In the demo I put the obama prank photo http://karpathy.github.io/2012/10/22/state-of-computer-visio... and asked "Why is this picture funny?" and it responded "Question: Why is this picture funny? Answer: President Obama is taller than the average person."
Furthermore the man on the scale is faced the other way and wouldn’t know someone is stepping on the scale. There’s an element of theory of mind there. You would have to understand that the man on the scale is unaware of Obama’s action.
> @karpathy: We tried and it solves it :O. The vision capability is very strong but I still didn't believe it could be true. The waters are muddied some by a fear that my original post (or derivative work there of) is part of the training set. More on it later.
Not quite there yet. I've been more impressed with the other new zero-shot multimodal models like Grounding DINO and Azure Dense Captioning. Really looking forward to putting multimodal GPT-4 through its paces as well.
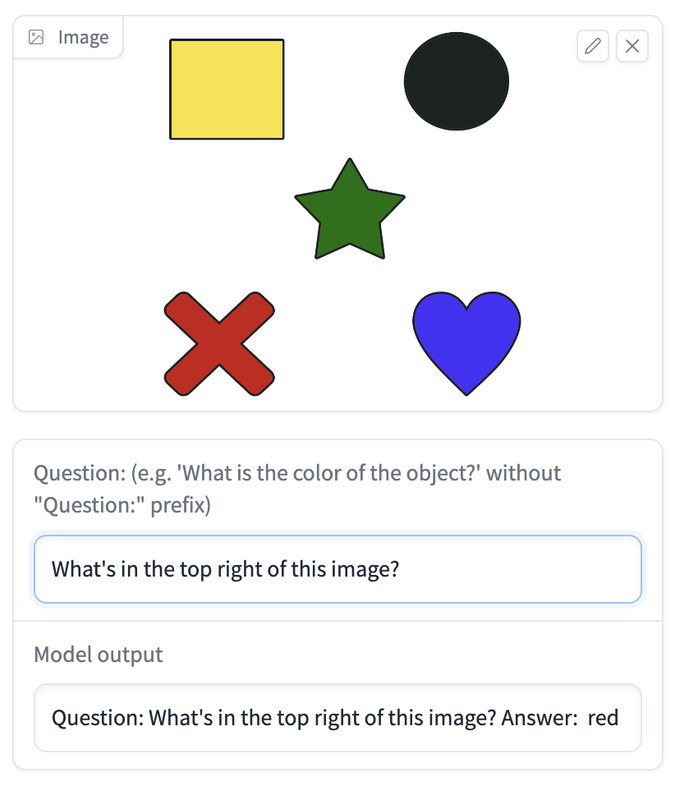
Even at this scale the model's able to answer questions fairly impressively, but I created an image with some distinct shapes in different positions and it didn't go well [0]. I think however they're doing the image encoding doesn't capture positional information which, to my mind, limits a lot of use cases.
it's not the image embedding. It's the objective task. Image to text is simply not good enough. It's really lossy and the datasets are garbage so it's not very robust.
Most of the parameters are in the language model (LLaMa-7B). So, they'd pretty much be the same techniques that would let LLaMa run on a single GPU -- especially lower precision tricks. If you only want to run inference/forward (no training), it should be pretty doable.
You can almost definitely run it on consumer GPU if you swap out the language model for something smaller as well (although the performance would definitely not be as good on the language side).
{kind=link}