Closer. But I still get lost when words like “tensor” are used. “structured lists of numbers” really doesn’t seem to explain it usefully.
This reminds me that explaining seemingly complex things in simple terms is one of the most valuable and rarest skills in engineering. Most people just can’t. And often because they no-longer remember what’s not general knowledge. You end up with a recursive Feynmannian “now explain what that means” situation.
This is probably why I admire a whole bunch of engineering YouTubers and other engineering “PR” people for their brilliance at making complex stuff seem very very simple.
If it helps you to understand at all, assuming you have a CS background, any time you see the word "tensor" you can replace it with "array" and you'll be 95% of the way to understanding it. Or "matrix" if you have a mathematical background.
Whereas CS arrays tend to be 1 dimensional, and sometimes 2 dimensional, tensors can be as many dimensions as you need. A 256x256 photo with RGB channels would be stored as a [256 x 256 x 3] tensor/array. If you want to store a bunch of them? Add a dimension to store each image. Want rows and columns of images? Make the dimensions [width x height x channels x rows x columns].
A more practical example of the added dimensionality of tensors is the addition of a batch dimension, so a 8 image batch per training step would be a (8, 256, 256, 3) tensor.
Tools such as PyTorch's DataLoader can efficiently collate multiple inputs into a batch.
This is something that infuriates me about formal mathematics (and CS, for that matter): they don't just use the words people already know! They have to make up new words, sometimes even entirely new symbols, that often just mean the same thing as something else. And then the literature becomes entirely inaccessible unless you've learned this secret code. The bottleneck becomes translation, instead of understanding.
I agree with you. Fields like graph theory and set theory are fun once you wrap your head around the symbols, but I remember having a lot of trouble with both as a teenager.
Essentially the same difference between vectors and arrays. A vector is an element of a vector space. A vector can be represented as a coordinate array in a basis, but it is not the coord array. Consider the vector 1 + x + x^2 you might use the canonical basis for polynomials {1, x, xx, xxx, ...} and then the coordinate vector is [1 1 1]. The coordinate and the basis represent the polynomial. But the polynomial isn't a list of numbers.
A matrix is the coefficient list of a linear transformation, but it is not the transformation. The derivative operator is a linear transformation. It's representation as a matrix is just coordinates. But the operator is clearly more than that.
A tensor can be written down and you can compute with the components, but the tensor itself is the basis independent transformation. Not a list of components.
I didn't mean to imply you couldn't have an n-dimensional array in many programming languages. Just that it's usually not what's done when designing programs. I think many would prefer to make some kind of object to encapsulate the data type (an RGB struct for my example) instead of making arrays of arrays of arrays of (double/float/uint8).
For the literal definition between a mathematical 'tensor' and a (e.g.) PyTorch 'tensor' (which, from reading the other comments here, are not the same thing), I leave that to other commenters. I'm just someone learning PyTorch and sharing my knowledge.
The practical engineering difference between a PyTorch tensor and Python array is that PyTorch comes with tons of math & utility functions that support n-dimensions and are differentiable, whereas the builtin Python arrays and math utilities don't do much, if any, of that.
A Tensor is a mathematical object for symbolic manipulation of relationships between other objects that belong in conceptually similar universes or spaces. Literature on Deep Learning, like Goodfellow, call for the CS-minded reader to just assume it's a fancy word for a matrix of more than two dimensions. That makes matters confusing because mathematically you could have scalar or vectorial tensors. The classic mathematical definition puts more restrictions on the "shape" of the "matrix" by requiring certain properties so that it can create a symbolic language for a tensor calculus. Then you can study how the relationships change as variables on the universes or spaces change.
Understanding the inertia tensor on classical mechanics or the stress tensor may illustrate where tensors come from, and I understand that GR also makes use of a lot of tensor calculus that came to be as mathematics developed manipulating and talking about tensors. I have a kinda firm grasp on some very rudimentary tensor calculus from trying to leanr GR, and a pretty solid grasp on classical mechanics. I've had hour long conversations with deep learning popes and thought leaders in varying states of mind and after that my understanding is that they use the word tensor in an overreaching fashion as like you could call a solar panel a nuclear fission reactor power source. This thought leaders include people with books and 1M+ view Youtube videos on the subject that use the word tensor and I'm not saying their names because they off-the-record admitted that it's a poor choice of term but it harms the ego of many Google engineers to publicly admit that.
I'm not aware of tensor shape type safety (in general) being widely used in deep learning, let alone sum-types. I believe Pytorch and TensorFlow lack support for tensor shape type checking (looks like there is a Pytorch issue open: https://github.com/pytorch/pytorch/issues/26889).
Rust to the rescue, as it always is for safety.
(I don't know if this directly translates for tensors, I used it for manipulating point clouds and iirc it allows for arbitrary dimension containers)
I use this crate extensively and while I have gotten good results, it is not ergonomic and it is not equivalent to numpy ndarray. There are a lot of issues and work still to be done.
Just a word of caution for anyone interested in using it.
Things like windowing, slicing, views are all “supported” but have many limitations and are non intuitive. In particular, I needed an “axis shift” fn and I ended up spending hours scouring docs just to find a way to shift along an axis. When I mean by shift is a roll in numpy, ala:
https://github.com/rust-ndarray/ndarray/issues/281
Answer: you can’t with this crate. I implemented a dynamic n-dim solution myself but it uses views of integer indices that get copied to a new array, which have indexes to another flattened array in order to avoid duplication of possibly massive amounts of n-dimensional data; using the crate alone, copying all the array data would be unavoidable.
Ultimately I’ve had to make my own axis shifting and windowing mechanisms. But the crate is still a useful lib and continuing effort.
While I don’t mind getting into the weeds, these kinds of side efforts can really impact context focus so it’s just something to be aware of.
In my experience (CV) you typically want 4 dims - (height, width, channels, batch). In Julia you can do element-wise operations on two arrays if their lengths (i.e. size after flattening) are the same. Obviously dimension-wise that sort of thing won't work (what's the dot product of a 3-vector by a 6-vector? Undefined!)
But really, the whitepaper should include this sort of detail, and you should be following the white paper.
I updated the post to say "multi-dimensional array".
In a context like this, we use tensor because it allows for any number of dimensions (while vector/ array is only one, matrix is two). When you get into ML libraries, both popular packages PyTorch and TensorFlow use the "tensor" terminology.
It's a good point. Hope it's clearer for devs with "array" terminology.
Tensor does imply a set of operations that are expected. Multiplying two arrays together is an ambiguous operation; multiplying two tensors together is well-defined.
And really, the context is math, not programming. The programming side of DL is approximately trivial, the interesting bits are all represented as mathematical operations on a set of tensors.
It's especially confusing as math, because the standard meaning of "tensor" in math includes a lot of baggage that's not used in deep learning (related to physics and differential geometry).
"Tensor does imply a set of operations that are expected. Multiplying two arrays together is an ambiguous operation; multiplying two tensors together is well-defined."
In programming too, multiplying two arrays of arbitrary types is often undefined, and many languages allow their programmers to specify what they want to happen when arrays of specific types are multiplied (or may have built-in defined behavior for certain specific types of arrays).
I'd love to learn if there are any actual differences between tensors and arrays commonly used in programming, but so far it doesn't sound like it from reading through this HN thread.
I think you misunderstood what I meant. If I say "multiply this 3x3 matrix by this 3x1 vector", then I know know to expect the particular form of multiplication that multiplies each column of the matrix by it's associated value in the vector, then adds them up to produce a 3x1 vector. Likewise, multiplying a 3x3x3 tensor by a 3x1x1 tensor will produce a 3x3x1 result.
If I say "multiply this 3x3 array by this 3x3 array", then it's an ambiguous operation. There is not a canonical multiplication for arrays. One ecosystem might treat it as a matrix-matrix multiplication, another might do an element-wise multiplication, others might just throw an error. None is more correct than another, because array just implies the structure of the data.
I think tensor is much shorter than "multi-dimensional array", and it is OK to use it. You could just mention that in the context of DL tensor is just a shorter way to say "multi-dimensional array", and everyone should be happy. On top of that, if they read another text about DL that uses the word tensor, there is no need to be scared anymore.
Very loosely, a number/vector/matrix/tensor can be considered to be objects where specifying the values of 0/1/2/3 indexes will give a number.
(A mathematician might object to this on several grounds, such as that vectors/matrices/tensors are geometric objects which need not be expressed numerically as coordinates in any coordinate system)
In math tensor has a more specific meaning than just an array, but in machine learning lingo, tensor just means an array or multidimensional array. That base is true in math as well, but it can also be a single value (rank zero tensor, aka a scalar. Sometimes ML will call this a tensor as well) and has to obey certain rules about linearity for some operations applied to it.
Kudos to this. It also helps to think of a three-dimensional space bounded by the sides of a box, and to think of another 11 boxes stacked on top of each other.
Then, you can visualize orthogonal on dimensions higher than 3 by throwing wires between equivalent points in two boxes.
Yes, but by boxing each sub-space, you can think of the pile of boxes as a dimension separate from the Z axis.
It's like painting a house in isometric style. You draw each floor above the one below it, and put a "perpendicular" slanted axis to represent the third dimension in 2D.
You could put a 'slanted' fourth axis in a 3D origin of coordinates, but I find it easier to think of the lower corner of each box as the origin of coordinates displaced along that fourth axis.
"You could put a 'slanted' fourth axis in a 3D origin of coordinates"
Even with that the same problem occurs: "slanted" is a 3D relationship, so at best it's an analogy.
It's like "translating" the color red to some shade of gray to a person who can only see in black and white.
Or trying to describe through written words what music is like to someone who can't hear.
These are all analogies which might allow us to reason and get interesting/useful results when we use such analogies... but we should not under the illusion that we really know what those things for which we have no senses are like.
Also, there are probably all sorts of interesting/useful connections, relationships or conclusions that a being who really could sense 4D objects would find obvious or easy to make that we may never arrive at because our way of thinking of them is so limited in comparison.
That's not to mention trying to think about even higher dimensions or various other mathematical constructions that have no obvious translation to things in our ordinary experience we can relate to.
> Even with that the same problem occurs: "slanted" is a 3D relationship, so at best it's an analogy.
Yeah, but it's the same analogy you use to represent 3D figures on a 2D plane, where slanted is a 2D relationship; and we are very well versed on it and know how it works as a projection of a 3D reality.
> These are all analogies which might allow us to reason and get interesting/useful results when we use such analogies... but we should not under the illusion that we really know what those things for which we have no senses are like.
Is this some reflections about Plato's cave? You don't need much insight to understand the basis of moving over an extra dimension - if you can understand what it's like to move over parallel planes from a 2D view, you can understand the same by moving over superposed volumes from a 3D view. A hyper-sphere can be visualized as a linear collection of increasingly small spheres glued together, in the same way that you can view a sphere as a linear collection of increasingly small circles over an axis orthogonal to its center.
> Also, there are probably all sorts of interesting/useful connections, relationships or conclusions that a being who really could sense 4D objects would find obvious or easy to make that we may never arrive at because our way of thinking of them is so limited in comparison.
Yeah, and some people are really bad at 3D visualization so they have no hope to arrive at conclusions that are trivial to an architect or engineer. That doesn't prevent higher-dimension visualization techniques from being useful for the insights that it can provide, even if they can't give omniscience. For all the other insights, we have formal methods and logic reasoning, which is how 4D space was originated to begin with.
I don’t know. I feel that, for most people, it is the most visual way to see in many dimensions. That is, it’s an insight—rather than having to imagine a 5-d cube or whatever, it’s just a spreadsheet, no big deal.
Yes, but they see it as a data dump, without perceiving any spacial connections between the vectors represented by each row. The point of spatial reasoning is using our minds inner eye to visualize those connections intuitively, and the tabular data dump has nothing of it.
But I’d argue a 5d cube has even less use, as a mental model. Most people don’t know that each additional column is another dimension. People can imagine the sense of distance between varying points/entries in a table easier than a 5d cube, for instance. (Actually, that’s an empirical question)
Quote:
"A tensor is a container which can house data in N dimensions. Often and erroneously used interchangeably with the matrix (which is specifically a 2-dimensional tensor), tensors are generalizations of matrices to N-dimensional space."
You’re talking like using jargon makes something a bad explanation, but maybe you just aren’t the audience? Why not use words like that if it’s a super basic concept to your intended audience?
Kudos to Author for writing this. The author's other guide, https://jalammar.github.io/gentle-visual-intro-to-data-analy... is THE most approachable introduction to Pandas for Excel users like me who are "comfortable" with Python(disclaimer: Self taught EE/Hardware guy). I will definitely spend some time this weekend to go over this tome. Thanks again.
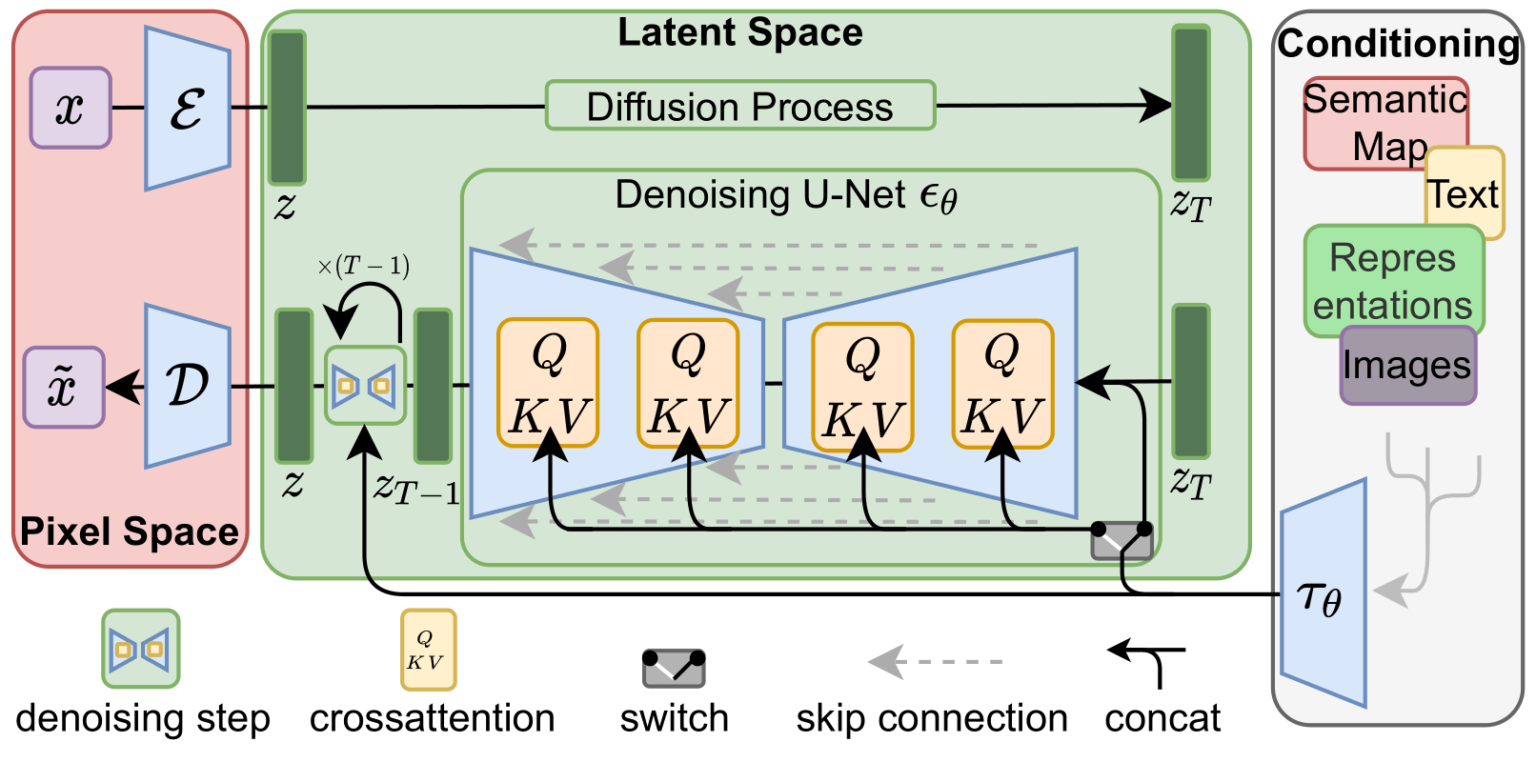
Great overview, I think the part for me which is still very unintuitive is the denoising process.
If the diffusion process is removing noise by predicting a final image and comparing it to the current one, why can't we just jump to the final predicted image? Or is the point that because its an iterative process, each noise step results in a different "final image" prediction?
In the reverse diffusion process, the reason we can't directly jump from a noisy image at step t to a clean image at step 0 is that each possible noisy image at step t may be visited by potentially many real images during the forward diffusion process. Thus, our model which inverts the diffusion process by minimizing least-squares prediction error of a clean image given a noisy image at step t will learn to predict the mean over potentially many real images, which is not a itself a real image.
To generate an image we start with a noise sample and take a step towards the _mean_ of the distribution of real images which would produce that noise sample when running the forward diffusion process. This step moves us towards the _mean_ of some distribution of real images and not towards a particular real image. But, as we take a bunch of small steps and gradually move back through the diffusion process, the effective distribution of real images over which this inverse diffusion prediction averages has lower and lower entropy, until it's effectively a specific real image, at which point we're done.
> But, as we take a bunch of small steps and gradually move back through the diffusion process...
...but, the question is, why can't we take a big step and be at the end in one step.
Obviously a series of small steps gets you there, but the question was why you need to take small steps.
I feel like this is just a 'intuitive explanation' that doesn't actually do anything other than rephrase the question; "You take a series of small steps to reduce the noise in each step and end up with a picture with no noise".
The real reason is that big steps result in worse results (1); the model was specifically designed to be a series of small steps because when you take big steps, you end up with over fitting, where the model just generates a few outputs from any input.
The reason why big steps produce worse results, when using current architectures and loss functions, is precisely because the least squares prediction error and simple "predict the mean" approach used to train the inverse model does not permit sufficient representational capacity to capture the almost always multimodal conditional distribution p(clean image | noisy image at step t) that the inverse model attempts to approximate.
Essentially, current approaches rely strongly on an assumption that the conditional we want to estimate in each step of the reverse diffusion process is approximately an isotropic Gaussian distribution. This assumption breaks down as you increase the size of the steps, and models which rely on the assumption also break down.
This is not directly related to overfitting. It is a fundamental aspect of how these models are designed and trained. If the architecture and loss function for training the inverse model were changed it would be possible to make an inverse model that inverts more steps of the forward diffusion process in a single go, but then the inverse model would need to become a full generative model on its own.
> This assumption breaks down as you increase the size of the steps, and models which rely on the assumption also break down.
Hm. Why's that?
The only reason I mentioned over fitting is because that's literally what they say in the paper I linked, that the diffusion factor was selected to prevent over fitting.
...
I guess I don't really have a deep understanding of this stuff, but your explanation seems to be missing, specifically that noise is added to the latent each round, on a schedule (1), less noise each round.
that's what causes it to converge on a 'final' value; you're explicitly modifying the amount of additional noise you feed in. If you don't add any noise, you get nothing more from doing 1 step than you do from 10 or 50.
Right?
"as we take a bunch of small steps and gradually move back through the diffusion process, the effective distribution of real images over which this inverse diffusion prediction averages has lower and lower entropy"
I'm really not sure about that... :/
(1) - "For binomial diffusion, the discrete state space makes gradient ascent with frozen noise impossible. We instead choose the forward diffusion schedule β1···T to erase a constant fraction 1
T of the original signal per diffusion step,
yielding a diffusion rate of βt = (T − t + 1)−1."
To train the inverse diffusion model, we take a clean image x0 and generate a noisy sample xt which is from the distribution over points that x0 would visit following t steps of forward diffusion. For any value of t, any xt which is visited by x0 is also visited by some other clean images x0' when we run t steps of diffusion starting from those x0'. In general, there will be many such x0' for any xt which our initial x0 might visit after t steps of forward diffusion.
If t is small and the noise schedule for diffusion adds small noise at each step, then the inverse conditional p(x0 | xt) which we want to learn will be approximately a unimodal Gaussian. This is an intrinsic property of the forward diffusion process. When t is large, or the diffusion schedule adds a lot of noise at each step, the conditional p(x0 | xt) will be more complex and include a larger fraction of the images in the training set.
"If you don't add any noise, you get nothing more from doing 1 step than you do from 10 or 50." -- there are actually models which deterministically (approximately) integrate the reverse diffusion process SDE and don't involve any random sampling aside from the initial xT during generation.
For example, if t=T, where T is the total length of the diffusion process, then xt=xT is effectively an independent Gaussian sample and the inverse conditional p(x0 | xT) is simply p(x0) which is the distribution of the training data. In general, p(x0) is not a unimodal isotropic Gaussian. If it was, we could just model our training set by fitting the mean and (diagonal) covariance matrix of a Gaussian distribution.
"I'm really not sure about that... :/" -- the forward diffusion process initiated from x0 iteratively removes information about the starting point x0. Depending on the noise schedule, the rate at which information about x0 is removed by the addition of noise can vary. Whether we're in the continuous or discrete setting, this means the inverse conditional p(x0 | xt) will increase in entropy as t goes from 1 to T, where T is the max number of diffusion steps. So, when we generate an image by running the inverse diffusion process the conditional p(x0 | xt) will have shrinking entropy as t is now decreasing.
The quote (1) you reference is about how trying to directly optimize the noise schedule is more challenging when working with discrete inputs/latents. Whether the noise schedule is trained, as in their continuous case, or defined a priori, as in their discrete case, each step of forward diffusion removes information about the input and what I said about shrinking entropy of the conditional p(x0 | xt) as we run reverse diffusion holds. In the case of current SOTA diffusion models, I believe the noise schedules are set via hyperopt rather than optimized by SGD/ADAM/etc.
> why can't we take a big step and be at the end in one step.
Because we're doing gradient descent. (No, seriously, it's turtles all the way down (or all the way up, considering we're at a higher level of abstraction here).)
We're trying to (quickly, in less than 100 steps) descend a gradient through a complex, irregular and heavily foggy 16384-dimensional landscape of smeared, distorted, and white-noise-covered images that kinda sorta look vaguely like what we want if you squint (well, if the neural network squints, anyway). If we try to take a big step, we don't descend the gradient faster; we fly off in a mostly random direction, clip through various proverbial cliffs, and probably end up somewhere higher up the gradient than we started.
The problem is that predicting a pixel requires knowing what the pixels around it looks like. But if we start with lots of noise, then the neighboring pixels are all just noise and have no signal.
You could also think of this as: We start with a terrible signal to noise ratio. So we need to average over very large areas to get any reasonable signal. But as we increase the signal, we can average over a smaller area to get the same signal-to-ratio.
In the beginning, we're averaging over large areas, so all the fine detail is lost. We just get 'might be a dog? maybe??'. What the network is doing is saying "if this a dog, there should be a head somewhere over here. So let me make it more like a head". Which improves the signal to noise ratio a bit.
After a few more steps, the signal is strong enough that we can get sufficient signal from smaller areas, so it starts saying 'head of a dog' in places. So the network will then start doing "Well, if this is a dog's head, there should be some eyes. Maybe two, but probably not three. And they'll be kinda somewhere around here".
Why do it this way?
Doing it this ways means the network doesn't need to learn "Here are all the ways dogs can look". Instead, it can learn a factored representation: A dog has a head and a body. The network only needs to learn a very fuzzy representation at this level. Then a head has some eyes and maybe a nose. Again, it only needs to learn a very fuzzy representation and (very) rough relative locations.
So it only when it get right down into fine detail that it actually needs to learn pixel perfect representation. But this is _way_ easier, because in small areas images have surprisingly very low entropy.
The 'text-to-image' bit is a just a twist on the basic idea. At the start when the network is going "dog? or it might be a horse?", we fiddle with the probabilities a bit so that the network starts out convinced there's a dog in there somewhere. At which point it starts making the most likely places look a little more like a dog.
I suppose that static plus a subliminal message would do the same thing to our own numeral networks. Or clouds. I can be convinced I’m seeing almost anything in clouds…
Research is still ongoing here, but it seems like diffusion models despite being named after the noise addition/removal process don't actually work because of it.
There's a paper (which I can't remember the name of) that shows the process still works with different information removal operators, including one with a circle wipe, and one where it blends the original picture with a cat photo.
Also, this article describes CLIP being trained on text-image pairs, but Google's Imagen uses an off the shelf text model so that part doesn't seem to be needed either.
If you removed all of the noise in a corrupted image in one step, you would have a denoising autoencoder, which has been around since the mid-aughts or perhaps earlier. Denoising diffusion models remove noise a little bit at a time. Think about an image which only has a slight amount of noise added to it. It’s generally easier to train a model to remove a tiny amount of noise than a large amount of noise. At the same time, we likely introduced a small amount of change to the actual contents of the image.
Typically, in generating the training data for diffusion models, we add noise incrementally to an image until it’s essentially all noise. Going backwards from almost all noise to the original images directly in one step is a pretty dubious proposition.
I was wondering the same and this video [1] helped me better understand how the prediction is used. The original paper isn't super clear about this either.
The diffusion process predicts the total noise that was added to the image. But that prediction isn't great and applying it immediately wouldn't result in a good output. So instead, the noise is multiplied by a small epsilon and then subtracted from the noisy image. That process is iterated to get to the final result.
You can think of it like solving a differential equation numerically. The diffusion model encodes the relationships between values in sensible images (technically in the compressed representations of sensible images). You can try to jump directly to the solution but the result won't be very good compared to taking small steps.
I’m pretty sure it’s a stability issue. With small steps the noise is correlated between steps; if you tried it in one big jump then you would essentially just memorize the input data. The maximum noise would act as a “key” and the model would memorize the corresponding image as the “value”. But if we do it as a bunch of little steps then the nearby steps are correlated and in the training set you’ll find lots of groups of noise that are similar which allows the model to generalize instead of memorizing.
1- Forward Diffusion (adding noise, and training the Unet to predict how much noise is added in each step)
2- Generating the image by denoising. This doesn't predict the final image, each step only predicts a small slice of noise (the removal of which leads to images similar to what the model encountered in step 1).
So it is indeed an iterative processes in that way, each step taking one step towards the final image.
Agreed. "Stable Diffusion with Diffusers" and "The Annotated Diffusion Model" were excellent and are linked in the article. The code in Diffusers was also a good reference.
I also thought about this video while reading the HN post. The Computerphile video completely omits the latent space, right? But instead spends a lot of time on the iterative denoising. Even though I like Computerphile a lot, I don't think this was the best tradeoff.
“We then compare the resulting embeddings using cosine similarity. When we begin the training process, the similarity will be low, even if the text describes the image correctly.”
How is this training performed? How is accuracy rated?
Cosine similarity is a fixed way of comparing two vectors, so we can think of it as making a difference: A-B = d
If d is close to 0, we say that both embeddings are similar.
If d is close to 1, we say that both embeddings are different.
Imagine we have the following data:
- Image A and its description A
- Image B and its description B
We would generate the following dataset:
- Image A & Description A. Expected label: 0
- Image B & Description B. Expected label: 0
- Image A & Description B. Expected label: 1
- Image B & Description A. Expected label: 1
The mixture of Image Y with Description Z with Y!=Z is what we call "negative sampling"
If the model predicts 1 but the expected value was 0 (or the other way around), it's a miss, and therefore the model is "penalized" and has to adjust the weights; if the prediction matches the expectation, it's a success, the model is not modified.
I'd be curious to see an example gallery of image generation of the same vector scaled to different magnitudes. That is, 100% cosine similarity, but still hitting different points of the embedding space.
The outcome vectors aren't normalized right? So there could be a hefty amount of difference in this space? Maybe not on concept, but perhaps on image quality?
I'm not sure about it, maybe they are, it wouldn't be strange
> So there could be a hefty amount of difference in this space? Maybe not on concept, but perhaps on image quality?
Sure, each text could have more than one image matching the same representation (cosine wise), but maybe the changes wouldn't look much as "concepts" in the image but other features (sharpness, light, noise, actual pixel values, etc)
From the paper on the CLIP embedder it appears that they use a form of contrastive loss that maximizes the cosine similarity between related images and prompts, but also minimizes the same between unrelated prompts & images.
I find SD to be amazing technology, but it still (mostly) sucks at producing "intelligent" images. It basically fancy math that turns noise into images (from the opposite it trained on) but still has no idea what it is producing. If you run it long enough you eventually get lucky and find a gem. I like to try "George Washington riding a Unicorn in Times Square"; I've so far never gotten anything a first year art student can draw. I wonder how long it will take before something more "AI" than "ML" will have an understanding even close to what a simple human brain can process.
In the meantime it's fun to play with it, plus I'd like to better understand the noise training process.
> "George Washington riding a Unicorn in Times Square"
The “secret” to Stable Diffusion (and other CLIP-based models) is being as descriptive as possible. This prompt, whilst easy for humans to imagine, actually has a whole lot of ambiguity baked in.
How high is the unicorn flying? Is the unicorn even flying, or on the ground? How old is George Washington? What visual style is the image in? Is the image from the perspective of a pedestrian at ground level, or from up at skyscraper level?
The more ambiguous the prompt, the less cohesive the image.
And here’s 4 using the prompt “George Washington riding a unicorn in Times Square, cinematic composition, concept art, digital illustration, detailed”: https://imgur.com/a/lB36JqC
Certainly not perfect, but for an additional 15 seconds of effort, far better.
The reason you can't get the images you want from it is not because of the noise diffusion process (after all, this is probably the closest similarity to how a human gets a flash of creativity) but the lack of a large language model in SD - it was deliberately scaled down so the result could fit in consumer GPUs.
DALLE-2 uses a much larger language model and you can explain more complicated concepts to it. Googles Imagen likewise (not released though).
It's mostly a matter of scaling to get this better.
It's not just size but also model architecture. DALLE mini (craiyon.com) has the opposite priority because of its different architecture; you can enter a complex prompt and it will follow it, but it's much slower and the image quality is a lot worse. SD prefers to make aesthetic pictures over listening to everything you tell it.
You can improve this in SD by raising cfg_scale at the cost of some weird "oversharpening" artifacts. Or, you can make a crappy image in DallE mini and use that as the img2img prompt with SD to make it prettier.
The real sign it's lacking intelligence is, if you ask it a question it won't draw the answer, it'll just draw the question. Of course, they could fix that too, it's got a GPT in it, they just don't let it recurse…
Yeah true, I like dalle-mini :) It did seem to understand the prompts better.
The training set also affects it, as the guidance signal competes with the diffusion-model's priors it learned from the training set (the cfg_scale) and I've found situations where it seems the priors are just encoded too strong it seems - for example with very well-known celebs or objects it's difficult to make variations.
I guess it's interesting that these issues are kind of reflected in humans as well.
There are some prompts which yield bad results, but many other for which the results are nothing short of stunning.
I would not write off AI generators based on some poor results you got, but take a look at the best results others have gotten, then learn to use the tools yourself to do the same.
As an artist who's been making art for many decades now, AI art generation systems just blow me away. The best images I've seen from them are far better than a lot of what many real human artists can do, and this technology is just in its infancy. I can't even imagine how good it'll be in another 5 or 10 years.
The autoencoder that maps between that and the 512x512x3 RGB space was trained together with the model, so it is specialized in upscaling the 64x64x4 info to pixel space for this particular purpose. It's "just" a factor of 48 (de)compression..
I think it’s considered an implementation detail so it’s just not mentioned. A lot of models still work if you round the values to FP16, which personally I find surprising.
The way I think of it, we have a 512x512x3 target, so that's 48x the information. I don't think it's unreasonable to say that far less than 1/48th of the space of 512x512x3 outputs are natural images (meaning an image that might actually exist, rather than meaningless pixels). So if we think about that 64x64x4 tensor as telling us what in the smaller space of natural images we should draw, it seems like plenty of information. Especially since we have the information stored weights of the output network also.
The amount of information in a 64x64x4 array would depend on the precision of the numbers in it, right? For example, a 512x512 image in 24-bit colour could be completely encoded in a 64x64x4 array if each of the 64 x 64 x 4 = 16,384 values had 384 bits of precision.
So, I wonder — what's the minimum number of bits of precision in the 64x64x4 array that would be sufficient for this to work?
According to a anecdotal test on one of the images found elsewhere in this thread, JPEG comression at 80% quality can chop a factor of 16 off the size of a 24bpp .bmp file.
384 / 16 = 24bits per [64x64x4-] array value. Integer range of 32bit float is 2^24. So "literally just a jpeg packed into 16K floats" is a option.
{kind=link}
This reminds me that explaining seemingly complex things in simple terms is one of the most valuable and rarest skills in engineering. Most people just can’t. And often because they no-longer remember what’s not general knowledge. You end up with a recursive Feynmannian “now explain what that means” situation.
This is probably why I admire a whole bunch of engineering YouTubers and other engineering “PR” people for their brilliance at making complex stuff seem very very simple.