Really excited for this. Once some more time goes by and the most important python libraries update to support no GIL, there is just a tremendous amount of performance that can be automatically unlocked with almost no incremental effort for so many organizations and projects. It's also a good opportunity for new and more actively maintained projects to take market share from older and more established libraries if the older libraries don't take making these changes seriously and finish them in a timely manner. It's going to be amazing to saturate all the cores on a big machine using simple threads instead of dealing with the massive overhead and complexity and bugs of using something like multiprocessing.
> using simple threads instead of dealing with the massive overhead and complexity and bugs of using something like multiprocessing.
Depending on the domain, the reality can be the reverse.
Multiprocessing in the web serving domain, as in "spawning separate processes", is actually simpler and less bug-prone, because there is considerably less resource sharing. The considerably higher difficulty of writing, testing and debugging parallel code is evident to anybody who's worked on it.
As for the overhead, this again depends on the domain. It's hard to quantify, but generalizing to "massive" is not accurate, especially for app servers with COW support.
Using multiple processes is simpler in terms of locks etc, but python libraries like multiprocessing or even subprocess.popen[1] which make using multiple processes seem easy are full of footguns which cause deadlocks due to fork-safe code not being well understood. I’ve seen this lead to code ‘working’ and being merged but then triggering sporadic deadlocks in production after a few weeks.
The default for multiprocessing is still to fork (fortunately changing in 3.14), which means all of your parent process’ threaded code (incl. third party libraries) has to be fork-safe. There’s no static analysis checks for this.
This kind of easy to use but incredibly hard to use safely library has made python for long running production services incredibly painful in my experience.
[1] Some arguments to subprocess.popen look handy but actually cause python interpreter code to be executed after the fork and before the execve, which has caused production logging-related deadlocks for me. The original author was very bright but didn’t notice the footgun.
Same experiences, multiprocessing is such a pain in python. It's one of these things people think they can write production code in, but they just haven't run into all the ways their code was wrong so they figure out those bugs later in production.
As an aside I still constantly see side effects in imports in a ton of libraries (up to and including resource allocations).
>which make using multiple processes seem easy are full of footguns which cause deadlocks due to fork-safe code not being well understood. I’ve seen this lead to code ‘working’ and being merged but then triggering sporadic deadlocks in production after a few weeks
Just the other day I was trying to do two things in parallel in Python using threads - and then I switched to multiprocessing - why? I wanted to immediately terminate one thing whenever the other failed. That’s straightforwardly supported with multiprocessing. With threads, it gets a lot more complicated and can involve things with dubious supportability
There is a reason why it's "complicated" in threads, because doing it correctly just IS complicated, and the same reason applies to child processes, you just ignored that reason. That's one example of a footgun in using multiprocessing, people write broken code but they don't know that because it appears to work... until it doesn't (in production on friday night).
I don't agree. A big reason why abruptly terminating threads at an arbitrary point is risky is it can corrupt shared memory. If you aren't using shared memory in a multiprocess solution, that's not an issue. Another big reason is it can lead to resource leaks (e.g. thread gets terminated in a finally clause to close resources and hence the resource doesn't get closed). Again, that's less of an issue for processes, since many resources (file descriptors, network connections) get automatically closed by the OS kernel when the process exits.
Abruptly terminating a child process still can potentially cause issues, but there are whole categories of potential issues which exist for abrupt thread termination but not for abrupt process termination.
This is not a matter of opinion. Always clean up after yourself, the kernel doesn't know shit about your application or what state it's in, you can not rely on it to cleanly terminate your process. Just because it's a child process (by default it's a forked process!) not a thread, doesn't mean it can not have shared resources. It can lead to deadlocks, stuck processes, all kinds of resource leaks, data and stream corruption, orphaned processes, etc. etc.
> This is not a matter of opinion. Always clean up after yourself, the kernel doesn't know shit about your application or what state it's in, you can not rely on it to cleanly terminate your process.
If you have an open file or network connection, the kernel is guaranteed to close it for you when the process is killed (assuming it hasn't passed the fd/socket to a subprocess, etc). That's not a matter of opinion.
Yes, if you are writing to a file, it is possible abruptly killing the writer may leave the file in an inconsistent state. But maybe you know your process doesn't write to any files (that's true in my case). Or maybe it does write to files, but you already have other mechanisms to recover their integrity in this scenario (since file writing processes can potentially die at any time–kernel panic, power loss, intermittent crash bug, etc)
Different programming languages have different guarantees when it comes to threads. If IO is hidden behind object semantics, objects aren’t killed by “killing” a thread, and they can be gracefully terminated when they are deemed to no longer be in use.
You have no idea what I'm actually doing, yet you are convinced something bad is bound to happen, although you can't say what exactly that bad thing will be.
That's why I've always liked Java's take on this. Throw an InterruptedException and the thread is considered terminated once that has dropped all the way through. You can also defer the exception for some time if it takes time to clean something up.
The only issue there is that sometimes library code will incorrectly defer the exception (i.e. suppress it) but otherwise it's pretty good.
I feel like most things that will benefit from moving to multiple cores for performance should probably not be written in Python. OTH "most" is not "all" so it's gonna be awesome for some.
I often reach for python multiprocessing for code that will run $singleDigit number of times but is annoyingly slow when run sequentially. I could never justify the additional development time for using a more performant language, but I can easily justify spending 5-10 minutes making the embarrassingly parallel stuff execute in parallel.
I've generally been able to deal with embarassing parallelism by just chopping up the input and running multiple processes with GNU Parallel. I haven't needed the multiprocessing module or free threading so far. I believe CPython still relies on various bytecodes to run atomically, which you get automatically with the GIL present. So I wonder if hard-to-reproduce concurrency bugs will keep surfacing in the free-threaded CPython for quite some time.
I feel like all of this is tragic and Python should have gone to a BEAM-like model some years ago, like as part of the 2 to 3 transition. Instead we get async wreckage and now free threading with its attendant hazards. Plus who knows how many C modules won't be expecting this.
I've always found the criticism leveled by the colored functions blog post a bit contrived. Yes, when you replace the words async/await with meaningless concepts I do not care about, it's very annoying to have to arbitrarily mark a function as blue or red. But when you replace the word "aync" with something like "expensive", or "does network calls", it becomes clear that "async/await" makes intrinsic properties about your code (e.g., is it a bad idea to put this call in a loop from a performance perspective) explicit rather than implicit.
In short, "await" gives me an extra piece of data about the function, without having to read the body of the function (and the ones it calls, and the ones they call, etc). That's a good thing.
There are serious drawbacks to async/await, and the red/blue blog post manages to list none of them.
EDIT: all of the above is predicated on the idea that reading code is harder than writing it. If you believe the opposite, then blue/red has a point.
But a synchronous function can and many do make network calls or write to files. It is a rather vague signal about the functions behavior as opposed to the lack of the IO monad in Haskell.
To me the difficulty is more with writing generic code and maintaining abstraction boundaries. Unless the language provides a way to generalise over asyncness of functions, we need a combinatorial explosion of async variants of generic functions. Consider a simple filter algorithm it needs versions for: (synchronous vs asynchronous iterator) times (synchronous vs asynchronous predicate). We end up with a pragmatic but ugly solution: provide 2 versions of each algorithm: an async and a sync, and force the user of the async one to wrap their synchronous arguments.
Similarly changing some implementation detail of a function might change it from a synchronous to an asynchronous function, and this change must now propagate through the entire call chain (or the function must start its own async runtime). Again we end up in a place where the most future proof promise to give for an abstraction barrier is to mark everything as async.
> But a synchronous function can and many do make network calls or write to files
This, for me, is the main drawback of async/await, at least as it is implemented in for example Python. When you call a synchronous function which makes network calls, then it blocks the event loop, which is pretty disastrous, since for the duration of that call you lose all concurrency. And it's a fairly easy footgun to set off.
> It is a rather vague signal about the functions behavior as opposed to the lack of the IO monad in Haskell.
I'm happy you mentioned the IO monad! For me, in the languages people pay me to write in (which sadly does not include Haskell or F#), async/await functions as a poor man's IO monad.
> Again we end up in a place where the most future proof promise to give for an abstraction barrier is to mark everything as async.
Yes, this is one way to write async code. But to me this smells the same as writing every Haskell program as a giant do statement because the internals might want to do I/O at some point. Async/await makes changing side-effect free internals to effectful ones painful, which pushes you in the direction of doing the I/O at the boundaries of your system (where it belongs), rather than all over the place in your call stack. In a ports-adapters architecture, it's perfectly feasible to restrict network I/O to your service layer, and leave your domain entirely synchronous. E.g. sth like
Async/await pushes you to code in a certain way that I believe makes a codebase more maintainable, in a way similar to the IO monad. And as with the IO monad, you can subvert this push by making everything async (or writing everything in a do statement), but there's better ways of working with them, and judging them based on this subversion is not entirely fair.
> ugly solution: provide 2 versions of each algorithm: an async and a sync
I see your point, and I think it's entirely valid. But having worked in a couple async codebases for a couple of years, the amount of stuff I (or one of my collaborators) have had to duplicate for this reason I think I can count on one hand. It seems that in practice this cost is a fairly low one.
What you write is eerily similar to one of the pain points of Haskell. You can write a compiler that is purely functional. But then you want logging so you must put wrap it with the IO monad. And then also every function that calls the compiler and so on.
> when you replace the word "aync" with something like "expensive", or "does network calls", it becomes clear that "async/await" makes intrinsic properties about your code explicit rather than implicit.
Do you think we should be annotating functions with `expensive` and/or `networking`? And also annotating all of their callers, recursively? And maintaining 4 copies of every higher-order function depending on whether the functions it calls are `expensive`, `networking`, neither or both?
No, we rely on documentation for those things, and IMO we should for `async` as well. The reason we can’t, and why `async`/`await` exist, is because of shortcomings (lack of support for stackful coroutines) in language runtimes. The best solution is to fix those shortcomings, not add viral annotations everywhere.
So here I think we differ fundamentally in how we like to read code. I much prefer being able to quickly figure out things of interest about a function by glancing at its signature, rather than look at documentation, or worse, having to read the implementation of the function and the functions it calls (and so on, recursively).
For example, I much prefer a signature like
def f(a: int) -> str:
over
def f(a):
because it allows me to see, without reading the implementation of the function (or, if it exists, and I'm willing to bet on its reliability, the documentation), that it takes an integer, and gives me a string. And yes, this requires that I write viral type annotations on all my functions when I write them, but for me the bottleneck at my job is not writing the code, it's reading it. So that's a small upfront cost I'm very much willing to pay.
> Do you think we should be annotating functions with `expensive` and/or `networking`? And also annotating all of their callers, recursively?
Yes, absolutely, and yes, absolutely. That's just being upfront and honest about an intrinsic property of those functions. A function calling a function that does network I/O by transitivity also does network I/O. I prefer code that's explicit over code that's implicit.
Fair enough, that's a valid philosophy, and one in which `async`/`await` makes perfect sense.
However, it's not Python's philosophy - a language with dynamic types, unchecked exceptions, and racy multithreading. In Python, `async`/`await` seems to be at odds with other language features - it feels like it's more at home in a language like Rust.
I completely agree with you. However I've always found the dynamic typing approach to be a bit at odds with
python3 -c "import this" | head -4 | tail -1
I think the fast and loose style that Python enables is perfect for small scripts and one off data science notebooks and the like. But having worked in large codebases which adopt the same style, and ones that avoid it through static typing and in some cases async/await, the difference in productivity I've noticed in both me and my collaborators is too stark for me to ignore.
I think I should've been more nuanced in my comments praising async/await. I believe that what I say is valid in large IO-bound applications which go beyond basic CRUD operations. In general it depends, of course.
> I think the fast and loose style that Python enables is perfect for small scripts and one off data science notebooks and the like.
Agreed - I only use Python for scripts like this, preferring statically-typed, AOT-compiled languages for larger programs.
That’s why I think Python should have adopted full coroutines - it should play to its strengths and stick to its fast-and-loose style. However, the people who decide how the language evolves are all employees of large companies using it for large codebases - their needs are very different from people who are only using Python for small scripts.
> The reason we can’t, and why `async`/`await` exist, is because of shortcomings (lack of support for stackful coroutines) in language runtimes
The JVM runtime has solved this problem neatly with virtual threads in my opinion. Run a web request in a virtual thread, and all blocking I/O is suddenly no longer blocking the OS thread, but yielding/suspending and giving and giving another virtual thread run time. And all that without language keywords that go viral through your program.
Yes, this is similar to how Go works. IIRC the same approach was available in Python as a library, “greenlet”, but Python’s core developers rejected it in favour of `async`/`await`.
The Python community seems to have a virulent hatred of threads. I don't understand the reason. Yes there are hazards but you can code in a style that avoids them. With something like BEAM you can even enforce the style. Async/await of course introduce their own hazards.
There's no hatred. There are just lots of libraries that can't be multithreaded, due to historical reasons. This is being worked on right now[0], though.
The GIL only gets in the way of parallelism. Yes there is real hatred. You can experience it if you visit #python on libera and ask anything about threads. "Aieee! The non-determinism! The race conditions! Etc." Of course the async requires an async version of the whole i/o system, it can block on long computations or the wrong system calls, etc. And many rock solid systems are written in Erlang, which uses preemptive lightweight processes for all its concurrency needs.
Lots of microcontroller OS's use cooperative multitasking but once there are enough machine resource's, OS's generally become preemptive. Async concurrency is basically cooperative multitasking with similar issues. Does Python give a way to open a file asynchronously in Linux? It's now possible with io_uring but it was impossible for a very long time (like decades). Erlang and GHC both use thread pools to deal with that. The use the old synchronous open(2) call but move it into an auxiliary thread so it won't block the calling thread.
> "Aieee! The non-determinism! The race conditions! Etc."
That doesn't sound like real hatred. Those sound like real concerns, which need to be addressed, and the attempt to remove the GIL is doing so very much with those concerns in mind.
I think it wouldn’t work as nicely with python, which deeply builds on C FFI. Java has a different history, and almost the whole ecosystem is pure, making it able to take advantage of it.
Yeah gotcha - I'm familiar with the colored functions argument. I see the conceptual downside, but it doesn't seem that bad in practice. I have a pre-commit hook that shouts at me if I call an async function synchronously.
I personally optimize more for development time and overall productivity in creating and refactoring, adding new features, etc. I'm just so much faster using Python than anything else, it's not even close. There is such an incredible world of great libraries easily available on pip for one thing.
Also, I've found that ChatGPT/Claude3.5 are much, much smarter and better at Python than they are at C++ or Rust. I can usually get code that works basically the first or second time with Python, but very rarely can do that using those more performant languages. That's increasingly a huge concern for me as I use these AI tools to speed up my own development efforts very dramatically. Computers are so fast already anyway that the ceiling for optimization of network oriented software that can be done in a mostly async way in Python is already pretty compelling, so then it just comes back again to developer productivity, at least for my purposes.
Right now you are right. This is about taking away that argument. There's no technical reason for this to stay true. Other than that the process of fixing this is a lot of work of course. But now that the work has started, it's probably going to progress pretty steadily.
It will be interesting to see how this goes over the next few years. My guess is that a lot of lessons were learned from the python 2 to 3 move. This plan seems pretty solid.
And of course there's a relatively easy fix for code that can't work without a GIL: just do what people are doing today and just don't fork any threads in python. It's kind of pointless in any case with the GIL in place so not a lot of code actually depends on threads in python.
Preventing the forking of threads in the presence of things still requiring the GIL sounds like a good plan. This is a bit of meta data that you could build into packages. This plan is actually proposing keeping track of what packages work without a GIL. So, that should keep people safe enough if dependency tools are updated to make use of this meta data and actively stop people from adding thread unsafe packages when threading is used.
So, I have good hopes that this is going to be a much smoother transition than python 2 to 3. The initial phase is probably going to flush out a lot of packages that need fixing. But once those fixes start coming in, it's probably going to be straightforward to move forward.
AMD EPYC 9754 with 128-cores/256-threads, and EPYC 9734 with 112-cores/224-threads. TomsHardware says they "will compete with Intel's 144-core Sierra Forest chips, which mark the debut of Intel's Efficiency cores (E-cores) in its Xeon data center lineup, and Ampre's 192-core AmpereOne processors".
What in 5 years? 10? 20? How long will "1 core should be enough for anyone using Python" stand?
Number crunching code in Python (such as using numpy/pytorch) performs the vast vast majority of its calculations in C/Fortran code under the hood where GIL can be released. Single python process can use multiple CPUs.
There is code that may benefit from the free threaded implementation but it is not as often as it might appear and it is not without its own downsides. In general, GIL simplifies multithreaded code.
There were no-GIL Python implementations such as Jython, IronPython. They hadn't replaced CPython, Pypy implementation which use GIL i.e., other concerns dominate.
Yes but jython am iron aren't the standard, and I feel the more relevant part is inertia, puppy is design whit lots of concern of compatibility, then being the new standard can totally make difference making both cases not a good comparison.
>> What in 5 years? 10? 20? How long will "1 core should be enough for anyone using Python" stand?
If you're looking for a 32x or 128x performance improvement from python supporting multi-core you should probably rewrite in C, C++, Rust, or Fortran and get that 100x improvement today on a single core. If done properly you can then ALSO get the gain from multiple cores on top of that. Or to put it another way, if performance is critical python is a poor choice.
"instead of taking advantage of hardware you own, you should do a LOT of work in a language you don't know" - how is that in any way a reasonable suggestion or alternative?
> "Or to put it another way, if performance is critical python is a poor choice."
To put it another way, just because performance isn't critical, doesn't mean that more performance for free is not desirable or beneficial, or that ignoring 127/128ths of available performance is fine.
Usually performance critical code is written in cpp, fortran, etc, and then wrapped in libraries for Python. Python still has a use case for glue code.
Yes, but then extensions can already release the GIL and use the simple and industrial strength std::thread, which is orders of magnitude easier to debug.
Concurrent operations exist at all levels of the software stack. Just because native extensions might want to release the GIL and use OS threads doesn't mean pure Python can't also want (or need) that.
(And as a side note: I have never, in around a decade of writing C++, heard std::thread described as "easy to debug.")
I expected that dropping down to C/C++ would be a large jump in difficulty and quantity of code, but I've found it isn't, and the dev experience isn't entirely worse, as, for example, in-editor code-intelligence is rock solid and very fast in every corner of my code and the libraries I'm using.
If anyone could benefit from speeding up some Python code, I'd highly recommend installing cppyy and giving it a try.
Sure! I tried pybind11, and some other things. cppyy was the first I tried that didn't give me any trouble. I've been using it pretty heavily for about a year, and still no trouble.
It seems like you might be able to enable some optimizations with EXTRA_CLING_ARGS. Since it's based on cling, it's probably subject to whatever limitations cling has.
To be honest, I don't know much about the speed, as my use-case isn't speeding up slow code.
It's not just about "raw-flop performance" though; it affects even basic things like creating data-loaders that run in the background while your main thread is doing some hard ML crunching.
Every DL library comes with its own C++ backend that does this for now, but it's annoyingly inflexible. And dealing with GIL is a nightmare if you're dealing with mixed Python code.
I think it is beneficial to some people, but not a lot. My guess is that most Python users (from beginners to advanced users, including many professional data scientists) have never heard of GIL or thought of doing any parallelization in Python. Code that needs performance and would benefit from multithreading, usually written by professional software engineers, likely isn't written in Python in the first place. It would make sense for projects that can benefit from disabling GIL without a ton of changes. Remember it is not trivial to update single threaded code to use multithreading correctly.
in Python language specifically. Their library may have already done some form of parallelization under the hood
> Code that needs performance and would benefit from multithreading, usually written by professional software engineers, likely isn't written in Python in the first place.
There are a lot of simple cases where multi-threading can easily triple or quadruple the performance.
I used to write a ton of MPI based parallel python. It's pretty straightforward. But one could easily imagine trying to improve the multiprocessing ergonomics rather than introducing threading. Obviously the people who made the choice to push forward with this are aware of these options, too. Still mildly puzzling to me why threads for Python are needed/reasonable.
A common pain point for me is parallel data loading and processing for PyTorch or TensorFlow. Multiprocessing has a lot of bugs and pain points to deal with when doing ML. Examples: https://github.com/search?q=repo%3Apytorch%2Fpytorch+multipr.... Most of these issues do not exist in a multithreading world, because resource sharing is trivial in that case.
Since Python leads over any other languages in the ML community, and ML is a hot topic right now, it makes sense for Python developers to secure the lead by making the life of ML developers easier, which is by introducing GIL-less multi-threading.
I know that document. It doesn't really answer this point though. It motivates the need for parallelism in slow python by noting that this is important once other performance critical code is in extensions.
But the mai point against multiprocessing seems to be that spawning new processes is slow ...
That single "alternatives" paragraph doesn't answer at all why mp isn't viable for python level parallelism.
I am no longer invested in python heavily, I am sure there are discussions or documents somewhere that go into this more. Might be that it's simply that everyone is used to threads so you should support it for sheer familiarity. All I am saying is it's not obvious to a casual observer.
>> Who descides why something should or should not be written I Python?
Why shouldn't someone who prefers writing in python benefit from using multiple cores?
I did use the words "most things". I'm not saying this is a bad development for Python, or that nobody should use it. But if performance is a top priority, Python is the wrong language and always has been.
I use Python from time to time, it's fun and easy to put certain kinds of things together quickly. But each time I do a project with it, the first thing I ask myself is "is this going to be fast enough?" If not I'll use something else.
it may not be tactful but it sure is factful (even if that last word is ungrammatical, at least the sentence is poetical). he he he.
jfc. guido knows ;), this thread is getting weirder and weirder, creepier and creepier.
are you literally implying that I should lie about known facts about python slowness?
"tactful" my foot.
then I guess the creators of PyPy and Unladen Swallow (the latter project was by Google) were/are not being tactful either, because those were two very prominent projects to speed up Python, in other words, to reduce its very well known slowness.
There is/was also Cython and Pyston (the latter at Dropbox, where Guido (GvR, Python creator) worked for a while. Those were or are also projects to speed up Python program execution.
Excerpt from the section titled "Rationale, Implementation" from the above link (italics mine):
[
Many companies and individuals would like Python to be faster, to enable its use in more projects. Google is one such company.
Unladen Swallow is a Google-sponsored branch of CPython, initiated to improve the performance of Google’s numerous Python libraries, tools and applications. To make the adoption of Unladen Swallow as easy as possible, the project initially aimed at four goals:
A performance improvement of 5x over the baseline of CPython 2.6.4 for single-threaded code.
100% source compatibility with valid CPython 2.6 applications.
100% source compatibility with valid CPython 2.6 C extension modules.
Design for eventual merger back into CPython.
tactful - showing skill and sensitivity in dealing with people.
Right or wrong, your comments do not contribute to the discussion. Open source development is about collaboration. Your irrelevant comments are disrespectful to all the hard working developers who have been working together to push the limits of what is possible with what may be the most widely used programming language of our time. I use Python for it's ergonomics and community, not for speed. Removing the GIL has been something we've been yearning for since the Python 2 days. And the speed has improved drastically in recent years with each release. You don't win a prize for being right.
>tactful - showing skill and sensitivity in dealing with people. Right or wrong, your comments do not contribute to the discussion.
just take a look at the depth of your incredibly rotten stupidity and ugliness of mind, you fucktard and dotard (dotard means something like a senile person, in case you didn't know):
hn user jacob019, you little mofo:
you say that "Right or wrong, your comments do not contribute to the discussion."
that itself is a contradiction in terms.
so you are saying that my comments do not contribute to the discussion even if i am right?
(what an utter fool and liar and swine you are.)
then why should i and anyone else think that your comments contribute to the discussion when they so totally fucking wrong, biased, shitheaded, pissheaded, and other choice epithets?
comgrats, you have really jumped the shark in terms of being a creep.
enjoy your miserable life for what it is worth, you worm.
if Google wanted a performance increase of 5x over the then existing python, I guess we can safely say that Python was slow, amirite. and yes, I know the version number mentioned, and what it is today.
It's very unpopular to mention Perl, but I did many cool things with it back in the day, and it still holds a special place for me. Perl taught me the power of regex--it's really first class in Perl. I still have some Perl code in production today. But to be fair, it is really easy to write spaghetti in Perl if you don't know what you're doing.
don't worry about unpopularity, bro. worry about being true. the rest will take care of itself. if not, you are in the wrong company, forum, or place, and better to work on getting out of there.
They’re probably downvoting you because you’ve posted like the laziest trope comment there is. lol Python slow everyone is paid to hide the truth amirite
Your comments feel like you want a reddit style battle of wits. You throw words like ignorant around rather freely. I downvote these comments because they lower the tone of the discussion. We're not here to talk about each other or feel smarter than others.. Well I'm not.
I don't give a flying fuck about your feelings or your opinions about my comments, just as you should not about mine. i am a free man. you should try to be one too. we can talk to each other, but that does not mean that either of us has to believe or be convinced by what the other person says. is this not fuckingly blindlingly obvious to you?
if not, you have a serious perception problem.
yes, I do throw around words, just like anyone else, but not freely, instead, I do that after at least some thought, which I do not see happening in the people whom I replied to, nor in your comment above.
You might be getting downvoted because many people know Python is among the slower dynamic languages, and there are other reasons to use it. Speaking for myself, the reasons that make me reach for Python for some projects are the speed of development, large ecosystem of libraries, large developer pool, and pretty good tooling/IDE support.
then it would be much preferable if they said so explicitly, although both of those are points I already know well. both are common knowledge, not just the first, i e. the slowness. the productivity and other benefits are common knowledge too.
downvoting is such a fucking dumb way of disagreeing. how does one know whether the downvote is because a person disapproves of or dislikes what one said or because they think what one said is wrong. no way to know. amirite? :)
> there is just a tremendous amount of performance that can be automatically unlocked with almost no incremental effort for so many organizations and projects
This just isn’t true.
This does not improve single threaded performance (it’s worse) and concurrent programming is already available.
This will make it less annoying to do concurrent processing.
It also makes everything slower (arguable where that ends up, currently significantly slower) overall.
This way over hyped.
At the end of the day this will be a change that (most likely) makes the existing workloads for everyone slightly slower and makes the lives of a few people a bit easier when they implement natively parallel processing like ML easier and better.
It’s an incremental win for the ML community, and a meaningless/slight loss for everyone else.
At the cost of a great. Deal. Of. Effort.
If you’re excited about it because of the hype and don’t really understand it, probably calm down.
Mostly likely, at the end of the day, it s a change that is totally meaningless to you, won’t really affect you other than making some libraries you use a bit faster, and others a bit slower.
Overall, your standard web application will run a bit slower as a result of it. You probably won’t notice.
Your data stack will run a bit faster. That’s nice.
Yes, good summary. My prediction is that free-threading will be the default at some point because one of the corporations that usurped Python-dev wants it.
The rest of us can live with arcane threading bugs and yet another split ecosystem. As I understand it, if a single C-extension opts for the GIL, the GIL will be enabled.
Of course the invitation to experiment is meaningless. CPython is run by corporations, many excellent developers have left and people will not have any influence on the outcome.
Removing the GIL requires operations that are protected by it when it exists to be made thread safe in ways which they don't need to be with it, which has some overhead. Even having multiple options from which the situationally correct one (e.g., a lighter-weight one in guaranteed single-threaded or GIL active cases) can automatically be selected has some overhead. (Conceptually, you could have separate implementations that can be selected by the programmer with zero runtime overhead where not needed, but that also has more conceptual/developer overhead, so other than particular things where the runtime cost is found to really bite in practice, that's probably not going to be a common approach for core libraries that might need to be called either way. There's no free lunch here.
If you assume two completely separate implementations where there is an #ifdef every 10 lines and atomics and locking only occur with --disable-gil, there is no slowdown for the --enable-gil build.
I don't think that is entirely the case though!
If the --enable-gil build becomes the default in the future, then peer pressure and packaging discipline will force everyone to use it. Then you have the OBVIOUS slowdown of atomics and of locking the reference counting and in other places.
The advertised figures were around 20%, which would be offset by minor speedups in other areas. But if you compare against Python 3.8, for instance, the slowdowns are still there (i.e., not offset by anything). Further down on the second page of this discussion numbers of 30-40% have been measured by the submitter of this blog post.
Actual benchmarks of Python tend to be suppressed or downvoted, so they are not on the first page. The Java HotSpot VM had a similar policy that forbid benchmarks.
> It also makes everything slower (arguable where that ends up, currently significantly slower) overall.
longer version:
If there was no reason for it to be slower, it would not be slower.
...but, implementing this stuff is hard.
Doing a zero cost implementation is really hard.
It is slower.
Where it ends up eventually is still a 'hm... we'll see'.
To be fair, they didn't lead the article here with:
> Right now there is a significant single-threaded performance cost. Somewhere from 30-50%.
They should have, because now people have a misguided idea of what this wip release is... and that's not ideal; because if you install it, you'll find its slow as balls; and that's not really the message they were trying to put out with this release. This release was about being technically correct.
...but, it is slow as balls right now, and I'm not making that shit up. Try it yourself.
If you're worried about performance then much of your CPU time is probably spent in a C extension (e.g. numpy, scipy, opencv, etc.). Those all release the GIL so already allow parallelisation in multiple threads. That even includes many functions in the standard library (e.g. sqlite3, zip/unzip). I've used multiple threads in Python for many years and never needed to break into multiprocessing.
But, for sure, nogil will be good for those workloads written in pure Python (though I've personally never been affected by that).
That means your code is using python as glue and you do most of your work completely outside of cPython. That's why you don't see the impact - those libraries drop GIL when you use them, so there's much less overhead.
The parent commenter said they're using the multiprocessing module, so it's irrelevant to them whether those modules drop the GIL (except for the fact that they are missing an opportunity to using threading instead). The overhead being referred to, whether significant or not, is that of spawning processes and doing IPC.
What about the pessimization of single-threaded workloads? I'm still not convinced a completely free-threaded Python is better overall than a multi-interpreter, separate-GIL model with explicit instead of implicit parallelism.
Everyone wants parallelism in Python. Removing the GIL isn't the only way to get it.
> It's going to be amazing to saturate all the cores on a big machine using simple threads instead of dealing with the massive overhead and complexity and bugs of using something like multiprocessing.
I'm saturating 192cpu / 1.5TBram machines with no headache and straightforward multiprocessing. I really don't see what multithreading will bring more.
What are these massive overheads / complexity / bugs you're talking about ?
FWIW, I think the concern though is/was that for most of us who aren't doing shared-data multiprocessing this is going to make Python even slower; maybe they figured out how to avoid that?
Pretty sure they offset any possible slowdowns by doing heroic optimizations in other parts of CPython. There was even some talk about keeping just those optimizations and leaving the GIL in place, but fortunately they went for the full GILectomy.
Not sure what this list means, there are successful languages without these feature. Also Python 3.13 [1] has an optional JIT [2], disabled by default.
The successful languages without efficient dependency management are painful to manage dependencies in, though. I think Python should be shooting for a better package management user experience than C++.
If Python's dependency management is better than anything, it's better than C++'s. Python has pip and venv. C++ has nothing (you could say less than nothing since you also have ample opportunity for inconsistent build due to mismatching #defines as well as using the wrong binaries for your .h files and nothing remotely like type-safe linkage to mitigate human error. It also has an infinite number of build systems where each system of makefiles or cmakefiles is its own build system with its own conventions and features). In fact python is the best dependency management system for C++ code when you can get binaries build from C++ via pip install...
C++ has apt-get etc. because the libraries do not change all the time. Also, of course there are vcpkg and conan.
Whenever you try to build something via pip, the build will invariably fail. The times that NumPy built from source from PyPI are long over. In fact, at least 50% of attempted package builds fail.
I pip3 installed something today. It didn’t work, at all.
I then yum installed a lib and headers, it worked well.
C++ on an msft platform is the worst. I can’t speak for Mac. C++ on a linux is quite pleasant. Feels like most of the comments like yours are biased for un-stated reasons.
This has nothing to do with languages. You can yum install python packages and expect them to work fine. You can install C++ files using an actual dependency manager like vcpkg or conan and have issues.
You're pointing out differences between software package management styles, not languages.
C++ on linux is indeed pleasant if you use only distro-provided library versions. Some specialized library with specific version, also no big deal. Need some upgraded version of a widely-used library -- get containerized or prepare for real pain.
If I had a penny for every time I gave up on compiling C++ software because there's no way to know what dependencies it needs, I'd be a millionaire. Python at least lists them.
Is that because the compiler failed with "foo.h not found" or the build system said "libfoo not found"? CMake is most common and it will tell you. Worst case it's difficult to derive the package name from the name in the diagnostic.
It's not great, but usually not a big deal neither IME. Typically a couple of minutes to e.g. find that required libSDL2 addon module or whatever, if there is that kind of problem at all.
Yes it is, and it's usually such a big deal for me that I just don't use that software. I don't have time to go through a loop of "what's the file name? What package is it in? Install, repeat". This is by far the worst experience I've had with any language. Python has been a breeze in comparison.
I’m not going to refute your points. If you’re going to wear rose-tinted glasses about all of the bad parts about python, that’s fine, I also like python.
Python's dependency management sucks because they're audacious enough to attempt packaging non-python dependencies. People always bring Maven up as a system that got it right, but Maven only does JVM things.
I think the real solution here is to just only use python dependency management for python things and to use something like nix for everything else.
Julia's package manager (for one) works great and can manage non Julia packages. the problem with python's system is that rejecting semver makes writing a package manager basically impossible since there is no way to automatically resolve packages.
Could you clarify what you mean? pip and every other Python package installer is absolutely doing automatic package resolution, and the standard (PEP 440) dependency operators include a compatible version operator (~=) that's predicated on SemVer-style version behavior.
There is no way to manage non-hosted dependencies, though, in a cross-platform way. Something attempting it is often worse than nothing, on a distro that has different assumptions — e.g. every package manager that downloads a dynamic executable will fail on NixOS, and gives no easy way to hook into how those get executed.
I agree that attempting it is worse than nothing, because you now have expectations that may fail at awkward times. But they've gone an done it so here we are.
NixOS is a stark contrast to Python here. It makes things that can't be done deterministically difficult to do at all. Maybe this sounds extreme from the outside, but I'd rather be warned off from that dependency as soon as I attempt to use it, rather than years later when I get a user or contributor than can't make it work for some environmental reason I didn't forsee and now everything rests on finding some hacky way to make it work.
If Nix can be used to solve Python's packaging problems, participating packages will have to practice the same kind of avoidance (or put in the work to fix such hazards up front). I'm not sure if the wider python community is willing to do that, but as someone who writes a lot of python myself and wants it to not be painful down the line, I am.
15y ago I was using apt-get to manage my c++ dependencies with no way of keeping track of which dependency went with which project. It was indeed pretty awful.
Now when I cd into a project, direnv + nix notices the dependencies that that project needs and makes them available, whatever their language. When I cd into a different project, I get an entirely different set of dependencies. There's pretty much nothing installed with system scope. Just a shell and an editor.
Both of these are language agnostic, but the level of encapsulation is quite different and one is much better than that other. (There are still plenty of problems, but they can be fixed with a commit instead of a change of habit.)
The idea that every language needs a different package manager and that each of those needs to package everything that might my useful when called from that language whether or not it is written in that language... It just doesn't scale.
Valid points. I was also thinking about apt install-ing some C library, try to pip install a package, have it fail to build, look for headers/debug packages in apt, set LD_LIBRARY… you know. It hurts, a lot.
And yet, python is a fantastic language because it’s the remote control to do the heavy, complex, low-level, high-performance stuff with relative ease.
I agree. I want to help save python from its packaging problems because it has so much traction out there (for good reason). People in this forum might be ok jumping ship to rust or whatever but most python users are students, scientists, business types... They're not going to learn rust and I don't think we benefit from leaving them behind.
I wish there was a standard interface that tools like pip could use to express their non-python needs such that some other tool can meet those needs and then hand the baton back to pip once they are met. Poetry2nix is an example of such a collaboration. (I'm not trying to be a nix maximalist here, it's just that it's familiar).
The python community is large enough to attempt to go it alone, but many other language communities are not. I think we'd see faster language evolution if we asked less of them from a packaging perspective:
> focus on making the language great. Provide a way to package deps in that language, and use _____ to ask for everything else.
Apt and brew and snap and whatever else (docker? K8s?) could be taught to handle such requests in a non alter-your-whole-system kind of way.
I guess that depends from your perspective. I'm not a Python developer, but like many people I do want to run Python programs from time to time.
I don't really know Rust, or Cargo, but I never have trouble building any Rust program: "cargo build [--release]" is all I need to know. Easy. Even many C programs are actually quite easy: "./configure", "make", and optionally "make install". "./configure" has a nice "--help". There is a lot to be said about the ugly generated autotools soup, but the UX for people just wanting to build/run it without in-depth knowledge of the system is actually quite decent. cmake is a regression here.
With Python, "pip install" gives me an entire screen full of errors about venv and "externally managed" and whatnot. I don't care. I just want to run it. I don't want a bunch of venvs, I just want to install or run the damn program. I've taken to just use "pip install --break-system-packages", which installs to ~/.local. It works shrug.
Last time I wanted to just run a project with a few small modifications I had a hard time. I ended up just editing ~/.local/lib/python/[...] Again, it worked so whatever.
All of this is really where Python and some other languages/build systems fail. Many people running this are not $language_x programmers or experts, and I don't want to read up on every system I come across. That's not a reasonable demand.
Any system that doesn't allow non-users of that language to use it in simple easy steps needs work. Python's system is one such system.
Virtual environments are the Python ecosystem's solution to the problem of wanting to install different things on the same machine that have different conflicting requirements.
If you refuse to use virtual environments and you install more than one separate Python project you're going to run into conflicting requirements and it's going to suck.
Have you tried pipx? If you're just installing Python tools (and not hacking on them yourself) it's fantastic - it manages separate virtual environments for each of your installations without you having to think about them (or even know what a virtual environment is).
Managing a farm of virtualenvs and mucking about with my PATH doesn't address the user-installable problem at all. And it seems there's a new tool to try every few months that really will fix all problems this time.
And maybe if you're a Python developer working on the code every day that's all brilliant. But most people aren't Python developers, and I just want to try that "Show HN" project or whatnot.
Give me a single command I can run. Always. For any project. And that always works. If you don't have that then your build system needs work.
Right so; I'll try that next time. Thanks. I just go by the very prominent "pip install X" on every pypi page (as well as "pip install .." in many READMEs).
Out of the 3 things I want to install 2 don't work. Both of these seem bugs in pipx so I reported one, but the feedback was borderline hostile and it ended up being closed with "unclear what you want". I'm not even going to bother reporting the other bug.
So whatever the goals are, it doesn't really work. And in general pipx does not strike me as a serious project.
I could say the exact same stuff about NodeJs, c++, go, rust, php, etc. All of these are easy to use and debug and "install easily" when you know them and use them regularly, and the opposite if you're new. Doubly-so if you personally don't like that language or have some personal pet peeve about it's choices.
Guys let's not pretend like this is somehow unique to python. It's only until about a few years ago that it was incredibly difficult to install and use npm on windows. Arguably the language ecosystem with the most cumulative hipster-dev hours thrown at it, and it still was a horrible "dev experience".
Pythons venvs are a problem to the solution of solving the dependency problem. Consider the following: it is not possible to relocate venvs. In what universe does this make sense? Consider a C++ or Rust binary that would only run when it is placed in /home/simonw/.
Normal users who just want to run some code shouldn't need to learn why they need a venv or any of its alternatives. Normal users just want to download a package and run some code without having to think about interfering with other packages. Many programming languages package managers give them that UX and you can't blame them for expecting that from Python. The added step of having to think about venvs with Python is not good. It is a non-trivial system that every single Python user is forced to learn, understand, and the continually remember every time they switch from one project to another.
This is correct. The whole application installation process, including the creation of a venv, installing stuff into it, and registering it with some on-PATH launcher should be one command.
I agree with that. Until we solve that larger problem, people need to learn to use virtual environments, or at least learn to install Python tools using pipx.
I reject the virtual environments and have no issues. On an untrusted machine (see e.g. the recent token leak):
/a/bin/python3 -m pip install foo
/b/bin/python3 -m pip install bar
The whole venv thing is overblown but a fertile source for blogs and discussions. If C-extensions link to installed libraries in site-packages, of course they should use RPATH.
This is mostly a curse of Python’s popularity. The reason you can’t pip install with system Python is that it can break things, and when your system is relying on Python to run various tools, that can’t be allowed. No one (sane) is building OS-level scripts with Node.
The simplest answer, IMO, is to download the Python source code, build it, and then run make altinstall. It’ll install in parallel with system Python, and you can then alias the new executable path so you no longer have to think about it. Assuming you already have gcc’s tool chain installed, it takes roughly 10-15 minutes to build. Not a big deal.
Its more probable that you are trying to install the deps in the system python. And using pip instal xxxxx -u will install them in your user directory rather than the system. I'm pretty sure modern Ubuntu warns you against doing that now anyway.
If you're installing for a small script then doing python -m venv little_project in you home dir is straightforward, just active it after [1]
I'm using rye[2] now and its very similar to Rust's Cargo, it wraps a bunch of the standard toolchain and manages standalone python versions in the background, so doesn't fall into the trap of linux system python issues.
Maybe I am biased, because I learned these things so long ago and I don't realize that it's a pain to learn. But what exactly is so confusing about virtualenvs ?
They really not that different from any other packaging system like JS or Rust. The only difference is instead of relying on your current directory to find the the libraries / binaries (and thus requiring you to wrap binaries call with some wrapper to search in a specific path), they rely on you sourcing an `activate` script. That's really just it.
Create a Virtualenv:
$ virtualenv myenv
Activate it, now it is added to your $PATH:
$ . myenv/bin/activate
There really is nothing more in the normal case.
If you don't want to have to remember it, create a global Virtualenv somewhere, source it's activate in your .bashrc, and forget it ever existed.
Yes, though just to illustrate that it's a matter of taste, I do prefer the solution of virtualenvs requiring to source a script that append to PATH, rather than a solution requiring the use of a wrapper that executes in its PATH.
I never remember how to run Javascript binaries. Is it npm run ? npm run script ? npx ? I always end up running the links in node_modules/bin
I don't care about the internals. I care about "just" being able to run it.
I find that most JS projects work fairly well: "npm install" maybe followed by "npm run build" or the like. This isn't enforced by npm and I don't think npm is perfect here, but practical speaking as a non-JS dev just wanting to run some JS projects: it works fairly well for almost all JS projects I've wanted to run in the last five years or so.
A "run_me.py" that would *Just Work™" is fine. I don't overly care what it does internally as long as it's not hugely slow or depends on anything other than "python". Ideally this should be consistent throughout the ecosystem.
To be honest I can't imagine shipping any project intended to be run by users and not have a simple, fool-proof, and low-effort way of running it by anyone of any skill level, which doesn't depend on any real knowledge of the language.
> To be honest I can't imagine shipping any project intended to be run by users and not have a simple, fool-proof, and low-effort way of running it by anyone of any skill level, which doesn't depend on any real knowledge of the language.
This is how we got GH Issues full of inane comments, and blogs from mediocre devs recommending things they know nothing about.
I see nothing wrong with not catering to the lowest common denominator.
I didn’t say that everyone is an idiot. I implied that gate keeping is useful as a first pass against people who are unlikely to have the drive to keep going when they experience difficulty.
When I was a kid, docs were literally a book. If you asked for help and didn’t cite what you had already tried / read, you’d be told to RTFM.
Python has several problems. Its relative import system is deranged, packaging is a mess, and yes, on its face needing to run a parallel copy of the interpreter to pip install something is absurd. I still love it. It’s baked into every *nix distro, a REPL is a command away, and its syntax is intuitive.
I maintain that the relative ease of JS – and more powerfully, Node – has created a monstrous ecosystem of poorly written software, with its adherents jumping to the latest shiny every few months because this time, it’s different. And I _like_ JS (as a frontend language).
This is the truth right here. The issues are with people using (not officially) deprecated tools and workflows, plus various half baked scripts that solved some narrow use cases.
same here. Been using python/pip for 10+ years and this was never a problem. In the java world, there is jar hell, but it was never a crippling issue, but a minor annoyance once a year or so.
In general, is dependency management such a massive problem it is made to be on HN? Maybe people here are doing far more complex/different things than I've done in the past 20 years
Guessing that folks who write such things are lacking sysad skills like manipulating paths, etc.
It does take Python expertise to fix other issues on occasion but they are fixable. Why I think flags like ‘pip —break-system-packages’ are silly. It’s an optimization for non-users over experienced ones.
The shitshow that is python tooling is one of the reasons I prefer java jobs to python jobs when I can help it. Java got this pretty right years and years and years earlier. Why are python and javascript continuing to horse around playing games?
Optional static typing, not really. Those type hints are not used at runtime for performance. Type hint a var as a string then set it to an init, that code still gonna try to execute.
If there’s any checking of types before program runs then it’s static typing. Gradual typing is a form of static typing that allows you to apply static types to only part of the code.
I’m not sure what you mean by variables not changing types during execution in statically typed languages. In many statically typed languages variables don’t exist at runtime, they get mapped to registers or stack operations. Variables only exist at runtime in languages that have interpreters.
Aside from that, many statically typed languages have a way to declare dynamically typed variables, e.g. the dynamic keyword in C#. Or they have a way to declare a variable of a top type e.g. Object and then downcast.
Is java dynamically typed as well, then? It does reify generics, so only some part is type checked, what is the level at which it is statically/dynamically typed?
Yeah Java is partially dynamically typed. I think we can safely conclude that all practical languages are hybrids where some of the type checking is done by the compiler and some of the type checking is deferred to the runtime.
Then when we call a language statically typed we mean most of the type checking is usually done statically. Dynamic type checking is the exception, not the rule.
Even in dynamically typed languages like Python, some of the type checking may be done by an optimizer in the compilation stage. The runtime type check guarding some operations may be removed, because the optimizer decides it knows the types of the values involved once and for all.
That’s not really “the definition”. Different type systems can express different properties about objects, and there are absolutely cases that something changes about a type.
E.g. in structural typing, adding a new field will change the type to a subtype. Will it make any structural typed language non-static?
the efficient dependency management is coming, the good people of astral will take care of that with the uv-backed version of rye (initially created by Armin Ronacher with inspirations from Cargo), I'm really confident it'll be good like ruff and uv were good
rye's habit of insisting on creating a .venv per project is a deal-breaker. I don't want .venvs spread all over my projects eating into space (made worse by the ml/LLM related mega packages). It should atleast respect activated venvs.
well that's good for you, but you're in the minority and rye will end up being a standard anyway, just like uv and ruff, because they're just so much better than the alternatives
I don't get how this optional static typing works. I had a quick look at [1], and it begins with a note saying that Python's runtime doesn't enforce types, leaving the impression that you need to use third-party tools to do actual type checking. But then it continues just like Python does the check. Consider that I'm not a Python programmer, but the main reason I stay away from it is the lack of a proper type system. If this is going to change, I might reconsider it.
The parser supports the type hint syntax, and the standard library provides various type hint related objects.
So you can do things like “from typing import Optional” to bring Optional into scope, and then annotate a function with -> Optional[int] to indicate it returns None or an int.
Unlike a system using special comments for type hints, the interpreter will complain if you make a typo in the word Optional or don’t bring it into scope.
But the interpreter doesn’t do anything else; if you actually return a string from that annotated function it won’t complain.
You need an external third party tool like MyPy or Pyre to consume the hint information and produce warnings.
In practice it’s quite usable, so long as you have CI enforcing the type system. You can gradually add types to an existing code base, and IDEs can use the hint information to support code navigation and error highlighting.
It would be super helpful if the interpreter had a type-enforcing mode though. All the various external runtime enforcement packages leave something to be desired.
I agree. There are usable third-party runtime type checkers though. I like Beartype, which lets you add a decorator @beartype above any function or method, and it’ll complain at runtime if arguments or return values violate the type hints.
I think runtime type checking is in some ways a better fit for a highly dynamic language like Python than static type checking, although both are useful.
At MPOW most Python code is well-type-hinted, and mypy and pyright are very helpful at finding issues, and also for stuff like code completion and navigation, e.g. "go to the definition of the type of this variable".
Works pretty efficiently.
BTW, Typescript also does not enforce types at runtime. Heck, C++ does not enforce types at runtime either. It does not mean that their static typing systems don't help during at development time.
> BTW, Typescript also does not enforce types at runtime. Heck, C++ does not enforce types at runtime either. It does not mean that their static typing systems don't help during at development time.
Speaking of C here as I don't have web development experience. The static type system does help, but in this case, it's the compiler doing the check at compile time to spare you many surprises at runtime. And it's part of the language's standard. Python itself doesn't do that. Good that you can use external tools, but I would prefer if this was part of Python's spec.
Edit: these days I'm thinking of having a look at Mojo, it seems to do what I would like from Python.
The type syntax is python. MyPy is part of Python. It's maintained by the python foundation. Mypy is not part of CPython because modularity is good, the same way that ANSI C doesn't compile anything, that's what gcc, clang, etc are for.
Mojo is literally exactly the same way, the types are optional, and the tooling handles type checking and compilation.
No, because in Mojo, type checking is part of the language specification: you need no external tool for that. Python defines a syntax that can be used for type checking, but you need an external tool to do that. GCC does type checking because it's defined in the language specification. You would have a situation analogous to Python only if you needed GCC + some other tool for type checking. This isn't the case.
You're really splitting hairs here all to prove some sort of "type checking isn't included with python" property. Even if you're technically right, half the world really doesn't care and most code being churned out in Python is type-hinted, type-checked, and de-facto enforced at design time.
It's honestly winning the long-term war because traditional languages have really screwed things up with infinite and contrived language constructs and attempts just to satisfy some "language spec" and "compiler", whilst still trying to be expressive enough for what developers need and want to do safely. Python side-stepped all of that, has the perfect mix of type-checking and amazing "expressibility", and is currently proving that it's the way forward with no stopping it.
I'm not saying that no one should use Python, I'm just saying why I don't like it. But if you instead like it I will not try to stop you using it.
This said, if most people use type hints and the proper tooling to enforce type checking, I would say this would be a good reason to properly integrate (optional) static typing in the language: it shows that most programmers like static typing. The problem I focused on in my example isn't the only advantage of a type system.
Third party tools (mypy, pyright, etc) are expected to check types. cpython itself does not. This will run just fine:
python -c "x: int = 'not_an_int'"
My opinion is that with PEP 695 landing in Python 3.12, the type system itself is starting to feel robust.
These days, the python ecosystem's key packages all tend to have extensive type hints.
The type checkers are of varying quality; my experience is that pyright is fast and correct, while mypy (not having the backing of a Microsoft) is slower and lags on features a little bit -- for instance, mypy still hasn't finalized support for PEP 695 syntax.
Optional static typing is just like a comment (real term is annotation) of the input variable(s) and return variable(s). No optimization is performed. Using a tool such as mypy that kicks off on a CI/CD process technically enforces types but they are ignored by the interpreter unless you make a syntax error.
I haven't used an IDE that has that but it is still just giving you a hint that there is an error and the interpreter is not throwing an error which was my point.
You don’t need an IDE for this, an LSP plugin + Pyright is sufficient to get live type checking. For instance, Emacs (Eglot), Vim (ALE), Sublime (SublimeLSP) all support Pyright with nearly no setup required.
That's true of most compiled languages. Unless we are talking about asserts, reflection, I think type erasure, and maybe a few other concepts, language runtimes don't check types. C does not check types at runtime. You compile it and then rely on control of invariants and data flow to keep everything on rails. In python, this is tricky because everything is behind at least one layer of indirection, and thus virtually everything is mutable, so it's hard to enforce total control of all data structures. But you can get really close with modern tooling.
>> and the interpreter is not throwing an error which was my point.
> That's true of most compiled languages
True of most statically typed languages (usually no need to check at runtime), but not true in Python or other dynamically typed languages. Python would have been unusable for decades (prior to typehints) if that was true.
That's just reflection. That's a feature of code, not language runtime. I think there are some languages which in fact have type checking in the runtime as a bona-fide feature. Most won't, unless you do something like isinstance()
> "I haven't used an IDE that has that but it is still just giving you a hint that there is an error and the interpreter is not throwing an error which was my point."
At this point, I'm not sure how one is to take your opinion on this matter. Just like me coding some C# or Java in notepad and then opining to a Java developer audience about the state of their language and ecosystem.
Nope. Type annotations can be executed and accessed by the runtime. That's how things like Pydantic, msgspec, etc, do runtime type enforcement and coercion.
There are also multiple compilers (mypyc, nuitka, others I forget) which take advantage of types to compile python to machine code.
The interpreter does not and probably never will check types. The annotations are treated as effectively meaningless at runtime. External tools like mypy can be run over your code and check them.
Python's typing must accommodate Python's other goal as quick scripting language. The solution is to document the optional typing system as part of the language's spec and let other tools do the checking, if a user wants to use them.
The other tools are trivially easy to set up and run (or let your IDE run for you.) As in, one command to install, one command to run. It's an elegant compromise that brings something that's sorely needed to Python, and users will spend more time loading the typing spec in their browser than they will installing the type checker.
I think static typing is a waste of time, but given that you want it, I can see why you wouldn't want to use Python. Its type-checking is more half-baked and cumbersome than other languages, even TS.
There are areas where typing is more important: public interfaces. You don't have to make every piece of your program well-typed. But signatures of your public functions / methods matter a lot, and from them types of many internal things can be inferred.
If your code has a well-typed interface, it's pleasant to work with. If interfaces of the libraries you use are well-typed, you have easier time writing your code (that interacts with them). Eventually you type more and more code you write and alter, and keep reaping the benefits.
This was the thing that started to bring me around to optional typing as well. It makes the most sense to me as a form of documentation - it's really useful to know what types are expected (and returned) by a Python function!
If that's baked into the code itself, your text editor can show inline information - which saves you from having to go and look at the documentation yourself.
I've started trying to add types to my libraries that expose a public API now. I think it's worth the extra effort just for the documentation benefit it provides.
This is what made me give it a shot in TS, but the problem is your types at interface boundaries tend to be annoyingly complex. The other problem is any project with optional types soon becomes a project with required types everywhere.
There might be more merit in widely-used public libraries, though. I don't make those.
I shouldn't have said it's a waste of time period, cause every project I work on does have static typing in two very important places: the RPC or web API (OpenAPI, gRPC, whatever it is), and the relational database. But not in the main JS or Py code. That's all I've ever needed.
I did try migrating a NodeJS backend to TS along with a teammate driving that effort. The type-checking never ended up catching any bugs, and the extra time we spent on that stuff could've gone into better testing instead. So it actually made things more dangerous.
Typescript is pretty much the gold standard, it’s amazing how much JavaScript madness you can work around just on the typechecking level.
IMHO Python should shamelessly steal as much typescript’s typing as possible. It’s tough since the Microsoft typescript team is apparently amazing at what they do so for now it’s a very fast moving target but some day…
Well the TS tooling is more painful in ways. It's not compatible with some stuff like the NodeJS profiler. Also there's some mess around modules vs "require" syntax that I don't understand fully but TS somehow plays a role.
A type checker is only going to add limited value if you don't put the effort in yourself. If everything string-like is just a string, and if data is not parsed into types that maintain invariants, then little is being constrained and there is little to "check". It becomes increasingly difficult the more sophisticated the type system is, but in some statically typed languages like Coq, clever programmers can literally prove the correctness of their program using the type system. Whereas a unit test can only prove the presence of bugs, not their absence.
I instead think that the lack of static typing is a waste of time, since without it you can have programs that waste hours of computation due to an exception that would have been prevented by a proper type system ;)
> what it has is "type hints" which is way to have richer integration with type checkers and your IDE, but will never offer more than that as is
Python is strongly typed and it's interpreter is type aware of it's variables, so you're probably overreaching with that statement. Because Python's internals are type aware, it's how folks are able to create type checkers like mypy and pydantic both written in Python. Maybe you're thinking about TS/JSDoc, which is just window dressing for IDEs to display hints as you described?
I don't think you can say that a language is strongly typed if only the language's internals are. The Python interpreter prevents you from summing an integer to a string, but only at runtime when in many cases it's already too late. A strongly typed language would warn you much sooner.
Your example is bang on when describing a "strongly typed" language. That said, strongly typed is different from "static typing", which is what you described later in your post. Python is both strongly typed and dynamically typed. It is all rather confusing and just a big bowl of awful. I have to look up if I haven't referenced it in a while, because the names are far too similar and there aren't even good definitions around some of the concepts.
Then we have very different ideas of what proper typing is :D
Look at this function, can you tell me what it does?
def plus(x, y):
return x+y
If your answer is among the lines of "It returns the sum x and y" then I would ask you who said that x and y are numbers. If these are strings, it concatenates them. If instead you pass a string and a number, you will get a runtime exception. So not only you can't tell what a function does just by looking at it, you can't even know if the function is correct (in the sense that will not raise an exception).
Python types are strictly specified, but also dynamic. You don't need static types in order to have strict types, and indeed just because you've got static types (in TS, for example) doesn't mean you have strict types.
A Python string is always a string, nothing is going to magically turn it into a number just because it's a string representation of a number. The same (sadly) can't be said of Javascript.
There's no magic going on here, just an attribute lookup. It's still possible to write terrible Python code -- as it is in any language -- and the recommendation is still "don't write terrible code", just as it is in any language. You don't have to like it, but not liking it won't make it any different.
The older I get, the more I like writing statically-typed code. I wrote a lot more Python (for my own use) in my youth, and tend towards Rust nowadays. Speaking of which: if you dislike the dynamic typing of Python then you must hate the static typing of Rust -- what does
fn add<T:Add<U>, U>(a: T, b: U) -> T::Output { a + b }
Yeah and even with static typing, a string can be many things. Some people even wrap their strings into singleton structs to avoid something like sending a customerId string into a func that wants an orderId string, which I think is overkill. Same with int.
It's very hard to write long-running daemons in python partially for this reason, when you make a typo on a variable or method name in an uncommon code path.
It can matter also in practice. Once I was trying some Python ML model to generate images. My script ran for 20 minutes to then terminate with an exception when it arrived at the point of saving the result to a file. The reason is that I wanted to concatenate a counter to the file name, but forgot to wrap the integer into a call to str(). 20 minutes wasted for an error that other languages would have spotted before running the script.
> you can't tell what a function does just by looking at it
You just did tell us what it does by looking at it, for the 90% case at least. It might be useful to throw two lists in there as well. Throw a custom object in there? It will work if you planned ahead with dunder add and radd. If not fix, implement, or roll back.
> You just did tell us what it does by looking at it, for the 90% case at least
The problem is that you can't know if the function is going to do what you want it to do without also looking at the context in which it is used. And what you pass as input could be dependent on external factors that you don't control. So I prefer the languages that let me know what happens in 100% of the cases.
> Protection from untrusted input is something that has to be considered in any language
Sure, but some languages make it easier than others. And that was just one example, another example could be having a branch where the input to your function depends on some condition. You could have one of the two branches passing the wrong types, but you will only notice when that branch gets executed.
It never happened to me, because I don't use Python ;)
On a more serious note, your comment actually hints at an issue: unit testing is less effective without static type checking. Let's assume I would like to sum x and y. I can extensively test the function and see that it indeed correctly sums two numbers. But then I need to call the function somewhere in my code, and whether it will work as intended or not depends on the context in which the function is used. Sometimes the input you pass to a function depends from some external source outside your control, an if that's the case you have to resort to manual type checking. Or use a properly typed language.
This isn't an actual problem people encounter in unit testing, partially because you test your outer interfaces first. Also, irl static types often get so big and polymorphic that the context matters just as much.
And if you specify that they are numbers then you lose the ability of the function to generalize to vectors.
Indeed assuming it adds two things is correct, and knowing that concatenation is how Python defines adding strings is important for using the language in the intended way.
Clearly the Python 2 to 3 war was so traumatising (and so badly handled) that the core Python team is too scared to do the obvious thing, and call this Python 4.
This is a big fundamental and (in many cases breaking) change, even if it's "optional".
My body is ready. I love python because the ease of writing and logic. Hopefully the more complicated free-threaded approach is comprehensive enough to write it like we traditionally write python. Not saying it is or isn't I just haven't dived enough into python multithreading because it is hard to put those demons back once you pull them out.
The semantic changes are negligible for authors of Python code. All the complexity falls on the maintainers of the CPython interpreter and on authors of native extension modules.
The GIL does not prevent race conditions in your Python code. It only prevents race conditions in internal data structures inside the interpreter and in atomic operations, i.e., operations that take a single Python bytecode. But many things that appear atomic in Python code take more than one Python bytecode. The GIL gives you no protection if you do such operations in multiple threads on the same object.
I think what many will experience, is that they want to switch to multithreading without GIL, but learn they have code that will have race conditions. But that don't have race conditions today, as it's run as multiple processes, and not threads.
For instance our webserver. It uses multiple processes. Each request then can modify some global variable, use as cache or whatever, and only after it's completely done handling the request the same process will serve a new request. But when people see the GIL is gone, they probably would like to start using it. Can handle more requests without spamming processes / using beefy computer with lots of RAM etc.
And then one might discover new race conditions one never really had before.
If you are writing Python code, the GIL can already be dropped at pretty much any point and there isn't much way of controlling when. Iirc, this includes in the middle of things like +=. There are some operations that Python defines as atomic, but, as I recall, there aren't all that many.
In what way is the GIL preventing races for your use case?
It is not about your code, it is about C extensions you are relying on. Without GIL, you can't even be sure that refcounting works reliably. Bugs in C extensions are always possible. No GIL makes them more likely. Even if you are not the author of C extension, you have to debug the consequences.
I mean that, if the GIL didn't prevent races, it would be trivially removable. Races that are already there in people's Python code have probably been debugged (or at least they are tolerated), so there are some races that will happen when the GIL is removed, and they will be a surprise.
The GIL prevents the corruption of Pythons internal structures. It's hard to remove because:
1. Lots of extensions, which can control when they release the GIL unlike regular Python code, depend on it
2. Removing the GIL requires some sort of other mechanism to protect internal Python stuff
3. But for a long time, such a mechanism was resisted by th Python team because all attempts to remove the GIL either made single threaded code slower or were considered too complicated.
But, as far as I understand, the GIL does somewhere between nothing and very little to prevent races in pure Python code. And, my rough understanding, is that removing the GIL isn't expected to really impact pure Python code.
My understanding, is that many extensions will release the GIL when doing anything expensive. So, if you are doing CPU or IO bound operations in an extension _and_ you are calling that operation in multiple threads, even with the GIL you can potentially fully utilize all of the CPUs in your machine.
> removing the GIL isn't expected to really impact pure Python code.
If your Python code assumes it's just going to run in a single thread now, and it is run in a single thread without the GIL, yes, removing the GIL will make no difference.
> If your Python code assumes it's just going to run in a single thread now, and it is run in a single thread without the GIL, yes, removing the GIL will make no difference.
I'm not sure I understand your point.
Yes, singled thread code will run the same with or without the GIL.
My understanding, was that multi-threaded pure-Python code would also run more or less the same without the GIL. In that, removing the GIL won't introduce races into pure-Python code that is already race free with the GIL. (and that relatedly, pure-Python code that suffers from races without the GIL also already suffers from them with the GIL)
Are you saying that you expect that pure-Python code will be significantly impacted by the removal of the GIL? If so, I'd love to learn more.
> removing the GIL won't introduce races into pure-Python code that is already race free with the GIL.
What do you mean by "race free"? Do you mean the code expects to be run in multiple threads and uses the tools provided by Python, such as locks, mutexes, and semaphores, to ensure thread safety, and has been tested to ensure that it is race free when run multi-threaded? If that is what you mean, then yes, of course such code will still be race free without the GIL, because it was never depending on the GIL to protect it in the first place.
But there is a lot of pure Python code out there that is not written that way. Removal of the GIL would allow such code to be naively run in multiple threads using, for example, Python's support for thread pools. Anyone under the impression that removing the GIL was intended to allow this sort of thing without any further checking of the code is mistaken. That is the kind of thing my comment was intended to exclude.
> But there is a lot of pure Python code out there that is not written that way. Removal of the GIL would allow such code to be naively run in multiple threads using, for example, Python's support for thread pools.
I guess this is what I don't understand. This code could already be run in multiple threads today, with a GIL. And it would be broken - in all the same ways it would be broken without a GIL, correct?
> Anyone under the impression that removing the GIL was intended to allow this sort of thing without any further checking of the code is mistaken. That is the kind of thing my comment was intended to exclude.
Ah, so, is your point that removing the GIL will cause people to take non-multithread code and run it in multiple threads without realizing that it is broken in that context? That its not so much a technical change, but a change of perception that will lead to issues?
> This code could already be run in multiple threads today, with a GIL.
Yes.
> And it would be broken - in all the same ways it would be broken without a GIL, correct?
Yes, but the absence of the GIL would make race conditions more likely to happen.
> is your point that removing the GIL will cause people to take non-multithread code and run it in multiple threads without realizing that it is broken in that context?
Yes. They could run it in multiple threads with the GIL today, but as above, race conditions might not show up as often, so it might not be realized that the code is broken. But also, with the GIL there is the common perception that Python doesn't do multithreading well anyway, so it's less likely to be used for that. With the GIL removed, I suspect many people will want to use multithreading a lot more in Python to parallelize code, without fully realizing the implications.
> Yes, but the absence of the GIL would make race conditions more likely to happen.
Does it though? I'm not saying it doesn't, I'm quite curious. Switching between threads with the GIL is already fairly unpredictable from the perspective of pure-Python code. Does it get significantly more troublesome without the GIL?
> Yes. They could run it in multiple threads with the GIL today, but as above, race conditions might not show up as often, so it might not be realized that the code is broken. But also, with the GIL there is the common perception that Python doesn't do multithreading well anyway, so it's less likely to be used for that. With the GIL removed, I suspect many people will want to use multithreading a lot more in Python to parallelize code, without fully realizing the implications.
> Switching between threads with the GIL is already fairly unpredictable from the perspective of pure-Python code.
But it still prevents multiple threads from running Python bytecode at the same time: in other words, at any given time, only one Python bytecode can be executing in the entire interpreter.
Without the GIL that is no longer true; an arbitrary number of threads can all be executing a Python bytecode at the same time. So even Python-level operations that only take a single bytecode now must be protected to be thread-safe--where under the GIL, they didn't have to be. That is a significant increase in the "attack surface", so to speak, for race conditions in the absence of thread safety protections.
(Note that this does mean that even multi-threaded code that was race-free with the GIL due to using explicit locks, mutexes, semaphores, etc., might not be without the GIL if those protections were only used for multi-bytecode operations. In practice, whether or not a particular Python operation takes a single bytecode or multiple bytecodes is not something you can just read off from the Python code--you have to either have intimate knowledge of the interpreter's internals or you have to explicitly disassemble each piece of code and look at the bytecode that is generated. Of course the vast majority of programmers don't do that, they just use thread safety protections for every data mutation, which will work without the GIL as well as with it.)
> if the GIL didn't prevent races, it would be trivially removable
Nobody is saying the GIL doesn't prevent races at all. We are saying that the GIL does not prevent races in your Python code. It's not "trivially removable" because it does prevent races in the interpreter's internal data structures and in operations that are done in a single Python bytecode, and there are a lot of possible races in those places.
Also, perhaps you haven't considered the fact that Python provides tools such as mutexes, locks, and semaphores to help you prevent races in your Python code. Python programmers who do write multi-threaded Python code (for example, code where threads spend most of their time waiting on I/O, which releases the GIL and allows other threads to run) do have to use these tools. Why? Because the GIL by itself does not prevent races in your Python code. You have to do it, just as you do with multi-threaded code in any language.
> Races that are already there in people's Python code have probably been debugged
Um, no, they haven't, because they've never been exposed to multi-threading. Most people's Python code is not written to be thread-safe, so it can't safely be parallelized as it is, GIL or no GIL.
The article states the goal is to eventually (after some years of working out the major kinks and performance regressions) promote Free-Threaded Python to be the default cPython distribution.
What are the common use cases for threading in Python? I feel like that's a lower level tool than most Python projects would want, compared to asyncio or multiprocessing.Pool. JS is the most comparable thing to Python, and it got pretty darn far without threads.
Working with asyncio sucks when all you want is to be able to do some things in the background, possibly concurrently. You have to rewrite the worker code using those stupid async await keywords. It's an obnoxious constraint that completely breaks down when you want to use unaware libraries. The thread model is just a million times easier to use because you don't have to change the code.
Asyncio is designed for things like webservers or UIs where some framework is probably already handling the main event loop. What are you doing where you just want to run something else in the background, and IPC isn't good enough?
Non-blocking HTTP requests is an extremely common need, for instance. Why the hell did we need to reinvent special asyncio-aware request libraries for it? It's absolute madness. Thread pools are much easier to work with.
> where some framework is probably already handling the main event loop
This is both not really true and also irrelevant. When you need a flask (or whatever) request handler to do parallel work, asyncio is still pretty bullshit to use vs threads.
Non-blocking HTTP request is the bread and butter use case for asyncio. Most JS projects are doing something like this, and they don't need to manage threads for it. You want to manage your own thread pool for this, or are you going to spawn and kill a thread every time you make a request?
> Non-blocking HTTP request is the bread and butter use case for asyncio
And the amount of contorting that has to be done for it in Python would be hilarious if it weren't so sad.
> Most JS projects
I don't know what JavaScript does, but I do know that Python is not JavaScript.
> You want to manage your own thread pool for this...
In Python, concurrent futures' ThreadPoolExecutor is actually nice to use and doesn't require rewriting existing worker code. It's already done, has a clean interface, and was part of the standard library before asyncio was.
ThreadPoolExecutor is the most similar thing to asyncio: It hands out promises, and when you call .result(), it's the same as await. JS even made its own promises implicitly compatible with async/await. I'm mentioning what JS does because you're describing a very common JS use case, and Python isn't all that different.
If you have async stuff happening all over the place, what do you use, a global ThreadPoolExecutor? It's not bad, but a bit more cumbersome and probably less efficient. You're running multiple OS threads that are locking, vs a single-threaded event loop. Gets worse the more long-running blocking calls there are.
Also, I was originally asking about free threads. GIL isn't a problem if you're just waiting on I/O. If you want to compute on multiple cores at once, there's multiprocessing, or more likely you're using stuff like numpy that uses C threads anyway.
Again, Python's implementation of asyncio does not allow you to background worker code without explicitly altering that worker code to be aware of asyncio. Threads do. They just don't occupy the same space.
> Also, I was originally asking about free threads...there's multiprocessing
Eh, the obvious reason to not want to use separate processes is a desire for some kind of shared state without the cost or burden of IPC. The fact that you suggested multiprocessing.Pool instead of concurrent_futures.ProcessPoolExecutor and asked about manual pool management feels like it tells me a little bit about where your head is at here wrt Python.
Basically true in JS too. You're not supposed to do blocking calls in async code. You also can't "await" an async call inside a non-async func, though you could fire-and-forget it.
Right, but how often does a Python program have complex shared state across threads, rather than some simple fan-out-fan-in, and also need to take advantage of multiple cores?
The primary thing that tripped me up about async/await, specifically only in Python, is that the called function does not begin running until you await it. Before that moment, it's just an unstarted generator.
To make background jobs, I've used the class-based version to start a thread, then the magic method that's called on await simply joins the thread. Which is a lot of boilerplate to get a little closer to how async works in (at least) js and c#.
Rust's version of async/await is the same in that respect, where futures don't do anything until you poll them (e.g., by awaiting them): if you want something to just start right away, you have to call out to the executor you're using, and get it to spawn a new task for it.
Though to be fair, people complain about this in Rust as well. I can't comment much on it myself, since I haven't had any need for concurrent workloads that Rayon (a basic thread-pool library with work stealing) can't handle.
That is a common split in language design decisions. I think the argument for the python-style where you have to drive it to begin is more useful as you can always just start it immediately but also let's you delay computation or pass it around similar to a Haskell thunk.
I feel you. I know asyncio is "the future", but I usually just want to write a background task, and really hate all the gymnastics I have to do with the color of my functions.
I feel like "asyncio is the future" was invented by the same people who think it's totally normal to switch to a new javascript web framework every 6 months.
JS had an event loop since the start. It's an old concept that Python seems to have lifted, as did Rust. I used Python for a decade and never really liked the way it did threads.
Python's reactor pattern, or event loop as you call it, started with the "Twisted" framework or library. And that was first published in 2003. That's a full 6 years before Node.js was released which I assume was the first time anything event-loopy started happening in the JS world.
I forgot to mention that it came into prominence in the Python world through the Tornado http server library that did the same thing. Slowly over time, more and more language features were added to give native or first-class-citizen support to what a lot of people were doing behind the scenes (in sometimes very contrived abuses of generator functions).
I am a big advocate for ThreadPoolExecutor. I'm saying it's superior to asyncio. The person I'm responding to was asking why use threads when you can use asyncio instead.
So, in Rust they had threading since forever and they are now hyped with this new toy called async/await (and all the new problems it brings), while in Python they've had async/await and are now excited to see the possibilities of this new toy called threads (and all its problems). That's funny!
Yeah I've never liked the async stuff. I've used the existing theading library and it's been fine, for those programs that are blocked on i/o most of the time. The GIL hasn't been a problem. Those programs often ran on single core machines anyway. We would have been better off without the GIL in the first place, but we may be in for headaches by removing it now.
It’s hard to say because we’ve come up with a lot of ways to work around the fact that threaded Python has always sucked. Why? Because there’d been no demand to improve it. Why? Because no one used it. Why? Because it sucked.
I’m looking forward to seeing how people use a Python that can be meaningfully threaded. While It may take a bit to built momentum, I suspect that in a few years there’ll be obvious use cases that are widely deployed that no one today has even really considered.
Maybe a place to look for obvious use cases is in other languages. JS doesn't have threads, but Swift does. The reason I can't think of one is, free threads are most useful for full parallelism that isn't "embarrassingly parallel," otherwise IPC does fine.
So far, I've rarely seen that. Best example I deal with was a networking project with lots of communication across threads, and that one was too performance-sensitive to even use C++, let alone Py. Other things I can think of are OS programming which again has to be C or Rust.
That's the kind of thing I stumble across all the time. Indexing all the symbols in a codebase:
results = Counter()
for file in here.glob('*.py'):
symbols = parse(file)
results.update(symbols)
Scanning image metadata:
for image in here.glob('*.png'):
headers = png.Reader(image)
...
Now that I think about it, most of my use cases involve doing expensive things to all the files in a directory, but in ways where it'd be really sweet if I could do it all in the same process space instead of using a multiprocessing pool (which is otherwise an excellent way to skin that cat).
I've never let that stop me from getting the job done. There's always a way, and if we can't use tool A, then we'll make tool B work. It'll still be nice if it pans out that decent threading is at least an option.
These are "embarassingly parallel" examples that multiprocessing is ok for, though. There was always the small caveat that you can't pickle a file handle, but it wasn't a real problem. Threads are more useful if you have lots of shared state and mutexes.
I think these examples would also perform well with GIL'd threads, since the actual Python part is just waiting on blocking calls that do the expensive work. But maybe not.
> Threads are more useful if you have lots of shared state and mutexes.
That's what always kicks me in such things. If the processes are truly completely separable, awesome! It never seems like they are as much as I wish they were.
Does anyone know if there is more serious single threaded performance degradation (more than a few percent for instance)? I couldn't find any benchmarks, just some generic reassurance that everything is fine.
Right now there is a significant single-threaded performance cost. Somewhere from 30-50%. Part of what my colleague Ken Jin and others are working on is getting back some of that lost performance by applying some optimizations. Expect single-threaded performance to improve for Python 3.14 next year.
To be honest, that seems a lot. Even today a lot of code is single-threaded, and this performance hit will also affect a lot of code running in parallel today.
There have been patches to remove the GIL going back to the 90s and Python 1.5 or thereabouts. But the performance impact has always been the show-stopper.
It’s an experimental release in 3.13. Another example: objects that will have deffered reference counts in 3.14 are made immortal in 3.13 to avoid scaling issues from reference count thrashing. This wasn’t originally the plan but deferred reference counting didn’t land in time for 3.13. It will be several years before free-threading becomes the default, at that point there will no longer be any single-threaded performance drop. Of course that assumes everything shakes out as planned, we’ll see.
This post is a call to ask people to “kick the tires”, experiment, and report issues they run into, not announcing that all work is done.
That kind of negates the whole purpose of multi threading. An application running on two cores might end up slower, not faster. We know that the python developers are kind of incompetent when it comes to performance, but the numbers you are quoting are so bad they probably aren't correct in the first place.
Clarifying a few days later: single-threaded performance in the normal ABI with the GIL does not have the same performance degradation. You only see the performance hit if you’re testing the experimental 3.13 free-threaded release.
To my understanding there is and there isn't. The driving force behind this demonstrated that it was possible to speed up the existing CPython interpreter by more than the performance cost of free threading with changes to the allocator and various other things.
So the net is actually a small performance win but lesser than if there was no free threading. That said, many of the techniques he identified were immediately incorporated into CPython and so I would expect benchmarks to show some regression as compared with the single threaded interpreter of the previous revision.
I remember back around 2007 all the anxious blog posts about the free lunch (Moore's law) being over. Parallelism was mandatory now. We were going to need exotic solutions like software transactional memory to get out of the crisis (and we could certainly forget about object orientation).
Meanwhile what takes the crown? - Single threaded python.
(Well, ok Rust looks like it's taking first place where you really need the speed and it does help parallelism without requiring absolute purity)
Takes what crown? Python is horrifically slow even single threaded. It's by far the slowest and most energy inefficient of the major choices available today.
I know, I know, 'not every story needs to be about ML' but.... I can only imagine how unlocking the GIL will change the nature of ML training and inference. There is so much waste and complexity in passing memory around and coordinating processes. I know that libraries have made it (somewhat) easier and more efficient but I can't wait to see what can be done with things like pytorch when optimized for this.
Pretty universally I have seen performance improvements in code when complexity is reduced and this could drop complexity considerably. I wouldn't be surprised to see a double digit percent improvement in tokens per sec when an optimized pytorch eventually comes out with this. There may even be hidden gains on GPU memory usage that come out of this as people clean up code and start implementing better tricks because of it.
Have you done any multi-gpu training? Generally every GPU gets a process. Coordinating between them and passing around data between them is complex and can easily have performance issues since normal communication between python processes requires some sort of serialization/de-serialization of objects (there are many * here when it comes to GPU training). This has the potential to simplify all of that and remove a lot of inter-process communication which is just pure overhead.
Of course ML will benefit from it. Soon you will be able to run your dataloaders/data preprocessing in different threads which will not starve your GPUs of data.
If you have done ML with PyTorch or Tensorflow you will know how much multithreading can improve data loading performance. Currently multiprocessing provides the necessary parallelization of data loading but it is painful and riddle with bugs.
I'm really curious to see how this will work with async. There's a natural barrier (I/O versus CPU-bound code), which isn't always a perfect distinction.
I'd love to see a more fluid model between the two -- E.G. if I'm doing a "gather" on CPU-bound coroutines, I'm curious if there's something that can be smart enough to JIT between async and multithreaded implementations.
"Oh, the first few tasks were entirely CPU-bound? Cool, let's launch another thread. Oh, the first few threads were I/O-bound? Cool, let's use in-thread coroutines".
Probably not feasible for a myriad of reasons, but even a more fluid programming model could be really cool (similar interfaces with a quick swap between?).
I think you'd be hard pressed to find a workload where that behavior needs to be generalized to the degree you're talking.
If you're serving HTTP requests, for instance, simply serving each request on its own thread with its own event loop should be sufficient at scale. Multiple requests each with CPU-bound tasks will still saturate the CPUs.
Very little code teeters between CPU-bound and io-bound while also serving few enough requests that you have cores to spare to effectively parallelize all the CPU-bound work. If that's the case, why do you need the runtime to do this for you? A simple profile would show what's holding up the event loop.
But still, the runtime can't naively parallelize coroutines. Coroutines are expected not to be run in parallel and that code isn't expected to be thread safe. Instead of a gather on futures, your code would have been using a thread pool executor in the first place if you'd gone out of your way to ensure your CPU-bound code was thread safe: the benefits of async/await are mostly lost.
I also don't think an event loop can be shared between two running threads: if you were to parallelize coroutines, those coroutines' spawned coroutines could run in parallel. If you used an async library that isn't thread safe because it expects only one coroutine is executing at a time, you could run into serious bugs.
Interesting. I don't disagree, in general, but I actually have worked with a lot of applications that like to do this. Specifically in the world of ML/AI inference there's a lot of moving between external querying of data (features) and internal/external querying of models. With recommendation systems it is often worse -- gather large data, run a computation on it, filter it, get a bulk API request, score it with a model, etc...
This is exactly where I'd like to see it.
I'd like to simultaneously:
1. Call out to external APIs and not run any overhead/complexity of creating/managing threads
2. Call out to a model on a CPU and not have it block the event loop (I want it to launch a new thread and have that be similar to me)
3. Call out to a model on a GPU, ditto
And use the observed resource CPU/GPU usage to scale up nicely with an external horizontal scaling system.
So it might be that the async API is a lot easier to use/ergonomic then threads. I'd be happy to handle thread-safety (say, annotating routines), but as you pointed out, there are underlying framework assumptions that make this complicated.
The solution we always used is to separate out the CPU-bound components from the IO-bound components, even onto different servers or sidecar processes (which, effectively, turn CPU-bound into IO-bound operations). But if they could co-exist happily, I'd be very excited. Especially if they could use a similar API as async does.
How is the no-gil performance compared to other languages like - javascript (nodejs), go, rust, and even java? If it's bearable then I believe there is enormous value that could be generated instead of spending time porting to other languages.
No-GIL Python is still interpreted - single-threaded performance is slower that standard Python, which is in turn much slower than the languages you mentioned.
Maybe if you’ve got an embarrassingly parallel problem, and dozen(s) of cores to spare, you can match the performance of a single-threaded JIT/AOT compiled program.
How do companies like Instagram/OpenAI scale with a majority python codebase? Like I just kick it on HN idk much about computers or coding (think high school CS) why wouldn’t they migrate can someone explain like I’m five
Python may well have been the right choice for companies like that when they were starting out, but now they're much bigger, they would be better off with a different language.
However, they simply have too much code to rewrite it all in another language. Hence the attempts recently to fundamentally change Python itself to make it more suitable for large-scale codebases.
<rant>And IMO less suitable for writing small scripts, which is what the majority of Python programmers are actually doing.</rant>
Great news !
It would be interesting to see performance comparison for IO-bound tasks like http requests between single-threaded asyncio code and multi-threaded asyncio
PEP703 explains that with the GIL removed, operations on lists such as `append` remain thread-safe because of the addition of per-list locks.
What about simple operations like incrementing an integer? IIRC this is currently thread-safe because the GIL guarantees each bytecode instruction is executed atomically.
Ah, `i += 1` isn’t currently thread-safe because Python does (LOAD, +=, STORE) as 3 separate bytecode instructions.
I guess the only things that are a single instruction are some modifications to mutable objects, and those are already heavyweight enough that it’s OK to add a per-object lock.
That sounds like the kind of thing that a JIT compiler should be optimizing. The problem with threading isn't stuff like this but people doing a lot of silly things like having global mutable state or stateful objects that are being passed around a lot.
I've done quite a bit of stuff with Java and Kotlin in the past quarter century and it's interesting to see how much things have evolved. Early on there were a lot of people doing silly things with threads and overusing the, at the time, not so great language features for that. But a lot of that stuff replaced by better primitives and libraries.
If you look at Kotlin these days, there's very little of that silliness going on. It has no synchronized keyword. Or a volatile keyword, like Java has. But it does have co-routines and co-routine scopes. And some of those scopes may be backed by thread pools (or virtual thread pools on recent JVMs).
Now that python has async, it's probably a good idea to start thinking about some way to add structured concurrency similar to that on top of that. So, you have async stuff and some of that async stuff might happen on different threads. It's a good mental model for dealing with concurrency and parallelism. There's no need to repeat two decades of mistakes that happened in the Java world; you can fast forward to the good stuff without doing that.
Good to hear. The authors are touching on the journey it is to make Cython continue to work. I wonder how hard it'll be to continue to provide bdist packages, or within what timeframe, if at all, Cython can transparently ensure correctness for a no-gil build. Anyone got any insights?
Yesterday someone presented preliminary benchmarks here at EuroPython 2024, comparing no-GIL to sub-interpreters and to multiprocessing. Upshot: This gon' be good!
It has been ready for a few months now, at least since 3.13.0 beta 1 which released on 2024-05-08, although alpha versions had it working too. I don't know why this is news now.
FTA: "Yesterday, py-free-threading.github.io launched! It's both a resource with documentation around adding support for free-threaded Python, and a status tracker for the rollout across open source projects in the Python ecosystem."
Many uses. There's tons of situations where you are already accelerating most of your heavy compute with tensor libraries, but the data input/output parts are still in python. They would benefit from loading data in parallel before batching.
Multiprocess, OS threads, and asyncio all solve different problems. Threads are pretty heavyweight compared to async coroutines (aka green threads). The big win with coroutines is it is very cheap to put them to sleep waiting on io. So a web server on a 4 core vm might have 4 worker processes, several threads per process, and dozens/hundreds of coroutines.
> So perhaps you can use this for slurping other people's IP in parallel and train the "AIs" that are supposed to make us redundant.
This has absolutely nothing to do with the technical merits of async or threads. For one, the above two examples are taken directly from work I did to combat deep fakes by identifying various "tells" from the media. Some of us are in fact using machine learning for good.
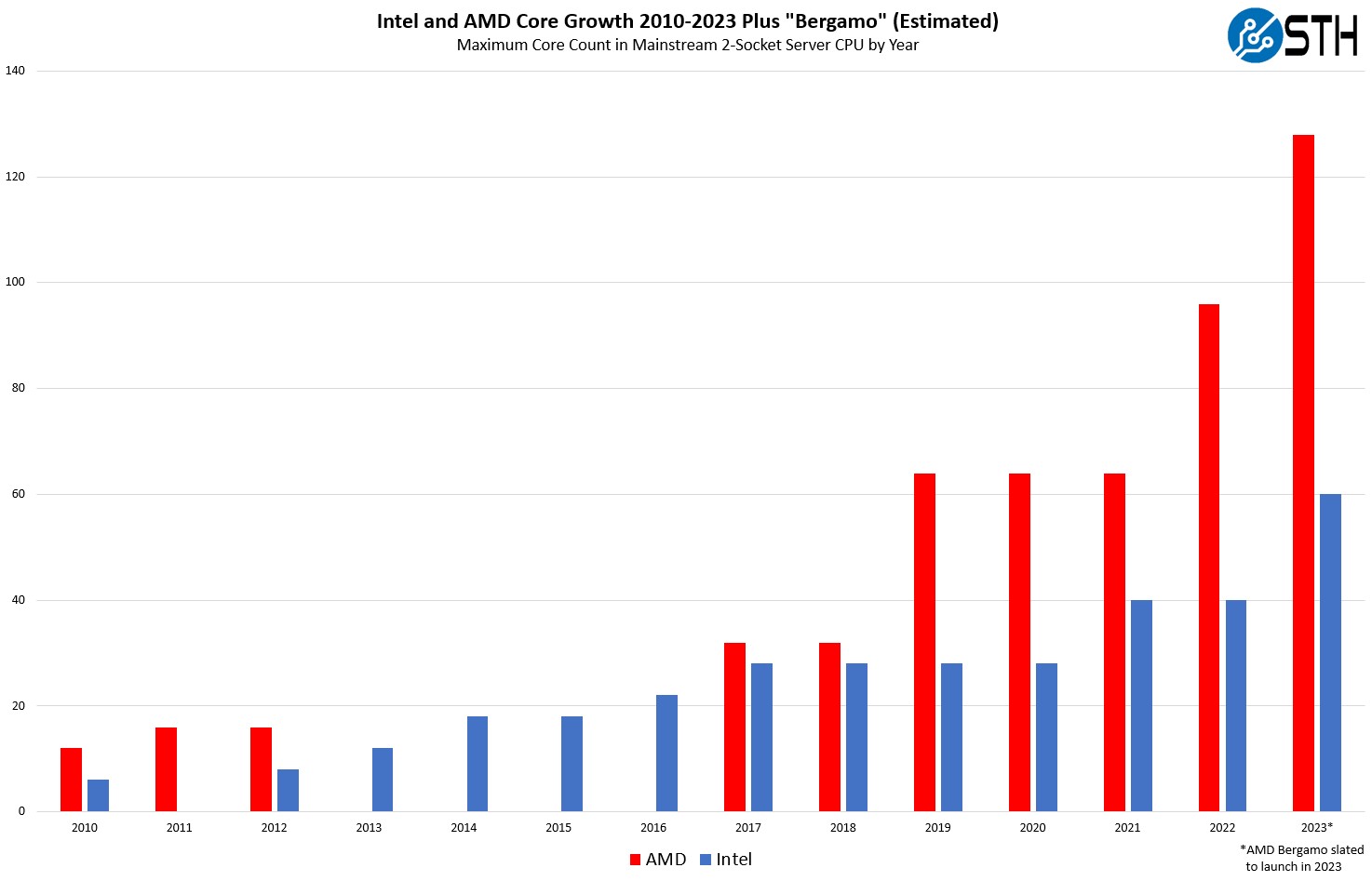{kind=link}