In terms of engineering tradeoffs, this reminds me of a recent talk by Alan Kay where he says that to build the software of the future, you have to pay extra to get the hardware of the future today. [1] Joel Spolsky called it "throwing money at the problem" when, five years ago he got SSD's for everybody at Fog Creek just to deal with a slow build. [2]
I don't use Facebook, and I'm not suggesting that they're building the software of the future. But surely someone there is smart enough to know that, for this decision, time is on their side.
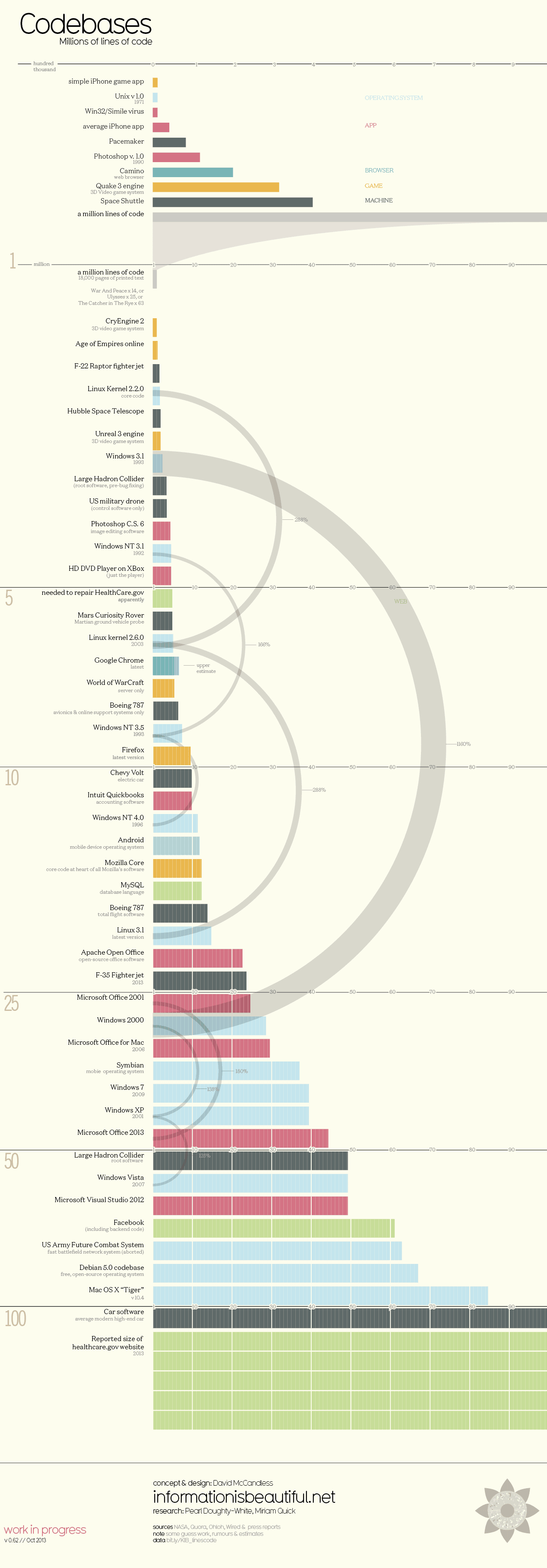
You should also watch his talk where he questions if it is really necessary to build large software products from such large codebases that, if printed out, would stack as high as a skyscraper. And, then talks about what he is doing to demonstrate that it is not :)
Facebook tends to throw engineer time at the problem, though. I know one Facebook DevCon I went to they presented how they completely wrote their own build system because Ant was too slow for them.
FYI phabricator originated at Facebook, but the guys who wrote it left and founded Phalicity, who supports it full time now. Facebook did the world a service by open sourcing phabricator.
Review board and Gerrit are both awful in comparison
If you are at the point where you are contemplating building your own dev-tool-everythings... then you've gone very wrong. Let the dev-tool guys make dev-tools, they are much better at it (it's all they do). Instead figure out how to make them work in your business environment. Facebook may have one of the largest sites on the web, and perhaps the most users... but their codebase itself is nothing special and does not warrant "special" tools. That's just BS and a measuring contest.
Having used ant as a build system for Android projects, I don't blame them.
In my admittedly limited experience (Windows 7 x64, ant, Android SDK) ant is terribly slow to build projects with multiple source library dependencies and throwing hardware at the problem doesn't speed it up that much.
I don't see how this is an Ant-specific issue. Ant is just calling into javac with a classpath parameter. The actual execution time spent in Ant should be minimal.
For example, most open source library projects that you include in a project don't change from build to build, but ant dutifully recompiles them each time instead of caching the output until the files in that project are changed or I manually clean the build output.
"Only worse" is probably not fair. Though, is it really surprising that a newer make file degenerates into the same problems as old ones?
Which will then lead down a path of a set of scripts/utilities on top of said system to standardize on a set of targets and deal with known issues. And suddenly we have reinvented another old tool, autotools. We'll probably find ourselves in their troubles soon enough.
There was a link submitted here (I can't find it now) a few weeks ago that talked exactly about that. Most build systems are just reimplementations of make, which makes them worse , because make has been battle tested for ages.
Amusingly, that story is what convinced me to finally read up on autotools. It has been interesting to see just how much they already covered.
In fact, the only thing the autotools don't do, that every current tool does, is download the dependencies. Which, is not surprising, since fast network connections are a relatively new thing.
And I'm actually not sure I care for the download of dependencies thing. It is nice at first, but quickly gets to people pushing another thing to download, instead of making do with what you have. This is plain embarrassing when the downloaded part offers practically nothing on top of what you had.
At my company, I wrote our own build system, because "make", "waf", "shake" and various others do not give any useful guarantee, and we've debugged cryptic under-specified dependencies way too many times. Make clean on a large repo and lack of automatic work sharing hurt too.
Also, auto detecting inputs rather than being forced to specify them is nice. Especially as virtually all input specs in Makefiles are wrong or incomplete.
Writing a build system is not such a big deal -- and outdoing the existing work is not very hard.
Perhaps that's true for your very specific use case but the same is likely to be true for other people using your build system. autodetection is great when it works and horrid when it fails.
I use file system hooks to autodetect dependencies, so it should always work as long as the file system is the input of the build and not other channels.
Explicit input specifications are virtually never correct. #include scanners for example, are generally wrong because they do not express the dependency on the inexistence of the headers in previous include paths.
Although this is large for a company that deals mostly in web-based projects, it's nothing compared to repository sizes in game development.
Usually game assets are in one repository (including compiled binaries) and code in another. The repository containing the game itself can grow to hundreds of gigabytes in size due to tracking revision history on art assets (models, movies, textures, animation data, etc).
I wouldn't doubt there's some larger commercial game projects that have repository sizes exceeding 1TB.
I am working on a game where head is 1TB. On top of code and assets this size includes a few full builds and a full set of game-ready data (the data build process takes something ridiculous like 7 hours, so that's done on a server and it checks the result in). All in the same repository.
1TB is rather a lot. My previous record was 300GB and even that seemed a bit much. But it is very convenient having everything in one place, including all the stuff that you only need occasionally but is handy to have to hand, such as old builds of the game that you can just run in situ and installers for all the tools.
(I don't know what the entire repository size must be like, but many of the larger files have a limited history depth, so it's probably less than 5-10TB. So not exactly unimaginable, though I'm sure buying that much server-grade disk space - doubtless in duplicate - might cost more than I think.)
But they surely don't use git for that, right? In scenarios like this a versioning system that does not track all history locally would be a better fit.
As the other replies say, Perforce is dominant in commercial game development.
However, Perforce does have Git integration now, allowing for either a centralized or distributed version control model. Considering the popularity of Git, I wouldn't doubt smaller Perforce-based game projects are going the DVCS route.
Also, hypothetically speaking, consider if you had a game project that would eventually grow to 1-2TB in repository size. If you spent $100 per developer to augment each of their workstations with a dedicated 3TB hard drive, you would have an awesome level of redundancy using DVCS (plus all the other advantages). I know it's no replacement for cold, off-site backups, but it would still be nice.
shallow clones the only issue for games. Another problem is, unlike code, art assets usually can't be merged. You can't merge 2 photoshop texture files or 2 edits to a 3d character made in Maya.
So, you need some central system to manage the assets so that people know "hey, don't edit this file right now because so-and-so is editing it".
Ideally you'd like to know this BEFORE you start editing. In other words, you don't want to spent 15-60 minutes editing something and only on saving or trying to check in get told "hey, sorry but someone else was editing this file so you'll have to discard your changes and start over". Some editors are better at this than others.
You could try to write something on outside of git to help with this but why when P4 already provides this?
> You could try to write something on outside of git to help with this but why when P4 already provides this?
Maybe because P4 is kind of a PITA? I used it for 10 months on a project (without any noticeable art assets, even; this was just code) and it regularly caused problems. The company had someone whose sole job was to administrate P4, and it was sorely needed.
Of course, it's been many years, and I no longer remember details about the precise problems encountered, just the overall frustration. Although the one thing I do remember is the aggravation caused when a coworker accidentally locked a file they weren't editing and then left for the day.
There are a lot of non developers using source control for game development. Perforce makes it easier for graphic designers and the like to use the VCS and not have to deal with a CLI. Perforce just handles binary blobs well.
Are you talking about git annex assistant or git annex? git annex does file versioning very nicely then again it doesn't work on Windows so that's probably not very useful for most game developers.
git-annex does file versioning, but it's extremely uncomfortable to use (and I say this as somebody totally comfortable with git) and I'd never expect an artist or other only-semi-technical person to use it even if it worked with Windows. Especially when Subversion or Perforce are right there.
git can not really deal with binary files well, if you have lots of png/gif/mov/mp3/jpg/etc to track git is not the option for you I think. git excels at source code, in txt format that is.
The new depth option [1] on git clone as of 1.9.x should make the .git dir much more reasonable.
> --depth <depth>: Create a shallow clone with a history truncated to the specified number of revisions.
If the OS and applications that are creating and modifying files are all honest about the file dates, it should be possible to only scan dates instead of reading out every file. Or even use ionotify-like events to track what changed.
EDIT: As sisk points out below --depth itself is not new, but as of 1.9 the limitations that previously came with shallow clones were lifted. Thanks sisk.
I've wanted this option for so long :-) Are there any downsides to it, apart from the obvious one of 'git log' not going all the way back in time? I mean, do any commands break unexpectedly?
The --depth flag has been around for a long time but, previously, came with a number of limitations (cannot push from, pull from, or clone from a shallow clone). As of 1.9.0, those limitations have been removed.
I bet they check in (or have checked in at some point) 3rd party libraries, jar files, generated files, etc. I battle this every day at $dayjob and we have a multi GB subversion repository with a separate one for the 3rd party binaries. Svn handles this a bit better than the DVCSes, so just checking out the HEAD is smaller than the full history you get in git/hg, and you can clean up some crud a bit. It just lives on the central server, not in everyone's working copy.
You can clone with a single revision in git. Still ends up being around 2X the size I believe since you have the objects stored for the single revision as well as the working tree.
Facebook now has 7000 employees and is 10 years old. Each employee would have had to write 14 kiB of code (357 LOC with 40 (random guess of mine) characters per LOC) every day during this 10 years to produce 8 GiB of code. (Obviously assuming the repository contains only non-compressed code and only one version of everything and no metadata and...)
If they've got memcached with their own patches, linux with their own patches, Hadoop with their own patches, etc. and tons of translations I can see 8 gigs of text.
Why would they put that all in the same repository? I'm pretty sure this 8 GB repo is just their website code. A frontend dev working on a Timeline feature shouldn't have to check out the Linux kernel.
8GB would be at least 100 million lines of code (upper bound with 80 characters per each line). For comparison Linux has 15+ million lines of code, PHP 2+M.
PHP's repo is around 500M. But I'd say it is probably tens to a hundred times smaller than Facebook should be, especially if you count non-public stuff they must have there. So comes out about right.
unlikely. they probably have a very dirty repo with tons of binaries, images, blah blah blah. It's highly unlikely they actually wrote 8GB of code, and the 46GB .git directory will be littered with binary blob changes, etc. This is really just to "impress" two people: 1) People who love Facebook 2) People who don't know anything about version control and/or how to do proper version control (no binaries in the scm).
When I can't avoid referring to binary blobs in git, I put them in a separate repo and link them with submodules. It keeps the main repo trim and the whole thing fast while still giving me end-to-end integrity guarantees.
I wrote https://github.com/polydawn/mdm/ to help with this. It goes a step further and puts each binary version in a separate root of history, which means you can pull down only what you need.
you're not going to merge binary files, so git isn't the right tool. the standard way is to use maven. git handles your sources, and anything binary (libs, resources etc) goes on the nexus (where it is versioned centrally) and is referenced in your poms: simple and powerful
git is "the stupid content tracker", not "the stupid merge tool". Even for things you have no intention of branching or merging, it still gives you control over versioning... and there's a huge gap between the level of control a hash tree gives you versus trusting some remote server to consistently give you the same file when you give it the same request.
I'm a bit confused. Whenever I've used git on my projects, I'd make sure the binaries were excluded, using .gitignore
Don't other people do that, too? What's the benefit of having binaries stored? I've never needed that; I've never worked on any huge projects, so I might be missing something crucial.
If there is a small number of rarely changing binaries (like icons, tool configs, etc.) then it may not be worth it to move them. Also if space is much cheaper than tool complexity and build time.
Well, it depends. Images are for instance binaries where a text diff makes little sense, so you have a copy of each version of the image ever used. And many projects use programs where the files are binaries. For instance, I've been on a project where Flash were used and the files checked in. Or PhotoShop PSD files, .ai files etc.
If you don't have the source that produced those binaries your only choice is to have them downloadable from somewhere else (which is a real hassle for the developer) or just check them into the repo.
Re-cloning a fresh repo should keep it small. There's also a git gc method which cleans up the repo. I guess another way would be to just archive all the history up to a certain point somewhere.
> Re-cloning a fresh repo should keep it small. There's also a git gc method which cleans up the repo.
There's only so much git gc can do. We've got a 500MB repo (.git, excluding working copy) at work, for 100k revisions. That's with a fresh clone and having tried most combinations of gc and repack we could think of. Considering the size of facebook, I can only expect that their repo is deeper (longer history in revisions count), broader (more files), more complex and probably full of binary stuff.
FWIW: Every time you modify a file in git, it adds a completely new copy of the file. 100mb text file, 100mb binary file - makes no difference. Modify one line, it's a new 100mb entry in your git repo.
The worrying point here is the checkout of 8GB as opposed to the history size itself (46GB). If git is fast enough with SSD, this is hardly anything to worry about.
I actually prefer monolithic repos (I realize that the slide posted might be in jest). I have seen projects struggle with submodules and splitting up modules into separate repos. People change something in their module. They don't test any upstream modules because it's not their problem anymore. Software in fast moving companies doesn't work like that. There are always subtle behavior dependancies (re: one module depends on a bug in another module either by mistake or intentionally). I just prefer having all code and tests of all modules in one place.
As much as i hate clearcase i have to say it has some "interesting" features to deal with this. When you look at a repo you don't look at one unique version of the whole repo, you can create quite advanced "queries" such that for folder /src you look at your branch, for folder /3dpartylibs you look at version 5 and for folder /tests you look at head(latest). And since your working directory can be network attached (dynamic view) you dont have to "update" manually, head is like a living animal! Its like having subrepos built in.
While this is interesting it also requires a lot of discipline and almost one person dedicated as full time "dba" to not end up with spaghetti. Since there is no unique version number of the repo you have to store these queries and manually keep adding labels to be able to go back to an exact point of time.
It does have some uses like being able to run a new test on old code to find the first version when something broke or being able to change versions of external libraries or blob assets quickly but its hard to say if its worth it since it comes with so many other problems.
Most big tech companies use a service-oriented architecture. The website is composed of many small services which communicate with each other over HTTP or RPC protocols. Each service has its own version control repo and is maintained by a different team. That's generally the best way of scaling up.
That only applies to deployment. You're not building these services from the ground up: they're all going to have common libraries that need to stay up to date.
These are all solved problems. You create a package system that allows you to specify versioned dependencies to other packages. Your build and deployment systems can then build your package even though it depends on code that lives in other repositories owned by different teams. Hell, this even works across different versioning control systems; one team can be lagging along on SVN, another can have packages in P4, and yet another can have theirs in git, but they can all build against each others code.
It works absolutely brilliantly. Division of labor and responsibility becomes clear, repos stay manageable, large scale rewrites can happen safely, in piecemeal, over time... it really is the best way to do it.
As others have noted elsewhere, this "solution" has its own problems if you are rapidly moving. Which I don't think anyone can claim facebook hasn't been doing.
So, yes, if you are able to control growth enough that you can make this happen, it is attractive. If you can't, then this leads to a version of the diamond problem in project dependencies. And is not fun.
Growth is the reason that companies should avoid what Facebook has done. The company I currently work for anticipated the scaling problems that Google later encountered with Perfoce (http://www.perforce.com/sites/default/files/still-all-one-se...) and recognized that while perforce could be scaled further by purchasing increasingly beefy hardware, ultimately you could only reliably scale so far with Perforce.
If you're not growing, then there is no problem. If you have linear growth maybe you can keep pushing it, but who plans on linear growth?
Google is already on multiple Perforce servers because of scaling, and that is not a situation that is going to improve. If you start using multiple centralized version control servers, you are going to want a build/deployment system that has a concept of packages (and package versions) anyway.
> If you can't, then this leads to a version of the diamond problem in project dependencies. And is not fun.
These sort of dependency resolution conflicts can and do happen, but far less often than you would think. Enforcing semantic versioning goes a long way (and along with it, specifying. In practice, the benifits of versioned dependencies (such as avoiding ridiculous workarounds like described by this HN comment: https://news.ycombinator.com/item?id=7649374) far outway any downsides.
You can even create a system that uses versioned packages as dependencies while using a centralized versioning system. In fact, this is probably the easiest migration strategy. Build the infrastructure that you will eventually need anyway while you are still managing on one massive repository. Then you can 'lazy eval' the migration (pulling more and more packages off the centralized system as the company grows faster and faster, avoiding version control brownouts).
Really good question. One that I am not pretending to know the answer to.
I do feel that the main reason they are successful is large manpower. That is, competent (but not necessarily stellar) leadership can accomplish a ton with dedicated hard workers. This shouldn't be used as evidence that what they are doing is absolutely correct. But, it should be considered when what they do is called into question.
If you have/know of any studies into that, I know I would love to read them. I doubt I am alone.
If you are a large company, you can move faster if devs aren't all working on the same repository. If all your code is in one repo and one team makes a breaking change to their part of it, everyone's code fails to build. If the source code is broken up into separate packages, each team can just use versioned releases of the packages they depend on and not have to worry about fixing compatibility issues.
While there is a strong appeal to your argument, Facebook stands as a resounding counter example. As does Google.
The counter argument appears to be this. If one team checks in a change that break's another team's code, then the focus should be on getting that fixed as soon as possible.
Now, if you are in multiple repositories, it can be easy to shift that responsibility onto the repository that is now broken. Things then get triaged and tasks must be done such that getting in a potentially breaking fix may take time.
Contrasted with the simple rule of "you can't break the build" in a single repository, where the impetus is on whoever is checking in the code to make sure all use sites still work.
Granted, an "easy" solution to this is to greatly restrict any changes that could break use site code. The Kernel is a good example of this policy. Overall, I think that is a very good policy to follow.
We use separate repos and it works out well. It's nice having separate Git histories that pertain to different areas of the codebase.
Our workflow covers all the potential problems you named (eg. scripts to keep everything up to date, tests that get run at build or push time after everything is already checked out from the individual repos, etc.).
We've been running this way for over a year with literally zero issues.
Yeah, doing it this way they can never make API incompatible changes without also fixing everything downstream... which effectively means once a library is popular enough it is locked at it's current API forever.
I've seen that happen at Google. At some point it's easier to write a new (differently named) library. Monolithic codebase + renames = poor man's versioning.
BUT this allows you to pay the prices of versioning (downstream burdened with rewriting => they never do => old code lives indefinitely) only in the worst cases.
If done right (lots of tests, great CI infrastructure), fixing everything downstream is practical in many cases, and can be a win.
A subtler question is how this interplays with branching.
You can't be expected to update downstream on every random/abandoned branch out there, only the head. Which deters people from branching because then it's their responsibility to keep up...
How does monolithic repos solve that. Surely people who fix bugs in a library aren't testing the entirety of Facebook every time (how long would that even take? Assuming they've even set such a thing up.)
It is at least easier to correlate the changes. When you have X+ modules, you have potentially X+ histories you have to look at to know when a change was seen with another change.
I bet most of that size is made up from the various dependencies Facebook probably has, though I'm still surprised it's that large. I expected the background worker things, like the facial recognition system for tagging people, and the video re-encoding libs, to be housed on separate repositories.
I also wonder if that size includes a snapshot of a subset of Facebook's Graph, so that each developer has a "mini-facebook" to work on that's large enough to be representative of the actual site (so that feed generation and other functionalities take somewhat the same time to execute.)
Having all code in a single repository increases developer productivity by lowering the barrier to change. You can make a single atomic commit in one repository as opposed to N commits in M repositories. This is much, much easier than dealing with subrepos, repo sync, etc.
Unified repos scales well up to a certain point before troubles arise. e.g. fully distributed VCS starts to break down when you have hundreds of MB and people with slow internet connections. Large projects like the Linux kernel and Firefox are beyond this point. You also have implementation details such as Git's repacks and garbage collection that introduce performance issues. Facebook is a magnitude past where troubles begin. The fact they control the workstations and can throw fast disks, CPU, memory, and 1 gbps+ links at the problem has bought them time.
Facebook made the determination that preserving a unified repository (and thus preserving developer productivity) was more important than dealing with the limitation of existing tools. So, they set out to improve one VCS system: Mercurial (https://code.facebook.com/posts/218678814984400/scaling-merc...). They are effectively leveraging the extensibility of Mercurial to turn it from a fully distributed VCS to one that supports shallow clones (remotefilelog extension) and can leverage filesystem watching primitives to make I/O operations fast (hgwatchman) and more. Unlike compiled tools (like Git), Facebook doesn't have to wait for upstream to accept possibly-controversial and difficult-to-land enhancements or maintain a forked Git distribution. They can write Mercurial extensions and monkeypatch the core of Mercurial (written in Python) to prove out ideas and they can upstream patches and extensions to benefit everybody. Mercurial is happily accepting their patches and every Mercurial user is better off because of Facebook.
Furthermore, Mercurial's extensibility makes it a perfect complement to a tailored and well-oiled development workflow. You can write Mercurial extensions that provide deep integration with existing tools and systems. See http://gregoryszorc.com/blog/2013/11/08/using-mercurial-to-q.... There are many compelling reasons why you would want to choose Mercurial over other solutions. Those reasons are even more compelling in corporate environments (such as Facebook) where the network effect of Git + GitHub (IMO the foremost reason to use Git) doesn't significantly factor into your decision.
Hello there, have you heard of service oriented architecture? You must be joking to justify a single repository with "easier to change". Your problem is that the code base must be tightly coupled if splitting the services out to different repos is not possible and you need to contribute to multiple repositories to get something done. I would say, the biggest change in Amazon's architecture was moving over to the service oriented way and it was worth the effort. Developers are forced to separate different functions to separate services and they are in charge of that service. If it goes down their are getting the alerts. All of the services are using 250ms timeouts so there is no cascading effect when a services goes down. The web page consists of few thousand service calls and it degrades gracefully. Facebook obviously have some tech depth that they need to fix. Using stupid design justified with some random crap that does not even make sense is not really acceptable (at least for me).
What if multiple services are utilizing a shared library? For each service to be independent in the way I think you are advocating for, you would need multiple copies of that shared library (either via separate copies in separate repos or a shared copy via something like subrepos).
Multiple copies leads to copies getting out of sync. You (likely) lose the ability to perform a single atomic commit. Furthermore, you've increased the barrier to change (and to move fast) by introducing uncertainty. Are Service X and Service Y using the latest/greatest version of the library? Why did my change to this library break Service Z? Oh, it's because Service Z lags 3 versions behind on this library and can't talk with my new version.
Unified repositories help eliminate the sync problem and make a whole class of problems that are detrimental to productivity and moving fast go away.
Facebook isn't alone in making this decision. I believe Google maintains a large Perforce repository for the same reasons.
> "What if multiple services are utilizing a shared library? For each service to be independent in the way I think you are advocating for, you would need multiple copies of that shared library (either via separate copies in separate repos or a shared copy via something like subrepos)."
No, you have a notion of packages in your build system and deployment system.
You want to use FooWizz framework for your new service BarQuxer? Include FooWiz+=2.0 as a dependency of your service. The build system will then get the suitable package FooWiz when building your BarQuxer. Another team on the other side of the company also wants to use FooWiz? They do the exact same thing. There is never a need for FooWiz to be duplicated, anybody can build with that package as a dependency.
I think you are missing the point. Versioning and package management problems can largely go away when your entire code base is derived from a single repo. After all, library versioning and packaging are indirections to better solve common deployment and distribution requirements. These problems don't have to exist when you control all the endpoints. If you could build and distribute a 1 GB self-contained, statically linked binary, library versioning and packages become largely irrelevant.
I'm telling you how corporations with extremely large codebases and a SOA do things. The problem that you described has been solved as I describe.
SOA is beneficial over monolithic development for many other reasons unrelated to versioning. It just happens to enable saner versioning as one of it's benefits.
When you are done writing boilerplate to wrap all the third-party functions, don't forget to write equivalent documentation too. And tests. Or are you just going to use the same function names? If the latter it's a pointless exercise, because it's unlikely you can shoehorn A different vendor library into the exact same API later.
I never said it was a magic bullet. What I am suggesting is to have separate services with independent software packages. This is all. Btw. you can't break a service with a commit, all the services are using versioned APIs so when you are building API version n+1 you are not ditching version n. Very simple, seamless upgrade, graceful downgrade. FYI such a system is powering Amazon and it works perfectly at scale.
> @readyState would massively enjoy that first clone @feross
The first clone does not have to go over the wire. Part of git's distributed nature is that you can copy the .git to any hard drive and pass it on to someone else. Then...
You're welcome! I really liked the 'push karma' too.
I liked this idea too : "all engineers who contributed code must be available online during the
push. The release system verifies this by contacting them automatically using a system of IRC
bots; if an engineer is unavailable (at least for daily pushes), his or her commit will be reverted."
That way, they are be able to react very quickly in case of a problem.
But this isn't a magic bullet...a commit can't always be reverted without conflicts, and even if reverted there's no guarantee that it leaves the codebase in a correct state. (Guess I should read the article you're talking about.)
Yes, but the new intern would be able to read all the source and "secret sauces".
I doubt that an intern on Google would've access to the search codebase. I'd wager that only a handful of trusted employees have access to that codebase.
> If you don't trust your employees why did you hire them?
On a small company, I agree. But on FB they're around 5k people. Let's say they have 3k engineers, that's a awful lot of people they're trusting with their source code
You are correct for the search codebase - it is separate from the main tree, as is a lot of the core ad placement code. If you aren't working on those projects, you don't have access.
So it is like the Coca Cola recipe? Only two people allowed to know it and not allowed to get the same flight? Yet everyone else able to mix and serve the syrup?
It should be possible to restrict each employee's access to specific parts of the repository. However, I can't really see Facebook doing that.
Everyone having access to everything must be worth the security trade-off. On the other hand, I suppose it's debatable whether it would be a trade-off at all.
I wonder, if this is the way a majority of big businesses do things, how come we don't see more leaks of entire codebases? It'd be trivial to put something up on TPB and just share all the code, but I don't see things like that happening. I also doubt that every single employee with access to the code has the moral standards not to do this. There must be something else keeping them from doing it.
>Everyone having access to everything must be worth the security trade-off.
I would find this extremely hard to believe, especially at Facebook. At any software company, your code base is what defines you as a company; there is no way they'd let the good stuff sneak out like that.
Lets say you managed to sneak out the code from facebook. You take the logo, draw a red cross over it and scribble "ProAmbook" below. You push it live.
Now what? How do you get users? "We are just like facebook - only your friends aren't here" probably wouldn't get users excited.
And if you somehow DID manage to get users, don't you think there are "watermarks" in the code, that they could detect and sue you to death with?
They have anti-spam heuristics, graph heuristics, models on how to serve the best ad for each user, tons on bugs that can be only discovered by reading the source, etc.
Having only the code wouldn't be enough. You need to also replicate comparable maintenance staff & data center capability. Even then you'll just have a clone of the tech, but nobody will actually use your service. There's so much more that makes facebook what it is. I think they may even be able to open source their tech with a net positive effect.
I think a lot of their value comes in the data the collect about users and how they use it to sell ads to vendors. That source code would be worth a lot. I'm not speaking about replicating a Facebook on your own servers, I agree there it would be futile. But how they run their business can probably be derived from their source code.
Facebook has never been defined by its code. They have had source leak before and no one has cared--it's PHP (heavily customized at that) and not of much worth outside of casual curiosity. The trick is to get a billion plus people to give you the details of your life every day.
> The trick is to get a billion plus people to give you the details of your life every day.
How they capture this data and use it would also be in their source code, no? This is absolutely where Facebook gets its worth. I would assume this is what they would want to keep in a limited exposure set? I might be wrong, but this is why they hire the best engineers out there.
When you split code across smaller repos, you gain a different problem: version management and potentially dependencies using different versions of the same project.
> When you split code across smaller repos, you gain a different problem: version management and potentially dependencies using different versions of the same project.
True, you do. What you gain is the ability of small pieces to move individually through API changes.
If your entire codebase is in one repo (as appears to be the case here), and you want to change an API, you must either do so in a backwards compatible way, and slowly eradicate any old callers, or change them all in one fell swoop.
By splitting to multiple repos, you can version them independently. Thus, a project can (hopefully temporarily) depend on the old API, which only gets bugfixes, while another project can depend on the new version.
The tricky bit is when you have one "binary" or something equivalent referring to two versions of a dependency. (Usually indirectly, i.e., A depends on B which depends on D v1, and A depends on C which depends on D v2, and D v1 and D v2 are incompatible.) You can't really do much about this, but if you keep your components small enough (think services with well separated interfaces) you should be able to keep the dependencies small enough as well.
It becoms a lot harder to keep everything in sync, especially if internal interfaces change frequently. At facebook scale though it's probably a good idea to defined boundaries between areas in the application better.
No, it doesn't. It's actually the complete opposite because you know, 'though shall separate those things that change frequently from those that don't'
You end up with less developers having to pull & merge/rebase if you have things in separate repos.
Individual libraries/dependencies get worked on by themselves, with an API that other applications use. Then the other apps just bump a version number and get newer code.
The problem with this, is that you are assuming the APIs change in some sort of odd isolation to the parts that use them.
That is, the reason an API changes is because a use site has need of a change. So, at a minimum, you need to make that change and test it against that site in a somewhat atomic commit.
Then, if the change has any affect on other uses, you need a good way to test that change on them at the same time. Otherwise, they will resist pulling this change until it is fixed.
Add in more than a handful of such use sites, and suddenly things are just unmanageable in this "manageable" situation.
Not that this is "easy" in a central repo. But at least with the source dependency, you can get a compiler flag at every place an API change breaks something.
And, true, you can do this with multiple repos, too. But every attempt I have seen to do that just uses a frighteningly complicated tool to "recreate" what looks like a single source tree out of many separate ones. (jhbuild, and friends)
So, if there is a good tool for doing that, I'd certainly love to hear about it.
Meh. I'm working on a comparably small project (~40 developers), and we're over 16GB.
Mostly because we want a 100% reproducible build environment, so a complete build environment (compilers + IDE + build system) is all checked into the repro.
Someone recently told me that Facebook had a torrent file that went around the company that people could use to download the entire codebase using a BitTorrent client. Is there any truth in this?
I mean, the same guy that told me this, also said that the codebase size was about 50 times less than the one reported in this slide, so it may all be pure speculation.
If you're interested in the deployment process at Facebook, look at the link of a Facebook engineers paper I submitted in my other comment in this thread : https://news.ycombinator.com/item?id=7648802
"The deployed executable
size is around 1.5 Gbytes, including the Web server and compiled Facebook application. The code
and data propagate to all servers via BitTorrent, which is configured to minimize global traffic
by exploiting cluster and rack affinity. The time needed to propagate to all the servers is roughly
20 minutes."
That sounds entirely believable. At $PREVIOUS_JOB, the Puppet git repository was large enough (several GB) that cloning it was painful, and new starters were handed a pruned repository via the local network so that they could get something done today.
NAFV_P@DEC-PDP9000:~$ python
Python 2.7.3 (default, Feb 27 2014, 19:58:35)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information
>>> t=54*2**30
>>> t
57982058496
# let's assume a char is 2mm wide, 500 chars per meter
>>> t/500.0
115964116.992 #meters of code
# assume 80 chars per line, a char is 5mm high, 200 lines per meter
>>> u=80*200.0
>>> v=t/u
>>> v
3623878.656 # height of code in meters
# 1000 meters per km
>>> v/1000.0
3623.878656 # km of code, it's about 385,000 km from the Earth to the Moon
>>> from sys import stdout
>>> stdout.write("that's a hella lotta code\n")
They aim for a completely linear history. They may even have a policy of not allowing merge commits. It is described in various places on the internet. I like https://secure.phabricator.com/book/phabflavor/article/recom... because it and its sister articles on code review and revision control are terrific reads.
Dear everyone: you should be using Phabricator. It is Facebook's collected wisdom about software development expressed in software. It has improved my life substantially. The code review is better than Github's, and their linear, squashed commit philosophy has worked out much better than the way I used to do things.
Oh yeah, it's great when one person can break the build and stop all active development. It scales so well. Oh I know, to prevent any issues, let's protect ourselves with feature toggles. Oh and let's build a set of database driven rules to manage those toggles. Oh what about dependencies? Let's build a manager to manage the DAG of feature toggle dependencies.
Need I go on? :-) You've replaced a relatively simple system of merge requests with some pseudo in-code versioning system controlled through boolean global variables.
I'll take feature branches any day of the week over that mess. The github model is far superior IMO.
My team uses Phabricator without any feature toggles in our code. You land code onto master when it's ready to ship. Until then, you have features developed and reviewed on separate branches. I don't get how that's more or less fragile than merges.
I was addressing the idea of committing directly to master, protecting your code with feature toggles so it doesn't break things. Maybe I misunderstood the OP.
I think feature toggles can be extremely useful, but still develop in a branch and merge after review/qa.
We're using Phabricator at my company, and I'm getting to the point of encouraging people to use it and start seeing the benefits. I work on infrastructure, so when people come to me with issues, I find out what problem they're having and then get them to submit a ticket to me. I've also started creating tickets for issues and assigning them to other people to get them to take a look at it, and people seem pretty receptive.
It hasn't become part of everyone's workflow yet, but it's pretty useful.
That might be a silly question but it's not useful for just an individual in a team, correct? We use GitHub at work, but I wouldn't be able to try Phabricator on my own, right?
Mostly correct. You can use the code review tools without needing your repository set up in Phabricator or anyone else with Phabricator accounts. You could comment on a diff and point your coworker to it, but it's unlikely to feel better than Github pull requests in that scenario.
Mixed bag. The code review part is much better than stash and significantly better than crucible. Namely, diff of diffs makes reviewing changes based on comments infinitely easier (especially on large reviews). We installed phabricator just for the code review piece initially. Repo browsing is about on par with stash, but it doesn't seem to experience the horrific slow downs that our stash server does. We don't use the tasks because a number of non engineering roles also use JIRA and the tasks functions in phabricator don't have nearly the depth of security and workflow options we need.
You can still merge from master (or whatever your main development branch is) into your feature branches. You just never merge into your main branch. You squash the commits and rebase. The history ends up looking much better, and `git blame` becomes much more useful.
There's a big difference between a linear history produced by actual linear development and one produced by `git rebase -i`. They both have the advantage of being easier to understand later, however.
That's not true dude. If you're following actual linear development you're likely to see a lot of 'poke build' and 'change css' and stuff like that. Git rebase -i gives you a change to rename your commit and organize it in a readable way.
So git rebase -i will be more readable, while actual linear history is always gibberish.
Last I knew, the FB mainline codebase was in fact still in SVN with git-svn dcommit (possibly hidden under arc) being how things land in "master" (and the revisions being merged quasi-manually to a release branch immediately before HH compile)
FB doesn't need to branch ... Gatekeeper (their A/B, feature flag system) really takes care of that concern logically
gosh, last time I had trouble with 8GB data checking in, it's very memory hungry when the data set is big and then you need check them in all at once, how much memory on the server side you need when you want to 'git add .' all the repo of 54GB?
what about a re-index or something, will that take forever?
I worry at such size the speed will suffer, I feel git is comfortable with probably a few GBs only?
anyway it's good to know that 54GB still is usable!
I hope everyone realizes this is not 54GB of code, but in fact, is more likely a very public showing of very poor SCM management. They likely have tons of binaries in there, many many full codebase changes (whitespace, tabs, line endings, etc). Also not to mention how much dead code lives in there?
Honestly, I prefer check-in everything shops. It's way too often otherwise some different Java version, or IDE version, or Maven central being down screws something up, or you have to wait a long time for a Chef recipe or disk image to give you the reference version. Half my day today was dealing with someone updating Java on half our continuous build system slave computers and breaking everything because it didn't have JAVA_HOME and unlimited strength encryption all setup properly.
That sounds like either poor Sys Admin'ing and/or poor documentation... SCM should not have "clutter" in it, otherwise you wind up with an all-day download of 54GB of dead or useless garbage. The Kernel's repo is only a few GB's and it has MANY more changes and much more history than FB does...
"The" repo. As if they had no choice but to put everything for every aspect of the business into ONE giant repo.
Hopefully they actually have some separate sites, separate tools and separate libraries. Or could understand how to use submodules or something rather than literally putting everything in one huge repository.
Whether to put images and other assets into git repos is a separate decision.
It is supposed to justify the engineering effort they put into switching to Mercurial, then trying to make it "scale." (Rather than just using separate repositories to begin with, according to the design of the tool and best practices)
Its not bad, is really nice, but Git has one problem, when you codebase is big, the process takes a long time, imagine git scanning those 8GB every time you do a commit, that is why Facebook was looking to port all their code to another VCS
I think it's worth making a distinction between the Git plumbing and the Git porcelain when talking about performance. The core functionality (the plumbing) is very fast regardless of repository size. The slowdowns people describe are almost always related to the porcelain commands, which are poorly optimized. Almost every porcelain-level command will cause Git to lstat() every file in your tree, as well as check for the presence of .gitignore files in all of the directories. It's very wasteful.
The fix for this is pretty simple: use filesystem watch hooks like inotify to update an lstat cache. I wrote something like this for an internal project and the speed difference was night and day. I remember reading that there had been progress on the inotify front on the git dev mailing list a few years ago, don't know what the current status is.
{kind=link}
I don't use Facebook, and I'm not suggesting that they're building the software of the future. But surely someone there is smart enough to know that, for this decision, time is on their side.
[1] https://news.ycombinator.com/item?id=7538063
[2] http://www.joelonsoftware.com/items/2009/03/27.html