> Perl is remarkably good for slicing, dicing, twisting, wringing, smoothing, summarizing and otherwise mangling text. … Perl's powerful regular expression matching and string manipulation operators simplify this job in a way unequalled by any other modern language.
Indeed! I still think in terms of PCRE (Perl-compatible regular expressions), and I love that Perl makes regexes a first-class citizen.
> Although the biological sciences do involve a good deal of numeric analysis now, most of the primary data is still text: clone names, annotations, comments, bibliographic references. Even DNA sequences are textlike. Interconverting incompatible data formats is a matter of text mangling combined with some creative guesswork.
This is still true! One common format (arguably the most common format) for sending around bits of sequenced DNA is the FASTQ format (https://en.wikipedia.org/wiki/FASTQ_format). FASTQ files are (ASCII) plain text, making them really easy to parse. Of course one byte per letter of DNA is wasteful, so FASTQ files are commonly exchanged GZIP-compressed, with the .fastq.gz extension. Many platforms & tools read in or write out .fastq.gz automatically, saving you the (de)compression step.
I went down a rabbit hole looking at how they distributed the original sequence for Covid-19 out of Wuhan. Pretty amazing to go back to January 2020 and see the conversations unrolling out in the open.[0] Also, here's the original sequence in FASTA format.[1] It's incredible to think that you can just email these files around, they're just text meant to be parsed by Perl!
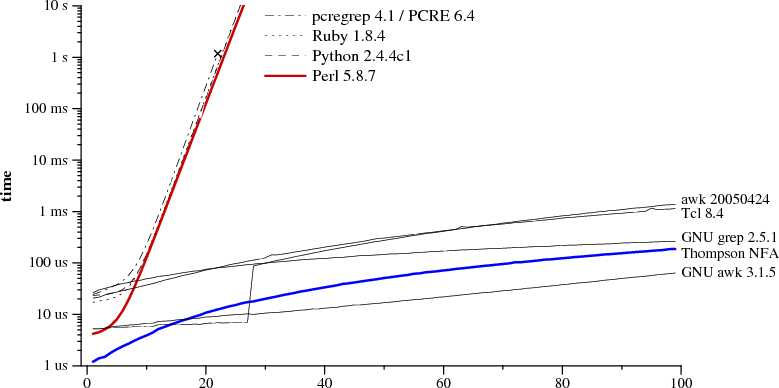
I think at this point something as expressive as PCRE should be table stakes for any language aspiring to be used for text processing. It's so successful that GNU grep added support:
-P, --perl-regexp
Interpret I<PATTERNS> as Perl-compatible regular expressions (PCREs). This option is experimental when combined with the -z (--null-data) option, and grep -P may warn of unimplemented features.
PCRE patterns are inherently unmaintainable; they're not (naturally) compositional or testable. They also cause unpleasant surprises due to accidental Turing completeness (indeed that's one of the more common causes of production outages that I've seen). IMO it's past time for newer languages to offer better alternatives, e.g. really good parser combinator support in the standard library.
Still, when you have a well-defined input and you can treat data as a flat string (no hierarchy), PCRE is probably the best choice you have - and certainly the fastest one.
The biggest surprise for many, myself included, around genomic software that arose after the Human Genome Project was that the useful things people wanted to do with sequence data didn’t need need the expressiveness provided by PCRE, et. al. String algorithms have a minor role in day-to-day genomics.
As mentioned in other comments, sequence analysis is probabilistic, so "matchers" instead tend to be statistical models, like HMMs. There is a rich relationship between statistical models like HMMs and parsing theory.
Really? String algorithms (in the stringology / compressed data structures sense) are the foundation of virtually every operation in genomics that interacts with raw data. Have you ever aligned a sequence?
Regexes are not important. But they are a tiny bit of string algorithms.
Not the op. Yes, I've done some work on this, then tested it against some of the software used in various environments for this kind of work and more than once spotted alternative, more efficient alignments. The practical upshot of that is that I ended up wondering if there is ever a serious bug found in such a piece of software if it shouldn't automatically cause all papers that used the software for their work to be at a minimum flagged for an additional round of review as well as potentially from being disqualified.
What also struck me is that the people using this software treat it like a black box, they have absolutely no way of verifying that what it did it did right.
You’re making a good point that’s usually ignored outside of genomics. Inside genomics, alignment is treated, correctly, as a probabilistic rather than deterministic process (i.e., an alignment is not “right” or “wrong”) and many choose to consider multiple alignments.
That works as long as you don't try to do things like phylogenetic trees, the ordering becomes so critical that even one swap can make things look like the order was the reverse. Of course you should never rely on just the one datum but the temptation to do so and to treat the software as correct is large due to the pressure to publish rather than to hold back and wait until there are multiple pieces of evidence.
There are probably serious bugs in all sequence alignment software, but it's unclear how much it does matter. Downstream analysis must assume that the alignments contain all kinds of known and unknown errors anyway. The sequence alignment problem itself is so ill-defined and there are so many sources of bias and errors, from data to algorithms, from code to reference sequences, from instruments to sample preparation, and including your definition of truth, that you often can't say confidently whether the alignment is correct. The scale of the data is often also big enough that you have to make deliberate trade-offs between costs and correctness.
I have! I even regularly contribute to a popular alignment application! Regardless, you’re absolutely correct and I should’ve chosen my words more carefully. Especially about the relationship to information theory. I meant “regular expressions, LL, LR, LALR, etc.”
In modern genomics, you are seeing more and more use of BAMs (Binary versions of SAM files which themselves are Sequence Alignment Files) even for unaligned data that FASTQ was normally used for. Not only are they smaller in size, but they themselves have a compressed format called CRAM which can use lossy or lossless compression depending on the use case.
Interestingly almost all of the petabyte scale and beyond processing of genomes (whole or exome) is done on the JVM as the library and toolkit ecosystem is extremely mature and it is significantly more performant than just scripting things in Perl. Having access to the big data ecosystem that runs on the JVM is also another reason why languages like Java and Scala are found in the high performance areas of genomics.
> Perl programs are easy to write and fast to develop. The interpreter doesn't require you to declare all your function prototypes and data types in advance, new variables spring into existence as needed, calls to undefined functions only cause an error when the function is needed. The debugger works well with Emacs and allows a comfortable interactive style of development.
I think each and every language that could undo this second "billion dollar mistake", did ("strict mode").
The point is, like PHP and FORTRAN it got millions of people programming who otherwise wouldn't have -- precisely because of its loosey-goosey philosophy (and lack of default strictness). And because it could be used to do some seriously powerful stuff, and get it out the door much more quickly than in the C/C++ world (arguably its only real competitor at the time).
Of course over time, these same people learned to program better, and its looseness and general wackiness grew into a liability.
But the important point here is: language design decisions (just like product decisions) aren't so much intrinsically right or wrong; but right or wrong at certain times.
In its heyday, Perl was, for many people, definitely the right way to go.
I was published in the journal Genome Research (https://pubmed.ncbi.nlm.nih.gov/25792610/) mainly because I wrote a collection of Perl scripts that helped a PhD student with Genomic search. Perl is still a secret weapon that I use to automate tasks and transmogrify data.
The latest major release of perl is perl5 version 34, but whatever's in /usr/bin/perl on your distro is almost certainly sufficient for learning with (some of my large scale OO codebases are a bit pickier, but for scripting you're somewhat unlikely to notice the difference).
Curtis Poe's Beginning Perl is a good all around introduction but I'm unsure if it's a good intro if you're aiming specifically for the text mangling side.
Whatever the last Perl 5 is. I know on my Mac I use MacPorts to install the latest version in /opt/local/bin/perl and that is the version I typically install modules for if I need them. Python is not quite the right tool for automation of file system tasks and regex matching and parsing text files -- I would rather just use C++ for most things I would be tempted use Python for.
Perl was, and is still, a remarkably powerful language. I used it starting in the early 90s to generate correct input decks for my simulations on supercomputers. Then I used it to orchestrate my (many) runs across a wide range of systems. We had small grants of CPU time, and lots of "you can use this box on nights and weekends" type access. Getting grants in the early 90s in a condensed matter theory group was hard, even had one larger one of ours cut so
its money could be diverted to another (infamous) project.
We had to make do with less. Perl was one of those tools that let us get our work done, as it enabled us to automate our tasks. Easily.
Later, I worked at SGI when all the kerfluffle about DVD decoding/playback was about. My recollection was that Perl was used for that as well[1].
When I started my company, most of my code was in Perl, with a little in C. I was using it daily until we closed in 2017. Now its a bit more sporadic.
At the day job, its Python everywhere. I've been told people would laugh at using Perl. Kind of a shame, as I see multiple pages of code that could be easily reworked into a far more readable, easy to reason about and comprehend small set of Perl code.
Perl really isn't great at mathematical operations, but then again, neither is Python without its C/C++/Fortran extensions. To Perl's discredit, the whole FFI bit took too many years for them to get right. Its there now, but the momentum is now behind other languages.
Again, a shame, as Perl is unmatched for its data wrangling capability. I didn't need 2 languages for the work I did in Perl. One sufficed, as I was happy to have simple language to reason about/support. This is curiously, why I like Julia so much.
Glad to see another Perl fan that appreciates Julia. I've always felt, in a way that's hard to articulate, that Julia captures a lot of the spirit of the design of Perl, beyond superficial syntax rules. Something about trusting its users with power, and solving real problems while keeping programming fun.
> At the day job, its Python everywhere. I've been told people would laugh at using Perl. Kind of a shame, as I see multiple pages of code that could be easily reworked into a far more readable, easy to reason about and comprehend small set of Perl code.
Could you give an example? I would be curious to better understand python’s limitations.
Perl is infamous for its concise syntax, allowing to write very dense programs. Contrary to popular opinion, it is very well possible to write both concise and well readable and understandable code.
Python in contrast emphasizes the "one statement per line" rule which gives somewhat more elaborate codes. And I am not even talking about "boilerplate codes" as in Java. Nevertheless, python is infamous for its very well readability, which is beyond the average Perl code.
The two groups decided to adopt a common data exchange format known as CAF (an acronym whose exact meaning was forgotten during the course of the meeting).
That line tickled my funny bone.
Having worked in insurance, this piece makes me wonder what languages are typically used to write software in insurance or other business medical type settings.
Insurance is just drowning in data and entry level claims processors have to interact with various databases all day long. Every time they update the software, they introduce new glitches.
I have a certificate in GIS, which involves some exposure to how databases work. So I was apparently more talented than average at parsing exactly what went wrong and how to get around weird new glitches.
Not really the best use for such spiffy training as I was not appreciated and would have been making vastly better money had I ever managed to get a job in GIS instead of insurance.
You need to remember that nobody really knew what software would use this data. There’s a famous quip from Eric Lander about the genome: it’s like having a dictionary for a language we don’t understand.
I think it's actually more like blueprints for a factory we don't understand. The code tells the body how to run bio fab works and we don't understand what tools will be printed and how they work and what modifications the code changes will make to the tools, the factory that builds them, etc.
It would probably be simpler if it were like a language.
> Having worked in insurance, this piece makes me wonder what languages are typically used to write software in insurance or other business medical type settings.
I'm not sure if it's different for medical insurance, but I worked with a company that did other types of insurance (mostly life with a smattering of others), and it was Java as far as the eye could see. Most things that pre-dated Java were done in COBOL.
I bet it's ftp servers exchanging csv files that are then parsed in Excel, the version from 1997, and that is the actual "database" - it's just all in excel.
Perl saved a lot of projects back in those days, and was pretty much the language of choice in the early internet days. In fact going as recently as 2015, was the de facto language of choice for server-side/backend applications.
Most people in this forum probably work in the internet industry. But Perl was huge in nearly every industry back then.
Things come and things go, but some tools leave behind an immense legacy and culture, Perl is one of those tools. It's not going anywhere and will come installed default in a lot of unixy distributions for years to come.
> In fact going as recently as 2015, was the de facto language of choice for server-side/backend applications.
I don't think that's accurate. I've been doing Perl professionally for over 20 years, and I've run a Perl-centric recruitment agency since 2014, and I don't think Perl has been the defacto choice since circa 2004?
I once got excited explaining this new thing I discovered about Process Substitution [1] to my bioinformatics friend, and they patiently explained to me that yes, this was the basics of all their work.
They do make several points farther down the page about Perl specifically, including:
"Perl is remarkably good for slicing, dicing, twisting, wringing, smoothing, summarizing and otherwise mangling text. Although the biological sciences do involve a good deal of numeric analysis now, most of the primary data is still text."
Which seems fair. Perl is very good at that sort of thing.
Perl was the tool for the job at the time no doubt. But the streaming pattern still applies no matter what language you use and really should be emphasized.
(I worked in bio as we were moving away from Perl)
Thing is, for simple to medium complexity streaming stuff the sed -> awk -> perl progression is still entirely valid.
I don't honestly think it's a bad thing on the science side that python's won for -programs- simply because maintainable perl at scale requires focus and discipline that is frankly energy the average scientist would be far better of expending elsewhere, but even if it's only really in commercial settings where large scale perl is still worthwhile it definitely still has its place in pipelines.
That's fair, but on the other hand, those aren't going anywhere for decades yet at least, and it's been a long time since Perl was much of anything to the industry at large beyond a punchline. We can let it have a moment in the sun.
Speaking as somebody who does consultancy and commercial support around the perl ecosystem the number of people who completely fail to realise how much revenue it's still generating for how many companies is part depressing, part hilarious.
Then again, Java, PHP etc. programmers seem to have the same experience on a regular basis, and these days the naysayers seem to have come for Rails as well.
Programming is, as ever, a pop culture, and given our tendency towards self deprecatory humour as a community the worst part of the whole thing for us a lot of the time is that 99% of the people criticising/insulting perl are so bad at it.
This article reminded me of one I’ve been trying to find.
Many years ago I read a story of how a (lowly) grad student watched the battle between private industry sequencing the genome and the university/research team doing so.
He was worried the genome would end up in private hands.
And so stayed up several nights and wrote tight C++ code to line up the data and raced the private team over the finish line.
> And so stayed up several nights and wrote tight C++ code to line up the data and raced the private team over the finish line.
I don't understand. Why would the university team have to finish it before the private team? If the private team finished it and encumbered access to the output, and the university team finished a short while later, wouldn't that have the same effect? Or would there some sort of funding drop-off once the task was achieved, that wouldn't account for whether the output was made accessible?
At the time it seemed plausible that the first group to sequence the human genome could patent it. That's since been struck down in US patent case law. But it was a real possibility.
Although this was a race it's fun to note that both sides we're learning from the other and using resources produced by the other. The assembly techniques were worked out by Gene Myers for instance, who worked at Celera.
Interesting article on the history of Perl for bioinformatics.
As someone who is currently a bioinformatics PhD student, Perl has become the vinyl of programming languages. While some older folks script with Perl, most packages I’ve seen published recently use either R, python, c++, and more recently, rust.
I’ve been working with biology data. A lot of our older scripts are Perl. It’s really good at this stuff. The great thing is the language is super stable so we don’t have to rewrite them usually.
The Perl scripts I wrote 20 years ago are still running on modern systems today. It's almost scary how stable the language and interpreter have been.
Turns out it's not an accident, though! There were a lot of good decisions that kept the language stable, and test frameworks and code coverage have been a critical part of Perl and its modules since the 1980's. In fact, pretty much all of CPAN gets tested on a matrix of Perl versions and operating systems (ex: http://www.cpantesters.org/distro/N/Net-Amazon-EC2.html)
i remember silly java consultants rabbiting on about TDD and agile while dismissing oss.
meanwhile, the curation of both testing and documentation as well as overall code quality on CPAN was light years beyond the best corporate code i've ever seen.
i'd argue that perl (with CPAN) was the first internet native programming environment.
Yes, I also was there in those years. Perl snippets were shared by everyone, but almost nobody knew how they work, much less how to tweak them to adapt to new scenarios or how to contribute to a library. I remember a snippet that read a FASTA file and counted the GC%, but it had an error somewhere that made it fail when it reached the 1001 sequence. Nobody was able to find the error, they just splitted the FASTAs in smaller files. Until someone wrote a less esoteric Python script, and the Perl snippet died.
Might be unrelated, but Perl does have a hard limit on recursion within the same function; after 100 recursions it'll die with an error and you have to unroll your loops.
$ perl -Mwarnings -E'sub f { $c++; say $c if 0 == $c % 1_000_000; f() } f'
Deep recursion on subroutine "main::f" at -e line 1.
1000000
2000000
3000000
4000000
5000000
6000000
7000000
8000000
9000000
10000000
11000000
12000000
13000000
14000000
15000000
16000000
17000000
18000000
19000000
20000000
Terminated
You get a warning after 100 calls which almost always indicates a bug. In case it's a genuine deep recursion, the warning can be easily suppressed with `no warnings "recursion"`.
On my computer, the program continues to run for about 10 seconds, consuming 9 GB virt./res. after which it is killed off by `earlyoom`.
I am currently learning Perl, and I love it so far. It seems very powerful for doing stuff with text. I get the impression people might say I am crazy for learning it in 2022 over, say, Python, but I am not sure why.
I'm in the semiconductor industry and I still write Perl scripts everyday. I learned it back in the mid-90's and it is still great for all the text files that I parse.
Most of the EDA CAD tools use Tcl and some of the younger people write their scripts in Python but most of the other 40-50 year old engineers still write Perl. I write all of my small home Linux sysadmin scripts in Perl as well. I started to learn Python. I'll probably get around to it sometime but I don't write big systems and 90% of what I do is text processing.
I love most everything about this. My first experience with perl was in the mid 90s and it was all headache. 6 months later I was a total believer. For almost 40 years Perl on my resume has gotten me places!! (Haven't used it in the workplace for almost as long)
Perl (5) is raw but powerful. Understanding it gets you really far. Is it right, no, but it makes you better.
I miss Perl. I used to do scaled up (for the time) systems management with tools built on Perl4. We’d drop a perl interpreter on the boxes as monitoring and management agents and use another framework to ship data back. Perl4 was ancient then, so we’d backport stuff from CPAN or compile Perl5 for certain things.
It’s definitely a language that was ideal for its user base… admins and early web people mostly. All of my serious coursework in college was C, C++ and Fortran, so just being able to bang out code and get shit done was amazing.
i vividly remember as a kid i saw an ad /show for "the human genome project" on "the national geographic channel" what was later called "natgeo".
i must have been a small kid back then but i remember thinking "boy, i wish i had those so i could check mine". in hindsight, they must've done a pretty good job of explaining the project because kid me could understand what they were trying to say. kudos to them. i have never seen it in the last 15 odd years, maybe more but today i can recall "elephants" in the ad for some reason.
Remember that in 1996, there weren't many free main-stream programming languages around. There was C, C++, and Java of course, but you'd have to be a more experienced programmer to get that up and running as a CLI tool. And then you'd have to deal with their (lack of) regexp implementations. Makes sense that Perl became the go-to language.
I guess python was around then but certainly not like it is now. I wonder if python 1 even had a regex library?
My lab, that does a mix of bioinformatics and population genetics, has people who know bash, python, and R. Honestly, I think bash is probably the one that gets used the most. So maybe my command line wouldn’t look that different to the ones used in the human genome project. Although technically I am using zsh most of the time.
If people are curious, the author, Lincoln Stein, is now at Ontario Institute for Cancer Research and is one of the people behind JBrowse the JavaScript successor to the popular Perl-based GBrowse.
Same here. Learned CGI.pm and read the Perl & MySQL book by Dubois as well as most of the O'Reilly Perl collection. Then I was off to the races. Built an app with CGI::Application which ran a client's business for over a decade without many hiccups. Programming Perl by Larry Wall and Mastering Regular Expressions by Jeffrey Friedl are still some of my favourite tech books.
Mason was supposed to be Perl's answer to PHP. Trouble is you could only get it to anywhere the speed of PHP by hosting it on mod_perl which wasn't an option with shared hosting deals. Same with Perl's heavyweight framework Catalyst - a veritable beast without mod_perl. All died a death in the fire of Perl's attempts to compete with PHP, Python and Ruby. Moose, Mouse, Moo, Mo - none of it really stuck because Perl's forte was procedural. Having said that The Damian did a great job promoting OO Perl. That guy's a true genius. The thing I miss most about my time with Perl in the 2000s is the cast of characters. No language I've come across since has anywhere near the range of acolytes which made the Perl community legendary.
Perl was my first language too! Believe it or not, there's a ton of b*ch work that still needs to be done by interns at legacy tech that involves the language (looking at you Veritas, although this was a long time ago so who knows).
I'm grateful Rust now exists and is able to match, and even beat, Perl in regex text surgery.
I sometimes miss the old days of writing CGI scripts. But then Java was all the rage and the tooling was so much better, and then JS and Python and a ton of new languages and frameworks and Perl seemed like it just ossified and never caught up.
I know for a fact (worked for him) that Hamilton smith - who was on the team for Craig venters side of the hgp - preferred writing sequence alignment and predictors using cobol.
And his colleague Clyde Hutchinson even used BASIC! At least in the 1980s. He even published a paper in Nucleic Acids Research on a system he wrote in BASIC for the TRS-80 model 100 (a very early laptop computer from 1983).
Lincoln was definitely one of the behind-the-scenes heroes for many years. I haven't been watching the perl space for many years now. Did the GUI tools ever get any better? It's a shame that so many interesting languages end up in the same kinds of backwaters were it's nigh on impossible to create attractive (native-ish) GUI applications.
The simple answer is no. There were Wx bindings at some point, bindings into Cocoa, but as a strong Perl developer who uses a Mac -- and was once pretty handy with Tk -- and would check back every year or so, nothing ever really seemed to stick or be easy to set up.
{kind=link}
> Perl is remarkably good for slicing, dicing, twisting, wringing, smoothing, summarizing and otherwise mangling text. … Perl's powerful regular expression matching and string manipulation operators simplify this job in a way unequalled by any other modern language.
Indeed! I still think in terms of PCRE (Perl-compatible regular expressions), and I love that Perl makes regexes a first-class citizen.
> Although the biological sciences do involve a good deal of numeric analysis now, most of the primary data is still text: clone names, annotations, comments, bibliographic references. Even DNA sequences are textlike. Interconverting incompatible data formats is a matter of text mangling combined with some creative guesswork.
This is still true! One common format (arguably the most common format) for sending around bits of sequenced DNA is the FASTQ format (https://en.wikipedia.org/wiki/FASTQ_format). FASTQ files are (ASCII) plain text, making them really easy to parse. Of course one byte per letter of DNA is wasteful, so FASTQ files are commonly exchanged GZIP-compressed, with the .fastq.gz extension. Many platforms & tools read in or write out .fastq.gz automatically, saving you the (de)compression step.