The amount of complication can be hundreds of times more than the
complexity, maybe thousands of times more. This is why appealing to
personal computing is, I think, a good ploy in a talk like this because
surely we don't think there's 120 million lines of code—of *content* in
Microsoft's Windows — surely not — or in Microsoft Office. It's just
incomprehensible.
And just speaking from the perspective of Xerox Parc where we had to do this
the first time with a much smaller group — and, it's true there's more stuff
today — but back then, we were able to do the operating system, the
programming language, the application, and the user interface in about ten
thousand lines of code.
Now, it's true that we were able to build our own computers. That makes a
huge difference, because we didn't have to do the kind of optimization that
people do today because we've got things back-asswards today. We let Intel
make processors that may or may not be good for anything, and then the
programmer's job is to make Intel look good by making code that will
actually somehow run on it. And if you think about that, it couldn't be
stupider. It's completely backwards. What you really want to do is to
define your software system *first* — define it in the way that makes it the
most runnable, most comprehensible — and then you want be able to build
whatever hardware is needed, and build it in a timely fashion to run that
software.
And of course that's possible today with FPGA's; it was possible in the 70's
at Xerox Parc with microcode. The problem in between is, when we were doing
this stuff at Parc, we went to Intel and Motorola and pleading with them to
put forms of microcode into the chips to allow customization and function
for the different kinds of languages that were going to have to run on the
chips, and they said, What do you mean? What are you talking about?
Because it never occurred to them. It still hasn't.
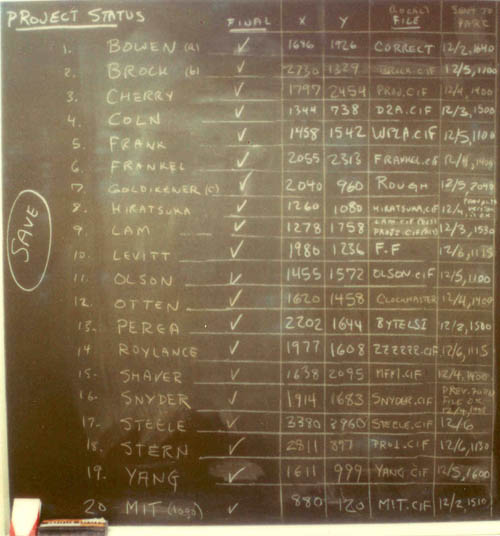
The Great Quux's Lisp Microprocessor is the big one on the left of the second image, and you can see his name "(C) 1978 GUY L STEELE JR" if you zoom in. David's project is in the lower right corner of the first image, and you can see his name "LEVITT" if you zoom way in.
The final sanity check before maskmaking:
A wall-sized overall check plot made at Xerox PARC from Arpanet-transmitted design files,
showing the student design projects merged into multiproject chip set.
One of the wafers just off the HP fab line containing the MIT'78 VLSI design projects:
Wafers were then diced into chips, and the chips packaged and wire bonded
to specific projects, which were then tested back at M.I.T.
We present a design for a class of computers whose “instruction sets” are based on LISP. LISP, like traditional stored-program machine languages and unlike most high-level languages, conceptually stores programs and data in the same way and explicitly allows programs to be manipulated as data, and so is a suitable basis for a stored-program computer architecture. LISP differs from traditional machine languages in that the program/data storage is conceptually an unordered set of linked record structures of various sizes, rather than an ordered, indexable vector of integers or bit fields of fixed size. An instruction set can be designed for programs expressed as trees of record structures. A processor can interpret these program trees in a recursive fashion and provide automatic storage management for the record structures. We discuss a small-scale prototype VLSI microprocessor which has been designed and fabricated, containing a sufficiently complete instruction interpreter to execute small programs and a rudimentary storage allocator.
Just 29 days after the design deadline time at the end of the courses, packaged custom wire-bonded chips were shipped back to all the MPC79 designers. Many of these worked as planned, and the overall activity was a great success. I'll now project photos of several interesting MPC79 projects. First is one of the multiproject chips produced by students and faculty researchers at Stanford University (Fig. 5). Among these is the first prototype of the "Geometry Engine", a high performance computer graphics image-generation system, designed by Jim Clark. That project has since evolved into a very interesting architectural exploration and development project.[9]
Figure 5. Photo of MPC79 Die-Type BK (containing projects from Stanford University):
The text itself passed through drafts, became a manuscript, went on to become a published text. Design environments evolved from primitive CIF editors and CIF plotting software on to include all sorts of advanced symbolic layout generators and analysis aids. Some new architectural paradigms have begun to similarly evolve. An example is the series of designs produced by the OM project here at Caltech. At MIT there has been the work on evolving the LISP microprocessors [3,10]. At Stanford, Jim Clark's prototype geometry engine, done as a project for MPC79, has gone on to become the basis of a very powerful graphics processing system architecture [9], involving a later iteration of his prototype plus new work by Marc Hannah on an image memory processor [20].
[...]
For example, the early circuit extractor work done by Clark Baker [16] at MIT became very widely known because Clark made access to the program available to a number of people in the network community. From Clark's viewpoint, this further tested the program and validated the concepts involved. But Clark's use of the network made many, many people aware of what the concept was about. The extractor proved so useful that knowledge about it propagated very rapidly through the community. (Another factor may have been the clever and often bizarre error-messages that Clark's program generated when it found an error in a user's design!)
9. J. Clark, "A VLSI Geometry Processor for Graphics", Computer, Vol. 13, No. 7, July, 1980.
[...]
The above is all from Lynn Conway's fascinating web site, which includes her great book "VLSI Reminiscence" available for free:
These photos look very beautiful to me, and it's interesting to scroll around the hires image of the Quux's Lisp Microprocessor while looking at the map from page 22 that I linked to above. There really isn't that much too it, so even though it's the biggest one, it really isn't all that complicated, so I'd say that "SIMPLE" graffiti is not totally inappropriate. (It's microcoded, and you can actually see the rough but semi-regular "texture" of the code!)
This paper has lots more beautiful Vintage VLSI Porn, if you're into that kind of stuff like I am:
A full color hires image of the chip including James Clark's Geometry Engine is on page 23, model "MPC79BK", upside down in the upper right corner, "Geometry Engine (C) 1979 James Clark", with a close-up "centerfold spread" on page 27.
Is the "document chip" on page 20, model "MPC79AH", a hardware implementation of Literate Programming?
If somebody catches you looking at page 27, you can quickly flip to page 20, and tell them that you only look at Vintage VLSI Porn Magazines for the articles!
There is quite literally a Playboy Bunny logo on page 21, model "MPC79B1", so who knows what else you might find in there by zooming in and scrolling around stuff like the "infamous buffalo chip"?
There are serious resource issues that made that unlikely:
About the time Sussman and company were getting back their first silicon, Intel was shipping the 8086 and 8088, which could, for example, address a whopping megabyte of memory.
Sussman and company did one or two generations of silicon, but from what I've heard the microcode one or the latter was flawed and never really worked. They simply didn't have the resources to sufficiently simulate it before committing to silicon (I'm told there was a bit of arrogance involved as well, which I believe).
Intel won and continues to win in part because of success reinforcing success, keeping their eyes on the ball, and massive investments. Process (fab lines), design, simulation, support for hardware developers (said to be a critical factor in many 808x design wins over the 68000), etc. etc. etc.
I've thought of paths that might have allowed custom Lisp hardware to survive, but they're in part 20/20 hindsight (people really should have believed Moore's Law, and made a minimum gates RISC chip ASAP), in part require a quality of management that none of these MIT based efforts ever had, and almost certainly in part wishful thinking (non-recurring engineering (NRE) costs were a killer, especially combined with the need to make profits vs. that keeping the ecosystem small by shipping small numbers of units).
Send me back in time with a zillion dollar budget and who knows? Short of that, as agumonkey says, what's done is done. Me, I want to see tagged architectures return (to enforce dynamic typing and make math fast by tagging each word in memory; also has potential for security, and of course helping GC).
I think part of the reason why generalized CPUs will win over specialized ones every time is that hardware that does one thing well is invariably worse at others and we're in a 'polyglot' environment these days. So if you specialize a CPU for language 'X' it will almost automatically be worse at all the others.
So the mass market will almost always favor general purpose CPUs and there may be niches where you'll find more exotic engines suited for a particular kind of computation, maybe even high level languages in hardware (greenarrays Forth offerings for instance).
Sadly can't remember where, but I once read an argument that today's CPUs are 'C Machines'. i.e. C code branches a lot, so we have branch predictors. C code uses contiguous memory, so we have caches. I have no idea if it's a legit argument, but I thought it was interesting.
Yes, of course the modern CPUs are designed with C in mind, and C-based benchmarks are always the first to be used to assess any new architectural change. So calling them 'C machines' is legitimate.
The worst bit of being a 'C machine' is the fact that the integers of unspecified nature and pointers are interchangeable, instead of forcing them to occupy the different register files. Another similar consequence is the lack of type tags, which could have been useful for many high level language features - GC, smarter caches pre-fetching the pointers from structures (most importantly for Lisp - pre-fetching the cons cells, depending on a way they've been accessed).
The key detail is economics, especially back in those days when gates were dear. One of the big things that LMI's Lambda improved on over the CADR was adding a TRW 16 bit multiply chip....
As these designs moved onto custom silicon, gates were at an extreme premium, and things like supporting the tagged architecture consumed resources that a general purpose chip could use profitably.
Now I don't think that matter much at all, if your CPU is a bit bigger you sacrifice a small fraction of caching. The lowRISC project suggests NRE costs are way down (collaboration helps a lot, as well as FPGAs for prototyping) and getting significant quantities of chips on competitive processes is not insane (don't know about mask fabrication costs, but they're evidently not a showstopper).
Oh, and lowRISC is looking to do two bits of tags per word, primarily for safety kludges for current not so safe languages.
The Novix FORTH chip was a pretty cool implementation of FORTH in hardware -- it had separate data and return stacks, which it could push or pop at the same time, so the compiler could combine several FORTH words into one opcode.
The Novix NC4016, formerly called the NC4000, is a 16-bit stack based microprocessor designed to execute primitives of the Forth programming language. It was the first single-chip Forth computer to be built, and originated many of the features found on subsequent designs. Intended applications are real time control and high speed execution of the Forth language for general purpose programming.
The NC4016 uses dedicated off-chip stack memories for the Data Stack and the Return Stack. Since three separate groups of pins connect the two stacks and the RAM data bus to the NC4016, it can execute most instructions in a single clock cycle.
The NC4000P is a single chip FORTH Engine based upon minimum
hardware concepts developed by Mr. Charles H. Moore. This
highly parallel machine architecture directly executes FORTH
primitives in a single clock cycle. The initial implementation
of this device is based upon a 4000 gate CMOS semicustom
integrated circuit operating at an 8 MHz clock rate.
But there isn't such a thing as a "general CPU", is there? Some are more general than others, but just like VM's, CPU's are designed and optimized for a specific flow. You're expected to adapt your problem to the architecture - tagged memory and different underlying architecture could make FP considerably faster (in an ideal world, not saying it'd be easy at all), but instead we have to find ways of shoehorning one paradigm on top of another.
On the other side of the spectrum there is also a whole bunch of heavily specialised architectures on a mass market - microcontrollers, DSP (think Hexagon and alike).
OTOH, GPUs are interesting in a sense that they're not confined in any backward compatibility considerations, and therefore this is an area where most of the architectural innovation is going to happen.
Heh, here I'm going to cheat and say "Forth is sufficiently magic that its success here is the exception that proves the rule!"
I'm very impressed by it. Not my cup of tea, Lisp is, then again they have more than a little bit in common (or so I thought when someone explained Forth to me in the mid-80s).
I've been avoiding mentioning ASICs since I've been defining the category I'm talking about as excluding them. Chips for sound cards definitely fit in the ASIC category as I count it, and have plenty of company. E.g. chips for DVD and now Blu-Ray players. The first generation of OPPO player I bought included an FPGA running licensed Anchor Bay IP, the volumes they anticipated selling didn't justify an ASIC.
Game consoles are a pretty good example, although how often do they adopt truly novel stuff vs. taking off the shelf CPU and GPU IP and making their own customized and cost reducible versions?
The PS-3's Cell is an interesting case, the effort certainly had ambitions beyond game consoles.
I'd argue it and the Amiga (the first PC I thought worth buying) are examples that prove this posited rule of general purpose beating specialized, both were in the end failures.
> I'd argue it and the Amiga (the first PC I thought worth buying) are examples that prove this posited rule of general purpose beating specialized, both were in the end failures.
Doom is often cited as one of the big factors in the downfall of the Amiga, and Doom was only possible because the PC world had embraced GPUs (as well as sound cards).
The Amiga did suffer to some extent from the tight integration, and the lack of easy expandability of the low end models, but the custom chips were vital for the success it did have early on - it would never have achieved success if they'd not been able to offload the CPU to the extent they did.
In addition to this, the Amiga also suffered with the transition to 3D games because of the bet on planar graphics. But this again was one of the things that made it possible for the Amiga to be as impressive as it was in earlier years.
That wouldn't have been a problem except that Commodore failed to realise early enough that 3D was coming, and that they badly needed a chunky graphics mode to stay competitive (and we got quick hacks like Akiko as stopgap measures - a custom chip in the CD32 console that in addition to the CD controller contained functionality to speed up chunky -> planar conversions to allow games to work on chunky modes internally)
Modern PC systems have a massive amount of specialized components, going far beyond what the Amiga ever did - if anything, the architecture of the modern PC validates a lot of the design choices made for the Amiga, by offloading far more work from the CPU (and indeed, adding far more CPUs - things like hard drives now often contain CPU cores a magnitude or more faster than the CPUs on the Amigas)
Valid arguments, and after buying the first model I didn't follow the Amiga story after it was clear it was going to fail.
Doom requiring GPUs would seem to be adding to the argument that for a very long time period as these things go, their specialization paid off given the volume in which they sell.
If/when GPUs get almost entirely subsumed into CPUs (I don't have any 3D requirements, and I'm typing this on my first, 1 year old computer with integrated into the CPU graphics), I don't think it'll invalidate their "success by specialization".
However, I think I'll still go with my thesis on the Amiga: the failure to gain sufficient market share and therefore volume, plus poor to bad management, doomed it just like the Lisp Machines. And perhaps the NRE costs on the chipset, perhaps the experience of doing it and facing having to do it again, deterred the managers from going for 3D.
I submit that the steady accumulation of all that logic into fewer and fewer ASICs, and much eventually into the CPU (nowadays memory controller and PCIe lanes) and a single chip "chipset", is just natural cost reduction aligned with (massive) volume sales. How to square that with the Amiga's chipset, I'd need to think about. Perhaps later.
What are you talking about? Doom never used any GPU since there weren't any in the PCs. It was banging bytes to the frame buffer. Doom could be faster on PC because one byte was one pixel. On Amiga, one had to use bitplanes which killed performance unless one could use the Blitter.
> Me, I want to see tagged architectures return (to enforce dynamic typing and make math fast by tagging each word in memory; also has potential for security, and of course helping GC).
I don't think that the return of tagged architectures would have significant performance benefits, see my reply in this old HN thread: https://news.ycombinator.com/item?id=4643520
IMO the things that would provide the biggest benefit for GC are hardware read and write barriers.
Not convincing. Tags (with separate register files for pointers) significantly reduce GC scanning time and simplify the precise GC implementation. And you don't really have to sacrifice your precious integer bits for your tags.
With modern hardware, I think it's not entirely obvious that specialized Lisp hardware would be a significant win. It's possible it would be, but not in the classic CISC-style approach of just baking important Lisp primitives into the instruction set. Without more, that would in practice just be implemented the way x86 is, translating the CISC-style instructions to RISC-style micro-ops, with no huge change to the basic CPU architecture. A more interesting question is whether significant architecture change would better suit some language paradigms.
There was an interesting series of posts on possibilities in that direction at Yosef K's blog:
The modern Lisp CPU may be almost the same as the modern OoO CPUs, with only a few additional bits (which would have been useful for things like JVM as well) - a hardware read and write barrier for the hardware-assisted GC, a tagged memory, a fully controllable cache prefetch and probably an additional scratchpad memory, and a smaller dedicated GC core. I'm currently working on such a design. ISA, besides the tagged memory, barriers and prefetching, does not matter much, can be a usual RISC thing.
It's not like Intel wanted that crude 8080-on-steroids to be the long-term future. They could dream about higher-level hardware too: http://en.wikipedia.org/wiki/Intel_iAPX_432
Many of the concepts that the Lisp ecosystem pioneered/popularized are, over time, migrating into the mainstream. When you stay in the industry long enough, you will indeed see that this is not unique to Lisp: everything old eventually becomes new again. This happens as what used to be constraints in the past morph into different concerns in the present.
Encapsulation, Protection, Ad Hoc Polymorphism, Parametric Polymorphism, Everything Is An Object, All You Can Do Is Send A Message, Specification Inheritance, Implementation inheritance/Reuse, Sum-Of-Product-Of-Function Pattern.
These are the only ones of which the news has come to Harvard, and there may be many others, but they haven't been discarvered. ;)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
https://www.youtube.com/watch?v=ubaX1Smg6pY&t=8m9s
EDIT added last para.