Argh, why do author's write stuff like this -- "It is, not to put too fine a point on it, a creaking old bit of wheezing ironmongery that, had the gods of microprocessor architecture been more generous, would have been smote into oblivion long ago."
Just because a technology is "old" doesn't mean it is useless, or needs to be replaced. I'm all in favor of fixing problems, and refactoring to improve flow and remove inefficiencies. I am not a fan of re-inventing the wheel because gee, we've had this particular wheel for 50 years and its doing fine but hey let's reimagine it anyway.
That said, the kink in x86 architecture was put their by "IBM PC Compatibility" and a Windows/Intel monopoly that went on way too long. But even knowing why the thing has these weird artifacts that just means the engineers are working under constraints you don't understand, doesn't give you license to dismiss what they've done as needing to be "wiped away."
We are in a period where enthusiasts can design, build, and operate a completely bespoke ISA and micro-architecture with dense low cost FPGAs. Maybe they don't run at multi-GHz speeds but if you want to contribute positively to the question of computer architecture, there has never been a better time. You don't even have to build the whole thing! You can just add it into an existing architecture and compare how you do against it.
Want to do flow control colored register allocation for speculative instruction retirement? You can build the entire execution unit in an FPGA and throw instructions at it to your hearts content and provide analysis of the results.
Okay, enough ranting. I want AARCH64 to win so we can reset the problem set back to a smaller number of workarounds, but I think the creativity of people trying to advance the x86 architecture given the constraints is not something to belittled, it is to be admired.
I would argue the author is not really saying "old" is "bad", but instead that we have been piling more and more craft onto the old so it has now become a significant engineering exercise to work around the idiosyncrasies of the old system every time you want to do something else.
To use your wheel analogy. It's sort of like starting with the wheel of horse cart and adding bits and pieces to that same wheel to make it somehow work as the landing gear wheel for a jumbo jet. At some point it might be a good idea to simply design a new wheel.
... while at the same time ensuring that the wheel can still function as the wheel of a horse cart, of a car and of a small plane, in the same exact way it functioned when it was designed, including past idiosyncrasies
Well, no one gets promoted/a raise by writing ‘and everything is actually fine’ right?
On the engineering side, similar more often than not. You get promoted by solving the ‘big problem’. The really enterprising (and ones you need to watch) often figure out how to make the big problem the one they are trying/well situated to solve - even if it isn’t really a problem.
> Well, no one gets promoted/a raise by writing ‘and everything is actually fine’ right?
But in this specific case, everything is absolutely not actually fine? x86 interrupt handling is terrible. It's slow, it's extremely fragile, and everything about it is just byzantine and overcomplicated.
> Well, no one gets promoted/a raise by writing ‘and everything is actually fine’ right?
Well, that's actually not true. There are quite a few live coaches and the likes making their living on positive writing. And there a quite a few writers, like Scott Alexander, which, while not being all positive, definitely don't need to or want to paint an overly dark or dramatic picture.
In the more conventional news sector, on the other hand, this is probably true.
If you look at revenue, they are the exception that proves the rule though right? 90-95% of the revenue is in the other camp, depending on how you define it.
For every life coach able to make a living, I’m guessing there are 10-20 business consultants, therapists, psychologists, etc. called in to fix a problem no?
I'm a native English speaker, and I see nothing wrong with "Honey, I Shrunk the Kids". It's a movie title, for Pete's sake.
I assume you are saying it should have been "Honey, I Shrank the Kids". Please correct me if I misunderstood you.
Yes, I know the technically correct usage of "shrank" and "shrunk". But let's take off our grammarian hats for a moment and say each one out loud a few times.
"Honey, I Shrunk the Kids" rolls off the tongue, while "Honey, I Shrank the Kids" just seems... odd to me. You may disagree.
If you actually shrank your kids, and you were in a panic and rushed to tell your honey about it, would you be concerned about correct grammar, or just getting the message across?
One might even argue that the incorrect use of "shrunk" helps convey this sense of panic.
Movie titles are not required to follow "correct" English grammar, any more than newspaper headlines. They should be memorable and fun to say when you tell your friends about a movie you enjoyed.
p.s. I've never been sure who Pete is, but I hear he has a very fine bottle of sake. If we ask him real nice, maybe he will let us try a sip!
> we've had this particular wheel for 50 years and its doing fine but hey let's reimagine it anyway
How is it doing fine? Apple is doing laps over Intel because -- it seems -- of their choice to use ARM. Would they have been able to design an x86/amd64 CPU just as good?
>Apple is doing laps over Intel because -- it seems -- of their choice to use ARM.
AMD processors are essentially equivalent to M1 in performance while still keeping x86, so probably yes (there are an ARM advantage in instruction decoding, but judging by performance differences, it's probably small).
Apple's advantage is mostly that Apple (via TSMC) can use a smaller processor node than Intel and optimize the entire Mac software stack for their processors.
AMD's listed "15W TDP" is irrelevant to the observed wattage and frequency (or performance) curves.
And we've seen Apple's A12, A13 on a similar TSMC 7NM node - older if I may add so AMD garners what little improvements are made on that process since then.
BTW: it doesn't improve too much on Zen 3. Slope is just not ARM, much less Apple-tier.
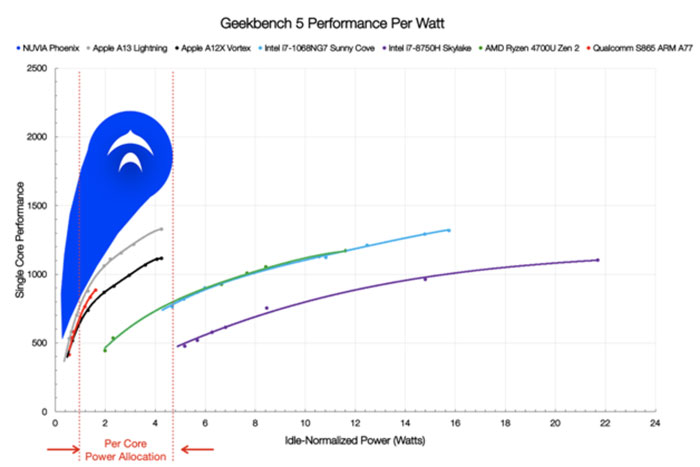
Inevitably someone will chime in and point out AMD's power efficiency is subpar due to boosting far beyond optimal points on the curve; while true this is inefficient we can truncate their frequency to Apple's 3.2GHZ or merely observe the slope of the p:w curves above - at almost any point on the y axis, an A12 or A13 will be taking AMD to the woodshed on performance per watt. And I'm not exactly amicable to handicapping the comparisons by giving AMD & X86 a half decade to work out the architecture before things are "fair". As it stands, Apple's architecture is simply more performant.
The Apple M1 and A14 SoCs were built on TSMC's 5nm process while AMD has been using TSMC 7nm for Zen. With the next generation of Zen on TSMC 5nm, we will see whether Apple's ARM or AMD's x86-64 implementations are more performant when starting with the same silicon.
That is only one of many important metrics. Technically speaking, a low power low frequency processor almost always beats out other processors in perf/watt, even if it is vastly inferior in processing capability.
Yeah, and die area isn't exactly going to be given away on a capacity constrained 5nm wafer line. If you can get the wafer starts at all. Performance per dollar is the only metric that matters, and maybe 7nm or even 14nm performs better at the moment.
DRAM, storage, networking, gpus, accelerators, etc are all eating huge chunks of power. CPU's tiny in comparison. Maybe you save 5% across a datacenter using those fancy unicorn wafers.
> Just because a technology is "old" doesn't mean it is useless, or needs to be replaced. I'm all in favor of fixing problems, and refactoring to improve flow and remove inefficiencies. I am not a fan of re-inventing the wheel because gee, we've had this particular wheel for 50 years and its doing fine but hey let's reimagine it anyway.
Can't get promotions if you don't NIH a slow half broken postgres
I think you misunderstood the comment. It wasn't calling Postgres slow and half broken, it was making a stab at other home-brewed (NIH, Not Invented Here https://en.wikipedia.org/wiki/Not_invented_here) databases, calling them slow, half baked copies of postgres, implying that they should have just used postgres, but that doing so wouldn't get them promotions.
>Just because a technology is "old" doesn't mean it is useless, or needs to be replaced.
Sure. But if on top of old it is "a creaking wheezing ironmonger" that "had the gods of microprocessor architecture been more generous, would have been smote into oblivion long ago", then it does need to be replaced.
And both the article mentions reasons why (they don't stop at mere old) and Intel/AMD share them.
I thought the author's phrasing was brilliant. The x86 architecture was terrible on purely objective grounds in 1980 and it's still quite terrible today. It stinks and it has always stunk. Intel knows this as well as anybody; they've tried many times to replace this botched Yugo of an architecture but those efforts always die because of the omnipresent PC compatibility issue that you pointed out.
Yeah, turning a Yugo into a moon rocket is impressive. But I'd have been a lot more impressed if Intel had said "No more x86 for you. It's gonna be Itanium now. It's better in every way. Deal with it."
Funnily enough, everyone I know who works at Intel who's expressed a thought about Itanium would not agree with the statement that Itanium is superior to x86.
Itanium of course was a huge win for Intel. By convincing all the RISC Unix guys to jump on the sinking Itanium they captured the high end server market for x86.
I have no idea if those Intel employees had direct experience with Itanium or they merely drank the "Itanium is bad" kool-aid. The hardware was pretty bad in the early years but Intel fixed those problems (speed, power, feature size, etc.)
At the end the problem was timing: We didn't know how to write compilers that could figure out micro-scheduling in advance so software couldn't take advantage of the Itanium, and when AMD64 came out and added a bunch of registers and did all that nasty instruction reordering and speculative execution in realtime on-chip everybody said "just use that." Nowadays compiler writers have a much keener understanding of static analysis and almost certainly could take advantage of the chip. And vulnerabilities like Spectre and Meltdown would never have happened because all that optimization would have been done in the compiler where it belongs.
In fact, several of them did have direct experience with the Itanium. One of the comments one had about it was the hardware team had a bad habit of creating problems and hoping that the compiler would fix it.
One of the things about Itanium that I do know is that it's basically VLIW. And VLIW is a technology that sounds really good on paper, but it turns out that you just can't get that good results for realistic workloads--they've basically been abandoned everywhere they've been tried except for DSPs, where they live on apparently because DSPs have so few kernels they care about.
And speaking as a compiler writer, no compiler will ever do a good a job as the hardware can at maximizing instruction-level parallelism. The compiler is forced to make a static choice while hardware can choose based on dynamic effects that the compiler will never be able to predict.
> The compiler is forced to make a static choice while hardware can choose based on dynamic effects that the compiler will never be able to predict.
At the limit of complete generality the Halting Problem guarantees your statement is correct. But it also appears to be extremely difficult to do this at runtime without side-effects that change global state such that information leaks. The real cost for speculative execution may be that it can't be done in a purely-functional manner.
It is true that we currently cannot hide the microarchitectural effects of unsuccessful speculation, as exposed by transient execution attacks like Spectre and cousins.
So what?
Most workloads / customers are much more about performance than security. We can trivially remove such attacks by switching off all speculation (branch prediction, caches, OOO, prefetching). Indeed you can buy CPUs like that, and they are used in environments where safety is of extreme importance. The cost of this is an orders-of-magnitude loss of performance
Most workloads (e.g. Netflix streaming, Snapchat filters, online advertising, protein folding, computer games, Instagram, chat apps) are simply not security sensitive enough to care.
Building a competitive general purposes CPU costs a lot (probably > $1Billion end-to-end), and who would buy a CPU that is safe against Spectre but 3 orders of magnitude slower than the competition? (Not to mention that there are many more dangerous vulnerabulities, from Rowhammer to Intel' Management Engine, to rubber hose ...)
The superficial VLIW-like encoding is abit of a red herring. The instruction bundles that resemble VLIW aren't really semantically too significant after instruction decoding. The grouping by stop bits is the Itanium specific feature that affects scheduling and depenendcies more.
It is not possible, in June
2021, to build a compiler that can schedule general workloads as
well as an out-of-order scheduler can at run-time in a modern CPU.
Note that the scheduling we are talking about is mostly to do with
data location in order to hide the latencies of data-movement: In order to hide data movement latencies, you need to know if needed data is in L1, L2, L3, or main memory. In general workloads this is very much data
dependent. How is a static, or even JIT, compiler supposed to know
with enough precision where data is located at run-time?
An additional problem is that compiler scheduling needs bits for
encoding scheduling information, which does not come for free:
those bits cannot be used for other purposes (e.g. larger immediate arguments).
For more specific workloads where data movement is more predictable,
i.e. not itself data-dependent, the situation is different, whence the
rise of GPUs, TPUs, signal processing cores etc.
Spectre and Meltdown are orthogonal. They come from speculation,
e.g. branch prediction. Compile-time branch prediction is similarly
infeasible for general workloads.
It is impossible to schedule any reasonable program in advance because you don't know what the latencies of any memory loads are. (Also, you'd need a lot of register names in the ISA - modern OoO CPUs have hundreds of physical registers backing ~16 register names.)
Besides that, if you think x86 is bad you should try using some supposedly clean architectures like MIPS or Alpha. They may be RISC but they are definitely too RISC.
I'm no CPU designer, but I seem to remember that Intel took the crown back from AMD with the Core 2 Duo. IIRC, that involved going back to an older design and going down a different path.
If Itanium was just ahead of its time, Intel could always try again. ARM and RISC-V are getting a lot of attention these days. Mill seems to be missing the window of opportunity. 2-nm fab seems like a fantasy. Announcing the new Gadolinium processor family wouldn't be a complete cringe.
I am doubting that if you walk over the aisle to the engineers in the other team, and state an obscure legacy issue to him/her. That person would, with decent chance, say something like "how could it be?" "was the original engineer dumb/imcompetent"? "was the original team got reorged"? etc....
Not saying the tech journalist is better in any sense. But let's be honest, there is no reason they should be doing better...
Sssh! "Old = bad" means job security for millions of engineers. We need yet another security attack surface, I mean "improved interrupt handling."
I don't understand why people, engineers of all people, fall for the Dunning-Kruger/NIH/ageism-in-all-teh-things consumerism fallacy that everything else that came before is dumb, unusable, or can always be done better.
Code magically rusts after being exposed to air for 9 months, donja know? If it's not trivially-edited every 2 months, it's a "dead" project.
Part of it I think is that for many people, it's more fun to build something than to maintain something. It's also easier to write code than it is to read it (most of the time).
So why not do the fun and easy thing? Especially if they aren't the one writing the checks!
Thanks for posting this link. I was curious about a, b and d:
>"(a) IDT itself is a horrible nasty format and you shouldn't have to parse memory in odd ways to handle exceptions. It was fundamentally bad from the 80286 beginnings, it got a tiny bit harder to parse for 32-bit, and it arguably got much worse in x86-64."
What is it about IDT that requires parsing memory in odd ways? What is odd about it?
>"(b) %rsp not being restored properly by return-to-user mode."
Does anyone know why this is? Is this a historical accident or something else?
>"(d) several bad exception nesting problems (NMI, machine checks and STI-shadow handling at the very least)"
Is this one these two exceptions are nested together or is this an issue when either one of these is present in the interrupt chain? Is there any good documentation on this?
Somewhat off topic from the main thread of the article, but I have always wondered about the multiple privilege levels. What's the expected/intended use for them? The only thing I think of is separating out hardware drivers (assuming ring 1 can still directly read/write I/O ports or memory addresses mapped to hardware) so they can't crash the kernel should the drivers or hardware turn out to be faulty. But I don't think I've ever heard of such a design being used in practice. It seems everyone throws their driver code into ring 0 with the rest of the kernel, and if the driver or hardware faults and takes the kernel with it, too bad, so sad. Ground R̅E̅S̅E̅T̅ and start over.
What I find myself wondering is why? It seems like a good idea on paper, at least. Is it just a hangover from other CPU architectures that only had privileged/unprivileged modes, and programmers just ended up sticking with what they were already familiar and comfortable with? Was there some painful gotcha about multiple privilege modes that made them impractical to use, like the time overhead of switching privilege levels made it impossible to meet some hardware deadline? Silicon-level bugs? Something else?
It works with the call gates. You could have a sort of nested microkernel idea if it wasn't such a mess with each ring able to include the lower privileged ring's address spaces. And not just a free for all, but the kernel really is just the control plane, but can set up all sorts of per process descriptor tables (the LDTs).
So you'd have a tiny kernel at ring 0 which could R/W everything but wasn't responsible for much.
Under that you'd have drivers at ring 1 that can't see the kernel, but can R/W user code at rings 2 and 3.
Under that you'd have system daemons at ring 2 that can R/W regular programs but not drivers or the kernel.
And then under that you had regular processes at ring 0 that have generally the same semantics as today's processes.
Each process of any ring can export a syscall like table through the call gates, and so user code could directly invoke drivers or daemons without going throught the kernel at all. Basically IPC with about the same overhead as a C++ virtual method call.
So what happened? The exact underlying semantics didn't exactly match many OSs anyone wanted to build (particularly OSs that anyone cared about in the late 80s early 90s). And you can enforce similar semantics all in software with the exception of the cheap IPC anyway.
I think OS/2 used every feature x86 had, including call gates and at least 3 privilege levels (0, 2, 3). That is why OS/2 is such a good test for any aspiring x86 emulator developer.
I think OS/2 and XENIX were the only two operating systems that ever used 80286 protected mode. I'm not surprised that OS/2 makes a good test case for emulators!
Given the multi core, NUMA and Spectre/meltdown reality we’re living in, and the clear benefits of the io_uring approach, why not just have a dedicated core(s) to handle “interrupts” which are nothing more than entries in a shared memory table?
This approach works for I/O devices (and for things like network cards the kernel will typically poll them anyway), but I/O isn't the only thing that generates interrupts. For instance, a processor fault (e.g. divide by zero) should be handled immediately and synchronously since the CPU core generating the fault can't do any useful work until the fault is handled.
At university we designed an architecture[1] where you had to test for page not present yourself. It was all about seeing if we could make a simpler architecture where all interrupts could be handled synchronously, so you'd never have to save and restore the pipeline. Also division by zero didn't trap - you had to check before dividing. IIRC the conclusion was it was possible but somewhat tedious to write a compiler for[2], plus you had to have a trusted compiler which is a difficult sell.
[1] But sadly didn't implement it in silicon! FPGAs were much more primitive back then.
[2] TCG in modern qemu has similar concerns in that they also need to worry about when code crosses page boundaries, and they also have a kind of "trusted" compiler (in as much as everything must go through TCG).
> where you had to test for page not present yourself.
I would think that implies you need calls “lock this page for me” and “unlock this page for me”, as using a page after getting a “yes” on “is this page present?” is asking for race condition problems.
This is why you need a trusted compiler. Basically it's "insecure by design" since the whole point of this optimization is to avoid any asynchronous exception so there's no need to implement that in the pipeline. The machine code must be forced somehow to implement these checks.
There have been architectures which have required a trusted compiler (eg. the Burroughs mainframes) or a trusted verifier (the JVM, NaCl). But it certainly brings along a set of problems.
It's unclear from here whether this is even an optimization. It looked a lot more compelling back in the mid 90s.
You’re thinking about computer architecture as designed today. There’s no reason there isn’t a common data structure defined that the CPU can use to select a backup process, much how it uses page table data structures in main memory to resolve TLB misses.
It was slow so operating system devs didn't use it. So it was removed. Probably becouse hardware saved, properly, all registers and software can save only needed few (and sometimes miss something).
In effect: we don't know how secure it was...
But if it was good and Intel removed it then why Intel keeps so many useless crap in ?? Good parts - remove, bad - needed for backward compatibility... Can, finally, someone tell backward compatibility with WHAT ? DOS 4.0 ? Drivers for pre-winonly modems using plain ISA or PCI slots ??
Or maybe just like with EVE Online code (few years ago?) - no one anymore knows how some parts works...
That was just an example, there are many other things the CPU can do that will generate a fault (for example, trying to execute an illegal instruction).
Then the CPU isn’t stopping and is moving on doing other work. Meaning the divide by zero could be processed by a background CPU and doesn’t require immediate handling. Same for page faults.
Incorrect. The "CPU" is stopping and handling the fault. There is no background CPU from your perspective. In a cloud provider you are always in a virtual environment and using a vCPU which is constantly being preempted by the hypervisor.
You cannot DOS a hypervisor just by bogging down your virtualized kernel.
There are a couple x86 corner cases where you can do so, by causing an endless stream of exceptions. But they are not going to happen in a hot path, so the hypervisors force a vmexit on those exceptions and avoid that the processor freezes forever.
There must be a way to alter a core's instruction pointer from another core or from hardware to support killing processes running untrusted machine code, and to support pre-emptive multithreading without needing to have compilers add a check for preemption on all backward branches and calls.
These features are very worth the hassle of providing this capability (which is known as "IPI"s), and once you have that hardware interrupts become pretty much free to support by using the same capability and the OS/user can then decide whether to dedicate a core, to affinity them to a core, to load balance them among all cores or to disable the interrupts and poll instead.
I was thinking rather than mucking with instruction pointers you would just send a message back to the other CPU saying “pause & switch to context X”. Technically an interrupt but one that can be handled internally within the CPU.
What do you think "switch to context X" does, if not muck with the instruction pointer? Where do you think mucking with the instruction pointer is handled, if not within the CPU?
Would guess it would be complicated and difficult to update the kernel to support something like that. Not sure Linus would entertain PRs for custom boards that do something like that. Would think it would need to be an industry wide push for that. But just speculation..
Yea, that could probably be an even bigger impediment to trying to implement a separate interrupt processing unit I guess. My grasp of this area is tenuous, didn't even contemplate that. Would a new physical setup be required for something like this? Or would it all be in the cpu architecture?
Since cloud servers are a bigger market than users who want to run an old copy of VisiCalc, why doesn't either Intel or AMD produce a processor line that has none of the old 16 and 32 bit architectures (and long-forgotten vector extensions), implemented in silicon? Why not just make a clean (or as clean as possible) 64 bit x86 processor?
All of these things were either rejected by the market or didn't even make it to the market.
Binary compatibility is one of the major if not the major reason that x86 has hung around so long. In the 1980's and 90's x86 was slower than the RISC workstation competitors but Intel and AMD really took the performance crown around 2000.
I think he's suggesting something more like the 80376, an obscure embedded 386 that booted straight into protected mode. So you'd have an x86-64 CPU that boots straight into Long Mode and thus could remove stuff like real mode and virtual 8086 mode. AFAIK with UEFI it's the boot firmware that handles switching to 32/ 64 bit mode, not the OS loader or kernel, so it would be transparent to the OS and programs.
But in order to not break a lot of stuff on desktop Windows (and ancient unmaintained custom software on corprate servers) you'd still have to implement the "32 bit software on 64 bit OS" support. That probably means you don't actually simplfy the CPU much.
Of course some x86 extensions do get dropped occasionally, but only things like AMD 3DNow (I guess AMD market share meant few used it anyway) and that Intel transactional memory thing that was just broken.
I think the idea is to go ahead and break lots of stuff on desktop Windows (and ancient unmaintained custom software on corprate[sic] servers). Let that software keep running on x86_64 hardware. But offer an additional choice--an x64-ng--that can only run a subset of software, but it can run it even better than x86_64 can. You don't fill an entire datacenter with these. Just a few aisles. Then you let people choose them for their whizbang modern workloads. Every year you replace an aisle of x86_64 racks with x64-ng racks. Twenty years from now, 25% of your datacenter is still the latest generation of x86_64 and they rent for a premium.
Just as if a datacenter today allocated some of its rackspace to zSeries or ARM or what have you. For workloads that gain advantages on those platforms.
A “64 bit clean” CPU would be nice, but practically you’d also want new 32 bit compatible CPUs for markets that need it. Gamers are still going to want to play old games with MORE POWER, business will want to throw more CPU at some process that is reliant on ancient code and so on. Apple has tried forcing the issue, and it didn’t exactly make everyone happy, and Apples view on compatibility is rather different to Microsoft’s or Linux / Linus’s.
So now you need to design and verify two CPU cores instead of one. The most efficient for an engineering staff and resource allocation perspective would be to just have the “x64-ng” core being the normal AMD64 core with legacy support lasered off. So probably not much in performance gains. If you had the designs actually diverge you’re going to end up with with duplicated work by more people / teams and thus less profit.
With the trend for dedicated low power cores, the companies already have two lines of core design to maintain, they aren’t going to want more.
I’m not saying it’s impossible, and a legacy free x86 core would be nice, but the business case for getting rid of 32 bit support probably isn’t there (yet?).
(You do also mentions Z series which has backwards comparability in some form going back to System 360 from the 60s - getting rid of this stuff is hard once it’s entrenched).
Binary compatibility kept x86 dominant, coupled with competing platforms not offering enough of a performance or price benefit to make them worth the trouble.
That formula has completely changed. With the tremendous improvement in compilers, and the agility of development teams, the move has been long underway. People are firing up their Gravitron2 instances at a blistering pace, my Mac runs on Apple Silicon (already, just months in, with zero x86 apps -- I thought Rosetta2 would be the lifevest, but everyone transitioned so quickly I could do fine without it).
It didn't already support arm64? Was nobody using it on iOS?
I remember trying to run Mercury on M1 recently and having problems getting it to build - some of that was because it had very old style probably wrong approaches to atomics written in x86 asm.
Also, a lot of games are still on x86, even constantly updated ones like Minecraft - and that's not even native code.
Both cpu you mentioned are locked in ... I hope less locks in the future , right now you can't buy graviton CPUs just rent in a Amazon datacenter, neither m1 cpu or install Linux on it..
Apple sell those cpu because they are "buying" users for their locked ecosystem witch will pay "lifetime" subscription in their services , probably in Future enriched with apple search and apple ads.. 1984 .. but it started with a good CPU.. Amazon is settling.. look how good is our cpu and how cheap.. while they are probably have 0 margin on those and 50% on competition .. look the argument for alternatives in CPU space is not bad.. it's been just the examples that you have chosen that are imo
Pricewise and performancewise a CPU can look better if the seller have secondary interest to sell those to you that are not monetary.. (take that 3nm tr7990wx at 300$.. in a locked system that we sell you for 1500$, we will take lifetime 30% cut from what you buy with it anyway ;) if you want 2tb ssd it's another 2k.. but hey the CPU is just 300$ ... ) I will judge m1 only if it will be compatible with Linux and sold separately from the apple (eco)system
Talking about architecture arm did a good job.. but under Nvidia.. I'm not so faithful for the future..
Sorry for the rant but some things are not comparable i see m1 and graviton vs Intel or AMD CPU and what i see really is like saying like as image hosting solution nextcloud+owned nas is bad and costly why Google photos is cheaper.. (free.. Until it's not..) ! The two are two different things one can be your.. the other.. not
No, there's a lot of PCisms that that can be removed and still allow for x86 cores. User code doesn't care about PC compat really anymore (see the PS4 Linux port for the specifics of a non PC x86 platform that runs regular x86 user code like Steam, albeit one arguably worse designed than the PC somehow). Cleaning up ring 0 in a way that ring 3 code can't tell the difference with a vaguely modern kernel could be a huge win.
Even so, doesn't having a more complex instruction set, festooned with archaic features needed by very few users, increase the attack surface for hacking exploits and increase the likelyhood of bugs being present? Isn't it a bad thing that the full boot process is understood in depth by only a tiny fraction of the persons programming for x86 systems (I'm certainly not one of them)?
As a sibling said, if you can get the cpu into real mode, you can probably do whatever else you want, so it being there isn't a real security worry.
Dropping real and virtual mode wouldn't save a whole lot anyway; for the most part, the instruction set is the same, regardless of mode, just register selection is a bit different, and fiddling with segment registers is significantly different.
Mostly, the full boot process isn't understood in depth by many people because very few people need to know about it in depth. Really full boot process includes detecting and enabling ram and all that, and there's a handful of companies that provide most of the firmware images for everyone ... OSes usually start from the BIOS boot convention or UEFI, so they don't need to know all that early boot stuff. Well, really, bootloaders start there, OSes can start at multiboot or UEFI if they want to save some work. An SMP OS will still need to know a little bit about real mode though, because application processors (non-boot processors) start in real mode, complete with segmented addresses, and need to get into protected mode themselves.
Not really. Basically none of these features can be used outside of the kernel anyways, which means that the attacker already has far more powerful capabilities they can employ.
The number of transistors sure. The engineer time to design new features that don't interfere with old features is high. The verification time to make sure every combination of features plays sensibly together is extremely high. To the extent that Intel and AMD are limited by the costs of employing and organizing large numbers of engineers it's a big deal. Though that's also the reason they'll never make a second, simplified, core.
When things get to the point where AMD is considering making nonmaskable interrupts maskable (as the article states), maybe it's time to invoke "force majeure".
Yep. Benefit = The cost of minimalism at every expense - the cost of incompatibility (in zillions): breaking things that cannot be rebuilt, breaking every compiler, breaking every debugger, breaking every disassembler, adding more feature flags, and it's no longer the Intel 64 / EMT-32 ISA. Hardware != software.
Since cloud servers are a bigger market than users who want to run an old copy of VisiCalc
Imagine if your VMs, which are being used to run old software, can't be used on cloud servers due to this feature absence. Virtualisation is used extensively for this purpose. The cloud providers certainly wouldn't like that.
>'The processor nominally maintained four separate stacks (one for each privilege level), plus a possible “shadow stack” for the operating system or hypervisor.'
Can someone elaborate on what the "shadow stack" is and what it's for exactly? This is the first time I've heard this nomenclature.
That is probably referring to System Management Mode (privilege level/ring -2) and Intel Management Engine (privilege level/ring -3). Two very terrible things.
Probably not. Shadow stacks don't really have anything to do with privilege levels or interrupts. And Intel only started shipping CPUs with "Control-flow Enforcement Technology" (which has their implementation of shadow stacks, and other things) last year.
> interrupt handling would be faster, simpler, more complete, and less prone to corner-case bugs.
If it's simpler, I can see why it will be faster and less prone to corner-case bugs (at least, the hardware will have fewer corner cases; the software is a different question).
But how can simplification supposed to make FRED more "complete"?
Given the recent trend initiated by cloud providers offering cheaper and almost equally performant arm based alternatives, I predict that arm and hopefully risc-v will be the popular choice in ~3 years.
As for the consumer vertical, samsung and the like will most likely offer arm based laptops to complete against Apple's M1.
In other words, x86 will be fading away as most of the money is being invested in alternatives including Intel.
This shift reminds me of the time when cloud was still a new trend and many were saying at the time that companies won't run their business in a cloud for security reasons and more.
When the alternative is simply better for businesses, they adjust to the new reality to stay in business.
{kind=link}
Just because a technology is "old" doesn't mean it is useless, or needs to be replaced. I'm all in favor of fixing problems, and refactoring to improve flow and remove inefficiencies. I am not a fan of re-inventing the wheel because gee, we've had this particular wheel for 50 years and its doing fine but hey let's reimagine it anyway.
That said, the kink in x86 architecture was put their by "IBM PC Compatibility" and a Windows/Intel monopoly that went on way too long. But even knowing why the thing has these weird artifacts that just means the engineers are working under constraints you don't understand, doesn't give you license to dismiss what they've done as needing to be "wiped away."
We are in a period where enthusiasts can design, build, and operate a completely bespoke ISA and micro-architecture with dense low cost FPGAs. Maybe they don't run at multi-GHz speeds but if you want to contribute positively to the question of computer architecture, there has never been a better time. You don't even have to build the whole thing! You can just add it into an existing architecture and compare how you do against it.
Want to do flow control colored register allocation for speculative instruction retirement? You can build the entire execution unit in an FPGA and throw instructions at it to your hearts content and provide analysis of the results.
Okay, enough ranting. I want AARCH64 to win so we can reset the problem set back to a smaller number of workarounds, but I think the creativity of people trying to advance the x86 architecture given the constraints is not something to belittled, it is to be admired.