People can read much faster than they can speak, and they can google a new words.
You can Ctrl+F arbitraly big text files for keywords. Good luck with doing the same with 2-hours-long video file or mp3. You will need to listen to the whole thing. That's what annoys me about the new trend to do tutorials as video.
You can easily diff text.
Text works with version control systems.
Text works with unix command line tools.
You can trivialy paste relevant fragments on wiki pages, in emails or IM discussions.
OK, there are so many advantages of text. I wholeheartedly agree and prefer plain text over most "smart" formats.
BUT.
I have this pet idea about source code. Text isn't the optimal format because a program is not a lineal thing, but closer to a tree structure.
Why have we settled on programs written in text? Pretty much for all the reasons you wrote and the fact that we've had bad experiences with other kind of formats in the past. Being able to fall back to plain text when things go wrong is very nice.
But it has its own sort of usability problems. There's an impedance mismatch between text and programs and sometimes it shows. Actually we don't see it more often because we tend to think that text is the way it is done, always was done and always will be done.
>Text isn't the optimal format because a program is not a lineal thing, but closer to a tree structure.
I can tell you what it's like from experience. The Interlisp D environment used a structure editor rather than a text editor. I found it infuriating and clumsy. Admittedly I had come from the emacs-infused PDP-10/Maclisp & Lispm world, so I gave it several months, but in the end I adapted an Emacs someone else had started and did all my editing in that.
I figure if this would work for any language it would be Lisp, and it didn't work for me. It sounds like a great idea, since if the editor's "buffer structure" is the program structure it's easy to write lambda functions to, say, support refactoring your code. But it was rarely convenient.
The other thing that didn't work for me was that it was of course a mouse-driven interface (this was PARC after all) and I found shifting my hand off the keyboard all the time slowed me down a lot too.
It's already done in most IDEs and you probably use it :)
Ctrl+click on method invocation - did it jumped to the declaration?
Click on some method name and choose "show all invocations" or sth like that. Here you have one of the possible tree views of code.
Another tree-view of code is visible when you have code folding feature enabled.
Another one - when you debug and show subfields of some variable.
Yes, it's nice to have these additional abstractions over plain text. But these abstractions are inherently leaky, and I much prefer to work with text files than with some binary format to fix the leaks.
It's already done in most IDEs and you probably use it :)
That's a kludge. "True" form is text and the the IDEs add a layers on top. The right way is making the tree be the canonical form and leave text just as an interchange format.
But these abstractions are inherently leaky...
Inherently. That's bold and you give no justification. Anyway I like how you prove my last paragraph. It's been conventional wisdom for so long that you consider text representation as the fundamental form and using a format closer to the real structure a leaky abstraction.
The tree would just give you code-folding for free. Callgraphs, searching for references etc would still need to be recalculated by the code indexer. The only advantage is - no parsing step.
Meanwhile you would need to rewrite all the universal text-based tools from scratch specifically for your particular binary format. And this almost never happens so people are left with no way to merge files (Oracle Forms I'm looking at you).
BTW - merging and diffing files is when the abstraction often leaks, too, or at least wants to leak.
For example - when you have 2 trees with every node the same, but root node changed from <interface> to <class>. I guess your tree-based tool shows the whole tree as a difference? What about when you wrap half of the tree in <namespace>?
Textual diff would be 2 lines in both examples.
There are many possible situations, and I admit that in some tree-based approach is better, but there are many situations where you need better granularity than is possible without leaking the lower level. With text format that lower level is human-readable, and you can automerge unsafely (but concisely) and leave fixing the result to human. With binary format if you couldn't detect concise description of the change - you just show "everything was deleted and that new file was added" which isn't particulary helpful to the person that merge changes.
Can you merge word documents or databases? There's certainly market for that.
Callgraphs, searching for references etc would still need to be recalculated by the code indexer.
The what? Sorry, I really don't know what you're talking about. If you want to introduce a reference, logical thing to do is checking it in the same moment.
The only advantage is - no parsing step.
There are many more, see my other reply to icebraining.
About tools, you seem to give more importance to diff than to write programs with a more powerful environment. I can't agree. Also I don't think creating a suitable diff for trees is a hard problem. I just need to convince Linus of the idea and he will write one in a couple of days :-)
Oh, my bad, so you write references into the sourcefiles - smart. Your code isn't a tree anymore, but a graph, but other than that it will work.
Of course you still need code indexers for reverse lookups. You can't write "I am called from a,b,c,..." to source files because printf would be several gigabytes and growing each second:) So you still need code indexer to look up the code graphs in your workspace and build the index where this is called from.
Regarding the diff/merge tooling - IMHO it's much more important than powerful editor. If my company forced me to write code in mcedit I could live with that. I would quit straight away if we had no version control, no matter the IDE we would use. I worked for a short time in oracle forms and I won't do that again.
Re: merging of trees - you keep references in the trees so it's not a tree anymore, but graph possibly with cycles - makes it even harder to merge them properly (and you can't do unsafe merges because people won't fix them if it's binary format).
you keep references in the trees so it's not a tree anymore, but graph possibly with cycles
Cycles, why? Tree+links can be treated as a tree visually.
Edit: Oh, I see what you meant with indexer. That information would be in memory. In the database it's stored in just one direction. When loaded it expands bidirectionally.
Visualy it's not a problem. But now you need to maintain the links at all times. So all the operations must be aware of the whole program calltree. I think this could cause problems, especially when linking across libraries boundary, doing dependency injection, reflection etc, but I may be wrong.
Would like to see it implemented out of curiosity. My mine problem with merging trees could be solved by @pshc idea so maybe it could work?
The key to merging trees is that your editor generates the diff on the fly as you write—your editor's undo/redo stack and your version control system become one and the same. Every time you add, move, copy, switch out, or delete a node, the editor notes the operation on your delta log. When you push your code externally, you're really just shipping the log.
With these semantic deltas, merging should be highly unambiguous and automatable, even in degenerate cases.
Hm, the history will be dirty with abandoned experiments etc, but so what - great idea. I'd like to use that system for a while, but I'm still not sure if it will work.
I remember using jbpm graph language - it had nice graphical editor, but we still switched to xml view to very often, because it was much faster to work with text.
Maybe it's just a matter of proper tools, but I can't imagine how you allow graphic language to do this for example:
sed s/foo\("bar", ([a-Z0-9]+), "baz"\)/foo\(\1\); bar\(\1\); baz\(\1\);/g
When I look at that line, my brain sees its structure, the different layers... :) It is totally representable without restoring to plaintext. With good fundamentals (ADTs) and good UX (an editor that looks like a text editor but is so much more) we can make it work.
That's a kludge. "True" form is text and the the IDEs add a layers on top.
Why is text the "true" form? What's the difference between an IDE that uses text as the "true" form and one which uses a tree as the "true" form but uses text as the UI and serialization format?
The difference is that the program is currently written as text and passed to the compiler, that expects text. The IDEs make a parallel construction to offer some goodies to the programmer.
How I think it should be: the IDE would actually do the syntax checking and reference resolving work, so any program you have written is in fact pre-validated.
There would be performance enhancements, but that's not the only advantage. One example that comes quickly to mind is applying macros, writing GUI generation wizards based on DB schema and in general applying "DRY".
How I think it should be: the IDE would actually do the syntax checking and reference resolving work, so any program you have written is in fact pre-validated.
But IDEs already do that. An example I'm familiar with is Java on Eclipse - it validates the code as you're writing it and marking compilation errors. Your others example have been done as well.
You're right that you need an AST to do the properly, but when there's a cheap and reliable way to convert a blob of text to an AST - parsing - the distinction is somewhat irrelevant.
It would be nice to have an IDE that surfaced something like the AST. Of course lots do to some extent, but I bet there is room for improvement here. This also seems like a place where Lisp would have an advantage since the syntax is so transparent.
For readers of yesterday's article about whether all the "easy" stuff has already been accomplished, here is an easy-to-read survey of the state of the art in diffing trees:
That sounds like a pretty interesting topic to research! And I note that his oldest citation is from 1997, and most are from the last ten years. He also briefly mentions "operational transformation," which I agree seems related and is another area of ongoing research. Both topics seem like they would have lots of practical applications, but right now the general-purpose tooling is weak or doesn't exist. So there is room not just for research but also for folks to implement that research.
Our ‘plain text’ is unfortunately not up to the task of representing all human written text; I'm thinking specifically of traditional mathematical notation, which is also a tree structure represented in two dimensions, and ancestral to programming notation, in that we first squeezed mathematical notation down to one dimension¹ and then augmented it with notations for control flow.
¹with a few forgotten exceptions like the Klerer-May system.
Totally agree! Plaintext is an unnormalized form of program code, and working in it generates all sorts of artificial problems. I've started various pet projects to try to be able to edit the AST naturally, but haven't seen much success yet. The UX is really difficult.
I think the Light Table team is trying to do this now with Eve, although it sounds like they are turning it into something even more revolutionary but further from textual visualization.
Counterpoints to show that it is just a compromise: The complexity of unicode, collation, encoding, translation, language.
However you're 100% right!
Our application actually used text files on a network share with an indexer over the top as the database engine a long time ago. It worked really well and integrated with NT security and file locking for concurrency control, plus it was very easy to back up. A work of genius. However, NTFS doesn't scale well with lots of small files as it stores them in the MFT so it fell off a cliff eventually.
Counter-counterpoint: all of your counterpoints exist or have equivalents in every other form of communication. You swap unicode (which is nearly universally agreed on) for H.264/Theora/VP8 and AAC/Vorbis/Opus, and you still have to deal with collation and translation/language (which, without transcription to text first, is pretty hard).
Yeah we do that now. We store them in a big file in pages that contain rows and an externally visible network process allows us to manipulate the things.
"You can easily diff text. Text works with version control systems."
Yes, yes, a thousand times yes.
It is very strange to me how hard it seems to be to convey this to almost anyone who has not experienced it in serious computer programming. E.g., a few times I talked about it with lawyers who work on complex documents, and got nowhere. And occasionally I have even run into subcultures of programmers who didn't get it (and/or, relatedly, the power of build-automation tools like "make").
There's no simple standard one, but there are a lot of solutions. The most basic is that MS Word can open two files and show you the differences.
Then there are various "document management systems". Sharepoint has a lot of features for revision tracking. There are multiple Salesforce based solutions.
So there are plenty of products in that market. I don't know if any of them are good. Sharepoint usually works well if you're already using Active Directory.
The one advantage of video tutorials is that they keep the viewer's attention more easily, particularly for viewers that aren't proficient with text searching and making mental summaries. Some people will get through the text, but without varied sensorial anchors getting stored in their memory they are left feeling confused, like they failed to grasp it as a whole (even if they actually did.)
> The one advantage of video tutorials is that they keep the viewer's attention more easily
Not mine. The information per unit of time is so low so my mind start to drift or I start doing something else and forget about the video. Much prefer text that I can skim and find the parts that are relevant to what I need to do and simply skip the sections that seems to be most fluff.
Agreed. I actually run all my 'speech' (e.g. presentation, tutorial etc) videos at 1.5x or 2x. Cutting a 30 minute video down to 15 is really, really awesome. Particularly when the guy speaks slowly, when he already speaks fast I'll do 1.25x or 1.5x.
I do this on youtube and things like treehouse. The reason I tend to watch youtube on my tablet in the browser and not the app is because the app doesn't allow this and my brain goes numb.
That having been said, I really love video for some things. For example, I'd much rather listen to Greenwald's speech at Brown on civil liberties than read the equivalent article. I tend to clean my room or play Pro Evolution Soccer while doing so and somehow that works brilliantly. I can't quite keep the same concentration when I read for 30 minutes.
But it really depends. If I want to look up some code documentation, that format is a billion times better in text than video. If I'm somewhat familiar with the topic, know what I'm looking for, the ability to easily skip over introductions, side topics and history and just Ctrl+F for e.g. a piece of code, it can save an order of magnitude of time. I tend to like videos for things I'm wholly unfamiliar with and want to listen to from start to finish, which frankly is pretty limited.
Playback at 1.5x or 2x makes an even bigger difference for audio books. A 20 hour audio book suddenly becomes "just" 10 hours, yet it is still understandable.
Video seems to be popular with younger people. I believe this was discussed on HN a while ago. It might also explain the enormous abundance of frighteningly long videos going over the most simple things. My 8 year old daughter regularly makes 20-60+ minute videos about play sessions (dolls, LEGO, Play-Doh - not that LEGO isn't fantastic, but there's a limit...). YouTube seems filled with similar stuff. I've seen 10+ minute videos that are really just about how to type tracert in a Windows command prompt. Someone apparently watches this stuff.
There's also the people that like having videos running while doing something else. I find this to be a disturbing habit, especially when it's done advertisement laden TV nonsense. But people seem to enjoy it.
I find video to be extremely useful for learning something new. For example, when learning math, I find Khan Academy's video lecture to be much more useful than reading the exact same thing out of a textbook.
I guess having something running in the background saturates your mind better? I certainly do it, switching from silence to music to lets plays to episodes of QI to MOOC lectures depending on how mentally engaging whatever i'm actually doing is at the moment. Otherwise my mind wanders off the topic at hand and i end up browsing hackernews for far too long.
Sitting at a computer means that there's about 10 possible distractions for me at a given moment, and if I want to do a consistent stretch of actual work, i just happen to need some background noise.
The only thing is the familiarity. If you've heard the song or watched the video a few times, it no longer interrupts focus and actually helps improve it.
An other example are music videos where they show you how to play a certain thing on an instrument. It takes 30 minutes for something that would take two sheets of music notation.
I really think many such videos are a step backward as far as carrying information goes.
I don't even start the video. They are almost always just marketing and hyperbole anyway. I assume that if they went through all the troubles of creating a video they must also have the information in much-easier-to-produce text form. This has come back to bite me only a few times when somebody points out information in an introduction video that is not covered in the "Introduction" page of the manual, but I consider the win of not having to sit through boring hour-long sales pitches much greater than the abysmal information loss.
Video can be by-product of internal training, I often suggest we record such meetings for people that were sick/fture workers. It's better than nothing.
The big thing with text is the ease of changing which piece of information you're consuming. Anything that's on the same page is an eye-movement away, which is the cheapest action a human can take. For a video, you have to interact with the controls and hope you get to the right place.
> text alone is not nice either. Good luck describing a complex design, I much prefer a diagram.
If you look at a detailed diagram of a complex design, it is even worse than text. I consider myself pretty good at spacial intelligence (Before discovering computers, I was leaning towards mechanical engineering and took 4 years of technical drawing at middle school level, not to mention my lifelong hobby: drawing/sketching), yet give me a call-graph with more than a hundred elements in it and my head will start aching in no time.
If there are high quality diagrams that represent any complex entity in a relatively accurate way is only a consequence of the fact that some (probably)human intelligence has devoted a significant amount of time to synthesize the essence of the problem at hand, abstract the irrelevant details away, and use a highly symbolic representation to communicate the results to others.
You can do that with text (it is called summarizing), but it requires more training for both the producer and the consumers to do it effectively, which takes us to the next point.
> Text can also be ambiguous and it requires more attention than a video
Video and other graphical media helps to lower the threshold to communicate this summarized bits of information, which has both advantages and disadvantages. If there are social advantages to communicate some information to the general population, then significant amounts of effort should be devoted to making the message as digestible as possible (without losing to much accuracy).
However, if you rely on this methods to train the professionals, you will end up with a bunch of marginally competent fools that are not capable of grasping just how much more learning they are missing. Then, they will take over the training of the next generations and knowledge loss is practically inevitable.
There are cases where precision is required, and anything that lowers the attention threshold is more a bug than a feature.
"If you look at a detailed diagram of a complex design, it is even worse than text."
Not necessarily. (Or horses for courses, or YMMV, or however you want to put it.) For some kinds of things, diagrams seem to do awfully well. Not all kinds of things, there are plenty of people who overuse diagrams, but some kinds of things.
E.g., consider the success of Feynman diagrams. They're at the edge of my expertise (I did a Ph. D. thesis on QM calculations, but not the kind that uses them) so I'm not 100% confident of this, but I have the strong impression that no one has developed a textual form that represents those relationships in a way that most people find comparably clear.
Or consider the humble "graph" (in the common usage, not the math "graph theory" usage). I do not want to deal with the text replacement of a nontrivial scatter plot in a typical experimental paper, or a diagram of a clever waveform in an radar ECM monograph.
Or consider the humble map (again in ordinary usage, not math usage) of e.g. Florida or the US interstate highway system.
Electronic circuit diagrams, medium-complexity Venn diagrams, and probabilistic inference networks also seem to be cases where diagrams can be hard to beat.
Wouldn't that mean that you are incapable of reading text out loud at a normal pace? That seems unlikely for a hackernews visitor, unless there is something impeding you like dyslexia or poor vision.
I think this is a common issue when reading materials not in your native language. I can read a book written in French at least twice faster than the same book written in English, even though I use English daily and consider myself fluent.
Depends how you use foreign language. I mostly read and write English, I can read it almost as fast as Polish, on the other hand my pronounciation is still bad.
I think the more general rule is that you write slower than you speak.
Speaking is a great form of communication when you are live with someone, but it is a frustrating way to get a one way conversation because as all the other posts say, it is not index-able and I definitely don't want to listen to someone drone on at me about stuff I don't consider important.
I agree that text is undervalued in our current media happy era; I say this as someone who uses terminal applications as much as possible (email, twitter, accounting, programming, etc. - I secretly pray for a return of the text only internet)
On the other hand, there are things that pictures can convey in ways that plain text couldn't approximate.
Just looking at this, in half a minute or so, you get a pretty good idea of the quantities involved, how they evolved over time, how they are linked together, etc. Conveying the same information with pure text would be much more lengthy.
I'm not going to make an entire case for this right here - just read Edward Tufte's books if you aren't too familiar with those ideas.
I'm a huge fan of Tufte, but even he would probably concede that quite a bit of text is needed to explain the nuances and details of the Minard graphic. I mean, hell, I sat through one of his day-long seminars and the part about Minard was not short.
In any case, the OP wouldn't disagree with you...there are things for which imagery beats text (notably, maps)...but otherwise, use text. And still, you can get pretty far with just a textual description. And even for imagery, text is still an essential component for conveying information...Try going through a gallery of World Press Photo winners without reading any of the captions, for example.
> there are things for which imagery beats text (notably, maps)
You are at the southern edge of a great cavern. To the south across a shallow ford is a dark tunnel which looks like it was once enlarged and smoothed. To the north a narrow path winds among stalagmites. Dim light illuminates the cavern.
> go south
You have moved into a dark place.
It is pitch black. You are likely to be eaten by a grue.
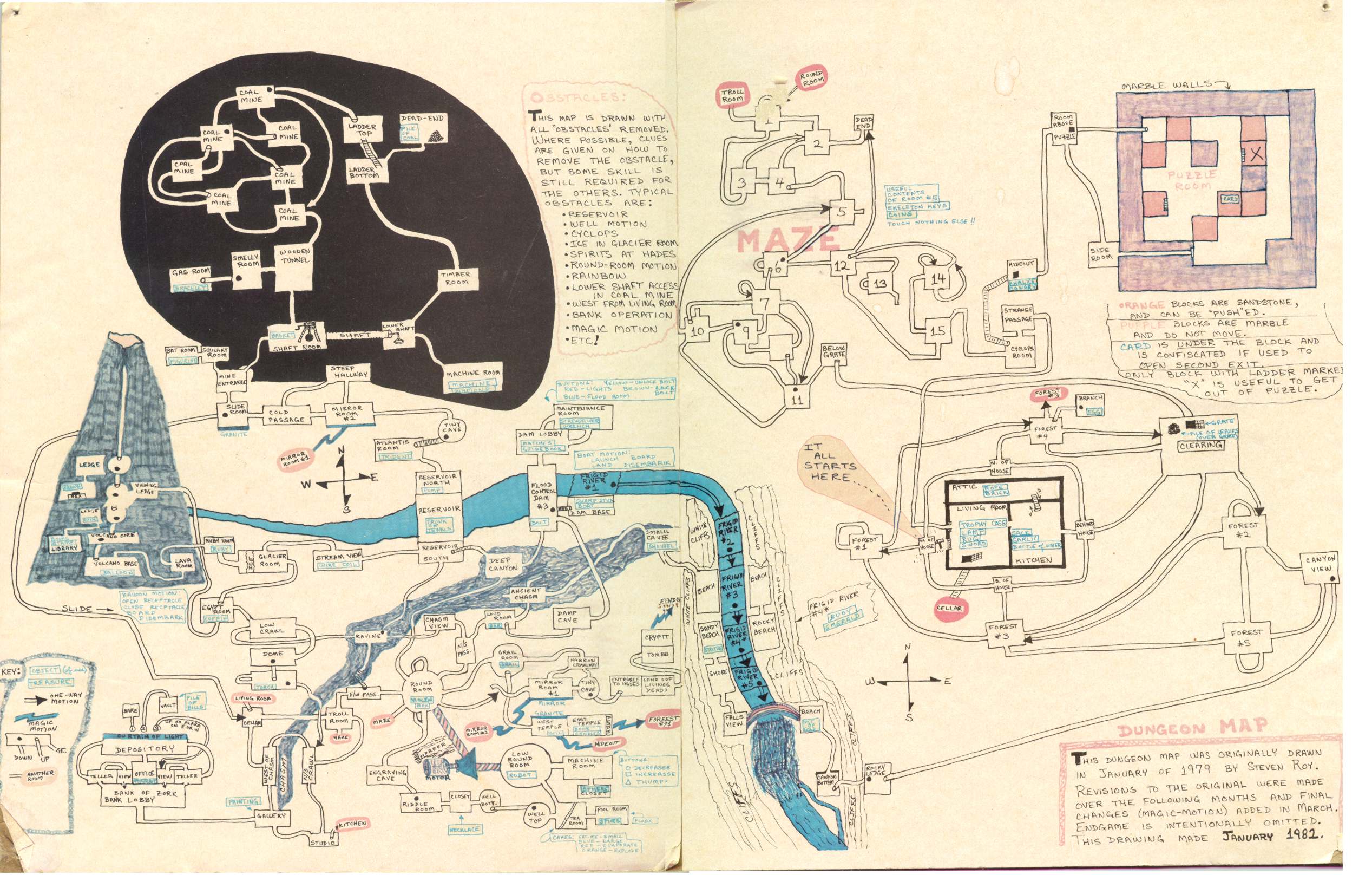
Even here graphics can help. You're probably familiar with this: http://almy.us/image/dungeon.jpg Drawing maps - visualizing what is conveyed in text in other ways in general - can be rewarding and useful.
I agree, the wikipedia example is especially strained, sure you can not represent that sentence clearly in picture, but can you represent Mona Lisa or Beethoven's 5th in text? Different types of representations are used for different things, sometimes they overlap and one is more efficient than the other and yes text has been pretty useful.
I'd argue that the moment we're not trying to convey emotional impact, but instead, raw information, text wins even in those cases.
Text is a very compact digital form, which is excellent for copying, splicing, recombining, algorithmic parsing, etc. Our computers are essentially, even in the case of MP3 or JPEG formats, storing it as a textual string and only at the very end, converting it back to images or sound.
The primary uses for non-string/text based formats (and encoding schemes related to those) is when we're trying to get our (or others') brains to react in a particular emotional manner, for which it obviously makes sense to poke the right buttons.
For musically gifted people who read sheet music every day, I have heard that they start to hear scores in their head while reading them, and that it's not so different than reading words. So in the case of classical music, the comparison to text is quite applicable. Shakespeare is almost unintelligible to me until I see it performed. I see no difference between this and a textually encoded symphony.
> 39. Re graphics: A picture is worth 10K words - but only those to describe the picture. Hardly any sets of 10K words can be adequately described with pictures.
> Text is the most efficient communication technology. By orders of magnitude. This blog post is likely to take perhaps 5000 bytes of storage, and could compress down to maybe 2000; by comparison the following 20-pixel-square image of the silhouette of a tweeting bird takes 4000 bytes: <Twitter Logo Here>.
My reaction when reading this was, "Yeah, but that's because you encoded it in PNG. That's a 'good-enough' encoding, but you can definitely make it more efficient by making it an SVG, since that image is of the kind that's ideal for vector graphics." And then I remembered SVG is a text-based image format.
Touché, frog hop. Touché.
Adding to the point: karma system on sites such as Reddit has incentivized converting text into images, because text posts don't get karma. For example, r/quotesporn[1] (safe for work) has many more users and quotes than r/quotes[2] which allows only text.
As a collector of quotes, this annoys me to no end, because I can't copy/paste the quotes into my personal quotes collection.
My reaction was: "20x20 pixels = 400 pixels so he's taking 10 bits for each pixel; no way should that be happening". So I copied the image into paint.net (I happen to be on a Windows box here) and told it to save it as a PNG. 998 bytes.
(I think it takes up 4k on my HD, but that's because of filesystem inefficiency; it would take up 4k if it were a text file just saying "tweet", too.)
I do agree with the general point, though: for most purposes 998 bytes of text (more if compressed) will tell you more than that little tweeting-bird image.
Doug Engelbart of Mother of All Demos fame talked a lot about artifacts. Books are an artifact of paper and text. WISIWYG is an artifact of print media.
The technology of the medium determines the best way to convey information through it. And on top of that, whatever people are used to may influence what they do in a newer medium. For example we write to imitate speech. We use books on screens and try to recreate the world of print with WISIWYG design tools.
Text may be an evolutionary winner so far, but it is by no means some ideal artifact for communicating when computers are widespread.
Yes. There are few serious attempts to come up with better artifacts because we're so used to existing ones.
And another point of Doug is we're too lazy to learn complex new artifacts. Reading and writing takes a while but it's worth it. If someone comes up with a better idea that needs time to master it will be a hard road ahead, people like short learning curves when dealing with computers.
On a small scale I do think we have been developing new ways of expressing and communicating though. Smileys to me are a good example of this, but you can even include the 'x is typing a message' and 'read at <time>'.
While there is no universal consensus on what exactly this kind of 'information' means, within specific groups (and ages) they can convey a lot.
I've been chatting since I was fifteen or so, and to me and many people I chat with, a particular smiley, or the 'is typing' message can have a lot of meaning. I even find myself actively 'manipulating' this information at times: I might intentional start and stop typing at times as an analogue to the face-to-face act of saying 'hmm', looking away thoughtfully and not answering immediately.
I suspect all this meaning encoded in non-text things (practically speaking) is even more common among younger people.
Yes, and this carries over very well when talking about code and programs.
Whenever I hear about the stories of the potential of graphical programming languages, "live" code environments living in their own VM, and graph-based logic stuff, the first thing that comes to mind is how come those systems have such a short shelf-life even when some of the concepts behind them are so brilliant.
Between the increased storage space, the interoperability issues, and the exponential difficulty in dealing with non-text media in a variety of operations, there's so much more additional friction to these systems that in the end they're not worth it. Unless, of course, they can be trivially converted to plaintext and parsed as such, then they have a fighting chance.
Every letter, number or any sign is a "picture". In fact every written text is in fact structured array of simplified pictures, which happens to be understandable under conditions of given language rules. What should be bet is information. It doesn't really matter what communication tool will be used - information is the creme de la creme. Think about this - I can write simple text: "Mother should love their childrens". Would you still bet on text, if i wrote this in different language? "Każda matka powinna kochać swoje dzieci" or "Kila mama lazima kuwapenda watoto wao" isn't as understandable by most of people, despite the fact letter I used are almost identical. And how about other characters? "יעדער מוטער זאָל ליבע זייער קינדער" or "すべての母親が子どもを愛する必要があります" (thanks google translate ;))? In the end what matter is not text itself, but message behind it.
The parent post even used google translate to generate some of those sentences. You can't do that with video/audio.
You could enter the sentence into google translate, have it attempt to synthesize a pronunciation, and then you verbally mimic it to the best of your abilities. But now, not only are you compounding the inaccuracies of google translate, plus the inaccuracies of the speech synthesizer, plus the inaccuracies of your own pronunciation, which means the viewer has no reliable way to return to the original source material. But the entire process is still reliant on text at one point.
Just to prove a sibling comment's point, I copied and pasted all of your translations in to Google, where it was able to auto-detect the language based on how text encoding works, and was able to render them in to my native language. It took under 5 minutes to do all of them. (I got the languages Polish, Swahili, Yiddish, and Japanese.)
I doubt it would have been nearly so trivial had you given us sound clips or a picture of those words written out.
It's simply the case that digital strings, of which text is a kind, are most amenable to algorithmic manipulation, and are the basis of most of our computing tools. Even when computers deal with other types of data, the first step is almost always to reduce it to this form. (Which would have been the case with a picture of the characters written - it would have located the characters and recreated the digital text.)
The difference is that text is, so to speak, digital. You can't copy a picture without information loss, but ten thousand people can copy a written sentence from each other and end up with exactly the same sentence at the end. If you're worried about "information", we can read political tracts from the second century and still understand what's meant - whereas the intended meaning of paintings or even plays from the same time period can completely pass us by.
I think the person you are replying to meant symbols when he said "pictures".
People aren't copying the text but the symbols.
Even if the symbols were more picture-esque there wouldn't be information loss unless the symbols were too complex.
You are right - ajuc, lmm, ObviousScience - text as digital form is most convenient form of communication. Also - thanks to all kind of text tools You were able to understand all those messages, and to be honest - I also used Google Translate to make them. Medium is important. My point is the text itselft, each letter, is kind of picture. We learned that particular pictures can be placed together and they will represent some words. We make tools which can write in those pictures allowing us to communicate. Author of this post make difference between pictures and text. And of course - on simple level - there is obvious difference. But using more metathinking about communication - text, letters, signs like in japanese or jidish, are in fact simplified images. We just made them usable at different way than paintings or ilustrations and called it "text".
No, text isn't picture. Pictures are just one representation of text for particular purpose. Text can be touch (brail script), sound(when you use screen reader), and to programs text is just a sequence of numbers.
The important thing about text is the restriced set of possible symbols and their compositions, and close correspondence of them to meaning (much closer than with general images, video, etc).
I was just telling my wife the other day about how much I'd hoped that text went away in favor of better communication mediums.
I feel shy to admit it, especially here, but I dislike text. I dislike it because it's unnatural. I view it as a hack that was adopted to help communicate ideas through time and space. It's a cool hack, but still unnatural. It requires huge amounts of training to participate, and it has other issues.
I dislike it at a more fundamental level because it tends to leave ideas 'set in stone'. Text, like architecture, seems to have an unnatural tendency to remain unmodified through time and space. It creates dogma and worship and takes up the space where new structures could have potentially formed. It creates things like the bible and the constitution - things that morph from their original intent into an unbreakable form of reverence. Since it disconnects the 'bodies' of the reader and the author, the reader has a tendency to mistake the text as something different from the author and his ideas.
Text has a place - to store the facts of the world at a given time and place, certainly. To store ideas that can be accurately represented with discrete symbology. To transmit the ephemeral. But, I truly hope that we abandon text as a 'serious' medium for ideas in favor of video, audio, simulation, and virtual reality.
Many of us have a bias toward text because that has been how we have lived our lives, through its symbols. Text has altered our brains. But, imagine that you could relive your life without it, with other forms of communication, would you still want it?
Text is the only good form of asynchronous communication we have in our daily lives. Without it, we'd all be recording voicemail for one another constantly. Who the hell wants to do that? Not to mention the fact that making audio recordings is much harder to do discreetly and impossible to do in many noisy or strict environs.
And seriously, what is natural? How is human architecture any less natural than a beehive or a beaver dam?
Natural is adapting to change, understanding that the environmental context is always changing. Architecture is usually built to last forever, but it always has to be torn down, at great expense. Or, the expense is too great, and it remains, an archaic eye-sore.
I text message as much as anyone. But, I think we all know that text messages are ephemeral. I've edited (ironically) to make that more clear.
> Architecture is usually built to last forever, but it always has to be torn down, at great expense. Or, the expense is too great, and it remains, an archaic eye-sore.
Just like beehives, beaver dams and ant hills.
> But, I think we all know that text messages are ephemeral
Much less than sound or vision.
To make vision, sound, touch, etc. good as foundations for information exchange, you'd have to give more control to the receiving party. Make the medium skimmable and searchable.
Huh? I've always thought of architecture as ephemeral. Everything in a house has a limited warranty. We're constantly gutting, tearing down, rebuilding. How is that different from beaver dams again?
I did some research on textual vs graphical representation for my master. According to that research (not on my comp so I can't reference it) - one of main advantages of text is a near universal set of symbols (like Ascii for images), more constrained relationships (images are 2D while text is essentially 1D).
Most of text is 2D.
What is usually regarded as text is just a collection of simplified and arranged 2D symbols.
What is usually regarded as a picture is collection of unarranged non-simplified 2D symbols.
1D text would be more like morse code.
I didn't meant as a visual reprentation. Text no matter how well formatted/displayed will only flow in one direction* (be it up-down/down-up and left-to-right/right-to-left). In a picture you have no such constraints. Thus a picture is harder to scan by humans and machines alike. It takes expert knowledge to tune out some of distractions of visual representation.
* Exception being texts that are deformed to instill a sense of confusion and to simply play with how text looks like. Or possibly some really obscure non-European writing system that writes non-linearly.
The research I cited about lack of standard vocabulary of Symbols (like ASCII for text) comes from work that is not in English, and I can't find a version online. It makes intuitive and logical sense. A true visual language would parse images and have a standard sense of what symbols it may encounter.
Early in science education is the very important lesson that you always write units for your answers, as they are more important than any numerical value you happened to get. The best teacher I ever had liked to use an example of a simple cake recipe: "2, 8, 9, 2.5" tells you nothing, while "flour, butter, eggs, sugar" is something you could experiment with to find the specific values. The text units (labels) convey far more information.
I propose that this is one of the key reasons why text files are vastly superior to binary formats. While they end up very similar in normal use, the readability enables investigation and experimentation, while writing a raw struct out to a file keeps the meaning in the (possibly lost or unobtainable) original program files.
// if speed is needed, you can always cache the parsed version of the text file
The opening of this post has the feel more of a fan blog about their favorite baseball team than something intellectually serious.
In the second paragraph the author says "text is the most powerful, useful, effective communication technology ever, period." I suppose this is the purpose of this post? I guess if he is saying if he could only have one form of communication, he would choose text (removing speech from the list). I guess, but is this actually a debate? Are there really different "camps" that prefer images over text or video, etc?
I could delve into the arguments presented in the article but I think first I need to understand the thesis.
EDIT: To the down-voter, do you have anything to ask or say? Or are you just down-voting because you disagree? Everyone is interpreting this article to mean "there is too heavy a bias towards multimedia on the web today" but this is not the thesis of this article as I see it. The author is making arguments that text is better than multimedia in an absolute/complete sense. This is an entirely different argument.
1) In addition to being searchable, text lends itself to other forms of automated processing such as translation and text-to-speech for the vision impaired.
2) I'm prone to debilitating eyestrain headaches when I try to do any kind of graphical work on a computer, yet I can write text without looking at the screen.
isn't it very temporary advantage, till couple of decade back text wasn't searchable, and in couple of decades images may be equally searchable. Also pictures commonly have universal meanings.
Imagine a technology that can create a present experience in the user's brain that engages all the senses and evokes a dream-like state of being there... that technology is called "text" (that's a loose paraphrase of someone in the interactive fiction community, though I can't remember who.)
Music, I will grant you (mostly), but text really is an unbelievably powerful, flexible medium. It can't do everything, and everything it can do requires a certain amount of work on the reader's part and a huge amount of work on the writer's.
The remarkable thing about text is it allows us to tame and control our dreams. We don't dream in text, but we can use text to evoke waking dreams. We can be in Mirkwood or on the slopes of Mount Doom in a way that mere video can't compare with.
Perhaps the tweeting bird could get its own Unicode character code. Then it would compress nicely (because the details of how to render it would be passed along to the font files).
No discussion of labor? You guys are missing a major part of the argument.
Looking at OPs article, if my purpose is to explain human rights, text is staggeringly more efficient in labor of creation, not just time spent interpreting it or storing it or searching it.
An artists life work might produce a painting that conveys the entire meaning of the definition from the article of human rights. Maybe. I bet that would be an amazing painting and I'd enjoy viewing it. But ... aside from high art, can we afford general commerce in an artistic style? Is it affordable for society to create an interpretive dance implementation of my mortgage statement and is that a wise use of limited artistic skill and labor?
Its possible to create deeply meaningful works of art, at staggering expense of materials and labor both creation and interpretation and storage and archiving. That doesn't mean that most human creations (my water bill, the instructions for my TV, the receipt Amazon included with my $4 HDMI cable) are worthy of artistic labor.
If a graphics artist or painter is any good, I don't want that artist to waste time on my electric bill, I'd much rather have the fruits of their labor hanging on a wall in a frame. If they're not any good, I don't want them screwing up my electric bill making it incomprehensible.
Not only is text durable, but plain text data is universal.
Take a document written in the word processor du jour 20 years ago. It is highly unlikely you could mount the physical media, let alone import the data with high fidelity. But plain text can be read by just about any tool, whereas binary/proprietary formats are limited by the longevity of the hardware/software that created them.
Indeed - ASCII is not "universal". It's just common.
Hand someone who's no knowledge of ASCII some ASCII bytes, and no compliant editors, and see how hard it is to figure out they're dealing with the English alphabet.
ASCII mostly benefits from being a single-byte format - if a tool parses ASCII, then it's very easy for humans to go "right, that's English" looking at the output.
But this would be just as true if we had tools which handled Unicode (and most editors do exactly that now). Or it we had some other type of common binary standard which also encoded units.
It's all about the metadata - which isn't necessarily always in-band.
It wouldn't be that hard. You can think of ASCII as a simple substitution cipher - practically a Caesar cipher, really - and simple frequency analysis makes cracking such a thing literally child's play. It might take a bit longer if the data were presented as a bitstream, and you had to work out what the char length was, but even that wouldn't be too hard as there's a lot of repetitive structure in ASCII bits.
”Hand someone who’s no knowledge of ASCII some ASCII bytes, and no compliant editors, and see how hard it is to figure out they're dealing with the English alphabet.”
It would not be impossible for them to determine that the bit patterns 01100101 and 01110100 are a lot more common than, say, 01111010. But probably harder if they didn’t know that the bits are supposed to be divided into groups of 8.
'Always bet on text' is a catchy slogan, but the author fails to define 'text'. This is confusing because the post contains a lot of pictures of things that I don't know we would all agree are text.
Let's start with a radical position. Is something text iff it can be directly encoded in UTF-8? What, then, about symbols that have not yet made there way into Unicode? Like an i dotted with a heart. Does it become text when the Unicode Consortium says so?
Nowadays memes tend to be distributed as (animated) bitmaps. But if we wanted to, we could encode them more efficiently. So are they text?
ASCII-encoded math is not without problems either.
Does 'text' include semantic markup like 'emphasis', 'heading', or 'list-item'? Does it include visual markup like 'italic', 'underline', 'blue', or 'Times New Roman'?
Does 'text' include newline and tab characters? Is it correct to say that newlines and tab characters exist on paper? If they don't then why do we use them to indent blocks of code?
If a sheet of paper with scribblings can be text, then can a bitmap be text too?
Now that I've brought up mathematics, HTML, and code, should we think of text as a linear medium or is it better to think of texts as trees?
What about handritten class notes that include arrows that link together different text fragments? Are these arrows part of the text? Does that mean that texts are directed graphs?
I'm even wondering if the author might actually have meant 'always bet on language', although that seems kind of obvious.
Or perhaps he meant 'don't needlessly throw away information', which is what would be happening if your CMS served pages as HTML image maps.
That is to say, even if we're all inclined to say that text is awesome, which we probably are, we might still be saying quite different things.
Alphabets are just symbols that have some sort of meaning to you. Alphabets in a row are text.
There are symbols that have no meaning to you but still are te xt such as Kanji or Korean alphabet for some people yet you consider them text.
Unicode has nothing to do with what is considered text. Humans have for millenia used pictures as symbols that are used for text, in egypt for example.
Would you consider integrals, powers, and fractions text? For readability, the usual notation uses two dimensions.
They can be written in one dimension of course, but so can anything that would count as language (given that all information can be written as a row of 0s and 1s).
Text also has a history and toolset that is hundreds (printing presses with moveable type) to thousands of years old (writing systems usable with some sort of scribe tool to mark clay tablets or draw on papyrus scrolls). The ability to quickly communicate in images is remarkably new relative to all that. In the renaissance you had three proper types of intaglio processes (drypoint, engraving, etching), but novel ideas required someone to create new printing blocks from scratch in a laborious process, especially relative to moveable type. Only since the advent of GUI computing systems have we had tools that make it easy to effectively communicate with images (CAD, vector and bitmap drawing apps, image manipulation apps, video editing). These tools are still very much in the realm of professionals, but tablets have done a lot to democratize the ability for laymen to use them to communicate. Furthermore, memes now form a basic form of communication, which you can see through reddit and hipchat integration.
In 100 years, what the average person will be able to communicate quickly with images is likely to be unimaginable to us today.
Anyways, I'm not saying text isn't superior in many ways, just that its way to early to judge images given technical limitations.
I think writing systems like the Chinese writing system is instructive in this respect. It had roots from thousands of years ago, like western writing systems, and both were about as effective until the end of the 19th century with the linotype machine and the mid to late 20th century with 7, 9, 14 and 16 segment liquid crystal displays. Western writing systems enjoyed a big advantage from a technical perspective until only recently because they were simple enough in form to be conveyed by simpler technologies than the Chinese writing system.
If such a gulf can exist, even if only for a few decades, between two "text" systems, then it's not a stretch to see image-based systems as comparable, but requiring better technology to become a powerful as text in the sense that Graydon is talking about here.
It's 28K, a full text definition might be smaller but will be hardly accurate. My brain can process this single picture faster than a possible text representation of it.
Text is more practical 99% of the time but it's actually small pictures, known as letters, used together to symbolize concepts. I don't think my brain interprets letters individually, but my eyes mostly catch word by word, hence a picture.
> I don't think my brain interprets letters individually, but my eyes mostly catch word by word, hence a picture.
That's a normal thing. You read words based on their outline rather than individual letters, what with the bits that stick upwards (ascenders) and downwards (descenders). Which is why ALL CAPS TEXT IS A LOT HARDER TO READ QUICKLY, and why if you jmuble some lettres in a few wrods you can still read them with relative ease.
So the way humans read text is still kind of image based - you match a word based on a preexisting idea of what they should look like. It's just they're coincidentally easy to read by computers, too.
To expand on that perspective, words signify small, almost atomic, concepts which are relatively easy to learn - optimal elements with which to express less universal and more complex concepts.
Each word can be viewed as a shorthand to a already previously defined expression.
In that context, letters would be to words what pixels are to bitmaps.
Make words more complex (also longer) and the set of those elements will be able to encompass a wider, more versatile set of "elementary" concepts (akin to a wide tree structure), but this will also be harder to learn within a reasonable amount of time. In case of pixels this is comparable to higher bit-depth.
Yes, nobody knows the full vocabulary of any natural language, but we still understand each other due to knowing a common subset of words, having redundancy within and between sentences passages etc.
Make words less complex and they will encompass a narrower set of concepts, but the whole set of them are easier to learn. You will usually have to use more of them to express concepts (deeper tree structure) though. Similarily, one would need to use a larger amount of pixels with low bit-depth to express intermediate colors.
This is comparable to having well named functions in program code - partition the program into functions well enough and you will have created a set of relatively universal concepts, which the another person might understand without delving too much into the body of the implementing function each time.
Similar relationships can be perceived on the word-sentence and sentence-paragraph level, of course. Therefore the difference between pictures and text has more to do with partitioning information between abstraction levels than with some fundamental difference.
The optimal way of partitioning data varies depending on content.
For example, concepts of left and right are inherently connected with our visual and spacial perception of the world and are therefore better expressed by invoking our spacial recognition (a two dimensional image). That is because definitions for these atomic concepts are practically hardwired and require no learning.
Therefore, finding the best way to express information for humans and computers alike is akin to finding the optimal point between two extremes of reduced set of simple concepts and a larger set of complex concepts, that are easy enough to parse by both.
In the case of humans, the physical medium will always most likely be eyes for read mode due to built-in parallel processing and high bandwidth, and a subset of our muscles (currently fingers) for write mode.
I'm not sure how fast can we successfully parse audio signals, and brain-to-computer interfaces are still too slow.
As for the partitioning of information - who knows? Physically we have colors, brightness, shapes, sounds, temperature, touch, and more at our disposal. But the best way depends on our brain, and what size of information units it is best equipped to process.
That's because pictures are a form of text.
If you didn't know what the hay, a starving black child or a vulture looked like it would just be modern art to you.
I am actually somewhat worried about the longevity of our current tools. When we die, what will happen to our digital photos, and writings? Will our children find our diary in our home directory like they do when it sits on the bedside table? Will they look at our wedding pictures like they do when they find old photo albums? Will they remember our PhD thesis when it was never printed, but only ever a pdf?
Quite possibly, we might end up a forgotten generation, since procedures for cataloging digital memorabilia will only be invented after the lessons learned from the deaths of the first digital natives. One can only hope that archive.org will at least have an ugly copy of our blog.
Text existed before the proliferation of other media probably because it was primitive and inferior. Chimpanzees lived for eternity before human beings appeared. I don't see anything great in that. We didn't use a lot of multimedia in the beginning, primarily because of tech limits. Now that the conditions are ripe, why not? If everybody is using more and more of it, it's for a reason. Apple and MS brought about a revolution, exactly because they unlocked the killer feature that was the GUI. Ask if many of us would like to go back to the 80s regarding computer UI, that would be a nightmare. I certainly feel a 2-min video overview of product features is tons better than an one-hour read. Images and in general sensory feelings are always much more natural to human beings, which in essence are still a kind of animal. Texts were invented to maintain civilizations and enforce social hierarchies, but it was never ever natural nor great in this matter.
The Twitter icon takes a lot of space in a digital form, yet it only takes one minute to draw by hand, while the author probably wrote for an hour.
In all it's just a pointless, childish and tunnel-sighted rant. "Bet" on text? Bet what? I'm quite amused by the number of upvotes here. Though gladly I see many sane counterarguments high up there also, which is quite reassuring :)
Not sure what the fuss is about. Sometimes text is optimal, other times images, video or something else is more suitable. I don't really understand the point of this article.
And 171b25e, after one hundred sixty and two log entries begat fe961ca.
And 171b25e continued as a tagged branch after it begat fe961ca while
the author made eight hundred more log entries, and begat further
experimental feature branches. And when the number of log entries
wase nine hundred sixty and two, 171b25e's branch was closed.
After fe961ca was sixty and five years log entries, and was known
as e56b8bd, who begat 882b79d. And e56b8bd was rebased to the
project root after it begat 882b79d.
And 882b79d preceded a hundred eighty and seven log entries and was
then known as b6ff3ed, and begat 99e395a. And b6ff3ed continued after
it begat 99e395a for seven hundred eighty and two log entries and
begat many experimental feature branches.
And the current HEAD of the house of proj/foo.git is still 99e395a.
--
Joke aside, technically that problem has been solved before.
For a serious answer, "git log" should be very durable, and if you want a nice graph with it, something like this has benefits of both text and graphs:
Well, can you draw an average commit graph, such as that for the Linux kernel, in such a way that it is both accurate and you can draw some insight from it?
What are the interesting things about a git commit graph? Usually not the whole graph, but significant branches, commits and merges.
"Tim branched v1.3 to work on feature E for a while. Important features A,B,C and fix D was commited to master in the meantime. Tim merged E shortly before the v1.4 release was made."
Of course, generating such a description cannot be automated, while generating a graph can.
People can read text and understand it. Computers need parsers. Parsers are hard to write, and the time needed to parse one text will be just proportionate to the length of the text. Parsing can't be parallelized.
I'm sure the browser industry could benefit from a open, compiled html format, it would be so fast. I still wonder why there is no such format.
It's not about filesize though, gzip does a really great job at compressing text, but it's just about making a page load faster. It's no surprise to see web browser use so much memory: html is very flexible (there's nothing better), but it's fat.
That is a problem somewhat similar to the RISC vs x86. Risc has a simpler set of instructions, is a faster processor, but executables are much much bigger, requiring more cache. x86 has a more complex set of instructions, so it's slower, but the executables are much smaller. It's a balance to find.
I wonder if you could extend battery life by using compiled html. I would love to test that kind of tech on "normal" cellphones and see if how it performs.
Microsoft already has the .chm format, so there might be a patent, but I'm no expert. I don't really know how their format works though. It might be compiled as in "obfuscated".
But I don't think there's any existing, open format like that. Plain text html has the advantage of being easily diagnosed and immediatly readable, but you could easily make a binary format decompilable. I guess most programmers prefer having plain text because it's right before their eyes, it also sort of is "open", but that's not what open source really means.
It's not a new idea, but when I think about it, compiled html is a good solution to speed up web browsers. Now the .CHM format is not what you would want, as it's more targeted towards documentation, and is not extensible with CSS like html is now. It's an abandoned format I guess. Lighter than PDF I think.
By the way, when I say compiled HTML, I mean a binary version of a webpage that is already parsed. Would be a tree structured file. The goal is to remove the parsing phase.
But indeed, that could be a good opportunity for big tech firms to push that format. As long as it's open it might be a big success.
There are 20 year old binary formats that we cannot recover because we have lost their decoders. There are 4000 year old texts we have been able to decipher because text is so many orders of magnitude easier to decode. There are anthropologists who argue that it wasn't tools or speech that led humanity out of caves, but writing (and the abstract thought that is facilitates.)
If done properly, multimedia can convey information that text cannot possibly do. Text just lack the dimensions that multimedia have. An example includes the RSA Animate series, which take really good books written by really good authors and condensed that into very informative 5-minute videos.
I liked the article, but in retrospect I'm not clear what it's arguing against. What are the technologies that people have promoted to the author but are trumped by text? I feel like there's an interesting story there.
I don't get the point of this to be honest ... things that can be stored as text generally are, those that aren't, e.g. videos, photos, sound files, can't be represented by text - they're media.
text is the most powerful, useful, effective communication technology
True, and very interesting to consider.
OTOH, if you can simulate a person who knows how to express themselves speaking to you personally, there's and even technology you tap into. That's a technology we have actually adapted to biologically.
Everything else is just hijacking faculties designed to allow your uncle to explain to you how to make rope from bark.
Find a book written in 1764 and see how much of the technical detail (how society works, laws, money, etc) you understand. It'll be virtually zero. Technical things just don't last.
The texts that stand the test of time are the stories, ideas, and human history ... Things that people will still be interested in hundreds of years later.
Me too, kinda. I mean I eventually (through trial and error) noticed it brought up a menu, but god that's not in any way obvious at first. It is funny because until I read something about it I didn't even know what it was supposed to represent.
Apparently its an old icon but I never really saw it (that I can recall) until mobile got popular.
I had a teacher in high school who thought the "graph" icon in Microsoft Word was "library books." She called it the "library books button." I guess 3 lines isn't enough information to convey meaning. Even though the button meant "put this information in graph form" she didn't see that the icon represented a bar graph.
I would like to point out that cave art far predates any substantial 'text' we might have. Even if just as a shape to form a glyph, images are by far the most powerful method of human communication—no language is at all necessary. Language can add power, but at such a cost (learning a language takes years).
Text is great, but graphs and diagrams are often better for representing certain kinds of information or relationships. When I read a scientific paper, the figures are often what I look at first after the title, sometimes even before the abstract.
There are plenty of advantages to text formats, to be sure. Others have mentioned many already, so I won’t repeat them. But let’s also consider both the disadvantages and how many of the advantages are “accidental” rather than inherent benefits of using a textual format.
One disadvantage of text is its lack of expressive power. Try reading the equation shown in the article aloud. Now try giving a one hour lecture on advanced quantum mechanics without the aid of mathematical notation. We can often represent information far more concisely and accurately with a good notation than with text alone, particularly when there is some inherent underlying structure that goes beyond what we can conveniently represent with some linear sequence of a tiny set of symbols. Computers are good at that kind of thing, but we don’t read Shakespeare in binary, and we certainly don’t draw the Twitter icon from the article using nothing but 1s and 0s.
Another disadvantage of text is how much it relies on everyone to use the same conventions, even though in the real world they don’t. Go just about anywhere in the world and you can recognise what the little pictures of a man and a women on the two doors in the restaurant mean. Replace them with ‘M’ and ‘F’ and you’ll see people who don’t speak English waiting outside to see who comes out of which door. We use different languages. We use different alphabets. In technology, we use different encodings for glyphs and invent all kinds of other concepts in an attempt to standardise how we represent written text, and we still create numerous bugs and portability issues and lost-in-translation problems. We’ve been using computers for half a century and change, and we still haven’t standardised what the end of a line looks like. Or was it the end of a paragraph?
Now, certainly the simplicity of a text format has big advantages today in terms of things like searching for data and programmatic manipulation. But how much of that is just convention and historical accident? Right now, I’m typing this using an input device heavily optimised for text, because that’s what my computer comes with. If I want to input some graphical notation, say an equation, my choices are probably limited to using some awkward purely textual representation (TeX notation, etc.) or some even more awkward half-text, half-mouse graphical user interface. Neither is an appealing choice, which is why it takes those of us working in mathematical disciplines forever to type up a simple note or paper today.
Technology does exist that can interpret a much wider range of symbols drawn with a stylus or other pointing device as an alternative means of input, but usually as a niche tool or a demonstration of a concept. Until we routinely build user interfaces that parse freeform input and readily turn it into whatever graphical notation was intended, a lot of us are still going to reach for a pencil and paper whenever we want to draw some quick diagram to explain an idea. But I bet a lot of us still do draw that diagram instead of speaking for another five minutes to try to explain it.
Personally, I’m looking forward to the day when source control doesn’t show me a bunch of crude text-based edits to my code, but instead a concise, accurate representation of what I actually changed from a semantic point of view. But to do that sort of thing, we have to have more semantic information available in the first place, instead of relying on simplistic and sometimes error-prone textual approximations.
Technology does exist that can interpret a much wider range of symbols drawn with a stylus or other pointing device as an alternative means of input, but usually as a niche tool.
Handwriting math equations is built into Windows 7 and 8. Over half a billion computers potentially have access to it.
That’s a great example of what I mean. The intent is laudable. For now, the tool is far too limited/flawed for professional work, but one day maybe our input/output devices will be kinder to this kind of interaction and our software will routinely support alternative forms of input to work with data that isn’t purely textual.
I think a more polished example that is available today is the use of stylus and graphics tablet with drawing software. That is a relatively mature field where the use of alternative input methods to keyboard+mouse is well established, and skilled users already do some amazing things.
That’s a stretch, no? Mathematical notation is textual in the same way that, say, a flow diagram, an org chart or the structural formula for a chemical compound are textual. That is, there are textual glyphs in the visual representation, but the positioning and the other symbols are important to the meaning as well.
Can you type a mathematical equation on a keyboard, represent it unambiguously in a standardised character set, put it under version control, diff it, merge your edits with those of a colleague, still have something you can display reliably at the end, and then go back a decade later and search your archive for a specific equation? Not with any tool set I’ve ever seen. It’s still difficult enough just representing non-trivial mathematics on a web page so that everyone can read it.
Speech isn't.
No, but one of the advantages of textual representations that has been offered in this discussion is that textual formats can be used as inputs to screen readers and the like for improved accessibility. So again, I think this points to the inadequacy of purely textual notations as a way of representing complex information.
> That is, there are textual glyphs in the visual representation, but the positioning and the other symbols are important to the meaning as well.
The positioning of symbols is important in plaintext too! There is a distinction between the space separating words, versus the space separating paragraphs.
Similarly, all those non-letter symbols are important to the meaning. (Like the parentheses indicating that this is a side comment.)
I'm not sure I understand your argument here -- do you think mathematics would be text if it didn't have superscripts and subscripts?
To some extent you seem to be arguing that because tools for working with mathematical text are currently woefully in adequate, mathematics is not text. But this view seems backwards to me -- surely other languages that are not based on the latin character set had proper tooling developed later?
I'm not sure I understand your argument here -- do you think mathematics would be text if it didn't have superscripts and subscripts?
The context for this discussion is how text formats offer various advantages, as cited in the original article. The kind of mathematical notation we’re talking about does not offer many of those advantages, so it isn’t text in the sense that the original article was using the term.
(One could certainly debate whether or not notations like mathematics are “text” by some broader definition, but that doesn’t seem to advance this particular discussion.)
To some extent you seem to be arguing that because tools for working with mathematical text are currently woefully in adequate, mathematics is not text.
In the sense of the original article, yes, I suppose I am.
However, I think the important point is that we have a useful notation that doesn’t enjoy the benefits of plain text because of the lack of good tooling. The words we use to classify that notation don’t matter much.
I guess I'll have to drop Blender and use text files to create 3D models, because some guy on the internet thinks that text is "the most powerful, useful, effective communication technology ever, period".
If the point of the article was to trick people into clicking, then it succeeded in that I guess.
The arguments presented are highly biased. Text is great but images conveying the same meaning are always better. Why ?
We can grasp the same information when conveyed via image. Say you are conveying an idea to someone or speaking to a conference - you always try to minimize text and use graphics to illustrate concepts as people tend to understand faster that way.
Show me a video of that half-hour conference presentation, and it takes me half an hour. Give me a well-written report with the same ideas, and I'm done in ten minutes, and understand the ideas at least as well as if I had watched the video.
> Say you are conveying an idea to someone or speaking to a conference - you always try to minimize text and use graphics to illustrate concepts as people tend to understand faster that way.
If you are speaking at a conference or conveying information in an oral presentation, you usually use minimal text and prefer graphics in visual aids because you don't want to engage the linguistic processing parts of the brain on two separate tracks (the verbal content of the oral presentation and the text content of the visual presentation) simultaneously.
This isn't because text is an inferior medium on its own -- which it isn't -- but because its inferior as a simultaneously complement to an oral presentation.
> Text is great but images conveying the same meaning are always better.
This is clearly false, and makes me think you didn't read the article, since the article provides a counterexample right near the beginning; try to express this in an image: "Human rights are moral principles or norms that describe certain standards of human behaviour, and are regularly protected as legal rights in national and international law."
Of course nobody's proposing we abandon images; they're indispensable for many things, like the conference slides you mention. But if I had to do a presentation and was forced to choose between only text and only non-text images, I think the best choice would be clear.
Slightly off topic but that's a terrible definition of human rights (and being in nice crisp text makes this immediately apparent).
A far better one is, "Human rights are political conditions necessary of the life of a morally autonomous being." Tyranny and democracy are both "political conditions", as is "the rule of law" and various other things. One useful thing about this definition is that under it rights are both natural and inalienable: a right may be violated (a condition may not be met) but the necessity of certain political conditions for moral beings to be able to make their own moral choices (moral autonomy) cannot be removed.
So not only does text enable us to present ideas more succinctly and precisely than images, it allows us to argue about them effectively, and to have those arguments remain somewhat accessible for thousands of years. Images can be used as components of an argument (I've never published a scientific paper without graphs) but without the accompanying text the argument is woefully incomplete, whereas text alone is capable of sustaining a vast range of arguments without any accompanying images.
It's not just about conveying the information. That's only one dimension in which value can be measured. Size, exactness, and ease of automatic manipulation are others.
Fuck Hacker News.
The comment system here sucks camel's ass.
After 5 comments I couldn't post for -1.5- 3 hours.
That's fucking retarded.
And your fucking emotional downvote shit.
Worst fucking site for discussion ever.
I thought I could come back but after being involved in more free communities this site feels like a fucking prison where you get beaten and put in a quarantine cell for saying nigger or jew or fucking anything that might offend someone's fucking ass.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You can Ctrl+F arbitraly big text files for keywords. Good luck with doing the same with 2-hours-long video file or mp3. You will need to listen to the whole thing. That's what annoys me about the new trend to do tutorials as video.
You can easily diff text.
Text works with version control systems.
Text works with unix command line tools.
You can trivialy paste relevant fragments on wiki pages, in emails or IM discussions.
Google translate works with text.
Screen readers work with text.