It just occurred to me, Zig could be a great learning-language for CS
When I was in college we mostly used C++, which exposed (and thereby taught) a lot of core concepts around how computers and low-level languages work. But it was also a bit of a nightmare for... unrelated, obvious reasons.
Rust is great for building software, but as a learning language I think it introduces too many additional concepts, has too many additional constraints, and has too many magical abstractions. Eg, doing manual deallocation helps you later appreciate what the borrow-checker does and why it exists
Zig is supposed to be C++ without all the pain and misery (esp around tooling). That could make it perfect for teaching people about pointers and heap allocations and working with bytes, with minimal extra pain and friction
I still think the first language when I was an undergraduate (so, last century) was the correct choice: an ML in our case SML/NJ
The stuff about how this actually works can come later, we're not teaching electronics students here (or are we? Zig as first language for electronics students makes some sense)
I agree that (safe) Rust has too much stuff for a first language for Computer Scientists. Lifetimes! Polymorphism! Two entire Macro systems! although it's simpler than C++, surely nobody should teach that as first language.
Zig has a compelling case as a second language if you learned something less practical like ML as first language. Apparently a colleague now teaches Haskell to the equivalent undergraduate classes as a second (or maybe third?) language, and I think Rust would also fit in there for the same purpose but given how practical the current first language is (now Java) he probably doesn't want more practicality.
One thing I'd say for Rust is that we need to start teaching Safety and Correctness early. There's a reason the Medics don't wait until year four to do Ethics and Consent. If we want to stop writing software which is crap we need to start teaching the next generation of CS graduates that's not OK up front, not just in some Friday afternoon class about the Therac-25 which has maybe 40% attendance.
> we're not teaching electronics students here (or are we? Zig as first language for electronics students makes some sense)
From an educational viewpoint, I don't like that EE and SWE programs have very little overlap. A lot of EE tools could be improved if EE's learned more software (particularly parsing and compilers). A lot of SWE don't get into the dirty details of a CPU and what makes it tick and see it some sort of magical black box, and ergo don't understand digital logic.
Datapoint: There are now thousands of programming languages. There are primarily two digital logic languages: VHDL and Verilog.
If you ever cross over to the EE side, you'll understand how terrible some of the software is.
> I still think the first language when I was an undergraduate (so, last century) was the correct choice: an ML in our case SML/NJ
Again, I don't know. So much of Computer Science programs hinge on getting that first educational experience right. Not so much a problem for MIT, but the program I'm aware of that used Scheme for there CS100 course shrank over time. People just dropped and changed their degrees, when in reality if Scheme/ML were a junior level course, they probably would have more students, higher budget, etc -- and possibly most students would have an easier time after learning a little bit of imperative programming.
Perhaps it's a fair point that CS100 should be a weed-out course. But on the other hand, we don't teach the theory of calculus before we teach students trigonometry.
As I understand you advocate a bottom - up approach rather than a top-down one. I personally prefer the former over the latter as it makes more sense to me to learn how to make basic programs work before I learn what incredible things I can do with them. I have over one year of C experience in my school doing things like rewriting functions of the C stdlib and reimplementin getline() before I learn about radix sort, implement a tree or make a basic ray tracer. Thats works for me but I know there are some theory/abstraction oriented people that like to learn about algorithms first and fill in the details late. In the end if you want programming to be interesting you need both practical and theoretical knowledge so I guess you should know yourself and take the approach that work for you. Having people who want to build stuff learn abstract concepts in Scheme may be as counter-productive than having people who want to learn about clever data structures learn how to make a basic text editor in C in the terminal.
In around 1995ish ISU moved to Scheme for their first level course, because they wanted to follow the MIT example.
At about 2000/2001 they had a healthy number of students in both the computer-science and pre-computer science programs. The problem you can see in the data is converting the pre-computer science majors to computer science. You can see that most just dropped.
Again you could say that maybe SICP should be a weed-out course, but the reality is, you can be a professional programmer without SICP. Yes SICP might be a nice to have for certain problem domains, but most people aren't functional programmers, and don't need to be.
Today, at ISU functional programming is a 300 level course, and the computer science program has 866 registered students for Fall of 2022.
SML/NJ is an absolutely marvelous first language. You will learn to think in abstractions and not get bogged down in any implementation details. The downside is that you will be amazed at the lack of union types and pattern matching in almost all mainstream languages you learn later.
I think it’s supposed to be C without all the pain and misery. C++ without pain and misery is allegedly Rust :).
But we were thrown into C and UNIX when I was at university. I think I’ll have Bus Error and Segmentation Fault core dump messages etched on my gravestone and may be request that the flower vases be labeled gdb (I forget the native debugger that came with the UNIX flavor I was using).
Either way we did data structures and algorithms with Pascal. But I think c should be essential learning from a systems perspective. Maybe I’m too old though.
Zig might be a good alternative as it matures. As far as I understand, zig makes a lot of things explicit which are not in C, like explicitly passing the allocator when it’s needed. This might be even more edifying than C which has a little bit of magic going on.
I think many teachers would disagree about the usage of Zig for CS, and over the widely accepted and used C language or even over popular newer ones such as Go, D, or Rust. Not to mention the strong push that Embarcadero still makes to push Object Pascal (Delphi) into classrooms, and how well known Pascal/Object Pascal still is in countries outside of the U.S.
1) Zig lacks features where they could teach about OOP.
There is no classes or inheritance. To include Zig doesn't lend itself so well to even the more general object-orientated concepts, which are in newer languages like Go or Vlang and others (structs that can be assigned methods and having interfaces). Like it or not (rightly or wrongly), class-based OOP still has many "hypnotized" and conditioned to its necessity.
2) There is the issue of having to address manual memory management.
While that would be the same problem for C, many teachers choose to go the easier route, and select languages like Python or Java. Others like Go, Vlang, D, etc... would make things easier as well.
And Pascal/Object Pascal (Delphi) is still around (a language made for being taught in CS), with a ton of books covering pointers, the heap, bytes, memory management, etc...
3) Zig is still a widely unknown and developing language.
Zig is years away from reaching 1.0. Many teachers are conservative. They often will go with what is already widely known and will likely create the least amount of controversy.
If more teachers can be convinced out of being so conservative, it would probably be because a language is being so strongly pushed by famous companies that are targeting schools or by demand in the job market. Google pushing Go, Oracle pushing Java, Microsoft pushing C#, etc...
Modern c++ needn't be "low level" particularly with c++20 and up, just sayin' . Back when I start school sure RAII was radical and "high level" and everything else was pretty low level. Modern C++ is a different creature. Anyway. I think small languages like c and zig are great for learning as a first language especially for computer engineering students. I still think that a lisp is the best first language for CS students however.
I tried Zig recently but I found the unsilenceable lints to be a huge productivity killer. I actually posted a link to the GitHub issue this morning. https://news.ycombinator.com/item?id=32751317
This makes a normal workflow with `watchexec zig test` basically impossible, since before I can even run the tests I have to spend time hunting down which variables are used/unused at the moment and (un)commenting them. And it seems like they're planning to double down on this by making you adjust even more trivial things like public/private and var/const before it will even compile your code. https://github.com/ziglang/zig/issues/335https://github.com/ziglang/zig/issues/224
Maybe I'm a bad developer, but my code is never perfect the first time around. I always spend time experimenting and refining my designs. I want to find a design that works, and only then spend time polishing and prettifying before I git push.
I do understand the reasoning (they don't want people committing poor quality code), but this implementation just seems completely backwards to me. It breaks the natural order. It's like saying we won't let you ctrl+s until your tests pass to make sure you don't commit broken code. Stop nannying me and let me get my work done!
> I do understand the reasoning (they don't want people committing poor quality code)
Not that this lint actually achieves that, or even prevents real errors. Go has the same, and it's so simplistic as to only be annoying. For instance not sure whether this fails in Zig but Go will allow this:
> If there's one thing I've learned over the years, it's that you can't prevent bad code by enforcing lint errors.
I completely disagree, I regularly catch mistakes/bugs in my own code due to enforced linting errors (both locally and in CI), and just in the past few months I can recall numerous instances where CI linting caught bugs in teammates' code too.
There are both false positives and false negatives with linting, but that doesn't make it useless at all.
And there are good and bad lints. If you want a somewhat view on what lints are good and bad go find some issues for Rust that discuss how to categorize a particular lint.
> That `a` is reassigned doesn't make it unused. It is, after all, a variable.
But that's exactly why it's bad, "unused variable" is not a super useful signal in the first place, and if you assert that everything must be used then you need to protect against "unused stores" instead.
SSA tells us there is essentially no difference between assigning and reassigning.
> I have to agree. If there's one thing I've learned over the years, it's that you can't prevent bad code by enforcing lint errors.
A lot of simple cases can be handled with linting rules, BUT that, IMO requires a few additional things. Namely, being expression based, rather than statement based, and enforcing something like a hindley milner type system.
Basically writing go without `staticcheck`[1] is not recommended. If you do have it set up, it's pretty easy to avoid simple errors like that. I do wish the compiler checked it for you.
> This really irritated me when I started working with go, but it stopped bothering me and now I even mostly like it.
Don’t get me wrong I like a good unused code warning.
What frustrates me is that Go’s is dumb / unreliable, and it will stop you from working entirely until you’ve complied with this whim, which has a fraction of a percent chance of identifying a real bug.
> Basically writing go without `staticcheck`[1] is not recommended.
So why have these things as mandatory compiler errors?
-Werror by default would still be mildly annoying, but I'd like it a lot better than what Go and Zig do. At least then I could shell alias "go" to "go -Wno-error".
I’d assume they care because Go was designed to keep the codebase as “neat” and clean as possible when being worked on by many developers. Given enough time and developers, things like unused variables will start to seep in and make the codebase dirtier.
Of course if you’re the only developer working on your own codebase, you’d wonder why they care but you’re also not the main group they were targeting.
> Why are dead variables any dirtier than dead stores?
If you mean stores to fresh local variables, I assume that should also count in a proper/ideal implementation of this.
If the idea is for code to be literally WYSISWYG, then your compiler will no longer eliminate variables or code for you, so you have to do it.
In principle, a dead variable in final code is also almost certainly a mistake: either by not including the variable in the computation or for declaring the variable at all. Maybe a little annoying while you're figuring something out, but makes sense in the context of polished code.
> I assume that should also count in a proper/ideal implementation of this.
It certainly does in a proper implementation, but not in zig. Or go.
> If the idea is for code to be literally WYSISWYG, then your compiler will no longer eliminate variables or code for you, so you have to do it.
That sounds stupid.
> a dead variable in final code is also almost certainly a mistake
See “final code” is the issue at hand. The problem with go is that it specifically does not do that. It has a half-assed implementation which it forces upon you all the time.
> Maybe a little annoying while you're figuring something out
It’s a bloody nuisance when you new figuring things out or in the middle or refactoring something.
> but makes sense in the context of polished code.
There’s a ton more which makes sense “in the context of polished code” which go can’t be arsed to do.
Checking that errors are not implicitly ignored for starters.
Stores for which there are no load can still be observable in concurrent scenarios. That's why I specified stores to locals with no load because those are not observable.
> That sounds stupid.
Sounds totally reasonable to me in scenarios where you need the output of the compiler to be very predictable.
This lint doesn't help with these situations, but other rules around values belonging to error unions would prevent you from porting this golang code to Zig.
is there no way to swap out lint "ignore" files for fucking around vs "I'm getting ready to test/release" rules ? That's what I do with c++ and python. I haven't only mucked around a bit with zig on godbolt though.
There's a push-and-pull on this in D, too. For example, sometimes I want a backtrace at a certain point, so I'll add an `assert(0);` there. The compiler complains that the rest of the code is unreachable. I then have to block out the code with a `static if (0) { ... }`, or comment it out, which is annoying.
But most everyone else likes this, so it stays in.
There are no real right answers here. Adding a switch for it just brings its own annoyance (every compiler switch is a bug). You just wind up settling for a local optimum.
I totally get where this is coming from, but on the other hand it seems like Rust and Zig both get a lot of value from having the compiler understand the difference between debug and release modes, and it seems like modern C++ suffers somewhat from not having any built-in way to do something similar. The optimal number of compiler switches might not be zero.
Nearly everyone I speak to hates the unreachable error messages, by the way.
It's not useless to have them but they can be utterly infuriating for exactly the reason you mention since most projects have warnings-are-errors turned on.
The way I shut it up in a class is usually by branching on the this pointer. Sneaky.
Have you considered adding a dedicated `breakpoint` keyword for this use case? Linters could ignore it, but the compiler could warn or error. The problem with workarounds like `assert(0)` is that the linter lacks context to do the right thing.
It's a good principle to pursue. But additional language features for production codebases vs toolchain features that happen to lean on changes to the language as a matter of UI are worth considering separately.
Doesn't D have a debugger? Hitting F9 then F5 sounds a lot faster than fiddling around with the code, hoping that you forget to remove the assert before you go home and that you won't spend time pleasing the compiler.
In Virgil I usually do "var x = 1/0;", but there's a command-line option "-fatal-calls=<method glob>", so you can crash on a call to a specific set of methods and get a stacktrace.
You and me both, in fact I made my voice heard in the Github issue.
What's damning is how much Stockholm Syndrome there is around this feature, with people saying it's no big deal and it helps catch bugs. It's more annoying than helpful, and it catches a very small amount of corner cases, while completely killing productivity.
And you know what's the reasoning behind this? "Zig doesn't have warnings." As if it's a massive undertaking to add warnings to a compiler. What a sorry excuse.
I have ranted about this before, so I already feel my blood pressure going up.
> And you know what's the reasoning behind this? "Zig doesn't have warnings." As if it's a massive undertaking to add warnings to a compiler. What a sorry excuse.
Setting aside the unused variables issue for a moment, you might want to take a moment to ponder the fact that not having warning messages is an explicit design choice, not a missing feature.
Well if one never stops to think about its potential merits, it can surely only be perceived as dogmatic. One thing is evaluating a choice in its full context and not liking it, another is demanding to have your vision be understood and accepted without being willing to grant the same courtesy first.
I don't program in Zig, but I can think of a few reasons in principle:
1. WYSIWIG compiler: how many people have been complaining lately about C compilers eliminating code on them due to undefined behaviour? If you eliminate certain optimizations so your complier doesn't do this, like dead code/variable elimination, then what the code looks like is exactly what executes. This means some important optimizations may have to be done by hand. Eliminating dead variables could be one of them.
2. Arguably dead variables are a mistake. Either they're a (major) mistake because you neglected to include a value in your computation, or a (minor) mistake because you declared a superfluous variable that's never used.
3. If you want your code to be clear and as self-documenting as possible, unused variables are an impediment. I can't speak to the accuracy of Zig's analysis, but I can see how it would be annoying while working out an algorithm.
> another is demanding to have your vision be understood and accepted without being willing to grant the same courtesy first.
Is it available somewhere? I can't think anything why that compiler patch[0] can't be upstream (of course not default, but under a flag/different build mode/config option).
We've had -Werror forever, the consensus is it's a bad idea. In addition to everything else, you can't ever change the warnings, including fixing bugs in them, without potentially breaking code.
I see this comment a lot in response to feedback: "Don't like it? Don't use it!" Every single time, it reads to me as "stop complaining!" For as many times as I've seen the comment, I haven't been able to read it any other way.
Am I being uncharitable or is it really just a clear-cut attempt to silence debate?
Well it would depend on context. For a FOSS software in domain where there are tons of other options, it is much easier to use what one likes and ignore what one doesn't. So calling it silencing the debate sounds too strong when software in question is not some controlling the world type.
On the other hand in case cloud services like those provided Google/FB/Twitter/Cloudflare etc it is much more difficult to just go with "Don't use if you don't like" because not only there are not much alternative but also because sometimes Cloud service providers act in unison. So if one is pushed out from a service they are likely to be pushed from all other services too.
"Don't like it? Just fork it!" is a variant I see a lot in the FOSS world. It's equally pernicious in my view. Either you end up maintaining your own fork that nobody uses (and who wants to do that) or the fork is successful and half the community starts hating you for causing more fragmentation. Perhaps the most recent example of this I can think of is neovim, though in the language world python 2 vs 3 is so infamous that people have started hating the entire community from the outside.
All of this says to me that Zig is taking the wrong approach. Making highly controversial, opinionated features the standard with no way to opt out just leads to these endless debates. Languages (or any tools, for that matter) that stay out of the debate and just give everyone a flag tend to have much more welcoming communities.
I agree with a lot of this, in terms of the polarization and tribalism, which is often the result. Unfortunately, there is little that can be usually done, except use other programming languages (which are more agreeable) or fork/make your own.
Yeah, it's just really frustrating when a language like Zig comes along. It does so many things right and seems to have a really good philosophy. But then it includes some highly opinionated "features" that make it a non-starter for so many people who could otherwise benefit from it.
Yeah, exactly right! I mean we all adjust people, places, things all the time. There is nothing special about programing languages that it has to be perfect fit for each feature one desires.
There's a lot of people in the community that feel this way as well but tolerate it. I think it's a certainty that whenever zig 1.0 arrives it will immediately be forked to turn the unused errors into warnings, at least for debug mode.
Another situation where I think the compiler is too eager with errors: unreachable code. A bare `@panic("")` won't compile, but you can "turn off" the error by doing `if (true) @panic("")`.
This also makes learning Zig frustrating for people who aren't yet used to this low-level programming style. I gave up after a couple hours because it felt like I wasted half the time commenting and uncommenting code to avoid this error. People will always find ways to circumvent safety measures anyway, warnings are just fine for the developers who care.
> I do understand the reasoning (they don't want people committing poor quality code), but this implementation just seems completely backwards to me. It breaks the natural order. It's like saying we won't let you ctrl+s until your tests pass to make sure you don't commit broken code. Stop nannying me and let me get my work done!
Could it be that this problem is due to Zig's stance on "no warnings"? It's admirable to try and partition things into strict "correct" and "incorrect" categories. But with only static information it seems like there's always things that seem a little grey.
I love Zig. It's built on such a better foundation than any of its competitors, old or new. I've never been happier or more productive doing systems programming.
But the "no warnings" philosophy alienates developers and seriously hurts adoption. It's almost tragic that a language so impressive is going to die on this hill.
This sort of overopinionated design is part of what killed Phabricator. Let me customize the phucking thing a little bit. "No, we're doing opinionated design, and it's our rubber ducky."
I commented on the github issue a while back as I was frustrated with this.
I originally looked forward to splitting my projects between Zig and Rust depending on the project parameters, but because of this one seemingly small issue I will never use Zig.
That's ok, I respect them having the right to do what they want with their language but it is a little sad because I liked pretty much everything else about Zig.
Refusing to compile takes the position that the compiler knows more than the developers. Or maybe are the compiler writers thinking they are the ones that know more? Maybe I'm being biased because I could consider using it in my free time and I already have enough bondage at work
When the code is "done" then I want the compiler to apply those strict checks and refuse to compile because of such issues. Every issue raised above is something that has come back to bite me in some bug later when not fixed. However like the others, I often do make a change for test purposes that I just want to see if it changes (not to be confused with fix!) the current issue, once I understand the problem better and have the right fix I will go back and clean it up, but right now I don't care about those little details when the big picture is wrong. In particular I often write code with TDD, once the current code passes the existing tests I'm going to add more code and then I'll need the thing the compiler is complaining about.
I'll be honest, it's one of those things that sounds alienating and painful. I am only going to talk about my experience with warnings in general to explain why I support that design.
I had to work in python for a long time where code tends to be incredibly relaxed. When I switched to strict mypy typechecking at every build I became much much more productive and found and fixed dozens of bugs way earlier in development. I now am worried about all warnings and always strive to fix them.
I am also making an analogy to "not being allowed to smoke indoors" when I see these complaints. People hated those laws when they were first proposed but everyone's cool with having to do a tiny bit work for health and safety.
We'll see how communities play out, but I'm all for being rigorous.
Yep. Exactly. We want to be able to silence the compiler for a few iterations while the code is taking shape and then cleanup all the compiler lints in later iteration. In production CI pipeline, we can have all compiler lints on. This capability is very much needed to have a fast local dev iteration where compiler can assist but not impede.
I want it to complain about the "allow", because there was never any deprecated warning emitted in the first place. Maybe it would be called #[expect(deprecated)]
I refactor code all the time and find these stray "allow"s that aren't doing anything anymore
His suggestion is even counterproductive in a way, because it makes it more likely people will accidentally commit unused vars they have silenced. I _want_ the compiler to help me find unused things... just not yet. Wait until my pre-commit hook to yell at me please!
It is not useless though. There is a big difference between an unused variable and explicitly defining an unused variable.
Kelly is designing Zig to do nothing surprising or change things underneath you. Even C does things that are surprising.
If you tell the compiler "Hey, I know this is unused but I am going to write it anyway" then the compiler _can_ make decisions such as eliding the variable.
I think we do all agree that it is sensible that a variable in code that is not used should be a compiler warning (if it is an error or not is clearly debatable).
> There is a big difference between an unused variable and explicitly defining an unused variable.
Which is not helpful when you're only doing it to hide a compiler error foisted upon you.
> Kelly is designing Zig to do nothing surprising or change things underneath you.
Refusing to compile my code because I've an unused variable is certainly surprising.
> If you tell the compiler "Hey, I know this is unused but I am going to write it anyway" then the compiler _can_ make decisions such as eliding the variable.
That is the opposite of making sense. If you are actively forcing the use of a variable then the compiler removing it anyway is exactly surprising.
> I think we do all agree that it is sensible that a variable in code that is not used should be a compiler warning (if it is an error or not is clearly debatable).
1. that it's an error is the entire problem here
2. and as far as I'm concerned it's a ridiculously weak warning, if your standard is that no action should be useless you need an unused store error, which subsume unused variables
This method is more a hack to confuse the compiler than a clean solution, and now this unused variable could stay in the code forever because the compiler won't ever mention it again.
Using `_ = var` to prevent the error is just as bad as handling Java exceptions with empty catch blocks.
My typical approach to warnings and lints is to treat them as fatal, and if there is a good reason to ignore it, specifically silence it for that specific instance, with a comment on why it is ok.
It really irks me when there isn't a way to have granular control over silencing warnings.
had the same problem, if you're just prototyping, it's easy to silence that with _ = someVar
you get used to it after some time - much better than for example rust, where you have to figure out all the lifetimes, muts and generic traits before.
> you get used to it after some time - much better than for example rust, where you have to figure out all the lifetimes, muts and generic traits before.
They aren't comparable. Everything you mentioned in Rust is necessary for typechecking. Unused variable lints aren't necessary for anything.
I am saying that prototyping (for me) is much easier in Zig. Some people like to define all the types (and traits) first, if it works for them then it's ok. I like to get feedback on something working as soon as possible because I'm likely a bit wrong and I will need to refine or rethink the whole thing again, rust is putting obstacles in my way, Zig is not.
Why would anyone use a new systems programming language that is not safe? Zig might be better than C in some aspects, but is it worth it to switch to Zig when you realize that it's not much safer than C? [0]
I don't agree at all about "not much safer" and Zig differs from C in so many ways -- including but not limited to safety -- but regardless, memory safety comes at a price, language safety is not an end (that would be program correctness) but just one of many means to that end, there is no consensus at all over what is the most effective way to reach that end, and there are other things people care about as well. So your very question is the wrong one. You're both setting an absolute priority as well as the best way to achieve it when there's no consensus over either one of these.
Put another way, the answer to your question is because even if program correctness were the only value that matters to anyone who does low level programming (and it isn't), there's no agreement sound memory safety in the language -- at least the way Rust does it -- is the best way to achieve correctness. Put yet another way, the answer is: for the same reason people would want to use a language with memory safety -- because they think it helps them achieve their goals better.
I think it is a big improvement, on the axes that matter most for low-level programming. In fact, Zig is so revolutionary (rather than evolutionary) that its power is sometimes missed on first glance.
Sure, comptime, comptime introspection, comptime type generation, incremental compilation, basically the most important things for low-level programming.
Many low level programming languages don't have them, including C, so while a nice feature, I don't see it as a killer feature, more like a nice to have.
C doesn't have the abstraction abilities of languages like C++ while Zig does, thanks to this feature. This is more than an exponential increase in expressivity (i.e. there are Zig programs that would take exponentially more code in C).
"Not much safer" isn't fair. Zig has full spatial memory safety, which is already a huge improvement over C. The Zig type system and how idiomatic code looks also prevent various safety risks. Also, Zig panics on integer overflow, avoiding various other dangers.
Zig does lack a general solution for temporal memory safety. That is a downside. But it can still have that safety in ReleaseSafe mode, at least - for example, by not reusing memory addresses. That adds overhead, which might rule Zig out in certain areas, but not others.
Also, while in many domains safety should be the #1 factor when when choosing a language (like building a web browser), that's not universally true. Other factors exist.
They prefer slices idiomatically, but that's not "full spatial memory safety". C also prefers you to pass the length of every array whenever you pass a pointer to it, in that correct code must do this. But the entire point of language memory safety is that we don't trust programmers to consistently do the right thing.
You might be able to say something like "Zig minus features X, Y, and Z has full spatial memory safety". I'd be interested to see what features those are: it looks like at a minimum you would have to get rid of multi-element pointers and extern unions.
> But it can still have that safety in ReleaseSafe mode, at least - for example, by not reusing memory addresses.
The overhead is extremely high, because it leaks an entire 4kB page if a single allocation from that page is still alive. In the worst case, it's equivalent to rounding every allocation up to 4kB. If you're OK with that overhead, you could just link in the Boehm GC and get the same safety with less memory usage, and as an added benefit you wouldn't have to call free anymore.
> Also, while in many domains safety should be the #1 factor when when choosing a language (like building a web browser), that's not universally true. Other factors exist.
In the vast majority of those domains, you could just use a GC'd language. I don't see much room for a new language that isn't memory-safe in 2022.
> They prefer slices idiomatically, but that's not "full spatial memory safety"
[*] is a syntactically delineated unsafe feature. Rust has the same thing. It's like saying Rust prefers safety, but doesn't enforce it because it has unsafe features; same goes for Haskell.
> I don't see much room for a new language that isn't memory-safe in 2022.
That statement [1] is about about as silly as "I don't see much room for a new language in 2022 that is obviously too complex to see wide adoption." If a language becomes popular then obviously there's room for it, and if it doesn't, then the question is moot. Maybe what you mean is that you don't think Zig would ever become popular -- and you may well be right -- but you work on a language that is subject to similar scepticism and doubt.
Both Rust and Zig have some huge challenges to overcome if either one of them is to have "room", and I wouldn't bet on their chances, but it's good to have some widely different approaches and see which, if any of them, turns out to have "much room".
[1]: Even disregarding the hard question over which of Zig or Rust make it easier to write correct programs, which could go either way; that sound memory safety is a better path to correctness than a balance of less soundness combined with simplicity is your opinion, and few would claim that Rust's flavour of safety doesn't come at a cost.
In Rust all of those features are delineated by unsafe. For one, you can disable unsafe with a compiler switch; Zig has no such equivalent feature.
Moreover, we shouldn't assume that Zig pointers are the only feature that breaks spatial memory safety. It was simply the first one I found after like 2 minutes of looking through the docs. After like 5 more minutes I found another: extern unions. Just now I found another: sentinel-terminated pointers, since you could delete the sentinel.
It feels a bit like these arguments are going like "Zig is spatially memory safe!" "Well, what about X?" "OK, other than X, Zig is spatially memory safe!" "What about Y?" "OK, other than X and Y, Zig is spatially memory safe!" At this point the burden of proof isn't on me anymore.
It's obvious that full spatial memory safety just isn't a design goal of Zig. It seems like Zig's goal is simply to add tools, like slices, that reduce memory errors. Which is the same goal that, for example, the C++ STL has. It's a great goal, but it shouldn't be confused with Rust's goal.
> [1]: Even disregarding the hard question over which of Zig or Rust make it easier to write correct programs, which could go either way; that sound memory safety is a better path to correctness than a balance of less soundness combined with simplicity is your opinion
It's my opinion in the same sense that it's my opinion that wearing seatbelts results in fewer deaths on the road. The idea that memory-safe programming languages improves real-world safety is backed up by decades of experience. Anyone arguing otherwise has a massive burden of proof. And the arguments I've seen by people arguing that you don't need temporal memory safety are weak. The idea that a simple language that doesn't have ironclad safety guarantees reduces errors over a more complex language with those guarantees sounds nice in theory, but it hasn't actually turned out that way in practice.
> Moreover, we shouldn't assume that Zig pointers are the only feature that breaks spatial memory safety. It was simply the first one I found after like 2 minutes of looking through the docs. After like 5 more minutes I found another: extern unions. Just now I found another: sentinel-terminated pointers, since you could delete the sentinel.
You're right on each of those points. But (AFAIK) all those types are explicitly there for C interop. When interfacing with C, yes, Zig will inherit much of C's unsafety. But the big picture is that
1. Idiomatic Zig should not use those things, and
2. Those things are (IIUC) mechanically-identifiable at the type level. A compiler flag could warn about them. You can check if a codebase uses them, and find out exactly where. No such thing is possible for C.
Maybe you'd prefer that an unsafe block be required to be placed around each of them, but in the end that's a matter of notation. In theory, Zig could decide to mandate such explicit unsafe blocks, but C couldn't - there isn't a useful safe subset to delineated.
I could be wrong, however. Possibly the Zig community will decide that say sentinel-terminated pointers are good to use in general (and not just for C interop). And maybe I've missed something and those types cannot be discovered mechanically for auditing purposes. If either of those is the case then I'd agree Zig lacks spatial memory safety.
(Btw, you seem downvoted atm. Not me, of course - there's probably no one else I respect more on the topic of memory safety than you! - and it's disappointing that people downvote comments just because they disagree.)
I do think the 'unsafe' notation is the crucial bit here. Rust has stuff that is heavily (although not completely) motivated by C interop. For example, 'union' in Rust is something that is rarely used outside of C interop. (With some notable exceptions in the standard library.) But, crucially, in order to actually use a Rust 'union', you do have to utter the 'unsafe' notation.
I'm not sure I have an opinion as strong as pcwalton here, but I do think that you can't call yourself memory safe (even on a particular dimension) if you have to delineate all of the various language features that are unsafe without having to somehow explicitly annotate it as such in the source. Or at the very least, I don't think you can say that Zig's spatial memory safety is on even footing with Rust's (assuming pcwalton's characterization of Zig's unsafe features is correct).
The annotation really is the point here, because you can pin everything (modulo bugs and OS features that permit subversion) with regard to memory safety down to an unsafe annotation somewhere. That's a powerful tool that crystalizes what it means to be a "safe API."
As I said, I don't necessarily share pcwalton's strong opinion (although I do weakly agree with him) that having an annotation like 'unsafe' is the only way to go. I do think it's possible to go the Zig route and reduce memory safety bugs. But we should be very clear eyed about the claims being made and how comparisons are drawn.
I don't think the annotation itself is actually the point. The point is being able to find all sources of unsafety and reason about them. Annotations do that, but other things can too.
Imagine if you could run a tool on a codebase, and it statically found all the unsafe locations, and in idiomatic code there were very few of those, and you could reason about them. That would be equivalent to writing "unsafe" in the code, except you need to run the tool to "see" the annotations. That would be as good as annotations - it could prevent the same number of bugs. (Though I guess an argument could be, maybe some people forget to run the tool; fair enough.)
No such tool can exist for C or C++. But such a tool could exist for a new language like Zig and Carbon, if they design themselves in certain ways, at least for spatial memory safety. Concretely, unsafe things like raw pointers in Zig have different types than safe slices, so a tool can actually find them; and unsafe things are (AFAIK) not idiomatic either, so they'd be rare.
I think we'll just have to agree to disagree. I'm not certain you're wrong, so we'll have to see how it shakes out. And I love what the Zig project is doing, so I wouldn't at all be surprised if they find some other way here that works well in practice.
Otherwise, I do think you underestimate the differences between an annotation like 'unsafe' and what you can find easily only through a static analysis tool. The key bit of the 'unsafe' annotation is the concept of "safe API" that it inspires, and also gives one a vocabulary for talking about things like 'soundness.' For example, you can mark Rust functions as 'unsafe' and then document the preconditions for avoiding UB. If you didn't mark that function as 'unsafe', then we would call it unsound because there exists an input that could cause UB, but it does not necessarily result in UB for every input.
The annotation gives people a way to talk about and crystalize precisely what it means for an API to be safe for all uses. It funnels everything about memory safety down into that one concept and makes reasoning about it much much easier. Without an annotation like that, it's cumbersome or downright difficult to even talk or communicate about soundness.
Well, let's turn this around. Is C++ spatially memory safe? C++20 has slices (ranges). They're bounds checked, via the .at() method. You can get the integer overflow semantics of Zig with "-fsanitize=signed-integer-overflow -fsanitize=unsigned-integer-overflow -fsanitize=float-cast-overflow". You could write a checker that enforces that only these features are used (in fact, this checker basically exists--ISO Core C++ Guidelines).
I don't see any reason why modern C++ wouldn't be just as spatially memory safe as Zig is, if we're allowed to subset the language in ways more trivial than "disable the unsafe keyword". The main thing that distinguishes Zig at that point would be that it's a simpler language. That's true. But I don't actually think that makes for safer programs, empirically speaking--otherwise, C programs would be safer than C++ programs, and they generally aren't.
Yes, technically there might exist a subset of C++ as safe as idiomatic Zig. But in practice inertia and legacy code and lack of ergonomics etc. work against that subset of C++ becoming popular - does anyone constantly type .at()? Zig can do better, if it doesn't squander the opportunity.
In other words, this isn't about theoretical subsets of a language. It's that there is an opportunity when designing a new language to use better defaults and have better idiomatic patterns. If Zig and Carbon do it properly, I think they can get to a place where they have practically no spatial memory errors in the real world. That is measurable, in principle, so we'll see how it plays out I suppose.
I think it's worthwhile to point out that there are two threads of argument here. One is what it means to be spatially memory safe. Another is whether and how effective various mitigations are.
Note that STL containers allow you to bounds check "[]" indexing even in release mode if you set the right preprocessor directives. The flag differs between compilers and stdlib implementations, though. For libstdc++ (default on linux), use _GLIBCXX_ASSERTIONS. For example, the following code aborts on release builds too:
MSVC provides similar functionality using the _ITERATOR_DEBUG_LEVEL directive. The point is that there is no inherent limitation that one has to use the .at() method for bounds checking STL container access.
> I don't see any reason why modern C++ wouldn't be just as spatially memory safe as Zig is
Well, you'd need to avoid arrays and pointer arithmetic, some of the most basic language primitives, but being safer than C++ (even though it is) is not Zig's only or even main differentiation from C++.
> But I don't actually think that makes for safer programs, empirically speaking--otherwise, C programs would be safer than C++ programs, and they generally aren't.
Once again you're begging the question by trying to draw similarities between C and Zig and using extrapolations that you yourself know to be wrong.
We both agree that the sweet spot for correctness is somewhere on the spectrum between C and Idris, but we really don't know more than that. No one is claiming that any language X that's simpler than another language Y will be more effective at producing correct programs, just as no one is claiming the same for any language X that can offer more sound guarantees than Y. In fact, we know that both of these statements are wrong.
What we know is that simplicity and soundness are both sometimes better for correctness but neither is always better for correctness. I.e., we know that we cannot make the extrapolations that you're making.
> In Rust all of those features are delineated by unsafe.
They're also delineated in Zig, just not with a single keyword. Extern unions, unknown-length arrays, and sentinel-terminated arrays are features, with clear syntax, used for C interop only.
> It's obvious that full spatial memory safety just isn't a design goal of Zig.
It's as much of a goal in Zig as it is in Rust; both allow circumventing it with clearly marked unsafe features.
> Which is the same goal that, for example, the C++ STL has. It's a great goal, but it shouldn't be confused with Rust's goal.
You're confusing means and end. No one's ultimate goal is having this feature or another. Both Zig and Rust have, as one primary goal, helping write correct software. They just try to achieve it in different ways. Why is that good? Because we have no idea what is the most effective way of achieving that goal, so we try different approaches.
> It's my opinion in the same sense that it's my opinion that wearing seatbelts results in fewer deaths on the road.
I don't think so, because seatbelts have few accident-related downsides, while a complex language has many.
> Anyone arguing otherwise has a massive burden of proof.
I'm not arguing against seatbelts. Anyone who claims that X leads to more correct programs than Y -- not by looking at this or that property, but as a whole -- has a massive burden of proof. I am not claiming Zig is more effective at writing correct programs than Rust. After years exploring issues in software correctness -- including with different formal methods -- my claim, which is closer to consensus than controversy, is that we simply don't know. We don't know which of Zig's or Rust's approaches leads to more software, and therefore we cannot say which of those approaches is preferable, even if correctness is the main thing we care about.
> And the arguments I've seen by people arguing that you don't need temporal memory safety are weak. The idea that a simple language that doesn't have ironclad safety guarantees reduces errors over a more complex language with those guarantees sounds nice in theory, but it hasn't actually turned out that way in practice.
We simply don't know either way. We might know that a language with ironclad guarantees leads to more correct software than C, but given that Zig is as different from C as Rust is -- and as different as they are to each other -- there's nothing that allows us to extrapolate.
Your argument amounts to, "my way is the best way", and your evidence is irrelevant extrapolations. One could then ask, if Rust's design is so great, how come, at its not-so-young age -- which is quickly nearing the age at which all languages (with the possible exception of Python) have reached or approached their all-time peak popularity -- so few people use it? Could it be that there's no "room" for it? (I'm not saying that's the case at all -- I think Rust, like Zig, is a very interesting language.) Its low popularity certainly makes claims along the lines of, "the design of this language is obviously the only design for which there's room in 2022," ring quite hollow. There's no room for anything other than an approach whose success is so uncertain? Really? Given that Rust has proven quite the opposite of an overnight success, I think some humility about its design choices is appropriate.
Part of the issue is that Zig is in a near category to Rust, and its areas of focus are more restricted as opposed to other general purpose and convenient to use languages. Rust already has major corporate backers and much more established popularity in the media. It can easily be seen how it can just simply overwhelm Zig, and particularly by emphasizing safety. Even if those very knowledgeable about the subject can argue to what degree safety should be the issue or is relevant with a particular project, Rust already has the hype and reputation behind it as being "safer".
Zig has to make stronger and more compelling arguments as to why people should use it, instead of just reaching for Rust.
> You might be able to say something like "Zig minus features X, Y, and Z has full spatial memory safety". I'd be interested to see what features those are: it looks like at a minimum you would have to get rid of multi-element pointers and extern unions.
Well, `[*]` pointers and extern unions exist for C interoperability. I'm sure that Rust has to do something comparable when interfacing with C.
These pointers actually do help making C interop more safe. In C there is no distinction at the type level between a pointer to a single element and a pointer to the first element of an array, so if you at some point get it wrong, the compiler can't help you.
In Zig, if you annotate `extern` function signatures correctly, the compiler will be able to tell you when you're wrongly trying to iterate over a single-element pointer (or viceversa).
That's a good feature to have, and IMO probably the worst supporting argument for your usual complaint about Zig's existence.
I didn't say that multi-element pointers were a bad feature, simply that they're a counterexample to the claim that Zig has spatial memory safety.
Generally in memory-safe languages the corresponding features are behind some kind of "unsafe" marker: in Rust and C# they're behind "unsafe", in Java they're behind "sun.misc.Unsafe", etc. I don't see any such marker in Zig.
Is the marker the critical thing here, though? I just wrote in another comment that I think the Zig compiler can warn about using an unsafe pointer.
The critical thing, I believe, is that unsafe can be discovered and audited. Unsafe pointers have a different type in Zig, so they are separable from the rest of the language, unless I'm missing something.
The bottom line is that in a memory-safe language it should be possible to find all the unsafety and reason about it. For spatial memory safety that's not possible in C, but it is in Zig.
I would want to see an example of such a tool before comparing the two approaches or giving credit to Zig. As you admit in the other comment, even if such an "after the fact" tool can exist, still the net safety will be less. A compiler that does not force the developer to consciously think about safety at the time of using the unsafe feature increases the probability of misuse and safety defects.
> They prefer slices idiomatically, but that's not "full spatial memory safety".
I don't think people say a language is unsafe if it has opt-in unsafety in controlled, non-idiomatic ways. Java, C#, Rust, etc. all have unsafe things you can do, but they are still memory-safe languages.
Specifically for Zig, I don't see a reason the compiler couldn't have an optional warning on using an unsafe pointer, so codebases can be audited for this risk, making this a controllable form of unsafety (unlike most of the unsafety in C!).
> The overhead is extremely high, because it leaks an entire 4kB page if a single allocation from that page is still alive.
In general you are right, and in a long-running process that would be the case. But consider a short-running wasm event handler: such overhead is generally not going to be significant there. So this rules out some uses cases, but not all.
> I don't see much room for a new language that isn't memory-safe in 2022.
Yeah, I agree the space for a language like Zig is limited: GC languages are the right answer for most things anyhow, as you said, and when they are not, often memory safety is crucial (like in a web browser) and I'd strongly prefer Rust over Zig there.
Still, there are use cases where Zig seems nice, like wasm event handlers that I mentioned: they're sandboxed anyhow, binaries are small, and it's nice to not have GC overhead. Zig's simplicity and fast compile times are a bonus.
Another use case are low-level things that you'd need lots of unsafe in Rust anyhow. I'm not sure if I'd prefer Rust or Zig in such a case myself. I'd prefer either over C, though.
I scratch my head when people think Rust is the "the answer". Zig has different trade offs to Rust and in some areas is safer. It is also a much smaller language , and hopefully won't need language lawyers to debate endlessly best practices. A gentle reminder to people that even "safe" Rust code can still crash. We always need to be vigilant and take our time to actually think about what we are doing and not just on the problem we are trying to solve.
Can you explain the areas in which Zig is safer than Rust?
I'm under the impression that crashes are considered perfectly safe because they don't lead to memory unsafety. They're inconvenient, but eliminating them is more or less impossible: if you don't want stack overflows, you have to ban recursion; if you don't want integer overflow, you have to ban addition or insert checks for overflow; etc.
> That adds overhead, which might rule Zig out in certain areas, but not others.
It seemed back when Rust was an upstart that everyone would ride its behind about how this and that feature could add runtime overhead compared to C or C++. Especially compared to C. But now people are comparing Zig and C and are saying (indirectly) that they are fine with runtime overhead in exchange for more safety? Has a shift happened?
Temporal (runtime) safety could actually be provided via tagged index handles (where the tag is a generation count). But this should be implemented by libraries, not built into the language (like: https://github.com/michal-z/zig-gamedev/tree/main/libs/zpool)
(it's of course not a "general solution", but I wonder if something like 'tagged pointers' could be that, even without hardware support, and at some runtime cost)
Why Zig When There is Already C++, D, and Rust? [1].
Also, safety is not the only consideration when writing software right? Otherwise, all software would have to be written using formal methods [2] ... clearly overkill for many (most?) applications.
Maybe it is a bit obvious, but I think someone would pick Zig because they like the set of features that the language provides, allowing this person to write reasonably bug free code in (hopefully) shorter time than using a different language or methodology.
I think most ppl choose the language because they like the tools/ecosystem/libs available, because it aligns with previous experience/s, because of how popular it is for the kind of app they are writing, and because they agree with the authors philosophy (as opposed to choosing it based on any particular language features).
It does seem confusing to me why someone would choose Zig. If you’re looking for a low-level language, Rust is safer with a better ecosystem. If you want a high-level language, Nim binaries are smaller and the Go ecosystem is better.
I would choose Zig because Zig has a much more approachable learning curve and Zig code is eminently legible compared to Rust code and it's overly complex type system.
Yeah, when people hear GC, they often get oddly dismissive. However, various languages have optional memory management, so have to look at the situation carefully.
I often write software in C to run directly on microcontrollers; no OS, no runtime.
I can see the advantage freestanding Rust would provide for e.g. 802.11 firmware. Broadcom repeatedly suffers from their choice to write the firmware for their WiFi chips in C.
… but would Rust provide any clear advantage to the programmers of a Furby or a keyboard controller?
Very good points, that can't be ignored. Zig looks to be trapped in a niche. It's going to have a really hard time pushing past other low-level languages, and because its small and focused on that area, will not be able to compete with numerous high-level general-purpose languages that do more for users.
Add to that, Rust and Go have strong corporate backing, continually get lots of shine in the media, and often are given positive spin or ratings whenever compared to other languages.
As you mentioned Nim, look how far uphill it still has to climb, after the many years (around 14 years) it has been out. TIOBE Index doesn't even have Nim in their top 50, and they aren't even on IEEE's top programming languages list (of around 60 languages). This is just as likely the fate of Zig as well. Not saying some people won't find Zig useful for particular niches, but rather it will likely never be on the level of Rust, Go, D, Object Pascal, etc... or possibly even Nim.
Some might find Zig to have better ergonomics and some work on systems where dynamic memory allocation and concurrency are inappropriate for safety reasons anyway.
- very easy and readable metaprogramming (compile time inline for over all enum variants, duck-typed and strong-typed anytype at the same time, @compileError for advanced compile checks so you can teach compiler new rules about your code instead of trying to fit your code in the extisting compiler rules)
I could see Zig thriving in a kernel, with its seamless integration with C. It would be a relatively simple upgrade to make. I still think Rust is the better choice though. Maybe the answer to your question is, if you're strictly a C developer and you want something a little nicer without too much more, then Zig might be the best choice for you.
The fanaticism of Rust devs makes me think it's probably massively overrated (see Node yesterday and Ruby/Rails the day before) and Go is associated with Google which gets a perhaps unfair but still unignorable knee-jerk reaction from me to avoid it.
I don't know enough about Nim to pass judgment.
Two reasons I decided to give Zig a try: The official chat channel is on IRC, instead of Discord or Slack (so the people involved care about efficiency, open standards, and avoiding trends/bandwagoning), and it has an early but promising-looking Swift UI-like cross-platform UI framework in development: https://github.com/capy-ui/capy
> The fanaticism of Rust devs makes me think it's probably massively overrated
Or it's enthusiasm for something that's genuinely worth being excited about. Such things do come along from time to time. It's probably not a good idea to be permanently jaded, to assume that everything is zero-sum, that we can never again make progress by bending tradeoffs.
Now, to Cyberdog's point, there is an IRC channel on libera (that I'm also a part of) and it's even bigger than Zig's channel, but it's "unofficial" and they did ask for an official one. Like, Zig's channel has the advantage of being a direct line to andrewrk which you won't get from the Rust channel.
There's no equivalent to a "direct line to andrewrk" because Rust does not have this one man setup.
Culturally, there's more of a "pitch in to help" and less "ask before touching". So people are mostly looking for hand-holding, "How do I?" and "Is this correct?" rather than decisions and permission.
>There's no equivalent to a "direct line to andrewrk" because Rust does not have this one man setup.
Nothing in my comment is about a "one man" setup. Core Rust devs hang out in the Discord server. They don't hang out in the IRC channel.
>Culturally, there's more of a "pitch in to help" and less "ask before touching". So people are mostly looking for hand-holding, "How do I?" and "Is this correct?" rather than decisions and permission.
I'm not sure why you're assuming that the Zig channel is about "decisions and permission", but it's not. It's about language discussion just like the Rust IRC channel and Rust Discord are.
Thanks for the correction! I conflated what (I believe) some rust teams use as the thing that every thing in official rust uses. I think Rust uses both Discord and Zulip[0].
The simple answer to your question (if you really meant it as a question) is that memory safety comes with ergonomic and performance costs. The Rust project is an experiment in hammering those costs down as small as possible, and sometimes maybe even turning those costs into benefits. But the costs do exist, and of course not every project in the whole world will want to pay them.
Rust cares about a subset of PL ergonomics, sure. But it is not true that Rust as a project is an experiment in hammering down costs on ergonomics as small as possible. If that were true, the Rust toolchain wouldn't be what it is.
As far as I am concerned, the alleged "memory safety" benefits of Rust do not have much more value or weight than wishful thinking, this kind of claim can only gain strength by standing the test of time.
Computer security is a real problem that must be fully addressed at every step of the design of a system, language and tooling can help, a bit, not much.
Rust is not a "safe" language. It might be -safer- than C/C++, but only time will tell if the difference is significant.
https://github.com/diem/diem is 387,952 lines of Rust code across 169 crates. In total there are 3 lines of unsafe code, which is less then 0.001% (1 thousandth of 1%).
> The launch was originally planned to be in 2020 but only rudimentary experimental code has been released until the project was abandoned in January 2022.
You’d have to demonstrate that this is the case before it’d be worthy of “attacking.”
You’d also have to define “serious system” and “significant portion” and if you really do mean “any,” that is, is a single counter example enough, and if not, what percentage of them would need to be so for this to be true. You’d also have to say what’s in bound or not, is it just the code you wrote for the system, is it any dependencies, etc etc etc. Does “significant” mean “large amount” or does it mean “most important”?
I prefer Zig for a lot of things, but I use Rust for $WORK, and I'll toss something out:
GhostCell is an interesting venture away from that idea. For the sorts of loopy data structures that upset the compiler, GhostCell provides a small, well-vetted, probably correct unsafe core and a safe API for accessing it that greatly reduces the amount of unsafe one should need. The core mechanism is just a higher order phantom (ghost) type parameter that gives the compiler enough information to vet that the thing you're handling was acquired properly.
The community has generally been pretty gung-ho about getting the most safe bang for your unsafe buck, and the compiler has enough bells and whistles to make many such ideas pretty seamless.
The world isn't just black and white, as is demonstrated by Rust's unsafe keyword (and Rust would be pretty much useless as systems programming language without unsafe).
I think Zig would be much easier to write code for compared to Rust in this use case. Rust is not some magical tool that stops all bugs as some people like to think it is. The lower you go, the more you will have to contort yourself, and the more likely it is for less experienced programmers to make mistake. I think Zig is much more approachable and fixes a lot of C foot guns and guides you into writing safer, faster code.
If you are writing web apps then Rust is probably "safer". If you are writing low level code that requires obtuse memory management then I don't think you can make a blanket claim that Rust is just "safer". A lot of this nuance is not often discussed.
zig is not meant to be just a systems programming language. It's stated goal is "Zig is a general-purpose programming language and toolchain for maintaining robust, optimal and reusable software." and Andrew really does intend for it to be useful far beyond systems programming. I hope they succeed, since I've been using zig regularly for over a year now, and I love it. I have decades of experience with assembly, Fortran, C, C++, Python, and Javascript, and I really appreciate what the Zig developers are trying to do. I hope they succeed!
It sounds like you're saying rust because I don't know what other languages claim both.
Rust is an awful language. That's why. If you're using a systems programming language then chances are unsafeness isn't the problem you're most concerned with
I noticed you deleted the tweet where you said employees would need to grind for the first 9 months, and that if you're looking for somewhere with a good work life balance this job isn't for you.
Would love to hear your experiences hiring devs and building projects in a new, scarcely-used language and ecosystem like this. I imagine you don't quite get the range of applicants you'd see hiring devs for Rust or Go or other trendy languages du jour, but maybe that's actually a good thing since it weeds out less experienced devs and résumé liars who probably don't even know Zig exists…?
Although the "Python Paradox" does not apply to Python anymore (it has become even more mainstream than Java), it does highlight an important point:
If you choose your language based on "I want the biggest pool of developers" you are also saying "I want the most average and mediocre developers that I can pay for cheap".
I maybe overstating it, but another contributing factor to its growing popularity may be the documentation. It is really nice and well presented. Reminds me of how the rust book also welcomed you to explore the language.
Zig has good docs now? Nice.
Last I looked Zig had some of the worst docs I'd seen to the point where I just looked at the std sources and eventually just gave up
For what it's worth, work on it as resumed now that the self-hosted compiler is mature enough. Still very far from being complete, so we don't link it yet on the front-page, but it's being actively improved.
Zig indeed is pretty nice, i just wish it had some more sweet to it
- my math type with + - * / overloads
- simpler way to fill an array, i can never remember the syntax, it doesn't feel natural `[_]u8{0} * 10;`
- smarter type system, i am tired of casting everything twice
A good language is not a language set in stone, a good language is a language that doesn't make me feel like i have to suffer because they made a stupid decision years ago and they refuse to make it better
D initially wasn't going to do operator overloading, mainly because C++ iostreams was a disaster (in my not-so-humble opinion) as well as the awfulness of overloading operators to create a DSL.
But I wound up being convinced that on balance it was a good thing. But I was able to inculcate a culture that operator overloading should be restricted to the creation of user arithmetic types.
Not allowing the overloading of unary *, &, and dot also help discourage non-arithmetic overloading.
C# has had extensive operator overloading from day 1, and the only instance of (mild) abuse that I can think of is the use of implicit conversions from strings in XLINQ. It really is mostly down to culture, I think.
What about something like R's custom infix operators? R has %*% for matrix multiplication (and a few other built-in ones), but you can define your own %op%. It lets users know that potentially "here be dragons".
That has come up a few times. Frankly, %*% looks even worse. Using Unicode sounds like a good idea, until one discovers that the source code is not parseable without semantic analysis.
The thing about operator overloading is that it was abused during one of the worst era of C++.
And vec2 + vec2 can probably be unambiguously translated to assembly code while mat4 * mat4 is an other story. In most cases it should be a function call, and not a trivial one, with SIMD it can be relatively fast but still several orders of magnitude slower than 1 + 1. (we're talking about more than 500 scalar-equivalent operations)
And unfortunately, from my experience, if you let people (especially new coders) use this kind of powerful syntactic sugar they tend to ignore the performance characteristics because it look so simple and basic, like if the CPU had a special instruction to multiply two 4x4 matrices.
I prefer when the function call is explicit, it is a bit more cumbersome to write, but there is less hidden complexity.
> I prefer when the function call is explicit, it is a bit more cumbersome to write, but there is less hidden complexity.
you hide and obfuscate basic operations with functions, that's worse, specially when you have to chain arithmetic operations, with functions it becomes ugly and unreadable
> Matrix multiplication or even worse, matrix inversion, is NOT a basic operation.
Neither is dividing floats, especially not on a softfloat & softdiv architecture. And yet, Zig is perfectly OK with you using division between 2 floats. Why does it get to insert expensive function calls behind operators but I can't?
Zig also lets you do remainder division for floats, which is also not a "basic operation." It's slower even then taking the sqrt of a float! Zig then also has specialized operators like saturating addition, which also isn't a "basic operation"
And then Zig also has `*` for array multiplication and `++` for array concatenation. Those are compile-time only, but still deviates from "basic operations only" territory surely. And also Zig overloads `||` to allow for the merging of enums (sorry, "error sets"), rather than only being a boolean OR.
Integer division isn't a simple one either though…
Matrix multiplication are “basic operations” in the sense that you use them as the basic block of your algorithms, and in code using such blocks you really appreciate having a simple operator for those instead of littering your formula with functions calls (which is basically writing your formulas in Polish notation, not the most legible way to write formulas …)
The programming world is made of niches. That's why arithmetic operator overloading is nice, the language doesn't need to know which niche I'm in to satisfy my needs.
I somewhat agree with you, I argue that mat*mat should be an element wise operation and use a different operator for matrix operations (like numpy does it).
> if we can do 1 + 1, we should be able to do vec2 + vec2, same with mat4 * mat4
why? operator overloading doesn't help you solve any problems. you can have the readability with methods which are named appropriately.
operator overloading seems so powerful and useful until you realize one day that it only changes the appearance of things, and makes no difference whatsoever to anything you are actually doing.
I think haskell does this right. You can make function infix by turning "add a b" into "a `add` b" and you can't overload existing operators but you can make your own and do "a _+ b" or whatever and everybody will know it isn't the standard + but it's still readable.
But we are using operator overloading already, + does work for the basic numeric types doesn't it? So why should the line be drawn at float or double (zig didn't have a complex type last I looked), why not vec?
readability is important. specifically, operator overloading is great because it makes code look more like math. when translating from math to code, this is highly useful.
Then no operators should exist at all. After all, adding 2 ints and adding 2 floats are drastically different runtime characteristics - performance and errors are completely different! Anarchy! Chaos! And let's not forget about all those architectures where the division operator is, gasp, a function call!
Also function overloads should never be allowed, either. After all, that's not explicit and the only thing that ever matters is being obsessively explicit for the sake of being explicit. How can I possibly tell what `min(a, b)` is going to do if function overloads or templates or macros exist?!? UNREADABLE!
I think at this point it's pretty well established that operator overloading is a net-good, and languages that don't have it end up with far more bugs than languages that do. Or they come up with arbitrary nonsense rules on why some types are allowed to have it but not your types you dirty filthy casual. Looking at you, Java, where the Integer class is allowed to overload operators but BigInteger isn't. Which, then again, is something Scala and Kotlin immediately completely reversed.
> A good language is not a language set in stone, a good language is a language that doesn't make me feel like i have to suffer because they made a stupid decision years ago and they refuse to make it better
It depends. Low level coding the like of which zig is tailored to tends to involve a lot "write and forget about it" infrastructure stuff. At least that's my use case.
It sucks to painfully go over that cryptographic hash, that codec or that compressing algorithm you wrote 15 years ago and still works flawlessly because it wouldn't compile with the modern version of the language.
I think zig is very nice but I wouldn't use it even for my personal projects because it's still unstable (and from my POV it will remain that way for at least 5-10 years).
C is terrible but it's not sufficiently terrible that I would use a language that is orders of magnitudes less popular and still in its infancy. Too risky.
I agree that array initialization syntax is weird a.f., but the other two points are very deliberate. I feel like you're implying they're legacy cruft.
> It’s a very appealing language to the modern low-end (and not only) applications
Current $work language is Go, which is so painful to use. I often look wistfully at all of Zig's features that improve on what Go does (particularly with regard to error handling). I hope in the future I can use Zig as a Go replacement and not just a C/C++ replacement.
> I hope in the future I can use Zig as a Go replacement
I've only scratched the surface of Zig myself, but my impression is that replacing Go with Zig will probably be painful in most cases. I think of the stereotypical Go project as a backend API service, where memory is relatively plentiful, and "make a copy of this string" is something you do all the time without thinking twice about it. It seems like Zig wants you to be more thoughtful whenever you're allocating memory, which makes a ton of sense for low level libraries or kernel code, but which sounds painful for typical large applications.
Yes I know :) Equally importantly, the Go GC will keep a string alive as long as you have a reference to it, so different objects can hold a pointer to the same string without worrying about who's going to free it or whether one of those pointers might become dangling. Python and Go (and others?) get a lot of mileage out of making strings shared and immutable, but languages with manual or destructor-based memory management don't really have that option.
Not fighting the borrow checker or making gratuitous copies of data to satisfy the borrow checker.
Zig's scope is just to be a better C that's free to add modern features like optional types, compile time expressions instead of string-macros, source level modules, packages, a more expressive syntax for writing bit-packed structures, a standard testing framework, deferred function calls, and so on. You can also directly include c headers directly in zig code, so this gives you a pathway to modernizing C Code incrementally.
This isn't going to be appealing to Rust current users though, because “fighting the borrow checker” is a learning curve issue, you don't fight the borrow checker anymore once you've internalized its rules.
> or making gratuitous copies of data to satisfy the borrow checker.
You get it backward. In Rust there's less gratuitous copies, not more, because the ownership rules and the borrow checker gives you compile-time guarantees, while “defensive copies” are common in C++ for instance, “to be safe”.
I still fought the borrow checker after a year of using Rust.
And I found many situations while using Rust where I either needed to clone, or use unsafe where it's easier to make a mistake than in other languages because the syntax is extremely unergonomic and the memory semantics are much less clear.
> I still fought the borrow checker after a year of using Rust.
That's interesting. How much Rust did you use during that year? And how level of proficiency did you reach?
> And I found many situations while using Rust where I either needed to clone, or use unsafe
That sounds like an uncommon trade-off. From my experience, the trade-off was usually “clone or put lifetime parameters everywhere”, which is annoying (and I really wish Rust analyzer could help with at some point, because it's pretty mechanical), but it was quite rare, because most of the time you can just move things (that is transferring ownership), unlike in C where you have either a copy or a pointer.
> or use unsafe where it's easier to make a mistake than in other languages because the syntax is extremely unergonomic and the memory semantics are much less clear.
This is unfortunately true. Miri helps, but there's a wide margin for improvement on that front.
For the first one, something between: “I was learning Rust on my spare time” and “I was working full time in a Rust-centric team”. And the second one is more subjective, about how confident you considered yourself with the language and how familiar you felt with its concepts.
I'd say that after using Rust for a year I also fought the borrow checker, but after using Rust for 6 years I definitely don't anymore. A lot of the difference between a year and 6 was unlearning C++ habits.
For Self referential struct, the typical answer is twofold:
- try to design your code not to need them.
- if you really need one, you can either use smart pointers (Rc & RefCell) or use unsafe and use the Pin API to be sure that you won't accidentally move your struct.
That being said, it's not easier in C (or at least, it's easier to write, but also very easy to misuse), since a memcopy will silently break your self-referential struct. Do Zig has “Copy constructors” like C++ to avoid this issue?
In most situations those are horrible non-solutions.
Ref counted cells can't be used in self-referential structures because you'll introduce cycles. So, you'll go through all this trouble just to make memory leaks in the end.
"Designing your code not to need them" usually means implementing a worse version of a data structure from first principles.
The only real answer is to write "unsafe" Rust here and there. Which is fine. But, to the prevailing Rust community that is absolutely heretical.
> Ref counted cells can't be used in self-referential structures because you'll introduce cycles. So, you'll go through all this trouble just to make memory leaks in the end.
You know about Weak references right?
> "Designing your code not to need them" usually means implementing a worse version of a data structure from first principles.
> The only real answer is to write "unsafe" Rust here and there. Which is fine.
If it's a specific “data structure” (1% of the time) and not just the way you've decided to structure your current code (99% of the time), then using unsafe is fine.
> But, to the prevailing Rust community that is absolutely heretical.
No, the rust community is totally fine with reasonable unsafe code (you don't see burntsushi being harassed for using unsafe in his crates for instance), rustaceans hate (to a point which leads to excessive behaviors) unsound code, like the Actix drama, where the author used unsafe in unsound ways (not checking invariants in any way, and declaring “safe” functions that could cause segfault is used incorrectly). But unsafe code used properly is fine.
Yes, I'm aware of weak references and I'm aware that they're not a universal solution to this problem. You risk having something removed as unused while it's actually still being used if you don't have some strong reference to it somewhere.
As to your assertion that this is only '1%' of code, it really depends on what you're doing. If you're just gluing together modules that's where linear types for memory are an applicable model. But, if you are actually designing some structure yourself, it's not an applicable model.
The Actix 'drama' is reason alone to avoid the rust 'community'. I'll wait for these features to make it in a language with better ergonomics, a large commercial backer, and professionals at the helm who are less religious about how mere mortals use their language and are willing to err on being more pragmatic about it.
> Yes, I'm aware of weak references and I'm aware that they're not a universal solution to this problem. You risk having something removed as unused while it's actually still being used if you don't have some strong reference to it somewhere.
In graphs yes, but we're talking about self-referential structure here, and there you don't face this risk: the self-reference should always be a weak reference (the struct should be dropped when and only when the external references are gone, the internal ones don't count).
> As to your assertion that this is only '1%' of code, it really depends on what you're doing. If you're just gluing together modules that's where linear types for memory are an applicable model. But, if you are actually designing some structure yourself, it's not an applicable model.
Either you're implementing a data structure from a research paper (and you're in the 1% case and unsafe is fine) or you are actually using such a data structure and you don't have to perform this gymnastic by yourself. In C, people tend to reimplement data structures in their project because the dependency management story is quite dated, but it's not something anyone else does in other languages: most of the time you just import the standard library's data structure (or someone else's) and call it a day.
> The Actix 'drama' is reason alone to avoid the rust 'community'.
You'll find internet mobs in any group of people, unfortunately…
> I'll wait for these features to make it in a language with better ergonomics, a large commercial backer
If you expect larger backers than Amazon, Microsoft, Facebook and Google combined[1], I think you'll need to hold your breath much too long for your own good…
> and professionals at the helm who are less religious about how mere mortals use their language and are willing to err on being more pragmatic about it.
You're confusing redditors (the actix stuff took place on /r/rust) and the language management…
> In graphs yes, but we're talking about self-referential structure here, and there you don't face this risk: the self-reference should always be a weak reference (the struct should be dropped when and only when the external references are gone, the internal ones don't count).
Graphs are a common example of a self-referential structure.
> Either you're implementing a data structure from a research paper (and you're in the 1% case and unsafe is fine) or you are actually using such a data structure and you don't have to perform this gymnastic by yourself. In C, people tend to reimplement data structures in their project because the dependency management story is quite dated, but it's not something anyone else does in other languages: most of the time you just import the standard library's data structure (or someone else's) and call it a day.
On the several occasions I've look for crates that do what I need. They either don't exist, or I read through the code and they're poorly written and make lots of gratuitous copies of data and are very inefficient. You also have people using crates.io for their blog, literally.
> If you expect larger backers than Amazon, Microsoft, Facebook and Google combined[1], I think you'll need to hold your breath much too long for your own good…
A few people at large companies doing resume driven development isn't a real investment. It's not from the top down. At best, you could say they have some R&D investment to hedge their bets.
> You're confusing redditors (the actix stuff took place on /r/rust) and the language management…
Then why doesn't this sort of thing happen with other communities which are also highly online? It doesn't matter if you try to do gate keeping to say "oh those redditors" or "oh those guys on hackernews" aren't the REAL Rust community, the end result was a real package being really deleted from the real Rust community.
But the problems still remain? The borrow checker is an automated way of what one would normally check by hand, or in their mind. Removing it means that, just as one does in C, one must still check for memory errors and will more likely miss such errors more than the borrow checker does.
Zig isn't "watertight" like Rust, but the memory safety is still much closer to Rust than to C or C++, just because Zig enforces a lot more correctness in the language, and because of runtime checks. And a lot of memory corruption issues in C and C++ are actually side effects of C's and C++'s fairly relaxed approach to things like integer conversions, over/underflow, range checking etc... these are all points that Zig covers (for some of those things even when compiling C/C++ code because of the much stricter default compile options than regular C/C++ compilers).
(disclaimer: Zig has or had some pretty big holes around escape-checking function return values - that's something that even C compiler are warning about these days, at least for simple cases - but apparently improving this aspect is on the todo list).
Yes THAT problem still exists. Zig does not try to solve that problem (currently). It tries to solve a lot of other problems with C. Using the ownership model is one way of solving memory problems. There are others. I've seen discussions that zig could have an ownership model at some point, or maybe it will have something other. To lock in on that the ownership model is the be-all-end-all of memory problem solutions is a bit much I would say. Don't get me wrong, the ownership model is a good one and I like that Rust is pushing the frontier in that area, but there is room for other system languages that take other approaches to its design and tries to solve other problems first.
They have a build in arena allocator. That would cover a lot of manual frees. Also they have the defer syntax to defer your call to free.
The borrow checker doesn't stop most memory errors, just the easy ones at the cost of making it painful to write basic data structures. There are many memory related CVE on common rust libraries.
> The borrow checker doesn't stop most memory errors, just the easy ones at the cost of making it painful to write basic data structures.
This is completely untrue. Anyone who has maintained a large Rust project and a large C++ project knows that, empirically, Rust projects have far fewer memory safety problems than C++ projects do.
"The borrow checker stops only easy memory errors" is not the impression I have of Rust, and I would love to learn more about this claim.
For example, I'd love to see examples of CVEs on common rust libraries that you mention, if they are caused by safe code (ie, not using `unsafe`, which means the borrow checker is in effect).
You realize that these are notable because they're so rare, right? The vast majority of these would never even be filed as CVEs in C++.
Like, consider https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-4569...: "An issue was discovered in the mopa crate through 2021-06-01 for Rust. It incorrectly relies on Trait memory layout, possibly leading to future occurrences of arbitrary code execution or ASLR bypass." In C++ this would never have been filed, because it didn't actually cause any problems. It was only filed for Rust because Rust has much higher standards around even the possibility of potential memory safety problems than C++ does.
Out of the 10 top ones in that list about Rust (there's one about C code in GCC),
1. 6 are because of unsafe code.
2. 3 are because of ouf-of-memory (OOM) errors.
3. 1 is due to unsafe code in `tokio`, but I think it's fair to consider unsoundness in tokio's safe abstractions (over unsafe code) as unsoundness in "safe Rust" because the crate is so foundational, even if its third party.
Regardless, I don't think any of the above support your claim that "the borrow checker only prevents the easiest memory errors".
I imagine one could argue that OOM vulnerabilities are less likely to happen in Zig because of its emphasis on fallible and explicit allocation, but that's still not an argument for the borrow checker only preventing the easiest memory errors I think.
> The borrow checker doesn't stop most memory errors, just the easy ones at the cost of making it painful to write basic data structures
I'm not the OP but I think the point here is that the borrow checker is only applicable for the "easy" code (which does make up an awful lot of code), but even "basic data structures" very often require abandoning the borrow checker. In such a case, it's perfectly accurate to say "the borrow checker doesn't stop most memory errors" since you must turn it off when you write the code responsible for "most memory errors" -- at least that is the case in my experience.
So in this type of discussion, consider arguments about the capabilities of "the borrow checker" as analogous to arguments about "the memory safety of Rust in general", rather than taking it so literally.
If you want to make a sensible argument on this front, it should be about unsafe belonging mostly in crates that have been thoroughly looked over and battle-tested by the community. That is after all, a major reason why the number of such errors is still impressively small. But unsafe errors are still Rust errors, and while the borrow checker is wonderful, it and Rust should still be held accountable for problems in necessary code that requires disabling the borrow checker.
I think Zig does pretty well on this front, with there being pros and cons to not having a clearly demarcated "unsafe" boundary built into the language. Lacking an unsafe keyword does make it more unsafe, but in my experience, not very much.
I maintain Rust cryptography libraries with over 30-40k LoC, and I have never resorted to unsafe to bypass borrowck. Our code is as performant as any C impl, without the memory safety bugs.
I wouldn't expect cryptography to need much unsafe. I've never worked in the area, but I expect code mostly falls into 3 domains: parsing, "business" logic (negotiating algorithms, checking certificates/signatures the right way, etc.), and actual crypto algorithms. I see great benefit for Rust in the first two domains. In the algo domain, I don't see how memory safety adds anything as memory issues are an insignificant problem. And there are big challenges like sometimes needing constant-time impls, etc., and how to do that without always having to dip down to hand-written assembly for each target platform. No language I know of provides help in getting bitslicing right, for example.
Again, Rust is great for an awful lot of code, but we should still assess Rust's memory safety claims against the data structures code where you often need to disable the borrow checker. An awful lot of people only use safe wrappers around well-tested unsafe code, which is great, but the unsafe code is still being executed and may still have memory "unsafe"ty.
> I don't see how memory safety adds anything [to algos in cryptography] as memory issues are an insignificant problem.
I'm not terribly experienced in cryptography either, but I'm pretty sure that memory safety is a HUGE deal in cryptography as a whole. Heartbleed[0] was a memory safety issue. Python's cryptography package switched to Rust specifically because of memory safety [1].
Heartbleed was in the parsing/business logic areas -- the areas where I said Rust's memory safety provides great benefits. When I say crypto algos, I mean implementing S-boxes in 3DES, etc.
If you agree that Rust's memory safety is hugely beneficial in cryptography, then I'd love to hear other (sub)domains (e.g., kernel code, networking code, blockchain, ...etc) that necessitate tricky data structures, making Zig a better fit than Rust (which, IIUC, is your main point here).
I don’t have a “zig/rust is better than rust/zig” point here. The point was to say you have to judge Rust’s success against the unsafe code it occasionally forces you to write (you don’t get to hand wave it away), especially since a great example of such unsafe code is data structures code, and that is where a lot of my memory errors occur. Then we got diverted into some minor points about how much benefit does memory safety at compile time give you in different domains.
I wouldn’t build a company or long-term project around Zig right now, since it’s quite young, so if the choice was just those two, I’d probably always pick Rust. But ignoring that, since Zig will probably “graduate” in a year or two: both are good for all those domains, and I’d be hard-pressed to say one is better or worse than the other without further constraints. Zig certainly seems less indirect and more lightweight, and has less of an immediate cognitive burden, but Rust’s additional burden there is providing some additional value. I really don’t like Rust’s allocation story though — AFAIK there are plenty of allocations in std that can only be controlled by swapping out the global allocator, possibly even at link time. C++ is clunky on this front too, just in a different way. C is “better” simply because the standard library is so meager, but that has never been a problem for me in practice.
> You have to judge Rust’s success against the unsafe code it occasionally forces you to write (you don’t get to hand wave it away).
Agreed.
> I really don’t like Rust’s allocation story though.
I presume this is because of the lack of ergonomic handling of OOM? Only time I've run into OOM was when training deep learning models (in Python backed by C++) on a GPU, but if I were to do that in Rust, I'm pretty sure I'd be able to avoid the memory leaks that caused OOM since allocations in a deep learning training loop are almost always deterministic.
So I would love to learn about the domains where you think OOM is a huge issue (apart from kernel code, which I'm already familiar with).
Btw, thanks for all the replies! I'm learning with every one.
It's not at all about OOM, actually. It's about performance, and to a lesser degree, simplifying code or architecture. Zig's FixedBufferAllocator and ArenaAllocator are very simple and very useful, and they conform to the Allocator interface that's used for every bit of allocation in std and non-std. Anyone who has written a lot of C or a certain kind of C++ will be very familiar with the concepts, and will have used them a lot. They're nothing revolutionary, but not having a "default" global allocator and having a culture of passing the Allocator as a parameter means there's a nice way to actually use these things without always having to rewrite/modify someone else's code -- all Zig code I've seen passes the Allocator as an argument. This also means you have some idea of when allocations occur, which is another thing I often want to know (I used to work on ultra low latency systems, measuring in nanoseconds -- no allocations allowed in the hot path).
> Zig's scope is just to be a better C that's free to add modern features...
The thing about that though, is there are a number of better C languages (both old and new) that have various levels of C interop. Languages like: D, Odin, Nim, Vlang, etc...
Eventually someone will make one that's ergonomic enough, provides enough features and can used to gradually refactor existing C with minimal changes code bases that it becomes a commercially viable alternative to just continuing to do maintenance programming on the C code.
I think there's three reasons one might use Zig instead of Rust. These are just opinions, and I would love yall's thoughts.
First: there's only a certain amount of effort that one is willing to put into accomplishing one's goals, effort that will be spent on learning tools and building a project. It's not unlimited. If I just want to make a game where a character walks around the world, and I only have 20 or so hours of time before the money / motivation / market opportunity runs out, and it takes 300 hours to master Rust, that's a non-starter. If someone has 2000 hours of time available, then it'll be worth it to learn Rust before starting. If someone has even more than that, then it might be even better to use more advanced proof tools to be even safer than Rust, if safety is an absolute priority.
Second: Zig offers a lot more freedom than Rust. The borrow checker historically has difficulties with observers, backreferences, dependency references, several forms of RAII, and graphs. If one just wants a struct to contain a pointer, sometimes it's just easier to use Zig than to change one's entire architecture, which takes a lot of time and effort that one might not want to spend. Of course, this isn't a problem if one uses Rc and RefCell more, which brings its own tradeoffs.
Third: There are a lot of cases where the cost of memory unsafety just isn't that high, and Zig's mitigations are more than sufficient. For example, if I'm making a non-safety-critical app or webassembly program that's sandboxed on the client's machine and only talks to its own trusted server, that's more than enough security for a lot of use cases. In these cases, a couple memory safety bugs are just like any other bug, and it's not worth it to spend the time reducing this release's bugs from 23 to 21. This is how it was on Google Earth; the vast majority of our bugs were logic bugs, not memory unsafety (and this was C++).
Coming from Rust, the first point likely doesn't apply to you as much. The second and third points might apply, depending on the situation.
I think Rust's tradeoffs are stellar for cases like medical devices or HFT where the cost of memory safety and higher latency is much higher than your average webserver (where Go might be a better fit) or your average single player game (where memory unsafety bugs are just inconvenient, not critical).
If I was to sum it up, I'd say: Rust is pretty close to perfect on paper, when you don't consider the other human factors, such as limited time, training, or that sometimes it isn't worth it to prove memory safety. When you consider these factors, other languages can make more sense.
> Third: There are a lot of cases where the cost of memory safety just isn't that high, and Zig's mitigations are more than sufficient.
But then why not just use a GC'd language? It isn't 1995 anymore; most apps are written in GC'd languages. C++ makes sense when you already have a lot of C++ code, but if you're talking about new code, I don't see a lot of room for a language without memory safety.
> But then why not just use a GC'd language? It isn't 1995 anymore; most apps are written in GC'd languages.
I mostly agree with you, and I'm enthusiastically using Rust. But I'd love to be able to develop new software, with modern developer conveniences, that could run on a 1995 computer. Assuming that implies a 32-bit OS, that seems plausible with Rust, albeit not with std (but alloc should be fine). Maybe I'll play with that for a side project sometime.
for native addons for GC'd languages you probably don't want to introduce another GC, rust is not well-suited for interfacing with FFI, C++ is a bit heavyweight but okish I guess and C is totally unsafe, Zig is just right.
> rust is not well-suited for interfacing with FFI
How so? Packages like neon [1] and rustler [2] suggest otherwise. I'm using both of those in a real product (I'm using neon directly, to write native modules for an Electron app; on the back-end, I depend on an Elixir package that uses rustler).
I admit it's a long time since I've been using neon so things might have changed but at the time I had a feeling that the whole thing is very fragile and not really safer than if I was using pointers directly.
Especially, if you callback into JS and that calls back to native then I think you don't have any guarantees from rust anymore (aka you are being lied) because compiler cannot not know about that.
Also builds were a bit tricky, it needed node.js headers in proper place, etc. In zig you just include napi.h because zig can import C including macros and everything. Or if you need to call glfw/nanovg/stb/xxx you just @cImport() and it works.
Zig also supports C-style strings in a better way and I can't recall all of the obstacles right now but I'm way way more productive with Zig after 1 month than I was with rust after 5ys.
you are right about cxx, I made this comment with C FFI in mind. and for that, Zig couldn't have better integration.
AFAIK there is no simple way to interface with C++ from Zig, you either have C headers or you write a bit of C++ to export what you need and then you're back in the game.
Or you flip it on its head and use zig as C++ compiler and call your zig-parts from C++ but I have no experience with this, I think bun does this.
One should keep in mind that Rust also has an unsafe subset. While it does not get rid of the borrow checker (quite intentionally) and it also introduces some pitfalls wrt. interacting with safe Rust, compared to C, Zig, Hare, Jai etc. it is in principle quite possible that future versions of unsafe Rust might become just as ergonomic as these competing languages.
Despite what students who never programmed professionally say, memory isn't a problem to a significant amount of C and C++ developers. I think it's been a year since I last access an invalid pointer and that only happened because I forgot that I am not suppose to add elements to array in a `for (auto var : array)` loop. It use to be a for index loop and it didn't take long to figure out the change broke something
I'm one of those who "has never programmed [C/C++] professionally".
Isn't your statement at odds with assessment from many big tech companies that memory safety is the prevailing reason for CVEs? I'm sure you're not suggesting that the folks who make these assessments are not experienced C/C++ programmers, so I'm curious about your thinking on this.
That's the wrong question to ask. Don't compare it to rust's memory safety as otherwise you're pretty much answering your own question with "you shouldn't".
Think of what zig has to offer instead and try it out to see how it works.
If it's simplicity, it seems like complex programs would be supported by complex libraries instead of complex language features, leading to the same level of complexity but with less consistency.
"Smallness" seems to be a sought after feature but I'm not sure why.
I must confess I had to suppress my knee jerk urge to downvote. It almost feels like you're asking "what's the appeal of elegance?" "What's the appeal of Chess, if you want complex gameplay just have complex rules." It almost feels alien that someone couldn't get it.
Here's a simple but perhaps disappointing theory. Painting with a broad brush for a moment, there are primarily two sorts of thinkers: memorizers and logicians. The former have astounding recall, and consequently have no qualms about learning loads of vocabulary. They, for some reason I will never understand, actually delight in learning a foreign language. When they end up in the sciences, it is more often than not some form of biology where knowing all the assorted physiological systems and every cataloged failure mode and the symptoms thereof is of great benefit. The latter can't do any of that, but if you pause for half a second in the middle of a thought they will start trying to complete your sentence by suggesting words. When they find themselves in a foreign country, they figure out how to use the washing machine and vending machines and generally fend for themselves without any help despite not being able to read any of the labels. They might never learn the language, but they quickly figure out which characters mean "road", "park", "river" etc based on nothing more than the subway station names. When they go into the sciences, they tend to end up in math or physics. Newton only makes you memorize 3 things, and from there literally everything else follows if you think hard enough.
So, for the logician type thinker, small languages are just deeply pleasing for the same reason Newtons laws and Chess are deeply pleasing. Those are the antithesis of learning a foreign language. Small coding languages let you know everything while learning as little as possible. The memorizer types must see the appeal of small language the same way I see the appeal of memorizing all the characters in the Chinese writing system. I see no appeal in learning all the characters in written Chinese. Why would anyone ever consider all those characters a sought after feature?
What a lame Mars/Venus theory. Language designers never make complex features in order to have more to learn and catalogue. They are nakedly compromises which are supposed to make certain things easier, maybe even simpler in certain senses (for example simpler library code: more complex features like pattern matching can make for less spaghetti control flow).
Then the retort might be “but they wittingly or unwittingly pursue the goal of complexity for its own sake!”, in which case that would just prove that you have stacked the deck in favor of the “logician” (who makes simple languages for simplicity’s sake—simple).
Another problem is that some language designers are logicians by trade already.
> So, for the logician type thinker, small languages are just deeply pleasing for the same reason Newtons laws and Chess are deeply pleasing.
Chess has Opening Theory. I bet the Half-Delayed Swashbuckler Sicilian just comes naturally to the oh-so exalted logician.
(Then the retort might be, oh I’m just talking about the game in the abstract, not the metagame. Well it is very important how a game is actually played and how a language is actually put to use.)
There are plenty of people who love chess but hate opening theory. They look to variants such as chess960 to get their logician fix on. They also tend to love Go (the board game) and perhaps even Stratego (which has such a game tree that dwarfs the rest).
It's not a lame dichotomy. There are loads of people who detest rote memorization and prefer to solve only the problem directly in front of them. Bobby Fischer himself invented his variant because he hated that aspect of the game. I, personally, empathize with this position as a university student who gets higher grades in pure math courses than in the "easier" applied versions due to the memorization aspect.
I feel like your take is simply too strictly bound to your personal preferences. Small is not the same as elegant. If it sad "Zig, the Elegant Language" that would be something else. Lace and watches are elegant but complex and intricate.
A large language might be more consistent and well thought out than a smaller one. That, again, is a separate detail.
And we're talking about the main selling point of the language. Not just 'oh and its pretty small too.' Of all the things to focus on, it would not be my priority for sure.
> memorizing all the characters in the Chinese writing system
Actually, there's a logic (a stroke order logic and also some common building blocks) to how to build the characters in Chinese (and other similar languages). So I would imagine the "logicians" might be OK with it :)
To me being able to keep the entire language in my head is invaluable. When working with Go for example I know that I can dive into the bowels of some library dependency and I will be able to read it and figure out how it works. This is because the language encourages straightforward code and has very little magic. The code does what it says.
We have to deal with complex libraries no matter of how big or small the language is. A small language that you can keep in your head makes dealing with them easier.
I would also argue that smaller languages lead to more consistency not less simply because there are fewer ways to do things. Look at early Python vs modern Python for example. In very early Python (pre-2000 or so) there was actually "one and preferably only one obvious way to do it". Modern Python with all the features it has grown over the decades is the exact opposite of that. C++ is another obvious example.
But it seems to me language features help the understanding. You'll need to learn whatever library or custom code was used instead of a language feature with the added headache that you need to learn it every time and you'll see many implementations.
That said, I'm used to Java or C# as far as language size goes and I don't feel suffocated by it. I'm not sure if its a natural inclination or a learned skill.
Not every language that is small (in the sense of having few rules and few primitive constructs) is necessarily simple (in the sense of easy to understand). Scheme (or its basic core) is quite small, but it's not easy to understand other people's code due to macros; RISC Assembly is also small but can be hard to understand because its abstractions are so limited. But a language that is very explicit, has reasonable abstraction, and is also small -- like Zig -- makes following the control flow quite easy, and so makes programs easier to comprehend: you mostly need to apply only local reasoning.
Go look at herb sutter's guru of the week articles, and consider how many C++ programmers can actually solve them. Then consider c++ has gotten even more complex in the past 9 years since he last published a gotw.
The main problem is that every c++ programmer has their favorite little bit of complexity in the language, and that favorite bit is different for everyone. So you end up with a codebase sprinkled with the full spectrum of language complexity if you're working with a large team, meaning you need to understand all of it if you want to understand the codebase generally.
At least with complex libraries, the complexity can be safely hidden behind the API. Not so with complex languages, at least in my experience.
Since it is considered a begginers language, how complex do you imagine Python actually is, given that the language reference is 186 pages and the standard library 2159 pages, plus whatever has changed between versions?
I think it is actually fairly complex as you point out. I certainly wouldn't hold Python up as a paragon of real simplicity or consistency. But, it is far, far less complex than any modern C++ version.
Going from N features to N+1 features creates N! new interactions to consider.
For example, if we have a bunch of language features, and we decide to add a new one, e.g. exceptions, we now have to consider:
- How exceptions work
- How exceptions interact with threads; how exceptions interact with dynamic binding; how exceptions interact with dynamic binding in threads; how exceptions interact with mutable variables; how exceptions interact with mutable variables in threads; how exceptions interact with dynamically-bound mutable variables in threads; and so on.
Also, all of the language's tooling needs updating: compilers, linters, documentation generators, static analysers, formatters, syntax highlighters, auto-completers, etc.
- Is small/simple/principled (i.e. understandable)
- Enables many desirable programming styles or capabilities
- Complements other features: ideally working even better in combination; or at least, working in an obvious way
Algebraic effects tick all these boxes IMHO. In particular, there are many languages which feature try/catch AND for/yield AND async/await AND call/return; whereas having algebraic effects subsumes all that, turning it into library code.
Note that we can get pretty much the same thing with, say, delimited continuations; so they're also cool. However, having delimited continuations AND algebraic effects would seem redundant/bloated.
> If it's simplicity, it seems like complex programs would be supported by complex libraries instead of complex language features, leading to the same level of complexity but with less consistency.
In my experience, languages with complex features still have complex libraries. Library complexity is a constant. If you simplify the language, at least you free up a little cognitive load there.
In addition, simplifying the language often implies (or is even equivalent to) minimizing footguns.
Like Smalltalk/Pharo, you have 6 keywords in the language and the syntax fits on a postcard. But all the classes/library/environment is huge and complex.
If you really want to argue about this, binary makes no sense in this scenario. There's assembly which gets assembled into machine code. Machine code for all intents and purposes is the lowest level that you would consider a language, binary by itself accomplishes nothing.
Now you can go see all the arguments about RISC vs CISC, which is the same argument. Should I have a small instruction set that bloats the final program's instruction count? Or a complex set with slower instructions?
Code is read more than it's written, so clarity is important. The fewer ways there are to do things, the closer everyone is to a common understanding of a given block of code, which makes understanding another programmer's intent easier. In turn, this makes onboarding to a project much more effective, and lets devs reach a minimum level of competency more quickly.
Note that small doesn't imply lacking features. For example, something like a std::transform is often "smaller" than iterating through an array with a for-loop, but it's also clearer and less error prone. It's a result of the language itself providing more powerful data structures, and interfaces that make manipulation of those structures easier, which is what I'd argue "small" is actually shorthand for. I don't want to be using a language that only has if-statements and goto, which would be "small" in one sense of the word; I want to use a language that has the minimum necessary number of keywords, decorators, or meta-languages, and instead provides clear, ergonomic ways to express my intent to the machine.
"Wirth’s philosophy of programming languages is that a complex language is not required to solve a complex problem. On the contrary, he believes that languages containing complex features whose purposes are to solve complex problems actually hinder the problem solving effort. The idea is that it is difficult enough for a programmer to solve a complex problem without having to also cope with the complexity of the language. Having a simple programming language as a tool reduces the total complexity of the problem to be solved."
For me, it isn't just the 'smallness' of the language that matters, it is the understandability of code bases written in the language that matters.
Having fewer language constructs (especially ones that offer overlapping alternatives) means that programs that solve the same problem will tend to look the same. This makes reading a new code base easier, which makes on-boarding engineers faster. This is the main reason I like smaller languages.
Languages like C++ (that seem to adopt every language feature that can be implemented) enable developers to solve similar problems in vastly different ways. In small programs that isn't an issue, but in large, old code bases it can become a very costly mistake. It can be hard to understand a large code base as it is, but when 100 different developers have touched the system and each has a pet style, you are in for it.
The most perfect code is no code at all. A language being small means it unlocks power without complexity. Smalltalk is a great example of this as it was rewritten over and over until it was tiny.
Of course, "no code at all" isn't useful, so there's a medium to be found.
I consider my most productive days as a programmer ones that I was net negative lines of code. Often those are the days when I implemented the most customer features. There is a lot of needlessly complex code out there.
Unlocking power without complexity is not implied by being small. Logo doesn't unlock power by allowing you to move turtle and binary encoding doesn't make things easier by allowing you to write 0 or 1 only.
As the total number of ways to accomplish a task increases it puts more burden on a programmer to recognize the usage and understand the semantic differences between the options. How many ways are there to iterate over a collection in say C++?
Libraries _can_ hide some of this, but then that might also be yet another function or operator that does the same thing. Internalizing when to use one method vs. another adds to the total cognitive load of using the language, and it takes away from the mental capacity available for the problem you are actually trying to solve.
Sometimes these differences are necessary and important, other times they are less so.
The number of ways to do something isn't the problem with C++, it is the number of inconsistent ways, some of which have big footguns. If the different ways were all consistent it would make it a lot easier to remember which was the right one to use in any particular context.
simpler languages are easier to learn and to remember. small languages make software easier to write and to read.
complex features (in a language that does the simple things correctly) are always easily composed from the simple features available.
the antithesis of small languages is C++, which is probably the most popular language on the planet in which 0% of its users know 100% of.
with a small language, i can’t use language features which you do not understand when it comes to read my code or take over maintenance, or even understand it.
Do you include size of the library with the size of the language? If you don't, then the difference in size between C++ (considered very large) and any other language isn't very much. If you do, then C++ is much smaller than languages like Java or Python.
The problem with C++ is not the size of the language, it is how inconsistent it is.
For many situations, a language will add a lot of complexity that doesn't bring much benefit. In the end, a language's complexity can sometimes be a net detriment to its user.
For example, one might be making an embedded program where all memory is pre-allocated up-front and there's no heap usage. There's not as many opportunities to mess that up than your average program. This is where Zig would shine compared to e.g. Rust whose borrow checker would be helping with less, yet is imposing its usual complexity burden on the programmer.
Language is the first layer; it should be as simple as possible.
Libraries then framework are the other layers, built on top of the language.
A language designer is unlikely to understand all the needs of the language users, trying to solve complex problems at the language level can seem neat and powerful for the exact use case it was intended, and also unnecessary/cumbersome/too general or not general enough for many more use cases.
I love zig but I have two pain points. Function naming convention as camelCase. I can overlook that and use snake_case in my code, which I do and people frown upon me. Second is inability to turn unused var check off.
I really wish Zig had closures and interfaces/traits. You can emulate them in hackish ways, but UX is awful and as there isn't a uniform way, there's next to no compatibility with regards to libraries. As is I'd rather just use a heavily restricted version of C++.
It feels like there's room for a better C today. I don't mean a really different language. I'm thinking something that is semantically C, and 99% syntactically C, but that a much better story around macros, builds, modules, linking, volatile pointers, and all of the other C foot guns. Not C++ or Rust (though I love Rust). I'm thinking just a smoothed out C. And done in a way where a codebase can incrementally move from C to better C, one file at a time.
I like the idea of Zig, but haven't got to actually use it yet. I still can't get over it's syntax. I think the manual memory management approach but easier than C is a good path to follow. It makes Zig a natural in other environments such as WASM. Compare that to Go or D which started with a garbage collector and struggle in WASM (Go has to compile it's garbage collector to WASM to work, D forces you to manage your memory manually).
The Go team did an amazing work to add generics with a very small impact on the language. They even managed to add generics without breaking the Go 1.0 compatibility guarantee.
I don't know Zig, but aren't we missing a return here?
fn count_nonzero(a: []const i32) i32 {
var count: i32 = 0;
for (items) |value| { // "for" works only on arrays and slices, use >"while" for generic loops.
if (value == 0) {
continue;
}
count += 1; // there is no increment operator, but there are shortcuts for +=, \*=, >>= etc.
}
}
I'm not super-great with Zig, but my understanding is that `count` should be the return value, post-increment.
When the return value is unspecified, Zig will default to an implicit return of the last-calculated rvalue. The same behavior is also found in Ruby, Lisp, and some other languages as well.
The size of the compiler toolchain is similarly small.
For example, according to xbps on Void Linux, GCC is a 172MB install. Zig is only 166MB. A Clang or Golang install is twice the size of Zig. A Rust install is three times the size of Zig. And so on.
is zig still one man's work and has a hit-by-a-bus risk factor? checked it a few weeks ago for a few hours, looks good, but I don't feel I need switch from c to zig yet. will re-try after 1.0 is out.
The "People" section on the right on their github organization[0] shows members of the core team. It's also free software and surrounded by a passionate community, so it's pretty hard that it would die out. Andrew is irreplaceable though.
Legally I am extremely replaceable because Zig Software Foundation is a 501(c)(3) non-profit, and I am only one of three board members who can make legally enforceable decisions.
As a software engineering lead I am becoming more replaceable every year as others learn to maintain various components of the project. Recently, I am proud to have dropped to having fewer than 50% of total commits in the Git repository for the compiler.
why do people care about binary size? I have never understood this. Disk space isn't free but the size of the binaries on my machine doesn't seem like a big problem to me in that regard.
I can't speak for others, but I care about binary size as a user because it tends to be a reliable signal of overall software quality (though there are definitely exceptions).
I also find it incredibly frustrating when an application I rarely use fails to launch because it wants to force me to download, process and install massive updates for features that I don't even want.
As an engineer, I care about binary size because gigantic binaries tend to require far more time to compile, move around and work with. Gigantic binaries tend to be a reliable signal of slow, toxic, internal processes that chew up positive energy and produce cynicism and frustration in it's place.
It's not about the disk space per se, it's about treating waste as if it's a virtue.
It's usually not the disk space that's the bottleneck, but rather, the CPU instruction cache. On modern Intel and AMD CPUs, the jump from L1 -> L2 alone can triple the latency of a memory fetch. For a "hello world" application, that doesn't really mater, but for, say, an OS kernel, it becomes really important to keep as much of your hot-path code in i-cache as possible.
The binary size tells you ~nothing about how good it is at effectively utilizing L1 icache. In fact, optimizations regularly increase binary size because it turns out inlining to avoid function calls can be even more important. See also loop unrolling, SIMD paths, etc...
I'm more likely to believe Zig's "small binaries" are more from lack of optimizations than some obsessive focus on L1 icache density. Which, given it's not a 1.0 language, isn't something that can be held against Zig. But it'd hardly be a strength, either.
I really am stretching to find a link between a typechecker and L1 cache. Perhaps some kind of dynamic analysis of code and averaged data could give you a non-empiric measurement of L1 cache utilisation but considering cache behaviour it's not standardised even within one vendor it would be a ball-park guess at best.
Given that the size of L1 cache can vary, I strongly doubt it. At best it can guarantee everything fits into a specific size, which may or may not be smaller than L1 cache.
In practice, binary size does not matter much for most use cases. (But for embedded and demo scene this is important)
It is a simple proxy/heuristic for the level of bloat / crust / overengineering of the runtime and to the quality of the compiler.
If a language / framework can't do an extremely simple task in an almost optimal fashion, then it is unlikely that it will improve with more difficult tasks.
It is like looking at the CPU/GPU load of an app in idle mode.
Yes. For example the Arduino 328P ("Uno" boards) has 31.5k of program flash available to you, while the ATMega 2560 has 256k (minus again 0.5k for the bootloader). The STM32F411RE, a Cortex-M4, has 512k.
In embedded development you can forget the overhead due to binary formats such as ELF (while the toolchain might output these as an intermediate, what is flashed is just the relevant sections), but if you are doing things like loop unrolling all over the place, you're going to get less functionality for static program space.
This is why ARM and PowerPC have "embedded" variants of their ISAs. What this means in practice is a compressed form of their instruction representation. Why? If you have compressed instructions, you can fit more of them in program flash. So both Thumb and VLE are variable length encodings. Thumb, for example, can use 16 bits for many instructions, i.e. two bytes, whereas ARM by default would simply take four bytes for all instructions. (For the avoidance of confusion, they still "address" 32-bits of memory and are thus still 32-bit microcontrollers). PowerPC's VLE is similar.
The driver here is cost. You could put in more program memory (the address space has plenty of room) but that costs more money, and when you don't need it, why do it?
For regular PC programs stored on disc it may not be much of an issue, but think about scenarios like embedded programming, WebAssembly running in web pages, or 4K demo contests.
Also IMHO, statically linked programs simply shouldn't contain any code that will never be called, just out of principle.
I think it is more of a proxy to the controlability, which is not often the case with C/C++ where a seemingly small stdlib feature triggers a larger dependency and you can't easily get rid of them.
I kind of care... I have a binary that I distribute (once and update a lot) to 20k+ servers across multiple geographic datacenters... some of the servers are 100mbit only, so even updating all of them at once, saturates the network and slows everything down.
I use golang with all the size optimization steps that I can use... it makes a difference to make the binary smaller... it doesn't have to be minimal, but 4megs is better than 10megs.
I’m in favor of big general purpose languages. Why? Not for their own sake. Just because it’s tedious to use multiple languages.
- How do they communicate? Maybe Json if it’s just data. For more control you need FFI
- And FFI is such a hassle that some languages seem to focus mostly on getting a nice C FFI
- ... That lingua franca that proves that you can have all the simple languages that you want as long as its name is one letter and starts with “c”
- All kinds of minute differences that are real tradeoffs when it comes to each individual language become major pains when switching between them
- Sometimes you seem to have to rule out languages just because they don’t have good libraries for X. Or can’t do concurrent tasks. How are multiple small languages supposed to flourish when 20+ year old languages can’t get good library coverage or get rid of their global interpreter lock?
I would like small languages if they all played nicely together. But they almost never do.
We're using it to build a game engine[0] competitive in spirit with unity/unreal/godot, right now it's just a really nice way to use WebGPU natively on the desktop[1] though.
Ah, I hadn't thought of that analogue, but it makes sense, then. It sort of recreates the opportunity to make the common bug, though, of allocating enough for the data but not the sentinel (or enough for the string but not the null terminator).
Not really, the sentinel is part of the type and the allocator interface in Zig is type-aware, meaning that you can't simply "forget" about sentinels. The type system will fight you.
So creating a pointer to a type with a fixed length and a sentinel and creating a new one will automatically allocate enough for the length + the sentinel? That's nice.
I'm still not sure I like the .len 'misreporting' since it would be harder to
manually optimize around, e.g. packing a struct with a 8 byte + sentinel array would take 16 bytes that I might not notice if I am going by `.len`. This is all speculation, though. I need to actually play around with Zig.
Zig is much lower level than Python or Go. This means that you can write programs that use very little memory and run really fast. If minimizing memory use and maximizing speed are your primary objectives, Zig could be a better fit than Go or Python.
If you're coming from Python and Go, then producing the fastest possible program that uses the least amount of memory probably isn't your top objective. Zig is fast, but you're going to have to think about memory management and other things you take for granted in garbage collected language. Zig also has nowhere near the number of libraries that exist in Python or Go, so you'll be building a lot more stuff yourself.
Also, the simplicity of a language like Zig may be a hindrance if you're working with really big code bases. If you need something that will scale to really large projects, like say a web browser, you're probably better off in Rust.
If performance is not an issue and you want something that will let you focus on the program's logic rather than the implementation, Python is probably what you want.
If you're writing a microservice to run in a datacenter, you'll be up and running in Go much more quickly and the performance is probably good enough.
But if you're writing a program for an embedded or limited environment, or you need something that's simple and fast, then Zig is worth a look. And of course, Zig is worth a look because it's very simple and easy to learn so you can be up and running very quickly.
Realistically, you probably shouldn't. Zig seems to be positioning itself as a systems-level language—more of an alternative to C/C++/Rust than to Python/Go. If you're building low-level, high-performance software, it might be interesting to you; otherwise, I don't see a practical benefit.
I wouldn't put those two languages in the same class. Go has about the performance of Java/C# with about the memory usage of C++. It's much closer in performance and resource efficiency to those languages than it is from a scripting language like Python.
They both emphasize productivity over other factors like performance and correctness, so I think they're very much in the same boat in terms of use cases.
Go was created for correctness. It is strongly, statically typed, it won't compile if there are unused imports or variables, and it won't compile either if you don't free up resources after usage. C/C++ don't do that and have UBs.
Go is in the same ballpark than C#: a modernized C with GC, good productivity although not as good as a scripting language, and good performance although not as good as ANSI C. They're popular because they stand in that sweet spot.
Python is easier than Go or C# to pick up, but it's also 20x slower than C rather than 2-3x.
Another use case aside from the typical "high perf" ones: if you're building a cross-platform library with bindings in various language (eg. Swift bindings, Kotlin, C#, etc.), I'd imagine you'd benefit in the long run from having manual memory management and a thin runtime that doesn't clash with the host runtime. But personally I'd choose C/C++ for this, for the sake of existing support in writing bindings and C interoperability.
It may be interesting for replacing C to write high performance Python extensions (in my experience, C and Python go very well together, and Zig should be able to replace C pretty well in such scenarios).
> hmmm but how much of a performance gain is there from say CPython or even Go?
It depends on what you are doing.
If your python code is mainly calling out to highly optimized math routines, well, not much.
If you are doing lots of computationally intensive work, quite a bit.
If your Python code does a lot of allocating of memory, throws around lots of large objects, or has to parse a lot of inputs, then moving to a native language can be very beneficial.
> I am excited for Zig but careful in adopting new languages but if this takes off, what sort of changes might we see? Cheaper C/C++ programmers?
Newer more powerful languages tend to result in more complex software being written. Ignoring CPU and memory limits, no one would have been capable of writing a modern AAA game with the tools available back in 1992.
It sounds like from your point of view, Zig, C, C++ and Rust are all pretty much interchangeable. I like Zig a lot, but don't expect that it will turn the world upside down. None of the new programming languages will make C, C++ or Rust more or less popular (not by a huge amount at least), they are just additional options to choose from. For instance C is alive and well at age 50, it will probably survive the next 50 years just fine (unless we switch to a completely different computing paradigm - but this would kill all other existing programming too).
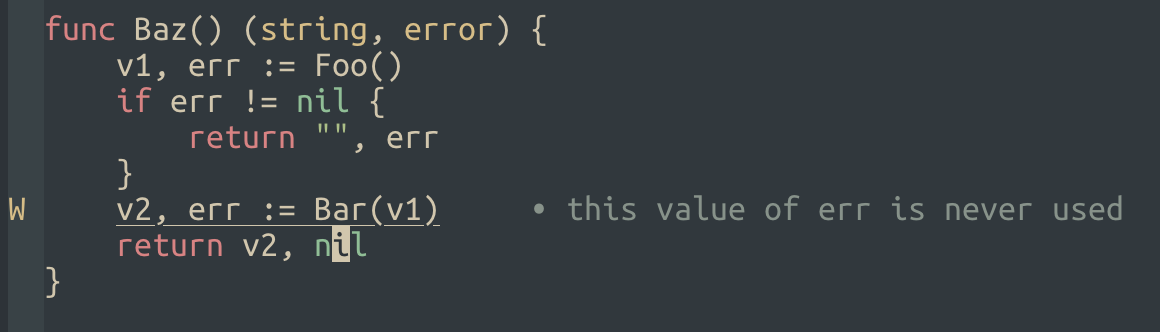{kind=link}
When I was in college we mostly used C++, which exposed (and thereby taught) a lot of core concepts around how computers and low-level languages work. But it was also a bit of a nightmare for... unrelated, obvious reasons.
Rust is great for building software, but as a learning language I think it introduces too many additional concepts, has too many additional constraints, and has too many magical abstractions. Eg, doing manual deallocation helps you later appreciate what the borrow-checker does and why it exists
Zig is supposed to be C++ without all the pain and misery (esp around tooling). That could make it perfect for teaching people about pointers and heap allocations and working with bytes, with minimal extra pain and friction