This is such a natural use case for IPFS that commercial adoption seems inevitable; as first mover you can offer the concierge edition and optionally gain a ton of credibility by open sourcing some of the core bits!
It sounds like your marketing will need to explain:
1. How updates work and how you guarantee staying universes away from NSFW/illegal content -- answered separately because nobody wants to find out what IPFS is infamous for as a part of discovering your service. (Both explanations need to function at two levels: one for techies and one for their bosses controlling the purse strings.) This may be possible to pull in quickly from existing CC-licensed documentation.
2. How users can link to content through multiple redundant WWW gateways/other services, and how to pay (you and others) for more reliability. Reliable reachability is absolutely key here, and should be built on multiple existing 3rd parties that are already used as status pages. For example: pay extra to whitelabel an auto-Twitter retweet bot.
Opportunity to be the "enterprise IPFS contact" here - explain from soup to nuts how to push status updates from anywhere (setup and simplified through your service but without requiring it be reachable) with any of multiple Yubikey/hardware auth tokens.
--
Consider a completely separate marketing push/landing page that doesn't even mention IPFS until potential customers ask how it works. IPFS is a buzzword here but commercial customers probably count it as a negative (analogy: ICO on HN). Focus on the unique features IPFS offers and write up how those features solve the status page problem!
It was used in Spain to host illegal websites organizing Catalonian independence. But yeah, its not a great pick for illegal activities against technically competent governments.
You have it somewhat backwards -- they wanted to get the word out, and the government had been suppressing discussion actively. They used IPFS to circumvent that.
All content received is automagically re-distributed by default, correct? It is similar to BitTorrent in this regard; very different from the more common client/server paradigm.
I will have to do a bit more research to see how the default clients handle caching popular, unrequested content.
No, if you run ipfs, you only host what you choose to host and things that you have recently requested. Your node doesn't passively accept content from others to host. (Otherwise, a joker would probably saturate the entire network's hosting capacity with /dev/urandom, or everyone would saturate the network's hosting capacity with their own encrypted backups, etc.)
I think there must be something wrong with the way ipfs presents itself, because I see this misconception (that just running ipfs causes you to host anything) often.
It's likely due to people thinking that "distributed" means "distributed by default". IPFS needs to gear it's docs to make people think in terms of Bittorrent (i.e. pinning, seeding, etc) and not in terms of RAID (i.e. sharding, high availability).
Oh, I just realized I missed the word "received" in your first sentence! I don't have much to add to how you actually worded the sentence.
I think the automatic re-sharing of recently requested content is only for a short time period (elsewhere someone mentions 30 minutes). Probably not anything anyone should rely much on; it just sounds like a bonus to maybe soften the blow a little bit if you get a lot of activity suddenly.
Yeah, it will eventually support having blacklists. So if you get a cease-and-desist letter, you can simply blacklist the offending content. It doesn't completely solve the issue, but it should help mitigate getting into legal trouble with it.
For anonymous content, you'd probably have to handle the encryption/decryption yourself and use IPFS as the distribution.
It supports blacklists now too. The bigger mitigation is that IPFS is a "push" and not a "pull" system, so you only store content you have explicitly requested.
Yep, and even the content you've explicitly accessed, it's garbage collected unless you pin it. So that helps further mitigate the issue, in case you mistakenly stumble upon undesirable content.
Depends on target market, so ideally non-technical perception (enterprise budget). There is probably still time to do effective marketing that conveniently doesn't emphasize it but discreetly assuages any concerns.
However, I am hard pressed to find any sizable HN discussion that doesn't mention it? It's basically worrying about what shows up as downsides when Googling, since most potential customers are starting from zero.
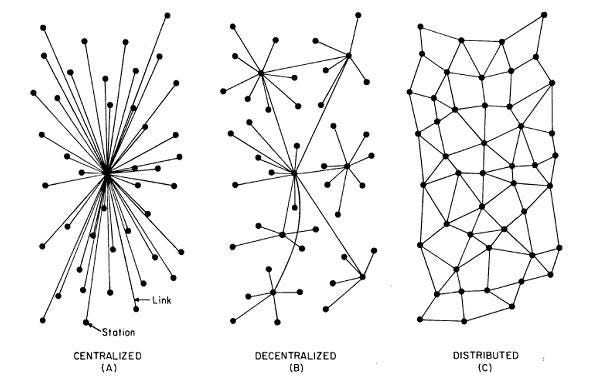
Well, I think it's showing a decentralized network, not centralized. Maybe closer to federated, who knows, it's not clear. It's for sure not distributed though, while IPFS is a distributed file system.
If the graph contained at least one other link between the nodes than via the center one, it would make it more clear.
I'm not sure this is actually Decentralized. I have been playing with IPFS quite a bit recently, and this looks to host the content on one node. That node goes away, your content goes away. You need more than one nodes 'pinning' the same content in order to actually be decentralized, and as far as I can tell this project doesn't provide that functionality.
That has been my biggest drawback so far with IPFS, there isn't really an easy way to get other nodes to pin the correct content, without passing around big nasty hashes (e.g., QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG) by hand.
The Dat project, which is somewhat similar to IPFS, and the people behind Beaker have addressed these things. So you can have a site like dat://9900f9aad4d6e79e0beb1c46333852b99829e4dfcdfa9b690eeeab3c367c1b9a/ or you can access the same thing as dat://fritter.hashbase.io using DNS-over-HTTPS for Dat (which is a mouthful, so I've been calling it DSN [Dat Short Names] instead). TTL is controlled by the publisher, just like with DNS. The main downside with the current incarnation is that while the content network itself is decentralized, short name resolution is not, since it's bootstrapped from the traditional DNS/HTTPS infrastructure for now. Which means the short name works only so long as the publisher continues responding.
Beaker is a web browser for Dat sites. The 0.8 release is supposed to happen sometime in the next month, I think. The same team set up hashbase.io to make it trivial to create a short name for a Dat site, and so that you can have Hashbase act as a fallback superpeer/permaseed for your content.
If I understand it correctly, it is decentralized. When pages are accessed they are automatically copied and hosted by nodes. Eventually, garbage collection will delete the copy. Pinning prevents it from being deleted so that the node hosts it permanently.
As far as I'm aware the 'automatic copying and hosting' currently lasts for around 30 minutes. You need to manually pin anything you want to live for longer than a day for sure.
Additionally, this project utilizes IPNS, which clears it's DHT of entries that haven't refreshed within the past 24 hours. So you DEFINITELY need at least one node online, pretty much always, for this content to load.
One of the main problems while I was researching about status page services and saw many having the same doubts here was about where to deploy the status page. Besides this market has a lot of players even the biggest one had problem when the big S3 outage happened last year (see ref-1).
What about do not depend on a centralized infrastructure to deploy you status page and kept always alive?
This project aims to deploy you status page on a decentralized infrastructure IPFS (see ref-2), after installed it, you will be running a status page service on top of a local IPFS node. So you’ll be able to to publish you status pages on IPFS while being part of the network.
I thought this use case fits perfect on a decentralized environment.
You can deploy this service on a VPS for 1/4 of the price you pay for your current status page service provider.
See an example of a status page deployed using D StatusPage:
IPFS nodes don't really rehost content for any substantial period of time (especially the gateway) so you're still stuck with some major problems:
1. You're still hosting off your IPFS node. This isn't worse, but it isn't better. You need to have a node and it needs to have connectivity.
2. IPNS resolution is glacial and it's a known issue without resolution currently. So any gateway trying to resolve your current version of the IPFS-hosted status page through a gateway using IPNS can often end up waiting seconds (sometimes even tens of seconds) for name resolution, giving the impression of a downed status page.
Sadly, IPFS is more of a decentralized presentation and perhaps caching framework. It doesn't really achieve the goal of decentralized storage until there is some reliable way to persist the data on the network beyond immediate use. Pinning services exist, but most seem quite expensive to me.
1. They're hoping that FileCoin will resolve that issue. Akin to Storj and Siacoin, people will offer to host (aka pin) content on their IPFS gateway node in return for FileCoins, and the market will decide the price.
2. In the meantime, you can set up a script to update your DNS TXT record to point to the most recent IPFS hash. I've got a static site generator that does this upon the completion of a build.
It's really too bad that anyone still thinks FileCoin is not a deeply flawed (if not outright scammy) endeavor. The only reason it isn't more widely decried is that the IPFS folks have a lot of goodwill in the community.
But it's a bad coin.
As for your #2, I don't use this solution because of propagation times. Instead, I use an nginx proxy that rewrites incoming requests on a specific path to root on IPFS node. When I rebuild, I rebuild that site config there.
But tbh, I'm going to undo that. I get absolutely nothing for being part of IPFS and there's effectively no reason to host content there. It's a DHT and while that's cool, it's actually substantially less efficient than alternatives.
I've been enthusiastic about IPFS because it's a neat white paper, but after using it for months I've concluded it's a tech demo with no real direction to go other than a deeply flawed cryptocurrency.
If I understand correctly, you still need a gateway VPS to proxy the ipfs site out to the internet over http. Isn't this a single point of failure, as your gateway server will be pegged. Or am I misunderstanding the implementation? You could have a VPS in multiple regions, but we're back at square one.
There is at least two ways of fixing this. First one is that browsers implements IPFS, and reshares the website when you visit it.
Second would be for paulogr to include js-ipfs in the webpage, so when users visits the page, they also reshare the website (if there is enough resources/not on battery/$other_criteria). Users would send the data for the website in-between them, just verify the data's signature.
Sounds like IPFS needs more ubiquity before this is something you can rely on. I know IPFS support is coming to Firefox soon, but I suspect it's much further off for other browsers.
Not exactly, as far as I understand it; you still need to manually install an addon, it's just that the addon can now handle ipfs:// links when you click on them.
Anybody can gateway the entire IPFS network, so not really. The officially maintained gateway is just one gateway. If you don’t want to rely on it, can run your own.
I'm brand new to the IPFS concept, this looks really cool!
I was surprised to see that the page served via IPFS supports HTTPS, do you happen to know how the secret key is securely shared among nodes in the decentralized environment?
The https version is served thru a proxy. This is the way you can get your status page visible to the HTTP world. The gotcha is that anyone on the IPFS network could have a copy of your page and serve them in your behalf.
> anyone on the IPFS network could have a copy of your page
Yes, but critically they can't modify it thanks to content addressing [0].
> and serve them in your behalf.
Yes, over IPFS. So anyone with an IPFS client will have a robust way to view your status page. If people want to view it via HTTPS, they hit ipfs.io, which is an IPFS/HTTP gateway. While it's possible for other people to run gateways, I believe ipfs.io is the main one. It could theoretically be a bottleneck.
IPFS has a so called IPNS system that use mutable hashes. So when you publish using this piece of software you got always a permanent link to share with your users.
IPNS has a huge flaw, as I understand it - there is no way to prove, as a consumer of an IPNS name, that you’ve got the latest data. A malicious node in the network could present you with outdated information and you’d have no way to tell.
You can't prove that you got the absolute latest data (same with DNS by the way) as it's being distributed. However, a malicious node in the network can't present you with outdated information or false information, as the IPNS record is signed with the key from the peer.
If the IPNS record wasn't signed, it would indeed be a huge flaw as it wouldn't be tied to a key from a peer. That would defeat the entire purpose of IPNS. Luckily, we don't have that flaw in IPNS :)
> However, a malicious node in the network can't present you with outdated information or false information, as the IPNS record is signed with the key from the peer.
False information - no. Outdated information - why not? What you've described in this comment doesn't solve it. If I signed that the name N points at hash H1 yesterday, and then signed that the name N points at hash H2 today, why can a malicious node not simply keep telling people asking for N that it points at H1?
Do IPNS signatures expire in a similar way to DNSSEC signatures? (Some poking around github says "maybe".) If so, does the owner of the IPNS name have to regularly connect to the network to refresh them? This would suggest that IPNS records can very easily disappear with no way to reinstate them, even if other nodes are keeping the data they point to up. Is this documented somewhere? Can I set a much shorter expiration time (e.g. 5 minutes for quickly-updating information)?
IPNS records have an optional and user-configurable expiry time, but more importantly, they contain a sequence counter.
So unless an attacker can completely disconnect you from everybody else who's interested in a particular IPNS address (and in that case you're lost anyway), they can't hoodwink you into going back to an old version.
I see. So if they can disconnect you from everybody else (for example, if they control the internet connection you're connected to), you have no way of telling whether they're replaying IPNS records to you.
The traditional internet solves the problem of not being able to trust your internet connection (say, in a coffee shop) with public key infrastructure so that the most a rogue internet provider can do is DoS you (they can't get a certificate for google.com and TLS is protected against replay attacks), so this sounds like a downgrade in actual security.
I think it's a bit unfair to pretend that TLS replay would be the same as having a not entirely updated IPNS record. The threat models are very different.
The corresponding attack against IPNS would be if the attacker could make your perspective of the world go backwards, and that is prevented by the sequence number.
Indeed, but TLS doesn't have the problem of replay at all (we hope), so IPNS is by design susceptible to a threat that the traditional internet is not in the case that your connection is untrusted.
But since the content can include timing and date information, it's pretty straightforward to work around this. IPFS bridges to HTTP, but is fundamentally a very different protocol that gives very different guarantees. Application developers need to recognize and mitigate these.
Being able to recognise the protocol's limitations and guarantees depends on those limitations and guarantees, as well as best practices for developing applications using the protocol, being openly documented.
Indeed I am - can you find me a document which describes whether IPNS is or is not currently vulnerable to replay attacks, in which scenarios its assumptions are broken, and/or best practices for handling any shortcomings of IPNS?
This isn't even a well-formed question: IPNS clearly documents what it does do. It provides superior guarantees to cached HTTP.
What's more, calling a node fault in a distributed quorum a "replay attack" suggests that application logic is hosted on IPFS. Since it is not and cannot be and redundancy is ultimately the responsibility of the storing agent, this seems like at best a misapplication of the term and at worst a disingenuous scare attempt.
In either event; IPNS is still considered a second tier, less complete that other "beta" parts of the protocol. It's not as experimental as pubflood, but less reliable than pinning.
It's all a moot point anyways, since IPNS is so slow as to be unusable in all but the least interesting cases anyways.
There is no clear specification of IPNS in the specs repo, never mind documentation in any of the repos I browsed. So no, it doesn't document anything useful to a user or application developer interested in knowing what they have to watch out for, including malicious nodes presenting outdated information.
While replay attack might not be exactly the correct terminology (although I think it is), the result is that you cannot trust any information pointed to by an IPNS record to be up to date. There's fairly trivial attacks I can think of that revolve around this - for example, if a git repository is hosted in IPFS with an IPNS record linking to it, you might actually get an older version of the code with known security flaws. This just isn't something you think about if you were using a more traditionally hosted git repository hosted on a trusted developer's server (or someone they trust, etc).
> This just isn't something you think about if you were using a more traditionally hosted git repository hosted on a trusted developer's server (or someone they trust, etc).
You don't until github accidentally rolls back your content, which they have done.
Unlike the github scenario, particularly popular content will have more than 1 node relaying it so you can form a consensus. It's also the case that only 1 value can be at consensus in the GHT at any given time, so the proper content node is verifiable from many content sources.
Now, do the clients DO this? No. They don't.
But in general this is so far down the list of IPNS concerns as to read odd. They have bigger fixes to make besides concerns about highly visible attacks like this.
Not if the page itself contains the time it was last updated (IMO all status pages should have this, IPFS or not). Then you could still get outdated information, but you'd be able to tell.
Procedurally; since updating IPNS records is free it's pretty straightforward to continuously deploy a tree.
What's obnoxious about that is that existing IPFS daemons aren't really good at managing multiple identities so if you have multiple trees to maintain you're left writing custom software or using docker containers.
The latest would be a link like /ipns/yourcompany.com, and you'd have a TXT record pointing at your node's IPNS hash (or an IPFS content hash directly) and you update it by either updating what your node's IPNS hash points to, or by editing the DNS record to point to the latest IPFS content hash.
No, if you put an IPNS hash in the TXT record you just update your IPFS node.
If you put an IPFS hash in the TXT record then you need to update that every time. I personally do this (domain name jes.xxx) because it means you don't need to leave your IPFS node running constantly in order for your IPNS name to be resolvable.
The record is:
jes.xxx. 300 IN TXT "dnslink=Qme12vJPtMpeUwmG2NLG11Q47jy2unSonegNJxQb9QgYax"
And I have a small shell script to update it automatically.
I believe that's what the previous poster means, you get a namespace that points to the canonical version of your resource, whatever that may be. Kind of like how HEAD is an alias for the latest SHA on a branch in git. But I don't know, this is just how I understood the previous comment.
One thing I'm missing (or misunderstanding) about IPFS is updates.
In a centralized system, like HTTP, a site has a single address: something.example.com. Any new entry (e.g. blog post) I create gets its own entry address, but is also referenced from the main site address.
As far as I understand, IPFS contains static copies of documents, so any document that would be the "front" page would have to be copied before updating with new entries, and would receive a new address.
How to let readers know that a new entry is available then? Would there need to be a centralized place referencing all existing entries?
It's a DNS-like system, though much slower than DNS due to propagation delays. It points to the latest version (hash) of a document, much like a git branch.
Being slow is kinda a deal breaker for a status page, isn’t it? The whole point is to notify your customers of an issue, and you need to do that fast. Most issues are only going to last a few minutes anyway, so any delay in update makes the whole thing pretty moot.
There's a PubSub implementation for IPFS that can provide support for dynamic content in this case. I'm pretty sure there is another way to provide fast updates through some indirection mechanism though.
The slowness of IPNS is something we're actively working on. Currently we have fixed so resolutions are faster after the first lookup, by using the libp2p feature pubsub. It being faster/slower than DNS depends on your case, but if you're close to the next node, it'll probably be faster. If you're offline, DNS won't work at all :) We also have more fixes for IPNS in general that will come soon.
Now if my service is screwed up enough that I can't host my own status page or easily find another service to host my status page - like all of Amazon's infrastructure or the entire east coast fiber network or something like that is down - I can see where IPNS would be useful for hosting. But since standard DNS is already distributed, why can't I continue using that to do name resolution? Why does IPFS need its own reimplementation of DNS?
(I ask this as someone very unfamiliar with IPFS, so please forgive if this is a stupid question.)
I've been trying to get into IPFS recently. One thing I can't wrap my head around is that IPNS only seems to persist for about 12 hours and then stops working.
It seems to defeat the purpose of a truely distributed name system, as my computer that needs to keep republishing the name becomes a critical part of the system?
Am I missing something or are there plans to resolve this in the future?
Not a network person by any means, but I think that this points out to what I think is the fatal flaw of IPFS: the apparent "one-wayness" of addresses to content.
Yes, I know that is supposed to be its main feature, but (again, naïvely speaking) it seems to induce a huge, possibly even intractable overhead... Think of, say, programming in C without being allowed to ever rewrite memory contents, or change what a pointer points to!
Again, not an expert; and I'm sure with all the money they raised, people with actual technical expertise in network protocols are hard at work on this and can vouch for the design... But I'm curious anyway how this is not an obvious dealbrealer, given the extreme latency requirements in networking..
I am a happy IPFS user, and it seems that it has more traction than DAT. But on the other hand, the Beaker Browser project (which is based on DAT) is very interesting, and doesn't seem to have an equivalent in IPFS. I'm also worried that the IPFS team might get distracted by Filecoin and not invest seriously in the IPFS ecosystem beyond what Filecoin needs.
Naive question: if data on IPFS is permanent, meaning it's hard or impossible to remove things from it, what mechanisms, if any, exists to prevent unlawful content from being uploaded to it?
As far as I understand it, proxying it is dangerous because IPFS will announce all your IPs so that the shortest routes can be established. You probably need to run it in a VM/container that only has access to Tor and no other network adapter.
Thanks! We're hard at work making everything better, especially the documentation and examples bit, but lots of work on the APIs as well.
If you have anything concrete to suggest or help out with, please open up a issue in the relevant repository, this would be the entrypoint to find your way around in our Github organization: https://github.com/ipfs/ipfs
You don't really upload things to IPFS, since it works like Bittorrent: you make files available by adding them, but that doesn't copy those files anywhere. They're only transferred via the network to clients that specifically request them, which makes this a non-issue.
Could you elaborate on why Filecoin is a different issue? Is it because I have to specifically download (or allow others to upload to me) the files so I can host them?
With FileCoin (the IPFS-related ICO with no implementation), the idea is that you're offering your storage space to others in exchange for a fee. So somebody could use your system to store, say, child porn.
With plain IPFS that cannot happen, because you're only downloading what you're interested in. That's what I meant when I wrote that IPFS is like Bittorrent.
I would hope that safe harbor laws would protect you in a case like that, similar to how Amazon doesn't get busted if one of their customers uses AWS to store illegal material.
Decentralized is the new buzzword in the crypto community and it is used everywhere to justify everything. I lost count how many times people were trying to sell me ideas with "its decentralized, you get it???". I am getting more and more resilient to take anything seriously that is solved with this. For me S3 is a perfect storage and with Cloudfront is decentralized enough for my use cases. As far as I am concerned a node that is not under AWS or my control is not the definition of decentralized it just means that you have less control over a distributed object store that has worse access patterns than for example S3. Bandwidth is one of the problems. If a typical IPFS node is a home computer than it has 10x upload speed compare to the download speed. This is going to limit how somebody can access content from IPFS. And so on. These access patterns are pretty relevant when you are hosting something other than backups on such a system.
> Bandwidth is one of the problems. If a typical IPFS node is a home computer than it has 10x upload speed compare to the download speed. This is going to limit how somebody can access content from IPFS.
This can easily be addressed by choosing hosts which have gigabit upload links if you are hosting high demand files. Personal computer backups may opt for hosts with 10mbit upload that offer much cheaper storage. It may not be possible to do so atm, but eventually the platforms will get there. It's still very early and most distributed storage technologies are nowhere near complete.
The URI on the footer of the status page points to here: https://www.statuspage.co - but it doesn't appear to load, is this an artifact from development?
I mean, your status page itself may be on ipfs but since ipfs isn’t natively supported as a browser protocol, your “decentralization” fails since you’ll likely need to host the http <—-> ipfs gateway somewhere. Might as well stick your status page on a couple of vps (literally just two on two different continents) and round robin them.
The gotcha there is that you can use multiple gateways to access you page. So you are right, you need to have a http <--> ipfs but you can have many of then and anyone hosting an IPFS node can have a copy of your page and serve it.
Speaking of which, what's up with the Twitter frame on the status page? I keep getting HN errors quite regularly, but the Twitter bot reports that the most recent failure happened two years ago...
Big fan of IPFS here, but silly question, isn't a status page suppose to have realtime updates of whether a service is online or not? This doesn't seem like a good fit unless you're using some realtime CRDT adapter on top like they list here https://github.com/ipfs/research-CRDT/blob/master/Readme.MD (disclaimer: I'm the author of https://github.com/amark/gun, which is one of the listed options). The StatusPage link is sparse on info, anybody know how it works underneath? Sorry if I'm confused on how status pages are supposed to work, can it really be static if it is supposed to be reporting services uptime liveliness (and thus requires some type of realtime monitoring)??
Really great ones show that all services are up, and often have timing information, graphs, or metrics, etc. An example of this would be https://status.bitbucket.org/
More basic status-sites generally only show useful detail(s) if something is currently broken, and perhaps will show you a summary of recent problems over the past few days. An example of that would be https://status.github.com/messages
(I wrote a simple status-page for my own site, but I elected to go the simple route. I do monitor availability and response-time(s) of various parts of the service, but I only update the site when there are problems, manually. This works for me because problems are rare, and my site is small.)
So... This still seems problematic though - if you manually update it, then the hash of the page is going to change, and then you'd need to retrieve a different IPFS item than the original status page. And so on... No? This just seems like an odd loop.
When I manually update my site, that just means I add a file to the git-repository with today's date. Once I commit and push that a Makefile rebuilds my (static) site.
I don't personally use IPFS, but I imagine if I did then I'd have a script to change DNS, or update the hash IPFS uses. I see from other replies that updating the "most recent" version of a site is simple enough that it shouldn't be a problem in practice.
Apologizes for blockchaining every comment, but one of the cryptocurrencies I'm interested in, from a tech perspective, is doing something similar. It lets you host your website on IPFS as well.
{kind=link}
{kind=link}
It sounds like your marketing will need to explain:
1. How updates work and how you guarantee staying universes away from NSFW/illegal content -- answered separately because nobody wants to find out what IPFS is infamous for as a part of discovering your service. (Both explanations need to function at two levels: one for techies and one for their bosses controlling the purse strings.) This may be possible to pull in quickly from existing CC-licensed documentation.
2. How users can link to content through multiple redundant WWW gateways/other services, and how to pay (you and others) for more reliability. Reliable reachability is absolutely key here, and should be built on multiple existing 3rd parties that are already used as status pages. For example: pay extra to whitelabel an auto-Twitter retweet bot.
Opportunity to be the "enterprise IPFS contact" here - explain from soup to nuts how to push status updates from anywhere (setup and simplified through your service but without requiring it be reachable) with any of multiple Yubikey/hardware auth tokens.
--
Consider a completely separate marketing push/landing page that doesn't even mention IPFS until potential customers ask how it works. IPFS is a buzzword here but commercial customers probably count it as a negative (analogy: ICO on HN). Focus on the unique features IPFS offers and write up how those features solve the status page problem!