- The meme that we are adding more and more features into the docker binary is unfounded. Please, please, I ask that before repeating it you do your homework and ask for actual examples. For example 1.4 is coming out next week: it has 500+ commits and basically no new features. It's all bugfixes, refactoring and a general focus on quality. That's going to be the trend from now on
- Swarm and Machine are separate binaries. They are not part of the core docker runtime. You can use them in a completely orthogonal way.
- Swarm follows the "batteries included but removable" principle. We are not doing all things to all people! There is a default scheduling backend but we want to make it swappable. In fact we had Mesosphere on stage today as part of a partnership to make Mesos a first-class backend.
- there is an ongoing proposal to merge compose into the docker binary. I want to let the design discussion play out, but at the moment I'm leaning towards keeping it separate. Now's the time to comment if you care about this - that's how open design works :)
Yes, our blog post is buzzwordy and enterprise-sounding. I am torn on this, on the one hand it helps make the project credible in IT departments which associates that kind of language with seriousness. We may find that strange but if it helps with the adoption of Docker, then it benefits every Docker user and that's ok with me. On the other hand, it is definitely not popular on HN and has the opposite connotation of dorky pencil holder suit douchiness. Being from that tribe I share that instinctive reaction. But I also realize it's mostly psychological. I care less about the specific choice of words than the substance. And the substance here is that we launched a lot of new stuff today, and put a lot of effort in keeping the focus on a small, reliable runtime, composable tools which do one thing well, pluggability, open APIs, and playing nice with the ecosystem. Basically everything the community has been worrying about recently.
While it is scary when a company takes its initial success in the technology scene and uses it to expand into its verticals, this is not quite the same case as the Microsoft analogy...Docker is open source, after all. I think the backlash that CoreOS started with its Rocket / AppContainer announcement ahead of DockerCon has caused some knee-jerk reactions.
Does Docker's expansion into orchestration and clustering endanger CoreOS and maybe other players? Certainly. Is it the same approach? Definitely not. The CoreOS approach to containerization using Docker, and now Rocket, is novel. I haven't considered it for any of the architectures I'm presently building for companies - I prefer to let the operating system do what it does best, and build my services on top using containerization.
I was worried about what Docker's plans for clustering entailed leading up to today. I have been using Mesos for the better part of a year, and see it answering many problems that reach beyond the container model. I think people should do as you suggest, and re-evaluate this on two fronts: 1) Swarm is separate from Docker, so we can continue to deploy Docker through Mesosphere Marathon onto Mesos as we've been doing. 2) Because scheduling is pluggable - as the source code validates for us - we can work in Mesos as we see fit.
As for the proposal, I vote to keep Compose (and the fig codebase ;) ) separate. It will be much easier to add the hooks necessary to do cluster management between Compose and Swarm without risking regressions to Docker.
Also - what has become of the Docker Governance Advisory Board? I think the ratification of a standard / specification would go a long way to solidify trust in the industry (much like CoreOS is trying to do with their App Container proposal).
Have you participated in any other open source projects? All of them with any success in the community (that I can think of) have a monarchy or oligarchy at the head. Anyone may contribute, and a group of committers review and add if the contribution fits the project... who determines what the project and its roadmap? Usually a select few, driven by even fewer or just one. So I don't think it's necessarily unusual that Solomon heads it.
You are right -- perhaps I'm being unfair. It is Docker's right to run their project as they see fit.
I'm glad to see the new projects (swarm, at least) layered on top of Docker. It is good to see those sink/swim on their own. I was uncomfortable when Docker was (last week) going down the path of building everything into their existing binary.
You're more than fair. They made the rules, and I guess they can break the rules. But really, the value of the project lies in the community's continued support and backing of the project.
The good thing is that this is open-source Apache-licensed code. Easy enough to fork it if necessary, even if just temporarily while we wait for another project to mature and replace it.
Even if they were in the main binary, do the technical consequences really outweigh the politics?
Joe I can appreciate the drive to aggressively monetize a specific business model ;) but if you really feel what you've seen at Google should win, you'll have much more leverage taking a pedagogical approach. Appreciate that you have certain duties.... perhaps you might have had more agency at Facebook?
Benevolent dictator can work. But here Docker has said they want to make it possible for the project to be community led and run over time. Actions on the ground speak otherwise. Hard to restore trust once lost.
Agreed. I'm very confused about how the concerns from the advisory board are (not) being addressed in an open manner.
From reading the minutes, it seemed to me like one of the clear conclusions (based on concerns raised by big stakeholders) was that Docker Inc. was going to be firewalled from the Docker open-source project and that development work going forward was going to be done in a more open fashion.
All of these things have happened. Do you have specific evidence of the contrary?
I gave a presentation on this topic at Dockercon today, it talks about how the project is organized, how the company is firewalled, and recent improvements we're working on since the DGAB. I will share the link with you once the video is available.
Speaking for the DevOps, a large part of the job is being responsible for building trusted systems from trusted components.
I want to continue considering Docker to be part of that trusted stack, but from looking at the minutes, it seems that you
are willing to mislead even large partners like Google while on the record.
JB (Google): Docker is an anchor of a large ecosystem of projects. Docker Inc
bought Fig, is it a separate project or is it going to be in Docker?
SH: it should be explicit. The Fig guys make proposals and those are reviewed
as every body else's.
JB (Google): The idea is we will be more comfortable if we know how to
contribute both to Docker and the larger ecosystem.
SH: The day after Docker Inc. acquired Fig nothing changed at all, everything
is still in the Open. The reason for the acquisition was to make Docker more
user friendly. The experience should be awesome. The more people we can throw
at the problem the better.
VL: Understanding what is off limits or at least where the limits are would
be helpful. This is entirely driven by technology? We can collaborate "here"
but maybe we can compete "there".
BG: It's absolutely right, there is a large number of projects competing with
Docker Inc. and that's fine. Some folks want Docker to remain a packaging
format. We should add a statement there on clarifying this.
Just today, the "Host management" proposal initiated by a Fig developer was closed (by him) without any discussion after he released the new Docker Machine project (which AFAIK was initiated without any public discussion or warning.) https://github.com/docker/docker/issues/8681
Joe Beda is just trying to reduce the amount of work and risk his GCE team takes on supporting Docker. Solomon is re-asserting the Docker project's autonomy. There's no scandal here. Tension, yes, but Joe Beda is playing textbook strategies in the interest of Google's business model, and Solomon is giving a mostly textbook response.
The Docker team needs some space to execute on the opportunity before them. Space to try, fail, innovate. The end product will be better if they have that space and don't have to achieve equilibrium with too many stakeholders or worry about political microfriction when attempting big leaps.
The bleeding edge is bloody; if you need full-featured orchestration TODAY, your best bet is probably something older than Swarm, Fig, etc.
A container, while it can be many processes, in the case of Docker is just one process. So its just a better Operating System process...
Why then is there all this fuss about how these projects are organized? If its a good idea (which it is) won't Linus just reimplement(conform) all of these projects and move them into the kernel anyways?
That is not true. It can be just one process. It does not have to be.
> So its just a better Operating System process
No. That's just a tiny bit of what Docker provides, and even that part of what Docker provides is largely "packaging" of cgroups functionality. That was largely there with tools like LXC
The real value Docker provides is a means of building and managing images, and mediating things like capabilities and port mapping in a user friendly way
> won't Linus just reimplement(conform) all of these projects and move them into the kernel anyways?
Not a chance. There's no reason why these things needs to be done in kernel space. Some features that they may want, such as improvement to filesystem overlay support, or low level "plumbing" to make overlay networks more efficient, could end up in the kernel if someone comes up with something good, but there'd still be plenty to do for the userspace tools.
I think the concern from third-parties is not so much about bloat or whether everything is bundled in the same binary but that by defining "the way" of doing things, you are taking the oxygen out of other ecosystem partners that have alternate approaches for doing so. You are making it pluggable but by having your official implementation it becomes the "de facto" standard.
By defining a standard way of orchestrating you make life easier for users that can deploy with confidence the same environment across multiple clouds, etc. BUT the tradeoff is that you alienate another set of parties (providers are commoditized, ecosystem partners offering alternate orchestration tools feel marginalized). Secondarily, there are concerns whether your approach is better than others and that is too early to tell.
I am curious to see how all this plays out, lots of things at stake here and a very thick fog of war :)
As someone who has followed Docker since it was part of dotCloud, I can tell you that some standard practices will be great. I've seen dozens of different ways of doing similar things with Docker.
By creating these orthogonal solutions, Docker isn't taking the air out of anything. Do these solutions hurt Amazon's proprietary use cases? Or Google's? Or [insert managed Docker platform here]? No.
If anything, they just make it possible to use Docker without third parties. Maybe that's scary to third parties, but there's no reason a company shouldn't compete in its own ecosystem as long as it doesn't unfairly punish competition.
So if Docker acts like modern-day Microsoft for enterprise, where solutions are sold from many vendors with many mixes of products, then great.
If they act like Apple, where they crush and eliminate overlapping services, then I guess we'll all be switching to the CoreOS containers someday...
Anyone who has used Docker for more than a trivial app sees the need for orchestration. If the requirement is that obvious then it clearly needs to be part of the core.
At the moment I have to choose between multiple competing solutions. Competition is good when there are strong differentiating features.
In the "Orchestrate Docker" field the requirements are so clear after using it for your first project that it isn't at all clear what benefit competition, or solutions outside of the core Docker product suite gives.
We are using Docker to package an on-prem product.
As the ecosystem is recent and evolving quickly, we are looking at ways to handle multiple containers and deploy them at scale. And often, there are several solutions.
Having docker provide the set of components (and it's great to have multiple components for that) helps in defining a standard direction.
And as long as all the components are open source and can be deployed on our end, we are glad to use them. We would consider switching if somehow the docker tools become tied to a proprietary service or tool, which is unacceptable for our customers.
I'd also lean towards keeping compose a separate binary, particularly given the community's concern over Docker's feature-creep, and the fact that it uses a separate configuration file, and doesn't need to be the same binary for any particular reason.
Also, I filed an issue on the Github repo for this, but "machine" is already used by a command line tool on OS X and other BSDs.
Perhaps "docker-machine" and "docker-compose" are good compromises in both cases.
Imagine if git, svn, cvs all installed their own "checkout", "clone", "commit", etc. executables. It would become chaos if you had more than one installed. I prefer when various software suites keep their executables in their own namespace, if only for sake of future-proofing, to prevent naming conflicts.
There are always symlinks and/or shell aliases if you want to override that locally.
Well, first of all, thanks for Docker, it is a great product, love using it!
My only criticism is:
I find it scary and kind of shortsighted that docker (and even more so rocket) seem to neglect basic networking features. From what i can tell everything is based on the approach that you write your webapp with docker in mind, but i for one, would like to use my legacy applications with docker and i would like to write applications with full networking in my control. I really, really don't want docker to choose some IP for me. And i really really don't want my apps to talk over some random ports. I want control.
So far everything is still based on some random interfaces and ports that are passed around.
We hear you and we already started working on addressing just that. The goal is to define a networking interface (a set of functions) that networking plugins would satisfy. Again: "batteries included but removable". There's a lot of work to be done and details to be figured out, but I can assure you that networking is not left out, and is going in the right direction as well.
We will send out a proposal on Github as soon as we can. Stay tuned!
FYI today we had a design session on this topic with several members of the ecosystem (Weave, ClusterHQ, Socketplane, Tutum, VMWare) during Dockercon. As soon as there's something worthy of a proposal, we'll open it up for comment on the repo. I'm pretty excited about this.
Bingo! We looked at Docker for VoIP a while ago and it didn't appear like it was a good fit for such applications. To be fair, Azure had the same odd-sighted flaw, although they have a weak workaround with public IPs now.
People who don't understand how much utility these improvements provide can complain all day. Personally you've delivered exactly what I have needed quickly and, from my use, bug free.
My vote (not that it gets counted here) compose should definitely be merged.
Great job on all the rest, ignore the haters, they just prove you've made it!
No. There is a question on how to get machine to cleanly change which machine Docker talks to. The current answer is: standard dynamic config system in docker core, which machine plugs into to change values.
I think I got swarm and machine mixed up. Swarm seems to be tied to the CLI, because the command is "docker run", with additional settings. I think I am skimming too skimmily.
Pluggable scheduling and placement is a good move. It all looks like a straightforward operations research problem ... until you discover that you built a SPOF subject to the network fallacies.
> because the command is "docker run", with additional settings
The `-m` flag was already present in docker run. Swarm makes use of that flag to decide on which host to put a container. The `constraint:` setting is indeed new, but (afaik) the values behind it are not pre-defined, so if someone develops an alternative clustering-backend they should be able to make use of that for their needs.
In any case, Swarm will be pluggable, so other back ends are possible and can be developed by other parties.
The supposedly incorrect uses of the term are also correct -- even with the blessing of the original creator of the word:
"""In 2013 Dawkins characterized an Internet meme as being a meme deliberately altered by human creativity—distinguished from biological genes and Dawkins' pre-Internet concept of a meme which involved mutation by random change and spreading through accurate replication as in Darwinian selection. Dawkins explained that Internet memes are thus a "hijacking of the original idea," the very idea of a meme having mutated and evolved in this new direction."""
I think the community really ought to take a good minute to consider, beyond technical reasons, whether it really makes sense to so tightly tie the future of computing to a single for-profit company's quickly enlarging platform.
Someone below compared this to systemd - it's really more like your entire containerization operating system. And since you run everything via containers, it effectively is your operating system/platform.
So, clearly they (and CoreOS, etc.) will want to monetize their container operating system/platforms. But is it really a good idea to build the entire industry's concept and implementation of containers themselves on the back of a single company's implementation, when we know a healthy ecosystem would see a number of companies with competing implementations of container OS with varying degrees of compatibility, and hopefully eventually open standards.
I really am beginning to see the CoreOS guys point here - if Docker could have just stuck to running containers and doing that awesome, there would have been space for other companies to build out the ecosystem around that shared interoperable container format. But if Docker is now set on tightly bundling a toolchain for the container operating system around their format, suddenly it looks a lot more like they took a Microsoft embrace-extend-extinguish approach to LXC.
> it looks a lot more like they took a Microsoft embrace-extend-extinguish approach to LXC
That's overstating things slightly, since it appears no Docker employee has ever contributed a single line of code to the LXC implementation itself (that would be hard work, rather than bikeshedding userspace tools, after all). The kernel tree contains only one reference to a Docker bug, fixed by a Red Hat employee, while the LXC tree contains a single reference to a Docker bug, fixed by a Canonical employee who looks to be one of the LXC maintainers.
The reality is replacing Docker isn't all that hard, as we're now seeing with Rocket. The kernel interfaces aren't tied to it (hell, its clear from Git logs the LXC devs are barely even aware of it).
edit: It's simpler to look at Docker and Rocket for what they both are: commercial plays built on the work of others. That work hasn't magically disappeared somewhere, it still exists and is in use (albeit by a slightly less PR/buzz-aware side of the community).
A vendor-independent implementation of containers already exists, as it did long before Docker did. If people are serious about seeing the "container ecosystem" flourish, they should be contributing cash, employment offers, or employee time to the real people and projects doing the work (as opposed to publishing upset blog posts and writing fashionable Go code)
I'm pretty sure the CoreOS CTO, Brandon Phillips, has personally made many significant contributions to open source, just check his GitHub[1], and is a Linux kernel developer. He's been an open source contributor for a very long time.
Or it could mean as a funded company Docker has more resources than a low profile open source project like LXC to reach out and generate interest and adoption.
There is undeniable confusion about LXC and Docker with a lot of folks whose first introduction to containers is via Docker who seem to think LXC is 'low level kernel capabilities' as it is mistakenly referred to on the Docker website, and since Docker was based on LXC they at least should be clear what LXC is.
The fact that LXC is an advanced project baking since 2009, supported by Ubuntu since 2012 which provides perfectly usable Linux containers, wide choice of OS templates, features like unprivileged containers and is easier to use than Docker is often lost in the noise.
LXC provides you system containers, Docker takes that base that to provide app containers, and there is definitely interest and value in that but it's a single use case of Linux containers. Would you want to reduce a container to an app for all use cases?
To conflate a single use case to container technology itself is a mistake, apart from the fact that once you go down a custom container format you will need to expend engineering resources to figure out how to make a lot of things like clustering, services, apps, networking that expect a normal OS environment work with the constraints.
> Would you want to reduce a container to an app for all use cases?
Yes, I would. At least for the work I do, it's exactly what I require, and takes a lot of the work and thinking out of what I need to achieve. That's not a bad thing, and I'm not arguing that it's how it should be for everybody, but that's the best part about open-source, you can choose a different implementation or write your own on the same tooling :)
>it appears no Docker employee has ever contributed a single line of code to the LXC implementation itself (that would be hard work, rather than bikeshedding userspace tools, after all)
You keep using this word, bikeshedding. I don't think it means what you think it means.
TL;DR; it's about discussing/debating trivial details instead of the important characteristics of a system, not about working on easy stuff vs more hard programs.
> while neglecting the design of the power plant itself
I think what hosay123 is trying to say is that LXC is the power plant and the tooling around it is Docker, which runs in userspace. Note I'm not trying to say that, I'm just saying things.
But the first difference (with bikeshedding) is that bikeshedding is not "doing the tooling around the power plant instead of the plant itself" but spending time discussing and designing some insignificant detail instead of the power plant.
(That is: bikeshedding is getting lost in DEBATING the easy and incosequential details of an implemntation).
Docker is neither "lost in discussion" (they're building things, and a lot, and fast), nor a trivial detail (that would be e.g. LXC code's tabs vs spaces convention etc).
Actually, I'm going to say: thus the need for Cloud Foundry.
I work for Pivotal Labs and I'm secondment to the CF Buildpacks team, so I'm biased. And this shouldn't be construed as official opinion, it's just mine.
Cloud Foundry is led by Pivotal, but we run it openly. Anyone can follow our repos[1][2] and our Tracker projects. The entire platform is being signed over into an independent Foundation with more than 30 paid members[3] (including Docker Inc). The whole project is being written the Pivotal Labs way. Everything is TDD, everything is pair programmed.
If I had to bet a company on a platform, I'd bet it on us. We're building the first and only truly independent, truly open source, truly open core, truly multi-company PaaS that is available.
You can buy support and hosting from us, IBM, HP and a series of mid-tier providers right now. You can do it in the public cloud or in a disconnected datacentre.
Oh, and we're going to have baked-in Docker support with our next-gen executor (Diego), in addition to Warden system we developed before Docker was released.
The comparison with systemd is unfair. Docker wants to be "batteries included, but swappable/removable". If you don't like host management, orchestration, build, etc., you can disable that specific component and put another one; and none of those components are strictly necessary.
Contrast with systemd, where it's impossible to use anything else, and the attitude of the maintainers is "our way or the highway" when people beg them to continue to support alternatives.
Compare Docker to frameworks like Django or Rails, which come with everything you need (templating, ORM, url mapping, etc.) but where each thing is replaceable if you don't like it; versus Rocket which would be like Flask or Sinatra, which are smaller and require to be combined with other things to be useful. Nothing wrong with either approach; but if the comparison is right, we can expect Docker to provide "reasonable defaults", and some people building some specific apps to use Rocket because they just want to run things and they don't need build/orchestration/API/etc (or they need special versions of those components).
You can use Django as swappable libraries. I worked on some projects at Google that used Django for the request routing, templates, and helpers, but completely swapped out the ORM for Google's own RPC system. Jinja2 is basically the Django templating language pulled out into its own library; before it existed, people would just use django.template. Some folks just use the ORM and request routing and then stick a JSON serializer on top to send data to an Angular SPA.
I am listening. Walk me exactly through how you think we should support alternatives, and why you think we're not. I will work it out right here with you.
I'm well-acquainted with Docker's architecture and some of the ways it's used in the field. I wouldn't call it modular. It might be well-factored and even separated into multiple modes and repos, but that's not modularity; that's just good code.
When you ship batteries, people depend on the batteries and that means you can't really swap them when you want to because things stop fitting. It doesn't help that all of this is baked by default into a single monolithically versioned binary with an API whose documentation isn't nearly rigorous or stable enough to promote alternative implementations.
I like Docker or I wouldn't be here commenting, but you know what would make me love Docker? If every piece was pipeable CLI command.
I know this is a crazy rethinking of how Docker's APIs work, but I think that fact perfectly demonstrates my point about how un-modular Docker really is as far as its users are concerned.
FWIW, as a startup cofounder with a non-technical partner who likes to do design/copyediting tweaks, the ability to do "docker up" and have it bring the whole system up on Linux, Mac, and cloud is a huge sell. I know how pipes work and can memorize a half dozen commands, but my cofounder certainly does not, and any tweaks she can do on her own is work that I don't have to.
I don't think it's crazy. I think it's cool and your points completely valid.
A good question we have to ask is how do we get from where we are, to the desired end state that you describe? There's nothing stopping it from happening, it's a fork away with a good chance of upstream contribution.
Today that's through proposals and discussions in freely available on github, irc, and mailing lists for the docker project and which we call fire hose of information symbolically.
Maybe we're missing an additional avenue for input and creativity. What do you think?
Well, I think that was my limit right there. If the above message got downvoted, I really don't see any constructive way to have a conversation here. I think I tried.
Come say hi on irc if you want to talk some more. We (the 200-ish people from all horizons on #docker-dev) don't bite.
Speaking only for myself, while I have no significant beef with Docker, I've found the general tone of your comments to be slightly off-putting. If others feel the same way, that might explain the downvotes.
I think it boils down to the tension between HN as a place for uninvolved commenters to discuss articles, and as a place for the subjects of those articles to engage in that discussion. Not to slight your intentions, but a comment like "I will work it out right here with you." comes across as an attempt to wrest control of the conversational dynamic, not to mention a little confrontational. For better or for worse, that's something that doesn't really fly when you have an obvious vested interest.
This is not meant as criticism, just food for thought that might help explain the frosty reception you've been getting around here.
"slightly off-putting" Argh, we are in a forum, this is communication deprived of non-verbal cues. Just focus on the intent and the information. I think shykes deserves more than judging of his tone. I also think it is cool he is hanging out here managing (mis)information. Are you all jealous or something? You have the chance to ask anything you want to someone who is the driving force behind a project of which the implications are hard to overestimate. And you find his tone off-putting.
I'm just a biologist but if any of the big names in my field (say, Hans Clevers, is that a stretch?) would be approachable on a forum, man that would great!!
I read it differently. I read it as: "it seems you have a key issue but I disagree with you. However, if you clarify your issue I will stay here and discuss it in the open right now."
>comes across as an attempt to wrest control of the conversational dynamic
And why shouldn't he do that? He's the one who sweated his ass to create the program, the other guy is just some random user who got it for free (and open source) and complains for something.
I think this is the kind of thing that might be at issue: https://github.com/docker/docker/issues/6791 [1] (I realize that the ticket is not closed, I just bring it up as an example of something that I see as counter to commoditization and thus counter to my goals as a user.)
One of the issues that I personally have with docker (much as I love it) is that it also wants to be a process supervision "framework" (for lack of a better word). I don't want that, I want a reliable way to supervise a docker-started process from whatever supervisor daemon that I want (whether that be systemd, runit, or whatever). This is not really for ideological reasons -- I want something that integrates properly into my distribution of choice, not something that wants to be a system unto itself.
[1] ... I'm obviously not the submitter of this issue. I just stumbled upon it during a related search.
I understand, but the problem is that to "just run a container" Docker needs to manage global system state and synchronize with other docker instances. Right now that is done with the daemon. How do I do this without? CoreOS's answer is basically "systemd should do all that". But to me that is not an acceptable answer. I don't want to tie Docker to systemd. It's already too monolithic as it is. Do we really want to absorb the docker daemon's functionality into it too? Because that's exactly what CoreOS is proposing with Rocket. I think that's a flawed design and the opposite of composable.
I don't think there's any danger as long as everything is open and interchangeable, and you can steer clear of Docker (the company) even if you like Docker (the format). So far that's basically the case with all of the Docker projects.
Ideally in the future, Docker will become an HTTP for servers, with standardized and competing servers/clients/services. I like the idea of that future. Publically, the Docker folks seem open to it.
However, I do see where you're coming from. As a for profit Docker has every incentive (perhaps even fiduciary duty) to pull the good ol' technology bait-and-switch: get Docker on every server, and the create a Kafkaesque technology dilemma to squeeze the dollars out of everyone who bought in. Microsoft's playbook has plenty of tips on how to do this.
I guess the only solution as a Docker user is to be hypersensitive to any sign that Docker wants to start locking the technology to the company. When you can imagine the day you can't use Docker (the containers) without Docker (the company), it's time to run the other way fast.
But I can't see that day yet, and I hope I never do. And I hope Docker as a company can find a way to grow without using that oldest, sleaziest trick in the book.
We should probably note this 'shingler' account was created exactly at the same time this post was submitted to HN, and this is the account's first comment... in support of this article.
Docker's overreach seems to resemble the overreach of Joyent in the io.js world. It's really hard to regain trust and momentum once the community starts to question you; in economic terms this would be termed as "a spike in transaction costs." If I were Docker, my next project would be a meetup/presentation/etc explaining how my new initiatives are for the benefit of the community, rather than just self-serving wheel reinvention. This isn't a consumer-facing business; the opinions of concerned developers can make or break them.
> my next project would be a meetup/presentation/etc explaining how my new initiatives...
You mean like the conferences they held before they even had a viable product?
Docker has stampeded onto the scene with zero competition, and the Parent comment is totally right -- we should take a good minute and consider that we are head-first rushing to implement everywhere a product made and perpetuated by a for-profit company who's end goal is literally to be on every server and be the de facto implementation so that once they start to monetize the product, you will have little choice but to funnel support funds into their company.
That's petrifying to me, because it means if realized, my company will be at the whims of Docker, not the other way around.
Furthermore, the backlash from the Docker creator himself the other day on the announcement by CoreOS, it really seems Docker never anticipated ever having any competition in this space, and have taken active steps to ensure they are their own custom thing that is not compatible with other existing or future container implementations.
Perhaps this will change now, and they will work with CoreOS to clearly define a universal specification for a container which can be portable between any implementation, but signs show they don't feel it's in their company's best interest to do so (and honestly it isn't in their best interest, but it's in the community's best interest for sure).
> You mean like the conferences they held before they even had a viable product?
The conference was awesome and there was plenty to announce at that point. It certainly helped drive home the conceptualization of containerization for many.
> we should take a good minute and consider
You're right we should consider - except what you're doing is making charges like;
"we are head-first rushing", "perpetuated by a for-profit company", "my company will be at the whims of Docker"
And other fear in this thread without providing your audience with the context of:
- for profit companies backing an innumerable number of major technologies in a variety of fields since technology was a thing
- most of the development of Docker happens outside of Docker Inc
- the project has an independent governance board
- the project has been nothing but the epitome of successful transparent open source
If Docker ends up achieving a cohesive ecosystem of holistically designed pieces solving one of the most difficult unsolved problems (a class of problems, really) in modern computing benefiting so many then is it really a problem paying Docker Inc for first class support to all of that? I imagine there are already companies selling support for Docker other than Docker Inc
It seems like you're the one imagining there is going to be no competition, honestly.
> if Docker could have just stuck to running containers
Do you argue the same for Amazon with AWS? They should have just stuck to running VMs on EC2 backed by S3? Amazon should not have added databases, scaling, load balancing, caching, DNS, email, search, analytics, etc. and left that up to the community to provide? Do you argue that Amazon has taken an embrace-extend-extinguish approach to AWS?
A lot of people have this fear. Amazon is a quickly expanding platform with a growing level of lock-in and immense power. This isn't good for the ecosystem - a dominant company can charge a premium, and choice is good.
Full disclosure: I say this as a founder of a higher-level cloud service (Zencoder) that Amazon decided to compete with head-on. We're doing just fine, thanks (growing quickly, differentiated product), but Amazon is aggressively expanding upstream and is going to continue to do so.
If you looked at volume of commits it might tell a different story - I'd imagine commits by contributor would follow a power law, so you might well have a project where 5% of the contributors made more than 50% of the commits, for example.
That's a non-sequitur. Are you trying to suggest a relationship between an open-source project with many contributors and a requirement to avoid building a complete platform? If so, could you provide an argument behind your statement?
> I really am beginning to see the CoreOS guys point here - if Docker could have just stuck to running containers and doing that awesome, there would have been space for other companies to build out the ecosystem around that shared interoperable container format.
It blows my mind that on Hacker News of all places, people are suggesting that the Docker folk should not compete because it might upset some other companies. That's crazy.
Well, they did throw quite an embarrassing tantrum when CoreOS decided to compete with them. I don't think that Docker shouldn't compete, but it would be nice to see a little more separation between the various components.
> tie the future of computing to a single for-profit company's quickly enlarging platform
The 'future' of compute is ubiquitous trustworthy compute for all. A federation where no one entity controls a pool of power over a given layer of the stack. The layers that run on top of that layer will continue to divide and stratify themselves, as it always has been. They will also assuredly be owned by someone or something. My vote is the something.
I'm a little bit afraid about the fragmentation occurring in the container world right now. I felt like in the beginning I could rely on Docker being focused on containers and really making that a stable building block and utilise tools around that provided by industry leaders. Now Docker have thrown their own hat in the ring, creating a monopoly for themselves. Do you choose docker and their whole ecosystem? Do you pick something else off the shelve? How about Amazon ECS container service, CoreOS with their array of tools.
I don't feel like I can depend on any of these things, so I stick with the absolute bare minimum of what will build me a container. Which of these technologies will stay? Which will go? What will change as time passes? What will be deprecated?
In all honesty with Kubernetes talking about supporting Rocket and probably any other container technology that creeps up in the next few years, I'm leaning towards using that as the point of stability which I can deploy anywhere and know that I get the exact same API. Google, the leader in cluster management writing open source orchestration technology, think that's where I'll keep my focus.
> I felt like in the beginning I could rely on Docker being focused on containers
This whole "wheres docker going" thing is getting blown way out of proportion. Docker Swarm was built by ONLY 2 people on the docker team (https://github.com/docker/swarm/) and they are totally separate binaries. Thats like saying I cant use Google X anymore because Google is building Google Y...
Some of these considerations are valid (vendor lockin, etc), but they've been valid for a long time. Nothing changed today or the day rocket was launched.
Disclaimer: I like docker but I have no horse in this race, my only affiliation is using docker.
After this announcement. I am looking towards rocket more then docker for the future. They seem to have the building block concept down better then Docker who looks to be moving towards a VMWare style system where they are all things to all people.
I think what Redhat is doing with Atomic and OpenShift is really great. They are building some awesome stuff around Kubernetes however I feel like that is going to be entirely geared towards the enterprise space. Much like OpenStack it's very complicated and the barrier to entry is still quite high. When I looked at the docs I immediately had to go look at reference info for all this new terminology they had introduced. They'd basically ignored what had come out of industry usage and naming. But in saying that, I do hope they cause massive shifts in the enterprise game.
I have quite a bit of experience in the microservice and cluster management space and have started to prototype something much more accessible to the masses. I'll know within the space of 6-8 weeks whether it's actually going to work or not but nonetheless we need people who understand and use these technologies on a day to day basis in the general tech space.
The current version of OpenShift (2.X) is essentially Linux container based (selinux, cgroups, kernel namespaces). OpenShift 2.X has been running in production for years now (openshift.com). The reason something like Docker wasn't used is because nothing existed, so Red Hat had to invent something. From an app perspective it's fairly good for what it does.
Thanks for the correction, I was wrong. I do note that Warden uses a lot of the same primitives (as do several projects building on the facilities that arose or were repurposed for Linux-VServer, OpenVZ, LXC etc etc).
Building a microservices ecosystem. Starting with one click Cluster as a Service with Kubernetes on multiple cloud platforms. Then leveraging that to offer a microservices platform which gets you started extremely quickly much like Heroku but with the idea of deploying multiple services that coordinate to create something much larger.
Just a single data point, but I went to a Redhat talk and their demos had several failing bugs. They also clicked around a lot, and said things like 'well, you now created an ip block, then designated an ip from the pool, but to make that actually work you need to...'.
I'm not so sure Redhat will make things simple enough and "just work" for non-corporate clients.
Wonderful. We just containerized all of our apps and are in the process of choosing our approach for running and deploying them in a cluster.
Now what?
Flynn? Deis? Kubernetes? Mesos? Shipyard? Pure Fig instead? CoreOS, Serf, Maestro? Rather stay on AWS with Elastic Beanstalk or the new docker service?
Welcome to the party, Swarm and Compose. By now we are not even sure anymore if Docker itself is still the way to go, now that Rocket and LXD have arrived. I don't even have the time to compare all these options, respectively get a deeper look into architectural considerations.
What to decide by? Company backing? Because it's good or bad? Github stars? Deis for self-announcing it's 1.0, even if it's based on pre1.0 components or Flynn for being honest they're still in beta?
Honestly, I've rarely been as tired of new technologies as I have been by now. I could roll a dice as well. If you have a good and reasonable choice for me, let me know (I'm actually serious)
Where I work the answer is easy: We're holding off on moving to containers for anything other than local development work (it's faster than Vagrant, hooray). When AWS gets around to releasing their Docker support (beyond what Elastic Beanstalk does) with 1:n VM:container support we will move to using that along with the rest of Amazon's infrastructure (which we already use).
Basically, we're going to let Amazon do it for us. Makes it easier that way :)
I'd invite you to check out http://tutum.co , but then again, I'm one of the cofounders, so I'm 100% biased. Take my invitation with a grain of salt. Feedback welcomed. Cheers,
Through all the noise, this comment is exactly what I care about. For a new project, which tech's should I choose?
If I were Docker, I would organize the ecosystem for the end user on a nice clean website that explicitly lists the specific layers and technology options, some of which are from Docker, and some of which are from third-parties. Yes, they'll give mention to competitors, but at least it creates clarity and puts some meat behind their claims of "Open".
At present, I'm thinking of the following:
* CONTAINER: Stick w/ Docker since until a competing standard like Rocket is mature, everyone has to support Docker, even CoreOS
* CONTAINER MANAGEMENT: Use CoreOS. Per above, they have to support Docker until Rocket is fully baked. Then Rocket and CoreOS will probably have synergies you can't get with Docker / CoreOS. Also, from [1]:
These three [Docker] orchestration services are targeted
for general availability in Q2, 2015.
I honestly don't know what the other layers and decisions are yet. Perspective and clarification is welcome.
We are in a similar position as yourself and share your opinion. What we are essentially doing is:
1. reviewing our immediate requirements
2. doing a quick paper research for those that match
3. selecting a top five based on GitHub stars and helpful resources on the web that we can find
4. proceeding with a more complete technology assessment
We plan to make things as agnostic as possible so we can keep a watch on the space as things progress and if things change we can swap out a component for something else which may better meet our future requirements and/or have better long term mindshare or traction.
The 2 examples in Docker Swarm were Redis and MySQL.
From the announcement: "Docker Swarm provides high-availability and failover. Docker Swarm continuously health-checks the Docker daemon’s hosts and, should one suffer an outage, automatically rebalances by moving and re-starting the Docker containers from the failed host to a new one.".
Does anyone know how they'll handle the data? Both Redis and MySQL have various ways to deal with high availability e.g. Redis Sentinel, MySQL master / slave or MySQL multi master with Galera.
I'd like to see a reasonable answer to this. Because up until now, I've been using data-only containers to mount directories into these app containers (i.e. Redis and PostgreSQL). The fail over handling has been horrendous for me, because there's no easy way to migrate the data across machines, unless you setup multiple hot slaves or something. And this happens often with CoreOS updates on the alpha channel.
Ultimately, I gave up and created a separate Ubuntu VM to run as an NFS server. Every CoreOS instance mounts it, and then my data-only containers now map back to the NFS mount. This way, when CoreOS moves the Redis or PostgreSQL containers, it has the data available to it.
It's not my favourite setup, but it's worked well-enough this past week that I haven't had to manually correct things while on vacation.
I'm hopeful that someone smarter/more experienced can share a better solution.
Mounting your database storage volume via NFS seems like a surefire way to cause yourself pain down the road. You might want to review the following (old but still relevant) article to understand some of the pitfalls:
The tl;dr basically boils down to the fact that PostgreSQL and MySQL (or really any good database engine running on *NIX systems) make very strong assumptions about the POSIX-ness of their underlying filesystem: flock() is fast, sync() calls actually mean data has hit disk, etc.
Docker/CoreOS/etc. aren't a replacement for a good SAN or other reliable storage. If you value your data I'd suggest keeping your core database(s) on dedicated machines/VMs (ideally SSD-equipped and UPS-backed). If managing those is too much work, consider a managed cloud database; DynamoDB and RDS can stand in for Redis and Postgres, respectively.
My immediate problem is that my software is running on a dedicated server hosted on-site; I have Internet access, but everything is hosted and run on a single massive VMWare ESXi server. I don't have the benefit of cloud-based services like RDS. I could modify my architecture to utilize that instead, and that's something I've thought about doing.
As it stands, the VM server is UPS-backed, but does not run on SSDs. There is no SAN. If I were to fix the existing implementation, I would:
a) Add a secondary VM server as a redundant backup.
b) Add a SAN
However, I don't think I can justify the capital expenditures for that. So what I'll likely do is replace the NFS server with a dedicated PostgreSQL server (VM), and perhaps start thinking about moving the majority of the infrastructure out of the building and into the cloud to take advantage of things like RDS. The latter is even more important for scalability as we add more customers.
I've created a tool to help with migrating volume data: github.com/cpuguy83/docker-volumes and also this PR to help bring forward volume management within Docker: https://github.com/docker/docker/pull/8484
We are super interested in building this as a plugin for Swarm, and are trying to work with Docker to make sure the plugins system is suitable for us to be able to contribute it for Swarm users in general.
No idea how Docker Swarm handles it, but that the data locality problem for ephemeral containers seems to be the central focus of https://clusterhq.com/ (makers of Flocker).
Deis is using Ceph to store persistent data for containers. I don't know if it will be suitable for databases, but I like the idea. http://deis.io/deis-0-13-0-ha-data-store/
I believe to start off with, anything with volumes won't be moved... at least this was what was said during the POC demo given for hack day last month.
I think this sheds a little more light on the reasons CoreOS decided to start building the Rocket container runtime[1], and not tie it's destiny to being paired with Docker.
Does any one agree it's still too hard for dumb dumb developers like me? I'm on windows (boo hiss) so in the past I've tried to use boot2docker, but you can't just point your webserver container at a place on your local file system and say serve that please
You have to bring in some crazy storage file container which will serve it all via samba or something and then you need to figure out linking those containers together and then how the hell do you tell a web server "hey you, document root is over here on another container"
At this point I'm usually like fuck it we'll use some bad idea .exe web stack and develop as normal
I like the idea of containers, quicker smaller than vms, nice file system history going on but in practice
it isn't easy enough in my opinion
1. Statically compile your application so that it can run standalone. For ruby, python or java that means including the interpreter and any dynamic libraries. Hard at first, but once you have a build setup it's pretty straightforward
2. Bundle your application with its assets in a zip file or tarball
3. Make it so that your application has a well defined set of resources it uses that are isolated from other applications. For example with a database you might have a `your-app\data` folder where it stores the actual database. Also make sure you are careful with ports
4. Pass around configuration via environment variables that you hand to your application (ie: DATABASE_HOST=127.0.0.1)
With a setup like that you can build a sensible stack that runs anywhere. You don't need containers:
1. You don't need the protection: just don't write processes which clobber other processes. It's not that hard.
2. The reuse mechanism seems cool, but it comes with baggage. Which version of ubuntu are you starting with? Does it include the latest updates to shared libraries? If it does how do you know that your application will still run down the road? And if it doesn't, how are you keeping on top of security updates?
3. Containers, as envisioned by docker, are way overkill. Why do you need an entire ubuntu to run a simple web app?
You're not dumb, the problem is that Docker is (currently) a Unix technology and trying to have one foot in Unix and one foot in Windows is always awkward. Maybe wait for the native Windows version of Docker.
Maybe I'm just thick in the head, but one of the thing that continues to disappoint me about Docker is the size of the binaries. Wouldn't it be good if we could build the container a single time, and then ship that top-level changeset around? For example. If I build a 200mb binary on top of `ubuntu:latest` I would like to be able to just ship that 200mb around, instead of 200mb + ubuntu:latest (another ~167mb?). If you colocate many services in a single machine (say 10-12) the network of grabbing those tarballs makes Docker less appealing.
edit: Also, its inefficient to build this Dockerfile every single time on every single host, which is why I'm talking about shipping tars. You could have 30 hosts with these 12 containers running on each one.
Any plans on dealing with something like this in the future?
The idea is that you build the image and push it to a registry. The service hosts then only pull the layers they don't already have.
In practice, running a private registry is a pain (last I checked the official Docker image for it crashed on startup). I like what Rocket is doing here with filesets and plain old URLs.
Docker can import arbitrary layers from a tar file either via the command line or the api. The problem is there is no official way of getting a set of arbitrary layers.
That might not seem like a big deal, but when your image has something heavy like mono or java and pushes upwards of a gig or more running on a relatively puny cloud instance with poor I/O that adds up.
If you want to have a much more efficient workflow, you have to roll this yourself like we did by going direct to the file system (at least for export). This is a messy pain in the ass and I would not expect most people to do it.
I would be very happy if Docker stopped trying to shove the registry down our throats and gave us a model where we could substitute our own push/pull code that better utilized our existing infrastructure.
This is a case where Docker feels more monolithic than it needs to be and I would be happier if it was broken up into a set of smaller more independent tools (e.g. docker, docker-push, and docker-pull).
Would it surprise you to know we completely agree in theory that push and pull should not be reliant or used at all with the registry if a user so chooses? But what we do care about is when you docker pull or docker push you have a set of assumptions that are always true?
Leading questions, I know, but I couldn't agree with you more and I know I'm not alone.
If you don't know the truth - open source works a lot like other software projects. You gather feedback in as many different forums as possible make a guess at how to solve that, work with your developer communities and vested parties to come up with a solution iterate a bunch of times and hopefully get something out in users hands that doesn't completely suck.
So the question is - Who's going to work on what and in what order? The feedback is important and with enough it would get higher on the list. But someone has to make it happen. Or make a proposal on how it would work. That would be truly welcome. Let me know how I personally, and we collectively, can help.
Trust me, I know how it works. I had a pull request to do at least one part of this but it was never accepted. I'm not bitter about it, I don't care, it wasn't right for Docker at the time. We had to get something done to meet our commitments so we hacked it and moved on. Agreement in "theory" doesn't help when you have real commitments and limited resources.
> So the question is - Who's going to work on what and in what order? The feedback is important and with enough it would get higher on the list. But someone has to make it happen. Or make a proposal on how it would work. That would be truly welcome. Let me know how I personally, and we collectively, can help.
The community clearly desires a more stable and pluggable core, doesn't like the registry workflow, and desires a daemonless mode. If the discussion over the last few days hasn't woken the Docker team up to that fact, then I don't know what to say.
The new features are big and flashy so they get the big announcements, however, you should not be surprised that when a new announcement is dropped the community collectively responds "what about x y and z?"
I think a Roadmap to 2.0 is what is missing and would give the community the confidence that is currently lacking.
Docker push/pull only do the layers that arent already available. What we did was create a base image that has docker + our main base image (ubuntu + the packages we want) and then we ship builds on top of the base image which won't be pulled down again. Code builds are like 30mb shipped (pretty much just the code). Note you need your own registry for this.
Also familiarity with how union FSes work and using 'docker history' to trim container size makes it a lot easier.
I'm excited to see Docker continue to progress so quickly, but I'll admit to being more and more confused over how many components and services you have to contend with now. I'm sure I could sort out all of these names if I spent more time playing, but it's getting a little confusing to me.
There's a lot to be said for making something only do one thing and doing it well, but it starts getting tough to keep track of when you've got a bunch of somethings.
> confused over how many components and services you have to contend with now
You don't have to. It really depends on what you're trying to do. Using Docker alone, you'll be able to build and run containers, link them together to build a "stack" etc.
If you want to make building a stack (a group of containers that together form your application) easier, you can use an orchestration tool to automate this, for example, Fig, Crane, or now Compose. Or, create a bash script to do this; it's up to you.
If you want to build a cluster (run your containers distributed over several servers), you can do that with docker alone, but it will get hard to manage. You can build a tool for that (making use of the Docker API), or use an existing tool, like Flocker, Shipyard or now Swarm.
So if all you need is running a few containers on a single host, Docker alone may be enough for you, in that case you can safely ignore the other stuff for now.
> So if all you need is running a few containers on a single host, Docker alone may be enough for you, in that case you can safely ignore the other stuff for now.
I should have clarified on that earlier, but I'm interested in Docker for the more clustered approach. I don't really want to re-invent any wheels if I can't help it, so I'd be using existing tech.
Whew. That's kind of what I'm chaffing on. I could learn all of this, but it's a lot harder to casually understand how it all would potentially fit together.
> Whew. That's kind of what I'm chaffing on. I could learn all of this, but it's a lot harder to casually understand how it all would potentially fit together.
This is part of what the things mentioned in the announcement should help with. There's a clear need for clustering and linking, and so lots of people have built different tools to solve it. That's grand, but it's incredibly confusing coming into it. Particularly since tools vary from production ready to beta to "not actually implemented yet".
The aim here is to still allow people to come up with all kinds of different approaches but to have a set of components that work and are supported by docker. So that you can just get it and it works, and then start swapping bits in and out for the new hotness or some ultra-performant component/etc.
To clarify, I'm not asking for a monolithic stack. I like the modularity. It's just getting confusing to those that don't look at this stuff every day. It's more of an ergonomic issue than an approach issue.
There could be some simple solutions to this, mostly centering around education and the promotion of the most popular components. I don't have answers, here, but figured I'd share that it's getting a little confusing in case someone had ideas.
I fully agree, I find the whole ecosystem really confusing. Every time I look at it there's some new combination of things, but then one turns out to be alpha/beta ...
What I hope is that the production of these new docker 'blessed' tools will allow me to go to their homepage and see a series of "getting started" tutorials and easily installable tools so I can at least get going.
These aren't new projects... just rebranded versions of half-baked feature proposals that I thought were still being reviewed/discussed. I guess somewhere a decision was made to move forward regardless of community concerns?
Baking these features into Docker is the beginning of the end of Docker's Enterprise story. Moving forward with these proposals guarantees the rise of Rocket and other Enterprise focused containers. Docker is forking its own community here.
I have now rebased the host management branch on top of #8265 and squashed it:
https://github.com/bfirsh/docker/compare/host-management
Any pull requests should now be based on top of that. The driver interface hasn't changed, so it should be a trivial matter to rebase any existing pull requests. The main thing which has changed is that drivers are expected to set up identity auth for communication with the host. See this commit for an example of how to do so.
The old branch is here for reference.
Full update and preview builds coming soon."
1 day ago, a message from tianon, core Docker maintainer:
Has there been any progress on splitting the actual driver implementations out of the core binary?
As a heavy fig user, it seems compose is really just fig, but rewritten in Go and merged into Docker. It should be kept as a separate project, if modularity and a 'tight core' really is the long term plan for the future of Docker.
I'm at DockerCon and nothing that was shown is baked into Docker. These are all separate projects that use the standard docker APIs like every other tool does/can.
In fact they announced a partnership with Mesosphere that will swap Swarm out and replace it with Mesos as an example.
If it's an open/pluggable system why the need for these 'partnerships'? Any OSS project can just quickly hack in support for Docker, just as they've been doing for almost 2 years now. This is getting ridiculous.
- the latter is a company that naturally needs to be profitable.
In fact I'm surprised so many people find Docker Inc. developing a "platform" around Docker a change of direction, let alone unexpected.
It's nothing new and in fact I feel like Docker Inc choice is the "right" one: historically Commercial Open Source companies have had only a handful of choices to monetise: 1) selling support and services around the open source product, 2) going Open Core, 3) developing orthogonal, complementary commercial products around the main open source one and 4) be acquired :-D
RedHat is really the only one that managed to make option 1 work at scale and it looks like a black swan the longer time goes by. Option 2 was a bad idea to begin with a few years ago and I'm still surprised there are companies going for it today (I experienced it on my own skin). Option 4 is what it is.
So Option 3 is really the only reasonable way to go: keep the open source product really open source and make money with complementary products. I kind of expected this to be the way to go for Docker Inc all along, with a little niggle at the back of my mind fearing they would go for Open Core instead.
The advisory board is just that -- advisory. It has absolutely no teeth. The open source project is 100% owned by Docker, Inc. Solomon believes strongly in a "firewall" between OSS Docker and Docker, Inc -- but it breaks down in various places where it comes to any online service.
Examples:
* The docker hub gets special privileges in the image namespace. It isn't built on DNS but instead rooted in a namespace owned by Docker, Inc.
* The newly announced swarm depends on a discovery endpoint that (as far as I've seen) is closed source and undocumented.
I'd love to see the online parts of the OSS docker project have the same "firewall" as Solomon believe he holds for the OSS components.
With their (current) control of the main docker index and namespace, they could have stuck with a simple GitHub model (pay for private indexes) and would have been fine. With the community goodwill that they had, it would have been impossible to compete with them.
The reason more people aren't paying for private indexes at this point is because the service is still slow and unreliable, and the UI needs serious work. With their current funding levels, fixing those items shouldn't be a problem. For comparison, Quay.io was able to do it with just a few engineers.
They're just being greedy and overreaching at this point.
(disclaimer: I run technology / alliance partnerships for Docker)
1) Money is definitely not the case - docker is well capitalized. A special benefit of being in that situation is you don't have to do unnatural things like partner for money.
2) We welcome contributions from everyone, partners or not. Influence is gained by real contribution.
The reason we build partnerships is to ensure a few main things
#1 (and the biggest) Docker is made available on a wide variety of platforms, allowing developers and admins to work in native environments instead of fork-lifting to another just to try it out.
#2 Enable a network of services, products, systems integrator, IT vendors, etc. to have support, training, and other necessary things as they offer docker features in their products. This allows those who do not make containers and container services the core of their business, and instead focus on making/solving different problems.
I am more than happy to walk you or anyone else through partner strategy at any time. I'm easy to find.
would be great if the other Docker employees were as clear as you are about that.
Are you willing to share the contract details involved in these partner agreements? What do partners have to agree to in order to be an official partner?
> Are you willing to share the contract details involved in these partner agreements?
Of course I can't do that, but I can talk about the different contract types thematically in an appropriate forum, absolutely.
> What do partners have to agree to in order to be an official partner?
1) Not to fork the Docker project (in the negative context, i.e use Docker but call it something else)
2) To use the Docker API (and not a derivative implementation)
As a general, official technology partner, that's pretty much it. And, most of the time, we're more than happy to promote (especially smaller partners) to that status in good faith without any paper work.
> What about prioritization, you may ask?
The list I provided above in terms of recruitment/opportunity criteria? That's prioritized.
My team has to prioritize the tremendous interest from some of the largest as well as some of the smallest companies in the world
A guiding principle is that special attention paid to those who make a commitment (and have shown ) to contribute their learning upstream - either via code contribution, proposal, activity on IRC, etc. I/we spend a tremendous amount of time on all of the feedback channels (like this one) to know who is active and from there form a relationship. If you follow my activity on any of these forums, you'll probably see a lot of "hey what you're doing is awesome. lets chat more" That's usually how it starts.
I hope that helps, and my inbox/calendar/time is always open for a conversation. If this is interesting to you or others, I'm a pretty open book. Don't hesitate.
I'm excited to watch this battle between CoreOS and Docker heat up. I recently took a CoreOS/Docker-based system into production on AWS and there are definitely still some missing pieces. Swarm appears to be a slightly higher-level version of fleetd. Compose is something CoreOS is missing though.
They sound like a closed-source vendor at this point. I'm surprised to see an open-source project mention "ecosystem partners":
Each one is implemented with a “batteries included, but
removable” approach which, thanks to our orchestration
APIs, means they may be swapped-out for alternative
implementations from ecosystem partners designed for
particular use cases.
So if I have a startup working on an orchestration solution, what is the process to become an approved 'ecosystem partner'. Do I need to sign a NDA and pay for an approval process to get my stuff merged in?
Not sure. Never heard of an official partnership program either, so I'm interested to know details about how this partnership program works. Could be innocent, but something about it smells like a OSS shakedown to me.
Just 'cause it's open-source doesn't mean there aren't any politics involved in what gets merged or not.
An example:
lmctfy support was added by the Google GCE team a long long time ago and I attended a meetup where the GCE team submitted the pull request right there... it was never merged. Languished for months without any public review comments from Docker maintainers.
I'd never seen anything like this before. Here we have Google engineers integrating their work with Docker on their own time and being completely ignored. Embarrassing is a nice way to put it.
There may have been outside discussions and real issues that made merging a bad idea, but as an OSS project I expect those discussions to happen in the pull request, not in some business meeting. I'm sure any technical issues would have been addressed if there had been any. I'm also sure that the GCE team would have been more than happy to maintain their driver. Politics and open-source are a happy mix.
Part of the problem here could definitely be communication.
For whatever reason, it's been incredibly hard to follow what is going on
with the Docker project. Keeping info in one place would
definitely help.
I'm not able to find any details that support what
you're saying. It seems that in June Eric Brewer was
still publicly asking for libcontainer to merge in
LMCTFY support.
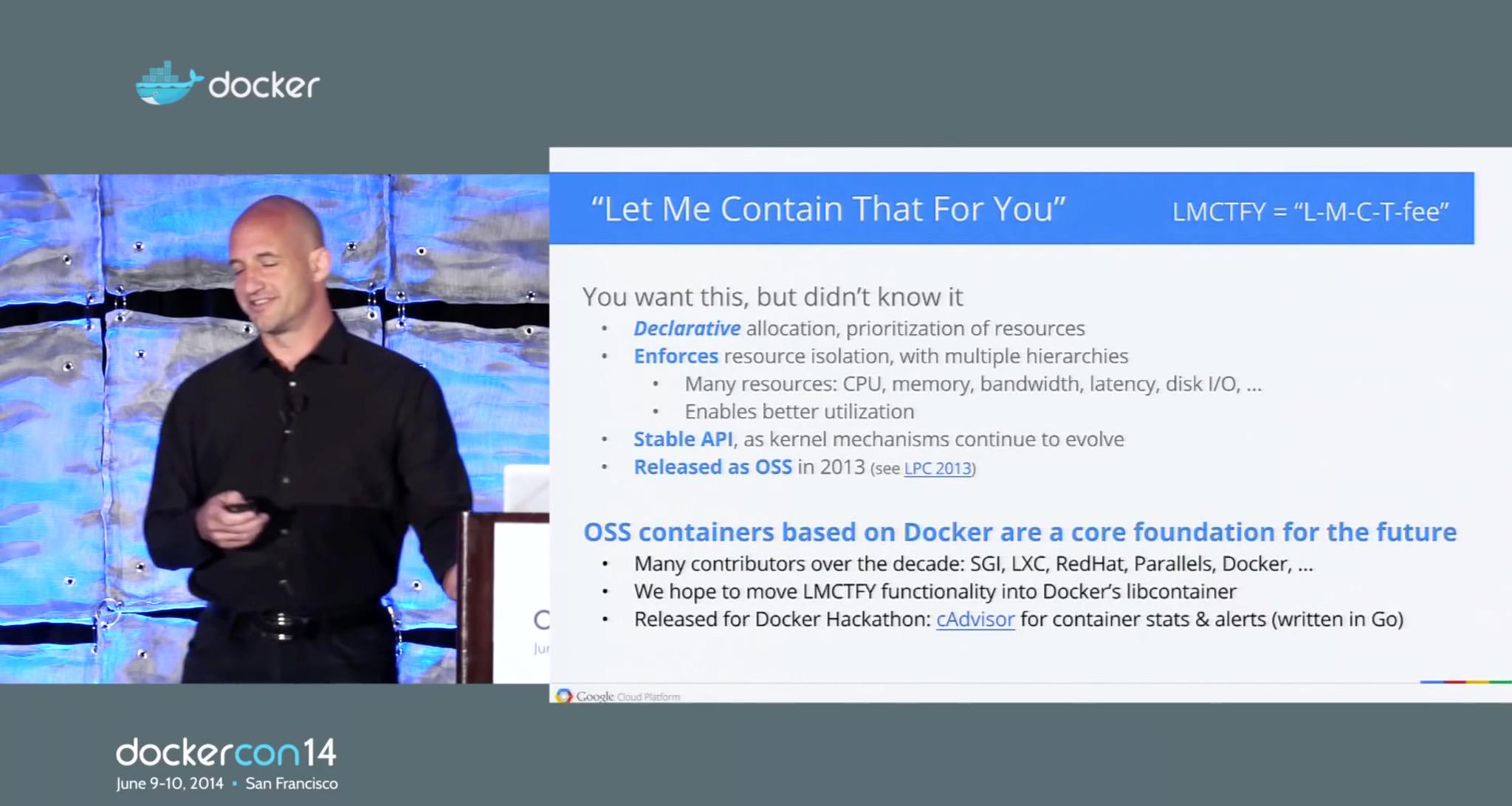
I definitely could be wrong, but looking at this screenshot from Eric's
June talk it looks like they were still trying to get it merged:
We’ve released an open-source tool called cAdvisor that
enables fine-grain statistics on resource usage for containers.
It tracks both instantaneous and historical stats for a wide
variety of resources, handles nested containers, and supports
both LMCTFY and Docker’s libcontainer. It’s written in Go with
the hope that we can move some of these tools into libcontainer
directly if people find them useful (as we have).
If this happened, it would be normal and expected for that to be noted on the PR/Issue Ticket. How can you expect someone say 6 months - 1 year from now to know this unless it's clearly documented? That is what the Issues system is for.
With this amount of buzz words needed to install and run an app I see a bright future for Go and its "all compiled in one, web-server included, ready to go" executable structure. I mean sure: you get automation and repeatability of installs but at what cost? You have to maintain all the buzz-word hoops that your app needs to be wrapped into - requiring what amounts to a full new job in medium sized software company. And you still need the sysadmin to actually make the servers work.
Mesos 0.20.0 adds the support for launching tasks that contains Docker images, with also a subset of Docker options supported while we plan on adding more in the future.
Users can either launch a Docker image as a Task, or as an Executor. The Docker Containerizer is translating Task/Executor Launch and Destroy calls to Docker CLI commands.
I haven't been reading Docker related news lately. Is there anything I should know if I already have my own working continuous deployment system made with Ansible, Jenkins and Docker? For example, it seems like I don't need Docker Machine if I already have my own Ansible recipes for provisioning.
The Raspberry Pi installation you get at Resin.io uses Docker on ARM and it works great! We also cross-compile containers in the cloud. Docker for ARM standalone is now available in several Linux Distro repos, Arch Linux is one I am aware of.
have used the resin.io docker images on arch on my pi. What I would love is a raspbian version as its just a super popular distro on raspi. I know its a bit of gridlock right now. It seems that its going into the jesse version of debian but the raspbian release of jesse isn't out the last time a checked (a couple weeks ago). I did try out lessbian - awesome name - on raspi and I am not recalling specifically why it didn't work out for me. I had some issue with the filesystem dependencies not being there and getting them was a pretty large undertaking (so much so that it would have been just as easy to do it on raspbian). Would love to contrib myself but right now i'm swamped and don't really have much expertise in either docker or arm. At least my experience should bring some clarity/insight into what I encountered.
Hey there. When we did Docker-on-ARM, we asked people to push their rpi-compatible containers to the Docker index with the rpi- prefix. Since then there have been many containers published, including several flavours of rpi-raspbian. There's nothing to stop you from packaging up your favourite distro and posting it on the Docker index.
totally, I think the painful part is prepping the underlying os with the filesystem dependencies as it requires modding the kernel? I could be way off though
Hi Nick, I'd love to get more info on how to get this conversation started. We've been doing quite a bit with Docker on ARM for a while now, have experience with systems in production, and we're even making early research into MIPS.
{kind=link}
- The meme that we are adding more and more features into the docker binary is unfounded. Please, please, I ask that before repeating it you do your homework and ask for actual examples. For example 1.4 is coming out next week: it has 500+ commits and basically no new features. It's all bugfixes, refactoring and a general focus on quality. That's going to be the trend from now on
- Swarm and Machine are separate binaries. They are not part of the core docker runtime. You can use them in a completely orthogonal way.
- Swarm follows the "batteries included but removable" principle. We are not doing all things to all people! There is a default scheduling backend but we want to make it swappable. In fact we had Mesosphere on stage today as part of a partnership to make Mesos a first-class backend.
- there is an ongoing proposal to merge compose into the docker binary. I want to let the design discussion play out, but at the moment I'm leaning towards keeping it separate. Now's the time to comment if you care about this - that's how open design works :)
Yes, our blog post is buzzwordy and enterprise-sounding. I am torn on this, on the one hand it helps make the project credible in IT departments which associates that kind of language with seriousness. We may find that strange but if it helps with the adoption of Docker, then it benefits every Docker user and that's ok with me. On the other hand, it is definitely not popular on HN and has the opposite connotation of dorky pencil holder suit douchiness. Being from that tribe I share that instinctive reaction. But I also realize it's mostly psychological. I care less about the specific choice of words than the substance. And the substance here is that we launched a lot of new stuff today, and put a lot of effort in keeping the focus on a small, reliable runtime, composable tools which do one thing well, pluggability, open APIs, and playing nice with the ecosystem. Basically everything the community has been worrying about recently.