I'm the person who's been working on this conversion for some time. This series of commits is actually the sixth, and there will be several more coming. (I just posted the seventh to the list, and I have two more mostly complete.)
I do like your hashname/nohash idea.
If we could come up with a simple compression negotiation protocol also: zlib -> zstd. But this will be much harder, as hashes are internal only, and compression is in the protocol.
kudos to brian m carlson to convince linus to use sha3-256 over sha256. this is really the only sane option we have.
I don't understand what you mean by "hashes are internal only"? Aren't the sha1's everywhere right now. I mean not only in the protocol but also part of the UI and from there they even spread into bug trackers, documentation and so forth.
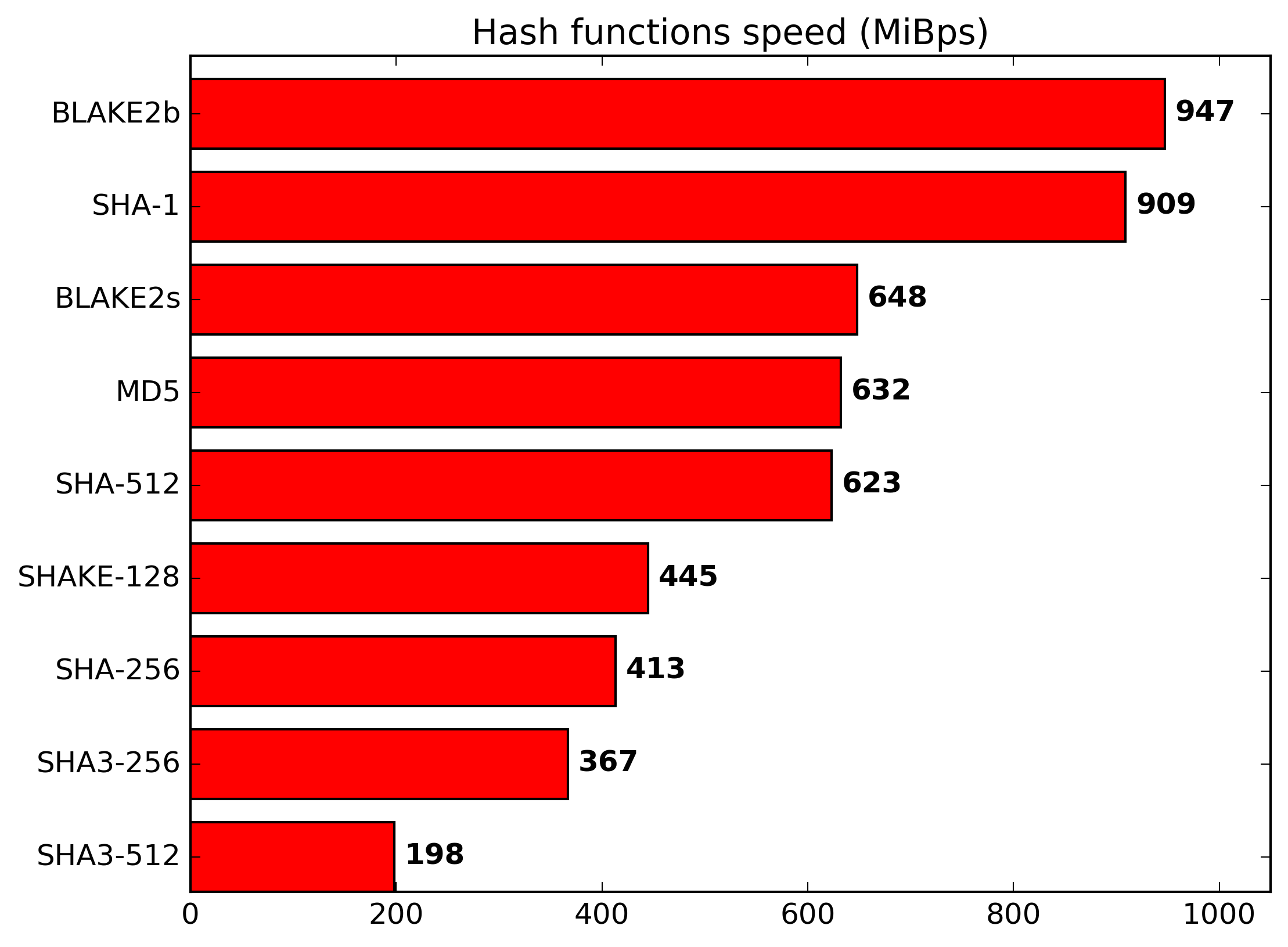
I'm not familiar with Git internals. Does the performance of the hashing algorithm contribute significantly to how Git deals with large files or with operations over a large number of small files?
I've run into performance problems with things like MathJaX, which includes thousands (or tens of thousands?) of files as a backup method for rendering equations. (I understand each file has a single character in some typeface.)
The hash function may not matter for overall git performance in virtually all dev machine setups, but there will be a (maybe tiny, maybe larger, depending on the repo and disk io speed) difference in cpu utilization and heat generation, right?
sha3 will probably get hw accel eventually. Blake2 is less likely to. It's like the dilemma between chacha20 and a stream cipher mode for aes. An argument could be made for either, depending on application specifics and available hardware.
Did you make any measurements or back of the envelope calculations what the real world performance impact of this change is.
I don't expect anything horrible, but still curious.
EDIT: After skimming OP I found a few answers.
The message from the The Keccak Team [1] is especially interesting. Summary is that we don't have to worry about performance degradation because of the hash calculation itself. There is a palette of functions which are considered to have a "security level [...] appropriate for your application" and are considerably faster than SHA1.
From the commit history, 2015 (commit 5f7817c85d4b5f65626c8f49249a6c91292b8513).
I proposed the idea of improved compile-time checking and maintainability, as there wasn't originally much interest in a new hash function, but the maintainability improvements were something people could go for.
I hadn't spent as much time working on it as I am now, so it moved slowly. Other people also helped by converting parts of the code that they were working on (like parts of the refs subsystem).
I'm not quite so familiar with the Git internals, how do you deal with the problem of having different non-leaf nodes scattered through the directory tree?
This might be a non-issue based on how Git stores the tree, but I can imagine one simple model where each directory would be a sort of "collection object", a binary encoding of a list of (filename, hash) pairs in filename order, and therefore the directory gets a hash of its own. But that means that when you're communicating with a SHA-1 repository you don't just need to rename this object; its contents also need to be changed pre-rename, and then you need to store every internal node twice. I'm not seeing that in your summary.
Is it just that Git doesn't have any internal nodes in the directory tree per se because the "filename" is a full POSIX path with subdirs? Or what?
https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
has descriptions of the objects. Both trees and commits are hashes over data that includes hashes of other objects so they must be different. The doc discusses converting them at transmission time, search for [convert to sha256] in it.
>b. A SHA256 repository can communicate with SHA-1 Git servers and clients (push/fetch).
Wouldn't fetching from a sha-1 repository degrade security? I think it would be better to show a warning (similar to how openssh does with 1024 bit dsa keys) every time you try to fetch from a SHA-1 git repo.
Same for pushing a signed commit to a sha-1 repository.
Uh, even a signed commit does still rely on the sha1 hash of the actual tree object and any parent commits. It won't stop something bad from happening if you fetch from a sha1 repo.
From a cryptographer's perspective, everything around SHA-3 is a little weird. We ended up with something that's pretty slow even though we had faster things, for which general consensus was that they were just as strong. Similarly, consensus was that some SHA-3 candidates made it as far as they did because they are drastically different from previous designs. Picking a major standard takes a while, and immediately preceding it we saw scary advances in attacks on traditional Merkle-Damgard hashes like SHA-0, SHA-1. Not SHA-2, but it's pretty similar, so the parallels are obvious.
Bow that we have SHA-3, we ended up with a gazillion Keccak variants and Keccak-likes. The authors of Keccak have suggested that Git may instead want to consider e.g. SHAKE128. [0]
It's a bit unfortunate that this is really a cryptographic choice, and it seems to mostly be made by non-cryptographers. Furthermore, the people making that choice seem to be deeply unhappy about having to make it.
This makes me unhappy, because I wish making cryptographic choices got much easier over time, not harder. While SHA-2 was the most recent SHA, picking the correct hash function was easy: SHA-2. Sure, people built broken constructions (like prefix-MAC or whatever) with SHA-2, but that was just SHA-2 being abused, not SHA-2 being weak.
A lot of those footguns are removed with SHA-3, so I guess safe crypto choices are getting easier to make. On the other hand, the "obvious" choice, being made by aforementioned unhappy maintainers, is slow in a way that probably matters for some use cases. On the other hand, not even the designers think it's an obvious choice, I think most cryptographers don't think it's the best tool we have, and we have a design that we're less sure how to parametrize. There are easy and safe ways to parametrize SHA-3 to e.g. fix flaws like Fossil's artifact confusion -- but BLAKE2b's are faster and more obvious. And it's slow. Somehow, I can't be terribly pleased with that.
I'm a long time fan of Fossil and contributed a bit to its development (in particular, TLS support and some protections against timing attacks). I'm not sure where you found provocative language, but let me try to explain it here more clearly.
Design deficiency
(This is unrelated to the choice of hash.)
Fossil stores blobs as-is. A file containing "hello world" will be stored as "hello world" and referenced as HASH("hello world").
Commits are stored as plain-text manifests, which are also referenced as HASH(manifest_contents). To distinguish between different types of artifacts (commit, file, wiki page, etc.), Fossil checks the contents of the blob.
* Attach the deconstructed artifacts with changes to a ticket in the original repository or to a wiki.
By doing this, you could make commits to the target directory by attaching files to tickets or wiki, and these commits were only visible to people who cloned the repo until rebuilding (then they would be visible to everyone).
This attack was prevented by compressing every attached file with gzip, making it impossible to attach a file that would be recognized as a commit, because gzip adds its own header.
I think this design is deficient: instead, each blob should have a type indicator — that is, file artifacts should have some prefix. This is how Git works: each object has a prefix indicating its type. Also, Plain 9 had a filesystem called... also Fossil! — which was based upon Venti content-addressable storage, which stored typed blobs.
Unfortunately, changing this will break compatibility, and since Fossil artifact format was built to last for ages, I don't think it will be changed.
SHA-1 claims
What made me rant about Fossil after congratulating them on switching to SHA3-256 is that they made false claims regarding their use of SHA-1 in the same documentation which shows these clams are false:
The SHA1 hash algorithm is used only to create names for artifacts in Fossil (and in Git, Mercurial, and Monotone). It is not used for security. Nevertheless, when the Shattered attack found two different PDF files with the same SHA1 hash, many users learned that "SHA1 is broken". They see that Fossil (and Git, Mercurial, and Monotone) use SHA1 and they therefore conclude that "Fossil is broken". This is not true, but it is a public relations problem. So the decision was made to migrate Fossil away from SHA1.
If you search the docs, you discover that they use SHA-1 for security:
Speaking of passwords, the automatically generated passwords are too short: I just created a repo with Fossil v2.1 and got "efc6f5" as initial password. It's 6 hex characters, or just 3 bytes — trivial to crack.
Finally, I as I said, I really like Fossil even though I don't use it anymore for open source projects (I still use it for some private projects) and have a great respect to its author and other contributors. But in my opinion, it needs at least a fundamental but simple change in the storage format to introduce object types.
If something is unclear or you have questions, I'm happy to answer.
Thank you very much for posting this --- this is exactly the information which was missing from the Twitter thread!
(My concern was that the twitter basically contained nothing of any content: no technical details, no link to a blog post, nothing which can be checked or verified... which makes it indistinguishable from insinuation; and so I have to dismiss what you said out of hand.)
(Regarding provocative language: I don't think publicly calling someone out as a liar, in so many words, particularly on a medium like Twitter which doesn't really allow for an effective response, is particularly effective in producing a useful result...)
Anyway:
Re the manifest issue: to paraphrase, to check I'm understanding you correctly: because each manifest refers to its predecessor, and not vice versa, adding any blob which looks like a manifest implicitly adds that manifest to the tree. Normally Fossil trusts authenticated users to add blobs to the tree, because they're authenticated, but ticket attachments can be added by anyone, which effectively means that you can bypass the authentication and commits can be done by anyone. Is that correct?
In which case, yeah, I agree; that's very bad. I can't spot any holes in your reasoning. It is possible to positively identify attachments by looking at their parent manifest, as each one should be pointed at by an A record, so I suppose you could disallow manifests if they're referenced like this, but my gut tells me that's going to be horribly fragile... you're right, adding a type prefix is obviously the right way to go.
If you create a manifest and check it in as a normal file, so it's referenced by an F record, is it still treated as a manifest? If not, could this machinery be extended to attachments as well?
When adding an attachment in Fossil, if the attachment is syntactically similar to a structural artifact (such as a manifest), then the attachment is compressed prior to being hashed and stored, thus making it very dissimilar to a manifest and incapable of being confused with a manifest. Hence, it is not possible for someone to add a new manifest as an attachment and have that confuse the system. Furthermore, there is an audit trail so that should an attacker discover and exploit some bug in the previous mechanism and manage to get a manifest inserted via an attachment, then the rogue manifest can be easily identified and "shunned".
Users with commit privileges are granted more trust and do have the ability to forge manifests. But as before, there is an audit trail and rogue manifests (and the users that insert them) can be detected and dealt with after the fact.
Structural artifacts have a very specific and pedantic format. You can forge a structural artifact, but you will never generate one by accident during normal software development activities.
Isn't the problem here, though, that they can be forged? If, by attaching a structural artifact in the correct format to a ticket, we're effectively allowing people without commit privileges to make commits --- potentially anonymous people.
I agree that this isn't likely to happen by accident, but Fossil servers are usually public facing, so we have to worry about malice as well.
Can it really be that simple though? If you are using a newer version of Git on your repo which is committing only with the newer
hash and I try to clone your repo with an older version I will be unable to do so. I guess maybe that's acceptable though?
> You want to have a model that basically reads old data, but that very aggressively approaches "new data only" in order to avoid the situation where you have basically the exact same tree state, just _represented_ differently.
> That way everything "converges" towards the new format: the only way you can stay on the old format is if you only have old-format objects, and once you have a new-format object all your objects are going to be new format - except for the history.
As soon as there is one new-hash commit in a repo, all users of it will have to upgrade their git client - and that git client will (probably?) default to writing new-hash commits.
I think backwards incompatibility would be acceptable. Add read support for the new format to git, but then don't have widespread repositories using the new format until some period of time later. By the time they do become commonplace, everyone should already be running a version of git supporting them. It's not exactly hard to upgrade git in most situations anyway, just a simple invocation of:
Well, it's not hard to update the command-line git client on Unix-y systems with package management. The trouble will be with the hundreds/thousands of other programs that use Git in various ways and are essential to development workflows in various places. Github themselves, Microsoft and Jetbrains IDEs, etc.
There's two potentially mitigating factors at play here:
I suspect a lot of the tools you mentioned also already treat hashes as strings, not as 160 bit numeric types. The entire front-end JS for GitHub, for example, just uses strings. That's what I'd do if I were writing IDE integrations and such too.
Secondly, the new format will likely still be a 160-bit numeric type, just calculated using a different hash algorithm (e.g. it might be the first 160 bits of the SHA256 result). The tools you mentioned likely don't have to calculate said hashes, they just display them. The entire GitHub front-end, for instance, just displays whatever is given to it; commit hashes are input data to it, not output data.
Just using the first 160 bits of a new hash function was proposed at one point, but it's not part of the current plan. The new plan is to introduce full SHA3-256 hashes (which are 256 bits in size). More information here: https://docs.google.com/document/d/18hYAQCTsDgaFUo-VJGhT0Uqy...
(Of course, CLI and frontend tools could still truncate display output to 40 hex characters, but internally full size hashes will be used.)
Woah, that's disorienting to be linked to a bluedoc unexpectedly like that, considering I'm not on my work account. I ever recognize one of the authors.
One straightforward way is to use the new sha only for new Git repos. Old repo could be migrated but it would require "re-commiting" everything to the new repo.
I don't have a good solution to this, but that sounds like it risks the same sort of crypto downgrade vulnerabilities which TLS cipher negotiation enabled.
Except if you drop SHA-1 support from a repository (goal #2 in the RFC on the top comment). Then your downgrades would only apply to new repos, and that's not really a vulnerability as there's no pre-existing trust; all the vectors available to you when you can create collisions are based on people not noticing changes.
It'd be like disabling TLS 1.0 and 1.1 on your server; a repo owner could just choose to do that. I guess the point stands if, like TLS downgrades, on the whole people don't specifically choose to do it and there are lots of vulnerable repos out there for a long time. Then it falls on GitHub/etc. to force repos to migrate fully.
I immediately looked at the length of this commit's hash to see if it was longer than 40 hex chars -- but no, it's just an SHA-1. It would have been cool if somehow the hash of this commit that added new hashes was a new hash.
Slightly similar: for a while I've wanted to recreate just enough of git's functionality to commit and push to GitHub. My guess is the commit part would be pretty trivial (as git's object and tree model is so simple) but the push/network/remote part a bunch harder.
If you have a repo with a lot of GPG signed commits, or you just don't want to change all your commit IDs (because you reference them in other places), then it'd be very valuable to be able to have a repo that's mixed old and new hashes.
Also your Git binary, if compiled with only the One True Hash™, wouldn't be able to work with older repos at all because the hashes it's calculating are now different.
(Edit: Another benefit of generalizing this is so that if/when, in the future, the new hash algorithm must be abandoned due to weaknesses, Git tooling will have been already introduced to the notion that hashes can be different and should hopefully be a less involved migration the next time around)
> Yes, this is correct. The struct object_id changes don't actually change the hash. What they do, however, is allow us to remove a lot of the hard-coded instances of 20 and 40 (SHA-1 length in bytes and hex, respectively) in the codebase.
No. We're talking about zoren's hypothetical case where git used a typedef from the beginning, instead of littering char[20]s all over the tree.
My prior comment was explaining why jffry's complaint is nonsensical (a typedef does not prevent moving from a single hash model to a multiple simultaneous hash model).
Hmm, not sure where there disagreement is, that's exactly what I'm saying. Obviously it wasn't done from the beginning, but the code is now changing from the char[20]s everywhere to the typedef precisely to be able support multiple hash functions.
That's exactly what this change is. You mean why wasn't it that way before the change? Maybe because it wasn't ever needed before? Git's been good with only sha-1 for 12 years. Think about the flip side of your question... what were the alternatives 12 years ago, or 5 years ago? And why would someone write code for alternatives that aren't expected to be used and maybe don't exist?
In my experience, generalizing ahead of need more often than not causes problems, and I've watched over-engineering result in far more effort to fix when the need it was anticipating does arrive than just waiting until the need is there.
> Think about the flip side of your question... what were the alternatives 12 years ago, or 5 years ago?
SHA-2 and RIPEMD.
> And why would someone write code for alternatives that aren't expected to be used and maybe don't exist?
That's the problem: the software industry is still suffering from MD5 getting cracked [0]! Cryptographic agility is a baseline requirement for security primitives.
> In my experience, generalizing ahead of need more often than not causes problems
I agree and Linus has valid complaints about security recommendations during the 25-year history of Linux: most of the security recommendations kill performance and are only partial fixes, so why bother?
But Linus is also engaging in premature optimization: computers are ~30 billion times faster than when he first starting programming Linux. Yes, SHA-2 is relatively slow, they could have at least not hardcoded SHA-1 into the codebase and protocol.
> I've watched over-engineering result in far more effort to fix when the need it was anticipating does arrive than just waiting until the need is there.
You clearly haven't done any safety related engineering. That's the thing about cryptography: millions of dollars and human lives are at stake. Despite the smartest people in the world working on these problems, cryptographic primitives/protocols are regularly broken. Due to Quantum computing, every common cryptographic primitive we use today will need to be replaced or upgraded at some point.
Thankfully, you don't need to worry about the engineering of a given cryptographic primitive as long as you can swap it out with a new one. But when you hardcode a specific hash function and length into your protocol/codebase you are now assuming the role of a cryptographer.
Even totally ignoring that SHA2 was a thing, anybody looking around would have noticed that MD4 was broken, MD5 was broken, and it would be unlikely that the hash of today would stand forever.
Yes, true. Correct. That is still true, and applies to SHA-2 as well. And Linus was aware of exactly what you say, back in 2005.
My point was that the choice that was made was considered good enough for the purposes for which it was intended. In the context of the OP's comment, criticizing git for not making different code design choices doesn't mean that Linus was wrong, it may mean that the OP doesn't know and/or understand all the considerations Linus had. And Linus has said many times that the security of the hash is not the primary consideration in his design.
Git's choice of SHA-1 was not at the time predicated on having the single most unbreakable hash in existence, the hash's use is not for security purposes, and to talk with such incredulity about Linus' choice may be to misunderstand git's design requirements.
Well, this whole mess proves that Linus was wrong. Typing "unsigned char [20]" everywhere is beyond amateurish to me in any case and raises a concern about the overall quality of code in git and linux kernel.
It shows that Linus is not a cryptographer, to be more precise. Though yes SHA-1 chosen prefix attacks are still very expensive at this point. I wonder how many non-cryptographers knew about SHA-2 back in 2003-2004.
No it's more than that. "unsigned char[20]" already has at least three potential points of failure (and why isn't it uint8 anyways). Moreover, it'll be referenced as unsigned char*, which opens another can of worms. And oh, by the way, have fun searching all references to sha1 on your source code now that you weren't pro enough to create a type for your object ids / hashes.
I'm guessing it's part lack of skill in design, part bad software development tools (uEMACS and makefiles or something), and part just being against c++ et al.
Linus regularly treats security as a second-class citizen and is famous for his outrageous harassment [0]:
> Of course, I'd also suggest that whoever was the genius who thought it was a good idea to read things ONE FCKING BYTE AT A TIME with system calls for each byte should be retroactively aborted. Who the fck does idiotic things like that? How did they noty die as babies, considering that they were likely too stupid to find a tit to suck on?
He deserves to eat this shit sandwich.
> I wonder how many non-cryptographers knew about SHA-2 back in 2003-2004.
Any systems engineer should have known about SHA-2. SHA-1 only provides 80-bits of security, so everyone else assumed that it would need to be replaced.
Linus has explained why he picked SHA-1. I'm not Linus, and I'm not defending his choice, but he has said repeatedly that git's hash is primarily for indexing and error correction, and not primarily for security. Clearly he felt like SHA-1 was "good enough". And if you have something that's "good enough" there are reasons not to write code for alternatives you're not going to use.
>but he has said repeatedly that git's hash is primarily for indexing and error correction, and not primarily for security
And he was wrong as openpgp signatures on commits and tags are a thing.
Not sure when that feature was introduced however, I doubt that it existed in the first version of git. That being said he should have changed the hash function the moment that feature was introduced.
The first attack on SHA-1 was published in 2003. Git showed up in 2005. Not only should git have allowed for something else, it never should have used SHA-1 in the first place.
Backwards compat requires that both old and new hashes work at the same time. A simple typedef is unlikely to handle all the semantics and space needed for such a change...
It is often hard to generalize when N=1. Now that the N=1 use case is established and we are moving towards N=2, it is painfully obvious to all that a better abstraction is needed.
Typedef or no, we would still need a full audit of the code to find spots where people "inlined" the expansion.
IMO, Linus should have done better here -- no crypto hash lasts forever, but this code is far cleaner than useless layers of abstraction.
I read those comments more than a decade ago. They seemed weak but tolerable then. They seem broken now. Git is supposed to guarantee that the code I see is the code the author saw, in a distributed and decentralized environment. This is Git's entire reason for existing.
A secure design is essential for trusting this functionality. My trust in Git has always been tempered by the weakness of SHA1.
A GPG signature is no stronger than its object ref.
Have you seen how many frameworks believe "auto-pull and compile deps by hash from github" is reasonable? They are assuming this isn't a massive attack vector. They are trying to build on a core feature that Git claims to have.
Recent events moved this from probably foolish to provably so.
That's what comes to mind every time someone brings up Linus' comments from way back when. If SHA-1 is insecure, then there is no way to have security. Forge an object, and GPG sign its commit, and you have broken the apparent security GPG signing was meant to bring. If SHA-1 was not meant for security, then security must have been a non-goal of Git.
The comments are brought up usually to explain why Linus didn't think much of it at the time, whereas they actually demonstrate the shift of thinking around what Git is meant to provide. Security is definitely a goal now, and the hash function is the critical piece of security infrastructure.
GPG signatures actually sign the hash digest of the text they're given. Fun fact, which I think (hope) changed in recent versions of GPG: the hash, by default, is (was?) SHA-1.
Interesting, I didn't know! Although it makes a lot of sense now that you bring it up.
I don't think it changes anything though, because of git's integrity. Stop me if I'm getting this wrong but, if you wanted to attack a signed git commit through the gpg signature's hash, you would have to modify the commit object itself... which yields a different commit hash in order to be valid. You'd have to get absurdly lucky to have a signature collision that contains a (valid) commit hash collision.
object $sha1
type commit
tag $name
tagger $user $timestamp $tz
$text
If you wanted to attack a signed git commit through the gpg signature's hash, you would have to do a second preimage attack on that text with a different commit sha1.
OTOH, if you wanted to attack a signed git commit through the git commit sha1, you would have to do a second preimage attack on that commit text, which is of the form:
See where I'm going? it's the same kind of attack.
Another way to attack it would be to do a second pre-image attack on the pointed tree, which is harder because there is not really free-form text available in a tree object.
Yet another way to attack it would be to do a second pre-image attack on one of the blobs pointed to by a tree, where the format is of the form:
blob $length\0$content
I don't think this is significantly easier than any of the second pre-image attacks mentioned above.
So, in fact, in any case, to attack a gpg signed git tag, you need a second pre-image attack on the hash. If git uses something better than SHA-1, but GPG still uses SHA-1, the weakest link becomes, ironically, GPG.
That being said, second pre-image attacks are pretty much impractical for most hashes at the moment, even older ones that have been deemed broken for many years (like MD5 or even MD4 (TTBOMK)).
That is, even if git were using MD4, you couldn't replace an existing commit, tree or blob with something that has the same MD4.
Edit:
In fact, here's a challenge:
Let's assume that git can use any kind of hash instead of SHA1. Let's assume I have a repository with a single commit with a single tree that contains a single source file.
The challenge is this: attack the hypothetical repository using the hash of your choosing[1] ; replace that source with something that is valid C because people using the content of the repository will be compiling the source. Obviously, you'll need the hash to match for "blob $length\0$content" where $length is the length of $content, in bytes, and $content is your replacement C source code.
But for the commit it's different, because the $text in your example affects the hash of the commit itself. And my understanding is that if you sign the commit, you're signing both the contents and the hash of the content. Am I incorrect?
Yes, Linus wrote that SHA1 isn't here for security, but that was a glaring misunderstanding of security on his part. Integrity protection of source code is a security function.
I think it's mainly due to a different threat model. Linus only pulls from his trusted lieutenants, who are unlikely to try to attack the source in that way (it's way easier to simply hide a bad commit in the lot, no need to fiddle with SHA1). They do the same.
The rest of the code is sent through mailing lists as patches, so the hash is irrelevant.
SHA1 here protects against "random" corruption (which is more than some VCS do), but not an attacker. At no point one is able to send trusted contributors bad commit objects.
Now, the use people have of git is very different from the kernel (or git) style, so their threat model is different, and SHA1 may become a security function.
Do they anticipate that one day we'll have to move from SHA256 to something else again? It's only matter of time. Hash function have lifecycle. Tre transition has to be done in a way that will also make the next transition more straightforward.
Reading even one changed line tells us that they replaced hardcoded char arrays for SHA1 with a generic struct that could be used as a container for any hash.
Some functions that previously operated on those char arrays have been changed to deal with the more generic struct instead.
I consider it unlikely that it will change again, but somehow it is unsatisfying that it doesn't have a hash version, e.g. in the first nibble of the hash. If they had done that we could have avoided the unpleasantness long ago.
A note on 'lifecycle': that's not how it works -- the age of use/lifecycle is not a function of the bit-length in hash, or inevitability of the current standard being broken.
Technically MD5(128bits) and SHA1(160bits) lengths are sufficient for hashes, but they had cryptographic weaknesses -- the functions had cryptanalytic attacks, which reduced bruteforce from the complete keyspace to something of a much smaller magnitude. These weaknesses are what has lead to the deprecation of MD5 and SHA1.
It is definitely possible that new crypt-analytic attacks could be shown on SHA256/512, but none have so far been publicly provided. Hence the confidence in them.
> Technically MD5(128bits) and SHA1(160bits) lengths are sufficient for hashes, but they had cryptographic weaknesses
Not true. A 128-bit hash gets collisions after ~2^64 tries. A big cluster can find targeted 128-bit collisions. To attack something like git, the entire attack can be done offline.
The big MD5 X.509 break needed cryptanalysis to make it day I because the attack needed to happen in real time.
That is misleading, since a birthday attack is not required. The security strength of hashes is not measured by the length of the hashes.
md5 was first "broken" in 1995. As of 10 years ago, a collision attack took only a few seconds. Plus, there are a _number_ of other attacks on the hash.
The argument I replied to concerned best-case for length. I.e. a perfect hash at 128 bits delivers 64 bits of security against collisions. (Note the 'perfect' part)
64 bits of security is good enough against most non-nation state actors.
Obviously, MD5 (and sha-1) aren't anywhere near perfect hashes. And obviously, you need to look at more than length when judging a hash.
Basically my point was that md5's hash length isn't a big problem.
You can rent Amazon time and create an md5 collision for less money than people spend going to a movie. Restating the issue as "a perfect hash is perfect" may be correct in a limited sense, but it is also highly misleading.
64 bits of ideal security is about half the industry accepted security strength in bits for a hash function.
For comparison, this is about the same level of cost as the recent collision attack on SHA-1. So even a perfect 128-bit hash is at least as broken as SHA-1 is.
On the other hand a hash function that works well in all scenarios that constitute a theoretically sound use of a cryptographic hash function is infinitely harder to misuse.
This is the chance to get rid of the object prefixes (i.e. "blob" plus file length) that prevent the generated hashes from being compatible with hashes generated by other software.
Since the majority of us are running x64 machines, will the hash be a truncated SHA-512/256 or will it be SHA-256? The former is significantly faster on x64 machines.
I didn't say all. I said the majority. If you think I'm wrong, show me a statistic that shows the most common platform for developers using git isn't x86-x64.
Hashing for integrity and authenticity are different things.
For instance, a mere four byte CRC-32 can reasonably assure integrity in some situations, like when used on sufficiently small payload frames; yet it is not useful as a digest for certifying authenticity.
That it may be, but in git, SHA-1 is also used for authenticity. "Signing a commit" only authenticates one commit, and is considered to authenticate the state of the repository only insofar as it authenticates the SHA-1 references contained in the topmost commit.
Yes, this is correct. The struct object_id changes don't actually change the hash. What they do, however, is allow us to remove a lot of the hard-coded instances of 20 and 40 (SHA-1 length in bytes and hex, respectively) in the codebase.
The remaining instances of those values become constants or variables (which I'm also doing as part of the series), and it then becomes much easier to add a new hash function, since we've enumerated all the places we need to update (and can do so with a simple sed one-liner).
The biggest impediment to adding a new hash function has been dealing with the hard-coded constants everywhere.
I feel like Linus (and others) have earned the right to be assholes on the mailing lists. He's demonstrated good judgement and made huge contributions, if he doesn't feel the need to be nice i don't think he should have to.
{kind=link}
The current transition plan is being discussed here: https://public-inbox.org/git/CA+dhYEViN4-boZLN+5QJyE7RtX+q6a...