I'm still hoping for a CRDT implementation with robust, thoroughly tested libraries for both Python and JavaScript that can talk to each other - I want to run Python on the server and JavaScript in the client and keep the two in sync with each other.
Closest I've seen to that is automerge but the Python version doesn't appear to be actively maintained or packaged for PyPI yet: https://github.com/automerge/automerge-py
Wouldn't any of the Rust implementations be what you need (Yrs, Diamond Types or the Automerge rust re-write)? Given you can bind to a Rust implementation in JS or Python or whatever else.
I've only looked into yrs. Unfortunately copying a js API into rust and using unsafe whenever you get a borrow check error feels doomed.
> Currently we didn't have any known undefined behaviour bugs caused by [casting pointers we don't have exclusive access to to mutable references]. In the future we may want to adopt different way of working with blocks with more respect regarding borrow checker rules, but currently priority was compatibility with Yjs.
Edit: I've only played around with my own toy crdt implementations, but I think this is also completely unnecessary. Yrs has a whole transaction API for concurrently mutating the same document instance through a shared handle. Not only is it unsound but there are also a bunch of places that will just panic if called concurrently. But you can just structure your program differently. For example, you could have a single thread/task per document that all the clients connect to.
That isn't to say yrs isn't impressive. It's quite good for someone's first rust project written all at once in a short period of time. But I don't think it's production ready, and I'm skeptical it's fundamental architecture can be.
This is certainly the direction most crdt libraries are headed. A fast, well tested rust implementation with native bindings to Python, go, c, java, etc. And a wasm bundle to run the same algorithm in the browser. Yjs (well, yrs), automerge and my own diamond types are all in rust and moving in this direction. Webassembly support amongst javascript bundlers has been getting a lot better lately. And having only one codebase to optimize and test cuts down immensely on work.
I want someone else to write the Rust-to-Python bindings for me because I'm lazy!
More importantly, I prefer not to be the only user of something like this - a Rust-Python wrapper that someone else has already tried running in production is a lot more trustworthy than something I knock together myself.
Author of Diamond types (and the data sets you’re using) here! Congratulations on getting this insane performance. I’d love to know how you’re doing it - that’s truly excellent work. I didn’t know it was even possible to get javascript to go that fast on this problem. And I say that as someone who has thought about crdt / text performance way more than is reasonable.
RIP my morning. I’m going to have to pour through your code to see how you’ve pulled this off. Do you have anything you recommend I read to understand how your algorithm works?
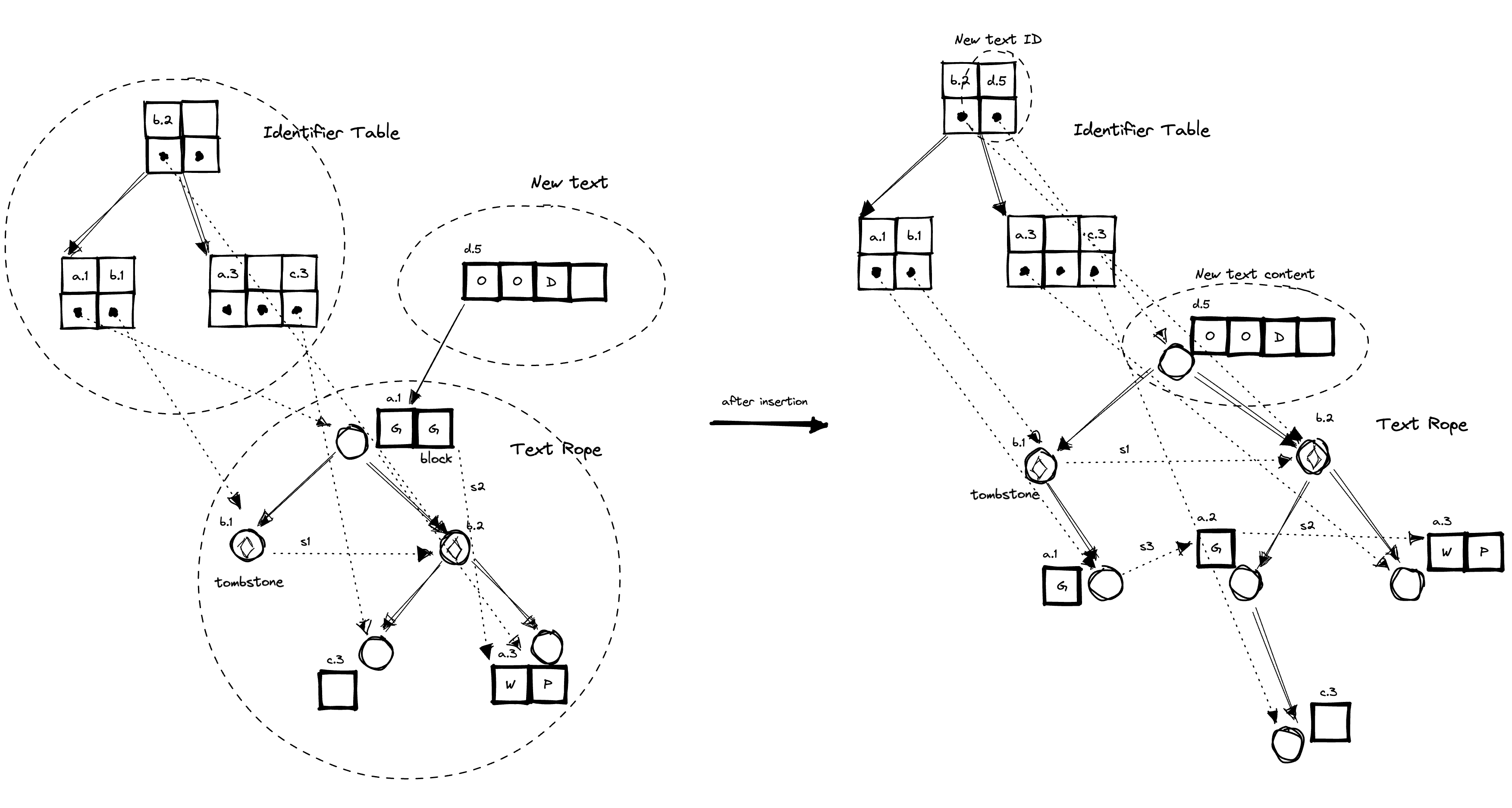
Can't wait for the future blogpost! I got the Rope text data structure both from the pic, and from the data structure in AbstractRga, but am unsure of the identifier table, I am guessing thats the ID -> Chunks binary tree.
> Do you have anything you recommend I read to understand how your algorithm works?
Not really, you should already know those. It is just Block-wise RGA with a tree for blocks and a tree for identifiers, also, with split link and insert-in-between optimization from Briot et. al (2016).
What I have not understood yet is how do you preserve invariants over a merge of JSON crdt. What do you do when a document has a structure that can be represented as a json, but not every valid json is a valid document? How do you avoid merges producing valid jsons but invalid documents?
General CRDTs will guarantee valid data structures, but not schema/domain model validity. Kind of like how CRDTs applied to text will guarantee a string, but not valid English.
This is a great analogy for something I've struggled to put into words.
I’ll add: if you have invariants, you almost by definition have conflicts. The C in CRDT is for conflict-free, so if you can have conflicts in the data domain you probably want something that can preserve them (like state machine synchronization) rather than a CRDT.
A CRDT (well, an operation based crdt) has all the information it needs to tell that conflicts have occurred, and which operations caused them. Something I’ve wanted for awhile is a crdt which can use that information to place the data in a “conflict” state.
We can do this today with keys / values pretty easily with “MV (multi value) Registers”. If two writers concurrently set the value, the next read can see both values and decide what to do about that.
But nobody (as far as I know) has yet made a crdt for code editing which uses this same trick to mark & annotate editing conflicts. And that seems like a missing piece if we want to replace git with something better.
I’m having trouble visualizing how a conflicted state might work. We still have to produce a valid state for the next edit to work on. Do you mean supplying conflict resolution handlers?
Also, do you mean a conflict from the perspective of “malformed data structures” or “domain invariant violated”?
But a JSON CRDT is in a sense a string with a particular grammar... However, my intuition ends here.
You could probably model the operations on a particular document structure at a higher level and try to find a simpler domain where it's easier handling logical merges, but it sounds like something that quicky becomes too complex
A “json crdt” doesn’t edit a string containing json grammar. That’s a misleading idea. Instead, a json crdt stores a tree of values. Values can be lists / strings / numbers / maps / etc. Operations modify that tree of data - maybe by setting a key in an object (map). That set operation will be replicated to other peers. Or by inserting into a list, or editing a text document.
When conflicting writes happen to a key in a map, a good crdt will either transparently pick a “winner” (and the other write disappears) or when you read, you can read all conflicting values and your application can choose what to do.
The downside of all this is you can’t have database style transactions, so many application side data integrity constraints are hard or impossible to implement. Like, you can’t enforce a constraint that a list has < 10 values in it because the merging algorithm may merge two inserts and put the list over your limit.
Perhaps relating to your other comment; is it theoretically possible to inject yourself into this logic? I.e., extend a general CRDT to be a domain specifc one, and do custom resolution before the "truth" is established?
Can you give some examples of what sort of domain specific rules you want to apply?
The trick is coming up with rules that let you merge concurrent edits in a consistent way on all peers, regardless of the order that any changes come in. Some things are easy - Max() is a valid CRDT. But lots of stuff is much harder than it sounds.
You need to design your document to minimize these kinds of issues. You can treat properties in the document as a last-write-wins register to minimize “strange merge” consistency within that property.
For use cases with a central server, you can use server reconciliation to handle “true conflicts”, essentially doing layer of OT-style ops at the application level around CRDT structures provided by a library. See how Replicache suggests handling text for example. They provide a server reconciliation framework, and suggest you use a CRDT for text within that semantics.
Yes, complexity! What I meant by OT-style operations is a command queue with optimistic updates on the client, and authoritative updates made by the server. This is an easy way to structure your application. "Full OT" means you need to be able to transform any operation type against any other operation of any type. It's quite complicated to implement your application's semantics in terms of operations while maintaining the M*M transform conditions.
Again, Replicache/Reflect.net is a very practical server-reconciliation based system that uses user-defined commands for application semantics, and delegates tricky merge situations to CRDTs; see https://reflect.net/#benefits:~:text=First%2DClass%20Text,st....
Notion also uses a command queue, but we don't use a CRDT for text - although I've been thinking about that for a long time
OT systems generally require a single, centralised server to be a party in between any two changes. CRDTs make it really easy to do multi-server deployments or peer-to-peer data replication. That is (basically) not possible using OT based systems.
Oh, absolutely. And OT based approaches work great here. CRDTs have the advantage that multi-server deployments are also easy, and modern CRDTs are increasingly faster and better optimized than most OT systems (certainly the ones I've worked on). But OT is a great approach.
Author of Yjs here. I'm all for faster data structures. But only benchmarking one dimension looks quite fishy to me. A CRDT needs to be adequate at multiple dimensions. At least you should describe the tradeoffs in your article.
The time to insert characters is the least interesting property of a CRDT. It doesn't matter to the user whether a character is inserted within .1ms or .000000001ms. No human can type that fast.
It would be much more interesting to benchmark the time it takes to load a document containing X operations. Yjs & Yrs are pretty performant and conservative on memory here because they don't have to build an index (it's a tradeoff that we took consciously).
When benchmarking it is important to measure the right things and interpret the results somehow so that you can give recommendations when to use your algorithm / implementation. Some things can't be fast/low enough (e.g. time to load a document, time to apply updates, memory consumption, ..) other things only need to be adequate (e.g. time to insert a character into a document).
Unfortunately, a lot of academic papers set a bad trend of only measuring one dimension. Yeah, it's really easy to succeed in one dimension (e.g. memory or insertion-time) and it is very nice click-bait. But that doesn't make your CRDT a viable option in practice.
I maintain a set of benchmarks that tests multiple dimensions [1]. I'd love to receive a PR from you.
What’s the future of this work? Is it planned to be entirely standalone? Planning to build integration with popular editors? Planning a websocket server implementation with hooks etc / a hosted solution?
I need to dig into this more, but I'm sceptical of only benchmarking ops/second, that's not really a problem that needs solving, the existing toolkits are fast enough. Also, this benchmark doesn't show document size and growth, that is something where more research is needed.
Always excited for any CRDT innovations though, and I'm sure there is stuff to learn from this work.
The death stroke for these types of projects seems to be lack of funding. This project is sponsored by nlnet[0] providing between 5k - 50k EU per year. Let's hope this gets additional resources.
As a note, it appears to use Elastic's 2.0 license preventing selling software that includes this library [1]
Very interested in seeing progress, JSON CRDTs benchmarked with JS objects and arrays, I currently have an implementation based on Automerge but it's borderline nonviable on our largest data structures.
Hey! Author of diamond types and the (linked) editing traces repository here. Would it be possible to make & share an editing trace or two from your application? Even a single user editing trace would be super helpful - like a big list of which objects were replaced by what values, in order.
I really want json based CRDTs to be fast, but one of the problems we have optimising this stuff is that there aren’t a lot of real world data traces around to use as baselines for benchmarking. I don’t know which parts of automerge are slow, and without that knowledge I can’t make them fast. If we have some data from your application, most upcoming json based CRDTs will almost certainly work well for your use case.
I think the idea of the Rust implementations of Y and A is portability, primarily. A JS implementation alone is very opinionated about, for example, what your backend should look like. A Rust ditto will be less opinionated and more accessible in a variety of environments.
I don’t think the main point is the supposed superiority of WASM vs JS in terms of performance, as the article surmises.
Great to see this comparison! I haven't heard about Json-joy yet, so I'm curious to learn more. We are using Yjs in production and it works like magic!
{kind=link}
Closest I've seen to that is automerge but the Python version doesn't appear to be actively maintained or packaged for PyPI yet: https://github.com/automerge/automerge-py
UPDATE: It looks like this might be what I'm after: https://github.com/y-crdt/ypy