You'd think a well-designed distributed system would be able to handle the failure of a component and fallback into a different configuration to handle the problem. That's the fundamental feature of Internet routing systems, i.e. they expect components to occasionally fail. Building a distributed system that can't handle such failures just seems like sloppy engineering.
The joke is that no matter how many redundancies, the complexity is so beyond human's ability to map at once, that you always miss a single point of failure.
Each failure scenario must be gracefully handled in each subpart to take into account all possible impact on the whole system.
You'll always get a random crap you never heard of destroying an assumption you made in your own crap.
I remember an instance where a national mobile phone provider in France got a single db outage but during a large sms day (think new year), so the failover happened but totally overloaded the new servers, and it created a chain reaction to other providers to a point you couldnt read your email for a day or two because of inability to get smses. Why is that random db in a provider I dont even use impacting my google account ? Because the system is distributed.
In our distributed systems lecture, my professor started the introduction lesson with some descriptions on 'what is a distributed system.' The one by Lamport was by far the most quoted in exams, as it is the most memorable, because it is funny.
After watching Lamports introduction to TLA+, I got the impression he's just a really funny guy (while being a genius, too).
Network is much much more reliable than it used to be. In a typical large-scale datacenter today, it is becoming common to deploy clos networks with multiple ECMP paths to get from one server to another. Also, cost of network relative to cost of the server is quite low (less than 8-10% of overall cost). Also, fat connectivity between datacenters in a metro area is much much cheaper than ever before (due to huge increases in fibre capacity in the last 10 years). If anything, network has become cheaper faster than compute has in the last 10 years. (And storage has done the same at an even higher rate). So, this affects architectural decisions in very interesting ways. Of course, public cloud make a huge profit on network bandwidths by billing to customers based on old mental models.
> Network is much much more reliable than it used to be.
But would anyone think of the bit flips?
> We've now determined that message corruption was the cause of the server-to-server communication problems. More specifically, we found that there were a handful of messages on Sunday morning that had a single bit corrupted such that the message was still intelligible, but the system state information was incorrect.
> We use MD5 checksums throughout the system, for example, to prevent, detect, and recover from corruption that can occur during receipt, storage, and retrieval of customers' objects. However, we didn't have the same protection in place to detect whether this particular internal state information had been corrupted. As a result, when the corruption occurred, we didn't detect it and it spread throughout the system causing the symptoms described above. We hadn't encountered server-to-server communication issues of this scale before and, as a result, it took some time during the event to diagnose and recover from it.
> Network is much much more reliable than it used to be
Within DCs, sure. At the same time, a lot more company networks become spread thin over 4G/5G networks and finicky cable ISPs in recent years with WFH.
This caused quite a strain on internal LOB apps which could reasonably assume zero packet loss and sub-1ms LAN latency beforehand :)
At the same time, IoT, mobile and roaming make for unreliability and consistent topology reshuffling. Granted different environment and for various reasons properly distributed solutions on these networks aren't widespread so far. Just saying there's another side to it.
Thanks so much for sharing this article, it reminded me of a fallacy before when we built TiDB cloud (a distributed database service) at first, the fallacy is Transport cost is zero.
We deploy TiDB in three available zone(AZ) in one region in AWS. Each AZ contains a SQL computing server, and a columnar storage replica server, sometimes the computing server will send request to the replica server in another region and get the data result, if the data acquisition volume is high, this will cost us much money. Unfortunately, we only found out about this when we received the bill from AWS. After that, We start optimizing the size of the transferred data :sob:
I have to say, this problem has not been well solved. But we've still been doing something:
- We used gRPC with no compression before, and we tune an acceptable compression level to achieve a balance of performance and data volume.
- Improve our SQL optimizer to consider the network cost more accurately and data placement rule to balance data more logically to reduce data transfer crossing AZ.
- As a cloud service, we will also expose the cost transparently to our customers like MongoDB Atlas does. :-)
There are "clouds" with lower networking costs, like Digitalocean/linode. But they are not "capable" enough to support a sizable company. Actually, networking is like a "tax" on top of the whole platform.
One of the real problems is that cloud providers can just waive cross-AZ traffic for their own managed services but charge a lot for cloud customers.
> One of the real problems is that cloud providers can just waive cross-AZ traffic for their own managed services but charge a lot for cloud customers.
That is why no matter how smart your software is they'll always have the upper hand and build things better themselves (why everybody using the BSL license).
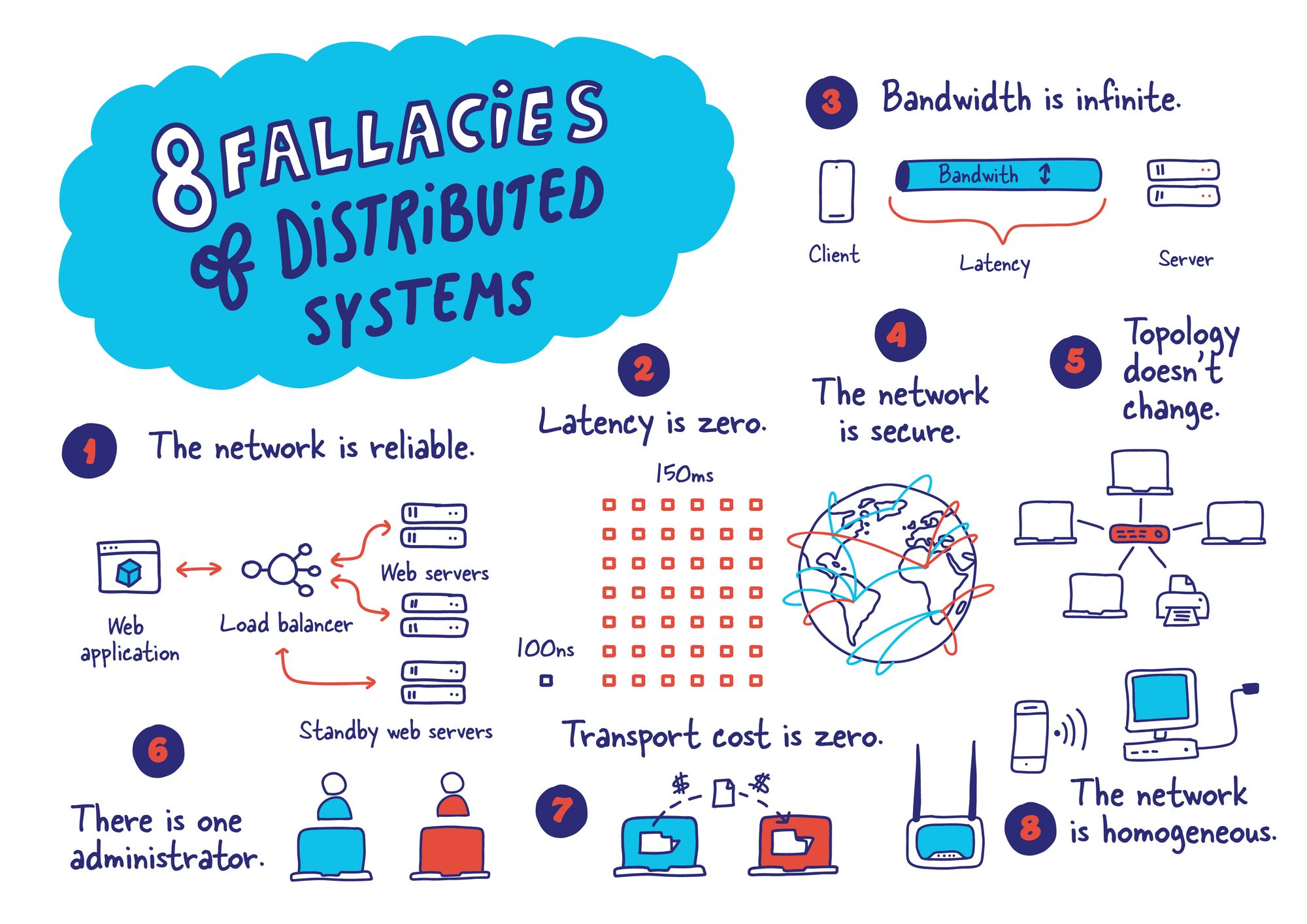
There is one administrator. I always found that fallacy the hardest to realize.
It’s like owning the entire supply chain. I remember this bit from someone who used to work at Heroku. It’s impossible for us to switch we spent so much time making the system work with AWS, switching or adding another provider would be a kin to starting over.
What can everyone do before that "new cloud" happens? The approaches like the above post mentioned how their cloud database tries different things from technology side seems the right and practical way to pursue though.
emm... moving and rebuilding whole systems onto another cloud is another wallet-ache thing, but yes, things may change if everyone votes with their wallet. The reality is that the big players like Snowflake or Databricks can have more bargain power than smaller players on the market, and as long as those big players stay with these providers, it may not change the game.
Some Conway’s Law hooey on my current job means I don’t even have that information. I’m doing work to reduce cluster size and maybe we’d be better off if I worked on cross-AZ chatter instead. No idea. Suspicions, yes. Dark, cynical suspicions, but no idea.
On single OSs Google runs an init that is deterministic; as do the BSDs and some distributions of Linux.
For distributed systems your ops team controls for this; usually on the service discovery layer. (Don’t publish until ready, don’t start service until you can establish a connection to required endpoints).
Many people think it is - but the realitiy is that it depends a lot on the system one is working on, can be super tricky, and often relying on it will cause some pain points later on.
e.g. let's take the example of an init system starting up all processes. Now what happens if a if one of the processes crashes and gets restarted by a processmanager? Now the order already changed, and e.g. a former process which relied on the restarted one might work based on outdated data. Similar things can also happen on other layers - e.g. one of the services in a dependency chain might disappear and reappear.
Another example is a developer/administrator manually changing the config of a certain service and restarting it to take effect - that could also trigger dependency problems.
Now those are absolutely solvable - either by making sure all services operate gracefully with any startup order or by other mitigations (e.g. "always reboot the full box"). But like everything else in the list, it still is a problem that is observed in very often in distributed systems.
These are fallacies of distributed systems, most of these are the reasons you want to have a distributed system. You build distributed systems because you know
- Servers restart, so you replicate and load balance
- Dependencies matter, so you build circuit breakers, and health checks
- Infra is heterogeneous, this is why you use containers
- Hardware is unreliable, again, replicate, load balance, and HA
- Provide APIs for your clients to communicate with your service
- Logging and metrics are expensive, collect what you need, prom helps with this, logging is not fully solved
- Do people really think there are no bugs?
“The network is reliable” is also the title of a relatively famous collaboration between Kyle Kingsbury and Peter Bailis which generated a long list of counter-examples.
This is like a meme in software development reposts and I hate it because it just says "things can go wrong with component X of your system". It doesn't say when, it doesn't say what the threshold is. There's no equations, no direction for someone that hasn't dealt with one of these problems before. It's less than useless.
And this is why before "fixing" the monolith by placing a network in the middle, one should start to learn about modules, packages and libraries on the language of choice.
YES! It is a shame one feels one has to fix organizational and coordination issues by introducing network barriers incidental to the real problems. I cannot wait for microservices to become unfashionable for cases where they are not solving technical scalability issues.
Software engineering is not a mature field but microservices feels like a dead alley everyone is marching on.
Any time you interact with a third party API you're creating a distributed system. The principles of distributed systems are useful for many more things than "microservices".
Short little post about Fallacies of Distributed Systems. These are some thoughts I feel often get downplayed when engineers are designing microservices.
I really don't think anybody believes the network is reliable, it's mostly that you have no freaking clue how the software layers lower than you will react to various conditions and the way an error will be visible to your app will be completely random.
"oh, today the underlying layer decided to wait 1min30 for a timeout",
"oh, the DNS resolution is broken",
"no route to host???",
"invalid certificate, did somehone hijack the DNS query?"
"this library decided to wrap the errors, now I have learn an entire new vocabulary of failure modes"
I am aware just didn’t want to correct the person correcting the inaccuracies. I suppose I could have given the red squares a unit value in the illustration.
And higher level issue for some types of workloads a disturbed system might never achieve the same level of performance and/or will cost orders of magnitudes more than a vanilla system making it impractical.
I’d love if someone created fallacies of big data technologies: most important being if you’re using spark, unless you’re really, really good at spark, you’re not actually working with big data.
My experience has been that spark actually doesn’t work with real big data without significant babysitting. It’s agorithms, be it window functions or joins, can take forever if not never finish on actual data that’s hundreds of terabytes large (even tens of tb). You immediately need to worry about crap like garbage collectors, worker memory, cache and data distribution. The majority of the data engineers out there can not actually deal with these problems but spark + actually not big data let’s them think they’re actually good at their jobs when in reality they’re not.
This is usually the product of not having to worry about costs combined with elastic platforms. Bad or inefficient methodology will still work but cost more which may result in surprisingly slower feedback loops before their work comes back to bite them.
Hey there’s a typo in the article. In the image of memory vs round trip says that roundtrip is 100ns and memory access 150ms I guess you meant the other way around :P
{kind=link}
{kind=link}
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” — Leslie Lamport