Has anybody in the client side community ever made the connection to rules engines?
This flow of logic is awfully close to how a rule engine works. I wonder if people will at some point arrive at it.
There isn't a whole lot of rules engine in JS. Just nools [1] which is huge. I'd love to see a very simple forward chaining rule engine + Immutable + React and see how that would work out.
My guess is that they aren't popular at all because they have the notion of being enterprisey (Drools/Jboss). I'm a big fan of them. They /can/ make life & code very nice and elegant. Maybe somebody writes an JS adapter to clara rules [2].
I would like to see a series of examples in the use of rules engines. I've worked in several places where people brought them up as suggestions, but their "enterprisey" brand made them harder sells.
"My guess is that they aren't popular at all because they have the notion of being enterprisey"
You have to wait a while before the JS community realise that enterprisey is just the inevitable end game of their wheel re-inventing.
In the same way they dismiss things they don't understand now due to complexity, they are adding more and more with all these frameworks and architectures.
Nothings new, everythings a remix. I imagine rules engines will be the next "revolution" on this already well trodden road.
Everytime I see the Flux architecture I wonder what does it bring to the table that a reactive programming library like RxJS or Bacon.js don't? It seems Flux is just hacking together well-defined concepts in these libraries.
* Stores could use Observables instead of EventEmitter
* Components become Observers by subscribing to Observables which is extremely similar to setting up Listeners.
* Instead of Actions through a Dispatcher, Actions become Proxies (or Subjects in RxJS terms or Buses in Bacon.js terms) that Stores subscribe to and Components push to.
The dispatcher really is just a simple pub/sub mechanism.
The thing that Flux helps define is how to manage data. We don't have models, but it gives you a coarse structure for your data, with which you can do stuff like data dependencies (derived data), only rerendering part of your UI when parts of your data changes, etc.
How events are used within all of this could certainly be re-purposed with Rx (I've repurposed it as channels myself). You are not wrong, but flux is a bit more formalized with a few more things.
That makes sense. Just all the code samples I have seen of Flux have most the lines of code dedicated to wiring up events instead of the more interesting things you have mentioned. I think just using either Rx or CSP would make the concepts of Flux clearer.
I bet if you dug around the internet there are some good examples of that. I've been meaning to show more examples with js-csp, but Rx is pretty popular so I bet there's some examples with that.
I bet many of the Flux implementations use a simple event system because that's the lowest common denominator; we're all pretty used to wrapping that in whatever we like anyway. But it does make a little more confusing to look through.
The only reason I haven't moved from Reflux to Rx or Bacon is because I want to see more about Falkor and Relay before deciding on a data management paradigm. Flux feels like a half measure on the way to something more robust; it works well enough, but I bet there's a better solution later this year.
Netflix's data model. They render asynchronously, which lets the render method itself ask Falkor for data it needs and delay rendering until it gets a response.
Is there a way to get rid of flux boilerplate? I don't want to write three different files (a file with actions, another file with constants, and the actual store). For example, I can achieve the same effect with just a simple array and some functions to modify it. I guess I know what the benefit of embracing flux is, but it still looks too much, and I am mostly lazy.
Sure - just use what you want. Outside of the dispatcher, flux is mostly a design specification for clientside information flow. Actions, stores, etc aren't native to flux - they're just approaches for accomplishing the desired information flow. Check out the examples closer - they aren't react classes.
That said, my personal opinion: the deeper you get into a big project the more you'll see the incredible value of the approach. The breakeven between the overhead of learning the approach vs the productivity (and performance improvement) of using it comes pretty early on, in my opinion.
With a lot of software, the more I get deeply into a project the more I feel I'm battling the artificial constraints of the tools I'm using. Flux is exactly the opposite. The deeper I get in, the more I feel it's working for me (and I'm not even using their dispatcher - since I had written my own initially before flux came out, so I can't speak directly to their dispatcher, just the Flux design styling within a React project).
I'm also using alt and enjoying it. I like that it sticks close to the FB implementation of Flux but there is less boilerplate along with utilities such as bootstrap, snapshot, etc.
You just articulated all the issues I have with these frameworks (Backbone is another one that comes to mind) - the boilerplate code violates the hell out of YAGNI, which for me is a core principle of my development style.
You end up building a ton of boilerplate code that is capable of handling anything your system evolves into, but most of it is wasted because each part of the system typically only uses a small subset of functionality of the framework. So you're left with a bunch of big crufty systems laying around. When I want to be the most lightweight and agile and capable of changing my direction is at the beginning of a project when I'm still learning how the system will work. These frameworks make it really tough (at least for me) to do that so I end up not using them.
Learning Flux sort of seems like learning how to drive stick shift on an '97 Civic while we wait for the new Tesla to arrive - useful, also a bit annoying. A central store architecture does seem a better match to what Relay will look like though.
Relay looks like it will partially replace Flux if you're using it to manage the client<->server state, but Flux still seems necessary if you have a lot of intra-client state to manage (such as in a document-editing SPA).
> If you're like me and you wanted to go further with React, you more than likely would've checked out Flux, had a glance, closed the tab and then reassessed your life as a * developer.
This accurately describes my experience yesterday.
I think React is quite expressive in it's simplicity. Flux on the other hand (even though it's good idea), is poorly tooled out.
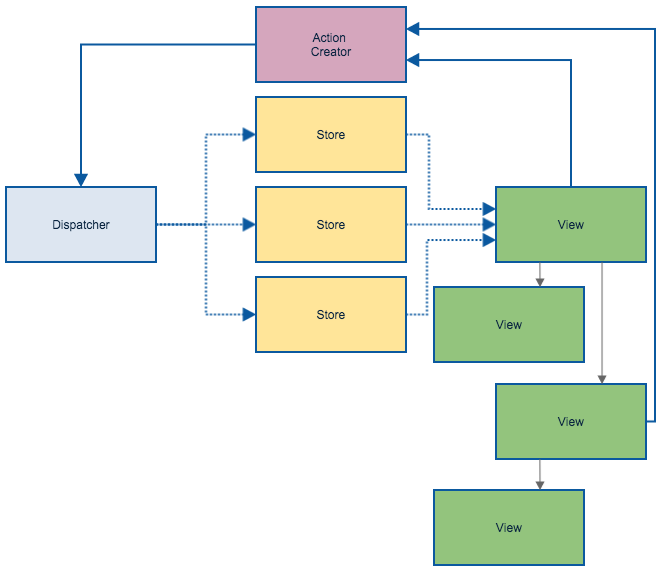
Heh, this post resonates with me - Facebook's description of Flux drew a wtf when I first looked at the diagrams on https://facebook.github.io/flux/docs/overview.html#content with its weird terminology, but when I did some more further research into it, I found out that I had a lot of very similar patterns with my Angular code.
I think they should have chose some better terminology/words to describe the overall components, in this case I found the words shutting down my thought process on first glance.
> had a lot of very similar patterns with my Angular code
I had the same "weird terminology" and "thought stopping" reaction to Angular's, Ember's, and Meteor's architectural terminology. I know they're all trying to differentiate themselves in a crowded market, but its just created more of a mess.
Time for me to go learn a new dictionary, to do the same job I did yesterday.
I find the idea of Flux fascinating, but one thing I'm a little curious about is where error feedback fits in here... If an AJAX query fails, or something fails validation, how does this information make its way back to the view? If it happens at the action dispatch level, you still have to pass the event through the store? That seems a little... Odd to me.
Right, my question isn't where the call should be made though. Makes perfect sense in the actions. My question is if the call fails how do I post a notification to the view itself to communicate to the user that something went wrong? Actions can't post back to Views, so... Send event to store, store passes along the error to view? It's an elegant system otherwise, but this really clumsy to me.
Stores hold the state your Views use to render. This can include more than just the data backing the Views. It can include things like which item is selected in a list, if a link is active or not, and any error messages as well.
I can accept this sort of thing if the payoff is high, like getting access to the performance and simplicity of virtual DOM operations in React, but these examples just seem to be to create basic objects.
Maybe object-assign is one of the javascript best practices that keep changing every 2 months and I'm just not paying attention enough? ES6 can't come soon enough.
The class in ES6 is just syntactic sugar over Object.create. Class is only coming out becuase most people wont learn that javascript has prototypal inheritance, and how to use it. Its a different mental model, in my opinion prototypal inheritance is more expressive and light weight than typical classes from other languages
Perhaps a huge coincidence but I pretty much wrote this framework in C# in 2004 (including rules engine) and was using it for mobile devices (wince/symbian). We abandoned it after 4 years for a simple CQRS system with event bus (before Udi/Greg went off on it or Fowler formalised it).
You know where we are now? Simple JSON REST API with local and remote queues per device updating a document store. All the queues have on receipt and on dispatch handlers attached and that is it. Each of these can modify the state or perform an external action.
YMMV but I'd probably start there first. It's much easier than the other two. I might write it up.
It's always nice to read a writeup on Flux.
I would love to hear more about possible isomorphic implementation of the architecture though. Right now besides Fluxible the architecture doesn't play well with server side rendering.
By the way, shameless plug, I wrote an article on Flux (backed by a Rails API) a while ago, if you're interested on the matter: http://fancypixel.github.io/blog/2015/01/28/react-plus-flux-...
What specifically do you mean when you say that it doesn't play nice with serverside?
I wrote my own Flux implementation (back when it was first announced, and there were no/limited libraries for it), and i don't recall having a problem with my implementations.
I probably broke a few rules though, hard to say. I'd be curious to hear your experiences with it :)
I can't speak for the OP, only my experience here. The docs on flux[1] recommend singletons for the dispatcher and stores. If your library is following that recommendation then things start breaking in a server-side environment as multiple requests start hitting, especially in parallel with asynchronous data retrieval.
Love going through live examples to learn, thanks for sharing!
But, I can get it to render (after doing npm/bower install then running gulp), but can't get it to actually do anything. Everything looks right but clicking around and nothing happens? Anyone else running into this?
The whole point of it is to eliminate spaghetti code. Traditional large frontend apps often end up with very complex chains of information dependency and it can become unclear as to what changing a piece of code will affect. Flux tries to prevent this by enforcing a uni-directional data flow, meaning working out what a certain component affects/is affected by is much simpler.
Hey, it has a cool name and it's made by Facebook. It must be state of the art tech, right?
Trolling aside, Flux really doesn't bring much to the table. It's trying to solve the pain caused by two-way-binding by forcing state to flow in one direction through an event bus, reinventing MVwhatever along the way.
You can already do this stuff in Angular (et al) if you stick to a few firm rules for how to structure your app.
Don't blame you if you don't have time nor motivation to respond, but care to share a 2 min. description of those rules?
I'm a fairly new developer working in my first post-uni role and we're starting to rack up a lot of Angular code and I'm not sure if I'm structuring things right as far as events vs $watches etc.
Don't people realize that returning HTML instead of JSON will solve their problem for 80% of the use cases?
Looking at Relay/GraphQL, the whole picture appears as a gigantic layer of indirection to generate a DOM tree, something you could do serverside 10 layers below.
Even 'Components' are just fragments of HTML, retrieving them in the format you want from the server is much easier. And be honest, replacing a fragment of HTML in the DOM is fast enough for most applications. (don't delete form input, though)
In 2006, after part 1 you would be done and call it a day. Now I understand that today you need 'realtime' updating. But the "notification count is off by one" Facebook example is really bad, because instead of doing all the math in JS, one can simply do a GET request to fetch the count from the actual Single Point Of Truth, which is your database.
Did this get so complicated because front-end development and back-end development is separated at many places?
Agree that the trend to assemble HTML client side has complicated development way more than it should have. However, returning html fragments isn't the solution for all use cases. Consider native apps for Android/iOS/OSX/Windows. They will need data to be delivered via an API. Instead of creating a one-off data pipeline for web browsers, consuming data from a standard API cuts out the need to assemble views for a specific platform. Creating applications via the browser just isn't up to par with the ease of creating applications in other environments (mobile, pc).
The way I did this in some of my apps is that JSON data is shared between web and Android/iOS client, BUT rendering that data into HTML is done server side:
The server detects if the request is coming from the browser or client app. If it's the client app. it just hands over the JSON data. If it's the browser, it uses the same data to render HTML and sends that to the browser.
On an architecture like Facebook they don't have a database and it wouldn't surprise me at all if the unread count was computed before you logged on. If you want to hide that for the client (so that it actually goes away the moment you click the notification) then you need to use some client state and when you need client state you can't just send dom objects.
In general things gets way, way, way more complicated once your system becomes "distributed".
HTML fragments are a (very) poor solution to real time websites.
Applications that use streaming data sets tend to use the data for more than just presentation. Does the backend send both HTML and JSON? The backend can't send the entire data set because that's too slow; the client needs to be responsible for maintaining its own copy of the data. What happens when there is a bug and the two sources are inconsistent?
Even if the client doesn't need the data, HTML fragments suck for practicality.
Does your website have any forms? You now have to write a bunch of code to copy the data and preserve the focus. Does your website ever use JS to update the DOM in response to user action? Does your website ever suck in any data from a third party? You now have to compare the state of the DOM (or whatever data generated it) against the HTML fragment and do something sane.
Even if you solve the problem of consistency and applying fragments to the DOM, chances are you will be left with performance problems. You will need to batch updates to control repaints.
Maybe, performance isn't an issue or you solve it, too. Congrats, you just spent man years rewriting React.
You don't have to write a bunch of code for forms, that was written 10 years ago.
Also, you wouldn't apply generating html on the server to everything, on the parts that make sense. If you want to use JS to update part of the DOM (e.g. showing an error that passwords don't match), then you'd obviously use JS. It's completely ok to use the right tool for the right job.
> Also, you wouldn't apply generating html on the server to everything, on the parts that make sense. If you want to use JS to update part of the DOM (e.g. showing an error that passwords don't match), then you'd obviously use JS.
In practice, this actually sucks to do. Now you need to query the DOM to get a handle on all the places you want to inject dynamic parts into. Now you've got coupling between the structure generated by the server and all the selectors in your client JS targeting those nodes. What if your client JS is served from a CDN and you can't guarantee the new version will be served up at the same time the server starts outputting different markup structure? You not only need to keep your code synced in two places, you need to keep the distribution of it synced. If it had all been generated in the client JS in the first place, you wouldn't have to worry about it.
And if an update to that markup arrives from an AJAX request or whatever, wiping out the existing markup as you're suggesting? you lose the dynamic stuff you injected and gotta do it all over again.
> It's completely ok to use the right tool for the right job.
Why is the server the right tool for generating DOM structure, something only a web browser cares about? For static documents, sure it still makes sense. But in the age of the DOM representing an application, people are rightly questioning why you'd ever generate the DOM structure on the server in the first place: it not only causes jank but just doesn't make intuitive sense.
{kind=link}
{kind=link}
{kind=link}
This flow of logic is awfully close to how a rule engine works. I wonder if people will at some point arrive at it.
There isn't a whole lot of rules engine in JS. Just nools [1] which is huge. I'd love to see a very simple forward chaining rule engine + Immutable + React and see how that would work out.
My guess is that they aren't popular at all because they have the notion of being enterprisey (Drools/Jboss). I'm a big fan of them. They /can/ make life & code very nice and elegant. Maybe somebody writes an JS adapter to clara rules [2].
[1] https://github.com/C2FO/nools
[2] https://github.com/rbrush/clara-rules