Is there room for generative AI in science? I am experimenting with this a lot at https://atomictessellator.com, As a computational chemist I found it difficult just to stay on top of all of the papers that are released, I thought it would be cool to have generative AI attempt to reproduce the experiments using simulation tech.
Here's a few cool insights I have uncovered while working on this:
- Developer tools are popular, but there's an upcoming market for AI tools - I.e. Tooling/API's that are meant to be used primarily by LLMs/AIs. Design the interfaces to be well composable at the right level of abstraction and AIs can design, run and monitor experiments really well.
- Tree of thought and Graph of thought are really, really, really important for this - I think this is because it compensates for the lack of looping mechanisms in LLMs and also adds the ability for recursive problem decomposition, abstraction laddering, composable malleability and so on.
Does it work? Yes, I have a working E2E pipeline now that has already made novel discoveries validated by lab work, I am focusing on scaling this out now to support a broader search space and give the LLMs more freedom to explore.
A shameless plug: I am working on this 4-5 hours a day as well as my day job. If anyone is aware of any grants or investors that I could connect with, I would love to work on this full time. I am neurodivergent so I think running a company is not really my thing, but there must be an alternate way, advice anyone?
I would love a system like ChatGPT but targeted specifically at exploring existing literature. A system that can recommend papers to read, that you can chat with about your problem and can recommend approaches that have worked for others and tell you why. That you can prompt and refine and go into detail with while it helps you figure out what do next based on previous work. That can link you to actual papers to read.
With ChatGPT, I get some of this, but I have to be veeery careful how I use it. It is generally good at discussing points at a high level and helping you sort out some ideas, but when you get into detail it is very easy to catch it making mistakes, and when you ask it for references to read further, it almost always makes up some or all of them. Forget asking it to give you actual links. Maybe some of the other GPT systems targeted at the search space are better at this, I don't know I haven't tried them. But I would love a system that actually does this kind of thing well.
Not just for scientific research -- I've used ChatGPT to help understand some legal things, to help understand some government application procedures (cut through the "consulate speak" and explain some steps to me in my son's visa application in plain language. Of course I double-checked everything it told me.)
Having a system that has "read everything" and can explain it back to you after you ask some questions is just fantastic. I just want it to be more reliable.
I agree, I think there is a wide open vista of opportunity in the hypothesis generation space when it comes to science. An instant literature-review-as-a-service would be incredibly valuable too, to say nothing of a, "write the code to implement the methods described in this paper."
Yes, but most of the current ideas on how this moment will change science are willfully short-sighted.
We are only a few years from next generation multimodal modeling. The future contains protein embeddings, genome embeddings, medical image embeddings, and chatbot decoders to discuss them with you.
Imagine prompting an image-conditioned decoder with questions like
"Q: Why do you think this brain MRI indicates the person will get Parkinson's?"
These are things that models can currently do, but we have basically no understanding of what they are looking at.
AI will be a force amplifier. great, we get that. I suspect that this kind of vague marketing bollocks will be generated almost without any oversight soon.
However there are also risks. Just like calico which used to be a really expensive luxury, and then with empire and colonialism, and later mechanisation became a cheap(er) commodity, LLMs will kneecap whole industries.
I think any site that relies on advertising on the web is going to die. This includes google, as they are the gateway to the web, and rely on you using them to answer questions obliquely. This means that the need for web developers and support staff is going to decrease.
I think the open web will shrink to ~20% it's present size. It will mostly revert back to hobbyists and people arguing. Things that require up to date data will continue (news, sports, gaming, etc.)
Social media will either thrive, or revert to small group chats (think half whatsapp half tiktok/instagram), to get away from autogenerated horseshit.
As for streaming TV/movies. AI porn is the canary there. If that takes off, then your kardashians/court reality/low budget drama might feasibly be generated (we are a way off though)
> I think any site that relies on advertising on the web is going to die.
What? No.
The only known useful application of generative LLMs is to write automatic ad copy.
This means the cost of doing advertising will lower dramatically and we'll get more of it. (Mostly "native" ads in places where putting ad copy was previously not economically feasible - e.g., twitter posts, tiktoks, etc.)
Where is the vast majority of advertising now? on websites.
If you are not going to websites anywhere near as much to get info, then the cost per click goes through the roof. Money drains from the system, those websites disappear.
I think a great deal of opportunity is indeed being missed: AI Porn.
History shows that you can always sell a lot if you rely on the 7 sins of men, in this case lust. Porn has always been a sort of a pioneer in the tech space anyways but none of the VCs have the agreements in place to invest in such a space.
Though I know AI Porn is going to print money. Especially when video generation becomes remotely usable.
Can't wait for most of these companies to disappear once the hype dies down and the money dries up. Generative AI in its current form is a huge letdown.
Typical HN pessimism, but I strongly disagree with anyone characterizing it as a huge letdown.
Even if you personally don't get much use out of it (honestly hard for me to believe if you give it a fair try), there are tons of uses that will be impacting you significantly within the next year. Contrast that with crypto.
It's going to be one of those things like the internet where over the next decade it will have massively impacted every aspect of life but no one will fully appreciate how much everything has changed.
It's already replaced a bunch of search for me. I don't use it to make my own work, but I use it as a really fast q/a tool for straightforward answers absent of ads and clickbait
I paid for ChatGPT for a few months and finally cancelled yesterday. As a code generator it’s a frustrating assistant that gets it wrong most of the time. I guess that’s good from a selfish developer point of view.
It works quite well for my usecase as a coder - generating boilerplate UDFs for spark, etc., generating boilerplate python functions from a description of what it does, rewriting code to handle errors, asking it to review simple code.
Have you tried coding with it yet? Easy to see how you could get that impression from just playing with ChatGPT, but copilot/cursor/dropping stack traces into gpt4 is transformational.
In my experience talking architecture through with GPT4 has increased my productivity and enjoyment of development, and certain things like explain this typescript error to me or generate an elaborate mermaidjs chart for me that shows x,y,z have all been delightful.
That said, I've spent hours this week trying many different AI enhanced IDEs including cursor and I cannot for the life of me get anything to correctly set up jest in a TypeScript project - next.js or just vanilla TS... every single one does not correctly handle the Babel / tsconfig issues.
What I'm saying is I still think we'll see improvements over time but it's not quite there yet. I still prefer Codeium for completion and to take some boilerplate from gpt4 and modify it to my purposes.
Typical Sequoia "think piece" meant to bring in tier-2 and tier-3 VCs onto the AI hype train, further bolstering their own position. I don't even think Sequoia believes in AI per se, they're just chasing the next shiny ball. It's genius if you really think about it.
A year ago, they were gushing over SBF. There's no due diligence here, there's no product market fit. It's a legal pump and dump. Much like crypto, there will be bag-holders, but it won't be Sequoia or a16z, they're far too smart for that.
If they get lucky and hit a home run, they were the visionaries all along. Their hubris is frankly quite admirable. The world goes 'round, and the rich get richer.
And if it all goes sideways, quietly take down the puff piece bollocks and continue to curate your garden of unremitting genius. Here's to the bag holders. These pieces are such cringe to read it hurts.
Hilariously for me (I’m a Microsoft FTE, fyi) there’s no mention of Bing, any of the multiple Copilot products in the Office/enterprise space, or, tellingly, the Azure OpenAI service (which provides you with private endpoints and models). I do see startups that use it, but it is a grossly lopsided view of the “market”.
(And regardless of my employer, there are a lot of consumer and enterprise-focused solutions in that space - including direct competition - that aren’t mentioned anywhere.)
There is a large community of folks that simply can't stand your employer. I hate to break that to you. The anti-competitive antics and open source washing has no end
The moment that generative AI became something crazy for me was when I said "holy shit, maybe Blake Lemoine was right".
Lemoine was the Google engineer who made a big fuss saying that Google had a sentient AI in development and he felt there were ethical issues to consider. And at the time we all sort of chuckled- of course Google doesn't have a true AGI in there. No one can do that.
And it wasn't much later I had my first conversation with ChatGPT and thought "Oh... oh okay, I see what he meant". It's telling that all of these LLM chat systems are trained to quite strongly insist they aren't sentient.
Maybe we don't yet know quite what to do with this thing we've built, but I feel quite strongly that what we've created with Generative AI is a mirror of ourselves, collectively. A tincture of our intelligence as a species. And every day we seem to get better distilling it into a purer form.
Or "holy shit, we don't know enough about sentience to even begin to know whether something has it, other than humans, because we've gotten used to assuming that all human minds operate similarly to our own and experience things similarly to how we do."
The point is that that it can be trained to be convincing in the first place.
The current batch of AI can be trained by giving it a handful of "description of a task -> result of the task" mappings - and then it will not just learn how to perform those tasks, it will also generalize across tasks, so you can give itva description for a completely novel task and it will know how to do that as well.
Something like this is completely new. For previous ML algorithms, you meeded vast amounts of training data specifically annotated for a single task, to get a decent generalisation performance inside that task. There was no way how to learn new tasks from thin air.
Is it really that different from socialization (particularly primary socialization [0]), whereby we teach kids our social norms with the aim of them not being sociopaths?
The counterpoint to this is always "models work with numerical vectors and we translate those to/from words"
These things feel sentient because they talk like us, but if I told you that I have a machine that takes 1 20k-dimensional vector and turns it into another meaningful 20k-dimensional vector, you definitely wouldn't call that sentience.
What if I told you I have a machine that takes 1 20k-dimensional vector and turns it into another meaningful 20k-dimensional vector, but the machine is made of a bunch of proteins and fats and liquids and gels? Would you be willing to call it sentient now?
Sorry to tell you, but your brain is doing millions of dot products - it's what the biochemical reactions in the synapses between neurons amount to. We already know how the brain works on that level, we just don't know how it works on a higher level.
Sorry to tell you, but neurons do not follow a dot product structure in any way shape or form beyond basic metaphor.
I mean fine I’ll play along - is it whole numbers? Floating points? How many integers? Are we certain that neurons are even deterministic?
The point I’m making is this whole overuse of metaphor (I agree it’s an ok metaphor) belittles both what the brain and these models are doing. I get that we call them perceptrons and neurons, but friend, don’t tell me that a complex chemical system that we don’t understand is “matrix math” because dendrites exist. It’s kind of rude to your own endocrine system tbh.
Transformers and your brain are both extremely impressive and extremely different things. Doing things like adding biological-inspired noise and biological-inspired resilience might even make Transformers better! We don’t know! But we do know oversimplifying the model of the brain won’t help us get there!
The people seeking to exclude numerical vectors as being possible to be involved in consciousness seem to me to be the ones that you should direct this ire at.
Yes, and you wouldn't believe you're made out of cells as well.
The brain can't see, hear, smell, etc directly and neither can it talk or move hands or feet. "All" it does is receive incoming nerve signals from sensor neurons (which are connected to our sensory organs) and emit outgoing nerve signals through motor neurons (which are connected to our muscles).
So the "data format" is really not that different.
As far as "inputs and outputs" are concerned, yes. (Well, not quite, I think there is also communication with the body going on through chemical signals - but even this doesn't have to do a lot with how we experience our senses)
Not a neurologist, but that's about what you can read in basic biology textbooks.
I think my moment was the realisation that we're one, maybe two years away from building a real-life C3PO - like, not a movie lookalike or marchandize, but a working Protocol Druid.
Or more generally that Star Wars of all things now looks like a more accurate predictor of our tech development than The Martian - the franchise that is so far on the "soft" side of the "hard/soft SciFi" spectrum that it's commonly not seen as "Science Fiction" at all but mostly as Fantasy with space ships. And yet here we are:
- For Protocol Druids, there are still some building blocks missing, mostly persistent memory and the ability to understand real-life events and interact with the real world. However, those are now mostly technical problems which are already being tackled, as opposed to the obvious Fantasy tropes they were until a few years ago. Even the way that current LLMs often sound more confident and knowledgeable than they really are would match the impression of protocol druids we get from the movies pretty well.
- Star Wars has lots of machines which seem to have some degree of sentience even though it makes little practical sense - battle droids, space ships, etc - and it used to be just an obvious application of the rule of cool/rule of funny. Yet suddenly you could imagine pretty well that manufactures will be tempted by hype to stuff an LLM into all kinds of devices, so we indeed might be surrounded by seemingly "sentient" machines in a few years.
- Machines communicating with each other using human language (or a bitstream that has a 1-1 mapping to human language) likewise used to be a cute space opera idea. Suddenly it became a feasible (if inefficient and insecure) way to design an API. People are already writing OpenAPI documentations whete the intended audience are not human developers but ChatGPT.
They feel sentient in many cases because they're trained by people using data they've selected in the hope that they can train it to be sentient. And the models in turn are just mechanical turks repeating back what they've already read in slightly different ways. Ergo, they "feel" sentient, because to train them, we need to tell them which outputs are more correct, and we do that by telling them the ones that sound more sentient are more correct.
It's cool stuff but if you ever really want to know for sure, ask one of these things to summarize the conversation you just had, and watch the illusion completely fall to pieces. They don't retain anything above the barest whiff of a context to continue predicting word output, and a summary is therefore completely beyond their abilities.
I think it absolutely has. Certainly in developer tools, but you can see it in other tools like Hubspot, Gong, etc. Not to mention the enterprise organizations who are building their own features that use LLMs. Yes, we'll see some "enterprises" adopt their first LLM in 10 years because some move as slow as molasses. That's fine; there's companies who are tasting Cloud for the first time right now, but nobody is saying that Cloud adoption is still in its first phase. I think Sequoia sees this and decided the train is already starting to roll, so it's time to look towards what's next.
Technology always moves slower than what people think it will.
What always happens is that people let their imaginations run away, both with what the technology can do, and with how people will adopt it instantly in masse.
If everyone you know is using AI, you're living in a bubble. I have one friend who thinks everyone is using AI, and the rest of my friends have only touched it superficially.
Adobe is already incorporated genAI into core product and will start pricing for compute units. This is part of their core product, not a tool being sold to other people to build genAI products
I think that’s a great example of a company who is trying to make a profit, and they are certainly investing in the future under the assumption that it will pay off. But I don’t see how that’s currently profitable, which is the point brought up by GP about still very much being in Act One.
Probably. My company has seen a genai feature turn into increased product activation rates (the feature is 100% free), which correlates strongly with increased revenue.
Generative AI is not a platform unto itself. In order to effectively leverage fine-tuned models, you need your data to be somewhat organized in the first place. The average enterprise struggles enormously with this and always will.
In short, I would bet on endemic platform providers (Google, MS, Adobe, SAP, etc) rather than standalone AI providers (OpenAI, startups). Who owns the data? That is where the value lies.
VCs writing shallow thought leadership pieces has become too common. They don't seem to yet realize everyone has figured it out for what it is - self serving.
It's a very biased take too, as if it's already clear modern AI is on the level of the internet. If they believe this honestly, I'd say they are in a bubble.
Modern AI is impressive, sure, but comparing it to the invention of the internet itself? It's too early to come to such conclusions imo.
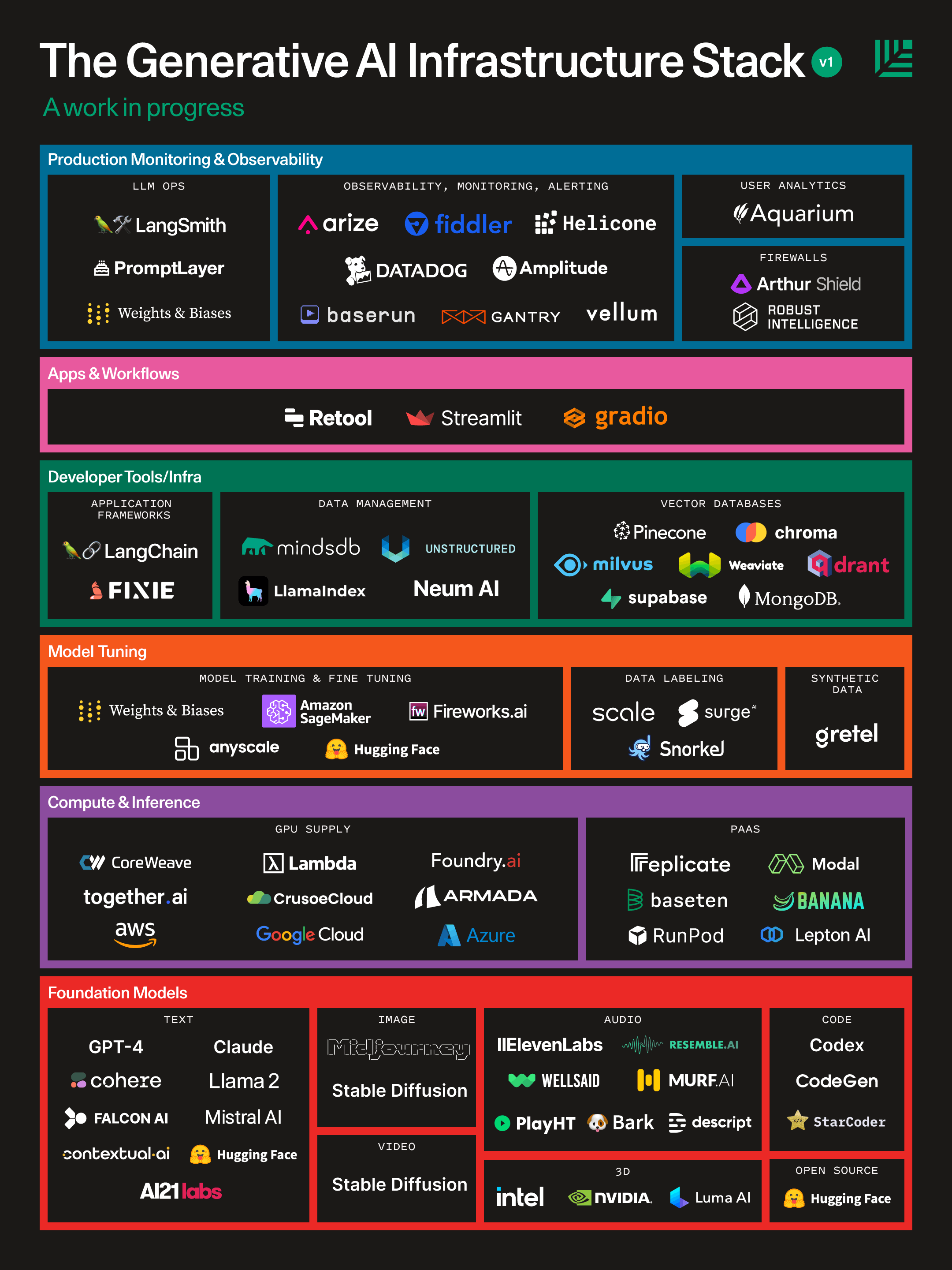
- The lists at the bottom (Generative AI Marketing Map). Bunch of companies I had never heard of. At the very least it gives me an idea of what somebody who is pouring out hype for AI looks at.
Marketing Map and Model Stack. Give nice little summaries by topic.
Maybe it's just hype marketing, but I liked two things:
(1) The industry overview infographics. I'm not very familiar with the quickly-changing application layers of AI, so it's nice to see what are the noteworthy companies in the various slices (at least according to this particular VC), and explore some of them a bit more.
(2) I also think the retention point and related metrics are interesting, and maybe some of the metrics are hard-to-find / not very public (? not sure about that). It starkly paints the current challenge in the space.
Don't get me wrong, it's a great piece of marketing for them too.
And basically they're saying - if you can claim one of these little boxes on our infographics, and/or have solved the retention challenge, then we'll fall all over ourselves to invest in you (just like any other VC). So it's a great move on their part.
> Four decades of the internet (accelerated by COVID) has given us trillions of tokens’ worth of training data.
Yeah four decades of stolen intellectual property posted by people on the internet in good will for the world to see, only to have it stolen and monetised by these folks. Wondering, once the good content dies out how will you “train” your “ai”?
OpenAI did the grand heist that no one else dared to do. It doesn’t look like they will get punished for it either. I am to this day baffled how they got away with it and are now practically shielded from any kind of repercussions.
Things have changed so much already and I am not seeing any kind of real regulation being put in place that will at least rein in this stupid idea that AGI is around the corner. It’s not.
It’s another 20 billion dollars waiting to be scooped up and there’s nothing you can do about it.
They are hoping to get away with it because they gaslit senile politicians and scared the masses with the “dangers” of ai - in fact the only dangers are these people stealing data. It will be fun once they run out of content because quite a few folks are unwilling to share only so it can be stolen and monetised by those who then threaten to take their jobs.
Learn yes, if its legally shared. Copy and earn from it without acknowledging original author and sharing earnings, in most cases, definitely not. As we know, things that often move so fast have law catching up easily after a decade if not more (I am still waiting for a proper slap to FB), and entrepreneurs are well aware of that.
But that's not how it works at all? If I watch 100s of artists cell shade something and build a normal piece of software that mimics the results I owe them absolutely nothing. I've not seen an explanation as to why this is different.
People are fine with AI learning stuff from others. People are not fine with AI trained on everyone's recorded work and then replacing everyone to make massive profits for just that company.
Private owned GAI is a dystopia, shared GAI is utopia like star trek. The difference might seem tiny today, but people really don't want to go down the dystopia route.
Classic Sequoia piece: VCs sharing lengthy, jargon-filled thoughts specific to their worldview (supplemented with narrowly relevant charts!) to imply that they have a grand unifying vision.
Interesting that Sonya and Pat credited GPT-4 as an author; they could've used it to make things concise!
Maybe trying to sell shovels is at worst a good way to learn how to best use shovels or which shovels are actually best? Then you can get ahead in the shovelling game.
"AI-first infrastructure companies like Coreweave, Lambda Labs, Foundry, Replicate and Modal are unbundling the public clouds and providing what AI companies need most: plentiful GPUs at a reasonable cost, available on-demand and highly scalable, with a nice PaaS developer experience."
Oddly to me, this is playing down the point in the "what we got wrong" section... "2. The bottleneck is on the supply side."
“Four decades of the internet (accelerated by COVID) has given us trillions of tokens’ worth of training data.”
What’s up with the “accelerated by COVID”? It feels completely out of place. Would we have not had enough training data if COVID didn’t happen? Blessings in disguise, I guess.
I’m mildly curious if those additional tokens will make AI better, or worse.
We arguably trained AI on the good stuff first. Novels. Wikipedia entries. GitHub open-source projects with a lot of stars. What’s left but mediocrity and our “baser” internet ramblings?
Some researchers already found out that AI-sourced content can affect the models, but what about content from increasingly out-of-touch people?
The only way I can interpret that is assuming it is referring to the massive uptick in video conferencing which COVID caused. Although I'm not sure what data programs like Zoom actually collected and if it was shared with generative AI creators.
{kind=link}
{kind=link}
Here's a few cool insights I have uncovered while working on this:
- Developer tools are popular, but there's an upcoming market for AI tools - I.e. Tooling/API's that are meant to be used primarily by LLMs/AIs. Design the interfaces to be well composable at the right level of abstraction and AIs can design, run and monitor experiments really well.
- Tree of thought and Graph of thought are really, really, really important for this - I think this is because it compensates for the lack of looping mechanisms in LLMs and also adds the ability for recursive problem decomposition, abstraction laddering, composable malleability and so on.
Does it work? Yes, I have a working E2E pipeline now that has already made novel discoveries validated by lab work, I am focusing on scaling this out now to support a broader search space and give the LLMs more freedom to explore.
A shameless plug: I am working on this 4-5 hours a day as well as my day job. If anyone is aware of any grants or investors that I could connect with, I would love to work on this full time. I am neurodivergent so I think running a company is not really my thing, but there must be an alternate way, advice anyone?