> A better approach is to optimistically merge most changes as soon as not-rocket-science allows it, and then later review the code in situ, in the main branch. And instead of adding comments in web ui, just changint the code in-place, sending a new PR ccing the original author.
This may work for small projects or open source projects that generally receive high-quality PRs, but this sounds truly infeasible for large teams or organizations.
There are a couple reasons why the code review process occurs before merging. First, it helps keep the canonical version of the codebase in a "correct" state. This is, ironically, an extension of the "not rocket science" principle that the article mentions. Without this invariant, any checkout of the codebase might contain what is essentially "WIP" code that will waste other engineers' time if they have to interact with it. Second, the social pressure of blocking someone else's work is an important and necessary force for motivating code review. The idea that folks will go back and review code that's already been merged is akin to "will add tests in a followup PR". It's a pleasant lie we tell ourselves, but it rarely comes true.
Relatedly, the article also seems to suggest that the code REVIEWER should be providing the changes necessary after code review. This is problematic for so many reasons: first, it places an even higher burden on code reviewers' time which no one wants; second, it encourages poor code hygiene if someone else is just going to fix up your crappy work later on; third, it robs junior engineers of what is perhaps their most valuable learning experience: getting feedback from more experienced engineers and acting upon it.
(there are other issues here; the general thesis of the article leans heavily towards making code easier to _write_ rather than _read_, which again I think it just not appropriate for a codebase with a significant lifetime or number of contributors)
> Second, not every change needs a great commit message. If a change is really minor, I would say minor is an okay commit message!
I want to slightly disagree on this for folks who are early on in career e.g me; I think there is a lot of value in learning to communicate precisely and having a habit of writing good commit message has certainly improved my skills, both verbal and written.
Even though, this activity appears futile for a minor change; it might help to improve other skills :)
Let's say your fix causes issues later. When I read the commit message, I want to understand what you were trying to fix so I don't accidentally re-introduce the problem when I fix your fix
Do you totally disagree that this is the minimum? I'm only saying that the context is the minimum. I refuse to disagree with you about things I'm not saying.
I'm disagreeing to both points. That's not an acceptable commit message at all. I don't need to know you were working on drivers, that's obvious from the files you were working on. The minimum for a commit message should be the why, not the what
For that you have external bug tracking systems. Although I tend to have a short summary and mention the ticket number. Therefore the comment stands alone but also has that extra detail outside.
At $work, I noticed someone was regularly committing with just a dot . as a commit message. The problem was that this repo does not have automatic scss => css for whatever reason and there's a designated person who untangles the mess and fixes people's bad scss and regenerates the css files (among other duties). After about a few dozen times, they just started putting a dot as a commit message.
Point is bad commit messages are sometimes a symptom to a larger problem and as with this vendor it is often a process problem, not an individual developer problem. In my opinion, the main problem here is that management simply doesn't care she it doesn't empower leads and developers who should care.
I agree such patterns are indicative of systemic issues. In my experiences, those process issues emit their own structured behavioral patterns. In your example, the "." commit is now a convention that indicates a specific process happened. I am not certain what the costs of fixing the root problem are, though I'd anticipate they could be expensive and difficult at this point given the time commitment to restructure the repo and automate the scss=>css. Whereas the expense of an esoteric "." commit appears relatively cheap given the need of a human to untangle the mess which cannot be automated away (without a redesign).
There’s another way that feels totally unnatural at first, but puts the subject (the most important part) of the commit message first. It makes the commit about the change and the code, rather than the author. This is how we do it in all of our projects. I fought it at first, but I was wrong and it’s a lot better.
Example:
EntityStore build method records the specifier argument when given
I would strongly disagree with it, because it misses the opportunity for using the commit message as a sanity check. Accidents happen, sometimes I select the wrong file for the commit, or include changes I didn't intend.
Even for the most minor commits, including "improve comment formatting ; utils.pl" allows skimming that message and comparing it to the actual commit.
It also helps me be aware of what I'm doing, pointing and calling style.
To nitpick, the git commit already contains information about which files are affected; adding it explicitly to the commit message does not add value and, like comments, may be incorrect. I like the angular style guide's concept of "scope", like, what category or module of the application does it apply to.
That said, an "utils" file is often a smell in code organization.
> the git commit already contains information about which files are affected;
Contra: while this is true, it's worth considering how 'information about which files are effected' scales when examining the history of a repo. A commit message that simplifies and clarifies the intent is more useful than one that requires a future reader to read each git commit in full to understand the effect.
Even something that simple falls into what vs why: You can tell it was spacing from the diff, so the commit message should be "linting" or "alignment" or something similarly more meaningful.
The diff may not be visible. The person might be doing a complicated cherry pick or merge and scrolling through hundreds of commits. If the message explains it, it saves them digging in.
My analogy is your bookshelf books still need jackets!
I’d take it one step further: if `git log`—a hierarchical view of the connection of commits—is the only way you (and your team) interact with commit messages, then yea it’s probably fine.
But, I think the value of commit messages become really apparent once you (or your team) are relying on other visualizations of commit messages like `blame` and `bisect`
Tracking down the introduction of a bug with bisect and resolving to a commit whose message in “minor”, because the person in the past didn’t think this change was important enough to describe intent can quite the temporal foot-gun.
I'm a beginner dev and I find it very odd both that vscode tries to limit my commit messages to 50 or 55 characters, and also that python linters want to make my lines of code so small. What's the reason behind this? Old small monitors of the past?
I also don't get why fediverse, mastodon seem to limit characters on a post, mimicking the stupid twitter, which is a niche social network. I way be wrong about the limit (never tried), but these platforms feel for ignorant outsiders like twitter-clones with a different infrastructure.
There are plenty of good reasons for short line lengths. Two factors constrain the max line length down to something not much more than 80 columns: side-by-side diffs and waning eyesight.
In-line diffs mix the flow of change in with the flow of execution, both going down the page. Side-by-side diffs makes those two axes orthogonal. With decorations (either in a terminal or a code review tool) even 80 column code requires a fairly small font. Editing two panes of code only needs 161 columns but a decorated patch might be more like 170.
The point font size is its height in increments of 1/72”, and most fonts are half as wide as their point height. The largest font one can use on a 27” monitor (24” wide) is 20pt. My eyes get knackered at anything smaller than 18pt.
Hah, this reminds me of my C++ professor requiring a max line width of 80 characters. My first question was “why not more!?” aswell.
He would have the homework submissions compiled to LaTeX and printed out - then he would write comments by hand. 80 characters was what would fit on a line. If you had more characters, lines wrapped wrongly and you’d get incorrect looking code - so he refused to grade.
I’ve since warmed up to the max line width idea. It’s nice to be able to read code on a small width window (I’ll rarely have a single full screen window with just code) and ensure each line is a valid syntax (and not unreadable due to softwrap in the editor). But I still think 80 chars is a bit extreme. 120 is nicer in my opinion.
80 char limits used to be very common in school and business, I’m old enough that most of my professors preferred it, and most students actually did too. My first programming jobs required it as well. There were a few students who felt limited, or had fun intentionally acting flippant or incredulous about these limits when their screens were more than 80 chars wide.
The rule is slightly anachronistic now, and originally came from the time when CRT terminals (and printers) were 80 columns of text, and there was no graphical window manager. The rule was primarily about making code comfortable to read for everyone involved, to meet the minimum display with of anyone in the group. If you have a wide display but I don’t then it sucks for me. Plus I’m pretty sure that when I first started programming, a lot of printers and text editors and a lot of software wasn’t very good at handling long lines and characters would get mugged or discarded. Almost everything today will just wrap and display reasonably, but that wasn’t always the case back in the days of ed/edlin and earlier.
These days I hardly ever hear about width limits anymore, though it does come up every once in a while when people have to work a lot in terminal or ssh sessions. I do have to drop into Linux non-graphical mode all the time, and even edits files and build code sometimes, and code that’s wider than the display is less fun to wade through. People still like having a reasonable limit, like we’d definitely get complaints if we start writing code that’s 500 characters on a line, right? :P
Independent of the origins of the 80 character line lenght rule. Some say it originated on punch cards. It is a useful rule. Classical news papers also have narrow columns. Why? Because it helps reading.
On my docked laptop with a quad-split 43” 4K, I am definitely in the camp of wider is better.
Then I pull out my 13” Air and remind myself that there are reasons for limits. For Python, I just default to black, which is 88 chars. Easier to not argue with people that way. Plus, I’m free to write it with super wide columns if I want, and then let my precommit hook fix it.
The first is agreeing on a width limit, whatever that width might be. Such a limit might already be controversial but it seems to make sense.
The second is the question of what that width limit should be.
There's a fun story about the with of our railway gauges and roads and Roman chariots that has the lovely quote that if you"...wonder what horse's ass came up with it, you may be exactly right."
The first line of the commit (the subject) should be short, succinct, but descriptive, because this way it will fit in all kinds of GUIs, CLI whatnot. There are a lot of interfaces for Git you doesn't even know about.
Not sure if you mean the git commit "title" and the "body", but the way git works is that the first line is the summary/title and then a blank line, then the body/description.
I really like this approach, a nice short message with a summary, followed by a longer description in the "body".
One feature I really like from GitHub is you can set an option when merging a Pull Requests that when merging the commit title will be the Pull Request title, and the body of the PR as the message.
I don't think the first example is a long line. Imagine opening a book, and to have to read sentences that span both pages rather than just one. It's uncomfortable for the eye and it makes it harder to keep track of the motion of finishing one line on the right, and starting the next one on the left.
Similar to how websites employ a lot of white space, imagine if instead the text went from the first pixel on the left to the last one on the right, it feels awkward.
Ideally, you would never access deep props like that. First it's easy to make a mistake, and secondly each of those keys can fail if the dict doesn't contain that prop. You probably want to de-structure it first, depending on the language, or use a path getter that has a fallback value (or even better, use strictly defined object types). Long lines are usually a code smell and harder to visually parse and understand. I don't adhere to 80 chars, but somewhere around 100-120 is comfortable.
both of the lines you've showed are poorly readable.
not for the length itself, but for the attached mental needs needed to understand the `MyDict` data structure (that is the only variable here in your expression).
that said, having a max-length, apart from the eyesight reasons, have this nice side effect that make it blatantly obvious that one expression is definitely too complex, as you've shown in your second example
it's very clear indeed, but makes the code much harder to navigate in my opinion, and makes it look more complex than it really is, particularly for absolute beginners. In python, specifically, where indents matter, these line breaks seem very confusing for those starting to learn.
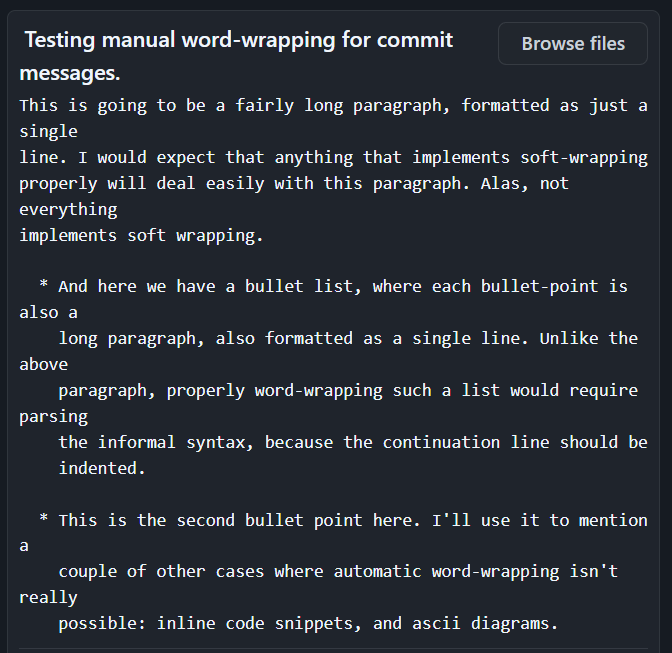
It's useful in situations where you don't have the entire commit message expanded on screen. For example, when running `git blame` on a file, or the same functionality in a web UI like here: https://vincenttunru.com/img/Commits-are-documentation/annot...
As for regular code, similarly, there are situations where the code doesn't take up the full screen, e.g. in split-screen mode, or viewing a side-by-side diff.
That said, there's a balance to be struck between facilitating those use cases and facilitating the common use case of reading (or even writing) the code, and there's no clear "right" answer. Which is probably why there are so many debates on this.
> I'm a beginner dev and I find it very odd both that vscode tries to limit my commit messages to 50 or 55 characters, and also that python linters want to make my lines of code so small. What's the reason behind this? Old small monitors of the past?
On my laptop with a 13.3" 1080p display I can fit two side-by-side terminals at 87 characters wide (two of these are used up by vim to display git symbols and linter markers, I don't use a number line).
This is not because I can't afford a laptop with a bigger screen, but rather that I value portability, lightness and thinness over screen size. That being said, on larger desktop monitors I also value easy readability meaning that the font size is usually so large that I don't get much more than 90 characters per column.
This means I can have a man-page or other form of documentation as well as an interpreter window on the right side of my screen (in two stacked windows) and the code on the left side of my screen.
I really don't even quite understand how people handle the defaults of VSCode with its enormous directory tree column and the minimap. about 40% of horizontal screen space is wasted in the default VSCode configuration. I mean, to some extent, multi-monitor setups help solve this, but again, I value portability and while I do have a multi-monitor setup, I don't want to be reliant on it to be able to comfortably get work done.
So, at least for me, there's an enormous amount of value in keeping things to 80 characters in width. This doesn't mean I never go over that limit, it just means that most of my code is comfortably readable both when using a small laptop and when using a larger desktop setup.
The other main reason is making it easier to read. It's not that helpful or easy to keep track of a line which is 120 characters long. Not least of all because in my setup it would either end up off-screen or badly hard-wrapped. There's a reason newspapers still use columns and it's so it's easier to keep track of where you are in a paragraph. Now in code, it's not usually 10 120 character lines one after another, but usually it's still harder to make sense of what you're looking at when it's one really long line.
Yeah it made sense for old monitors and then a lot of people got into their minds that it was some kind of rule that could never be changed.
The limits you should observe today are more like:
* Code line length: ~120-140 characters. Longer than that and it gets unwieldy especially in side-by-side views. But you don't need to be strict about it. It doesn't matter if the occasional line overflows. The best code formatting algorithm I know (the Prettier algorithm) doesn't have a strict limit.
* Commit subject length: 72, because Github will overflow anything longer into an ellipsis.
* Commit body line lines: No limit (unless you are developing the Linux kernel). I don't know of an interface other than email that doesn't wrap them.
(You're going to get a lot of old farts disagreeing with this advice, but don't listen to them.)
>>> (You're going to get a lot of old farts disagreeing with this advice, but don't listen to them.)
"I used to be with 'it', but then they changed what 'it' was.
Now what I'm with isn't 'it' anymore and what's 'it' seems weird and scary.
It'll happen to you!"
seriously, it's not "being old farts", it's being reasonable with your eyes and your tools: while you may have 20/20 eyes, you will agree with me that viewing a diff of two columns of code at 10px fonts is not an happy thing to do, as the difference may be just a comma or a dot, and those on a 15" 4k monitor are about 0.3mm. And you cannot really view the whole columns without scrollbars or overflows if you set the font much bigger.
2. `git log` in a full-screen terminal wraps at window width, not at a readable length.
3. In VS Code in Magit, lines are not wrapped at all by default. It is possible to enable wrapping, but then they are wrapped at the screen edge, not at a readable line length. I _think_ VS Code actually has a setting to visually wrap at column, but I wasn't able to make that work.
Additionally, if you look at that commit message, you'll see that, to properly soft-wrap it, you'll need a markdown parser to recognize an indented bullet list. VS Code actually wraps that list correctly, but I expect very few other tools to do that.
(Every time I see someone advocating for _not_ wrapping plain text formats, I can't get an image of a hammerhead shark sitting in front of a 16:9 display out of my mind :-)
For me it’s one of those things without a “scientific” answer, but the status quo is good enough that it’s easier to just go with it and never think about it again. Like linting and autoformatting, tabs vs spaces, all trivial stuff that detracts energy from building a product for customers.
I've written a lot of code in a lot of different languages and have preferences for each that are based on the general type of code that tends to be written. E.g. what length are the identifiers and standard function names, what is the standard spacing, how are idiomatic language features used.
My subjective opinions on a few of them:
Java I find works well with a soft 100, hard 120. The language and library tends to prefer and encourage longer class and function names, and these are often repeated multiple times in a single line.
C# seems to work well with 100.
Rust I find well works with 100, and this is the default out of the box format for rustfmt.
Javascript (especially with 2 spaces) works well with 80 characters.
When writing code for documentation sites (e.g. https://ratatui.rs/tutorials/hello-world/), often the code block fits in an area which is surrounded by prose with a width optimized for reading. The resulting width of the code block tends to be ~80 or less. It's worth making this tweak to your formatting for such example code.
> 80 should be fine for most single lines of good code in most languages.
It feels like what's doable in one language, might be a bit more restrictive and annoying to follow in another one. For example, Java, when written in an idiomatic way, with verbose variable names etc.
> tries to limit my commit messages to 50 or 55 characters
The tools try to limit the summary line of Git commit message to 50 characters. Not the whole message. That is a useful convention. The usual convention is described here: https://git-scm.com/docs/git-commit#_discussion
Yeah the git thing is just a dumb hangover from very old times that really should not exist anymore. The lines should be as long as they need to be, and the frontend like the git CLI or GitHub can wrap them if needed. Thats how we do it in literally any other sane context because the frontend has the information on the available display size. "ls" doesn't randomly force you into 80char columns it adjusts. I don't like break this comment every 50 chars either. Only in git world everyone accepts this insanity.
Join me, ignore the dumb red lines and make your commit message as long as you like. Linters are usually easy to configure and set to wrap at e.g 120 as well.
Instead, adjust the asserts such that they lock down the current (wrong) behavior, and add a clear // TODO: comment explaining what would be the correct result. This prevents such tests from rotting and also catches cases where the behavior is fixed by an unrelated change.
Don't do that, because they are still comments and even worse, the tests are lying. In pytest, there is a way to tell that those tests are expected to fail: xfail, so it will show in the test results every time and it's clear it's just a temporary things and should be fixed.
> Second, not every change needs a great commit message. If a change is really minor, I would say minor is an okay commit message!
It's very hard to rank them, but very high on my list of things that make me want to send people actionable threats is when I'm searching down the history of a bug to figure out if it was a deliberate change that had unexpected consequences or just a mistake is when the git blame path ends on a commit like this.
I don't care how minor you think your change is, if you're working on something collaboratively you need to express intent in your commit messages!
If I'm working on something "by myself", I'm really collaborating with my future selves, who will appreciate the information that I'll forget after the next context switch.
No change is minor enough that you don't need to explain what it does.
If the commit message is "fix indentation" then I will ignore it and skip over it while searching the commit history. If it's "minor" or "fix" then I have to open the commit and look to see what it actually is.
These "minor cookies" add up rapidly.
(side note, people that squash important changes together are also on The List)
To be pragmatic, the number of times I’ve had to fix or outright create CI for other teams because they didn’t bother to add these basics is too damn high.
For anything with my team (or personal projects), where I can be guaranteed everyone understands exactly what I’ve set up, I add a pre-commit hook to fix minor linting issues and then add the change to the commit. If black, tf fmt, shfmt, etc. can just fix the problem, then do so, and don’t bother asking me if I’m sure.
> I think the authors point is that some changes are so minor that elaboration is not required, like changing indentation.
Is the change _just_ changing indentation or is it changing something else which is hidden by a bunch of indentation changes?
The difference between a commit message like "reindent" and "." is that the former makes it clear that the change is intended to be completely superficial and (unless you're writing python) should have no impact on anything.
Now the person who wrote that commit message may be lying, or may have made a mistake, but, with even a commit message such as "reindent", it's much easier/faster to approach the issue if your bisect lands on such a commit message as you can go straight for "well let's normalize both versions to see if there's an accidental change hidden in here" rather than getting frustrated trying to figure out what the commit was about.
> But most people also tend to squash several changes together, because it's easier.
Don't.
I also disagree with the author of the article about having an unclean history, it's not that hard to keep a clean history and, combined with actually properly splitting and isolating changes, makes it much easier to review the code. Proper use of git isn't solely centred around making bisect work.
This. If it looks like my change is blowing up in prod at 4 AM, and I didn’t write down what I was trying to do, you are absolutely entitled to wake me up and demand an explanation.
>if you want to reliably record file moves during refactors in git, you should do two commits: the first commit just moves the file without any changes, the second commit applies all the required fixups.
Yes this will record a file move in one of the commits but if you diff between before and after the two commits a file move might not be shown. When thinking about file moves in git it is worth remembering this comes from the diff tool not from the commits since the commits just show the state of the file system at the point it is committed.
The fact that Git is incapable of effectively tracking files across moves is such a failure of Git. It’s critical information that ought to be robustly tracked.
I dunno, it kind of makes sense. If you do just rename a file it can track it. If you do more than renaming, it immediately becomes ambiguous as to whether you actually renamed the file or just deleted it and made a new very similar file. Or multiple similar files.
I think the real failing is that it isn't very good at handling the "rename and slightly modify" case, even when it theoretically could. Of course it's non-trivial to detect that case, and there are flags you can use to improve the detection but it's still not great in my experience.
It might make sense to allow adding hints to the git commit message to help it. Dunno if anyone has tried implementing that.
I think GP's point was that there is an argument that `git` should be able to track "real" metadata about what changed. e.g. `git mv foo bar` should be able to record that "foo" was definitely renamed to "bar" - even in the presence of massive changes. Whereas `git rm foo; git add bar` should be able to record that "foo" was deleted and "bar" was added, even if the files are substantially similar. And that this should be more meaningful to `git` itself than just hints in the commit message.
(Personally, I've not come across the need for such a feature. But I can understand why people might want to have it be available.)
Files just need to know where they moved from, if anywhere. Copy, modify, delete operations can be auto-detected almost all of the time. Lineage can be edited after the fact if needed.
If you use “svn mv” inconsistently, you rapidly land in conflict resolution hell (this was a nearly weekly ordeal on a former team). If you forget to use “git mv,” git still works.
The flipside is when two files are combined, git blame can track history across both sources. Can't do that when explicit moves are recorded, one of the source files would be recorded and the others treated as new lines.
Moving single functions or groups of lines (like extracting something common into a function) I'd say is more common than even that, and this same functionality tracks those changes across files too.
Due to (async) code reviews slowing down the development, we've adopted some workflows described at https://martinfowler.com/articles/ship-show-ask.html and it's working out pretty great. The committer decides how many approvals they need to merge a pull request, based on how confident they are about the code they wrote. This allows us to quickly merge small incremental improvements that would otherwise be bundled in a crowded feature pull request.
I feel like the number of reviewers should be predicated more on how well the reviewers understand the relevant part of the code review.
Most code review tooling is too coarse in the sense that it expects a small number of reviewers to know the full context of the change or has too many reviewers that slow down things.
Tools to show relevant parts of the change to specific reviewers and potentially break apart a large change into smaller ones automatically will go a long way especially in large scale codebases or when team sizes are large enough that the full context is not understood by everyone on the team
That is a technical solution to something that could be handled by the team. While tooling might help people in the team still have to make same and sound decisions like unblocking team member that needs to do a quick fix.
Why bother keeping minor commits in feature branches? They just clutter the main branch without adding any useful information that a future maintainer could use.
because squashing multiple changes into one change for the sake of decluttering is irreversible and also unnecessary, since whomever wants to view the log in such a squashed manner can do so with a flag
If the minor commits are related to the feature branch, by all means squash it into the feature commits if you feel that makes your feature branch easier to review.
However,should you, while developing your feature, find some minor thing that needs improving (e.g. adding comments, spelling fixes or tests to some existing API you encountered while developing your feature), it can be better to keep it separate, so there's fewer red herring in both the history and the review.
> That’s why for typical project it is useful to merge pull requests into the main branch — the linear sequence of merge commits is a record of successful CI runs, and is a set of commits you want to git bisect over.
This is kind of obvious after reading but no one ever explained this to me until now
I feel this advice has some merit when dealing with oss projects, systems/backend or small teams.
It tends to break apart when working with large teams or when working on mobile apps where one can't just rollback a change easily after it's shipped. The descriptions need to be more detailed and capture lot more information.
For example, our team would require all mobile devs to add information about feature flags for each change to turn the feature off if things go wrong. This also places additional review burden to make sure the flag covers all the new code introduced and does not interact in a bad way with other existing feature flags
> When fixing a bug, add a failing test first, as a separate commit. That way it becomes easy to verify for anyone that the test indeed fails without the follow up fix.
I would genuinely like to know in what world this is useful advice. Maybe in personal projects or small teams or companies with a maniacal lead?
I just can’t imagine someone in a sufficiently large organization (which most companies hope to be someday) goes sifting through feature commits to get to the bottom of a failing test.
I don't really understand your reaction. Adding a test that fails before and passes after the fix is good practice (do you disagree?), and putting that in a separate commit is a trivial effort (do you disagree?)
It's basically the lowest-friction way I know to do the part of TDD that counts.
Yes, but if you run git bisect and then try to run your unit tests, a failure that was intentional will tell the bisect to potentially divide the commits at the wrong point.
You'd need to either exclude the test (probably not a great idea) or mark the commits as skippable. Also not a great idea.
Are you suggesting using the unit tests at the HEAD selected by the current git bisect step as the binary signal for bisect?
Because if so, I agree that a commit that introduces a failing test will break bisect (there will be a pass->fail transition AND a fail->pass transition, and bisecting requires there to be at most one such transition). But even more importantly: Without the separate commit containing only the failing test, every commit will pass. That is, bisect will have no useful signal at all.
I think that can't be what you're suggesting, so could you clarify what bisect process you have in mind?
Sure, there have been occassions where on a particular architecture or there is a particular set of circumstances where a test will succeed on a particular system but will fail elsewhere.
If you try to bisect such a situation, you'll not be able to run git bisect run on your tests because of the failing test.
I'm not against a failing test being committed, but I believe it isn't hugely productive. The test failing is surely a signal only to the developer who wrote the test that it failed? Or perhaps it should be failed on a seperate branch and then merged to the master branch, which is pristine.
Every organisation has there own workflow, I suppose.
Edit: a crucial bit of info I didn't note was that you keep developing and add a lot more commits before it is noticed.
I don’t think it is. By all means add a failing test, but I’d tend to commit it along with the code that makes it pass. This makes the commit cohesive. If I must commit it as work in progress I would, but I’d probably amend it once I had the test passing.
The 50-character summary thing is bizarre. As far as I can tell, what happened is someone did statistics on summary lines, found that the average was around 50, and then louder people with strong opinions missed the word "average" and declared 50 as a maximum.
My hot take is that you should use exactly as many characters as you need to write a meaningful summary, and people who insist on using tiny terminal windows can deal with the consequences of their actions.
For a summary line, I don’t see big problem with recommending they be kept that short. The git commit docs say this:
> Though not required, it’s a good idea to begin the commit message with a single short (no more than 50 characters) line summarizing the change, followed by a blank line and then a more thorough description.
It’s like the headline of an article, it doesn’t need to tell you everything. That’s the job of the “more thorough description”. And if you omit the summary line, then you’re just writing a description, and the limit no longer applies. It’s not a hard limit anyway.
I’m not sure it has to do with tiny terminal windows so much as encouraging people to be concise. It allows you to skim commits without reading essays, for example.
To add insult to injury, that 50 char maximum sneaked its way into several syntax highlighting and linting tools, so now my computer is also complaining about my commit messages.
It feels like there's a tiny bit of conflicting advice in this. There's the "not rocket science" rule which results in "no CI-failing commits on main" and then there's this:
> Third, our review process is backwards. Review is done before code gets into main, but that’s inefficient for most of the non-mission critical projects out there. A better approach is to optimistically merge most changes as soon as not-rocket-science allows it, and then later review the code in situ, in the main branch.
But the tip about adding a failing test as a separate commit on the feature branch wouldn't survive a merge and it wouldn't live long enough to be reviewed either.
I like most of the advice in this article but this review one is giving me pause.
Regarding the review process ... one thing that I find challenging and don't know a good solution to is documentation. I've received many PRs where the change itself is fine, but the PR is dragging out because the documentation is lacking, and getting the PR author to improve it sometimes takes a lot of review rounds.
What would you do to avoid this?
Sometimes the same situation comes up with tests, but it is not as common in my experience.
Get people to write the docs first. Not many people like writing docs after the fact, and much of the value of working documentation is lost if you do it after the implementation.
Assuming we’re not taking about user guide kind of docs, then a major benefit of writing docs first is to clarify your thinking. Being able to explain your intent in the written word is valuable because you will often uncover gaps in your thinking. This applies to a specification, or to acknowledging problem reports and updating with theories on what the cause of said problem is and an approach to confirming or fixing it. You can even reference that problem report in commits and merge requests. It pretty beneficial all around.
And docs don’t have to me masterpiece works of art. Just getting people to clarify intent is a huge win. Peer reviewers don’t have time to do a super deep dive into code. If they know what you intended code to do, that’s something many reviewers can check pretty quickly without having to know much context.
It’s selfish and naive to disregard basic documentation of intent.
One option would be to take an initial stab at the documentation yourself - that makes it clear to the submitter where things are unclear, because you made mistakes or omitted things, and they can just correct that, which is a lot more feasible to do than figuring out what's important while your head is in the code.
> However, in a typical project, landing a trivial change is slow. How long would it take you to fix it's/its typo in a comment? Probably 30 seconds to push the actual change, 30 minutes to get the CI results, and 3 hours for a review roundtrip.
It doesn’t have to be like this. This is a choice. There’s no reason a team cannot work towards a world where they can push a small fix to master directly after running their 5 second test suite on their local machine.
We are used to squalor, but it’s not necessary. It’s the result of a series of choices. There are other ways to do our work that maintain continuity of productivity. Old projects can feel like new projects.
Any time someone writes something like this, they are normalizing slights against our fellow developers. They may not recognize it as such because it’s all they’ve ever known, but we should (collectively) know that better is possible and strive for it.
What does it say about us as an industry when someone gets downvoted for saying our work lives can be better? I always picture lobsters pulling each other back into boiling water. It’s sick, honestly.
> Within a feature branch, not every commit necessary passes the tests (or even builds), and that is a useful property! Here’s some ways this can be exploited:
> When fixing a bug, add a failing test first, as a separate commit. That way it becomes easy to verify for anyone that the test indeed fails without the follow up fix.
As a reviewer, I want the first commit to be passing and then the bugfix commit update the test to still pass
- Makes change of behavior obvious to reviewer
- Assumeing all commits are tested, ensures the test is testing the right thing
> Instead, adjust the asserts such that they lock down the current (wrong) behavior, and add a clear // TODO: comment explaining what would be the correct result. This prevents such tests from rotting and also catches cases where the behavior is fixed by an unrelated change.
Yuck! Tests asserting wrong behavior?! Then you might as well not have the thing. Just remove it entirely.
Yeah, but I disagree with his reasoning. Tests should either confirm correct behavior, or not exist at all. Confirming bad behavior is just a way to give everyone ‘make work’.
The information preserved by a merge is greater than or equal to that of a rebase. Since you can construct the rebase from a merge. Further, it allows you to work on changes that have been committed on main since you started the work.
The downside is there can be dragons in the merge commit (you can make arbitrary changes there) so it requires discipline. I only rebase if the merges conflict and therefore introduce a chance for dragons. So, yeah sometimes I turn right.
I tend to think it's better to have merge conflict changes be in a merge commit. That way the original commits are still present and if there was a mistake made, it'll be in its own commit. Contrast that w/ rebasing, where the original commit goes away and gets modified to account for the conflict. Compound this w/ the fact that when you rebase you may have to resolve related merge conflicts in multiple commits, and I think rebasing to deal with merge conflicts is the opposite direction of what I would recommend.
If it happened because say someone else did a refactor then rebasing on that refactor (and that might actually mean manually doing a lot of stuff) is easy to inspect. The problem comes through as a commit with something weird unrelated to the change.
It does require line by line code review by the coder, which few might want to do, but I like to do before opening any PR. Because in any case it is so easy to have an editor window open while your cat walks on the keyboard and pastes your password, or whatever :-).
Honestly, we have so many repositories and such high communication between work cells that merge conflicts are exceedingly rare.
If someone did change something out from under me, I could very well see myself doing my work over on top of theirs, and a rebase may help with that, but I would certainly try to merge first.
I tend to use rebase solely when I specifically want to rewrite history so as to pretend it was different than it was.
> Instead, adjust the asserts such that they lock down the current (wrong) behavior, and add a clear // TODO: comment explaining what would be the correct result.
This is awful advice. The test is there to prevent regression. Why would you change it to not only allow the wrong behavior, but to enforce it? Either fix the test or decide that you won't, in which case remove it. If neither option appeals to you then mark it as optional and let CI succeed with a warning. But changing the test to lock the wrong behavior? No, just no.
I can’t help but feel that the fact that rebase and merge are treated as different commands is broken. This topic keeps coming up on HN lately and it feels like the framing is all wrong. I dunno.
At the end of the day it’s all just a sequence of commits and some commit labels.
{kind=link}
{kind=link}
This may work for small projects or open source projects that generally receive high-quality PRs, but this sounds truly infeasible for large teams or organizations.
There are a couple reasons why the code review process occurs before merging. First, it helps keep the canonical version of the codebase in a "correct" state. This is, ironically, an extension of the "not rocket science" principle that the article mentions. Without this invariant, any checkout of the codebase might contain what is essentially "WIP" code that will waste other engineers' time if they have to interact with it. Second, the social pressure of blocking someone else's work is an important and necessary force for motivating code review. The idea that folks will go back and review code that's already been merged is akin to "will add tests in a followup PR". It's a pleasant lie we tell ourselves, but it rarely comes true.
Relatedly, the article also seems to suggest that the code REVIEWER should be providing the changes necessary after code review. This is problematic for so many reasons: first, it places an even higher burden on code reviewers' time which no one wants; second, it encourages poor code hygiene if someone else is just going to fix up your crappy work later on; third, it robs junior engineers of what is perhaps their most valuable learning experience: getting feedback from more experienced engineers and acting upon it.
(there are other issues here; the general thesis of the article leans heavily towards making code easier to _write_ rather than _read_, which again I think it just not appropriate for a codebase with a significant lifetime or number of contributors)