All these new, low-bitrate codecs are amazing, but ironically I suspect that they won't actually be very useful in most of the scenarios Meta is using them:
To keep latency low in real-time communications, the packet rate needs to be relatively high, and at some point the overhead of UDP, IP, and lower layers starts dominating over the actual payload.
As an example, consider (S)RTP (over UDP and IP): RTP adds at least 12 bytes of overhead (let's ignore the SRTP authentication tag for now); UDP adds 8 byte, and IPv4 adds 20, for a total of 40. At at typical packet rate of 50 per second (for a serialization delay of 1/50 = 20ms), that's 16 kbps of overhead alone!
It might still be acceptable to reduce the packet rate to 25 per second, which would cut this in half for an overhead of 8 kbps, but the overhead would still be dominating the total transmission rate.
Where codecs like this can really shine, though, is circuit-switched communication (some satphones use bitrates of around 2 kbps, which currently sound awful!), or protocol-aware VoIP systems that can employ header compression such as that used by LTE and 5G in IMS (most of the 40 bytes per frame are extremely predictable).
Latency is the mind killer, but if available bandwidth is low, you save a ton of overhead by bundling 2-5 of your 20ms samples. Enough that the codec savings start to make sense, even though 100ms packets adds a ton of latency. Fancier systems can adapt codecs and samples per packet based on current conditions. The one I work on is a static codec and 60 ms of audio per packet, which isn't ideal, but allows us to run in low bandwidth much better than 20 ms per packet.
Edit to add: Meta can also afford to add a bit more sampling delay, because they've got very wide distribution of forwarding servers (they can do forwarding in their content appliances embedded in many ISPs), which reduces network delay vs competing services that have limited ability to host forwarding around the globe. Peer to peer doesn't always work and isn't always lower delay than going through a nearby forwarding server.
> you save a ton of overhead by bundling 2-5 of your 20ms samples.
You pay that price back when the packets are dropped. We use a lot of advanced codec managers for broadcast, and while they do combining like this, they also offer the ability to repeat frames within subsequent packets. So you may get a packet with frames [1,2,3] then a packet with frames [2,3,4].
The best codecs actively monitor the connection and adjust all these parameters in real time for you.
I think this is likely incorrect based on how much voice/audio distribution meta does today with facebook (and facebook live), instagram and whatsapp - moreso with whatsapp voice message and calling given it's considerable market share in countries with intermittent and low-reliability network connectivity. The fact it is more packet-loss robust and jitter-robust means that you can rely on protocols that have less error correction, segmenting and receive-reply overhead as well.
I don't think it's unreasonable to assume this could reduce their total audio-sourced bandwidth consumption by a considerable amount while maintaining/improving reliability and perceived "quality".
Looking at wireshark review of whatsapp on an active call there was around 380 UDP packets sent from source to recipient during a 1 minute call, and a handful of TCP packets to whatsapp's servers. That would yield a transmission overhead of about 2.2kbps.
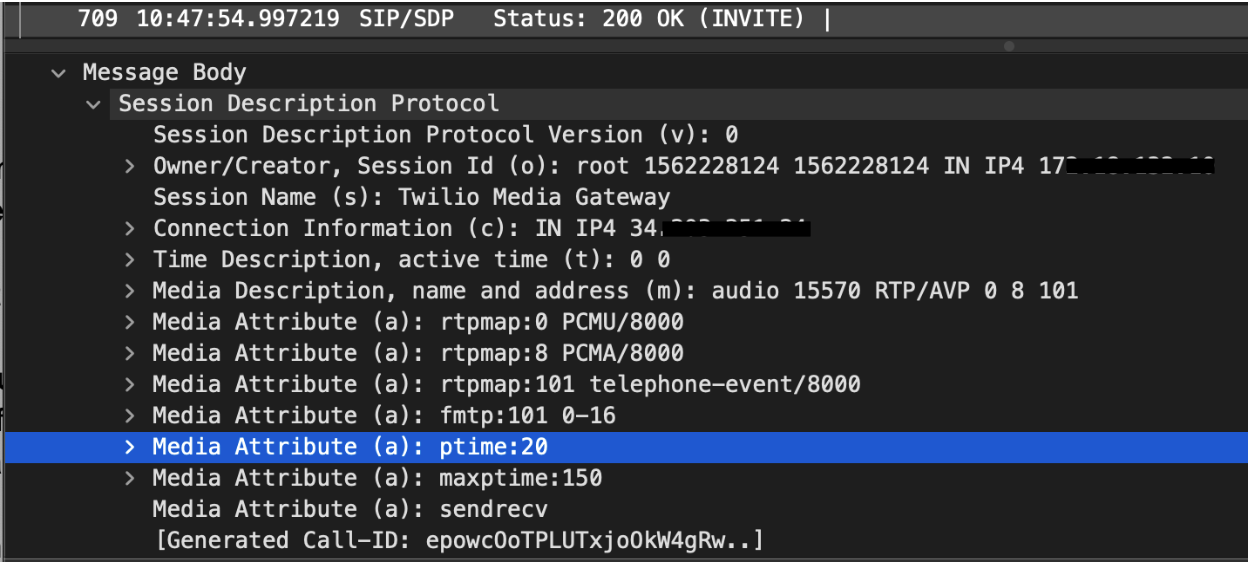
quick edit to clarify why this is: you can see starting ptime (audio size per packet) set to 20ms here, but maxptime set to 150ms, which the clients can/will use opportunistically to reduce the number of packets being sent taking into consideration the latency between parties and bandwidth available.
What part of that calculation is incorrect in your view?
> 380 UDP packets sent from source to recipient during a 1 minute call, and a handful of TCP packets to whatsapp's servers. That would yield a transmission overhead of about 2.2kbps.
That sounds like way too many packets! 380 packets per second, at 40 bytes of overhead per packet, would be almost 120 kbps.
My calculation only assumes just 50, and that’s already at a quite high packet rate.
> you can rely on protocols that have less error correction
You could, but there's no way to get a regular smartphone IP stack running over Wi-Fi or mobile data to actually expose that capability to you. Even just getting the OS's UDP stack (to say nothing of middleboxes) to ignore UDP checksums and let you use those extra four bytes for data can be tricky.
Non-IP protocols, or even just IP or UDP header compression, are completely out of reach for an OTT application. (Networks might transparently do it; I'm pretty sure they'd still charge based on the gross data rate though, and as soon as the traffic leaves their core network, it'll be back to regular RTP over UDP over IP).
What they could do (and I suspect they might already be doing) is to compress RTP headers (or use something other than RTP) and/or pick even lower packet rates.
> I don't think it's unreasonable to assume this could reduce their total audio-sourced bandwidth consumption by a considerable amount while maintaining/improving reliability and perceived "quality".
I definitely don't agree on the latter assertion – packet loss resilience is a huge deal for perceived quality! I'm just a bit more pessimistic on the former, unless they do the other optimizations mentioned above.
I think you’re misreading OP, as he says 380 packets per minute, not second. That would give you an overhead of 253 bytes per second, sounds a lot more reasonable.
Yes 380/min = ~6/s which is a very open ptime of >100ms, this can also be dynamic and change don the fly. It ultimately comes down to how big the packet can be before it gets split which is a function of MTU.
If you have 50ms of latency between parties, and you are sending 150ms segments, you'll have a perceived latency of ~200ms which is tolerable for voice conversations.
One other note is that this is ONLY for live voice communication like calling where two parties need to hear and respond within a resonable delay - for downloading of audio messages or audio on videos, including one-way livestreams for example, this ptime is irrelevant and you're not encapsulating with SRTP - that is just for voip-like live audio.
There is a reality in what OP posted which is that there is diminishing returns in actual gains as you get lower in the bitrate, but modern voice implementations in apps like whatsapp are using dynamic ptime and are very smart about adapting the voice stream to account for latency, packet loss and bandwidth.
In my personal experience, Whatsapp's calling is subpar compared to Facetime audio, Skype or VoWIFI even. Higher latency, lower sound quality and very sensitive to spotty connections.
Wow, that would be an extremely low packet rate indeed!
That would definitely increase the utility of low bitrate codecs by a lot, at the expense of some latency (which is probably ok, if the alternative is not having the call at all).
Voice activity detection and comfort noise have been available in VoIP since the very beginning, but now I wonder if there's some clever optimization that could be done based on a semantic understanding of conversational patterns:
During longer monologues, decrease packet rates; for interruptions, send a few early samples of the interrupter to notify the speaker, and at the same time make the (former) speaker's stack flush its cache to allow "acknowledgement" of the interruption through silence.
In other words, modulate the packet rate in proportion to the instantaneous interactivity of a dialogue, which allows spending the "overhead budget" where it matters most.
Another interesting use case for these kinds of ultra-low bitrate voice compression systems are digital radio systems. AMBE+2 and similar common voice codecs used on radio systems sound pretty miserable and don't handle dropped packets nearly as gracefully as compared to these newer codecs.
According to the blog post, this is all practical research that Meta is doing to improve their services. Maybe that is BS, but I kind of doubt that given that Meta is in fact one of the biggest providers of voice and video calls on low bandwidth devices.
What makes you think that they have somehow just been misleading themselves the whole time?
I don't know of any setups which would support muxing in exactly the way I am thinking, but another interesting use case is if you have multiple incoming audio streams which you don't want to be mixed by the server -- potentially because they are end-to-end encrypted -- and so a single packet can contain the data from multiple streams. Doing end-to-end encrypted audio calls is finally becoming pretty widespread, and I could see Facebook being in a good position for their products to do custom muxing.
this codec is for RTC comms - it supports 20ms frame rate. They did mention it's launched in their calling products:
"We have already fully launched MLow to all Instagram and Messenger calls and are actively rolling it out on WhatsApp—and we’ve already seen incredible improvement in user engagement driven by better audio quality."
I’m not totally certain about your argument for the specific amount of overhead (if the receiver/sender are on mobile networks, maybe something happens to the packet headers for the first/last legs before the real internet). But doesn’t the OP already give an example where the low bit-rate codec is good: if you can compress things more then you have more of an opportunity to add forward error correction, which greatly improves the quality of calls on lossy connections. I wonder if smaller packets are less likely to be lost, and if there are important cases where multiple streams may be sent like group-calls.
You are right that OPUS already hits the ball for most audio applications. 20kbps is pretty good, and 30 kbps is almost perfect.
Meta has tons of Indian and South Asian users with insanely poor network. It's already using 60ms/120ms packets (16.6/8.3 packet rate) for those people, but still, some calls are still bad.
What this new codec does is to further make the call accessible by bringing down the bitrate, which seems to help their DAU.
Nitpick: measuring packet rate on your device doesn't usually work. I think meta (as well as most other voip providers) is using DTX, so when user doesn't talk, packet rate is 2/sec.
Default configuration for SIP used to be 20ms, the rationale behind it was actually sourced in the fact that most SIP was done on LANs and inter-campus WAN which had generally high bitrate connectivity and low latency. The lower the packet time window the sooner the recipient could "hear" your voice, and if there were to be packet loss, there would be less of an impact if that packet were dropped - you'd only lose 20ms of audio vs 100ms. The same applies for high bitrate but high latency (3g for example) connectivity - you want to take advantage of the bandwidth to mitigate some of the network level latency that would impact the audio delay - being "wasteful" to ensure lower latency and higher packet loss tolerance.
Pointedly - if you had a 75ms of one-way latency (150ms RTT) between two parties, and you used a 150ms audio segment length (ptime) you'd be getting close to the 250ms generally accepted max audio delay for smooth two-way communication. the recipient is hearing your first millisecond of audio 226ms later at best. If any packet does get lost, the recipient would lose 150ms of your message vs 20ms.
Modern voice apps and voip use dynamic ptime (usually via "maxptime" which specifies the highest/worst case) in their protocol for this reason - it allows the clients to optimize for all combinations of high/low bandwidth, high/low latency and high/low packet loss in realtime - as network conditions can often change during the course of a call especially while driving around or roaming between wifi and cellular.
> the rationale behind it was actually sourced in the fact that most SIP was done on LANs and inter-campus WAN which had generally high bitrate connectivity and low latency
In addition to that, early VoIP applications mostly used uncompressed G.711 audio, both for interoperability with circuit switched networks and because efficient voice compression codecs weren't yet available royalty-free.
G.711 is 64 kbps, so 12 kbps of overhead are less than 25% – not much point in cutting that down to, say, 10% at the expense of doubling effective latency in a LAN use case.
200ms is noticeable but in conversation it's still pretty good, and certainly way better than the average WhatsApp call which is on the order of 0.5-1s.
Anything over 40ms will be noticeable. Just to give you an idea how sensitive our ears are - there’s a max distance certain instruments can sit away from each other in an orchestra booth or they start falling out of sync due to speed of sound delay
To clarify this even further, as someone who professionally plays an instrument that is traditionally placed at the back of an orchestra, you absolutely cannot play by ear: you MUST play by watching a combination of the stick in the conductor’s hand and the bow of the first violinist and cellist at the front. If you play what sounds in sync to you, the conductor and audience will hear you too late; the round trip from the front to the back of a stage, plus the sound traveling through the brass tubes of your instrument, plus the trip from the rear of the stage to the first row of the audience simply takes so long that it will sound noticeably wrong. The same is true for the far sides of an orchestra pit underneath the stage of a musical or opera. It only takes 20 meters/yards to become an issue.
It is generally said that the lowest threshold for people to perceive time delays is around 10-15ms.
Speed of sounds is roughly 343 meters per second. Which means translates we can sense the delay difference of about 4-8 meters or so.
Which 100% corresponds with what you are saying. 20 meters is a 58ms-ish delay.
A 200ms is about 70 meters. Which would be like having conversation between people using one of those accidental sound projection features that sometimes happens with large open buildings like sports stadiums.
people talk in a cadence of around 100-200 words per minute. I guess we could say that is 300-600 syllables per minute. So that is about 200-100ms per syllable.
Yes 100ms feels horrible. People constantly interrupting each other because they start talking at around the same time and then both say "you go first". Discord has decent latency and IMO it's a major reason behind their success
Having traveled widely in three of the four most populous countries I’m a bit dubious of this claim. Having decent 4G in the middle of nowhere in India or Indonesia is pretty standard these days. I haven’t been to Africa, but a quick search suggests more than two thirds of the population of the continent has 4G coverage, and more than 80% has 3G. Where are these huge numbers of people on 2G?
what you're saying is that tcp/ip sucks at 9600 baud and below, nothing to do with voice really. this is a well-known fact, and solutions to the problem include cslip, vj header compression in ppp, and csp, as well as the lte and 5g stuff you mention
Facebook the social network reputation may be not shiny, but Meta the engineering company reputation is pretty high, to my mind.
It's somehow similar to IBM, who may look not stellar as a hardware or software solutions provider, but still have quite cool research and microelectronics branches.
Microsoft Research also puts out some really cool stuff, but that does not mean the "same" Microsoft can't show ads in their OS' start menu for people's constant enjoyment. I noticed this interesting discrepancy in Microsoft some years ago as a teenager; it does not surprise me at all that Facebook has a division doing cool things (zstandard, etc.) and a completely separate set of people working towards completely different goals simultaneously. Probably most companies larger than a couple hundred people have such departmental discrepancies
I racked my brain and couldn’t think of a single example of something released by Microsoft Research offhand, so I proceeded to visit their website. It can be found at https://www.microsoft.com/en-us/research/
I found exactly zero things that they have provided to the world. Literally none, and I really came in with an open mind. All I found was marketer drivel telling me how I should feel about the impact of the marketing copy I was currently reading. No concrete examples after fanning out 3 links deep into every article posted on that site. I must be missing something so can you point me to at least one example of work that’s come out of Microsoft Research on the same scale as Meta’s LLM models or ReactJS?
This is a surprisingly negative take, you should look a little further. Microsoft Research has done an incredible amount of high quality research. I've mostly read papers from them on programming languages, they have or did employ leading researchers behind C#, F#, Typescript (of course), as well as Haskell (Simon Peyton Jones and Simon Marlow spent a long time there), F*, and Lean (built by Leonardo de Moura while at MSR). MSR's scope has been much broader than just languages, of course.
I've heard in interviews that MSR's culture is not what it used to be (like Bell Labs, maybe), but over time they've funded a ton of highly influential research.
Leslie Lamport's TLA+ comes from MSR. You have likely directly benefited from this project, since it's been used to prove the correctness of many distributed systems, including pieces of AWS.
Z3 is a very popular open source SMT solver, also originating from MSR.
There's probably dozens of similar examples. You might not know about some of the work coming out of MSR, but it's probably impacting you indirectly.
It's similar to how we indirectly benefit from fundamental nuclear physics. Places like CERN have to solve engineering issues and those solutions trickle down to everyone.
That page is written for marketing. My experience with industry research labs is that just like many places with somewhat misplaced incentive structures, a lot of the good research does not get marketed properly. e.g., the research marketing people will likely extoll more of the recent GenAI advances given that's more eyeball catching.
(Also on top of my head DeepSpeed is by MSR, which is used a lot in large scale ML training.)
Or you can recognise that ‘Meta’ isn’t a conscious entity, and that it’s perfectly likely that there are some people over there doing amazing open-source work, and different people over there making ethically dubious decisions when building their LLMs.
I’ve worked for dozens of organisations in my career. Large and small, competent and not. Usually not.
In that time did I make some ‘ethically correct’ choice to leave an enormous organisation because some other part of that organisation did something that wasn’t ethically perfect?
Never. Not one time.
And I’m an ethical person. I consider this stuff deeply. Here I am bothering to have this conversation with you.
But, what, every person who has an interesting job doing good things — remember, we’re talking about engineers developing a new audio codec — so those people who have interesting jobs doing good things with a great team are expected to look over there to some distant part of the org, to teams they’re barely aware of, let alone have spoken to, and they’re expected to quit their jobs because of the ‘ethically dubious’ stuff going on over there?
Sorry. Unrealistic, idealistic bullshit. I’ve never done it and neither have you.
Not the person you're responding to, but I guess I would just have to flip that back around and say really this is bullshit to be honest.
I guess I don't really feel that you can just say you're an ethical person and have it absolve yourself of impact of your work.
It doesn't seem a stretch to say that the goals of meta are propagated by the things meta focuses work on, and even if one isn't on the forefront of stealing data, intruding on privacy, or maximizing engagement at all costs, doesn't mean nothing they do will play a part in those teams.
At the end of the day, even accounting at the orphan crushing factory plays a part in the orphan crushing machine.
How the hell does releasing one audio codec undo years and years of privacy nightmare, being a willing bystander in an actual genocide, experimenting with the emotions of depressed kids, and collusion to depress wages?
You will need to provide citations on the last point as Facebook are widely known to have broken the gentleman's agreement between Apple and Google that was suppressing tech pay in the early 2010s.
This article seems to not really mention the "knowingly" or the "abetted". If there are people killing other people, I wouldn't say that a communication method was to blame. In Scream, Sidney didn't sue the phone company who let the killer call her from inside the house. The idea that some news feed posts whipped people up into a killing frenzy just sounds absurd.
I wish the author could see that, and if the case is valid, to provide it, instead of some pretty tenuous claims of connection strung together to lead up to a demand for money.
I did try to go to the link that evidenced the "multiple" times Facebook was contacted in a 5 year period, but I couldn't get through. How many times was it, for anyone who can?
This is a very low-quality comment. Amnesty International published a substantial, well-researched, well-sourced study. Your comment is low-effort Internet skepticism based on ignorance and a straw-man argument.
> If there are people killing other people, I wouldn't say that a communication method was to blame. In Scream, Sidney didn't sue the phone company who let the killer call her from inside the house. The idea that some news feed posts whipped people up into a killing frenzy just sounds absurd.
This is the core of your point and a comment on the idea itself, not the way the article portrayed it. I think it's fare to characterize your dismissal as glib.
it isn't just one audio codec. they also released and continue to release the best self hostable large language model weights, they have authored many open source projects that are staples today such as zstandard, react, pytorch
Zstd is a personal project? Surely it's not by accident in the Facebook GitHub organization? And that you need to sign a contract on code.facebook.com before they'll consider merging any contributions? That seems like an odd claim, unless it used to be a personal project and Facebook took it over
All Google dev’s personal projects are under the Google account on GH for legal reasons. I assume the same for Facebook. I believe fb championed zstd and lets the dev work on it at work but it was a personal project iirc.
According to cheema33 React is most "popular frontend stack", but I'm not allowed ask questions of why websites demand JS to display basic content... I suppose my reply could have been more _constructive_ as to ask "by whose count" or "how does popularity correspond to quality" but that's like playing chess by one step in front of you.
Look, I'm seeing an increase of blogs made with an implication that _infinity_ amount of visits requires less resources than one and I don't just find it true.
The lack of any reference or comparison to Codec2 immediately leads me to question the real value and motivation of this work. The world doesn't need another IP-encumbered audio codec in this space.
Or speex narrowband or others. I think the tendency to pick Opus is just because it has a newer date on it -- its design goals were not necessarily to optimize for low bitrate; Opus just happened to still sound OK when the knob was turned down that far.
One other point I intended to make that is not reflected in many listening/comparison tests offered by these presentations -- in the typical applications of low bitrate codecs, they absolutely must be able to gracefully degrade. We see Mlow performing at 6kbps here; how does it perform with 5% bit errors? Can it be tuned for lower bitrates like 3kpbs? A codec with a 6kbps floor that garbles into nonsense with a single bit flip would be dead-on-arrival for most real world applications. If you have to double the bitrate with FEC to make it reliable, have you really designed a low bitrate codec? The only example we heard of mlow was 30% loss on a 14kbps stream = 9.8kbps. Getting 6kbps through such a channel is a trivial exercise.
My understanding was Opus was specifically developed with the idea of replacing both Speex and Vorbis. "Better quality than Speex" is literally one of their selling points, so I'd be interested to hear more details.
> how often is significant numbers of bit errors a problem, or when does that come up?
It depends on the transport. If you are going over something like TCP you will have a perfect bitstream or you will have nothing, so your codec doesnt have to tolerate bit errors or loss. If you are pushing raw bits over the air with GMSK modulation with no error correction, you'll have to tolerate a lot of errors.
In real world applications you almost always have to consider the tradeoffs on what things you want to leave to the codec and what things you want to leave to the transport layer.
At very low bitrates, the overhead required to create reliability and tolerance for errors or omissions become significant enough that the entire system performance matters a great deal. That is to say that the codec and transport have to be designed to be complimentary to one another to achieve the best final result.
From the presentation they show us mlow at 6kpbs and then again at 14kbps with 30% packet loss (effective datarate 9.8kbps). They do not say if the loss is random bit errors or entire packets, but let's not worry about that. Let's just assume the result of both of these is that you get final audio of about the same quality. This means that mlow has some mechanism to deal with errors on its own, but is using an obscenely high overhead rate (133%) to accomplish it. They also dont let us hear how it actually degrades when exposed to other types of transport errors. These numbers and apparent performance just aren't very good compared to other codecs/systems in this space.
Lyra goes against the design goals of MLow though, by using machine learning techniques, and thus possibly not running on the devices that Meta is targeting with MLow.
Google claims SoundStream can run on low-end devices, though, so indeed I would like Meta to show that it still doesn't work well enough for their usecase. Specifically, I would like to know if it's possible to get SoundStream running in very old Android versions in low end devices, before a lot of APIs related to NNs in Android came around.
Somebody knows if this is better compared to whatever Google Meet is using? With choppy near unusable slow Internet Google Meet still fulfils its purpose on Audio Calls where all other competitors fail (tested e.g. while being in Philippines on a remote island with very bad internet). However Google Meet's tech is not published anywhere afaik.
Depends on your call; u-law has poor frequency response and reasonable dynamic range. Not great for music, but ok enough for voice, and it's very consistent. 90s calls were almost all circuit switched in the last mile, and multiplexed per sample on digital lines (T1 and up). This means very low latency and zero jitter; there would be a measurable but actually imperceptible delay versus an end to end analog circuit switched call; but digital sampling near the ends means there would be a lot less noise. Circuit switching also means you'd never get dropped samples --- the connection is made or its not, although sometimes only one-way.
Modern calls are typically using 20 ms samples, over packet switched networks, so you're adding sampling delay, and jitter and jitter buffers. The codecs themselves have encode/decode delay, because they're doing more than a ADC/DAC with a logarithm. Most of the codecs are using significantly fewer bits for the samples than u-law, and that's not for free either.
HD Voice (g.722.2 AMR-Wide Band) has a much larger frequency pass band, and sounds much better than GSM or OPUS or most of these other low bandwidth codecs. There's still delay though; even if people will tell you 20-100ms delay is imperceptible, give someone an a/b call with 0 and 20 ms delay and they'll tell you the 0 ms delay call is better.
> and multiplexed per sample on digital lines (T1 and up).
Technically even on ISDN because you had channel bonding there. Although it's all still circuit switched. The timeslot within the channel group is reserved entirely for your use at a fixed bandwidth and has full setup and tear down that is coordinated out of band.
> HD Voice (g.722.2 AMR-Wide Band) has a much larger frequency pass band, and sounds much better than GSM or OPUS or most of these other low bandwidth codecs.
At what bitrate, for the comparison to Opus?
And is this Opus using LACE/NoLACE as introduced in version 1.5?
...and is Meta using it in their comparison? It makes a huge difference.
Yeah, I probably shouldn't have included Opus; I'm past the edit window or I'd remove it with a note. I haven't done enough comparison with Opus to really declare that part, and I don't think the circumstances were even. But I'm guessing the good HD Voice calls are at full bandwidth of ~ 24 kbps, and I'm comparing with a product that was said to be using opus at 20 kbps. Opus at 32kbps sounds pretty reasonable. And carrier supported HD voice probably has prioritization and other things going on that mean less loss and probably less jitter. Really the big issue my ear has with Opus is when there's loss.
I don't think I've been on calls with Opus 1.5 with lace/no-lace, released 3 months ago, so no, I haven't compared it with HD voice that my carrier deployed a decade ago. Seems a reasonable thing for Meta to test with, but it might be too new to be included in their comparison as well.
> Really the big issue my ear has with Opus is when there's loss.
That would definitely complicate things. Going by the test results that got cited on Wikipedia, Opus has an advantage at 20-24, but that's easy enough to overwhelm.
And the Opus encoder got some other major improvements up through 2018, so I'd be interested in updated charts.
Oh and 1.5 also adds a better packet loss mechanism.
Phone ear speakers are quieter than they used to be, so if the other person isn't talking clearly into the mic, you can't crank it up. I switched from a flip phone to an iPhone in 2013, huge difference. I had to immediately switch to using earbuds or speakerphone. Was in my teens at the time.
Yes, but it doesn't deteriorate in such a way as to cause someone speaking to sound like gibberish and/or random medium-frequency tones, which happens in nearly every single cell phone conversation I have that lasts more than 5 minutes.
My experience is that phone calls nowadays alternate between a much wider-band (and thus often better sounding) experience and "WTF was that just now?"
Are they releasing this or is this just engineering braggadocio? I can't find any other references to MLow other than this blog post.
Facebook/Meta AI Research does cool stuff, and releases a substantial portion of it (I dislike Facebook but I can admit they are highly innovative in the AI space).
If you think about 'implementing then algorithm in a product' it seems so:
(From the article)
"We are really excited about what we have accomplished in just the last two years—from developing a new codec to successfully shipping it to billions of users around the globe"
Honest question: why do we need to optimize for <10kbps? It's really impressive what they are able to achieve at 6kbps, but LTE already supports >32kbps and there we have AMR-WB or Opus (Opus even has in-band FEC at these bitrates so packet loss is not that catastrophic). Maybe it's useful in satellite direct-to-phone use-cases?
There’s a section (“Our motivation for building a new codec”) in the article that directly addresses this. Assuming you have >32 kbps bandwidth available is a bad assumption.
The best assumption would be that you either have connection available or not available.
Then, if it is available, what is the minimal data rate for connections which are available in general? If we do statistical analysis for that, is it lower that 32 kbps? How significantly?
For some reason, I would assume that if you have connection, it is faster than 2G these days.
The question isn't really the minimal bandwidth of the PHY rate it's about the goodput for a given reliability. Regardless of your radio there will always be some point where someone is at the edge of a connection and goodput is less than minimal PHY bandwidth. The call then turns choppy/into a time stretched robot you get every other syllable from. The less data you need to transmit + the more FEC you can fit in the goodput then the better that situation becomes.
Not to mention "just because I have some minimal baseline of $x kbps doesn't mean I want $y to use all of it the entire time I'm on a call if it doesn't have to".
Are there really many situations where a 10kbps connection would actually be stable enough to be usable? Usually when you get these kinds of speeds it means the underlying connection is well and truly compromised, and any kind of real-time audio would fail anyway because you're drowning in a sea of packet loss and retransmissions.
Even in cases where you do get a stable 10kbps connection from upstream, how are you going to manage getting any usable traffic through it when everything nowadays wastes bandwidth and competes with you (just look at any iOS device's background network activity - and that's before running any apps which usually embed dozens of malicious SDKs all competing for bandwidth)?
Yes; backhaul connections in telephony applications are often very stable and are already capacity managed by tuning codec bandwidth. Say you are carrying 1000 calls with uLaw (64kbps * 1000) over a pair of links and one fails. Do you A) carry 500 calls on the remaining link B) stuff all calls onto the same link and drop 50% of the packets or C) Change to a 32kbps codec?
It seems you may be imaging the failure case where your "ISP is slow" or something like that due to congestion or packet loss -- as I posted elsewhere in the thread the bandwidth is only one aspect of how a "low bitrate" codec may be expected to perform in a real world application. How such a codec degrades when faced with bit errors or even further reduced channel capacity is often more important in the real application. These issues are normally solved with things like FEC which can be incorporated as part of the codec design itself or incorporated as part of the modem/encoding/modulation of the underlying transport.
Yes; but what is your point? A congested network like you describe isnt ever going to reliably carry realtime communications anyway due to latency and jitter. All you could reasonably due to 'punch through' that situation is to use dirty tricks to give your client more than its fair share of network resources.
6kbps is 10x less data to transfer than 64kbps, so for all the async aspects of Messenger or WhatsApp there is still enormous benefit to smaller data.
> Are there really many situations where a 10kbps connection would actually be stable enough to be usable?
Yes there are. We ran on stable low bandwidth connections for a very long time before we had stable high bandwidth connections. A large part of the underdeveloped world has very low bandwidth, and use 5 - 10 Kbps voice channels.
Are you talking about the general "we" or your situation in particular? For the former, yes sure we started with dial-up, then DSL, etc, but back then software was built with these limitations in mind.
Constant background traffic for "product improvement" purposes would be completely unthinkable 20 years ago; now it's the norm. All this crap (and associated TLS handshakes) quickly adds up if all you've got is kilobits per second.
I assume the general-ish “we”, where it is general to the likes of you and I (and that zeroxfe). There are likely many in the world stuck at the end of connections run over tech that this “general subset” would consider archaic, and that zeroxfe was implying their connections, while slow, may be similarly stable to ours back then.
Also, a low bandwidth stable connection could be one of many multiplexed through a higher bandwidth stable connection.
Let's not move the goalposts here :-) The context is an audio codec, not heavyweight web applications, in response to your question "Are there really many situations where a 10kbps connection would actually be stable enough to be usable?" And I'm saying yes, in that context, there are many situations, like VoIP, where 10kbps is usable.
Nobody here would argue that 10kbps is usable today for the "typical" browser-based Internet use.
> Are there really many situations where a 10kbps connection would actually be stable enough to be usable?
Yes (most likely: that was an intuited “yes” not one born of actually checking facts!). There are many places still running things over POTS rather than anything like (A)DSL, line quality issues could push that down low and even if you have a stable 28kbit/s you might want to do something with it at the same time as the audio comms.
Also, you may be trying to cram multiple channels over a relatively slow (but stable) link. Given the quality of the audio when calling some support lines I suspect this is very common.
Furthermore, you might find a much faster unstable connection with a packet-loss “correcting” transport layered on top effectively producing a stable connection of much lesser speed (though you might get periods of <10kbit here due to prolonged dropouts and/or have to institute an artificial delay if the resend latency is high).
i live in a third-world country, and simplifying a bit, my cellphone plan gives me 55 megabytes a day. i get charged if i go over. that's 2 hours of 64kbps talk time on jitsi but would be 12 hours at 10kbps
Meta's use case are OTT applications on the Internet, which are usually billed per byte transmitted. Reducing the bitrate for the audio codec used lets people talk longer per month on the same data plan.
That said, returns are diminishing in that space due to the overhead of RTP, UDP and IP; see my other comment for details on that.
More than that, in developing countries, such as my own, Meta has peering agreements with telephony companies which allow said companies to offer basic plans where traffic to Meta applications (mostly whatsapp) is not billed. This would certainly reduce their costs immensely, considering that people use whatsapp as THE communications service.
AMBE currently has a stranglehold in this area and by any and every measurable metric, AMBE is terrible and should be burned in the deepest fires of hell and obliterated from all of history.
Internet connectivity tends to have a throughput vs latency curve.
If you need reliable low latency, as you want for a phone call, you get very little throughput.
Examples of such connections are wifi near the end of the range, or LTE connections with only one signal bar.
In those cases, a speedtest might say you have multiple megabits available, but you probably only have kilobits of bandwidth if you want reliable low latency.
Load ratios of > 0.5 are definitely achievable without entering Bufferbloat territory, and even more is possible using standing queue aware schedulers such as CoDel.
Also, Bufferbloat is usually not (only) caused by you, but by people sharing the same chokepoint as you in either or both directions. But if you're lucky, the router owning the chokepoint has at least some rudimentary per-flow or per-IP fair scheduler, in which case sending less yourself can indeed help.
Still, to have that effect result in a usable data rate of kilobits on a connection that can otherwise push megabits (disregarding queueing delay), the chokepoint would have to be severely overprovisioned and/or extremely poorly scheduled.
Correct buffer sizing isn't a good solution for Bufferbloat: The ideal size corresponds to the end-to-end bandwidth-delay product, but since one buffer can handle multiple flows with greatly varying latencies/delays, that number does not necessarily converge.
Queueing aware scheduling algorithms are much more effective, are readily available in Linux (tc_codel and others), and are slowly making their way into even consumer routers (or at least I hope).
Perhaps you know this already (not really clear on what your comment is saying), but Dave Taht is one of the authors of FQ-CoDel, which is what the author of CoDel recommends using when available.
Maybe something like this would be helpful for Apple to implement voice messages over satellite. Also a LOT of people in developing countries use WhatsApp voice messages with slow network speeds or expensive data. It's too easy to forget how big an audience Meta has outside the western world
If you mean for storage, real time codecs are actually pretty inefficient for that use case because they don't get much use of temporal redundancy. Although I'm not actually aware of a non-real time audio codec specialised for voice. They probably exist in Cheltenham and Maryland but for Meta this likely doesn't make a big enough part of their storage costs to bother
I worked for a company 20 years ago that had a modified G.729 codec that could go below 8kbps but sounded decent. We used this for VoIP over dial-up Internet, talk about low bandwidth.
Turns out some of the more interesting bits were in the jitter buffer and ways to manage the buffer. Scrappy connections deliver packets when they can and there is an art to managing the difference between the network experience and the user experience. For communications, you really need to manage the user experience.
It appears to be entirely closed source at the moment. This is just the announcement of development of in-house tech. Nothing public yet that could even be licensed.
Maybe it's just me (or maybe I've invested too much money into headphones), but I actually liked the Opus sound better at 6 kbps. The MLow samples had these... harsh and unnatural artifacts, whereas the Opus sound (though sounding like it came from a tin-can-and-string telephone and lacked all top-end) at least was 'smooth'. But I'm pretty sure that's because they are demonstrating here the very edge of what their codec can do, at higher bitrates the choice would probably be a lot clearer.
It's not exactly reasonable to expect super high fidelity audio at the bitrate constraints they're targeting here, and it certainly sounds a lot better than the Opus examples they're comparing against.
The more complicated the codec, the more fascinating the failure modes. I love watching a digital TV with a bad signal, because the motion tracking in the codec causes people to wear previous, glitched frames as a skin while they move.
A little bit on a tangent, a technique called Linear Predictive Coding, which was developed by telecoms in the sixties and seventies, has a calculated bandwidth of 2.5 kbit/s. The sound quality is not any good, and telephone companies of the time didn't use it for calls, but the paper I read describing the technique says the decoded speech is "understandable". LPC found its way into musical production, in a set of instruments called "vocoders" used to distort a singer's voce. There are, for example, variations of it in something called "Orange Vocoder IV".
So, now I'm wondering, can MLow be used to purposefully introduce interesting distortions in speech? Or even change a singer's voice color?
This is actually an old idea, minus the AI angle (1930s). It’s what voders and vocoders were originally designed for, before Kraftwerk et al. found out you can use them to make cool robot voices.
You need a bunch of bandwidth upfront for that, which you might not have, and enough compute available at the other end to reconstruct it, which you really might not have.
You're adding more complexity to both the transmitter and receiver. I'd be pretty pissed if I had to endure unintelligible speech for a few minutes until the model was downloaded enough to be able to hear my friend. I'd also be a little pissed if I had to store massive models for everyone in my call log. Also both devices need to be able to run this model. If you are regularly talking over a shit signal, you're probably not going to be able to afford the latest flagship phone that has the hardware necessary to run it (which is exactly what the article touches on). The ideal codec takes up almost no bandwidth, sounds like you're sitting next to the caller, and runs on the average budget smartphone/PC. The issue is that you aren't going to be able to get one of these things so you choose a codec that best balances complexity, quality, and bandwidth given the situation. Link quality improves? Improve your voice quality by increasing the codec bitrate or switching to another less complex one to save battery. If both devices are capable of running a ML codec, then use that to improve quality and fit within the given bandwidth.
Does anyone happen to know if ChatGPT's voice feature uses audio compression similar to Opus? Especially the "heavy 30 percent receiver-side packet loss" example sounds a LOT like the experience I have sometimes.
How low can we go? Ultimately we just need to send "who's speaking" at the beginning and the content as text. So about 20 bps. Plenty of room at the bottom.
Maybe SiriusXM can pick this up. The audio quality is generally awful but especially on news/talk channels like Bloomberg and CNBC. There is no depth or richness to the voices.
It actually comes down to the SiriusXM receiver that is being used - I've witnessed the built-in sirius/xm on on the latest GM platform (a $100,000+ Cadillac) sounding like AM radio to immediately sitting in a better-than-apple-streaming quality rendition of the exact same channel on an older lexus a few minutes apart...
The mobile xm receivers (like ipods) that they used to sell also had very good quality and I never noticed any quality shortcomings even with good headphones.
I think the "high" quality stream is 256kbps/16k which is fairly high compared to most streaming services that come in around 128/160.
My old Sirius portable receiver sounded like garbage despite the marketing material saying "Crystal Clear". My 2006 Infiniti Sirius receiver didn't sound any better despite being a massive space heater in the trunk. The later cars I've used it in sound good, at least good enough to sound as clear as FM radio or even HD radio. I think some of the channels are still in lower bitrates like the news channels for example, they've always sounded bad. There's something I've read about SiriusXM using terrestrial transmitters which may improve the signal whereas the satellite link may be of lower bandwidth.
I am archiving some music at 40kbps using Opus and the quality is pretty amazing. I think once things get over 20+kbps all the codecs start sounding pretty good (relative to the these low bitrates).
That is a marked improvement compared to the other examples provided. Nice to see it also has less compute resources required for that higher quality output.
iPhones use Globalstar, which theoretically supports voice bitrates of (I believe) 9.6 kbps, although only using dedicated satphones with large, external antennas.
Apple's current solution requires several seconds to transmit a location stamp of only a handful of bytes, so I think we're some either iPhone or satellite upgrades away from real-time voice communication over that.
Starlink has demonstrated a direct-to-device video call already, though, so we seem to be quickly approaching that point! My strong suspicion is that Apple has bigger plans for Globalstar than just text messaging.
Starlink is in a better position as their satellites are in a low earth orbit - 30 times closer than geostationary. It correlates to 1000 times (30dB) stronger signal on both sides.
Globalstar is LEO as well, although a bit higher (~1400 km) than Iridium (~780 km) and Starlink (below Iridium; various altitudes). In terms of SNR, they're very comparable.
Newer GEO direct-to-device satellites also have huge reflectors and often much higher transmit power levels that can compensate for the greater distance somewhat. Terrestar and Thuraya have had quite small phones available since the late 2000s already, and they're both (large) GEO.
Iridium and Globalstar aren't geostationary. They are LEO not much higher than Starlink.
Starlink is doing direct-to-cell. Talking to existing phones requires a large antenna. The bandwidth for each device is slow, not enough for mobile data, but better than Iridium. I think they recently showed off voice calls.
They claim it's 10% lower than Opus, specifically for the decoder iirc but since they speak of the 10-year-old hardware used to make million of WhatsApp calls daily, the encoder can't be computationally complex either
But, yeah, some actual data (if they're not willing to provide running code) would have been a welcome addition to this PR overview
Have you ever looked at the size of losslessly compressed video? It's huge. Lossy compression is the only practical way to store and stream video, since it's typically less than 1% of the size of uncompressed video. Lossless compression typically only gets down to about 50% of the size. It's amazing how much information you can throw out from a video, and barely be able to tell the difference.
For time discretization, the Nyquist–Shannon sampling theorem[1] says a band-limited, continuous-time signal can be perfectly reconstructed from a discrete-time signal with a sufficiently high (but finite) sampling frequency. Human hearing is naturally band limited to about the range 20Hz to 20kHz, and audio recordings typically use sufficient sampling frequency to losslessly recontruct thos bandwidth.
For quantization, any recorded analog signal is a true signal plus some level of measurement noise. Quantization of a signals can also be thought of as adding some noise to a continuous amplitude signal[2]. If the "quantization noise" is much smaller than the measurement noise of the signal, then the discretization is effectively lossless. Typical audio formats have a maximum quantization error far, far smaller than typical audio recording hardware's measurment error (and the human ear's).
So typical quantized, discrete-time audio formats can be considered lossless representations of the anolog sound signals humans can hear (assuming proper capture and processing). On the other hand, no quantized or discretized signal can losslessly represent a non-band-limited, zero-noise audio signal.
{kind=link}
To keep latency low in real-time communications, the packet rate needs to be relatively high, and at some point the overhead of UDP, IP, and lower layers starts dominating over the actual payload.
As an example, consider (S)RTP (over UDP and IP): RTP adds at least 12 bytes of overhead (let's ignore the SRTP authentication tag for now); UDP adds 8 byte, and IPv4 adds 20, for a total of 40. At at typical packet rate of 50 per second (for a serialization delay of 1/50 = 20ms), that's 16 kbps of overhead alone!
It might still be acceptable to reduce the packet rate to 25 per second, which would cut this in half for an overhead of 8 kbps, but the overhead would still be dominating the total transmission rate.
Where codecs like this can really shine, though, is circuit-switched communication (some satphones use bitrates of around 2 kbps, which currently sound awful!), or protocol-aware VoIP systems that can employ header compression such as that used by LTE and 5G in IMS (most of the 40 bytes per frame are extremely predictable).