I’m also unconvinced that the distinction between := and = is essential; feels like unnecessary ceremony.
I think that's actually almost my favorite thing about the language, I don't know how many times I've wished that Python and Lua worked that way. Having a low-ceremony means of declaration while also preventing you from accidentally over-assigning something when you want to be declaring it is really nice.
"After a few painful instances of searching for things like “go array literals” and “go repl” I got into the habit of sticking with Golang; and so will this diary."
>The second big gripe is that Golang has neither an IDE nor a REPL.
The IDE part is not true at all, why do people keep saying this? LiteIDE (aka golangide) works great, I use it all day everyday. It has syntax highlighting, autocomplete, gofmting, building, debugging, etc and is very lightweight.
As for the merit if REPL over something like the go playground (http://play.golang.org/) or a debugger, I can't say. Most of the code I wrote before Go was C/C++/C#/Java.
The main benefit of a true REPL over the Go playground is that a REPL allows you to interact with the state of a partially-run program. By contrast, the Go playground is one-shot. Your code runs quickly, but completely, and you see the result. But you can't examine the data structures interactively.
For instance, when debugging a simple Python utility, I will often put the steps it goes thru into individual functions and tie them together with a main() function normally called via "if __name__ == '__main__':main()".
That allows me to import the program as a module into a REPL session, from which I can call the functions individually and examine the resulting outputs. If something's not right, I can alt-tab to the editor, make a change, save the program, and use the reload() function in the REPL. Sometimes, the REPL-obtained data is all I'm looking for, and I never get around to running the code from the command line.
OK, in a compiled language like Go a REPL implementation looks hard- am I wrong? It seems like besides the code being R/O a debugger is pretty close too.
When testing with a debugger I setup my program to run the same tests, read the same input etc. In this way I can use the debugger, find and issue, change the code, set a break point, re-run the program and I'm right back where I left off. This sounds functionally similar to using a REPL.
The post is fun, thanks. I like Tim's idea of "taking the journey" with a programmer on discovering new content. It's certainly the best way to introduce the topic to others. All the potential sticking issues have been handled for you!
I was also excited when he said "I filed a bug on June 6th, and it was fixed on the 12th. Gotta love that.". There is no better feeling than sending a pull request and having someone thank you, merge it, and fix the issue within a few hours or days of you sending it.
In this case, however, I think his joy may be premature. Rob Pike replied to the bug saying it was indeed an issue and either the code or documentation should be fixed. Having Rob Pike reply is a good start, considering he's the primary author of Go. Someone else then came along and fixed it in a way the article's author is unhappy with, though[1].
Agreed, that bug is quite a bit different from the impression in the blog post. Tim is completely right, however: Why can't he use the automatically differentiated leading underscore test? And the fix of the documentation is, as he mentioned, just as wrong as it already was. Now I wonder if his bug comment was sarcastic, because it would be had I written it.
Why can't he use the automatically differentiated leading underscore test?
The go tool currently ignores all files with a leading '_' in the name. Changing the tool to use a file with the name '_test.go' complicates the rule for ignored files and might break an existing project. The workaround of using 'all_test.go' is not onerous.
> Having Rob Pike reply is a good start, considering he's the primary author of Go
According to himself and the Go FAQ he's just one member in the team, the beginnings are described as "Robert Griesemer, Rob Pike and Ken Thompson started sketching the goals for a new language on the white board on September 21, 2007"
>Golang will not let you compile if there’s an import or declared variable that’s unused. OK, I understand that Cleanliness Is Next To Godliness, but this is seriously slowing me down; probably a third of my attempts to run my damn program fail because I’ve forgotten to remove debugging apparatus, or I’ve sketched in a variable but not used it yet. How about a compiler switch or something?
I don't find this an issue with vim using syntastic. When I save, I get notified in the gutter of issues like this and then I can use the official go vim support to do things like :Drop to remove the import without even navigating to the imports section. Syntastic picks up on most issues before you even think of compiling.
>There doesn’t seem to be a way to declare a constant array, what in a Java class I’d call final static String[] COLS = {"Red", "Blue"};
Constants in Go are evaluated at compile time and arrays don't exist at compile time. You can manage at the package level by using a unexported variable then exporting a function that returns it.
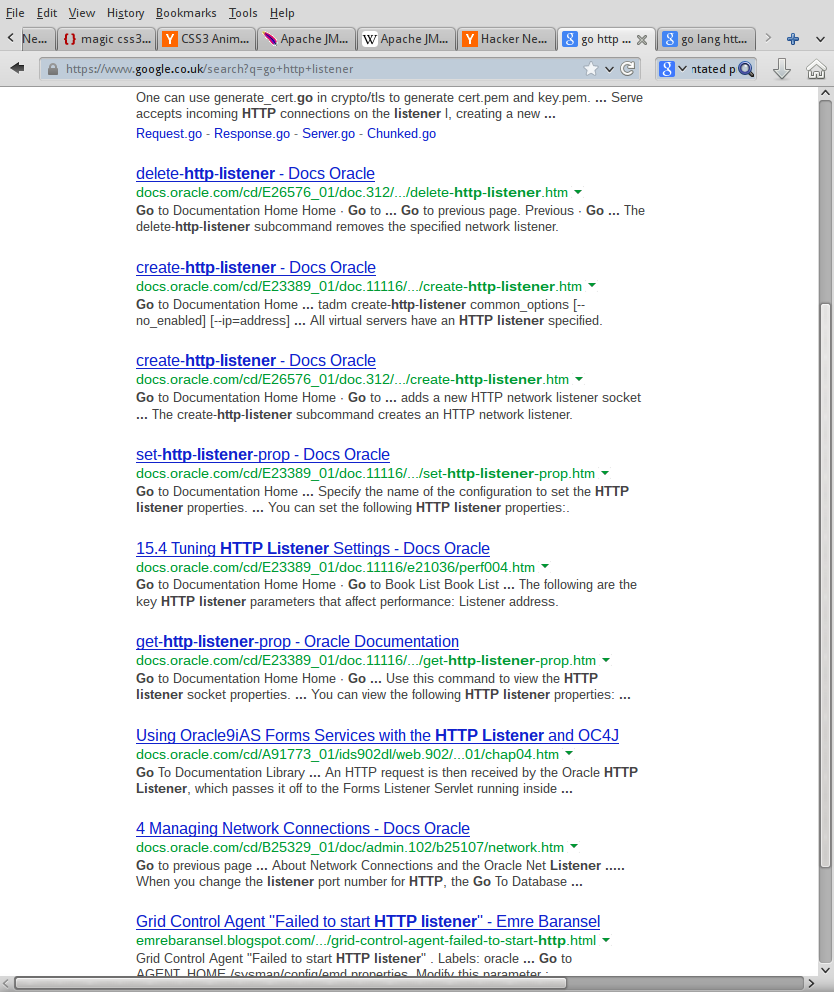
>First, the name. “Go” has too many meanings and is among the world’s lousiest Google search disambiguators.
Enough with this old wives tale. Yes, "Go" is too generic. Nevertheless, Google understands it just fine. Case in point:
>"After a few painful instances of searching for things like “go array literals” and “go repl” I got into the habit of sticking with Golang; and so will this diary.
Both his examples ("go array literals" and "go repl") return a page full of Go related results (the documentation, the golang-nuts discussion list, related blog posts, etc).
Maybe Google is tailoring your results to bring back sites that include the programming language based on a) your past searching habits and b) the emerging trends for those specific search patterns.
Google's results are highly tailored, thus two people can search for the same term and get different results.
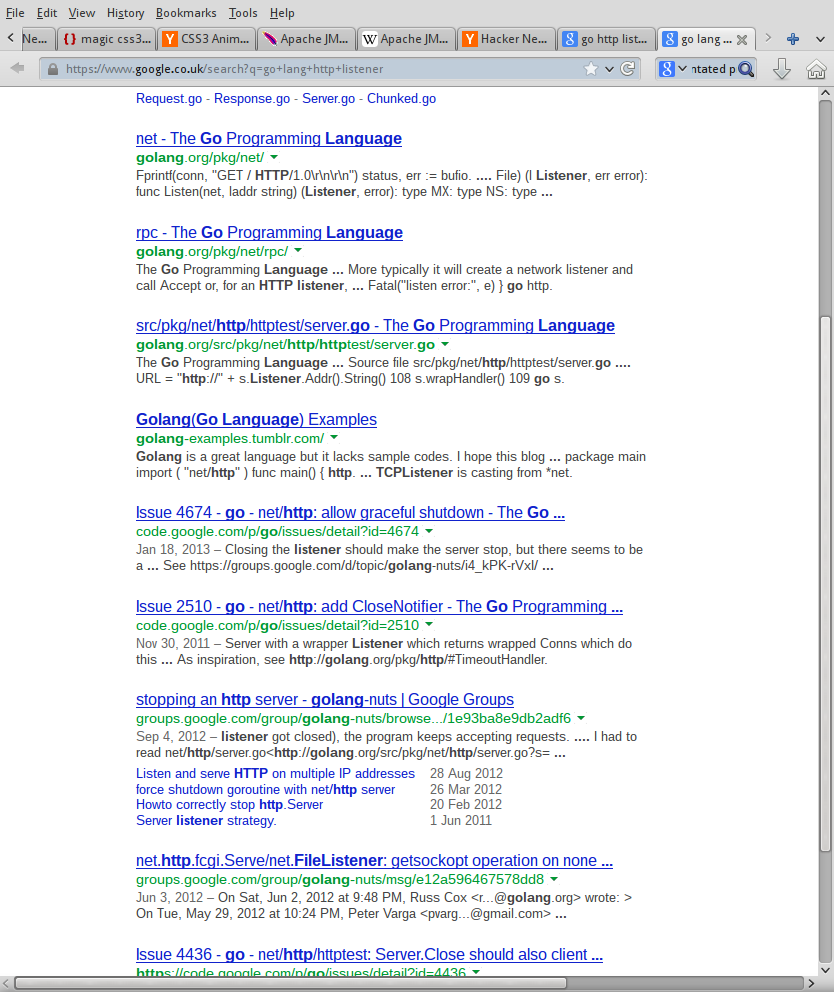
Going back to the original point raised, I too have gotten into the habit of searching for "go lang [query]" rather than just "go [query]" due to the same frustrations in the past. What the author describes isn't a unique quirk he's experienced, it's actually a very common complaint.
>Maybe Google is tailoring your results to bring back sites that include the programming language based on a) your past searching habits and b) the emerging trends for those specific search patterns. Google's results are highly tailored
Well, tried the same thing logged out from Google, in incognito mode and with cookies turned off. Same results.
I can also try to proxy my search to a remote VPS I never use and see what happens.
But anyway, forget the "fitler bubble". Google is smarter that the naive "Go means the verb" in all contexts.
In example 1, only 1 item on the 1st page is related to Golang. In example two, every result is related. (and that's without me dipping into incognito mode)
People like yourself and the OP can love to prove people wrong and argue that same popular searches work perfectly for you, but until you've spent a few months learning the language and thus making frequent searches online like myself and the author have, all you're doing is making pointless arguments (i mean does it really matter that much to you when you're not actively developing in the language?) which are based upon flawed experiments (as already discussed) and inexperience.
If that sounds condescending, then I'm sorry, but I've been working in Go for > 6 months now -so I'm still a new comer- but even just in that time I've noticed how poor the results are without specifying "lang" in the criteria. So I resent having a non-go developer tell me that I'm imagining the last 6 months of online research. Particularly when several (read: not just one other, but several other) Go developers have spoken up in this very same thread and confirmed the same issues I've been raising. This isn't some blip in Google's results. This is a genuine issue with the searchability of "Go".
But don't just take my word for it, here's some screenshots:
>People like yourself and the OP can love to prove people wrong and argue that same popular searches work perfectly for you, but until you've spent a few months learning the language and thus making frequent searches online like myself and the author have, all you're doing is making pointless arguments
Besides the BS ad hominem ("people like me", really?), you just reversed the whole argument against my results. How's that for contradiction?
People argued above that I was getting them because I was in a "filter bubble" for having searched for the language a lot in the past.
Suddenly the problem is that I haven't "spent a few months learning the language and thus making frequent searches online [like yourself]"?
What for? To appreciate the subtle nuances and variable results of using go vs golang?
Not to mention, I never said golang didn't work best (which you somehow assumed I did). Just that "go +stuff" worked well too.
>which are based upon flawed experiments (as already discussed)
Nothing of the short was shown. What was the "flawed experiment" and in what way?
Surely not that I was in a "filter bubble", because now you argue for the inverse (that I didn't perform enough searches). If that was the case, then you should be in a filter bubble too, after all your "frequent searches", which wouldn't explain your results.
Plus, I did the same from totally different account with no cookies and got the same results (as I patiently explained).
You're arguing the same points I'd already addressed in my previous post. You clearly haven't bothered to read my points nor look at the examples as they demonstrate exactly why "go +stuff" doesn't always work. So what's the point in me answering your questions again? You're clearly only going to ignore me, again. Just like how you've ignored everyone else that's replied to you.
> Besides the BS ad hominem ("people like me", really?), you just reversed the whole argument against my results. How's that for contradiction?
You're absolutely right. But I'm defending the author; and feel obliged to defend him because I'm sick and tired of reading lazy negative posts against authors who've taken the time to contribute back to the community. Particularly when a) the criticisms have very little relevance to the wider topic and b) the guys making the remarks aren't even experienced in the technologies they feel compelled to make authoritative judgements about.
This place used to be a safe haven from the trolls and egos of other communities, but these days if feels like the constructive and informative posts are outnumbered by the opinionated who have very content to contribute -and often, no interest in the subject either- but yet still feel compelled to comment.
And yes, I know I've swerved woefully off topic now. I'm certainly not trying to accuse you as being the worst that HN has to offer. I'm just frustrated that I've let myself get dragged into this dumb argument when I should have just broken my personal "down-voting rule" so that the healthier discussions in this thread could have risen to the top of the page.
>You're arguing the same points I'd already addressed in my previous post. You clearly haven't bothered to read my points nor look at the examples as they demonstrate exactly why "go +stuff" doesn't always work.
If the "previous post" is the one I replied to, I not only read it thoroughly (and nowhere it addresses those points, you're welcome to correct me with citations), but also replied to it quoting you.
If the "previous posts" is something else up or down the thread, not addressed to me, then no, I haven't read it. Should I check and re-check everything in a thread?
Screenshots of what you got are not proof. I (and others) already said we got different results. So, it might not "always work", but it does work for some (contrary to what Tim says), and it's not due to a "filter bubble".
Heck, he WOULD be wrong EVEN if it was due to a "filter bubble", because then the lack of results would only be temporary, until Google learns his habits with regards to Go.
>But I'm defending the author; and feel obliged to defend him because I'm sick and tired of reading lazy negative posts against authors who've taken the time to contribute back to the community.
So you do it because you have an agenda, specifics be damned. I don't care if someone "took time to contribute back to the community" -- if there are points that need to be criticise they SHOULD be criticised. Not doing it would be a disservice to the community. Also, what he did as "contribution to the community" is just posted on his blog: not very different from what we do here, discussing in public.
>This place used to be a safe haven from the trolls and egos of other communities
Nowhere did I attacked the author. I responded to his claim and provided my contrary experience with similar searches. When confronted with the "filter bubble" explanation, I redid the experiment outside the "personalised search" effect.
You chose to come as a "defender of the author", attacking me, and talking about "trolls" and "egos". Maybe the problem lies with you?
No I don't have an agenda. I happen to agree with the author. And I also happen to think your opening argument was rude, irrelevant and wrong - in equal measures. Maybe not intentionally rude, but unnecessary none the less.
What's more, neither Tim nor myself said that Go never works. Just that Go is a lousy search term and that "go lang" usually yeilds better results. My screenshots are evidence of that (and your reasoning for dismissing them is completely wrong because nobody else had commented on those examples. So don't give me that crap about "and others")
The issue here is that you've decided to post the typical easy reps via unrelated negative, and did so by overstating the authors point about the quality of Go as a search term. But then, sadly, you were too bloody stubborn to admit when you were wrong despite numerous developers (read: people who actually know what they're talking about on this matter) politely trying to demonstrate that a) not all users get the same results, b) popular results for similar search patterns will be biased in everyones results and c) not everyone uses Google.
But who cares about experience and expertise when people like you can voice an opinion after only 5 minutes of button bashing on thier keyboard. who cares about the fact that several go developers have all said that it's just easier to get into the habbit of using "go lang", after recieving disappointing results in the past. And who cares that Google themselves advice using golang for searches, because obviously Google are less of an authority on this subject than you clearly are.
Anyhow, we're never going to agree on this and you're not even interested in this subject anyway. So I suggest we quit while we're ahead.
>No I don't have an agenda. I happen to agree with the author. And I also happen to think your opening argument was rude, irrelevant and wrong - in equal measures.
"Enough with this old wives tale" was rude?
And yet you used: "people like yourself", "trolls and egos", "lazy negative posts", "you've ignored everyone else that's replied to you", "you're not even interested in this subject anyway", "people who actually know what they're talking about on this matter",
against my very simple statementthat his queries also work with "go" -- and it's not due to some "filter bubble".
Well, FUCK YOU, your insults and your condescending tone.
As for your points:
(a) "not all users get the same results" -- I replied to this, testing the "personalised bubble" effect. What else exactly do you think is in play? Divine intervention?
(b) "popular results for similar search patterns will be biased in everyones results" -- irrelevant, since I used the very terms Tim Bray tried. Why weren't they "biased" in HIS results? Isn't he a member of "everyone"?
(c) "not everyone uses Google." -- almost everybody does, and Tim for his examples used (and even works at) Google. Irrelevant again.
> "Enough with this old wives tale" was rude? And yet you used: "people like yourself", "trolls and egos", "lazy negative posts", "you've ignored everyone else that's replied to you", "you're not even interested in this subject anyway", "people who actually know what they're talking about on this matter",
You're selectively sampling data there. Those comments of mine are from later on in this debate - where you've been equally condescending. At the start I was polite.
> a) "not all users get the same results" -- I replied to this, testing the "personalised bubble" effect. What else exactly do you think is in play? Divine intervention?
Indeed you did. Albeit just the once. More tests would be required if you truly cared about disproving the bubble effect as your results could easily have fallen into the (b) point I raised.
> b) "popular results for similar search patterns will be biased in everyones results" -- irrelevant, since I used the very terms Tim Bray tried. Why weren't they "biased" in HIS results? Isn't he a member of "everyone"?
[sigh] Because they might not have been popular when he searched for them. His blog might have caused others to Google those terms and thus skew the results (in fact it definitely has caused others to Google his search terms as we're here arguing about it now). This is why I posted examples of other search terms, which you clearly haven't looked at yet. If you're not going to look at my examples, then why don't you try a few more irregular searches of your own.
In this whole argument you've basically taken one example as proof that your argument works every time. You've not even attempted other irregular search patterns of your own (or perhaps you have but they proved my point so you opted to ignore them as well?) so I really don't know how you can be so confident when you assert your point so absolutely. You do realise that multiple experiments need to be performed if you want to prove a statistical average? Just as myself and all the other Go developers have done with our time spent troubleshooting code.
> c) "not everyone uses Google." -- almost everybody does, and Tim for his examples used (and even works at) Google. Irrelevant again.
Of course it's relevant. You're arguing that "Go" is good enough on it's own - Google searches are just an example. If your point was valid then your results would be similar in other search engines. Later confining your point to one search engine seems a little like moving the goal posts mid-match.
Perhaps these examples weren't the best. When searching for more general things it helps to put in golang. For example "Running go on multiple machines" or "Running go on multiple cores":
So, if you want to use Go you pretty much have to use Google search since no-one else made a special case for Go. It is a bit of a problem for some people.
Golang will not let you compile if there’s an import or declared variable that’s unused.
I think that is the result of an explicit design goal of Go: optimizing for large projects that involve many files and packages developed by many people. Having extraneous package or variable declarations in parts of a program are not an issue for small, one-off exploratory programs, but can be for large projects. So they're consciously making it slightly more painful for small projects because they're designing for large projects.
They can produce a warning on unused stuff, instead of an error and not force this idea on everyone, especially considering they have zero proof on this idea.
Also, every large project starts from a small one.
Take a look at this adaptation of a keynote talk on the design of Go, with the title "Language Design in the Service of Software Engineering": http://talks.golang.org/2012/splash.article
The first step to making Go scale, dependency-wise, is that the language defines that unused dependencies are a compile-time error (not a warning, an error). If the source file imports a package it does not use, the program will not compile. This guarantees by construction that the dependency tree for any Go program is precise, that it has no extraneous edges. That, in turn, guarantees that no extra code will be compiled when building the program, which minimizes compilation time.
Compiler can ignore unused dependencies and variables, since it detects them anyway and still guarantee that no extra code will be compiled when building the program, which minimizes compilation time. So the argument itself is flawed and only gives a perception of rational decision, while not actually being rational.
The compiler cannot ignore an unused dependency. The compiler must first process the imported packages, then compile the current package. It only knows that an imported package was not used until after it has finished compiling the entire current package.
I don't know how Go compiler works, but I don't see a problem detecting unused dependencies very early just by walking an AST of current package, since in Go you have to specify package name explicitly in order to use something from it (well, not all the time, but almost all the time).
And even this is probably unnecessary, you only have to process additional unused dependencies in your current package, other packages already did.
Anyway, it's just a technical problem with a few simple solutions.
Packages are processed before the current package is compiled. You can only establish that packages are unused after compiling the current package. So, you will still process unused packages. That is exactly the problem they want to avoid.
Your solution is, I think, to scan the current package twice: once to establish which packages are used, then process the packages, then actually compile the current package. But now you're scanning through each package twice, which will significantly add to compilation times, and make the compilation process more convoluted. Their solution is, I think, far simpler.
You're dismissing the problem, but I'm not sure you understand what the problem is.
I just checked, they actually do it very early, similar to what I suggested, but instead of ignoring and producing warning they simply throw yyerror and they do that without even walking a tree, but during parsing. So I'm still correct. You can verify it by executing "go run .." multiple times with and without import error, you'll notice how fast it generates "imported but not used" error, compared to actual compilation.
And the whole point of their solution has absolutely nothing to do with unused imports and variables. They are just reusing object files without recompiling and they can't have circular dependencies to do that. There is nothing more to it.
Based on your statements, I am not confident that you understand the compilation process and the terminology we use to describe it. In particular, I don't how you can say they don't "walk a tree," but do it "during parsing." Nor is timing the compiler sufficient to determine this kind of behavior.
In order to establish that a particular package was unused, they must: at least parse the header for that package, and parse the entirety of this package. Parsing the unnecessary package is the problem they want to avoid. Because that package could also have unnecessary packages, in large projects you could end up parsing more unnecessary packages than necessary packages.
This isn't even considering the building process, which is what actually produces the headers that get parsed for packages. So, if you import a package and it has not been built yet, it will build it. If that was an unnecessary package, then there's even more wasted time.
What can possibly be so confusing about parsing and walking a tree? Scanner (lexer) and parser are the very first stages of compilation. Parser produces syntax tree and some other stuff, like symbol table, there is no alternative terminology. Walking a tree cannot have multiple meanings either. Most of the work is done after parsing. And timing a compiler is sufficient to understand exactly that, since you claimed, that detection of unused dependencies required package to be compiled, which is of course total bullshit. For most unused packages even parsing is not required, you can look at symbols during parsing and set "used" flag for every package, that was used and only parse it if it has this flag set.
And parsing is not what they want to avoid. Parsing is cheap. They want to avoid full-blown compilation of unused packages.
I know what parsing and walking a tree is. And parsing is walking a tree. It requires going over the entire source, which is my point: they're trying to avoid processing unnecessary code.
You do not need to do code genration to establish what the unused packages are. But you must parse and perform semantic analysis of the entire package to determine what the unused packages are. There is more to "compiling" than code genration and optimization.
Parsing is what they want to avoid, not just code generation. Parsing is cheap for small projects. But nothing is cheap at scale. From the talk I have already linked to:
The construction of a single C++ binary at Google can open and read hundreds of individual header files tens of thousands of times. In 2007, build engineers at Google instrumented the compilation of a major Google binary. The file contained about two thousand files that, if simply concatenated together, totaled 4.2 megabytes. By the time the #includes had been expanded, over 8 gigabytes were being delivered to the input of the compiler, a blow-up of 2000 bytes for every C++ source byte.
As another data point, in 2003 Google's build system was moved from a single Makefile to a per-directory design with better-managed, more explicit dependencies. A typical binary shrank about 40% in file size, just from having more accurate dependencies recorded. Even so, the properties of C++ (or C for that matter) make it impractical to verify those dependencies automatically, and today we still do not have an accurate understanding of the dependency requirements of large Google C++ binaries.
If Go allowed including unused packages, you would end up with the exact same problem.
That's my entire point: you can't ignore unused dependencies. I've explained at length why this is the case - the Go designers have also explained this. Simply, you must look at imported packages before you look at this package. You can only establish that a package is unused in this package after looking at all code in this package. Hence, you only can only recognize that a package is unused after you have looked at it.
Yes, you can avoid generating code for that package. But the designers of Go want to avoid looking at the package at all. They have collected data from inside Google which clearly establishes that this is a problem.
You and Go designers are misleading people by claiming false statements.
You don't have to look into the package to ignore it, I even explained to you how exactly to do it, but you keep repeating this bullshit. You have to look into the package and therefore parse it in one case only: when this package is imported into current namespace, which is almost never the case in Go. You can detect and ignore unused package with looking no farther than current package almost all the time, because each imported package uses unique namespace. If there were no symbols present with that namespace in current package - you don't have to look into the package with that namespace, it's that simple. And gc (Go's compiler) already detects unused packages in similar way.
And as I explained already, that complicates, and probably lengthens, the parsing and semantic analysis. (Instead of establishing the contents of a package before processing the current package, you have to track what symbols this packages has used from other packages, and then verify they are used correctly, or exist at all.) Which goes against their design goal.
What's the argument for allowing un-used imports? I've never run into a case where I wished I had imported something but didn't want to use it
If you're looking at future code, you can accomplish that by commenting out the import. But I've never run into the situation where writing future code has been good, or where I wouldn't have remembered to import the package I needed when I wrote that code. If you really need to import packages you're not using, and for some reason can't spend the time to comment those out, GO probably isn't for you. I just haven't heard of a case where doing otherwise would have been helpful.
I think this is a matter of the way an individual person writes code, and not something that can be generalized by saying "this is never useful" or "this is always useful". Some people will find it annoying, others not.
I personally find it annoying because I compile often. In my workflow I write code for a few minutes then compile it and run some quick tests or even run it through the debugger to make sure everything is working the way I expect. If everything checks out I start on the next bit. I may be adding a feature that I know in advance will use libraries xxx, yyy, and zzz. The natural thing to do is to add those imports when I open the source files that will use them, then get to work implementing the feature.
Another useful reason is to import a library just to make sure it's installed correctly, before writing the code that uses it, although that's less common.
I don't know how people write their code, but I don't like thinking about satisfying compiler when I'm working on some idea, it takes some of my thinking power. I'd rather do that later, probably together with unit tests.
Say you're trying to debug something, and you add a call to fmt.Printf. 'Compile error, "Undefined: fmt."' No problem, add 'import "fmt"' at the top.
Now it's debugged, so let's remove the annoying logging statement. Oops: 'Compile error: "imported and not used: fmt."' So now you remove the import, knowing full well you're going to be adding it back again in a minute or two. Annoying!
Or maybe, as part of debugging, you temporarily comment out a block of code. You just made a bunch of variables and imports unused, and you can't even test your changes until you clean them up.
Exploratory programming and debugging puts code in transiently dirty states, and Go's enforced hygiene is onerous in those cases.
People ignore warnings. Want proof? Go grab damn near any open source project and compile it. It's almost guaranteed that the default compile options, chosen by the authors, will generate dozens if not hundreds of warnings. Everyone's so very noble at the start of a project, "We shall turn on all warnings, and then fix them!", but really once the program compiles and seems to run properly, all that goes out the window.
This is largely due to compiler version differences. I can fix every warning my compiler emits, and you are likely to still get warnings on yours.
Go's enforced -Werror can work in a smallish community, where there's a single compiler and a culture of everyone always using its latest version. But I don't see how it can survive an environment where there's multiple compilers, each with multiple versions. Who here could write a C program that is guaranteed to never produce a warning on any C compiler?
It makes it easier for me to read your code when I checkout a copy: there's not a bunch of unused cruft I have to mentally skip over to look at it. You'll be glad later that I'm not leaving a bunch of left over Rob's stupid crap (TM) that you have to wade through as well :-)
It's not just imports, assigned-but-not-used is also a failure. This keeps the cruft down.
Go is a rather opinionated language. They could produce a warning, but then with large projects, one has to decided, should all warnings be made errors? Will there be exceptions to the rule? They simplified that for large projects by making one decision, and forcing it on everyone.
(Please note that I am explaining what I think their motivations are. I am not arguing for the perspective.)
I agree. I would like an option to have unused imports and variables ignored during development. But I would also like them gone in the final code, because they are noise inhibiting future human understanding of the code.
It might also be useful to have gofmt auto-remove unused imports and variables.
> Golang will not let you compile if there’s an import or declared variable that’s unused. OK, I understand that Cleanliness Is Next To Godliness, but this is seriously slowing me down; probably a third of my attempts to run my damn program fail because I’ve forgotten to remove debugging apparatus, or I’ve sketched in a variable but not used it yet. How about a compiler switch or something?
Agreed, this is really annoying and makes it very hard to prototype things.
The language was conceived under four years ago, and only quite recently was considered production ready.
Yes, in the pantheon of programming languages it is very new. Further many of us have stayed at a distance until the ecosystem of supporting libraries and supports are robust enough (I love everything about developing, but my primary concern remains paying the bills and pulling in the lucre, so exploratory or academic languages don't get prioritized).
I am quite sure that a large percentage of HNers are interested in the language, but haven't yet taken the dip and thus are intrigued by things like this.
I never worked with Algol, but I worked with Pascal years before C. The part of Go syntax that seems "bastardized" to me is trying to hide the language in C syntax, when clearly it seems more like Modula.
Type blocks? Var blocks? Types-after-names? Makes sense to me (a former Turbo Pascal user)
I suspect the only reason they kept C's pointer token instead of using ^ is to maintain the fiction that this is really a 'C' family language rather than a derivative of Pascal and Modula.
Please call it Go, not golang. Golang is the domain name of the language's website, a useful hashtag, and an occasionally useful search term. It is not the name of the language should not be used as such. The language is Go, it should be called Go.
That's why he did it, but it's not necessary. Google search can determine that a page is about the Go programming language without repeated use of "golang".
This is exactly the kind of thing I was looking for - more please. I'm interested in golang but don't need general programming tutorials. How go is different from other languages and what it's idiosyncracies are is good to know.
{kind=link}
{kind=link}
I think that's actually almost my favorite thing about the language, I don't know how many times I've wished that Python and Lua worked that way. Having a low-ceremony means of declaration while also preventing you from accidentally over-assigning something when you want to be declaring it is really nice.