In the article, it states that after a certain point, parallelization hits limits. Is that due to Scylladb's architecture or other constraints within the system?
For reads (unless there is another bottleneck), by 10x'ing the parallelism, an application can compensate for 10x the average latency and still deliver the same throughput.
Scylladb talked about their IO scheduler a good deal:
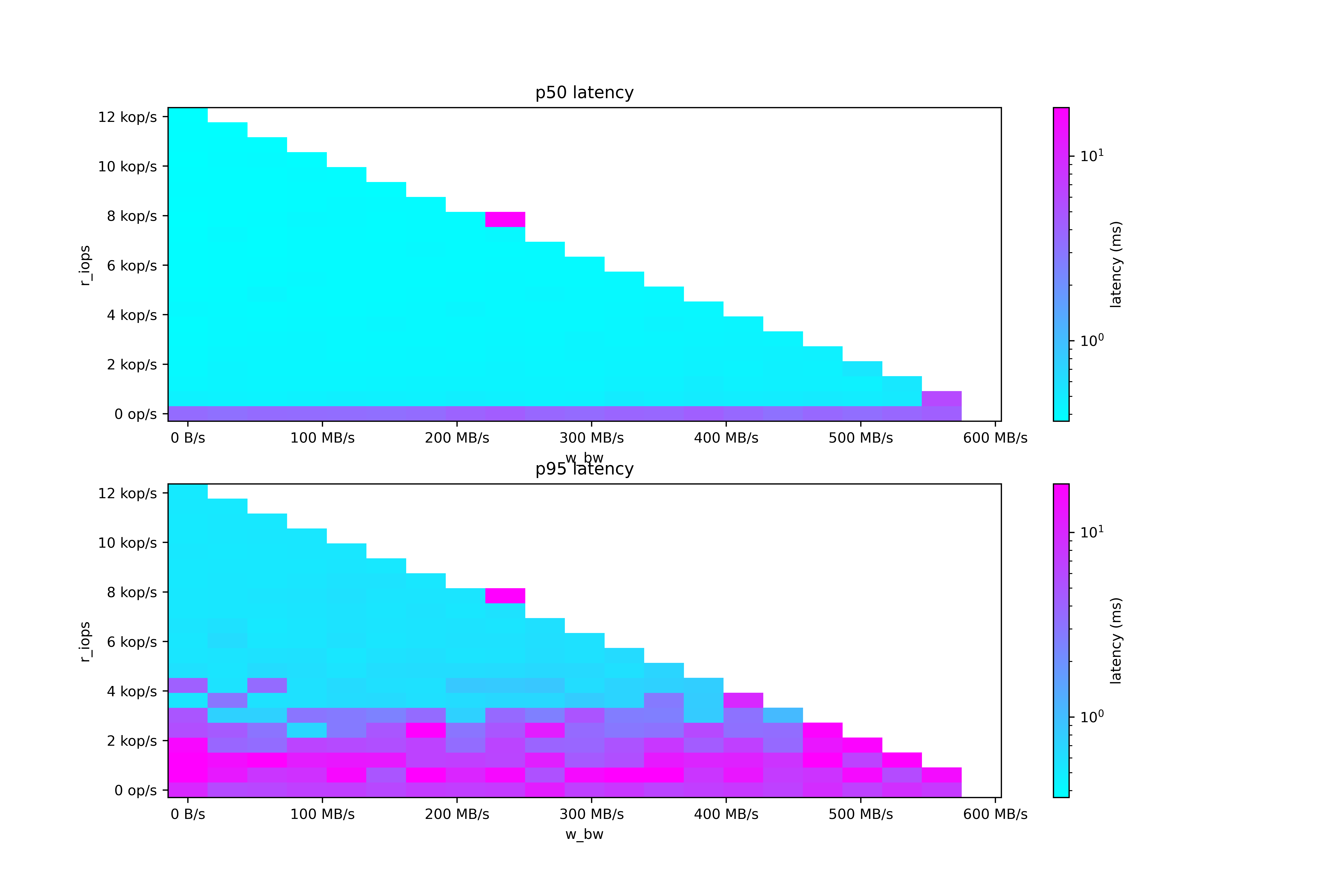
Persistent Disk read latency is usually good, but jitters up to 100ms. The scheduler can compensate for high latency (essentially applying Little's Law) but cannot compensate for jitter without saturating the disk.
Very odd - notice how the latency is high when the read IOPS are low. When the read IOPS climb, 95th percentile latency drops.
Looks like there is a constant rate of high latency requests, and when the read IOPS climb, that constant rate moves to a higher quantile. I'd inspect the raw results but they're quite big: https://github.com/scylladb/diskplorer/blob/master/latency-m...
{kind=link}
For reads (unless there is another bottleneck), by 10x'ing the parallelism, an application can compensate for 10x the average latency and still deliver the same throughput.
Scylladb talked about their IO scheduler a good deal:
https://www.scylladb.com/2021/04/06/scyllas-new-io-scheduler...
https://www.scylladb.com/2022/08/03/implementing-a-new-io-sc...
Naively, it seems like it should have been able to compensate for the Persistent Disk latency for read heavy workloads.