I like how the first three or so anti-patterns are in the exact opposite direction as the last three or so. The art of being a programmer is literally "don't waste time over-thinking things, but also don't ship under-thought trash". For all our fixation on simplistic and ease of use, programming is actually incredibly difficult and way more art than science.
And it's exactly this requirement of masterful manipulation of balance that makes me love this field so much and long to get better at it. Getting a handle on the artsy spirit of programming is really what separates the wheat from the chaff in terms of programmer skill. There is no formal programmer guild in real life, but if there was, and there was some sort of test a journey-man programmer must undergo in order to become a master programmer, it would be the test of being given a large project and then deciding correctly exactly how much technical debt to take on to be able to ship a product within a reasonable time-frame and yet have its internals not be complete unmanageable spaghetti.
They have some use as starting-points for discussion, but identifying when one (or which of a complementary pair) is appropriate requires good judgement, and the people who get dogmatic over these things are missing the point.
I think the fact that these sorts of argument feature so much in the discussion of software design and development indicates that there is some way to go before it becomes a fully-mature technical / engineering discipline.
It reminds me of the quip:
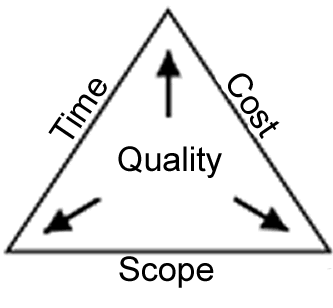
"I can deliver your project quickly, cheaply and of good quality - pick two".
That said, in my experience, clients tend to see software quality as the least important attribute of the three.
Yeah, I think it might be better to say "quickly, cheaply, or something that can be improved on in the future without starting again", because at least that way they're all at the same level.
It's the one attribute they can't see immediately. But they will see it eventually. When fixing critical bugs take months and their customers are breathing down their necks they will see software quality at work. It's our job to educate them about these risks since they have a delayed appearance.
I don't think "educating" clients about quality is worth the effort. Just deliver code to a quality you are happy with and tell them that it takes as long as it takes (giving them feedback as regularly as you are capable of, so they get a sense of progress).
Good clients will understand and bad clients will filter themselves out quicker (which is a blessing in disguise even if they do sometimes give you money).
I prefer to let cold, hard reality do the teaching.
I always tell them, "You can have what you want quickly or you can have what you want cheaply, if you insist on both, you won't be getting what you want."
The cheaply part puzzles me. If it takes X hours to build something, it doesn't matter if you work D hours per day for X/D days, or D/2 hours per day for 2X/D days -- it's the same amount of hours, therefore the same amount of money. The client will pay less per day, but the same amount overall. You could charge on a curve, i.e. 8hrs/day is X, but 10hrs/day is 2X, but we all know overtime doesn't work in the long run.
It seems to me, that that saying works for only the small set of tasks that can be worked on in consistent overtime. Can someone clarify?
you can cut corners by never refactoring and not thinking the design through thoroughly. In the long run this will actually cost you time but in the short run the customer gets something sooner. The problem is that the customer is usually unaware of the looming debt they are accumulating unless an engineer takes the time to explain it to them.
Though there is truth to that quip, not all the pairs of that triangle are equal. Its much easier to deliver quick and cheap, easier to deliver cheap and quality, and really hard to deliver quick and quality.
I wouldn't say it is more, but I see it is a balance of both. I think the "MongoDB is Web scale" video shows the worst side of treating it as an art, when there is a more engineering type approach you can take.
I've seen this a lot, and is often made worse by attaching a load of unnecessary baggage/repurposing to classes.
For example, I've worked on PHP projects which, over time, have gained coding standards like:
- All classes should be in separate files, named to match the class name
- All classes should be built from a PHPSpec specification
- All classes should have their own test class
- No class can instantiate another, unless it's a "Manager" class which does only that. Everything else is dependency injected.
- Test classes can only instantiate their associated class; everything else must be mocked
And so on.
Now, each of these has its merits, but as each new practice was added, it increased the 'fear of adding classes', even if just subconsciously. Refactoring to break up classes became less and less common, since a simple code change would require:
- Whole new test classes (OK)
- New files (seems a bit like Java-envy, but OK)
- Injecting new instances wherever the old class was used (seems a bit overkill...)
- Mocking the behaviour of the first class in tests for the second, and vice versa (this is getting a bit silly...)
- Creating 'Manager' classes to instantiate the new classes (hmm...)
- Creating new test classes for these managers (erm...)
- Mocking the dependencies of the managers...
In the end, it was just far easier to just throw all new logic into existing classes, which grew and grew.
I've worked on a codebase where objects inherited from a class named "Abstract" which contained, apparently, methods used in more than one class, regardless of purpose.
Other fun anti-pattern: make a Facade class hiding services. Then:
- add logic directly in your facade
- make the services using the facade depend themselves on the facade (circular dependencies FTW)
This an excellent way of ensuring your code will NOT be reused.
I always get a bit nervous when I see Knuth's quote about premature optimisation. While the points the author makes are valid, the fact that it gets bandied about as an out-of-context sound bite results in a lot of code getting written with a complete disregard for any optimisation whatsoever.
Another far more common antipattern that isn't mentioned here is premature abstraction. You see a lot of this in enterprise .NET codebases -- such as the widespread "best practice" to build ineffective and obstructive abstraction layers "just in case you might want to swap out Entity Framework for a web service."
I've heard about the same "ineffective and obstructive abstraction layers" in Java too and worked with the C++ code base where some development managers introduced such things, because "they're the managers, the must design with abstractions, the underlings can think about the details, and ho-ho, we certainly shouldn't be bothered to make something effective, don't prematurely optimize, everybody knows that, ha!"
So I consider it the effect of the"culture," "environment" and "organization" more than the particular language. It didn't help that the "patterns" were introduced exactly as the unstated promise to the managers to give them a "meta" approach. Like UML before etc. And that people started to think the more abstractions they force in the code, the better it becomes.
My favorite problem description is by Rico Mariani:
"The project has far too many layers of abstraction and all that nice readable code turns out to be worthless crap that never had any hope of meeting the goals much less being worth maintaining over time."
The word "optimisation" should not be confused with considering computational complexity, and I believe we are in dire need for a catchy word for the latter.
One of the most important steps in programming is:
How many elements could this code actually have to process, and if there could be many: is this datastructure/algorithm suitable for that?
This is almost never premature.
This should NOT be called optimisation.
Yes you should always think about optimisation, even if you never end up coding for it. Every function I write I think about what is the effect that it will have on the rest of the code and what will I need to change if it later turns out to be a bottle neck. The advantage of this is I sometimes avoid writing some dumb code - even if it never matters from a performance perspective I have thought a little bit more deeply about what I want to accomplish.
To answer your question how does thinkthencode sound?
I think the operative word is "premature". If you actually have a reasonable idea of how much data you're going to be working with, it's not premature at that point to put some time into optimization.
Also, I would restate the rule as something like "don't spend too much time prematurely optimizing. If you're building a lookup, it's obviously a Good Thing to use a hash instead of a linked list, and in 99% of cases shouldn't take you any longer to code.
While not particularly original, I would place this under 'thoughtfulness' / 'thoughtfully'. Code thoughtfully, but don't dive into premature optimization.
For the former, I always preferred Joe Armstrong's quote in Erlang and OTP in Action. “Make it work, then make it beautiful, then if you really, really have to, make it fast. 90 percent of the time, if you make it beautiful, it will already be fast. So really, just make it beautiful!”
It's the same idea as the Knuth quote, but gives you guidance over what to optimize for (rather than just leaving you with the idea you shouldn't optimize for anything). Beautiful code will oftentimes include an elegant, efficient algorithm. Many times I've found that when I've had a performance bottleneck, the fix also made the code more correct (not just on a performance standard, but things like "Oh...yeah, we totally didn't need that there" or "tweaking that to be faster also meant we just fixed a possible, if unlikely, race condition"), or more beautiful ("oh, we just removed a duplication of effort...that when called this way was turning an O(N) operation into an O(N^2) operation"); had I just adhered more stringently to those two, I would have had the performance already.
> Another far more common antipattern that isn't mentioned here is premature abstraction. You see a lot of this in enterprise .NET codebases -- such as the widespread "best practice" to build ineffective and obstructive abstraction layers "just in case you might want to swap out Entity Framework for a web service."
Where I get twitchy is the practice of coding has changed a lot since Knuth made that quote. Optimizing code in that era typically made it brittle and hard to reason about. Pre-optimizing meant continuously painting yourself in a corner. I used to think about it as like a seamstress sewing a dress, she doesn't start out sewing nice neat tight stitches, that's for later. Once she knows she's not going to have to rip the seams apart again.
Some optimizations don't matter anymore. Back in the hoary old days pointers in C were faster than indexed arrays. Not anymore. But people still assume it's worth it. Twenty years ago, you paid a serious price for unaligned accesses. Not any more. Yet compilers still rigorously align data in memory. Which might actually make things slower.
As the follow on poster said, make the code clean and easy to reason about. People often like to think they are writing code like the big boys, where it'll get used by vast number of people. Much like a lot of hardware designers design stuff as if they are going to make millions of units. 99% of the time that's not true. Thus the NRE costs totally dominate.
Yeah, I also found that making educated guesses about optimization spots early is important. You cannot not optimize all the time. Overspending resources on optimization happens because the team is not working together well or the developers aren't experienced enough. This can't be changed with a quote though. It needs time, training and good guidance by the management.
> Another far more common antipattern that isn't mentioned here is premature abstraction
He does address this one in point 9:
Useless (Poltergeist) Classes
Useless classes with no real responsibility of their own, often used to just invoke methods in another class or add an unneeded layer of abstraction.
Over-abstraction is extremely common in 'Enterprise' Java codebases too.
>While the points the author makes are valid, the fact that it gets bandied about as an out-of-context sound bite results in a lot of code getting written with a complete disregard for any optimisation whatsoever.
This is still preferable to premature optimization.
What I really can't stand is developers who tell me that this piece of code that already runs in production with no complaints is 'slow'.
I think the article is taking it to mean what we want it to: don't write obtuse/opaque code just because you think that the straightforward way to do it, relevant language feature, natural abstraction, etc. is "too slow."
Find out whether sacrificing clarity for speed is even categorically worth it in this particular function, and find out whether your alleged speed improvement is proportional to its readability costs.
I read A Big Ball Of Mud while in high school, left a big impression on me. Unfortunately, I've since seen that my projects all gravitate towards it at the end.
You forgot the most important anti-pattern of all:
"Not Invented Here".
The urge to rewrite things that you encounter is strong in software engineers, and you should always be suspicious when you find yourself thinking "I could do this so much better." Especially when it's true!
The "not invented here" pendulum has swung a long way, and I think that there's now a real, hidden anti-pattern in industry: "never invent here".
At some point, it's important for us as programmers to indulge that "I could do this better" instinct. If you're right you could make a real contribution to your employer or the community. If you're wrong then you'll still be a better engineer (and possibly a domain expert) for the effort.
If everyone embraced "not invented here" as a philosophy then the whole industry would stagnate.
Most of the time I can do it better because my problem space is so much smaller.
And sometimes I look at components and I'm so disgusted by the code or the API that I merely use it as an example and re-write the code for my own purposes. Just because somebody put it on Github or built a package doesn't automatically make the code good.
Most of the "not invented here" I come across is from developers who never look for 3rd party solutions. It doesn't even occur to them. And it's usually obvious stuff like XML or JSON parsing! Which is why the message of "Not Invented here" is a good one to repeat over and over.
> Which is why the message of "Not Invented here" is a good one to repeat over and over.
So, there is a problem where many developers would rather work on abstractions rather than concrete value-providing things. I suffer from this myself - if abstractions weren't interesting to us, we wouldn't be working in software.
However, over the years I've discovered that many software projects are gaining negative value from some of their libraries, and I'm not sure which is the larger problem.
So true. You always have to weight the cost of carrying around a dependency and what that will mean for others who will have to use and build your code in the future and on platforms like Windows where dependency resolution is far from trivial. Seen this way sometimes it's worth spending a few of hours writing a JSON parser to avoid adding a dependency. Probably not woth an XML parser though.
There is one case when those wheels can be worth (partially) reinventing: if you only need them to parse some files which use XML or JSON in a very restricted way. Say you've got a bunch of XML files which only go one level deep, only use ASCII, don't use namespaces, etc. A full XML parser comes with a whole ton of bloat you don't need for that! Plus, if there's ever a problem with those files, the outsourced XML parser will tend to give the end-user absolutely useless error messages.
This is often a slippery slope. Assumptions tend to erode over time, eg. I've seen code assuming ASCII-only input fall over due to people copy/pasting from Word (which automagically turns hyphens, quotes, etc. into non-ASCII).
Also, whenever there's a lot of data being looped over, it can be very tempting to add new features to the existing loop, rather than adding a new pass (inefficient) or trying to collate the results after they've been spread out (complicated & error-prone). This can turn a simple parser into a core piece of business logic, and of course it's then only a matter of time before custom, XML/JSON-incompatible 'directives' start creeping in to control that business logic.
I guess one cannot pick a non-controversial example. I recently had to deal with someone generating XML by string concat and it worked for years until recently. Something with international characters suddenly started causing problems. The solution was simple; I replaced the code with a proper XML library and it just worked. I didn't even bother to figure out what the underlying issue was.
Worrying about the bloat is premature optimization. If your process is actually too slow and parsing is the bottleneck then by all means rip out the XML parser library and roll your own.
> then I'm pretty sure I can write something a lot more efficient
Sure.
> and portable
...it's hard to be "a lot more portable" than a simple C library that compiles out of the box on all your preferred compilers and platforms. Care to elaborate how you end up being "a lot more portable"?
> with better error reporting
Plenty of room to do your own error reporting with off the shelf parsers.
> and I can do it in 10 minutes
The bug reports, on the other hand, will last a lifetime. Because that format will change, your underlying assumptions will be invalidated, and your parser will eventually grow into one of the 4+ fully featured redundant XML parsers in your project, each with their own set of weird assumptions, inconsistencies, and "supported bugs" (for backwards compatibility), and all of them will need to be maintained.
At least until someone takes the time to make a breaking change to the data format, and rip them out to replace them with a proper off-the-shelf JSON parser that has orders of magnitudes more eyeballs fixing the corner cases. Then you'll only have 3+.
> A full XML parser comes with a whole ton of bloat you don't need for that!
I'll take minor binary bloat over major maintenance bloat any day. And you're wrong: It turns out I actually need a lot of that "bloat" in the next revision.
> Plus, if there's ever a problem with those files, the outsourced XML parser will tend to give the end-user absolutely useless error messages.
If you have a blindly auto-generated XML-to-binary-format reflection based converter, sure. That's not a good reason to write off "off the shelf" XML parsers outright though, when there's plenty of ways to use them that will give you perfectly fine error messages.
To keep with your theme of generalizations: in-house XML parsers tend to give the end-user no error messages, which is far worse ;)
I've personally seen this in two separate projects that decided they needed their own XML parser. In one case, they simply didn't know better. And proceeded to get the basics wrong, like empty elements.
In the other case, they used XML for no good reason, then, gasp, decided parsing 30KB XML files all over the place (thousands a second, deeply integrated into all parts of the code) wasn't very quick. So they copied libxml's source, then hacked it up, breaking things like character encoding. Oh, and they added an XML pre-processor while they were at it, to do file includes and variable substitution. Thus it's not even compatible with XML, yet they still pay all the overhead. Awesome.
>then I'm pretty sure I can write something a lot more efficient and portable, with better error reporting
I would give pretty good odds that you couldn't.
Good json/XML parsers (you did pick a good one, right?) are usually heavily optimized in ways you wouldn't even think of and cover more edge cases than you can imagine because heavy usage in production has picked them up.
So, the immediate costs to use are that you have to research a bunch of parsers to see which fit your needs and are 'good'. Then you have to write the code to use them, which depending on their interface may itself add a significant number of lines of code with potential for their own bugs (given a simple enough example, the integration code can be larger than the code you would have written). Then you have to include not just the library, but all its dependencies in your codebase. You're then committed to keep track of the library and all its dependencies, and updating them if and when dangerous bugs are discovered. This means that your code now has a reason to change or rot (API changes from upstream) that has nothing to do with you or any feature or bug you've written. If your requirement is later found out to be slightly unusual and not exactly covered by the library, you're in for a world of pain working around that too (e.g. in the example given, this probably isn't a valid xml file because it doesn't have a single surrounding tag and there may be other nonstandard issues in the input).
The amazing thing is that this actually is worth it in many cases, but people often underestimate the cost.
Sure, the poster you're replying to isn't a special flower that can write a better parser for whatever format, but he's saying that in this case he doesn't need one. A number of other commenters have pointed out that requirements change and the generic parser will be a better choice than evolving your homegrown simple code into a poorly thought out monster. This is true, but it's also premature optimisation.
The right time to pull in those libraries is on the first non trivial change, not at the beginning.
>So, the immediate costs to use are that you have to research a bunch of parsers to see which fit your needs and are 'good'.
Yep. This is known as an investment. It keeps paying dividends every time you use it.
>Then you have to write the code to use them, which depending on their interface may itself add a significant number of lines of code with potential for their own bugs (given a simple enough example, the integration code can be larger than the code you would have written).
Only if you're a bad programmer, and/or you used a bad library.
>Then you have to include not just the library, but all its dependencies in your codebase.
For me this means adding one line to a file called "requirements.txt". E.g. python-cjson==1.1.0. The setup scripts take care of the rest. Trivial.
>You're then committed to keep track of the library and all its dependencies, and updating them if and when dangerous bugs are discovered.
Yep. Once a month or so I upgrade all of my libraries, run the tests and see what breaks. Mostly nothing breaks and the amount of thinking I have to do to take care of this problem is usually zero.
>This means that your code now has a reason to change or rot (API changes from upstream) that has nothing to do with you or any feature or bug you've written.
While true, stuff like cjson just doesn't change its APIs. In practice, while this is a problem for some libraries, it's one that is relatively minor.
The reverse is more usually true: upgrade everything and you get bugfixes for free. Good library designers do not change their APIs often but they do fix bugs frequently.
> If your requirement is later found out to be slightly unusual and not exactly covered by the library, you're in for a world of pain working around that too (e.g. in the example given, this probably isn't a valid xml file because it doesn't have a single surrounding tag).
Hence "choose a good library". For xml that means choose one that can deal with invalid XML because invalid XML is a problem you're just going to have to deal with eventually if you use XML. I use libxml2. It's good. It's fast and it handles invalid XML well. I recommend it.
Better yet, don't use XML coz it's crap (not always avoidable, I know).
>The amazing thing is that this actually is worth it in many cases, but people often underestimate the cost.
The cost is higher if you choose poor libraries. Choosing a good library is more art than science, but if you do it right you will drop your costs like a rock.
It also helps to pick a big ecosystem + language that has good libraries.
>Sure, the poster you're replying to isn't a special flower that can write a better parser for whatever format, but he's saying that in this case he doesn't need one. A number of other commenters have pointed out that requirements change and the generic parser will be a better choice than evolving your homegrown simple code into a poorly thought out monster. This is true, but it's also premature optimisation.
This is a misuse of the term premature optimization. You can prematurely optimize for speed. You cannot prematurely optimize to eliminate not invented here syndrome, code duplication or tight coupling.
>The right time to pull in those libraries is on the first non trivial change, not at the beginning.
No, the right time is at the beginning. If you need to parse JSON use a json parsing library. If you need to parse XML, use an XML parsing library.
If you're worried google what people have to say about it. Do they say that it sucks? It's glacially slow under the wrong conditions?
If you write loosely coupled and cohesive code as well, you can vastly reduce the costs of choosing a bad library later on.
Covering numerous edge cases implies generality at the cost of efficiency. I don't know the parent, but his point was that he didn't need to worry about all of those edge cases, so writing an efficient parser is trivial. In general, he's right.
My employer has a history of using CDFs (Comma Delimited Files) for lots of things. They're just like CSV, only not. It works great right up until someone wants to know if they can store data with internal commas in it like "Acme, Inc." Then we have to reinvent CSV anyway.
I would say that over the past 10 years or so, especially with the rise of frameworks, PaaS and web API's, "never invent here" has become a much bigger and more troublesome anti-pattern.
Especially since the latter seems to have a much deeper and irreversible impact on the engineering culture.
Just grab 20 different containers, slapdash them together with silly string, and prey to your deity of choice that none of them hold some glaring security hole?
> At some point, it's important for us as programmers to indulge that "I could do this better" instinct.
Sure, and that point is pretty easily defined: the point at which the existing solution has produces real, tangible, definable problems with achieving your current goals is the time to invent a replacement that "does it better", with better defined in exactly the terms of the problem that you are addressing.
Its also okay to do it as something exploratory, off the critical path of a real project for understanding/skill-building.
What's not okay -- and is instead a dangerous, expensive (both in the short-term and in maintenance terms), ultimately unproductive diversion of effort -- is making a reinvention of something that works adequately a dependency for some other effort.
And then there's that cold, dark morning when you find the profound, deeply embedded assumption at the core of a library that means you now have irreconcilable differences...
NIH can be bad but it's sad that so many programmers live in the vaccum where the MVP has to be shipped tomorrow. It's great to write really good code that will out live your VC's whim.
Well people have kids all the time yet they come out more or less all the same. If you want to re-invent - go ahead and do it. Who knows, it might turn out great.
I think example 9. (the stack that wraps a linked list) is not a necessarily an antipattern. Removing degrees of freedom and adding obvious constraints make systems simpler and easier to comprehend.
Surely the purpose of the LabStack example is to restrict the interface of a LinkedList to that of a Stack? Defining a new type to present a more restricted interface is not useless... it helps one reason about what has or hasn't been done to an object.
I agree - Defining a 'Stack' class is useful even if it's just a wrapper over LinkedList, because stacks have an expected way to act, and while a LinkedList fits the bill it does more then a stack actually has to do. And with that, nothing says you have to implement a 'Stack' with a LinkedList, it's just an easy way to do it. By defining the 'Stack' class, you could always go back and improve it to not use LinkedList and instead do it yourself.
That said, I do agree with the author that, in the context of a programming class, writing the 'LabStack' class is absolutely useless because it teaches you nothing about actually using a linked-list to implement a stack, which I'm sure was the real intent of the assignment. The 'LabStack' class is useful in the context of being used in a larger program, it's not really useful for learning how to actually implement a stack because it just passes the implementation off to 'LabStack'. (That said, because Java doesn't support defining objects as value-types, using the 'LabStack' interface adds an extra level of indirection you may want to avoid - You have to access 'this.list' to get the LinkedList object, instead of just accessing it directly. This is more a fault of Java then anything else though.).
The note about programming class isn't really relevant to programming as a whole though, which is where the disconnect happens.
I'm a little confused. I'd say that an anti-pattern is something one can avoid. Sure, I can think about every optimization I'm doing, and if I already know well enough that I'll need it and doing it right. But I can't really avoid discussing about something that is unimportant in my eyes, because the person who will discuss about it usually thinks it's important. I'd say that in the "bike shedding" regard my anti-pattern would be that I ignore some complaint as unimportant because I still don't understand it well enough.
Other things are also hard to avoid by myself, like
- God Classes (I could refactor here, but then the anti-pattern is fear of refactoring)
- Management by Numbers (I'm not a manager, what can I do about it? Actually I'm happy if my management is already that good that they have numbers. Nothing is more horrible than management who doesn't tell you explicitly what they want and then complains about details for half a year, then starts with the next project without declaring the last one to be finished or anything. I'd say numbers are good, finding the right ones is tricky, though.)
- Useless classes are avoided by simply not writing them? No, they develop when code gets refactored and nobody had looked at the responsibility of that specific class for some time. Nobody writes classes without having a goal for them in mind. Mostly calling methods of another class is fine. It happens in design patterns like Observer, Delegator, or Compositor.
I read this many years ago. Let me find the source.
Edit: I can't find it. Anyone else remember reading this? The mysql job queue reference was from a popular article that went out about it at the time
Edit 2: the job queue article is from 2011.
Edit 3: still can't find it. But I know every part of this article before seeing it ... I tested myself and remembered all the details... Where is this thing from?
Still can't find it. My confidence in the permanence of the web is pretty destroyed right now. I can't even find references to it existing.
Yes. This article came out after that. I realized a few paragraphs in that I had read all of it. I tested it by guessing the content and was 100% correct. But I can't find it.
This isn't the first time I wanted a searchable version of archive.org that effectively timecapsuled the interactive internet. Things fall off the net far more than common folklore suggests
I'm glad to see someone else echoing my anxiety. I had the impression that Uniform Resource Locators were meant to be treated as bookmarks into a web of knowledge, so it's like brain damage when they break. It's too bad it happens so frequently, because for a few blissful years my urge to hoard was quieted by the assumption that the internet was doing it for me.
Those enormous URLs that describe nothing but a document GUID are also a sin.
I've resorted to capturing every single interesting link as a complete HTML page to DEVONthink, which is a mac application specifically meant for storing large amounts of data. It's already proven quite handy in two ways:
1. I can access articles that have disappeared off the net
2. I have a very powerful search function and 'similarity engine' constrained to only the information I've found useful so far. It's often the first place I look for certain kinds of information before I try google.
I can strongly recommend using such a tool to make sure you don't 'lose' stuff on the internet that is important to you.
I don't understand how to avoid this even if you break it up in smaller classes. You still need a point of entry where the logic begins and where it is decided which components to use. ThIs always means some kind of Manager or Main class for me. How do I fix it?
Well there's an entry point of course, but it shouldn't know much. Your entry point knows about your option parser which knows about the high-level actions your program performs which know about the sub-processes involved in accomplishing them, etc.
It's important to keep this graph as acyclic as possible, and to try not to have any one component directly interact with too many other components, because then your abstraction is too fragile.
Enjoyed this list. Over the years I've become better and better at spotting these issues, but even still sometimes it's hard to see them creeping up on you.
The worst for me these days is analysis paralysis. I'm currently working on my own so I don't have anyone around to bounce ideas off. For smaller tasks it's not a problem, but there are bigger design decisions that have ended up taking longer than probably should. When you're left to figure them out on your own it takes a lot longer to convince yourself of the "better" way of doing something.
To me, the problem in choosing the "better" way of doing something is that I can't stop comparing diverging design choices.
I like to think that the best way to choose between seemingly equally advantageous designs is to start with the one whose first step(s) is(are) the most straightforward. The thing is, while I prepare myself for implementation of that first step, I've a background loop in my mind that constantly checks against other implementations choices. What I am losing here, what I would gain otherwise.
In the end, I never really make definitive decision before starting. I start with that background brain noise on the “most simple first step design”, and when the background noise stops and the raw pleasure of coding kicks in, I known I'm on a good track.
I guess I do go through that process once I start work, but I'll definitely keep your advice in the back of my mind. Don't let the choice become overwhelming, get started knowing that it's ok to change your mind during the process.
For any feature / bit of work that's in isolation, I don't really worry. I figure out an approach and I implement it. When it comes to changing data structures / larger changes within the product there's a fear of getting it wrong and having a mess to unpick later.
"It seems that perfection is attained, not when there is nothing more to add, but when there is nothing more to take away."
Great quote - It reminds me of the story of when Michelangelo unveiled the statue of David, someone asked him how he managed to create such a masterpiece and Michelangelo answered "It was simple, I just chipped away all the rock that wasn't David".
I don't think reduction only leads to perfection. If it would be, then our starting point must always be the right one. But in practice you start somewhere, reduce, move forward, add stuff, move sideways, try out and test. Sometimes you need to add stuff to make it clearer to your users.
Having worked for big corporations in Europe, I'd like to see manager types spend 10% of time technical people spend on self-optimising themselves, their working environment, post-mortems, understanding antipatterns, productivity etc.
Same here, unfortunately. It drives me nuts. It's oh so easy and tempting to vialoate the DRY principle. But what's even worse is people actually defending their Ctrl+C Ctrl+V behaviour with false/uninformed arguments such as
- why waste time with creating a function when I can copy-paste?
- but I'm never going to have to change this code anymore
- but it's more readable else I have to figure out what the function will do, browse to it, ... (well, good luck navigating any codebase at all)
- but it occurs only twice (ok, twice is debatable, but still: before you know it the same is used again in another place an there we go again..)
- but it's faster because it doesn't require an actual function call (this is by far the worst one: they claim this without having even measured it, without having checked if there even is a bottleneck, without realizing that in compiled laguages any decent optimizer would inline and generate assembly anyway)
It's nice to notice that top three actually does not have anything to do with programming. Those are absolutely general issues when ever doing anything at all.
I don't know about this one...we need something have a chuckle (or cry) about over beer after work, and to make sure software archaeologists in 100 years time have an interesting job (not to mention plenty of opportunities to write blog-spam)!
It's not bad advice, if used in moderation. The problem is that most developers take it too far, to the point where no number is safe from becoming a named constant.
My default these days is to write numbers as numbers, plus maybe a comment if things are unclear. I only turn numbers and strings into named constants if they are used in more than one place, or if they are true configuration values that need to be tweaked.
This makes the program easier to read (the ultimate goal) by avoiding the need to jump around in the codebase. Comments are better at explaining things than cryptic variable names anyhow.
Definitely, although there can also be refactoring benefits to look out for. In the article example it would be much easier to change the default popup window size (800x800) across the project if they're all using the same variable.
On the other hand, tools like CheckStyle can make people do some strange things when they take it too literally.
I once reviewed code that defined: static final int ONE_HUNDRED = 100;
Right, but your window size example would be a case of using the same value in more than one place, so it would be better as a named constant.
Actually, the whole example smells ripe for refactoring. Where are there multiple windows throughout the app all sharing a default starting size? Sounds like it's time for a base class or something. Once you've eliminated the redundant sizing code, you will find that your default size values now exist in only one place (the base class). Since they are only in one place, you can write them as numbers again instead of named constants.
I've played this pattern out more times than I can count. The problem isn't magic values sprinkled through the code; it's having redundant code in the first place. Once you solve that, the magic numbers tend to evaporate.
And ... the funny could have been eliminated if the named constant had just had a useful name, or been replaced by a function, rather than a passive-aggressive response to a code analyzer or coding standards ("There, I fixed it."). The conflict between the name and its value would have been eliminated, and the comment may have never been written in the first place.
Lol - I have to say that I have seen this sort of thing a few times in the past. I actually don't mind this as it is a flashing red light that the code that uses this constant needs to be looked at very, very carefully and rewritten.
That one stuck out to me as well, but for a different reason.
I think the idea that "explicit is better than implicit" is a good idea for more than simply "magic numbers and strings".
I much prefer seeing the code in front of me than having to jump through multiple functions across several source files + tracking down the configuration values I'm looking for because someone decided to use DI.
I'm not saying DI is a bad practice, but unless you really need it, prefer explicit dependencies.
And on and on with just about everything you do, if all things are equal, prefer explicit over implicit.
What are good queue replacements? My problem with activemq et. al. style queues is that monitoring them is much harder than a simple database. Ie. checking for pending items in the queue and also for debuggin processed items later. And somehow I don't "trust" these queues as much as a simple database. If I write a row to the database it is there and can easily be checked and used (no queue product has any comman line utilities or sql like general functionality to check the queue etc.)
The previously linked article also warns that do not use a database as the backend for the queue solution or you will have worst of both worlds...
Having done this (years ago), there are good reasons sometimes. At the time I was working on a relatively complex hotel reservation system with a distributed database and the need for batch execution of background processes (things like sending emails and digital fax from a queue).
The master interface to the database was a series of PHP functions since the data massaging that had to occur (to facilitate correct interaction in multiple human languages across disparate timezones versus user preferences and time of day, etc.) ruled out direct DB access from anywhere else, back-end processes included.
I think the end solution was something like 'every minute run PHP X from cron, which checks if there are jobs, if so successively spawn children to handle'. It was basic but it worked. Godawful pain with MySQL replication over lossy Chinese internet WAN ... never again.
I inherited a similiar system. It was painful to say the least. I didn't realise how painful until I started using proper queueing systems and Sidekiq.
Sidekiq doesn't really look that different to what we used.
Anyway, neither decent ruby unicode handling nor RoR nor sidekiq existed back then. I actually considered rewriting the whole system in ruby at one point, but the unicode support was still dodgy.
{kind=link}
And it's exactly this requirement of masterful manipulation of balance that makes me love this field so much and long to get better at it. Getting a handle on the artsy spirit of programming is really what separates the wheat from the chaff in terms of programmer skill. There is no formal programmer guild in real life, but if there was, and there was some sort of test a journey-man programmer must undergo in order to become a master programmer, it would be the test of being given a large project and then deciding correctly exactly how much technical debt to take on to be able to ship a product within a reasonable time-frame and yet have its internals not be complete unmanageable spaghetti.