So the new top-end Nvidia cards will have dedicated ray tracing cores. However, real-time ray tracing is still so computationally expensive that games can only implement a hybrid form of it whereby ray tracing is applied for a certain effect or single object, and plain old rasterization is used for everything else.
I applaud NV for stepping up and delivering something in a new direction. Just think- how long has it been since something truly new has been introduced in the gfx world?
Reading through the full article, it was no small feat to dream up and build these cards. A very complex project from both product and engineering perspectives. Hardware-wise, the 2080 specs are quite insane, and these babies are thirrrsty, drawing ~250 watts.
That said, the move definitely seems risky, as it increases complexity significantly for game devs to code for this hybrid approach. What if the market doesn't warm up to this, or perhaps ATI or someone else comes up with something more novel?
I also wonder if it's just a few years premature. Not feeling compelled to give up the good old 970GTX yet. Wake me up when full ray tracing is ready :)
---
P.S. I couldn't help but snicker when looking at the table near the end showing which games will support what new imaging modes.
Of course, PUBG doesn't support ray tracing. Hardly a surprise, considering they can't patch without hours of downtime, and also frequently deliver patches containing "fixes" which break more than they fix.
(FWIW I've stopped PUBG and moved on to Elite:Dangerous, aka space truckers, thanks to it being recommended in an HN thread. Fun game, if you enjoy the solitude of loneliness of endless space! ;)
One thing I hope these cores can do is walk a tree that's more general purpose than just volume intersection, like a BSP tree for z-sorting.
We could have scenes with exponentially more geometry if the geometry is culled more efficiently. Stuff like walls covered in pipes/debris, cloth that wraps around the model's body as it moves, much more complex and overlapping shadow volumes, etc.
Constructing a robust BSP tree is very expensive, because you need exact rational arithmetic and the number of bits grows quite large. You wouldn't want to do that at runtime, so you could only use this for static geometry.
If most of your geometry is opaque, you can already achieve the same reduction in lighting complexity with a Z pre-pass.
Even if PUBG would support ray tracing, most users would probably turn it off, because being able to spot things in competitive games is more important than visuals. Good players even turn off shadows and post processing effects in order to get an advantage over players who dont. Ray tracing is a nice feature for single player games or multiplayer games that are not competitive (e.g. PvE games like Diablo).
MS is pushing this kind of hybrid ray-tracing in DirectX 12. I imagine that Nvidia has been holding off on this until that came about because otherwise it would’ve been way too hard to push.
Of course you know Microsoft worked with all the major vendors because they don’t want to be seen as playing favorites. I would expect AMD would have whatever their version of this is in their next generation chip.
The article made it sound like DirectX only specifies a very high-level interface. So there’s probably a lot of room for AMD and Nvidia to maneuver for performance and quality without breaking compatibility.
I was under the impression from the initial coverage that they were actually getting something like 1 to 2 rays per pixel per frame. Perhaps even less.
From there they were using some sort of smoothing and/or temporal anti-aliasing to gather the data from multiple frames to get decent quality out of it.
Or are you proposing how many raise they would NEED to be able to do real time full raytracing? By the time we have that ability I imagine everyone will just want the 4K version anyway and we will be behind again.
Either way what nVidia has shown looks great. It’s too bad I’ll have to wait years to be able to use it as a console gamer.
Due to noise and aliasing. If multiple features (edges, materials etc) cover a single pixel, you usually get aliasing. If you do random sampling (of reflections, lights, whatever) you get noise.
For anti-aliasing you'll usually want at least on the order of 10 rays per pixel for a nice result. If you do random sampling, you quickly need 100 to 1000 rays per pixel to get an acceptable noise level.
One ray represents many photons, and those photons scatter off in many different directions when they hit most surfaces. To get a reasonable picture of where they went, you need a lot of samples.
A single raycast also only gets you one step of the light's journey. That means, for example, that following light as it bounces from a light source, to a surface, to another surface to your eye requires at least 3 rays even for perfectly mirrored surfaces.
It depends on what you wan't to use ray tracing for.
If you want to calculate global illumination with path tracing (which is a form of ray tracing) then you need multiple samples per pixel to get a noiseless result.
It's a stochastic process and it needs many samples per bounce. Basically, unless the surfaces are perfect mirrors, each angle of reflection is a probability function. Look for Monte Carlo methods for more information.
For the secondary rays for reflection, refraction and shadows.
At one ray per pixel, you can only do the primary ray and find which triangle it hits. The exact same thing can be done with rasterization much faster and with equal results.
Looking at the demo video Nvidia released yesterday[1], it is pretty obvious that the performance is still bit limited. The shadows and reflections are distinctly low-resolution and I don't think its solid 60fps either.
Sure it's still pretty nice for first-gen product, so not complaining too much. But there is still fair bit of road to go on.
Why are RT cores so different than normal shader cores? What instructions/memory fetch does a ray trace operation do that couldn't be implemented as an added instruction set on the shader cores to navigate the volume tree?
From the article, the best I can see is the following, but can't that be solved with microcode or as an extra rendering pipeline stage?
> In comparison, traversing the BVH in shaders would require thousands of instruction slots per ray cast, all for testing against bounding box intersections in the BVH
I ask, because having more slightly larger general purpose cores seems better for traditional rendering and raytracing than dedicating all that die space to pure single-purpose RT cores.
RT cores are different because raytracing wants AoS (array of structures) rather than SoA (structure of arrays).
Let's look at the ALU perspective. Normal shader cores are essentially SoA: all ALU operations operate on 32 (NVidia) or 64 (AMD) items / threads at a time.
Implementing a ray-box intersection requires 6 multiply-adds to determine the intersection-time of the ray with each box plane, plus a bunch of comparisons to determine whether and when you hit the box. So if you're walking a standard (binary) BVH, you need 12+x ALU instructions (roughly equal to cycles) to handle one step of a wave / warp.
The picture is still fairly rosy when you start out your BVH walk, but then you get ray divergence. Some of your rays may finish early, some rays may want to do ray-triangle intersection instead. This means that only some of the SIMD lanes will be active and your ALU utilization drops. You're using the same number of cycles, but get much lower bang / buck.
In a dedicated RT core, you can operate one ray at a time instead of one instruction at a time. So you can do all multiply-adds for intersecting a single ray with both boxes in your BVH node in a single cycle, and then follow up with the comparisons in the remainder of your pipeline.
The upshot is that when rays diverge, you can still fully utilize the ALU units in your ray-box intersection pipeline -- it simply takes you fewer cycles to process all rays in a warp.
A similar argument applies to the memory system as well -- due to ray divergence, you obviously want to store your BVH nodes as AoS. A BVH node requires 12 floats to store the dimensions of two boxes, plus some space for child node links, which makes 64 bytes a natural node structure size, and you want to keep it contiguously in memory so that loading one node means loading (part of) one cacheline. But this makes it difficult to get the data through a normal shader core's load unit, which is optimized for SoA.
It is more like a texture unit than a shader core. Tree traversal is a pointer chasing problem, where the CPU/shader core executes a few instructions, then starts a memory load and then sits idle for tens or hundreds of clock cycles waiting for memory. Cache prefetching can help but is usually not a good fit for tree traversal where there is very little computation per node.
It is all about memory latency hiding and not really about computation.
But GPU cores are already king at latency hiding. They can run hundreds of threads doing pointer chasing, switching between them round-robin as the memory reads complete.
The switching isn't free. Waking up a thread to do just a few computation cycles (a few ray-aabb intersections) and then going back to sleep while waiting for the next node to be fetched from the memory is super inefficient.
If there was significant computation needed per node, this wouldn't be an issue.
It absolutely is, on current GPUs. Think of it like a larger-scale version of SMT (Intel's hyperthreading). GPUs are able to do this because they execute instructions in-order and do not need to track thousands of instructions per thread.
Well, yeah. If you are memory bandwidth-constrained it's a bad idea to go off-chip.
But for ray-tracing, what does it really matter? We are already assuming that you will wait a full memory fetch cycle to get the next node's child AABBs and child indices. The warps will do their intersection test on the data they just read and fire off the next read. Each thread's hot context should fit in under a cache line, since it's basically just a single ray to keep track of.
Seems to me like ray-traced rendering provides a feasible path to foveated rendering for VR, meaning much better performance for VR scenes at high resolutions. This would be a big deal for VR developers, since they don't have to do unlikely amounts of magic to implement this. If NVIDIA is able to drag everyone along, they will get the hardware for this without making any huge strategic moves on their own part.
Don't forget that NVIDIA is not only a gaming company. They are involved in a lot of computational geometry fields, localization reconstruction, machine learning, etc.
There are a lot of use cases for ray tracing that are not games. So far NVIDIA has done a great job at changing their GPU architecture in a way that is mutually beneficial to all of their diverse customer base.
The use case that seems obvious to me is computationally efficient ray-tracing in robotics/autonomy simulation. I wonder if ISAAC sim will take advantage of RTX. What do you think?
The thing that strikes me with the RTX announcement is a general point about how important identifying useful intermediate steps are to bringing about new paradigms.
Unless a technological breakthrough is just around the corner, or you have the resources to push it forward (Space Race / Manhattan Project), it’s better to spend your energy identifying useful intermediate steps that you can offer to the market to fund & bridge yourself to the new paradigm. By having funding all along the way, you can gain a significant advantage to those pursuing the new elegance directly. [1]
A few examples:
STREAMING. People used to go to video stores to rent movies. As the internet emerged we dreamed of a new, more elegant paradigm: streaming. No more driving to a store, no more physical copy or late fees or damages, etc. But it was the clever discovery of an intermediate step - to use the internet to rent DVDs via mail - that created the brand and customer base that established the market leader (Netflix). Once internet infrastructure caught up, the switch was seamless. Meanwhile, there were many people who pursued streaming directly, but failed because they didn’t take the intermediate step (Broadcast.com).
ELECTRIC CARS. Traditional cars have super complex drivetrains. As battery tech improved, we dreamed of a new, more elegant paradigm of electric vehicles that improved efficiency and eschewed most moving parts, transmissions, exhaust systems, etc. But there existed a valuable, infrastructure-free intermediate step to get there: hybrids. Ironically they were even more complex, but they employed many new techs that helped move electric cars forward. Toyota has hugely benefitted from being the discoverer of this intermediate step. Obviously we now have Tesla leading the vanguard, but in the context of global development, nobody can predict if an Elon will show up in your generation.
AUGMENTED REALITY. Our current physical reality is awash in information - street signs, road paint, branding, menus, maps, clocks, games, warnings, nutrition labels, interfaces, etc. These are often completely irrelevant to us at a given time, and certainly not personalized to our needs. We dream of the day we can render overlays on our eyes to deliver the personalized versions of these (as well as entirely new things), which would over time mean our physical reality would get simpler, cleaner, and less wasteful. To deliver this elegant solution requires a lot of breakthroughs in display technology that are years if not decades away. Bundling SLAM tech into smartphones (looking at you Apple) and pursuing incremental use cases is an intermediate step that can grow the market until the point where the displays are ready, at which point those who best pursue this are likely to be the market leader.
Ray tracing is now on the same course. It's been known for decades that it is a far more elegant paradigm to reason about and generate images (vis-a-vis rasterization), but its compute requirements are so high that there's been this chasm people haven't been able to cross to get to ray tracing. Nvidia has now provided a bridge between these two worlds, by allowing raytracing of parts of the rendering pipeline alongside rasterization. Subsequent generations will slowly swallow the remaining parts that rasterization performs today. Basically the RTX is the graphics card equivalent of a Prius, growing into a full electric.
The addition of ray-tracing cores in the RTX line was a pleasant surprise to me, not only because it speeds the development of ray-tracing hardware, but because it showed intermediate steps existed that I didn’t know about before. It showed me we weren’t stuck waiting indefinitely for a promise of an elegant future that always seems a decade away. Pretty exciting.
[1] What I mean by paradigm is not just incrementalism or an evolution of one product into another (like iPod -> iPhone), but of a wholly different way to solve a problem that is more elegant / higher abstraction than previous ways, but that require breakthroughs in enabling technologies to get there. Rockets -> Space Elevators (material science; elegance is in ease of transport), Retail -> Online Shopping (internet; elegance is in personalization + stay-at-home), Coal -> Solar (energy storage; elegance is in eco footprint, low entry point & simpler tech), Driving -> Autonomous Driving (ML/sensors; elegance is in time savings / one less thing to learn & simplification+density of road infra). This is admittedly a fuzzy definition, and perhaps these examples are not perfect.
Toyota is just as far ahead as Tesla. Electric cars isn't better than hydrogen. Just different. And Toyota can sell 1000 cars and have less problems than one Tesla.
The Turing architecture is also used in Quadro RTX cards, and those have a ridiculous amount of VRAM.
Is there any professional/computational use for these RT cores beyond raytracing?
One case that comes to mind is perhaps raytracing acoustics, and although interesting it's technically still raytracing.
As far as gaming is concerned, personally I'd love if the RT cores could contribute—however inefficiently—to rendering workload in non-RTX games. It's annoying that 50% of the die is allocated to hardware that requires feature-specific implementations.
The whitepaper brings up physics simulation and occlusion/visibility testing as possible non-raytracing applications of the RT hardware, plus acoustic simulation as you said.
> It's annoying that 50% of the die is allocated to hardware that requires feature-specific implementations.
That's the future. While we may be able to cram more transistors onto "7nm" chips, only a tiny fraction of the chip area can be powered on because leakage currents are no longer decreasing with transistor size [1]. Hence Apple's Neural Engine and Nvidia's RTX. You have to waste the extra transistor count on something specialized.
The RT and Tensor cores are primarily intended to power raytracing and DLSS, respectively. Both of those features will be used in conjunction with traditional shading/compute units, so the entire die is utilized at once, at least at a high level.
It would be really interesting to know the power consumption of a Turing card maxing out just its shading units, versus full utilization with RTX/DLSS.
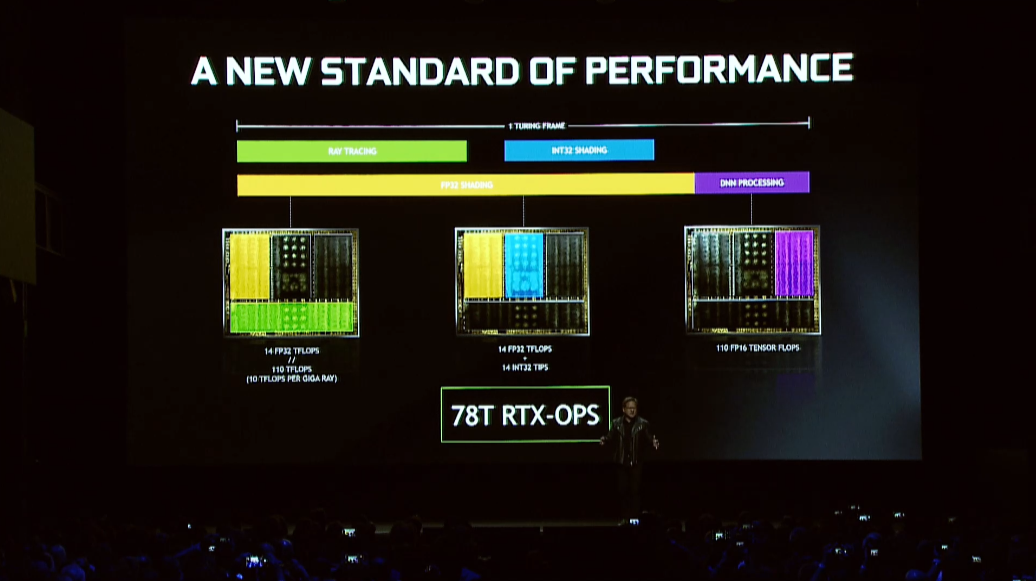
A) that's a marketing image. The green box is placed over a random portion of the die, not just the raytracing units. (They are distributed throughout the die, not shoved on one side).
Just by looking at that you can intuitively see that the colored boxes in the previous image appear to be arbitrary. On the other hand, the previous image does seem to be trying to convey that a substantial portion of the die isn't shading units, even if the distribution is misrepresented.
>B) that said, looks more like 30% to me.
Was talking about RT and Tensor combined, not just RT.
We are at the end of the console cycle, which means games hardware requirements will plateau until the next gens are out. So from now, at 1080p, a 1070 is enough to handle everything at 60fps until then. That probably translates to a 2060 this generation - which is the card I'm really interested in.
Other than that Nvidia cards are severely restricted due to their lack of support for Adaptive Sync or HDMI 2.1 VRR.
Considering that 1070 is struggling already with some 2016 games[1], I find the claim that it would be able to handle everything until next console gen comes out (2020 earliest?) very dubious.
{kind=link}
{kind=link}
I applaud NV for stepping up and delivering something in a new direction. Just think- how long has it been since something truly new has been introduced in the gfx world?
Reading through the full article, it was no small feat to dream up and build these cards. A very complex project from both product and engineering perspectives. Hardware-wise, the 2080 specs are quite insane, and these babies are thirrrsty, drawing ~250 watts.
That said, the move definitely seems risky, as it increases complexity significantly for game devs to code for this hybrid approach. What if the market doesn't warm up to this, or perhaps ATI or someone else comes up with something more novel?
I also wonder if it's just a few years premature. Not feeling compelled to give up the good old 970GTX yet. Wake me up when full ray tracing is ready :)
---
P.S. I couldn't help but snicker when looking at the table near the end showing which games will support what new imaging modes.
Of course, PUBG doesn't support ray tracing. Hardly a surprise, considering they can't patch without hours of downtime, and also frequently deliver patches containing "fixes" which break more than they fix.
(FWIW I've stopped PUBG and moved on to Elite:Dangerous, aka space truckers, thanks to it being recommended in an HN thread. Fun game, if you enjoy the solitude of loneliness of endless space! ;)