STW has to die. I love that the goal is 10ms but in some environments the world has passed you by in 10ms and with STW you've timed out every single connection.
I want badly to fall in love with Go, I've enjoyed using it for some of my projects but I've seen serious challenges with more then four cores at very low latency (talking 9ms network RTT) and high QPS.. I cheated in one application and pinned the go process to each cpu and lied to Go and told it there was only one CPU but then you loose all the cool features of channels etc.. That helped some but a Nginx/LuaJIT implementation of the same solution still crushed it on the same box, identical workload.
It would be nice if we have to have STW to have it configurable, in some environments swapping memory for latency is fine and should be configurable.
The way Zing handles GC for Java acceleration is quite brilliant, not sure how much of that is open technology, but it would be cool to see the Go team reviewing what was learned in the process of maturing Java for low-latency high qps systems.
I believe what your parent was looking for is being able to pin a specific goroutine to a single CPU. If you are doing network traffic analysis, if a goroutine will jump between CPUs, you get the cache-miss overhead. This is the reason snort[0] (all in C) doesn't even use threads and sticks to a single process. To be able to use multiple threads when network processing you need hardware support (or something like PF_RING[1]) to distribute your load between cores. You want to be able t keep a data stream (TCP stream) pinned to a given CPU core, and doing that in Go is near impossible with how go-routines are scheduled.
> You want to be able t keep a data stream (TCP stream) pinned to a given CPU core, and doing that in Go is near impossible with how go-routines are scheduled.
channels work fine in a single-cpu context, but in the setup OP described you won't be able to use them to have the various processes talk to each other.
At least not without using one of the various netchan-alikes or rolling your own channel<->ipc solution, neither of which is likely to result in an elegant solution (note how the original netchan was abandoned by the Go team).
Correct it was the only way to get Go to scale to a reasonable response rate for this application and it thus meant my CPU loading was not even since it was based on the randomness of socket connections that persisted on one cpu or another.
I'm not sure how much of it applies to Go, but I'm guessing it's quite a bit more complicated than the current collector. It also may only work on 64 bit X86 hardware (which is fine by me, but looks like a subset of what go currently supports).
That was a great thread thanks for linking it! If Go wants to be a serious solution in many applications pauseless GC needs to happen and until it does it will be just like all the other solutions that can't play at scale and low latency. If it stays in that zone it'll have to compete with a very large set of perfectly fine solutions with massive libraries and lots of people who know how to code in those languages.
That's a good point and often passed over when talking about C4. It's a real shame, because that is a fairly large sticking point. There was an attempt to get the kernel changes needed by C4 pushed into the standard kernel, but I remember it got a lot of push-back by the kernel devs.
Depending on your usage profile, there is very little more efficient from a throughput standpoint than STW collection, except maybe manual memory management with clever use of pool allocation. Even malloc()/free() will be slower in situations where you're creating a lot of short-lived garbage.
Concurrent Gen1 seems fine. You still have to worry about STW Gen2, but it's much better.
FWIW, no one serious about allocations in native code uses naive malloc()/free(). My favorite trick is in game programming where you have a current frame pool that you just reset every frame.
The thing I like about pools is that they seem to actually reduce the cognitive load required to consistently get memory management "right" in a large application.
With manual memory management you have to worry about the ownership convention of each chunk of code, with GC you have to worry about architecting strong/weak references so as not to inadvertently retain everything (not to mention latency issues), and with reference counting you have to worry about ownership cycles. In practice I haven't come up with a better strategy than enforcing some sort of top-down hierarchy which effectively smashes most of the differences in cognitive load between manual/refcounting/GC. GC has slightly less upfront busywork but in practice the tooling tends to be poor so it's a wash (if that). In GC and refcounting it's easy for one inexperienced/tired/sloppy individual to create a massive leak completely out of proportion to the footprint of their immediate code.
Pools, in contrast, allow the same top-down approach with the very significant benefits that I don't have to think about the hierarchy at a finer level than the pool itself (which I have to do for the 3 other approaches) and that memory management mistakes don't typically lead to the globally-connected-component of the dependency graph sticking around indefinitely.
One big problem with pools is that you have to deallocate the pool sometime (or else your program's working set will continually grow over time), and when you do, all the pointers into that pool become dangling.
Another problem with pools is that you can't deallocate individual objects inside a pool. This is bad for long-lived, highly mutable data stores (think constantly mutating DOMs, in which objects appear and disappear all the time, or what have you).
Another big downside to pools is that a lot of GC implementations will scan only 'live'objects. Large object pools unnaturally increase the number of objects that need to be scanned during GC, negating a (sometimes) useful GC efficiency tick.
Precisely. This is an especially important point in response to the oft-repeated "just use pools if you want to avoid the GC in a GC'd language" fallacy.
If your GC is triggered after the allocated memory increases by X% (which is fairly common), then this technique is effective, since it lowers allocation rate.
Also, Go doesn't scan arrays that are marked as containing no pointers, so representing an index as a massive array of values has proven quite effective for me.
Fair enough. I suppose there are a significant number of applications where there isn't an obvious way to perform coarse-grained partitioning of object lifetimes. If you are a language designer looking to force a memory management scheme on all of your users pools would be a bad choice.
> That helped some but a Nginx/LuaJIT implementation of the same solution still crushed it on the same box, identical workload.
That's very interesting because LuaJIT has GC as well. Could you please reveal a bit more about the type of application, number of lines, and if the code is public?
Sadly it's not public but yes I was very happy to see how well LuaJIT with Nginx peformed for this problem set. I developed several solutions in C, C++, Java, Java+Zing, LuaJIT and Go. The Nginx/LuaJIT (openresty to be exact) solution had a great ratio of "approachable code" to "performance" factor. I was able to get it built and transfer its use to several other teams without them having to know C and still be able to make changes effectively.
Static compilation can do it to some degree as well, but in most mutation-happy languages (Go included) it cannot prove the allocation does not escape frequently enough to matter.
Allocation sinking is much more general. It works even if the allocation escapes (the allocation is sunk to the point where it escapes).
Additionally, all allocations can be sunk, not just stuff like the point class used in the example on that page. Growing dynamic buffers, string concatenation, etc, are all sinkable.
My understanding is that it's fairly tricky to implement (requires special consideration in runtime design) and so is not very widely used. Last I checked, the Dart compiler is the only other place I've heard of it being used.
FWIW its not really a thing Go would need anyway, given that you actually have control over your allocations.
>I cheated in one application and pinned the go process to each cpu and lied to Go and told it there was only one CPU but then you loose all the cool features of channels etc.. That helped some but a Nginx/LuaJIT implementation of the same solution still crushed it on the same box, identical workload.
If your primary motivation for using Go is lightweight concurrency, it has been developed for Lua, though in fairness not as extensively as goroutines:
If only someone would invent a co-processor that we could offload our rendering to. A "graphics processing unit," so to speak. Oh well. One day!
If you want to update some physics model at 60 FPS, you will be updating every 16 ms. An occassional 10 ms pause is not going to prevent that. Anyway, any reasonable game design needs to deal with pauses that are caused by network congestion intelligently, which can often be longer than 16 ms anyway.
Dude you have NO idea what you are talking about. An occasional 10ms pause absolutely will "prevent that". Those of us who work on software that does a lot of rendering using these fabled GPUs you mention know that feeding the GPU properly is a big problem and requires a lot of code to be running on the, err, CPU.
I don't even know what you are talking about wrt network congestion. What are you talking about??
If you're playing a multi-player game, you could easily lose touch with the servers or other players for more than 10 ms. So the game engine needs to be able to handle these pauses and extrapolate what happened with physics during the time you lost touch. It's the same thing here.
I developed games for Android at one point. GC pauses were common there. In the 1.0 version of Android, the pauses could be up to 200 ms. Now, it's more like 5 or 6 ms on average, as they improved the Dalvik VM. The GC hasn't stopped a lot of good games from being written for Android.
People need to be aware of the realities of scheduling on commodity computer hardware. A 10 ms guarantee is actually very good. You can't get much better than 10 ms timing on commodity PC hardware anyway. Even a single hard disk seek or SSD garbage collection event will probably block your thread for more than 10 ms.
Whether this guarantee is good enough for you depends on what you're doing. But I guarantee you that 99% of the crowd here doesn't know what you need to do to get better guarantees than 10 ms anyway (hint: it involves a custom kernel, not doing any disk I/O, and realtime scheduling).
Extrapolation is not at all the same thing. When you aren't getting network packets, yes, you run locally to do some kind of approximation to what is happening (in fact for a good game, your frame rate is never contingent upon what is coming in over the network, you just always do your best to display whatever info you have right now).
But that is totally different than the GC situation. With a STW GC you cannot even run, how do you expect to be able to display anything on the screen? Even with a non-STW GC, the reason the GC has to collect is because you are running out of memory (unless you are massively over-provisioned), and if you are out of memory for the moment how are you going to compute things in order to put stuff on the screen?
Accessing disk/network/etc induces latency, yes, but that is why you write your program to be asynchronous to those operations! But this is a totally different case than with GC. To be totally asynchronous to GC, you would need to be asynchronous to your own memory accesses, which is a logical impossibility. I do not see how you even remotely think you can get away with drawing an analogy between these two situations.
We both know that to acheive 60 FPS, you need to update every 16 ms. A 10 ms pause should not prevent you from doing this, provided that your code is appropriately fast to run in the remaining 6 ms. And if your code is not appropriately fast, you're going to have a lot of trouble dealing with older and slower machines anyway.
Having the latency be capped at 10 ms is an extremely powerful guarantee. It means that even if your machine is not fast enough to play game X one year, next year's machine will be. Because the GC latency doesn't change, and the rest of the program logic will run 2x as fast because of more memory and cores.
If you want to act shocked, shocked that GC has an overhead, then go ahead. If you want to pretend that nobody can ever build a game in a GC langauge (despite the fact that hundreds of thousands have, on Android and other platforms), then go ahead. Hell, even if you want to continue to use C or C++ to squeeze out every last drop of performance, then go ahead. But I find these comments really disingenuous.
Not sure if this makes it any better, but a bit later on they talk more about how the STW scheme will work. They call each thread which is not the concurrent GC a mutator, and part of the GC scheme will be ensuring that a mutator thread be stopped for less than 1ms, and that the 1ms pause should not stop any other mutator threads. If they can manage it, this scheme sounds promising for most soft real time programs.
I read them to mean that the one GC thread would stop the world for no more than 10 out every 50 ms, and in addition the concurrent garbage collector could ask any mutator thread to pause and do no more than 1 ms worth of GC work during any 40 ms non-STW period.
So in terms of real time, your deadlines could be no less than 11 ms.
That's not how I understood it. It says they're doing a hybrid STW and concurrent GC.
(a) A mutator may be stopped for up to 10 ms of every 50 ms by the STW collector.
(b) If more collection is needed, it will transition to a concurrent collector for the remaining 40 ms. Concurrent may pause stop a mutator for up to an additional 1 ms.
Therefore the worst case is 10 + 1 = 11 ms, not 1 ms.
People use the JVM in soft realtime / financial applications, and the trick is to reduce allocations, especially of objects that are long-lived enough to make it to gen 2.
Go is better suited than Java for those kinds of applications, because it's easier to avoid allocations (Java doesn't have stack allocations, but Go does.) Also hard upper limits on GC time are very helpful for those cases where allocations can't be reduced any further. The standard library additionally has a Pool type that allows for reducing pressure on the GC through object reuse.
We use Go for a soft realtime application (RTB), and it works well enough. We essentially have two performance issues, one being the particular database we use (which is not directly related to Go itself), the other one being GC pressure. Before Go 1.3, too many allocations were _very_ noticeable with GC pauses sometimes being close to 100ms (which is a problem when your maximum RTT is 100ms), but Go 1.3 improved things enormously. I'm confident things will get even better with Go 1.4.
When you're 90ms into your bid calc and Go pauses for 10ms STW you will loose all your connections and timeout your bids.
It's fine for basic stuff but if you want to really listen to full RTB bid stream and have real time responses you need pauseless GC to win. Or you have to budget for considerably less time to make a decision.
Also there are places in RTB where you have 10ms RTT and Go fails ought right in that situation at scale. :-)
It has a pauseless generational collector called C4 (which is detailed in the Garbage Collection Handbook). Gil Tene, the CTO and founder of Azul, appeared on the Go mailing list a while back and outlined the steps towards implementing the C4 collector in Go.
This looks like progress towards that. But I don't know if C4 is any kind of concrete (or even speculative) goal. I would love it if standard Go was running a C4 GC implementation.
The HotSpot JVM stack allocates (actually, even better: it SROAs) in very similar conditions to when Go does: when escape analysis decides that a value does not escape. Even if it doesn't stack allocate, bump allocation in the nursery ends up being about as fast as stack allocation (which is, as far as I know, why HotSpot chose only to lock elide and not to stack allocate when they implemented escape analysis).
I haven't looked into the JVM's stack allocation logic in several years, so it may have improved to the point where that is now true. (It wasn't so in 2010.) However, Go does have features that make it easier to control allocations than Java. One example,
type s struct {
x int32
y int32
}
v := make([]s, 1e5)
The object v uses 1e5 * 8 bytes of storage. Equivalent Java code would require boxing of each s value. That is, instead of []s, you end up with []*s and allocating each s.
I wrote a blog post that showed how powerful JVM compilers like the new Graal can be with removing allocations. I can show a test case in Ruby running on Graal where there are many complicated objects that cross many method boundaries, and they're all entirely removed.
Graal can do normal escape analysis, and so scalar replacements, but it can also do partial escape analysis - that is doing scalar replacement even if an object will later escape.
I don't believe that. Yes, the bump allocation step is just as fast as stack allocation because you just increment a pointer. But the extra allocation triggers more frequent collections of the nursery which is much slower than decrementing the stack pointer which is how you "free" objects on the stack. Intuitively nursery allocation just can't be as stack allocation but I haven't seen any benchmarks.
Yes, it's true in general that stack allocation can be faster than even bump allocation in the nursery. But I wouldn't be surprised if the reason HotSpot doesn't bother is that doing SROA, post-inlining, covers enough cases in practice that doing interprocedural escape analysis in order to do stack allocation for a few more objects doesn't help much.
I don't know why you're getting downvoted. Variance is terrible for games. We're at the cusp of a VR renaissance where frames are ideally rendered every 11ms (90fps), and VR is way broader than video games! STW is basically a non-starter in this environment.
10ms is an upper bound. Games typically don't do a lot of allocations during gameplay, so it's unlikely that Go's GC would be an issue for most gaming applications.
And, as I mention whenever this comes up, Minecraft is written in Java and suffers from huge GC pauses, yet it's one of the most successful games of the last decade.
And yet the GC pauses are noticable and annoying. It's not game-breaking because Minecraft is just that good, but I doubt it'd work well for other games.
I brought up Minecraft as proof that gamers are willing to tolerate the occasional bit of lag. And, honestly, I haven't played an AAA game that doesn't lag out and drop frames from time to time.
To return to the topic at hand: 60fps is 16ms per frame. The proposed GC would achieve sub-10ms pauses. So, worst case you might drop the odd frame. To assume that Go is unsuitable for games because of garbage collection is to ignore reality.
Lots of low-end, non-premium-experience games are made with those things. And e.g. games that use Lua usually only use it for high-level gameplay logic, i.e. most of the running code is in C++ or something.
And yes, it's a problem.
See the other comments here about VR. With VR you want to render at 90 frames per second, in other words, you get 11 milliseconds to draw the scene twice (once for each eye). That is 5.5 milliseconds to draw the scene. If you pause and miss the frame deadline, it induces nausea in the user.
But this comment drives me up the wall:
"GC doesn't seem to be a show stopper for them, you just have to be smart about allocations..."
The whole point of GC is to create a situation where you don't have to think about allocations! If you have to think about allocations, GC has failed to do its job. This is obvious, yet there are all these people walking around with some kind of GC Stockholm Syndrome.
So now you are trapped in a situation where not only do you have to think about allocations, and optimize them down, etc, etc, but you have also lost the low-level control you get in a non-GC'd language, and have given up the ability to deliver a solid experience.
> The whole point of GC is to create a situation where you don't have to think about allocations!
Nope. The point of GC is memory safety.
GC also means you don't have to think about freeing memory, which is important in concurrent systems.
But even if GC was about "not thinking about allocations", what's bad about only having to think about allocations when it's important? Code clarity trumps performance, except at bottlenecks.
You can get memory safety without GC, and a number of GC'd systems do not provide memory safety.
If you think that, for concurrent systems, it is a good idea to let deallocations pile up until some future time at which a lot of work has to be done to rediscover them, and during this discovery process ALL THREADS ARE FROZEN, then you have a different definition of concurrency than I do. Or something.
If you want to know about code clarity, then understanding what your program does with memory, and expressing that clearly in code rather than trying to sweep it under the rug, is really good for clarity. Try it sometime.
> The whole point of GC is to create a situation where you don't have to think about allocations!
I would say for most uses, that's true. For high performance code, it's not. You have to be aware of your allocations on the fast path whether you are using malloc, GC, or something else. Schemes used in C++ to reduce allocations with malloc (which is slow as dirt) also work in Go.
Let's get real here for a second. A maximum pause of 10ms is one-third of your frame budget at 33fps. If you reduce the garbage you're generating it won't even be that much. I don't see how that makes it a show stopper for games.
At the same time, I don't see how it's a great language for games either. Go is slow at calling into C, like 2000 cycles slow. And to do any kind of work with with the cpu vector units, you need to call into C. That seems to be a bigger issue than the GC in my opinion. Rust seems much better suited for games, and I would expect to see some triple A titles using the language once it's more mature.
>Lua has a much worse STW garbage collector and it's commonly used in games.
No, Lua's current GC is better for games. It is an incremental GC. For example World of Warcraft originally had performance issues caused by the standard STW GC in Lua 5.0 but those largely went away after they switched to Lua 5.1 which was the first release featuring the new incremental GC.
Value Types are coming in the next version of Java. Yes, it is great to be able to allocate on the stack, but then Java has better garbage collectors, including a completely pauseless one available commercially. Even in this announcement the new GC mentioned for Go is non generational. I have a feeling that even Java's good old CMS is better. Java also does escape analisys. All in all, once value classes are in, it is going to be awesome.
For those interested in additional technical details of high-performance garbage collection, the book cited (The Garbage Collection Handbook: The Art of Automatic Memory Management) is a fantastic reference. It's one of the best-written technical books I own, and distills much of the modern literature. If you need to do GC performance tuning or reason about memory management issues in the JVM, having this book around will be very useful.
My apologies for going off topic for a second, but is it well-known that Amazon seems to use Uber-esque surge pricing?! I (like apparently a lot of people) went to Amazon to buy the book cited as soon as I saw it (and it looks like a great book!). There were eight copies left in stock, and I bought it for $62.69.[1] When I went back to Amazon a few minutes later (following someone else's link), there was only one copy left in stock, and it was listed for $98.60.[2] With my apologies again for being off-topic, is this a known phenomenon?
Anyway, thanks for seconding their recommendation of the book; I'm looking forward to reading it -- and glad I saved the 35 clams!
As another poster said, these aren't 100% identical books, but you can see that for exactly the same book, too, if two booksellers that sell through the Amazon web site have bots that try to outsmart each other. For an extreme example, see http://news.discovery.com/tech/amazon-lists-books-for-23-mil...
Check again later, and you may see the price go back down (or up higher). There are third-party price history trackers for Amazon as well that let you see the volatility of prices for specific items over time.
Garbage Collection: Algorithms for Automatic Dynamic Memory Management is the original book, whereas The Garbage Collection Handbook: The Art of Automatic Memory Management is the new and updated version. I have the original, but it would be nice to know everything the new book adds.
Seems like the 10ms pause thing provokes a much sharper reaction (at least among this crowd) than this little nugget:
"Hardware provisioning should allow for in-memory heap sizes twice as large as reachable memory."
So I know "memory is cheap"(TM) but surely a 100% physical RAM overhead for your memory management scheme is worth at least a small amount of hand-wringing. No?
It is normal, not even a too big demand, as soon as you accept that the system depends on the GC. They are just being honest, even slightly optimistic. The current state of art is, you should suspect anybody who claims to you that GC systems don't need significantly more RAM.
That is misleading (and that article is really bad in other ways, too, but that's a different story).
First of all, the "most GCs" are the non-generational GCs.
That's well known. The amount of tracing work that a non-generational allocator has to do per collection is proportional to the size of the live set. Thus, collecting less frequently (by increasing the heap size before another collection has to occur) makes GC faster, using time roughly inversely proportional to how much bigger you make the heap.
Generational collection can greatly mitigate tracing of the live set for when you have many short-lived objects that never leave the nursery.
Second, the benchmark compares the allocation/collection work of various garbage collectors vs. an oracular memory manager using malloc()/free(). Not only do alternative solutions that don't use automatic memory management not necessarily match this performance (naive reference counting tends to be even slower, pool allocation also can have considerable memory overhead, etc.): more importantly, it's an overhead that applies only to the allocation/collection/deallocation work. For example, if your mutator uses 90% of the CPU with an oracular memory manager, then a 100% GC overhead means 10% total application overhead.
Agree with what you wrote, but the GC system also imposes various forms of overhead that aren't reflected in the paper. Some are explicit: read/write barriers, finalizers, weak references, etc. Others are implicit in the language limitations necessary to support GC: no unions, no interior pointers, no pointer packing, no easy C interop, etc.
It's difficult to measure this overhead, because you design the program around the limitations of your language. The point is that, by rejecting GC, you gain certain flexibilities that can enable higher-performance designs. Merely removing GC from a Java app doesn't capture that.
I really welcome the links to the better measurements and graphs. Please give me the hard data, properly presented, don't write the claims without the citations. I really want to learn more.
Correct me if I'm wrong, but even the "generational" GCs present their own problems: the "costs" of having the GC increase not only with having "too little" memory but also with trying to use "too much" memory (as "more than e.g. 6-8 GB, which can be needed on the server applications). As far as I know, only Azul's proprietary GC is claimed to avoid most of the problems typical for practically all other known GCs. fmstephe in his comment here linked to one discussion where the Azul's GC author participated. But I nowhere read the claim that any GC doesn't need significantly more RAM than manual management.
Please be clear. Do you claim it's misleading that the GCs need at least twice as much RAM to be performant? If so, based on what actually do you claim that the graph I linked doesn't support that? Can you give an example of some system that does better, with measurements etc?
> Do you claim it's misleading that the GCs need at least twice as much RAM to be performant?
This is not what you wrote. You said that "most GCs start being really slow even with 3 times more memory than needed with the manual management", while the generational mark-sweep collector has essentially zero overhead with 3x RAM in that benchmark. The "most GCs" you're referring to are algorithms that are decades behind the state of the art.
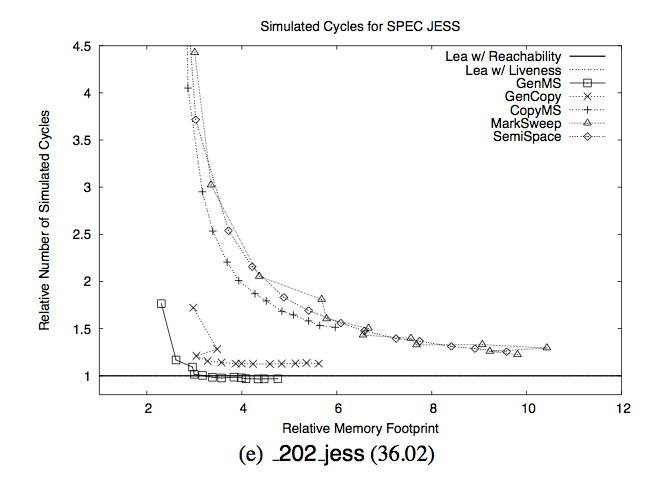
Also, "really slow" is a fuzzy term and I am not sure how you come to that conclusion from the image.
Remember, they're compared to an oracular allocator that has perfect knowledge about lifetime/reachability without actually having to calculate it. That ideal situation rarely obtains in the real world. The paper uses this case to have a baseline for quantitative comparison (similar to how in some situations speeds are expressed as a fraction of c), not because it represents an actual and realistic implementation.
You answered nothing what I asked from you. I asked for links, measurements, graphs.
Your only arguments: after showing that I wrote "most need even 3 times more" then you give an example of one which needs 2 times more. Then you complain that "really slow" is fuzzy. Then you claim that "ideal situation rarely obtains in the real world."
My point is that you don't understand your own source. The "links, measurements, graphs" are in the paper you referenced, they just say something different from what you believe they are saying.
If you're struggling with understanding the paper, there's really nothing more I can do to help.
Apart from the claim that I use "fuzzy" words or that my set of "most GCs" unsurprisingly doesn't include the kind that Go still doesn't have and probably won't have for some years more, what have I written that you actually refuted?
You can trade CPU usage for heap size, for the purposes of the plan it sounds like they wanted to be able to pick some concrete goals so they've picked 100% slack RAM and 25% additional CPU as their numbers. If you wanted 50% then the CPU overhead might be 50% on the same workload.
For a lot of applications on a GCed runtime 100% isn't an unreasonable number though. To get the overhead down you can manage your memory more carefully (pooling, keeping most objects pointerless) and tell the GC to run earlier.
This does not sound accurate. Memory access dominates in most current programs, and it dominates by a factor of several hundred (meaning one memory access takes more time than 100 L1 cache hits). If you use more memory, by necessity your cache will be less efficient. In the vast majority of cases, it's not worth it.
If you trade cpu usage for heap size, you'll lose in all modern cpus. In fact it's getting to the point where worse algorithms that are space-efficient are starting to beat the best known algorithms in practice, even if their constants are different. Dual TLB lookup when running virtualized doesn't help with that either.
If you can avoid a memory read with 4-500 assembly instructions (say a C/C++ function of half a screen), that is actually worth it. I did a test on my newest machine that showed that it's actually more efficient to run the sieve of Eratosthenes algorithm for prime numbers under ~800, than to have a table in memory with those primes.
It also means that you should easily be able to execute about a page of inlined C/C++ code in the time it takes the cpu to simply jump to a virtual function. Go and Java only have virtual functions.
Likewise, having programs work directly in compressed memory is actually a net-win. E.g. storing protobufs in memory and unpack single fields out of them when used instead of using unpacked structs directly is actually a win for even quite large structs. Not for megabyte-long ones, but you know, in 2 years there'll be a new intel micro-arch and who knows ?
Good luck keeping objects pointerless in Java. Or go for that matter (you can't use any interfaces or pointers if you do).
But don't take my word for this. Here's a trivially simple test. Gcc can compile java programs down to machine code. The memory model of those compiled things is different from the jvm. Take what you consider a slow java program, gcc it, and execute it. Note the 100%+ improvement in speed. (only really works for memory intensive stuff, of course). Rewriting it in C++ (assuming you know what you're doing) will get you another 100%+ improvement.
I think we're talking different scales here. At the scale of things that are roughly cache sized your point makes sense. The big concern about pauses is mostly coming from users with heaps in the 10s of GB and it's pretty unlikely on a PC you'll have more than 100MB of L2.
When it comes to designing the data structures your app uses you have a point but I think it's not directly to your app or runtime's policy for reclaiming freed objects. This does raise an idea that hadn't occurred to me before though: once you have a generational moving collector you may actually get virtuous cache effects because your nursery is densely packed with live objects.
...
Ok, it turns out that this has not only been studied a little but but at least PyPy tried this at one point (I looked at the code but couldn't find it).
100% over-provisioning is roughly what is currently required for performance by all systems that allow arbitrary allocation of arbitrarily sized data. Including most GC implementations and most malloc/free implementations. (You can of course do much better if you can limit the size or timing of allocations.)
10 milliseconds is far too long for STP for anything in the financial industry. I can see it as also not being great for robotics or several other latency critical industries.
It's interesting. While I've seen a lot of stuff about GC in Go and have been programming in Go on and off for a while now, this is the first time I've seen any quantification of the latency, other than one report that's undoubtedly a far outlier.
For games, 10ms is way too high. I'm working on Oculus Rift stuff at the moment and really, you have about 13ms per frame to play with in total, and skipped frames are bad.
However, for typical web apps without low-latency realtime requirements, a guarantee that the GC will not add more than 10ms latency at once, and no more than 20% overhead (in the same thread) seems pretty good, especially considering that it can do this under high load conditions with relatively constrained resources (Java is probably faster, but likely to use more memory; most other languages will be significantly slower).
The one outlier report I mentioned was of GC randomly stopping processing for several minutes, which clearly isn't within the bounds of acceptable response time for web apps. This will completely eliminate the possibility of that happening, which is good.
All in all it seems like a decent trade-off for the sorts of applications Go is already fairly good at. The stuff it's no good at might come later, but in the meantime everyone knows you can't use Go for those things (in fact you can, if you can design your entire application to use stack allocation only, in which case you can turn off the GC entirely, but that's easier said than done).
Problem is, web apps that require low-latency realtime requirements are not that uncommon. Think about anything related to trading or bidding. Of course, if the plans are to be believed, then a guarantee that the GC doesn't exceed X ms is good for soft real-time requirements, which is often enough.
> The one outlier report I mentioned was of GC randomly stopping processing for several minutes, which clearly isn't within the bounds of acceptable response time for web apps
That's not acceptable for any kind of app and the problem gets bigger the more heap memory you have. The sweat spot for GC enabled apps seems to be 4 GB - anything bigger than that and one should prepare for surprises.
While the transfer of the assets after a sale may take several days, the buying and selling takes place in milliseconds. If something is offered for sale at a bargain price, and 8ms later I accept while a Go user is stuck in a 10ms GC run, I get the deal, and he misses it.
If 8ms matters, aren't we talking about HFT? I'd be incredibly surprised if the rest of the industry ran on that kind of timing. Doesn't it take minutes to hours for a trade to happen if, for example, I click buttons on E-Trade or call my broker?
FYI, if you trade on ETrade, the slower their infrastructure is, the harder it is for you to buy/sell large amounts of anything. Why? When you pull the trigger to buy 100000 shares of xfoobarx, the market will see that and react accordingly. The faster you can actually buy those shares, the less time the market has to react, and as a result, you'll manage to succeed in making more of the trades you want.
Like it or hate it, electronic trading is the natural progression of the markets, just like the car eclipsed the horse. Low latency in trading applications affects me when I move my 401k as much as it affects the big electronic trading firms. Thinking it doesn't affect you is a mistake :)
When you, or a hedge fund, or any other market participant, decide to sell or buy a security, the trade is submitted to a broker. That broker may submit the trade to the floor, an ECN, or market maker, and so on. Only in very specific cases -- particularly an ECN to a specific exchange where it might have a spread with a regional exchange, is timing so critically important.
But for 90% of those trades, it's a block limit order that sits on the order book until it's filled.
For many trades this is irrelevant. For those where it does matter, it is the very last, smallest part of the system -- the execution engine -- where timing is everything. That is the part of the system where HFT engineers are building hyper-speed interconnects and optimizing every single instruction, but it is not relevant to the majority of the stack.
Delays everywhere else in the system are largely meaningless -- yeah prices may have changed slightly, but unless you've mastered market timing (which no one has), it will generally even out and is irrelevant.
You mention two industries with extremely demanding performance profiles (financial industry and robotics). I don't know if I'd trust any 5 year old platform in those contexts.
There are lots of other contexts where the performance profile outlined in this document are sufficient. If you love writing Go, then I'd suggest staying out of the financial industry and robotics.
Not sure about self-driving cars. I work in robotics, and there are a few modules that need to hit hard real-time deadlines. You wouldn't use GC languages for those, but there are a LOT of other parts that don't, and you can get a BIG win by writing those in a more concise language.
Go was written by google for high throughput and concurrent infrastructure. The "web scale" problem is basically the polar opposite of the finance problem. That doesn't mean golang can't (eventually) be used in both, it just needs a bit of work before it gets there.
As far as gc bits, the Azul Systems pauseless gc is certainly as state of the art as it gets. Too bad it is for java
> 10 milliseconds is far too long for STP for anything in the financial industry.
Does Java give any guarantees about garbage collection latency?
The LMAX Disruptor inter-thread communication library[1], that is the heart of the high performance[2][3] limit order book used by the LMAX Exchange is written in Java.
Just because a language can't guarantee that the duration of GC stops are below a certain threshold, does not mean that you cannot write programs in this language that offer better latency 99.99% of the time.
> Does Java give any guarantees about garbage collection latency?
Java has multiple JVMs and garbage collectors available.
The concurrent GC (CMS) in Oracle's JVM doesn't give any guarantee. The new G1 GC in Oracle's Java 7 does provide guarantees while trying to minimize STW pauses. Azul Systems' Pauseless GC is advertised as being completely pauseless, though it is commercial.
Quite painful is that for small heaps, the more you try to do concurrent garbage collection with small latencies, the more throughput suffers. On the other hand, the more you add memory, the bigger the latency. So depending on the app, the memory layout and its access patterns and the hardware used for deployment, one has to pick a GC strategy, as there's no one size fits all.
FWIW, the LMAX Exchange currently uses Oracle's HotSpot JVM, but they've announced they want to switch to Azul's Zing.
I guess my overall point is that the GC guarantee in question is an upper bound. It's perfectly acceptable for a financial application to only deliver x ms latency 99.9% of the time.
Also, the JVM is only one component in the stack. If you aren't using a real-time OS kernel, you're not guaranteed any maximum latency anyway.
I've heard of people who just "GC on market close". In the applications I've worked on you don't have the luxury of a "market close". They're 24/7 applications and literally 90B transactions per day at peaks of 1.8M qps...
It's not out of the question, just use your mind. If your financial upfuckery is implemented as a wide array (say 1000+) instances of a Go program, each of which is capable of saying "stop sending me traffic, I'm about to stop for a full GC" a few milliseconds before actually stopping for GC, then latency will not be impacted and throughput will only be degraded by the time required to cork and uncork the input with respect to the time required for the GC round.
A technique along similar lines is to run your upfuckery implementation on multiple servers and have each of them publish the results. Then you can take the output of the first server, and discard the rest. This can be effective at weeding out a majority of small pauses.
That sounds like a possible solution but a bit overcomplicated. Might as well stick to something like C++ than risk additional complexity in my opinion.
Sure. You will still have uncertainty around memory allocation timing, even in C++. For example tcmalloc or jemalloc may need to take a global lock in order to satisfy a heap allocation if thread-local spans are exhausted.
10 milliseconds is far too long for STP for anything in the financial industry
Somehow very niche HFT trading platforms have come to define finance, when the reality is that the massive bulk of the industry runs on Excel spreadsheets, Java, or Fortran. An extraordinarily small subset of the stack has real-time needs, and is engineered as such.
The financial industry is a huge industry with an enormous variance of needs, and the overwhelming bulk of applications have absolutely no such real-time requirement.
I should mention that I've built systems in the financial industry for about a decade now, so I always marvel when people make broad, untrue, absolute statements.
I'm absolutely in love with C++'s RAII scheme but it seems almost no languages use it and, instead, go with a complex garbage collecting scheme that requires pausing.
I want to like GO but a language that targets native development but still uses garbage collection just seems like an odd pairing to me. Maybe it's just me especially since I rarely get an opportunity to do native development.
> I'm absolutely in love with C++'s RAII scheme but it seems almost no languages use it
RAII is but one resource-management strategy, and one intrinsically linked to C++'s memory model. But if that's what you're looking for, Rust uses the same: http://doc.rust-lang.org/std/ops/trait.Drop.html
And in the absence of cycles, refcounted implementations have similar properties (although of course that assumption will break with alternate non-refcounted implementations if refcounting is not part of the language semantics).
> I want to like GO but a language that targets native development but still uses garbage collection just seems like an odd pairing to me.
Not that rare. OCaml is native and GC'd, so is D, or most lisps with native compilers. Hell, Boehm's GC exists.
ObjC, with automatic-reference-counting (and now Swift, I assume, though I haven't looked into it) is close to garbage collection, but has deterministic destruction.
The price you pay is you have to manually avoid cycles by annotating some references as weak.
Thread-safe reference counting usually has lower throughput than tracing garbage collection. If it's throughput you're after, you're not going to get it with atomic reference counting.
Actually, even without cycles the destruction time is in general unbounded. Just think what happens when you allocate a very long linked list one element at a time and then drop the head. With a bit of ill luck or intention, you can make each element be allocated from a different page with enough different pages so that they fall out of the TLB. In that situation, even without having pages written out to disk, you can expect each element to take ~ a thousand cycles to free. On a million element list, that's ~500ms for freeing the head.
Spending the last month swapping between Swift and Clojure, there's still a very large safety difference between ARC & a memory-safe VM.
The problem is, compiler magic gives the illusion of safety, and then you segfault and remember that you're in a non-memory safe language. Swift is a big improvement, but it's still basically a DSL on top of objC, with all of the downsides that implies.
Question: If you use only strong and weak ptrs (no unsafe_unretained), avoid doing pointer arith, unchecked array accesss, or blowing the stack, can you still get segfaults? No, right?
If you stay in pure swift, it's much harder to segfault, but it's still possible, mainly due to the amount of objC code you interact with. Today, it's not reasonable to expect a swift programmer to be proficient without knowing objC, the way it's reasonable for a Java programmer to not know C.
The segfault I hit yesterday had to do with a CoreData API that didn't retained its argument, when I assumed it did. The bug doesn't appear when compiling with -Onone, but does appear in -O. Compiler flags are another place where Swift is still very much in C-land, rather than Java/Python/Ruby land. You still need to understand the C compilation model, and e.g. getting your ARC flags wrong in a cocoapod will still cause crashes.
To be clear, swift is a big improvement over objC, but you can't pretend it's a VM managed language.
>Memory safety does not require VM management (or so Rust is trying to prove).
I agree, with a few qualifications. I think Haskell has already proved it's possible.
I think Swift + ARC isn't a strong enough guarantee of memory safety for two reasons:
1) Swift has to interact with a huge amount of objC code, of varying degrees of quality (some Apple code, some OSS code via cocoapods). Swift itself would be much safer if all objC was rewritten in Swift.
2) ARC isn't as strong a guarantee as either GC or Rust's pointer semantics. For example, it's easy to hold weak references to something you thought was retained, and then dereference an invalid pointer.
So yes, you can have a memory safe language without a VM, but I think you need GC and/or much stronger pointer semantics, ala rust.
Yes. According to http://clang.llvm.org/docs/AutomaticReferenceCounting.html#s..., ARC assumes that self is valid for the lifetime of the call. This will not be the case if the last reference to the object is changed or cleared during the call, which may result a segfault. The performance loss of retaining and releasing self across all methods was deemed too much compared with the safety gains.
> I want to like GO but a language that targets native development but still uses garbage collection just seems like an odd pairing to me.
Why? I don't see what is weird about that combination. Garbage collection is usually something that is used in high-level languages, and high-level languages might as well be natively compiled as opposed to interpreted, running on a vm, etc.
If anything, C/++ seems like the odd pair out with their more manual memory management among native languages.
"Quantitatively this means that for adequately provisioned machines limiting GC latency to less than 10 milliseconds (10ms), with mutator (Go application code) availability of more than 40 ms out of every 50 ms" --- once they get there, they should try to make those targets customizable, with default values being 10ms/50ms. That'd be marvellous.
Be fast and use Cheney (copying, double memory) or be slow with Mark&Sweep and only the current memory usage.
Nothing new here.
Catching up old GCs via concurrent GC states is fine and tandy, but it is still just catching up, and it requires GC state. Cheney not.
And a typical Cheney GC is 3-10ms not 10-50ms.
Go is a language built on concurrency. Today's computers are usually allocated a lot of memory resources.
Garbage collection is required but even a hybrid STW only reduces latency but doesn't eliminate it. Nor is there seemingly any foreseeable way of allowing developers to issue a GC request in a timely fashion.
What if, prior to enacting GC, Go concurrently shifted from it's current memory allocation to an exact clone, cleaned up, then shifted back? Or maybe it cleans as it's cloning, enabling a shift to a newer, cleaner allocation? Sure, there would be latency during the switch, but it would be considerably less than stopping everything and waiting for GC to finish.
When there's talk of making sure the GC doesn't take up more than 10ms out of every 50ms, this is only when the GC is actually happening and not during regular running, right?
I think it means that GC will never run for a total of more than 10ms during any 50ms span. It doesn't mean GC would take 20% of total program runtime, except in worst cases. it means that GC will run often and concurrently enough that it won't "stop the world" too long.
Depends what you mean by "realtime". Pauses of 10ms is still 60% of a frame budget potentially every 3 frames. You're probably not simulating the game at 60fps, but it's worth about 2000 miles of network delay[0].
All in all, depends whether you're serving for a turn-by-turn roguelike, an RTS or an FPS. Won't be an issue for the first one, may not be for the second one, the latter though...
I smile every time I read that story. I'm up-voting for the link alone. (But yeah, it really sounds like they didn't have games in mind when they designed Go.)
Well 'games' is a quite wide concept, there's been a ton of games released through XNA which used a 'stop the world' garbage collector until late in it's existence IIRC.
So there's no reason why your typical indie style game would not be written in Go, but of course if you want to write AAA style 'push the boundaries of realtime graphics and physics', Go or any other garbage collected language is not a very likely candidate.
I tried, but stopping the world hurts. Reusing stacks helps, but you're fighting the language from the very beginning. It wouldn't be a wise choice for even soft real-time IMO, you may as well just use Python or Ruby if you don't care about stopping the world..
Python doesn't have a STW garbage collector, it uses deterministic reference counting. So while slower than go you won't have random pauses in your server processes due to memory management.
Why do people assume that cleanup in reference counting has to be synchronous?
You can deal with deallocation chains in reference-counted systems without having arbitrarily-long pauses. You keep a stack of <pointers to items to be removed + current child index in item>. When something's reference count goes to 0, push it onto the stack, with a child index of zero. Every so often, pop the last item off of the stack, if (the child index is after the last child) {deallocate the memory}, else {decrement the reference count of the child of the object indexed by the child index, pushing that onto the stack with a child index of 0 if the child is now dead, and push it back onto the stack with an incremented child index}. You can do any/all of this in batches.
It's well-known that you can incrementally free objects that are known to be garbage but it's not usually implemented for reference counting since it's not typically seen as a good fit because it undermines the advantages of reference counting a bit: now, objects aren't freed deterministically when they become garbage (that is objects are destroyed at unpredictable times) and you're now introducing unpredictable pauses into the language runtime to free garbage objects (short though those pauses may be). Maintaining the free stack also adds overhead. It's just not a very good fit.
In my very limited understanding, hard real time systems collect memory in a fashion _more_ like this than previously. The idea is to use a ticky-tocky garbage collection system that always takes a certain amount of time ('tick') but guarantees the system enough usable time ('tock') to respond to the outside world in an appropriate fashion.
The point, (again note I'm not an expert in this stuff) is that there's no such thing as an infinitely responsive real-time system - even hardwired analogue electronics, or a program running entirely in CPU cache, have a response time. So realtime always means that the system responds acceptably quickly for the application, without slowing down.
Now as to how this applies to games, obviously a 10 ms pause is not a great help for updating a 60 Hz game every 16 ms. But for some lower speeds it could reduce latency and give an overall smoother feel to networked gaming. A couple of other posters on this thread have already mentioned tricks to get around this, if multiple processes can share the load and gracefully garbage-collect.
But on the whole it seems like offering some configurability would make Go more versatile. In the extreme you might want to turn off the GC and make use of a manual free-type function. (I gather the Go developers oppose this on philosophical grounds).
Curious, how "real time" can a large application get in Go by judiciously working with pre-allocated structs and slices? Perhaps if the underlying system libraries don't require much garbage collection, then you can avoid stopping the world for too long.
More than many think. :) You can recycle objects to reduce GC frequency, reduce the number of pointer-containing objects to speed up the mark phase, batch or avoid allocations to speed the sweep phase. The sheer brawn of modern chips helps esp. given multicore GC; just sweating hotspots (e.g., big buffers) can do a lot; worst case, sometimes apps can be decomposed well into more processes each with their own smaller heaps.
When GC comes up here (and not only on Go things), a lot of comments pop up that are like "welp, [tool] is no use for me if GC is involved," sometimes with a horror story or worst-case scenario. Sometimes I'm sure that's entirely rational and comes down to the type of app they work on (I don't wanna rewrite Unreal Engine in Go), but sometimes I wonder if whoever's saying it just doesn't know much about GC in practice.
That lets you make GC infrequent but the amount of heap will determine the pause time when the GC comes calling. If you have a large number of live objects with pointers in them then pauses are unavoidable with the current Go GC, it sounds like if all goes according to plan things will be a lot better in 1.5 though.
Certainly if you could get away from all allocations but it's pretty likely you'll end up with some from the standard library or some other external code.
As a side issue, are there any plans to switch to gcc as thr main compiler? It can do everything that 6c can do from what I understand, and produces much faster code due to gcc well tuned optimizer.
Nope; gccgo is a separate project. Its good code generation is totally cool for particular purposes, but the Go project has its own priorities that they're going to implement in their own toolchain.
From my understanding, this only happens when the GC is run. Currently (Go1.3) the GC runs every 5 minutes or unless you manually invoke it. Currently the GC will stop the world and do the entire cleanup at once. From my understanding of this, the GC will do the cleanup in small 10ms bursts, so you won't have a 200ms pause every 5 minutes.
{kind=link}
I want badly to fall in love with Go, I've enjoyed using it for some of my projects but I've seen serious challenges with more then four cores at very low latency (talking 9ms network RTT) and high QPS.. I cheated in one application and pinned the go process to each cpu and lied to Go and told it there was only one CPU but then you loose all the cool features of channels etc.. That helped some but a Nginx/LuaJIT implementation of the same solution still crushed it on the same box, identical workload.
It would be nice if we have to have STW to have it configurable, in some environments swapping memory for latency is fine and should be configurable.
The way Zing handles GC for Java acceleration is quite brilliant, not sure how much of that is open technology, but it would be cool to see the Go team reviewing what was learned in the process of maturing Java for low-latency high qps systems.