JSONB capabilities in Postgres are amazing, but the syntax is really annoying - for example, I'm forever mixing up `->` and `->>`. This new syntax feels far more intuitive.
Not much different from some_jsonb#>>'{some,path}' and once you add the need to convert out of jsonb to text, you'll not be saving any characters either. At least for queries.
It shouldn't matter so much, but when you don't use one language as much as you do other languages, it becomes that much harder to remember unfamiliar syntaxes and grammars, and easier to confuse similar looking operations with each other.
In that case this does not help. SELECT json['a']; will not return the value of the string in {"a":"ble"} (like it does in Javascript), but a JSON encoding of that string, so '"ble"'. You'll still not be able to do simple comparisons like `SELECT json_col['a'] = some_text_col;` Superficial familiarity, but it still behaves differently than you expect.
Is there even a function that would convert JSON encoded "string" to text it represents in postgresql? I didn't find it.
So all you can do is `SELECT json_col['a'] = some_text_col::jsonb;` and hope for the best (that string encodings will match) or use the old syntax with ->> or #>>.
> Is there even a function that would convert JSON encoded "string" to text it represents in postgresql? I didn't find it.
Oddly, no, there's no specific function for taking a root-level scalar JSON term (like '"foo"'::jsonb), and extracting said scalar to its equivalent native Postgres type.
You can still do it (for extracting to text, at least), but you have to use a 'vacuous' path-navigation to accomplish it, so it's extremely clumsy, and wastes the potential of the new syntax:
looks a bit meh. And custom right unary operators are on the way out, so one can't even create one for this use case.
Anyway, for fun:
create function deref_jsonb(jsonb) returns text as $$ begin return $1#>>'{}'; end $$ language plpgsql;
CREATE OPERATOR # ( leftarg = jsonb, function = deref_jsonb );
select '"sdfasdf"'::jsonb #;
select jsonb_col['a']# FROM somewhere;
Downvoters could instead provide a way to get a decoded text of a property with this new syntax, like it's possible with #>>. That would be more useful.
Wouldn't one big difference be that with this syntax, you can use bind-parameters / joined row-tuple fields / expression values as jsonpath keys?
ETA: no, actually, I was wrong — #>> takes text[], so you can already pass it an ARRAY[] literal containing expressions. It's just all the examples in the PG docs that use the IO syntax to represent the path, and then rely on an implicit cast to text[].
Would you be able to give a bit of context for the limitations of the new syntax that you’re pointing out? Could they be overcome (and if so why did it ship like this) or are they inevitable?
I don't think it's a limitation, it's just by design. a['b'] is equivalent to a->'b' not to a->>'b', otherwise deep references (a['b']['c']) would not work because first a['b'] would return text and not jsonb value.
Postgres is bowing to the inevitable, JSON support is too much in demand.
But this is going to be a classic example of bad design. Databases are a bad place to be storing JSON, which is a good interface and a bad storage standard. It is pretty easy to see how JSON will play out: some bright young coder will use JSON because it is easier, then over the course of 12 months discover the benefits of a constrained schema, and then have a table-in-a-table JSON column.
It isn't so out there to think that ongoing calls for JSON support will lead Postgres to re-implement tables in JSON. We've already got people trying to build indexes on fields inside a JSON field.
This is needless complexity engineered by people who insist on relearning schemas from scratch, badly, rather than trusting the database people who say "you need to be explicit about the schema, do data modelling up front".
I think PostgreSQL has always been very pragmatic. It's supported JSON natively since 9.2 (Sep 2012).
> Databases are a bad place to be storing JSON
You're right that "mature" features and projects have a very good understand of the schema. But not everything is that.
Suppose I want to collect info from the Github API about a bunch of repos. I can just store the entire JSON response in a table and then query it at my leisure.
There's also something to be said for contiguous access. Joining tons of little records together has performance problems. Composite types and arrays can also fill this void, but they both have their own usability quirks.
I use the json features of postgres to turn json into relation data. Store all json messages received in a table, then use a materialized view to extract the relevant parts into columns. Works well, and lets me keep the original data around.
> Databases are a bad place to be storing JSON, which is a good interface and a bad storage standard.
That's why in 99% of cases, Postgresql uses jsonb as storage standard, which is binary and compressed.
> This is needless complexity engineered by people who insist on relearning schemas from scratch
No, this is the right tool for situations where schemas are polymorphic, fluid, or even completely absent (like raw third-party data). I love SQL and following normal forms, and it is the right tool for most situations, but not all.
I've learned and applied my schema normalization and what have you got. But it's not the be-all and end-all of good engineering. What I greatly appreciate about hierarchical value storage in contrast to related flat records, is that it is so much easier to store and retrieve a tree. No need to generate ids and insert rows one by one, no need to decode the result of large joins. Because it doesn't only take time to write code for that, it can contain errors too.
If you've got hierarchical data and you just want to store, update and retrieve it as a whole (which is my use case), JSON is a good choice. Granted, it could be stored as a string/blob in my case. I don't really need to search within.
JSON in Postgres is a bit like a nail gun. Used correctly, it's incredibly useful. But in inexperienced hands (and lacking good technical leadership), it's easy to shoot yourself in the thigh.
You don't even need JSONB to commit war crimes on a Postgres database. There's many things that Postgres can do, but probably shouldn't be done:
- Storing "foreign keys" in an array column, instead of using a join table
- Storing binary files as base64 encoded strings in text columns
- Using a table with `key` and `value` string columns instead of using redis
- Pub/sub using NOTIFY/LISTEN
- Message queueing
- Other forms of IPC in general
- Storing executable code
- God tables
Even when trying to use Postgres appropriately, plenty of engineers don't get it right: unnecessary indices, missing indices, denormalised data, etc.
This isn't unique to Postgres, or relational databases in general. Any form of storage can and will be used to do things it's not designed or appropriate for. You can use as easily use S3 or Elasticsearch for message queuing, and can even find official guides to help you do so. Go back 20 years or so, and you can find implementations of message busses using SOAP over SMTP.
The problem isn't JSONB (or any other feature). It's bad engineering. Usually it's an incarnation of Maslow's Hammer: when all you have is a hammer, everything looks like a nail.
> Storing "foreign keys" in an array column, instead of using a join table
Very bad idea for a base table, sure. OTOH, potentially great idea for a (possibly materialized) view (as might eagerly storing an array of row values instead of keys.)
> Storing binary files as base64 encoded strings in text columns
That might not be a bad idea depending on size, and depending on how often you needed the binary vs. a base64 encoded string: if most of the use of the binary is in a context where it will be sent as base64 encoded, storing it that way might be a great idea.
> Using a table with `key` and `value` string columns instead of using redis
If you need an in-memory cache, sure. Otherwise...you could use redis, but I’m not sure why it would always be preferred.
> Pub/sub using NOTIFY/LISTEN - Message queueing
NOTIFY/LISTEN are a pub/sub mechanism. You shouldn’t use them alone as an application level message queueing system, but you definitely can build such a system on PG and might well use NOTIFY/LISTEN in the implementation.
> - Storing executable code
There are probably problems that involve specific instances of doing this, but this is at best to general to describe a thing yoi shouldn’t do.
Yeah re the binary base64 encoding - we found that when using text based queries (the default for pg gem on ruby and most other client libraries AFAIK), base64 in a text column outperformed byte columns as it avoids extra conversions to and from base64.
We did switch to using binary queries though (by passing result_format as 1), and at that point we did see a speedup from using bytea columns - but it’s quite a bit of work to get the type mapping correct then so probably not worth it in most cases
> Databases are a bad place to be storing JSON, which is a good interface and a bad storage standard.
JSON makes perfect sense in a database that already supports all of: BLOB, TEXT, XML, ARRAY, and composite datatypes, including any datatype, including those on this list, for members of ARRAY and composites.
OTOH, Postgres has had XML since v8.2 (2006) and JSON since 9.2 (2012), and “tables in <supported structured serialization format>” hasn’t happened yet, even as discussion item AFAIK, so perhaps it would be bad, but even so it seems to be just fantasizing something to worry about.
> This is needless complexity engineered by people who insist on relearning schemas from scratch, badly, rather than trusting the database people who say "you need to be explicit about the schema, do data modelling up front".
The reason is with some projects/data it's hard to be explicit about the schema which is why NoSQL had it's popularity phase.
Now most applications don't have either entirely structured or entirely unstructured data, they will have a mix - so it's absolutely brilliant for one tool to do both. If they didn't support JSON I have a strong suspicion that they wouldn't have had some of the growth we have seen for Postgres across the last few years.
Postgres is one of those pieces of software that’s so much better than anything else, it’s really incredible. I wonder if it’s even possible for competitors to catch up at this point - there’s not a lot of room for improvement in architecture of relational databases any more. I’m starting to think that Postgres is going to be with us for decades maybe even centuries.
Do any other entrenched software projects come to mind? The only thing comparable I can think of are Git and Linux.
There's a ton of room for improvement in the architecture of relational databases. This isn't a dig against Postgres, or ignoring how difficult it will be to get a new system to the same level of maturity. But databases designed natively for cloud/clustering, SSDs, (pmem soon perhaps), etc are quite a bit different. There's enormous simplifications and performance gains possible.
There's been a lot of exciting work in this area over the last decade or so. Andy Pavlo's classes are great surveys of the latest work: https://15721.courses.cs.cmu.edu/spring2020/
CosmosDB is an example of a relational (multi paradigm properly) database with a quite different architecture vs the classic design, that's moved into production status quite rapidly.
FaunaDB and CockroachDB are moving with solid momentum too.
- scaling is non-trivial (you can't just add a node and have PostgreSQL automagically Do The Right Thing™)
- you can only have so many connections open to the database, causing issues with things such as AWS Lambda
- I don't remember if this was changed, but I got the impression a while ago that having dynamic DB users was a bit cumbersome to set up (plug PostgreSQL to AD/LDAP)
You must be kidding me with the CosmosDB mention. It doesn't even have foreign key constraints. I have to work with it and I have never seen such a feature-poor dbms before.
I'm talking about the general category of everything built atop BW-Tree and the Deuteronomy architecture. Murat Demirbas's blog has nice summaries of the papers. CosmosDB is a brand that encompasses more than one database engine, but I used that term as most people aren't familiar with the literature on the topic.
Foreign key constraints are not practical for distributed data stores. And are actually more controversial than you’d think for regular databases, due to their heavy performance cost.
There are also technologies like NVMe over Fabric/RDMA, eBPF, XDP, io_uring etc which are just starting to get traction and are game changers for performance. None of which are being used.
All of these require a different architecture so expect to see newer databases push things even further.
It isn't really a surprise in this case since both ethnic Mongolians and those with Downs syndrome are not in many Americans' social circles.
"Almost all" does sound like a bit of a surprise, but thinking back on it the only one I know for a fact I heard for the first time outside of a corrective context was my elder uncles friends who enjoyed self-depreciating jokes, usually with slurs for eastern Europeans in them. I first heard those as a child and only realized years later they were offensive. Most others, I think, I honestly have no idea when i was first exposed to them.
It's implied that someone is going around calling people with Down's syndrome "Mongos." "Mongol" is an actual non-offensive[0] word which means, unsurprisingly, someone who can trace their lineage back to the area around Mongolia.
Mongol is not (as far as I am aware) an offensive word. Mongoloid[0] (which "mongo" is a shortened form of) in reference to people with Down Syndrome, definitely is.
My pet theory is that the database is named after a character in "Blazing Saddles", and I want to be able to store candy in it.
I always thought it was a reference to valuable stuff picked from trash, which I understood to be slang from sanitation workers, but apparently that's local to the NYC area.
I don't know about other languages, but in German "Mongo" is pretty much a forbidden word as it is derogative descriptor for people with down syndrom and other visible defects, especially movement defects.
I don't know about other languages, but in German "Mongo" is pretty much a forbidden word as it is derogative descriptor for people with down syndrom and other visible defects, especially movement defects.
In the UK that would be "mong", for us Mongo is the planet Ming The Merciless is from.
Click schedule in the link in my above comment, or in any of the previous classes on the same topic. It's all online. They only restrict a handful of guest lectures, usually from the usual suspects like oracle or amazon.
I'm an enormous fan of Postgres, it's my default go-to RDBMS. But the memory expense of connections is a huge issue and this article doesn't convince me that it's solved.
The machine being used for this benchmark has 96 vCPUs, 192G of RAM, and costs $3k/mo.
My business runs just fine on a 3.75G, 1 vCPU instance. But idle connections eat up a huge amount of RAM and I sometimes find myself hitting the limits when a load spike spins up extra frontend instances.
Sure I could probably setup pgbouncer and some other tools but that's a lot of headache. I'm acutely aware that MySQL (which I dislike because no transactional DDL) does not suffer from this issue. I also don't see this being solved without a major rewrite, which seems unlikely.
So Postgres has at least one very serious fault that makes room in the marketplace. The poor replication story is another.
It isn't solved, and no one claimed it to be solved. The scalability improvement is related to how we build MVCC snapshots (i.e. information which transactions are visible to a session). That may reduce the memory usage a bit, but it's more about CPU I think.
As for the per-connection memory usage, the big question is whether there really is a problem (and perhaps if there's a reasonable workaround). It's not quite clear to me why you think the issues in your case are are due to idle connections, but OK.
There are two things to consider:
1) The fixed per-connection memory (tracking state, locks, ..., a couple kBs or so). You'll pay this even for unused connections.
2) Per-process memory (each connection is handled by a separate thread).
It's difficult to significantly reduce (1) because that state would no matter what the architecture is, mostly. Dealing with (2) would probably require abandoning the current architecture (process per connection) and switching to threads. IMO that's unlikely to happen, because:
(a) the process isolation actually a nice thing from the developer perspective (less locking, fewer data races, ...)
(b) processes work quite fine for reasonable number of long-lived connections, and for connection pools address a lot of the other cases
(c) PostgreSQL supports a lot of platforms, some of which may not may not have very good multi-threading support (and supporting both architectures would be quite a burden)
I wonder if the amount of RAM used by a new process can be reduced. Code and other RO segments are shared anyway, so it's only basically the new heap and various buffers.
Reducing this amount would also run Postgres in more constrained environments.
There are two parts of this - the memory allocated by OS and internally.
At the OS level, we can't really do much, I'm afraid :-( I don't think we're wasting too much memory there, exactly because a lot of the memory is shared between processes. Which also makes it difficult to determine how much memory is actually used by the processes (the sharing makes the various metrics in ps/top are rather tricky to interpret).
As for the internal memory, it's a bit more complicated. We need a little bit of "per process" memory (per-backend entries in various internal data structures, etc.) - a couple dozen/hundred kBs, perhaps. It's hard to give a clear figure, because it depends on max_locks_per_transaction etc. This is unlikely to go away even if we switched to threads, because it's really "per session" state.
But then there are the various caches the processes keep, memory used to run queries etc. Those may be arbitrarily large, of course. The caches (with metadata about relations, indexes etc.) are usually a couple MBs at most, but yes, we might share them between threads and save some of this memory. The price for that would be the need for additional synchronization / locking, etc. The memory used to run queries (i.e. work_mem) is impossible to share between threads, of course.
Overall, there's very little chance PostgreSQL switch to threads (difficulty of such project, various drawbacks, ...). But I do agree having to run a separate connection pool may be cumbersome, etc. There was a proposal to implement integrated connection pool, which would address at least some of those problems, and I wouldn't be surprised if it happened in foreseeable future.
And this right here is why PostgreSQL will never overtake MySQL and its forks. The entire industry is sick of these excuses regarding process-per-client instead of a proper multi-threaded model. There may have been a valid argument for this 15 years ago, but not anymore.
Your definition of "reasonable number of long-lived connections" is anything but reasonable. Then "connection pools address a lot of the other cases", when a connection pool/bouncer is unwanted, unwarranted, and just adds another point of failure that needs to be deployed and maintained.
Firstly, it's not the goal of the PostgreSQL project to overtake MySQL or other databases, but to serve the existing/new users. This also means we're investing the development effort in a the highest benefit / effort ratio. Even if switching from process-based to thread-based model improved the per-connection overhead, the amount of work needed is so huge the benefit / effort ratio is so utterly awful no one is going to do it. There are always better ways to invest the time / effort. Especially when there are practical solution / workarounds like connection pools.
Secondly, every architecture has pros/cons, and switching from processes to threads might help in this respect but there are other consequences where the process model is superior (some of which were already mentioned). Focusing on just this particular bit while ignoring the other trade-offs is rather misleading.
And no, the arguments did not really disappear. To some extent this is about the programming model (locking etc.), and that did not really change over time. Also, PostgreSQL supports platforms, some of which may not have particularly great threading support.
I'm not claiming there are no workloads / systems that actually need that many long-lived connections without a connection pool. In my experience it's usually "We don't want to change the app, you have to change the DB!" but fine - then maybe PostgreSQL is not the right match for that application.
> Even if switching from process-based to thread-based model improved the per-connection overhead, the amount of work needed is so huge the benefit / effort ratio is so utterly awful no one is going to do it.
Then other products will emerge and overtake some of PostreSQL's marketshare in the long run. It's already happening in fact. Just like more efficient and easier to configure webservers like nginx and caddy are gaining marketshare over Apache httpd.
I love PostgreSQL and don't want to see it becoming the next Apache httpd, slowly but surely fading. Perhaps FAANGs could fund such refactor.
Perhaps a cheaper solution was to incorporate pgBouncer inside PostgreSQL so it would naturally sit in front of PostreSQL in the default installation without extra configuration.
> Then other products will emerge and overtake some of PostreSQL's marketshare in the long run. It's already happening in fact. Just like more efficient and easier to configure webservers like nginx and caddy are gaining marketshare over Apache httpd.
Maybe, we'll see.
It however assumes the other (thread-based) architecture is somewhat universally better, and I doubt that's how it works. It might help the workloads actually requiring many connections to some extent, but it's also likely to hurt other workloads for which the current architecture works just fine.
But let's assume we decide to do that - such change would be a massive shift in programming paradigm (both internally and for extensions developed by 3rd parties) and would probably require multiple years. That's a huge investment of time/effort, with a lot of complexity, risks and very limited benefits until it's done. I'd bet there'll always be a feature with better cost/benefit ratio.
So reworking the other architecture might actually gain us some users but loose others, and drain insane amount of development resources.
> Perhaps a cheaper solution was to incorporate pgBouncer inside PostgreSQL so it would naturally sit in front of PostreSQL in the default installation without extra configuration.
Yes, I already mentioned that's quite likely to happen. There has already been a patch / project to do exactly that, but it didn't make it into PG14.
Setting up pgbouncer is not much headache and for for OLTP workloads, it works great. You can even see it in the graph, that best performance is when number of CPU cores = number of connections. And so will be memory use. :)
You may be right that it's easy to set up, but pgbouncer doesn't help with this problem most of the time. It's a problem that needs to be solved within postgres.
There are three pooling modes:
- Session pooling. Doesn't help with this issue since it doesn't reduce the total number of required connections.
- Transaction pooling / statement pooling. Breaks too many things to be usable. (eg. prepared statements...)
Personally I don't expect this to be ever improved in PostgreSQL (ie. change from process per connection model to something else), so I design my multi-user apps so that everything works fine with session pooling (quick short sessions/connections to pgbouncer) and connections that wait for NOTIFY get made directly to postgresql server, and are also limited in number.
And it works fine on low-resourced machines that I tend to use for everything.
Switching to a threaded model would be a lot of work, but there is a simpler solution that retains most of the benefits: using a process-per-connection model for active connections only, and allowing a single process to have multiple idle connections.
I follow the mailing list because I'm interested in this exact issue. Konstantin Knizhnik sent a patch implementing a built-in connection pooler in early 2019 that uses a similar approach to what I just described. The work on that has continued to this day, and I'm hopeful that it will eventually be merged.
Can you elaborate / quantify the memory requirements a bit? I don't have much experience with MSQQL in this respect, so I'm curious how big the difference is.
Sure, SQL Server supports a maximum of 32767 connections each of which use around 128kB. Meaning that if you use the max connections you’ll need 4GB for the connection overhead.
We see no noticeable drop in performance with increased idle connection with our workload.
They mention this in the article. But to sum up, each connection in PG is handled by its own OS process. Postgres behind the scenes is composed by multiple single-threaded applications.
This comes with the advantes for Pg developers (and us!) that they don't need to deal with tons of data races issues, but the trade off is that memory wise, a process takes way more memory than a thread.
> Do any other entrenched software projects come to mind?
Elasticsearch is underrated here, IMO. Yes, there are alternatives for simple fulltext search. But there’s a lot more it can do (adhoc aggregations incorporating complex fulltext searches, with custom scripted components; geospatial; index lifecycle management) and if you’re using those features, there’s nothing else comparable.
It’s pretty stable, too, once you’ve got the cluster configured. We don’t have outages due to problems with Elasticsearch.
To provide an opposing viewpoint here: ES and it’s monstrous API and resourcing requirements are a pain to manage and run. It’s a product that has pivoted in so many directions that it’s just become a bit of a mess. I don’t want a full-text search engine that also has graphs, ML, some bizarre scripting feature, log management, etc all stapled in on top. Geospatial and other analytic stuff I’d rather use a dedicated OLAP db like Redshift or ClickHouse.
I’m currently evaluating typesense vs ES for a fts project and typesense is winning so far by simply be “not painful” to deal with.
> I don’t want a full-text search engine that also has graphs, ML, some bizarre scripting feature, log management, etc all stapled in on top
Sure, so use something else. I do need (most all of) that at my work (plus the horizontal scaling), and there's no competition. I know we're not the only ones.
Also, there's nothing bizarre about the scripting feature. There are several options for scripting, it's very flexible, and it suits implementing custom logic when you need it.
And, I'm not saying ES is perfect! I'm saying that there's a set of use-cases that only ES (to my knowledge) can fulfil, and that's complex aggregations also involving complex full-text search, over tera/petabytes of data. Clickhouse can do aggregations, but doesn't have anything close to the search chops (again, to my knowledge).
I don't know about elasticsearch specifically, but I'm skeptical of special-purpose systems for databases.
They are great in some cases and terrible in others, and over time, use cases push database systems into their worst cases. Use cases rarely stay in the sweet spot of a special-purpose system.
That being said, if the integration is great, and/or the special system is a secondary one (fed from a general-purpose system), then it's often fine.
I’m not sure I fully understand your comment (databases that are special-purpose and evolve out of a sweet spot, or special-purpose systems using databases in worst-case ways?).
I certainly wouldn’t say ES is the former. We use it for some conplex things that (AFAIK) no other (publicly available; I don’t what eg Twitter or Google has going on) system could provide at the scale we need. Everything we’re doing is well within the realm of what ES is built for, and it’s the only system built for it. It’s not perfect, but most of our performance issues could be solved by scaling out, where query or index optimization isn’t tractable.
It’s frustrating to need a run-time team for a piece of infrastructure, especially one sold as IaaS.
It’s totally understandable that you’d need developers to have expertise in patterns and anti-patterns, as well as needing an expert to set things up in the first place, but you shouldn’t have to have a dedicated ES monitoring / tuning / babysitting team like Oracle DBAs of yore. That you do, means it isn’t there yet as a product.
It absolutely does not “just work”, there’s so much to configure and then get-right for your use-case that you almost certainly need people with a solid understanding of the JVM + ES. Let alone fixing it when something inevitably breaks.
No more than any other database. I mean relative to SQL Server, Postgres, MongoDB or any other database. There's no extraordinary difficulty to manage ES above any other production system. It is very usable out of the box, and needs minimal tuning for many use cases. Of course some uses cases will require additional tuning and maintenance, sometimes quite a lot if you have a very large system, JUST LIKE ANY OTHER DATABASE SYSTEM.
In our case for a small website serving the general public (a few tens of thousands of requests per day) it just worked OOTB with hardly any tuning or maintenance at all.
We had a cluster. It was low maintenance. Any clustered / distributed database will require maintenance. At my current job we have SQL Server and there's a shitload of admin/maintenance required for that.
I'm pretty hopeful that DuckDB will replace some of the use of SQLite. SQLite is great but it sucks that it's entirely dynamically typed (the types specified for columns are completely ignored).
I like to say that "Postgres is a great default". It's generally very good, and also very adaptable to special purposes, so it covers a wide range of use cases.
The Postgres 13 baseline for the benchmark/test case (actually HEAD before the patch was committed, but close enough to 13) showed that certain indexes grew by 20% - 60% over several hours. That went down to 0.5% growth over the same period. The index growth much more predictable in that it matches what you'd expect for this workload if you thought about it from first principles. In other words, you'd expect about the same low amount of index growth if you were using a traditional two-phase locking database that doesn't use MVCC at all.
I forgot to mention that the test case had constant long-running transactions, each lasting 5 minutes. Over a 4 hour period for each tested configuration.
This level of improvement was possible by adding a relatively simple mechanism because the costs are incredibly nonlinear once you think about them holistically, and consider how things change over time. The general idea behind bottom-up index deletion is that we let the workload figure out what cleanup is required on its own, in an incremental fashion.
Another interesting detail is that there is synergy with the deduplication stuff -- again, very nonlinear behavior. Kind of organic, even. Deduplication was a feature that I coauthored with Anastasia Lubennikova that appeared in Postgres 13.
I am not very familiar with this topic, but need to maintain large and frequently updated DB, which requires periodic VACUUM FULL with full tables lock, so, does PG suffers from index bloat only and your fix solves it, or there is some other type of bloat for general table data too, which will still exists after your improvement?
It's not possible to give you a simple answer, especially not without a lot more information. Perhaps you can test your workload with postgres 14 beta 1, and report any issues that you encounter to one of the community mailing lists.
I think the point is that git isn't "so much better" than mercurial, while pgsql has had a lead on mysql for quite some time on a lot of technical measurements.
I would say that that's pretty dubious claim with modern versions of Postgres and MySQL/InnoDB, running on modern hardware. See for example this recent comparative Benchmark from Mark Callaghan, a well known member of the MySQL community:
I'm not claiming that this benchmark justifies the claim that Postgres broadly performs better than MySQL/InnoDB these days -- that would be highly simplistic. Just as it would be simplistic to claim that MySQL is clearly well ahead with OLTP stuff in some kind of broad and entrenched way. It's highly dependent on workload.
Note that Postgres really comes out ahead on a test called "update-index", which involves updates that modify indexed columns -- the write amplification is much worse on MySQL there. This is precisely the opposite of what most commentators would have predicted. Including (and perhaps even especially) Postgres community people.
"Is table a heap with indexes on the side or is table a tree with other indexes on the side (i.e. 'clustered index')" is a more complicated discussion.
The former makes it possible to have MVCC (and thus gives you snapshot isolation and serializability) and makes secondary indexes perform faster, at the cost of vacuum or Oracle-style redo/undo/rollback segments with associated "Snapshot too old" issues.
The latter pretty much forces use of locking even for read so queries block each other (but don't require vacuum or something), makes clustering key selective queries perform faster than secondary index ones and makes you think really hard about the clustering key.
It's not really a feature you would have, but a complicated design tradeoff.
I was aware maria had temporary tables, but not mysql proper. Any links you can point me to? Every search is coming up with 'temporary' table info, not temporal.
mysql8 has gis/spatial stuff built in now. may not quite be on par with postgis, but... i also don't have to futz with "doesn't come baked in". Dealt with someone who wrote a whole bunch of lat/lon/spatial stuff in client code because we're on postgres but ... he couldn't get postgis installed (then even if he could, figuring out how to convince the ops people to add a new 'thing' in production would have been a delay).
MySQL has atomic ddl, which means if a ddl operation fails it is reverted. But PostgreSQL has really transactional ddl which means you can do ddl operations in a transaction and you can commit/rollback multiple ddl operations at once and not each by it‘s own like MySQL does.
You claim that MySQL 8 is ahead when it comes to scalability. What are the bases of this claim? When I see comparisons or entire systems that rely on a database (that is, not micro-benchmarks) such as the TechEmpower web framework benchmarks [0] , I notice that the 'Pg' results cluster near the top, with the "My" results showing up further down the rankings. I understand this isn't version 14 of the former versus version 8 of the latter. But it makes me wonder what the basis of your claims is.
Techempower is not a database benchmark. The tests that involve a DB exist to include a DB client in the request flow, not to put any serious load on the database.
Aren't those run on a single node DB server? And the queries don't really seem realistic at all, e.g. single query test fetches 1 out of 10 000 rows, with no joins at all. Fortunes fetches 1 out of 10 rows. This seems extremely trivial.
Not an expert, but it is my understanding that Julia is becoming an ever more serious competitor day by day.
> Excel for business spreadsheets.
Honest question, what does LibreOffice miss compared to Excel? In any case, (again not an expert) spreadsheets seem quite inferior to a combination of Julia, CSV and Vega (Lite); although there are certainly more people that are familiar with operating Excel.
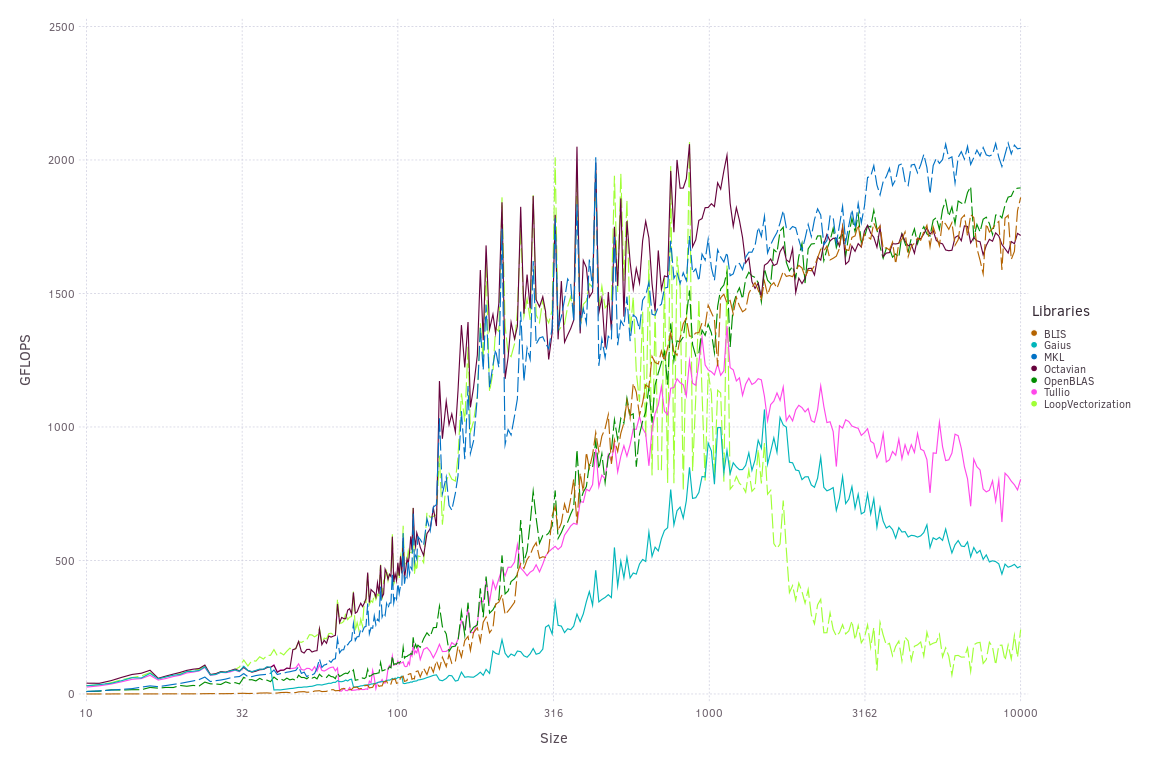
Not necessarily. All of the DifferentialEquations.jl defaults use pure Julia BLASes which outperform the Fortran BLASes. Mainly, RecursiveFactorization.jl and Octavian.jl, which tend to match or outperform MKL and OpenBLAS on our benchmarking computers, form our workhorse.
What issue do you have with the use of RecursiveFactorization.jl in DifferentialEquations.jl? I can't think of a maturity issue so I'm curious what you have found, or whether this comment isn't grounded in specifics.
Did my original post even mention RecursiveFactorization.jl or DifferentialEquations.jl? (or is this an implicit package promotion? I do not have issues with them anyway, perhaps great work, have not used them...) Regarding your second point, let's see if the language and its various package APIs remain stable, actively maintained, and backward-compatible just ten years from now, let alone 3 quarters of a century. Such issues do not become visible right away or overnight. I am not against the language, just stating the fact that it has yet to pass the test of time.
Big corporations are horribly inefficient and Enterprise Software necessarily so from that...if you're saying Java is terrible by nature of it being the goto for enterprise, then that makes sense. It took 20 years for it to swap places with COBOL and I expect it will be something else in 20 more.
I don't work with Java, but I can think of a few advantages off the top of my head:
- appreciation of backwards-compatibility (here it wins with Python);
- great debuggers and performance tools (e.g. Java Flight Recorder or Eclipse Memory Analyzer);
- easy deployment - you can just give someone a fat JAR (here it wins with all scripting languages, so Python, Ruby, PHP, or any other flavour of the month);
- industry-grade garbage collectors;
- publicly-available standard spec (here it wins with all the defined-by-implementation languages such as Python, PHP, Rust, basically most languages, and with languages which are standardized, but their specs aren't public: C, C++, Ruby);
- kind of like the previous point, but anyway: multiple implementations to choose from;
- I've been told it has good performance. I've never seen a real-world Java application which felt fast, but I've heard people put it at the pedestal and the Debian programming languages benchmarks game seems to corroborate that story;
Besides, the question wasn't about which technologies we like, but which we believe are entrenched so much, they aren't going to go away for a very long time. I don't see Java going away for another 100 years, no matter how much I would or wouldn't like to work with it.
I started using java 16 after a long hiatus from java 7 (instead doing rust and clojure) - I'm pretty happy with some of the new language features - lambdas, records, type inference, streams
IMO the Java stdlib also strikes just the right balance between control and abstraction. You can write thread-safe, performant code that makes reasonable tradeoffs between data structures without worrying too much about the details about memory layout and allocation. Said code also is easy to debug even without a debugger because there's almost never undefined behavior caused by use-after-free type bugs and error messages are clear. And the tooling - just IDEs alone, never mind debuggers - is mature and effective.
After using Python, Go, PHP, and C++ it's easy to see why Java is the go-to language for server development.
It wouldn't need as much research into efficient GCs if it was possible to write efficient programs in it. e.g. everything has a lock word, there's no value types or fixed length arrays, you have to allocate boxed integers.
people complain about java's verbosity, but I see that as a feature in places where there's a revolving door of consultants working on things. Everything is so explicit it is easy to see what some code does.
I think anyone who has worked a lot with MSSQL would disagree with Postgres being "so much better". It's only really in the last few years that postgres has pulled ahead, MSSQL was lot more feature rich and performant for a decade.
MSSQL ? As in Microsoft SQL Server? I have heard this argument a lot and all the comparisons I have seen are specific benchmarks on specialized hardware. My own personal experience wasn’t anything like the benchmarks
MSSQL still has a few features that set it apart from Postgres. Off the top of my head are Filestream (basically storing files in the database while still having them accessible as files on the filesystem) and temporal tables without the need for extensions.
Personally if I were choosing the tech stack for my company I'd still go for Postgres though
What's the issue? Just on Windows? Mac OS X with 13.2 has no issue for me with the 1.1gigabyte 20million record csv just imported last week, or some bigger ones I did a few months back.
What exactly makes Postgres better than MySql?
There seem to be certain design decisions like WAL or process per connection that cause problems at scale
Anyone whose ever had to upgrade postgres ever knows postgres can't fail fast enough. They must fix their upgrade paths and it's endless means to completely fuck you if they want to be taken seriously.
Any progress on high availability deployments yet? Or does it still rely on problematic, 3rd party tools?
Last time I was responsible for setting up a HA Postgres cluster it was a garbage fire, but that was nearly 10 years ago now. I ask every so often to see if it has improved and each time, so far, the answer has been no.
But there's so much more to it than this, e.g. upgrading, failing over, point in time recovery, monitoring.
I manage both a cockroachdb cluster and a few PG setups. Out postgres' have streaming replication to a standby with barman running on the standby. They are night and day.
Sure 2021 PG is way better than 2010 PG. But relative to available options, it's much worse.
I have been looking at patroni for years. But i still do not feel compatible using it in a production environment. If something fails it will be really really hard to fix it, but i have the same feeling for almost all these complex kubernetes operator doing a lot of magic work to have a simple solution.
And 200+ other improvements in the Postgres 14 release!
These are just some of the many improvements in the new Postgres release. You can find more on what's new in the release notes, such as:
The new predefined roles pg_read_all_data/pg_write_all_data give global read or write access
Automatic cancellation of long-running queries if the client disconnects
Vacuum now skips index vacuuming when the number of removable index entries is insignificant
Per-index information is now included in autovacuum logging output
Partitions can now be detached in a non-blocking manner with ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY
the killing of queries when the client disconnects is really nice imo -- the others are great too
It would be nice to hear how much of problem XID wraparound is in Postgres 14 - do the fixes below address it entirely or just make it less of a problem?
I see no mention of addressing transaction id wraparound, but these are in the release notes:
Cause vacuum operations to be aggressive if the table is near xid or multixact wraparound (Masahiko Sawada, Peter Geoghegan)
This is controlled by vacuum_failsafe_age and vacuum_multixact_failsafe_age.
Increase warning time and hard limit before transaction id and multi-transaction wraparound (Noah Misch)
This should reduce the possibility of failures that occur without having issued warnings about wraparound.
Clearly it doesn't eliminate the possibility of wraparound failure entirely. Say for example you had a leaked replication slot that blocks cleanup by VACUUM for days or months. It'll also block freezing completely, and so a wraparound failure (where the system won't accept writes) becomes almost inevitable. This is a scenario where the failsafe mechanism won't make any difference at all, since it's just as inevitable (in the absence of DBA intervention).
A more interesting question is how much of a reduction in risk there is if you make certain modest assumptions about the running system, such as assuming that VACUUM can freeze the tuples that need to be frozen to avert wraparound. Then it becomes a question of VACUUM keeping up with the ongoing consumption of XIDs by the system -- the ability of VACUUM to freeze tuples and advance the relfrozenxid for the "oldest" table before XID consumption makes the relfrozenxid dangerously far in the past. It's very hard to model that and make any generalizations, but I believe in practice that the failsafe makes a huge difference, because it stops VACUUM from performing further index vacuuming.
In cases at real risk of wraparound failure, the risk tends to come from the variability in how long index vacuuming takes -- index vacuuming has a pretty non-linear cost, whereas all the other overheads are much more linear and therefore much more predictable. Having the ability to just drop those steps if and only if the situation visibly starts to get out of hand is therefore something I expect to be very useful in practice. Though it's hard to prove it.
Long term, the way to fix this is to come up with a design that doesn't need to freeze at all. But that's much harder.
> Very interesting thanks for the update - how great is the Internet to hear directly from the developer!
I see the names of a few people that also work on Postgres on this thread. We're not all that hard to get a hold of if you're a user that has some kind of feedback or question, for what it's worth. The culture is very open in that sense.
> Do you know if anyone is turning their attention to this or is it not currently being tackled by anyone?
This is one of the goals of the zheap project. I myself have some very tentative ideas for tackling it within the standard table access method, heapam. I have not specifically committed to working on it on any timeframe. I haven't completely convinced myself that the approach I'm thinking of is truly robust and practicable. It's pretty complicated, especially because I cannot really know what will break and need to be fixed until I spend significant effort on the implementation.
I agree this is a great addition, but FWIW it isn't normal for ^C to not work in psql. Perhaps you are using some other client that doesn't support aborting queries properly, or have something on the network between you and the server behaving poorly and dropping connections?
It's psql through an ssh-tunnel to RDS on AWS, postgres 10.6 usually. But I've had the same experience on other versions and locally too.
The problem usually isn't that it doesn't work ever, just that it can take a very long time, especially if the query is reading some crazy amount of data. I've always found pg_cancel_backend() to be almost instant though.
If you’re interested in recent enthusiastic (nearly effusive) discussion of Postgres and more specifically it’s potential as a basis for a data warehouse, you might enjoy this episode of Data Engineering Podcast with Thomas Richter and Joshua Drake:
I'm thinking of using Postgres for a project, but a DBA friend told me operationally it's more challenging than MySQL. Unfortunately, he can't elaborate. Does anyone have real work experience? Or is it based on outdated "PG must manually vacuum frequently"?
Postgres has some disadvantages that can pop up on certain workloads (eg. bloat) but so does MySQL. And most of those limitations are only when you've got long open transactions, trying to hammer it IO wise, or you're making really big databases (100GB-1TB or more). However for both Postgres and MySQL there is plenty of documentation about these problems, and how to resolve them. So you'll never be "stuck" with issues.
In general I find postgres "just works" a lot more than MySQL. MySQL has a really bad habit of sticking with bad defaults for a long period, while having better configuration available. On the other hand postgres devs actively remove/change defaults so you're always getting the best it has to offer.
If you pick one, and you don't like it there are plenty of tools to change between them. If you're curious you could even deploy both of them.
One thing is that Postgres doesn’t let you just upgrade to a new major version, as it doesn’t update the format of the on-disk binary database files; you must replicate from an existing node or dump/restore. MySQL upgrades the previous version when a new version is installed (which can cause problems, but is certainly “easier”).
Pg_upgrade [0] is an official part of postgres and does the binary inplace upgrade for you. You should obviously test before running in production, but it has worked perfectly for us when upgrading a 10+TB cluster from pg11 to pg13
That's hardly a PostgreSQL issue. If your container tech does not allow installing both old and new version of the binaries, it's a silly container tech.
Why not? Having the whole application in one Kubernetes setup, with all databases and other services is very convenient. Are you talking about performance overhead, or are there other drawbacks to this approach?
The main problem is "persistent storage". In k8s, a PVC/PV is probably close to the right answer, but in general that gives you a file-system view of the storage, not a block-device view, which for some databases might matter).
Also, in general, that persistent storage is (generally) not locally attached, which means that (some) file system interactions may have unexpected semantics. Now, with a DB, you're probably only going to have the PV attached on a single worker node, so most of that will actually just work.
How can someone with 10k karma write such a statement? Were you trolling? Are you serious? 10TB of relational database can be definetly troublesome to manage and pose challenges to many organizations.
I think this is very convenient; you don't want to automatically upgrade a big database because you probably want to choose the downtime window. This is obviously by design, but I'd also like being able to automate the pg_upgradecluster pg_dropcluster process, specially for install-and-forget little databases.
IMO, the biggest shock from the MSSQL/MYSQL to PostgreSQL migration was not having 1 or 2 specific files per database, specially if you used to backup the files instead of doing a formal database backup.
Are you going to operate it our just rent out some cloud service?
Postgres by itself doesn't have a great horitzontal scaling strategy as of now I think. You need Citus or somt like that on top, maybe your friend was referencing that?
You can fiddle with the autovacuum daemon[1,2] but we've never really had to. These days we just run AWS RDS when it counts or a dedicated VPS when it doesn't and things go fine--
If I have a Django + PG query that takes 1 second and I want to deeply inspect the breakdown of that entire second, where might I begin reading to learn what tools to use and how?
EXPLAIN ANALYZE in Postgres will give you the query plan, learning to understand that output is very useful to figure out why a query is slow. If the query isn’t slow, you can look into Django, but the DB is often a good first guess in these cases.
If you only have the Django queryset and not the SQL, you can generate pseudo-sql using "print(queryset.query)".
Note that this isn't valid SQL, just an approximation, because Django doesn't generate a single SQL string, but uses the underlying library's parameterization. So you'll have to fiddle with quotes and such to get SQL you can run the EXPLAIN on that's mentioned in the other replies.
Vitess for PostgreSQL will probably just be... Vitess.
The concepts behind Vitess are sufficiently general to simply apply them to PostgreSQL now that PostgreSQL has logical replication. In some ways it can be even better due to things like replication slots being a good fit for these sorts of architectures.
There are no plans right now.If the Postgres community (or a Postgres user) would like to take this project up, the best way to proceed would be to do it as a fork of Vitess. Once the implementation has been proven in production, a “merge” project can be planned to bring the fork back into upstream.
Delete From "APCRoleTableColumn" Where "ColumnName" Not In (Select SC.column_name From (SELECT SC.column_name, SC.table_name FROM information_schema.columns SC where SC.table_schema = 'public') SC, "APCRoleTable" RT Where SC.table_name = RT."TableName" and RT."TableName" = "APCRoleTableColumn"."TableName");
I know this is not an optimized SQL. But this takes about 5 seconds in Postgre while the same command runs in milliseconds in MSSQL Server. The APCRoleTableColumn has only about 5000 records. The above query is to delete all columns not present in the schema from the APCRoleTableColumn table
I used to be a heavy MSSQL user. I do love Postgre and have switched over to using it in all my projects and am not looking back. I wish it was as performant as MSSQL. This is just one example. I can list a number of others too.
If I remember correctly, SQL Server will convert NOT IN to anti-join. PostgreSQL currently does not do that due to NOT IN being incompatible with anti-joins in regards to NULL values. There's room for improvement there by detecting if NULLs can exist or not, and converting if they can't.
If you don't need the NOT IN weirdness around NULL values then I'd suggest you just use a NOT EXISTS. That'll allow something more efficient like a Hash Anti Join to be used during the DELETE. Something like:
Delete From "APCRoleTableColumn" Where Not EXISTS (Select 1 From information_schema.columns SC INNER JOIN "APCRoleTable" RT ON SC.table_name = RT."TableName" Where RT."TableName" = "APCRoleTableColumn"."TableName" AND SC.column_name = "APCRoleTableColumn"."ColumnName" AND SC.table_schema = 'public');
It’s a little hard to parse that on mobile but it looks like you’re doing correlated subqueries against the dB schema for each row in the table you’re deleting from.
As others have said, explain analyze will show you what’s going on. I’m fairly sure this query would be fixed by flipping and / or adding an index. 5k records is nothing to pg.
Never had the use for it or even heard of it, guess it depends on usage patterns? I've mostly worked with longlived java servers, and there having an internal db pool has been standard since forever, so no need for another layer.
It's not clear to me if the OP want's to run without any connection pool (incl. a built-in one), or just without a separate one.
In an ideal world PostgreSQL would handle infinite number of connections without a connection pool. Unlikely in practicem though.
There are good practical reasons to actually limit the number of connections:
(a) CPU efficiency (optimal number of active connections is 1-2x number of cores)
(b) allows higher memory limits
(c) lower risk of connection storms
(d) ... probably more
Some applications simply ignore this and expect rather high number of connections, with the assumption most of them will be idle. Sometimes the connections are opened/closed frequently, making it worse.
Eliminating the need for a connection pool in those cases would probably require significant changes to the architecture, so that e.g. forking a process is not needed.
But my guess is that's not going to happen. A more likely solution is having a built-in connection pool which is easier to configure / operate.
Separate connection pools (like pgbouncer) are unlikely to go away, though, because being able to run them on a separate machine is a big advantage.
For now yes. The idle connection changes help but it's still inefficient. I would like to see connection pooling functionality merged into core PG at some point. Eliminate the need for network hop/IPC and enable better back-pressure etc.
Lots of good ops-y stuff, and, with my dev hat on, multirange types are just a whole layer of awesome on top of the awesome that range types already were.
{kind=link}