
IMHO ease of development isn't guaranteed with microservices. It's usually a bit more complicated to manage multiple services all coordinating the completion of a single task. Where it does help is to define responsibility, and allow different teams to work without stepping on each others toes.
Also, there are cases where microservices would make sense even with one person on the tech team. For instance if you want to scale services independently of each other. For example, your web app isn't used that much, but you get heavy traffic on the mobile API. In that case, maybe having the mobile API as a separate service helps.
As with any trendy technology or architecture approach, you should first be asking "What problem are we trying to solve?"
That's where the discussion should start. Better yet if that is a business problem, then dive into technical solutions. Many times technologists take a new (but not really) silver bullet and try to fit it in somewhere without understanding if it solves a problem or not.
It also seems like we like to reskin solutions with new names and the industry picks up on this, starts their marketing engines and the guys in suits come around trying to sell the new silver bullet.
As of late I've come to a new belief as to the real reason for microservices' current popularity. DevOps, deployment, and whatever-hyperopaque-cloudy-service-amazon-have-launched-this-week are the cool & fun things happening at the moment. Having loads of microservices to manage simply gives you plenty of toys to play with.
Personally, the microservice-y project I'm currently working on makes me want to burn my face off every day.
It seems to me the overhead of microservices in terms of productivy is O(1) - but I can be wrong. If the overhead is O(1) then the question becomes whether or not you already have the framework to do microservices. If you dont, so yeah maybe you should do a monolith.
Just like Agile and vendor-based software solutions of the past it seems like microservices are following the same path. I've seen projects starting off with microservices because someone several pay grades above deemed it so. Lots of resume-driven-development done here.
This makes me wonder, are there any systems that make it easy to build a modular monolith that can relatively easily be split into microservices in the future?
Erlang (OTP?) comes to mind (though I have very little experience with it so I could be off)
It's totally possible to write code that's straightforward to port later. I'd say the biggest blockers tend to be database and code-organization related.
If you make a component that is the sole entrypoint to it's concerns, gets it's own database, and have an ORM or database context layer that is capable of dealing with that,
moving to a microservice is as simple as taking that same code, exposing an http layer to it, and making your original interface call to the service instead.
If other code is joining into the relevant tables, skipping said interface and doing it's own thing with the guts of it, you'll have issues.
This can of course be done in any language, really, though database tooling can definitely vary in ease of doing it
I wish the author discussed microservices in the context of domains and models. If you model your application and find a distinct isolated domains, then consider creating separate services for them.
But again, why? Making them services means distribution and that has a cost. You must have some reasons to make them distributed. You should first consider simply having the isolated domains as modules in your application monolith.
It doesn't have to be: you can use (Ruby) modules, classes and namespacing to split the application into logical pieces. Then start to enforce encapsulation between these pieces, so all access to a given piece of the system goes through a small, well defined and documented interface.
If you are thinking about migrating to microservices at some point, it's also beneficial to try to limit the areas of the database schema that each of these pieces accesses. There's no point having lots of microservices running over the top of a single monolithic database schema: extracting microservices should imply extracting the relevant part of the database schema and putting it into a private database with operational access only through the microservice. You can make this much easier while still working in a monolithic application by being more disciplined about how much of the schema a piece of the application needs to know about.
Module is an overloaded term in software engineering. The most generic definition is just some bunch of code packaged somehow with a well defined interface.
sometimes the idea of microservices seems like an attempt at taking the unix philosophy of doing one thing and doing it well, and adding on the additional requirement of doing it over the net. i dont think its a bad idea, but surely its not worth the effort in lots of cases.
The Unix philosophy is popularly simplified to "do one thing and do it well", sure, but that simplification is not accurate. Many Unix programs do much more than one thing. What the Unix philosophy actually is:
"The Unix philosophy emphasizes building simple, short, clear, modular, and extensible code that can be easily maintained and repurposed by developers other than its creators. The Unix philosophy favors composability as opposed to monolithic design."
Which is a lot more akin to what's now called microservices. Unix philosophy has always been about software modularity and do we really need to use 'microservices' these days to describe such an approach? The meaning is not clearly defined anyway, what one company describes as a microservice architecture might not be described as such by another. I certainly don't need any buzzwords (e.g. re-invented terminology) to describe a modular software system, and whether your processes IPC mechanism is HTTP/JSON, pipes, or sockets, we are talking about exactly the same kind of system.
In my experience the desire to move to microservices results in people going overboard when decomposing their monoliths. Authentication services, payment services, comments service, etc.
The projects I've seen getting to technical bankruptcy have been with no exception monoliths.
With microservices you have the ability to take one service and fix it, reimplement it or replace it if necessary. Also use whatever technology makes more sense for that project, as long as it speaks the same protocols and sticks to the same interfaces.
With monoliths, there's always the analysis paralysis related to the possible ramifications of a change, which slows down everything.
You could also have a "monolith" in a single or multiple compatible languages (C, Rust, C++, etc) and have different features/modules separated in different libraries. These libraries could then act as the "microservices".
Developers could be tasked with working on these libraries that would have 0% overhead (since they are just a piece of code that can be used in another library), instead of creating REST/SOAP/RPC APIs that come with the HTTP/SOAP/RPC overhead.
This means you can start small, with a public REST/SOAP/RPC API. Less infrastructure, less server config, etc. And if at some point you need more scalability, you can always do an actual microservice (ie a separate REST/SOAP/RPC API) with the library code the day you absolutely need it for horizontal scalability or whatever.
I have seen this pattern used in the Rust world a lot. Projects expose both a library and a binary. And the binary is built on top of the library. This means you have 0 overhead if you want to use the binary's features, since you can simply include the library and get going.
Also, I think that having the tools to support deprecation is big advantage when working with a monolith. I think Rust has built-in support for compile-time deprecation notices. PHP, for instance, doesn't have that particular feature yet, as far as I know. Symfony tries its best by adding deprecation notices when you call a deprecated method/function. But you have to call it to realize it's deprecated.
I'm not here to promote Rust or hurt PHP, I actually love both. The statements above apply to a lot of other languages as well. I just took the examples of Rust and PHP because these are the ones I've worked with the most.
If you divide your project so self-contained components with scoped set of responsibilities that are not coupled to the rest, that's fine as well. I've used that pattern with great success.
Microservices are a way of achieving this, but as you describe it, is not the only way. Discipline is another way.
Now, as you have more people involved, or release deadlines get tighter, chances that tech debt gets introduced increase. Unless you go back and repay the tech debt, situation would worsen.
In that sense, microservices are some sort of cap on the impact of tech debt from rushed deadlines and lack of discipline.
Just saying that you're using microservices doesn't guarantee that you'll be avoiding or capping tech debt. I've seen some hopelessly entangled "microservices" that are so full of assumptions about how other parts operate that they're essentially unusable anywhere except for one or two places. You need that discipline whether you are separating components by service boundaries or just by organization of code within a monolith.
I agree that microservices tend to make it harder to accrue tech debt past a certain point, though. Although they can also dramatically complexify the process of figuring out what is going on in an app if log files are spread around a ton of places (which is mainly a tooling problem).
Yes, that's why I said it's a tooling problem. But not everyone has log aggregators set up (or set up in a sane/totally adequate way), and even with log aggregators, it takes a little more care to make sure you're exposing the right information and exposing it in a way where it's easy to trace the important stuff that's happening chronologically.
I'm not saying that it's an unsolvable, or even unusually difficult problem, I'm just saying that it's very possible to do wrong. If an organization can fill a monolith with tech debt, they can probably find a way to do the same with microservices.
This is true but for meaningful aggregation is not easy. You need to provide correlation identifiers to identify log entries which are part of user request invocation. This complicates the protocol between distributed services if they are in different business domains with APIs using unrelated resource identifiers. Usually correlation ID is dispatched over e.g. HTTP header or separate API parameter.
With monolith the issue also occurs but loggers usually take care of this with thread local variables or some other contextual storage.
Not every interpreted language has this problem. I'm thinking that there probably is a way to get compile time deprecation notices in Typescript. If there isn't, this will probably be possible in the coming years. Typescript is somewhat compiled, but the same applies to Dart, which is both interpreted in a VM and/or compilable to Javascript. Maybe Hack (the Facebook version of PHP) could have that too (it is both interpreted and statically checked).
I've worked on a codebase where a jsp app would call an API served by a mod_perl app, which would call a remote API to a c++ app. Technical bankruptcy can and does creep up even in services made in the micro style. They may not be as common now because the microservice trend is fairly recent, but as years go on, I'm betting you're going to see more issues with microservice systems where code done may be using a decade's worth of changing Best Practices.
You just reminded me of one I worked on too, back before the buzzword existed but still a microservice architecture. It was all c# but service1 would call service2 which would call service3 which would call service1. It had all the spaghetti of a monolithic system with 1/10th the debugability and performance (serialization can be relatively expensive).
>The projects I've seen getting to technical bankruptcy have been with no exception monoliths. With microservices you have the ability to take one service and fix it, reimplement it or replace it if necessary.
The worst kind of technical debt is usually about having the service boundary in the wrong place and crappy APIs. With microservices this problem is amplified. It's harder to unpick a service than it is a module.
If you've ever tried debugging a problem across a series of microservices as well, you'll wish you hadn't...
> With microservices you have the ability to take one service and fix it, reimplement it or replace it if necessary.
You can do that inside a monolith too. Microservice as a solution points to architectural problems, we try to build systems that are too vertical, our architecture should be horizontal. Microservices enforce this horizontalness, but it's not the only way to achieve it.
The issue is when you have multiple teams working on a monolith.
I haven't seen a configuration of teams that doesn't screw up the monolith by creating "spaghetti" dependencies between the pieces. Hence making the transition to microservices a multi year journey.
Monoliths assume that every single developer that will ever touch that codebase will do the right thing. That is everyone from the intern to the 3 month contractor to someone who only cares about finishing off their cards before the end of the sprint.
So I am in your boat that every single screwed up, beyond repair project has been a monolith. And always because a small handful of developers decided at some point to cross a logical boundary and introduce spaghetti-like dependencies.
>>Monoliths assume that every single developer that will ever touch that codebase will do the right thing. <<
This is just false, there are pull requests, reviews and all. Morealso there are modules and just because you can deploy the 'monolith' as a single process and use shared memory doesn't mean you can't add/remove parts or have to compile all at once.
Analogy with microservices - your login service is borked. The rest of your site is kind of useless even if perfectly operational.
Pull requests are a relatively new concept to software development. So if you're working on an existing project then chances are the model that was used was "as long as the unit/style tests pass it's fine". And of course there's the very common "we have a fixed deadline so let's just cut this corner and we'll fix it up later".
And in the Java world at least modules aren't real. They are purely logical constructs that developers can work around by importing from packages in other modules. And creating the spaghetti code problem again.
I'd say the microservices fad is newer than the distributed source repositories but disregarding something because deemed 'new' doesn't make a good argument.
And in the Java world at least modules aren't real. The statement shows lack of understanding how modules should be utilized (it has very little to do with packages). Interfaces (can) do exactly the same what protocols in microservices do. Enforcing that might be harder but facades/proxies ensure there would be no (feasible) way to bypass. There is no substitute for good data models/responsibility.
It's not really that new, it's just the term "pull request" that's new. I've worked in several projects where prior to committing code change, it was shared out to the team in form of a patch, feedback gathered, and only when everybody was happy with it, it got committed.
Or, a bit dirtier solution - a commit was made with an explicit request for a closer review from the rest of the team.
And microservices guarantee that every single fad is represented in a hundred different ways in every different microservice, and that there is not a single bit of consistency in the code base.
The mental overhead of that is HUGE. Every new bit of functionality you have to figure out how this microservice was built? Opening a microservice and learning what developer X did with developer Y's "I don't understand functional, but I'm damn well going to use it, and wouldn't it be great to build this in the Zebeedeee framework that trended on HN two weeks ago and then mysteriously disappeared forever".
Bad programmers are going to muck up microservices even worse than they're going to muck up monoliths.
At least with monoliths they might actually reuse some code rather than cut and paste it from the last microservice they worked on.
I somewhat recently worked on a huge monolith where certain parts were "off limits"; I was told to the effect of "noone changes those classes, we don't really understand them". That business is not going too well now.
I searched the article for "domain" and "bounded contexts", found nothing. Article is not without merit, however; Sam Newman in his book [1] cautions about going too aggressive, i.e. splitting down into too many microservices before the domain is fully understood. On the other hand, having systems cross obvious domains is a definite warning sign (of disaster).
So the motto might be, use them, but in moderation (as with a lot of things).
The author did a better job convincing me of the benefit of micro services than they did trying to outline the cons. I'm now more of a proponent for them than I was when I started reading.
Additionally, if you're actually having issues with scaling microservices or using them reliably for some reason, it's usually pretty easy to integrate two of them into a bigger piece. Virtually always easier than extracting a new microservice from an existing monolith.
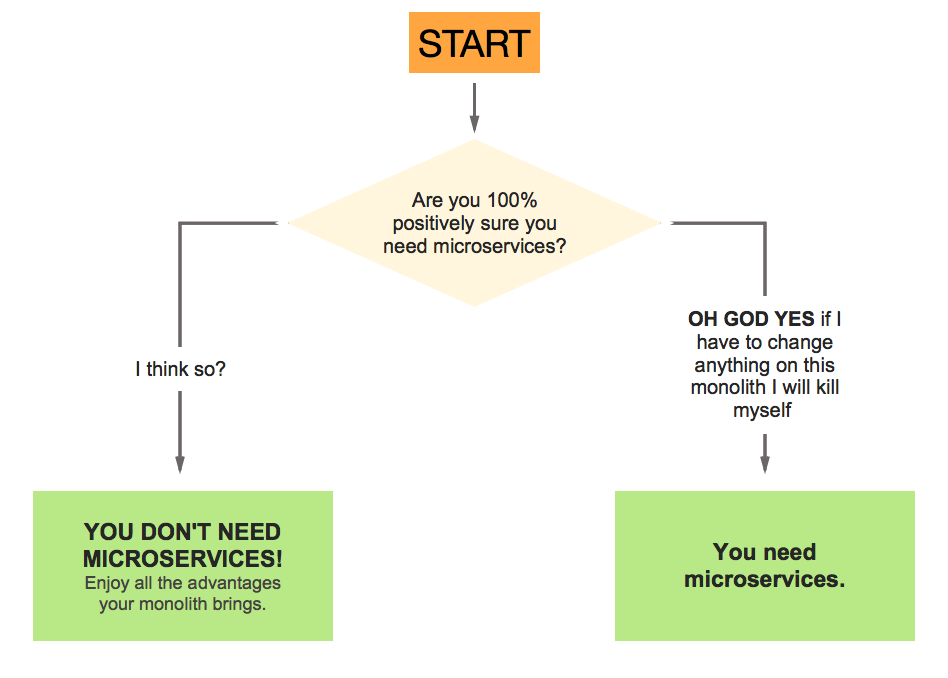{kind=link}
Any sufficiently complicated infrastructure that has uptime requirements and significant revenue associated with it is going to have a DevOps Team (or the equivalent) ultimately responsible for ensuring that things are working. I guess it's possible to turn your entire dev team into part-time DevOps engineers, while still calling them Software Engineers, but I've usually found that doesn't work long-term and causes employee retention issues. It's like saying your company does 'No-Support' because you don't hire Support Engineers, while in fact you've enlisted your Software Engineering team to handle all support requests.
Also, if you're working in a regulated field like Healthcare or Finance, or anything that touches PII, your developers often can't have access to deploy code directly to production. Again, you could maybe work around this in the short-term by turning all developers into developers+devops, but they're different skillsets.