All these products that pitch about using AI to find insights from your data always end up looking pretty in demos and fall short in reality. This is not because the product is bad, but because there is enormous amount of nuance in DB/Tables that becomes difficult to manage. Most startups evolve too quickly and product teams generally tries to deliver by hacking some existing feature. Columns are added, some columns get new meaning, some feature is identified by looking at a combination of 2 columns etc. All this needs to be documented properly and fed to the AI and there is no incentive for anyone to do it. If the AI gives the right answer, everyone is like wow AI is so good, we don't need the BAs. If the AI gives terrible answers they are like "this is useless". No one goes "wow, the data engineering team did a great job keeping the AI relevant".
I couldn’t agree more. I’ve hooked up things to my DB with AI in an attempt to “talk” to it but the results have been lackluster. Sure it’s impressive when it does get things right but I found myself spending a bunch of time adding to the prompt to explain how the data is organized.
I’m not expecting any LLM to just understand it, heck another human would need the same rundown from me. Maybe it’s worth keeping this “documentation” up to date but my take away was that I couldn’t release access to the AI because it got things wrong too often and I could anticipate every question a user might ask. I didn’t want it to give out wrong answers (this DB is used for sales) since spitting out wrong numbers would be just as bad as my dashboards “lying”.
Demo DBs aren’t representative of shipping applications and so the demos using AI are able to have an extremely high success rate. My DB, with deprecated columns, possibly confusing (to other people) naming, etc had a much higher error rate.
Agent reasoning systems should learn based on past and future use, and both end users and maintainers should have power in how they work. So projects naturally progress on adding guard rails, heuristics, policies, customization, etc. Likewise, they first do it with simple hardcoding and then swapping in learning.
As we have built out Louie.ai with these kinds of things, I've appreciated ChatGPT as its own innovation separate from the underlying LLM. There is a lot going on behind the scenes. They do it in a very consumer/prosumer setting where they hide almost everything. Technical and business users need more in our experience, and even that is a coarse brush...
Our theory is we are having simultaneously a bit of a Google moment and a Tableau moment. There is à lot more discovery & work to pull it off, but the dam has been broken. It's been am exciting time to work through with our customers:
* Google moment: AI can now watch and learn how you and your team do data. Around the time Google pagerank came around, the Yahoo-style search engines were highly curated, and the semantic web people were writing xml/rdf schema and manually mapping all data to it. Google replaced slow and expensive work with something easier, higher quality, and more scalable + robust. We are making Louie.ai learn both ahead of time and as the system gets used, so data people can also get their Google moment. Having a tool that works with you & your team here is amazing.
* Tableau moment: A project or data owner can now guide a lot more without much work. Dashboarding used to require a lot of low-level custom web dev etc, while Tableau streamlined it so that a BI lead good at SQL and who understood the data & design can go much further without a big team and in way less time. Understanding the user personas, and adding abstractions for facilitating them, were a big deal for delivery speed, cost, and achieved quality. Arguably the same happened as Looker in introduced LookML and foreshadowed the whole semantic layer movement happening today. To help owners ensure quality and security, we have been investing a lot in the equivalent abstractions in Louie.ai for making data and more conversational. Luckily, while the AI part is new, there is a lot more precedent on the data ops side. Getting this right is a big deal in team settings and basically any time the stakes are high.
> Around the time Google pagerank came around, the Yahoo-style search engines were highly curated
Hmmm, no. Altavista was the go-to search engine at the time (launched 1995), and was a crawler (i.e. not a curated catalog/directory) based search. Lycos predates that but had keyword rather than natural language search.
Hotbot was amazing back in the day. Google scored me post high school schoolin', however, so I won't complain...Shoot Google helped me make the local news back in the day!
Yep. A lot more on our roadmap, but a lot already in place!
It's been cool seeing how different pieces add up together and how gov/enterprise teams push us. While there are some surprising implementation details, a lot has been following up on what they need with foundational implementations and reusing them. The result is a lot is obvious in retrospect and well-done pieces carry it far.
Ex: We added a secure python sandbox last quarter so analysts can drive richer data wrangling on query results. Except now we are launching a GPU version, both so the wrangling can be ML/AI (ex: auto feature engineering), users can wrangle bigger results (GPU dataframes), and we will move our own built-in agents to it as well (ex: GPU-accelerated dashboard panels). Most individual PRs here are surprisingly small, but opens a lot!
Those are pretty normal needs for us and our users. A big reason louie.ai exists is to make easier all the years of Graphistry helping enterprise & gov teams use python notebooks, streamlit/databricks/plotly python dashboards, and overall python GPU+graph data science. Think pandas, pytorch, huggingface, Nvidia RAPIDS, our own pygraphistry, etc.
While we can't those years of our lives back, we can make the next ones a lot better!
Mostly agree. I suggest to keep using ETL and create a data warehouse that irons outs most of these nuances that are needed for a production database. On a data warehouse with good meta data I can imagine this will work great.
I think getting clean tables/ETLs is a big blocker for move fast and break things. I would be more interested in actually github copilot style sql IDE (like datagrip etc.), which has access to all the queries written by all the people within a company. Which runs on a local server or something for security reasons and to get the nod from the IT/Sec department.
And basically when you next write queries, it just auto completes for you. This would improve the productivity of the analysts a lot. With the flexibility of them being able to tweak the query. Here if something is not right, the analyst updates. The Copilot AI keeps learning and giving weights to recent queries more than older queries.
Unlike the previous solution where if something breaks, you can do nothing till you clean up the ETL and redeploy it.
that is correct. GPT-4 is good on well-modelled data out of the box, but struggles with a messy and incomplete data model.
Documenting data definitely helps to close that gap.
However the last part you describe is nothing new (BI teams taking credit, and pushing on problems to data engineers). In fact there is a chance that tools like vanna.ai or getdot.ai bring engineers closer to business folks. So more honest conversations, more impact, more budget.
Agreed, maybe I wasn't clear enough. I don't view it as BI team vs platform team vs whoever. Maybe a decrease in the need for PhD AI consultants for small projects, or to wait for some privileged IT team for basic tasks, so they can focus on bigger things.
Instead of Herculean data infra projects, this is a good time for figuring out new policy abstractions, and finding more productive divisions of labor between different days stakeholders and systems. Machine-friendly abstractions and structure are tools for predictable collaboration and automation. More doing, less waiting.
More practically, an increasing part of the Louie.ai stack is helping get the time-consuming quality, guardrails, security, etc parts under easier control of small teams building things. As-is, it takes a lot to give a great experience.
There used to be a company/product called Business Objects aka BO (SAP bought them), which had folks meticulously map every relationship. When done correctly, it was pretty good. You could just drag drop and get answers immediately.
So yes, I can understand if there is incentive for the startups to invest in Data Engineers to make well maintained data models.
But I do think, the most important value here is not the chatgpt interface, it is getting DEs to maintain the data model in a company where product/biz is moving fast and breaking things. If that is done, then existing tools (Power BI for instance has "ask in natural language" feature) will be able to get the job done.
The google moment, the other person talks about in another comment, is where google or 1998 didn't require a webpage owner to do anything. They didn't need him/her to make something in a different format. Use specific tags. Use some tags around key words etc. It was just "you do what you do, and magically we will crawl and make sense of it".
Here unfortunately that is not the case. Say in a ecom business which always delivers in 2 days for free, a new product is launched (same day delivery for $5 dollars), the sales table is going to get two extra columns "is_same_day_delivery_flag" and "same_day_delivery_fee". The revenue definition will change to include this shipping charges. A new filter will be there, if someone wants to see the opt in rate for how many are going for same day delivery or how fast it is growing. Current table probably has revenue. But now revenue = revenue + same_day_delivery_fee and someone needs to make the BO connection to this. And after launch, you notice you don't have enough capacity to do same day shipping, so sometimes you just have to return the fee and send it as normal delivery. Here the is_same_day_delivery_flag is true, but the same_day_delivery_fee is 0. And so on and on...
Getting DE to keep everything up to date in a wiki is tough, let alone a BO type solution. But I do hope getdot.ai etc. someone incentivizes them to change this way of doing things.
The AI needs to truly be 'listening' in in a passive way to all Slack messages, virtual meetings, code commits, etc and really be present whenever the 'team' is in order to get anything done.
I feel like by the time I could turn it into a product, Microsoft & friends will release something that makes it look like a joke. If there is no one on the SQL Server team working on this right now, I don't know what the hell their leadership is thinking.
I am not chasing this rabbit. Someone else will almost certainly catch it first. For now, this is a fun toy I enjoy in my free time. The moment I try to make money with it the fun begins to disappear.
Broadly speaking, I do think this is approximately the only thing that matters once you realize you can put pretty much anything in a big SQL database. What happens when 100% of the domain is in-scope of an LLM that has iteratively optimized itself against the schema?
Microsoft may well catch the rabbit that queries schemas and generates valid SQL.
But that rabbit can't understand the meaning of the data just by looking at column names and table relationships.
Let's say you want to know how sales and inventory are doing compared to last year at your chain of retail stores.
Will Microsoft's rabbit be smart enough to know that the retail business is seasonal, so it must compare the last x weeks this year with the same weeks last year? And account for differences in timing of holidays? And exclude stores that weren't open last year?
Will it know that inventory is a stock and sales is a flow, so while it can sum daily sales, it's nonsensical to sum daily inventory?
The real AI magic isn't generating SQL with four joins, it's understanding the mechanics of each industry and the quirks of your organization to extract the intent from ambiguous and incomplete natural language.
If I can TLDR your comment, which I agree with: the real value is in doing real work.
“Hustlers” burn countless hours trying to “optimize” work out of the picture.
Historically, there’s a lot of money in just sitting down with a to-do list of customer problems and solving them at acceptable cost, come hell or high water.
I will be extremely surprised if Microsoft build this for open source databases, however someone else will definitely build it if you don't, that is completely true :-)
Disclaimer: I work at Microsoft on Postgres related open source tools (Citus & PgBouncer mostly)
Microsoft is heavily investing in Postgres and its ecosystem, so I wouldn't be extremely surprised if we would do this. We're definitely building things to combine AI with Postgres[1]. Although afaik no-one is working actively on query generation using AI.
But I actually did a very basic POC of "natural language queries" in Postgres myself last year:
Postgres is dear to me. Met its founders when I was in college at Berkeley, worked heavily with it at a previous company around 2015, used it for all my own projects. I'm glad to see it getting more attention lately (seemingly).
I didn’t know this, it seems they love open source even thought they have competing commercial products. Maybe there is just more money is selling cloud than there is in selling commercial databases?
> I feel like by the time I could turn it into a product, Microsoft & friends will release something that makes it look like a joke. If there is no one on the SQL Server team working on this right now, I don't know what the hell their leadership is thinking.
If Cortana for Azure isn't a thing in the works, I *really* don't know what the hell their leadership is working on. I could see insane value in "why is my website slow?" and getting actionable responses.
If the do release it , they will only release it for enterprise. Many many sql server installs are sql server standard. There is an entire ecosystem of companies built on selling packages that support sql server standard, wee DevArt, RedGate.
> Microsoft & friends will release something that makes it look like a joke
True, Microsoft & Friends have gotten greedy every passing year. Before they used to develop the platform (OS,DB etc.,) and let others develop and sell apps on it that would benefit them as well as the whole ecosystem.
Now they want every last dollar they can squeeze out of the ecosystem. So they don't leave any stone unturned and they have big pockets to do that.
There are already several products out there with varying success.
Some findings after I played with it awhile:
- Langchain already does something like this
- a lot of the challenge is not with the query itself but efficiently summarizing data to fit in the context window. In other words if you give me 1-4 tables I can give you a product that will work well pretty easy. But when your data warehouse has tens or hundreds of tables with columns and meta types now we need to chain together a string of queries to arrive at the answer and we are basically building a state machine of sorts that has to do fun and creative RAG stuff
- the single biggest thing that made a difference in effectiveness was not what op mentioned at all, but instead having a good summary of what every column in the db was stored in the db. This can be AI generated itself, but the way Langchain attempts to do it on the fly is slow and rather ineffective (or at least was the case when I played with it last summer, it might be better now).
Not affiliated, but after reviewing the products out there the data team I was working with ended up selecting getdot.ai as it had the right mix of price, ease of use, and effectiveness.
Shameless plug – we're working on this at Velvet (https://usevelvet.com) and would love feedback. Our tool can connect and query across disparate data sources (databases and event-based systems) and allows you to write natural language questions that are turned automatically into SQL queries (and even make those queries into API endpoints you can call directly!). My email is in my HN profile if anyone wants to try it out or has feedback.
What made you say this? How is this different from the hundreds of AI startups already focusing on this, or even the submission that we're having this conversation on?
I'm really curious as to the reasoning behind your question and why you think an LLM generated query somehow would have unfettered access and permissions.
What's stopping anyone who can run ordinary SQL queries? The LLM just simplifies interaction, it is neither the right tool nor the right place to enforce user rights.
Author of the package here. That's pretty much what this package does just with optimization around what context gets sent to the LLM about the database:
What surprises me is the amount of programmers and analysts that I meet the don’t do this yet. Writing complex, useful SQL queries is probably the most valuable thing that ChatGPT does for me. It makes you look like a god to stakeholders, and “I’m not strong in SQL” is no longer an excuse for analysis tasks.
I think a lot of people tried just asking GPT-3.5 to "Write me full stack web app no bugs please." when it first came out. When it failed to do that they threw up their hands and said "It's just a parrot."
Then GPT4 came out, they tried the same thing and got the same results.
I keep seeing comments regarding it not being helpful because "super big codebase, doesn't work, it doesn't know the functions and what they do."
...so tell it? I've had it write programs to help it understand.
For example: Write me a Python program that scans a folder for source code. Have it output a YAML-like text file of the functions/methods with their expected arguments and return types.
Now plug that file into GPT and ask it about the code or use that when it needs to reference things.
I've spent the last year playing with how to use prompts effectively and just generally working with it. I think those that haven't are definitely going to be left behind in some sense.
It's like they aren't understanding the meta and the crazy implications of that. In the last year, I've written more code than I have in the last 5. I can focus on the big picture and not have to write the boilerplate and obvious parts. I can work on the interesting stuff.
For those still not getting it, try something like this.
Come up with a toy program.
Tell it it's a software project manager and explain what you want to do. Tell it to ask questions when it needs clarification.
Have it iterate through the requirements and write a spec/proposal.
Take that and then tell it it's a senior software architect. Have it analyze the plan (and ask questions etc) but tell it not to write any code.
Have it come up with the file structure and necessary libraries for your language.
Have it output than in JSON or YAML or whatever you like.
Now take that and the spec and tell it it's a software engineer. Ask it which file to work on first.
Have it mock up the functions in psuedo code with expected arguments and output type etc.
Tell it to write the code.
And iterate as necessary.
Do this a few times with different ideas and you'll start to get the hang of how to feed it information to get good results.
The amount of code I now "write" (I've started calling it directing) and features I've put into my side projects has been more than the last 5-10 years combined this last year.
I successfully created a sold a product within 3 months. Start to finish, because of the productivity power I received.
I'm also using GPT-4 for my side projects. For the database specifically, I can write a short sentence describing my table. Then get GPT-4 to generate the SQL to create it, plus a TypeScript interface and data repository module for access with the methods and SQL for basic CRUD. If I need more than basic CRUD, it can usually create methods for that also.
Its also pretty good at generating basic tests, amongst other things.
I think the main reason people don't do something like this more often is that this turns you from a "coder" to a "manager". Your task now is to serialize the issue and to ask the right questions / keep everything moving along.
I don't particularly mind because I cre more about building something than doing my craft but I can totally see how this will be different for many people.
Here's the philosophical conundrum: Do we prioritize learning new things (improve craft) or create value (build stuff)? The first used to lead to the second, but not as much anymore.
Yeah that's exactly it. You have to build up the proper context first. Get all the documentation to be nice and coherent and it will happily write beautiful code.
I already know SQL, and yes it can take time to form exceptionally complex queries, but ChatGPT doesn't seem to do those accurately (yet). CGPT is more useful for general programming languages where there's a lot more boilerplate.
While I recognize the efforts in developing natural language to SQL translation systems, I remain skeptical. The core of my concern lies in the inherent nature of natural language and these models, which are approximative and lack precision. SQL databases, on the other hand, are built to handle precise, accurate information in most cases. Introducing an approximative layer, such as a language model, into a system that relies on precision could potentially create more problems than it solves, leading me to question the productivity of these endeavors in effectively addressing real-world needs.
The key here is to always have some structured intermediate layer that can allow people to evaluate what it is the system thinks they're asking, short of the full complexity of SQL. You'll need something like this for disambiguation anyway - are "Jon Favreau movies" movies starring or directed by Jon Favreau? Or do you mean the other Jon Favreau? Don't one-shot anything important end to end from language. Use language to guide users towards unambiguous and easy to reason about compositions of smaller abstractions.
I think AI to direct SQL will have use cases, but I personally have found it more of a fun toy than anything close to the main way I would interact with my data, at least in the course of running a business.
I am a fan of a semantic layer (I made an open source one but there are others out there), and think having AI talk to a semantic layer has potential. Though TBH a good UI over a semantic layer is so easy it makes the natural language approach moot.
I think you have a point. I also think people who share this mindset and keep sticking with it will have a tough future.
The technical benefits and potentials clearly outshine the problems and challenges. That's also true in this example. You just have to let go of some principles that were helpful in the past but aren't anymore.
A translation engine between natural language and SQL means that everyone can communicate with a SQL database now. That's huge. Soon also DB people will use it to get the response for complex questions and queries. It's just more natural and way faster.
With technology like this, there is little reason to even know SQL anymore as the average developer. Just like today, the average developer doesn't know how databases work because the cloud takes care of it. We're moving up on the abstraction ladder and tomorrow all you need to know for SQL is to ask the right question.
This somewhat already exists in the form of semantic layers, which if done well can handle many of the queries necessary in the course of business without business users needing to know any SQL. There will still be cases where you need direct SQL, and AI tools can help the development process there at a minimum.
Yes, there will be cases where you need SQL knowledge. There will also always be cases where knowing exactly how a database works under the hood is necessary. I think this is somewhat of a weak argument because you can always construct an example of how something may be helpful for a small group of people.
The relevant question is: How many people who work with databases need to have a lot of experience with SQL? My argument is that while the answer today is "most," the answer in a couple of years might be "very few."
Sure, AI will assist more and more in the cases where people must write SQL or manage a database, perhaps to the point you suggest.
But my point was actually that more people think they need to know SQL today than is actually the case. Excluding people that manage databases or cases that go direct to SQL for things like complex ETL, your average business user / marketer / etc should not be asked to write SQL or have to ask someone else to write SQL for them. Use a semantic layer instead with a UI on top and it's almost as easy as natural language.
Here is a example of one I made below, but there are others out there with more support. At my company, and the last few I've worked for, we use this approach for ~all day to day querying and a chunk of backend SQL replacement.
I have similar thoughts on this - so few members of a team actually know what the underlying data model looks like. Gets even harder when you start trying to query across your database(s) + external sources like analytics/event systems. Natural language lets the whole team peel away at the black box of data and helps build common ground on which to improve products. I already mentioned it in another part of this thread so I won't spam my project but would love to get your feedback on my natural language to SQL tool if you're interested.
Lots of average developers these days do not (or just barely) know SQL, and it shows when the ORM generates some nonsense and nobody can figure out why the app is suddenly two orders of magnitude slower.
Use this to POPULATE sql based on captured NLP "surveillance" -- for example, build a DB of things I say as my thing listens to me, and categorize things, topics, place, people etc mentioned.
Keep count of experiencing the same things....
When I say I need to "buy thing" build table of frequency for "buy thing" etc...
Effectively - query anything you've said to Alexa and be able to map behaviors/habits/people/things...
If I say - Bob's phone number is BLAH. It add's bob+# to my "random people I met today table" with a note of "we met at the dog park"
Narrate yourself into something journaled.
Makes it easy to name a trip "Hike Mount Tam" then log all that - then have it create a link in the table to the pics folder on your SpaceDrive9000.ai and then you have a full narration with links to the pics that you take.
It's not a public facing product, but there was a talk from a team at Alibaba a couple of months ago during CMU's "ML⇄DB Seminar Series" [0] on how they augmented their NL2SQL transformer model with "Semantics Correction [...] a post-processing routine, which checks the initially generated SQL queries by applying rules to identify and correct semantic errors" [1]. It will be interesting to see whether VC-backed teams can keep up with the state of the art coming out of BigCorps.
We have been piloting louie.ai with some fairly heavy orgs that may be relevant: Cybersecurity incident responders, natural disaster management, insurance fraud, and starting more regular commercial analytics (click streams, ...)
A bit unusual compared to the above, we find operational teams need more than just SQL, but also Python and more operational DBs (Splunk, OpenSearch, graph DBs, Databricks, ...). Likewise, due to our existing community there, we invest a lot more in data viz (GPU, ..) and AI + graph workflows. These have been through direct use, like Python notebooks & interactive dashboards except where code is more opt-in where desired or for checking the AI's work, and new, embedded use for building custom apps and dashboards that embed conversational analytics.
Please add Ibis Birdbrain https://ibis-project.github.io/ibis-birdbrain/ to the list. Birdbrain is an AI-powered data bot, built on Ibis and Marvin, supporting more than 18 database backends.
the "check back in a month" soon. I have versions of it that work but I just haven't been satisfied with. also, the major underlying dependency (Marvin) is going through a large refactor for v2. once that stabilizes a bit, I'm going to upgrade to it and that might simplify the code I need a lot
the main problems we see in the space:
1) good interface design: nobody wants another webapp if they can use Slack or Teams
2) learning enough about the business and usually messy data model to always give correct answers or say I don't know.
It would be for people who are not that fluent in SQL. Even as a dev, I find ChatGPT to be easier for writing queries than hand coding them as I do it so infrequently.
Sounds like you are describing a semantic layer. You don't need AI to achieve that, though it is fun when it works. Example of a semantic layer I made below, but there are others out there with more support behind them.
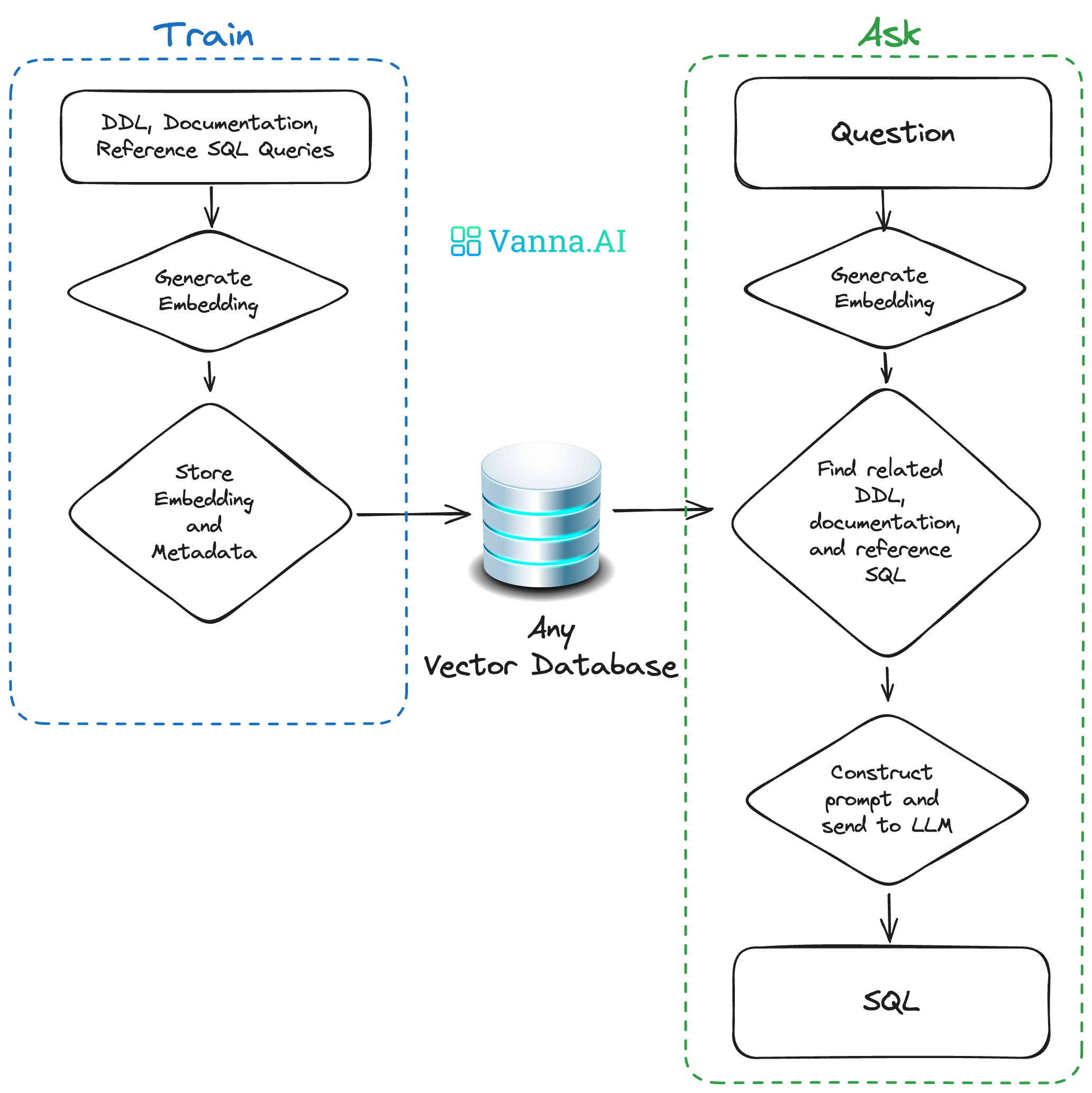
I love that this exists but I worry how it uses the term “train”, even in quotes, as I spend a lot of time explaining how RAG works and I try to emphasize that there is no training/fine-tuning involved. Just data preparation, chunking and vectorization as needed.
Author of the package here. I would be open to alternative suggestions on terminology! The problem is that our typical user has never encountered RAG before.
Hm we typically talk about that phase as “data ingestion”. We also use verbs extract, chunk, index, but those are parts of ingestion. Another phrase we use is “data preparation”. The tricky thing is that your train() method is on the vanna object, so if you called it “ingest”, it wouldn’t be clear where the data was headed. But I think it’d be clearer than “train” given that has such a specific meaning in this space. You could also look to LlamaIndex API for naming inspiration.
Why quotes. Your file manager is just feeding readdir into tableViewDataSource, and your video player is just feeding video files into ffmpeg and then connects its output to a frameBuffer control. Even your restaurant is just feeding vegetables into a dish. Most products "just" do something with existing technologies to remove the tedious parts.
Basically, yeah. It is shockingly trivial to do, and yet like playing with alchemy when it comes to the prompting, especially if doing inference on the cheap like running smaller models. They can get distracted in your formatting, ordering, CAPITALIZATION, etc.
This is awesome. It's a quick turnkey way to get started with RAG using your own existing SQL database. Which to be honest is what most people really want when they say they "want ChatGPT for their business".
They just want a way to ask questions in prose and get an answer back, and this gets them a long way there.
Author of the package here. Thank you! That's exactly what we've seen. Businesses spent millions of dollars getting all their structured data into a data warehouse and then it just sits there because the people who need the information don't know how to query the database.
We did something similar for our reporting service which is based duckdb. Overall it works great, though we've ran into a few things:
* Even with low temperature, GPT-4 sometimes deviates from examples or schema. For example, sometimes it forgets to check one or another field...
* Our service hosts generic data, but customers ask to generate reports using their domain language (give me top 10 colors... what's a color?). So we need to teach customers to nudge the report generator a bit towards generic terms
* Debugging LLM prompts is just tricky... Customers can confuse the model pretty easily. We ended up exposing the "explained" generated query back to give some visibility of what's been used for the report
Our primary issue is that our DB is a dynamic Entity-Attribute-Value schema, even quite a bit denormalized at that. The model has to remember to do subqueries to retrieve "attributes" based on what's needed for the query and then combine them correctly.
NLQ is a somewhat new feature for us, so we don't have a great library to pull from for RAG. Experimenting, I found that having a few-shot examples with some CoT (showing examples of chaining attributes retrieval) sprinkled around did help a lot.
Even still, some queries come out quite ugly, but still functional. I'm thankful that DuckDB is a beast when tackling those :D
> Did you folks experiment with building an Agent-like interface that asks more questions before the LLM finally answers?
That's something I want to figure out next:
1) try to check if a generated query would work but would generate absolutely junk results (cause the model forgot to check something) and ask to rephrase
2) or show results (which may look "real" enough), but give an ability to tweak the prompt. A good example is something like "top 5 products on Cyber Monday" <- which returns 0 products, cause 2024 didn't happen yet, and should trigger a follow up.
Maybe you could utilize views to make your EAV schema more friendly for the LLM? Whether that's realistic depends on the specifics of your situation of course.
>Did you folks experiment with building an Agent-like interface that asks more questions before the LLM finally answers?
We built something similar to query DB. Created two versions, one of which was agent based that had a maker-checker style of generation. Basically one generates and the other checks its correctness and if objective has been acheived.
The accuracy improves in the agent driven framework, at the cost of latency.
I'm curious to see if people have tried this out with their datasets and seen success? I've been using similar techniques at work to build a bot that allows employees internally to talk to our structured datasets (a couple MySQL tables). It works kind of ok in practice, but there are a few challenges:
1. We have many enums and data types specific to our business that will never be in these foundation models. Those have to be manually defined and fed into the prompt as context also (i.e. the equivalent of adding documentation in Vanna.ai).
2. People can ask many kinds of questions that are time-related like 'how much demand was there in the past year?'. If you store your data in quarters, how would you prompt engineer the model to take into account the current time AND recognize it's the last 4 quarters? This has typically broken for me.
3. It took a LOT of sample and diverse example SQL queries in order for it to generate the right SQL queries for a set of plausible user questions (15-20 SQL queries for a single MySQL table). Given that users can ask anything, it has to be extremely robust. Requiring this much context for just a single table means it's difficult to scale to tens or hundreds of tables. I'm wondering if there's a more efficient way of doing this?
4. I've been using the Llama2 70B Gen model, but curious to know if other models work significantly better than this one in generating SQL queries?
For 2. we ended up stuffing the prompt with examples for common date ranges "this month", "last year", "this year to date" and some date math, and examples of date fields (we have timestamp, and extracted Year, Month, Day, etc)
Current date: `current_date()`
3 days ago: `current_date() - INTERVAL 3 DAY`
Beginning of this month: `date_trunc('month', current_date())`
...
4. I get best results with GPT-4, haven't tried Llama yet. 3.5 and 4-turbo tend to "forget" stuff for complex queries, but may be we need more tuning yet.
That is, store your trained custom data in vector db and then use RAG to retrieve relevant content and inject that into the prompt of the LLM the user is querying with?
All the podcasts I've been listening to recommend RAG over fine-tuning. My intuition is that having the relevant knowledge in the context rather than the weights brings it closer to the outputs, thereby making it much more likely to provide accurate information and avoid hallucinations/confabulations.
> All the podcasts I've been listening to recommend RAG over fine-tuning
I'm always suspicious that is just because RAG is so much more accessible (both compute wise and in terms of expertise required). There's far more profit in selling something accessible to the masses to a lot of people than something only a niche group of users can do.
I think most people who do actual fine tuning would still probably then use RAG afterwards ...
One added benefit of RAG is that it's more "pluggable." It's a lot easier to plug into newer LLMs that come out. If and when GPT-5 comes out, it'll be a one character change in your code to start using it and still maintain the same reference corpus.
I listen to Data Skeptic and Practical AI. It's interesting content, and I find Practical AI has guests who are particularly relevant to what I want to learn, but you should keep in mind that the guests are usually trying to promote their own products, so everything they say should be taken with a grain of salt
We can get a lot done with vector db + RAG before having to finetune or custom models. There are a lot of techniques to improve RAG performance. Captured a few of them a while back at https://llmstack.ai/blog/retrieval-augmented-generation.
Sorry, maybe I'm just too tired to see it, but how much control do you have over the SQL query that is generated by the AI? Is there a risk that it could access unwanted portions or, worse, delete parts of your data? (the AI equivalent of Bobby Tables, so to speak)
Yes. Then again, in a project where queries are simpler than granting relevant access to a third party, I guess the AI chat product is just not a good fit.
In some SQL providers, your can define rules that dynamically mask fields, suppress rows, etc. based upon connection-specific details (e.g. user or tenant ID).
So, you could have all connections from the LLM-enabled systems enforce masking of PII, whereas any back-office connections get to see unmasked data. Doing things at this level makes it very difficult to break out of the intended policy framework.
Guessing its intended use case is business analytic queries without write permissions —- particularly for non-programmers. I don’t think it’d be advisable to use something like this for app logic
100% -- in fact originally the package used to parse out SELECT statements and only execute SELECT statements. After some feedback, we decided that the permissions on the user should handle that level of detail.
Or rather, run a cosine similarity search on a large data set that won't fit in the prompt, find only the bits that are relevant to the query, and put that in the prompt.
RAG, at its core, is a very human way of doing research, because RAG is essentially just building a search mechanism for a reasoning engine. Much like human research.
Your boss asks you to look into something, and you do it through a combination of structured and semantic research. Perhaps you get some books that look relevant, you use search tools to find information, you use structured databases to find data. Then you synthesize it into a response that's useful to answer the question.
People say RAG is temporary, that it's just a patch until "something else" is achieved.
I don't understand what technically is being proposed.
That the weights will just learn everything it needs to know? That is an awful way of knowing things, because it is difficult to update, difficult to cite, difficult to ground, and difficult to precisely manage weights.
That the context windows will get huge so retrieval will be unnecessary? That's an argument about chunking, not retrieval. Perhaps people could put 30,000 pages of documents into the context for every question. But there will always be tradeoffs between size and quality: you could run a smarter model with smaller contexts for the same money, so why, for a given budget, would you choose to stuff a dumber model with enormous quantities of unnecessary information, when you could get a better answer from a higher intelligence using more reasonably sized retrievals at the same cost?
Likewise, RAG is not just vector DBs, but (as in this case) the use of structured queries to analyze information, the use of search mechanisms to find information in giant unstructured corpuses (i.e., the Internet, corporate intranets, etc).
Because RAG is relatively similar to the way organic intelligence conducts research, I believe RAG is here for the long haul, but its methods will advance significantly and the way it gets information will change over time. Ultimately, achieving AGI is not about developing a system that "knows everything," but a system that can reason about anything, and dismissing RAG is to confuse the two objectives.
That's the problem, it's just search. If search was the answer, Google would of achieved AGI long ago. The problem is there's no intelligence. In some situations it can find semantically similar content, but that's it. The intelligence is completely missing from the RAG mechanism, because it's not even part of the model itself.
I think some of the doubters here are conflating a few things.
Any analyst will struggle if data quality is a mess, and there is a lack of clear semantic layer/useful documentation around how to query metrics/join tables from your warehouse. These are problems that affect human analysts as well as LLM based 'virtual' ones... However, these are separate problems being addressed by other players.
An llm powered chatbot that can consume adequate context from company systems should be able to perform on par with a junior analyst with a similar level of context. All else equal, the LLM analyst will be orders of magnitude cheaper and open up data analysis to non-sql-literate people (huge unlock).
I haven't loaded this up so maybe this has been accounted for, but I think a critical feature is tying the original SQL query to all artifacts generated by Vanna.
Vanna would be helpful for someone that knows SQL when they don't know the existing schema and business logic and also just to save time as a co-pilot. But the users that get the most value out of this are the ones without the ability to validate the generated SQL. Issues will occur - people will give incomplete definitions to the AI, the AI will reproduce some rookie mistake it saw 1,000,000 times in its training data (like failing to realize that by default a UNIQUE INDEX will consider NULL != NULL), etc. At least if all distributed assets can tie back to the query people will be able to retroactively verify the query.
This is a good idea. I think what you'd want to do is override the generate_sql function and store the question with the "related" metadata and the generated sql somewhere:
I generally found this worked quite well. It was good at identifying which fields to query and how to build where clauses and aggregations. It could pull off simple joins but started to break down much past there.
I agree with the peer comment that being able to process and respond to error logs would make it more robust.
I have seen good results from just describing the schema to ChatGPT-4 and then asking it to translate English to SQL. Does this work significantly better?
That’s mostly what the products and libraries around this like llamaindex or Langchain are doing. If you look at the Langchain sql agent all it’s doing is chaining together a series of prompts that take the users initial query, attempt to take in a db and discover its schema on the fly and then execute queries against it based on that discovered schema, ensuring the result makes sense.
The tough part is doing this at scale as part of a fully automated solution (picture a slack bot hooked up to your data warehouse that just does all of that for you that you converse with). When you have tens or hundreds of tables with relationships and metadata in that schema and you want your AI to be able to unprompted walk all of them, you’re then basically doing some context window shenanigans and building complex state machines to walk that schema
Unfortunately that’s kind of what you need if you want to achieve the dream of just having a db that you can ask arbitrary questions to with no other knowledge of sql or how it works. Else the end user has to have some prior knowledge of the schema and db’s to get value from the LLM. Which somewhat reduces the audience for said chatbot if you have to do that
Thanks so much for making this and making it under MIT to boot.
I’ve been thinking about how to do this for about 6 months now and just started working on a demo for querying just one table // JSON column today.
I would feel a lot more comfortable with putting this (and/or my demo) into production if the database had been set up with a schema+db user per account rather than every tenant sharing just the one set of tables.
Author of the package here. Apologies if this wasn't clear in the documentation, but what you're talking about is absolutely possible. Feel free to join our Discord -- we have other users who have this multi-tenant setup.
In general, if something has been around for a very long time and nobody apparently seems to have thought to improve it, then odds are the reason is it's pretty good and genuinely hard to improve on.
I think that might be a bit more positive than I would be. Broadly speaking, I think you could say that the downsides of the legacy technology in question aren’t larger than the collective switching costs.
But I’d definitely agree that when something has been around that long, it’s prob not all bad.
Well, if you think about it, a huge percentage of dinosaurs survived (birds), and for the rest, can you really fault them for going extinct when a humongous boulder hit the planet?
https://prql-lang.org/ might be an answer for this. As a cross-database pipelined language, it would allow RAG to be intermixed with the query, and the syntax may(?) be more reliable to generate
My fear with this approach is that the first implementation would be severely handicapped compared to SQL, amd it'd take years to support some one-off need for any organizational user, so it'd never be fully utilized.
It would be fun if you could actually train your raw sql and the llm output is the actual answer and not sql commands. In this way its just another language layer on top/in between of sql. Probably hurts efficiency and performance in the long run.
We have recently added support to query data from SingleStore to our agent framework, LLMStack (https://github.com/trypromptly/LLMStack). Out of the box performance performance when prompting with just the table schemas is pretty good with GPT-4.
The more domain specific knowledge needed for queries, the harder it has gotten in general. We've had good success `teaching` the model different concepts in relation to the dataset and giving it example questions and queries greatly improved performance.
im curious to know how you get around the hallucinations? for example, for the query: "give me <products / sales / rows> that were created yesterday"
the llm hallucinates as to what "yesterday" means, there are other instances as well where the generated SQL is valid syntax-wise but not in intent. This is especially dangerous for aggregation queries such as MAX, COUNT, etc because it will spit out a number but is it the right number? and the only way to check is to read the SQL itself and verify, which defeats the whole purpose of it.
I wonder if this supports spatial queries as in PostGIS, SpatiaLite, SQL Server Spatial as per the OGC standard?
I'm interested in integrating a user friendly natural language query tool for our GIS application.
I've looked at LangChain and the SQL chain before but I didn't feel it was robust enough for professional use. You needed to run an expensive GPT-4 backend to begin with and even then, it wasn't perfect. I think a major part of this is that it wasn't actually trained on the data like Vanna apparently does.
Perhaps an uninformed question, but why do we need an llm rather than a simpler natural language to SQL NLP translator? Wouldn't that be much more efficient and reliable?
What would be missing from that is the ability to look up what tables are in the database, how they join together, what terminology the business uses, preferences around whether to exclude nulls from certain columns, etc.
This allows you to ask more of a “business question” like “who are the top 10 customers by sales?” and the LLM will be able to construct a query that joins the customers table to an orders table and get the results that you’re looking for.
With a simple NL to SQL, you’d have to say “join the customer table with the sales table, aggregate on the sales column from the orders table and limit the results to 10 rows” or something along those lines.
Author of the package here. It was originally because it's both a name and a finance term because I was originally using this to query a financial database.
I have tried things like this, they are good for debugging and asking simple questions but is really hard to train them to be good enough for production. You'll get enough frustrating results, that you'll abandon them soon.
> In the age of ORMs and so on, many people have probably forgotten how to write raw SQL queries.
I’ve heard this general sentiment repeated quite a lot - mostly by people that don’t use ORMs. In my experience pretty quickly you reach the limits of even the best ORMs and need to write some queries by hand. And these tend to be the relatively complicated queries. You need to know about all of the different join types, coalescing, having clauses, multiple joins to the same table with where filters, etc.
Not that this makes you a SQL expert but you can’t get too far if you don’t know SQL.
ORM abuse are absolutely rife in small-scale/volume build industries i.e. web agencies, outsourced crews
8/10 projects I look into don't have any indexes set up.
Use of ORMs with little thought into lazily loaded relations lead to 100s of queries being done per request.
It's pretty mad. Do not underestimate the propensity of a developer to stick to the only tool they know how to use. Unfortunately ORMs like Eloquent make it way too easy.
> small-scale/volume build industries i.e. web agencies, outsourced crews
Well that could explain it. I’ve only worked in companies where everyone working on the app codes with the expectation that they could be dealing with their mistakes for years.
Author of the package here. Joining 5 tables is not a problem.
The training does not necessarily require you to write the queries by hand. A trick that we've seen people do is to just train with DDL statements and then ask "leading" questions if it can't answer on the first try.
I've been using the package myself for about 6 months and while I haven't forgotten SQL, what I have forgotten are the fully qualified table names and which tables live in which schemas etc since I never have to think about that.
From my experience, GPT-4 will do just as well with joins as without. And that needs no specific, separate SQL training (which I assume tens of thousands of examples are already in).
disclaimer: founder of textql.com (yea i know the name is super obvious)
I would happily bet a kidney that not a single product that has an LLM of any kind writing SQL using next-character-prediction will ever be useful to get results for a business person in an enterprise setting (~5+ people on the data team of a company). Although it's fine for technical users as advanced autocomplete
I'm surprised no one has pointed out that as a building block: english doesn't map 1:1 to SQL at all.
"Can you get me a list of users who've ordered more than 10 red products"
doesn't make it at all clear whether you're writing
- s from u where u.ordered_more_than_10_red_products = True
- s from u where u.red_products_ordered > 10
- or any other combination of variants
15 years of VCs have poured well over 10 billion dollars claiming to solve "text to sql" of some kind and 15 year later we're still writing SQL - something something chesterton's fence... at least we don't have training sessions where data eng people sit in a room and hard code synonyms for "revenue" into thoughtspot anymore
The only way you can approach something like this at scale is w/ a mature ontology structure for your data. What that means in is a very opinionated data modeling method (handful of valid ones) that is enforced at the level of the data modeling system - dbt / sqlmesh / stored procedures, or otherwise - semantic layers are... kinda ok but mostly doesn't get there on expressiveness either
^lots of ways to do the above, small handful of cool people who are working on it. (yes that kinda includes us - sorry for the implicit self promo)
- obvious second disclaimer that if your "database" is 3 tables w/ clearly labeled joins, feel free to disregard everything I just said
- oh, also the correct query according to chatgpt is
SELECT u.user_id, COUNT(o.product_id) AS total_red_products
FROM users u
JOIN orders o ON u.user_id = o.user_id
JOIN products p ON o.product_id = p.product_id
WHERE p.color = 'red'
GROUP BY u.user_id
HAVING COUNT(o.product_id) > 10;
- obvious 4th disclaimer - if i'm wrong, i don't know what i'm talking about
This looks really helpful! I'm working a lot on graph databases and am wondering, if there are similar projects working with say neo4j.
I guess because you don't have a schema, the complexity goes up.
I'll be giving this a go with one of my side projects which has several tables with data that isn't super normalised, as it'd be interesting to see if it can cope with it
What I'd really be interested in is being able to describe a problem space and have it generate a schema that models it. I'm actually not that bad at generating my own SQL queries.
This works pretty well without a dedicated application today, e.g. "Knowing everything you do about music and music distribution, please define a database schema that supports albums, tracks, and artists". If you have additional requirements or knowledge that the response doesn't address, just add it and re-prompt. When you're done, ask for the SQL to set up the schema in your database of choice.
Maybe my prompting needs to improve, I tried recently to get chatgpt to provide a schema for an sqlite database that implements vcard data in a normalised way. I gave up...
ChatGPT-3.5 isn’t even worth touching as an end-user application. Bard is better (due to having some integrations), but it’s still barely useful.
ChatGPT-4 is on an another level entirely compared to either 3.5 or Bard. It is actually useful for a lot.
ChatGPT-3.5 can still serve a purpose when you’re talking about API automations where you provide all the data in the prompt and have ChatGPT-3.5 help with parsing or transforming it, but not as a complete chat application on its own.
Given the bad experiences ChatGPT-3.5 gives out on a regular basis as a chat application, I don’t even know why OpenAI offers it for free. It seems like a net-negative for ChatGPT/OpenAI’s reputation.
I think it is worth paying for a month of ChatGPT-4. Some people get more use out of it than others, so it may not be worth it to you to continue, but it’s hard for anyone to know just how big of a difference ChatGPT-4 represents when they haven’t used it.
I provided a sample of ChatGPT-4’s output in my previous response, so you can compare that to your experiences with ChatGPT-3.5.
great tool and as someone mentioned there are quite a few AI products/libraries that accomplish this.
The main challenge for production settings
1) soon becomes optimizing the latency for each step and
2) dealing with complex queries at a reasonable cost (GPT-4 is bit expensive at scale)
We evaluated multiple options and settled on GPT-3Turbo in the short term. However we are not happy with the latency, especially if you create an agentic solution.
Does it work with Google/Facebook ads data? Can I ask it to show best performing ads from BigQuery Facebook/Google ads data by supermetrics or improvado.
The extremely-lucrative days in IT for large numbers of people, are drawing to a close. On the other hand, while you won't make more than someone who works at 7/11, there will be rudimentary IT jobs available, if you want them.
{kind=link}