The 7740X retaining dominance in browser-oriented tests demonstrates the continued bottleneck we suffer due to the "single-threaded" (or nominally single-threaded) predilection of web browsers, the DOM, and JavaScript. Servo and other concurrency-oriented innovations are going to be very welcome when they arrive in earnest.
I don't understand why anyone would design a website so complex that there is a noticeable benchmark difference between $100 processors and $1000 processors.
They wouldn't, but they do. Frameworks upon frameworks upon frameworks, and nobody knows what happens underneath. If you are a gmail.com user, have you ever tried the plain HTML version? The difference in speed is mind-boggling. Yes, the Javascript version is doing more, but it should also be able to be faster as it doesn't have to load the whole page each time.
Fun anecdote: I tried using newegg.com to build a PC based on these new processors. My 2 year old Macbook Pro almost melted, with only about 6-7 tabs (all pointing to different parts on newegg.com) open. This is kind of ironic: you need a really powerful PC to use a web site which sells powerful PCs. Catch-22.
No. I do not want a web page to be able to eat up more than one core. Frankly, I feel like I want to try a browser extension that "locks" any web page within 20% of a core performance.
These developments make me believe that browser-based apps, that were "around the corner" 10 years ago, is a lost cause. Despite numerous optimizations done to Javascript engines and despite tremendous performance of modern CPUs, browser-based apps continue to crawl at a speed of early IBM PCs of the 80s. Even a 286 circa 1992 running DOS apps felt faster than newegg.com in 2017 on a modern Intel i7.
Sure its tempting to blame "lazy programmers" and bloated frameworks, but bad engineering, tight schedules and tech debut have always existed, for all platforms, all the time. There's just something fundamentally broken about apps built on asynchronous loading of dozens of UI components from a remote location and assembling them into a coherent UI screen as the pieces arrive.
Similarly: running with e.g. noscript reminds you that internet speeds actually have improved over the years. Pages load in instants rather than seconds, it's wonderful.
The view that web apps can only be for simple things is a dated perspective, but also probably a symptom of the fact that it's not really possible to take full advantage of many CPU cores in a web application.
An in-browser photo editor or 3D modeling software would be expected to run much better and apply complex effects or render models much faster on high-end hardware. It sort of works this way with WebGL content, but even there you're limited to feeding the render pipeline with a single thread.
I want the web as a platform to succeed. It is the only truly universal runtime and with some care it could offer very few performance trade-offs. I sincerely hope tools like servo and others unlock this potential.
From first principles, one shouldn't expect the menus or other simple rendered parts (things not involving backend traffic) of a user interface to have any perceptible lag on a sub-100 processor, be it an application for web, mobile or desktop. Most likely they shouldn't involve millions of computations or hundreds of megabytes of memory reads.
But looking from the other end, somehow they definitely do. And we're probably wasting trillions on this problem. Wasted time, wasted electricity, wasted batteries, wasted computers and phones.
I think the web should succeed as a platform for so-called "content", but I don't see why the web ought to be best for progams or applications. I still hold the "dated" belief that native is better.
The "universal runtime" idea doesn't make sense to me, it's just a single language (javascript) that everyone implements bad, competing interpreters for on different platforms. I don't see why this has to be the only or best way to distribute cross-platform applications.
Granted, web apps can be used for complex software. Maybe someday soon we'll install an Electron runtime and install the software to run on it, and it'll be good enough for most things, doubly so moving forward into webassembly.
> An in-browser photo editor or 3D modeling software would be expected to run much better and apply complex effects or render models much faster on high-end hardware.
Servo is a layout engine but the benchmarks are mostly testing javascript performance. Extra cpu cores are not going to speed up JS benchmarks, not because JS is single-threaded but because the benchmarks themselves have to be designed to test multiple threads. The same would be true if the benchmarks were written in C, if you want to test multithreading you have to write code to do it. Javascript benchmarks could test multithreading via Web Workers but for whatever reasons they don't seem to.
browser benchmarks could test more than javascript execution. dom layout, canvas rendering, scrolling etc.
Some of those things can benefit from multiple threads even if JS is single-threaded.
Allocation-heavy workloads will also benefit from concurrent and parallel GC implementations.
> Javascript benchmarks could test multithreading via Web Workers but for whatever reasons they don't seem to.
Well, like I said, JavaScript has a long history and therefore a predilection for single-threading. Yes, you could write tests that exercise Web Workers, but Web Workers are still infrequently used in the wild, let alone in benchmarking suites. I've used Web Workers in a few projects and I'm underwhelmed by their current features. I can't really blame the JavaScript community at large for not using them much yet.
The DOM and other elements of browsers also have single-threaded assumptions or behaviors.
More multi-threaded capability is a first step, and then we'll need to take advantage of that capability.
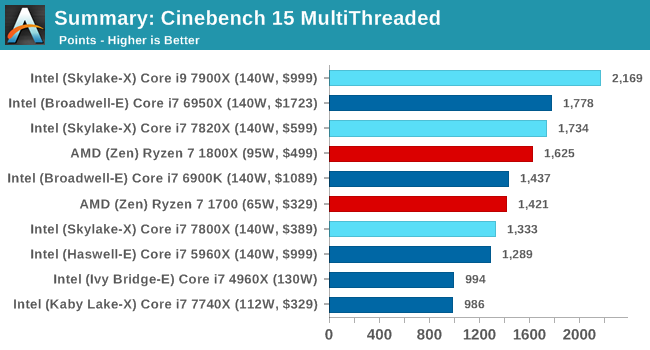
TL;DR: Intel is having hard time to keep up against AMD. It reminds me the Pentium 4 era, when Intel had to push clock and power consumption to crazy levels [1]
It's a pretty natural consequence of how much crap Intel piled in on this release. Cache, mesh, and AVX512 all consume a great deal of power.
Contrary to what the sibling comment says, Ryzen is nowhere near Intel's performance here. Even in very parallel tasks like x264 video encoding, the 7800K (6-cores) is beating the highest-clocked 8C Ryzens by almost 6%. Comparing apples to apples, the 7820X (8C) is 33% faster than the 1800X.
That's a very good place for Intel to be overall, even if their power consumption is higher than I'd like to see. Downclocked Xeons will probably beat Ryzen's efficiency. And there may be some UEFI/microcode gains to be made here as well, both in efficiency and total performance.
The bigger problem (for the enthusiast market) is the thermals. Intel just switched from solder to TIM on the HEDT processors and it's very clear that they cannot move heat out of the package fast enough and it's limiting the total OC, which would likely reach 5 GHz a good chunk of the time.
33% faster encoding x264, at what price? Ryzen 7 1800X: $499, Core i7-7820X: $599 (+20% over Ryzen). You can also cherry-pick tests where the Ryzen gets better performance or better performance/price, and not just tests involving AVX usage. Also, in cheaper Ryzen's the performance/price gets abysmal in favor of AMD. BTW, you can compare also a $599 GPU performance encoding x264 versus that Intel CPU and see how "fast" are Intel CPUs in comparison.
No, when I encode my vidya sessions for archival I use 1440p variable-fps (60fps) NVENC H264 for the first pass at an absurd bitrate (40mbps) and then I use x264 variable-fps veryslow CRF 24 for the archival pass.
veryslow is where the magic happens. As far as I can tell that's where you start getting decent quality/compression. If I increase CRF any higher (decrease quality) then shit gets super blocky super fast. Unfortunately I haven't found a way to crush high-quality streams like that in remotely realtime, you need to record 1440p (and dump an archival stream to disk) and then transcode to 1080p since that's doable.
We haven't seen AMD HEDT yet, so comparing the 7820X to the 1800X is not apples to apples. (For starters, the former has twice the memory channels compared to the latter).
The[1] biggest take away to me in the review. The AMD at 95W was within striking distance of the 140W Intel part. Then a 65W snuck above a 140W part. Yes TDP is measured differently, etc. But still interesting.
In the meantime, the 6 core Broadwell-E I7-6850K has seen a big price drop - down from $650 to $480 on several sites. It's still expensive compared to the Kaby Lake I7-7700K, but if you wanted two more cores then it's now a much more reasonable option. People seem to have very good results overclocking it, too.
Edit: Having just seen that the i7-7800X is priced at $389, I'm thinking the I7-6850K is still overpriced, unless you need 40 PCI-E lanes.
I looked into this and was going to buy a Ryzen or wait for the Threadripper for a huge multicore video transcoding server we run, in an attempt to source parts for an upgrade for our last-gen i7 platform. Unfortunately Ryzen's performance in ffmpeg is dismal, relating to its poor AVX performance, it seems.
I've seen comments on their platform being "poor" due to software not tuning for the platform specifically, which is definitely possible. But unfortunately I can't bank on that for now, so we had to stay with Intel for our batch transcoding processes. Still very excited to monitor this product line; it's been a long time coming.
That Phoronix FFmpeg test clearly measures 2 - 4 threaded speed only, so Intel's fast quad core CPUs shine there. The test description is "H.264 HD to NTSC DV" where the main bottleneck is slow H.264 decoding (CABAC decoding is somewhat difficult to parallelize).
You should look for x264 (H.264/AVC encoding) or x265 (H.265/HEVC encoding) tests. HandBrake is often used as a frontend for these, so the test may be named Handbrake H.264 HQ encoding or something like that.
x265 benefits a bit more from Intel's faster AVX instructions, but Ryzen (or Threadripper/Epyc) is still a very valid choice for high quality HEVC encoding. The GPU alternative would be Intel Skylake's GPU-accelerated encoder through Media Server Studio, which has scored well in MSU's test: http://compression.ru/video/codec_comparison/hevc_2016/
As for H.264 encoding, there are no GPU encoders that could approach x264 quality.
Great post. I can tell you my benchmarks using GPUs and various platforms didn't favor x264 encoding, as you also noted.
>x265 (H.265/HEVC encoding)
Not something our services can reasonably support or use currently, so even if true, Ryzen/Threadripper is still probably not something we can go with.
I look forward to switching in 2-3 years when we re-visit this conversation, or adopting it for other services soon. I'm very excited for AMD's competition and fully willing to switch; I just haven't seen the evidence that supports that it would be a good idea for our particular use case.
Please also note that there is a new x264 version that supports AVX512 in nightly as of a few weeks ago.
It may not have made it down the pipe to everyone's package managers yet but it's out there and should improve performance on Skylake-X and related Xeons.
Curious - why are you doing video transcoding on CPUs?
The CPU to GPU speedup is so massive that it's really not worth it. I don't recall the exact numbers, but I got an order of magnitude boost going from HEVC encoding on CPU to GPU with no noticeable quality difference. Works out to several times more efficient too FPS/watt wise.
As I understand it, video encoding continues to perform worse on GPUs. Hardware H.264 video encoding is comparable in quality and speed to the x264 "ultrafast" preset, with the only benefit being lower power consumption. More importantly, hardware encoding is incapable of producing higher-quality output, comparable to software encoders' higher presets.
It actually looks quite good in my experience. Definitely better than the "ultrafast" preset on CPU encoding.
I use CRF though mostly for GPU encoding which should remedy the issue at the possible cost of file size (didn't seem to be a significant increase, but was a slight one).
I'm also talking HEVC and not H.264 though primarily - and using NVENC not a CUDA based encoder as your link mentions. I've also seen it mentioned that things have improved a lot on the newer GPUs, so might be worth a try again if you've got a 10xx card around.
>The CPU to GPU speedup is so massive that it's really not worth it.
Not in my experience. Furthermore, there are a lot of errors (comparatively) that are introduced when GPUs are used at high speeds. Other comments have linked articles indicating why this can be the case.
I'm surprised at how well Ryzen is holding up in FP terms despite the relative lack of flops on paper. I guess having a separate floating point cluster is enough of an advantage to make up for that? It really makes me want to see how it works with robot motion planning at work.
Saw some test results on Chinese website claiming that once fully loaded the temp can jump to 100+ degrees when running at stock frequency without any form of overclocking.
These are the first Intel HEDT chips to not have a soldered heat-spreader. Instead they are using thermal paste between the chip and the heat-spreader. This is generally accepted to be bad practice since they use cheap paste and it's dependent on how the paste was spread on each chip. I also believe that Intel has basically said water cooling is a must for these chips.
Well anandtech already found that water cooling is simply insufficient to cool these for overclocking. You need an active thermal sink AKA a compressor cooler, and then you're still limited by the TIM-gunk; heat-spreader at 25 °C, core at 100 °C.
I suppose for the next generation Intel will announce that liquid nitrogen is basically required.
My 1700x build for video processing has suffered major instabilities -- app crashes and BSODs -- memory corruption type errors. I went through 4 different types of DDR4 memory until I found some that works, even though it isn't on the ASUS's Qualified Vendors List. My advice is to make sure your RAM can do 15-15-15-36 timings (or better).
This is why I'd rather lose 25% of the performance these days and take a canned pre-built PC. I just can't afford the time to find this out. It was bad enough trying to find a working set of drivers for my T440 and that only took an hour or so.
I lived through the age of self build K6's, Athlons, dual Celerons and SLI Voodoo 2's and heatsinks the size of a can of coke. I'd rather just have a shitty old thinkpad and a box in AWS now. This all happened when I realised a naff old Pentium III 1.4 GHz (Compaq AP230) was actually my goto machine despite having things 3-5x the speed.
I run a fair few high CPU/RAM simulations with LTspice as well for ref.
I ran all the usual suspects (memtest86 etc) for 24 hours after I built it, not had a single issue in 2 weeks under Linux (Fedora 25) though I've seen people having a lot of issues with various RAM configurations.
I went for 32GB of Corsair Vengeance over 2x16GB at a conservative timing (the newer beta bios for the mobo I have supports more memory options as was as clocking) since it's a machine at work.
I've also heard the same. I've made comments on this post about the issues and poor performance with transcoding (specifically ffmpeg benchmarks), which is unfortunately why I've had to stay away.
i7 7820X is the CPU is probably the best system price/performance overall in the long run right now. Threadripper might be competing it depending on what you do but we don't know about it yet. For software developers having over 50% lead in compilation performance compared to ryzen 7 1800X (nightly build of chromium on visual studio) should make it a good choice.
A) In system price there are many components and that
makes ultra cheap CPU:s in other vice identical configurations not so good price-performance.
B) Performance is really the performance differential from what you upgrade. And even more importantly the performance differential years from now to systems of that time, if you upgrade to a system that lasts 5 years before you upgrade or to a system that lasts 7 years before you upgrade is significant in terms of price/performance because later means you get the high performance early and price last longer.
C) Significantly higher single threaded performance compared to Ryzen 7 the main contender. There are still many tasks that are single threaded, especially if you run legacy code.
D) AVX-512 I doubt the review benchmarks are in AVX-512 but some legacy code. AVX-512 increases both width of vector and fraction of code and algorithms that can be parallerized significantly. Once compilers are well tuned to use AVX-512 the code compiled with AVX-512 optimizations turned on should be significantly faster than what it was before hand. Simply being able to do 8-16 times work per cycle in large variety of tasks is significant advantage even if that is for a good fraction of time instead of all the time.
Personally I7-920 has given me far better price-performance compared to people who bought dual core at the time simply because it has lasted LONGER so it had superior price/(time between CPU upgrades) measurement. Right now in that same measurement I7-7820X is the king.
So in conclusion I7-7820X is faster in both real legacy code and the future code, and gives good enough performance longer simply because code that you run when you would start considering upgrades run much faster on it simply because of extensions.
I wonder if it's linking the huge binaries at the end of the compile that makes all the difference, especially with the difference in L3 caches? I'd be surprised if the individual compile units were that much larger as to make a difference.
The chrome compile test doesn't like L3 victim caches. Ryzen does badly as a result. Clock for Clock the Skylake-SP cores do bad as well, but Skylake-X is well clocked with cores, so it's still top of the charts.
i7-7820x does 26 compiles per day, ryzen 1800x 16 compiles per day. The core count is the same, thread count the same. The performance difference can't be explained by frequency difference only.
Well, if you look at the power consumption and the price, they really aren't. The article compares Ryzen processors against Intel's high-core offerings, which makes sense in some ways but not in others.
This is something Intel has said for over 2 years now, AVX512 has several instruction sets under it.
CD is probably the biggest gamechanger since it now allows you to vectorize code that you couldn't before due to memory conflicts that arise from identical elements in the array.
But the difference between Skylake-EP/X and XeonPhi in relation to AVX-512 support were known way in advance.
> But the difference between Skylake-EP/X and XeonPhi in relation to AVX-512 support were known way in advance.
I don't think differences in specific instructions were known in advanced, at least at/ shortly after KNL launch. Or rather I was instructed not to mention it.
https://software.intel.com/en-us/articles/performance-tools-...
"The instruction groups common to both the Intel Xeon Phi processor x200 and the Intel Xeon processor are AVX-512F and AVX-512CD. The AVX-512ER and AVX-512PF groups are implemented in the Intel Xeon Phi processor x200 only. The AVX-512BW, AVX-512DQ and AVX-512VL groups are implemented only in the Intel Xeon processor."
https://software.intel.com/en-us/blogs/additional-avx-512-in... This used to lead to a PDF with the tables, the PDF is still there but it's a living document which is updated every time, the latest revision was in 2017 but as early as 2014 there was already a split into COMMON-AVX512, MIC-AVX512, CORE-AVX512 with a difference between future Xeon Phi and Xeon processors.
Looks like we're back to P4-style levels of power use. Not sure how I feel about consumer chips running 150 watts on the regular. That's a lot more carbon in the atmosphere for questionable reasons.
Incredibly, the 7900X is hitting 240 watts. When was the last time we had a chip that burned that much energy? Granted, its destined for the server room, but a 2U quad CPU box will be hitting 1000 watts on CPU usage alone at 100% utilization. That's close to a medium-sized window AC unit.
Yes, those TDPs made them dead on arrival for me. I moved to mini-ITX for my main system and won't be going back. There's no room in my case for any watercooling hardware. I run a Ryzen 7 1700 which is a 65W TDP 8 core, 16 thread CPU.
I was going to hold off for Intel's response, but I knew they wouldn't have anything with 8 cores that was anywhere near 65W TDP. CoffeeLake should offer lower TDPs, but with 6 cores max which seems unappealing compared to 8C.
I'm going to revisit Intel after they've had time to prepare a real response to Ryzen in ~2020 or so.
One of the best computer investments I've made, since getting my first SSD. Instead of a loud whine occasionally, I get a steady hum. I have a Silverstone SG13 case, which is about the size of a sneaker box, fit into that one without any issues.
I've built multiple mini ITX cases with WC, but in anycase AMD calculates TDP in a very different manner to Intel, they calculate the average sustained power draw over a period of time which includes throttling, Intel calculates it based on the maximum instantaneous power draw possible.
Intel has changed the power distribution design, it now has a linear voltage regulator on the CPU, it seems that some of the motherboards have issues with it.
The situation where delidding pays off is pretty frustrating. It costs me more to delid and replace the TIM then it does for Intel to charge more and do it right the first time.
Hopefully competitive pressure will get them to start taking their process more seriously.
Intel has changed the voltage regulation this time its back on the CPU.
Skylark-EP gets nowhere near those power draw levels even at similar clocks I have a strong suspension that this is a BIOS issue and the CPU voltage regulator is running full steam (this is equivalent of locking the phase frequency of your VRMs on the motherboard to the max).
I dont think that an additional 100W under load 20W idle is going to have a meaningful effect on global warming?
Lets imagine it spends 4 hours per day under load and 6 hours idle and the rest of the time sleeping. We are talking about 0.5 kwh or 15ish per month. The average us household uses by comparison around 900 kwh in the average month.
Upgrading to one of these will in that scenario increase your household energy budget 1.6%.
Those are only technically consumer chips; you're never going to see any computer without the word "workstation" on it running those chips from any OEM.
Those Base/Turbo numbers seem off 3.6 / 4.0 GHz (6 core) 3.3 / 4.3 GHz (8 core) while they both are 140W parts.
ED: looks like it's missing the favored core mode which is probably important for gaming. Which brings up an interesting question if CPU's are now going to last ~5 years, is buying a 500+$ CPU reasonable?
Intel treats TDP numbers as more of a vague classification than an actual indication of power consumption. "140W" is basically code for "tons of power".
In PCPerspectives i9-7900X review you can see it uses significantly more power than the i7-6950X despite them both ostensibly being 140W parts.
Thermal Design Power (TDP) should be used for processor thermal solution design targets. TDP is not the maximum power that the processor can dissipate. TDP is measured at maximum TCASE. TCASE is the temperature measured on the heat spreader over the CPU.
> No, Intel classifies TDP as the instantaneous maximum power draw
That's not correct. Both Intel's TDP and AMD's TDP are maximum-typical values, for different scenarios. Every processor can exceed it's TDP by a significant margin with some notorious applications.
> No, Intel classifies TDP as the instantaneous maximum power draw
Are you sure about that? I can't dig up the link at the moment, but I seem to recall some hardware hacker thread where people would regularly exceed the TDP of Intel chips by running SSE/AVX-heavy workloads like Prime95, and Intel's response was basically, "That's not a real workload, it doesn't count". Which is not an unreasonable answer, but it's definitely not defining TDP as the maximum possible power draw.
Intel isn't really circling the drain and their future woes are more likely to be caused by overall shrinking of the PC market, not by loss of market share to slower chips. As good as Ryzen is, it will probably only increase AMD's market share from 5% to 10% due to inertia and such.
Speaking of browsers, they aren't really a good benchmark for 6-10 core processors since anything is going to be fast enough. Also, existing JS can't really be parallelized so I suspect even a magical browser would still benefit from single-thread performance.
I've enjoyed some comments you've made elsewhere, and don't want you to run afoul of HN rules and culture. I believe that discussing the fact of the downvotes is strongly discouraged on HN.
Wow. From multiple sites releasing reviews it's clear that an embargo was just lifted.
And anandtech couldn't bother writing a proper article? Sentence after sentence just hard to read, with extra commas and just poor sentence structures. Did they not have time during the embargo?
{kind=link}
{kind=link}
{kind=link}