The process took around a month in my spare time, and involved copy-and-pasting the OCR plain text, then marked up as DocBook XML, then converted with my own XSLT stylesheets into HTML5. There were many transcription mistakes, some from OCR from the 35 year old daisy-printer monospace printout, some were in that printout because of electrical noise in the printer serial line in 1986. I fixed those I found by hand, then a couple of readers have reported others.
Since then I’ve corrected more OCR errors, and polished a bit more the HTML rendition.
From the introduction to this edition:
“It features an instance of Douglas Engelbart’s implicit links, automatically linking all appearances of certain terms to their definitions elsewhere in this document. This is done through a Javascript function that operates on the HTML content from the web server. It also shows his structural statement numbers, those little labels to the right of each paragraph that allow high resolution linking.”
Doug Engelbart was not part of Xanadu, although he was a close friend of Ted Nelson for decades. It’s just that those aspects of his NLS (of 1968 “Mother of all demos” fame) fit well this document, and work relatively well on web browsers.
I did try to implement transclusion as an example, but the target web server did not provide a CORS header and browsers refuse to load their content.
> “It features an instance of Douglas Engelbart’s implicit links, automatically linking all appearances of certain terms to their definitions elsewhere in this document. This is done through a Javascript function that operates on the HTML content from the web server. It also shows his structural statement numbers, those little labels to the right of each paragraph that allow high resolution linking.”
Yo this is really cool! I'm glad you came back to update us.
You are right, and with a server-side component you could fetch arbitrary content, the endpoint could look something like example.com/transclude/a.b.com/section/page?path=2a14n which would make the server download a.b.com/section/page, extract the HTML element which is the 13th ('n') child of the 14th child of the first ('a') child of the second child of the root element, and return it.
I’m sure there are implementations of this already.
It's very clever, but solves the wrong problem. It's basically doing what a revision control system like Git does, but for a different reason. Everything is pay per view in Xanadu. It's micropayments to the max. Everybody who contributed to the article gets a cut, in proportion to how much content they contributed. So there's all that tracking.
Also, pictures? What are those? Audio and video? Don't even think about it.
It's an elaborately optimized design that optimizes for the wrong thing. It belongs to the world in which Mead Data Systems and MEDLINE and NEXIS and LEXIS, all pay to search and read systems, dominated information access. If Elsevier had designed the Web, it would work like this.
I knew that crowd back when they were doing this. Great people, but too many were of the "everything should be a market" persuasion.
> Also, pictures? What are those? Audio and video? Don't even think about it.
While I agree with some of your critique, as Ted pointed out in https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.45..., video is almost always edited with EDLs, edit decision lists, which are sequences of transclusions of the source footage. And transclusion is the way we've always done images on the WWW. So I think that at least that criticism is off-base.
Much of the elaborate optimization is simply a concession to the realities of 01984, when 1-MIPS workstations with 1 MB of RAM were fairly high-end workstations. (But some of it was just blunders.) You probably remember how in 01993, 4½ Moore's-Law doublings later, Mosaic struggled to deliver a usable networked hypertext browsing experience on the personal computers of the day, except those made by SGI or Sun. And that was without half of Xanadu's features: versioning, linkrot-proofness, and editability.
I don't think the computer performance came up in the design of this protocol. After all, one of the foundations of it is _immutable_, append only data structure where all the information is stored (I-stream). Surely it was clear even in 1984 that this can not be achieved with the computers of the day?
And if you are postulating unlimited storage, why not put videos there as well?
The primary concern of this architecture document from beginning to end is how to get adequate performance out of the computers of the day, given the features they considered to be fundamental.
BTW, as I understand it, the I-stream isn't the append-only data structure; the granfilade is. They contain mostly the same information, but in different orders, so that you can insert into the I-stream by appending to the granfilade.
I don't think it's true that forever storing all the text the system's users would write was infeasible in 01984; the revenues expected from readers would have paid orders of magnitude more than the cost of the space required, even in 01984. A book might be 1 megabyte; you might write another megabyte or two in the process of writing it. Someone writing a book in Xanadu — a level of success the system never in fact achieved — would have to pay to store those 2–3 megabytes forever, perhaps copying them onto a new computer every 6 years, at ⅛ the cost of the previous computer. How much might that cost?
I don't have good pricing data from 01984, but I do have here the Sun price list from December 01988; a Sun-3/100 at that time contained a 16.67-MHz 68020, 4–12 MiB of RAM, and if you got it with a disk, it would be a model 514D 141-MiB disk. The 3/140M-4-P5 configuration, with a 19" monitor, cost US$23700. 3 MB of text would have been about 2% of the machine's capacity, and so would have cost about US$237 in 01988. Four years earlier it probably would have cost about US$1000. Then it would have cost another US$125 for new storage in about 01990, US$16 in 01996, US$2 in 02002, etc., a total of a bit under US$1145. If you amortized the initial investment of the space for the book over the same 6 years, it would be about US$190 per year, so the system would be immediately profitable for any book that was expected to produce more than about US$190 of revenue per year across all its readers. A book with 100 readers per year, each paying US$10 to read the book, would earn five times the cost of its storage space.
Data transmission was plenty fast enough; people can only read at about 300 baud, or 150 baud with huffman coding. The Hayes Smartmodem 300 was introduced in 01981, and in 01984 1200-baud modems were common and 2400-baud modems were starting to appear.
Then the problem would merely be to build data centers fast enough, stuff them full of fileservers, and somehow keep the whole wild system from collapsing in chaos.
That wasn't the problem they had, though. The problem that they had was that their system design was so ambitious that they never shipped a working product.
As for video, well, even with modern codecs a two-hour-long movie can gobble up over a gigabyte of storage space (US$300 000 at the price I estimated above), and people were paying US$1 for a matinée movie ticket and US$0 to watch pan-scan-converted movies on late-night TV. There was actually a somewhat popular product a few years later to do data backup onto VCR tapes, called ArVid; it could get 4 gigabytes onto a 4-hour tape. (A few people were doing that starting in the early 01980s, but they were the people who had gigabytes of data, so there wasn't a mass-market product.) Although I was watching postage-stamp-sized MPEGs with mpeg_play_motif on SGI workstations in 01993, fullscreen digital video playback didn't become computationally feasible at all for mass-market hardware until the late 01990s; earlier systems like the Dragon's Lair arcade game overlaid the digital content on analog video backdrops.
So to deliver text to customers in 01984 and store it forever, you needed 300-baud modems, which were already a mass consumer product, a data center with fileservers, a packet-switching network like Tymnet, and textual data that averaged at least a few readers per month. Tymnet had been a commercial offering since 01972, and this whole package is something companies like The Source, CompuServe, and (as Animats pointed out) the vile Mead Data Central were already doing.
To deliver video without modern codecs, you would have needed four orders of magnitude more storage space in your data center, and you would have needed each video customer to either contract a T1 line to their premises or better, or also have the customers store the video data locally, perhaps on a VHS tape, so they could download it at slower than real time. With a 2400-baud modem you would be able to download a few seconds of video per day, though, so maybe you'd need to contract at least a 64-kbps frame relay link from the phone company, so you could download a minute of video per day. Then you could watch a single movie every other month.
The conclusion I draw from this is that Xanadu is quite a different usage model than the web. The first webpage I remember reading (over dial-up connection to university server) was physics experiments for beginners. The first webpage I made (in the end of 1990's) was to publish plays from the drama club. Those would be be totally infeasible under "every published document must earn money" model.
I wonder if Xanadu could ever get completed, who would have used it? It will be probably be a Serious Place full of Professional Authors writing Real Books. Nothing like fun, random places of early internet [0] -- "a guide for backpackers and wilderness trekkers; [...]; a Grateful Dead fan page"....
It's probably true that it would have started with literature expected to have mass appeal ("Real Books") and only gradually moved downmarket. But let's not exaggerate!
I'm guessing there were more than two people in the drama club, so it's likely that even your first webpage had more than two readers a month, which was the breakeven point I calculated above for extrapolated 01984 storage pricing. By my extrapolated 01990 pricing it would have been economical at three readers per year, and by my extrapolated 01996 pricing at one reader every 3 years. Since you called it a "webpage" and not a "BBS" or "FTP site" I'm guessing that this was more like 01994 than 01984, so you would have been fine.
These numbers are no different for Xanadu and the WWW, it's just that on the WWW they are paid by the publisher (or their friend or university or something), and in Xanadu they would be paid by the users.
All this is assuming the value to the reader is about US$3 per megabyte, a number I based on the idea that a book is about a megabyte, people commonly pay about US$10 for a book, and the edit history for the book might be three times the size of the final book. (Maybe people paid US$2.50 for a paperback, while a hardcover might be US$40. Roughly 01984 dollars.) If you were reading 40 hours a week at 350 words per minute at this speed, that works out to US$15 a week, US$66 a month, or US$789 a year.
A more reasonable path is to figure that by 01994 people might pay US$20 a month for using the Xanadu service 40 hours a week, with half of that (US$10 a month) flowing to the author and hosting costs. That's only 46¢ per megabyte, but by 01994 storing a megabyte only cost about US$30 instead of US$1000, maybe US$5/year, so anything with more than one reader a month would pay for itself.
And if it didn't, well, a play might be 100kB, and maybe the drama club would spend US$3 up front to pay a Xanadu operator to store those 100K for eternity, money they'd get back if people read the play, but if nobody ever read the play on Xanadu then that would just be an expense. I feel like US$3 is not a prohibitive expense for vanity-publishing a play and having it never go out of print. I mean xeroxing it at the library probably cost almost that much. Per copy!
(In 01996, a single Moore's-Law doubling later, I bought my first computer. It had an 800MB hard disk and cost me about US$900, half of which was the monitor, and would have been a perfectly capable fileserver even though it was a cheap IBM PC clone instead of a Sun workstation. So my US$30/MB for 01994 might be too conservative. Maybe it would be more like US$3/MB. And by that time gzip and 14.4kbps modems were mainstream, dropping costs further.)
Now, it's possible that authors (or the Xanadu operating company) would have been too greedy, and charged much higher prices than that, which would have had the result you describe. (There's some evidence that people did shift from things like CompuServe and AOL over to the WWW because publishing on the WWW was cheaper.) Or it's possible that they would have subsidized the initial wide dissemination of their work, as we in fact did with the WWW, so as to build up a customer base.
Quote a lot of inconvenience and hubris for the astronomically slim chance anyone will be reading these comments in 8,000 years, and even in the case someone does, it's at best what, considerate?
While I don't like that, I don't really see how some kind of pay-infrastructure is avoidable in the long run.
The way the Internet solved that by being owned in large part by a handful of mega cooperations, being full of ads and spam and turning the user into a product is not what I'd call a good solution either.
The fully open and free web is not sustainable, as we have seen by it dying out over the last 20 years. And the open web isn't even all that great to begin with, given that link rot is still an unsolved and extremely common problem.
The open web is still growing. The perception that it's dying is just because proprietary services like Facebook and Twitter have dominated public discourse on the web, but it's still alive and well.
It's not growing as fast as it was, sure, but for example the number of active blogs has grown by 12% in the last 7 years and 4.4 million blog posts are published every day, more than ever before.
This page claims "70 million posts from wordpress users", which comes out to 2.3 million per day. And there are many more other blogging platforms out there.
If you are interested in non-Facebook/Twitter I recommend getting an RSS client first. Then as you read Hacker News, add the feeds of the interesting authors to your reader -- many front-page articles have RSS links somewhere. You'll have nice, non-FB reading list in no time.
"The computer world is not just technicality and razzle-dazzle. It is a continual war over software politics and paradigms. With ideas which are still radical, WE FIGHT ON.
We hope for vindication, the last laugh, and recognition as an additional standard-- electronic documents with visible connections." - https://xanadu.com/
Looks like they would fit right into the crypto world..
"[...]
Cyberspace consists of transactions, relationships, and thought itself, arrayed like a standing wave in the web of our communications. Ours is a world that is both everywhere and nowhere, but it is not where bodies live.
We are creating a world that all may enter without privilege or prejudice accorded by race, economic power, military force, or station of birth.
We are creating a world where anyone, anywhere may express his or her beliefs, no matter how singular, without fear of being coerced into silence or conformity.
Your legal concepts of property, expression, identity, movement, and context do not apply to us. They are all based on matter, and there is no matter here.
[...]"
The really funny thing about Xanadu is that unlimited transclusion is not how copyright works. If you buy two movies, you don't get the right to publish an edit list that stitches the movies together. That itself violates copyright. In fact, you aren't even allowed to open the movie up in an editor (unless you break DMCA 1201). Artists are very much accustomed to not only controlling the market for copies of their work, but also remixes of their work, which are licensed separately and cost far more money than mere copies.
This is by and large false, but it's somewhat less profoundly false than it was in 01984. Referring to copyrighted works has never been a right restricted by copyright, and in the US copyright system transformative use ("remixing") weighs heavily in favor of a finding of fair use, which makes copyright infringement legal. There are also a number of compulsory licensing provisions in the existing copyright law to, for example, permit covering a song you don't have copyright to, whether the copyright holder likes it or not.
A Xanadu transclude - or the moral equivalents in HTML today - isn't the same as merely a "reference", like an HTML link or a citation footnote in a book. The latter just tells you to go look at another thing; but what Xanadu wanted was that the system would create a whole work out of your additions and the original work (in the same way that, say, a dynamic linker would). This isn't a reference, it's a copy, and the argument then comes down to where the copying actually happens and who should be liable for it.
That being said, while looking for court cases that supported "transclusion equals derivative work", it turns out this is actually more contentious among actual judges than I thought. If you ask the 9th Circuit, embedding by reference doesn't violate copyright because infringement is stored in the server[0]. If you ask other courts this is obviously wrong[1].
My gut feeling is still that the 9th is wrong on this, because embedding by reference not tripping copyright opens up a huge loophole in the law[2]. Think about how many low-effort articles are just "X is going viral" plus an embed of X - that's exactly the sort of behavior copyright is intended to prohibit. And given that we live with a legal regime that's obsessed in drowning the world in "innovation" and "intellectual property", I don't see how "evade licensing photos by just embedding them off the photographer's Instagram" is going to stay legal.
Putting that aside, if a reuse of a work by transclusion fell under Fair Use, then you wouldn't need the Xanadu payment system in order to license it anyway. You would be free to just reupload the portions of the work being fairly reused and not pay. So even if paid transclusion wiped away infringement, it would still be a tax on fair users (in the same way that YouTube Content ID is).
Compulsory licensing probably wouldn't matter much as copyright has very few situations in which you can purchase such a license. The ability to refuse to sell a license at any price is considered a key feature of the law by the copyright maximalists.
I think Xanadu's business plan here was to only host works by authors who were willing to contractually permit unrestricted transclusion and get paid for it. I agree that the setup would tax fair use, but I'm sure that wouldn't have prevented it from being financially viable or legal. Not shipping a working product is what prevented that.
Maybe the things you like about the web happened because of liberalism, not in spite of liberalism, as you seem to think. As you point out, that's true of Wikipedia, but it's also true of the commercialization and privatization of the internet, it's true of the EFF, it's true of the DMCA's safe-harbor provisions, and it's true of the Open Source Initiative. It was ultimately liberalism — Dan Bernstein's years-long court battle for due process — that struck down the US's prohibitions on open-source cryptography, too.
More generally, the internet itself ended up being built in the US, even though adequate industrial capacity for it existed in many countries: the USSR, the UK, France, Japan, and so on. There are a number of possible reasons for that, and the UK and France did in fact build nationwide teletext systems with some degree of interactivity, and the UK also built JANET; but very plausibly the US was the one who built the internet because such a liberal network design was too threatening to the other countries, and it happened to work better than designs like Tymnet (which was also built in the US) and Minitel.
Of course the internet was famously non-market-oriented before the com-priv era, not at all like the Digital Silk Road proposed by the Agorics guys (unrelated to the darknet market, of course).
But the WWW - that is, the "Internet" as most people know it and as relevant in this context - was build by a Brit in Switzerland, wasn't it? By basically adding the URL concept, anchors/links, and HTTP to an SGML vocabulary readily described in ISO 8879 (SGML) to implement visual paradigms already known from early-90s multimedia apps.
Yes, except for the visual paradigms thing, and the "as relevant in this context" bit; the WWW was text only for years, except in the sense that you could use it to download files of any type. And he wasn't doing it for profit. But he was doing it on a network that allowed that kind of decentralized extensibility, unlike CompuServe, Minitel, Tymnet, AOL, Facebook, or AT&T.
An interesting feature of capitalism that Marx liked to talk about a lot is that they can be unstable, like democracies: participants in a free market are free to pursue their own profits, but by far the most profitable situation for them is to become a monopoly or monopsony, which destroys the freedom of the market and ends capitalism. So we have this interesting situation where the internet, arising from government planning and with commercial use prohibited for decades, ended up being freer even for commercial use than the alternatives established by for-profit companies like CompuServe, Tymnet, and AT&T.
(In the same way, a politician in a democracy is free to pursue power by getting elected, but if they are sufficiently successful at pursuing power, they end democracy.)
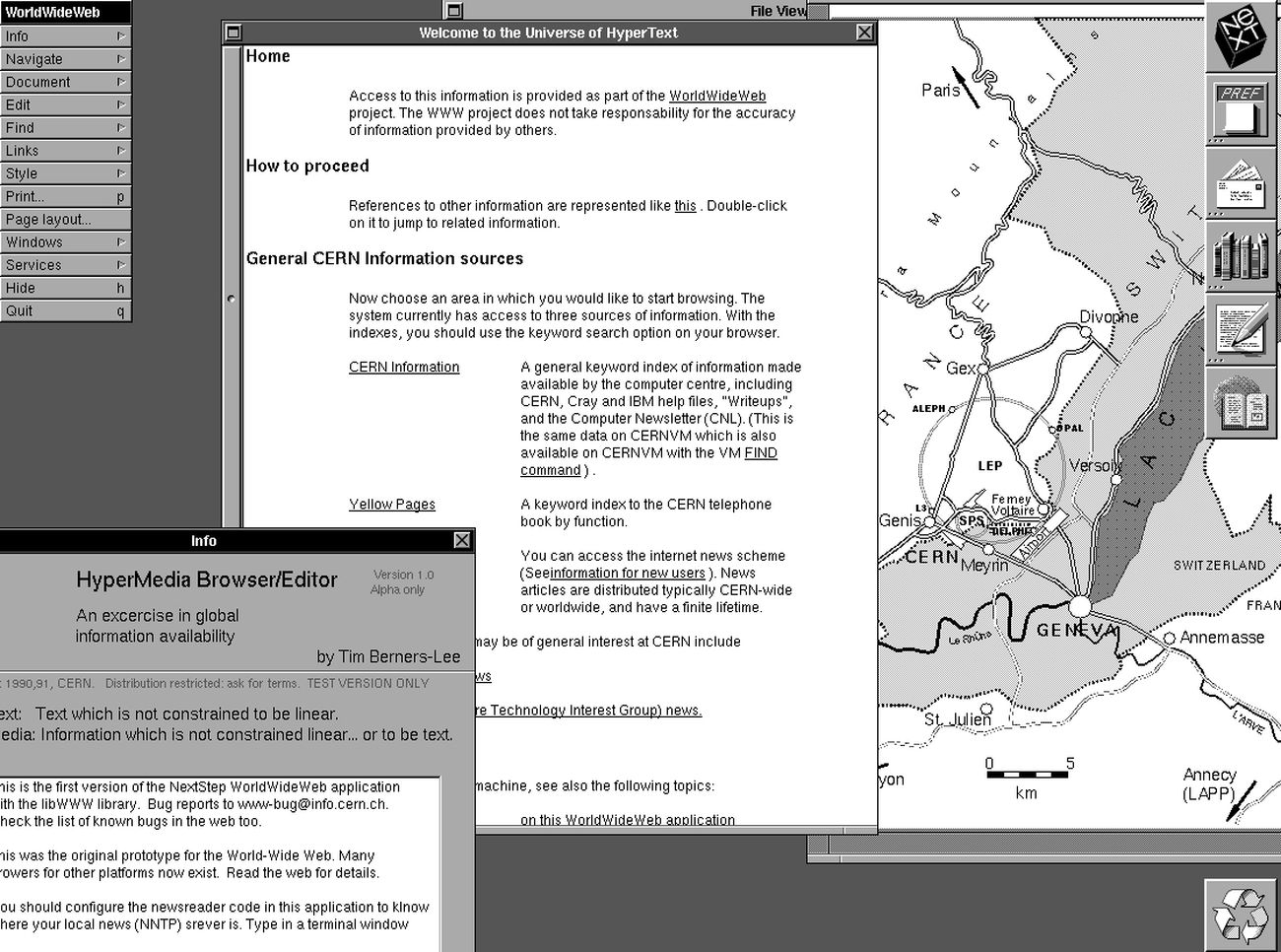
> WorldWideWeb is capable of displaying basic style sheets, downloading and opening any file type with a MIME type that is also supported by the NeXT system (PostScript, movies, and sounds), browsing newsgroups, and spellchecking. In earlier versions, images are displayed in separate windows, until NeXTSTEP's Text class gained support for Image objects. WorldWideWeb is able to use different protocols: FTP, HTTP, NNTP, and local files. Later versions are able to display inline images.
In 1990 the "Hypermedia Browser/Editor" by Sir Timothy John Berners-Lee already supported images [2]
I said, "the WWW was text only for years, except in the sense that you could use it to download files of any type."
You seem to have responded that actually it wasn't because you could use it to download files of any type, including images (which you could display), and that years later it was able to display inline images (after pmarca added them to Mosaic in 01993). Well, that is true, but your implication that it contradicts what I said is false.
> You seem to have responded that actually it wasn't because you could use it to download files of any type
I'm not English native speaker, but I'm quite sure this sentence doesn't mean what you think it means.
I'll quote it again
> In earlier versions, images are displayed in separate windows, until NeXTSTEP's Text class gained support for Image objects
BTW, yes, everything you see in a browser's webview is "downloaded", even today
Inline or not, the web wasn't text only from inception (it was designed to support different media types according to the mime type mappings of the system, it's not a coincidence).
Lee called it hypermedia browser, not hypertext.
> years later it was able to display inline images
by years later I think you mean by 1990
This [1] is from the NEXTSTEP Reference Volume 2 (published in 1990)
Even though the browser would guess MIME types based on filename, HTTP didn't have MIME types until HTTP 1.0; HTTP/0.9 as of 01992 still didn't have them: https://www.w3.org/Protocols/HTTP/Response.html
I didn't use the NeXT WorldWideWeb browser, so I don't have firsthand knowledge, but in http://web.archive.org/web/20110131164401/http://diveintomar... you can read TimBL commenting in 01993 about possible alternative ways of adding inline image support in ways that make it clear that he hadn't yet implemented any kind of inline image support. So I guess either the Wikipedia page is wrong or the page you posted is wrong about what NeXtStEp could support in 01990.
> Even though the browser would guess MIME types based on filename, HTTP didn't have MIME types until HTTP 1.0
correct
but guessing the mime type is what many tools still do today
MIME types were one of the (many) emergent features added to HTTP out of necessity
like, for example, HEADERS
HTTP/0.9 had no headers, no status code it was basically nothing more than
- GET THAT
- HERE IT IS ITS RAW CONTENT
But Lee HyperMedia browser had support for different file types because he already envisioned it as a mean to browse a "web" of hosts in search of "resources of different kind"
WWW was text only the same way Excel was text only, meaning they could not show text and images side by side, not in the sense "VT100 text only"
Ask you this: was there another software that let you click on a link representing a file on another computer possibly on the other side of the planet, download it and show it to you in (almost) real time?
This [1][2] is the best Microsoft could do using all its resources in 1990, on a platform that was already very advanced for graphics (Word 1.1 for Windows looks like sh*t), T.B.Lee was basically himself writing the code for the server, the client on a platform that was still in its infancy while also having to learn the framework (NeXTSTEP)
Oh, agreed. And when I started using the WWW in 01992 it was obvious that it was going to be a huge thing. But "visual paradigms already known from early-90s multimedia apps" is mutually exclusive with "they could not show text and images side by side". HyperCard, PowerPoint, and other "early-90s [or late-80s] multimedia apps" showed text and images side by side incessantly. Or sometimes on top of each other.
There was "another software that let you click on a link representing a file on another computer possibly on the other side of the planet, download it and show it to you in (almost) real time"; specifically, Gopher, which came out at the same time as WWW.
Can you elaborate on what you're saying about Word 4.0 for Macintosh?
This has the feel of a "history by the victors" view.
There were contemporaneous research networks in a range of different countries, some - like the UK NPL network - which influenced ARPANET in various ways (the term "packet switching" comes from Donald Davies work on NPLs network; though Paul Baran at RAND beat Davies to inventing, Davies was not made aware of Baran's work until a year after he'd independently invented it and was told by the UK MoD), and most of them became part of the internet rather than being replaced by it.
Pouzin, designing the French CYCLADES, beat ARPANET to a layered architecture with the connection endpoints responsible for reliability in the vein of TCP. Both Davies and Pouzin provided feedback to Kahn and Cerf on TCP and are acknowledged in their papers.
The internet looks most like ARPANET looking backwards because of a combination of the military interests in the early international connections which made ARPANET the first to see significant push in international expansion before other standardisation efforts got traction, coupled with the simplicity of TCP/IP.
To the international push, Norway got the first international link to ARPANET because of NORSAR[1] - a seismic array used to monitor Soviet nuclear tests.
The NORSAR link led to work on connecting UCL in the UK, and led to work on gatewaying the UK network to ARPANET, and also led to e.g. Kirstein's [2] involvement with the spread of TCP/IP. See [3] for example. Or this article on his Marconi prize [4] which talks about how Kirstein was instrumental in helping TCP/IP win out over OSI in Europe.
Had ARPANET simply never happened, history would certainly have looked different, but we most likely would still have had an internet. Whether it'd have the characteristics we like about the current internet is an open question, but it's worth noting that people like Kirstein pushed an open interconnection model that ultimately contributed to the "win" of TCP/IP because a lot of the European networks were already getting connected by the time ARPANET opened up, and so Kirstein's work on promoting TCP/IP and interconnection to ARPANET gave TCP/IP a leg up in the race to define the internetworking protocol set.
E.g. by 1976 at least 6 European countries had national networks interconnected via EIN; by 1979 Euronet connected at least 9. Euronet was operated by private providers.
By that point a number of public and private providers in Europe were also offering packet-switched services to private companies. By 1978, X.25 was internationally available via IPSS, linking a number of different national providers.
The irony of mentioning Minitel is that if anything, Minitel was in many ways a demonstration of what the internet could have ended up as had the "everything should be a market" crowd won out - it nickel and dimed almost everything. But Minitel was not the only French network.
But "everything should be a market" in the sense implied above (the nickel and diming approach of Xanadu etc.) is entirely orthogonal to liberalism.
You seem to be arguing against a view that USans invented everything about internetworking, but that's not a view I hold. I know lots of people from lots of places did pioneering internetworking research! What I was saying is that the US is where the internet got deployed. Surely you are correct that without ARPANET someone still would have built an internet, and eventually it would have become worldwide. But what I'm pointing out is the contingent political facts that resulted in it happening in our timeline in the US rather than, for example, the USSR, where access to photocopiers was still tightly controlled.
I don't think "everything should be a market" is orthogonal to liberalism. At a large enough social scale, liberalism always produces markets unless warfare erupts; strong restrictions on commerce are necessary to prevent markets from arising among groups much larger than Dunbar's number.
I agree with you about Minitel; in fact, monopoly for-profit providers like CompuServe and Tymnet imposed the same kinds of restrictions on innovation that prevented the WWW from arising on their networks: https://news.ycombinator.com/item?id=30916796
"1987"? The first ARPANET link was active in 01969, and the ARPANET switched from NCP to TCP/IP on January 1, 01983, though the TCP/IP RFCs start in 01976 or 01977. Do you mean it was still deployed as a research network in 01987, as it was in, for example, 01992?
Perhaps you meant that 01987 was the last year it was US-only? But vidarh pointed out above that the ARPANET was connected to NORSAR, a research center in Norway, in June 01973, and Norway is in Europe, so in fact our current internet has had some international connections for almost 49 years now.
> 1987"? The first ARPANET link was active in 01969,
ARPANET is not INTERNET
there were many network similar to ARPANET for scope (maybe not size, but Europe was politically much different back then and the wall in Berlin was still there) at the same time ARPANET was alive
Russians had their network too since the late 70s, and at one point they connected to the US directly even during the cold war years! (mid 80s).
> Perhaps you meant that 01987 was the last year it was US-only?
no, it was the year it became "a public accessible network", after NSFNET was established. The year later research centers in Europe were connected to it and were contributing to it.
> You seem to be arguing against a view that USans invented everything about internetworking
No, I was arguing that there is sufficient evidence that the basic internetworking would have been independently invented even if ARPANET had never happened, and that as such, this is also not supported by history:
> What I was saying is that the US is where the internet got deployed
This is why I said it read like a "history by the victors" view.
"The internet" got only got deployed in the US if you take the view that the dozens of other contemporaneous networks at the time did not combine with ARPANET to form the internet, but that ARPANET alone became the internet and replaced the others, or in the strict technical sense that "the Internet" was first used about what sprung out of ARPANET. So, sure, "the" Internet arguably got deployed in the US.
But many internets were built in the 1970's. And while ARPANET was early in some respect (e.g. packet switching was first invented at RAND), many of the aspects were also invented or reinvented independently elsewhere, and both academic and commercial deployment of internationally internetworked networks was well developed long before ARPANET connectivity became widely available internationally.
As such, an internet would have still existed had ARPANET never happened. It'd have looked different, but not that different.
We're left with something ARPANET flavoured because TCP/IP won and existing networks were gradually switched to TCP/IP, not because there weren't alternatives, because there were multiple commercial and public alternatives by the late 70's, predating both TCP/IP and the opening up of access to ARPANET. If you wanted global networking at that time, you'd likely buy access from an X.25 provider, so had ARPANET and/or TCP/IP failed entirely, at worst we'd still have services built on an X.25 descendant (that truly is the worst timeline.... shudder). [Compuserve and Tymnet both used X.25 for at least parts of their networks]
Even by the time I started an ISP in '95, not everyone were still convinced TCP/IP was the way forward, and people were still doing things like tunnelling TCP/IP over X.25 because X.25 was still more easily available some places.
> I don't think "everything should be a market" is orthogonal to liberalism. At a large enough social scale, liberalism always produces markets unless warfare erupts; strong restrictions on commerce are necessary to prevent markets from arising among groups much larger than Dunbar's number.
The point is that the commenter above was not arguing against the existence of markets, but the kind of nickel and diming proposed by Xanadu on expectation of markets for everything. But in terms of writing and knowledge, one of the things the Xanadu people failed to grasp is that the supply far outstrips the demand. For most writing there is no commercial market. In fact, for a whole lot of writing, the commercial value of the writing as a product is negative: people want to pay to push it on others more than people want to pay to read it. Trying to build markets for ideological reasons even where a whole lot of people are desperate for distribution rather than payment is a folly.
So I agree with you that liberalism will always produce markets, but I don't think that is relevant to the point. The ideological bent to try to find ways to extract money out of everything is a particular right-libertarian/objectivist subset of liberalist ideologies that most liberalist ideologies do not share.
I see! Thank you! I agree, especially about the nightmarish X.25 shadow universe.
An interesting thing about Wikipedia is that it's not very compatible with charging for access, but not because Wikipedia editors are desperate for distribution (we do our best to discourage the ones who try to use Wikipedia to get distribution for their point of view). It's more that charging for access discourages people from contributing in a variety of interestingly different ways.
I don't know if it's true that Jimmy Wales named one of his daughters after an Ayn Rand heroine (none of them seem to be named Dominique or Dagny, but maybe I just haven't read enough Ayn Rand) but he is definitely pretty bullish on liberalism and specifically capitalism.
Interesting, was there a ceiling? I'm thinking of those 1-900 premium-rate phone scams in the 01990s where you'd find out after calling that you had just spent US$27 when you thought you were going to spend 50¢.
I think it really is plausible that transaction costs of various kinds would have confined Xanadu to a niche, which would have been particularly catastrophic for the two-sided market they were trying to build. But CompuServe and AOL seemed to do okay, and that wasn't in fact what killed Xanadu.
I presume anyone could've written a client for the frontend protocol -- I don't think I ever read that protocol draft. There was a general vibe that good frontends were an important problem and people would want a variety.
Yeah, it's questionable whether their business strategy could've evolved into a winning one even if they'd made it to launch.
I was just questioning the parent's perspective on "right libertarian ideology" -- my impression of Xanadu's vision was not so much "people love markets for information!" as "it's vital for the health of the info ecosystem that basic costs be paid directly", so e.g. the problem of UIs that people can rely on against scams should be faced and not avoided in favor of structurally leaning hard on advertising. (Yes, some kind of ads are inescapable.)
(It sounds like you've gotten to quiz MarkM on Xanadu directly; I'm going by largely-forgotten reading mostly in the last millennium.)
```
The current Xanadu backend is constructed using three essential data structures:
- granfilade, used to implement the grandmap
- poomfilade, used to implement orgls
- spanfilade, used to implement the spanmap
```
I will never, ever again complain about the density of a W3C RFP:
> The index space used by the granfilade is I-stream tumbler space. The wid of a granfilade crum is a tumbler specifying the span of I-space beneath the crum (i.e., the distance, in tumbler space, from the first to the last bottom crum descended from it). The widdative function is tumbler addition, therefore a crum’s wid is simply the tumbler sum of its children’s wids. Bottom crums have an implicit wid of 0.0.0.0.1 (i.e., spanning no nodes, no accounts, no orgls, no V-spaces and spanning a single atom). Granfilade disps are tumbler offsets in I-space from the parent crum.
Somehow I feel like Buckminster Fuller could have written this
It might be the case that you could have invented a new kind of publishing without making up a bunch of new jargon to name the concepts required to make it work, but the WWW definitely does not represent a proof that this is possible.
> The style IDL attribute must return a CSSStyleDeclaration whose value represents the declarations specified in the attribute, if present. Mutating the CSSStyleDeclaration object must create a style attribute on the element (if there isn't one already) and then change its value to be a value representing the serialized form of the CSSStyleDeclaration object. The same object must be returned each time. [CSSOM]
The WWW-specific jargon here ("IDL", "attribute", "CSSStyleDeclaration", "declarations", "element", and arguably even "object" and "mutate") is only slightly less dense than the bit you quoted. The difference is that, because we've all spent the last quarter century embedded in the world it describes, its vocabulary is familiar to us. On the other hand, because Xanadu failed, its vocabulary is unfamiliar to us, so this passage seems opaque, even where it's doing things like helpfully restating what role a widdative function plays in generalized enfilade theory in case we've forgotten, or restating what the parts of a tumbler are for the same reason.
Incidentally, if the W3C spec you're looking at is ECMAScript, some of the authors are the same as the authors of the Xanadu spec.
— ⁂ —
What's being described in the passage you quoted is a tree structure over a sort of space of strings called "I-space" that is used to name documents or parts of them, similar to how URLs are used in WWW. The strings (tumblers) consist of sequences of nonnegative integers, rather than sequences of letters drawn from some finite alphabet like ASCII or Unicode. Tumblers have a lexicographical ordering on them: 1.2.3.4.5 comes after 1.2.3.4.4 or 1.2.3.3.6089235802, but before 1.2.3.4.6 or 2.0.0.0.0.
The tree is sorted by this lexicographical ordering, so in some sense all the data in the granfilade forms one single very long string, with tumblers like 1.2 or 1.2.3.4.5 identifying contiguous subsets of it. But this is not an advantageous way to organize the tree for efficient access, because 1.2.3.4 might be enormous compared to 1.2.3.3 or 1.2.3.5; instead the storage tree is made out of nodes that are about the same size at a given level of the tree, which are called crums. A crum might include all the data from 1.2.3.4.5 to 1.2.3.4.17 (exclusive); by subtracting these two tumblers we get its width ("wid"), which is 0.0.0.0.12, which means that it spans 12 leafnodes ("bottom crums"). If that crum and another crum that covers 1.2.3.4.17 to 1.2.3.4.25 (wid = 0.0.0.0.8) are the two children of a single parent node ("parent crum"), then the parent crum has a wid of 0.0.0.0.12 + 0.0.0.0.8 = 0.0.0.0.20.
This leaves us with the question of how to efficiently store this range "1.2.3.4.17 to 1.2.3.4.25". We could of course store it as a 12-byte sequence: 01 02 03 04 11 ff 01 02 03 04 19 ff or something like that. But there is obvious redundancy here, particularly considering the context of walking down the tree ("granfilade") from the parent crum which covers "1.2.3.4.5 to 1.2.3.4.25"; it's more efficient to just store the crum's wid 0.0.0.0.8, as something like 04 08, and its displacement ("disp") relative to the parent crum's starting point, which is 1.2.3.4.17 - 1.2.3.4.5 = 0.0.0.0.12, which is simply the tumbler sum of the wids of its preceding siblings.
This representation not only permits us to use less bytes, it also doesn't need to be modified if we graft a whole subtree from one part of the granfilade to another, or even (and I forget if they did this!) transclude it. And it allows us to build a nicely balanced sequentially-written B-tree of crums that guarantees logarithmic-time access to any atom, permits guaranteed crash recovery and even rollback, and doesn't have too much write amplification for localized writes. It doesn't handle large batches of dispersed writes as nicely as a log-structured merge tree does, but I don't think LSM-trees were known yet when they designed the granfilade.
Hopefully that clears things up a bit. I don't really understand Xanadu but I have spent a little time digging into it to try to figure it out.
— ⁂ —
In general enfilade theory there's the possibility of arbitrary sorts of "wids" and "disps" that are computed bottom-up and top-down in the same way: the wid of a node is computed by its widdative function from the wids of its child nodes, while the disp of a node is combined with the effective disp of its parent node to get its effective disp.
For example, if your wids and disps are numbers of bytes, you get a rope that efficiently supports indexing by byte offsets.
And if you use ordinary vector addition as the dispative function on a tree of nested windows, using the (x, y) offset of each window relative to its parent window as the disp, you can compute the absolute pixel offset for each window. You can almost do hbox/vbox layout this way, too: your wids are (width, height, orientation) triples, and your widdative function is something like
where ∨ is the pairwise max function; but at some point you need to turn a stack of hboxes into a vbox or vice versa, which either needs an N-ary widdative function (rather than binary) or a postprocessing function used once per node to flip the orientation.
As this indicates, the Xanadu folks were very much in love with the mathematical approach to software that seeks maximally general solutions to everything, and I think sometimes that didn't serve them well.
The difference is that the words you cited in the HTML spec are all rooted in English vocabulary and words, without modification. Creating an entirely new set of vocabulary - not mere jargon, but full-on /new words/ with their own declensions. Those are very different beasts.
This is true to some extent, although "IDL", "CSSStyleDeclaration", and "HTML" are full-on new words. (None of them have their own declensions because in English only pronouns have irregular declensions.)
However, given the choice between naming a new concept with an initialism like "CSS" or "HTML", a standard English word used with a subtly different meaning such as "attribute" or "tumbler", or a totally-made-up word like "granfilade" or "crum", I think the third is by far the least objectionable choice. The unfamiliar word puts you on notice that it names a concept you're unfamiliar with, unlike "style" or "attribute", which you might erroneously think you already understand.
In this it is similar to initialisms, but initialisms pose several difficulties to communication: they are awkward to pronounce ("WWW" is nine syllables), have inadvertent collisions with unrelated concepts ("CSS" is also the DVD Content Scrambling System, the Congregation of the Sacred Stigmata, the Colorado Springs School, chirped spread-spectrum radio, and dozens of other things), literarily unevocative, and except for thoroughly assimilated acronyms like "laser", they always make you look like you're shouting.
So I don't think it's the nomenclature that accounts for the impenetrability of the text; it's just the unfamiliarity of the concepts it explains.
The most similar thing I've seen is https://www.cs.tufts.edu/~nr/cs257/archive/brent-yorgey/mono... (with the qualification that I'm basing this not on the document we're discussing in this thread, but my earlier tries at understanding enfilades from poorly-preserved explanations. With that caveat, I thought the Yorgey paper described the same idea.)
BTW I've found the codebase in udanax-1999-09-29.tar.gz to be a fairly illuminating complement to this document. It would be pretty hard to read without some of the context in this proposal, but it adds a lot more detail.
MarkM lectured me about it one afternoon for an hour or two but we didn't record it. But I haven't actually tried implementing the Ent or other enfilade data structures, so even my perception that the lecture was very informative is suspect.
I spent a few years trying to build a Xanadu-two-way-hyperlinks-but-with-Javascript kind of a thing and I eventually started to wonder, like, if you watch a lot of Ted's videos he's got this idea of a kind of potential for what computers could be like-- he often makes reference to this experience he had as a kid that motivated his work-- it kind of seems to me that with what's possible today you could make something that goes far beyond either World Wide Web or Xanadu or anything really conceived yet-- something so fluid and adaptable and humane that it becomes an real extension of the fluid way we think with all of the advantages that come from it being a, "computer interface" (ability to recall past states, discrete calculation, ect)
The real question is-- given the enormous economic potential for the creation of, "next generation" computers why isn't that we can't create groups like SRI, Xerox PARC, ARPA (..) in the modern age to create modern, "Engelbartesque" problem solving machines? Why is it that people like Ted Nelson and Douglas Engelbar have issues having their ideas realized when by comparison every dogshit computer company in the world has had a metaphorical step up to plate in terms of potential for investment in broad horizon R&D projects? Apple has enough money to, "Manhattan Project" big breakthroughs (so does Google, Microsoft, Meta...) so why don't they? What holds back, "real" innovation? Why the hell can't I buy a Apple Nelson-Engelbartron at Wal-Mart? What gives Tim Cook?
It seems like whatever kind of, "held Xanadu back" is the same thing that held back the Engelbart stuff which held back the Alan Kay/Dan Ingalls Scratchland/E-Toys stuff which relatedly holds back the Seymour Papert/LOGO stuff. It seems like neoliberalism creates a kind of, "censorship by appeal to market forces" where there's so much demand for, "meh" (simulations of paper documents/office processes and video games which didn't exist commercially until the passing of the Mansfield Amendment; neat coincidence) that, "big ideas" aren't able to catch on in the nascent culture. If you look at this historically it's really rather unexceptional-- it's generally a small percentage of the total population that is, "highly literate" and this doesn't seem to be any different in the age of personal computers despite the lofty ideals that surround open source and the World Wide Web. Until you can build an, "adult Dynabook" which solves social inequality it seems like it's going to stay the same. Panem et circenses.
"You program computers for a living and you think this is the best design for universal problem solving machines? Do you have no imagination? No grasp of the history of these machines?!"
I agree. It's consequently one of the reasons why I have issues with code interviews being labeled as "problem solving". Yes, it's solving a problem. But it doesn't capture the whole field of problem solving. More importantly, these problems that you talk about are not being solved.
Compatibility is part of it. The VPRI project to build a personal computing experience in 20kloc never proposed to include a web browser because it'd take dramatically more code than that to support all the crap in HTML5. And that's without even getting into USB, my God, or GPUs. Or fucking ACPI. And, Jesus, those fucking Broadcom Wi-Fi cards. Even keybindings are a compatibility problem; Engelbart didn't have to worry about whether his users were conditioned to use control-W to delete the last word while he was using it to close a window, because his users weren't conditioned to use computers at all yet. And did you know that PDF files can embed TrueType fonts, which include hinting programs for a bytecode virtual machine? You have to interpret those too. Also, JavaScript.
Secrecy is another part of it. Speaking of GPUs, NVIDIA won't tell you their instruction set, and they're busily trying to sabotage your attempts to run code on their GPUs they don't approve of, such as cryptocurrency miners. Only the Raspberry Pi is fully documented as hardware, and that requires giant undocumented GPU blobs to even boot. Intel was founded by a group of deserters from Fairchild, which was founded by a group of deserters from Shockley; today they'd end up in prison like Anthony Levandowski, who tried to do the same thing. A lot of what we know about the history of computing comes from papers engineers took home and kept when they left their companies; nowadays that too could send them to prison. Did you know there was a time when signing NDAs wasn't a routine part of taking a new tech job? And you could just walk into the offices at HP and start helping out?
But a third part of it, and I think the biggest, is that people stopped believing in progress. Up until about 01769 if someone got themselves killed trying to fly or heating up the wrong kinds of rocks together, if they were lucky their neighbors would just write it off to stupidity getting its due; if they were unlucky their family might be burned at the stake for bringing down the wrath of the gods with their impiety and witchcraft. Roughly from 01770 to 01970, they would instead be lauded as martyrs to the noble cause of human progress; kids grew up wanting to be "inventors" and "engineers". But, in part due to the actual Manhattan Project, since about 01970 progress has become unfashionable again; people dismiss as naive the idea that you can just make up new rules for how things work and make them work that way, or that this activity makes people better off, or even that it is a coherent idea for people in general to be better off than before in absolute terms (as opposed to some people being better off than others).
And so we see political obstructionism; people like Aaron Swartz getting prosecuted; nuclear power plants no longer getting built; mass homelessness; Beechcraft going bankrupt; endless wars against abstractions like "terror", "poverty", and "drugs"; ruinous regulatory burdens that amount to paying some people to dig holes and other people to fill them in --- and no new Engelbarts.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The process took around a month in my spare time, and involved copy-and-pasting the OCR plain text, then marked up as DocBook XML, then converted with my own XSLT stylesheets into HTML5. There were many transcription mistakes, some from OCR from the 35 year old daisy-printer monospace printout, some were in that printout because of electrical noise in the printer serial line in 1986. I fixed those I found by hand, then a couple of readers have reported others.
Since then I’ve corrected more OCR errors, and polished a bit more the HTML rendition.
From the introduction to this edition: “It features an instance of Douglas Engelbart’s implicit links, automatically linking all appearances of certain terms to their definitions elsewhere in this document. This is done through a Javascript function that operates on the HTML content from the web server. It also shows his structural statement numbers, those little labels to the right of each paragraph that allow high resolution linking.”
Doug Engelbart was not part of Xanadu, although he was a close friend of Ted Nelson for decades. It’s just that those aspects of his NLS (of 1968 “Mother of all demos” fame) fit well this document, and work relatively well on web browsers.
I did try to implement transclusion as an example, but the target web server did not provide a CORS header and browsers refuse to load their content.
This document goes into detail about the addressing scheme for documents (https://sentido-labs.com/en/library/201904240732/Xanadu%20Hy...), the enfilade data structure (https://sentido-labs.com/en/library/201904240732/Xanadu%20Hy...), their then-future plans, etc.