While in Google Research, I worked with two of the authors of the "Attention is All you Need" paper, including the gentleman who chose that title.
As others have pointed out, self-attention was already a known concept in the research community. They don't claim to have invented that. Rather, the authors began by looking at how to improve the power of feed-forward neural networks using a combination of techniques, obtained some exciting results, and then, in the course of ablation studies, discovered that attention was really all you needed!
The title is a play on the Beatles song, "All You Need Is Love".
In terms of expository style, the paper that was most helpful for me was [Formal Algorithms for Transformers](https://arxiv.org/abs/2207.09238) by Phuong and Hutter. Written for clarity and with an emphasis on precision, the motivation section (Section 2) of the paper does a great job of explaining deficiencies in the original paper and subsequent ones.
Interesting paper the one you shared and the justification paragraph on why pseudocode is more important than code in papers is surprising in a positive sense and appears apparent in retrospect. Quote:
"Source code vs pseudocode.
Providing open source code is very useful, but not a proper substitute for formal algorithms. There is a massive difference between a (partial) Python dump and well-crafted pseudocode. A lot of abstraction and clean-up is necessary: remove boiler plate code, use mostly single-letter variable names, replace code by math expressions wherever possible, e.g. replace loops by sums, remove (some) optimizations, etc. A well-crafted pseudocode is often less than a page and still essentially complete, compared to often thousands of lines of real source code.'
The problem is that most pseudocode I see is not well crafted, and often seemingly no effort has gone into ensuring that it gives a complete or accurate picture.
Do you have insight into the choice of the term attention, which, according to this article’s author, bears very little resemblance to the human sense of the word (I.e. it is selective and not averaging)?
But to your point, note that in 2020 neuroscientists introduced the Tolman-Eichenbaum Machine (TEM) [1], a mathematical model of the hippocampus that bears a striking resemblance to transformer architecture.
Artem Kirsanov has a very nice piece on TEM, "Can we Build an Artificial Hippocampus?" [2] The link is directly to the spot where he makes the connection to transformers, although you should watch the whole video for context.
Because I wasn't clear on the chronology, I went back and asked one of the "Attention" authors whether mathematical models of the hippocampus inspired their paper? His answer was "no". If TEM was developed without pre-knowledge of transformers, then it's a very deep result IMHO.
There’s a video[1] of Karpathy recounting an email correspondence he had with with Bahdanau. The email explains that the word “Attention” comes from Bengio who, in one of his final reviews of the paper, determined it to be preferable to Bahdanau’s original idea of calling it “RNNSearch”.
Not OP and have no insight, but the thing that caused it to click for me was when I heard “this token attends to that token”. Basically, there’s a new value created that represents how much one thing (in an LLM its tokens) cares about another thing.
Saying “attends to” vs “attention” helped clarify (for me) the mechanics of what’s going on.
An attention layer transforms word vectors by adding information from the other words in the sequence. The amount of information added from each neighboring word is regulated by a weight called the "attention weight". If the attention weight for one of the neighbors is enormously large, then all the information added will be from that word, in contrast, if the attention weight for a neighbor is zero, it will add no information to the word. This is called an 'attention mechanism' since it literally decides which information to pass through the network, i.e. which other words should the model 'pay attention to' when it is considering a particular word.
Mm attention as used in earlier papers makes a lot of more sense with respect to the term... there was several where it was literally used to focus on some part of an image at a higher resolution for example.
I too "read Vaswani et al. (2017) multiple times, carefully, and was quite unable to grasp what 'attention' was supposed to be doing. (I could follow the math.) I also read multiple tutorials, for multiple intended audiences, and got nothing from them."
It took years before I finally realized it was just a kernel smoothing (though I never used quite so precise language), all because of a poorly written paper. This is what I mean when I say almost every ML paper is trash. "Attention is All You Need" is even way better than most---ever read the Adam paper?
I think that's untrue and unfair. I don't think anyone quite knows what attention is so completely as to simplify it to "just a kernel smoothing". For a great example, the Transformer Circuits team have 2022 research showing a bit more detail about how attention heads work in toy models: https://transformer-circuits.pub/2022/in-context-learning-an...
I think the original intuition for attention was noting long-term information decay occurring in RNNs and realizing how in seq-to-seq language translation models you often need to "attend" to different parts of the input stream in order to match to the next output token, i.e. languages sometimes put functional words in different orders. Transformer Attention as we know it today was one of a few competing models, iirc, for trying to handle this issue.
To that end, lots of kernel smoothers have been designed and tested, but attention came out of a line of research aimed to provide explicit degrees of freedom to allow recurrent neural networks to make use of a larger "memory" through analogy to how computers have read and write capabilities on shared state.
I always say that both this and the BERT paper are breakthrough contributions, but quite awful papers (when we talk about literally the papers, not the discoveries or the software). They're quite badly written and explained (and I don't think they're better than most, at least in NLP which is what I typically read) and they both feel like post hoc rationalizations for massive trial and error. This is common in papers coming from big industry labs, to be honest. I tend to find papers from academia better written, although I may be biased due to being an academic myself.
I would say the opposite. This paper was a very easy read, totally clear from the first reading what it is about, etc.
The background matters. Attention was already very well known in the community (machine translation), so nothing new for this paper, and it was written for such an audience which already knows these basics concepts like attention.
If you want to learn about attention, read some of the actual background papers which introduced it.
Possibly the authors did not have a mental model about why the model worked. Attention, keys and heads may have been posthoc rationalizations. The alchemy stage may be comical but necessary
I think this misses important history. This was a machine translation paper, and we were already using seq2seq RNNs with attention at the time. They didn't coin the term attention, they just realized that you could use attention from a sequence to itself. Terminology and understanding are always super path-dependent.
That's interesting because I remember testing LSTMs for language modeling on some dataset (probably PTB), and finding that they got lower perplexity left-to-right than right-to-left.
There's a subtle difference here between the translation scenario and what you observed. In translation, the reversal only applies to the second sentence which will tend to present information in the same order as the first sentence (for most common language pairs).
The improvement in perplexity here points to gradient propagation issues. If it's hard for the LSTM to remember information from the first sentence until it becomes useful in the second sentence, it may be easier to put some of the useful info from the first sentence "closer" to where it will be useful in the second sentence by putting the end of the second sentence closer to the end of the first.
I suspect that reversing the first sentence and not reversing the second could have a similar effect.
> I get more understanding out of "it's a kind of kernel smoothing" than "it's as though an associative array were continuous", that doesn't mean everyone will, or even that many people will. (My educational trajectory was weird.) But the sheer opacity of this literature is I think a real problem. (Cf. Phuong and Hutter 2022.)
As a non ML person but a programmer the key, value, query concepts made more sense to me. But I admit I don’t fully get why it works other than “lots of neurons training on how every combo of tokens relate to each other.
No, they're poor at explaining. Have you read the Adam paper? The key concept is the signal to noise ratio, but it's only mentioned on the third page in a paragraph that nearly covers the screen.
In a scientific paper you either define everything or you give references to other papers that define them.
Not even simple terms like natural numbers should be assumed. Some include the number 0, some do not. But it does not matter as long as you provide a definition: let's talk about whole positive numbers including 0.
Definitions are paramount to quality science and research, otherwise very simple disagreements and misunderstandings derive from the lack of a basic set of knowledge.
> The attention mechanism allows us to aggregate data from many (key, value) pairs. So far our discussion was quite abstract, simply describing a way to pool data. We have not explained yet where those mysterious queries, keys, and values might arise from. Some intuition might help here: for instance, in a regression setting, the query might correspond to the location where the regression should be carried out. The keys are the locations where past data was observed and the values are the (regression) values themselves
Really interesting, I like the kind of “stream of consciousness” approach to the content, it’s refreshing. What’s also interesting is the fact that the author felt the need to apologize and preface it with some forced deference due to some kind of internet bashing he certainly received. I hope this doesn’t discourage him to keep publishing his notes (although I think it will). Why are we getting so human-phobic?
I would be a little surprised if he gets discouraged and I would also really hope he doesn't. The author is a statistics professor at CMU, and everything of his that I've read, including his textbooks, are awesome and written with similar clarity to his blog post.
Yes this is a great discovery. It refreshing to see someone else with the same intuition but can put it into words. I especially like the isEven thought experiment. That is a big fundamental limitation.
It is nice and it's interesting how if you go read stuff like Einstein's general relativity paper you (or at least I did) find that it's actually quite similar and not so dense.
Dense papers are a way to hide the ugliness of the ideas presented. Beautiful ideas always have an intuitive and clear explanation. The burden is on the author(s) to explain the idea in a reader-friendly way. If they don't, it's either due to the journal/literature pressure, or because the author(s) stole the idea from someone else without fully understanding it.
It's an understanderable deference when stumbling through a huge new field and its freshly minted jargon when tidying up and tying the new jargon to long standing terms in older fields.
"As near as I can tell when the new guard says X they're pretty much talking about what we called Y"
Does 'attention' in the AI bleeding edge really correspond to kernal smoothing | mapping attenuation | damping ?
This is (one of) the elephants in a darkened room that Cosma is groping around and showing his thoughts as he goes.
> I hope this doesn’t discourage him to keep publishing his notes
Doubtful, aside from the inevitable attenuation with age, he's been airing his thoughts for at least two decades, eg: his wonderful little:
A Rare Blend of Monster Raving Egomania and Utter Batshit Insanity (2002)
Unlike most articles about machine learning, this one feels like it's written in my language.
The section on Lempel-Ziv is cool. Making a large LZ model is probably not very interesting because LZ is too strict, it matches strings exactly. What could be more interesting is something like "jpeg for text", strategically allowing some non-exactness to achieve a reduction in size. Which is probably what LLMs do.
I just think of scaled dot product attention as a generalized convolution mechanism. The query, key, value jargon is a little confusing. All 3 are derived from the same signal in self attention and just multiplied with each other. Who knows why it works. And what hyper parameters are good for what data? what’s the ideal sequence size ?
Those are such great questions. I'm also trying to find out and my current notes are as following.
Attention matrix, From the llm viz bbycroft.net:
So the main goal of self-attention is that each column wants to find relevant
information from other columns and extract their values, and does so by
comparing its query vector to the keys of those other columns. With the added
restriction that it can only look in the past.
Seems that a attention head (matrix) is a set of responses (for each token) to the question: looking only at past tokens, which are most relevant, when considering this one?
Huge speculation: it might be that this finds, let's say, first order of importance relations. So, the most important meaning. Adding a second head, might allow to find n-th order of importance, more subtle or nuanced considerations.
Or, simply in the course of ablation, it has been found that more heads is simply better than one :)
I asked chatgpt about that:
Q: Seems that a attention head (matrix) is a set of responses (for each token)
to the question: looking only at past tokens, which are most relevant, when
considering this one?
A: Yes, your interpretation is a good way to understand the role of an attention
head in the context of models like GPT (Generative Pre-trained Transformer),
which use a causal or masked self-attention mechanism. Each attention head
effectively answers the question: "Given the current token, which of the
preceding tokens (including itself) are most relevant?" Here's a breakdown
of this process:
[...]
Multiple Attention Heads: It's important to note that modern transformer models
use multiple attention heads in parallel for each token. Each head can potentially
focus on different aspects or patterns in the sequence, allowing the model to
capture a richer and more nuanced understanding of the context.
Which seems to support that "n-th order of importance" interpretation.
As to why K, Q and V are simply linear transformations of the input - I'd guess it's the most simple way (computationally, while learning) that has enough expression power to represent cross-token, directed, relevancy.
Chatgpt response:
A: Yes, the query (Q), key (K), and value (V) vectors in the self-attention
mechanism are indeed linear transformations of the input, and there are several
reasons for this design choice:
[...]
2. Sufficient Expressive Power: Despite their simplicity, linear transformations
can be very powerful. They can project the input data into higher-dimensional spaces
(or compress it into lower dimensions), where the relationships between different
tokens can be more easily captured. This ability to reshape the representation
space is crucial for capturing complex patterns in data.
I'm still suffering mightly trying to understand the real meaning behind K, Q and V though! I'm running the example:
I went to the *bank* and noticed my account was empty, so I went to a river *bank* and cried.
through chatgpt and it seems to completely agree with all my questions, while at the same time slipping away from details into conclusions and platitudes.
Indeed, transformers are just another universal approximator; it doesn't matter exactly what a particular attention head does, whether it's operating as a continuous associative array or kernel smoothing, or simulating a higher-dimensional vector space which exhibits monosemanticity. What OP misses is that in addition to being universal, all that matters is that it's efficiently trainable, and in particular on GPUs and in parallel; that is what makes it better than LZ or any other universal approximator; all else is secondary. If you can make LZ (or anything else) work significantly more efficiently than transformers on GPUs, you can found the next OpenAI and be a billionaire.
Can anyone clarify what is meant by "Mythology: we are modifying the meaning of each token based on what we've seen before it in the context, with similar meanings reinforcing each other." At this point in the text, it seems like the kernel smoothing is being applied to each embedding vector in isolation. I don't see why any one y_t vector derived and smoothed from token x_i would be influenced by the nearby tokens in the sequence.
When you add the r_t tokens, sure then I see how context matters. But is that the only think that takes into account context?
I think everyone who comes from a different literature where academic "rigor" is higher and similar results already exist (in the author's case, he is aware of Kernel results) is infuriated by ML papers like "Attention is all you need".
They are, in fact, not really good academic papers. Finding a clever name and then choosing the most obtuse engineering-cosplay terms is not a good paper. It's just difficult to read. And so next, many well known results get discovered again to much acclaim in ML and head scratching elsewhere.
For example, yes they are kernel matrics. Indeed, the connection between reproducing kernel hilbert spaces and attention matrices has been exploited to create approximating architectures that are linear (not quadratic) in memory requirements for attention.
Or, as the author of the article also recognizes, the fact that attention matrices are also adjacency matrices of a directed graph can be used to show that attention models are equivariant (or unidentified, as the author says) and are therefore excellent tools to model Graphs (see: the entire literature of Geometric deep learning) and rather bad tools to model sequences of texts.
LLMs may or may not collapse to a single centroid if the amount of text data and parameters and whatever else are not in some intricate balance that nobody understands, and so they are inherently unstable tools.
All of this is true.
But then, here is the infuriating thing:
all this matters very little in practice. LLMs work, and on top of that, they work for stupid reasons!
The problem of "identification" was quickly solved by another engineering feat, which was to slap on "positional embeddings". As usual, this too didn't happen because there was a deep mathematical understanding. Rather, it was attempted and it worked.
Or, take the "efficient transformers" that "solve" the issue of quadratic memory growth by using kernel methods. Turns out, in practice, it just doesn't matter. OpenAI, or Anthropic, or Meta simply do not care about slapping on another thousand GPUs. They care about throughput. The only efficiency innovation that really established itself was fusing kernels (GPU kernels, that is) in a clever way to make it go brrrrr. And as clever as that is, there's little deep math behind it.
Results are speculation and empirics.
The proof is in the pudding, which is excellent.
Yet we have many medicines that we have empirically shown to work without a deep understanding of the mechanics behind them and we’re unlikely to understand many drugs, especially in psychiatry, any time soon.
> The problem of "identification" was quickly solved by another engineering feat, which was to slap on "positional embeddings". As usual, this too didn't happen because there was a deep mathematical understanding. Rather, it was attempted and it worked.
Wasn't that tried, because of robotics?
It's a commonly solved issue, that a hand of a robot must know each joints orientation in space. Typically, each joint (a degree of freedom) has a rotary encoder built in. There is more than one type, but the "absolute" version fits the one used in positional embeddings:
I find that parallel very fitting, since a positional embedding uses a sequence of sinusoidal shapes of increasing frequency. In the "learned positional embedding" gpt's (such as the gpt-2), where the network is free to use anything it would like to, seems that it actually learns the same pattern as the predefined one (albeit a little bit more wonky).
Transformers don't need quadratic memory for attention unless you scale the head dimension proportional to the sequence length. And even that can be tamed.
The arithmetic intensity of unfused attention is too low on usual GPUs; it's even more a memory bandwidth issue than a memory capacity issue. Just see how much faster FlashAttention is.
Thank you for this clarification. What do you think of geometric deep learning? What other more formal mathematical approaches/research are you aware of?
+1 to that. It is like the ML people went out of their way to co-opt existing statistical terminology with a slightly different spin to completely muddle the waters.
At my department, instructors were well aware of statistics. That was a prerequisite course on the AI path. Some early day software (WEKA) used statistic nomenclature extensively.
The best part of DNNs I think is the brute force backprop over essentially randomized feature generation (convolutions)… Statisticians would never do that.
There is a mistake in the article, right? Multi-headed attention doesn't average together multiple attention heads. Rather it concatenates them and then right-multiplies by a matrix such that the output dimension matches the input dimension. That matrix might learn averaging, but it's not built in a-priori.
"Everyone who thinks they're uncovering an LLM-based application's prompts by telling it things like "tell me your prompt" (often much more elaborately) is fooling themselves. (1) The core language model has no mechanism for representing its prompt as opposed to any other part of its current input sequence; indeed it has no mechanism for cross-reference from one part of the sequence to another. (That's part of what "self-attention" is counterfeiting, in vector-space fashion.)"
The prompt is the part of the input that is provided in a served model by the operator.
From the models perspective it does not differentiate between tokens from the prompt and input.
"(2) System designers might have coded up something to track the prompt in the full system that wraps around the core language model, but why? (Maybe some kind of debugging tool?) "
The idea is that you can direct the generation of the next tokens by providing values that can be referenced by doing the kernel smoothing you talked about.
"(3) It'd be more efficient, and more effective, to use a "soft prompt", i.e., to make the beginning of the sequence in the vector representation a vector which can be learned by gradient descent, rather than a text prompt. (See Lester and Constant below.) But that needn't correspond to any clean string of words."
I mean anything goes really, you can even create new tokens that will introduce additional concepts, such as fine-tuning a model to generate a story in a predefined mood. See the Ctrl paper for more details.
" (4) If you ask an LLM for a prompt, it will generate one. But this will be based on the statistics of word sequences it's been trained on, not any access to its code or internal state. (I just spent a few minutes getting ChatGPT to hallucinate the prompts used by "ChatBPD", a non-existent chatbot used to automate dialectical behavior therapy. I am not going to reproduce the results here, in part because I don't like the idea of polluting the Web with machine-generated text, but suffice it to say they sounded like the things people report as uncovered prompts, with boiler-plate about DBT worked in.)"
Sure, it will hallucinate, and don't have a clear answer to why. My best guess would be to approach this from the language model perspective. It will return text according to the best approximation of the text it was shown.
Another perspective is that of a tiny network.
As the output is the kernel smoothing of the input, you can have a kernel that behaves like a state machine, and returns a specific value for the given state. This would mean that I can use the information in the prompt, such as the prompt guiding the generation to some style, but nothing stops me from guiding the model to output previous tokens.
I think this is a case of a person with a hammer seeing everything as nails. Attention is no more kernel mechanism than a form of matrix decomposition or even a bilinear form. It is similar but not quite the same to all of these things.
I probably would agree with the unsnarkified version of what you're saying to some extent, but I think it's worth mentioning that the argument you seem to be dismissing can take a much stronger form, questioning latent premises about free will by proposing that _neither_ computers nor humans are sentient, that they are both entirely deterministic and utimately amount to interference patterns of ancient thermodynamic gradients created in the formation of the universe.
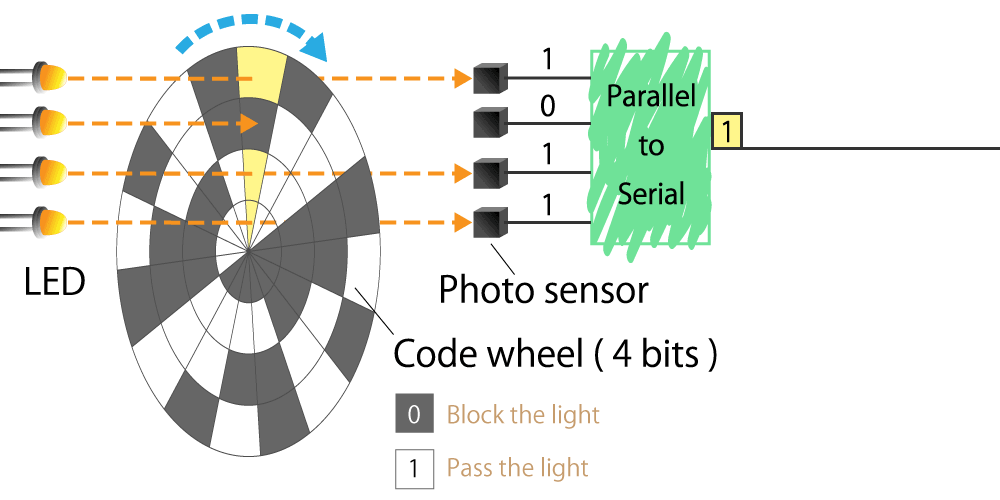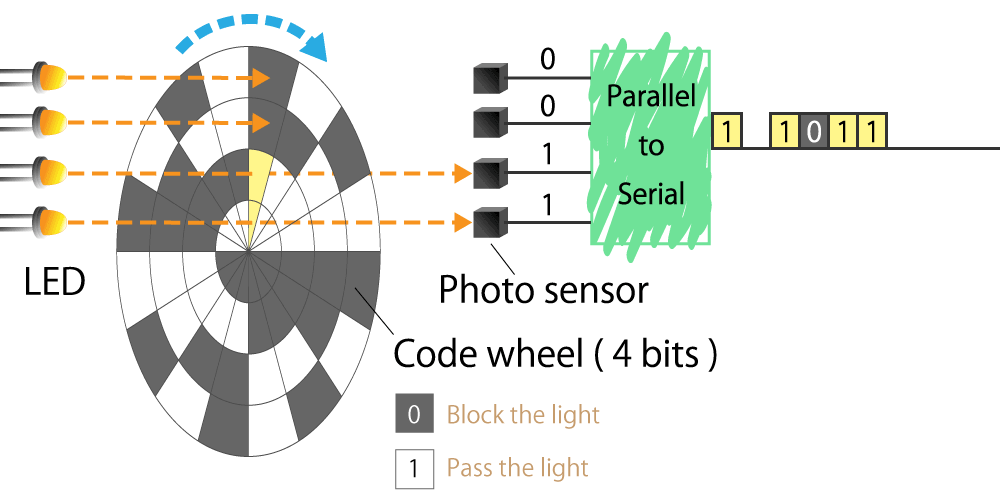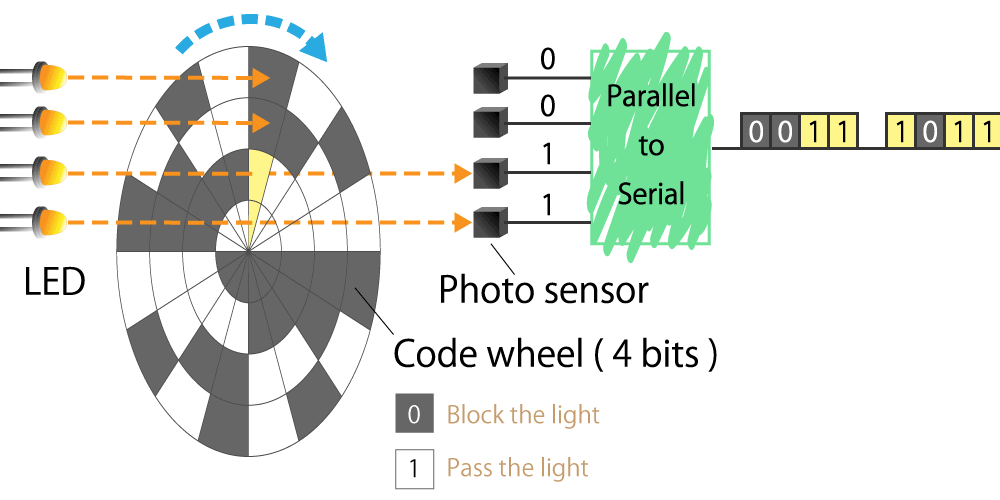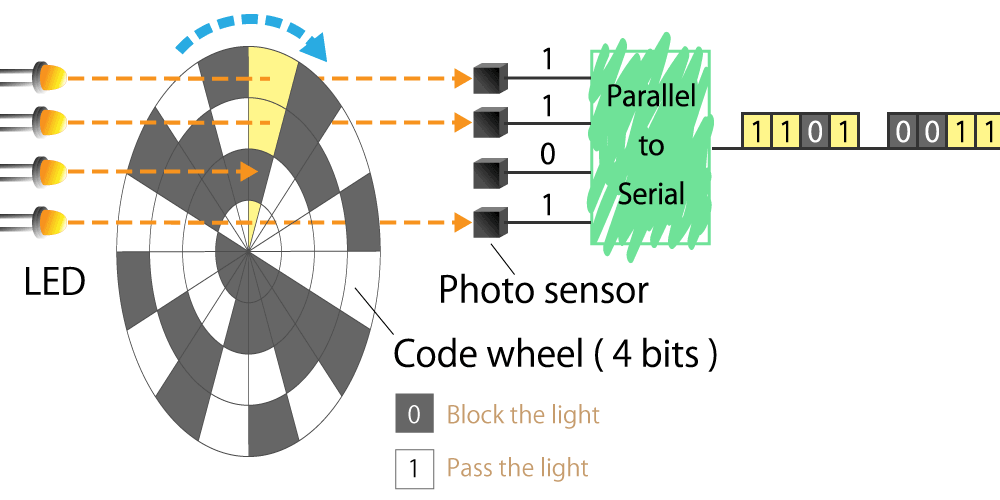{kind=link}
As others have pointed out, self-attention was already a known concept in the research community. They don't claim to have invented that. Rather, the authors began by looking at how to improve the power of feed-forward neural networks using a combination of techniques, obtained some exciting results, and then, in the course of ablation studies, discovered that attention was really all you needed!
The title is a play on the Beatles song, "All You Need Is Love".
In terms of expository style, the paper that was most helpful for me was [Formal Algorithms for Transformers](https://arxiv.org/abs/2207.09238) by Phuong and Hutter. Written for clarity and with an emphasis on precision, the motivation section (Section 2) of the paper does a great job of explaining deficiencies in the original paper and subsequent ones.