That's a common misconception that Lisp macros are mostly used to 'delay' evaluation.
What Smalltalk calls 'blocks' are just (anonymous) functions in Lisp. Books like SICP explain in detail how to use that for delayed evaluation in Lisp/Scheme:
> misconception that Lisp macros are mostly used to 'delay' evaluation.
It was in the examples. No generalization to all of LISP was made or intended, though it would be interesting to make a survey study of actual macro usage by developers.
It is also clear that you actually need the delay-evaluation mechanism in order to get something like "if" out of the language and into the library.
> what Smalltalk calls 'blocks' are just (anonymous) functions in Lisp
"but blocks/anonymous functions seem quite different from alternate argument-passing mechanisms."
I think the history also explains why Smalltalk blocks were a bit odd as anonymous functions go: they did not start out as a "function" mechanism, they started out as just a delayed evaluation mechanism, and Smalltalk has no ordinary functions, just the anonymous kind. Which is also odd.
The Smalltalk developers were well aware of LISP, cite it as a major source of inspiration in fact. They initially had a more macro-ish mechanism (the unevaluated token-stream), then moved to a pure delayed-evaluation mechanism which then turned into blocks. They never added a macro mechanism again. I think that's interesting. YMMV.
- The non-selected possibility isn't evaluated/executed (i.e. the evaluation of the possibilities is delayed until after one has been selected)
This is very important for imperative languages, since executing both branches would have observable effects even if we only returned one result.
This is also true in functional programming languages, even pure ones, since it's needed to e.g. terminate recursive calls. For example, if we define factorial by branching on whether the argument is 0 (base case) or not (recursive case), then evaluating both branches before selecting one would cause an infinite recursion for all arguments.
In the case of your Lisp code, we couldn't implement a recursive function like factorial unless we delay the evaluation e.g. by using macros to do the selection, or by switching from Lisp's default evaluation order (call-by-value) to something non-eager like call-by-name or call-by-need.
Yes. Obviously. Of course. That's how Smalltalk does it, though it doesn't have general functions, it only has anonymous functions aka (roughly) blocks. Any other language that can pass functions or some sort of equivalent as arguments can obviously also do this.
(A little surprised that this compiled on the first try. More surprised that clang didn't show any warnings, even with -Wpedantic. Shows you how well I understand C/C compilers ¯\_(ツ)_/¯ ).
And function definitions, lambdas, blocks etc. all delay the evaluation of their bodies.
> they did not start out as a "function" mechanism, they started out as just a delayed evaluation mechanism
Do you have a citation for this? Not disputing it, I'd just like to see whether there's something in Smalltalk's history I have overlooked, or didn't notice on my first reading.
That was what the article was about. The scans link to the source material Smalltalk-80: Bits of History, Words of Advice, one to the book on Amazon, the other to a PDF scan.
Quite frankly, I was a bit surprised so much of the discussion has been about LISP features that are neither in dispute nor subject of the article.
> they did not start out as a "function" mechanism, they started out as just a delayed evaluation mechanism
I still don't see where you are getting this from. The scans you provide [1] don't make this claim. For instance, look at page 17 of Technical Characteristics of Smalltalk-76 [2]:
> heights _ students transform each to each height
The document seems to have some OCR problems - I'm pretty sure that underscore is meant to be a left arrow, or := in more modern Smalltalks. I understand this to be the equivalent of Smalltalk-80's
> heights := students collect: [:each | each height].
which is clearly a mechanism for mapping a function over a collection, not just a delayed evaluation mechanism.
[1] You might add to your article a footnote specifying that the citations from Bits of History, Words of Advice are from pages 14-15
> Quite frankly, I was a bit surprised so much of the discussion has been about LISP features that are neither in dispute nor subject of the article.
It's because Lisp macros and their motivations were described inaccurately, and some people want to make sure that these inaccuracies are not perpetuated.
When an FEXPR is called, it gets unevaluated args and can then at runtime decide what to do.
Macros OTOH are a different mechanism, where expressions get rewritten at macro expansion time, which can be for example at compile time. The macro then gets called with arbitrary expressions it encloses (those don't need to be valid code by themselves) and computes new source.
Thus macros are code generators from expressions. In a compiled implementation, macro expansion is done with compilation interleaved: each form gets expanded, even repeatedly until it no longer expands into a macro, and then the resulting non-macro form gets compiled.
Thus in a way a macro does not delay execution, it does the opposite: it actually shifts computation to compile time -> the computation of code from expressions and the computation of arbitrary side effects in the compile-time environment.
In an interpreter version of Lisp, the macro gets also expanded at runtime - but in its own macroexpansion during evaluation. There eval will call the macroexpander repeatedly until it gets a non-macro form.
"The primary purpose of the DATA statement is to give names to constants; instead of referring to pi as 3.141592653589793 at every appearance, the variable PI can be given that value with a DATA statement and used instead of the longer form of the constant. This also simplifies modifying the program, should the value of PI change."
Or, quoting the other aphorism, what is constant for someone is a variable for someone else.
What is run time for LISP (which lacked good compiler at early stages - the famous two horse asses width constraint) can freely be a compile time for other language. Or for a LISP, for that matter, in our time.
The compile time expansion allows for better (because faster) error checking.
I don't think what I wrote is a FEXPR, which doesn't evaluate the result of the function call. I'm having a hard time parsing what you wrote or any of the sources you linked in such a way that says the semantics of macros differs from what I wrote (certainly the implementation gets a lot more complex and there are subtleties).
CL-USER 36 > (test)
(:RUNTIME :B 21 :C 42) ; <- the printed output
(:RUNTIME :B 21 :C 42) ; print also returns its arg
Thus all the macro expansions have been done at compile time and we have generated some code there. No macro expansion at runtime.
Thus it has to do with code generation and code execution at macro expansion - nothing about 'delaying' something.
The example isn't useful, but imagine a macro INFIX
(infix a * b + c)
which rewrites the expression to the Lisp expression:
(+ (* a b) c)
There is nothing about 'delaying' -> it's just rewriting the form. Ideally at compile time. There are many other examples which do something different.
While experienced lispers already know this, it may not be clear to everyone that in Common Lisp "compile time" routinely happens repeatedly in a running image. cl-ppcre[1] relies heavily on this. It can take a regexp pattern as a runtime input and compile a recognizer down to machine code on the fly. This technique gets used routinely.
Edit: In fact, I strongly suspect that this resulting unsuitability of Lisp for proprietary code played a major role in its commercial failure before the widespread advent of services.
A normal function call evaluates the arguments and then calls the function.
Because macro expansion does something before evaluating the arguments, you can say that evaluating the arguments has been delayed.
I feel this is just looking at the same thing from two different directions.
Of course, macro expansion does _more_ than just delaying the evaluation of the arguments, and if people say that macros delay evaluating the arguments, you might think that's all they do.
> Because macro expansion does something before evaluating the arguments
It does something independent of evaluation. When the code gets compiled, the macroexpander already has transformed the code. The code might never be evaluated in this Lisp. It might be written to disk and later be loaded into another Lisp.
If something does not get evaluated, gets evaluated later, gets always evaluated or never -> that depends on the generated code.
Thus 'delaying' something is the wrong idea and it limits the imagination of what macros are used for. Think of 'general code transformation', often independent of execution in a compilation phase.
A macro or FEXPR may never evaluate an operand at all. They simply receive the unevaluated forms and decide what to do with them, with explicit evaluation being just one option which can be performed on the operand.
Delayed (lazy) evaluation merely prevents an operand being evaluated at the time of call and until you want to read its reduced value, after which it is automatically evaluated.
But an infix transform does delay the evaluation of expressions you've passed to it. Eg (infix (avg b) * (sgn a)).
And most practical uses of macros involve passing in expressions that will be later evaluated verbatim, e.g. (time (reduce + (range 100)))
I was only intending responding to this:
"That's a common misconception that Lisp macros are mostly used to 'delay' evaluation."
Which just seems to me confuses the matter in response to the article that was posted. At a very low level, macros operate by having the evaluation of their arguments delayed. At a higher level, they're used to implement sugared forms which usually contain valid code (though not necessarily code that makes sense in isolation).
I know you're very experienced with lisp, and I'm not trying to correct you technically, but to me this stuff only clicked when implementing a metacircular evaluator and learning when and how to perform evaluation. The blog post to me reads like the author was going through a similar process.
> But an infix transform does delay the evaluation of expressions you've passed to it. Eg (infix (avg b) * (sgn a)).
It doesn't 'delay' anything. It just rewrites at compile time
(infix (avg b) * (sgn a))
into
(* (avg b) (sgn a))
That's all. At runtime only the rewritten statement will be executed.
> At a very low level, macros operate by having the evaluation of their arguments delayed
Not at all. The main purpose of macros is to compute code from arbitrary expressions at compile time. There is no 'delay' -> it's mostly about rewriting expressions at compile time.
> implementing a metacircular evaluator and learning when and how to perform evaluation.
You can build a macro expansion phase into an interpreter. That's what Lisp interpreters do. But the main purpose of macros is to enable code transformations at compile time and thus only to have a cost at compile time, not at runtime. In an interpreter the macro expansions would also happen at runtime and have a cost there. But Lisp compilers are popular and to make the most out of code transformations at compile time, the idea of macro and their expansion at compile-time was introduced. Thus one gets for example new embedded languages, without the need to parse them at runtime.
I believe that if you're trying to understand what macros do from a fundamental level, treating them like functions with different semantics is a very good learning method. You implement them in a SICP style interpreter and then write a few. Totally clears up the mystery.
I'm not arguing with you about what happens in any production lisp. I'm sure you know more than me, but I do understand how they're implemented in practice, and the warts that brings - eg no (apply or <list>), and first class macros are so esoteric purely from the runtime cost that they're barely even written about in the literature.
I'm just saying the mental model of where macros fit in in an interpreter has value, and that view has not changed. In my opinion you're an expert coming in correcting a bunch of people attempting to learn the basics, and you're not wrong, but you are muddying the waters.
treating them like functions with different semantics is a very good learning method
If you mean run-time functions that act a bit funny about evaluation order, that mental model is incompatible with common introductory examples like `let`.
No, it's not. You eval the return value of the call. There is no loss of expressive power. Compile time macro expansion in this model is simply partial evaluation.
The first argument is not evaluated but used as data, the second argument is evaluated after the macro function returns, as part of the macro evaluation rules, i.e. (eval (let '((x 3) (y 5)) '(+ x y)))
In conclusion, it's working exactly as I laid it out in my original post:
fn: (a b c) => (call a (eval b) (eval c))
mac: (a b c) => (eval (call a b c))
Everyone jumped on it, as production lisps don't implement macros this way. But it's the natural way to implement them in a SICP style metacircular evaluator, and a good way to learn them.
This is about mental models, not implementation details. And in my opinion this thread is full of experts who have forgotten what it's like to not understand how macros work.
The sequence of events you describe is a thing that functions do not do at run time: they do not operate on pieces of syntax. Macro expansion time is a different series of events than run time. Macros operate on pieces of program syntax, not on anything from run time.
Everyone jumped on it, as production lisps don't implement macros this way. … This is about mental models, not implementation details
It looks to me like you're the one who brought up implementation details, talking about what happens "at a very low level." You're the one who has presented a questionable implementation strategy as a mental model and has been corrected on it multiple times by multiple people. Everyone else has been describing the semantics of macros. Having separate timelines for expansion and execution is a semantic distinction, not merely a common implementation strategy.
And in my opinion this thread is full of experts who have forgotten what it's like to not understand how macros work.
Your confusion is because you insist on a mental model of macros that is incompatible with their semantics. Letting that model go is necessary in order to understand macros. Otherwise, refusing to distinguish expansion time from run time, you are working towards reinventing fexprs.
SICP is a great way to learn lisp and learning macros by extending the evaluator is a natural progression.
I don't care how many lisp experts are "correcting" me on the way it works in the real world, because:
a) I actually do understand how they're implemented in existing production lisps. No, really. I am not confused. In my own toy lisp compiler, I rely on first class macros and am attempting (and so far failing) to use partial evaluation to make the implementation cost somewhat sane. I am under no illusions this is normal.
b) Being an expert doesn't automatically make you good at teaching (often the correlation is reversed), and the article being commented on was a tutorial on macros.
The smug lisp weenie trope exists for a reason, and it's that the lisp community is too busy falling over themselves to prove how smart they are with arcane knowledge to give a shit about the experience beginners face. Clojure gets no end of flak from CL users who bristle at the suggestion that it even be called a lisp, but the community actually gets it and does a great job of teaching.
I have an opinion on how best to teach macros. Maybe I'm wrong. Maybe it's not a good idea to extend SICP with macros, or maybe there's a better way, and I'd love to hear arguments in those directions. But correcting it by explaining how they're implemented in CL is absolutely baffling to me.
SICP is a book for beginner computer science students, with a focus on functional programming as base.
As a Lisp book it's not really good, since it covers only very little actual Lisp and uses only a core Scheme language.
There is literally nothing about macros in SICP. They are mentioned only in a few places (for example it is mentioned that DELAY would be implemented by a macro).
> The smug lisp weenie trope exists for a reason, and it's that the lisp community is too busy falling over themselves to prove how smart they are with arcane knowledge to give a shit about the experience beginners face
Since you ignore the large amount of literature, teaching & research on macros in the Lisp community, what you write is rather strange. Surprise: people teaching Lisp in the 60s already 'gave a shit about the experience beginners face'.
> I have an opinion on how best to teach macros. Maybe I'm wrong. Maybe it's not a good idea to extend SICP with macros, or maybe there's a better way, and I'd love to hear arguments in those directions. But correcting it by explaining how they're implemented in CL is absolutely baffling to me.
Lisp teachers usually taught macros in context of actual Lisp languages and actual usage examples. Personally I prefer that as a first approach, over trying to explain how to extend a toy implementation with some homebrew macro implementation.
That's fine; I prefer the latter. Maybe I'm wrong. But if I am, it's not because I don't understand how macros are actually implemented in the real world, as everyone in this massive thread seems to assume.
I regret my initial comment, which was written in haste. Had I known the sheer volume of people that would jump out the woodwork to demonstrate their superior technical knowledge while avoiding the argument I was actually making, I'd have been a lot more careful about what I was trying to communicate (or more likely not have bothered, which would have saved us all a lot of time).
That is where the "smug lisp weenie" trope comes from, and it's real. I don't know what it is specifically about lisp that brings it out; I can't imagine having this discussion about C#, TCL or SQL.
You can't teach "macros": you have to choose and teach a specific macro system (at a time), whose behavior is linked to the way(s) it is implemented. Each has its own mental models; there is no single mental model for all macros everywhere.
Which is just as effective an argument against the entire of SICP. In a real lisp, a (list? <some-fn>) doesn't return true. You can't dig around inside a closure and walk the entire environment which is made up of a list of pairs.
But the point of a toy model is that you can read an implementation, build your own, reason about it and send code through it with little difficulty.
Once you've built eval and sent real programs through it, it's not a big jump from that to understanding how real tools work, which can generally be done incrementally.
That was certainly my lisp journey, and that includes macros (which were a separate step). After implementing them in eval, learning how they're in the real world was about as challenging as reading a restaurant menu.
> Everyone jumped on it, as production lisps don't implement macros this way. But it's the natural way to implement them in a SICP style metacircular evaluator, and a good way to learn them.
I don't think it is overly useful to explain people how to extend a SICP style metacircular evaluator with some custom macro system. It's often a part of the Lisp journey, but not something I would recommend for basic Lisp teaching.
If I want people to program in Lisp, I give them a real Lisp and teach them how to program with it.
> This is about mental models
Sure, but you are teaching them the wrong mental models (macros tied to an evaluator), while I would focus on the model of general code transformations and the tools to make effective use of them.
> And in my opinion this thread is full of experts who have forgotten what it's like to not understand how macros work.
Not sure who you talk about, but I have been explaining macros to people already in the 80s.
What are lisp macros for if not to delay evaluation?
One class of use cases not covered in the blog post is that a variable appearing as a function's argument can only be a bound occurrence, a use of some name already in scope. A variable appearing as a macro's argument can be the binding occurrence of that name. This is why (using Racket examples) match, define-struct, for/list, and such things aren't functions.
I think it's "'delayed evaluation' + 'transparent internal structure'". So delayed evaluation isn't enough, because the only thing you can do with N closures is to call them in any order, you can't create a complex new expression dependent on the substructure of the closures.
The closest thing to a macro in (eg. python) imo looks like this.
Instead of
d = c * (a + b)
class Adder:
def __init__(self, left, right):
self.left=left
self.right = right
class Multiplier:
def __init__(self, left, right):
self.left = left
self.right = right
d = Multiplier(Adder(a, b), c)
Fill out the __call__ function and/or create an evaluator that recursively calls each class instance with it's parameters and you've made a system that works a lot like a lisp with a macros. Now you can do broadly /anything/, eg. replace every instance of an adder in the call tree with an adder+1. That's using the second required element of my description of macros- the complex substructure, to perform arbitrary transforms. You can't do that with just closures, unless they make their bound parameters accessible (and normally they don't directly, in python they do because it's absurdly dynamic). Of course this is not at compile-time, it's at "delayed execution time", but the difference is kind of slight imo. The benefit of a real lisp over doing this in python is that you don't need to rewrite every fn, operator, control flow statement into your own abstracted level by hand, and it's much faster. Also you can complete the loop and trivially write it back down into eval-able source code text.
Take a macro like (infix x + vx * dt). It's not equivalent to calling some function with thunked arguments -- it has to analyze the literal text of the arguments to turn this into (+ x (* vx dt)).
Macros determine what requirements apply to the processing of syntax. Which parts of that syntax, if any, are evaluated according to what rules, in what environment.
i'll defer to lispm's expert opinion, but i always thought of macros as _conditional_ evaluation. `if` is a special form because it does not evaluate the branch not taken. it's tricky to implement `if` without using `if` or `cond`. macros make it easy to implement your own special forms. in your example, you might want to implement `first`.
(first b c) -> (eval b)
i can't think of a way (but it might be possible) to not evaluate c with a regular function. first is trivial and dumb, but it's obvious how to turn that into short circuiting `and` or `or`.
Macros are more general than that; they are generalized expression rewriters. `if` is tricky to implement in general because you need a primitive to select an alternative based on whether a given value is truthy or falsy. Let's pretend we have such a primitive that's not a special form called `call-if`. Then you can implement `if` in terms of `call-if` by writing it as a macro that transforms this:
(The semantics of `call-if`, by the way, are exactly the semantics exposed by the Smalltalk ifTrue:ifFalse: family of methods.)
But macros can do more than merely wrap things in lambdas, which alone is sufficient for delayed and conditional evaluation. They can quote identifiers that are passed into them, allowing you to write new defining forms and even introduce new bindings. A nontrivial, but understandable, example is the `define-record-type` special form from SRFI 9, which can define a new disjoint record type and a constructor, predicate, and field accessors for that type all in one form. If you are willing to break hygiene and have `defmacro` or something like `syntax-case` available, you can even introduce new identifiers from out of nowhere, and write something like Common Lisp's `defstruct` which lets you define a type and automatically derive names for the constructor, slot accessors, etc. from the names of the type and slots.
Macros are a tremendously powerful, general code generation and rewriting tool, built right into the language. Underestimate them at your own peril!
aww, now i'm embarrassed about my lack of imagination. I have to admit i forgot about the magic you can do with define.
Excellent point. i kinda sorta think defun in common lisp injects the new function at top level regardless, but in scheme it's scoped. So in CL you could probably get away with a simple lambda (or function) to make your struct syntax, scheme would need the macro to put all of that stuff at the top level.
In Common Lisp, DEFUN runs side effect code at compile time. For example it notes the function in the compile-time environment, it may record its definition/the location of the definition, ... It also may rewrite the code it defines: for example by adding some declarations, etc.
Smalltalk blocks are anonymous functions sure, but the evaluation is delayed - you have to pass the message #value (and its variants) to it. This not the case in Scheme and maybe Lisps, where evaluation is eager.
Passing Smalltalk blocks and Scheme/Lisp lambdas into functions have different behaviours.
With a bit more effort, we could also parse a parameter list.
But Lisp does not go the route of making IF a function, because it typically provides three different types of language expressions and IF then is a special operator:
1) function calls
2) macro forms
3) a small set of special operators, which are implemented as built-in functionality. One of them is a core conditional operator. More complex conditional operators then are implemented as macros, which expand eventually into the core conditional operator. The interpreter and compiler will have to specially recognize and implement these special operators.
Okay, but if you have macros, you might as well use them. The idea is more about exploring what can be done when designing a less powerful language, without macros.
> The idea is more about exploring what can be done when designing a less powerful language, without macros.
Lot's of things. But the language won't be able to easily compute code at compile time, which a main purpose of macros. Lisp has a simple data format for source code and thus code transformations are relatively simple to do and even integrated into the language.
Considering the username of the person you are replying to, you might consider that they are very likely to have implemented macros in a lisp.
In common lisp, defining a macro defines a function that receives as its arguments the unevaluated forms passed to it plus (optionally) the lexical environment. This part is indeed "essentially a lambda without argument evaluation."
The magic isn't there, the magic is in the interpretation of the value it returns. It can return any arbitrary lisp forms. This allows macros to do far more than just delay evaluation. Pretty much anything that involves code walking is not possible with lambdas, for example. Some setf expanders would be impossible with lambdas as well.
> If you ever try, you'll quickly find out that a macro is essentially a lambda without argument evaluation. That's it.
> If we take another look on it, yep, that's a form of delayed evaluation of lambda parameters, however I would prefer the term "delayed expansion".
To me, 'delayed evaluation' implies something like call-by-need (e.g. Haskell) or call-by-name (e.g. Algol60), where we can't distinguish an evaluated argument from an unevaluated one, since any attempt to 'look at' (i.e. branch on the value of) the argument will force it to be evaluated. For example, if `(expensive-calculation)` evaluates to `42`, there could be no difference in the behaviour of `(my-delayed-function (expensive-calculation))` and `(my-delayed-function 42)` (although there would presumably be a difference in running time).
In contrast, Lisp macros let us inspect the AST without forcing evaluation, so we can distinguish between these two values, and hence `(my-macro (expensive-calculation))` might behave completely differently to `(my-macro 42)`.
Lambdas are about delayed evaluation.
Macros are about disabling evaluation.
Lisp code is just an abstract syntax tree notation format (s-exps) that comes with default evaluation semantics. Macros allow you to disable those evaluation semantics to reuse the AST for a different programming language.
So for example to add pattern matching facilities to the language, you come up with a syntax and its representation in s-exp AST and then write a macro that describes the unification operation using the default semantics.
Same for logic programming or any other paradigm not initially supportet.
Languages like clojure also bootstrap quite a bit of the language from a simpler to implement dialect. (look at all the functions with a * in clj source they're the base language)
Different name for the same thing, whats your point? Lambdas/AF are used to delay evaluation but keep the default semantics.
Macros are more than simple code transformers, that wording somehow implies that they somehow retain the semantics of the data passed to them, which mighy be the case but is not required at all.
S-Expressions are just a serialisation format for the m-expression AST.
Lambdas are just functions. Delaying functionality is just one use of functions.
> that wording somehow implies that they somehow retain the semantics of the data passed to them
Since they can do arbitrary transformations, retaining semantics is not in focus. Since the input may not have any semantics defined, the semantics is actually provided via the macro implementation.
> S-Expressions are just a serialisation format for the m-expression AST.
S-expressions know nothing about 'syntax'. Thus they can't be an 'abstract syntax tree'. (3 4 +) is a valid s-expression, but carries no information about any syntax (what is the + ? in an s-expression it's just a symbol) and is also an invalid Lisp expression.
An abstract syntax tree would be the result of parsing a program according to some grammar and it would represent the syntactic categories. The parsing stage would already eliminate invalid programs of that programming language.
I know you're rigorous and mostly right, but you forget to admit that for most practical uses s-exps encode trees and are used as ad-hoc AST's. People just make implicit grammars based on spec like predicate patterns.
He's not even right. He's pseudo rigorous to support is CL zealot trolling.
He made it far enough into the wikipedia article to find a graphic that pseudo supports his claim, but not far enough to actually read the definition of an Abstract Syntax Tree (the thing we talk about) vs Concrete Syntax Tree (the thing he talks about).
> This distinguishes abstract syntax trees from concrete syntax trees, traditionally designated parse trees, which are typically built by a parser during the source code translation and compiling process.
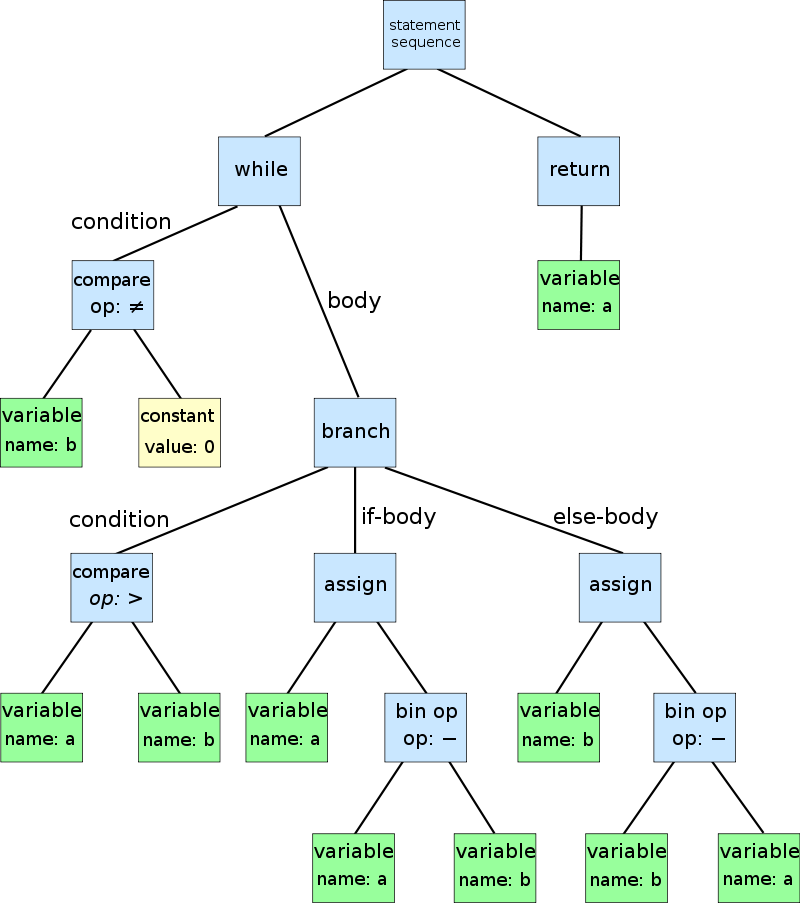
It has a node which is a BRANCH and which has three relations CONDITION, IF-BODY, ELSE-BODY.
In an s-expression this is just
(if (> a b)
(setq a (- a b))
(setq b (- b a))
Thus there is no representation that IF is a branching expression, there is no representation that A and B are variables. There is no representation that > is a compare op. And so on.
The s-expressions are just nested lists of tokens without any idea what the tokens refers to or what language construct it stands for. All we know is what the tokens are and a hierarchy. A is a symbol, but what kind we don't know: it could be a data object, a variable name, a function name, a goto tag, a name of a class, a name of a type, ...). In the abstract syntax tree the > is identified as a compare op, IF is identified as a branch, A is identified as a variable identifier, ...
The Lisp reader also does not create that information. It just creates a data structure, which could be anything, any kind of data.
> Delaying functionality is just one use of functions.
This is why explicitly said Lambdas. Name one use of lambdas not covered by functions that is not delayed evaluation.
If you want to be pedantic please be so consistently.
> S-expressions know nothing about 'syntax'. Thus they can't be an AST.
You seem to be confusing what the CL Hyperspec calls syntax, which is actually the semantics of evaluating a certain expression list, with the actual parse tree that can be generated from M-Expressions. And you seem to confuse Abstract Syntax Trees which can contain pretty much anything with Concrete Syntax Trees generated by parsing (it's explained on the very wiki page you linked). And even IF they were the same, M-Exps themselves are so flexible that they can express everything as function calls and arguments, and since the original Lisp only had a single symbol type your (3 4 +) argument itself is flawed.
You're way to focused on how CL does things, maybe it's your CL background that actually causes you to miss the bigger picture of lisp, something you accuse the people of that come from Java.
The reader in Racket reads expressions into syntax objects. In a second pass it then creates a complete parse.
In an Interpreter based Lisp one reads the s-expression into an internal representation of lists, symbols, numbers. The interpreter then has the syntax encoded into its code and walks these lists keeping track of functions, variables, built-in operators, bindings, ... etc.
That's pretty much what a Lisp interpreter did since the dawn of time. Two decades before CL even existed.
I thought I'd weigh in, as a casual Racket/Elisp user
> Lambdas/AF are used to delay evaluation but keep the default semantics.
You and lispm seem to agree that lambdas can be used to delay evaluation, e.g. `(lambda () (+ 1 2))`. They are also used to abstract/parameterise, e.g. `(lambda (x) (* x x))`.
These two ideas coincide in most languages, since it's often not clear how we would evaluate a parameterised expression (e.g. how might we evaluate the `(* x x)` above, whilst keeping `x` as a free parameter?). Hence most languages don't evaluate inside a parameterised expression (lambdas) until called, and hence we can use them to delay evaluation.
In fact, we can evaluate "under a lambda", which is what happens during inlining, constant folding, or more generally partial-evaluation and supercompilation. This shows that parameterising and delaying evaluation are two distinct ideas, but they're usually represented with one language construct (lambda). We could imagine a separate language construct, like `(delay foo)`, which prevents any form ofevaluation (including inlining, supercompilation, etc.) from being applied to its argument, until it's 'forced' (maybe with a 'force' construct, or maybe by overloading function call syntax).
As for whether Lisp code is a syntax tree I would say:
- If we're allowing the possibility of the reader being altered, then our code doesn't have to be a tree, but I personally wouldn't call it "Lisp code" if it differed that much from s-expressions, regardless of whether a Lisp implementation can read it or not. In that case it's more like we're repurposing a Lisp implementation to act on some non-Lisp language. For example, if we used reader macros to consume regular expressions, that doesn't mean that regular expressions are Lisp.
- To me "Lisp code" is a syntax tree, but it is concrete not abstract (for the reasons lispm says, e.g. `+` is just an opaque symbol rather than an arithmetic operator; we can interpret it in any way we like, using macros).
- I wouldn't say that Lisp code is s-expressions, since there are alternative representations (e.g. I-expressions, sweet-expressions, etc.). Yet as long as they're equivalent to s-expressions (which, in particular, requires that they're trees and that we can impose our own semantics using macros!), then I'm happy calling them Lisp.
> This shows that parameterising and delaying evaluation are two distinct ideas, but they're usually represented with one language construct (lambda).
We delay evaluation because it may be expensive (potentially non-terminating), or because it may involve side-effects.
Delayed evaluation allows us to create new semantics, like lazy data structures.
The steps of a procedural program which are have not yet executed are delayed evaluation. Sometimes that is important, because those steps require some external event to have taken place, so that their own effect takes place after that event, or because that event provides a needed input. Mechanisms like closures and continuations give us new useful ways to structure this.
> We delay evaluation because it may be expensive (potentially non-terminating),
Indeed, we must delay (full) evaluation if we want a function to be recursive. This is also why we can't inline every function call (even if we're prepared to accept the inevitable code bloat).
> or because it may involve side-effects.
> The steps of a procedural program which are have not yet executed are delayed evaluation. Sometimes that is important, because those steps require some external event to have taken place, so that their own effect takes place after that event, or because that event provides a needed input.
I didn't explicitly talk about side-effects, but I was making an implicit assumption that evaluating under a lambda would never move an effect from runtime to compile/expansion time, and would preserve the partial-order of runtime effects (i.e. the absolute order may change, if there's a race condition and our partial-evaluation manages to speed up one path more than the other, but those which are causally-linked like triggering an event handler or waiting for input would preserve their order). To me, these requirements are just part of what it means for the evaluation to be correct, just like a call to `foo` should run the code for `foo` rather than some arbitrary other function, etc.
A partial-evaluator/supercompiler/inliner/constant-folder/loop-unroller can partially-evaluate code by treating parameters as opaque symbols (since we don't know what their value will be), and they can likewise treat language primitives which have side-effects as opaque values. For example we can treat `(lambda () (print "hello world"))` as being in normal form (and hence we do no further evaluation), whilst still treating `(lambda () (print (concat "hello " "world")))` as not being in normal form, since we can go ahead and run the `concat` call.
> Delayed evaluation allows us to create new semantics, like lazy data structures.
> Mechanisms like closures and continuations give us new useful ways to structure this.
I agree, I was just pointing out we can (a) implement such things without `lambda` (e.g. using a separate `delay` construct) and that (b) we can implement `lambda` in a way which doesn't allow forms (e.g. by allowing evaluation under a lambda, by limiting what we count as a normal form).
I'm not saying it's practical or desirable to do so, just that it's important to know which properties are inherent to a feature (like `lambda`) and which are under our control to choose.
Note that you may also have a Lisp form like #1=(programmable . #1#), which represents not a tree but a graph. With lispm's remarks in mind, you can see that it's not abstract, not syntax, and not a tree.
Experience shows that most Clojure users come from Java and have very little idea about Lisp. It might help to bring in some perspective, since Clojure is not a very typical Lisp: no interpreter, no linked lists as base data structure, no Lisp in Lisp, no Lisp runtime, no images, not the typical debugging tools like break loops, the runtime is from the JVM or another environment (.net, JavaScript), ...
Lisp existed already before Clojure and has a rich history, much of which is not in Clojure.
ClojureScript is interpreter, unless you run Closure compiler in compilation phase. Interpretation is done by default in repl. There is also Joker [0].
> no linked lists as base data structure
Not true. Linked lists are base data structure on the same level as vectors and hash maps. Unlike Scheme where hash maps are sometimes implemented as assoc-ed lists.
> no Lisp in Lisp
Check for CinC and derivatives [1] or Ferret [2].
> no Lisp runtime
What you define by "runtime"?
> no images
By this requirement, 90% Lisps out there would not be Lisp ;) Even some Common Lisp implementations (ABCL) doesn't have it. Or if you want another extreme, V8/nodejs can generate image/snapshot or you can dump JVM image via Criu [3].
> not the typical debugging tools like break loops
IntelliJ has it, CIDER has it, there is clj-debugger... It is not part of default implementation, just like Scheme doesn't have it.
For example the stuff the JVM provides: memory management, data layout, interrupt handling, threads, loading code, talking to the environment, ...
> By this requirement, 90% Lisps out there would not be Lisp
I'd think it's more like 70% use images... just a guess. The exceptions usually are Lisps using runtimes which can dump/load images (like probably every Lisp on the JVM) or which by choice don't do (like some Lisp to C compilers, ...).
> Even some Common Lisp implementations (ABCL) doesn't have it.
That's the same limitation of the JVM. There are a few more implementations which don't have it. But generally there is a rich choice of full language implementations with and without images.
According to [0], these days it is hard to distinguish between compilers/interpreters. However, it translates code to javascript and execute it immediately, just like python does (converting code to own bytecode, before execution). No translation to machine language.
> For example the stuff the JVM provides...
I still fail to see what (Common) Lisp runtime gives over JVM, except direct translation to machine language (Hotspot does that in runtime) and maybe restarts - there are few clojure libraries which implements this, but thing would be much better if is baked in language/jvm.
> I'd think it's more like 70% use images
If you count into that Scheme implementations, that number would be significantly different ;)
In Lisp an interpreter means something slightly different: it means an interpreter for s-expressions. It's not about a virtual machine interpreter or similar.
A Lisp interpreter runs directly the s-expressions. This is independent from the idea of evaluation. Evaluation could be implemented by an interpreter or by a compiler.
Let's break into the function if the argument N is 0:
CL-USER 33 > (trace (fak :break (eql (first *traced-arglist*) 0)))
(FAK)
CL-USER 34 > (fak 5)
0 FAK > ...
>> N : 5
1 FAK > ...
>> N : 4
2 FAK > ...
>> N : 3
3 FAK > ...
>> N : 2
4 FAK > ...
>> N : 1
5 FAK > ...
>> N : 0
Break on entry to FAK with *TRACED-ARGLIST* (0).
1 (continue) Return from break.
2 Continue with trace removed.
3 Continue traced with break removed.
4 Continue and break when this function returns.
5 (abort) Return to top loop level 0.
Type :b for backtrace or :c <option number> to proceed.
Type :bug-form "<subject>" for a bug report template or :? for other options.
CL-USER 35 : 1 > :bq
FAK <- FAK <- FAK <- FAK <- FAK <- EVAL <- CAPI::CAPI-TOP-LEVEL-FUNCTION <- CAPI::INTERACTIVE-PANE-TOP-LOOP
<- MP::PROCESS-SG-FUNCTION
CL-USER 36 : 1 > :n
Interpreted call to FAK
CL-USER 37 : 1 > :lambda
(LAMBDA (N) (DECLARE (SYSTEM::SOURCE-LEVEL #<EQ Hash Table{0} 41B01C37FB>))
(DECLARE (LAMBDA-NAME FAK))
(IF (ZEROP N) 1 (* N (FAK #))))
You see above the actual s-expression being executed for that stack frame. It's not executing any compiled or translated code. It's actually interpreting the source directly without any such step.
If we want, we could inspect, alter it with the usual Lisp functions and continue running.
> I still fail to see what (Common) Lisp runtime gives over JVM
More efficient data representation, more efficient execution, saving and loading of images, tailored GCs, mixing compiled and interpreted (see above) Lisp code, deeper runtime inspection, resumeable exceptions, efficient stack traces, efficient function calls, fast startup times, etc etc.
Something like Lisp, which may have a bunch of very dynamic parts, is hard to implement efficiently on the JVM. Clojure is designed to map better to the JVM.
Macros work much better in homoiconic languages like Lisp than they do in other languages. Most of the code I write these days is in Elixir and I avoid macros unless absolutely necessary. The benefits generally don't outweigh the (long-term) costs.
One of the differences between macros in Lisp and some other languages which provide macros is that the expressions themselves don't need to be valid code in some programming language -> they don't get parsed by a language parser upfront.
Thus I can write a postfix macro and then write code like this:
(postfix 2 3 + 3 *)
even though Lisp requires code to be nested prefix expressions.
Some other languages won't allow this, because the expression 2 3 + 3 * is not legal in their language. Thus it only may allow macro transformations from legal expressions to other legal expressions...
Yes. One of the examples from the talk was a comment macro. Very cool (and the talk was about fun/cool stuff, not about practicalities).
The question is whether you want that sort of power in day-to-day programming. My guess is no. That's also what the PARC/LRG folks found out with Smalltalk-72. It's also something I hear from some very seasoned LISP hackers. It's also the sense I am getting from these very powerful DSL/LOP workbenches.
From TFA:
The reason the question is relevant is, of course, that although it is fun to play around with powerful mechanisms, we should always use the least powerful mechanism that will accomplish our goal, as it will be easier to program with, easier to understand, easier to analyse and build tools for, and easier to maintain.
It's also why I use the C pre-processor very reluctantly. Though I do use it. From time to time. And then try to get rid of that use if I can[1]
And no need to explain how much better LISP macros are :-) In a sense, like Smalltalk, LISP may be just too powerful, in the words of Alan Kay "Lisps frequently 'eat their children'" so that there's always an answer (use a macro) that will cut off an interesting question.
Well Lisp and Smalltalk were designed for two entirely different purposes and audiences[1] so of course they were trying to jettison everything they could and keep things absolutely as simple as possible in Smalltalk. That doesn't mean that what was jettisoned didn't have value[2] in the right circumstances or hands, just that it wasn't appropriate for the needs of their project. Trying to do some things in Smalltalk without either something as rich as macros or as basic as a preprocessor can be downright painful at times.
[1] Lisp as a mathematical notation for computation vs. Smalltalk as a programming language primarily targeting children.
[2] Some of what they ended up doing in the STEPS project with DSLs looks very much to me like a rethinking and attempt to get even more leverage than what macros provide. In a way it was working toward 'computing for adults' that I've heard Alan refer to in several talks that was never the focus with Smalltalk.
> Lisp and Smalltalk were designed for two entirely different purposes and audiences
> Smalltalk as a programming language primarily targeting children.
Not entirely sure that is right. See The Early History Of Smalltalk[1]
'One day, in a typical PARC hallway bullsession, Ted Kaehler, Dan Ingalls, and I were standing around talking about programming languages. The subject of power came up and the two of them wondered how large a language one would have to make to get great power. With as much panache as I could muster, I asserted that you could define the "most powerful language in the world" in "a page of code." They said, "Put up or shut up."'
'I had originally made the boast because McCarthy's self-describing LISP interpreter was written in itself. It was about "a page", and as far as power goes, LISP was the whole nine-yards for functional languages. I was quite sure I could do the same for object-oriented languages plus be able to do a reasonable syntax for the code a la some of the FLEX machine techniques.'
'It turned out to be more difficult than I had first thought for three reasons. First, I wanted the program to be more like McCarthy's second non-recursive interpreter—the one implemented as a loop that tried to resemble the original 709 implementation of Steve Russell as much as possible. It was more "real". Second, the intertwining of the "parsing" with message receipt—the evaluation of parameters which was handled separately in LISP—required that my object-oriented interpreter re-enter itself "sooner" (in fact, much sooner) than LISP required. And, finally, I was still not clear how send and receive should work with each other.'
You are correct regarding the initial concept, but what were the objectives of the Learning Resource Group that Alan Kay was leading at the time? And what were the various iterations of Smalltalk (i.e. -72 through -80) working towards? Squeak? Etoys? Croquet? (etc.) Alan has been pretty explicit in every paper and presentation I've seen from him: his career has been very much focused on computing as it applied to childhood education and development.[1] Of course Smalltalk is also an incredibly powerful language and still one of the better ones for adults to use IMO. But when push came to shove, the language design decisions were at least biased toward, if not explicitly based on what would work for children.
[1] Which is both profound and enlightened because in the same breath he'll say he didn't really care about educating children... he just wanted to help make better adults.
"Although Smalltalk-80 is not meant to be used by children, application programs can be written that will allow them to be creative and, at the same time, learn about programming."
Is the Smalltalk- System for Children?, Byte, 6(8), August 1981. 3. Adele Goldberg , Steven T. Abell , David Leibs
Keep in mind that was at a time when Adele was working to commercialize Smalltalk in the real world[1] eventually as a business venture selling to businesses (i.e. ParcPlace Systems) so there was more than a little bit of spin involved. (especially given the writing, photo and video evidence to the contrary from the 70's with Adele in-frame :-) Also, look back at the Early History link from your first post and you'll find 'children' mentioned 35 times including this quote: 'and a language I now called "Smalltalk"—as in "programming should be a matter of ..." and "children should program in ..."'
[1] If I'm not mistaken the only reason Squeak and its derivatives even exist today was that during this time, as Xerox was trying to figure out what to do with what PARC produced, Apple received one of the handful of the Smalltalk-80 Version 1 licenses. IIRC, the Version 2 license was more restrictive and wouldn't have let Apple do what it did in terms of open sourcing Smalltalk. Notice that there was never a Smalltalk-82 etc... virtually all future work came from the commercial side until Squeak came along.
>> "Although Smalltalk-80 is not meant to be used by children..."
> spin
So when the people involved directly und unambiguously contradict your opinion, for which you have presented zero evidence, they are lying.
When I looked at Smalltalk in 1975, I was looking at something great, but I did not see an enduser language, I did not see a solution to the original goal of a "reading" and "writing" computer medium for children.
That's Alan in Early History.
> 'children' mentioned 35 times
That's an odd metric at best, but let's play. First mention of "children" after the introduction:
A month later, I finally visited Seymour Papert, Wally Feurzig, Cynthia Solomon and some of the other original researchers who had built LOGO and were using it with children in the Lexington schools. Here were children doing real programming with a specially designed language and environment.
Hmm..LOGO. What's LOGO?
Logo is a multi-paradigm adaptation and dialect of Lisp, [..] The goal was to create a mathematical land where children could play with words and sentences
Oh, and LISP is mentioned 29 times. Having read this document many times, as well as the History papers and listened to talks etc., I have yet to find any evidence that anything was done to "dumb down" Smalltalk in order to make it work for children. Quite the contrary:
One of the basic insights I had gotten from Seymour was that you didn't have to do a lot to make a computer an "object for thought" for children, but what you did had to be done well and be able to apply deeply.
This incident and others like it made paramount that any tool for children should have great thinking patterns and deep beauty "built-in."
Shortly after that:
As I mentioned previously, it was annoying that the surface beauty of LISP was marred by some of its key parts having to be introduced as "special forms" rather than as its supposed universal building block of functions. The actual beauty of LISP came more from the promise of its metastructures than its actual model.
By this time [Smalltalk-80] I was both happy about the cleanliness and elegance of the Smalltalk conception as realized by Dan and the others, and sad that it was farther away than ever from the children
"we should always use the least powerful mechanism that will accomplish our goal"
I like this when implementing something for non proficient users. But when it comes to providing tools for (supposedly) advanced users, like programmers... There's late-"socialism" joke in Bulgaria: "thrift is mother of misery". A designer doesn't know ahead of time what problems "creative" users will face long term. Providing a set of simplest mechanisms for today's challenges would possibly constrain them in the future - combination of multiple mechanisms in ways not foreseen may add large incidental complexity (like OO design patterns). Which could be avoided if less by count but more powerful mechanisms were used in first place. Macros have main role in keeping Common Lisp relevant to the latest paradigm hypes despite the standard being set in stone. Opposite to this, for example, C++ must keep introducing piles of new least-powerful mechanisms to keep pace.
Sounds very related to "shadow languages" ( https://gbracha.blogspot.com/2014/09/a-domain-of-shadows.htm... ) where we add a feature to our language in a very limited form, e.g. imports; then we end up wanting that feature to be a little more powerful, so we add some special case for that, e.g. conditional imports; then we want to use that feature some other way, so we add support for that, e.g. renaming imports; etc.
We end up with a language that has a complicated, limited, special-purpose second-language built in just to handle that feature.
The alternative is to try implementing the feature using existing facilities right from the start, e.g. making imports first-class values that can use the language's own conditionals, variable names, etc. for imports.
We can also go one step further and rather than just trying to re-use the existing language features as they are (e.g. conditionals, variables, etc.), we can ask what new feature could we use to build both the new functionality and the old functionality. That way, rather than e.g. using the built-in conditionals to implement conditional imports, we might decide to something more powerful than both, like macros, and use macros to implement conditional imports and replace the built-in conditionals :)
> The question is whether you want that sort of power in day-to-day programming
It's good to use the least powerful mechanism, no doubt. But it seems you are trying to sneak the usual "macros are too powerful for everyday use" so better be left out of a language altogether? I think when the storm comes - you'd better be equipped. Having varied ways to tackle problems (and macros are sort of linguistic abstraction orthogonal to lambda calculus/Turing machine derived toolboxes) allows for less complex solutions.
> sneak the usual "macros are too powerful for everyday use"
Not trying to "sneak" anything, I openly say that language design, which is what macro usage is, is not something you should have to engage in everyday. In fact, I would turn it around: if you have to (repeatedly) resort to language design in your everyday programming, your programming language is (woefully) inadequate. Most are.
Which is why the reasons for hitting that boundary interest me: where do I have to resort to metaprogramming, why, and what can I do about it? What non-metaprongramming facilities are missing here so that I don't have to resort to metaprogramming? And if I don't want to just add those facilities to the base, which I don't, what mechanisms can I add to the language so that users of the language can use plain, non-meta mechanisms to provide those facilities themselves?
This is a bit tricky, but I am making good progress using a software architectural approach[1], with frequent surprises as to how much simpler things can be.
> left out of a language altogether?
Quite the contrary. I think "escape hatches" (metaprogramming) are fundamental and your everyday language(s) should be built 100% on top of those mechanisms. Heck, I named my company "metaobject"[2] 20 years ago, after The Art of Metaobject Protocol.
Consider for example CL:WITH-SLOTS, or CL-WHO:WITH-HTML-OUTPUT... such macros establish context, and are not really about delaying evaluation. On Lisp has a section about uses of macros, which is not exhaustive, but shows there's more to them than "delayed evaluation".
Lisp user here. I'll chime in with another example of using macros for more than just delaying evaluation.
I wrote a library called Chancery[1] for procedurally generating strings (and other data). It's inspired by Tracery[2] but takes advantage of macros to make it easier to read and feel more like part of the language. I use it to write stupid Twitter bots like https://twitter.com/git_commands and https://twitter.com/rpg_shopkeeper for fun.
As an example let's say we want to generate a message about the loot we receive from a monster in a fantasy, D&D-style story. Maybe we'll start with some random weapons:
This simple case actually could be done just by delaying evaluation, as long as we get every body clause as a separate thunk. Now let's define a rule for generating the material of a weapon:
This case needs more than just delayed evaluation. If you receive `(100 "iron")` as an opaque thunk, where all you can do is evaluate it, there's no way to pull out the weight and body components.
If we add a few more rules, we can see more cases where we need to go beyond delayed evaluation:
(defun currency-amount ()
(+ 10 (random 100)))
(chancery:define-string (currency-type :distribution :zipf)
"copper"
"silver"
"gold"
"platinum")
(chancery:define-string loot
#((weapon-material weapon-type) chancery:a)
(currency-amount currency-type "coins"))
(chancery:define-string discovery
("You open the chest and find" loot :. ".")
("You find" loot "in the monster's hidden stash.")
("You find nothing but dust and cobwebs."))
(discovery) ; => "You find nothing but dust and cobwebs."
(discovery) ; => "You find an iron sword in the monster's hidden stash."
(discovery) ; => "You find 61 copper coins in the monster's hidden stash."
(discovery) ; => "You open the chest and find a steel sword."
Macroexpanding the last one:
(DEFUN DISCOVERY ()
(CASE (CHANCERY::CHANCERY-RANDOM 3)
(0 (CHANCERY::JOIN-STRING "You open the chest and find"
(PRINC-TO-STRING #\ )
(LOOT)
"."))
(1 (CHANCERY::JOIN-STRING "You find"
(PRINC-TO-STRING #\ )
(LOOT)
(PRINC-TO-STRING #\ )
"in the monster's hidden stash."))
(2 (CHANCERY::JOIN-STRING "You find nothing but dust and cobwebs."))))
Here we can see the macro walking the lists and doing different things to each element: strings are included raw, symbols are turned into function calls, and the special keyword :. suppresses the usual joining space character inserted between everything. There's also some special handling of vectors, in the LOOT example, which I won't go into. This is more than just delayed evaluation — we're inspecting the actual structure of the code received by the macro at macroexpansion time. If all we had were an opaque thunk that we could evaluate later, we couldn't do this.
Delayed evaluation is enough for certain kinds of abstraction, like writing basic control structures, but isn't as powerful as full macros. Macros let you transform arbitrary code into other arbitrary code using the full power of the language.
{kind=link}
What Smalltalk calls 'blocks' are just (anonymous) functions in Lisp. Books like SICP explain in detail how to use that for delayed evaluation in Lisp/Scheme:
https://mitpress.mit.edu/sites/default/files/sicp/full-text/...