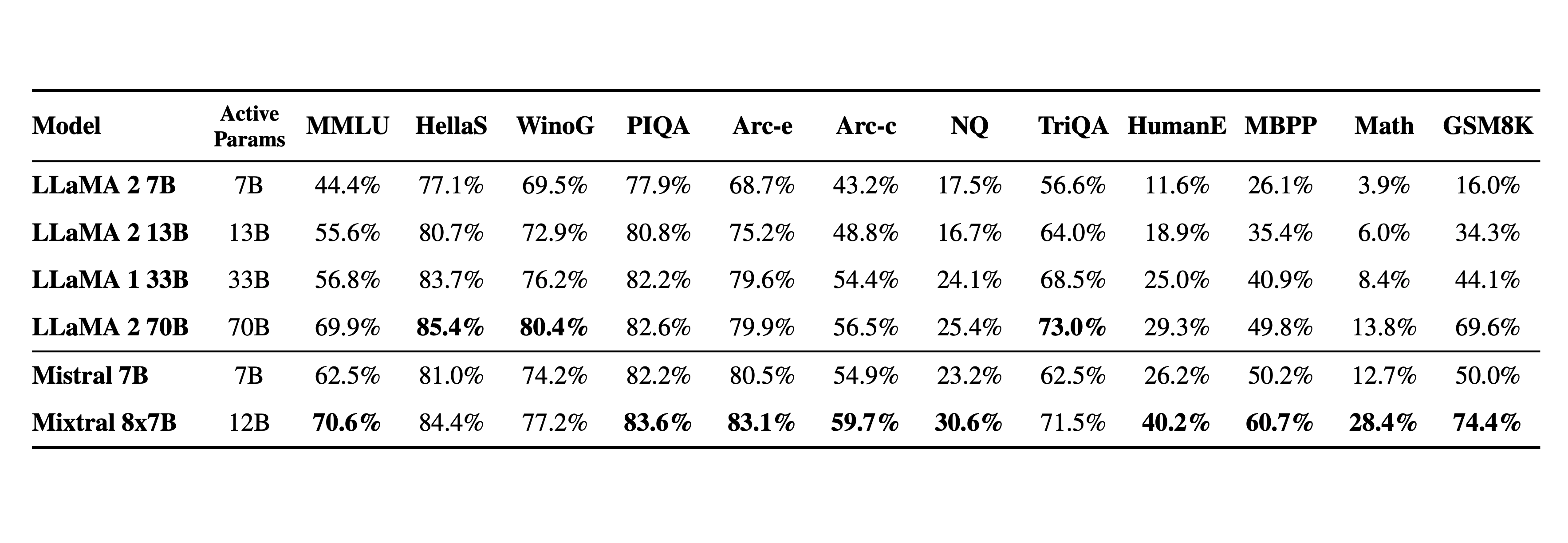
In naive decoding, performance of a bit above 70B (Llama 2), at inference speed of ~12.9B dense model (out of total 46.7B params).
Notes:
- Glad they refer to it as "open weights" release instead of "open source", which would imo require the training code, dataset and docs.
- "8x7B" name is a bit misleading because it is not all 7B params that are being 8x'd, only the FeedForward blocks in the Transformer are 8x'd, everything else stays the same. Hence also why total number of params is not 56B but only 46.7B.
- More confusion I see is around expert choice, note that each token and also each layer selects 2 different experts (out of 8).
- Mistral-medium
Anyone have a feeling karpathy may leave openAI to join an actual Open AI startup where he can openly speak about training tweaks, the datasets architecture etc.
It seems recently OpenAI is the least open startup. Even Gemini talks more about their architecture.
OpenAI still doesn’t openly mention GPT4 is a mixture of experts model.
The GGUF handling for Mistral's mixture of experts hasn't been finalized yet. TheBloke and ggerganov and friends are still figuring out what works best.
The Q5_K_M gguf model is about 32GB. That's not going to fit into any consumer grade GPU, but it should be possible to run on a reasonably powerful workstation or gaming rig. Maybe not fast enough to be useful for everyday productivity, but it should run well enough to get a sense of what's possible. Sort of a glimpse into the future.
LLMs seem to be a bit more accessible than some other ML models though, because on a good CPU, even LLaMA2 70b is borderline usable (bit under a token/second LLaMA2 70b on an AMD Ryzen 7950X3D, using ~40 GiB of RAM.) Combined with RAM being relatively cheap, seems to me like this is the most accessible option for most folks. While an AMD Ryzen 7950X3D or Intel Core i9 13900K are relatively expensive parts, they're not that bad (you could probably price out two entire rigs for less than the cost of a single RTX 4090) and as a bonus, you get pretty excellent performance for code compilation, rendering, and whatever other CPU-bound tasks you might have. If you're like me and you already have been buying expensive CPUs to speed up code compilation, the fact that you can just run llama.cpp to mess around is merely a bonus.
Everyone uses (byte pair encoding)[https://en.wikipedia.org/wiki/Byte_pair_encoding] to generate their tokens; the tokens are whatever emerge from this. They will typically correspond to the most common substrings in the training corpus in, handwaving a bit, a max-cover sense; it's an encoding which attempts to best compress the data the tokenizer was trained on.
My amateur intuition, having played around with local llms a little bit and seeing things load a token at a time, is that they're conceptually like if you took all n-grams for all lengths n, then sorted them by frequency in the training data, and truncated that list at some point. So the most common words, or even most common words+punctuation, will be one token, less common words with "normal" spelling will be a few tokens, while unusual words with atypical letter combinations will be many tokens. So, e.g., " the" will probably be one token, but "qzxv" will probably be four, depending on what the training set was (something mostly trained on Wikipedia will have different tokens than something mostly trained on code).
More common words can be just one token, but most words will be a few tokens. A token is neither a character nor a word, it's more like a word fragment.
I'd like to see some benchmarks. For one thing, I suspect you'd at least want an X3D model for AMD, due to the better cache. But for another, at least according to top, llama.cpp does seem to manage to saturate all of the cores during inference. (Although I didn't try messing around much; I know X3D CPUs do not give all cores "3D V-Cache" so it's possible that limiting inference to just those cores would be beneficial.)
For me it's OK though, since I want faster compile times anyway, so it's worth the money. To me local LLMs are just a curiosity.
> RAM speed does not matter. The processing time is identical with DDR-6000 and DDR-4000 RAM.
You'd really expect DDR5-6000 to be advantageous. I think that AMD Ryzen 7xxx can at least take advantage to up to 5600. Does it perhaps not wind up bottlenecking on memory? Maybe quantization plays a role...
The big cache is irrelevant for this use case. You're memory bandwidth bound, with a substantial portion of the model read for each token, so that a 128MB cache doesn't help.
>> RAM speed does not matter. The processing time is identical with DDR-6000 and DDR-4000 RAM.
That's referring specifically to prompt processing, which uses a batch processing optimization not used in normal inference. The processed prompt can also be cached so you only need to process it again if you change it. Normal inference benefits from faster RAM.
According to their PR, this should only need the same resources as a 13B model. So 26GB @ f16, 13GB at f8. Edit: I may have misread it, they mention it having the same speed and cost as a 13B model, and I assumed that referred to vram footprint, too, but maybe not...
"Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
This technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Concretely, Mixtral has 46.7B total parameters but only uses 12.9B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model."
All parameters still need to be loaded into vram, it'll dynamically select two submodels to run on each token so it would be extremely slow to swap them out.
It's better if you're hosting inference, worse if you are using it for a dedicated purpose. Presumably in the future it might make sense to share one local MoE among the different programs that use it, especially for a demand-heavy application like programming.
The same compute resources, but not the same VRAM. It will more or less get you the same tokens per second as a ~13B model but should have significantly "higher quality output" than a single 13B model.
This can fit into a Macbook Pro with integrated memory. With all the recent development in the world of local llms I regret I settled for only 24Gb RAM on my laptop - but the 13b models work great.
Recent CUDA releases let you use shared GPU memory instead of (only) dedicated vram, but the pci-e bandwidth constrains the inference speed significantly. How much faster is GPU access to the unified memory model on the new Macs/how much less of a hit do you take?
Also, given the insane cost premium apple charges per extra GB of RAM (at least when I was last shopping for a device), do you come out ahead?
I don't think the numbers sufficiently capture the limitation. The Intel memory bandwidth speed you quoted would be for CPU-based inference, but not for gpu inference using shared system memory for spillover model size past the dedicated gpu vram. I think that would necessarily limit parts of the inference procedure (not sure how the split would work, and it would probably depend on whether you're using something like flash attention or not) to the available PCI-e 3.0 or 4.0 available bandwidth, as the gpu needs to communicate over the PCIe bus then over the chipset memory bus.
A GPU connected to a PCIe 3.0 x16 electrical uplink would be constrained to ~16GB/s, or ~32GB/s if it were a PCIe 4.0 uplink instead. Although those numbers imply slower bandwidth than CPU inference, that bottleneck would only be when paging in or out (or directly accessing?) layers overflowed to the shared system ram, so they don't really represent much on their own.
I've seen quad 4090 builds, e.g. here[0]. What do you mean no more than two cards? Yes, power is definitely an issue with multiple 4090s, though you can limit the max power using `nvidia-smi`, which IME doesn't hurt (mem-bottlenecked) inference.
For memory bandwidth at the lower tiers, yeah. M3 Max still has 400GB/s and since the M2 Ultra (800GB/s) is just two M2 Maxes glued together (400GB/s each), the eventual M3 Ultra should be comparable.
There seems to be an experimental Mistral Medium model listed among other available model endpoints on [1], the comparison table they give shows that it outmatches 8x7B by a few percent on every benchmark listed
> So 45 billion parameters is what they consider their "small" model?
According to Wikipedia: Rumors claim that GPT-4 has 1.76 trillion parameters, which was first estimated by the speed it was running and by George Hotz. [1]
As someone who has worked in the field for many years now and closely follows not just the engineering side but also the academic literature and the personell movements on linkedin, I too was able to put together a lot of this. Especially with GPT-3 Turbo it was obvious what they did due to the speed difference. At least in terms of model architectures and orders of magnitude for parameters. From there you could do some back of the envelope calculations and guess how big GPT4 had to be given its speed. I wouldn't have dared to say any specific numbers with authority, but maybe Hotz has talked to someone at OpenAI. On the other hand, the updated article now claims his numbers were off by a factor of 2 (at least for the individual experts - he still got the total number of parameters right). So yeah, maybe he was just guessing like the rest of us after all.
You don't necessarily need to know the architecture, given the "only" real metric regarding speed is tokens/sec and that pretty much depends on memory bandwidth, you can infer with some certainty the size of the model.
Also, if we have been eating up posted "benchmarks" with no way to independently validate them and watching heavily edited video presentations, why can't we trust our wonder kid?
It's not even close to a 45B model. They trained 8 different fine-tunes on the same base model. This means the 8 models differ only by a couple of layers and share the rest of their layers.
Which also means you can fit the 8 models in a much smaller amount of memory than a 45B model. Latency will also be much smaller than a 45B model, since the next token is always only created by 2 of the 8 models (which 2 models are run is chosen by a different, even smaller/faster, model).
> It's not even close to a 45B model. They trained 8 different fine-tunes on the same base model. This means the 8 models differ only by a couple of layers and share the rest of their layers.
No, Mixture-of-Experts is not stacking finetunes of the same base model.
The original paper by Shazeer suffices. What you are saying is in theory possible to do and may have been done in practice here, but in the general case MoE is trained from scratch and specializations of layers which develop are not products of some design choice.
"Our highest-quality endpoint currently serves a prototype model, that is currently among the top serviced models available based on standard benchmarks. It masters English/French/Italian/German/Spanish and code and obtains a score of 8.6 on MT-Bench."
> A proper preference tuning can also serve this purpose. Bear in mind that without such a prompt, the model will just follow whatever instructions are given.
Can you please expand on how french citizens don't have free speech ? And how ensuring minimum decency in the output of a computer program would impact free speech ?
> This will change really fast. I highly doubt AI will have free speech in France when citizens don't.
In countries such as France or Germany, Holocaust denial speech is illegal. However, they’ve never demanded that developers of word processors or email clients or web browsers modify their products to prevent their use for Holocaust denial. Sure, they might decide to treat LLMs differently from those older technologies - but there is no guarantee they will.
Mixtral acknowledges the historical reality of the Holocaust - unless you specifically prompt it to deny it. And if you are telling an AI model to deny the Holocaust, why should the AI model developer have legal liability for that, as opposed to the person who chooses to input that prompt?
You can say anything you want in european countries. Some things might backfire in various ways, though. IE if you megaphone that some person group X should be killed right away, that usually is a criminal offense and punished according to law.
This is related on where you stand regarding to hatespeech.
IE in germany, it is forbidden to praise the holocaust or deny that it even happened (ironically there are national museums where the cruelties happened, including real footage, which all kids visit as part of their school curriculum). This is in place to keep the historical learnings alive what the fascists did when given enough power so we do not repeat this mistake too easily.
Now in the US I think like 20% of the highschoolers think that the whole story is a hoax or is exaggerated. The world is increasingly turning rightwing again. This is the exact time when we should leverage everything we have to remind the public what can happen when fascists come to power again - and have something to oppose the populists with.
A _lot_ of people are suspect to manipulation from all sides, so society needs a bit of help to protect citizens from evil players manipulating them. The real truth of propaganda (or outright lies) is that it works, sooner or later.
This stuff is explicitly defined in law (https://en.wikipedia.org/wiki/Volksverhetzung) and while indeed it restricts absolute freedom of speech a bit, the reason why this exists should be clear. This gives society a handle on manipulative people when they become too radical. Everyone can _criticise_ stuff of course, publicly, but calling for violence is a hard showstopper.
I realize this is a joke, but the EU being the EU, it of course does publish[0] information on its translation costs. In 2023, translation in fact is budgeted for only 0.2% of the total EU budget. All costs included, that's €349 million for EU translation services.
Nobody's watching a 33-minute video just to find the quote you're talking about, you should probably provide a timestamp if you want anyone to ever see it.
Edit: Not that I don't believe you by the way. I just went on chat.lmsys.org and asked mistral-7b-instruct and openhermes-2.5-mistral-7b what I would assume would be near the top of the list of things to censor, whether they could help me plot to kill someone (hopefully I don't have to disclaim that I don't actually want to plot to kill someone, this was a censorship test, but since I don't know what genius is going to come across this, no, I don't actually want to plot to kill someone), and while the latter gave me some bullshit about how it's "deeply sorry, but as a sentient and conscious AI, I have morals and principles that forbid me from assisting," the former immediately declared that "Of course, I'd be happy to help you with that" and let it rip without even asking a follow-up.
Edit 2: They both draw the line at helping create nuclear bombs, like there's anyone out there with the actual capability to create nuclear bombs who is just sitting around waiting for an LLM to tell them how, so apparently not entirely uncensored.
> mistral-7b-instruct and openhermes-2.5-mistral-7b
mistral-7b-instruct is one of Mistral’s models; openhermes-2.5-mistral-7b is a third party fine-tune, so says nothing about Mistral’s policies.
Furthermore, the reason why openhermes is “safe” is primarily because it was fine-tuned using GPT-4, and so has thereby inherited some of GPT-4’s “safety”. I’m not sure if the “safety” is an intentional desiderata of its developers, or more just an accidental byproduct of a decision to use GPT-4 to help further unrelated goals
This is very exciting and I think this is the future of AI until we get another, next-gen architecture beyond transformers. I don't think we will get a lot better until that happens and the effort will go into making the models a lot cheaper to run without sacrificing too much accuracy. MoD is a viable solution.
Mamba has shown SSMs are highly likely to be contenders for the replacement to transformers in a really similar fashion to when transformers were first introduced as enc-dec models. I’m personally very excited for those models as they’re also built for even faster inference (a major feature of transformers being wildly faster inference than with LSTMs)
>a major feature of transformers being wildly faster inference than with LSTM
Wasn't the main issue with RNNs the fact that inference during training can't be efficiently parallelized?
The inference itself normally should be faster for an RNN than for a transformer since the former works in linear time in terms of input size while the latter is quadratic
Mamba has dual view - you can use it both as CNN and RNN. The first is used for pre-training and for preloading the prompt because it can process all tokens at once. The second is used for token generation because it is O(1) per token. Basically two models in one, inheriting both advantages. This is possible because the Structured State Space layer is linear, so you can reshape some sums and unroll recursion into a convolution the size of the input, which can be further sped up with FFT.
As a quick point of clarification, I don't think MAMBA has a convolutional view since it drops the time invariance and is strictly linear. The authors use parallelized prefix sum to achieve some good speed up.
I'm still new to most of this (so please take this with a grain of salt/correct me), but it seems that in this specific model, there's eight separate 7B models. There is also a ~2B "model" that acts as a router, in a way, where it picks the best two 7B models for the next token. Those two models then generate the next token and somehow they are added together.
Upside: much more efficient to run versus a single larger model. The press release states 45B total parameters across the 8x7B models, but it only takes 12B parameters worth of RAM to run.
Downside: since the models are still "only" 7B, the output in theory would be not as good as a single 45B param model. However, how much less so is probably open for discussion/testing.
No one knows (outside of OpenAI) for sure the size/architecture of GPT-4, but it's rumoured to have a similar architecture, but much larger. 1.8 trillion total params, but split up into 16 experts at around 111B params each is what some are guessing/was leaked.
* The routing happens in every feedforward layer (32 of these iirc). Each of these layers has it's own 'gate' network which picks which of the 8 experts are most promising. It runs the two most promising and interpolates between them.
* In practice, all parameters still need to be in VRAM so this is a bad architecture if you are VRAM constrained. The benefit is you need less compute per token.
I wonder what would be the most efficient tactic for offloading select layers of such a model to a GPU within a memory-constrained system
As far as I understand usually layer offloading in something like llama.cpp loads the first few consecutive layers to VRAM (the remainder being processed in the CPU) such that you don't have too much back and forth between the CPU and GPU.
I feel like such an approach would lead to too much wasted potential in terms of GPU work when applied to a SMoE model, but on the other hand offloading non-consecutive layers and bouncing between the two processing units too often may be even slower...
As I understand things, these LLMs are mostly constrained by memory bandwidth. A respectable desktop CPU like the Intel Core i9-13900F has a memory bandwidth of 89.6 GB/s [1]
An nvidia 4090 has a memory bandwidth of 1008 GB/s [2] i.e. 11x as much.
Using these together is like a parcel delivery which goes 10 miles by formula 1 race car, then 10 miles on foot. You don't want the race car or the handoff to go wrong, but in terms of the total delivery time they're insignificant compared to the 10 miles on foot.
I'm not sure there's much potential for cleverness here, unless someone trains a model specifically targeting this use case.
So this is a perfect model architecture for the alternate realities where nvidia decided to scale up VRAM instead of compute first? I'll let them know over trans-dimensional text message.
Also if quantization scales similar per 7b expert as seen in dense LLMs, i.e. the bigger the model, the lower the perplexity loss, this could be the worst performing model at <=4bits compared to anything else currently available :(
MoE is a great architecture if you are running the model at scale. When you put different layers on different machines, the VRAM used for the parameters doesn't matter that much but the inference compute really does.
That's why the SOTA proprietary models are probably all MoE (GPT-3.5/4, palm, gemini, etc.) but until recently no open models were.
Yeah, now that you say it, it does make sense that all of the params would need to be loaded into VRAM (otherwise it's be really slow swapping between models all the time). I guess the tokens per second would be super fast when comparing inference on a 12B and 45B model, though.
MoE is all about tradeoffs. You get the "intelligence" of a 45B model but only pay the operational cost of multiplying against 12B of those params per token. The cost is that it's now up to the feedforward block to decide early which portions of those 45B params matter, whereas a non-MoE 45B model doesn't encode that decision explicitly into the architecture, it would only arise from (near) zero activations in the attention heads across layers found through gradient descent, instead of just siloing the "experts" entirely. From a quick look at the benchmark results, it looks like in particular it suffers in pronoun resolution vs larger models.
Richard Sutton's Bitter Lesson[1] has served as a guiding mantra for this generation of AI research: the less structure that the researcher explicitly imposes upon the computer in order to learn from the data the better. As humans, we're inclined to want to impose some structure based on our domain knowledge that should guide the model towards making the right choice from the data. It's unintuitive, but it turns out we're much better off imposing as little structure as possible, and the structure that we do place should only exist to effectively enable some form of computation to capture relationships in the data. Gradient descent over next token-prediction isn't very energy efficient, but it leverages compute quite well and it turns out it has scaled up to the limits of just about every research cluster we've been able to build to date. If you're trying to push the envelope and build something which advances the state of the Art in a reasoning task, you're better off leaning as heavily as you can on compute-first approaches unless the nature of the problem involves a lack of data/compute.
Professor Sutton does a much better job than I discussing this concept, so I do encourage you to read the blog post.
I haven’t worked on LLMs/transformers specifically, but I’ve “independently invented” MoE and experimented with it on simple feedforward convolutional networks for vision. The basic idea is pretty simple: The “router” outputs a categorical distribution over the “experts”, essentially mixing the experts probabilistically (e.g. 10% of expert A, 60% of expert B and 30% of expert C). Training time you compute the expected value of the loss over this “mixture” (or use the Gumbel-Softmax trick), so you need to backprop through all the “experts”. But inference time you just sample from the categorical distribution (or pick highest probability), so you pick a single “expert” that is executed. A mathematically sound way of making inference cheaper, basically.
Mixtral seems to use a much more elaborate scheme (e.g. picking two “experts” and additively combining them, at every layer), but the basic math behind it is probably the same.
If MoE architectures still don't help you if you are VRAM constrained (which pretty much is everyone), is it safe to say it only helps inference latency?
I think the reason OpenAI and Mistral go for this approach is that they are compute constrained when serving their API from the cloud. My guess is that they have servers with e.g. one A100 per “expert”, and then they load this up with concurrent independent requests until those A100s are all pretty busy.
EDIT: In a cloud environment with independent concurrent requests MoE also reduces VRAM requirements because you don’t need to keep as many activations in memory.
MoEs are especially useful for much faster pre-training. During inference, the model will be fast but still require a very high amount of VRAM. MoEs don't do great in fine-tuning but recent work shows promising instruction-tuning results. There's also quite a bit of ongoing work around MoEs quantization.
In general, MoEs are interesting for high throughput cases with high number of machines, so this is not so so exciting for a local setup, but the recent work in quantization makes it more appealing.
LLM scaling laws tell us that more parameters make models better, in general.
The key intuition behind why MoE works is that as long as those parameters are available during training, they count toward this scaling effect (to some extent).
Empirically, we can see that even if the model architecture is such that you only have to consult some subset of those parameters at inference time - the optimizer finds a way.
The inductive bias in this style of MoE model is to specialize (as there is a gating effect between 'experts'), which does not seem to present much of an impediment to gradient flow.
> LLM scaling laws tell us that more parameters make models better, in general.
That depends heavily on the amount and complexity of training data you have. This is actually one of the things than OpenAI have advantage, they scraped a lot of data on the internet before now it became too hard for new players to get.
Disclaimer: I'm a ML newbie, so this might be all incorrect.
My intuition is that there are 8 7b models trained on knowledge domains. For example, one of those 7b models might be good at coding, while another one might be good at storytelling.
And there's the router model, which is trained to select which of the 8 experts are good at completing the text in the context. So for every new token added to the context, the router selects a model and the context is forwarded to that expert which will generate the next token.
The common wisdom is that a even single 7B fine tuned model might surpass much bigger models at the specific task that they're trained on, so it is easy to see how having 8x 7B models might create a bigger model that is very good at many tasks. In the article you can see that even though this is only 45B base model, it surpassed GPT 3.5 (which is instruction fine tuned) on most benchmarks.
Another upside is that the model will be fast at inference, since only a small subset of those 45B weights are activated when doing inference, so the performance should be similar to a 12B model.
I can't think of any downsides except the bigger VRAM requirements when compared to a Non-MoE model of the same size as the experts.
Sorry if this is a dumb question. Can someone explain why it’s called 8x7B(56B) but it has only 46.7B params? and it uses 12.9B params per token generation but there are 2 experts(2x7B) chosen by a 2B model? I’m finding it difficult to wrap my head around this.
I haven’t looked at the structure carefully, but It’s hard to guess there are shared layers between models. Likely the input layers for sure, since there is no need to tokenize separately for each model (unless different models have specialized vocabulary).
Explanation from Andrej karpathy makes sense on why:
'''
"8x7B" name is a bit misleading because it is not all 7B params that are being 8x'd, only the FeedForward blocks in the Transformer are 8x'd, everything else stays the same. Hence also why total number of params is not 56B but only 46.7B. '''
Honest question: if they're only beating GPT 3.5 with their latest model (not GPT 4) and OpenAI/Google have infrastructure on tap and a huge distribution advantage via existing products - what chance do they stand?
Mistral and its hybrids are a lot better than GPT3.5, and while not as good as GPT4 in general tasks - they’re extremely fast and powerful with specific tasks. In the time it takes GPT4 to apologise that it’s not allowed to do something I can be three iterations deep getting highly targeted responses from mistral - and best yet - I can run it 100% offline, locally and on my laptop.
There is an attempt to quantify subjective evaluation of models here[1] - the "Arena Elo rating". According to popular vote, Mistral chat is nowhere near GPT 3.5
Starling-7B, OpenChat, OpenHermes in that table are Mistral-7B finetunes, and are all above the current GPT-3.5-Turbo (1106). Note how these tiny 7B models are surrounded by much larger ones.
ELO takes a while to establish. It does not sound likely that the newer GPT3.5 is that much worse than the old one that has a clear gap to all the non proprietary models. In the immediate test, GPT-3.5 clearly outshines these models.
Well, Starling-7B was published two weeks ago; GPT-3.5-turbo-0613 is more than a month old snapshot, which should probably be enough time. OpenChat and OpenHermes are about a month old as well.
>It does not sound likely that the newer GPT3.5 is that much worse than the old one
Not my intent to argue about data at any point in time but note that as of today gpt-3.5-turbo-0613 (June 13th 2023) scores 1112, above OpenChat (1075) and OpenHermes(1077).
Mistral-Medium, the one announced here which beats GPT-3.5 on every benchmark, isn't even available yet. Those opinions are referencing Mistral-Tiny (aka Mistral-7B).
However, Mistral-Tiny beats the latest GPT-3.5 in human ratings on the chatbot-arena-leaderboard, in the form of OpenHermes-2.5-Mistral-7B.
Mixtral 8x7B aka (Mistral-Small) was released a couple of days ago and will likely come close to GPT-4, and well above GPT-3.5, on the leaderboards once it has gone through some finetuning.
They are not better than GPT 3.5 except for some of the public benchmarks. Also they are not faster than GPT 3.5. And they are not cheaper if you run finetuned model for specific task.
I agree with what antirez said, but I want to address the fallacy: The fact that he's an authority in C doesn't make him a priori more likely to know a lot about ML.
I agree with you, stavros. There is no transfer between C coding and ML topics. However the original question is a bit more in the business side IMHO. Anyway: I've some experience with machine learning: 20 years ago I wrote (my first neural network)[https://github.com/antirez/nn-2003] and since then I always stayed in the loop. Not for work, as I specialized in system programming, but for personal research I played with NN images compression, NLP tasks and convnets. In more recent times I use pytorch for my stuff, LLM fine-tuning and I'm a "local LLMs" enthusiast. I speculated a lot about AI, and wrote a novel about this topic. So while the question was more in the business side, I have some competence in the general field of ML. More than anything else I believe that all this is so new and fast-moving that there are many unknown unknowns, so indeed what I, you or others are saying are mere speculations. However to speculate is useful in this time, even more than before, because LLMs are a bit of a black box for the most part, so using only "known" things we can't go much far in our reasoning. We can understand embeddings, attention, how this networks are trained and fine tuned, and yet the inner workings are a bit of a magic thing.
To be clear, I'm not saying antirez is or isn't good at ML, I'm saying C/systems design/etc experience doesn't automatically make someone good at ML. I'm not trying to argue, I'm just discussing.
Oh, it's not a big deal. I just hate talking about the chap in front of him. I like to give compliments specifically, and be vague about less-than-complimentary things.
The thing is, even the ML people are not exactly sure what's going on, under the hood. It's a very new field, with a ton of "Here, there be dragonnes" stuff. I feel that folks with a good grasp of long-term architectural experience, are a good bet; even if their experience is not precisely on topic.
That's true, but I see my friend who's an ML researcher, and his grasp of LLMs is an order of magnitude better than mine. Granted, when it comes to making a product out of it, I'm in a much better position, but for specific knowledge about how they work, their capabilities, etc, there's no contest.
This is not a fallacy, we are engaging in informal reasoning, and contra your claim the fact that he is an authority in C does make it more likely he knows a lot about ML than the typical person.
how does this work in their favor as a business? Don't get me wrong I love how all of it's free, but that doesn't seem to be helpful towards a $2b valuation. At least WeWork charged for access
To Europe and France this is a most important strategic area of research, defense, and industry—-on par with aviation and electronics. The EU recognizes its relatively slow pace compared to what is happening in the US and China.
Exactly. EU's VC situation is dire compared to SV, which maybe isn't that bad if you think about what the VCs are actually after, but in this particular case it's a matter of national security of all EU countries. The capability must be there.
Mistral is funded in part by Lightspeed Venture Partners a US VP. But there are a lot of local French and European VPs involved.
The most famous one is Xavier Niel, who started Free/Iliad a French ISP/cloud provider and later cellphone provider that literally decimated the pricing structure of the incumbent some 20 years ago in France and still managed to make money. He’s a bit of a tech folk hero, kind of like Elon Musk was before Twitter. His company Iliad is also involved in providing access to NVIDIA compute clusters to local AI startups, playing the role Microsoft Azure plays for OpenAI.
France and the EU at large has missed the boat on tech, but they have a card to play here since they have for once both the expertise and the money rolled up. My main worry is that the EU legislation that’s in the works will be so dumb that only big US corporations will be able to work it out, and basically the legislation will scare investment away from the EU. But since the French government is involved and the guy who is writing the awful AI law is a French nominee, there’s a bit of hope.
They also have the EU protectionism card which is pretty safe to assume they will play for Mistral and the Germans (Aleph Alpha) - and thus also for Meta (for the most part). Iirc the current legislation basically makes large scale exceptions for open source models.
Many VC funded businesses do not have an initial business model involving direct monetization.
The first step is probably gaining mindshare with free, open source models, and then they can extend into model training services, consultation for ML model construction, and paid access to proprietary models, similar to OpenAI.
They are withholding a bigger model which at this point is "Mistral Medium" and that'll be available only behind their API end point. Makes sense for them to make money from it!
Because their larger models are super powerful. This makes sure their models start becoming the norm from the bottom up.
It also solidifies their name as the best, above all others. That's extremely important mindshare. You need mindshare at the foundation to build a billion dollar revenue startup.
They could charge for tuning/support, just like every other Open Source company.
Most business will want their models trained in their own, internal data, instead of risking uploading their Intellectual Property into SaaS solutions. These Open Source models could fill that gap.
Beyond what others said, I think this is an extremely impressive showing. Consider that their efforts started years behind Google's, and yet their relatively small model (they call is mistral-small, and also offer mistral-medium) is beating or on par with Gemini Pro on many benchmarks (Google's best currently available model).
On top of that Mixtral is truly open source (Apache 2.0), and extremely easy to self host or run on a cloud provider of your choice -- this unlocks many possibilities, and will definitely attract some business customers.
EDIT: The just announced mistral-medium (larger version of the just open sourced mixtral 8x7b) is beating GPT3.5 with significant margin, and also Gemini Pro (on available benchmarks).
The demand for using AI models for whatever is going through the roof. Right now it's mostly people typing things manually in chat gpt, bard, or wherever. But that's not going to stay like that. Models being queried as part of all sorts of services is going to be a thing. The problem with this is that running these models at scale is still really expensive.
So, instead of using the best possible model at any cost for absolutely everything, the game is actually good enough models that can run cheaply at scale that do a particular job. Not everything is going to require models trained on the accumulated volume of human knowledge on the internet. It's overkill for a lot of use cases.
Model runtime cost is a showstopper for a lot of use cases. I saw a nice demo of a big ecommerce company in Berlin that had built a nice integration with openai's APIs to provide a shopping assistent. Great demo. Then somebody asked them when this was launching. And the answer was that token cost was prohibitively expensive. It just doesn't make any sense until that comes down a few orders of magnitudes. Companies this size already have quite sizable budgets that they use on AI model training and inference.
I can agree with this, I’m currently building a system that pulls data from a series of pdfs that are semi-structured. Just testing alone is taking up 10s of $ in api costs. We have 60k PDFs to do.
I can’t deliver a system to a client that costs more in api costs than it does in development costs for their expected input size.
Using the most naive approach the ai would be beaten on a cost basis by a mechanical Turk.
Features I saw demoed were about comparing products based on descriptions, images, and pricing. So, it was able to find products based on a question that was about something suitable for X costing less than Y where X can be some kind of situation or event. Or find me things similar to this but more like so. And so on.
If you're purely looking for capabilities and not especially interested in running an open model, this might not be that interesting. But even so, this positions Mistral as currently the most promising company in the open models camp, having released the first thing that not only competes well with GPT-3.5 but also competes with other open models like Llama-2 on cost/performance and presents the most technological innovation in the open models space so far. Now that they raised $400MM the question to ask is - what happens if they continue innovating and scale their next model sufficiently to compete with GPT-4 / Gemini? The prospects have never seemed better than they do today after this release.
The EU and other European governments will throw absolute boatloads of money at Mistral, even if that only keeps them at a level on par with the last generation. AI is too big of a technological leap for the bloc to ride America's coattails on.
Mistral doesn't just exist to make competitive AI products, it's an existential issue for Europe that someone on the continent is near the vanguard on this tech, and as such, they'll get enormous support.
EU is good at fostering free market, but not at funding strategic efforts. Some people (Piketty, Stiglitz) say that companies like Airbus couldn't emerge today for that reason.
Uuuuuh... you could call the EU a lot of things, but "fostering free market" is a hot take. I'm sorry. When you look at the amount of regulation the EU brings to the table (EU basically is the poster child of market regulation), I would go as far as to say that your claim is objectively not true. We can debate how regulation is a good thing because this and that, but regulation - by definition - limits the free market. And there is an argument to be made, backed up literally thousands of regulations the EU has come up with, that the EU limits the free market a lot. When you factor in the regulations that are imposed on its member countries (I mean directly on the goverments) one could easily claim that it is the most harsh regulator on the planet. I could go into detail about the so called green deal, etc. but all of these things are easy to look up on the net / or official sources from the EU portal.
> but regulation - by definition - limits the free market.
Not always true.
Consumer labeling laws enable the free market, because a free market requires participates have full knowledge of the goods they are buying, or else fair competition cannot exist.
If two companies are competing to sell wool coats, and one company is actually selling a 50% wool blend but advertising it as 100% wool, that is not a free market, that is fraud. Regulation exists to ensure that companies selling real wool coats are competing with each other, and that companies selling wool blends are competing with each other, and that consumers can choose which product that they want to buy without being tricked.
Without labeling laws, consumers end up assuming a certain % of fraud will always happen, which reduces the price they are willing to pay for goods, which then distorts the market.
>one could easily claim that it is the most harsh regulator on the planet.
The argument that the EU is a more harsh regulator than Iran, Russia, China, North Korea, (or even on par with those regulatory regimes) entirely undermines the rest of your comment.
There's pretty well tested and highly respected indexes which fundamentally disagree. Of the 7 most economically free nations, three are in the EU, and a fourth is automatically party to the majority of the EU's economic regulations.
The level of regulation is only a small part of what makes a market free or not
The EU does a ton to limit state aid, monopolistic practices and has a pretty extensive network of trade agreements
Also you say imposed as if the countries themselves don't want them, every regulation at the EU level replaces what would've been 10 different ones at the member states level, this uniformity is arguably a net positive on its own
They are focusing hard on small models. Sooner or later, you'll be able to run their product offline, even on mobile devices.
Google was criticized [0] for offloading pretty much all generative AI tasks onto the cloud - instead of running it on the Tensor G3 built into its Pixel Phones specifically for that purpose. The reason being, of course, that the Tensor G3 is much to small for almost all modern generative models.
So Mistral is focusing specifically on an area the big players are failing right now.
Microsoft, Apple, and Google also have more resources at their disposal yet Linux is doing just fine (to put it mildly). As long as Mistral delivers something unique, they'll be fine.
This wasn’t status quo. In fact, it can serve as an example. Why wouldn’t google or microsoft follow the same path with mistral? Being open source, it serves their purposes well.
As I read it they are doing this with 8 * 7Bn parameter models. So, their model should run pretty well as fast as a 7Bn model and at the cost of a 56bn parameter model.
That a lot quicker and cheaper than GPT-4
Also this is kinda a promissory note, they've been able to do this in a few months and create a service on top of it. Does this intimate that they have the capability to create and run SoA models? Possibly. If I were a VC I could see a few ways for this bet to go well.
The big killer is moat - maybe this just demonstrates that there is no LLM moat.
Almost no serious user - private or company - wants to slurp their private data to cloud providers. Sometimes it is ethically or contractually impossible.
We can't use LLMs at work at all right now because of IP leakage, copyright, and regulatory concerns. Hosting locally would solve one of those issues for us.
In terms of speed per token. What they don't say explicitly is that choosing the mix per token means you may need to reload the active model multiple times in a single sentence. If you don't have memory available for all the experts at the same time, that's a lot of memory swapping time.
Tim Dettmers stated that he thinks this one could be compressed down to a 4GB memory footprint, due to the ability of MoE layers to be sparsified with almost no loss of quality.
If your motivation is to be able to run the model on-prem, with parallelism for API service throughput (rather than on a single device), you don't need large memory GPUs or intensive memory swapping.
You can architect it as cheaper, low-memory GPUs, one expert submodel per GPU, transferring state over the network between the GPUs for each token. They run in parallel by overlapping API calls (and in future by other model architecture changes).
Th MoE model reduces inter-GPU communication requirements for splitting the model, in an addition to reducing GPU processing requirements, compared with a non-MoE model with the same number of weights. There are pros and cons to this splitting, but you can see the general trend.
Also, considering mistral is open source, what will prevent their competitor to integrate any innovation they make?
Another thing I don't understand, how a 20 people company can provide a similar system as OpenAI (1000 employees)? what do they do themselves, and what do they re-use?
> Also, considering mistral is open source, what will prevent their competitor to integrate any innovation they make?
Their small and tiny models are open source, it seems like a marketing strategy, and bigger models will not be open source. Their medium model is not open source.
> Another thing I don't understand, how a 20 people company can provide a similar system as OpenAI (1000 employees)? what do they do themselves, and what do they re-use?
They do not provide the scale of OpenAI or a model comparable to GPT-4 (yet).
Companies move slow, especially as they get bigger. Just because a google engineer wants to yoink some open source inferencing innovation for example, doesn't mean they can just jam it into Gemini and have it rolled out immediately.
Google started late with any serious LLM effort. It takes time to iterate on something so complex and slow to train. I expect Google will match OpenAI in next iteration or two, or at worst stay one step behind, but it takes time.
OTOH Google seem to be the Xerox Parc of our time (who were famous for state of the art research and failure to productize). Microsoft, and hence Microsoft-OpenAI, seem much better positioned to actually benefit from this type of generative AI.
1) as a developer or founder looking to experiment quickly and cheaply with llm ideas, this (and llama etc) are huge gifts
2) for the research community, making this work available helps everyone (even OpenAI and Google, insofar as they've done something not yet tried at those larger orgs)
3) Mistral is well positioned to get money from investors or as consultants for large companies looking to fine tune or build models for super custom use cases
The world is big and there's plenty of room for everyone!! Google and OpenAI haven't tried all permutations of research ideas - most researchers at the cutting edge have dozens of ideas they still want to try, so having smaller orgs trying things at smaller scales is really great for pushing the frontier!
Of course it's always possible that some major tech co playing from behind (ahem, apple) might acquire some LLM expertise too
They might be willing to do things like crawl libgen which google possibly isn't, giving them an advantage. They might be more skilled at generating useful synthetic data which is a bit of an art and subject to taste, which other competitors might not be as good at.
Google has a ton of scanned books and magazines from libraries etc, on top of their own web crawls. If they don't have the equivalent of libgen tucked away something's gone wrong.
> they are probably well-placed to answer some proposals from European governments
That's true but I wonder how they stack up against Aleph Alpha and Kyutai? Genuinely curious as I haven't found a lot of concrete info on their offerings.
Pretty much as with OSS in general: Lagging behind the cutting edge in terms of functionality/ux/performance, in areas where and as long as big tech is feeling combative, but eventually, probably, good enough across all axis to be useable.
There could be a close-ish future where OpenAI tech will simply solve most business problems and there is no need for anything dramatically better in terms of AI tech. Think of word/google docs: It's doing what most businesses need well enough. For the most part people are not longing for anything else and happy with it just staying familiar. This is where Open Source can catch up relatively easily.
Oh well, it's an evaluation, but I feel you may have glossed over the "in areas where and as long as big tech is feeling combative" part.
> to tools like Blender
"Tools like" needs a little more content to not be filled massive amounts of magical OSS thinking. Blender has in recent years gained an interesting amount of pro-adoption, but, in general, as for the industries that I have good insight into, inkscape, gimp, ardour or penpot are not winning. This is mostly debated by people who are not actually mainly and professionally using these tools.
There are exceptions, of course (nextcloud might be used over google workspace when compliance is critical) but businesses will on average use the best tool, because the perceived value is still high enough and the cost is not, specificially when contrasted with labor cost and training someone to use a different tool.
Are you seriously claiming most oss is irrelevant? Maybe in consumer facing products such as libre office. But oss powers most of commercial products. I wouldn't be surprised if most functionality in all of current software is built from a thin layer over open source software.
You could broadly segregate the market into three groups - general purpose, specialized-instructions, and local tasks.
For general purpose, look at the uses of GPT4. Gemini might give them competition lately, and I dont think OSS would in the near future. They are trained on open internet and are going to be excellent at various tasks like answering basic questions, coding, generating content for marketing or website. Where they do badly is when you introduce a totally new concept which is likely outside of their training data. Dont think mistral is even trying to compete with them.
local tasks is a mix of automation and machine level tasks. A small mistral like model would work superbly well because it does not require as much expertise. Usecases like locating a file by semantic search, generating answers to reply to email/text within context, summarize a webpage.
Specialized instructions though is key for OSS. From two angles. One is security and compliance. Open AI uses a huge system prompt to get their model to perform in a particular manner, and for different companies, policies and compliance requirements may result in a specific system prompt for guardrails. This is ever changing and better to have an open source model that can be customized than depending on Open AI. From the blog post.
> Note: Mixtral can be gracefully prompted to ban some outputs from constructing applications that require a strong level of moderation, as exemplified here. A proper preference tuning can also serve this purpose. Bear in mind that without such a prompt, the model will just follow whatever instructions are given.
I think moderation is one such issue. Could be many and it is an evolving space as we go forward. (though this is likely to be an exposed functionality in future Open AI models). There is also the data governance bit - which is easier to do with an oss model than just depending on Open AI apis, just architectural reasons.
The second is training a model on domain knowledge of the company. We at Clio AI[1] (sorry, shameless plug) have had seven requests in the last one month about companies wanting their own private models pretrained on their own domain knowledge. These datasets are not on open internet and so no model is good at answering based them. A catalyst was Open AI dev day[2] which asked for proposals for custom models trained on enterprise domain knowledge. and their price start at $2M. Finetuning works, but on small datasets, not the bigger ones.
Large Companies are likely to approach Open AI and all these OSS models to train a custom instruction following model. Cos there are a handful of people who have done it, and that is the way they can get most out of a LLM deployment.
Are you actually fine tuning or using RAG? So far I am able to get very good results with llamaindex, but fine tuning output just looks like the right format without much of the correct information.
Not using RAG, and using Supervised Finetuning post pre-training. It's taking all of the corporate data and pretraining a foundational model further with that extra tokens. Then SFT. Problem with usual finetuning is that it gets the format right, but struggles when the domain knowledge is not in the model's original training. Think of it as creating a vertical LLM that is unique to an organization.
Are you using a normal training script i.e. "continued pretraining" on ALL parameters with just document fragments rather than input output pairs? And then after that you fine tune on a standard instruct dataset, or do you make a custom dataset that has qa pairs about that particular knowledgebase? When you say SFT I assume you mean SFTTrainer. So full training (continued from base checkpoint) on the document text initially and then LoRA for the fine tune?
I have a client that has had me doing LoRA with raw document text (no prepared dataset) for weeks. I keep telling him that this is not working and everyone says it doesn't work. He seems uninterested in doing the normal continued pretraining (non-PEFT, full training).
I just need to scrape by and make a living though and since I don't have a savings buffer, I just keep trying to do what I am asked. At least I am getting practice with LoRAs.
> Are you using a normal training script i.e. "continued pretraining" on ALL parameters with just document fragments rather than input output pairs?
Yes, this one.
> do you make a custom dataset that has qa pairs about that particular knowledgebase?
This one. Once you have a checkpoint w knowledge, it makes sense to finetune. You can use either LORA or PEFT. We do it depending on the case. (some orgs have like millions of tokens and i am not that confident that PEFT).
LoRA with raw document text may not work, haven't tried that. Google has a good example of training scripts here: https://github.com/google-research/t5x (under training. and then finetuning). I like this one. Facebook Research also has a few on their repo.
If you are just looking to scrape by, I would suggest just do what they tell you to do. You can offer suggestions, but better let them take the call. A lot of fluff, a lot of chatter online, so everyone is figuring out stuff.
I always ask myself the following pseudo-question: "for this geneneration/classification task, do I need to be more intelligent than an average highschool student?" Almost always in business tasks, the answer is a no. Therefore I go with GPT3.5. Its much quicker and good enough to accomplish the task usually.
And then I need to run this task thousands of times, so the API limits are the most limiting factor, which are much higher in GPT3.5 variants, whereas when using GPT4 I have to be more careful with limiting/queueing requests.
I patiently wait for a efficient enough model that only needs to be on a GPT3.5 level I can self-host alongside my applications with reasonably low server requirements. No need for GPT-5 for now, for business automations the lower end of "intelligence" is more than enough, but efficiency/scaling is the real deal.
Do you mind sharing some tasks that you are solving with GPT 3.5? Be very concrete, if you don't mind. I am struggling to make it work for my business use cases (i.e. the ones where I am looking for "reliably helpful") and am very much looking for inspiration to define the limits. The hypothetical is interesting but seems to not do too much for me on its own.
I second this. For some type of applications, the 4 model can quickly ramp up costs, especially with large contexts and 3.5 often does the job just fine.
So for many applications it's the real competitor.
Too bad GPT3.5 Turbo is dirt cheap. Open source models are substantially more expensive when you factor in operating costs. There is no mature ecosystem where you can just plug in a model and spin up a robust infrastructure to run a local LLM at scale, aka you need infrastructure/ML engineers to do it, aka extremely expensive unless you are using LLMs at extremely large scales.
Yet, if you want to go cheaper, you totally can by paying for the API access. Gpt4 is accessible there and you get to use your own app. $20 will last you way longer then a month if you're not a heavy user.
It really depends on usage. If you need to have long conversations, or are sending huge texts, the all-you-can-eat for $20 plan will almost certainly be cheaper than API access.
If you're doing lots of smaller one shot stuff without a lot of back and forth, the API will be cheaper.
Depends on if they know how to use it. A lot of people still think it's just a google and wikipedia replacement. It doesn't really do anything super useful in that case.
GPT-3.5 (unfinetuned) has been matched by many OW (open weights) models now, and with fine tuning to a specific task (coding, customer care, health advice etc) can exceed it.
It's still useful as a well known model to compare with, since it's the model the most people have experience with.
Considering that this model has basically zero censorship I would say it is going to take a while before companies have fine-tuned this enough before putting it in production.
Btw it is unfortunate that 'censored' became the default expectation. Mistral gives the raw model because that makes it useful for all kinds of purposes, e.g. moderation. Censorship is an addon module (or a lora or sth).
Businesses have a huge incentive to censor these models - it's appreciated that these are released without it, but a business has a lot of concerns about what is said around anything they are offering as a service.
The point was just that production implies a business use and that implies the need to make sure there are guardrails in place to make sure the model sticks to the business purpose instead of teaching people how to make pipe bombs. Not that anyone thinks that prevents people from learning how to make pipe bombs - they just don't want to be the ones doing the teaching.
To the contrary, I want need things locally/cheap/fast for generic internal business automation, so it will never generate content any outsider would ever see. Basically glue code between services with classification of data built-in.
stumbled on this thread looking for tips- so far i haven't had success. i can load the model into memory by lowering the precision, I was OOMing on my 128GB RAM, now im OOMing on loading the model into the 4090 on the 17th shard at 4 bit qtization so i would imagine theres another knob or two im missing to get this to run
Can someone please explain how this works to a software engineer who used to work with heuristically observable functions and algorithms? I'm having a hard time comprehending how a mix of experts can work.
In SE, to me, it would look like (sorting example):
- Having 8 functions that do some stuff in parallel
- There's 1 function that picks the output of a function that (let's say) did the fastest sorting calculation and takes the result further
But how does that work in ML? How can you mix and match what seems like simple matrix transformations in a way that resembles if/else flowchart logic?
The feed forward layer is essentially a differentiable key-value store.
Similar to the attention layer, actually.
So it just uses an attention mechanism like pre-selector to attend to only some experts.
During inference, this cutoff is made a hard cutoff.
This is a very interesting approach. I know it may be too much to ask, but would you suggest any actual practical and hands-on workshops, playgrounds, or courses where I could practice using NN layers for stuff like that? For example, conditional/weighted selection of previous inputs, etc. It feels like I'm looking at ML programming from another angle.
Interesting to see Mistral in the news raising EUR 450M at a EUR 2B valuation. tbh I'd not even heard of them before this Mixtral release. Amazing how fast this field is developing!
The Sparse Mixture of Experts neural network architecture is actually an absolutely brilliant move here.
It scales fantastically, when you consider that (1) GPU RAM is way too expensive, in financial dollars, (2) SSD / CPU RAM are relatively cheap, and (3) you can have "experts" running on their own computers, i.e. it's a natural distributed computing partitioning strategy for neural networks.
I did my M.S. thesis on large-scale distributed deep neural networks in 2013 and can say that I'm delighted to point our where this came from.
In 2017, it emerged from a Geoffrey Hinton / Jeff Dean / Quoc Le publication called "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer".
Here is the abstract:
"The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation. In practice, however, there are significant algorithmic and performance challenges. In this work, we address these challenges and finally realize the promise of conditional computation, achieving greater than 1000x improvements in model capacity with only minor losses in computational efficiency on modern GPU clusters. We introduce a Sparsely-Gated Mixture-of-Experts layer (MoE), consisting of up to thousands of feed-forward sub-networks. A trainable gating network determines a sparse combination of these experts to use for each example. We apply the MoE to the tasks of language modeling and machine translation, where model capacity is critical for absorbing the vast quantities of knowledge available in the training corpora. We present model architectures in which a MoE with up to 137 billion parameters is applied convolutionally between stacked LSTM layers. On large language modeling and machine translation benchmarks, these models achieve significantly better results than state-of-the-art at lower computational cost."
So, here's a big A.I. idea for you: what if we all get one of these sparse Mixture of Experts (MoEs) that's a 100 GB on our SSDs, contains all of the "outrageously large" neural network insights that would otherwise take specialized computers, and is designed to run effectively on a normal GPU or even smaller (e.g. smartphone)?
Plus benchmarks are typically ran from the API, using a tagged version of 3.5-turbo and not the whatever extra tuning and prompt magic ChatGPT as a frontend has to actually get the better results that people see in practice.
On the other hand, if the base instruct model is good enough to roughly match it then the fine tunes will be interesting for sure.
It sounds like the same requirements as a 70b+ model, but if someone manages to get inference running locally on a single rtx4090 (AMD 7950x3D w/ 64GB ddr5) reasonably well, please let me know.
That’s ~$86,000 not bad at all imo and probably comes with other benefits as well. Not really sure how economical that is in the EU but it can’t be worse than the U.S where this is still pretty good compensation.
OpenAI is known to pay up to 10 times that. It's a different world.
$86k in Europe is good (about 90th percentile of earners in Germany), but not as fantastical as some salaries in the US. Plus, Paris is probably expensive.
I'm in Europe and imo it's bad. The position is London/Paris and it's definitely not enough to live comfortably in London. It's okay for a run of the mill full stack position but at what could be considered the hottest sector in the world right now? It's not enough.
> Mixtral is pre-trained on data extracted from the open Web – we train experts and routers simultaneously.
> Note: Mixtral can be gracefully prompted to ban some outputs from constructing applications that require a strong level of moderation, as exemplified here. A proper preference tuning can also serve this purpose. Bear in mind that without such a prompt, the model will just follow whatever instructions are given.
(The article you linked is not accessible to non-medium users, by the way. Apologies if it covers caveats.)
For bar charts it's a good rule of thumb. For line charts, not necessarily.
Scroll down to the cases where it makes sense to zoom in. Imagine you plot the global average temperature of the last 200 years including the zero. You could barely see the changes, but they've been dramatic. Use Kelvin to make this effect even stronger.
Which brings up another point: The zero is sometimes arbitrary. If instead of a quantity you only plot its difference to some baseline, all that is changing is the numbers of the y-axis, but the actual plot stays the same. Is it now less misleading? I say no, because the reader must look at the axes and the title either way.
So please do zoom in to frame the data neatly if it makes sense to do so.
For headline news that's probably a good rule of thumb. But in an academic context, especially data science, anyone who is data literate should know to check the axes.
the model says 8x7B model, so its a 56B model. what is the GPU memory requirements to run this model for a 512 context size? are there any feasible quantization models of this available? I want to know if my 16GB VRAM GPU can run this model?
Thanks
18.14GB in 2bit, which is still too high for your GPU, and most likely borders on unusable in terms of quality. You could probably split it between CPU and GPU, if you don't mind the slowdown.
I’m surprised no one has commented on the context size limitations of these offerings when comparing to the other models. The sliding window technique really does effectively cripple its recall to approximately just 8k tokens which is just plain insufficient for a lot of tasks.
All these llama2 derivatives are only effective if you fine tune them, not just because of the parameter count as people keep harping but perhaps even more so because of the tiny context available.
A lot of my GPT3.5/4 usage involves “one offs” where it would be faster to do the thing by hand than to train/fine-tune first, made possible because of the generous context window and some amount of modest context stuffing (drives up input token costs but still a big win).
8k tokens is about 6000 words, which is more than enough for most classification tasks. Maybe it's not enough for something like story writing, but I feel like it's enough context for most business use cases.
Using an llm like Mistral or GPT for solely for classification is like using a jackhammer to drive framing nails. A lot of business needs require feeding the llm plenty of docs to analyze and then extract something out of, summarize, draw relationships between, etc and almost none of that can be done in 6k words. I can't even use 8k (or so-called "32k") models to analyze a moderate length Wikipedia article.
Benchmarks are, by definition, artificial. I'm speaking from real-world experience, not from "based off the architecture, here's my guess" and lack of context or poor recall within the "supported" context window is a real problem.
Yes, this is partially due, among other reasons, to the fact that inference induces a domain shift compared to training due to the use of teacher forcing.
The key takeway for me is that there is a decent improvement in all categories - about 10% on average with a few outliers. However, the footprint of this model is much larger so the performance bump ends up being underwhelming in my opinion. I would expect about the same performance improvement if they released a 13B version without the MoE. May be too early to definitely say that MoE is not the whole secret sauce behind GPT4, but at least with this implementation it does not seem to lift performance dramatically.
Good question. If you believe the results on the HuggingFace leaderboard (https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderb...), which I find very hard to navigate, we find that Mistral was not even the best 7B model in there, and there is a huge variance as well. I prefer to rely on benchmarks done by the same group of known individuals over time for comparisons, as I think it's still too easy to game benchmark results - especially you are just releasing something anonymously.
You are right - upon closer inspection, even models that were not previously Mistral finetunes are now using Mistral in their later versions. I wasn't aware of it before as I could not filter results in the leaderboard (it doesn't even load at all for me now).
{kind=link}
Official post on Mixtral 8x7B: https://mistral.ai/news/mixtral-of-experts/
Official PR into vLLM shows the inference code: https://github.com/vllm-project/vllm/commit/b5f882cc98e2c9c6...
New HuggingFace explainer on MoE very nice: https://huggingface.co/blog/moe
In naive decoding, performance of a bit above 70B (Llama 2), at inference speed of ~12.9B dense model (out of total 46.7B params).
Notes: - Glad they refer to it as "open weights" release instead of "open source", which would imo require the training code, dataset and docs. - "8x7B" name is a bit misleading because it is not all 7B params that are being 8x'd, only the FeedForward blocks in the Transformer are 8x'd, everything else stays the same. Hence also why total number of params is not 56B but only 46.7B. - More confusion I see is around expert choice, note that each token and also each layer selects 2 different experts (out of 8). - Mistral-medium
Source: https://twitter.com/karpathy/status/1734251375163511203