This one of those things were the default reaction is to say "Cool! This will be super handy" but then realize your existing computer is still running PCIE4 and and PCIE5 devices are still rare. I didn't realize that PCIE6 was already done and "out".
Consumer devices don't really need the bandwidth doubling, outside power users treating it as a way to have less lane contention instead of increased bandwidth per device, yet. Most of the attraction is for large systems hoping to remotely access/share memory in a cluster. On the consumer side the only thing really close to mattering is "higher speed sequential SSD reads/writes on an x4 m.2 NVMe slot" and even then the speeds are already a bit silly for any practical single drive purpose.
I am hoping for some PCIe x16 Gen N to 2x PCIe x16 Gen (N-1) switches - or even 4x PCIe x8 Gen (N-1).
Modern consumer devices have an x16 connection for a GPU, an x4 connection for an NVMe, and an x4 connection to the chipset for everything else. If the motherboard has more than one "x16 slot", the other slots usually only have an x1 connection!
Want to add a cheap 10G NIC? Sorry, that uses a Gen 3 x4 connection. x16-to-4xNVMe? Not going to happen. HBA adapter? Forget it.
Meanwhile, the GPU is barely using its Gen 5 x16 connection. Why can't I make use of all this spare bandwidth? Give the GPU a Gen 5 x8 instead, and split the remaining 8 lanes into 1x Gen 3 x16 + 2x Gen 3 x8 or something.
Many motherboards do allow splitting the GPU lanes into two it's just not many consumers see the need for an NVMe drive +GPU+ 2nd high speed device + 3rd high speed device that can't be served off the chipset instead.
For the prosumer crowd if you do something like the z790 you can have x4, x8, x8, and x8 to the chipset to be split as needed (x16 to be split if 3.0.
If I understand correctly, you're concerned about using older peripherals with a newer motherboard/CPU? If so, the PCIe spec requires backwards compatibility so it should still work.
A gen3 x4 card in a gen5 x1 slot gets... gen3 x1 speed. Even though gen5 x1 has the same bandwidth as gen3 x4.
So, is there such a thing as an adapter that would plug into a fast narrow slot and provide a wide slower slot with the same overall transfer rate? Or, provide multiple slower (but still just as wide) slots from one faster slot?
A PCIe switch does just that. It connects at its native speed then each port is backwards compatible effectively making wider effective slots if you connect older things downstream.
It can be hard to sort between expensive/high end enterprise stuff from low end single lane stuff for crypto mining when trying to find something useful though. NVMe m.2 storage is the best chance of finding cheep consumer options but even then you have to sort through the endless bifurcation cards to find the ones that are actual switches though.
You're making the same 64k should be enough for anyone argument.
Just because we don't need it now, doesn't mean we won't. Just because we might not, the mere fact it becomes available drives prices of existing drives down. That is something everyone needs. That is something that moves society forward.
No, I don't think it's the same "64K should be good enough" at all. Even then many people were rightly skeptical btw.
As a guy who did the very occasional data science job, my iMac Pro's SSD tops out at ~2.7 GB/s in sequential workloads. For 4.5 years of using it I've only seen 3 programs being able to use its SSD to the absolute maximum, and the tasks lasted 30-40 seconds. So it didn't matter much.
I get it, there are people who do specialized work and are doing it every day and they need absolutely everything that the hardware can give them but realistically your average JS / Python / Golang / Rust dev having a 5700x with 32GB RAM and a 1TB NVMe SSD (e.g. topping at 4 GB/s) is not just quite fine, they are likely over-served even.
As a guy who peeked under the hood of a lot of open-source software, I have found that software is 99% of the bottleneck, even today. Almost nothing has changed.
These are pure hypotheticals and as such are not interesting at all.
People back then knew very well what they'd do with beyond 64K. Unlike you who is simply hand-waving this away by saying "who knows what will we use it for".
You're also forgetting financials which is quite a glaring omission. Modern computer prices haven't dropped much in a while now, like 5 years or so, because the bleeding edge remains expensive. Most people are unwilling to pay bigger and bigger prices for what they perceive as the same processing power -- and their perception is largely correct because software remains the dominating bottleneck in computing power.
So nope, it's not the same 64K argument again. We have companies that desperately want us to believe that we want 512 GB/s RAM modules and we should pay thousands for the privilege of having hardware that is only 0.1% likely to be utilized properly.
People do get hyped up when they see these impressive numbers, yes. But when they see the prices, they suddenly get smarter.
Nowhere am I saying consumers won't eventually use more bandwidth, just not in the current generation of hardware.
Also I'm not sure it really prices existing drives down any as much as prices new classes of drives up. Similar to data center GPUs not making the nvidia 4000 series dirt cheap compared to previous years - nearly the opposite it detracts from focus on the budget standard consumer focused segments
The standard needs to be developed well in advance of the devices that support it. PCIe 7.0 is not coming particularly quickly when compared to past standards.
PCIe 5.0 first draft was out in 2017, final spec released in 2019, platform support first available in 2021, devices that actually supported it on the market in late 2022.
PCIe 6.0 first draft out in 2020, final spec released in 2022, first devices (and hopefully platform support?) out this year.
PCIe 7.0 first draft out in 2024, spec scheduled to be released 2025, devices and platform support out probably a few years after that.
It's not that the standard is moving super quickly, but that because everyone needs to collaborate for the standard to actually be interoperable, you get to see how the sausage is made and so the news about it seems to be out very early.
Hell yes. I will never forget the day that I upgrade from spinning hard drive to an NVMe drive. It blew my mind. That was a "post I/O" moment for me. Up until then, almost all of my computing experiences were limited by slow hard drives. I had "enough" CPU, memory, and network, but the disks were always too slow. NVMe was a 100x improvement.
I still remember apps opening in less than one “bounce” on the OS X dock back in the snow leopard days. That was on a hackintosh with a 7200rpm hard drive.
To be honest, I don’t really remember my first real Mac (a Haswell late 2013 MBP with NVME) feeling all that different. I’m sure large disk operations were faster, and compile times were faster because of the better CPU, but something about that “good enough” snow leopard desktop setup withh spinning metal worked great; maybe they warmed up some caches of apps they knew you were likely to use to make the basics feel fast.
Overall I feel like things have gotten less snappy since then, but it’s hard to be objective after all these years.
I would agree for expansion cards, such as GPUs and network cards. But I would disagree for NVMe drives. There are plenty now. And really, how many do you need? Even if there are three options for PCIe 5.0 NVMe drives, it will be enough. All will be far faster than you will ever need.
For NMVe drives? All the components are made by third party vendors -- except Samsung who makes their own ASIC. As long as your GB written per day is well below their warranty, you will be fine.
Warranties are always presented in terms of years rather than TBW. When shopping you have to go to the manufacturers' websites and pull the data sheets for every single model. Two drives for the same price could both have 5 year warranties but have vastly different endurance ratings. It's similar to x-mile, y-year warranty system with cars but in this case you have to hunt down the x-mile piece yourself.
On top of that, newer versions can release within same product line but have much worse endurance ratings. For example, my old Corsair MP600 2TB drives from 2020 are rated for 3600 TBW. The newer MP600 Core XT and Elite models have 450 TBW and 1600 TBW respectively. My MP600 drives are currently at 1.5-2.0 PB written.
External cable size is limited by flexibility. In theory the 4x variant could drive an external GPU at PCIe 5 x16 bandwidth.
Alternatively, it could drive a 4x16 card and have bandwidth left for fast SSDs and fast Ethernet and various USB stuff at the same time. That sounds great for laptop docks.
I wonder how this might affect GPU access to system RAM. Right now, people wanting to large language models on GPUs are constrained by the amount of VRAM the cards have. GPU access to system RAM is enough of a bottleneck that you might as well run your application on the regular CPU. But GPU access to system RAM is fast enough, then this opens more possibilities for GPU acceleration for large models.
Latency and cache coherency are the other things that make this hard. Cache coherency can theoretically be resolved by CXL, so maybe we’ll get there that way.
AI models do not need coherent memory, the access pattern is regular enough that you can make do with explicit barriers.
The bigger problem is that by the time PCIe 7.0 will be actually available, 242GB/s per direction will probably not be sufficient for anything interesting.
> AI models do not need coherent memory, the access pattern is regular enough that you can make do with explicit barriers.
response to both this and the sibling: even for training, I remember some speculation that explicit synchronization might not even be needed, especially in the middle stages of training (past the early part, before fine tuning). it's not "correct" but the gradient descent will eventually fix it anyway, as long as the error signal doesn't exceed the rate of gradient descent. And "error signal" here isn't just the noise itself but the error in gradient descent caused by incorrect sync - if the average delta in the descent is very slow, so is the amount of error it introduces, right?
actually iirc there was some thought that the noise might help bounce the model out of local optimums. little bit of a Simulated Annealing idea there.
> The bigger problem is that by the time PCIe 7.0 will be actually available, 242GB/s per direction will probably not be sufficient for anything interesting.
yea it's this - SemiAnalysis/Dylan Patel actually has been doing some great pieces on this.
background:
networks really don't scale past about 8-16 nodes. 8 is a hypercube, that's easy. You can do 16 with ringbus or xy-grid arrangements (although I don't think xy-grid has proven satisfactory for anything except systolic arrays imo). But as you increase the number of nodes past 8, link count blows out tremendously, bisection bandwidth stagnates, worst-case distance blows out tremendously, etc. So you want tiers, and you want them to be composed of nodes that are as large as you can make them, because you can't scale the node count infinitely. https://www.cs.cmu.edu/afs/cs/academic/class/15418-s12/www/l...
Past about 16 nodes you just go to a switched-fabric thing that's a crossbar or a butterfly tree or whatever - and it's still a big fat chip itself, the 2nd gen nvswitch (pascal era) was about as many transistors as a Xeon 1650v1. They are on gen 3 or 4 now, and they have three of these in a giant mixing network (butterfly or fat tree or something) for just titanic amounts of interconnect between 2 racks. I don't even want to know what the switching itself pulls, it's not 300kW but it's definitely not insignificant either.
any HPC interconnect really needs to be a meaningful fraction of memory bandwidth speed if you want to treat it like a "single system". Doesn't have to be 100%, but like, needs to be 1/3 or 1/4 of normal memory BW at least. One of the theories around AMD's MCM patents was that the cache port and the interconnect port should be more or less the same thing - because you need to talk to interconnect at pretty much the same rate you talk to cache. So a cache chiplet and an interconnect could be pretty much the same thing in silicon (I guess today we'd say they're both Infinity Link - which is not the same as Infinity Fabric BTW, again the key difference being coherency). But that kinda frames the discussion in terms of the requirements here.
anyway, to your point: pcie/cxl will never be as fast as ethernet because the signal integrity requirements are orders of magnitude tighter, pcie is a very short-range link etc and requires comparatively larger PHY to drive it than ethernet does for the same bandwidth.
ethernet serdes apparently have 3x the bandwidth as PCIe (and CXL) serdes per mm of beachfront, and GPU networking highly favors bandwidth above almost any other concern (and they utterly don't care about latency). The denser you make the bandwidth, the more links (or fatter links) you can fit on a given chip. And more links basically translates to larger networks, meaning more total capacity, better TCO, etc. Sort of a gustafson's law thing.
(and it goes without saying that regardless, this all burns a tremendous amount of power. data movement is expensive.)
the shape this is taking is basically computronium. giant chips, massive interconnects between them. It's not that chiplet is a bad idea, but what's better than lots of little chiplets fused into a single processor? lots of big chiplets fused into a single processor.
And in fact that pattern gets repeated fractally. MI300X and B200 both take two big dies and fuse them together into what feels like a single GPU. Then you take a bunch of those GPUs and fuse those together into a local node via NVSwitch.
Standard HPC stuff... other than the density. They are thinking it might actually scale to at least 300 kW per rack... and efficiency actually improves when you do this (just like packaging!) because data movement is hideously expensive. You absolutely want to keep everything "local" (at every level) and talk over the interconnects as little as possible.
MLID interviewed an NVIDIA engineer after RDNA3 came out, iirc they more or less said "they looked at chiplet, they didn't think it was worth it yet, so they didn't do it. and gonna do chiplets in their own way, and aren't going to be constrained or limited to chasing the approaches AMD uses". And my interpretation of that quote has always been - they see what they are doing as building a giant GPU out of tons of "chiplets", where each chiplet is a H100 board or whatever. NVLink is their Infinity Link, Ethernet is their Infinity Fabric/IFOP.
The idea of a processor as a bunch of disaggregated tiny chiplets is great for yields, it's terrible for performance and efficiency. "tile" in the sense of having 64 tiles on your server processor is dead dead dead, tiles need to be decent-sized chunks of silicon on their own, because that reduces data movement a ton (and network node count etc). And while of course packaging lets you stack a couple dies... it also blows up power consumption in other areas, because if each chiplet is slower then you are moving more data around. The chip might be more efficient, but the system isn't as efficient as just building computronium out of big chunks.
it's been an obvious lesson from the start even with ryzen, and RDNA3 should have really driven it home: data movement (cross-CCX/cross-CCD) is both performance-bottlenecking and power-intensive, so making the chiplets too small is a mistake. Navi 32 is barely a viable product etc, and that's without even hitting the prices that most people want to see from it. Driving 7700XT down to $349 or $329 or whatever is really really tough (it'll get there during clearance but they can't do it during the prime of its life), and idle power/low-load power sucks. You want the chunks to be at least medium sized - and really as big as you can afford to make them. Yields get lower the bigger you get, of course, but does anybody care about yielded price right now? Frankly I am surprised NVIDIA isn't pursing Cerebras-style wafer-scale right now tbh.
again, lots of words to say: you want the nodes to be as fat as possible, because you probably only get 8 or 16 nodes per tier anyway. So the smaller you make the nodes, the less performance available at each tier. And that means slower systems with more energy spent moving data. The analyst (not NVIDIA)'s claim is that he thinks water-cooled 300kw would be more efficient than current systems.
(e: power consumption was 150-200 kW for Cray-2 so NVIDIA's got a ways to go (currently 100 kW, rumored 200 kW) to even to reach the peak of historical "make it bent so there's less data movement" style hyperdense designs. Tbh that makes me suspect that analyst is probably right, it's both possible and might well improve efficiency, but due to the data movement factors this time, rather than latency. Ironic.)
> networks really don't scale past about 8-16 nodes. 8 is a hypercube, that's easy. You can do 16 with ringbus or xy-grid arrangements (although I don't think xy-grid has proven satisfactory for anything except systolic arrays imo). But as you increase the number of nodes past 8, link count blows out tremendously, bisection bandwidth stagnates, worst-case distance blows out tremendously, etc.
I don't think cube/hypercube is optimal, the opposite corner is too many hops away.
For 8 nodes, 3 links each, you're better of crossing some of the links to bring the max distance down to 2. Even better is a Petersen graph that can do 10 nodes at max distance 2.
If a proper 16-node hypercube is acceptable, 4 links per node and most distances 2-3 hops, then better arrangement lets you fit up to 41 nodes at max distance 3.
If you allow for 5 links or max distance 4 you can roughly double that node count, and if you allow both you can have over 200 nodes.
If you let the max distance climb, then it will seriously bloat your bandwidth requirements. But you can fit quite a lot of nodes at small max distances.
> anyway, to your point: pcie/cxl will never be as fast as ethernet because the signal integrity requirements are orders of magnitude tighter, pcie is a very short-range link etc and requires comparatively larger PHY to drive it than ethernet does for the same bandwidth.
Why does the short range link have much tighter requirements, and what would it take to sloppen them up?
As long as the GPU-local memory can hold a couple layers at a time, I don't think the latency to the currently-inactive layers matters very much, only the bandwidth.
They just moved that silicon to the CPU side is all. The same issues existed in the northbridge days particularly in multi-CPU setups where you'd have to go over hyper transport if the memory access was on the other controller.
Not saying these issues don't exist. It's just that they really haven't changed much here except moved logic from the motherboard to the CPU itself.
> You would still be limited by the CPU memory bandwidth, and you will share it with it.
The word I take issue with here is "still", in that today GPUs accessing main memory are not limited by CPU memory bandwidth but instead by the PCIe link bandwidth.
I'm assuming that we will, in practice, still be limited by PCIe link bandwidth; but perhaps much less so.
> It is significantly faster to access memory directly via CXL than to use message passing with JSON or gRPC.
I'm not talking about supercomputing. We're in a thread talking about the feasibility of running larger models on "smaller GPUs".
Do you think that GPUs access host memory using JSON or gRPC?
CXL is nice because it allows coherent, low-latency access to memories. This is not going to move the needle a whole lot on running large models on GPUs, because they are more bandwidth sensitive than latency sensitive, and coherence is not a huge concern.
I also think that RAM interfaces are going to scale much quicker than IO interfaces, so it's at best a temporary win over local GPU memory for inference.
That is significantly more bandwidth than a DDR5 memory bus. Is there something about PCIe that makes it infeasible to use as a memory bus? Otherwise that just seems like a ton of free memory bandwidth just being left on the table.
PCIe is a pretty complicated protocol based on messages. Using this for RAM would mean the CPU and everything will be required to speak this protocol. Using PCIe for RAM will also have impact on latency, which is undesired.
I wonder if this is to help support a newish arch. like the one Microsoft and Intel are proposing (Taipei conf.) with each laptop/pc having a dedicated NPU, CPU, GPU to bring some of the Copilot button back on PC? Everything I see today I inadvertently read in "oh this will help me as a hobbyist". It generally doesn't. Probably just technology doing what it does and moving forward.
SerDes overhead and high pin count? PCIe is not a real "bus" architecture but parallelized hub architecture system. I don't know enough to explain why but these leads to higher power consumption than bus at scale. M.2 SSDs with 3.0 x4 links already had issues with controllers thermal throttling often explained as heat from on-chip serializer/deserializer.
200ns latency for communicating with another CPU or GPU device is pretty good. Just imagine how many microseconds it would take to do all of this over ethernet.
It would be nicer to see the ability to extend GPUs with off-the-shelf RAM, think SO-DIMM clipped to the back of the GPU. Then being able to choose to buy 2 x 64 GB DIMMs or just a 8GB one, maybe also have some GBs of good RAM soldered onto the GPU like it is now. One can dream.
Without being a domain expert, my intuition would be that PCIe is optimized for throughput over latency and there's probably a throughput compromise when you want low-latency access.
Yeah but DDR is starting to move to more complex modulations, CXL is bringing down PCIe latency, and PCIe is starting from a position of elevated competence when compared to other standards. For example, you might expect that PCIe obtains parallelism by sending different packets down different lanes but in fact it shreds packets across lanes specifically because of latency. When PCIe eats another standard, the average quality of the standards ecosystem generally goes up.
That said, memory latency is so important that even small sacrifices should be heavily scrutinized.
I've seen some very recent research proposing just that: https://arxiv.org/pdf/2305.05033.pdf . Of course still far from production, but interesting that in some cases it actually also improves latency.
I dug into this for a hn comment months ago, but I think it's 2-3 orders of magnitude difference in latency. RAM is measured in nanoseconds, PCIe is measured in microseconds
I don't think you've checked those numbers. SSD access is in the order of 10-20 microseconds (10,000 - 20,000 ns) and memory bus access is ~10-15 nanoseconds.
Here's the comment I made a couple months ago when I looked up the numbers:
I keep hearing that, but that's simply not true. SSDs are fast, but they're several orders of magnitude slower than RAM, which is orders of magnitude slower than CPU Cache.
Samsung 990 Pro 2TB has a latency of 40 μs
DDR4-2133 with a CAS 15 has a latency of 14 nano seconds.
DDR4 latency is 0.035% of one of the fastest SSDs, or to put it another way, DDR4 is 2,857x faster than an SSD.
L1 cache is typically accessible in 4 clock cycles, in 4.8 ghz cpu like the i7-10700, L1 cache latency is sub 1ns.
I have absolutely checked those numbers, and I have written PCIe hardware cores and drivers before, as well as microbenchmarking CPUs pretty extensively.
I think you're mixing up a few things: CAS latency and total access latency of DRAM are not the same, and SSDs and generic PCIe devices are not the same. Most of SSD latency is in the SSD's firmware and accesses to the backing flash memory, not in the PCIe protocol itself - hence why the Intel Optane SSDs were super fast. Many NICs will advertise sub-microsecond round-trip time for example, and those are PCIe devices.
Most of DRAM access latency (and a decent chunk of access latency to low-latency PCIe devices) comes from the CPU's cache coherency network, queueing in the DRAM controllers, and opening of new rows. If you're thinking only of CAS latency, you are actually missing the vast majority of the latency involved in DRAM operations - it's the best-case scenario - you will only get the CAS latency if you are hitting an open row on an idle bus with a bank that is ready to accept an access.
https://en.wikipedia.org/wiki/CAS_latency is how long it takes to read a word out of the active row. Async DRAM had "row access strobe" and "column access strobe" signals.
Synchronous DRAM (SDR and DDRx) still has a RAS wire (row address strobe) and CAS wire (column address strobe), but these are accessed synchronously - and also used to encode other commands.
DDR DRAM is organized into banks (for DDR4/5 these are grouped in bank groups), rows, and columns. A bank has a dedicated set of read/write circuits for its memory array, but rows and columns within a bank share a lot of circuitry. The read/write circuits are very slow and need to be charged up to perform an access, and each bank can only have one row open at a time. The I/O circuits are narrower than the memory array, which is what makes the columns out of the rows.
The best-case scenario is that a bank is precharged and the relevant row is open, so you just issue a read or write command (generally a "read/write with auto-precharge" to get ready for the next command) and the time from when that command is issued to when the data bus starts the transaction is the CAS latency. If you add in the burst size (which is 4 cycles for a double-data-rate burst length of 8) plus the signal propagation RTT to the memory, you get your best-case access latency.
The worst-case scenario for DDR is then that you have just issued a command to a bank and you need to read/write a different row on that bank. To do that, you need to wait out the bank precharge time and the row activation time, and then issue your read or write command. This adds a lot of waiting where the bank is effectively idle. Because of that wait time, memory controllers are very aggressive about reordering things to minimize the number of row activations, so you may find your access waiting in a queue for several other accesses, too.
Also, processors generally use a hash function to map logical addresses to physical DRAM banks, rows, and columns, but they set it up to optimize sequential access: address bits roughly map to (from least to most significant): memory channel -> bank -> column -> row. It is more complicated than that in reality, but that's not a bad way to think about it.
CXL supports cache-coherent memories and even the numbers claimed in marketing materials are ~5x when it comes than DDR5 access times measured on desktop CPUs in microbenchmarks. It's still a lot better than having software handle the coherency protocol and could be really useful to allow either very large ccNUMA systems or memory capacity and bandwidth hungry accelerators to access the host DRAM as long they can tolerate the latency e.g. something along the lines of a several SX-Aurora cards hooked into a big host with a few TiB of DRAM spread over ≥16 DDR5 or later channels.
A PCIe 7.0 x4 NVMe Drive would give ~64GB/s. I am not sure if we could unlock any new paradigm with it. But in terms of Gaming even with hardware compression the PS5 with 8GB/s already spends 95%+ of its time in CPU.
Or are we going to do heavy Paging and stick with 8GB of RAM. My Mac currently does about 200-500GB write per day simply due to Kernel_Task Paging from Safari. Both the SSD Controller and NAND will continue to get cheaper and faster. While Production Cost of GB on DRAM hasn't moved much.
The thing that strikes me the most any time there's such a technologically jump is that, judging by the past 30 years, it is very likely that the most common apps, such as Chrome or Microsoft Office, will require these 64 GB/s NVMe drives to work correctly in a decade or so. We will look back at our meagre 4 GB/s NVMe of today as old junk.
I truly wonder what abomination will we create to require that much disk bandwidth in 10 years to run a web browser.
> We will look back at our meagre 4 GB/s NVMe of today as old junk.
Nah, I don't think so. There is a natural resistance against the newer more expensive machines. The non-tech people largely started looking on the area as always chasing the new shinies, and they are absolutely correct.
I as a programmer, had to replace my gaming PC last year because the old one (which was 11 year old) had its motherboard give up. And I settled for 5600x with 1080 Ti and DDR4 RAM and a 4-7 GB/s NVMe SSD.
Some of the more demanding games struggle because the GPU is old but outside of that that machine is impressively and hugely powerful. Even in those games it still keeps 45-60 FPS just fine. I would want to get a better GPU but honestly, the price jump from a 1080 Ti all the way to the 3070 and beyond is just insane and I can't justify it. I am gaming something like 4h a week, 12h in rare cases, usually about 6h.
I really don't see the draw of all these innovations. Servers, surely, okay, but even for workstations I'd think we are much more in a need of machines with more memory channels -- that the Threadripper Pro stations offer -- and not RAM and SSDs that go into the higher double-digits of GB bandwidth. It's very obvious that most programmer tooling is not making full use of hardware resources. You have to go as low as a Celeron J CPU to actually see programmer tooling monopolize your machine. Even i3 CPUs and old Ryzens are flying.
Unless you are crunching data all day every day then a normal NVMe SSD that tops at 7 GB/s during sequential bursts but is otherwise working stably at 2 GB/s, is good enough and then some more.
Chrome pushing for their future WebAI standard, which will allow people to write extremely advanced AGI systems... in pure Javascript.
People are concerned about Bitcoin's energy usage, and do not stop to think how many cycles and joules are wasted running the world, very slowly and inefficiently, on Javascript.
>To achieve its impressive data transfer rates, PCIe 7.0 doubles the bus frequency at the physical layer compared to PCIe 5.0 and 6.0. Otherwise, the standard retains pulse amplitude modulation with four level signaling (PAM4), 1b/1b FLIT mode encoding, and the forward error correction (FEC) technologies that are already used for PCIe 6.0. Otherwise, PCI-SIG says that the PCIe 7.0 speicification also focuses on enhanced channel parameters and reach as well as improved power efficiency.
So it sounds like they doubled the frequency and kept the encoding the same. PCIe 6 can get up to 256 GB/s, and 2x 256 = 512.
In any case, it'll be a long time before the standard is finished, and far longer before any real hardware is around that actually uses PCIe 7.
This answers the question in the literal sense, but I'm nonetheless surprised (as a relative outsider to the world of high-speed signalling).
"just double the frequency" isn't something we're used to seeing elsewhere these days (e.g. CPU clock speeds for the last couple of decades). What are the fundamental technological advances that allow them to do so? Or in other words, what stopped from from achieving this in the previous generation?
I don't think that makes the answer to the question clearer at all. The slight differences in encoding are interesting but they don't answer the big question:
They made a significant signalling change once, with 6. How did they manage to take the baud rate from 5 to 8 to 16 to 32 GHz?
To go a bit deeper, while still keeping it at a very high level what changes were made between each generation:
PCIe 1.0 & PCIe 2.0:
Encoding: 8b/10b
PCIe 2.0 -> PCIe 3.0 transition:
Encoding changed from 8b/10b to 128b/130b, reducing bandwidth overhead from 20% to 1.54.
Changes here in the actual PCB material to allow for higher frequencies. Like changing away from PCB material like FR-4 to something else [2].
PCIe 3.0, PCIe 4.0, PCIe 5.0:
Encoding: 128b/130b
There is plenty to dive deep on, things like:
- PCB Material for high-frequency signals (FR4 vs others?)
- Signal integrity
- Link Equalization
- Link Negotiation
Then decide which layer of PCIe to look at:
- Physical
- Data / Transmission
- Link Layer
- Transaction
A good place to read more is from the PCI-SIG FAQ section for each generation spec that explains how they managed to change the baud rate as you mentioned.
PCI-SIG, community responsible for developing and maintaining the standardized approach to peripheral component I/O data transfers.
PCIe doesn't have to do anything as complex as a general-purpose CPU. Increasing the frequency is a lot easier when you don't need to worry about things like heat, pipelining, caching, branch prediction, multithreading, etc. It's just encoding data and sending it back and forth. We've gotten very, very good at that.
It wasn't really like it was impossible before now - it's just more that it wasn't in demand. With the proliferation of SSDs transferring data over PCIe, it's become much more important - so the extra cost of better signaling hardware is worth it.
Not to dismiss it completely, it's still a hard problem. But it's far easier than doubling the frequency of a CPU.
Why would pipelining, caching, branch prediction make increasing the frequency difficult? Why would heat be less of a problem for a pcie controller than for a cpu?
I see you don't have any responses, so I'll give it a shot. I don't remember the actual math from my coursework, and have no experience with real-world custom ASIC design (let alone anything at all in the "three-digit GHz" range), but the major variables look something like this (in no particular order):
1) transistor size (smaller = faster, but process is more expensive)
2) gate dielectric thickness (smaller = faster, but easier to damage the gate; there's a corollary of this with electric fields across various PCB layer counts, microstrips, etc. that I'm nowhere near prepared to articulate)
3) logic voltage swing (smaller = faster, but less noise immunity)
4) number of logic/buffer gates traversed on the critical path (fewer = faster, but requires wider internal buses or simpler logic)
5) output drive strength (higher = faster, but usually larger, less efficient, and more prone to generating EMI)
6) fanout (how many inputs must be driven by a single output) on the critical path (lower = faster)
Most of these have significant ties to the manufacturing process and gate library, and so aren't necessarily different between a link like PCIe and a CPU or GPU. Some things can be tweaked for I/O pads, but broadly speaking a lot of these vary together across a chip. The biggest exceptions are points #4 and #6. Doing general-purpose math, having flexible program control flow constructs, and being able to optimize legacy instruction sequences on-the-fly (but I repeat myself) unavoidably requires somewhat complex logic with state that needs to be observed in multiple places. Modern processors mitigate this with pipelining, which splits the processing into smaller stages separated by registers that hold on to the intermediate state (pipeline registers). This increases the maximum frequency of the circuit at the cost of requiring multiple clock cycles for an operation to proceed from initiation to completion (but allowing multiple operations to be "in flight" at once).
That being said, what's the simplest possible example of a pipeline stage? Conceptually, it's just a pair of 1-bit registers with no logic between the input of one register and the input of the next one. When the clock ticks, a bit is moved from one register to the next. Chain a bunch of these stages together, and you have something called a shift register. Add some extra wires to read or write the stages in parallel, and a shift register lets you convert between serial and parallel connections.
The big advantage that PCIe (and SATA/SAS, HDMI, DisplayPort, etc.) has over CPUs is that the actual part hooked up to the pairs that needs to run at the link rate is "just" a pair of big shift registers and some analog voodoo to get synchronization between two ends that are probably not running from the same physical oscillator (aka a SERDES block). In some sense it's the absolute optimal case of the "make my CPU go faster" design strategy. Actually designing one of these to reliably run at multi-gigabit rates is a considerable task, but any given foundry will generally have a validated block that can be licensed and pasted into your chip for a given process node.
It makes sense why links can reach higher speeds than CPU cores, but it's not enough explanation for how symbol frequencies got 25x faster while CPU frequencies got 2x faster.
The simple answer to this is that signaling rates were far behind the Pareto frontier of where they could be, and CPU clock rates are pretty much there. CPU clocks are also heat-limited far more than I/O data rates. CPUs are big and burn a lot of power when you clock them faster, while I/O circuits are comparatively small.
Transmitting and receiving high-speed data is actually mostly an analog circuits problem, and the circuits involved are very different than those in doubling CPU speed.
Too much energy is used (and heat generated) at high frequencies. For something like PCIe, you don't need to double the frequency for the whole circuit to double the frequency of the link. You can double the front/back and then double the parallelization of the rest of the circuit. Most of the circuit can still run at a more energy efficient frequency. Potentially it was possible earlier, but the circuit size made it cost prohibitive.
PAM4 allows the frequencies involved to stay close to the same, at the expense of higher required precision in other parts of the transmit/receive chains, so they didn’t “just double the frequency”
>> To achieve its impressive data transfer rates, PCIe 7.0 doubles the bus frequency at the physical layer compared to PCIe 5.0 and 6.0. Otherwise, the standard retains pulse amplitude modulation with four level signaling (PAM4), 1b/1b FLIT mode encoding, and the forward error correction (FEC) technologies that are already used for PCIe 6.0.
Nothing else changed, they didn't move to a different encoding scheme. PCIe 6.0 already uses PAM4. Unless they moved to a higher density PAM scheme (which they didn't), the only way to increase bandwidth is to increase speed.
I'm thinking huge progress recently both on ADC tech and increase in compute power near the rx/tx source, are getting widespread adoption, be it on Ethernet (latest raw lane speed being industrialisés is 224Gbps, useful 200Gbps, and you bunch lanes together in e.g. quad- or octo-sfp/quad-sfp-double-density - not sure osfp-224 is already available...) and get to 800G or 1.6Tbps ifffff you have the switch or controller for this (to my knowledge no Ethernet controller yet - NVIDIA connectx 7 stops at qsfp-112) but it's mostly because of PCIe ?
The future NVIDIA B100 might be PCIe 6.0 but hopefully will support 7.0 and maybe NVIDIA (or someone) gets a NIC working at those speeds by then...
>In any case, it'll be a long time before the standard is finished, and far longer before any real hardware is around that actually uses PCIe 7.
The standard is expected to finish in 2025, and hardware / IP for PCIe 7 are already in the work. Since there is so much resemblance of it and PCIe 6. In terms of schedule it perhaps may be the least lead time of recent PCIe from Standard 1.0 to IP available. The HPC industry is really pushing for this ASAP.
It's not really the same physical interface. The connector is the same, but quality requirements for the traces have gotten much more strict over time.
> Why haven't we seen the need for a PCI-X or VLB-style PCIe interface expansion?
My impression is they use the standards process as a kind of objective-setting function to ensure the industry continues to move forward. They seem to figure out what will be just possible in a few years with foreseeable commercialization of known innovations, and write it down. It seems to have worked for > 20 years.
Yeah, I always see these announcements from the standards body, “we’ve doubled pcie bandwidth again”, but I never see any articles actually digging into the engineering challenges involved, and what innovations have been made to enable such progress.
I would love to get more information on the cost implications of this generational doubling. Are we going to get this “for free”, or does it come with, say, twice the power usage, or a requirement for tighter tolerances on physical components that are thus going to be more expensive to manufacture?
We should pay more attention to the distinction between technologies which are a fundamental advancement, and technologies which are just a way to spend more resources.
Intel have offered us many great examples of the latter: CPUs which are faster, but at great power and cooling cost.
Or, to pick another industry, supercars with incredible acceleration and top speed, but with billionaire-only price tags. I don’t think those are really advanced cars. The true advancements lie in figuring out how to do more with less (like we saw with Apple Silicon), not more with more.
I hope this is all irrelevant to PCIe 7.0 and it does in fact raise the baseline for everyone, but we can no longer take this for granted in this industry.
This stuff tells me it could be only useful for AI things if they get the cost and power down so you don’t need to run the AC in the winter with it on.
I used to use a pc built in 2013 with the then latest-and-greatest, but it did really stop being viable in my games ~early 2022 when they had some updates and four haswell cores just weren't enough anymore. Upgraded to 12th gen intel at that time and quadrupled my fps. (Notably cpu-bound games)
Games that are less demanding can be fine, but if you're playing something where frames matter might be harder to play.
Depends. NVLink advertises bidirectional bandwidth, whereas PCIe and standard networking calculate bandwidth in a single direction. So a 1800 GBps NVLink is actually 900 GBps in PCIe and standarding networking terms.
Therefore, a 512 GBps PCIe would sit between the current H100 NVLink (450 GBps) and next generation B200 NVLink (900 GBps). With that being said, NVLink still has lower power draw and smaller chip area, so it would still have a competitive advantage even if the bandwidth is similar.
I think you've mixed your Bytes and bits here. Not sure where the power and area numbers come from but I'd expect NVLink to be worse on both counts for similar bandwidths since they shipped much, much earlier.
PCIe 7.0 is 512GB/s and not 512Gbps. 512GB/s is the full-duplex bandwidth. It sits between NVLink2 and NVLink3.
Checked your numbers in another thread - excellent breakdown. Thanks for the clarification.
I did not read the original anandtech post so I did not realize the 512GBps already refers to the full-duplex bandwidth. You are right that PCIe 7.0 x16 sits between V100 and A100 NVLink.
NVLink doesn't have as strict latency requirements as PCIe does. Stricter latency requirements mean you need more die area per GB/s of bandwidth. In practice this means that if you think of it from an mm^2 perspective, you can get much higher bandwidth -- higher GB-per-second-per-mm^2 -- with NVLink than you can PCIe. For many compute/bandwidth heavy workloads where that latency can be masked, this makes NVLink a superior choice, because die space is limited.
NVidia advertises their latest GPUs as having 18 NVLinks, but each link is 4 lanes. Make a 72x PCIe link, and you will see that the numbers are very similar.
Recent announcement during GTC was Blackwell would do x2 on nvlink, 900GB/s => 1800GB/s. And iirc nvlink can do multi-node (gpus in different servers) too now... so... no?
NVLink advertises combined bandwidth in both direction, so the 1800 GBps NVLink on Blackwell is actually 900 GBps for everyone else. PCIe can also do multi-node direct transfer via PCIe switches and has been already widely adopted. NVLink still has the power and chip arena advantage even if the bandwidth is similar.
I was just saying they've announced x2 already, around the same pace as PCIe. And it's G-Byte-ps on nvlink, while G-bit-ps on PCIe, right? I'm probably missing something...
Both the PCIe and NVLink numbers here are full-duplex bandwidth. So no, you're not missing anything, you are correct. NVLink 5.0 is far ahead (but presumably it's not actually shipping yet either). Next-gen PCIe 7.0 512GB/sec full-duplex bandwidth actually sits between NVLink 2.0 (300GB/sec) and NVLink 3.0 (600GB/sec).
NVLink 5.0's 1800GB/sec comes from 18 NVLinks, with each NVLink comprised of 2 lanes of 200Gbps (single-duplex). So in normal single-duplex numbers, each NVLink is 400Gbps, and 18 links together provide 7200Gbps. When advertised as full-duplex bandwidth that's 14400Gbps (or 1800GB/sec).
In comparison, PCIe 7.0 uses only 128Gbps lanes: 128Gbps x 16 lanes x 2 directions = 4096Gbps (or 512GB/sec).
PCIe has always been way behind cutting-edge serdes speeds. NVidia just made it more obvious to those working outside of specialist HPC and Networking. But we must cut PCIe some major slack, it has to (eventually) work on relatively cheapo hardware from hundreds of different vendors, in a restricted power and thermal environment i.e. consumer devices.
I don't know either way, hence my question! Is there some fundamental design issue that means NVLink (or ultra Ethernet in the future) are likely to maintain their bandwidth advantage? Or is PCIe likely to close the gap?
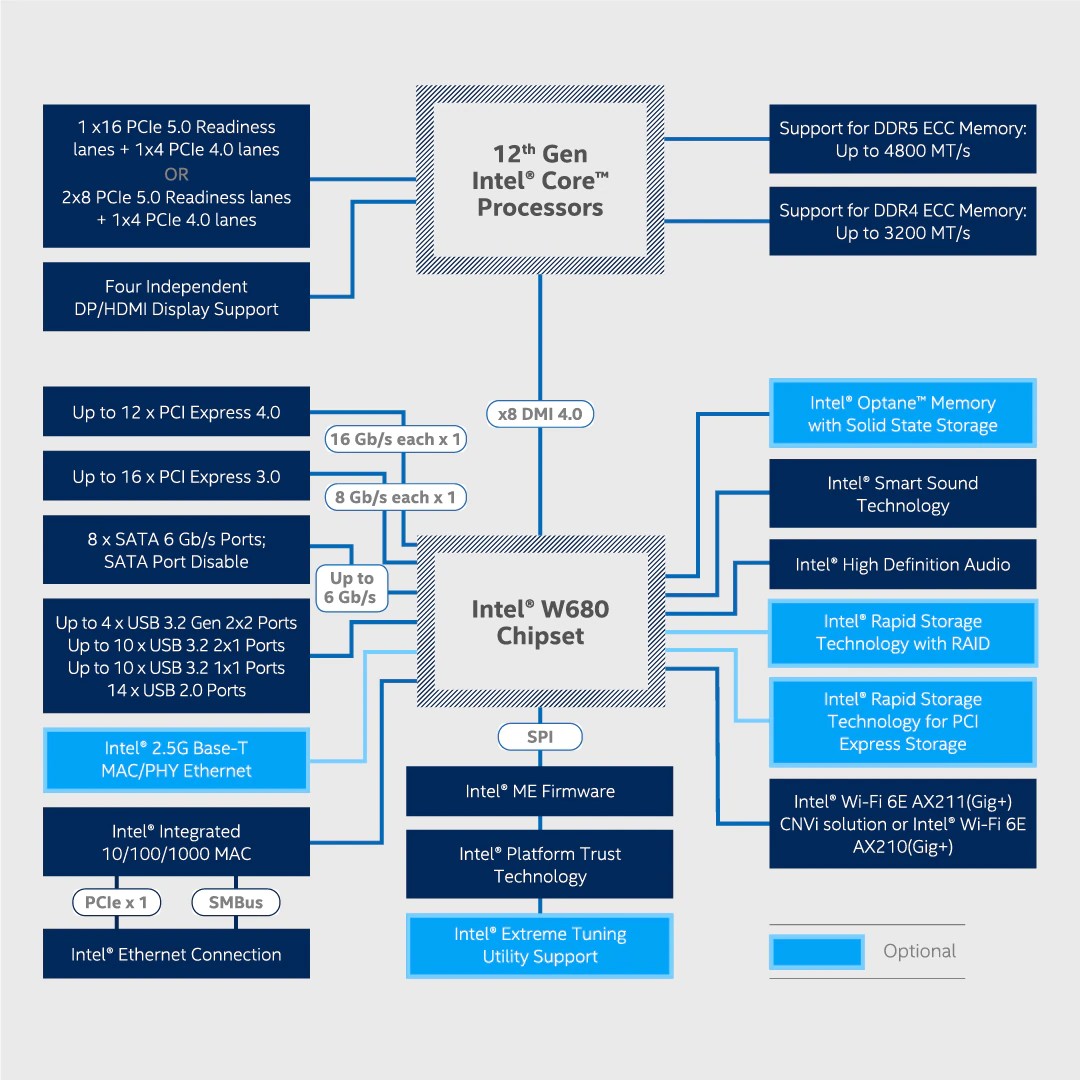
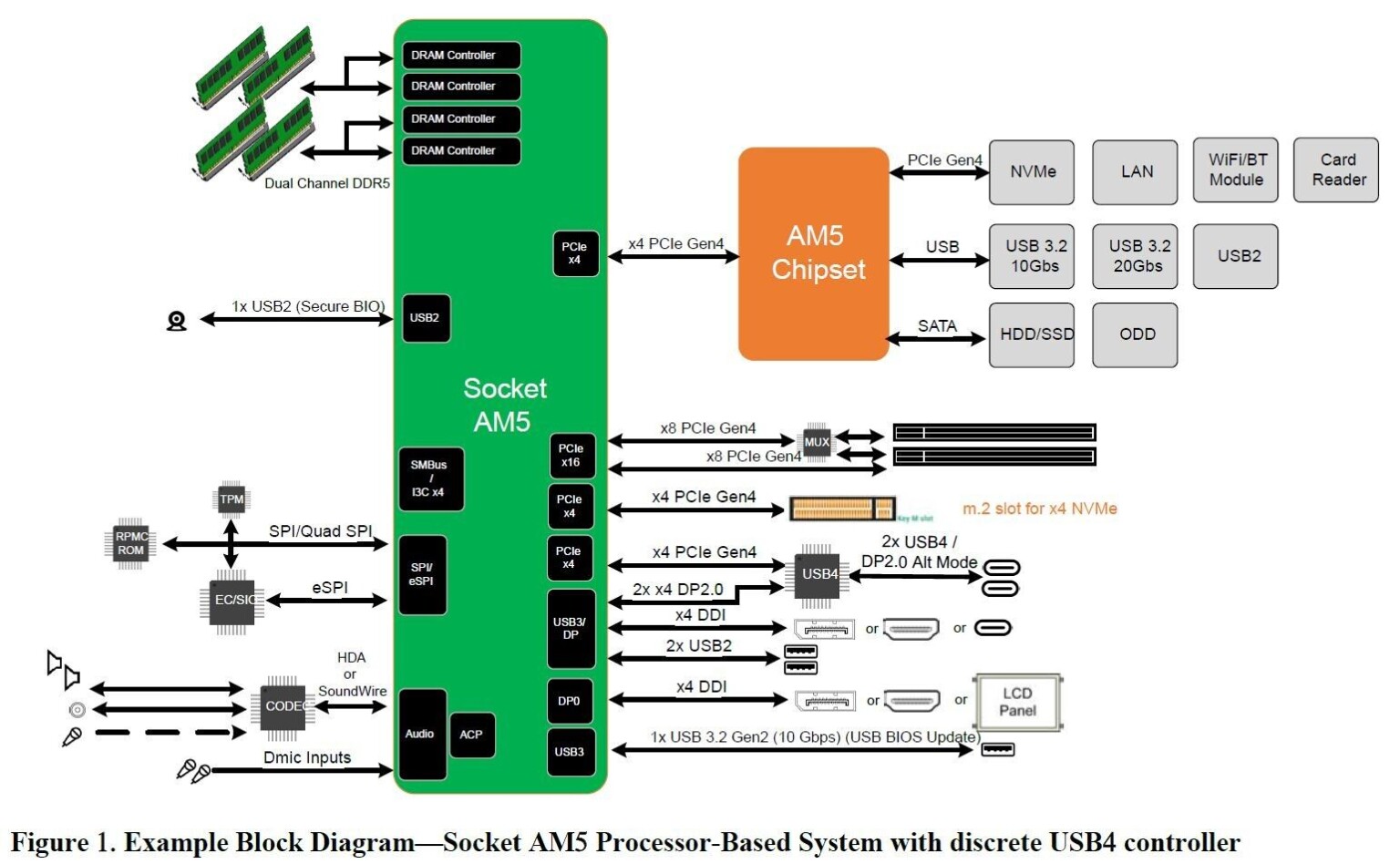
Modern consumer motherboards are in a bit of a weird place at the moment.
Even if you buy the fanciest consumer motherboard out there, you'll find it only comes with one PCIe slot that actually runs at 16x speed, one that's maybe 4x speed (but 16x size), and that's about it.
You want a motherboard with two 16x slots, to run a dual-GPU setup at full speed? Buy a threadripper.
From a market segmentation perspective this makes sense from the processor manufacturers' point of view - get the people who want lots of IO onto your high-margin server/workstation product range.
Back in the 1990s you needed to plug in a graphics card, a sound card, an ethernet card, maybe a separate wifi card, and so on, each of which would use exactly one slot - but these days other than the GPU, it's all integrated on the motherboard already, and the GPU might block 2 or 3 slots anyway. So modern consumer motherboards still sell OK despite having fewer slots than ever before!
That's not the motherboards fault, the PCIe controller is on the CPU and needs to have corresponding I/O pinout on the socket. And even from the CPU manufacturer side, it's not artificial market segmentation. The I/O die alone on an EPYC/ThreadRipper Pro is more than double the die area of the CPU, GPU and I/O chips in a Ryzen 7 7800, and it's on a single chip which makes yields way worse. The socket and package need 1700 connections in one case and 6000 on the other. The high I/O CPU is way more expensive to manufacture, and on the lower end the prices start at ~1k for 512 GB/s of full duplex PCIe bandwidth and 12 memory channels.
The 1x16/2x8 GPU port and 1x4 M.2 port goes directly to CPU, Rest of ports come through the Chipset/PCH/Northbridge/Southbridge/however you call it. The CPU-Chipset link is not real I/O bus coming from CPU die for quite some time. So motherboard brands can't just offer x16 to everyone.
Breaking out full sized full speed buses was possible with PCI and PCI-X because those were real buses bridged to real CPU buses. That's not the case with PCIe.
Some of the fancier PCIe 5.0 motherboards out there today actually do have two PCIe 16x slots -- one 5.0 and one 4.0. So you can run dual-GPU, though I don't see a reason to do this anymore except some niche GPU virtualization stuff. (multi-GPU proprietary tech is dead, DX12 mGPU never really took off, etc.)
> Even if you buy the fanciest consumer motherboard out there, you'll find it only comes with one PCIe slot that actually runs at 16x speed, one that's maybe 4x speed (but 16x size), and that's about it.
Maybe in the Intel World, this is true. Intel has always played games at consumer's expense...
Here's the cheapest AMD AM5 socket ATX mobo sold by NewEgg, complete with two (2) 16x PCIe gen 4 slots[1].
Here's an AM5 mATX board with two (2) 16x PCIe gen 4 slots[2].
Eh, on both boards the 2nd PCIe x16 slot only has 4 PCIe lanes - physically its an x16 slot and you can put x16 devices in it, but they will only be able to talk x4 speeds.
My board two slots PCI-E 5.0 that work as x8 to CPU if both used to x16 if only one used. As well as two PCI-E 5.0 x4 m.2 slots.
To my understanding on a consumer market there isn't much that can utilize that much bandwidth. Current consumer GPUs tap out at 4.0 speeds, but use 5.0 (probably due to "more number more better" marketing). To benefit from 5.0 for NVMe it has to be very specific access patterns.
It's only sad on Intel side because they want strong market segmentation and got away with it because AMD wasn't a competitor for years.
I think there are a surprising number of people who would use two x16 slots (not the latest generation bandwidth requirements, just the electrical connection to support older products at full speed), one for a GPU, one for something like a networking or storage card. But it makes workstation and server class offerings weaker in comparison.
Well, for that I have a board from Super Micro with Epyc in it.
NICs that can utilize x8 from PCIe 5.0 or even 4.0 probably don't usually go into consumer or even prosumer hardware. PCIe 3.0 x4 is enough for a single 10G NIC. One PCIe 4.0 x8 can handle 4 of those, double that on PCIe 5.0.
There is currently no GPU on a market with PCIe interface that can utilize PCIe 5.0 x8 fully.
Storage is probably the only area where what you get from PCIe is not enough. However, by the time such bandwidth makes sense - the price of CPU and motherboard is a drop in a bucket, and you are probably limited by more than just the number of PCIe lines.
Sure, but outside of a few SSDs (that aren't worth buying currently, need to wait for the 2nd gen pcie 5 controllers to tame their power draw), what consumer (or enthusiast) hardware is actually using PCIe 5 right now? If you slot 2 4090s into those x8/x8 5.0 slots, they'll "only" run at x8/x8 4.0 speeds.
As much as anything that's also due to Intel limiting lanes to on consumer CPUs keep from competing with their Xeon line. But yeah make each lane fast enough and it's less of a concern.
Yeah, I mean for AM5 platform for example, it would have been awesome if some motherboards took x4 PCIe 5.0 lanes and turned them into x16 PCIe 3.0 lanes or something like that. That would benefit me way more than the current AM5 motherboards out there.
Of course, as you note, the reason we don't see this is likely because the PCIe switch chips cost more than the rest of the motherboard.
It was kinda like that with regular PCI before PCIe as well. A single gigabit NIC could saturate the 133MB/s bus, so two or more wouldn't let you build a router with two full speed gigabit NICs for example.
I linked the section of the PCIe Wikipedia article that could be updated with this latest 512 GB/s spec ann, which is newer than the 242 GB/s max spec listed in the infobox.
The 242 GB/s in the Wikipedia article is the per-direction bandwidth available after removing the encoding overhead. The 512 GB/s in the headline is the raw bi-directional bandwidth. Both are actually the same number.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}