I really need the "core concept" first, before diving into examples, (unless the core concept is extremely simple).
Many tutorials are like hand-holding Lego building. Here's your Lego pieces, watch me and follow me in building this toy project, and you'll know how to Lego at the end of the day.
I just don't function very well in this model. I want to know how and why decisions are made. I want to see things from the author's perspective. I want to know how the Lego pieces each feels like, and how they connect to each other, and how you arrive at certain designs in a certain way. Trying to follow tutorials before at least some high-level, conceptual discussion, feels to me like I'm trying to reverse-engineer something that I shouldn't need to.
Most of the time if I'm approaching a new library or framework, I read read the introduction texts, and skip the "Getting started" code samples. Usually, there's going to be some sort of "Advanced" section where a lot more talking and discussing of concepts happens, and that's what I'd like to dive into first. I'll go for the API references next, try to grasp what the important interfaces look like, and finally I'll get back to the basic code samples in the beginning of the tutorial.
I used to think I was a "core concept" kind of person, but later I realized I took that way too far and would refuse to do things outside of my comfort zone unless I felt like I truly understood everything ahead of time.
Nowadays I'm much more likely to just jump in and start working with examples directly, and I feel much more productive. It's partly a thing of trust: I just trust that the makers of high quality software have put in enough thought to make their interfaces easy to understand, for the common use cases, without digging too deep into the internals.
It frequently happens, of course, that I hit a roadblock where I do have to go deeper -- but that's only because there were 10 other things where I was successfully able to get by on surface impressions alone. So I find that even when I do dig in it's often time well spent.
I would much rather have 60 different examples of middling quality covering a majority of use cases than a 5-page exposition about why the maintainer chose whatever database or why I should think of components as conveyer belts or whatever strained analogy they come up with. This only works with a lot of examples though, I've come across numerous projects where they think they're doing this but they've got a toy-level "Hello World" style example and maybe one more and that's it.
But in a perfect world, they'd have both. The GP can read that essay and get their bearings, and I can click "Examples" and start copying & pasting until I start to figure out how things work.
I also want to add that I hate these "project generators" such as create-react-app when I'm just getting started. (It's just an example: I'm glad I learned React long before its existence.) They create an opinionated folder structure with template files and preconfigured tools. I don't function well in this model: if I don't immediately have a high-level overview of what the created files do, why they are created this way, I just become uneasy at all this magic that I do not understand. Each time a new thing is introduced, I need a high-level introduction covering its purpose that relates to the concepts I already know. I'm not comfortable dealing with magical black boxes unless I have at least a rudimentary understanding of the main interface of that black box.
To put this back into the concrete example, it means that hypothetically if I were to be learning create-react-app from scratch, I would immediately begin to investigate the purposes of the tools that have been configured by it, like Babel and ESLint.
I think this way too and I think it's because I'm autistic. I don't WANT to clone a project in one click. I want to understand every tool well enough to create my OWN project that serves MY use cases.
I absolutely loathe those “frameworks“ with billion files in billion directories. If can't start with single file and build upon it - it is complete trash. Android projects with Gradle come to mind.
I have the same (and ran into this trying to wrap my head around why Maven didn't work... I don't want a tutorial explaining how to get started, I need to understand the fundamentals to understand what's happening!).
I think, however, that starting from the examples might help with good API design: if you design your API to be "core concept first", this will likely lead to an API that _can only be used after you understand the core concepts_, which is not great when people are only occasional users.
Well put, you beat me to it! Specifically this line started my disbelief:
Humans don't learn about things this way.
Naturally, as is the hacker way, with no citations. I’ve only scratched the surface of pedagogy, but it’s a massive and mature academy drawing its modern principles from the empirical psychology of Dewey and Piaget. There’s a LOT more to say about it than can be covered in a blog post, much less a subsection of a blog post!
As you point out, the biggest issue is that people are different. The next biggest issue is we aren’t even sure why those differences occur, or how stable they are over time…
Well written post otherwise and it’s a good dive into the pragmatics of a particular educational strategy — I just would ask to see more humility, I guess!
This may be a cultural trait too. Erin Meyer in her "Culture Map" Book mentions this idea that every culture approach persuading others differently from theory-first to examples-first.
I write very verbose tutorials ([0] has my latest effort). I walk through the reasoning, from start to finish, and usually use things like Git tags and releases, to support the prose. I also like to provide examples that are very “real-world.”
It doesn’t seem that people read it. I think folks prefer videos and unrealistically sparse examples.
All coding tutorials I’ve come across struggle with this. I couldn’t care less about some scripted video building a trivial piece of software, even if it’s pretty close to what I was going to build. The optimal coding tutorial in my eyes would just be a day in the life of a software engineer building something new and thinking out loud. Of course that wouldn’t do well in video format.
I think this is just the tech equivalent of teach a man to fish instead of yada yada.
I’m generally okay with high level concepts talk, and don’t often find it too abstract. We are talking about documentations for libraries or frameworks after all. I’ll take a gentler approach if it’s an actual theoretical firld.
Obviously, during the first read, my understanding of those concepts would be full of holes. And I plug them as I continue reading the API references and later when I start to try it hands-on.
Yeah, I don't know why this post is so either/or. Why not both? I like projects that have docs with core concepts in one section, examples in another. Or where the core concepts give working examples as code snippets.
This whole issue of writing for people really distills down to two skills:
1. Empathy
2. Writing
There is a world of difference between writing some code and writing an application, a product. That is all this article is about, though less explicitly. Empathy is a factor in this because its the difference between self-orientation and external-orientation. Self-orientated developers are primarily concerned with easiness, convenience, code vanity, and other subjectivity criteria. It comes down only to their effort of delivery.
Externally-oriented developers are primarily concerned with architecture and documentation because for them success is all about how other people receive their work product. Simplicity is more important than easiness because externally-oriented developers know they cannot read minds and have no idea what other people find easy, but they do know how to reduce steps and keep their code small.
In the brain writing an application, from a holistic product perspective, is no different than writing an essay, article, or book. Its all about organization and features. The code is something that comes later, like words on a page. For people who only write pieces of code they never develop the higher order organizational skills that brings it all together. It also works in the inverse in that if a person cannot write an essay with ease they cannot envision writing a new application.
Those are the reasons I super detest frameworks. Frameworks deprive developers the practice necessary to write original software which means they are not developing those organizational skills. Its a massive gap that the inflicted cannot see, but is so enormously apparent to those that can see it. From a behavior perspective its no different than a learning or neurological disorder in that the inflicted know something is missing, but have no means to see what that something is, and that drives massive emotional insecurity.
So true, and this is a dilemma, right? People who build frameworks do so to make it easier for others to ship products. In the process of building the framework, they become better developers themselves. However, others now have to learn their abstractions, which distances them from the underlying concepts. This can make it harder for them to master the core skills needed to surpass the framework. I had that feeling when I learned Rails, only to realize it hid so much from me that I eventually had to drop it and try doing things from scratch.
I think what developers need to understand is that these large frameworks aren't there for them. Developers are not the primary audience or the primary benefactor. The primary benefactor of these frameworks are employers.
The large challenge employers face is where to find developer talent then how to select it. Developers then become a replaceable commodity selected on the basis not of capabilities or potential but solely on the basis of current compatibility on a bell curve. That devalues the better half of developers. It ultimately costs the employers more by allowing employment for people who otherwise are not capable at interference to future cost saving ventures from creative solutions. Also consider that employers are still reliant on recruiters to find potential developer candidates, so frameworks don't even help with identifying talent.
Im quite good at writing pieces of code but if the application gets sufficently complex i tend to attack the problem by rewriting things in a circle. Sometimes complexity puts me in an infinite loop of rewrites. That this is an entirely different skill is quite the eye opener. Its now a known unknown if you like. Thanks!
Empathy is great but you need to understand cognition otherwise the empathy will be misplaced.
How is this code going to appear or show up for someone whose boss is breathing down their neck, or who is fixing a production problem at 2 am? You don’t know how valuable that answer is until you actually need the answer, and then you’ll pay a lot for it. If you can find someone who knows how to do it. Few people do.
A lot of that is just experience from practice. If a person has solved a given problem before they will be able to do it faster the next time.
Another part of that is simply being hypo neurotic, low fear. If a person is hypo neurotic those conditions are just not stressful at all. For example being shot at by a violent aggressor is stressful but not writing code at a different time of day. It’s hard to explain unless you are that person or personally know someone who is. It’s also apparently a massive gaping hole in psychology. Neuroticism is generally viewed as negative, so the less of it the better. That does not account for the extreme states, that bottom 2%.
> “Humans learn from examples, not from “core concepts”
Nitpicking maybe but I disagree with tfa on this point; not all humans work this way. Those of us who might actually prefer the general -> specific direction are already largely ignored in k12 and may only begin to thrive in higher education. Since we’re already kind of underserved, there’s no need to also deny that we exist!
I recently learned to ride with a stick, on a trip with my girlfriend and her dad. My gf just told me what to do, when to press the clutch and when to let go of it. This didn't help me at all; I didn't understand the nuances of what to do when, which things to do completely simultaneously and which to one just right after another. And then her dad chimed in, briefly explaining to me what the clutch actually does, and how does the connection between wheels and engine affect both of them. I instantly got it and didn't have to even hear instructions what to do in any particular situation. About 20 minutes later I was able to drive a car from a hand brake on a backwards slope, which is supposed to be one of the hardest things to do with a stick.
Understanding how something works from first principles is much more useful for some people, and I think that there's a lot of "some people" among the software engineers.
I need both. Truly learning for me is learning core concepts, but examples are “known correct” cases I can test that understanding against. If something in the example is surprising, I know my model isn’t complete yet (or the example is wrong lol)
I also find “known incorrect” examples to be useful, for analogous reasons.
But the worst is when there is no good and thorough description of the conceptual model and of how the concrete examples relate to it, because then the system remains a black box you can’t properly reason about, regardless of how many hands-on tutorials and cookbook examples you’ve seen.
Yes! Both are valuable, and sometimes you need to iterate between and within each. Like if the conceptual components are mutually recursive (A is defined in terms of B, B in terms of A (SOLR anybody?)), skimming the docs can give you a "pencil sketch" level model, examples can flesh out the relationships between components, and re-visiting the docs with extra context can provide a more precise model.
Maybe I'm dimmer than the average techie, but I need both. Much of my current job is frustrating because it's a big company and every new task I encounter is presented with only an example of how the previous person did it. Instead of, "This is what we're trying to achieve, this is how the thing works, this is how we do it," all that ever gets exposed to ICs is the "this is how we do it" part. This makes it impossible to reason about, adjust, and troubleshoot when even the slightest deviation is required. Yes, there is often SOME documentation tasks which are performed very often, but it's often outdated or incomplete. But it's not in a wiki, so not just anyone can updated at any time, there's a whole obnoxious process for updating the docs, which is why they never get updated.
Now that I think of it, this reminds me quite a bit of my time in the military...
The thing is that you can derive the “this is how to do it” from the first two, but not the other way around. While it’s very helpful to have all three, the first two are essential while the last one is not.
I'm with you on this. My learning style is to read the reference manual cover to cover (metaphorically now). I can recall numerous instances of wanting to get into a new thing and finding the vast majority of recommended introductions to be the polar opposite of what I was looking for.
I'm going through this now as I decided to spend some time today learning the Drizzle ORM. The first things I found were all "here are half a dozen examples of queries", and I started getting frustrated: why are you using that syntax and not something else? What are the other options? I closed those and I'm much happier doing it my way: reading every page of the documentation before doing anything else.
Query-language docs are a great example of this, especially proprietary ones. 3000 examples, many with blog post baggage and other distracting discussion, and when you try to find a description of the grammar, crickets.
I only started thriving in school once I started practicing theory construction in my head.
Hypothesis->test->refine
I’m not sure I could still do it in realtime today. It takes a lot of cycles to do this and reading or pausing videos to process is more my speed now.
I’ve ended up spot tutoring a lot of people who still don’t get it. Having a theory of the system lets you answer their questions where a classmate would not be able to because they’re barely past rote.
This is something I'm starting to pick up and use from a mentoring and onboarding perspective. By now, I fairly openly wonder if someone needs conceptual or architectural clarification, technique on handling a thing, or a solution right there. And when we should have a follow-up call in the first two cases.
And having both thoughts and material available for a specific -> general, as well as a general -> specific path around is very good, because in more complex topics, it helps to be able to do both. Let them get a grip on some concrete things, then bring in the abstract ideas. Or let them learn the abstract concepts and show them how they can do concrete things with it.
Hopefully some teachers are actively looking for which approach students need, like you are.
I always found the focus on say audio vs visual learning styles to be strange because for me, abstract vs concrete is much more important.
Showing a collection of examples to illustrate an abstraction is fundamentally kind of bizarre to me, especially when the abstraction is short and easy to state. Because really, the concrete examples might have many things in common and I won’t be sure which ones the teacher wishes to indicate.
This problem is more obvious with math/code maybe, but I see the same issues with teaching / learning things like philosophy and history. Examples very often just obscure the lesson for me, especially when they come first. Just hit me with the abstraction and generalities first so I can orient, then I can understand which part of the concrete examples I’m supposed to consider.
I need an example and an explanation of what problem is being solved.
Pages of dense text with lots of jargon, like a recent K8s course I've been doing are just something I find utterly useless for learning unless it involves a good amount of accompanying hands-on learning.
Yeah, it might be me. I learned microcontrollers by learning assembly, gdb, as, ld, then gradually switched to C, wrote my own "library", then slowly learned about vendor library and gradually replaced by code with proper approach.
Can't imagine learning this stuff from the vendor code examples. I wouldn't understand a thing.
This approach works for me, but only when documentation is extensive. When vendor suggests "copy this example and tinker with code until it works the way you want", this approach just throws me off and I absolutely lose any will to learn. Examples are very important, but not as starting point.
This also stood out to me as obviously wrong in the article. Since time immemorial, we have taught math by teaching the core concepts and building on them incrementally. Since people do successfully learn how to do math, this directly disproves the author's claim that people don't learn that way.
It may be that people successfully learn something entirely new to them from studying core principles not thanks to such an approach, but despite it. Some would say the approach unnecessarily limits the amount of people who would otherwise easily grasp the topic.
Math is usually introduced by way of examples (counting apples and such), and it could be that using those more would make more complicated topics more accessible.
I wish I had ever seen math taught that way. Usually I'd is taught as "here's a bunch of example problems. Solve all the problems and hopefully intuition will magically result"
> Since time immemorial, we have taught math by teaching the core concepts and building on them incrementally.
This is just false. Some of the earliest examples we have of what appears to be writing used in teaching contexts, it's heavily focused on repetition of examples.
“The smaller part of the job of programming is writing a program so that the computer can read it; the larger part is writing it so that other humans can read it.” (P.733)
"Programs are meant to be read by humans and only incidentally for computers to execute."
From the preface to the first edition of Structure and Interpretation of Computer Programs by Abelson & Sussman (which predated Code Complete by a decade).
It's a maxim I live by although my employers always seem to insist on the computers executing part for some reason.
The computer executing part is the one that's both necessary and sufficient. The human reading part is neither. It's nice, important, and long-term indispensable - exactly the kind of thing economic pressures fight against.
Bit of a side issue for me: I was working on my Unity game the other day and thought to myself, have IDE's really not progressed all that much in the last 10-20 years?
Default intellisense has definitely gotten a lot better, but apart from that and a few other minor things the whole concept of coding feels pretty much the same today as back then.
The biggest positive change for me is outside of the editor, it has become easier thanks to much more access to libraries, documentation and just the sheer volume of user questions and answer sets we now have access to (and finally some new tools like ChatGPT that can aggregate those answers to on occasion deliver a reasonable answer).
But overall the act of writing code seems to be stuck. As a result I'm currently taking some time out from my game to run some experiments. I don't want to create a new language, but instead I want to try and offload everything I can to the computer, let it do the drudge work while allowing me to create.
Just 3 of the initial things I want to test:
- Why do I need to worry about small language specifics like brackets, terminators and so on when tools should be able to auto-complete them for me? What about the private-public access chain (as well as other modifiers such as unsafe) when tools can auto-determine the most efficient set?
- You're editing a file (or parts of different files) and are focusing on say 5 methods that are interacting. I want to see all of them on the screen at the same time, without having to struggle to open and manage many windows with for example VS horizontal/vertical sliders.
- Data conversion. So I created a HashSet for something but realize I need to change it to a Dictionary or a Tuple, just make it happen. If it requires brainwork then show me all the places that requires supervision where I have to say ok or make an edit myself. In the case of Unity I also want to be able to click on a method and/or data set and tell it to convert it to a Burst Job with its accompanying NativeData sets.
> The whole concept of coding feels pretty much the same today as back then.
The whole concept of programming languages has not changed that much. We have the two big pillars that is the Turing Machine and Lambda Calculus (and various others) Everything after that has been abstractions, and when the abstractions are good, we call them paradigms. But it's all abstractions, and ultimately we are just writing instructions for a really dumb machine to compute data for us.
> Why do I need to worry about small language specifics like brackets, terminators and so on when tools should be able to auto-complete them for me?
Because the computer is something really simple, and the programming language is just a idea conduit from your mind. Those delimiters are as important as the language keywords, because they are part of the RULES. Auto-completing them will require more RULES and more delimiters.
> You're editing a file (or parts of different files) and are focusing on say 5 methods that are interacting. I want to see all of them on the screen at the same time
Vim and Emacs. Or Smalltalk IDEs like Pharo
> Data conversion
Vim and Emacs macros. But the truth is data encodings are very important, because for the computer, it's all bits, we assigned meanings to these bits and enacted RULES that describes how to manipulate them according to these meanings. Morphing from a set of RULES to another will require more RULES.
I will urge you to try a live programming environment (SLIME for Common Lisp, Pharo for Smalltalk, The web inspector for Javascript (not great)). It feels like working on a boat in the middle of the sea instead of having it on land imagining what it feels to sail it.
Slime or Slimv with a file/buffer as the REPL input it's one of the best things ever.
Refactor your code doing crazy data mangling on functons? On Lisp you just redefine functions/macros with ease. With the rest of languages the complexity raises exponentially.
It is, but not directly. The practice of working directly on canonical plaintext representation is what's bottlenecking programming.
At any given moment, the programmer cares about different aspects of code. One moment, they're trying to correctly structure an abstraction layer; an hour later, they may be debugging an issue that needs them to walk up and down the abstraction ladder several times. One moment, they need to understand the data flow on success path; the other, modify the overall parallelism characteristics of the program.
Cramming all these conflicting requirements and cross-cutting concerns into the same files, to be read and written directly, is what's bottlenecking us. That's why we have never-ending holy wars on what is "clean code", why our editors work on such low conceptual level, why we get languages like Haskell or Rust, packed with cutting-edge math research output. We're hitting a Pareto frontier - trying to make some things more readable and explicit makes other things harder.
The solution is to stop working on code files directly, and let software synthesize views amd editing interfaces - textual and graphical - on demand. Many perspectives on the same underlying artifact, that itself will not need to be optimized for human consumption.
And Emacs and VIM already have all the bits for improving your experience, but you have to integrate them yourselves. Or get an IDE that does it for the language you use. What you need to do is develop your own meta-language to shorten the time between idea and execution. Snippets, code generation, auto-completion, code analysis and navigation, all help.
I agree about auto-complete, but already the editor Brief for MS-DOS, at least some 35 years ago, allowed you to define arbitrary templates for auto-completion.
For example, when writing a C program you could choose to have "f<TAB>" expanded to "for (=; <=; ++) {<LF><TAB>;<LF>}<LF>" or whatever indentation you preferred.
There are many modern programming editors that allow a similar customization, though unfortunately for many of them this requires a more complicated procedure than in the far past.
For any programming language with a verbose syntax, I consider necessary to take your time and define in your editor templates that would allow the fast writing of any program structure with a minimum number of key presses.
I may not be understanding you correctly, so please let me know if I've gotten it wrong.
Some of the stuff you're talking about -- like brackets and terminators -- make explicit the syntax and greatly improve tooling. Usually editors have features that can add these in or you. But in some cases something is obvious to you, but is really one valid choice among many and the tooling can't read your mind without something like a design doc to guide its decisions.
For others -- like whether to use a HashSet or Dictionary or Tuple -- those have performance implications and it's not always clear in the abstract when to use one or the other. But for explicit languages like Java (and I would assume C#) you should be able to refactor a method call to take a different type. Then you just have to change one method and refactor all the calls to it.
I've been experimenting with the pro Gemini and ChatGPT o1. They're both really bad at coding Python and JavaScript. They write buggy code and will often introduce bugs when attempting to fix another. Both feel like they're rushing to answer instead of thinking about the requirements. I'd say we're still a bit away from having tools that can "read your mind" or understand what matters to you and what doesn't the way you'd (or we'd) like them to.
Potentially even worse: consider the data we're training on. These tools will be adopting the thought patterns of the average coder since most code is produced by average and below average coders. Even if we trained the tools only on the highest quality code, it's not clear that most coders would know how to prompt it correctly. So I think if you've been coding for 10-20 years chances are decent that you'll always be a little disappointed with the tooling if you're expecting instant wizardry.
That said, non-AI static analysis tools have been great for a while and will get even better. Adding AI to them will improve them further. So I think you can have a great experience if you're thinking of the tools as helping you be an artist rather than as an artist you can give a spec to and get back a decent result.
EDIT: It might be fun to experiment with telling the AI what you want your editor to do more of and asking the AI to help you configure it. There's a lot of non-AI tooling in plugins. Getting an LLM to help you pick the right plugins for your lifestyle may be the best bang for your buck.
Yeah I've also been playing with ChatGPT etc. and sometimes they can produce great code, or at least get you up to speed a lot faster. As long as you ask them questions about well known problems they're great, but break down after that. But they're definitely going to play more and more of a role going forward.
What I really want to explore (and where I think there might be some big room for improvement) are around how we represent and visualize both code and data, as well as how we interact with it. Full visual programming has often been tried before and while it works fine for a while it begins to break down once projects become more complicated.
I instead want to explore some alternate text based options where we use the visual aspect as an assistant, whether by grouping or collating blocks that we're working on, changes that needs to be made and so forth.
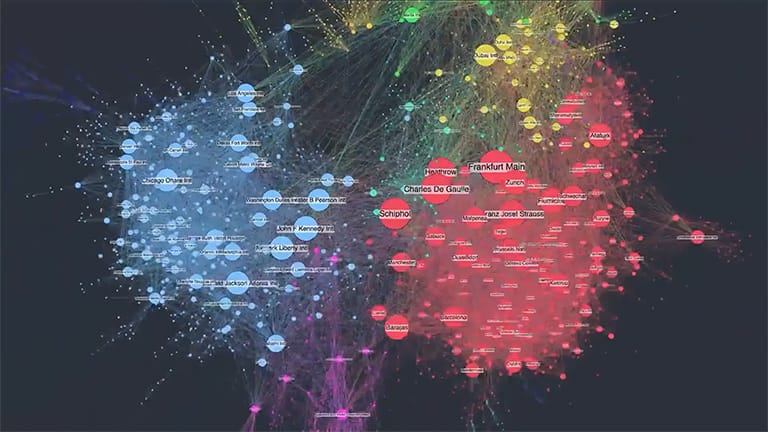
I'm mildly skeptical of visual programming because code generally won't be a planar graph and it's rarely useful to visualize a complicated enough graph. You can try to embed the graph in hyperbolic space, but I'm not sure how much you get out of it. For example of visualizing a graph where it's not clear what's going on: https://cambridge-intelligence.com/wp-content/uploads/2021/0...
Coding is a logic/language type activity that uses the language parts of your brain. Visualization can help see that certain relationships are true (e.g. visualizing the graph of a function), but I think the fundamental bottleneck we're dealing with here the inadequacies of the visual regions of the brain to do logic, not a lack of AI tooling.
I'd be happy to have my mind changed though.
EDIT: Although, an AI version of something like Chernoff Faces for visualizing data would be cool.
> You're editing a file (or parts of different files) and are focusing on say 5 methods that are interacting. I want to see all of them on the screen at the same time, without having to struggle to open and manage many windows with for example VS horizontal/vertical sliders
Regarding this, maybe haystack could be interesting for you
This looks awesome, any users out there that can opine?
Not sure this is the answer but for sure this is highlighting the right question. I’ve never been a teacher, but having been involved in mentoring newbies more often than I expected.. error traces with absolute filenames and terminals with Click-to-edit-file support are the smallest effort you can put in to get the biggest results (although this can also lead to confusion with virtual envs and such).
That’s just the beginning of the nav we really want though. The key point is all about focusing on “don’t make me mess with file systems” because the code already has many dimensions of inherent structure.
Some of what you described, having 5 methods on screen, or finding all locations failing type checking, I have been using (neo)vim for successful over many years.
I load the output of the type checker (or compiler) into vim. I then have a list of locations to inspect. I can move between the locations. I can open multiple locations (same file or not) at once on the screen. Nowadays, Copilot assists in the refactoring besides the usual vim commands/regex/macro.
Opening 5 pane for 5 methods is similarly easy. I can also use a side panel to quickly view all methods and jump between them in addition to the traditional vim motions.
Language servers (LSP) of course makes the whole experience delightful. Jumping and navigating around the code etc.
All of that is keyboard driven, with many keyboard shortcuts personalized to my liking.
Here is an example of my workflow. I run the compile/typecheck command in a terminal, via a script that runs the command as soon as a source file has changed. It also saves the output into a file at a standard location. Saving in vim triggers the command to re-run. Then a key press reloads the output of the command to quickly jump around.
And navigating and modifying brackets is trivial in vim, especially with the right extension. Auto inserting brackets, I never found a plugin that I liked enough yet.
It's not all nor exactly what you asked for. But it's something.
I think one of the main improvements we've - interestingly - been unable to widely adopt is an actual live programming environment. Smalltalk was this. Nowadays I mainly use Common Lisp for something reasonably close.
We're still mostly stuck in an edit->compile->test cycle. Stuff like TDD and debuggers help here, but considering the untapped potential for what programming environments could be, it seems to me like we're stuck on a local maximum.
Edit: Don't get me wrong, programming in Smalltalk didn't seem entirely pragmatic to me. Reproducibility becomes something you need to actively worry about, with popular tech stacks it's kinda built in. My point is the potential of such approaches, not the pragmatic viability of the implementations we've had so far.
> You're editing a file (or parts of different files) and are focusing on say 5 methods that are interacting. I want to see all of them on the screen at the same time, without having to struggle to open and manage many windows with for example VS horizontal/vertical sliders.
I think that is, why editors like emacs and vi are really popular.
- Data conversion. So I created a HashSet for something but realize I need to change it to a Dictionary or a Tuple, just make it happen. If it requires brainwork then show me all the places that requires supervision where I have to say ok or make an edit myself.
How different would that be from changing the type and editing all the places the compiler complains about?
>How different would that be from changing the type and editing all the places the compiler complains about?
Currently in VS if let's say I change the Set to a Dictionary it will compile in the background and then complain about all the errors from where I can click on them to be taken there, and/or I would search on the variable name and find all the references and just scan through all of them to make changes as necessary.
Some ideas there could be:
a) We can use multiple windows (or lines in 1 window) to just quickly display all of the required changes directly on screen without me having to manually go from one to the next.
b) Let's say we were doing a standard List.Add but now its a Weird.Blob (ie. a non-standard class with no built in conversion support). I can perform a replace all .Add with .Blob which text editors can already do, but what if we only applied it to this current set of windows that have opened up, so as to not break other things? Again you could have done that with a narrower replace, but this way might be easier or faster.
c) In text editing you might have to replace a few lines several times, so you'd copy the new line or a segment of it, then replace all the parts of the old instances. What if we sorted all those opened windows so that the ones that are most similar are located next to each other, then if we change one we just drag it (or parts of it) to the other windows to make replacements. If they are exactly the same then provisionally change them automatically, the user just accepts the whole block of changes (as if they had done a search/replace for a specific line, or part of a line).
When it comes to writing code being stuck in time, I'm expecting that LLMs replace programming languages rather than programmers. We aren't there yet and LLMs, or the next iteration of architecture, need to get better at logically working through and validating code, but I do think we'll get there.
When you think about it, its really pretty ridiculous that a programmer will ask an LLM to write code that the programmer can copy and ultimately compile into machine code for yet another computer to use. Cutting out the intermediary steps seems like a logical next step.
About the first item on your wishlist: If by "brackets" you mean {} (in C-like languages), there are IDEs that can be configured to create pairs of them every time you hit return after an expression that can take them. The downside (if you care) is that, if you wanted to write an if, while, or for with only one line, and therefore no scope delimiters, it will force you to create the scope anyway. You may not care.
If by "brackets", you mean [], to access an element of an array or vector or map or whatever, yes, it could do that as soon as you gave it the name of an array or vector or map or whatever. But then if you wanted to deal with the array or vector or map as a whole (which you want to do sometimes), the brackets have to go. I would estimate that 30% of the time I want to deal with the array as a whole, so such a feature would be annoying and in my way 1/3 of the time.
Terminators are a win more of the time. But when they're not, I meant to be continuing one line of code across two lines of file. If it auto-added a terminator (semicolon, say) at the end of the first line as it opened the second, I might not even notice until compile time. That would be highly annoying.
Public and private I don't want determined by a tool auto-determining the "most efficient" set. I want them determined by my sense of what the class is, and therefore what the public interface should be. Some of the things that are private are less efficient, but are private because they're implementation details and I don't want callers able to fiddle with them.
So, that's my whiny personal take on some things on your list. Maybe I've adapted myself to the existing tools. But I personally think that many of your items, if you implement them, you will find that you don't really like how they work out.
Yeah some of my points are really space dependent. For example I'm working on a solo game project, so my comment on the public/private etc. modifiers is really aimed at that where nothing will ever be exposed and the modifiers are pretty much irrelevant.
>So, that's my whiny personal take on some things on your list. Maybe I've adapted myself to the existing tools. But I personally think that many of your items, if you implement them, you will find that you don't really like how they work out.
You could very well be 100% correct there. As developers we really become used to our tools and its quite hard to adapt to new ways of doing things. But I figure its worth a shot, at the worst I'll have learned a few things along the way.
Verified pre and post conditions would be nice. Especially in the era of LLM's, which can usually fill in the implementation given a sufficiently clear specification.
What's the problem? Golang is more than a decade old. Python predates Linux. Common Lisp with ANSI C is from early 90's too, but it began as Lisp in the 50's.
"Why do I need to worry about small language specifics like brackets, terminators and so on when tools should be able to auto-complete them for me?"
Actually, if you are using an IDE, there's probably a flag you can flip for that. It's a very common feature, to the point that I often find it in places I'm not expecting, like the web-based security training code platform my employer periodically pushes us through.
I'm not a fan, but some of it is just that my habits haven't developed around it.
There have been a number of tries at going even deeper, and trying to make it so the code is valid at all times. I suspect this one fails because we pass through more invalid states than people realize. For instance it's not uncommon for me to copy & paste some data from somewhere to embed into a program, and to massage it in my code editor until it is valid syntax, but it isn't "valid" until the very end. Smaller scale things like this happen all the time. It is more constricting than I think people generally realize to have to be valid every second.
"You're editing a file (or parts of different files) and are focusing on say 5 methods that are interacting. I want to see all of them on the screen at the same time, without having to struggle to open and manage many windows with for example VS horizontal/vertical sliders."
We've tried that already... and actually I'm with you, it's awesome. I suspect this is just because by the time you've got all the other IDE gizmos on the screen it's hard to do too much splitting. But my normal code setup is three emacs windows side-by-side on the screen (and, that is, windows, managed by the windowing system, not "frames" within emacs), each of which then can and often are further split once vertically. If I have to go all the way up to truly using 6 contexts at a time, something has probably gone wrong architecturally, but 2 is extremely common and bursts up to 3 and 4 a daily occurrence.
Watching some people recently trying to get into a largish code base, and watching them interact with it basically through a single window and at times not even with an IDE, really makes me think one of the larger problems is people learning how to "turn the lights on" in a code base. It isn't even a matter of implementing features at this point, honestly almost any environment already has a ton. You need to learn to use them.
"Data conversion. So I created a HashSet for something but realize I need to change it to a Dictionary or a Tuple, just make it happen."
We tried that already... and it comes with some substantial costs you may not realize.
First there's the obvious performance one. Make it easy to auto-convert them back and forth without any syntax fuss and you'll end up people writing loops in which the 1,000,000-million element hash table is converted both back and forth between a hash table and a tuple list in a loop, once per element, and you end up with the sort of bloated programs we all like to complain about. (Indeed, this sort of thing is one of the root causes, though far from the only one.)
The more subtle one is that automatic coercion, of which this is an example, is just generally a bad idea. The programmer ends up with a too-fuzzy idea of what is going on, and that fuzziness manifests not just in the aforementioned performance issue, but also, bugs, when it turns out that the properties of various structures being autoconverted back and forth are actually important to the code. The most common example which is increasingly widely regarded as a bad idea is "falsiness", where the language tries really hard to have a concept of true or false for all sorts of data structures, but the bugs that emerge from empty strings being read as false unexpectedly and such make this generally not worth it. In the case you cite, the data structures are not the same; they differ substantially in what they do with multiple values for a given key, and how order-sensitive they are, and in the world of programming, these details all matter. Especially because they end up being used to construct security systems.
It is hard to see the general sweep of programming language development, but in general at the moment I think languages are headed away from auto-conversion. What you can see is languages and libraries developing better "interface"-like abilities, where maybe they can declare that they just need this or that bit, and then you can pass multiple different structures in. See for instance __getitem__ in Python. This is a much better approach; there's still some fuzziness cost but the offsetting benefits are much stronger so it's a much better trade.
Some good feedback here and in the thread overall.
I also use a 3-way horizontal split these days for editing, I've found that the wider our screens get the less I use the edges. So now often I'll keep the left focused on the headers to variable definition, the middle for the main editor and the right for methods where the middle is calling or being called by something.
In Visual Studio you don't have to dock windows, but the current generation of floating window doesn't really conform to what I want. Someone else mentioned Haystack which I haven't seen before:
https://haystackeditor.com/
I quite like the layout of Haystack, although I don't think one wants to take it too far such that it begins to resemble visual scripting. I think a block based approach where you have different blocks for the different types such as classes, variables and code might be worth exploring.
I'll definitely post back sometime with feedback on whether I've come up with anything interesting.
I hope you do. I know it's easy to just crap on someone's ideas, but I'm really trying not to do that. I think it's a great idea to learn from what came before, because if anything's going to succeed it is almost certainly going to be at least a little different than what someone else tried. Sometimes it can be the smallest difference that decides the matter. I wish you the best of luck in your explorations.
Visual Basic in VS has aggressive autocomplete and it gets pretty annoying. You often want to write things in a different order and end up having to delete the auto-inserted endif/quotes/brackets/variable names (if it's not yet declared, it changes it to become something else that is), etc.
The title of the post is debatable, as code is only written for humans. Computers don't need "code", and especially not high level code. They're happy with machine instructions. We write code because machine instructions are much too hard for us to write, and even harder to read.
We should not think of code as a way to interact with computers. Code is a way for us humans to formalize our thoughts so that they become so unambiguous that (even) a machine can follow them.
Selfless shill of a blog post I wrote & shared last week:
Move Fast & Document Things [1]
My goal wasn't to be philosophical but share actual tips on how our small team [2]
enforces (not automated, not AI, but deep, hard reviews) a culture for
writing code for ourselves and each other.
All my personal friends who are engineering leaders at other orgs said
"We do the same thing but you actually wrote it down".
> Too many programming books and tutorials are like “let’s build a house starting from scratch, brick by brick” when what I want to “here is a functioning house, let’s learn about it by changing something and then seeing what happens”
That's how I taught myself how to program. I spent years getting good at writing small, simple, kinda crappy programs. Later on I learned I wasn't eligible for better software development jobs, because I had absolutely no fundamental knowledge about software design, programming languages, and computers. It was humbling walking out of a job interview realizing how much I didn't know because I never learned the boring way.
Always read the whole manual. Always learn the fundamentals.
Whether that's me, or some other poor schmuck who'll have to figure out my intent years from now.
I don't find code-writing hard. Reasoning comprehensively about your problem, collaborating with other stakeholders to discover and guide them along the best path, learning specialized skills (eg. new math or industry conventions), devising efficient algorithms, conveying your program's structure and patterns such that they're obvious and have elegant boundaries - that's the part that showcases talent. A lot of it comes down to communication and clarity.
It's basically saying: don't just provide a reference, provide how-tos as well, and lead with them because they're the part of the total documentation which users generally want to see first. Generally, mind you, I tend to go straight to the reference material but not always.
A nice read, but I think there is a contradiction here that needs to be cleared up:
1) On one hand, the author says that humans learn from examples, not core concepts.
2) On the other hand, the author emphasises the importance of reducing "conceptual overload", by reducing the number of concepts while maintaining their expressiveness.
So it is not that core concepts are not important for learning. Rather, it is essential to have a set of well-defined and well-documented core concepts which cover what the system can do. But of course, you also need plenty of insightful examples, and of course a "Getting Started" guide should start with examples, not core concepts. But if the core concepts are simple and few enough to fit into a "Getting Started", that's a win.
I didn't find it contradictory. The first one is about how to start learning about something more easily and the second one about how to organize it all so that it's easier to use and understand as a whole. That may also help with getting started too.
I personally agree that examples are a very efficient way to get started and you can learn the details incrementally in a top-down fashion. Some text books during my studies took the bottom-up approach (even explicitly mentioned it) and I never quite liked it.
If the core concepts are simple and not too many, then it probably doesn't matter that much. The point is to get started easily.
again, not contradictory. have good core concepts, combine with good entry corridors. good concept with entry blocked by obtusity and esoterics is not a product ready for consumption.
i didn’t see the authors suggest that good concepts are unimportant.
Sure, it isn't really the whole product, but I interpreted it as an exaggeration, meaning that easy onboarding would be very essential part of the product and which is the first thing users experience.
To interpret the headline literally: Writing code for humans is actually relatively easy; it’s called “literature” (or “technical writing”). What’s hard is writing code (for computers) which is also easy for humans to understand. Anyone who has written polyglot code knows the enormity of the challenge, but also knows the tricks to make it work. I.e. you have to do a lot of things which means something to one “reader”, but is meaningless to the other, and vice versa. For example, variable names are meaningless to the computer, but very important to humans. And so on.
Easier to use libraries over highly complicated (supposedly performant) have a significant advantage in driving more adoption.
Recently I was trying to generate text embeddings from a huggingface model. Nvidia triton and text-embedding-inference (built by huggingface) were my two options.
> why large companies are generally incapable of delivering great developer experience.
I wanted to curl up and cry while trying to make nvidia-triton spit out embeddings . The error messages are cryptic and you need to have jedi like intuition to get it to work. I finally managed to get it work after like 2 days of wrangling with the extremely verbose and long-winded documentation (thanks in part to claude, helped me understand with better examples)
Triton's documentation starts off with core-principles and throughout the entire documentation, they have hyper links to other badly written documentation to ensure you know the core concepts. The only reason I had endured this was because of the supposed performance gains triton promised but underdelivered (this highly likely being I had missed some config/core-concept and did get all the juice)
On the other hand, text-embedding-inference has a two line front and centre command to pull the docker image and get running. The only delay was due to my internet speed before it started serving the embeddings. Then deploying this on our k8s infra was a breeze, minor modifications to the dockerfile and we are running. And on top, it's more performant than triton!
Obfuscated C contest seems to be challenging your view. Or Brainfuck.
Intentional coding-trolling aside, if whatever is happening in the head of the original developer is muddled, the resulting code is likely to be confusing even for people who know computers from the inside out.
On a side note, I have wondered if LLMs work more effectively with code that is well-structured and easy for humans to read than they do with spaghetti. Has anybody researched this?
My approach to dealing with lots of concepts is pretty much stolen from how babies learn language.
Grownups talk around non-verbal babies as if they're not there. We refer to all the objects in the room (or anywhere else) whether the baby understands them or not. "How was your day at work?" "Oh it was okay, but traffic was bad so I didn't have time to get my usual coffee." Babies don't understand what traffic or coffee is, and they don't have to. They still eventually learn the language and really focus on the things that matter to them.
At some point, a lot of us try to simplify by reducing the number of concepts we're exposed to, and we try to feel like we understand those fewer concepts. I've switched my approach to just being immersed in the way experts talk about the field, and just getting used to used to not really knowing what most things mean. It turns out you get a ton of information this way. Not only do you learn the vocabulary before you need it (reducing the time required later when you eventually need it) but also you pick up a sense of which things are fundamental (they come up a lot in conversation) and which things are extraneous detail (they're barely mentioned or only mentioned when something goes wrong).
> We refer to all the objects in the room (or anywhere else) whether the baby understands them or not.
And that helps the baby enormously; I remember reading that the more words that infants hear, the more their brains develop.
But we still point to objects — or to pictures in a children's book, as I did the other day helping my wife babysit a neighbor's grandbaby — and say the words.
The flood of feedback from power users shouldn't prevent a simple experience for a new user. The hard part is gradually exposing the new user to ever more complicated goodness in the correct order to upgrade them gradually.
and I've found that John Ousterhout's recent book, _A Philosophy of Software Design_ is one of the most notable programming books of the past decade and speaks to many of these difficulties so well that I added it my effort at a list of (mostly) Literate Programming books:
The other issue here is the still unanswered question:
>What does an algorithm look like?
and by extension, the further question of:
How does one manage a visual representation of a program when it gets beyond the size of one screen/window, or a page in a book, or for the largest ones, a poster?
With a bit of help of tex.stackexchange.com I was able to put together a Literate Programming system which allows me to use (La)TeX w/o the comment character which docstrip mandates:
(it's a little clunky, since that file has to be customized for the files in a given project)
but it allowed me to switch from having three files open in three different OpenPythonSCAD windows to a single .text file which makes a .pdf: https://github.com/WillAdams/gcodepreview/blob/main/gcodepre... which has a ToC, and multiple indices all nicely hyperlinked, and which makes a search/review of the code into a vertical scroll.
[pedantically: the theory generated by a program and the theory generated by the axiomatisation in the heads of its programmers should be equivalent, but if you only have one it'll be easier to derive the former given the latter than the other way around]
I've seen the aircraft / bullet heatmap diagram a few times. However, I'm always left wondering "was this a purely empirical analysis?". Clearly engineers would have some sense of what areas would bring an aircraft down (loss of engine, loss of tail strike me as obvious with no experience in aircraft design beyond paper planes). It is a great prop for survivorship bias of course!
At the end the author wrote something without explanation that I found cryptic. It is something I am curious about as I am starting to work on a software package:
Avoid “scaffolding” (code generation)
I wasn't sure what this meant, so wanted to highlight it.
I chatted with ChatGPT the following is an edited transcript of what we came up with. Note it is not a direct quote from GPT but highly edited cyborg quote from long conversation we had:
The term "scaffolding" in software development refers to frameworks that automatically generate boilerplate code to quickly set up the structure of a project (think Django). This can include things like generating project directories, files, and initial code to get started with minimal manual setup.
In the context of that article, the rule "Avoid scaffolding (code generation)" likely is implying that while scaffolding tools can be useful for quickly getting a project off the ground, they can generate generic or bloated code that can make the project harder to maintain and understand/read in the long run, with a steep learning curve. And *readability* is the point of the article.
If your guiding values in writing a software package is producing easy-to-read, easy-to-learn, and easy-to-use code *for humans*, then avoid scaffolding.
That last sentence is all me sorry.
I have no idea if the author would agree with the above sentiment, but it seems pretty reasonable. Like most coding rules, there are reasonable exceptions.
Opinionated is sometimes good, and the justification for it may scale with the complexity of the subject matter and the intended users and use case. E.g., how many different ways are there to achieve the goal(s) of your software, and do you want to enforce one particular way, given your intended user? If so, then depending on the specifics of the problem you are solving, you may need scaffolding.
For instance, DeepLabCut (https://github.com/DeepLabCut/DeepLabCut) is great software with tons of scaffolding. It is a machine vision framework written for experimentalists to track animal behavior, so boilerplate is great for them. The developers have put a ton of thought into how individual projects should be structured so the users who don't know anything about machine learning don't mess things up.
Anyway, this is useful for me to think right now as I am building a new project so I'm curious what others think.
Writing code is easy.
Knowing /what/ to write is hard.
I know how to write English.
But that doesn't mean I can write a book (that someone would want to read).
AI can write code.
But it still has to be told what to write.
>> Humans learn from examples, not from “core concepts”
So true. Humans are great at building mental models from raw data. Only after we learn our mental model is wrong we RTFM (unless your role is very specialized of course).
Someone, a one day old account, wrote and then deleted this while I was writing a reply:
> No other engineering discipline thinks this way. You design circuits for performance, manufacturing, and cost, not other engineers.
Yeah, that's why we don't produce schematics, diagrams, and blueprints or maintain those things over the years.
Software development is a design discipline, not a construction discipline. The analogs in engineering disciplines to source code are not the circuit, the car, or the bridge artifacts, but the schematics, diagrams, and models that go into their development.
And yes, practitioners in engineering disciplines absolutely care about communicating with other people (including other engineers), that's a substantial portion of their job in fact.
it definitely helps if you design it to be easy for people before you start writing the code, that’s the primary goal of the project architecture design imo
Right, but "psychopathic scammer" dials the criticism up a few notches, possibly to unreasonable levels - which i suspect is the point being made here.
(That's certainly the point I'd have been making if I'd written the post you replied to.)
{kind=link}
{kind=link}
I really need the "core concept" first, before diving into examples, (unless the core concept is extremely simple).
Many tutorials are like hand-holding Lego building. Here's your Lego pieces, watch me and follow me in building this toy project, and you'll know how to Lego at the end of the day.
I just don't function very well in this model. I want to know how and why decisions are made. I want to see things from the author's perspective. I want to know how the Lego pieces each feels like, and how they connect to each other, and how you arrive at certain designs in a certain way. Trying to follow tutorials before at least some high-level, conceptual discussion, feels to me like I'm trying to reverse-engineer something that I shouldn't need to.
Most of the time if I'm approaching a new library or framework, I read read the introduction texts, and skip the "Getting started" code samples. Usually, there's going to be some sort of "Advanced" section where a lot more talking and discussing of concepts happens, and that's what I'd like to dive into first. I'll go for the API references next, try to grasp what the important interfaces look like, and finally I'll get back to the basic code samples in the beginning of the tutorial.