My cofounder accidentally exposed a bunch of our API keys and we didn't know until we got a billing alert. I've wanted to use a secrets manager before and have asked a few friends what they use for advice, but I want to see what I may have missed.
The place I work has a list of security guidelines that is, like, ten pages long and full of links to more detailed explanations.
The exact advice depends on how you’re running your services. My starting advice, for cloud, is this:
1. Run in multiple, separate accounts. Don’t put everything in one account. This could be as simple as having a beta account for testing and a separate production account.
2. Use cloud-based permissions systems when possible. For example, if you are running something on AWS Lambda, you create an IAM role for the Lambda to run as and manage permissions by granting them to the IAM role.
3. If that’s not possible, put your credentials in some kind of secrets management system. Create a process to rotate the secret on a schedule. I’d say 90 days is fine if you have to rotate it manually. If you can rotate it automatically, rotate it every 24 hours.
4. Set up logging systems like CloudTrail so you can see events afterwards.
Finally, as a note—people at your company should always authenticate as themselves. If you are TheBigDuck234, then you access your cloud resources using a TheBigDuck234 account, always.
Cloud platforms for development really shine here. They've mostly solved all the problems for you, you just have to use their services. When running code locally, a service will use my account to access the dev secret manager and when running in the cloud it uses its own account to grab whatever it needs. At no point are secrets ever stored on my machine and I'm happy with that.
> If you are TheBigDuck234, then you access your cloud resources using a TheBigDuck234 account, always.
Or have a 'sudo' TheBigDuck234-to-AdminAcct mechanism if possible, or TheBigDuck234_admin account.
On my Linux machines I do sudo-to-root, but on macOS, my daily driver account does not have sudo access so I have to first su to "admin" and then can sudo from there (for GUI requests I enter "admin" (or whatever)).
So, this would be done in AWS by having e.g. IAM roles that you can assume from your user account. Your user account is your identity, and the IAM role that you assume is what grants you permissions. You can then log something like “this action was performed by Admin assumed by TheBigDuck234”, because the original identity is also recorded.
There are some rough edges around the experience here if you really do want the best security posture, but you don’t have to go all the way. You can just create your one IAM user (just one per person) and then create multiple roles. When you log into the console, you authenticate as the user and then choose the account + role you want to use. I recommend creating a “read only” role. The purpose is to let people poke around in the console and debug problems without risking creating problems in production infrastructure—this is more of an operations than a security problem, though.
+1 for sops, I've used it across a dozen projects for keeping encrypted secrets directly in the repo. And for configuring infra with Terraform, the sops provider [1] is extra convenient.*
I'm a huge fan of SOPS, especially since it can integrate with numerous crypto providers, from `age` for a fully offline crypto source to Hashicorp Vault and big cloud secret / crypto providers.
I wanted a tool that allowed me to store secrets safely without tossing them in plain text env files called `sops-run`. It manages yaml manifests to store your environment variables based on the name of the binary you're running, and only applies the environment variables to the context of app you're running. I never did tidy this up into an installable python package so it can't be easily installed with pipx yet (I keep putting off finishing all of that, pull requests welcome ;-) ), but I like it better than simply using direnv or equivalents, since it doesn't load the environment variables into the shell context, though it could probably be combined with it to hot-load shell aliases for the commands you want to run.
Sops is probably ideal for lowest ceremony possible. Combine this with direnv for a seamless experience.
If you don't want to commit/share secrets you could avoid sops and put this in your direnv envrc: `[ -e ~/.local/secrets/myproj.env ] && source ~/.local/secrets/myproj.env`
- It let's you decrypt same file using multiple credentials/keys (every team member has its own)
- it can use cloud vaults for encryption/decryption - for instance, keep your keys in Azure Key Vault or similar, and let the team access that using their own setup of AZ cli and SSO login you use to interact with the cloud anyway
- it will be able to keep the encrypted file semantically correct, so you still can use linter checks on push to git, etc
There are varying degrees to this but I'll focus on the early stage, low effort approaches I've found work.
For an easy, slightly hacky version I've used git-crypt (https://github.com/AGWA/git-crypt) with tiny teams. You'll need to share the decryption key (e.g. via 1password shared vaults).
As your need for security grows (but you're still not working with a giant team) you're better off using non-committed .env files locally (with need-to-be-shared dev keys stored in shared vaults in 1password) and prod GCP/AWS secrets managers remotely.
Once you work with a bigger team you'll need to start minting API keys limited in scope to each individual, for them to work with locally. The prod keys will only live in the remote environment, managed by some kind of secret manager offered by the platform and will need to be rotated frequently.
> You'll need to share the decryption key (e.g. via 1password shared vaults).
Not really. It also supports keeping the symmetric decryption key encrypted with the GPG key of each added user (and handles this automatically). This is the default behavior.
What you're saying also works (quoting from readme, emphasis mine: "Alternatively, you can export a symmetric secret key, which you must securely convey to collaborators."), but feels worse from a security point of view.
So what you see when you look at the repo in Github et al is the encrypted file and locally you see the file unencrypted? That's neat, a bit like ansible-vault but less of a hassle for the user.
yes, exactly right. it's an encrypted binary on github, but locally (provided you've decrypted it) it'll be unencrypted. If you edit the file locally, it automatically encrypts. It's a neat bit of tech.
so are they 2 separate files? because otherwise how will the system read it unencrypted? (such as an env file)
I ask because I'm currently using a scheme where I have a .secrets env file that is .gitignore'd from the repo but it has a corresponding .secrets.gpg file which isn't, but it's a pain to synchronize these; I suppose this is the problem `sops` solves...
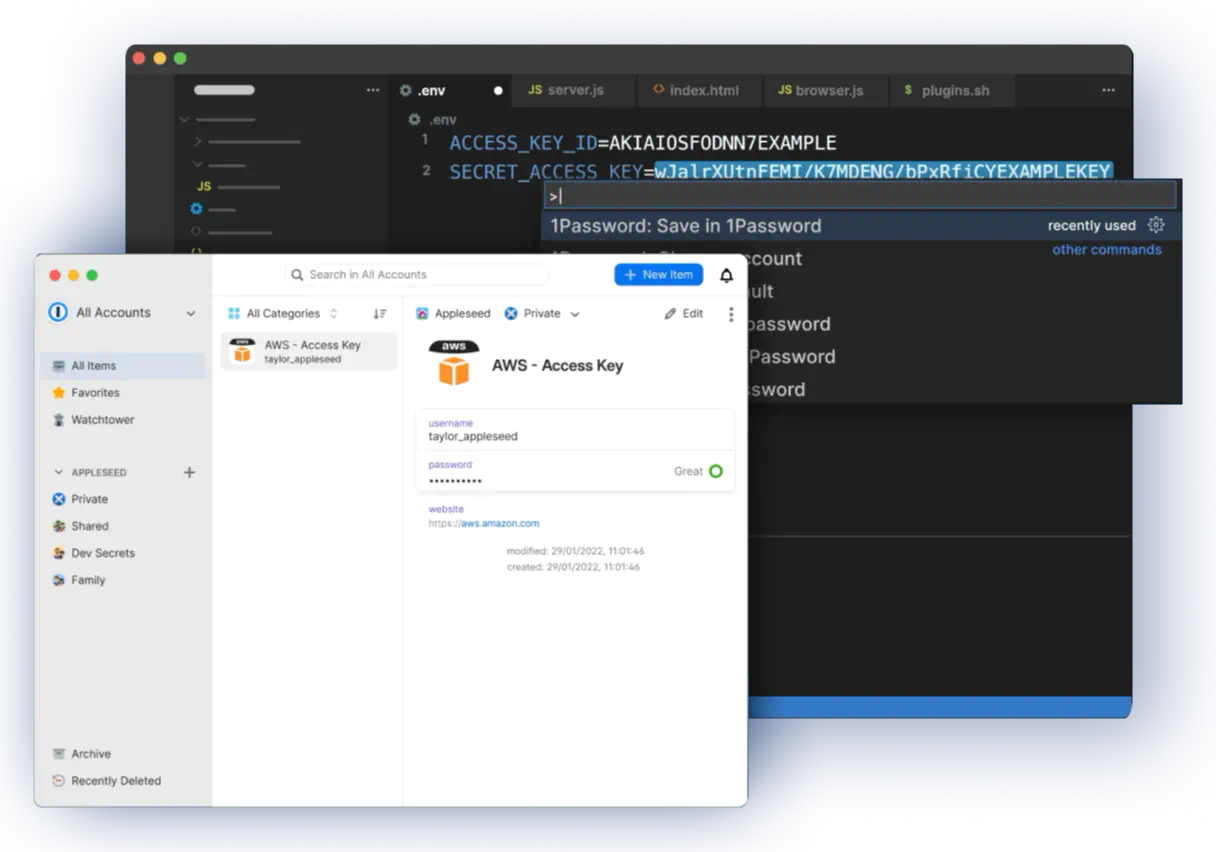
I tried to get my head around the 1Password implementation of this, but as far as I could work out, every single secret is stored as an individual item in 1Password and the 1Password app makes no accommodations for the differences between a server secret and a login. We have maybe 100 projects, with multiple environments for each, and multiple secrets in each environment - managing this in 1Password looks like it would be an absolute nightmare.
Edit: to expand on this a little, even the image [0] they show on their secrets management landing page is baffling. It's showing an entry in the 1Password app called `AWS - Access Key`, which for some reason has a username and password. Now if I need to inject that into the environment variables on my server, what's the name of the envvar, because `AWS - Access Key` isn't going to work. How do I separate staging variables from production variables? How do I know which project this is the AWS access key for?
You can use different vaults for different projects and different environments. IIRC you can then automatically switch between, for example, dev and prod vaults using environment variables in the references in the .env files.
So on a dev machine it could use the dev vault for your project, but when you deploy it could use the prod vault.
Within vaults you can name and organise how you like, you’re not limited to usernames and passwords. You can have arbitrarily named fields, whole text blocks, or files.
just guessing but since access keys are paired with secrets that’s why you see a username and password there.
1p lets you create arbitrary fields in an entry, so you could create one with a VARNAME field or something, or just use a naming convention on the entry. for project isolation you could create separate vaults or use tags to distinguish.
I came here to mention the 1Password cli[1] which has a great DX for solving this problem since one can check in the reference to the Secret[2] and it will be resolved by anyone who has permissions to said Secret at the time of consumption
They also have a plugin system[3] that makes it work moderately seamlessly with various other CLI utilities which expect credentials in the environment, such as the `gh`[4] CLI and bazillions of others
I agree that using a hosted secrets manager is better than storing a random assortment of secrets in an .env file that's written right next to your source code. Just make a with-secrets shell script that checks your 2FA and fetches them into the environment as it starts your application.
This way, the opportunity to expose the secrets is more limited to the actual run-time of the application. You don't need to risk exposing your secrets every time you git push.
I use a hybrid approach of .env files and whatever secret manager my cloud platform has available (in this case, AWS Secrets Manager), where anything that's sensitive that needs to be present within the .env file is essentially a macro that gets resolved later by a library I've written.
For example, my .env file may have something like this in it:
DB_PASSWORD = @AWS::db_password
Whenever my library reads a value that begins with `@AWS::`, it knows to resolve (and cache) that value by querying AWS's Secrets Manager at runtime and looking for the config setting set there (`db_password` in this case).
This is nice because I can check-in these .env files since they don't contain anything sensitive, but still gives me the flexibility to hard-code in secrets when working locally in my dev env.
If you're already using systemd, you can use its built-in credentials manager[0] which uses a combination of an on-disk key and the TPM2 to encrypt secrets at rest.
Probably annoying if you have more than one machine though
Hey, this is real cool. Is encryption at rest the only benefit over, for example, injecting the secrets as environment variables into a running systemd service?
I ask because my research suggests that there's a class of security vulnerabilities where attackers can read arbitrary files - but since /etc/system/systemd can be limited to be only readable by root, and the services it runs started by other less privileged users, I wonder how bad it would be to store a plaintext secret right in the .service file would be in practice. Especially since it seems this credentials management thing seems to just create a directory for the process with the decrypted passwords readable anyway (although maybe that's still not readable by an attacker? Still trying to figure this all out myself).
Gonna answer my own question here: No, actually systemd-creds is much better than just putting the plaintext secret into the .service (although that's still probably better than leaving it in a .env file if you have good user permissions set up).
Among other things, TPM and TPM2 are physical chips, which means even someone who steals your actual hard drive couldn't actually decrypt your stuff unless they also somehow got access to the rest of the computer containing that TPM chip. Huge improvement, although I'm not sure if your run of the mill cloud VM has (or even could have) such a chip permanently and uniquely bound to them.
I would suggest NOT using env files. They are a hack. The environment belongs in the environment, not a file on disk; and if it is on a file on the disk, it belongs outside your repository.
There is a script in the repository that will bootstrap your local env by storing encrypted secrets into ~/.config/ by asking some questions that you get from the shared passwords manager for development credentials. The key to decrypt them is password protected and requested at application boot.
1. Stop using API keys. Configure SSO integration for developers and OIDC for automation. For example, this is very easy to setup with AWS.
2. If the above is not possible, then store credentials encrypted at rest. Decrypt them only at runtime. For example, SOPS to store encrypted credentials into the repo, then AWS KMS holds the decryption key. The SOPS Readme is very helpful.
I was curious about this and went sniffing around and it seems that their instance metadata[1] doesn't include anything that demonstrably associates the instance with Hetzner nor your specific account, making chain of custody ... tricky.
The best work-around I could come up with (not having a Hetzner account to actually kick the tires upon) is that you could inject a private key that you control into the instances via cloud-init (or volume attachment) and then sign any subsequent JWT using it. For sure it would not meet all threat models, but wouldn't be nothing either. I was hoping there was some chain of custody through Vault[2] but until Hetzner implements ANY IAM primitives, I'm guessing it's going to be a non-starter since the instances themselves do not have any identity
Another new (open source!) tool to check out in this space is https://dmno.dev
It's a bit different than most of the other tools listed here, in that it is designed to generally solve the papercuts of dealing with config (both sensitive and not), and is not coupled to storing your sensitive config in a specific platform (paid or otherwise).
You define a simple schema for all of your config, and you get validations, built-in documentation, full type safety, and the ability to compose config together in any way you choose. You can also easily share config across a monorepo (if you are using one).
Additionally, our drop-in integrations (node, vite, nextjs, astro, remix, more on the way) go a bit deeper and do things like help you detect and stop leaked secrets, redact secrets in logs, and deal with the footguns of boot vs build time config in hybrid rendering environments.
As for storing/syncing sensitive data, we currently have 2 plugins but more are in the works and will be guided by user demand. The first lets you store your secrets encrypted within your repo (like dotenvx, git-crypt, etc), and the second lets you sync with 1password. Personally we think the 1password plugin makes sense for a lot of teams, since they are probably already using it. You can wire up individual items to your schema, or pull from dotenv style text blobs. You can (and should!) segment items into multiple vaults, and use multiple service accounts to access them. You can even mix and match plugins to pull secrets from multiple services.
In the future, we'll have deeper support for things like key rotation and single-use keys, k8s, way more backends, etc. It's all open source, so come and tell us what you need (or even help us build it) and we'll make it happen!
If it's not obvious already, I am the creator :)
PS - Feel free to hit me up for more info or a demo - theo at dmno dot dev
I usually have .env files in the repositories with the structure and examples. It's a kind of documentation. But I have a template file that gets filled by the CD pipeline with the necessary set of secrets that the deployment need.
I advise against dynamic secrets. In my opinion deployment should be immutable. If you need to change secrets, you need another deployment. The usual exception is where the deployment is too costly or you can't do zero-downtime blue-green/canary deployments.
The template file can be something like a .env.j2 and the secrets can be pulled from something like hashicorp vault, which enables you granular permission for the pipeline runners to read just the necessary kinds of secret that particular deployment needs.
You need however to put a little effort into creating these pipelines, but the benefits are huge.
Usually `.env` files are sourced into your development shell and also ignored by `.gitignore`.
The problem with `.env` files is that you're leaving credentials unencrypted on disk and it's easy to leak these files during screen sharing and with multiple projects there will eventually there will be so many secrets spread/sprawled everywhere that you lose track of what credentials are being used and what are expired. You want to be able to inject the required keys only when needed and leave no trace behind when not needed.
We are still working out the kinks but I expect that one should be able to easily do `. <(polykey secrets env project-vault)` in whatever development shell you have, perhaps even reference a schema for expected keys.
Yes, you are right to point this out. We are dogfooding Polykey in our own company's operations, specifically integrating it into all of our team member's NixOS development platforms with the control plane beta PKE (Polykey Enterprise).
Using Polykey in the CI/CD situation as you point out in your links is actually one of the major complex usecases we designed Polykey for, however it's actually quite a complex problem domain. We expect to do a sort of "painkiller" phase 1 first where PK is used as the network for sharing secrets, and then a subsequent "vitamin" phase 2 where secrets are no longer shared at all, because authority is delegated through trust federation.
Right now PK is a decentralized secret sharing system (every agent is a P2P node), so there's no well-known trust anchor to form a trust federation via OIDC. However once we have PKE ready, then we plan to enable OIDC customer portals within PKE following ideas from https://openid.net/specs/openid-federation-1_0.html (e.g. yourcompany.enterprise.polykey.com). This requires a more sophisticated policy-logic system integrated into each Polykey node's sigchain, atm we have work in progress for public/private network segregation.
In our internal documentation, I have a diagram of how PK would integrate into a CI architecture, just haven’t shared it publicly yet. I’ll try to get it out soon. Let me know if you’re interested in more details!
This is by far the simplest solution. It’s easier to understand and setup than the other solutions mentioned. It simply encrypts the value portion of the variable so its safe to commit the entire env file. The only draw back is developers could still potentially commit private keys the repo or commit the decrypted env file. If you’re working with env variables that don’t require updates often it’s a decent solution.
Don't store secrets in env files. Use a secrets manager and a password manager. Configure SSO for everything. Use MFA for everything. Rotate your keys regularly. Do not allow long-lived user accounts to exists.
A while ago, I had this exact problem and I threw a template together using a combination of age + passage + agenix (nix) solution to automate my secret management solution.
EDIT: This is meant to used in a nix-based deployment setting, and also you don't want to commit the identities file unless you use yubikeys (Something which I forgot to mention in the readme).
We use infisical to manage 100s of secrets in our various environments. Honestly don’t know how we coped before it.. Makes it very easy especially for a team where devs jump between projects. It has a few areas which can get frustrating and they had a few bugs some time ago.. but it has been a excellent improvement in our workflow for day to day dev and deployment.
Environment variables (+managing them with .env files) are a better start than putting keys in your codebase, but this can also be leaky/hard to keep up to date.
Most cloud providers have some sort of secret management tool. Vault by Hashicorp is another solid option if you want to run your own.
If you’re hosted on AWS, I’m personally a big fan of Credstash[0], which is basically a simple wrapper around DynamoDB+KMS.
Cheaper than the AWS Secrets product and fast enough.
I previously built a config that would take secrets from Credstash, env vars, and .env files (in that order). This offered the best of both worlds for local and remote deployments.
If you develop in .Net, User Secrets. Best idea ever.
If you don’t, .env files with a proper .gitignore
Or AWS secrets manager, GitHub secrets, Azure KeyVault and inject them.
If you run on something like Azure, use Managed Identities. Passwords shouldn’t be used period. API keys should be securely injected in a pipeline from a vault.
You could put them all in Secrets Manager or Parameter Store, whichever is appropriate for the secret, then have your CI process fetch the secrets and setup your environment. That way, developing locally does not depend on access to AWS Secrets Manager or Parameter Store.
I use Onboardbase, it has a lot of features, where I can manage different environments, and its very easy and developer friendly most of the team is very responsive for your thoughts
People keep talking about cloud vault providers, but a lot of my secrets are mine alone. I just macos keychain at devtime. There a nice little libs for interacting with it with your language of choice
We ended up going with Doppler for secrets management. Was super easy to set up. I looked at a few others, but we would either need to self host or they were going to be clunky to set up. No more .env files to leak!
{kind=link}
The exact advice depends on how you’re running your services. My starting advice, for cloud, is this:
1. Run in multiple, separate accounts. Don’t put everything in one account. This could be as simple as having a beta account for testing and a separate production account.
2. Use cloud-based permissions systems when possible. For example, if you are running something on AWS Lambda, you create an IAM role for the Lambda to run as and manage permissions by granting them to the IAM role.
3. If that’s not possible, put your credentials in some kind of secrets management system. Create a process to rotate the secret on a schedule. I’d say 90 days is fine if you have to rotate it manually. If you can rotate it automatically, rotate it every 24 hours.
4. Set up logging systems like CloudTrail so you can see events afterwards.
Finally, as a note—people at your company should always authenticate as themselves. If you are TheBigDuck234, then you access your cloud resources using a TheBigDuck234 account, always.
This is just the start of things.