Do you expect to be able to insert utf8 into utf8 columns? Don't be naive. Read the docs and you'll discover utf8mb4 or as I like to refer to it: mysql_real_utf8.
How about transactions? Surely a real SQL database supports transactions right? Or at the very least if it doesn't it would complain loudly when you use a transaction where not supported right? Once again this behavior is helpfully documented https://dev.mysql.com/doc/refman/8.0/en/commit.html
Do you expect to be able to put a value into MySQL and get that same value back out? You are SOL. But it's documented.
I can honestly say that the only appropriate time to use MySQL is when you can't use postgres and you are willing to move from a RDBMS to something that requires significantly more work to prevent data corruption.
I respect the hell out of MySQL engineers in terms of raw performance and the engineering of Innodb. I'm sure they aren't happy there's a million broken applications relying on defaults they can't change. I'm sure they aren't happy that fundamental limits in how pluggable storage engines work make ACID transactions not possible in the general case.
Postgres, for all of it's issues, feels like a database that has your back.
This seems overly negative and a lot of FUD. Some of these issues are minor, and/or when aware of it are easy to work around. MySQL is much more than a "nosql with mature replication".
> MySQL is much more than a “nosql with mature replication”
Yes. It is, and the parent is saying why (despite the fact it had more features) it shouldn’t be treated as anything more than a nosql document store with mature replication.
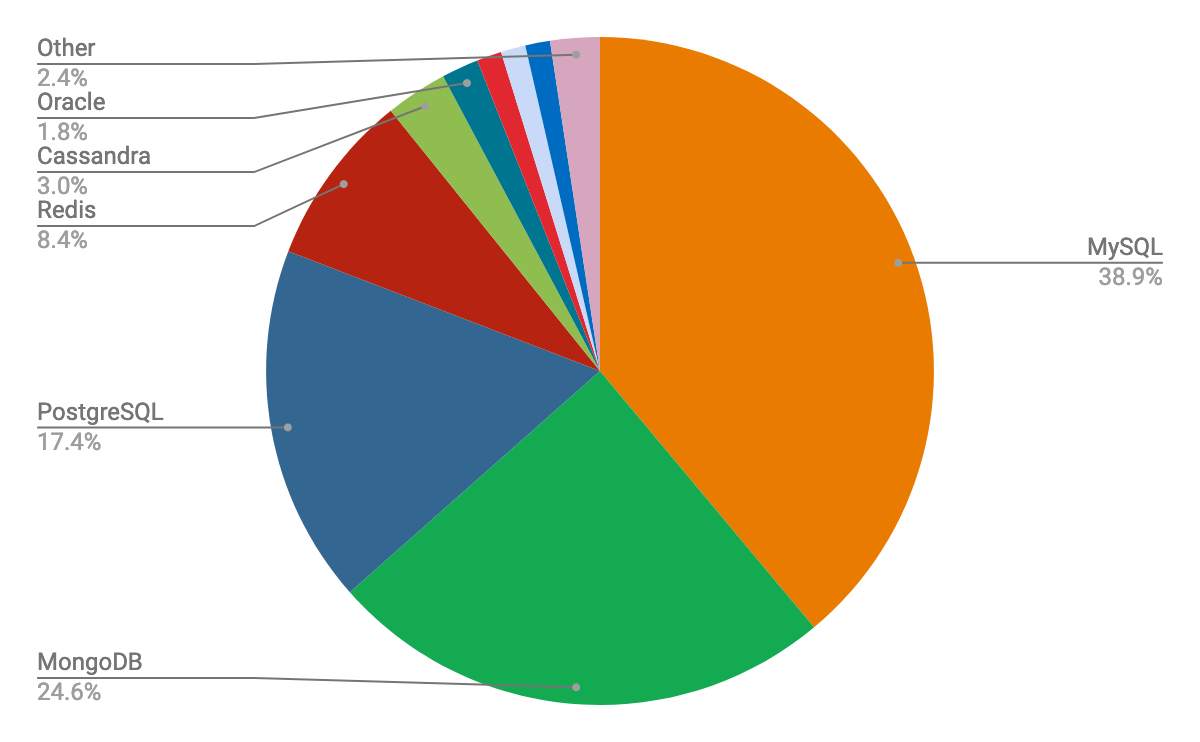
FWIW I’ve used MySQL, MongoDB, Postgres, Cassandra and a plethora of others at huge scale and I cannot possibly be clearer:
MySQL is full to the brim of foot-guns;
storage specific behaviours, leaky transaction isolation and silent data corruption behaviours et al.
You CAN, absolutely navigate it well enough to never lose a bit or get bitten by any of its “weird” behaviours, but it requires that every person touching the database is very well versed in the entire documentation of the database.
That is why the parent is not spreading FUD, because MySQL as a technology should be approached with caution, and the fact that it looks like it’s working when it’s corrupting your data is the worst design consideration of the entire thing; which necessitates this behaviour and reinforces the myth that MySQL is not dangerous.
> Yes. It is, and the parent is saying why (despite the fact it had more features) it shouldn’t be treated as anything more than a nosql document store with mature replication.
This is very unfair to innodb which is a mature enterprise level relational engine.
InnoDB is very nice, especially when compared to myISAM. If this post only contained information regarding myISAM then there would be a lot to unpack and it would look like flaming.
I think I’m being fair to innodb though. It’s not necessarily InnoDBs fault that it cannot handle schema changes in a transaction, or munges data if the column isn’t the right size, or that it fails a commit but overwrites data anyway.
These are generally MySQL problems, and it doesn’t matter which storage engine you use.
> or munges data if the column isn’t the right size
Same behaviour as Ms sql server or sybase. Would you be so harsh with them?
> it cannot handle schema changes in a transaction.
Same behaviour for some cases on sql server and sybase.
Also in MySQL 8 some schema changes are indeed atomic.
You are being unfair as those limitations are perfectly fine to live with.
Your comments in this thread crossed repeatedly into getting personal (taking the form 'you are this', 'you need to that', etc., and impugning someone else's level of knowledge). Would you please not do this when posting here? It isn't necessary, it's provocative and distracting, and indeed it provoked and distracted.
Ugh, this is going to get tedious, you're obviously feeling defensive for some reason. Please try not to be.
MSSQL does not munge data if the column is not equipped for it, I have no idea about sybase. You can test this easily by making an int column and putting a maxint+1 in.. it will tell you "NO" and not insert anything.
MSSQL supports schema changes in transactions, fully, again, not sure about sybase. MySQL 8 might support it /sometimes/ but the major concern I had with this fact is that MySQL doesn't tell you it's going to break its transaction isolation. -- it just commits in the middle of your transaction and moves on.
My final point is mitigated somewhat by MySQL "Strict" mode, which nobody enables.
> Ugh, this is going to get tedious, you're obviously feeling defensive for some reason.
Please edit this sort of thing out of your posts to HN, regardless of how defensive someone else is being or how provoked you feel. If they're really being so defensive, nothing good will come of arguing and it's best to let go anyhow.
> MSSQL does not munge data if the column is not equipped for it, I have no idea about sybase. You can test this easily by making an int column and putting a maxint+1 in.. it will tell you "NO" and not insert anything.
It does truncate strings.so does MySQL. But you need to enable strict mode. Easy.
Mssql does allow ddl in transactions, but do not do it, you will have huge locking issues. It will also not work in snapshot isolation.
My point stands: all major enterprise dbms have limitations. And you are dismissing MySQL, but by your standards Mssql and sybase would also be dismissed.
This is unfair.
You just need a semi competent dev to know those limitations. And MySQL with innodb is not that far from sql server or sybase.
> My point stands: all major enterprise dbms have limitations. And you are dismissing MySQL, but by your standards Mssql and sybase would also be dismissed.
You are refuting a claim I never made. My issue is not with the limitations, these are a fact of life with any and all technology.
My issue is with silent data corruption and subtle issues that break expectations
Thus, requiring any user of the system to be fully versed in all the documentation and to be prescient enough at all times when interacting with the database.
I can’t make such guarantees, and PostgreSQL follows the principle of least surprise much better. If I have two options and one of them has odd silent failure modes and the other holds your feet to the fire to ensure correctness. I will consistently choose the latter.
> it shouldn’t be treated as anything more than a nosql document store with mature replication.
This is the outrageous statement I was replying too.
I get it, postgresql is your thing (I'm a postgresql dba BTW). However you are being excessive and unfair.
You are just repeating a meme without having administered databases professionally. You need to study your database of choice. Postgresql or Mysql.
Are you aware of postgresql's fsync bug ? Is postgresql more than a nosql database because of that ?
> My issue is with silent data corruption and subtle issues that break expectations
SQL server and sybase do truncate data too. Silently.
Are they nothing more than nosql databases because of that ?
You've made a few comments about me here which I feel are undeserved, if you knew me you would not assume I am "repeating a meme", I am a classically trained sysadmin, not historically a coder, and I've been the bastion of data consistency in a few very high transaction/heavy database driven companies and I've been in the industry close to 15 years now. -- incidentally the only time I lost data was due to silent corruption bugs in the application or as a discovery made after inheriting a MySQL 5.1 cluster.
My choice of database technology is driven by industry experience, not fanboyism (many who know me, know that I fought very hard against the fad of mongodb, for instance). And it's true I prefer PostgreSQL these days, mostly because the only time it's ever bitten me was with the autovacuum and that was all the way back in postgresql 8.2!
It's possible I'm incompetent, but I'd rather not go into a slinging match about competency right now.
I am aware of postgresql's fsync bug, but that's not _at all_ comparable to: defined, documented behaviour in a database engine.
Yes, bugs happen and bugs are bad, but what the grandparent stated was absolutely not a bug, it's documented behaviour, it's known behavior and it's only _just_ becoming addressed and only in the loosest of terms (incidentally as programmer mindshare is starting to focus on alternatives).
FWIW, I personally believe that MySQL and its ilk should be relegated to legacy applications, I do not hold it as fact that there's a cojent reason to choose it for a new project even as a NOSQL solution unless a few things are true:
1) All your developers only know MySQL and MySQL specifics (as in, you're a pure mysql shop and you know it very well)
2) You already have a product built on MySQL, it's costly to move.
3) You are the people who are building/designing mysql and trying to compete with more competent database engines.
You bring up truncation of strings, but I was talking primarily about ints/floats.
As a person who has 'dba' in his name you've made a lot of claims disparaging MSSQL, some of them I told you that you were wrong about and you agreed; but I am fairly certain that MSSQL does not truncate a string on insert. I'm going to test this claim.
EDIT::
Sorry it took me an hour to install MSSQL on my laptop, I'm on vacation in Russia and internet here is hard to come by.
Anyway: MSSQL does not silently insert varchars.
#> create table #sometable(acolumn varchar(8))
#> insert into #sometable(acolumn) values('blah blah blah way more than 8 chars')
Msg 8152, Level 16, State 14, Line 7
String or binary data would be truncated.
`select *` shows no new rows, which is what I would expect.
It all depends on the ANSI_WARNINGS switch. Some clients set it, some don't. Thus you have to be explicit or you might have a NoSQL database.
You should also read about arithabort and arithignore.
As I told you, you need to study the database engine you are using. For Mssql too. So you assumed it's always on. The type of mystake some non diligent devs do with MySQL. Gives it an undeserved bad rep. A dba can help you and teach you the nuances. Ask them at your company.
There have been a considerable amount of efforts made to improve innodb. It's plenty fast and properly used, it's well behaved. Just like Mssql.
You are talking past the person you are replying to. Parent comment points out that MySQL has quirks that helps you shoot yourself in the foot moreso than other engines. Eventually you will slip up, no matter how diligent you are. The argument is that it's easier to slip up and with more frequency in MySQL, so when faced with a choice there are safer alternatives.
To summarise: Broadly the grandparent is correct, but some of his problems have been addressed in a very new version of the database in question. Is that fair?
> Most of the "problems" also exist in enteprise scale database server such as sql server and sybase.
You've repeatedly dumped a long string of personal attacks based on statements of fact that were fundamented rather well, and in spite of your repeated appeals to authority you've failed or refused to comment on the technical aspects and decided to react with attacks and repeated assertions that in your eyes other alternatives are not perfect. Perhaps its high tine for you to step away from the keyboard and think about what you've been doing in this thread and how you've decided to portay yourself in this discussion.
i'm looking for a test suite that is used to verify query isolation and correctness at high levels of concurrency. ie do you know of anything that you could run against both databases to quantitatively say that postgres is better in this regard than mysql ?
or that would somehow highlight that it's more complicated to get compliance from one that the other, eg because the required SQL is more complicated
> it shouldn’t be treated as anything more than a nosql document store with mature replication.
For years, Windows NT claimed to have Unicode support, but what they called Unicode was in fact the UCS subset that used 2 bytes for each character. They still haven't adopted UTF-8 which is ubiquitous on the web.
Windows uses NTFS which is a mess ridden by compatibility constraints. For instance, the recent releases of NTFS at last introduce a snapshot feature, but mounting the volume may destroy the snapshot. FAT was even uglier. Linux and BSD are fully compatible with many mature file systems, while Windows has few options.
Windows should not be treated as anything more than a volatile UI with mature drivers. Windows is dangerous and everyone should switch to Linux or BSD (MacOS for the hipsters).
/sarcasm
As inconsistent and dangerous as it may be, MySQL is more than a nosql document store.
Curious which many hidden gems the open source BSDs contain in the way of mature file systems, since I haven't encountered any in my travels so far.
The only things I've had luck interoperating between the BSDs have been ISO9660, FAT32, and ext2. Windows has full support for the former two, and to be honest all of those are less-than-ideal.
I think the point here is that when software calls an encoding "utf8," it is reasonable to expect that it means what every other piece of software is likely to mean by "utf8." MySQL violates that expectation. It's nice that they've changed the default encoding to be "utf8_for_realsies" but that should have been what was meant by the encoding with the name "utf8" all along.
Beyond that, I get that "utf8" meant "utf8...psych" before, but the alias for "utf8" should have been made an alias for the real utf8 several versions ago. And that's just one single quirk... no other RDBMS has so many quirks that weren't eliminated across major versions like mysql.
Changing the defaults across a major release is something they've had several opportunities to do, time and again they have kept a LOT of weird behaviors.
One detail that is not always obvious is how much work goes into limiting regressions. The work to switch to utf8mb4 really started in MySQL 5.6 by not allocating the sort buffer in full (and then further improved in 5.7). 8.0 then added a new temptable storage engine for variable length temp tables.
These are not small cases either: When you compare to latin1 because the _profile_ of queries could change from all in memory to on disk, we could be talking about 10x regressions. In MySQL 8.0 it is more like 11% https://www.percona.com/blog/2019/02/27/charset-and-collatio...
Edit: Also forgot to mention, switching the default character set broke over 600 tests. It's not as easy as it sounds!
While I appreciate that it's the default now (utf8mb4)... If someone specified (by error) "utf8" as the collation, is that real utf8 or some other implementation currently?
If it would only run flawlessly on Windows, I would gladly run Postgres. It doesn't though, so I chose MySQL for my project. This was two years ago however, things might have changed.
*edit: I recognize a lot of what you mentioned though, and MySQL sure has its draw backs. Still it seems to work fine for a lot of people.
FWIW we're running a lot of instances on Windows, and there are differences for sure, performance falls off a cliff, but for testing it's decent enough.
i'm looking for a test suite that is used to verify query isolation and correctness at high levels of concurrency. ie do you know of something that you could run against postgres to quantitatively say that it is "a database that has your back", and then run against mysql and see that it fails ?
I mean, I'm not too upset that they're focusing on one DB engine, but their reasons are a bit facetious.
> There are lots of great use cases for MySQL, our specific needs just didn't seem to be a good fit. Our use of MySQL had a number of limitations. In most cases, it wasn't as simple as adding support to MySQL, but that by bending MySQL we typically broke PostgreSQL. To name a few limitations:
> We can't support nested groups with MySQL in a performant way
All they had to do was implement a nested set pattern for their groups [1]
> We have to use hacks to increase limits on columns and this can lead to MySQL refusing to store data
A hack? Their DB creation schema specified a TEXT column when it should have been a LONGTEXT column. Using LONGTEXT is not a hack, it's a choice when your data is more than 65535 characters, and they made the wrong choice out of ignorance.
> MySQL can't add TEXT type column without length specified
That's just incorrect. What they MEANT to say is that they had a column to store filenames that was a varchar(255) column and people were running out of space with long directory paths and filenames. They could have moved to a TEXT column, but didn't because they thought it couldn't be indexed without specifying a length... But they were wrong, you CAN index a TEXT column without specifying the TEXT column length, you just have to specify the length of the substring you want to index.
Alternatively, since this is filepaths and filenames, they could have used a nested set pattern again and gotten 255 characters for each component of the path and a lot more feature options for their search system!
> MySQL doesn't support partial indexes
This is true, but is it really a show stopper?
> As a side note – we don't use MySQL ourselves
I think this is the real reason. They just didn't have the necessary talent to implement the features correctly. Wrong schema specifications and not knowing to implement nested set patterns is a sign that they don't have a knowledgeable DBA on staff.
I can’t comment on their data model but in my own experience partial indexes are an invaluable feature. In particular partial unique indexes as it both expands the guarantees of your data model that can be enforced by the database while taking up (what could be) considerably less space.
>> As a side note – we don't use MySQL ourselves
> I think this is the real reason. They just didn't have the necessary talent to implement the features correctly. Wrong schema specifications and not knowing to implement nested set patterns is a sign that they don't have a knowledgeable DBA on staff.
This must be the big one.
Given enough experts and a drive to make it work, technology finds a way.
Given no experts and not enough users to complain or care about breaking compatibility, technology finds the door.
> Given enough experts and a drive to make it work, technology finds a way.
Given no experts and not enough users to complain or care about breaking compatibility, technology finds the door.
> All they had to do was implement a nested set pattern for their groups
I've been told a million times that SQL is declarative, meaning you say what you want, not how to get it.
I've also been told a million times that I need to write my queries in a specific way, or use a specific data structure, or add hints for the query optimizer. Otherwise it'll pick the wrong "how" for your "what".
Is there any practical difference between a declarative language with a Sufficiently Dumb Compiler, and an imperative language with weak features and an awkward syntax? However I'm forced to write it, we all know I'm really trying to do is get it to LOOP first over these items here, and not those there.
What's the point of being declarative if common tasks require us to bend over backwards to design our schema/queries/indices/hints in exactly the right way, in order for it to be performant on two popular SQL databases (when that's even possible)?
Even if the vaguely-English-like syntax that's completely unlike any other computer language weren't problematic for those reasons, it seems that the lack of abstraction is a complete buzzkill. These two databases require different implementations for "nested groups", but there's no (remotely portable) way to define a CREATED NESTEDGROUP to allow for a similar interface.
Of all the languages I have to use, SQL are the ones I hate most. From decades of writing SQL, I can say GitLab got one thing absolutely right: it's easiest to just treat it as a family of incompatible proprietary languages. It's easier for me to target JS and the JVM from the same program than two different SQL databases from the same queries.
A major benefit is declarative constraints. If you declare something UNIQUE, it's going to be unique no matter what. No race conditions, no "whoops, I guess there was a bug in version 4.7.3 of the application that didn't properly check for an existing entry, and it was silently fixed later in some refactoring, but we still have duplicate entries floating around".
Same for foreign keys and check constraints.
Queries are pretty intelligent, also, and mostly just work efficiently. You are right that some queries don't, and you have to know about the internals to make it do what you want. But here's what you are missing in that story: your data lives for a long time across many different applications. If you program everything yourself imperatively, you are bound to either over-engineer or under-engineer a lot of queries. The over-engineered pieces will look like premature optimization, clutter your code and tests, and be a time sink. The under-engineered pieces will come back to haunt you when your data grows and changes. Declarative relational systems actually do a pretty darn good job of handling this problem with a cost-based optimizer. Is it perfect? No, but it's an improvement in an awful lot of cases.
Also, you are ignoring places where databases do a good job with queries, like parallelization. It's easy to say that you'll just write all the queries imperatively yourself, but a lot of people don't want to spend the time to do the harder stuff even if it really matters for performance.
> What's the point of being declarative if common tasks require us to bend over backwards to design our schema/queries/indices/hints in exactly the right way,
Because 99% of the time you don't notice that it just works. 99% of the time you don't have to bend your query or schema to make it work.
99% is a strong claim. Maybe 70%? If you have a query that needs to look at over about 5K rows and you need responses under 100ms you need to know what its doing.
This is why decoupling RDBMS from the application is rarely ever useful, and why no app really changes databases anyway unless there's a massive cost or technical problem.
The app I’ve been working on for the past 24 years is currently on its third DBMS, and I would be unwilling to bet on whether it’s on its last DBMS.
There is zero SQL code in our app above a very low level. All high-level code calls through a DB API, and all SQL code is behind that abstraction layer.
That said, each one of these transitions was a “pull up stakes and move” kind of thing. We never tried to support multiple back-ends at once. So on those grounds, I think this is probably a good move for GitLab.
If you're using basic ANSI/92 SQL syntax then it'll work pretty much anywhere, especially with a decent ORM, but as soon as you start using any of the interesting features of a particular database, then you're locked in.
Supporting multiple databases at this point is usually not economically feasible.
That's the thing: it's super tempting to use nonstandard features. On our last SQL transition, we were most bitten by use of data types the new DBMS didn't support and by changes in the way "standard" text data types behaved between the two. (Just as GitLab was, on that last one.)
That's why I don't regret putting all of our SQL behind that DB layer: to port to the new DBMS, we just had to rewrite parts of that layer, rather than go on a hunt through the whole application for one-off SQL calls, as would probably occur if we didn't enforce this discipline.
> But why prioritize portability over better functionality at all?
It's not just about portability, or even primarily. It's simply good application layering to put the DB code behind a layer. Intermingling SQL code in your application logic is just as bad as intermingling GUI code in your core app logic.
But even that aside, we haven't felt the lack from putting such code a single function call layer away. I suppose it may give us a slight amount of pause when we consider whether it's worth creating another function in that helper library, but that's probably a good thing. If we decide we can get our work done by calling one of the existing functions, then why write yet another DB access function?
Example: if a table is known to have at most 5 rows, and the query that would allow the DB to return just the one we actually want is complicated, and it's almost never called, why not call the existing "SELECT all" one and iterate over the rows? The performance hit of being inefficient will be immeasurable.
> Why did you move databases so often?
That's once every 8 years on average. A lot changes in the computing world over that span.
The first change did coincidentally happen about 8 years after the company was founded, and it was because much better DBMS tech became available to us, within the constraints we had on choosing.
That DBMS lasted us for the next 14 years. By that time, enough had changed in the computing world that it was worth swapping again. The new one runs about twice as fast, takes far less code space, and is simpler to use all around than the prior one.
We'd have to switch again this year in order to maintain the mean of once every 8 years. My sense is that this is more likely a nonlinearly increasing growth curve, so that the next switch will be closer to 20 years than 14, if it happens at all.
We might be talking about different things. Of course using an ORMs and Query constructors to programmatically generate SQL is the best option instead of handwritten code everywhere, but that's a different issue.
What we're discussing isn't the SQL code, it's SQL syntax and features of a particular database over another. JSONB, partial indexing, text search, extensions, etc. in Postgres are not available in MySQL, and not using those features just to have the ability to switch or run on multiple databases is almost never worth the effort.
Simple CRUD apps with an ORM can probably do so, but otherwise most business apps shouldn't avoid using functionality for some "what-if" scenario. Having to switch databases after a decade is just a normal development item if it needs to happen, and usually coincides with heavy rewrites anyway, so I don't see much value in pre-planning for that at the architectural level.
Not OP, but over 24 years some major db upgrades may as well be an entirely new db. In addition database vendors go out of business and when their assets are bought, the buyer is often buying customer base and not so much the obligation to keep developing a separate product forever. E.g. IBM and Oracle have each bought lots of their prior competition, and sometimes they only offer customers an upgrade path to a different product. Each time something like that happens you are going to re write your db support anyway.
I have migrated apps from one database to another several times. The decoupling was very helpful.
I have also seen instances where the decoupling helped us abstract out differences between different versions of the same database product during upgrades.
As a long time PostgreSQL user, I'd say that decoupling has been very useful for most of the last two decades, but it's quickly becoming irrelevant for reasons that should be obvious here.
I've more often seen the app change from on top of the DB, than the DB change from under the app. Actually I'm not sure I've ever seen the latter happen IRL. App rewrite/replacement but DB remaining? Several times. Network message format/tech change? Several times. DB even going from one SQL server or one NoSQL server to another of the same general sort? Never. I know it does happen but I've stopped bothering to give it so much as a thought when designing a system. DB techs are more likely to be added on and maybe, maybe some earlier one(s) replaced over time alongside rewrites, than to be swapped out from under an app directly.
Yeah, SQL in applications that need to be performant and responsive is a huge pain and I have found it to not be worth the effort.
If you don't need performance or responsiveness though you can save a lot of effort except in very simple cases. I've seen it shine in quickly built proof of concept applications and in ad-hoc analytics queries.
It can also be made to work for highly-responsive but relatively small data sets: At Justin.tv, the scaling issues we hit with the first-generation video system were net splits and an increasing percentage of processor time being devoted to synchronization. The replacement system used a single PostgreSQL server (with a hot backup) to hold the real-time status of the entire system: Where every channel was being put into the system, the entire replication graph for every channel, active BGP routes, and the current load of every server and network link.
Whenever a viewer showed up to the website, we’d do a relatively complicated query against this database to figure out which server to direct them to for the channel they wanted to watch. The net result was a system that showed video sooner, with less latency, and more cheaply than any of our competitors were able to achieve. I don’t know what their setup looks like these days, but this basic setup took them from before the Twitch.tv rebrand all the way to their Amazon acquisition.
There was a lot of tuning that we had to do to make this work (like running off of a ramdisk, and having a pool of read-only clones), and it certainly had its hair-tearing-out moments, but in retrospect it was absolutely the right choice. We kept expecting it to fall over, but the plan to shard the database onto multiple servers collected dust for years because there was always a way to get the performance gains we needed through basic tuning.
I tend to prefer to treat SQL databases as dumb and generic as possible... you can go a LONG way supporting multiple databases until you need something more complex. For most organizations, supporting more than a single SQL variant is just painful. The only time I ever saw, for example, Microsoft Data Application Blocks in a useful scenario was an enterprise app that had to support MS-SQL and Oracle. Most of the variance was custom stored procedures for each named the same with the same signatures... It actually really sucked.
I don't blame them, and despite supporters, mySQL is constantly the most inconsistent non-standard SQL database of them all. I wished they'd just do a major version shift, dump the historical defaults, and be strongly consistent and compliant by default. Much like Oracle, I have no intention of ever using mySQL unless managing the thing is something I never have to do.
> I wished they'd just do a major version shift, dump the historical defaults, and be strongly consistent and compliant by default.
Regarding the historical defaults and consistency, they fixed that 4 years ago in MySQL 5.7. And last year's release of MySQL 8.0 added more modern SQL features (CTEs, window functions, etc).
There's still some non-standard idiosyncrasies, but that's true of every relational DBMS :) And while it's certainly possible that MySQL is arguably still more idiosyncratic than MS-SQL or Postgres, it's not like an order-of-magnitude difference anymore.
While I am glad to hear it... I've been very happy with mssql and postgres, with little chance of giving mysql/mariadb much in the way of future opportunity. I've just been burned too many times with other open and commercial options that give me what I expect.
> vaguely-English-like syntax that's completely unlike any other computer language
COBOL is also English like.
I'm not negative about SQL. I'd rather write queries in SQL than having to learn for the nth time how to write SQL in language X with ORM/module Y. I'm doing it with Django, Rails and Phoenix in the same week since a long time now and it feels a bit pointless. But then there is the deserialization in the data structures of the language. I just wish those libraries would be smarter and know how to handle some hypothetical code like
sql("select * from users").each |user| do
something(user)
end
The best experience I know of in this regard is from some packages in ML languages, where the string literal query you write gets sent _at compile time_ to a database engine for parsing, using the database's API to determine the query's expected return type (column names and types).
They're most used in F#, which calls them type providers:
You're conflating the nitty gritty of schema design (which I agree with you is not that declarative) with the usual case of "I know what I mean why doesn't the machine know what I mean" which is different.
You're still expected ask for what you want specifically.
> It's easier for me to target JS and the JVM from the same program than two different SQL databases from the same queries.
"I know how to express what I mean in such a way that I can target two very different platforms like JS and the JVM, why isn't there something as powerful for SQL?"
If the real reason is they don’t want it, who cares what the other reasons are?
In your critique of their argument, I don’t see a single reason why they should use MySQL. So why should they continue to use MySQL? Why should they solve nested groups and long text columns? What does that buy them?
> All they had to do was implement a nested set pattern for their groups [1]
I admit I have a sensitivity to knee-jerk “can’t you just” comments, but reading the first paragraph of your link, this doesn’t sound like an automatic win. Is it possible that they tried this and found out that it actually couldn’t be supported in a performant way? (Edit: turns out they did exactly that https://news.ycombinator.com/item?id=20344575) Either way, it sounds tricky... so back to the real question... why bother?
“Updating requires renumbering and is therefore expensive. Refinements that use rational numbers instead of integers can avoid renumbering, and so are faster to update, although much more complicated.”
IMO the point is that they’re creating misinformation with incorrect statements about MySQL. It’s not clear why they had to publish a blog post in the first place, to excuse themselves or to prove a point? Put that info in a FAQ and be ready to address incorrect info. I understand that MySQL doesn’t fit their use case and I wouldn’t try to smartass them out, but it’s wrong of them publishing incorrect data. If they thought this would help them and their conversation with existing and potential customers, it’s actually damaging their reputation, because it feels like their engineers don’t know what they’re doing.
> the point is that they’re creating misinformation with incorrect statements about MySQL
Which statements are incorrect? Someone from the team responded directly to all points above here https://news.ycombinator.com/item?id=20344575 If you want to debate the reasons why, maybe respond to that thread? I don't, but I assume they're competent and telling the truth. The claims here about the reasons being wrong and the team not being competent appear to be incorrect and emotionally based. I can understand people being upset about losing support for something they use, but the assumptions and accusations seem misplaced, and fwiw, two years late.
> It’s not clear why they had to publish a blog post in the first place
Why shouldn't they? What's the functional difference between a blog post and a FAQ anyway? I don't understand your complaint - are you asking why they published anything or asking why it's not on a different web page? Your critique, like the one above it, is still not making any case for why they should continue to support MySQL.
I would assume that having announced this move two years ago, they've had a few customers ask why. I would assume that a company that cares about it's users but needs to drop support for something some of them still use, they would take some time to elaborate on their reasons, precisely because they care.
The parent comment. I'm referring to "I think this is the real reason." but I could have quoted that to make it more clear. And to be clear, they have more reasons, I'm asking why they need more reasons.
They are invaluable for performance as well (somebody mentioned unique partial indexes as constraints). They generally let you avoid partitioning your data (eg. partioned tables) and getting the same performance benefits by simply having conditional indexes.
They are sometimes the difference between a sequential scan of a 150M row table and an index lookup in <10ms (especially if the index is in the memory cache).
Once you try them and get the benefit, you can't go back to not having them.
Eh, maybe all of those things CAN be done in MySQL, but they are done differently. I think it's totally legit that it takes a lot more development hours to support two DBs than one.
And they said this clearly, they're not hiding that this is the motivation.
Creating the abstraction architectures to support more than one "thing" tends to more than double development effort to support two "things". (Although then lets you add additional more-than-two "things" with less incremental cost. But there's a lot of cost to more than one thing in the first place).
> All they had to do was implement a nested set pattern for their groups
The nested set pattern was considered at the time we added support for nested
groups, or improved it with CTEs (not sure which one of the two it was). The biggest drawback of nested sets is that adding sub groups can now
become expensive. The storage needs are also far from ideal.
Using PostgreSQL CTEs allowed us to work around all of this, at the cost of not
supporting MySQL. This seems like a fairly reasonable trade-off, but I might be
biased as I implemented it [1].
> A hack? Their DB creation schema specified a TEXT column when it should
> have been a LONGTEXT column. Using LONGTEXT is not a hack, it's a choice
> when your data is more than 65535 characters, and they made the wrong
> choice out of ignorance.
It's not ignorance, it's MySQL coming up with bizarre limits for the "TEXT"
type. In MySQL, the limit for TEXT is 64 KB. In PostgreSQL, IIRC it is 1 GB.
Looking back there may have been better decisions, but it's always easy to judge
in hindsight.
More importantly, moving away from MySQL allows us to stop worrying about this
at all.
> Alternatively, since this is filepaths and filenames, they could have used
> a nested set pattern again and gotten 255 characters for each component of
> the path and a lot more feature options for their search system!
At the cost of requiring more storage space, and writes taking (potentially)
much longer. You may want to mention that, instead of acting as if nested sets
are a silver bullet.
> This is true, but is it really a show stopper?
Yes.
> Wrong schema specifications and not knowing to implement nested set
> patterns is a sign that they don't have a knowledgeable DBA on staff.
You may want to do some more research before going down the path of suggesting
GitLab employees lack knowledge. For the last two years or so we've had various
engineers with excellent database knowledge working on GitLab, myself included
(though I don't consider myself a PostgreSQL expert).
Some of the weirder decisions were made before the right people were hired, and
often these decisions are difficult to improve upon. Sometimes removing support
for something is a much more efficient way of spending your time. Removing MySQL
support in GitLab is one such case.
They have to engineer their software for the highest-scale cases it’s going to be put to by people running it in a particular configuration. Just because Gitlab works without partial indexes for you doesn’t mean that Gitlab works without partial indexes for everyone, and software that doesn’t work for the 1% of users who use it most heavily (and probably pay GitLab the most money in support contracts) is also known as “software that doesn’t work.”
I don't think mySQL/MariaDB is particularly easier than PostgreSQL to setup for someone less familiar with them.
Every single time I've used mySQL, I come across some odd quirk from historical context. Limiting TEXT and creating LONGTEXT instead of increasing the bounds for TEXT. Keeping utf8 as some wierd non-final version of utf that isn't a spec, instead of aliasing it to the actual utf8 spec version in new configurations. Not sure if this is still an issue, not being able to create foreign key relationships with ansi-quoted table names (backticks only here). "BINARY" fields being collated as case invariant by default (led to some really bad bugs on a primary key field).
I can't think of a single time I've used mysql and didn't get odd behavior. I can't think of a single time I've used PostgreSQL, or even MS-SQL that I did. Oracle and DB2 have had some oddities as well, but at least consistent, unlike mysql.
MySQL is used in some of the largest scaled workloads and Postgres is just as easy to install and run today, if not easier.
With the huge rise in ready to run container images and managed database services, database ops is no longer a serious problem for small users and multiple DB choices shouldn't really be a major design consideration for software providers.
Yes, it works great. That article is very outdated. The official container images all store data and logs at configurable paths, and you can easily mount external volumes to those paths with docker or kubernetes. If these volumes are persistent disks in the cloud then you also get simple snapshotting and replication.
This is a great setup and effectively provides a database compute "shell" that sits on top of persistent block storage so backups and upgrades are simple to run. Add in orchestration like Kubernetes and you can also run replicas easily.
actually this is from 2016 and not true anymore..
you can easily run postgres/any database on k8s without any problems at all. heck you can even make it high available on gke with using replicated drives. (single instance of course, but with way less downtime. even gclouds db offerings are based on that)
Is that relevant outside of software that can run on random shared hosting? There being able to use MySQL is a large factor, but GitLab isn't in that category.
> they support mysql purely to make it easier for their smaller users to setup and manage instances.
That's not a real reason to support mysql, which is no more pleasant for non-DBAs to set up than any other traditional RDBMS. Rather, that's a reason to support sqlite. (See also, the reason sqlite is the default DB in Rails.)
In my experience it is easier for the people not well versed in RDBMS administration to get MySQL going rather than postgres (this was always one of the adoption advantages). MySQL has also been easier to setup on any kind of server compared to postgres, and for features like replication. It is also true though that MySQL (at least up to 5.6/5.7) has plenty of limitations in implementations that really let you down at scale or in some cases (only one index per table per query across multiple tables, single threaded select, query planner has opaque view to how data is stored). The query planner being separate has been a boon in other places like mysql-ndb and rocksdb as storage engines but becomes a constraint you become increasingly aware of once yo get in the 0.3TB and up table club.
Sqlite is also an inappropriate database engine for any system that requires concurrent read/write access for multiple processes. While most people probably think they can work around this most people forget things like event logging and last checked timestamps which is a requirement for production applications.
I also want to mention that I did not read it in the comments here but I feel like MySQL and MariaDB still haven't settled their differences while postgres (to me) feels more stable. Then you also have the feature compatible DBaaS like AWS RDS. Also knowing you have PL/perl or PL/python in the back pocket seems hard to give up.
I mean, nobody uses sqlite for rails in production (except when they do because their load is genuinely low.) It's mostly there for when you're just running something for yourself on your own dev machine, most often for testing purposes. For something like this it makes a lot of sense to use sqlite. Avoid that in production though obviously.
Oh, I know people do it. My point isn't that they should or shouldn't do it, but rather that supporting sqlite as a low-config option specifically to facilitate testing makes a lot of sense. Arguably more sense than continuing to support mysql when postgres exists.
I just have to say this, for me as a kid who grew up on Windows, installing MySQL was easier, it was also always available at all hosting providers, who also provided PHP to everyone.
To be fair, these days it might not be easier, for me user management was easier to understand.
Though these days I'm looking at Postgres and seeing only advantages:
1. Compliant
2. Not split into a billion versions
3. JSON
I understand https://wiki.postgresql.org/wiki/Don't_Do_This#Text_storage in a way that Postgres encourages users always to stick to the text type. Which is, from a non-DB-centric view, certainly the most convenient thing to do: Tell the database just to store a string, don't worry about length or so. Having worked with MySQL a lot in the past, I wonder if this is a kind of paradigm shift, whether PostgreSQL tries to be programmer-friendly or whether this is just the way how to do SQL nowadays...?
Postgres built up a whole separate infrastructure for BLOB storage, with a streaming API in/out of BLOBs et al; but after landing the TOAST-table logic, it became basically† obsolete—you can just use a regular TEXT or BYTEA column to achieve the same things now.
† BLOBs are still relevant in the cases where you have such huge data in each BLOB that you need to work with it in a streaming manner. But people don’t tend to build systems with this concern (i.e. object stores) on top of RDBMSes, so it’s pretty darn rare that anyone actually turns to Postgres’s BLOBs to solve a problem in practice.
There have always been low-level differences in the way MySQL treats the two (VARCHAR <> TEXT/BLOB) data types, although some have been removed over the time.
A notable example is that before version 8, internal temporary tables didn't support BLOBs when in-memory¹, so that they would swap to disk, causing a performance penalty.
Regarding the length, an important concept is that it can be used for optimizations.
InnoDB adds a certain number of bytes for each value stored, depending on the size. For example, a TINYTEXT consumes 3 bytes less than LONGTEXT for the same value.
Another difference is the location of the data. TEXT/BLOBs up to 40 bytes long will be stored in line, while the limit is 768 bytes for VARCHARs. A 100 bytes long TEXT will require one page access more than the corresponding VARCHAR.
Of course, it's up to the engineer to choose whether to consider optimizations like this or not, but as a matter of fact, those differences exist.
¹=note that this concept is different from tables backed by the `MEMORY` engine, and different from user temporary tables.
My manager used to do that so much with outrageous over-simplification that I instituted a rule. If, in any budget/estimation/planning meeting, anyone said "all you have to do is ..." or "it's just ...", they were volunteering for that task to be assigned to them.
Epilogue: it was a Pyrrhic victory. He wrote absolutely terrible code which was difficult to read, impossible to maintain, had no tests or docs, and ignored all coding standards. Every task looked easy to him because all it needed was a drive-by hack to make it look good for a quick demo on Friday, and he wasn't going to be the one to fix the inevitable bugs found in it next week.
> MySQL can't add TEXT type column without length specified
>> That's just incorrect. What they MEANT to say is that they had a column to store filenames that was a varchar(255) column and people were running out of space with long directory paths and filenames. They could have moved to a TEXT column, but didn't because they thought it couldn't be indexed without specifying a length... But they were wrong, you CAN index a TEXT column without specifying the TEXT column length, you just have to specify the length of the substring you want to index.
Unless I am misunderstanding the SQL documentation, doesn't the prefix length specification essentially make it such that you can only partially index the field, up to the first 3072 bytes? (https://dev.mysql.com/doc/refman/8.0/en/create-index.html) After that limit, the index _may_ still be performant, but does not at scale I would imagine that YMMV. You make a fair point that there are other patterns.
IMHO The article was not about bashing MySQL rather the GitLab team decided to choose one database platform to support and provided some basic reasoning around why they chose Postgres over MySQL. Both are great platforms, but you should choose the right tool for the job. While I agree that some of their arguments are weak but I am not sure that matters given that their strategic choice was one or the other.
Frankly, I would have liked to have seen some data that represents what their install base utilizes. If it is 90% mysql and 10% postgres their choice would be strange given the weak arguments. We just don't have that data.
As a bostonian I'd mention that facetious has a gained meaning in that area of "misleading with malintent" I believe this meaning is pretty wide spread over the east coast in general but it might also be an artifact of word collision due to the local accent.
Partial indexes allow you to do stuff like keep session tokens for some longer time to facilitate logging of attempted use of expired credentials, without significantly hurting your authentication-validation performance. In most cases you will not hit the disk, as the partial index is in memory.
In general, you can keep selective indexes in memory, possibly even with supplementary columns to eliminate disk access for the actual data you're trying to fetch by the key the index is based on.
I'm not a MySQL expert, but I've been told that TEXT has very different storage and performance characteristics than VARCHAR, because it is always stored outside of the database tuple and that TEXT can have bad performance. I can imagine that is a reason for them not wanting to use TEXT variants in MySQL.
In PostgreSQL, TEXT/VARCHAR (same type) is only stored outside the tuple if it's large.
"Bad performance" is not exact. I'd say "worse" performance, in the cases where TEXTs cause extra page accesses. The distinction is important because in some cases, a performance that is "negligibly worse" can still be "good" - as in general, in software engineering :-)
It used to be that TEXT/BLOB data was stored outside of the table row in a separate area of the database. Any retrieval of this involved scanning to a separate spot on the disk.
In the days of spinny-disks this was a pretty huge penalty, you couldn't do linear reads to get the data, the heads would have to veer over to that other sector, read a bit of data, then skip back to read the next row. That was especially punishing as no amount of disk cache could help buffer against these reads that, to the operating system, seemed completely random.
MySQL moved the first X bytes of this data into the table row structure a while back (5.6? 5.7?) for performance reasons. It will only skip to the blob-data storage area if the data is longer than can fit in the size put in-row.
The opposite engineering philosophies of providing use cases to support theories, versus providing generic arguments are incompatible; I'm closing here.
> > We can't support nested groups with MySQL in a performant way
> All they had to do was implement a nested set pattern for their groups [1]
Nested sets come with significant downsides. They are a hassle to implement, but more importantly, a single insert can require writes to lots of rows. This is both problem for concurrent transactions and for row-based replication.
Cached paths is usually pretty cheap for adding new nodes, but it can be quite expensive if you need to be able to move non-leaf nodes around (caveat: I've not looked at their use-cases here, I don't know if moving non-leaf nodes is an important matter) especially if the forest is deep rather than (or as well as) wide.
> All they had to do was implement a nested set pattern for their groups
Nested set is not at all performant. It has much worse read and worse write performance (also, takes more storage space) than adjacency list with in-DB recursive queries.
> Wrong schema specifications and not knowing to implement nested set patterns is a sign that they don't have a knowledgeable DBA on staff.
In my personal experience, startups and even top tech companies don't really have DBAs on staff. They hire good generalist programmers, but they rarely get true specialists, especially DBAs.
DBAs are generally found in banks and in non-tech enterprise companies, from what I've seen.
This seems to be a pretty common attitude here on HN, that specialists like DBAs are a waste of money. Just a couple of days ago someone posted (only slightly paraphrased) "it's a waste of money to hire skilled DBAs. You should hire DevOps engineers who can solve the most common problems with your database. DBAs have outlived their usefulness."
Given the prevalance of that attitude, I'm a little surprised to see that the general tone of responses here is "This wouldn't have been a problem if they'd just hired people who knew what they were doing." The point is, they didn't. They hired devops engineers who knew enough to solve common problems, in line with the conventional wisdom here. Their stated reasons for ending MySQL support are perfectly in line with the view that specialists are a waste of money. Indeed, I'm not sure what other outcome should have been expected.
Having a DBA certainly would've helped them when they accidentally deleted their prod database with no backups too, that probably wouldn't have happened if they had someone who knew how to properly manage DBs
It’s two different approaches to the same problem. Given the problem “the business layer wants to do X, and that’s inefficient in storage layer Y”, DevOps engineers solve the problem by adding another storage-layer component Z that follows a paradigm where the queries from X are “automatically” efficient; while DBAs solve the problem by informing the design of the business layer to make queries that are optimal given the storage layer in use.
For example, a DevOps engineer solves “we need to do search queries” by standing up an ElasticSearch instance and writing code to ingest data from the DBMS into it. A DBA solves the problem by using the search-enabling features of the existing DBMS, and suggesting constraints on the way search is exposed at the business layer that make those queries easier on the DB.
Both approaches “work”, in the sense that you can do either and have a profitable company.
Choosing the right data types for columns is not "solved" by switching to entirely different RDBMS's. Particularly for the TEXT requiring a length comment. None of these reasons were discussed or deliberated in detail as people point out in the comments.
This is the worst kind of attitude to have and is why I see incredibly poorly implemented databases all the time. Databases that are are often not properly normalized, not properly permissioned, storing lists of delimited strings, extensive use of cursors, use of scalar and table functions where constraints could've been used, etc.
It's very annoying to come in and see things like this, most of which would've been resolved if companies didn't treat development like a silo derived from abstract communication.
> All they had to do was implement a nested set pattern for their groups [1]
Per your source, though, "Nested sets are very slow for inserts because it requires updating left and right domain values for all records in the table after the insert."
The same must generally be true for any solution that maintains its own index in order to guarantee a single* query can traverse the graph. You're memoizing the traversal, after all. It's much simpler and faster if the DBMS can simply perform a traversal, and it's what you want.
And, again, you're maintaining a lot of unnecessary code for one system, which was their chief complaint.
* You could probably implement a scheme that doesn't require materializing all adjacencies so you strike a balance between the number of queries and number of updates, but that's a lot of engineering, and again the same basic complaint.
When GitLab started supporting MySQL officially (on the paid version), there was a market reason to that. Big corporations used to by expensive Oracle support licenses.
The demand for that have decreased by a lot. I can speculate that Heroku did a good job making PostgreSQL popular as a jack of all trades solution, and a default one for many FOSS communities. The market just followed.
Also consider that some of the issues are due to how Rails and ActiveRecord expect things to be.
Both are great platforms, but ... how many of those customers who reported running on PostgreSQL did so because they didn't know they could use MySQL, or just took the defaults?
> > We can't support nested groups with MySQL in a performant way
> All they had to do was implement a nested set pattern for their groups
Or an association matrix.
Though if their concern is performance and they are using recursive CTEs in postgres, they may have hold of the wrong end of the stick.
Because CTEs are an optimisation fence for predicate push-down in postgres they can sometimes result in much more expensive query plans than in other DB engines (for instance, MS SQL Server), resulting in excess index/table scanning. This makes them far more a code convenience feature rather than a performance one (they might improve the performance of your coders by making maintenance easier, but might not improve the performance of your system in action).
> > MySQL doesn't support partial indexes
> This is true, but is it really a show stopper?
No, but yes. On their own systems it isn't, as they don't use mySQL. On small self-installs it isn't as they are unlikely to have enough data for it to make a measurable difference. Larger self-installs can just throw hardware at the problem... But supporting a backend that doesn't have them, when they find them useful in their own large installs, means either doing without across the board or needing to maintain two code paths which means more work and more bugs.
> > As a side note – we don't use MySQL ourselves
> I think this is the real reason
I would agree there, though I'd not go as far as to suggest a lack of talent.
The fact that their dev teams and their own production environments don't routinely use MySQL means that they are less likely to hit specific issues that they code has with that back-end during early dev, instead catching them in later QA when fixes are more expensive to implement or worse not catching them at all until release.
Furthermore, supporting mySQL does not just mean supporting the latest version: 8.0 may be over a year old now but that is not nearly long enough for older releases to have been replaced globally especially as 5.7 is marked as officially supported up to 2023. This will be why recursive queries are an issue: mySQL prior to 8.x does not support them, all supported versions of postgres do.
> I think this is the real reason
A cynic (who? me?) might also suggest that an extra reason factoring into their decision is user selectivity. There is a perception that mySQL is easier to install and optimise, or that there is more support out there because it is more commonly supported out-of-the-box on managed hosting. While this perception may not be true, that it exists has an effect and it might put off certain (less experienced) admins from installing themselves, potentially reducing support burden and perhaps funnelling some of them towards GitLab's own hosted services...
If one disagrees with an argument because it's superficial, then one might call it "specious." If one disagrees because the argument is invalid, then the word is "spurious." I think based on the counter argument, "spurious" is what was wanted.
Yeah, I think it's funny that they're claiming that MySQL can't represent a tree structure performantly. What they should have said instead is that their db structure assumes the existence of WITH RECURSIVE and they don't want to change it.
FTA: ”In July of 2017 GitLab documented that we would be deprecating support for MySQL”
According to Wikipedia, MySQL 8 was released about a year later, in April 2018 (there was also “MySQL Server 8.0.0-dmr (Milestone Release)”, in September 2016, but scanning https://lists.mysql.com/announce/1106 and the two other parts, that didn’t seem to have CTE’s)
True, but it's an 8.0+ feature. It looks like from the thread that they needed to support older versions as well. Seems odd to drop all of MySQL rather than have a min. version. The more you pry in the thread the more it seems like their developers already wanted to drop MySQL and just wanted an excuse.
Apparently they don't need the support from their pov at all. If will is there they could build up MySQL 8. MySQL 8 is out for a while and ahs seen good testing in different production workloads.
> developers already wanted to drop MySQL and just wanted an excuse
This seems to be the true reason. And it's valid. Supporting many variations of systems and architectures is hard. Supporting combinations you don't use yourself, while using something else intensively is hard.
Personally I think a system like this would benefit from many of the recent replication improvements in MySQL 8, which help in scaling and HA. But I'm obviously biased ;)
Random aside, do you know when MySQL will finish the spatial stuff? I saw MySQL 8 had SRID support but when I tried to use it I just got messages that said it was not yet implemented.
Hi! I'm the team lead for the team doing spatial support in MySQL. Thank you for trying the spatial features in MySQL! :-)
We do indeed have SRID support, but there are still some functions that only support Cartesian spatial reference systems. Is that what you're thinking about? I'm curious to know which functions you're trying to use that don't support your use case.
We are working to close these holes. In many cases it involves extending Boost Geometry (the library that we use) with more geographical computations, and that is hard and time consuming work. But we're doing it. The work we have to do to support it in MySQL once it's in Boost Geometry is pretty simple and straight forward.
Since extending Boost Geometry is such a time consuming task, people not working on those tasks have time to extend MySQL in other directions, maybe giving the impression that we're avoiding adding the missing parts. But it's just a result of some task being simple and fast to implement, while others (especially adding geography support) are more long running. In any case, the result is an uneven trickle of new functionality in more or less every new version of MySQL.
I hope that explains a bit what you're seeing. We are filling in the blanks, but it takes time to get to 100%.
I don't remember exactly, we had points and polygons in 4326 and were trying do things like distance/intersects/area. Count me in as eagerly awaiting full support of SRIDs.
Geographic ST_Distance is currently limited to points and multipoints because of limitations in Boost Geometry, but we've got that fixed in Boost now, so full type support should soon arrive also in MySQL.
I did quite some work with MySQL+srid, mostly with OpenStreetMap data, but also other, but I'm no expert there. Maybe your specific SRID wasn't supported? (While a huge number is supported)
The nested set pattern is fine for making tree reads fast, but it makes tree writes expensive, because it's not actually a tree. Is there some other pattern that emulates WITH RECURSIVE without blowing up the cost of writes? If not, then it's quite literally true that MySQL (pre 8.0) can't represent a tree structure performantly.
> Is there some other pattern that emulates WITH RECURSIVE
You could use an association matrix.
Or cached paths, but that has a list of disadvantages that make me consider it an anti-pattern these days (I maintain a legacy system that uses this model a lot).
> without blowing up the cost of writes?
It is a long time since I went over the relative performance of common operations on these structures, so I'll not try compare them (some research for you, dear reader!).
The performance of updates to an association matrix depend largely on the depth of the forest: when adding a new node you insert one row per level it is away from its trees root. Removing or moving a leaf node is the same amount of deletes or updates respectively. Moving a branch node can be pretty expensive as you have to make changes to the matrix for all the nodes under it.
All their more general points in the post are perfectly valid arguments for focusing on a single database that I've heard from other projects, but naming specific technical issues like that actually makes it seam more nit-picky and less valid.
I'm not sure many people would have found anything to argue with them about if they had simply said "Tagetting multiple DBs requires more resources to develop and test, limits our ability to make the most of what Postgres offers, and increases the cost of support. The proportion of users using MySQL is decreasing, so we have decided to focus on Postgres to give the maximum benefit to the largest group. We understand this may cause issues for some users so here is a comprehensive migration guide/toolset".
right, but by naming all the issues they had, they also opened up the discussion for learning how to solve those problems as the posts here demonstrate.
i therefore approve of the way the announcement was made, because it brought more benefits to the readers.
sure, some readers will walk away with the impression that mysql is somehow limited, but i think that's a reasonable price to pay for everyone else who gets to learn from the ensuing discussions.
I remember like 10 years ago it was all the rage to support 45 different databases. I'm so glad that time has passed. It wasn't feasible. Yes you can orm the crap out of things so you never see a line of SQL but you end up with index tuning on multiple database platforms. I noticed the trend thankfully just sort of walked itself away about the time non-traditional databases entered the picture and well it was pretty much impossible to support Mongo and Mysql (reasonably). I'm assuming more things are going back to Mysql/Postgres/Sybase/DB2 again, but I hope more companies and OSS projects stick to just one this time?
The bottom line argument is this: When you make the decision to support multiple databases think of the 10-20 years of changes your product will exist through (and possibly a lot longer) and realize how much extra work that is going to be even if you use ORM. Then if you come to the decision Gitlab is - are you going to want to write the porting software for your users or just let them be shit-out-of-luck?
The keywords here. Even though every dev on my team knows postgres equally or better than mysql, management chose mysql.
I'm one of the equally camp, and don't possess a strong personal preference, but I was surprised that it was the favorite of the devs and not trusted by the business.
Sadly, Oracle Java could also be in that blacklist. I've tried going through the hoops of downloading Oracle's "community" versions of MySQL in the past -- Java 6 for Android development IIRC. Today, I appear to have openjdk version "1.8.0_212", is this a fork?
The MySQL community server can be downloaded from https://dev.mysql.com/downloads/mysql/ the biggest "hoop" is that it asks for an account or registration in big letters, while there is a link to bypass that below the big box.
Alternatively there is http://www.github.com/mysql and contrary to older versions this compiles quite easily if CMake and compilers are around.
They just decided to use boring technology (http://boringtechnology.club/). Given they have limited resource spreading it across two databases seems a miss, and taking that time and attention and putting it back into git-ty stuff looks like a win.
Does this really count as using boring technology? they're choosing the younger of the two DBs and to use some of the latest features e.g lateral joins
Funny, since you mention Postgres: 1996 is only PostgreSQL's first release. POSTGRES goes back even further [0]:
> POSTGRES has undergone several major releases since then. The first "demoware" system became operational in 1987 and was shown at the 1988 ACM-SIGMOD Conference. Version 1, described in The implementation of POSTGRES , was released to a few external users in June 1989. In response to a critique of the first rule system ( A commentary on the POSTGRES rules system ), the rule system was redesigned ( On Rules, Procedures, Caching and Views in Database Systems ), and Version 2 was released in June 1990 with the new rule system. Version 3 appeared in 1991 and added support for multiple storage managers, an improved query executor, and a rewritten rule system. For the most part, subsequent releases until Postgres95 (see below) focused on portability and reliability.
Your point stands, nonetheless. There are no whippersnappers present.
Their statement is somewhat ambiguous. They may have tried to express that "you can't add a column of the TEXT class without specifying the exact type".
So they could be "right", but expressed the concept in an imprecise form.
In a way, I think this shows their lack of expertise with MySQL - I reckon that somebody with a long experience would have phrased the concept more precisely.
Good for them. Both MySQL and PostgreSQL are Good^. But supporting both doesn't work and it totally makes sense to focus on one. Personally, I don't generally use PGSQL but my GitLab instance does. Why? It's easy to run a dedicated PGSQL instance for GitLab using Docker. Or... Using AWS RDS. Or... Any number of ways.
(^ Good is relative. People have their opinions on which is subjectively better but at the end of the day, lots of big sites and applications use both options to great success.)
It also creates huge discrepancy between what a developer using an ORM like ActiveRecord writes and how the engines end up optimizing, meaning that should you want to write a performant one, you have to learn both, or, short of that, notify your DBAs of what you did, and in both cases huge resources are wasted. I never understood combining both from a business perspective anyway.
I think here can be a good place to share my story why I never use MySQL in my projects. Once I was working for the company where I was an architect for some new project. And we have few gigabytes of data from a few sources. But with plans to gather much more in the near future. I came up with some database structure for the first draft of the early stage of development. It was nether big nether complicated for my scale comparing to the other projects I was working before. Since I'm python expert I choose SQLAlchemy for ORM layer and use its features to create the initial database schema. Postgres was a natural choice for me and almost fit to my requirements. I was worried about performance in the future but decided that we always can optimize when we have something. As I said it was early stage and we were on the research stage.
Everything was smooth development-wise but the database was pretty slow since we most use desktop-grade computers for prototyping. 3 weeks before the first internal release owners ask me to change the database to MySQL. I was against this step, we don't have time or resources for the experiments. But point was that company have MySQL experts that have more than 10 years of the optimization experience. I simply have no choice. They force me to do this against my will.
Since I wasn't sure that in production we will use Postgres I don't allow to use any special database dialect specific capabilities for the developers. And switching to another backend from Postgres to the MySQL was literally equal to a connection string change.
MySQL wasn't ready to handle 40-60 tables and queries with 5-10 simple joins. On our data, every request just hang server (they quickly provided a server with a lot of memory and storage for this). A few days later we found that actually MySQL is working but the same simple queries run for 4 or more hours. So-called "experts with 10 years of optimization" spent a week trying to fix indexes and other things but it never happened.
After release, I left the company, because of the toxic atmosphere, but it is another story. But since that, I lost all my faith in MySQL. Maybe for others, it is an option but never for me.
So you created an app without considering the current staff or stack, made a zero effort change to satisfy the actual requirements, and then abandoned your work at the first performance problem you encountered?
I'd like to hear about thoses cases. Even when using an ORM, some feature just won't work with some backends. Example: Django has warnings all over it's documentation because "PostGreSQL has X feature but MySQL has not".
I realize my comment hit a sensitive spot but it's really not meant to be negative.
It is 100% legit to give that up, it is 100% legit to go with the clear winner in your mind (it is the same in my mind too), but the technical reasoning is weak IMHO.
if you wanted to support both, you can, but you clearly don't (and that's ok too).
It's great that the simplicity argument doesn't really apply. It's a testament to developers getting better at programming in the large over the years. The database layer can be neatly abstracted away from the business rules.
I have used postgres for so long that a lot of the baked in functions and features that were super convenient for me.
I recall wanting to change a data type in my query and having to actually use the cast function. Also it was mentioned but when I was using it CTEs were not implemented yet. However, they weren't with postgres until 9.x as I recall either.
Regarding performance, I mean, that is as much design as it is rdbms choice. Also i'm no DBA.
Just look how slow gitlab is on a 8cpu with 32gb or ram instance ... It's crazy !
I'm not sure about which part is because of Rails or the way gitlab is implemented.
Issue is not about MySQL but more about the lack of knowledge / talent at gitlab
I guess I'm in a MySQL shop, but when it comes to Gitlab, I just want it to run its regular upgrades without me having to do anything (and it does! I love Gitlab). I never considered running Gitlab on MySQL.
We rarely have to fiddle in the database itself (it may have happened once or twice during our migration from Redmine), for the rest we use the Gitlab API.
If you are at the level where you need strong control on your Gitlab install, then you're a Gitlab shop, and you should either use the recommended dependencies, or assume that you will be helping maintain the niche features.
All of the MySQL "they just shoulda" and "they just coulda" arguments here are irrelevant.
There's no distinct advantage of MySQL over Postgres, either in smaller or larger environments for the gitlab use case and with their development team.
My personal experience is that Postgres is much closer to operating commercial RDBMSs which makes the experience of DBAs much more portable and relevant. Moving someone from the Oracle or MSSQL world to Postgres is relatively much easier than moving them from the MySQL world.
It wasn't sarcasm. I totally support their decision to drop MySQL. I prefer PostgreSQL in my projects too, especially with JSON/JSONB queries, it is amazing.
{kind=link}
Do you expect your triggers to fire? You are SOL https://bugs.mysql.com/bug.php?id=11472
Do you expect to be able to insert utf8 into utf8 columns? Don't be naive. Read the docs and you'll discover utf8mb4 or as I like to refer to it: mysql_real_utf8.
How about transactions? Surely a real SQL database supports transactions right? Or at the very least if it doesn't it would complain loudly when you use a transaction where not supported right? Once again this behavior is helpfully documented https://dev.mysql.com/doc/refman/8.0/en/commit.html
Do you expect to be able to put a value into MySQL and get that same value back out? You are SOL. But it's documented.
I can honestly say that the only appropriate time to use MySQL is when you can't use postgres and you are willing to move from a RDBMS to something that requires significantly more work to prevent data corruption.
I respect the hell out of MySQL engineers in terms of raw performance and the engineering of Innodb. I'm sure they aren't happy there's a million broken applications relying on defaults they can't change. I'm sure they aren't happy that fundamental limits in how pluggable storage engines work make ACID transactions not possible in the general case.
Postgres, for all of it's issues, feels like a database that has your back.