This is very cool and I explored doing this with our feeds at Standard Ebooks.[0]
But there's a gotcha:
This works fine if you serve the feed with `content-type: text/xml`, because with that content type the browser typically renders the result in-browser. But `text/xml` is technically not the correct content type for RSS feeds, `application/rss+xml` is; and when you serve it with that content type, browsers typically either open a download window instead of rendering the feed, or they render it as plain text without styling.
So you're stuck. Have a styled feed but serve it with the wrong content type, or be technically correct and serve it with the right content type, but no styling for you.
Practically, content type really doesn't matter that much, and most (all?) RSS readers are fine with `text/xml`. But for those of us who like to be technically correct...
Which means it would prefer to get a response from the server in (basically) the order shown, but it will accept any response type (*/*). So ideally the server would be using that information and making the decision to serve the RSS feed as application/xml instead of application/rss+xml. AFAIK if the "subtype" (rss+xml in this case) has a + in it, then it basically means it conforms to the format after the + (e.g. application/xml) and thus is just providing a bit more context, but is still valid as the more generic version.
Though I do think the browser should also keep that same thing in mind and attempt to render any application/whatever+xml in its XML renderer.
Edit: another thing you could try to add this response header:
RSS maybe not be dead, but it's definitely less alive than it uses to be. The number of "blogs" these days that don't have a feed is absolutely tremendous. The decisions of the browser companies to remove the RSS icons / deemphasize the features is criminal (especially Firefox, who doesn't have the nefarious interest the others have).
Those blogs "don't have it" or "don't advertise it"? Seeing that most blogs are Wordpress or another platform that has RSS baked in by default it seems rare to come across one without a feed, even if you have to dig for it a bit.
Often don't have it, my method this day is to copy the URL of the website to a feedreader.
The first few times it didn't pick up a feed, I would inspect the page source, and sure enough, no `link` tag in the head for the feed (nor references to "rss" or "atom" or "feed" anywhere in the page).
I don't know what stack they use, but I find this particularly common for company blogs.
That's true, I follow a lot of blogs that I get the RSS with trial and error, mostly typing /feed or /RSS, because they don't offer a straight link anywhere
Yeah, idk what GP is referring to. I can't remember the last time I saw a blog that didn't have an RSS feed. Maybe some exceptions being Medium posts (lol) and corporate blogs where it's posted as part of a larger site, not just someone's personal blog.
Many people who have switched from batteries-included, purpose-built blogging stacks like WordPress to e.g. static site generators (or similar roll-your-own setups) don't have a feed by virtue of the fact that the folks publishing those sites haven't gone out of their way to write the feed template. This is not unlike any other subject where participation comes down to opting in versus opting out.
That isn't to say any claims that feeds are almost a thing of the past holds any water. There are almost certainly more feeds now than at any point before. The second derivative is probably a flat line, though, which is what I imagine is behind the perception of deathliness. Feed consumption, on the other hand, is almost certainly down—but only if you exclude podcasts.
RSS feeds don't have to provide the whole content of the blog post, so there's no reason why RSS can't be compatible with the various user-hostile techniques prevalent today.
Many RSS SaaS providers would request the RSS once from their own server and then serve the cached request to all users subscribed to it. This basically makes it impossible to track the user in any form.
> especially Firefox, who doesn't have the nefarious interest the others have
It's important to note that Firefox is all but legally owned by Google at this point. It exists on Google's dollar so Google can point at it during anti-trust lawsuits.
When I was young, naive, and still in HS, I thought XSLT would be the future. Imagine, one XML file, many representations! It could be your Database, your Website, everything! Writing one took forever, but never until I learned programming in university was I so amazed how some code had such a visible result.
I once built an entire site where the frontend was XSLT applied to XML from the middleware that spoke to the various data sources. You could set a url parameter and switch off the server side transformation to let the browser do it client side (and another to transform it into RSS instead of HTML).
I liked the overall approach of a declarative transformation, but XSLT is absolutely awful and the lack of an alternative that's supported by browser made me not do it again.
The big challenge with XSLT was that the basics were verbose but easy - just pulling fields from the xml and putting them into a template. But then you ran into things that's simple with other solutions, like re-formatting dates and ended up with either humongous functions or biting the bullet and including multiple pre-formatted versions in the XML, and the moment you start down either of those paths you start to dislike XSLT pretty quickly.
In a way modern React etc. frontends can be seen as a "fix", in the sense that at least it means most sites effectively have APIs, whether or not they officially expose them to users, but without the pain of XSLT. If they support server side rendering as well, they're getting close to what we were doing.
And that was the original driver for the site design I mentioned - every URL was an API endpoint with a well defined set of expectations, letting you effectively explore the API by browsing the site as normal until you had sliced and diced the data the way you wanted and then just add a parameter to get it in the format you wanted (just as you can with Reddit - e.g. append ".json" or ".rss"). And I try to do that as much as possible still.
Yep. I built my blog to serve the markdown over HTTP and have a minimal stub to make the browser render it nicely. But that turned out to be much cleaner to do with Javascript than with XSLT. HN hates it, but I really think it's the way forward.
I think HN would look at lot more favourable on it if it defaulted to do serverside rendering, but you could turn it off. I had a look, and for me at least on the initial load there's also a flash as the markdown displays and then gets replaced with rendered content, which kinda drives home that something unusual happens - it might also make it feel nicer to hide the markdown with css until it's rendered. (It's odd because it doesn't seem to happen consistently, even with a hard refresh.)
Before the "XSLT adventure" I wrote a big webapp in C++, and we actually had a C++ rendering pipeline that had a component model to render not all that different to an initial React server-side rendering, combined with a pipeline where custom tags could be registered to further rewrite the output. I really liked that apart from being C++ and lacking the ability to optionally to client-side rendering.
> had a look, and for me at least on the initial load there's also a flash as the markdown displays and then gets replaced with rendered content, which kinda drives home that something unusual happens - it might also make it feel nicer to hide the markdown with css until it's rendered. (It's odd because it doesn't seem to happen consistently, even with a hard refresh.)
It's because the browser renders the <xmp> content itself first. I used to have that set to display:none which prevented the flash, but HN complained about not being able to see anything with Javascript turned off :/.
Oh man, you bring back memories. It had so many appealing features, but trying to do all kinds of logic with XPath et cetera became annoying very quickly.
While XSLT is far from perfect, what I always loved was it was built into the browser. People have spent/wasted twenty years rebuilding templating systems in JavaScript. Browsers have had it all along but because it's related to XML it seems web devs' brains just seize up thinking that's only used by boring old Enterprise development.
To be more charitable I think the problem has always been tooling. There's not a lot of good design tools that have supported XSL stylesheets as output. You've always had to do a lot of manual editing to get make a decent stylesheet and do any complicated functions.
What's annoying is XSL can be used for any XML documents like you said. Your "pages" could just be serialized database entries with a stylesheet on them. Since all the styling was done client side the server is really just an API server.
This was a design conceit of ATOM. It was mostly used for syndication but it was meant to be an XML API interface. It supported posting to a server in the ATOM XML definition as well as pulling. The idea being you'd come across a server with an ATOM API and be able to post comments or whatever to it right from a browser, no HTML form or JavaScript required.
Yeah, I was quickly dissuaded from that the first time I tried to write a XSLT.
The same way that DTDs are very easy to work with... until you get a complex one created by a lot of people.
XML is so incredibly full of horrible decisions that it's not funny. And they are never on the macro level of "this format is useless", they are always in the details.
Author here. What many people claiming "RSS is dead" for the last 20+ years mean is that RSS-as-feed (for written content) is not mainstream, and that's somewhat true. Most podcast listeners don't have a proper RSS reader apart from their podcast app. Also, big platforms removing existing RSS support is often taken as another sign of RSS dying.
What's interesting is that this particular post had been posted by someone on HN before I've shared it anywhere. So it got through RSS right onto the HN front page. This is what I meant with "thriving, especially among tech users".
My experience as someone who's in the tech sphere but writes not only about tech is that RSS is all but dead. Not sure if i'm an outlier in this but the % of requests in my server logs coming from RSS is very high.
Like you I tried to figure out how many of those are actual users to have a sense of how many people still use it and the numbers still don't make any sense to me.
That said, what do you think is the benefit of styling an RSS page? The point of the rss is to be consumed via an RSS reader so I don't see the benefit of having styles on a page like that. But maybe there's something I'm missing here.
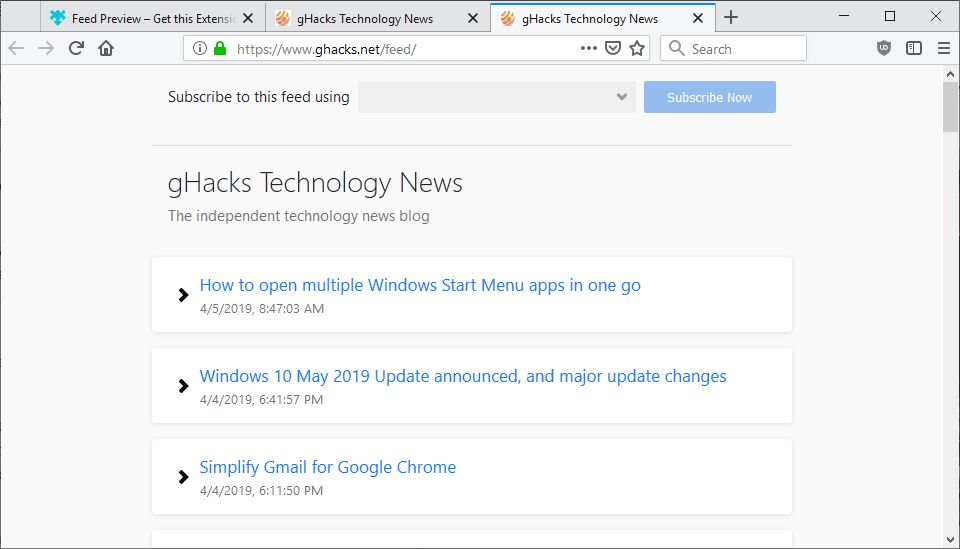
Yes, styled RSS feeds don't provide any value when consumed by RSS readers. But when I visit a blog and click an RSS feed link for the first time, it's nice to have a short preview of the existing posts without having to parse XML visually. The main benefit I see is however to educate people who don't know what RSS is. Imagine a person clicks "RSS feed" and all they see is some strange-looking file. On my feed [0], there is a big banner with a short explanation and a link to learn more about the technology.
Yeah that's probably useful. Btw your recent blog posts are sorted in a weird order according to the dates.
Also, and not sure why this is happening, I have the Reeder extension installed on safari and it usually automatically prompts me to open an rss link in the app but it doesn't happen in your case.
I can't even use the button in the browser toolbar to open the feed in the app directly. The only way for me to add it is to manually copy paste the url.
The posts are sorted by date, newest being at the top. I haven't posted much in 2022 and 2023, so maybe "Jun → Dec → Mar → Dec" looks confusing if you miss the according year?
Regarding Reeder, I've included the feed in the markup, so I'm not sure what is going on. I will definitely have a look, thanks for the finding!
Oh, you mean in the feed preview. Yeah, they're sorted by publish date but I only display the last update date. I see that it's quite confusing, I'll fix that. Thanks!
The author is pointing out that someone who clicks an RSS/Atom link and gets a page of gibberish is not going to understand all that XML, and they will likely just go back to the site confused.
Instead, you can have a readable page with a message like the one in the post: "This is an RSS feed. Subscribe by copying the URL from the address bar into your newsreader. Visit About Feeds to learn more and get started. It’s free."
I can see some value in redirecting people towards a page that explain what RSS is. Not entire sure about the first part about letting people know how to subscribe to an rss feed because people who decide to use an RSS reader probably know already how to use it since it's a somewhat technical tool but still, probably doesn't hurt to provide extra info.
I work in podcasts and not with written content RSS feeds, but at least in the podcasting world, I would take traffic from RSS endpoints with a grain of salt - a lot of reader clients like to request updates very frequently, and it's not unreasonable at all that a user that consumes your content primarily through RSS makes one or even two order of magnitudes more requests than someone who visits your site.
The parent might be referring to my other post [0]. Some RSS readers - at least Inoreader, Feedbin and Feedly - send the actual subscriber count as part of their HTTP request. Which is nice to get at least a minimum number of total subscriptions. Not sure if popular podcasting apps do that as well, though.
I wrote about my findings here[0] and honestly I don’t even know what to make of those numbers. RSS stats are stupidly hard to track, especially if you only rely on server logs which is what I do.
> ... tech is that RSS is all but dead. Not sure if i'm an outlier in this but the % of requests in my server logs coming from RSS is very high.
I'm not sure which you meant here—is your perspective that RSS is thriving (judging from your traffic) or nearly dead?
There are two very similar English idioms that have opposite meanings: "all but dead" means basically dead, "anything but dead" means not even a little bit dead.
> Most podcast listeners don't have a proper RSS reader apart from their podcast app.
Sure, but I would assume that "RSS is dead" isn't so much about consumer awareness of RSS, but rather about the technology being invisibly supported and used in the infrastructure they make use of (through podcast clients et al) such that content producers still care about publishing through RSS.
Like, if I said "TLS1.0 is dead", I wouldn't be referring to greenfield projects not using it any more; but rather to the fact that the browsers and libraries that invisibly use it (and nothing newer) are themselves not being used by anyone any more — so nobody on the content-delivery end has to think about supporting TLS1.0 clients any more, and can drop any code that was supporting that.
But that's definitely not the case with RSS. There are still many important systems that depend on consuming RSS feeds. So there are people who still need to support RSS. So it's alive.
> RSS is alive and well and mainstream with podcasts.
Spotify (and other big players) are doing their best to end this.
As many as one in four podcast listeners currently use spotify to listen. The growing number of spotify-only podcasts are not available via RSS. Most of the listened-to podcasts may also be available as RSS, but the listeners wouldn't know either way. Spotify's goal is to be the chokepoint for podcasts.
Spotify isn't the only one. The way to make money on podcasts is by being the distribution platform, and by locking people in with non-open standards.
Spotify still uses RSS as a distribution channel from your host to Spotify - you supply a RSS feed through Spotify for Podcasters or another ingestion service. They don't allow adding by RSS feed for end users, but that's not all that rare among players.
But there are also spotify-only podcasts, which are not distributed to spotify like that, are not available via RSS or any other method but a spotify client.
This is an intentional business move by spotify. They are attempting to change the podcast landscape.
Although googling for recent sources, it looks like there's been some pushback and slight retreat -- looks like their plan wasn't exactly working. Yet. I'm sure they haven't given up yet:
> After the cancellations and resulting layoffs, members of the Gimlet union blamed Spotify’s exclusivity strategy for disappointing numbers. Although the shows were not behind a paywall (free subscribers to Spotify could access them, as well), they did not enjoy the kind of wide distribution that the shows did before the acquisition. It’s not like they don’t have a big platform — according to a study by Cumulus and Signal Hill, Spotify is tied with YouTube as the most-used podcasting platform. But even then, it only has about one-fifth of the market.
Spotify and Apple are both acting anti-competitively in different ways. Spotify has their exclusives (which from the looks of it seem to be largely not a huge success outside of Joe Rogan and something they appear to not be focusing on as much), but Apple is very anti-competitive when it comes to direct podcast monetization like support and subscriptions where Spotify has taken a very open approach.
If your player wasn't spotify, now you know why! Spotify bought them and took them spotify-exclusive, in part of an attempt to gain control of podcasting landscape.
And if you are typical, apparently the gimlet staff were right to be worried that this hurt their numbers!
Not so sure about podcasts. At least where I am from (Italy) a great deal of podcasts are either Spotify exclusives, or consumed mostly through Spotify, or bundled in some producer-specific app (e.g. the state-owned radio does this, and doesn't provide feeds).
The vast majority of podcast content is distributed via RSS. In fact if its not distributed via RSS, no one is listening. It’s so important its even advertised as part of Spotify’s podcasting platform.[0]
Of course Spotify has incentive to prioritize you listening in their app, but they can still put ads into the audio feed so it doesn’t matter as much to them. And your state-owned radio is absolutely limiting their audience by not using the accepted standards for podcast content.
I would not be surprised if Spotify themselves get the audio from the source via RSS/Atom.
No doubt the podcast creator may have to create an account and tell Spotify manually (and also on Apple, Google, etc), but once the feed is in their system the creators/producers just need to update things in one place and all the 'distribution points' get the new episode.
Ah, I only skimmed the article and missed that. The BBC RSS feed was the main example I referred back to while I was learning XSLT around 2010-ish.
AFAIK it's the only major implementation of this technique. Most other big sites that provided an RSS feed didn't bother, and most of those RSS feeds are dead now. The BBC one has hardly changed since those days and it still works really well as a dual-delivery system.
I'm not a frequent XSLT user but I'm aware for example that, for example, you can add any text you want to the presentation of the feed with <xsl:text>. Can you add script, images, and basically end up with something similar to a modern webpage?
You have to wonder. What would the world look like if more publishers had gone the route of styling RSS or Atom feeds, and maybe supported and extended the relevant standards in the places they found those standards to be deficient?
Could we have ended up with a world where content delivery was all RSS, the relationship was exclusively between you and the publisher, and we didn't need Meta as the middle-man sucking publisher profits dry while convincing our daughters to kill themselves?
...Nahhhhh, I'm sure that going full neanderthal, RSS LOOK SCARY, clubbing it over the head and removing it from a website is the better approach. /snark
I've never really liked JSON as replacement for XML. Had we continued with RSS, Atom and XML, not only would we make peer to peer distribution far easier, we'd have a very easy publishing mechanism.
But we threw out XML for JSON.
With JSON we need loads of custom, client side code to turn it into a DOM that the user can look at. With XML we only need XSLT. It won't work for all cases, but the majority of sites wouldn't need a single line of JS to renders sites. Yet here we are: shadow DOM, event listeners, useeffect, JSX, progressive hydration, and so forth and so on. To build web-experiences that we could deliver back in early 2000 but were deemed too complex and too daunting.
Not sure if I understand correct, but the things I listed (event listeners, AJAX, etc) are things needed to be implemented so that you get what XML+XSLT in a browser give you for free.
To be clear: there are lots of things that XML+XSLT cannot do, but which JavaScript+HTML can do (in an HTTP context).
But for the most typical HTTP usecase: a website presenting information, XML+XSLT is fully up to the task, yet we forego that, and instead pull out the big, complex "guns", entire JS frameworks. A knee-jerk reaction that I blame on the bad rep XML got, and the praise it's incomplete but simpler replacement, JSON, got.
JSON is great, but lacks one feature that XML and its ecosystem has - extensibility and deep standarisation. XSLT, XML Schema, XML signing and encryption, native support of ids and refs, etc. All that missing points are doable with JSON or were added quite late, but yeah, standarisation is important.
> Can you add script, images, and basically end up with something similar to a modern webpage?
Sure, you can use anything you would on a regular HTML page. I was consuming my local news website via their RSS feed in my browser, as it looked like a regular website (but without all the fluff). Unfortunately, they've dropped the custom view completely, and it's now back to raw XML content :(
I didn't know the RSS feed could be styled - it's an interesting insight.
That said, on the RSS as a whole, for most websites (mostly publications I suppose), adding RSS feed is a set-and-forget thing.
Sure, it's great for readers as it allows them to read all the content from one reading app but, on the other hand, the publication can't provide a custom experience, or - what's most important for some publications - display ads. That's likely why RSS is slowly moving into obscurity, at least IMHO.
> Sure, it's great for readers as it allows them to read all the content from one reading app but, on the other hand, the publication can't provide a custom experience, or - what's most important for some publications - display ads. That's likely why RSS is slowly moving into obscurity, at least IMHO.
Sure. But a title-only RSS feed seems like a very reasonable compromise.
And it's so much better than what everyone seems to have moved to, which is email notification.
There are a lot of feeds now with titles and maybe a short paragraph of text, like the beginning of the article or a summary.
There is a world of difference between sites maintaining those feeds vs. nothing at all. Having a signal that an article is there with even the slightest amount of context is so much better than the alternative.
It's mildly annoying to visit a site for the full text (with your ad blocker), but signing up for newsletters etc. from each site one-by-one is really painful.
If I'm going to take 5+ minutes to really read something, it's OK to visit the site. That means something is interesting or relevant enough to invest my time in. That signal can usually be gleaned from a title and short paragraph. Compared to the number of new things published every day, it's relatively rare to find things worth those 5+ minutes.
From what I can gather, many people use RSS readers to follow 5-10 feeds, and they slowly look through and read most of the articles. It serves as a convenient way to follow their top few sites and maybe a few aggregators like HN. Other people track 100s of feeds and quickly scan what's happening, only diving into something if it's interesting or important.
I'm building a service for the second type of person (mainly because I'm that type of person, TBH). No idea what the ratio of "completionists" vs. "scanners" is. Having title-only feeds is not ideal for the latter group, but it's usually fine.
I’ve found some respite in email-to-RSS, but its still not great.
I’m definitely interested in a (hopefully FOSS) service for us “scanners”. I average around 300~ articles in my RSS daily, and I’m always hungry for more information. Though I should probably see about re-organizing it all so I’m not as consistently overwhelmed.
I want to make a FOSS reader that we can run on our own machines. It would poll on demand and be really good at archiving sites/posts. A combination of feed reader and scraping/archiving from residential IPs (at a low rate) where it will almost always be successful.
I want to pair that with an (opt-in) service for syncing feed subscriptions and handing off a stream of things worth archiving (it's often not urgent that this happens, you just want to make sure it happens soon so the content is not lost in a few years). That service could be a very low cost monthly subscription thing plus a FOSS option that you could run on a cheap VPS, etc.
24/7 services are also essential for generating notifications when something in a filter is spotted, being able to have an email gateway, doing things like POSTing items to other sites automatically, etc.
Making that "full" service FOSS is not in the near term plans, though. This is a distributed system that has run 100s of millions of jobs already, has a very specific security and monitoring setup, uses a number of queues and databases, etc. From my past experience, it's really hard to support people with on-premises distributed systems software like this (FOSS or not). I couldn't do this part alone (bootstrapping and can't afford to hire anyone yet).
i found out a tool that convets emails back into RSS, it even provides a custom e-mail address that you can use per feed. it can be self hosted, or used on their website (which is ad free): https://kill-the-newsletter.com
This might be the solution. RSS readers could serve as a general link aggregators (like HN), but with immediate listings of the latest content from your favorite sites. Too bad most just prefer to get rid of RSS entirely.
On the other hand, I don't necessarily dislike the email model (especially when having dedicated address just for newsletters) but it's much less comfortable than RSS and quite limiting from the publishing standpoint (given how far behind emails are behind modern Web).
Personally I still try to have RSS in all my content websites (with full content) as I'm primarily thinking about reach rather than ads. The ones that I haven't implemented RSS for yet, are just because it was more challenging or required more effort when integrating with e.g. CMS or something.
Have you used any modern RSS reader recently like inoreader, they load the content of the page without visiting the publishing website. So still, no ads.
> Have you used any modern RSS reader recently like inoreader, they load the content of the page without visiting the publishing website.
I'm happy with newsboat[1]; but I'm not surprised that people have integrated scraping into RSS readers.
Fundamentally, that's not a problem with RSS, that's a war between scrapers and content providers. If the email newsletter model persists long enough, I'd expect that people will come out with "newsletter readers" that scrape websites too.
I'm not sure there's a good long-term solution to the problem. Aside from constant vigilance (obfuscation).
Sure, you can obfuscate all you want.
But my point still stands valid.
Earning a living from ads for these types of people.is not sustainable. They will have adblocker installed, so you are also wasting respurces with no income.
RSS or newsletter or whatever scrapper, it's there today already.
Adding ads into feeds works, just make them an entry in the feed. I have also seen embedded images with ads.
Issue is that Google Ads and such don't offer this and you don't get the "typical" ad networks.
If RSS were more popular there wouldn't be a problem to build the required tooling.
Even when feed readers don't send cookies etc. while fetching you can do a permanent redirect to a feed with an unique ID in the URL and most feed readers will store that URL, thus you can do tracking (incl. personalizing URLs in the feed) and all that.
What saves reader privacy currently is the small user base.
Yeah, that's roughly aligns with what I've experienced. RSS is beneficial to publishers when reach is the top priority (e.g. it's a company marketing blog or the ads are "embedded" directly into the content).
In a parallel world the whole web is served as XML and XSLT directly from the databases, or from rss authoring software. Web servers only serve the blobs like images and other media. Content Management is done by combining rss feeds according to site hierarchy via an enhanced OPML dialect, also parsed client side. One or more feeds per page. Some pages show only the newest entry, others show the first ten with pagination, or all entries. This is configured via the OPML dialect. The data sources of a website can be completely federated. A machine readable licensing system enables integration of content from third parties on your site — without any backend changes! Social networks are basically thousands or millions of different sources in one huge OPML file plus some intelligence in the XSLT. Efficient caching on the network allows for very small and cheap servers for every content creator. Even your tablet could serve your feed.
I wanted to style my RSS page for non-tech readers, but I thought I need to return XML or HTML based on HTTP Accept header, therefore not possible for my static blog.
It's good to know that all I miss is a xml-stylesheet. I'm going to implement that once I'm free.
Do you remember when Feedburner promised to style feeds in a nice way while still providing RSS access for your feed readers? And then Google acquired it?
While I appreciate this approach, what I really want is when I click on an RSS link, the browser detects its an RSS and shows me a dialog telling me its an RSS page and shows a "Copy URL" button. If I click the button (or close the dialog) the browser returns to the page I was on.
Making an RSS file look good for a human is nice, but it isn't for a human to look at.
With RSS autodiscovery[1] your browser (or today an extension) can identify an RSS feed and with one click submit it to your RSS reader. You don't even need to find the RSS link in the HTML.
This is very cute, not sure how I missed this. I never liked the aesthetics of the XML that shows up when you click an RSS feed. Will make some time to style my websites' feeds soon. :)
I had been waiting for this tech for the longest time. When it was finally implemented by all, RSS started falling out of favor. I went back to this now, and it took forever to try to come up with a stylesheet.
I would say don't waste your time. Just get something off the shelf and start tweaking that one instead.
I love RSS, but the one thing that almost makes me anxious is whether I'm going to make one of those mistakes that ends up republishing the whole RSS feed in people's readers.
Just changing the ID of an entry. (Atom: //atom:entry/atom:id. RSS: //item/guid.)
The main time this happens is when people switch website backend or site generator or whatever, and don’t take care to keep the same IDs. In practical terms, IDs are just opaque strings, but they’re supposed to be IRIs (… even though you mustn’t assume it can be dereferenced) and universally unique, so a common approach is to use the page’s URL, which could lead to something like this if you change it:
An ancient proposal for stable IDs were Tag URIs [RFC 4151]: URIs which still have an understandable identifier like a domain but with a date encoded at the time of minting the URI which keeps the URI "valid" even if the domain lapses and minting "authority" moves to someone different.
tag:chrismorgan.info,2019-01-01:blog/slug
But the real problem, of course, is people caring: You'll need to store the ID with the content and continue using them when moving CMSs or domains. People, apart from your notable exception, don’t do that.
(Sorry for minting an example tag URI in your authority! I shouldn’t have done that according to the RFC.)
I'm still not entirely sure. I think Reddit's had the same issue with some of its feed when subreddits went from private to public, so if even they struggle with it, then it might not be entirely straightforward.
Not even sure RSS readers like Thunderbird have features to deal with duplicates like that.
The significance of this trick goes far beyond just adding styles to RSS.
The common practice is separating the the Human-readable interface (HTML) from the Machine-readable interface (XML) and build both of them on top of some source layer(e.g. a CMS or Markdown files)
XSLT allows you to use XML as the source layer and build a presentation layer on top of that. Admittedly, the styling workflow can be cumbersome but you get a browser-supported templating language that seems Turing complete (anyone confirms?) and with the power of CSS, you can pretty much get a full featured static site generator that runs on the client!
I've seen styled RSS once in a while and never thought about it until now. I'd love to give this technique a try. It feels like one of those Semantic Web ideas that should have taken off decades ago.
RSS is the easiest way to stay on top of new posts on small blogs. I'm unlikely to randomly browse to a blog that has one new post every few months or so, but if I add it to my feed reader I won't have to.
A corollary: if you have a small blog and you'd like people to notice your new posts (without you promoting them on social media), make sure it supports RSS!
We style RSS feeds as part of our custom RSS tool. Most users of that aren't necessarily technical and so providing a more user friendly interface makes a huge difference. You can see an example at https://sniprss.com/sniprss/curiously-creative/
I'd love to explore how we could do more with this as well as I see so much value but like it has been pointed out here, RSS is set and forget for many people and therefore isn't in the majority of user's minds. Also the utility of having content in a feed is undervalued IMHO.
You don’t seem to be doing the same thing: rather, you’re sniffing for an Accept header, and if it includes text/html, you serve HTML, and if it doesn’t, you serve an Atom feed with no XSL stylesheet.
Incidentally, given this behaviour your response should include `Vary: Accept`. This is actually messing Firefox up a bit: open the document, it loads the HTML, View Source, it renders the source of the Atom, loading it from the cache according to the dev tools, not sure how it got there, force reload and you get the source of the HTML. Your server is also not handling HEAD requests, but improperly responding 405 to them.
Firefox removed built-in support for RSS feeds years ago. When I try to view the feed in that image, Firefox just downloads the RSS file (sometimes Firefox will show me the raw XML instead). You probably have an extension installed that styles them.
Many, many years I had the misfortune to end up on a project that used Symphony[0] as the CMS for a client website. The entire theming system is based on XSLT, which makes some things really nice and simple, and other basic stuff an absolute pain in the arse (trees, parents, changing values based on something else etc).
I wish more people would consider XML + XSLT to build out web applications to improve tooling and the ecosystem around it.
I know it's not in style—today it's all about exposing data as JSON and then templating it with something like Web Components. Meanwhile this is stuff that XML and XSLT has been doing for over a decade.
Seeing a post about XSLT in 2023 :) in the midd 2000th when XML was all the rage I had to learn a lot of this stuff to be forgotten forever :). To be fair I think XML was a good idea with too much complexity and ambition. Our old backend was based on SOAP to talk to flash over an XML RPC protocol. Got to love it.
Feels strange to say, but while looking at those XSL files I’m thinking: that looks really good.
I cut my teeth on HTML5 and JSON APIs from 2010 and beyond, so I never really had to work with XML.
I’ve never felt wholly comfortable with the mixing of semantic markup and data with the presentational elements required for styling. While advancements in CSS have improved the situation, I really like the boundaries demonstrated here and the inversion of of priorities: ie. we fetch the data and then we consider presentation rather than downloading the presentational layer which then in turn fetches the data.
I know there is a lot of baggage around XML, but this aspect of it really does seem superior.
This is a fantastic guide, I've been meaning to try doing this to my website for a while but I wasn't sure if browsers even supported XSLT anymore. Guess this is my reminder to get around to doing it!
Haven't tried now, but it should be possible to just use CSS as long as the feed is served as text/html to convince your browser to interpret <style> elements as stylesheets.
Update: problem might be that browser sniffing for UTF-8 won't work, and that the doc might have multiple (RSS) title elements where the browser expects one (!) in head content
Interesting idea. But another issue might be that RSS readers won't be able to parse the content correctly if it's not served as text/xml (just an assumption).
I dunno that I would trust feed readers to do content negotiation properly. Again, I work with mostly podcast RSS feeds, but clients are generally atrocious about following standards (just ran into one recently where Apple Podcasts flat out ignores XML namespaces).
XSLT is great for this kind of thing.
Back in the day I added similar styling to make a convoluted but important XML config file readily human readable. The support guys loved it.
Main drawback is that without good tool support debugging XSL and XPath gets quite painful but IntelliJ had it covered.
Awesome. I was able to get this going easily enough on my jekyll-created site that uses the jekyll-feeds plugin. You just have to name the template right and it just works.
I've seen that previously on https://curiosity-driven.org/ (the main page is a feed file) but I'm not sure if XSLT support won't get deprecated and/or removed in browsers (since it's quite an old tech).
I guess the point is that XSLT 2.0+ is not shipped as part of browsers, nor is it expected to be in the future, considering the only implementation is (commercially licensed) Saxon, by the author of W3C's XSLT spec himself ;)
I can only hope this isn't the case, XSLT is a brilliant idea that's very underrated and a great tool to have in your toolbox.
I don't count how many times I've seen people attempting to create simple reports from some XML taken from some obscure back office and try to reinvent the wheel by doing some JSON conversion and process that from some other program that build up an html report
As another example, mine: https://chrismorgan.info/blog/tags/meta/feed.xml. I’ve also deployed almost exactly the same stylesheet in one or two other places, e.g. https://ganintegrity.com/blog/feed.xml which also demonstrates pagination (very uncommonly encountered, and I have no idea of feed reader support, but a useful concept that allows you to keep your feed file small while still (at least nominally) containing all the historical entries).
My XSL stylesheet is rather fancy in what it supports. Sometimes because I actually use that fanciness (e.g. supporting HTML in all text constructs, not just <atom:content>, because I use HTML titles), sometimes just for the sake of correctness or completeness (e.g. passing through xml:lang as a lang attribute, or more obscure elements like atom:rights), and sometimes for things that I might use some day but haven’t yet (e.g. turning audio/video enclosures into <audio>/<video> elements, for podcasts). https://chrismorgan.info/atom.xsl is for Atom, and I’ve also written an RSS variant of it, purely for use in podcasts since podcasts are stupidly stuck with RSS (and it’s almost all Apple’s fault and I hate it): https://temp.chrismorgan.info/2022-05-10-rss.xsl.
Developing using XSLT is an interesting throwback to how web development used to be, because this stuff is basically frozen as it was twenty years ago. Almost all errors are fatal, diagnostics vary between nonexistent and poor (remember when you basically had to bisect to figure out what precisely broke things?), and the dev tools you’ve grown used to can’t help you when anything goes wrong. Also there are probably more bugs than there used to be. And documentation is bad (a lot of load-bearing functionality is completely undocumented). And browsers are much more inconsistent in their behaviour than you’ve grown used to (welcome back to the days of enforced trial and error, and having to check things in multiple browsers). (You get some of the same weirdnesses if you try shipping HTML using XML syntax, but it’s mostly XSLT-specific.)
Some particular issues:
• The stylesheet needs client-side JavaScript to render any type="html" content (HTML serialised as text), because Firefox doesn’t support the (admittedly optional) disable-output-escaping="yes" XSLT feature. (I’m puzzled by this lack even when using <xsl:output method="html"/>—and yes, Firefox and Chromium do both produce HTML-syntax documents in this case, not XML-syntax documents. I check this by searching for an xmlns attribute an all elements’ outerHTML, not sure if there’s a more direct check and I’d love it if someone knew one, ’cos this stuff regularly matters in JavaScript libraries—loads of libraries will break if run in an XML-syntax document due to assumptions made that no longer hold. OK, enough of this long parenthesis.) Therefore I recommend using XML syntax for the HTML instead (type="xhtml" in Atom, no equivalent in RSS because RSS is a disaster), and expect to do so for whatever next refresh I do of my own website.
• The stylesheet needs client-side JavaScript to resolve URLs if you use xml:base, since browsers just don’t support that at all any more (if they ever did?).
• If you make an error in the XSLT, Firefox will often point to exactly where the error is, but just as often give a completely useless generic old-school XML parse error screen. It validates declared XSLT 1.0 stylesheets, and is all round not very forgiving of errors, which is good, except that I wish the error reporting was more reliable.
• Chromium is more forgiving of errors, mostly for the worse, blithely ignoring some XSLT 1.0 errors that you really wish it would point out because you have certainly done something wrong. On errors it won’t overlook, it will leave you with an document empty save for an xml-stylesheet ProcessingInstruction, not put anything in the dev tools console, and print the error to stderr (and with no stack trace in the XML or XSLT, which is painful)—I’m mildly surprised with myself that I even thought to run it in a terminal to see if there was any output there, but I guess I was getting desperate one time when everything was working fine in Firefox but not in Chromium.
• In Firefox, pages that use XSLT will sometimes just hang during loading (seems to happen very often, maybe even always?, when it’s the first navigation in a new tab). Haven’t ever filed a bug about this. My wild guess is that this probably started happening at some point in the switch to a multi-process architecture.
• If you reload the page in Firefox while the dev tools are open, the dev tools are now effectively dead until you close and reopen them. Bear in mind also that the dev tools operate on the post-transform document, not on the source XML. Haven’t ever filed a bug about this.
If you try working on this stuff, you’ll want to keep a copy of the XSLT 1.0 and XPath 1.0 specs open. They’re the best documentation you’re likely to find, and honestly pretty good. Because each is a single document, you can search through for keywords nice and easily.
I’ve been very tempted to try shipping a website where pages are Atom documents (the list, a feed document, and individual pages entry documents), mostly just for fun, but I’d want to inspect browser support more carefully before doing this, and I’d need to nail down that Firefox hang first too.
> And try putting xml:base on the atom:content tag.
I’m not sure what you mean. xml:base is supposed to work everywhere, for whatever is the appropriate scope, and my stylesheet copies the xml:base attribute across, and then includes JavaScript to make it more or less work, wherever you use it, since browsers don’t support xml:base at all any more.
{kind=link}
{kind=link}
But there's a gotcha:
This works fine if you serve the feed with `content-type: text/xml`, because with that content type the browser typically renders the result in-browser. But `text/xml` is technically not the correct content type for RSS feeds, `application/rss+xml` is; and when you serve it with that content type, browsers typically either open a download window instead of rendering the feed, or they render it as plain text without styling.
So you're stuck. Have a styled feed but serve it with the wrong content type, or be technically correct and serve it with the right content type, but no styling for you.
Practically, content type really doesn't matter that much, and most (all?) RSS readers are fine with `text/xml`. But for those of us who like to be technically correct...
[0] https://standardebooks.org/feeds/rss/new-releases