I've been using pyroscope oss for about a year now. It's more mature, supports more agents, but isn't as interactive as Phlare. It integrates with Promethues and Grafana. No complaints, it's pretty good.
>Note: This panel is currently in beta & behind the flameGraph feature toggle.
With these two issues in mind, announcement of this product feels a bit rushed just to show it during ObservabilityCON, when I can't run it locally with stable images and plugins. I hope to see it release in mainstream repos soon!
Why can't one storage thing be used for everything instead of disparate datastores? I need Loki for logs, Tempo for traces, Prometheus for metrics, and now Phlare for profiling. Three of those are using object storage under the covers, why not one datastore to rule them all?
You forgot file systems. The main problem to date is that there has not been a single system that can handle all the different kinds of data. We store all the unstructured data in files. Highly structured data goes into a bunch of different relational databases. All the semi-structured data gets distributed into various NoSql stores. Then we need many connectors to tie related data stored within different silos together.
I have been working on a single datastore that can effectively manage all the different kinds of data. So far it can manage hundreds of millions of files better than file systems. It can form relational tables that query faster than other databases (https://www.youtube.com/watch?v=Va5ZqfwQXWI) and it has a schema flexible enough to handle stuff normally stored within Json files. It still needs a lot of work, but it is currently in open beta.
Would love to see this integrate with magic trace [1]. I'll need to look at the code for the flamegraph plugin, because handling nanosecond timestamps in flamegraphs seems to break most tools due to float precision.
> Make sure the system you want to trace is supported. The constraints that most commonly trip people up are: VMs are mostly not supported, Intel only (Skylake2 or later), Linux only.
I'd guess this rules out AWS as well as containers, too, right?
re multi-lang support via pprof - afaics python hasn't been touched in years, java is shiny new albeit also first party, in golang pprof is native, and rust pprof seems active.
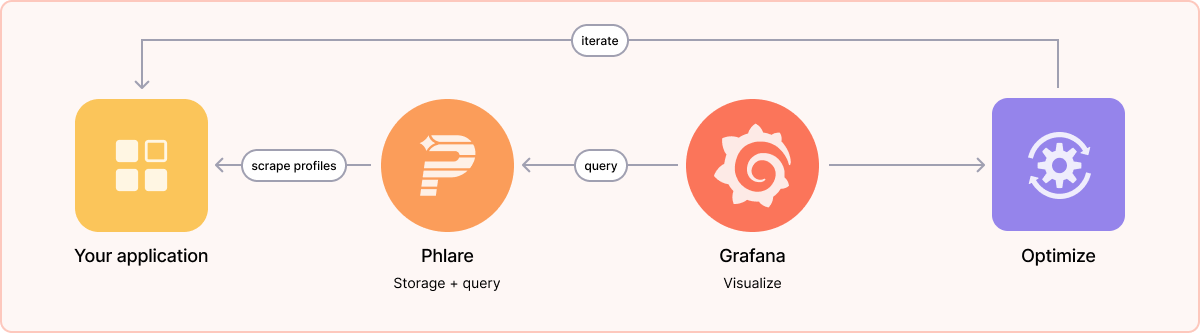
Other than a reference to ebpf at the end, it wasn't super clear to me where the profiles come from and what they support. Phlare itself is just a database for storing/querying profiles, right?
>Phlare itself is just a database for storing/querying profiles, right?
Sounds like it, with the addition of a Grafana panel. It seems like there is a bit of overlap between this and the other products like Tempo, Loki, and Mimir. This graphic seems to indicate it stands independently though, aside from Grafana visualizations.
https://grafana.com/static/assets/img/diagrams/grafana-diagr...
Elsewhere they reference making updates to the Grafana Agent in the future, but it's hard to say what "scrape profiles" means.
But I really, really like the idea. Often when I want to test the performance of a change I'll launch test and control canary instances with a small percentage of live traffic, run perf against each, collect the data, load it into a local https://profiler.firefox.com/, and try to compare the differences. It would be awesome to automate that process. Beyond that, I often keep notes about the tests but the profiles themselves are a real pain to store and catalogue.
It replaces no other projects. Continuous profiling solves a different problem to Mimir, Cortex, and Tempo. Mimir and Cortex are for metrics, Tempo is for distributed tracing, Phlare is for collecting profiling samples over time.
Profiling is a layer below tracing and metrics in that it requires very minimal and generic instrumentation (of the runtime), while the others require specific instrumentation (of the application).
Profiles like CPU, heap allocs, goroutines, etc are collected on a continual basis, allowing you to see at any time how your application was making use of its runtime resources.
I think their goal is for Grafana to be the abstraction layer for every datastore. You just hook up their specialized cloud hosted datastore for each type of data and then plugin Grafana and don't even think about it much.
Basically they are churning out all these different projects that just need to be "good enough" from a performance perspective
I have used Grafana in conjunction with Influxdb (1.x & 2.x), postgresql, mssql and mariadb with little issue for ~5 years. I have not dipped my toes in the water experimenting with the log aggregators. Some of the 3rd party plugins have been difficult to use and there are some odd bugs here and there (histograms on older versions finding the proper xmin and xmax). What specifically has been confusing?
Thanks Grafana team, but no thanks. I've been using Grafana for years, but I started to be cautious with them, when they began to shift things around, probably due VC pressure for more $$$ or internal bureaucracy. First, they change the license to AGPL3 - I don't mind it, but a sudden license change (from a more open Apache license to a more restrictive AGPL) should raise some eyebrows.
Second, when you go to download OSS version, they will first nag you with the cloud version (I'm downloading that thing, not signing up!), then will, by default, link to the enterprise version. Something similar Elastic has done for years.
Also, their cloud offering advertises "Free Forever" (whatever) - we all know how these things end ;)
Honestly, I see the same pattern with all OSS products that are funded by VC. I guess they have to show those growth numbers. I don't have a problem with them trying to make money but OSS almost seems like a gimmick/dangling carrot to really just signup for their cloud version. I would rather have them be honest.
I suspect this is partially because internal efforts and agendas take priority over open source community at this point.
For example, I created an issue requesting a flamegraph visualization in grafana[1] and now it makes sense that they didn't initially respond because they were building it internally in secret and didn't want to spoil the big reveal (when they did respond they did mention that it was a secret).
They're also less incentivized now to tend to issues and PRs that help others outside of their ecosystem (i.e. competing logs, metrics, tracing, profiling, etc products).
>Sorry for this being a bit secret until now but we tried to quickly build and iterate something usable. There isn't much documentation for it as it is behind feature flag it's not a GA feature but hope that will come soon.
Secrets kinda conflict with the whole Open part of OSS.
>No it doesn’t. Open community doesn’t have to be open source. Open source doesn’t have to have an open community.
That's in direct contract with Grafana's own messaging. The following is from their OSS marketing page.
>Open Source is at the heart of what we do at Grafana Labs. We believe building software in the open, with thriving communities, helps leave the world a little better than we found it.
https://grafana.com/oss/
As I said, please stop conflating open source software with open communities. They’re part of a thriving and healthy project, but are not the same thing.
While they are open-source projects, I bet their software is still driven by customer feedback. I wouldn't put it past them to prioritize paying customer requests which takes time away from implementing features, doing bugfixes or code review.
I don't think it's fair to say that paying customer feedback is prioritised at the expense of the open-source community.
The thing with the core Grafana product being open source is that there's not that much dissimilarity between paying/enterprise Grafana users, and open-source users. Feedback from one set will almost always work in favor for the other.
If an open source community is sufficient, it should implement pull requests itself while sufficient paid developers continue to contribute after earning enough to provide for themselves by working on customer feedback.
Also it's a bit hard to judge what the number of open issues means right now, because we use github issues also to track internal tasks (for better visibility). So as we have more engineers and more users there will inevitably be more open issues/PRs at any given moment.
1.1K pull requests but only 760 commits to the main branch, ~300 of which are made by dependency bots. I'm not saying Grafana isn't doing anything. Just the numbers you provided are a bit misleading in representing their work.
{kind=link}
https://pyroscope.io/docs/
Edit:
Just tried to run it in Grafana, but it's not easy. Datasource for Phlare is not in a stable grafana image:
flamegraph plugin is in beta behind feature flaghttps://grafana.com/docs/grafana/next/panels-visualizations/...
>Note: This panel is currently in beta & behind the flameGraph feature toggle.
With these two issues in mind, announcement of this product feels a bit rushed just to show it during ObservabilityCON, when I can't run it locally with stable images and plugins. I hope to see it release in mainstream repos soon!