Do we have any hope for garbage collecting CPUs 40 years later or are they a doomed venture?
> In 1975, Intel's next big plan was the 8800 processor designed to be Intel's chief architecture for the 1980s. This processor was called a "micromainframe" because of its planned high performance. It had an entirely new instruction set designed for high-level languages such as Ada, and supported object-oriented programming and garbage collection at the hardware level.
I'd much rather have a security-oriented processor with tagged bounds checked pointers... such a facility could also make garbage collecting more efficient, but what it could do for security would be wonderful.
The 8800 (iAPX 432) provided bounds checking too. Every object reference wasn't a pointer but an "Access Descriptor" that included permissions. So you couldn't access anything out of bounds. I should emphasize that this isn't like a JVM, but was implemented at the machine instruction level. It's hard to understand how strange and radical this processor was.
Every time I hear about abandoned "improved" tech like this, I always wonder why the idea was shelved. The link kinda handwaves it away. Any good resources on why the idea didn't take off?
You'd probably have to find an Intel insider to know the real truth.
But the most likely possibility is that the plan was too grand for the time (note, this was 197x to ~ 1984ish, the IBM PC with its 8088 had only been on the market about three or so years) and therefore much too expensive for any market to bear.
Additionally, the iAPX432 was being worked upon during the same time that the IBM PC suddenly brought the x86 chips to significant popularity.
Combine the concepts of pouring money into an arch. that was too big and grandiose for the integration tech. at the time, with a sudden influx of profit from the x86 chip line, and it seems that a likely reason was simply to devote resources to the chip line that was suddenly producing those same resources.
"Using the semiconductor technology of its day, Intel's engineers weren't able to translate the design into a very efficient first implementation. Along with the lack of optimization in a premature Ada compiler, this contributed to rather slow but expensive computer systems, performing typical benchmarks at roughly 1/4 the speed of the new 80286 chip at the same clock frequency (in early 1982).[7] This initial performance gap to the rather low-profile and low-priced 8086 line was probably the main reason why Intel's plan to replace the latter (later known as x86) with the iAPX 432 failed. Although engineers saw ways to improve a next generation design, the iAPX 432 capability architecture had now started to be regarded more as an implementation overhead rather than as the simplifying support it was intended to be."
That makes sense. I remember absolutely huge data sheets and reference manuals for the IAPX432. So it's very possible that Intel didn't think hard about re-licensing the somewhat janky 0x86 design because they expected it to be a dead end.
Historically speaking, I'm not sure if Intel ever -wanted- to license x86.
The main reason that AMD (and others) manufactured x86 CPUs early on was because IBM had a 'second source' requirement; i.e. there had to be another vendor who could provide the same part.
So an AMD 286 was no different from an Intel 286.
By the time of the 386, IBM had relaxed/dropped the second-source requirement. Thus the Am386 isn't the same design as the i386 (and there was a court battle to try to keep the AMD part out of the market.)
Am386 was reverse engineered design, but microcode was 1:1 Intel copy :). There was no
court battle over this chip. Intel was forced into arbitration due to second source agreements, and lost.
Court battle was over 287 and later Am486. AMD announced clean-room design ... and gave their clean room engineers 386 microcode copy :]
Possibly the fact that the 432 was so slow and the momentum was with the 8086 and successors following the success of the IBM PC.
RISC, which in some senses is the polar opposite of the approach taken with the 432, also started to generate a lot of interest at about the same time.
There is an excellent paper by Robert Colwell exploring why the 432 was slow and how it could have been speeded up:
> Every time I hear about abandoned "improved" tech like this, I always wonder why the idea was shelved. The link kinda handwaves it away. Any good resources on why the idea didn't take off?
My guess it is it was something like the "AI Winter:" a hyped idea fails in in a high-profile way, so it gets shunned for some period of time because people are afraid of failing again in a similar way. It seems like some of the features of that processor lead it to be a nonstarter for practical reasons:
> According to the New York Times, "the i432 ran 5 to 10 times more slowly than its competitor, the Motorola 68000".
Back then, personal computers didn't have much performance to spare.
IIRC, Intel has had several high-profile failures when radically new non-x86 CPU architectures. Only backwards-compatible conservative evolutions of the x86 seem to get traction.
It probably didn't help performance. But there's some good news: ARM has added pretty much the same thing, called MTE (Memory Tagging Extension) [1], which uses the upper 4 bits of memory addresses as a region identifier.
My theory is evolution. The "more advanced" idea has higher up-front costs so the cheaper, worse idea gets used, iterated upon until it's so polished that it's better than the infant stages of the better idea (the better idea has the potential to be even more polished with investment, but never will be) so everybody uses it and now we're stuck with it...
Usually it's one or more of several common factors: cost to make, cost to buy, cost to integrate, slower/inefficient performance, loss of compatibility, some unintended design defect, poor or over-ambitious marketing, or some assumption that compatible/optimized/"unobtanium"/Carnot-efficient software will solve Issue X for us. See Itanium, DEC Alpha, Transmeta, Consumer Power/PowerPC, OS/2, Commodore, PCjr, ETX motherboard standard, Java Processors, etc.
I used the CONV-86 8080 to 8086 converter tool mentioned in the article on a project back in 1983. It really worked quite well, with hardly any fixup required on a fairly large (at that time) code base.
I remember thinking that the 8088 (in the IBM PC) was a speed demon compared to the 8080 (in the CP/M system I was converting from).
CONV-86 came on 8" floppy disk for the ISIS-II operating system on Intel MDS development boxes. Even if you found a copy, you'd need an MDS-80 to run it on.
After the IBM PC came out, everyone tossed their MDS-80 systems when Intel started to provide their tools on MS-DOS.
With the current interest in retro computing, I wish I had saved more stuff from back then. I kick myself for not saving an Intel i960CA evaluation board that I used in 1992. I loved the i960 architecture and developed quite a few products with it.
However, I still have the processor from that board because I replaced it with an i960CF.
The funny thing is, back in the day I wrote a 8080 emulator that could run CP/M programs on MS-DOS, and then I went the extra mile and adapted it to run ISIS-II programs for the Intel blue boxes we had. There were some 8051 Dev tools I thought were worth bringing over. But that would have been in the 80s, and the 8 inch drives went to the landfill decades ago. So yeah.
Of course if you had a NEC V20/V30 (pin-compatible 8086 clone), it had a special mode for running 8080 code! It couldn't run Z80 code because it lacked the extensions like LDIR.
I'm toying with the idea of writing something in C64 assembly (something I never did learn back when I was a kid and owned one). I'm delighted to see there's an active scene of C64 fans coding new games for it even today.
Real life will interfere, of course, but a man can dream...
Funny, I got on a C64 kick recently as well, but it ended up bringing me down a weird rabbit hole to CollapseOS, and now Forth, so I am thinking maybe I'll write a Forth for C64 in assembly for fun. I won't bother googling it, but I assume Csixtyforth is already taken.
You gotta love that weird segmented memory model though, to allow it to address up to 1MB of RAM using 20 lines, combining a pair of 16 bit registers to generate the 20 bit address. The Motorola 680x0 was a bit saner.
I think that the face of computing would have changed quite dramatically if Intel had decided to make the x86 segment paragraph size 256 bytes (8 bits) instead of the useless 4 bits. Imagine not having a 640K (or 1MB) ceiling (without hacks like "expanded" or "extended" memory). It would not have been a big deal for Intel to do this; I'm pretty sure they could have multiplexed four more pins worth of address lines.
It would have given the x86 a native 24MB address space, equal to the 68000's physically provisioned 24 bits (which is all most 68K systems supported anyway, certainly the Atari ST and the Mac).
For instance, in the mid 80s, VisiCorp was trying really, really hard to fit their products into 640K. They had some whizzy stuff, but the address space problem pretty much killed them. Later, Microsoft and IBM came along, did the disgusting memory-space hacks that plagued users for a decade or more, and VisiCorp foundered.
Also, the 68000 would still have the clearer upgrade path, as the 24 address lines restriction was in the design of the chip, not in its architecture. As long as code didn’t assume addresses were modulo 2²⁴, code would run unmodified on a CPU with over 16MB memory, and use all of it.
Also, the idea with the 8086 was that programs would actually use 16-bit pointers for objects, not 20-bit ones. That would be wasteful of memory if the granularity of such addresses were 256 bytes.
> I think that the face of computing would have changed quite dramatically if Intel had decided to make the x86 segment paragraph size 256 bytes (8 bits) instead of the useless 4 bits.
I've made that argument in the past too, but I tend to think the 8-bit paragraph shift would've been a nice third mode on the 286 (or maybe a second mode on the 186). So a 286 would've had:
* Real mode with 4 bit shift
* Real mode with 8 bit shift
* Protected mode with indirection through descriptor tables
It seems plausible to me that it would've been possible to make software that would have binary compatible with either of the two real modes, which was not possible between real and protected. That would've opened up 286 users to easier access to memory beyond 1MB.
But I don't know that this would've been a huge change for the industry, aside from killing off the need for LIM/EMS bank switching between 1985 and its death at the hands of Windows 3.0 in 1990. (And towards the later end of that period, the 386 could be made to provide EMS memory without additional hardware.)
I think the best argument for it being a major change is that it might have undermined the need for OS/2.... but even then, OS/2 was the way it was, not due to memory constraints, but due to IBM's need to attempt to regain control of a market it'd lost control over. So 8-bit paragraphs would've been nice for big spreadsheet/dBase users in the 1986-88 period, but not much nore than that.
(And all of this is just five or six years, really.... no time at all.)
> if Intel had decided to make the x86 segment paragraph size 256 bytes (8 bits) instead of the useless 4 bits
It would also have increased memory fragmentation. Many memory allocations were aligned to a segment boundary, so you'd be wasting up to 255 bytes instead of up to 15 bytes on each allocation.
Large model memory allocators would allocate memory on segment boundaries. This is more or less essential if you need to use more than 64K of memory in your program.
An 8-bit paragraph size (rather than the 4 that were used) would've forced all segment allocations to 256-byte boundaries, so that's where the fragmentation issue comes from.
I wish Intel had just added some address lines and increased the price by $10 or whatever.
I remember writing 68k assembly code and it was very pleasant to work with. 8 address registers, 8 data registers, if you want to access memory, you just put a 32-bit address into an address register.
Then I read a book about 80286 assembly and though "ugh this is horrible" and never wrote a single line of x86 assembly code. Worrying about segments and memory models (tiny, small, medium, compact, large, huge) seemed like such a drag on programmer productivity.
It's not a matter of address lines; registers are 16-bit (can addresss only 64 kilobytes), so you need segmentation regardless of whether your segements are mapped into 1MB, 16MB, or 4GB. (For Abus = Areg + Sreg << 4, 8, or 16 respectively.)
Yes, but that's not a matter of "just add[ing] some address lines"; it's a matter of adding additional bits to the registers (and probably the ALU and internal data buses, but the registers are the limiting factor: if you don't have 32-bit registers you can't have (32-bit) flat address space). Even if it were "just", it would be "just add some register bits".
I have heard that IBM chose the 8088 because Intel sowed some FUD about Motorola's ability to supply the 68000 in sufficient quantity for IBM. The decades of insanity we could have saved if IBM had chosen differently...
Intel had introduced the first x86 microprocessors in 1978. In 1981, IBM created its PC, and wanted Intel's x86 processors, but only under the condition that Intel also provide a second-source manufacturer for its patented x86 microprocessors. Intel and AMD entered into a 10-year technology exchange agreement, first signed in October 1981 and formally executed in February 1982. The terms of the agreement were that each company could acquire the right to become a second-source manufacturer of semiconductor products developed by the other; that is, each party could "earn" the right to manufacture and sell a product developed by the other, if agreed to, by exchanging the manufacturing rights to a product of equivalent technical complexity. The technical information and licenses needed to make and sell a part would be exchanged for a royalty to the developing company. The 1982 agreement also extended the 1976 AMD–Intel cross-licensing agreement through 1995. The agreement included the right to invoke arbitration of disagreements, and after five years the right of either party to end the agreement with one year's notice. The main result of the 1982 agreement was that AMD became a second-source manufacturer of Intel's x86 microprocessors and related chips, and Intel provided AMD with database tapes for its 8086, 80186, and 80286 chips.
-end quote-
How much really was Intel sowing FUD vs. IBM demanding a second source be available is probably lost to time.
The explanation I read back in the early 80's was Intel had the 8088 which required 8 DRAM chips. And the 68000 required 16 DRAM chips. For early microcomputers the cost of DRAM was the dominant cost.
Interesting point. I know that with the Nintendo 64, the use of RDRAM was similar (lower overall chip count, which also helped with board cost in that case)
I think also a narrower data bus which might allow a smaller PCB with fewer layers. Used to be higher layer count PCB's $$$$.
Friend worked on a layout where they did the board design first and then designed the processor pinout to match. So they could get away with a small two layer board. Ground on the bottom layer and all the signals on the top layer.
And before that, we had decades of insanity. Segmentation. Six different memory models. Extended memory managers. Extended vs. expanded memory. Those needless complications burned tons of person-years of developer time that could have been spent on useful things.
I've heard a story that due to the hardware divide instruction in 68000, IBM engineers were concerned about interrupt latency (the instruction took many cycles to execute and couldn't be pre-empted by in interrupt).
I think the idea of the segment registers is to create isolated memory ranges for multi tasking. These segments are at the granularity of 16 bytes and have a starting offset and length within 1MB of RAM. There are multiple segments so the code segment can be shared between processes and have separate stack and data segments. When you imagine it as one big 1MB address space this memory model looks wierd.
What the segment registers actually allowed was a primitive form of relocatable code: the 8086 didn't have PC-relative addressing modes, so instead what you got was 16-bit absolute addressing that was segment-relative. DOS could load .COM files (which had a 64KB limit and used the "tiny" model where all the segment registers point to the same 64KB region of memory) at any offset in conventional memory without needing to perform any runtime relocation. Combined with the lack of any header this made perfect sense for small utilities that needed to execute quickly.
I've never bothered to check this, but recently I was told that COM files could be >64K. The DOS loader would just keep loading data until the real 640K end of memory was reached. The program itself would be responsible to modify segment register to gain access to the unreachable parts of itself.
It seems technologically possible, as a program could always assume memory above its own segment (up to A000 of course) was free.
I can't speak for DOS support but I love building COM binaries on Linux which exceed 64k thanks to SFX which allows us to respect the GPL with source code bundling.
Intel leaned into this with the 286's protected mode - segments became references to "selectors" so the OS could place your 64k chunks of code/data wherever it wanted within 16M.
I think the existing base of 8080 software (including CP/M software) was on their minds. You see the same thing in the 386/486, they have the large flat virtual address space software devs wanted, but until the early 90s their commercial value was running 8088 software really fast.
>I think the existing base of 8080 software (including CP/M software) was on their minds.
This is the generally accepted history. According to what's in Wikipedia (https://en.wikipedia.org/wiki/Intel_8086#The_first_x86_desig...) the design was developed very quickly, and intentionally built as a straightforward 'extension' of the 8080/8085 chips into the 16-bit world:
-quote-
The first x86 design
The 8086 project started in May 1976 and was originally intended as a temporary substitute for the ambitious and delayed iAPX 432 project. ... Both the architecture and the physical chip were therefore developed rather quickly by a small group of people, and using the same basic microarchitecture elements and physical implementation techniques as employed for the slightly older 8085 (and for which the 8086 also would function as a continuation).
Marketed as source compatible, the 8086 was designed to allow assembly language for the 8008, 8080, or 8085 to be automatically converted into equivalent (suboptimal) 8086 source code, with little or no hand-editing. The programming model and instruction set is (loosely) based on the 8080 in order to make this possible. However, the 8086 design was expanded to support full 16-bit processing, instead of the fairly limited 16-bit capabilities of the 8080 and 8085.
I liked being able to compile tightest code to fit the appropriate memory model. Tiny was a favourite with all segment registers pointing to the same segment. Another favourite was the huge memory model, multiple code, data and stack segments. Until the day came when one couldn't fit anymore in. I was glad when the mighty 386 came along.
It turns out that it wasn't actually necessary for a COM file to have the segment registers all the same. The Zortech COM file generation only required that the COM file be less than 64K. The startup code would fix things up so it would load and run.
Intel was trying to maintain backward compatibility, so the segments made sense. (They let you default to using the same 16-bit pointers as the earlier 8-bit CPU's, and only use the extended capability if you explicitly opted in by adjusting segment registers and the like.)
And given the cost of memory and CPU packaging pins, 20-bite probably didn't seem like too much of a loss compared to 24-bit addressing (or Motorola's internal 32-bit).
I remember back in my early CS courses where the teacher explained "microcode is this or that" and it sounded so dry. He could have explained microcode was magical goblins for all I cared. It didn't help that I knew nothing (and still don't) about circuitry.
But actually seeing registers and microcode there in the photo is amazing. All this stuff I was taught about actually has a physical form that can be seen!
The lowly 8086 really went a long way from its humble origins.
The 6502 has a PLA, as do many other early microprocessors such as the 6800, 8080, and Z-80. The PLA is a structured arrangement of logic gates, rather than a microcode ROM. But they both have a similar grid-like appearance.
Of course you're the expert here, but isn't this a little nitpicking? The decode logic of the Z80 (from your site[1]) works in much the same way as microcode by stepping through a set of fixed "instructions".
> Of course you're the expert here, but isn't this a little nitpicking?
No, a PLA [1] and a microcode ROM are two very different animals.
A PLA is a way of compactly specifying combinatorial logic circuits (arrangements of and/or/etc. gates) and in the form that gave it the name, it is end user programmable (the P stands for Programmable). But at its heart, a PLA is just a big arrangement of logic gates. A signal goes in, and after the necessary gate delays settle, the result signal comes out.
Microcode is literally a "program" and is 'executed' in the same way that all other programs are executed, one instruction at a time, addressed by a program counter. There are also often branching instructions that generate new program counter values to use to sequence through the various steps. None of which exists in a PLA.
The appearance of similarity arises because both look similar in a silicon die photo (rows and columns of transistors), but they are very different and perform quite different functions on the chip.
A consequence of this is the so-called "undocumented" opcodes of the 6502. Extra instructions such as LAX (load A and X from the same value) "work" because the instruction activates two different blobs of logic (the one for LDA plus the one for LDX). From my experience, it's less clear that microcode would function this way when confronted with an illegal opcode.
The PLAs on the Z80 and 6502 aren't user programmable, but had their functions fixed in the mask just like regular logic or a mask ROM would be.
Talking about the PLAs in these processors versus ucode ROM, the big difference is that in a PLA, typically several lines are enabled at a time. In contrast a ROM will only have one line active at a time with an address decoder sitting in front of it.
You absolutely could use a microcode ROM in the place of how these chips use their PLAs, it'd just take more die area.
You can see this logic/data equivalence in other places of hardware design too. For instance how FPGAs are a sea of SRAM, but are equivalent to standard cell chips. FPGAs are just slower, larger, and easier to modify.
> The PLAs on the Z80 and 6502 aren't user programmable,
I never said they were.
I said: "and in the form that gave it the name, it is end user programmable (the P stands for Programmable)" which is in the context of generic PLA's, not the specific PLA in a Z80 or 6502.
The difference is less clearcut than you're assuming. A PLA and a ROM are both types of lookup tables, after all, and in this application they're both being used to control the next state of a FSM.
> No, a PLA [1] and a microcode ROM are two very different animals.
Technically a microcode ROM (or any ROM, really) is a (degenerate case of a) PLA. Hence the visual similarities, since that type of grid pattern will be observed with any PLA, whether ROM or general-logic.
I suspect that at the time microcode was copyrightable while masks (and therefore PLAs) were not (note the actual (C) message on the die explicitly calling out the microcode)
Protection for "mask works" was introduced in the Semiconductor Chip Protection act of 1984. You'll see a circled-M on modern dies indicating this protection. (I got the mask work symbol added to Unicode recently, but font support is lacking: 🆭.) The 8086 is the only chip I've seen with a copyright specifically designating the microcode.
In the context of IC chip layouts, the determining factor is almost always die area. Some functions will be smaller on the die in PLA form, other functions will be smaller on the die in microcode form. Since die area is almost always a scarce resource, the chip designer will usually pick the design that reduces die area consumption for any given function.
(puts on chip designer hat) yes and no, as I said upstream the copyright laws of the time did not protect designs, chip copying (stealing) was rampant.
I can imagine that some CPU designers from a particular world view (especially in the 70s) might only design in terms of microcode - but also design tools were pretty minimal, I can imagine that it might have been far easier to design things in terms of microcode rather than as PLAs - what you might be seeing here is the differences between different teams' in house custom tooling
Not yet, but with these new high-resolution die photos it is only a matter of time.
Meanwhile the US4449184 patent [1] referenced in the post's footnotes has a lot of information about how the microcode works (and the meaning of the 21 instruction bits) and, in Tables 7-12, shows the microcode listings for some of the microcoded 8086 instructions.
probably not, but the data from this project should make that pretty easy
However to be useful you need to know what each of those 21-bits is connected to, some will essentially be risc-like uCode instructions, the others will be tied to particular functions in the CPU or memory interface
The Z-80 has an interesting way of executing instructions, but it's different from microcode. The first step is the PLA, which basically pattern-matches instructions into related categories, e.g. generating a signal for bit pattern 01XX100X, which might be instructions that read a value from the accumulator for instance.
There are two ways this is different from microcode. First, one instruction can trigger multiple "categories". Second, time is not an input here, so there is no stepping through operations.
The next part of the Z-80 instruction decoding is a big pile of AND-OR gates that generate the control signals based on the PLA outputs and the timing signals. For example, a gate might trigger the read-from-A-register signal for PLA-output-1 and time-1 or PLA-output-3 and time-1 or PLA output-1 and time-4. (These gates are all complex and were hand-drawn.)
The point of this is that both microcode and discrete logic generate particular control signals based on the instruction and time step, but they use very different ways to do this. With microcode, you can point to each micro-instruction as it executed, but in the Z-80, things are happening all over the place seemingly randomly.
I've always wondered why that is, given the space-constraints that affected the other areas of those parts' architecture. I assume it was just for development speed, given that the array was easier to lay out (and maybe even had some kind of primitive EDA tooling)?
A PLA is reasonably space-efficient if you need gates with a fixed set of inputs and outputs. Even the 8008 used one for instruction decoding. In addition to the microcode ROM, the 8086 has several PLAs of various sizes. For instance, one PLA converts the ALU operation into the necessary ALU control lines.
A key distinction is that in a ROM, only one row is active at a time. But in a PLA, multiple rows can be active simultaneously.(This is from "The Architecture of Microprocessors".)
>"The photo above shows part of the microcode ROM. Under a microscope, the contents of the microcode ROM are visible, and the bits can be read out, based on the presence or absence of transistors in each position. The ROM consists of 512 micro-instructions, each 21 bits wide."
I was curious why 21 bits? I would have expected this would have been a multiple or instruction size or perhaps also 16 bits. Or is there really no correlation between size of an instruction and it's underlying micro-ops?
One other question I had was in regards to the "Closeup of some transistors in the 8086" photo where the author states:
>"The circles are connections (called vias) between the silicon layer and the metal wiring, while the small squares are connections between the silicon layer and the polysilicon."
Vias are alway vertical correct? So are we looking at the chip from the top looking downward then? Why don't we see the metal layers then? Or do the metal wires themselves constitute the metal layer?
Why 21 bits? The first factor is there is absolutely no need for an instruction to be 8, 16, or 32 bits. Modern processors use these sizes to be compatible with the 8-bit byte, but older processors used whatever word size was convenient: 12 bits, 13 bits, 17 bits, 27 bits, or pretty much anything.
The second factor is that (as you suspect) there isn't any connection between the size of the machine instructions and the size of the micro-instructions.
Finally, the width of a micro-instruction depends on how much you want to control at once. You can have a micro-instruction that is 100 bits wide, letting the processor do different things in parallel (e.g. IBM 360 mainframe), or a very short micro-instruction that doesn't do very much. The choice of 21 bits is enough for each micro-instruction to do two things (a data transfer and an operation). Having a 100-bit wide micro-instruction would improve performance but make the ROM too large, so it is a tradeoff. (Lookup vertical and horizontal microcode for more information.)
For your second question, the photos are all looking downward onto the chip through a microscope. In the first die photo, you're looking at the metal layer. But in the closeup photo, I've removed the metal and polysilicon layers with acid, so you see the silicon layer. It's tricky to show how all the overlapping layers are connected, so I didn't do that in this post. But I have another post that shows how the layers work together in the 6502: http://www.righto.com/2013/01/a-small-part-of-6502-chip-expl...
>"Modern processors use these sizes to be compatible with the 8-bit byte, but older processors used whatever word size was convenient: 12 bits, 13 bits, 17 bits, 27 bits, or pretty much anything."
Indeed. I guess it's easy to forget that processor in the 1950s up until 1970's or
really before the microprocessor era were all over the map with word sizes.
Thanks for the clarification of the die photo. That makes sense.
By the way I really enjoy these posts and the discussions. Keep up the great work. Cheers.
> I was curious why 21 bits? I would have expected this would have been a multiple or instruction size or perhaps also 16 bits. Or is there really no correlation between size of an instruction and it's underlying micro-ops?
From the US4449184 patent [1], the microcode format was:
5 bits - S (data source)
5 bits - D (data destination)
2 bits - TYP (microinstruction type, e.g. 1 for an ALU op)
5 bits - A (opcode)
3 bits - B (varies by instruction type)
1 bits - F (whether to update the status flags)
In the second figure of the patent, you can clearly see the source/dest controls (each 5 bits) leaving the microcode ("STG 2 ARRAY") and labelled "S-BUS" and "D-BUS". There's another 5 bits (labelled "A-BUS") going to the ALU opcode decoder, 2 bits going to the "CR INC" regsiter (for jumping/branching within the microcode) and a couple of other miscellaneous bits that seem to influence the decoding of further instruction bytes.
So why 21 bits? That's exactly how many bits were needed to encode all of the various microinstruction fields, no more and no less. Since the ROM is internal to the CPU, there's no need to fit the instructions into an integral number of bytes.
The thing that puzzles me is there are 6 values for TYP (patent col 24 line 63) but only two bits instead of three. So they must be doing something tricky like borrowing a bit from A or B.
Also, kiwidrew, if you're examining this closely, the 2 bits go from CR INC to the MUX, not to CR INC. What they are doing is generating a microcode start address from the instruction, and assigning 16 micro-instructions to that instruction by default. CR INC is a counter that steps through these micro-instructions. The idea is that most instruction (< 16 micro-instructions) won't need to do any jumps. A tricky part is that 2 bits of CR INC are part of the microcode row address, while the other 2 bits select 1/4 of the row. In other words, there are four 21-bit micro-instructions in each physical 84-bit row, so the ROM array isn't excessively tall and skinny.
Ah ha, thanks for explaining CR INC, that makes sense now. I have only been looking at the diagrams in the patent.
The patent does enumerate (col 25 line 15) the TYP values: 0, 1, 4, 5, and 6. (The microcode listings also sometimes use a value of 7 for TYP.) So this would suggest that types 0 [conditional jump] and 1 [ALU operation] use a full 5-bit A field (to set the ALU opcode) while types 4-7 use a different format for the A and B fields. The MSB of TYP would select between the two formats, and this would explain the absence of a type 2 or type 3 instruction.
> I was curious why 21 bits? I would have expected this would have been a multiple or instruction size or perhaps also 16 bits. Or is there really no correlation between size of an instruction and it's underlying micro-ops?
There is no direct correlation between the external instruction size and the internal microcode width. The microcode ROM only needs enough bit width to generate all the control signals necessary to drive the hardware. And when laying out a mask ROM on an IC, the designer can make the ROM any bit-unit width they need for the task at hand.
In this case, the 8086 only needed 21 bits to drive the hardware and so the layout was a 21 bit wide ROM.
You can divide a processor into two blocks connected to each other: the control and the data path. A 1970s book illustrated this as a puppet controlled by strings, with the puppet being the data path and the hands at the other end of the strings as the control. How many strings do you need?
The data path has a bunch of registers, things like an ALU, busses and multiplexers. You need a "write enable" wire for each register (or a single enable plus a small number of address bits), select signals for the multiplexers and some control bits for the ALU. 21 bits is as reasonable a number as any other. A slightly different data path might require fewer or more control signals even when used to execute the exact same instructions.
The metal layer is deposited on the whole wafer, but then everything is etched away except where you want wires. So the "wires" and the "metal layer" are indeed the same thing. The vias are just little wells in the oxide beneath the metal layer. So when you deposited metal on the whole wafer some of that filled in the little well making a vertical connection between the wire and what was under the oxide.
>"A 1970s book illustrated this as a puppet controlled by strings, with the puppet being the data path and the hands at the other end of the strings as the control. How many strings do you need?"
That's a great visual. I would love to find the original text if you or anyone else remember's the title.
You create the microcode exactly as wide as necessary to control all the hardware. Any extra bit would double the size of that storage area, and it's already one of the largest things on the chip.
Oh, that's right. It increases linearly with the size of the CPU instruction words in a dimension and the size of the microcode instruction words on the other dimension.
The entire exponential addressing space is not used, since there is an overall structure to both instruction sets.
Yeah - basically, a (like a couple years, that first comment was made in ~1998) while after that comment I went on a hike with a guy in research and we were talking about then secret research that was happening - and he stated they had a 64 core version (yes, 64 cores - but I do not know how functional this test chip was - just that the number of cores was 64) on a test chip that could function.
This was in ~2002 or so? I cant recall.
But the compute power was low - it was more about the interconnects, IIRC?
Anyway -- I ran the gaming lab and was responsible for testing games with SIMD instruction optimizations against games on the first celeron and pentium based CPUS to determine if they passed a subjective muster, as intel would give a company $1MM in marketing funding if they advertised their games as being opt for intel procs...
My greatest claims from intel was:
I never once sat in my cube.
I had the same pee schedule as Andy Grove and for some reason, like every single time I went pee... he was there also and we peed "together"
The most I ever said to the Titan was "Hi How Are You" GOTO 10 "Oh Shit, He Is Here Again"
Yes, it will be interesting to look at the microcode. Intel's 8086 patent discusses the microcode in some detail and gives examples of the microcode for a few instructions. So I'm not expecting any huge surprises.
I've ordered an 8088 so I can compare the internal circuitry of the chips. They should be mostly the same, except that the 8088 has an 8-bit data bus externally and has 4 bytes of prefetch buffer instead of 6.
That's fantastic news! I'm interested to see whether the 8086 and 8088 use the same microcode or whether the only difference between the chips is in the BIU itself.
I've always wanted a "visual 6502" style emulation of the original IBM PC, and a high-resolution die photo is the first step. Cycle-accurate emulation of the 8088 is fiendishly difficult thanks to the complex interactions between the EU and BIU.
Now I really want to get a 8086 on a bread board and see if I can do things with it! What else do I need to put on the breadboard to build a minimum computer?
Probably just a voltage regulator, a clock source, reset pin logic, a couple ROM chips (2 8-bit wide chips or 1 16-bit wide), some static RAM, a PAL/GAL/74xx logic for address decoding and chip select pins, stuff to deal with the multiplexing, and whatever input/output you want (bus buffers for parallel I/O, off the shelf UART chips, etc)
I’ve only done it with the 6502 and Z80, but the 8086 shouldn’t be too much harder. There are plenty of resources available online for those two chips that you could adapt!
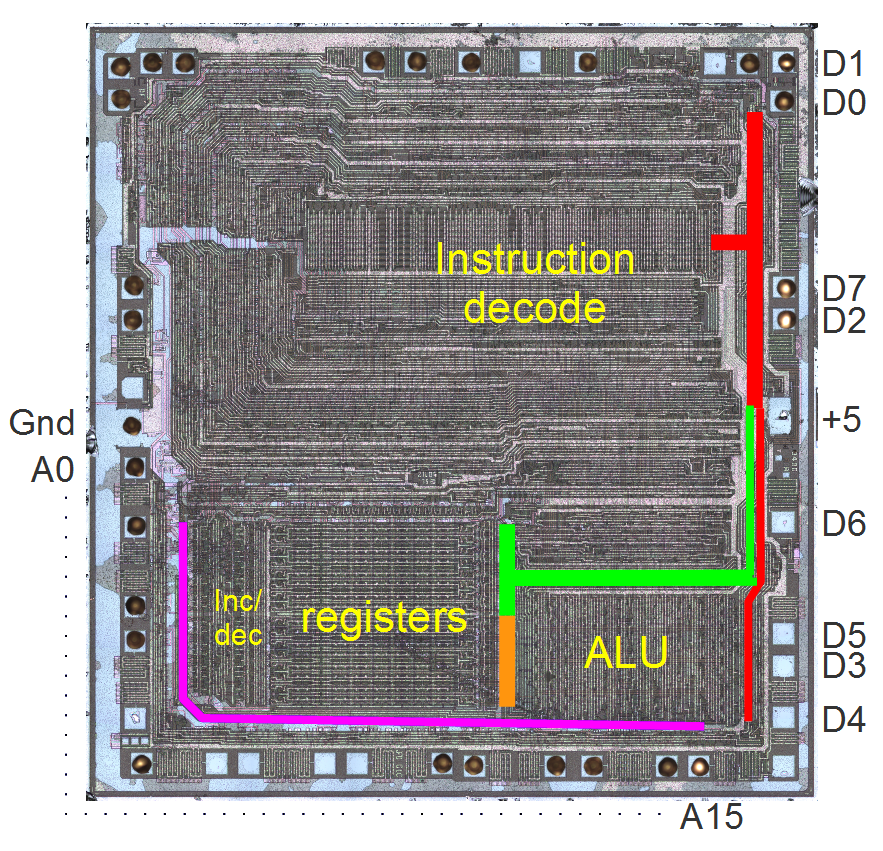
The registers are made of small repeated blocks, one per bit, so they form a grid. The adder (and ALU) is also repeated for each bit, but each unit is much larger and more complex. It also helps that the block diagrams and patent diagrams roughly match the die layout.
I was current on every other processor of this era, but I avoided 8086 because of the crappy addressing scheme. They (apparently) wanted to keep some sort of connection to 16-bit addressing, so they came up with the "segment registers", which were a real kludge. I guess I was wrong, and once they graduated from "real mode", it got better.
{kind=link}
{kind=link}
{kind=link}
> In 1975, Intel's next big plan was the 8800 processor designed to be Intel's chief architecture for the 1980s. This processor was called a "micromainframe" because of its planned high performance. It had an entirely new instruction set designed for high-level languages such as Ada, and supported object-oriented programming and garbage collection at the hardware level.