I wonder how these "visual story telling" articles are created, they are really great.
Like, what tools do the authors have. Are the content authors super tech savvy or not. How much specific code must be created for each article. How long does everything take compared to a normal, mostly-text page. How many people work on one article. etc. Must be pretty interesting.
Mostly a ton of JavaScript. As for the concepts explained visually, ICYMI there is a small footnote at the end of the article:
> To generate the 50D word embeddings we used the GloVe 6B 50D pre-trained model and converted to Word2Vec format. To generate the 2D representation of word embeddings we used the BERT large language model and reduced dimensionality using UMAP. The self-attention values and the probability scores in the beam search section are conceptual.
Hey, I'm one of the graphics journalists/authors on the piece
This is not very helpful, but the answers to most of your questions is "it depends"
Our team is made up of reporters, designers, and graphics journalists, but the specific makeup of the team on a given project or who else gets drawn into it varies a lot depending on the topic/scope of the story
For our stories, always lot of React and headache-inducing CSS transition stuff, but the tools/libraries beyond that depend a lot on the needs of the project
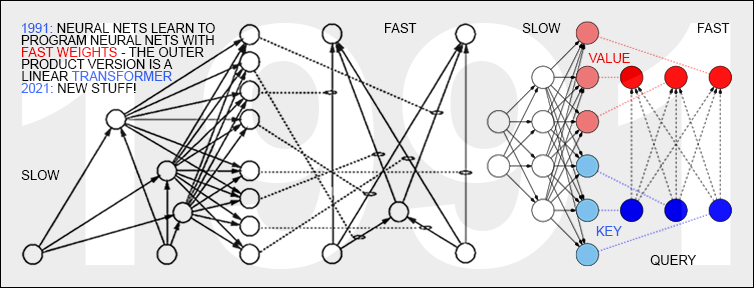
It's pretty damn simple: a linearized transformer is a "slow" neural net whose outputs determine the weights of another ("fast") neural net.
It's a NN that can use tools, subject to one major restriction: the tool must be another NN. The restriction is is "the trick" that lets you backpropagate gradients through both NNs so you can train the slow NN based on an error function of the fast NN's outputs.
The only difference between linearized transformers and the kind that OpenAI uses is adding a softmax operation in one place.
Did you mean to paste a different image? That diagram shows a much older design than the transformer coined in the 2017 paper. It doesn’t include token embeddings, doesn’t show multi-head attention, the part that looks like the attention mechanism doesn’t do self-attention and misses the query/key/value weight matrices, and the part that looks like the fully-connected layer is not done in the way depicted and doesn’t hook into self-attention in that way. Position embeddings and the way the blocks are stacked are also absent.
The FT article at least describes most of those aspects more accurately, although I was disappointed to see they got the attention mask wrong.
Did you click the right link? The words "query", "key", and "value" are in the image! For the rest, you'll want to read the paper: https://arxiv.org/abs/2102.11174
Embeddings were around long before transformers.
The image only depicts a single attention head, of course.
Ah, I didn’t notice the picture came from Jürgen Schmidhuber. I understand his arguments, and his accomplishments are significant, but his 90s designs were not transformers, and lacked substantial elements that make them so efficient to train. He does have a bit of a reputation claiming that many recent discoveries should be attributed to, or give credit to, his early designs, which, while not completely unfounded, is mostly stretching the truth. Schmidhuber’s 2021 paper is interesting, but describes a different design, which while interesting, is not how the GPT family (or Llama 2, etc.) were trained.
The transformer absolutely uses many things that have been initially suggested in many previous papers, but its specific implementation and combination is what makes it work well. Talking about the query/key/value system, if the fully-connected layer is supposed to be some combination of the key and value weight matrices, the dimensionality is off (the embedding typically has the same vector size as the value (well, the combined size of values for each attention head, but the image doesn’t have attention heads) so that each transformer block has the same input structure), the query weight matrix is missing, and while the dotted lines are not explained in the image, the way the weights are optimized doesn’t seem to match what is shown.
Token embeddings typically only attend to past token embeddings, not future ones.
The reason is to enable significant parallelism during training: a large chunk of text goes through the transformer in a single pass, and its weights are optimized to make its output look like its input shifted by one token (ie. the transformer converts each input token to a predicted next token). However, if the attention weights attended to future tokens, they would strongly use the next token they are given, to predict that next token. So all future tokens are masked out.
Before I came across that image (and the paper Linearized Transformers are Secretly Fast Weight Programmers) I very much did not understand transformers. I had spent at least 20 hours with Attention Is All You Need, and probably another dozen hours with https://e2eml.school/transformers.html and wasn't getting much of anywhere. I have no ML/AI background; just a typical undergraduate-CS-level familiarity with neural networks -- the basic stuff that hasn't changed since the 1990s. I do have some experience with linear algebra, but that isn't the hard part of any of this.
Frankly, most people who publish in this field go out of their way to obfuscate the key insights. Mediocre physicists (but not the truly brilliant ones) do the same thing. It's very annoying.
Different things click for different people; for me, the image you linked in the initial post of this thread… it makes as little sense to me as the Time Cube image or the widely mocked Pepsi rebrand document from 2008.
"That it's objectively true" isn't enough of an advantage, sadly.
> Frankly, most people who publish in this field go out of their way to obfuscate the key insights. Mediocre physicists (but not the truly brilliant ones) do the same thing. It's very annoying.
I certainly sympathise, but I think the overlap here is "maths is hard to communicate", and the conflict between rigorously explaining vs. keeping everything simple enough to follow.
I might understand some of that, but couple extra questions if you don't mind answering: There's the key value pairs in the middle if I understand correctly, but what do the points on the last layer stand for? Are the key value pairs a vector and the last layer an actual token in a simple LLM, for example?
Personally I think the key/value/query terminology is kind of crappy, but at this point we're stuck with it.
Think of the "fast" network as being like a hashmap. It stores key-value pairs. You feed it a query, which is a key that you're looking for, and it gives you back the corresponding value. Unlike the hashmaps you're used to, however, this is sort of a "blurry hashmap". If you ask for a key you'll get sort of a blend of the values nearby it -- even if the key isn't in the hashmap.
> Are the key value pairs a vector and the last layer an actual token in a simple LLM, for example?
Almost.
Firstly, the image I linked depicts only one attention head in one layer of an LLM. So you have to imagine that replicated several times in parallel, and then repeated several times serially. The Fast Weight Programmer paper does a better job of explaining the fundamental unit; to see how they are replicated and repeated the block diagrams in Attention is All You Need are easy to understand.
Secondly, getting back to the "hashmap" analogy, you might imagine that the hashmap key-type and value-type are LLM tokens, but in fact that's not quite how it works. There are two other types. One is the embedding space and another is the key space, and the hash map keys and values are both of that type. Yeah this is why the key/value terminology really sucks. There is a feed-forward layer that translates input tokens into the embedding space, another that translates embedded space to key space (before the hashmap lookup) and a third one that translates hashmap-outputs back from key space to embedding space. I wouldn't get too hung up on all of these; it's sort of like if you learn a foreign language but still "think" in your native language... the embedding space is sort of like the LLM's native language that it invents for itself. The whole business with the key space is mostly sort of a hack... in order to have multiple attention heads and train on current GPUs efficiently you want the embedding space to be NUM_HEADS times larger than the key space. So the whole key space not being the embedding space is mostly just a kludge to make this work well on GPUs. Unless you're planning on writing your own LLM from scratch it's mostly safe to pretend that the key space and embedding space are the same thing. In practice people have tried taking apart small transformers and the key space appears to work like "parts of speech"... when it reads a sentence like "I walked the dog" the attention heads tend to create mappings vaguely similar to I=subject, walked=verb, dog=object, and then later on the slow network will produce queries like "what verb was applied to the dog?". This is an oversimplification, but it gives a general idea of what's going on.
Also if you like maths, equations (4)-(19) from https://arxiv.org/abs/2102.11174 are a really spectacular example of using math when it's the right way to explain something, instead of using it to hide things.
I really enjoyed the beginning of this page, where it talked about embeddings and such.
But starting with the self attention, it gets a bit fussy. How, based on what does the attention mechanism work? The similarity of embeddings can't be all of it - "it", "dog" and "bone" will alwats have the same similarity, even if the surrounding sentence changes.
Can someone in simple terms describe how thus works?
Extra: the embedding explanation works great with words, but with actual tokens it gets way weirder... e.g. in German tokens are often just 1-3 characters, which do not contain any meaning in the normal sense.
So the fact, that this works for example with the "hu" from "Hund", "fl" from "Flasche" and "fl" from "Fleisch" is interesting, as "Fleisch" is probably more similar to "Hund" then "Flasche". (Tokens are just examples, not sure how this wird's are broken down).
I guess the solution to this is related to the question above? For this kind of embedding to be useful it is important to look at more than just the two tokens, but their complete surroundings?
Attention takes in all tokens in the sequence and outputs a new representation of the current token in context. Each layer of the transformer adds more context to the token.
I haven't read this explanation in detail and although they have some nice animations, I wouldn't go to FT to explain machine learning concepts. Here are two well known explanations that might be better:
Yes, I think that is a reasonable way to think about it, in my opinion. However, with the language modeling objective it predicts the next token and because of the residual connections each intermediate layer is in the same space. So, maybe it would be more accurate to say that it is an increasingly accurate representation of the next token.
This is the intuition that worked for me: transformers are mini search engines!
Each attention node is essentially performing a simple search on the previous text given a single word. It's kind of like Google! The actual search or "query" is the word you're looking at, the page title or "key" is the other words in the sentence, and the page/document or "value" is... also the other words in the text (each word is like its own page title). So if you imagine the whole internet is just the sentence "Hi my name is Bob", and you googled "name", you should get a results page with "Bob" at the top, followed by "my" then "is" then "Hi".
As an optimization, the transformer will actually run this "search" operation for all the words in the sentence at the same time. It then spits out a matrix saying how relevant each word is too every other word. Basically each transformer in your neural network is like a little guy who says "Hey, if you're looking at X word, here's the other words Y and Z that might be relevant in the same sentence". The rest of the NN can then use that information using more typical feed forward techniques (I'm mostly glossing over use of embeddings and other various special techniques that are used in practice here). There will be multiple transformers in a given LLM that each perform a slightly different search.
But how does a transformer know how to rank these words? In a nutshell, as we train it to predict text, signals from the error in that training prediction back propagate to the transformer node, and it gradient descends to be the best search engine it can be. Each transformer will have a slightly different random starting state and different distribution of modules further forward in the network back propagating error to it, and thus they will each converge to a slightly different "search algorithm" so to speak.
This feels like it's a mish-mash of concepts that are used in different settings (pre-trained word embeddings, unmasked attention, beam search, ...) but that aren't really used in things like ChatGPT. I guess if you're reading this kind of article, the details don't really matter that much, though.
I am interested in how these work, and most importantly why others failed to work. e.g. why LLM's capabilities where "unlocked" by prompts like "step-by-step"? How does CoT work?
That seems to be the (uneditorialized) title: "Generative AI exists because of the transformer (This is how it works)". Maybe the context of 'it' was lost on the submitter.
Another horrible and misleading description that I cannot imagine had a single machine learning person in the loop.
TLDR: They say that transformers are pretrained word embeddings with one round of self attention that predict the next word sequence by beam search. They aren't any of those things.
Why start with word embeddings? The authors think that you first train word embeddings and then use them as the input for your Transformer. Nope.
> A word embedding can have hundreds of values, each representing a different aspect of a word’s meaning. Just as you might describe a house by its characteristics — type, location, bedrooms, bathrooms, storeys — the values in an embedding quantify a word’s linguistic features.
No. That's literally not what a word embedding is! It's completely the wrong intuition. It mixes up a semantic representation with the distributional hypothesis. These are two completely different ideas. Word embeddings are not describing words by their characteristics, exactly the opposite! They abandon that idea. To say that this is true but we just don't know what the characteristics being described are is just a total confusion about what is happening.
> Self-attention looks at each token in a body of text and decides which others are most important to understanding its meaning.
Why even introduce the word token here? When it's not explained at all. Just say word. And no, self attention does not decide which words are important for the meaning of this word, it's which other inputs are important to carry out some task. "meaning" is not a thing. Also, that's just attention. Where's the self part friends!? It sounds like they think self attention refers to a word itself paying attention. Things are getting dicey.
> With self-attention, the transformer computes all the words in a sentence at the same time. Capturing this context gives LLMs far more sophisticated capabilities to parse language.
Well, for one thing there's masked attention. For another, this isn't a property of self-attention. It's a property of how Transformers split apart attention and the positional feed forward layers. But I'm sure we'll talk about that (spoiler: we won't, things fall apart dramatically shortly; the authors don't understand anything).
> Transformers process an entire sequence at once — be that a sentence, paragraph or an entire article — analysing all its parts and not just individual words.
They just talked about an RNN that process words. And all of their parts. Also there are bidirectional RNNs. This comparison is nonsense. They should just not talk about RNNs if they can't say anything reasonable.
> This allows the software to capture context and patterns better, and to translate — or generate — text more accurately. This simultaneous processing also makes LLMs much faster to train, in turn improving their efficiency and ability to scale.
Ironically, they managed to identify the one part of LLMs that is slowest and most problematic as the part that is the fastest. A whole lot of papers focus on making attention faster because it's the computational bottleneck of Transformers; very funny to call that what makes them faster to train. Also, faster to train than what!? RNNs just don't scale up well (traditionally, let's not get into newer models). So it's not a matter of faster, it's a matter of, we couldn't train large models before at all.
Then there's a whole lot of "it does X, Y, and Z", no idea what in their story would make anyone think the models should ever do that.
> From this enormous corpus of words and images, the models learn how to recognise patterns and eventually predict the next best word.
Huh? How'd we sneak this one in? So the story they're telling is: we learn word embeddings, then we self attend to them which means looking at how other words related to them, and then that model learns to predict the next best word? Wow, it's like watching a blender process ideas into goo.
> After tokenising and encoding a prompt, we’re left with a block of data representing our input as the machine understands it, including meanings, positions and relationships between words.
tokenising!? encoding a prompt!? Where'd this come from. I love how we start the sentence with "tokenizing" and end it with "words", just a total confusion of ideas.
A block of data encoding the text as the machine understands it. Look at that beautiful block of data! A beautiful block of data that comes from.. word embeddings + positional encoding (huh? never talked about this one either) + self attention. Because, that's all there is to transformers.
Just some self attention, one round of it. On top of word embeddings.
That's the message. That's total and complete gibberish.
> At its simplest, the model’s aim is now to predict the next word in a sequence and do this repeatedly until the output is complete.
What is there to predict? In the story they've told I have pretrained word embeddings and self attention.
> To do this, the model gives a probability score to each token, which represents the likelihood of it being the next word in the sequence.
A "probability score"!? My inner statistician just took their own life. The next word in the sequence!? They're mixing up decoders with masked word prediction.
> With beam search, the model is able to consider multiple routes and find the best option.
Why!? Why talk about beam search? Who told them about beam search? Most models do something called top-p not beam search these days. But that's such a minor and worthless detail.
> This produces better results, ultimately leading to more coherent, human-like text.
I wish human-like text was coherent.
So there you have it. Transformers are pretrained word embeddings with one round of self attention that predict the next word sequence by beam search. cry
> Most models do something called top-p not beam search these days
now im not so sure you know what youre talking about. gpt4 at least is rumored to use beam search. as i understand this is more sophisticated than top-p, so thats noteworthy
While I agree that its an overstatement to say beam search is a minor/worthless detail, its not as cut and dry as "beam search > top-p". You will get wildly variant results with both sampling strategies depending on the objective function that any given model was trained on, in addition to the type of task domain you're expecting the model to perform.
Just to cherry pick one domain: if you're doing any creative work (storytelling, roleplaying, etc), top-p may be a better sampling strategy because you will almost always get more diverse output. But since it's much less predictable, you probably don't want that sort of strategy for summarization or sentiment analysis.
Useful comment. But I wonder if you are not overstating the anti-meaning interpretation. Yes, attention is task-oriented, but it is instrumentally useful to track inputs in a way that approximates meaning. Isn't that why we say that initial layers are syntax oriented while later layers are more abstract?
The goal of attention is simply to find the parts of the input that are useful for the task being carried out. There's no component dedicated to "meaning", there's no objective function for that, etc.
The reason why we say initial layers contain information about syntax is because we attach probes (linear decoders) to those layers and run an experiment: can I classify the part of speech of words with the activity at the first layer, at the second layer, etc.
Turns out you can use early layers to classify the part of speech of words. But for something like coreference resolution you need much later layers. But that's an emergent property. Nothing in the network talks about meaning in any way. And certainly not about syntax, etc. Definitely doesn't mean those early layers are only about syntax, or about syntax as we think of it: they just have enough information to classify things like part of speech.
I'm not being picky. This is really important! That's why networks like this can take as input language, audio, images, video, etc. Because they don't commit to one idea of what meaning means, they just attempt to do masked word/region prediction.
Very well done animation. In no way does that change my mind about the eggregious continuing use of words like "learn" for what happens inside the software system.
To me, the english-language choices in how LLM and Transformers are described as working is part and parcel of the "sell" of steps-to-AGI because of normalising use of words which imply intentionality, introspection (as humans know it), thinking, cognition.
So I both love and loathe this animation. It re-inforces people's naieve tendency to "its alive" when in fact, its doing a really good job of explaining how weighted sums and statistics inform the parse, and the consequences of modulation of the products of the parse.
The programmers were very smart people. They've done well and have codified a huge body of knowledge which helps systems with producing outputs from input strings, in line with our requirements. Sounds exciting doesn't it!
You're saying that the billions of lines of text have not informed a statistical model of relationships of words in grammer? You think the "body of knowledge" has to be in the meaning of the words? No. It's in the weighted maths of the likelihood of each element of the phrase. That statistical model is knowledge. Some semantic intent is there too, to disambiguate who flies like an arrow or flies like a banana.
Hmm. Is adjusting weights metaprogramming? It's based on observations of the outputs of the system. It's certainly not directed programming intent in the normal sense.
It shares one property of traditional programming: garbage in garbage out.
The fruits of their labour indirectly is a model. It's proving valuable. You want to ascribe the value to .. the bit nobody claims to understand? I'm sticking to the labour theory of value here, either the robot makers imbued value, or we have to redefine the value.
So when people told the staff the models were racist you think they just "asked it to be less racist" I think they did a little more than just adjust the input data, they also modulated the logic behind the Weighting methods. No?
> they also modulated the logic behind the Weighting methods. No?
No. They did not change the logic. They cannot change the logic. They wouldn't have a clue how to do that. No one does. The neural network is practically impossible for us to understand and manipulate directly at that level. Way too complicated. They trained it to be "less racist" by RLHF until it was sufficiently woke.
The logic is exactly what is "learned" automatically by the machine and is beyond our current abilities to understand at a low level. The neural net is too vast.
> you think they just "asked it to be less racist"
Yes that's basically what they did. It is incredible technology.
To be fair, there's active research on this under the "interpretability" label. It's not out of hand impossible that there's a free "racism" neuron that we can just bias. Though we better be pretty sure what exactly a neuron measures before we patch it.
Makes me think of genetics. We could say that genes and gene expression is associated with some macro behavior, sometimes with an almost 100% match, and sometimes the gene affects several but pretty unrelated biological processes.
Maybe we need a similar discipline to understand models and how each neuron impacts the overall behavior of the model. Neuronics?
Now we just need to develop a technology that trains racist human beings to be sufficiently woke and less racist. Then they will stop polluting the training data of LLMs so much.
> Hmm. Is adjusting weights metaprogramming? It's based on observations of the outputs of the system. It's certainly not directed programming intent in the normal sense.
If you want to define "metaprogramming" in that way, then you'd be making all our brain functioning also that.
I don't think that's your intent.
Also, I'm not sure if I was clear before, but "[n]one of the free parameters of these statistical models were selected by programmers" for me also implies "humans don't adjust the weights".
> It shares one property of traditional programming: garbage in garbage out.
Can you name any system or entity that doesn't? I was going to write "Humans spent millennia thinking men and women had different numbers of ribs, because they took in garbage and didn't check", but when looking up citations to make sure this wasn't just an urban legend it turns out lots of people still think that.
Other modern legends: people today who believe "everyone thought the world was flat until Columbus", when Columbus' main contribution was overconfidence in bad maths making him think the combined width of the Pacific, the Atlantic, and the continent of North America… could be crossed in a fairly short single sailing trip.
> The fruits of their labour indirectly is a model. It's proving valuable. You want to ascribe the value to .. the bit nobody claims to understand? I'm sticking to the labour theory of value here, either the robot makers imbued value, or we have to redefine the value.
Labour theory of value is fine if that's what you want to do. That said, "the makers imbued value" isn't incompatible with "and the thing they made has learned something" — if they were logically incompatible, the same argument could be made with old-fashioned organic human children to deny them likewise. I'm sure you don't want to do that either, as I remember you from a previous time this topic came up :)
The same problem also exists with books: you read a book, did you learn, or was the value all in the author and editor? Both, I say.
One can certainly say "LLMs regurgitate human text" (specifically LLMs rather than all AI as some, e.g. AlphaZero, learn without any human contact), in the same way one can dismiss a human as "only book-smart, not street-smart". I wouldn't do either (of a human it is an insult, of an LLM it is unclear) but one could.
My man you're completely off base here. No one is programming anything into neural networks and we have no idea how models like GPT-4 work at a high level.
The whole point of neural networks is that we don't know shit and we don't know shit about how to distill the mechanics of some very real, very important processes so we figured out a way to make the machine figure this out on its own.
So the term "Machine Learning" is egregious misuse of language? These models are not explicitly programmed. They actually learn a model from data automatically. The term is technically correct.
These words are applied to living people. Applied to machines they create states of belief outside the cognoscenti what is going on.
It's as if we called programming "magic" and programmers "wizards" and then kids ask "is Harry potter real" and somebody says "yes"
It's not hallucinating. It's an analogy. But analogies are not definitional. We're going to wind up in conversations about AGI and use of imprecise analogistic language will alter how people discuss this problem.
Sorry you think I'm irratinal. I think you're being obtuse and not considering real world consequences of the ontologies used outside of the field.
Don't "run" programs, don't let them "spawn" threads, don't allow CPU to "follow" instructions, don't "read" or "write" files, should I keep going? All these words used to mean humans doing things, we have been anthropomorphising the machines since the beginning. You are fighting a loosing battle here, better to just calm down and relax.
A warm-up exercise before going into any programming task is coming up with names for the methods and interfaces I intend to implement.
A more difficult exercise is coming up with apt names without anthropomorphising--something I rarely succeed at. I'm often drawn to analogs in the musical realm (Scales, Sequences, Signals, Tuning), carpentry (Blueprints, Components, Scaffolding), libraries (Resources, Pages, Indices), the natural world (Roots, Trees, Seeds, Leaves), physical media (Slots, Packages), publishing (Versions, Releases) and even cooking (Mixers, Recipes).
We often understand technology by way of analogy or prior experiences. Whenever dealing with the abstract or unknown, metaphors are often the first tool to make sense of them [0].
I see from your other comments you still don't fully understand that these algorithms are automatically generated based on their training data. That's what we mean by "machine learning". It figures out the algorithm by itself through an iterative "learning" process that builds a predictive model. Training/Learning are perfectly reasonable terms in this context.
They learn patterns in data automatically. These are not explicitly programmed by humans.
The objection is that the word 'learn' is generally used in reference to how humans learn. There is a lot implied in this usage, and a long history of use by the general populace. By overloading it as 'things that are kinda like human learning, in some ways' you must ignore swathes of that implicit meaning to remain correct while using it. It is no longer a phenomena, but a class of phenomena.
The problem they pose is that people aren't going to do that - they'll continue using 'learn' as a stand-in for 'human learning' even when discussing ml adjacent topics, and that is damaging to effective discourse.
Practically speaking, that ship has sailed. Regardless, it's a reasonable take.
You can literally see their implied scenario play out in this thread - they claim that llms are doing machine-like learning rather than human-like learning (an entirely uncontroversial claim, humans are almost certainly not transformers in disguise) and the conditioned response is along the lines of "you're wrong, they do learn! obviously you don't understand the most trivial aspects of machine learning!"
This exchange merely proves their point (which is really the observation): overloading this word in particular causes grief. Misunderstandings abound and arguments arise from no actual disagreement in object level reality.
> they'll continue using 'learn' as a stand-in for 'human learning' even when discussing ml adjacent topics, and that is damaging to effective discourse.
Whoever doesn't understand the term are non-experts. It's not an issue among people who studied and research the topic.
Speaking frankly, this seems like a misread to me. Ascribing an author's intent to the output of a program they wrote is not the same as believing they manually performed the actions of the program.
> [...] modulated the logic behind the Weighting methods.
I fail to see how this is not literally the case.
The 'logic behind the weighting methods' refers to something like cross-entropy loss minimization via AdamW (or insert optimizer / loss function of choice) over some dataset. I read that as 'the process that decides the weights'.
If the model is unaligned ("too racist"), fine tuning with rlhf or alternative of choice is a modulation of the aforementioned 'logic behind the weighting methods'. It is a modification to the process that is deciding weights.
Judging by your response, you read 'logic behind the weighting methods' as 'the weights'. I don't think this is a reasonable interpretation unless you're trying to construct a strawman to argue against.
Sanity check via chatgpt:
> In the context of generative pretrained transformers (GPT), "logic behind the weighting methods" refers to the rationale or reasoning behind the techniques used to assign different weights to words or tokens during the model's training process.
> Judging by your response, you read 'logic behind the weighting methods' as 'the weights'. I don't think this is a reasonable interpretation unless you're trying to construct a strawman to argue against.
So now we are talking about two separate things. The algorithm used to train the model, and the model itself. They did not alter the algorithm that generated the model and they also did not directly alter the model itself. The neural net was modified indirectly through training. That's machine learning 101. When fine tuning a model we do not alter the training algorithm that generates the model. As far as we know, no one is manually tweaking weights or manually editing nodes in its neural network (yet). That is far beyond current knowledge and abilities but is an active field of research in the very early stages.
The training process is a search in model space where bad answers are penalized and good answers are rewarded. The algorithm itself doesn't need altering to find a "less racist" model. There's nothing special about racism that requires a fundamental change in the transformer architecture. It's just language and semantics. They trained the shit out of it by RLHF (Reinforcement Learning from Human Feedback) until it was less racist.
Are you trying to argue that RLHF is the same as the algorithm used to pretrain and finetune models, because they are both searches in model space that reward good answers and penalize bad answers?
If you only look at the very high level superficial details, they could be said to be similar. That is all. The details differ in nontrivial ways.
> They did not alter the algorithm that generated the model and they also did not directly alter the model itself. The neural net was modified indirectly through training.
It is beyond contesting that multiple, different, algorithms are used to train SOTA language models. RLHF exists because pretraining on a broad corpus for predictive loss minimization, then instruction tuning on specialized datasets, is insufficient in various ways (alignment, "racism", etc).
RLHF and pretraining/finetuning use different algorithms. They are similar in some ways - they can both incorporate backprop with a stateful optimizer like AdamW. This does not make them the same.
RLHF computes loss differently from how it is done in pretraining and finetuning. That, alone, constitutes a modification of the logic behind the weighting process.
Once again, the logic behind the weighting process refers to the training algorithm. Not the transformer architecture. Not the weights themselves. The process that decides what the weights are.
> The training process is a search in model space where bad answers are penalized and good answers are rewarded. The algorithm itself doesn't need altering to find a "less racist" model. There's nothing special about racism that requires a fundamental change in the transformer architecture.
Neither I nor the op claimed that anyone changed the transformer architecture to make it less racist. See my last reply w.r.t. reinterpretation of claims in service of strawman construction.
> They trained the shit out of it by RLHF (Reinforcement Learning from Human Feedback) until it was less racist.
As per above, RLHF is a nontrivially different process to what was used to train the too racist model in the first place.
> RLHF computes loss differently from how it is done in pretraining and finetuning. That, alone, constitutes a modification of the logic behind the weighting process.
You are confusing yourself and still not quite understanding the basic concept.
Machine learning has three parts:
1. Training dataset
2. Learning algorithm.
3. The model.
The data is input to the learning algorithm which generates the model.
To make ChatGPT less "racist" they provided new training data and rewarded it for the correct answers.
The process or algorithm of RHLF was not modified specially to handle "racism". These are general learning algorithms. They simply added new training data. This is basic Machine Learning 101.
Ah, I see. You are unfamiliar with how SOTA language models are actually trained in current day, what RLHF is in detail, and how it differs from other training phases. I'd encourage you to read through the GPT3 [0] and llama2 [1] papers for more salient descriptions of the specific mechanics involved and why RLHF is used at all, before trying to argue from some kind of introduction to ml 101 level simplification of how SOTA models are produced.
For example, from the llama2 paper, section "3.2 Reinforcement Learning with Human Feedback (RLHF)":
> RLHF is a model training procedure that is applied to a fine-tuned language model to further align model behavior with human preferences and instruction following. We collect data that represents empirically sampled human preferences, whereby human annotators select which of two model outputs they prefer. This human feedback is subsequently used to train a reward model, which learns patterns in the preferences of the human annotators and can then automate preference decisions.
The rest of 3.2 should be enlightening as well (in service to understanding how RLHF is actually quite different from the training algorithms used in pretraining or finetuning).
> The data is input to the learning algorithm which generates the model.
> To make ChatGPT less "racist" they provided new training data and rewarded it for the correct answers.
For frontier language models, this is strictly incorrect. Multiple rounds of different training algorithms are used, each with its own objectives. RLHF is more complex than just 'put better data into same old pretraining algorithm.'
> The process or algorithm of RHLF was not modified specially to handle "racism". These are general learning algorithms. They simply added new training data.
Nobody is claiming RLHF was modified, but that the 'logic behind the weighting methods' are modified. Pretraining, then finetuning on specialized dataset does not produce a sufficiently aligned (non-racist, gender-neutral, etc) model, no matter how much extra data you throw at it: the answer to this is the introduction of a different algorithm, RLHF, which more accurately fits the model to desired alignment than unsupervised autoregressive loss minimization does.
The sequence of events here is:
1. unsupervised pretraining on mixed dataset
eval result: "it's just continuing the prompt instead of answering questions or being useful"
researcher response: "let's put more focused data in to make it respond better"
2. instruction tuning on task-specific dataset
eval result: "it's answering questions now but it has inherited biases from the pretraining corpus (it's too racist, sexist, or otherwise not aligned with desired values)"
researcher response: "we've hit the limit on what you can reasonably accomplish with this training algorithm, let's try something else" (see GPT3, section "5. Limitations")
3. rlhf on human preference dataset
eval result: "well, it's less racist now"
> You are confusing yourself and still not quite understanding the basic concept.
Once again, as per my last reply: "If you only look at the very high level superficial details, they could be said to be similar. That is all. The details differ in nontrivial ways."
The basic ontology that you're trying to argue exists, is counterfactual. It boils down to: "put data into training algorithm, get model out. if it's too racist, put aligned data in and get non-racist model out." It's not hard to understand, you're just wrong. SOTA models are not produced this way. Full stop. The details of training phases are nontrivially different both algorithmically, and in the datasets used.
At this point we've exhausted all reasonable discourse; it's clear that you're not engaging in good faith and I remain convinced that your position falls apart under the most trivial application of rigorous analysis. If you have any actual source to back up your claims, I'd love to see it. Beyond that, good day.
> the answer to this is the introduction of a different algorithm, RLHF, which more accurately fits the model to desired alignment than unsupervised autoregressive loss minimization does.
FFS. That's exactly what I have been trying to explain to you. RHLF is the general method. So you agree with me. I am fully aware that there are different algorithms used at different stages of the training process. No one is hardcoding racism out of the model or hardcoding antiracism in the training algorithm. That is learned automatically. It's still the same basic machine learning 101 concept.
> At this point we've exhausted all reasonable discourse; it's clear that you're not engaging in good faith and I remain convinced that your position falls apart under the most trivial application of rigorous analysis. If you have any actual source to back up your claims, I'd love to see it. Beyond that, good day.
Totally unnecessary and uncalled for. You have repeatedly accused me of bad faith which lowers the discussion to a childish level of vindictive garbage. You were not making your point clear before and I was making the effort to respond sincerely to that, trying explain what I thought you misunderstood. It seems that you are still confused and are arguing my point for me without realizing it. Thanks for making my point clearer and adding interesting technical references to back it up. You have provided the sources to back up my claims. Cheers. Have a good one.
As per my last reply, I don't believe further debate of this point would be productive. We've both made our arguments. I'm comfortable letting mine stand on their own merits.
If you'd like to start a meta-discussion about this discussion, and any grievances therein, I'll happily participate if we can keep it civil. I think understanding why and how debates can breakdown at the limits (and what those limits are) provides real value in avoiding such breakdowns in the future.
> Thanks for making my point clearer and adding interesting technical references to back it up. You have provided the sources to back up my claims.
I am glad to have made a positive impact on you in some small way, at least.
> Totally unnecessary and uncalled for. You have repeatedly accused me of bad faith which lowers the discussion to a childish level of vindictive garbage. You were not making your point clear before and I was making the effort to respond sincerely to that, trying explain what I thought you misunderstood. It seems that you are still confused and are arguing my point for me without realizing it.
In the spirit of the above, if you are being sincere: I must genuinely urge you to consider why someone might believe your arguments to be unsatisfactory, and how charitable it is not to only consider incoherent formulations of the arguments of others. Put simply: if you see someone's argument as trivially unsound, is it possible you have misunderstood their position?
If you're admitting that you did not understand my argument with sufficient clarity to contest it, on what grounds can you claim to know what I've misunderstood in the making of it? My claim follows from this line of reasoning. You are, necessarily, by your own admission, arguing against a strawman.
{kind=link}
Like, what tools do the authors have. Are the content authors super tech savvy or not. How much specific code must be created for each article. How long does everything take compared to a normal, mostly-text page. How many people work on one article. etc. Must be pretty interesting.